Hive update实现方案V1.0
使用FlutterHiveBloc写一个待办小demo
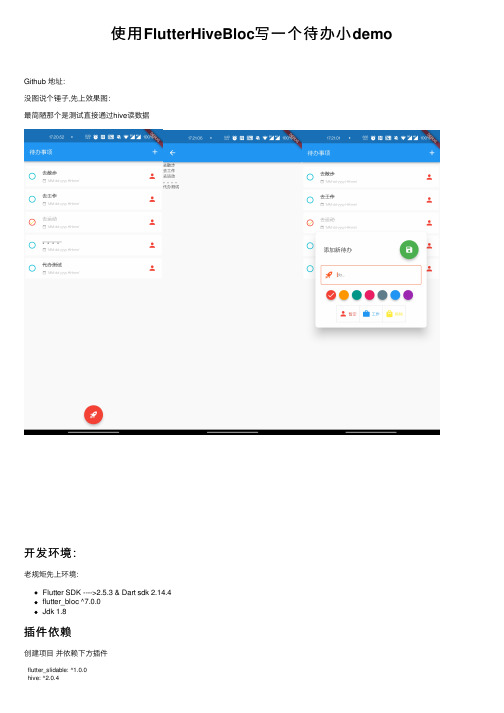
使⽤FlutterHiveBloc 写⼀个待办⼩demoGithub 地址:没图说个锤⼦,先上效果图:最简陋那个是测试直接通过hive 读数据开发环境:⽼规矩先上环境:Flutter SDK ---->2.5.3 & Dart sdk 2.14.4flutter_bloc ^7.0.0Jdk 1.8插件依赖创建项⽬ 并依赖下⽅插件flutter_slidable: ^1.0.0hive: ^2.0.4hive_flutter: ^1.1.0uuid: ^3.0.5material_design_icons_flutter: ^5.0.6295flutter_material_color_picker: ^1.1.0+2google_fonts: ^2.1.0animated_text_kit: ^4.2.1intl: ^0.17.0bloc: ^7.0.0equatable: ^2.0.0flutter_bloc: ^7.0.0meta: ^1.3.0在项⽬根⽬录创建 packages的路径,如下图创建项⽬⼯具包新建两个包选择项⽬根⽬录的packages位置(如图):选择packagey因为我们只是在这边写⼀些⽅法,如果创建插件项⽬就太⼤并不合适两个包名分别为:todos_repositorytodo_repository_simpletodo_repository的编写在 todo_repository 包添加依赖hive: ^2.0.4hive_flutter: ^1.1.0创建⼀个 todo_modle 的dart⽂件写⼊如下代码在Teminal中cd 到 todo_repository 的⽬录执⾏这⾏代码,⽣成.g⽂件。
也就是 todo_model 的适配器,可以⾃⼰⼿写flutter packages pub run build_runner build如果报错尝试执⾏这条flutter packages pub run build_runner build --delete-conflicting-outputs 如果还是报错那就直接copy这⾥的代码todo_model:// GENERATED CODE - DO NOT MODIFY BY HANDpart of 'todo_model.dart';// **************************************************************************// TypeAdapterGenerator// ************************************************************************** class TodoCategoryAdapter extends TypeAdapter<TodoCategory> { @overridefinal int typeId = 1;@overrideTodoCategory read(BinaryReader reader) {switch (reader.readByte()) {case0:return TodoCategory.personal;case1:return TodoCategory.work;case2:return TodoCategory.shopping;default:return TodoCategory.work;}}@overridevoid write(BinaryWriter writer, TodoCategory obj) {switch (obj) {case TodoCategory.personal:writer.writeByte(0);break;case TodoCategory.work:writer.writeByte(1);break;case TodoCategory.shopping:writer.writeByte(2);break;}}@overrideint get hashCode => typeId.hashCode;@overridebool operator ==(Object other) =>identical(this, other) ||other is TodoCategoryAdapter &&runtimeType == other.runtimeType &&typeId == other.typeId;}class MyColorAdapter extends TypeAdapter<MyColor> {@overridefinal int typeId = 2;@overrideMyColor read(BinaryReader reader) {switch (reader.readByte()) {case0:return MyColor.red;case1:return MyColor.orange;case2:return MyColor.teal;case3:return MyColor.pink;case4:return MyColor.blueGrey;case5:return MyColor.blue;case6:return MyColor.purple;default:return MyColor.red;}}@overridevoid write(BinaryWriter writer, MyColor obj) {switch (obj) {case MyColor.red:writer.writeByte(0);break;case MyColor.orange:writer.writeByte(1);break;case MyColor.teal:writer.writeByte(2);break;case MyColor.pink:writer.writeByte(3);break;case MyColor.blueGrey:writer.writeByte(4);break;case MyColor.blue:writer.writeByte(5);break;case MyColor.purple:writer.writeByte(6);break;}}@overrideint get hashCode => typeId.hashCode;@overridebool operator ==(Object other) =>identical(this, other) ||other is MyColorAdapter &&runtimeType == other.runtimeType &&typeId == other.typeId;}class TodoModelAdapter extends TypeAdapter<TodoModel> {@overridefinal int typeId = 0;@overrideTodoModel read(BinaryReader reader) {final numOfFields = reader.readByte();final fields = <int, dynamic>{for (int i = 0; i < numOfFields; i++) reader.readByte(): reader.read(), };return TodoModel(content: fields[0] as String,done: fields[1] as bool,time: fields[2] as DateTime,category: fields[3] as TodoCategory,color: fields[4] as MyColor,);}@overridevoid write(BinaryWriter writer, TodoModel obj) {writer..writeByte(5)..writeByte(0)..write(obj.content)..writeByte(1)..write(obj.done)..writeByte(2)..write(obj.time)..writeByte(3)..write(obj.category)..writeByte(4)..write(obj.color);}@overrideint get hashCode => typeId.hashCode;@overridebool operator ==(Object other) =>identical(this, other) ||other is TodoModelAdapter &&runtimeType == other.runtimeType &&typeId == other.typeId;}todo_model.g.dart:// GENERATED CODE - DO NOT MODIFY BY HANDpart of 'todo_model.dart';// ************************************************************************** // TypeAdapterGenerator// ************************************************************************** class TodoCategoryAdapter extends TypeAdapter<TodoCategory> { @overridefinal int typeId = 1;@overrideTodoCategory read(BinaryReader reader) {switch (reader.readByte()) {case0:return TodoCategory.personal;case1:return TodoCategory.work;case2:return TodoCategory.shopping;default:return TodoCategory.work;}}@overridevoid write(BinaryWriter writer, TodoCategory obj) {switch (obj) {case TodoCategory.personal:writer.writeByte(0);break;case TodoCategory.work:writer.writeByte(1);break;case TodoCategory.shopping:writer.writeByte(2);break;}}@overrideint get hashCode => typeId.hashCode;@overridebool operator ==(Object other) =>identical(this, other) ||other is TodoCategoryAdapter &&runtimeType == other.runtimeType &&typeId == other.typeId;}class MyColorAdapter extends TypeAdapter<MyColor> {@overridefinal int typeId = 2;@overrideMyColor read(BinaryReader reader) {switch (reader.readByte()) {case0:return MyColor.red;case1:return MyColor.orange;case2:return MyColor.teal;case3:return MyColor.pink;case4:return MyColor.blueGrey;case5:return MyColor.blue;case6:return MyColor.purple;default:return MyColor.red;}}@overridevoid write(BinaryWriter writer, MyColor obj) {switch (obj) {case MyColor.red:writer.writeByte(0);break;case MyColor.orange:writer.writeByte(1);break;case MyColor.teal:writer.writeByte(2);break;case MyColor.pink:writer.writeByte(3);break;case MyColor.blueGrey:writer.writeByte(4);break;case MyColor.blue:writer.writeByte(5);break;case MyColor.purple:writer.writeByte(6);break;}}@overrideint get hashCode => typeId.hashCode;@overridebool operator ==(Object other) =>identical(this, other) ||other is MyColorAdapter &&runtimeType == other.runtimeType &&typeId == other.typeId;}class TodoModelAdapter extends TypeAdapter<TodoModel> {@overridefinal int typeId = 0;@overrideTodoModel read(BinaryReader reader) {final numOfFields = reader.readByte();final fields = <int, dynamic>{for (int i = 0; i < numOfFields; i++) reader.readByte(): reader.read(), };return TodoModel(content: fields[0] as String,done: fields[1] as bool,time: fields[2] as DateTime,category: fields[3] as TodoCategory,color: fields[4] as MyColor,);}@overridevoid write(BinaryWriter writer, TodoModel obj) {writer..writeByte(5)..writeByte(0)..write(obj.content)..writeByte(1)..write(obj.done)..writeByte(2)..write(obj.time)..writeByte(3)..write(obj.category)..writeByte(4)..write(obj.color);}@overrideint get hashCode => typeId.hashCode;@overridebool operator ==(Object other) =>identical(this, other) ||other is TodoModelAdapter &&runtimeType == other.runtimeType &&typeId == other.typeId;}View Code创建两个抽象⽅法,分别是TodoRepositoryabstract class TodoRepository {///加载待办事项Future<List<TodoModel>> loadTodos();///保存待办事项Future saveTodos(List<TodoModel> todos);}ReactiveTodosRepositoryabstract class ReactiveTodosRepository {///添加新的待办Future<void> addNewTodo(TodoModel todo);///删除待办事项Future<void> deleteTodo(List<String> idList);///获取全部待办事项Stream<List<TodoModel>> todos();///更新待办事项Future<void> updateTodo(TodoModel todo);}熟悉java的都知道,这和java项⽬中定义的接⼝是⼀样的,应该都能看懂todos_repository_simpletodos_repository的代码基本上就这样,接下来看看 todo_repository_simple在todo_repository_simple 我们要做的事情是请求⽹络数据或者本地数据,并将数据返回到页⾯给到⽤户观看的⼀个⽅法⾸先还是添加插件hive: ^2.0.4hive_flutter: ^1.1.0todos_repository:path: ../todos_repositoryhive插件我们已经分别添加了三次,因为项⽬⾥不能像安卓那样直接通过根项⽬拿到依赖,所以只能重新再依赖⼀次⽽ todos_repository则是我们刚刚写的插件,我们需要在这边去实现它的⽅法,所以就得把它依赖进来好,那接下来创建⼀个本地存储的⽅法FileStorage代码:class FileStorage {final String tag;final Future<Directory> Function() getDirectory;const FileStorage(this.tag,this.getDirectory,);Future<List<TodoModel>> loadTodos() async {final todoBox = await Hive.openBox<TodoModel>("todos");List<TodoModel> todos = [];todos.addAll(todoBox.values.map((e) => e).toList());return todos;}Future saveTodos(List<TodoModel> todos) async {final settingsBox = await Hive.openBox<bool>('settings');final todosBox = await Hive.openBox<TodoModel>('todos');await todosBox.addAll(todos);await settingsBox.put('initialized', true);}Future saveTodo(TodoModel todoModel) async {if (todoModel.isInBox) {final key = todoModel.key;Hive.box<TodoModel>('todos').put(key, todoModel);} else {await Hive.box<TodoModel>('todos').add(todoModel);}}}在这⾥实现两个⽅法,其中 loadTodos 是通过 hive中读取⽤户的全部待办事项,当然,当前 hive box 还没初始化,如果现在直接调⽤肯定是会报错的,等会会在根项⽬中进⾏初始化saveTodos 保存全部待办事项创建⼀个 WebClient这个⽅法理应上是获取⽹络的数据,不过⽬前没有搭后台,所以就先写个模拟数据⽤⽤WebClient:class WebClient {final Duration delay;const WebClient([this.delay = const Duration(milliseconds: 3000)]);Future<List<TodoModel>> fetchTodos() async {return Future.delayed(delay,() => [TodoModel(category: TodoCategory.personal,color: MyColor.purple,content: '去散步',done: false,time: DateTime.now().subtract(const Duration(days: 1))),TodoModel(category: TodoCategory.shopping,color: MyColor.orange,content: '去⼯作',done: false,time: DateTime.now().subtract(const Duration(days: 2))),TodoModel(category: TodoCategory.work,color: MyColor.blueGrey,content: '去运动',done: true,time: DateTime.now().subtract(const Duration(days: 3)))]);}Future<bool> postTodos(List<TodoModel> todos) async {return Future.value(true);}}可以看到上⾯设置⼀个Duration的东西,⽤来模拟请求⽹络的⼀个延迟效果fetchTodos⽅法中则是模拟获取数据的postTodos 是往服务器推待办数据,还是因为后台没写,搁置先,后⾯有⼼情在继续更创建TodosRepositoryFlutter这个⽅法是继承todo_repository的⽅法,并通过上⾯写的两个⽅法获得数据,代码如下// Copyright 2018 The Flutter Architecture Sample Authors. All rights reserved.// Use of this source code is governed by the MIT license that can be found// in the LICENSE file.import 'dart:async';import 'dart:core';import 'package:meta/meta.dart';import 'package:todos_repository/todo_repository_core.dart';import 'file_storage.dart';import 'web_client.dart';class TodosRepositoryFlutter implements TodoRepository {final FileStorage fileStorage;final WebClient webClient;const TodosRepositoryFlutter({required this.fileStorage,this.webClient = const WebClient(),});///⾸先从⽂件存储中加载待办事项,如果不存在则通过web端去加载@overrideFuture<List<TodoModel>> loadTodos() async {try {final todos = await fileStorage.loadTodos();if(todos.isEmpty){final todos = await webClient.fetchTodos();fileStorage.saveTodos(todos);return todos;}return todos;} catch (e) {final todos = await webClient.fetchTodos();fileStorage.saveTodos(todos);return todos;}}//将TODO持久化到本地磁盘和web@overrideFuture saveTodos(List<TodoModel> todos) {return Future.wait<dynamic>([fileStorage.saveTodos(todos),webClient.postTodos(todos),]);}@overrideFuture saveTodo(TodoModel todoModel) {return Future.wait<dynamic>([fileStorage.saveTodo(todoModel)]);}}其实 saveTodo 并不应该写在这⾥,这个⽅法最开始想要达到得结果是读取全部数据和添加全部数据,⽽像添加新的待办事项和删除等操作是应该写另⼀个地⽅,但是这⾥出于偷懒得原因,直接就写这⾥了,后续完善后会进⾏修改那todo_repository_simple的代码也就暂时告⼀段落,接下来就是根项⽬的编写了回到 flutter_bloc_hive_todo中⾸先还是依赖包,依赖我们刚刚写的两个包todo_repository_simple:path: packages/todo_repository_simpletodos_repository:path: packages/todos_repository在lib中创建两个个⽂件夹分别是 blocs 和view先来看看bloc。
Hive入门

Hive⼊门第⼀章 Hive 基本概念1.1 什么是 HiveApache Hive是⼀款建⽴在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop⽂件中的结构化、半结构化数据⽂件映射为⼀张数据库表,基于表提供了⼀种类似SQL的查询模型,称为Hive查询语⾔(HQL),⽤于访问和分析存储在Hadoop⽂件中的⼤型数据集。
Hive核⼼是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执⾏。
