shell学习笔记(4)
shell函数参数传递详解

shell函数参数传递详解摘要:一、shell编程基础二、函数定义与调用三、参数传递方式四、实战案例解析正文:一、shell编程基础Shell是一种命令行解释器,主要用于执行脚本程序。
它基于Unix操作系统,可以理解为一种简化的、面向任务的编程语言。
在shell编程中,我们可以使用脚本文件来实现各种功能,如文件操作、系统管理等。
本文将重点介绍shell函数参数传递的相关知识,帮助大家更好地掌握shell编程。
二、函数定义与调用在shell脚本中,函数是一种组织代码的方式,它可以将一系列相关操作组合在一起,提高代码的可读性和可维护性。
函数的定义和使用类似于其他编程语言,如Python、Java等。
函数定义:使用`function`关键字,followed by 函数名、括号和括号内的参数列表。
例如:```bashfunction my_function() {echo "Hello, $1!"}```函数调用:使用函数名,可以带参数,也可以不带参数。
例如:```bashmy_function "World"```三、参数传递方式在shell脚本中,函数参数的传递主要有以下几种方式:1.位置参数:根据参数在函数定义中的位置来传递。
如:```bashfunction my_function() {echo "Hello, $1!"echo "Hello, $2!"}my_function "World" "Linux"```2.命名参数:通过为参数指定名称来传递。
如:```bashfunction my_function() {echo "Hello, $1!"echo "Hello, $2!"}my_function "World" "Linux" "Unix"```3.关联参数:通过关联数组传递。
shell编程学习笔记(四):Shell中转义字符的输出

shell编程学习笔记(四):Shell中转义字符的输出
通过echo可以输出字符串,下⾯看⼀下怎么输出特殊转义字符,⾸先我先列出来echo的转义字符:
\\ 输⼊\
\a 输出警告⾳
\b 退格,即向左删除⼀个字符
\c 取消输出⾏末的换⾏符,和-n选项⼀致
\e Esc
\f 换页符
\n 换⾏
\r 回车
\t 制表,即Tab
\v 垂直制表符
\0nnn 按照⼋进制ASCII码表输出字符,其中0为数字零,nnn是三位⼋进制数
\xhh 按照⼗六进制ASCII码表输出字符,其中hh是两位⼗六进制数
以下蓝⾊字体部分为Linux命令,红⾊字体的内容为输出的内容:
# cd /opt/scripts
# vim script04.sh
开始编写script04.sh的脚本,脚本内容为:
#! /bin/sh
echo -e "hello world\nhello\n"
echo -e -n "hello\n"
echo -e "this is a new line.\n"
# chmod +x script04.sh
# ./script04.sh
hello world
hello
hello
this is a new line.
上⾯的代码⽐较简单,我主要说⼀下echo后⾯带的选项:
-e 必须添加-e选项,输出的内容才⽀持转义输出
-n 不输出⾏尾的换⾏符,默认每⼀个echo都会在最后添加⼀个换⾏符。
注意-n选项并不被所有Linux版本⽀持。
POSIX标准中并未包含此选项。
shell脚本编程(完结版)

if [ 条件表达式 2 ] then …… …… else …… …… fi
命令串; else
命令串; fi
如有任何疑问,请联系作者,作者 QQ:1028150787,或者到韦脚本编程学习笔记 2013 年 5 月 2 日 追风~忆梦
1. 整数测试运算
test int1 -eq int2: 判断两个数是否相等 test int1 -ne int2: 判断两个数是否不相等 test int1 -gt int2: 判断整数 1 是否大于整数 2 test int1 -ge int2: 判断整数 1 是否大于等于整数 2 test int1 -lt int2: 判断整数 1 是否小于整数 2 test int1 -le int2: 判断整数 1 是否小于等于整数 2 整数测试也可以使用 let 命令或双圆括号 相关操作为:== 、!= 、> 、>= 、< 、<= 如: x=1; [ $x -eq 1 ]; echo $? x=1; let "$x == 1"; echo $? x=1; (($x+1>= 2 )); echo $? 两种测试方法的区别: 使用的操作符不同 let 和 双圆括号中可以使用算术表达式,而中括号不能 let 和 双圆括号中,操作符两边可以不留空格
1. 整数测试运算 .................................................4 2. 字符串测试运算 ...............................................4 3. 文件测试运算 .................................................5 4. 逻辑运算 .....................................................5 第二节 在 shell 脚本中进行条件控制 ................................ 5 第三节 在 shell 脚本中进行 for 循环 ................................ 7 第四节 在 shell 脚本中进行 while 循环 .............................. 8 第五节 在 shell 脚本中使用 util 循环 ............................... 8 第六节 在 shell 脚本中使用函数 .................................... 8 第七节 shell 脚本之 echo 和 expr 讲解 ................................ 9 第八节 shell 脚本循环终止之 break 和 continue ..................... 10 第九节 shell 脚本之 exit 和 sleep ................................. 11 第十节 shell 脚本之 select 循环与菜单 ............................. 11 第十一节 shell 脚本之循环控制 shift 命令 .......................... 11 第十二节 shell 脚本之字符串操作 ................................... 11 第十三节 shell 脚本之数组实现 ..................................... 12 第十四节 shell 脚本之脚本调试 ..................................... 12 第十五节 shell 脚本之编程小结 ..................................... 12 程序例程 ......................................................... 14 习题实训 ......................................................... 29 综合实例 ......................................................... 31 1. 需求分析....................................................31 2.系统设计 ....................................................31 3.程序代码 ....................................................31 声明 ............................................................. 35
shell编程基础知识点

