SVM分类器设计
svm实验报告总结

svm实验报告总结SVM实验报告总结支持向量机(SVM)是一种常用的机器学习算法,它在模式识别、分类、回归等领域有着广泛的应用。
本文将对SVM算法进行实验,旨在探究SVM算法的原理、应用和优缺点。
一、实验原理SVM的基本思想是将低维度的数据映射到高维度的空间中,从而使数据在高维空间中更容易被线性分隔。
SVM算法的核心是支持向量,这些支持向量是距离分类决策边界最近的数据点。
SVM通过找到这些支持向量来建立分类器,从而实现数据分类。
二、实验步骤1. 数据预处理本实验使用的数据集是Iris花卉数据集,该数据集包含了三种不同种类的花朵,每种花朵有四个属性:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
首先需要将数据集划分为训练集和测试集,以便在训练模型时进行验证。
2. 模型训练本实验使用Python中的sklearn库来构建SVM分类器。
首先需要选择SVM的核函数,有线性核函数、多项式核函数、径向基核函数等。
在本实验中,我们选择径向基核函数作为SVM的核函数。
接着需要设置SVM的参数,包括C值和gamma值。
C值是惩罚系数,用于平衡模型的分类精度和泛化能力;gamma值是径向基函数的系数,用于控制支持向量的影响范围。
3. 模型评估本实验使用准确率和混淆矩阵来评估模型的性能。
准确率是指模型在测试集上的分类精度,而混淆矩阵则可以用来分析模型在不同类别上的分类情况。
三、实验结果本实验使用径向基核函数的SVM分类器在Iris数据集上进行了实验。
实验结果表明,SVM分类器的准确率达到了97.78%,同时在混淆矩阵中也可以看出模型在不同花朵种类上的分类情况。
实验结果表明,SVM分类器在分类问题上有着较好的表现。
四、实验总结SVM算法是一种常用的机器学习算法,它在模式识别、分类、回归等领域有着广泛的应用。
本实验通过对Iris数据集的实验,探究了SVM算法的原理、应用和优缺点。
实验结果表明,在SVM算法中,径向基核函数是一种比较适用的核函数,在设置SVM参数时需要平衡模型的分类精度和泛化能力。
(完整版)支持向量机(SVM)原理及应用概述

支持向量机(SVM )原理及应用一、SVM 的产生与发展自1995年Vapnik(瓦普尼克)在统计学习理论的基础上提出SVM 作为模式识别的新方法之后,SVM 一直倍受关注。
同年,Vapnik 和Cortes 提出软间隔(soft margin)SVM ,通过引进松弛变量i ξ度量数据i x 的误分类(分类出现错误时i ξ大于0),同时在目标函数中增加一个分量用来惩罚非零松弛变量(即代价函数),SVM 的寻优过程即是大的分隔间距和小的误差补偿之间的平衡过程;1996年,Vapnik 等人又提出支持向量回归 (Support Vector Regression ,SVR)的方法用于解决拟合问题。
SVR 同SVM 的出发点都是寻找最优超平面(注:一维空间为点;二维空间为线;三维空间为面;高维空间为超平面。
),但SVR 的目的不是找到两种数据的分割平面,而是找到能准确预测数据分布的平面,两者最终都转换为最优化问题的求解;1998年,Weston 等人根据SVM 原理提出了用于解决多类分类的SVM 方法(Multi-Class Support Vector Machines ,Multi-SVM),通过将多类分类转化成二类分类,将SVM 应用于多分类问题的判断:此外,在SVM 算法的基本框架下,研究者针对不同的方面提出了很多相关的改进算法。
例如,Suykens 提出的最小二乘支持向量机 (Least Square Support Vector Machine ,LS —SVM)算法,Joachims 等人提出的SVM-1ight ,张学工提出的中心支持向量机 (Central Support Vector Machine ,CSVM),Scholkoph 和Smola 基于二次规划提出的v-SVM 等。
此后,台湾大学林智仁(Lin Chih-Jen)教授等对SVM 的典型应用进行总结,并设计开发出较为完善的SVM 工具包,也就是LIBSVM(A Library for Support Vector Machines)。
SVM在文本分类中的应用实践

SVM在文本分类中的应用实践随着互联网的快速发展,大量的文本数据被生成和存储。
如何从这些海量的文本数据中提取有价值的信息并进行有效的分类成为了一个重要的问题。
支持向量机(Support Vector Machine,SVM)作为一种强大的机器学习算法,被广泛应用于文本分类领域。
一、SVM的基本原理SVM是一种监督学习算法,其基本原理是通过找到一个最优的超平面来将不同类别的样本分开。
在文本分类中,每个文本样本可以看作是一个特征向量,其中每个特征表示一个词或短语的出现频率。
SVM通过学习这些特征向量的线性组合,将不同类别的文本样本分开。
二、特征提取与向量化在将文本样本输入SVM之前,需要将文本转化为数值特征向量。
常用的方法有词袋模型(Bag of Words)和TF-IDF(Term Frequency-Inverse Document Frequency)。
词袋模型将文本视为一个无序的词集合,忽略了词序和语法结构。
通过统计每个词在文本中出现的频率,将文本转化为一个稀疏向量。
然而,词袋模型忽略了词之间的关系,可能导致信息的丢失。
TF-IDF考虑了词在文本集合中的重要性。
它通过计算一个词在文本中的频率和在整个文本集合中的逆文档频率的乘积,得到一个词的权重。
TF-IDF能够更好地反映词的重要性,提高了特征向量的质量。
三、核函数的选择SVM通过核函数来处理非线性分类问题。
常用的核函数有线性核函数、多项式核函数和径向基核函数。
线性核函数适用于线性可分的情况,对于简单的文本分类问题有较好的效果。
多项式核函数能够处理一些非线性问题,但容易产生过拟合。
径向基核函数是最常用的核函数之一,它能够处理复杂的非线性分类问题,并且具有较好的鲁棒性。
四、参数调优与模型评估SVM中的参数调优对于模型的性能至关重要。
常见的参数包括惩罚系数C、核函数参数和松弛变量参数。
通过交叉验证等方法,可以选择最优的参数组合。
模型评估是判断模型性能的重要指标。
基于HOG+SVM的图像分类系统的设计与实现

基于HOG+SVM的图像分类系统的设计与实现姜经纬;程传蕊【摘要】Image classification has high practical value in the industrial, medical, reconnaissance, driving and other fields.We want to design an image classification system through the analysis of image classification technology, the idea of software engineering, HOG+SVM and OpenCV.After testing, the system interface is simple, with easy and stable operation, and you can accurately classify image, access to image information.%图像分类在工业、医疗、勘测、驾驶等领域都有较高的实用价值,通过分析图像分类技术,采用软件工程思想,基于HOG+SVM和OpenCV,设计实现一个图像分类系统. 经测试,本系统界面简洁,操作简单,运行稳定,可以准确地进行图像分类,获取图像信息.【期刊名称】《漯河职业技术学院学报》【年(卷),期】2017(016)002【总页数】4页(P46-49)【关键词】图像分类;HOG特征;SVM分类器【作者】姜经纬;程传蕊【作者单位】沈阳航空航天大学, 辽宁沈阳 110000;漯河职业技术学院, 河南漯河462000【正文语种】中文【中图分类】TP391.41随着互联网、电子技术、成像技术的快速发展,数字图像已成为一种重要的信息表达方式。
从日常生活中的图像广告、二维码到医学研究的显微图像,从卫星中的遥感图像到精密的指纹检测,人类无时无刻都在和图像打着交道。
支持向量机(SVM)2演示报告PPT

目录
Contents
1.线性SVM分类器原理 2.非线性SVM和核函数 3.SVM手动推导 4.SVM分类器上机演示 5.总结
大小
假设在一个二维线性可分的数据集中,我们要 找到一条线把两组数据分开。但哪条直线是最 佳的?也就是说哪条直线能够达到最好的分类 效果?
