32位单周期RISC处理器设计
《数字逻辑与计算机组成》实验讲义-实验5

实验5:单周期处理器的控制器设计实验一、实验目的1、理解随机访问存储器RAM和只读存储器ROM的操作原理。
2、理解指令类型与指令格式之间的关系,掌握取指部件、指令解析和立即数扩展器的设计方法。
3、理解每条目标指令的功能和数据通路,掌握单周期处理器的控制器设计方法。
二、实验环境Logisim-ITA V2.16.1.0。
三、实验内容1、利用Logisim中的RAM组件进行数据读写操作实验。
Logisim中RAM的地址位宽最多可设置为24位,数据位宽最多可设置为32位。
在属性窗口的数据接口中有三种不同的工作模式。
若设置为“分离的加载和存储引脚”模式,则有两个数据端口分别连接输入数据和输出数据(如图1所示);否则,使用同一数据端口连接数据总线。
注意:当设置数据位宽为32位时,采用按字编址方式(32位),而不是采用按字节编址方式。
图1 采用分离加载和存储模式的32位数据读取实验图实验要求RAM组件的地址位宽设置为12位,数据接口模式设置为分离的加载和存储引脚模式。
实验过程与验证步骤如下:(1)设置数据位宽为32位,即可访问空间大小为16KB;连接必要的输入输出信号并选择合适的控制信号;从0地址处开始顺序写入以下两个32位的十六进制数据:0x4E4A5543、0x53657200;然后再读出所存储的数据。
(2)设置数据位宽为8位,即可访问空间大小为4KB;将输出数据端口连接到如图2所示的文本终端TTY;从0地址开始顺序写入以下八个字节的十六进制数据:4E4A554353657200;然后按字节为单位读出并输出到文本终端TTY,观察显示的内容。
图2 采用分离加载和存储模式的8位数据读取实验图(3)Logisim中RAM和ROM组件的数据输入还可以采用Logisim十六进制编辑器和直接读取二进制编码文件的方法实现。
把鼠标移到存储器组件上,点击鼠标右键,则弹出菜单框(如图3所示),选中“编辑存储内容”,则打开Logisim十六进制编辑器(如图4所示),可按照存储器设置的数据位宽,直接使用键盘输入数据;输入数据后,可点击保存按钮,把输入的数据保存到数据镜像文件(image)中。
32位嵌入式CPU内核MCORE

32位嵌入式微处理器核主要内容MCORE/CCORE概述寄存器及编程模型MCORE/CCORE指令集中断与异常处理RISC(Reduced Instruction Set Computer)型处理器已普遍被嵌入式系统所采用MCORE/CCORE是目前常用的一种RISC型处理器,主要特点:高性能、低价格、低功耗C*Core是苏州国芯科技有限公司在摩托罗拉技术的高起点平台上,建立和发展的具有自主产权的高性能32位嵌入式RISC微处理器C*Core是面向高性能、低成本的嵌入式控制领域设计的,具有极低的系统功耗。
适用于电池供电的便携式产品以及为适合高温环境而设计的高集成度部件◆完全可综合的32位嵌入式RISC CPU◆低功耗,高性能,高代码密度◆特别适用于手提设备(PDA、移动电话)、通讯设备(无线局域网、路由器)、汽车工业(ABS、安全气囊、电喷控制、刹车控制)、家用电器以及众多的工业过程控制。
◆C*Core嵌入式CPU的主要类型:C210C310CS320本课程主要以C210为重点。
CCORE(C210)结构框架C210的主要特征32位RISC处理器架构固定16位指令长度16个32位的通用寄存器高效的4级执行流水线多数指令为单周期指令分支指令以及存储器访问仅需两个时钟周期支持字节、半字和字三种类型的存储器访问16个专用的交替寄存器支持快速中断支持矢量和自动矢量的中断具有两套处理器状态PSR和程序指针PC影子寄存器硬件整数乘法器阵列(C310)16-bit x 16-bit in 1 clock32-bit x 32-bit in 2 clocksCCORE(C210)微架构C210的指令执行流水线包括下列四级:取指指令译码/读寄存器文件执行寄存器回写16个通用寄存器用于存放操作数和指令结果。
寄存器R15被用作联接寄存器,存放子程序的返回地址。
寄存器R0存放当前的堆栈指针CCORE微结构(续)执行单元包括:一个32位的算术/逻辑单元(ALU)一个32位的桶型移位器Find-First-One (FF1)单元结果前馈硬件其他一系列用于支持乘法和多寄存器读取和存储的硬件程序计数器单元:一个PC累加器一个专用的分支地址加法器指令流水线和时序处理器流水线由取回指令、指令译码、执行和回写结果四个级别组成处理器还包括指令预取缓冲器,允许在指令译码的前一级别缓冲一个指令。
计算机设计与实践——MIPS基本指令