shell编程基础知识点
一、Shell 编程基础知识
1、什么是 Shell
Shell 是一种用户使用的解释型程序,它是操作系统的一部分,派生自多种不同的系统。
它是一种命令解释器,它可以读取用户的输入,解释该输入,并执行相应的命令。
Linux 的 Shell 有很多种,如 bash,csh,ksh 等。
2、Shell 的特性
(1) 交互式:用户可以通过 Shell 的界面实现与计算机的交互,以便用户和计算机之间的信息交换。
(2) 自动化:Shell 可以将用户编写的一系列命令,保存为脚本,并在需要的时候自动执行,以减少用户的工作量。
(3) 扩展性:Shell 可以实现过滤和管道功能,可以与其他应用程序和编程语言结合使用,实现不同应用程序、不同编程语言之间的信息传递。
3、Shell 命令
(1)ls : 列出目录内容。
(2)cd : 改变目录。
(3)pwd : 显示当前所在目录。
(4)mkdir : 创建目录。
(5)rm : 删除文件或目录。
(6)cat : 显示文件内容。
(7)echo : 向屏幕输出指定字符串。
(8)exit : 退出当前 shell 环境。
(9)man : 查看指定命令的帮助文档。
(10)chmod : 改变文件权限。
linux+shell脚本语言基础知识

linux+shell脚本语言基础知识linuxshell脚本语言基础知识一.shell简介linux系统的shell做为操作系统的外壳,为用户提供更多采用操作系统的界面,更确切的说,shell是用户与linux操作系统沟通的桥梁。
用户既可以输入命令执行,又可以利用shell脚本编程,完成更加复杂的操作。
shell就是一个命令解释器,它从输出设备加载命令,再将其变为计算机可以以了解的指令,然后执行它。
在linux中,shell又不仅是简单的命令解释器,而且是一个全功能的编程环境。
linux的shell种类众多,常用的存有:bourneshell(/usr/bin/sh或/bin/sh)、bourneagainshell(/bin/bash)、cshell(/usr/bin/csh)、kshell(/usr/bin/ksh)、shellforroot(/sbin/sh),等等。
不同的shell语言的语法有所不同,所以不能交换使用。
每种shell都有其特色之处,基本上,掌握其中任何一种就足够了。
通常用bash,也就是bourneagainshell进行编程。
二.shell采用1.建立和运行shell程序shell脚本程序:按照一定的语法结构把若干linux命令非政府在一起,就是这些命令按照我们的要求完成一定的功能。
它可以进行类似程序的编写,并且不需要编译就能执行。
(只需修改其权限)像是撰写高级语言的程序一样,撰写shell程序须要一个文本编辑器,如vi和vim,通常采用vim文本编辑器,积极支持更便捷的填入模式。
首先采用vim编辑器编辑一个hello.sh文件:#!/bin/bash#helloworldexampleecho\这样,一个最简单的shell程序就撰写完了。
第一行:#!说明hello.sh这个文件的类型的,这有点类似于windows系统下的用不同的文件后缀来表示不同的文件类型,但又不完全相同。
《Linux命令行与shell脚本编程大全 第4版 》读书笔记PPT模板思维导图下载

引言
致谢
第一部分 Linux命令行
01
第1章 初 识Linux shell
02
第2章 走 进shell
03
第3章 bash shell基 础命令
04
第4章 更 多的 bash shell命 令
05
第5章 理 解shell
06
第6章 Linux环 境变量
第7章 理解 Linux文件权限
第8章 管理文件 系统
02
9.2 基于 Debian 的系统
03
9.3 基于 Red Hat的系 统
04
9.4 使用 容器管理 软件
06
9.6 小结
05
9.5 从源 代码安装
01
10.1 vim编辑 器
02
10.2 nano编 辑器
03
10.3 Emacs 编辑器
04
10.4 KDE系编 辑器
06
10.6 小 结
05
10.5 GNOME 编辑器
第9章 安装软件
第10章 文本编辑 器
1.2 Linux发行 版
1.1 Linux初探
1.3 小结
2.1 进入命令行
2.2 通过Linux 控制台终端访问
CL...
2.3 通过图形化 终端仿真器访问 CLI
2.4 使用 GNOME Ter min a l...
2.6 使用xterm 终端仿真器
《Linux命令行与shell 脚本编程大全 第4版 》
最新版读书笔记,下载可以直接修改
思维导图PPT模板
01 引言
目录
02 致谢
03
第一部分 Linux命令 行
05
beaglebone_black_学习笔记——(4)闪烁LED之shell命令