苹果
梨 颜色
PART 01
2 非线性SVM的引入
将数据从低维空间投影到高维空间,使其线性可分; 如果数据在原始输入空间不能线性可分,那么我们
可以应用映射函数φ(•),将数据从2D投影到3D(或 者一个高维)空间。在这个更高维的空间,我们可 能找到一条线性决策边界(在3D中是一个平面)来 拆分数据。 SVM 通过选择一个核函数,将低维非线性数据映射 到高维空间中。
1 理解SVM的工作原理
在训练初期,分类器只看到很少的数据点,它试着画出分隔两个类的最佳决策边界。 随着训练的进行,分类器会看到越来越多的数据样本,因此在每一步中不断更新决策 边界。
随着训练的进行,分类器可以看到越来越多的数据样本,因此越来越清楚地知道最优 决策边界应该在哪里。在这种场景下,如果决策边界的绘制方式是“–”样本位于决 策边界的左边,或者“+”样本位于决策边界的右边,那么就会出现一个误分类错误。
2 核函数
简单地说,核函数是计算两个向量在隐式 映射后空间中的内积的函数。核函数通过 先对特征向量做内积,然后用函数 K 进行 变换,这有利于避开直接在高维空间中计 算,大大简化问题求解。并且这等价于先 对向量做核映射然后再做内积。
在实际应用中,通常会根据问题和数据的 不同,选择不同的核函数。当没有更多先 验知识时,一般使用高斯核函数。
THANKS
感谢观看
SVMKNN分类器——一种提高SVM分类精度的新方法

SVM-K NN 分类器———一种提高SVM 分类精度的新方法李蓉,叶世伟,史忠植(1.中国科技大学研究生院(北京)计算机教学部,北京100039;2.中国科学院计算技术研究所智能信息处理实验室,北京100080)摘要:本文提出了一种将支持向量机分类和最近邻分类相结合的方法,形成了一种新的分类器.首先对支持向量机进行分析可以看出它作为分类器实际相当于每类只选一个代表点的最近邻分类器,同时在对支持向量机分类时出错样本点的分布进行研究的基础上,在分类阶段计算待识别样本和最优分类超平面的距离,如果距离差大于给定阈值直接应用支持向量机分类,否则代入以每类的所有的支持向量作为代表点的K 近邻分类.数值实验证明了使用支持向量机结合最近邻分类的分类器分类比单独使用支持向量机分类具有更高的分类准确率,同时可以较好地解决应用支持向量机分类时核函数参数的选择问题.关键词:支持向量机;最近邻分类;类代表点;核函数;特征空间;VC 维中图分类号:TP301文献标识码:A文章编号:0372-2112(2002)05-0745-04SVM-!NN Classifier ———A New Method of lmproving the Accuracy of SVM Classifier LI Rong ,YE Shi-wei ,SHI Zhong-zhi(1.Dept.of Computing ,Graduate School ,Science and Technology Uniuersity of China ,Beijing 100039,China ;2.National Key Laboratory of Intelligent Information Technology Process ,The Institute of Computing Technology ,Chinese Academy of Sciences ,Beijing 100080,China )Abstract :A new algorithm that combined Support Vector Machine(SVM )with K Nearest neighbour (K NN )is presented and it comes into being a new classifier.The classifier based on taking SVM as a 1NN classifier in which only one representative point is selected for each class.In the class phase ,the algorithm computes the distance from the test sample to the optimal super-plane of SVM in feature space.If the distance is greater than the given threshold ,the test sample would be classified on SVM ;otherwise ,the K NN al-gorithm will be used.In K NN algorithm ,we select every support vector as representative point and compare the distance between the testing sample and every support vector.The testing sample can be classed by finding the k-nearest neighbour of testing sample.The numerical experiments show that the mixed algorithm can not only improve the accuracy compared to sole SVM ,but also better solve the problem of selecting the parameter of kernel function for SVM.Key words :support vector machine ;nearst neighbour algorithm ;representative point ;kernel function ;feature space ;VC Di-mension!引言统计学习理论是一种专门的小样本统计理论,为研究有限样本情况下的统计模式识别和更广泛的机器学习问题建立了一个较好的理论框架,同时也发展了一种模式识别方法—支持向量机(Support Vector Machine ,简称SVM ),在解决小样本、非线形及高维模式识别问题中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中[1].目前,统计学习理论和SVM 已经成为国际上机器学习领域新的研究热点并已被应用于人脸识别、文本识别、手写体识别等领域.在对SVM 的研究中,提高它的分类能力(泛化能力)是所有研究的出发点和归宿.SVM 和其他分类方法相比具有较高的分类精度,但目前在SVM 的应用中还存在一些问题,如对不同的应用问题核函数参数的选择较难,对较复杂问题其分类精度不是很高以及对大规模分类问题训练时间长等.已有的解决方法包括建立分类性能的评价函数,然后对SVM 中的核函数的参数进行优化,或者使用直推方法[1]对给定待样本设计最优的SVM ;所有这些方法的设计和计算都非常复杂,实现的代价都很高.我们对SVM 分类时错分样本的分布进行分析发现,SVM分类器和其它的分类器一样[1],其出错样本点都在分界面附近,这提示我们必须尽量利用分界面附近的样本提供的信息以提高分类性能.由SVM 理论知道,分界面附近的样本基本上都是支持向量,同时SVM 可以看成每类只有一个代表点的最近邻(Nearst Neighbour ,NN )分类器(详细推导见附录).所以结合SVM 和NN ,对样本在空间的不同分布使用不同的分类法.具体地,当样本和SVM 最优超平面的距离大于一给定的阈值,即样本离分界面较远,则用SVM 分类,反之用K NN 对测试样本分类.在使用K NN 时以每类的所有的支持向量作为收稿日期:2001-06-15;修回日期:2001-10-06第5期2002年5月电子学报ACTA ELECTRONICA SINICA Vol.30No.5May 2002代表点组,这样增加的运算量很少.实验证明了使用支持向量机结合最近邻的分类器分类比单独使用支持向量机分类具有更高的分类准确率,同时可以较好地解决应用支持向量机分类时核函数参数的选择问题.2SVM、!NN分类器简介2.1SVM分类器SVM是一种建立在统计学习理论基础上的分类方法[l].