MIPS 基本指令和寻址方式:MIPS 是典型的RISC 处理器,采用32位定长指令字,操作码字段也是固定长度,没有专门的寻址方式字段,由指令格式确定各操作数的寻址方式。
MIPS 指令格式一般有三种格式: R-型指令格式 I-型指令格式 J-型指令格式R _Type 指指指指262116116316bit6bit5bit5bit5bit5bitOP : 操作码rs : 第一个源操作数寄存器rt : 第二个源操作数寄存器(单目原数据) rd : 结果寄存器 shamt :移位指令的位移量 func : 指令的具体操作类型特点:R-型指令是RR 型指令,其操作码OP 字段是特定的“000000”,具体操作类型由func字段给定。
例如:func=“100000”时,表示“加法”运算。
R[rd] ← R[rs] + R[rt]I _Type 指指指指2621163115特点:I-型指令是立即数型指令双目运算: R[rt] R[rs](OP )SignExt(imm16) Load 指令:Addr ← R[rs] + SignExt(imm16) 计算数据地址 (立即数要进行符号扩展) R[rt] ← M[Addr] 从存储器中取出数据,装入到寄存器中Store 指令:Addr ← R[rs] + SignExt(imm16) M[Addr] ← R[rt]J _Type 指令格式26316bit26bit25特点:J-型指令主要是无条件跳转指令,将当前PC 的高4位拼上26位立即数,后补两个“0”,作为跳转目标地址。
j L //goto L 指指指指指指指指指jal L //$ra 指PC+4;goto L 指指指指指指指指指R 型指令:定点运算: add / addu , sub / subu , sra , mult/multu , div/divu 逻辑运算: and / or / nor , sll / srl 比较分支: beq / bne / slt / sltu 跳转指令: jrI 型指令:定点运算: addi / addiu 逻辑运算: andi / ori 比较分支: slti / sltiu数据传送: lw / sw / lhu / sh / lbu / sb / luiJ 型指令: j / jal设计模块划分,教学安排1、MIPS格式指令系统设计2、指令存储器设计3、寄存器堆设计4、ALU设计——基本算术、逻辑单元的设计32位超前进位加法器的设计32位桶式移位寄存器的设计5、取指令部件的设计6、立即数处理单元设计7、单周期处理器设计——R型指令的数据通路设计I型指令的数据通路设计Load/Store指令的数据通路设计分支指令/转移指令的数据通路设计综合12条指令的完整数据通路设计8、ALU控制单元设计9、主控制单元的设计10、单周期处理器总体验证11、异常和中断处理及其电路实现12、带有异常和中断处理功能的处理器的设计设计示例1:指令存储器设计1、 指令存储器模块定义:指令存储器用于存放CPU 运算的程序指令和数据等,采用单端口存储器设计,设计最大为64个存储单元,每个存储单元数据宽度为32bit 。
32位MIPS CPU设计

实验四32位MIPS CPU设计实验
1设计要求
使用Logisim 软件依次完成4 个子电路的设计,如下:
1. 指令译码器
2. 时序发生器状态机(定长指令周期)
3. 时序发生器输出函数(定长指令周期)
4. 硬布线控制器
在此基础上完成对“单总线CPU(3 级时序)”的联合调试,使之可以运行
简单的冒泡排序算法MIPS 汇编程序,实现排序功能。
2方案设计
2.1 指令译码器
原理:
根据MIPS指令格式表中各个指令的op字段,和IR送来的指令op字段比较,若相同则是该指令,注意SLT 指令还需要判断funct字段为101010,用异或门判断OtherInstr
电路:
图1指令译码器
2.2 时序发生器状态机(定长指令周期)
原理:
由于是定长指令周期,所以次态只和现态有关,Si->Si+1 (0<=i<=10),S11->S0
电路:
图2状态机
2.3 时序发生器输出函数(定长指令周期)
原理:
定长指令周期分为3个机器周期(取指,计算,执行)每个机器周期分为4个节拍S0~S3取指周期,S4~S7计算周期,S8~S11执行周期
每个机器周期内节拍递增
电路:
图3输出函数
2.4 硬布线控制器
原理:
状态暂存器输出到状态机计算出次态再返回状态寄存器,同时现态送到输出函数电路:
图4硬布线控制器
3实验步骤
按照设计连接电路,在电路图中“单总线CPU(3 级时序)”子电路中进行调试,测试CPU 是否可以正确执行冒泡排序程序
4测试与分析
发现数据6,5,4,3,2,1,-1按递减排序
实验结果符合预期。
MIPS单周期CPU实验报告