beaglebone_black_学习笔记——(4)闪烁LED之shell命令上⼀篇笔记在终端输⼊shell命令实现了LED灯的点亮与熄灭,作为初学者,已经兴奋了⼀阵,因为终于有了零的突破。
⼿动点亮LED总会⽐较⿇烦,还是得通过程序让它⾃⼰去点亮与熄灭,这样才更好玩。
这篇笔记⾥,笔者通过学习shell脚本,实现LED的闪烁,这样才好玩。
本篇笔记还是先从现象看起,然后在分析其实现原理。
第⼀步:实现LED灯闪烁1、先来个简单的shell脚本,了解⼀下shell脚本的使⽤流程。
下图为创建⼀个名为hello_sh的shell脚本编辑执⾏的过程。
⼏点说明:(1)shell脚本可以没有⽂件后缀名,但是为了⽅便,也可以添加.sh为其后缀。
上图中⽤_sh作为表⽰,也可以没有;(2)shell脚本创建可以利⽤touch filename的形式来创建;(3)编辑shell脚本可以直接使⽤vi编辑器,关于vi编辑器的简单实⽤请查看上⼀篇笔记;(4)shell脚本是不需要编译就可以运⾏,有shell解释器完成命令的解读与执⾏;(5)新建的shell脚本需要为其添加可执⾏权限,否则执⾏时会出错;(6)运⾏shell脚本直接使⽤ ./* 就可以运⾏;(7)上图中hello_sh脚本⽂件⾥只有⼀⾏内容,⽬的是输出hello字符,脚本内容如下图。
2、下⾯就进⼊今天的主题,⾸先还是要⼿动创建shell脚本⽂件,笔者的⽂件名为led_sh。
创建和添加权限的过程就不在此贴了,请参考上⽂。
下⾯直接贴出led_sh的内容。
⼏点说明:(2)简答解释⼀下脚本内容:1)第1⾏:在终端显⽰hello led⼀串字符;2)第2~4⾏:这部分是⼀个if语句,⽬的是查看是否有gpio44⽂件,如果没有,通过第3⾏脚本添加⼀个;3)第4⾏:为gpio44添加输出属性;4)第7~13⾏:这部分是⼀个while语句,在while语句⾥⾯先点亮LED,然后睡眠0.25秒再熄灭LED,再睡眠0.25秒。
学习笔记_cshell
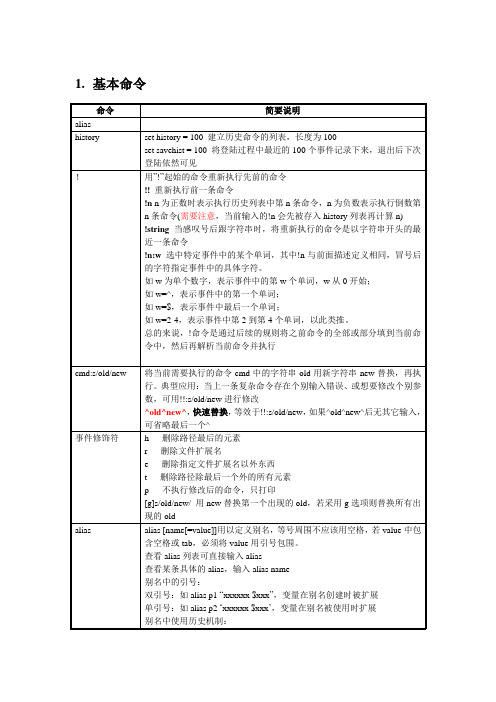
1.基本命令2.表达式表达式可由常量、变量和以下运算符组成,其中部分是涉及文件而不是数值表达式遵守以下规则:1)shell将丢失参数或零参数看作是0;2)所有的结果都是十进制数;3)除了!=和==外,运算符的参数都是数字;4)用户必须将表达式的每个元素与比邻的元素用空格分开,除非相邻元素是&、/、<、>等。
3.shel变量格式序列结果%U 命令运行用户代码所消耗的时间,单位是C P U秒(用户模式)%S 命令运行系统代码所消耗的时间,单位是C P U秒(核心模式)%E 命令所消耗的Wa l l时钟时间(整个时间)%P 任务周期内C P U所耗费的时间百分比,按照( % U + % S ) / % E计算%W 命令进程交换到磁盘的次数%X 命令使用的平均共享代码内存量,单位是千字节%D 命令使用的数据代码内存量,单位是千字节%K 命令使用整个内存内存量,就是% X + % D,单位是千字节%M 命令使用的最大内存量,单位是千字节%F 主页错误数(不得不脱离磁盘读取的内存页)%I 输入操作数%O 输出操作数作为开头的shell变量4.控制结构if(expression) simple-command只对简单命令起作用,对管道或命令列表无效。
可以用if….then控制结构来执行更复杂的命令除逻辑表达式外,用户可以用表达式来返回基于文件状态的值如下:如果指定的文件不存在或不可访问,csh将表达式的值算作0。
否则如果测试结果是true,则表达式的值为1;如果为false,则表达式的值为0。
goto labelgoto命令将控制传送给开始于label的表达式。
onintr label中断处理当用户在脚本执行过程中按下中断键,shell将把控制传递给以label:开始的语句。
该语句可以让用户在其被中断时正常终止脚本。
if…then…else形式1if(expression) thencommandsendif形式2if(expression) thencommandselsecommandsendif形式3if(expresstion) thencommandselse if(expresstion) thencommands...elsecommandsendifforeachforeach loop-index(argument-list)commandsendwhilewhile(expresstion)commandsendbreak/continue可以用break中断foreach或while,这些语句在传递控制前执行命令行中剩下的命令。
Shell脚本-从入门到精通

ex4if.sh,chkperm.sh,chkperm2.sh, name_grep,tellme,tellme2,idcheck.sh
第22页,共74页。
ex4if.sh
#!/bin/bash # scriptname: ex4if.sh
# echo -n "Please input x,y: "
echo echo –e "Hello $LOGNAME, \c"
echo "it's nice talking to you." echo "Your present working directory is:" pwd # Show the name of present directory
echo
then
# 那么
commands1 # 执行语句块 commands1
elif expr2 # 若expr1 不真,而expr2 为真
then
# 那么
commands2 # 执行语句块 commands2
... ...
# 可以有多个 elif 语句
else
# else 最多只能有一个
commands4 # 执行语句块 commands4
\t 插入tab; \v 与\f相同; \\ 插入\字符; \nnn 插入nnn(八进制)所代表的ASCII字符; --help 显示帮助
--version 显示版本信息
第8页,共74页。
Shell 脚本举例
#!/bin/bash
# This script is to test the usage of read # Scriptname: ex4read.sh echo "=== examples for testing read ===" echo -e "What is your name? \c" read name echo "Hello $name" echo echo -n "Where do you work? "
shell脚本基础(又长又详细)