它主要基于以下三种考虑(l)基于结构风险最小化,通过最小化函数集的VC维来控制学习机器的结构风险,使其具有较强的推广能力.(2)通过最大化分类间隔(寻找最优分类超平面)来实现对VC维的控制,这是由统计学习理论的相关定理保证的.(3)而SVM在技术上采用核化技术,根据泛函中的Mercer定理,寻找一个函数(称核函数)将样本空间中内积对应于变换空间中的内积,即避免求非线形映射而求内积.2.2!NN分类器近邻法(简称NN)是模式识别非参数法中最重要的方法之一,NN的一个很大特点是将各类中全部样本点都作为“代表点”[l].lNN是将所有训练样本都作为代表点,因此在分类时需要计算待识别样本x到所有训练样本的距离,结果就是与x最近的训练样本所属于的类别.K NN是lNN的推广,即分类时选出x的I个最近邻,看这I个近邻中的多数属于哪一类,就把x分到哪一类.3SVM-!NN分类器实现3.1对SVM分类机理的分析在本文中,通过对SVM的分类机理分析,找到了SVM和NN分类器之间的联系,此联系由下面的定理给出:定理1SVM分类器等价于每类只选一个代表点的l-NN 分类器.证明见附录.区域",如分类用SVM,只计离测为支练分两示.旋示螺问题.差,的年惩罚参数C=5,分类阈值!选为0.8.选择了四组不同的核函数参数测试,比较两种算法对不同参数的分类效果.实验结果如表1所示.(2)文本分类实验:将下载的5642个中文网页后通过人工方式将其分为十三类后,对各个类标明其输出.这时一个多类分类问题,针对此多类问题我们构造了SVM多值分类器,构造方法采取一对一方式[4],训练了!(+1)2(=13)个SVM二值子分类器.本次实验所选取的核函数为感知机核函数(x,xi)=tanh(g !(x・x i)+c),大量数据测试证明对于网页分类数据,采用感知机核函数在分类准确率和速度上均优于其它核函数.在此实验中错误惩罚参数C=5,分类阈值!取为0.6.除了对综合测试集进行测试外,我们还从中选取了有代表性几个类分别测试,测试结果如表2所示.表!双螺旋线分类SVM和K SVM算法比较核参数分类算法圈数:2圈数:3圈数:4g=0.5SVM54.7312%50.9241%47.1546% KSVM49.3677%48.4618%50.0917%g=0.05SVM61.6282%50.9241%50.6731% KSVM95.7631%86.3446%81.0137%g=0.03SVM81.6002%82.1874%72.8237% KSVM92.8041%86.3446%85.1858%g=0.01SVM95.9519%87.8010%57.6668% KSVM95.7631%86.3446%85.1876%表"对于文本分类SVM和K SVM算法比较核参数分类算法综合类工业类体育类生活类政治类g=2SVM65.1423%56.9759%83.8684%63.3834%75.7044% KSVM68.8713%60.3927%88.8192%64.5993%78.3995%g=0.5SVM66.6612%59.888%83.3060%66.4731%81.4176% KSVM69.1269%62.0845%87.9798%65.5740%82.2401%g=0.1SVM46.2187% 2.9668%59.4340%26.8909%87.9119% KSVM64.1182%61.8701%85.3217%54.3182%89.1481%g=0.05SVM30.2999%0%31.3306%0%92.7028% KSVM64.0689%61.3808%82.9425%51.1887%93.9405%(3)实验分析从实验的结果数据可以得出两个结论:一是使用SVM-K NN分类可以减轻对核函数参数选择的敏感程度,缓解对参数选择的困难.对于SVM分类器,核函数参数的选择是非常重要但很困难的.如表1中当参数g=0.5、g=0.01及表2中的g=0.5、g=0.05,SVM的分类性能差别很大.对于同一参数,问题不同分类效果差别也很大,如上表1中g=0.01,对圈数为二、三的螺旋线,SVM的分类效果很好,但对于四圈的螺旋线,SVM的识别率不如选择g=0.03的识别率.带入K SVM算法后,对于参数的选择不是很敏感.如表1中的g= 0.05和g=0.01,K SVM算法的效果差别很小,性能比较稳定.第二个结论是使用SVM-K NN分类器在一定程度上比使用SVM具有更好的性能.针对四圈情况,数据的线形不可分程度高,使用SVM分类性能低,而使用K SVM算法分类精度提高较明显.而当实际问题相对好分时(表1中的二、三圈螺旋线),二者的分类效果差别不大.这是因为当实际问题比较易分时,SVM训练后所得到支持向量个数少,在K SVM中所选取的代表点也少;实际问题复杂程度高时,SVM训练后所得到支持向量个数多,K SVM算法所携带的信息更高,而此时SVM 分别对正反例支持向量组仅合成一个代表点,损失的信息也相对较多.#结论本文将SVM和K NN分类器相结合构造了一种新的分类器,该分类器基于将SVM分类器等价于对每类支持向量只取一个代表点的1NN分类器,针对当测试样本在分界面附近时容易分错的情形引入K NN分类选取每个支持向量作为代表点.SVM-K NN分类器是一种通用的分类算法,使用该分类器的分类准确率比单纯使用SVM分类器一般有不同程度的提高,并且该分类器在一定程度上不受核函数参数选择的影响,具有一定的稳健性.进一步的工作是从SVM的分类机理得到启发,不一定采用每个支持向量作为代表点,而对它们进行组合选取多个代表点进行分类.附录:定理!证明已知线性可分样本集为(xi,yi),i=1,…,l,xi"Rd,y"{-1,+1}为类别标志,d空间维数.最优分类面问题可以表示成如下优化问题的对偶问题W(")=#li=1"i-12#li,j=1"i"j y i y j(x i・x j)(1)约束条件为:0$"i,i=1,…,I与#li=1"i y i=0(2)根据Kuhn-tucker条件,这个优化问题的解必须满足"i(y i[(w,x i)-J]-1)=0,i=1,…,l(3)相应的分类函数也变为f(x)=Sgn#iy i"i・(x i,x)-()J(4)首先分别利用正、反例支持向量组成两个代表点#(x)+ =1C#lyi=1,i=1"i#(x i),#(x)-=1C#lyi=-1,i=1"i#(x i).其中#yi=1"i=#yi=-1"i=C(根据目标函数对偶问题的等式约束条件#li=1"i y i=0),对于最优解w=#li=1"i#(x i)=C(#(x)+-#(x)-),由式(3)对任意正例的样本有"i((w,#(x i))-J-1)=0,从而有0=#yi=1"i((w,#(x i))-J-1)=(w,#yi=1"i#(x i))-C・J-C=(C(#(x)+-#(x)-),C#(x)+)-C・J-C=C[C((#(x)+-#(x)-,#(x)+))-J-1](5)这样有J=C(#(x)+-#(x)-,#(x)+)-1同样由式(3),对任意反例的样本有747第5期李蓉:SVM-K NN分类器———一种提高SVM分类精度的新方法J=C((!(x)+-!(x)-,!(x)-))+1(6)由(式(5)+式(6))/2可得J=C2((!(x)+-!(x)-,!(x)++!(x)-))=C2((x+,x+)-(x-,x-))(7)在SVM的分类过程代入1NN分类,可得到下式:g(x)=!!(x)-!(x)-!2-!!(x)-!(x)+!2=2(x,x+)-2(x,x-)+(x-,x-)-(x+,x+)=2C"i"i y i(x,x i)+C2[(x-,x-)-(x+,x+ {})](由式(7)可得)=2C"i"i y i(x,x i)-{}J(8)参考文献:[1]Vapnik V N.The Nature of Statisticai Learning Theory[M].NY:Springer Veriag.[2]边肇祺,张学工.模式识别[M].北京:清华大学出版社.2000.[3]Vapnik V N.Estimation of dependencies based on empiricai data[R].Beriin:Springer Veriag,1982.