MIPS单周期CPU实验报告一、实验目的本实验旨在设计一个基于MIPS指令集架构的单周期CPU,具体包括CPU的指令集设计、流水线的划分与控制信号设计等。
通过本实验,可以深入理解计算机组成原理中的CPU设计原理,加深对计算机体系结构的理解。
二、实验原理MIPS(Microprocessor without Interlocked Pipeline Stages)是一种精简指令集(RISC)架构的处理器设计,大大简化了指令系统的复杂性,有利于提高执行效率。
MIPS指令集由R、I、J三种格式的指令组成,主要包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
在单周期CPU设计中,每个指令的执行时间相同,每个时钟周期只执行一个指令。
单周期CPU的主要部件包括指令内存(IM)、数据存储器(DM)、寄存器文件(RF)、运算单元(ALU)、控制器等。
指令执行过程主要分为取指、译码、执行、访存、写回等阶段。
三、实验步骤1.设计CPU指令集:根据MIPS指令集的格式和功能,设计符合需求的指令集,包括算术逻辑运算指令、存储器访问指令、分支跳转指令等。
2.划分CPU流水线:将CPU的执行过程划分为取指、译码、执行、访存、写回等阶段,确定每个阶段的功能和控制信号。
3.设计控制器:根据CPU的流水线划分和指令集设计,设计控制器实现各个阶段的控制信号生成和时序控制。
4.集成测试:进行集成测试,验证CPU的指令执行功能和正确性,调试并优化设计。
5.性能评估:通过性能评估指标,如CPI(平均时钟周期数)、吞吐量等,评估CPU的性能优劣,进一步优化设计。
四、实验结果在实验中,成功设计了一个基于MIPS指令集架构的单周期CPU。
通过集成测试,验证了CPU的指令执行功能和正确性,实现了取指、译码、执行、访存、写回等阶段的正常工作。
同时,通过性能评估指标的测量,得到了CPU的性能参数,如CPI、吞吐量等。
通过性能评估,发现了CPU的性能瓶颈,并进行了相应的优化,提高了CPU的性能表现。
stm32f103简介

数据手册STM32F103xC STM32F103xDSTM32F103xE增强型,32位基于ARM核心的带512K 字节闪存的微控制器USB 、CAN 、11个定时器、3个ADC 、13个通信接口初步信息功能■ 内核:ARM 32位的Cortex™-M3 CPU − 最高72MHz 工作频率,1.25DMips/MHz(Dhrystone2.1), 在存储器的0等待周期访问时 − 单周期乘法和硬件除法 ■ 存储器− 从256K 至512K 字节的闪存程序存储器 − 高达64K 字节的SRAM− 带4个片选的灵活的静态存储器控制器。
支持CF 卡、SRAM 、PSRAM 、NOR 和NAND 存储器− 并行LCD 接口,兼容8080/6800模式 ■ 时钟、复位和电源管理− 2.0~3.6伏供电和I/O 管脚 − 上电/断电复位(POR/PDR)、可编程电压监测器(PVD)− 内嵌4~16MHz 晶体振荡器− 内嵌经出厂调校的8MHz 的RC 振荡器 − 内嵌带校准的40kHz 的RC 振荡器 − 带校准功能的32kHz RTC 振荡器 ■ 低功耗− 睡眠、停机和待机模式− V BAT 为RTC 和后备寄存器供电■ 3个12位模数转换器,1μs 转换时间(多达21个输入通道)− 转换范围:0至3.6V − 三倍采样和保持功能 − 温度传感器■ 2通道12位D/A 转换器■ DMA− 12通道DMA 控制器− 支持的外设:定时器、ADC 、DAC 、SDIO 、I 2S 、SPI 、I 2C 和USART ■ 多达112个快速I/O 口− 51/80/112个多功能双向的I/O 口 − 所有I/O 口可以映像到16个外部中断− 除了模拟输入口以外的IO 口可容忍5V 信号输入■ 调试模式− 串行单线调试(SWD)和JTAG 接口 − Cortex-M3内嵌跟踪模块(ETM) ■ 多达11个定时器− 多达4个16位定时器,每个定时器有多达4个用于输入捕获/输出比较/PWM 或脉冲计数的通道− 2个16位6通道高级控制定时器,多达6路PWM 输出,带死区控制− 2个看门狗定时器(独立的和窗口型的) − 系统时间定时器:24位自减型计数 − 2个16位基本定时器用于驱动DAC ■ 多达13个通信接口− 多达2个I 2C 接口(支持SMBus/PMBus)− 多达5个USART 接口(支持ISO7816,LIN ,IrDA 接口和调制解调控制)− 多达3个SPI 接口(18M 位/秒),2个可复用为I 2S 接口− CAN 接口(2.0B 默认) − USB 2.0全速接口 − SDIO 接口 ■ CRC 计算单元 ■ ECOPACK ®封装 表1 器件列表打印从开始到第十页1介绍本文给出了STM32F103xC、STM32F103xD和STM32F103xE增强型的订购信息和器件的机械特性。
RISC技术的设计技巧