Hive由Facebook实现并开源。
1.2 为什么使⽤Hive使⽤Hadoop MapReduce直接处理数据所⾯临的问题⼈员学习成本太⾼需要掌握java语⾔MapReduce实现复杂查询逻辑开发难度太⼤使⽤Hive处理数据的好处操作接⼝采⽤类SQL语法,提供快速开发的能⼒(简单、容易上⼿)避免直接写MapReduce,减少开发⼈员的学习成本⽀持⾃定义函数,功能扩展很⽅便背靠Hadoop,擅长存储分析海量数据集1.3 Hive与Hadoop的关系从功能来说,数据仓库软件,⾄少需要具备下述两种能⼒:存储数据的能⼒分析数据的能⼒Apache Hive作为⼀款⼤数据时代的数据仓库软件,当然也具备上述两种能⼒。
只不过Hive并不是⾃⼰实现了上述两种能⼒,⽽是借助Hadoop。
Hive利⽤HDFS存储数据,利⽤MapReduce查询分析数据。
这样突然发现Hive没啥⽤,不过是套壳Hadoop罢了。
其实不然,Hive的最⼤的魅⼒在于⽤户专注于编写HQL,Hive帮您转换成为MapReduce程序完成对数据的分析。
1.4 Hive与MysqlHive虽然具有RDBMS数据库的外表,包括数据模型、SQL语法都⼗分相似,但应⽤场景却完全不同。
Hive只适合⽤来做海量数据的离线分析。
Hive的定位是数据仓库,⾯向分析的OLAP系统。
因此时刻告诉⾃⼰,Hive不是⼤型数据库,也不是要取代Mysql承担业务数据处理。
update语法汇总

update语法汇总UPDATE语法是用于修改关系型数据库中表中的数据的重要语法之一、通过UPDATE语法可以更新表中已有的数据,并且可以根据需要更新一条或多条数据。
下面是对UPDATE语法的详细介绍,包括UPDATE的概述、UPDATE的语法结构、UPDATE的使用方法以及UPDATE的注意事项等。
一、UPDATE的概述1.UPDATE是用于更新表中已有数据的关键字,它是SQL语句中最常用的关键字之一;2.UPDATE语句可以根据条件将表中的一条或多条数据进行更新,通过设置不同的条件,可以实现精确的数据更新操作;3.UPDATE语句可以更新表中的一个或多个列,从而修改表中的数据。
二、UPDATE的语法结构UPDATE语句的语法结构如下:```sqlUPDATE<表名>SET<列1>=<值1>,<列2>=<值2>,...[WHERE<条件>]```1.`UPDATE`:表示要进行更新操作;2.`<表名>`:需要更新数据的表的名称;3.`SET`:后面跟着要更新的列名以及对应的值,用逗号分隔,表示进行更新的列及其新值;4.`<列1>=<值1>,<列2>=<值2>,...`:表示要更新的列及其新值;5.`[WHERE<条件>]`:可选项,表示对更新的数据进行过滤,只更新满足条件的数据。
三、UPDATE的使用方法1.更新全部数据:如果不设置WHERE条件,则会更新表中的全部数据;```sqlUPDATE表名SET列1=值1,列2=值2,...```2.更新部分数据:如果只想更新满足条件的部分数据,可以通过设置WHERE条件实现。
WHERE条件可以使用比较操作符、逻辑操作符以及通配符进行设置;```sqlUPDATE表名SET列1=值1,列2=值2,...WHERE条件```3.更新多列数据:可以同时更新表中的多个列,只需在SET后面用逗号分隔每个列的更新操作;```sqlUPDATE表名SET列1=值1,列2=值2,...WHERE条件```4.更新特定的列:有些时候,只需要更新几列的数据,而不需要更新表中的全部列。
Hive用户手册)_中文版

Hive 用户指南v1.0目录1. HIVE结构 (5)1.1HIVE架构 (5)1.2Hive 和Hadoop 关系 (6)1.3Hive 和普通关系数据库的异同 (7)1.4HIVE元数据库 (8)1.4.1 DERBY (8)1.4.2 Mysql (9)1.5HIVE的数据存储 (10)1.6其它HIVE操作 (10)2. HIVE 基本操作 (11)2.1create table (11)2.1.1总述 (11)2.1.2语法 (11)2.1.3基本例子 (13)2.1.4创建分区 (14)2.1.5其它例子 (15)2.2Alter Table (16)2.2.1Add Partitions (16)2.2.2Drop Partitions (16)2.2.3Rename Table (17)2.2.4Change Column (17)2.2.5Add/Replace Columns (17)2.3Create View (18)2.4Show (18)2.5Load (18)2.6Insert (20)2.6.1Inserting data into Hive Tables from queries (20)2.6.2Writing data into filesystem from queries (21)2.7Cli (22)2.7.1Hive Command line Options (22)2.7.2Hive interactive Shell Command (23)2.7.3Hive Resources (24)2.7.4调用python、shell等语言 (25)2.8DROP (26)2.9其它 (26)2.9.1Limit (26)2.9.2Top k (26)2.9.3REGEX Column Specification (27)3. Hive Select (27)3.1Group By (27)3.2Order /Sort By (28)4. Hive Join (28)5. HIVE参数设置 (31)6. HIVE UDF (33)6.1基本函数 (33)6.1.1 关系操作符 (33)6.1.2 代数操作符 (34)6.1.3 逻辑操作符 (35)6.1.4 复杂类型操作符 (35)6.1.5 内建函数 (36)6.1.6 数学函数 (36)6.1.7 集合函数 (36)6.1.8 类型转换 (36)6.1.9 日期函数 (36)6.1.10 条件函数 (37)6.1.11 字符串函数 (37)6.2UDTF (43)6.2.1Explode (44)7. HIVE 的MAP/REDUCE (45)7.1JOIN (45)7.2GROUP BY (46)7.3DISTINCT (46)8. 使用HIVE注意点 (47)8.1字符集 (47)8.2压缩 (47)8.3count(distinct) (47)8.4JOIN (47)8.5DML操作 (48)8.6HAVING (48)8.7子查询 (48)8.8Join中处理null值的语义区别 (48)9. 优化与技巧 (51)9.1全排序 (53)9.1.1 例1 (53)9.1.2 例2 (56)9.2怎样做笛卡尔积 (59)9.3怎样写exist/in子句 (60)9.4怎样决定reducer个数 (60)9.5合并MapReduce操作 (61)9.6Bucket 与sampling (62)9.7Partition (62)9.8JOIN (63)9.8.1 JOIN原则 (63)9.8.2 Map Join (64)9.8.3 大表Join的数据偏斜 (66)9.9合并小文件 (67)9.10Group By (67)10. HIVE FAQ: (68)1.HIVE结构Hive 是建立在 Hadoop 上的数据仓库基础构架。
Hive(二)hive的基本操作

Hive(⼆)hive的基本操作⼀、DDL操作(定义操作)1、创建表(1)建表语法结构CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [COMMENT col_comment], ...)] //字段注释[COMMENT table_comment] //表的注释[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] //分区,前⾯没有出现的字段[CLUSTERED BY (col_name, col_name, ...) //分桶,前⾯出现的字段[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][ROW FORMAT row_format][STORED AS file_format][LOCATION hdfs_path]分区:不⽤关注数据的具体类型,放⼊每⼀个分区⾥;分桶:调⽤哈希函数取模的⽅式进⾏分桶(2)建表语句相关解释create table:创建⼀个指定名字的表。