shell脚本基础(⼜长⼜详细)第⼗⼀章 BASH脚本(⼀)常见的Shell变量的类型包括环境变量、预定义变量、位置变量、⽤户⾃定义变量。
本节将分别学习这四种Shell变量的使⽤。
11. 1、 Shell的环境变量通过set命令可以查看系统中所有Shell变量(包括环境变量和⽤户⾃定义变量),由于内容输出较多,建议使⽤less命令分页查看。
常⽤环境变量:PATH 决定了shell将到哪些⽬录中寻找命令或程序HOME 当前⽤户主⽬录HISTSIZE 历史记录数LOGNAME 当前⽤户的登录名USER 当前⽤户名UID 当前⽤名的UIDHOSTNAME 指主机的名称SHELL 前⽤户Shell类型LANGUGE 语⾔相关的环境变量,多语⾔可以修改此环境变量MAIL 当前⽤户的邮件存放⽬录PS1 基本提⽰符,对于root⽤户是#,对于普通⽤户是$PS2 附属提⽰符,默认是“>”例:以分号分隔,显⽰当前的⽤户的⽤户名、宿主⽬录、登录Shell。
例:查看当前命令的搜索路径,并将/opt/bin⽬录添加到现有搜索路径中去,从⽽可以直接执⾏此⽬录中的命令。
环境变量的配置⽂件⽤户可在当前的Shell环境中直接为环境变量赋值,但需要长期变更所使⽤的某个环境变量时,可以修改配置⽂件。
在Linux系统中,⽤户环境变量的设置⼯作习惯上在 /etc/profile ⽂件及宿主⽬录中 .bash_profile⽂件中进⾏,前者称为全局配置⽂件(对所有⽤户起作⽤),后者称为⽤户配置⽂件(允许覆盖全局配置)。
例:在当前⽤户环境中,将⽤于限制历史命令的环境变量HISTSIZE的值改为100。
例:编辑“~/.bash_profile”⽂件,修改PATH的设置,以便⽤户在下次登录后能够使⽤服务/opt/bin ⽬录作为默认的搜索路径。
# vi /root/.bash_profielPATH=$PATH:$HOME/bin:/opt/binExport PATH11.2 Shell位置变量为了在使⽤Linux程序时,⽅便通过命令⾏给程序提供操作参数,Bash引⼊了位置变量的概念。
shell总结

shell总结1.shell的⼼得 学习shell的时候必须把重点放在流程控制上和shell⼯具上。
⼀定要⽤⼼记语法和命令。
2.介绍shell shell是⼀种解释型语⾔,程序不需要编译,程序在运⾏时由解释器翻译成机器语⾔,每执⾏⼀次都要翻译⼀次。
因此解释型语⾔效率低。
其实也是⼀种编译型语⾔。
程序在运⾏之前就被编译器编译过成机器语⾔,执⾏的时候执⾏编译过的结果就⾏了效率⾼。
shell的编译器是bash。
3.总结shell 3.1Linux提供的解析器有 [jinghang@hadoop101 ~]$ cat /etc/shells /bin/sh 是bash的⼀个快捷⽅式 /bin/bash bash是⼤多数Linux默认的shell,包含的功能⼏乎可以涵盖shell所有的功能 /sbin/nologin 表⽰⾮交互,不能登录操作系统 /bin/dash ⼩巧,⾼效,功能相⽐少⼀些 /bin/tcsh 具有C语⾔风格的⼀种shell,具有许多特性,但是也有⼀些缺陷 /bin/csh 是csh的增强版本,完全兼容csh 3.2变量 系统变量分为:$HOME、$PWD、$SHELL、$USER等 ⾃定义变量就是⾃⼰取名字。
特殊变量:$n $0该脚本名称,$1-$9第⼀到第九个参数⼗个以上需要⼤括号${10} 特殊变量:$# 获取参数的个数 特殊变量:$*、$@ $*:这个变量代表命令⾏中所有的参数,$*把所有的参数看成⼀个整体. $@:这个变量也代表命令⾏中所有的参数,不过$@把每个参数区分对待 特殊变量:$? $?:最后⼀次执⾏的命令的返回状态。
如果这个变量的值为0,证明上⼀个命令正确执⾏;如果这个变量的值为⾮0(具体是哪个数,由命令⾃⼰来决定),则证明上⼀个命令执⾏不正确了。
3.3运算符 “$((运算式))”或“$[运算式]” + , - , *, /, % 加,减,乘,除,取余 expr + , - , \*, /, % 加,减,乘,除,取余 3.4条件判断 = 字符串⽐较 -lt ⼩于(less than) -le ⼩于等于(less equal) -eq 等于(equal) -gt ⼤于(greater than) -ge ⼤于等于(greater equal) -ne 不等于(Not equal) 3.5流程控制 if[ 条件判断式 ]; then 程序 fi 或者 if[ 条件判断式 ]then 程序 elif[ 条件判断式 ]then 程序 else 程序 fi case $变量名 in "值1")如果变量的值等于值1,则执⾏程序1 ;;"值2")如果变量的值等于值2,则执⾏程序2 ;;…省略其他分⽀… *)如果变量的值都不是以上的值,则执⾏此程序 ;;esac for (( 初始值;循环控制条件;变量变化 )) do 程序 done while [ 条件判断式 ] do 程序 done 4.shell⼯具命令 4.1 cut cut的⼯作就是“剪”,具体的说就是在⽂件中负责剪切数据⽤的。
第六章-shell编程-基本知识

test命令
数组
• bash 2.x 版本提供了创建一维数组的能力。 数组允许你把一串数字、一串名字或者一 串文件放在一个变量中。数组的尺寸没有 限制,脚标也不必须
• 是一定顺序的数字。获取数组中某个元素 的语法是${arrayname[index]}。
${#friend[*]}表示数组的尺寸,即元素个数, ${#friend[0]}表示第一个元素的长度。
Shell从哪里找到命令,就把该 位置赋值给PATH变量
规定光标的基本显示形式。光标将以以下的 形式在Shell窗口出现:用户名(\u)、@符 号、主机名(\W)及$符号
ulimit命令(Shell内置命令)限制核心文件的最 大容量为1 000 000 字节。核心文件是破坏了的 程序文件的转存,而且占用相当大的磁盘空间。
#删除变量pathname中匹配模式/home的 smallest leading portion,也就是删除开头 的/usr。
##删除变量pathname中匹配模式的la leading portion
${#variable}语句显示赋值给变量name的 符串的字母个数,这里共有18个字母。 位
环境变量EDITOR没有被设置过
修改符“-”用/bin/vi替换变量EDITOR的Байду номын сангаас
因为EDITOR没有被设置,因此打印结果 空
环境变量EDITOR没有被设置过
修改符“-”用/bin/vi替换变量EDITOR的
因为EDITOR没有被设置,因此打印结果 空
位置参量
• 通常情况下,特定的内建变量,被称为位 置参量,它们被用于从命令行向脚本传递 参数,或者在函数中用于保存传递给函数 的参数。这些变量被称作位置参量是因为 它们以数字1、2、3……区分,这些数字与它 们在参量清单中的位置有对应关系。 • Shell脚本的名字保存在变量$0 中,位置参 量可以被set 命令设置、重置和清空。
shell基础知识总结