[4]Burges C J C.A tutoriai on support vector machines for pattern recogni-tion[J].Data Mining and Knowiedge Discvery,1998,2(2).[5]Weston J,Watkins C.Muiti-ciass support vector[J].machines.Royai Hoiioway Coiiege,Tech Rep:CSK-TR-98-04,1998.[6]Thorston Joachims.Text Categorization With Support Vector Machine:iearning with reievant features[R].University Dortmund,1998.作者简介:李蓉女,1973年生于北京,1996年于北京理工大学获工学学士位,1999年进入中国科技大学研究生院(北京)计算机软件专业攻读硕士学位,2000年10月至今在中科院计算技术研究所智能信息处理开放实验室做硕士论文,师从于史忠植研究员,研究方向为机器学习、神经计算,已发表学术论文3篇.叶世伟男,1968年生于四川,分别于1991年、1993年、1996年于四川师范大学、北京大学、中科院计算技术研究所获得理学学士、理学硕士和工学博士学位,现任中科院研究生计算机教学部院副教授,主要研究方向为神经计算、优化理论,已发表学术论文十余篇###############################################.2002国际存储展览暨技术研讨会在京召开由信息产业部电子信息产品管理司、中国电信、国家邮政局及中国计算机学会信息存储技术专业委员会支持,中国电子信息产业发展研究院(CCID)主办,赛迪展览公司承办的“2002国际存储展览暨技术研讨会(Storage Infoworid2002)”4月25~27日在北京中国国际科技会展中心隆重举行.信息产业部苟仲文副部长参加开幕主题演讲并致欢迎辞,随后在信息产业部有关司局领导的陪同下饶有兴趣地参观了展览会,并与参展企业代表亲切座谈.来自各有关部委和行业用户部门的三十多位领导和近千余名专业人士出席了展览及研讨会.Sotrage Infoworid2002聚焦存储领域热点,汇聚如EMC、SUN、HP、Network Appiiance、Xiotech、Seagate、CA、Auspex、RC、Spectra Logic、VERITAS、Ouantum、Maxtor、SONY、ANEKtek、清华同方、亚美联等三十余家国内外知名存储软硬件厂商、存储系统集成商、存储技术开发商及相关的经销商和渠道合作伙伴,内容涵盖网络存储、光存储、移动存储、存储软件及存储应用解决方案.EMC公司在展会上推出了一系列高级、整合并经过验证的业务连续性解决方案;Sun公司的Storage ONE体系架构提供了一个开放、集成化和自动的存储管理解决方案;Network Appiiance作为数据存储和内容传输领域的世界领先者,为当今数据激增的企业提供开放的网络存储解决方案;亚美联公司作为国内首家完全自主知识产权的企业级存储产品供应商,推出的国内第一套达到国际先进技术水平的企业级存储系统Estor NAS18/2800、Estor SAN产品系列;Spectra Logic 公司的Spectra64000企业级磁带库、昆腾公司的基于磁盘的产品系列———第一款产品Ouantum DX30等都在展会上亮相.在两天半的研讨会中,来自EMC、SUN、HP、XIOtech、CA、Spectra Logic、清华同方等公司的国内外存储专家,将从存储的最新动态、发展方向、最新技术、解决方案和成功案例等方面发表精彩演讲.IT界称2001为存储年,而2002年将为中国存储市场迎来又一高峰.Storage Infoworid2002作为国内IT存储领域举办的权威盛会,必将以优质的服务为国内外关注中国存储市场发展的厂商及用户架起供需沟通的桥梁.847电子学报2002年。
企业集团信用风险评估SVM集成分类器的构建与应用

易 金额 两个 方 面实证检 验 了关联 交易 对企 业集 团信 用 风 险的负 面影 响[ 6 ; 杨 扬等 利用 合作 博弈 理论 刻 画了企 业集 团 内部 的非 公 允 关 联交 易 行 为 , 从 理 论 上 证 明了非公 允 关联交 易会 增加 企业 集 团的信 用风 险[ 8 ] 。上 述研 究成果 为 本文构 建科 学 的企业 集 团信 用 风 险评估 指标 提供 了依 据 。在 企业 集 团信用 风 险 评估方 面 , 蒙 肖莲 等 首 先 运 用 E D F( e x p e c t e d d e — f a u l t f r e q u e n c y ) 模 型 得 到 企 业 集 团 的 预 期 违 约 概 率, 然后 将之 作 为企业 集 团的违 约指标 , 考 察 了企业
李 丽 , 周 宗放
( 1 .电子 科 技 大 学 经 济 与 管 理 学 院 , 成都 6 1 0 0 5 4 ; 2 .云 南 师 范 大 学 数 学 学 院 , 昆 : 将 Ad a B o o s t 算法与支持向量机( S VM ) 相结合 , 建立 了 S V M 集成 分类器 , 并 将 之 应 用 于 商 业 银 行 的 企 业 集 团信 用 风 险 评 估 中 。 实证 检 验 结 果 表 明 : S VM 集 成 分 类 器 较 单 一 的 S V M 方 法 具 有 更 高 的 分 类
团控股 公 司信 用 风 险 的方 法 _ 1 。 。 ; 随后, 他 们 又 利 用 期权 定 价技术 对具 有股 权联 系 的集 团母 公 司进行 信 用 风 险度量 , 研究 结 论极 大地 丰富 了 现 有 企业 集 团 信 用风 险评估 的理论成 果 _ 1 。在实 证 研 究方 面 , 自 刘 云焘 首次将 支 持 向量 机 ( s u p p o r t v e c t o r ma c h i n e , S VM) 应 用 于 商业 银 行 的信 用 风 险评 估 后_ 1 , 冯 一
svm分类器原理

1、数据分类算法基本原理数据分类是数据挖掘中的一个重要题目。
数据分类是指在已有分类的训练数据的基础上,根据某种原理,经过训练形成一个分类器;然后使用分类器判断没有分类的数据的类别。
注意,数据都是以向量形式出现的,如<0.4, 0.123, 0.323,…>。
支持向量机是一种基于分类边界的方法。
其基本原理是(以二维数据为例):如果训练数据分布在二维平面上的点,它们按照其分类聚集在不同的区域。
基于分类边界的分类算法的目标是,通过训练,找到这些分类之间的边界(直线的――称为线性划分,曲线的――称为非线性划分)。
对于多维数据(如N维),可以将它们视为N维空间中的点,而分类边界就是N维空间中的面,称为超面(超面比N维空间少一维)。
线性分类器使用超平面类型的边界,非线性分类器使用超曲面。
线性划分如下图:可以根据新的数据相对于分类边界的位置来判断其分类。
注意,我们一般首先讨论二分类问题,然后再拓展到多分类问题。
以下主要介绍二分类问题。
2、支持向量机分类的基本原理支持向量机是基于线性划分的。
但是可以想象,并非所有数据都可以线性划分。
如二维空间中的两个类别的点可能需要一条曲线来划分它们的边界。
支持向量机的原理是将低维空间中的点映射到高维空间中,使它们成为线性可分的。
再使用线性划分的原理来判断分类边界。
在高维空间中,它是一种线性划分,而在原有的数据空间中,它是一种非线性划分。
但是讨论支持向量机的算法时,并不是讨论如何定义低维到高维空间的映射算法(该算法隐含在其“核函数”中),而是从最优化问题(寻找某个目标的最优解)的角度来考虑的。
3、最优化问题我们解决一个问题时,如果将该问题表示为一个函数f(x),最优化问题就是求该函数的极小值。
通过高等数学知识可以知道,如果该函数连续可导,就可以通过求导,计算导数=0的点,来求出其极值。
但现实问题中,如果f(x)不是连续可导的,就不能用这种方法了。
最优化问题就是讨论这种情况。
SVM的常用多分类算法概述

SVM的常用多分类算法概述摘要:SVM方法是建立在统计学习理论基础上的机器学习方法,具有相对优良的分类性能,是一种非线性分类器。
最初SVM是用以解决两类分类问题,不能直接用于多类分类,当前已经有许多算法将SVM推广到多类分类问题,其中最常用两类:OAA和OAO算法,本文主要介绍这两类常用的多分类算法。