如果相同名字的表已经存在,则抛出异常;⽤户可以⽤ IF NOT EXISTS 选项来忽略这个异常。
external :关键字可以让⽤户创建⼀个外部表,在建表的同时指定⼀个指向实际数据的路径( LOCATION), Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被⼀起删除,⽽外部表只删除元数据,不删除数据。
(经典⾯试问题)partitioned :在 Hive Select 查询中⼀般会扫描整个表内容,会消耗很多时间做没必要的⼯作。
有时候只需要扫描表中关⼼的⼀部分数据,因此建表时引⼊了 partition 概念。
MYD-AM335X Windows Embedded Compact 7 用户手册

MYD-AM335XWindows Embedded Compact 7用户手册版本记录目录目录 (1)1 概述 (2)2 WinCE开发环境搭建 (3)2.1 安装Visual Studio 2008 (3)2.2 安装Visual Studio 2008 SP1 (4)2.3 安装Platform Builder (4)3 系统编译 (6)3.1 复制源文件 (6)3.2 使能串口调试信息 (6)3.3 关于FlashDisk和RamDisk的配置说明 (7)3.4 电容或电阻触摸屏的配置 (7)3.5 Sysgen和编译BSP (8)4 烧写映像 (10)4.1 TF卡映像更新 (10)4.2 NAND Flash 映像更新 (16)5 WinCE APP开发例程 (17)5.1 创建项目 (17)5.2 在对话框上创建按钮 (20)5.3 添加代码 (22)5.4 编译工程 (23)第1章概述本章主要讲述如何在MYD-AM335X开发板上安装运行Windows Embedded Compact 7系统和其相应的应用开发。
具体包括搭建开发环境、编译、映像更新以及应用开发的实例分析。
第2章WinCE开发环境搭建本章介绍MYD-AM335X WinCE开放环境的软件安装,在开始配置开发环境之前,必须准备如下软件:Microsoft Visual Studio 2008 Professional EditionMicrosoft Visual Studio 2008 Professional Service Pack 1Windows Embedded Compact 7(包含或者更高版本的Update - update 1 to update 4 (Oct 2011))所有这些软件的安装,建议电脑至少预留有40GB的硬盘空间。
2.1 安装Visual Studio 2008将Microsoft Visual Studio 2008 Professional Edition安装到Windows系统主机中,如下图2-1所示:图2-1点击“Install Visual Studio 2008”,并按照安装指引一步步安装。
hive执行计划

hive执行计划Hive执行计划。
Hive执行计划是在Hive查询执行过程中生成的一种重要的执行计划,它描述了Hive如何执行查询,包括数据的读取、处理和输出等过程。
了解Hive执行计划对于优化查询性能和调整Hive配置非常重要。
本文将介绍Hive执行计划的生成过程、执行计划的内容以及如何通过执行计划优化Hive查询。
Hive执行计划的生成过程。
在Hive中,当用户提交一个查询任务时,Hive会首先对查询进行解析,然后生成对应的执行计划。
执行计划是一个逻辑执行计划,它描述了Hive如何执行查询,包括数据的读取、处理和输出等过程。
Hive执行计划的生成过程主要包括以下几个步骤:1. 查询解析,Hive首先对用户提交的查询进行解析,包括语法解析和语义解析。
在语法解析阶段,Hive会检查查询语句的语法是否正确;在语义解析阶段,Hive会对查询进行语义分析,包括表的解析、字段的解析等。
2. 逻辑执行计划生成,在查询解析完成后,Hive会根据查询语句生成对应的逻辑执行计划。
逻辑执行计划是一个逻辑执行流程图,它描述了查询的执行顺序和执行方式,但并不包括具体的物理执行细节。
3. 物理执行计划生成,在生成逻辑执行计划后,Hive会根据逻辑执行计划生成对应的物理执行计划。
物理执行计划是一个具体的执行计划,它包括了数据的读取、处理和输出等具体的执行细节,可以直接用于执行查询任务。
Hive执行计划的内容。
Hive执行计划包括了查询的执行顺序和执行方式,以及具体的执行细节。
一个典型的Hive执行计划通常包括以下几个部分:1. 查询计划,查询计划描述了查询的执行顺序和执行方式。
它包括了查询的逻辑执行流程图和具体的执行步骤。
2. 执行计划,执行计划描述了查询的具体执行细节,包括数据的读取、处理和输出等过程。
它是一个具体的执行计划,可以直接用于执行查询任务。
3. 优化信息,优化信息描述了查询的优化情况,包括优化规则的使用、优化器的选择等信息。
(完整word版)HIVE说明文档

HIVE说明文档一、HIVE简介:1、HIVE介绍Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。
它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL语句作为数据访问接口。
Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行,通过自己的SQL 去查询分析需要的内容,这套SQL 简称Hive SQL,使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据.2、HIVE适用性:它与关系型数据库的SQL 略有不同,但支持了绝大多数的语句如DDL、DML 以及常见的聚合函数、连接查询、条件查询。
HIVE不适合用于联机(online)事务处理,也不提供实时查询功能。
它最适合应用在基于大量不可变数据的批处理作业。
HIVE的特点:可伸缩(在Hadoop的集群上动态的添加设备),可扩展,容错,输入格式的松散耦合.hive不支持用insert语句一条一条的进行插入操作,也不支持update操作。
数据是以load的方式加载到建立好的表中。
数据一旦导入就不可以修改。
DML包括:INSERT插入、UPDATE更新、DELETE删除。
3、HIVE结构Hive 是建立在Hadoop上的数据基础架构,它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制,Hive定义了简单的累SQL 查询语言,称为HQL,它允许熟悉SQL的用户查询数据,同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理內建的mapper和reducer无法完成的复杂的分析工作。
Hive性能调优指南

Hive性能调优指南目录目录 (2)第一章 Hive调优的总体原则 (4)1.1 计算性能的优化 (4)1.2 I/O的优化 (5)第二章 Hive优化的相关原理 (5)2.1关于Join (6)Ø 2.1.1 Reduce Side Join (6)Ø 2.1.2 Map Side Join (7)Ø 2.1.3 Semi Join (9)Ø 2.1.4 Reduce Side Join + Bloom Filter (10)Ø 2.1.5 Hive提供的Join方式 (10)Shuffle Join (10)Broadcast Join (11)Bucket Map Join (11)Sort-Merge-Bucket Join(SMJ) (12)Skew Join (13)Left Semi Join (14)2.2关于排序 (15)Ø 2.2.1 Order By (15)Ø 2.2.2 Sort By (15)Ø 2.2.3 Distribute By (16)Ø 2.2.4 Cluster By (16)2.3数据倾斜问题 (17)Ø什么是数据倾斜 (17)Ø数据倾斜的常见场景 (17)l空值数据倾斜 (17)l不同数据类型关联产生数据倾斜 (18)l大表Join的数据偏斜 (18)Ø数据倾斜的解决方案 (19)l参数调节 (19)l SQL语句调节 (20)2.4关于Shuffle (20)ØShuffle概述 (20)ØMap端Shuffle过程 (21)ØReduce端Shuffle过程 (22)第三章Hive调优方案及分析 (24)Ø 3.1 Hadoop计算框架的特点 (24)Ø 3.2 Hadoop调优策略 (25)应用程序级别调优 (25)作业级别调优 (26)任务级别调优 (27)管理员级别调优 (30)操作系统级别调优 (30)JVM级别调优 (31)Ø 3.3 Hive调优项目checklist (32)Ø 3.4 Hive优化的常用案例 (32)l优化Join连接 (32)ØJoin的原则 (32)Ø使用Map Join (33)l合理设置map task数 (35)l怎么设置reduce的任务数 (37)l exist in子句 (39)l合并小文件 (39)l开启本地Map任务 (39)l优化limit (40)l JVM重用 (40)l推测式执行(Speculative Execution) (41)l Group By (41)l使用Multi-group by合并MR数 (41)l Bucket and Samping (42)l Partition (42)l Strict模式 (43)l避免笛卡尔积 (44)l慎用count(distinct) (44)l利用Hive中的union all特性减少Map/Reduce个数 (45)l Controlling data locality with Hive (46)l使用ORC File (47)l使用Tez (47)l数据加载场景的优化案例 (48)l多表关联的优化 (49)l使用并发 (51)l Urber模式 (51)l本地map 任务 (52)Ø 3.5 Hive调优参数 (53)第五章 附录-参数 (58)第一章 Hive调优的总体原则 1.1 计算性能的优化原则:合理调整map/reduce的任务数量,充分利用集群中的CPUa)尽量保证每个map任务处理的数据量保持均衡b)Reduce任务数量=总任务槽*0.95:这样为一个推测式执行任务提供空闲机器。
2.Hive常见操作命令整理

2.Hive常见操作命令整理该笔记主要整理了《Hive编程指南》中⼀些常见的操作命令,⼤致如下(持续补充中):1. 查看/设置/修改变量2. 执⾏命令3. 搜索相关内容4. 查看库表信息5. 创建表6. 分区7. 修改表(重命名、修改列、删除列、增加列)8. 找到表位置并导出⾄本地9. 去空格10. case...when...then句式11. 操作符12. group by...having句式13. JOIN14. order by和sort by15. 抽样查询16. 视图17. 分桶表18. 函数19. with...as20. rank() over (partition by ... order by ... asc/desc)和row_number()21. 时间相关的函数(from_unixtime,unix_timestamp,date_add,months_between)22.substr()23.regexp_replace()和regexp_extract()24.动态分区25.nvl和grouping set26. concat_ws()、group_concat()和collect_list()teral view explode()1. 查看/设置/修改变量$ hive############# 查询环境变量############hive>set env:HOME;# 打印命名空间hivevar, hiveconf, system和env所有变量hive>set;# 还打印Hadoop所定义的所有属性hive>set -v;############# 设置hive变量############hive>set hivevar:foo=bar# 查看刚设置的变量hive>set foo;hive>set hivevar:foo;############# 修改属性变量############# hiveconf: Hive相关的配置属性# 不进⼊Hive进⾏配置属性修改hive --hiveocnf hive.cli.print.current.db=true# 进⼊hive进⾏配置修改hive>set hiveconf:hive.cli.print.current_db=true;2. 执⾏命令# 执⾏命令⽅式1:使⽤下⾯的 “⼀次使⽤”命令(-e是指⼀次执⾏,-S是指静默模式,在输出结果中不显⽰Ok和Time taken字段)hive -e -S "select * from mytable limit 3";# 执⾏命令⽅式2:调⽤Hive执⾏hql⽂件hive -f /path/query.hql# 执⾏命令⽅式3:在Hive shell内执⾏hql⽂件$ hivehive>source /path/query.hql3. 搜索相关内容# 模糊搜索set命令的输出结果中某个于warehouse相关的属性$ hive -S -e "set" | grep warehousehive.metastore.warehouse.dir=/user/hive/warehousehive.warehouse.subdir.inherit.perms=false4. 查看库表信息# 查看数据库,使⽤like是以ahf开头,以其他字符结尾(即.*)的数据库名show databases;show databases like 'ahf.*';# 查看表的详细表结构信息(formatted⽐extended输出内容更详细且可读性更⾼)describe mydb.table;describe formatted mydb.table;describe extended mydb.table;5. 创建表# 拷贝表结构,⽽不拷贝数据(⽤like)create table if not exists mydb.mytable like mydb.mytable2;# 拷贝表结构,且拷贝数据(⽤as)create table if not exists mydb.mytable asselect*from mydb.mytable2;# 直接创建表结构create table if not exists mydb.mytable(id string comment 'id',name string comment '姓名')partitioned by (class string)stored as orc;6. 分区# 建⽴分区create table(字段1 字段类型, 字段2 字段类型)paritioned by (字段名3 字段类型, 字段名4 字段类型);# 查看分区show partitions table_name;# 查看某个特定分区键的分区show partitions table_name partition(⼀个分区字段='该分区字段下的某个值');# 增加分区alter table log_message add partition(year=2012, month=1, day=2);# 删除分区alter table log_messages drop if exists partition(year=2012, month=1, day=2);7. 修改表(重命名、修改列、删除列、增加列)# 表重命名alter table log_messages rename to logmsgs;# 修改列信息, 在下⾯的例⼦中,# 我们将字段hms重命名为hour_minutes_seconds,修改其类型和注释,再转移到severity字段之后# 如果⽤户想将这个字段移动到第⼀个为位置,只需要使⽤first关键字替换after severityalter table log_messages change column hms hour_minutes_seconds intcomment 'the hours, minutes, and seconds parts of the timestamp'after severity;# 删除或替换列, 下⾯的例⼦移除了之前所有字段并重新指定了新的字段alter table log_messages replace columns(新字段1 int comment '...',新字段2 string comment '...');# 增加列alter table log_messages add columns(app_name string comment 'application name',session_id long comment 'the current session id');8. 