shell基础知识总结1. shell 对于⼀台计算机⽽⾔,其硬件受系统内核的控制,使⽤者想要控制计算机,就必须有与系统内核进⾏通讯的⼿段。
⽽shell就是使⽤者与计算机进⾏通讯的⼿段之⼀。
从命名上看,shell其实是相对于kernel(内核)⽽⾔,指系统与外界(使⽤者)进⾏接触的部分,⼀个提供系统功能给⽤户使⽤的软件,它接受来⾃⽤户的指令,然后调⽤相应的应⽤程序。
为了满⾜不同的需求,shell提供了两种执⾏命令⽅式:a. 交互式:解释并执⾏⽤户输⼊的命令或者⾃动地解释和执⾏预先设定好的⼀连串的命令。
b. 程序设计式:作为⼀种脚本语⾔,提供变量、控制结构和函数,再通过解释器解释并执⾏。
Linux上常见的shell有sh、bash、ksh、tcsh等,不同解释器在某些语法的执⾏⽅⾯可能有些不同。
通过查看/etc/shells⽂件就可以知道本系统所⽀持的shell解释器类型。
如shells的⽂件内容如下:ryeshen@~$ cat /etc/shells/bin/sh/bin/bash/sbin/nologin/usr/bin/sh/usr/bin/bash/usr/sbin/nologin/bin/tcsh/bin/csh/bin/ksh/bin/zsh ⽽linux默认是⽤的解释器是bash。
在脚本头可以声明本脚本所使⽤的解释器,声明⽅式: #!/bin/bash2. 变量a. 赋值赋值⽅式:variable_name = variable_value等号两边不能有空格符;增加变量内容:PATH=”$PATH”:/home/bin取消变量:unset variable_name变量类型:可以使⽤declare [[-/+]aixr] [name[=value] …],其中-表⽰赋予变量属性,+表⽰去除变量属性,a-数组,i-整数,r-只读,x-环境变量b. ⾃定义变量与环境变量使⽤“=”赋值得到的⾃定义变量,这个变量的作⽤域为当前shell进程。
使用shell的基本操作命令

使用shell的基本操作命令使用Shell的基本操作命令Shell是一种命令行解释器,它是连接用户与操作系统内核的桥梁,可以通过输入不同的命令来操作计算机系统。
本文将介绍一些常用的Shell基本操作命令,并对其功能进行详细说明。
1. cd命令cd(Change Directory)命令用于切换当前目录。
通过输入cd命令,后面跟随要切换到的目录路径,即可切换到指定目录。
例如,输入cd /home,即可切换到/home目录下。
2. ls命令ls(List)命令用于列出当前目录下的文件和子目录。
通过输入ls命令,即可显示当前目录下的所有文件和子目录的名称。
例如,输入ls,即可显示当前目录下的所有内容。
3. pwd命令pwd(Print Working Directory)命令用于显示当前所在的目录路径。
通过输入pwd命令,即可显示当前所在的目录路径。
例如,输入pwd,即可显示当前目录的路径。
4. mkdir命令mkdir(Make Directory)命令用于创建新的目录。
通过输入mkdir命令,后面跟随要创建的目录名称,即可在当前目录下创建新的目录。
例如,输入mkdir test,即可在当前目录下创建名为test的目录。
5. touch命令touch命令用于创建新的空文件。
通过输入touch命令,后面跟随要创建的文件名称,即可在当前目录下创建新的空文件。
例如,输入touch test.txt,即可在当前目录下创建名为test.txt的空文件。
6. cp命令cp(Copy)命令用于复制文件或目录。
通过输入cp命令,后面跟随要复制的文件或目录路径,以及目标路径,即可将文件或目录复制到指定位置。
例如,输入cp file.txt /home,即可将当前目录下的file.txt文件复制到/home目录下。
7. mv命令mv(Move)命令用于移动文件或目录,也可以用于文件或目录的重命名。
通过输入mv命令,后面跟随要移动或重命名的文件或目录路径,以及目标路径或新的名称,即可将文件或目录移动到指定位置或重命名。
Shell 脚本基础学习笔记

Shell 脚本基础学习笔记shell脚本的解释用“#”号,本文档为了习惯方便,解释大都用“//”,也有用“#”的SHELL 最基本的语法基本元字符集及其含义(2008-05-24)abc 表示abc 三個連續的字符, 但彼此獨立而非集合. (可簡單視為三個char set)(abc) 表示abc 這三個連續字符的集合. (可簡單視為一個char set)a|b 表示單一字符, 或a 或b .(abc|xyz) 表示或abc 或xyz 這兩個char. set 之一. (註二)[abc] 表示單一字符, 可為a 或b 或c . (與wildcard 之[abc] 原理相同)[^abc] 表示單一字符, 不為a 或b 或c 即可. (與wildcard 之[!abc] 原理相同)^ 只匹配行首$ 只匹配行尾* 只一个单字符后紧跟*,匹配0个或多个此单字符[ ] 只匹配[ ]内字符。
可以是一个单字符,也可以是字符序列。
可以使用-表示[ ]内字符序列范围,如用[ 1 - 5 ]代替[ 1 2 3 4 5 ]\ 只用来屏蔽一个元字符的特殊含义。
因为有时在s h e l l中一些元字符有特殊含义。
\可以使其失去应有意义. 只匹配任意单字符p a t t e r n \ { n \ } 只用来匹配前面p a t t e r n出现次数。
n为次数p a t t e r n \ { n,\ }含义同上,但次数最少为np a t t e r n \ { n,m \ }含义同上,但p a t t e r n出现次数在n与m之间现在详细讲解其中特殊含义1、使用句点匹配单字符例一:beg.n:以beg开头,中间夹一个任意字符。
例二:. . . .X C. . . .:共10个字符,前四个之后为XC例三:列出所有用户都有写权限的目录或文件:ls -l |grep ...x..x..x2、行首以^匹配字符串或字符序列^只允许在一行的开始匹配字符或单词。
shell 笔记