关键词:SVM;多分类;最优化自从90年代初V. Vapnik提出经典的支持向量机理论(SVM),由于其完整的理论框架和在实际应用中取得的很多好的效果,在模式识别、函数逼近和概率密度估计领域受到了广泛的重视。
SVM方法是建立在统计学习理论基础上的机器学习方法,具有相对优良的分类性能。
SVM是一种非线性分类器。
它的基本思想是将输入空间中的样本通过某种非线性函数关系映射到一个特征空间中,使两类样本在此特征空间中线性可分,并寻找样本在此特征空间中的最优线性区分平面。
它的几个主要优点是可以解决小样本情况下的机器学习问题,提高泛化性能,解决高维问题、非线性问题,可以避免神经网络结构选择和局部极小点问题。
1. SVM方法若样本集Q={(x i,y i)|i=1,……,L}∈R d*{-1,+1}是线性可分的。
则存在分类超平面w T x+b=0,x∈R d对样本集Q中任一(x i,y i)都满足:在空间R d中样本x=(x1,…, x d)r到分类超平面的距离d=|w T*x+b|/||w||,其中||w||= .当存在x 使得w T x i+b=±1, 则图1中超平面的分类间隔margin = 2/ ‖w ‖。
使分类间隔margin 最大的超平面即为最优分类超平面。
寻找最优分类超平面的问题将转化为求如下一个二次规划问题:minΦ( w) =1/2‖w ‖满足约束条件:y i ( w T x i + b) ≥1 , i = 1 ,2 , ⋯, L采用Lagrange 乘子转换为一个对偶问题,形式如下:满足约束条件:0≤a i,i=1,……,L )其中a i为每一个样本对应的Lagrange 乘子, 根据Kuhn2Tucker 条件,这个优化的解必须满足:a i (y i [w T x i +b]-1)=0,i=1,……,L因此多数样本对应 a i将为0 ,少部分不为0 的a i对应的样本就是支持向量。
基于SVM模式识别系统的设计与实现代码大全

基于SVM模式识别系统的设计与实现1.1 主要研究内容(1)现有的手写识别系统普遍采用k近邻分类器,在2000个数字中,每个数字大约有200个样本,但实际使用这个算法时,算法的执行效率并不高,因为算法需要为每个测试向量做2000次距离计算,每个距离计算包括了1024个维度浮点运算,总计要执行900次,此外需要保留所有的训练样本,还需要为测试向量准备2MB的存储空间。
因此我们要做的是在其性能不变的同时,使用更少的内存。
所以考虑使用支持向量机来代替kNN方法,对于支持向量机而言,其需要保留的样本少了很多,因为结果只是保留了支持向量的那些点,但是能获得更快更满意的效果。
(2)系统流程图step1. 收集数据(提供数字图片)step2. 处理数据(将带有数字的图片二值化)step3. 基于二值图像构造向量step4. 训练算法采用径向基核函数运行SMO算法step5. 测试算法(编写函数测试不同参数)1.2 题目研究的工作基础或实验条件(1)荣耀MagicBook笔记本(2)Linux ubuntu 18.6操作系统pycharm 2021 python31.3 数据集描述数据集为trainingDigits和testDigits,trainingDigits包含了大约2000个数字图片,每个数字图片有200个样本;testDigits包含了大约900个测试数据。
1.4 特征提取过程描述将数字图片进行二值化特征提取,为了使用SVM分类器,必须将图像格式化处理为一个向量,将把32×32的二进制图像转换为1×1024的向量,使得SVM可以处理图像信息。
得到处理后的图片如图所示:图1 二值化后的图片编写函数img2vector ,将图像转换为向量:该函数创建1x1024的NumPy 数组,然后打开给定的文件,循环读出文件的前32行,并将每行的头32个字符值存储在 NumPy 数组中,最后返回数组,代码如图2所示:图2 处理数组1.5 分类过程描述 1.5.1 寻找最大间隔寻找最大间隔,就要找到一个点到分割超平面的距离,就必须要算出点到分隔面的法线或垂线的长度。
线性分类器

中心问题:
1.存在一个间隔,满足
tic
Yd = svmSim(svm,Xt); %测试输出
t_sim = toc;
Yd = reshape(Yd,rows,cols);
%画出二维等值线图
contour(x1,x2,Yd,[0 0],'m'); %分类面
hold off;
3.3支持向量机实验结果参见下图:
评价三种方法的方法???
for i=1:N
if((X(i,:)*w)*y(i)<0)
mis_clas=mis_clas+1;
gradi=gradi+rho*(-y(i)*X(i,:))';
end
end
w=w-rho*gradi;%最后推到的那个公式
end
s(1)=1.6; t(1)=-s(1)*w(1)/w(2)-w(3)/w(2);
s(2)=11.2; t(2)=-s(2)*w(1)/w(2)-w(3)/w(2);%确定直线需要的两个点
figure(2)
plot(X(1:45,1),X(1:45,2),'*',X(46:100,1),X(46:100,2),'o',s,t);%绘制分界线
axis([0,12,0,8]);
1.3感知器算法实验结果参见下图
其中是第次迭代的权向量估计,并且是一系列的正实数。但是在这里必须注意:不连续的点除外。从感知机代价的定义以及有小点可以得到,
基于SVM分类决策与闭环控制的教室灯控系统

• 166•当前,我国学校教室灯光由于无法自动调控,照明灯的强弱易影响学生的视力;此外,当光线充足或无人少人时的“长明灯”会导致照明电能浪费。
(夏勇,黄子豪,教室灯光节能控制系统的设计:科学与财富,2014)本文采用以深度学习技术为核心的SVM 多分类学习决策,通过挖掘多种传感器的数据信息进行分析决策,并结合PID 控制系统实现教室灯光的自动调控,且满足当前环境所需的最优的亮度。
实践表明,该系统能充分适应室内人员的健康照明需求,又能最大程度的降低照明能耗,节约电能,具有一定的实际意义与推广价值。
1 引言2018年8月,教育部、国家卫健委等8部门联合印发了《综合防控儿童青少年近视实施方案》,呼吁社会要共同呵护好孩子们的眼睛;当前,我国的中小学学生每天约60%的时间在教室,教室灯光不达标严重的影响了学生的日常用眼(程丹丹,张广群,大学教室室内光环境测试分析:安徽建筑,2019),是学生近视的主因之一;而另一个方面,由于大学均为开放型教室且学生节能观念不强,在我国高校教室里存在着如白天光线充足或无人少人的情况下“长明灯”等现象,造成了校园电能的大量浪费。
而国内的绝大多数教室灯光无法根据实际情况进行自动调控,达到节能护眼效果。
为了解决上述两类问题,本文设计了一套基于SVM 多分类决策,以深度学习技术为核心,多种传感器辅助检测以及PID 控制的教室灯光控制系统。
还系统能充分且健康的满足室内人员的照明需求,解决无效照明的问题,实现了对教室灯光的智能化控制及节约电能。
图1 基于SVM多分类决策教室灯控制管理系统结构设计图2 系统工作原理本文对教室进行区域划分,在每个照明区域配备一个控制监测节点,该节点以ESP8266芯片为核心控制模块,外围配以多种模块进行温度、亮度以及灯管对应区域人员的检测,通过WiFi 将采集到的多种数据传至中控电脑进行SVM 多分类决策并将所得最优值反馈至ESP8266,输出PWM 控制可控硅调光模块调节灯管亮度。
SVM分类器实现实例
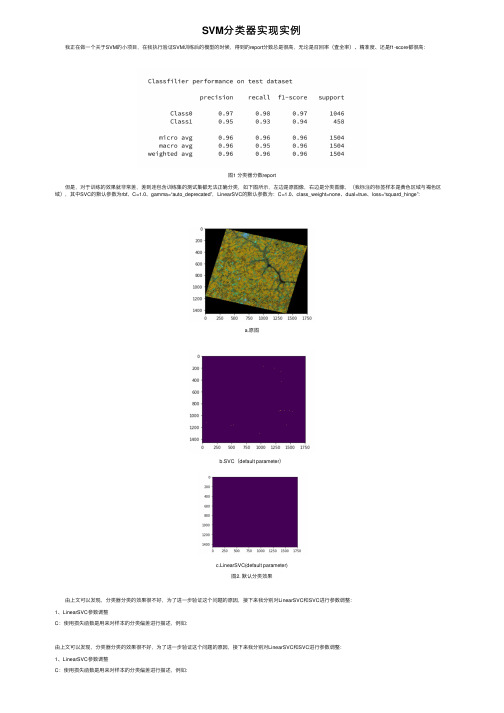