找到表位置并导出⾄本地# 找到表位置describe formatted mydb.mytable;# 例如:Location:hdfs://alg-hdfs/warehouse/user/alvinai.mydb/mytable# 导出⽂件hadoop fs -cp [表来源][⽬标导出路径]9. 去空格# 去空格 ltrim去左空格,rtrim去右空格ltrim(string s)10. case...when...then句式select name,salary,case when salary <5000.0then'low'when salary >=5000.0and salary <70000.0then'middle'else'high'end as bracketfrom employees;11. 操作符# 常见的谓语操作符A<>B跟A!=B是⼀样的A<==>B是指任⼀为NULL,则结果为NULLA is null还有A is not nulla not betweenb and c, between是闭区间# LiKE和RELIKE谓语操作符A like B, A relike B前者是SQL,后者是JAVA的正则表达式A like B, ‘x%’表⽰A必须以字母x开头,‘%x’表⽰A必须以字母x结尾,‘%x%’表⽰A包含字母x,可以位于开头结尾或者字符串中间A relike B, .号表⽰任意字符,*表⽰重复左边的字符串零次到⽆数次,表达式(x|y)表⽰x或者y匹配例⼦:查找住址以Ave结尾的⼈select name, address from where employees where address like'Ave.';例⼦:查找地址以0开头的⼈select name, address from where employees where address like 'O%';# split操作符select split(row_key, '_')[0] as account_id12. group by...having句式# 如果想要对group by语句产⽣的分组进⾏条件过滤,可以⽤having例如:select year(ymd),avg(price_close) from stockswhere exchange ='NASDAQ'and symbol ='AAPL'group by year(ymd)having avg(price_close) >0.0;13. JOINHive连接有:inner join: 交集,就是join。
hive todate函数

hive todate函数Hive todate函数详解Hive是一个基于Hadoop的数据仓库基础设施,它提供了类似SQL 的查询语言HiveQL,可以方便地进行数据分析和处理。
在HiveQL 中,有一个非常有用的函数叫做todate函数,该函数可以将字符串转换为日期类型。
本文将详细介绍Hive中的todate函数的使用方法及注意事项。
一、todate函数的基本语法和用法在Hive中,todate函数的基本语法如下:todate(string timestamp, string format)其中,timestamp是一个字符串类型的参数,表示要进行转换的日期字符串;format是一个字符串类型的参数,表示日期字符串的格式。
下面是一个示例,展示了如何使用todate函数将字符串转换为日期:SELECT todate('2022-01-01', 'yyyy-MM-dd');在上述示例中,我们将字符串'2022-01-01'转换为日期类型,并以'yyyy-MM-dd'的格式进行输出。
输出结果为'2022-01-01',表示成功将字符串转换为日期。
二、todate函数支持的日期格式todate函数支持的日期格式包括年、月、日、小时、分钟和秒。
下面是一些常用的日期格式及其含义:- 'yyyy-MM-dd':表示年份-月份-日期,例如'2022-01-01'。
- 'yyyy/MM/dd':表示年份/月份/日期,例如'2022/01/01'。
- 'yyyy-MM-dd HH:mm:ss':表示年份-月份-日期小时:分钟:秒,例如'2022-01-01 12:00:00'。
- 'yyyy/MM/dd HH:mm:ss':表示年份/月份/日期小时:分钟:秒,例如'2022/01/01 12:00:00'。
hive load 本地文件 原理

文章标题:深度解析hive load本地文件原理及应用一、引言在大数据处理领域,Hive作为一种数据仓库基础设施,被广泛应用于数据的存储、查询和分析中。
而在实际应用中,我们时常需要将本地文件加载到Hive中进行数据处理,因此了解Hive load本地文件的原理及应用显得尤为重要。
二、Hive load本地文件的原理1. 数据加载过程Hive load本地文件的过程主要包括以下几个步骤:(1) 用户将本地文件上传至HDFS中,然后通过Hive的LOAD DATA 命令将数据加载至Hive表中;(2) 在加载数据的过程中,Hive会自动地将数据进行分区,并生成相应的元数据信息,以便后续的查询和分析。
2. 数据加载原理Hive load本地文件的原理主要涉及到Hive的元数据管理和数据加载两个方面:(1) 元数据管理:Hive将用户上传的本地文件通过元数据的方式进行管理,包括数据结构、数据类型等信息;(2) 数据加载:通过类似MapReduce的方式,Hive会将数据加载至Hive表中,并生成相应的Hive元数据,以便后续的数据查询和分析。
三、Hive load本地文件的应用1. 数据迁移Hive load本地文件在数据迁移方面有着重要的应用,用户可以通过简单的命令将本地文件加载至Hive表中,从而实现数据的快速迁移和整合。
2. 数据离线处理Hive load本地文件可用于数据离线处理过程中,用户可以先将离线数据上传至HDFS,然后通过Hive load的方式加载到Hive表中,进行数据分析和处理。
四、个人观点与总结Hive load本地文件的原理相对简单,但在实际应用中需要注意一些细节问题,比如数据格式、数据质量的保证等。
在实际运用中,我们需要充分了解Hive的数据加载机制和数据管理原理,从而更加灵活地应用于实际项目中。
五、回顾与展望通过本文的探讨,我们对Hive load本地文件的原理及应用有了更深入的了解。
hive动态分区实现(hive-1.1.0)

hive动态分区实现(hive-1.1.0)笔者使⽤的hive版本是hive-1.1.0hive-1.1.0动态分区的默认实现是只有map没有reduce,通过执⾏计划就可以看出来。
(执⾏计划如下)insert overwrite table public_t_par partition(delivery_datekey) select * from public_oi_fact_partition;hive 默认的动态分区实现,不需要shuffle那么hive如何通过map就实现了动态分区了呢,stage1根据FileInputSplit决定有⼏个map,假如数据量较少只有⼀个map,这个job是没有reduce的,那么就不会有sort merge combine等操作。
假设这个map读的数据有10基数的delivery_datekey,那么这个map每读到⼀个不同delivery_datekey数据就会打开⼀个file writer,⼀共会打开⼗个file writer。
其实是相当浪费⽂件句柄的。
这也就是为什么hive 严格模式是禁⽌⽤动态分区的,就算关闭严格模式,也是限制job最⼤写分区数的,甚⾄限制每台节点写分区数,就是怕某个动态分区的hive任务把系统的⽂件句柄耗光,影响其他任务的正常运⾏。
当stage1 map把数据写到相关分区后,再由stage 2启动分区数(其实⼩于等于⽣成的分区数)个map进⾏⼩⽂件的合并。
由于我们stage1 只有⼀个map不会涉及每个分区下有多个⽂件,并不⽤启动stage2,进⾏分区下⼩⽂件合并。
hive 优化后动态分区实现,开启reduce,需要shuffle# 使⽤这个参数开始动态分区优化,其实就是强制开启reduceSET hive.optimize.sort.dynamic.partition=true;实现思路就是把分区字段delivery_datekey作为key(细节可能跟源码有出⼊,因为没看源码,不过这⾥怎么实现都⾏,就看源码想不想根据其他字段排序了,不影响整体理解),其他字段作为value,也根据分区字段delivery_datekey分区partition,然后通过shuffle传到不同的reduce,这样合并⼩⽂件的操作有reduce完成了。