$LINENO 记录它所在脚本中它所在行和行号,一般用于调度
$MACHTYPE 显示系统类型,系统架构
$OLDPWD 老的工作目录
$OPTYPE 操作系统类型
$PATH 指向Bash外部命令所在位置,系统在它指向的目录下搜索命令
Ctrl+a 移到命令行首
Ctrl+e 移到命令行尾
Ctrl+u 删除到行首的命令
Ctrl+k 删除到行尾的命令
Ctrl+a后再Ctrl+k 或者Ctrl+e后再Ctrl+u就是删除输入的全部命令
Ctrl+->/<- 向左/右移动一个单词(远程ssh终端不可用)
Ctrl+c 终止当前任务
$DIRSTACK 、$PWD 结果 等于dirs命令结果
$EDITOR 脚本调用的默认编辑器
$EUID "effective"用户ID号
$FUNCNAME 当前函数名字
$GROUPS 当前用户属于的组
$UID 用户ID号
$HOME 用户home目录
$HOSTNAME 系统主机名
shell脚本可移植性好,在unix/linux系统中可灵活移植,几乎不用任何设置就能正常运行
shell脚本可轻松方便读取和修改源代码,不需要编译
掌握shell可以帮你解决一些故障问题,比如脚本引起的故障问题
掌握shell是一个中级以上系统工程师必需要会的
掌握shell是你系统管理进阶的必经之路
选项:
-a 将后面的变量定义成为数组 (array)
SHELL脚本学习方法

1.1 shell命令行书写规则执行shell命令时多个命令可以在一个命令行上运行,用分号(;)分隔命令,例如:[root@localhost root]# ls a* -l;free;df 长shell命令行可以使用反斜线字符(\)在命令行上扩充,例如: [root@localhostroot]# echo “this is \ “>”符号是自动产生的,而不是输入的。
1.2 编写/修改权限及执行shell程序的步骤1.2.1 编辑shell程序编辑一个内容如下的源程序,保存文件名为date,可将其存放在目录/bin下。
[root@localhost bin]#vi date#! /bin/shecho “mr.$user,today is:”echo &date “+%b%d%a”echo “wish you a lucky day !”注意:#! /bin/sh通知采用bash解释。
如果在echo语句中执行shell命令date,则需要在date命令前加符号“&”,其中%b%d%a为输入格式控制符。
1.2.2 建立可执行程序编辑完该文件之后不能立即执行该文件,需给文件设置可执行程序权限。
使用如下命令。
[root@localhost bin]#chmod +x date 1.2.3 执行shell程序执行shell程序有下面三种方法:方法一:[root@localhost bin]#./ date 方法三:为了在任何目录都可以编译和执行shell所编写的程序,即把/bin的这个目录添加到整个环境变量中。
[root@localhost root]#export path=/bin:$path 1.3 在shell程序中使用的参数shell程序中的参数分为位置参数和内部参数等。
1.3.1 位置参数由系统提供的参数称为位置参数。
位置参数的值可以用$n得到,n是一个数字,如果为1,即$1。
跟着360架构师学shell笔记

跟着360架构师学shell笔记Shell是一种用于在操作系统中进行编程的脚本语言,它是系统管理员和架构师必不可少的工具之一。
随着云计算和大数据技术的发展,Shell脚本在配置管理、自动化运维和数据处理等方面发挥着越来越重要的作用。
在本文中,我们将跟着360架构师学习Shell,探讨Shell脚本的基础知识、实战应用和最佳实践。
一、Shell脚本的基础知识1. Shell脚本的语法和特点Shell脚本是一种解释型语言,它使用命令解释器(如Bash、Zsh 等)来执行命令。
Shell脚本的语法类似于C语言,但更加灵活简洁。
在Shell脚本中,可以通过变量、条件语句、循环语句、函数等来实现各种功能。
此外,Shell脚本还支持命令行参数传递、输入输出重定向、管道等特性,方便进行系统管理和数据处理。
2. Shell脚本的基本命令和常用工具在Shell脚本中,可以使用一系列Linux命令和工具来完成各种任务。
比如,通过ls、cd、mkdir等命令可以进行文件和目录的操作;通过grep、awk、sed等工具可以进行文本处理;通过ssh、rsync、scp等命令可以进行远程操作。
掌握这些基本命令和工具对于编写Shell脚本至关重要。
3. Shell脚本的调试和优化编写Shell脚本常常面临各种错误和性能问题,因此需要掌握调试和优化技巧。
在Shell脚本中,可以通过set -x命令开启调试模式,以查看每个命令的执行过程;通过time命令统计脚本的执行时间,找出性能瓶颈。
此外,还可以通过代码重构、并发编程等方式来优化Shell脚本,提高效率和可维护性。
二、Shell脚本的实战应用1.系统管理和配置管理Shell脚本在系统管理和配置管理方面有着广泛的应用。
比如,可以通过Shell脚本自动安装软件包、配置系统环境;通过Shell脚本定时备份数据、清理日志;通过Shell脚本监控系统状态、报警处理异常等。
这些任务可以通过编写简单的Shell脚本来实现,提高工作效率和可靠性。
shell知识及面试题