SVM分类器实现实例 我正在做⼀个关于SVM的⼩项⽬,在我执⾏验证SVM训练后的模型的时候,得到的report分数总是很⾼,⽆论是召回率(查全率)、精准度、还是f1-score都很⾼:图1 分类器分数report 但是,对于训练的效果就⾮常差,差到连包含训练集的测试集都⽆法正确分类,如下图所⽰,左边是原图像,右边是分类图像,(我标注的标签样本是黄⾊区域与褐⾊区域),其中SVC的默认参数为rbf、C=1.0、gamma=“auto_deprecated”,LinearSVC的默认参数为:C=1.0、class_weight=none、dual=true、loss=“squard_hinge”:a.原图b.SVC(default parameter)c.LinearSVC(default parameter)图2. 默认分类效果 由上⽂可以发现,分类器分类的效果很不好,为了进⼀步验证这个问题的原因,接下来我分别对LinearSVC和SVC进⾏参数调整:1、LinearSVC参数调整C:使⽤损失函数是⽤来对样本的分类偏差进⾏描述,例如:由上⽂可以发现,分类器分类的效果很不好,为了进⼀步验证这个问题的原因,接下来我分别对LinearSVC和SVC进⾏参数调整:1、LinearSVC参数调整C:使⽤损失函数是⽤来对样本的分类偏差进⾏描述,例如:引⼊松弛变量后,优化问题可以写为:约束条件为:对于不同的C值对于本实例中的分类影响为,如图3所⽰:图3. LinearSVC在不同惩罚系数C下的表现由此可以看出SVC在惩罚系数为0.3、4.0、300时能够较准确根据颜⾊对图像进⾏分类。
但是作者发现,惩罚系数相同,重新训练时,会有不同的效果展⽰,才疏学浅,尚未能解释,如果有知道为什么的⼤神,敬请指点迷津。
2、SVC参数调整SVC模型中有两个⾮常重要的参数,即C与gamma,其中C是惩罚系数,这⾥的惩罚系数同LinearSVC中的惩罚系数意义相同,表⽰对误差的宽容度,C越⾼,说明越是不能容忍误差的出现,C越⼩,表⽰越容易⽋拟合,泛化能⼒变差。
SVM分类器的原理及应用

SVM分类器的原理及应用姓名:苏刚学号:1515063004学院:数学与计算机学院一、SVM分类器的原理SVM法即支持向量机(Support Vector Machine)法,由Vapnik等人于1995年提出,具有相对优良的性能指标。
该方法是建立在统计学习理论基础上的机器学习方法。
通过学习算法,SVM可以自动寻找出那些对分类有较好区分能力的支持向量,由此构造出的分类器可以最大化类与类的间隔,因而有较好的适应能力和较高的分准率。
该方法只需要由各类域的边界样本的类别来决定最后的分类结果。
支持向量机算法的目的在于寻找一个超平面H(d),该超平面可以将训练集中的数据分开,且与类域边界的沿垂直于该超平面方向的距离最大,故SVM法亦被称为最大边缘(maximum margin)算法。
待分样本集中的大部分样本不是支持向量,移去或者减少这些样本对分类结果没有影响,SVM法对小样本情况下的自动分类有着较好的分类结果.SVM方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(Hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题。
简单地说,就是升维和线性化。
升维,就是把样本向高维空间做映射,一般情况下这会增加计算的复杂性,甚至会引起“维数灾难”,因而人们很少问津。
但是作为分类、回归等问题来说,很可能在低维样本空间无法线性处理的样本集,在高维特征空间中却可以通过一个线性超平面实现线性划分(或回归)。
一般的升维都会带来计算的复杂化,SVM方法巧妙地解决了这个难题:应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”。
这一切要归功于核函数的展开和计算理论。
选择不同的核函数,可以生成不同的SVM,常用的核函数有以下4种:⑴线性核函数K(x,y)=x·y;⑵多项式核函数K(x,y)=[(x·y)+1]^d;⑶径向基函数K(x,y)=exp(-|x-y|^2/d^2);⑷二层神经网络核函数K(x,y)=tanh(a(x·y)+b);二、SVM分类器的应用2.1 人脸检测、验证和识别Osuna最早将SVM应用于人脸检测,并取得了较好的效果。
基于SVM的车辆自动分类方法研究与实现的开题报告

基于SVM的车辆自动分类方法研究与实现的开题报告一、研究背景车辆自动分类技术是指通过计算机视觉、机器学习等技术,对车辆进行自动分类识别,可以应用于智能交通、安防监控等领域。
目前,车辆自动分类技术已经成为计算机视觉和模式识别方向的研究热点之一。
SVM(Support Vector Machine)作为一种机器学习算法,也被广泛应用于车辆自动分类领域。
二、研究目的本研究旨在基于SVM算法,通过对车辆图像特征的提取和分类器的训练,实现车辆自动分类的目的。
具体来说,研究将完成以下几个方面的任务:1.选择合适的车辆数据集,并对数据集进行预处理,包括图像去噪、图像增强等。
2.提取车辆图像的特征,根据分类任务的不同,选择不同的特征提取方法,如颜色直方图、纹理特征、形状特征等。
3.建立SVM分类器,选择合适的核函数和参数,进行训练和优化。
4.评估分类器的性能,包括分类准确度、召回率、F1值等指标。
5.实现基于SVM的车辆自动分类系统并验证其效果。
三、研究方法和步骤1.数据集的选取和处理。
选择CARPK和PKU-VehicleID两个公开数据集进行实验,并对图像进行预处理,包括去噪,增强等。
2.特征提取。
选择经典的颜色直方图、LBP(Local Binary Pattern)等特征提取算法,并结合PCA(Principal Component Analysis)等降维算法,提取最能表示车辆的特征。
3.分类器的建立和训练。
选择SVM算法,并通过网格搜索法选取合适的核函数和参数,对分类器进行训练和优化。
4.分类器的评估。
使用交叉验证和ROC曲线等方法来评估分类器的性能和稳定性。
5.系统实现和性能测试。
基于Python语言实现基于SVM的车辆自动分类系统,并对其分类准确度、召回率等进行测试。
四、研究意义本研究对车辆自动分类技术的发展有一定的推动作用,同时也可以应用于智能交通、车辆安防等领域,为实现智能化生产和生活服务做出贡献。
3种线性分类器的设计及MATLAB建模
线性分类器设计(张天航空天科学技术研究院201121250314)1 问题描述对“data1.m”数据,分别采用感知机算法、最小平方误差算法、线性SVM算法设计分类器,分别画出决策面,并比较性能。
(注意讨论算法中参数设置的影响。
)2 方法描述2.1 感知机算法线性分类器的第一个迭代算法是1956年由Frank Rosenblatt提出的,即具有自学习能力的感知器(Perceptron)神经网络模型,用来模拟动物或者人脑的感知和学习能力。
这个算法被提出后,受到了很大的关注。
感知器在神经网络发展的历史上占据着特殊的位置:它是第一个从算法上完整描述的神经网络,是一种具有分层神经网络结构、神经元之间有自适应权相连接的神经网络的一个基本网络。
感知器的学习过程是不断改变权向量的输入,更新结构中的可变参数,最后实现在有限次迭代之后的收敛。
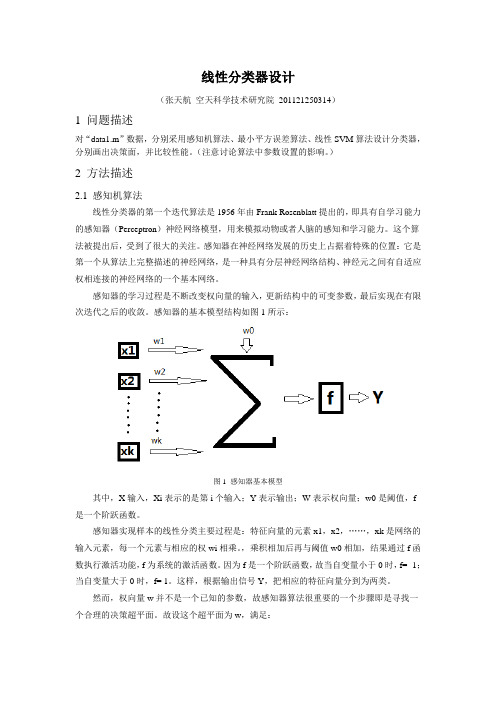
感知器的基本模型结构如图1所示:图1 感知器基本模型其中,X输入,Xi表示的是第i个输入;Y表示输出;W表示权向量;w0是阈值,f 是一个阶跃函数。
感知器实现样本的线性分类主要过程是:特征向量的元素x1,x2,……,xk是网络的输入元素,每一个元素与相应的权wi相乘。
,乘积相加后再与阈值w0相加,结果通过f函数执行激活功能,f为系统的激活函数。
因为f是一个阶跃函数,故当自变量小于0时,f= -1;当自变量大于0时,f= 1。
这样,根据输出信号Y,把相应的特征向量分到为两类。
然而,权向量w并不是一个已知的参数,故感知器算法很重要的一个步骤即是寻找一个合理的决策超平面。
故设这个超平面为w,满足:12*0,*0,T Tw x x w x x ωω>∀∈<∀∈ (1)引入一个代价函数,定义为:()**T x x YJ w w xδ∈=∑ (2)其中,Y 是权向量w 定义的超平面错误分类的训练向量的子集。
变量x δ定义为:当1x ω∈时,x δ= -1;当2x ω∈时,x δ= +1。
【推荐】svm算法实验实验报告-范文模板 (13页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==svm算法实验实验报告篇一:SVM 实验报告SVM分类算法一、数据源说明1、数据源说远和理解:采用的实验数据源为第6组:The Insurance Company Benchmark (COIL 201X) TICDATA201X.txt: 这个数据集用来训练和检验预测模型,并且建立了一个5822个客户的记录的描述。
每个记录由86个属性组成,包含社会人口数据(属性1-43)和产品的所有关系(属性44-86 )。