大数据,数据仓库,hive不能使用update更新操作解决方案

大数据,数据仓库,hive不能使用update更新操作解决方案在数据仓库建设,处理日常业务需求的过程中,经常会遇到各种各样的问题。
在处理更新操作数据时,遇到数据重复问题。
前期因为没考虑到关系型数据库update操作,把数据同步到hive时有数据重复问题,在业务日常报表分析时,带来很大困扰。
今天就简单来说一下,遇到这样的场景该如何处理。
其实只要用到hive的窗口函数即可解决。
业务背景首先,要来谈谈为啥会遇到这个问题。
如何不结合业务背景讨论这个问题,那么是毫无意义的。
我们公司在建设数仓过程中,使用的是第三方平台,类似阿里云这样的平台。
公司购买的第三方产品,省去了底层的开发工作。
很多东西,都是已经封装完成的,拿来使用即可。
数据仓库建设,使用传统关系型数据库进行数据存储,显然是不现实的。
我们需要把关系型数据库,如mysql,oracle等库里的数据同步到分布式文件系统(HDFS)上,我们公司使用的是hive这种非关系型数据库。
注意:hive的元数据管理使用的是mysql数据库,但是业务数据都是存储在HDFS上的。
从关系型数据库同步数据的时候,第一次选择全量同步。
因为数据量非常大,单个表的数据就几百G不等。
但是后续继续使用全量同步显然是不显示的,只能考虑使用增量同步,来同步增量数据,使用修改时间这个字段进行判断数据是否为新增数据。
在日常生产中,使用关系型数据库,大家知道有update更新操作。
比如某个用户的状态改变以后,只需要在数据库中更改这条已经存在的记录即可。
但是这种更新我们需要实时的同步到hive中,可是hive并没有update的更新操作。
把关系型数据库中更新的数据同步到hive中,就会存在数据重复的问题。
(因为以前可能已经同步过这条数据)。
那么怎么解决这个问题呢?曲线救国,选择出最新的记录hive没有update的更新操作。
但是我们可以通过hive的序列函数和窗口函数来解决这个问题,非常简单。
使用row_number函数即可。
Hive update实现方案V10 甄选

Hive update实现方案V1.0(优选.)Hive update实现方案1.问题由于hive数仓的特性,不容许数据进行修改,造成hive中的数据更新活着删除很困难的问题,自hive 0.11版本之后,hive也尝试在测试环境允许进行update和delte操作,但这些操作还不成熟,不敢在生产环境放心使用,其中也有一样不足。
所以就需要找一种可靠的方案实现hive的数据更新或者删除。
2.方案2.1.创建数据表创建两张数据结构一模一样的hive数据表TEST、TEST_TEMP,其中TEST表的存储格式为“ORCFILE”(性create table TEST_TEMP (id string,name string,agestring) comment '临时表'partitioned by (y string,m string,d string)row format delimited fields terminated by','stored as textfilecreate table TEST (idstring,namestring,age string) comment '最终表'row format delimited fields terminated by','stored as orcfile2.2.初始化1.通过hive数据load的方式先把数据加载到TEST_TEMP表中(此处也可以通过sqoop进行数据抽取,不再详述)。
load data local inpath '/home/hadoop/a.txt' overwrite intotableTEST_TEMP2.通过hive insert overwrite的方式把临时表的数据加载到最终表TEST中。
insertintotableTEST selectid,name,agefromTEST_TEMP2.3.日常1.通过hive数据load的方式先把数据加载到TEST_TEM表中(此处也可以通过sqoop进行数据抽取,不再详述)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hive update实现方案
1.问题
由于hive数仓的特性,不容许数据进行修改,造成hive中的数据更新活着删除很困难的问题,自hive 0.11版本之后,hive也尝试在测试环境允许进行update和delte操作,但这些操作还不成熟,不敢在生产环境放心使用,其中也有一样不足。
所以就需要找一种可靠的方案实现hive的数据更新或者删除。
2.方案
2.1.创建数据表
创建两张数据结构一模一样的hive数据表TEST、TEST_TEMP,其中TEST表的存储格式为“ORCFILE”(性能高),TEST_TEMP 表的存储格式为“TEXTFILE”(方便数据加载)。
ID NAME AGE
主键姓名年龄
create table TEST_TEMP (
id string,
name string,
age string
) comment '临时表'
partitioned by (y string,m string,d string)
row format delimited fields terminated by',' stored as textfile
create table TEST (
id string,
name string,
age string
) comment '最终表'
row format delimited fields terminated by','
stored as orcfile
2.2.初始化
1.通过hive数据load的方式先把数据加载到TEST_TEMP表中
(此处也可以通过sqoop进行数据抽取,不再详述)。
load data local inpath '/home/hadoop/a.txt'
overwrite intotable TEST_TEMP
2.通过hive insert overwrite的方式把临时表的数据加载到最终
表TEST中。
insertintotable TEST
select id,name,age from TEST_TEMP
2.3.日常
1.通过hive数据load的方式先把数据加载到TEST_TEM表中
(此处也可以通过sqoop进行数据抽取,不再详述)。
load data local inpath '/home/hadoop/b.txt'
overwrite intotable TEST_TEMP
2.通过数据比对方式,找出非更新和非增量的数据,人后把这
部分数据覆盖到TEST表中,即保证TEST中的数据和
TEST_TEMP中的没有重复(前提是表中必须有主键)。
INSERT OVERWRITE TABLE TEST
SELECT id,name,age FROM TEST a LEFT JOIN
TEST_TEMP b on a.id=b.id WHERE b.id is null;
注:上述语句其实就是not in的逻辑,如果日常数据上包含增、
删、改标识,则只需在关联时在TEST_TEMP表上加条件判
断即可。
3.经过第二步的数据比对重复处理之后,则可以直接把
TEST_TEMP中的数据追加(append)到TEST表。
insertintotable TEST
select id,name,age from TEST_TEMP;
****************增、改实现****************
注:实现比对出增、改标识
SELECT
a.id,
,
a.age,
CASEWHEN b.id ISnullTHEN'新增'ELSE'更新'END
FROM
TEST_TEMP a
LEFTJOIN TEST b on
a.id =
b.id;
数据插入
insertintotable TEST
SELECT
a.id,
,
a.age,
CASEWHEN b.id ISnullTHEN'新增'ELSE'更新'END
FROM
TEST_TEMP a
LEFTJOIN TEST b on
a.id =
b.id;
3.总结
上述的方案在逻辑上虽然解决了hive的更新操作,但只是抛砖引玉,在实际的环境可能还要进行一些表分区等优化措施。
针对方案的第二点,实际也可能存在安全问题,如果这一步未执行成功那怎么回退?是在做overwrite之前做备份还是copy一份新的数据join,需要结合实际项目情况进行决策。