1、运行Shell脚本有两种方法。
1)作为可执行程序将上面的代码保存为test.sh,并 cd 到相应目录:chmod +x ./test.sh #使脚本具有执行权限./test.sh #执行脚本2)作为解释器参数这种运行方式是,直接运行解释器,其参数就是shell脚本的文件名,如:/bin/sh test.sh3)当前shell环境执行,.a.sh或者source a.sh执行。
2、./ 和 sh的使用区别1)使用“./”执行脚本,对应的xxx.sh脚本必须要有执行权限(绿色);2)使用“sh” 执行脚本,对应的xxx.sh没有执行权限,亦可执行;如果我直接运行./a.sh,首先你会查找脚本第一行是否指定了解释器,如果没指定,那么就用当前系统默认的shell(大多数linux默认是bash),如果指定了解释器,那么就将该脚本交给指定的解释器比如a.run文件内容是这个:#!/usr/bin/pythonprint("This is Python script")那么你如果运行./a.run,结果就是输出一行文字,但是如果你运行sh a.run,会报错。
sh:#!/bin/bash 可以不写。
因为将a.sh作为参数传给sh(bash)命令来执行的,这时不是a.sh自己来执行,而是被人家调用执行,所以不要执行权限,采用系统默认bash解释器。
6)Shell文件包含例如,创建两个脚本,一个是被调用脚本 subscript.sh,内容如下:echo "shell测试"一个是主文件 main.sh,内容如下:#!/bin/bash. ./subscript.shecho $url执行脚本:$chomd +x main.sh./main.shshell测试注意:被包含脚本不需要有执行权限。
2、Shell变量Shell变量的定义、删除变量、只读变量、变量类型。
1)定义变量Shell 支持以下三种定义变量的方式:variable=valuevariable='value'variable="value"3)变量的单引号和双引号的区别#!/bin/bashurl="中文网11"website1='中文网:${url}'website2="中文网:${url}"echo $website1echo $website2运行结果:中文网:${url}中文网:中文网11以单引号' '包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令需要反引起来)也会把它们原样输出。
Shell学习笔记之shell脚本和python脚本实现批量pingIP测试