社会人口数据是由派生邮政编码派生而来的,生活在具有相同邮政编码地区的所有客户都具有相同的社会人口属性。
第86个属性:“大篷车:家庭移动政策” ,是我们的目标变量。
共有5822条记录,根据要求,全部用来训练。
TICEVAL201X.txt: 这个数据集是需要预测( 4000个客户记录)的数据集。
它和TICDATA201X.txt它具有相同的格式,只是没有最后一列的目标记录。
我们只希望返回预测目标的列表集,所有数据集都用制表符进行分隔。
共有4003(自己加了三条数据),根据要求,用来做预测。
TICTGTS201X.txt:最终的目标评估数据。
这是一个实际情况下的目标数据,将与我们预测的结果进行校验。
我们的预测结果将放在result.txt文件中。
数据集理解:本实验任务可以理解为分类问题,即分为2类,也就是数据源的第86列,可以分为0、1两类。
我们首先需要对TICDATA201X.txt进行训练,生成model,再根据model进行预测。
2、数据清理代码中需要对数据集进行缩放的目的在于:A、避免一些特征值范围过大而另一些特征值范围过小;B、避免在训练时为了计算核函数而计算内积的时候引起数值计算的困难。
因此,通常将数据缩放到 [ -1,1] 或者是 [0,1] 之间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SVM分类器设计1.引言支撑矢量机(SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
SVM分类器在推广性和经验误差两方面能达到平衡,是目前比较盛行的分类器。
1.1 什么是SVM分类器所谓支持向量机,顾名思义,分为两个部分了解,一什么是支持向量,简单来说,就是支持或者是支撑平面上把两类类别划分开来的超平面的向量点;二这里的“机”是什么意思。
“机(machine,机器)”便是一个算法。
在机器学习领域,常把一些算法看做是一个机器,如分类机(当然,也叫做分类器),而支持向量机本身便是一种监督式学习的方法它广泛的应用于统计分类以及回归分析中。
SVM的主要思想可以概括为两点:⑴它是针对线性可分情况进行分析;(2)对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
1.2 SVM分类器的优点和缺点优点:(1)由于核函数隐含一个复杂映射,经验误差小,因此针对小样本数据利用支持向量能够完成线性或非线性规划问题;推广性和经验误差平衡。
(2)SVM 的最终决策函数只由靠近边界的少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”。
(3)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性。
这种“鲁棒”性主要体现在:①增、删非支持向量样本对模型没有影响;②支持向量样本集具有一定的鲁棒性; ③有些成功的应用中,SVM 方法对核的选取不敏感缺点:(1)在训练分类器时 ,SVM的着眼点在于两类的交界部分 ,那些混杂在另一类中的点往往无助于提高分类器的性能 ,反而会大大增加训练器的计算负担 ,同时它们的存在还可能造成过学习 ,使泛化能力减弱 .为了改善支持向量机的泛化能力。
(2)SVM算法对大规模训练样本难以实施。
由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间。
(3)用SVM解决多分类问题存在困难。
经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。
可以通过多个二类支持向量机的组合来解决。
主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。
主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。
如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器1.3 SVM分类器当前研究热点(1)针对大样本数据训练难度问题,对SVM算法的改进。
例如J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法。
(2)如何降低边界混杂点(即所谓统计误差导致的“不干净”点)导致的不必要的训练计算负担,增强泛化能力。
这种思路聚焦于样本数据预处理的探索,例如NN-SVM。
(3)分类器设计思想之间的融合以及取长补短。
例如[2]采样支撑矢量机和最近邻分类相结合的方法,在提高支撑矢量机的精度的同时,也较好的解决了核参数的问题。
1.4 本文所解决的问题本文对所给的二类样本,随机生成等容量的训练样本和测试样本,利用训练样本使用三种核函数生成最优决策超平面,对测试样本进行判决,将测试结果与训练目标进行比较。
使用“特异性”和“敏感度”两个指标评估不同核函数的下支撑矢量机的性能。
2.SVM 方法论述支持向量机中对于非线性可分的情况,可使用一个非线性函数)(x ϕ把数据映射到一个高维特征空间,在高维特征空间建立优化超平面,判决函数变为:⎥⎦⎤⎢⎣⎡+><=∑=n i i i i b x x y Sgn x f 1)(),()(ϕϕα一般无法知道)(x ϕ的具体表达,也难以知晓样本映射到高维空间后的维数、分布等情况,不能再高维空间求解超平面。
由于SVM 理论只考虑高维特征空间的点积运算><)(),(j i x x ϕϕ,而点积运算可由其对应的核函数直接给出,即=),(j i x x K ><)(),(j i x x ϕϕ,用内积),(j i x x K 代替最优分类面中的点积,就相当于把原特征空间变换到了某一新的特征空间,得到新的优化函数:Max: ),(21)(1,1j lj i i i j i li i x x K y W ∑∑==-=ααααSubject to C i ≤≤α0,0=∑i ii y α l i i ,,2,1,0 =≥α求解上述问题后得到的最优分类函数是:⎥⎦⎤⎢⎣⎡+=∑=n i i i i b x x K y Sgn x f 1),()(αb 是分类阀值,可以用任一个支持向量求得,或通过两类中任意一对支持向量取中值求得。
其中核函数),(x x K i 可以有多种形式,常用的有:(1)线性核,Linear :>⋅=<y x y x K ),(;线性分类时使用 (2)多项式核,Poly :di i x x x x K )1,(),(+><=,d 是自然数;(3)径向基核,Radial Basis Fuction(RBF)核0),gp ex p(),(22>--=gp x x x x K j i i(4)sigmoid 核:dT i y k x x K )x tanh(),(j δ-=,其中k, δ均是常数3.实验及验证3.1流程图及其解释Fig1 支撑矢量机训练以及测试设计流程图实验步骤:1.将数据随机分为两组,一组用来训练一组用来测试;2.分别使用三种核函数对训练样本进行SVM 训练;3.将三种核函数的结果分别针对测试集测试;4.分析测试的结果。
3.2实验衡量指标本文使用三个指标定义参数的影响:敏感度(sensitivity)、特异性(specificity ),耗时长(time-consumption )。
1.敏感度:%100*ds +=c censitivity2.特异性: %100*ba+=a y specificit3.耗时长: start end T T n consumptio time -=-数据读取并随机分组训练样本测试样本SVM 训练多项式核高斯核反曲核3种决策超平面训练结果分析测试结果分析判别其中,a定义为类1判定为类1的样本数目,b为类1判定为类2的样本数目,c为类2判定为类1的样本数目,d为类2判定为类2的样本数目。
T start为程序自二次优化开始的时间,T end为程序计算出所有参数后的时间。
3.3实验结果分析Fig2 训练集得到的决策超平面,红色‘O’标定支撑矢量Fig3对应利用决策平面对测试集的分类效果红色‘O’标定错误分类样本Fig2和Fig3是在定义拉格朗日乘子上界为C=100,径向基核参数gp=2的分类效果。
那么涉及到径向基核参数gp和拉格朗日乘子上界C最优问题,本实验以这两者为自变量,以敏感度,特异性,耗时长为因变量。