Shell学习笔记之shell脚本和python脚本实现批量pingIP测试0x00 将IP列表放到txt⽂件内先建⼀个存放ip列表的txt⽂件:[root@yysslopenvpn01 ~]# cat hostip.txt192.168.130.1192.168.130.2192.168.130.3192.168.130.4192.168.130.5192.168.130.6192.168.130.7192.168.130.8192.168.130.9192.168.130.10192.168.130.11192.168.130.12192.168.130.13192.168.130.14192.168.130.15192.168.130.16192.168.130.17192.168.130.18192.168.130.19192.168.130.200x01 使⽤Shell脚本实现创建shell 脚本:[root@yysslopenvpn01 ~]# vim shell_ping.sh#!/bin/shfor i in `cat hostip.txt`doping -c 4 $i|grep -q 'ttl=' && echo "$i ok" || echo "$i failed"doneexit()注意:请不要直接粘贴复制,如果使⽤以上shell请在linux主机的vim中⾃⼰⼿动编写,不然会出现换⾏符报错!# syntax error near unexpected token `do!添加脚本权限[root@yysslopenvpn01 ~]# chmod +x shell_ping.sh执⾏:[root@yysslopenvpn01 ~]# sh shell_ping.sh192.168.130.1 ok192.168.130.2 failed192.168.130.3 failed192.168.130.4 failed192.168.130.5 failed192.168.130.6 failed192.168.130.7 failed192.168.130.8 failed192.168.130.9 failed192.168.130.10 failed192.168.130.11 failed192.168.130.12 failed192.168.130.13 failed192.168.130.14 failed192.168.130.15 failed192.168.130.16 failed192.168.130.17 failed192.168.130.18 ok192.168.130.19 ok192.168.130.20 ok0x02 使⽤Python脚本实现创建python脚本:[root@yysslopenvpn01 ~]# vim ping.py#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:xieshengsen# 实现批量ping IP测试import reimport subprocessdef check_alive(ip,count=4,timeout=1):cmd = 'ping -c %d -w %d %s'%(count,timeout,ip) p = subprocess.Popen(cmd,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE,shell=True)result=p.stdout.read()regex=re.findall('100% packet loss',result)if len(regex)==0:print"\033[32m%s UP\033[0m" %(ip)else:print"\033[31m%s DOWN\033[0m" %(ip)if__name__ == "__main__":with file('hostip.txt','r') as f:for line in f.readlines():ip = line.strip()check_alive(ip)执⾏结果:[root@yysslopenvpn01 ~]# python ping.py 192.168.130.1 UP192.168.130.2 DOWN192.168.130.3 DOWN192.168.130.4 DOWN192.168.130.5 DOWN192.168.130.6 DOWN192.168.130.7 DOWN192.168.130.8 DOWN192.168.130.9 DOWN192.168.130.10 DOWN192.168.130.11 DOWN192.168.130.12 DOWN192.168.130.13 DOWN192.168.130.14 DOWN192.168.130.15 DOWN192.168.130.16 DOWN192.168.130.17 DOWN192.168.130.18 UP192.168.130.19 UP192.168.130.20 UP。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1
-
2 8 0 9
=
3
--
4
==
5
338.vi:用一条命令删除第 50 行到 100 行:50,100d
339.除了手动单个赋值、for循环赋值之外,split赋值也是不错的想法:echo "123:456"|awk '{split($0,a,":" ); print a[1]}'
echo "assdf='hello'"|sed "s/.*='\(.*\)'/\1/" 双引号里面的单引号已经失去原意,因此单引号不用转义了
319.关于单双引号的转义问题:a=3;echo "'$a'" :'3' ; a=3;echo '$a' :$a 双引号去掉了单引号的特殊意义,所以变量被shell解析了
16:27:13#www#~> a=1
16:27:16#www#~> b1=2
16:27:18#www#~> eval echo \$b$a
2
解析两次,第一次得到$b1,然后得到2
如果2是作为一个变量名呢 ? eval echo $\{$(echo $ABC$DEF$H)\} ;$ (A=aa;B=bb;aabb=T; eval echo \$$(echo $A$B));c=$(eval echo \$b$a)
331.top按了R、1、P分别表示逆向排序、显示所有cpu、翻页
332.对find . -path ./src/emacs -prune -o -print的几点说明:
find 表达式由 options, tests and actions 三部分组成 ,如果actions 没有 ,执行-print ,-prune 也是action ,所以有action 不执行-print
302.awk具有解释类脚本的便捷,又有编译程序的效率。awk内部采用的是编译的过程,词法上采用了yyacc解析成语法树,外层用运用c代码对树递归调用。做为一个便捷的shell utility,效率上已经相当不错了~~~perl比awk更接近于语言,脱离了工具的固定模式约束,拿awk跟perl比,就像拿汽车跟交通公具比,没有多大意义
311.管道就是多一个启动进程的时间,如果你的进程运行的时间都很短,那么多一个管道对你的影响很大,如果你的进程运行时间很长,那么影响不大。
还有数据在两个进程中传递也需要时间,不过内存里面应该很快的。
312.less 里搜索字母大小写无关: 运行less的时候加-i ; man 大小写无关 ;查看大文件的时候还是less好。vi不行
313.cron里面%是换行,要转义
314.%s/.\{80\}/&\r/ sed中每80个字符添加一个换行
315.关于awk gsub返回值的问题:gsub返回的是替换了几次的次数,要想获取改变的值,直接打印变量或者被替换值重新赋给某一变量。
echo "qqqq|2010-10-11 23:21:23|www"|awk -F"|" '{print gsub(/-| |:/,"",$2)}'
awk 'BEGIN{RS="[=-\n]+"}NR%2==0'
awk 'BEGIN{RS="[-=]+"}{print $2}'
awk 'BEGIN{RS="\n=+\n";FS="-+\n"}{print $2}' da #RS是\n=+,所以没把最后的换行算进去, cat da|tr '\n' ' '看的清楚点
你执行一个sleep 99 &然后ps -fe|grep sleep看看,然后退出,再ps -fe|grep sleep看看区别,进程的父进程变了。
前面哪个sleep是哪个shell的子进程,后面哪个是init的子进程 ,那如果我想把它再调到前台可以吗?没办法的 。
324.命令后面即使+&退出终端,命令就自动结束了:看发行版的,不同发行版处理不一样,还有用nohup或者disown过后就可以了。
echo "qqqq|2010-10-11 23:21:23|www"|awk -F"|" '{gsub(/-| |:/,"",$2);a=$2;print a}' 或者直接print $2
316.grep返回匹配部分并且匹配单词:echo "ass23(30123)we---b(30124)---c(30125)"|grep -Eo "\<[0-9]+"
eteassdf='hello'weeteassdf='hello'"|sed "s/[^']*'\([^'*]*\)'/\1/g"
hellohellohellohellohellohellohellohello
[root@rac0 ~]#
或者:awk来处理 awk -v RS="'" -F"'" 'NR%2==0' ; -F是参数,FS、RS是内部变量要用-v或者放在BEGIN里面,亦或者放在最后awk -v RS="'" "NR%2==0" FS="'"
303.本地和远程判断 设备存不存在
igi@igi-gentoo ~/test $ ssh localhost test -e /dev/shm
igi@igi-gentoo ~/test $ echo $?
0
304.wait 命令 保证进程同步 等待一个子进程结束 多个并发就用多个wait; 等待jobs完成
16:05:34#www#~> #还有,如果错误实在内部产生的,你在外部2>是没用的。
334.awk也支持sed的&:echo "a b c"|awk '{gsub(/.*/, "&'$a'");print}'
335.eval解析:
我为SUN狂.marvel<walkerxk@> 16:27:43
336.设置时区:date -u ; tzselect ;TZ='Asia/Shanghai'; export TZ
337.awk巧设状态值(标志位)实现模式打印:
seq 9|awk '/3/{a=1;next}/5/{a=0}a==1{print $0}' #就是找到-------------那行,然后标记开始打印,然后找到===========那行,标记结束打印
325.for i in `cat ems.txt` 这个要打开这个文件N次,done >是打开一次,各有优缺点。
>>次数多,每次数据量小,>次数少,每次数据量大,如果数据量很大,就用>>,免得内存不足。
326.()和<来传数据:grep -vf <(cut -f1 a.txt) ቤተ መጻሕፍቲ ባይዱ.txt
327.看内核还可以:cat /etc/issue
328.find查找时间段文件:那还要加个grep。find的printf就可以打印时间的。
329.sh apply.sh 2>&1 : 2是错误输出,1是标准输出,2>&1表示把错误输出放入到标准输出里面
330.查找刚好包含16个字母的单词: grep -w “[a-zA-Z]\{16\}”file ; grep -w "^.\{16\}$" file
但是因为没有-print,所以其实啥也不干 , 因为前面是真 所以-o 后面的都不执行
333.正确的使用错误重定向:2>
16:00:41#www#~> ls sfdsd|grep abc 2>/dev/null
ls: 无法访问sfdsd: 没有那个文件或目录
16:05:25#www#~> ls sfdsd 2>/dev/null|grep abc
双引号:除$ ` \ 仍保留其特殊意义外,其余字符均作为普通字符对待
单引号:$ 也被作为普通字符对待 ;查man bash 里的"QUOTING"一节,会有更多的收获
echo "'$a'" 最外面的" " shell 解析,echo不解析;
find等其它命令会解析引号内的内容,比如find -name "*.txt" 这个*就是find解析的
305.sed中的 \0 等价于 & ,匹配时是贪婪匹配,不支持非贪婪,但可以x[^X]x变相的非贪婪。.*的优先级是最低的:echo "IP 1234"|sed 's/\(IP\).*\([0-9]\)/& Add:/'
306.转换中文:echo %E4%B8%AD%E5%9B%BD|sed 's/%//g;s/^/0:/'|xxd -r
307.shell启动-》读入history文件->维护当前history(进程环境里)-> -a:写入文件->继续维护(进程环境里)->退出shell(写入文件)