在gp]10,1[∈∈C],1000,100[的范围内寻找最优点,结果画图如下。
Fig4.敏感度随拉格朗日乘子上界C和径向基核参数gp的变化Fig5.特异性随拉格朗日乘子上界C和径向基核参数gp的变化Fig6.耗时长随拉格朗日乘子上界C和径向基核参数gp的变化敏感度(sensitivity):反应实际为真(训练目标表征为1)且检测出来也为真的概率,值越大说明分类器越灵敏。
从Fig4我们可以很明显看出,固定核参数gp,当上界为400时,敏感度达到谷底,故朗格朗日乘子上界C应该尽量偏离这个值。
特异性(specificity):反应实际为假(训练目标表征为-1)检测也为假的概率,此值越大说明分类越精确。
从图Fig5可以看出,固定核参数时gp时,在100<=C<=800时候,特异性较强,而大于800的时候,有明显的快速下降趋势。
耗时长(Time-consumption):反应算法的运行时间。
由图Fig6可以很清楚的看出固定径向基参数,耗时长波动较大。
综上所述,径向基核的核参数gp对分类器影响并不是最直观的,相反,朗格朗日乘子的上界对于分类效果有着很大的影响。
对于本次分类实验,设定径向基参数gp=2,C=800效果较好。
3.3实验不足实际上,本次实验并没能利用多项式核和sigmoid核获得较好的分类效果,其中多项式核尚能出现分类决策面,而sigmiod核完全无法获得优化效果。
其中利用多项式核获得的结果如下:Fig7 训练集得到的决策超平面,红色‘O’标定支撑矢量Fig8对应利用决策平面对测试集的分类效果红色‘O’标定错误分类样本如上所述,利用sigmoid核并未获得期望的结果,故此处未说明并展示。
4.实验结论以及后期探索本次实验有分别利用三种核函数对训练集训练得到SVM分类器,继而对测试集进行测试,其中定义了敏感度、特异性和耗时长三种指标定义分类器性能。
结论如下:1.本实验的样本集近似于高斯分布,采用径向基核(RBF)取得了较满意的效果;其次是多项式核,sigmoid核并未展示出较好的性能。
2.对于径向基核函数。
相较于核参数,朗格朗日乘子上界对敏感度、特异性、耗时长有较为大的影响。
实验证明,当朗格朗日乘子上界C=800,核参数gp=2;时,三个衡量指标能够达到平衡。
3.核函数对于实验结果影响较大,核函数参数的设定需要一定的工作量。
本次实验最大失败是未能对多项式核和sigmiod核的性能作出探索,未达到预期的效果,未来的探索应该集中在:1.SVM分类器的改进与加强,如样本的预处理;2.核函数的本质与最新发展。
附录1 主函数%function [sensitivity,specificity,time]=svm(x,y,xtest,gp,C)clc;clear all;%*************************************************************%% 获得数据%*************************************************************%[X1,X2]=getdata();m=length(X1);n=length(X2);%*************************************************************%% 将数据的1,2类样本随机分为2组,一组训练一组测试%*************************************************************%x1=zeros(2,m/2);x2=zeros(2,n/2);%存储训练样本x3=zeros(2,m/2);x4=zeros(2,n/2);%存储测试样本temp1=randperm(m);%随机将数据分为两组,一组用于训练一组测试temp2=randperm(n);for i=1:m/2x1(:,i)=X1(:,temp1(i));%训练用x3(:,i)=X1(:,temp1(i+m/2));%测试用endfor j=1:n/2x2(:,j)=X2(:,temp2(j));%训练用x4(:,j)=X2(:,temp2(j+n/2));%测试用endy1=ones(1,m/2);y2=-ones(1,n/2);Y = [y1,y2];%训练目标1*n矩阵,n为样本个数,值为+1或-1X = [x1,x2];%训练样本2*n矩阵Xtest=[x3,x4];%*************************************************************%% 获得训练结果并对测试样本分类%*************************************************************%t1=clock;%四种核函数的调用格式:%调用格式中的参数解释:% degree - Degree d of polynomial kernel (positive scalar).% offset - Offset c of polynomial and tanh kernel (scalar, negative for tanh). % width - Width s of Gauss kernel (positive scalar).% gamma - Slope g of the tanh kernel (positive scalar).% ker = struct('type','linear');%ker = struct('type','ploy','degree',2,'offset',1);%ker = struct('type','gauss','width',2);ker = struct('type','tanh','gamma',2,'offset',0);%相应的核函数产生训练结果svm=svmtrain(ker,X,Y,800);%利用训练样本对测试样本分类Ytest=svmtest(svm,Xtest);g=Ytest-Y;t2=clock;%*************************************************************% % 性能指标计算%*************************************************************% fp=length(find(g==2));fn=length(find(g==-2));tp=length(find(g(1:50)==0));tn=length(find(g(51:105)==0));sensitivity=tp/(tp+fn);specificity=tn/(tn+fp);time=etime(t2,t1);%*************************************************************% % 显示%*************************************************************% %显示训练样本figure(1);plot(x1(1,:),x1(2,:),'b*',x2(1,:),x2(2,:),'g+')xlabel('Training Set with SV Maked by "red O"');hold on;%标记支撑矢量a=svm.a;e=1e-8;sv=find(abs(a)>e);plot(X(1,sv),X(2,sv),'ro');grid on;%画出决策面drawing(svm);figure(2);%画出错误分类的测试样本temp=find(abs(g)>0);plot(x3(1,:),x3(2,:),'*',x4(1,:),x4(2,:),'+');hold on;plot(Xtest(1,temp),Xtest(2,temp),'ro');xlabel('The Test Result with Error Dots marked by"O"');%标记决策面drawing(svm);其中调用的子函数说明,子函数见压缩包gedata.m 读取样本数据子函数smtrain.m 训练SVM分类器子函数svmtest.m 使用已经训练出的分类器对测试样本进行测试子函数kernel.m 使用结构体变量为参数返回不同的kernel矩阵子函数。