RISC技术的设计技巧RISC的设计原则是使系统设计达到最高的有效速度,将那些能对系统性能产生净增益的功能用硬件实现.其余大部分都用软件实现.它排除了那些实现复杂功能的复杂指令,所谓。
"精简"并不是简单的减少.而是保留经验证明的能提高机器性能的指令,另外还将编译器作为机器的功能.而且RISC微处理器使编译器能够直接访问基本的硬件功能,RISC设计的基本目的在于使计算机结构更加简单、更加合理、更加有效.指令经过精简后.计算机体系结构自然趋于简单.在这个基础上,还必须克服CISC的许多缺点.使得计算机速度更快,程序运行时间缩短.这样.RISC才能以崭新的面貌出现.自从80年代中期RISC结构的计算机商品化以来,全世界几乎所有计算机系统制造厂商都竞相采用,半导体厂商也不断研制性能越来越强、集成度越来越高的RISC微处理器,甚至一向以发展CISC而著称的Motoro1a和Intel公司也同时发展RISC微处理器产品系列.RISC不是一个产品而是一种设计技术.人们可以根据不同要求选择使用这些设计技术用于各类计算机系统中,以利于改善和提高机器性能.RISC技术的主要设计技巧及其特点分述如下.1短周期时间为了指令的快速执行,就必须快速选择译码和减小寄存器存取时间,尽量采用先进工艺技术以缩短机器周期时间,也即提高机器的工作频率.2单周期执行指令由于RISC微处理器的指令经过精选,所有指令长度都相同.大多数指令都能在-个机器周期内执行完.实际上,大多数RISC微处理器在没有增加并行技术时,平均每条指令执行时间为1.25-2个机器周期时间,而CISC微处理器在相同工艺技术条件下平均执行每条指令需5-8个机器周期时间,RISC微处理器力求达到每一个机器周期时间执行一条指令.单周期执行指令是RISC微处理器性能增强的基础.必须简化指令系统和采用流水线技术.3 load(取)/Store(存)结构每当一条指令得要访问主存信息时.机器的执行速度将会降低.RISC的load/restore指令只有在访问内存时才使用,所有其它的指令都是在寄存器内对数据进行运算.一条存取数指令(load)从内存将数据取出放到寄存器中,在那里可以对数据进行快速处理,并把它暂存在寄存器里,以便将来还要使用.在适当的时候.一条存数指令(store)可将这个数据送回到它在内存中的地址中去.CISC微处理器支持那些直接从内存处理信息的指令.这些指令需要多个机器周期时间才能完成.R15c的设计技术与CISC 的设计技术相比.有大量寄存器.由于允许数据在寄存器中保留较长的时间.这样就减少了存/取指令对内存访问的需要.在寄存器中.每当再被使用时不必再次访问内存.这种Load /restore结构通过寄存器对寄存器进行操作的方式乃是获得单周期执行的关键.4简单固定格式的指令系统所有指令采用32位固定长度,寻址方式不超过三种,简化了逻辑和缩短译码时间.确保单周期执行指令,同时也有利于流水线操作的执行.这是由于指令的固定格式保证指令译码和取操作能同时进行.5不用微码技术由于RISC的设计采用简单.合理的指令系统和简化的寻址方式.所以排除微代码设计技术.也即不采用微码只读存贮器(ROM),而是直接在硬件中执行指令,这意味着省去将机器指令转换成原始微码这一中间步骤,这也就减少了执行一条指令所需要的机器周期个数,这也就节省了芯片的空间使得可以利用这些节省下来的芯片空间扩展微处理器功能.6大寄存器堆RISC微处理器中大量的计算都在ALU高速寄存器中执行.由编译器产生、分配和优化寄存器的使用.从而简化流水线结构和使指令周期降到最小,同时又不访问内存.允许调用的嵌套执行,但这也增加ALU周期中的寄存器存取时间和一些选址机构.因此在任务变换中需要较高的开销.7哈佛(Harvard)总线结构采用指令和数据高速缓存(cache),利用双总线动态访问机构.填人执行程序有利于单周期执行指令,又可双倍增加数据带宽以提高数据吞吐置.在片高速缓存容量的增加将占较大芯片空间,而脱片cache也将增加存取延迟时间.8高效的流水线操作当前不论什么结构的微处理器都毫无例外地采用流水线技术,以达到高速执行指令的能力,因为流水线的每一级都负责执行一个单个的操作段.比如、指令译码或取操作数。
(完整word版)32位单周期RISC处理器设计

第一章32 位单周期RISC处理器设计要设计一款处理器,首先要选择体系结构,本题选择的是RISC体系结构,因为它适合于流水线设计。
然后需要选择一个标准的指令集,本题选择的MIPS指令集并按照常规的五段流水的方式来实现流水线。
流水线的实现过程将在第二章介绍。
1.1目标处理器指令集与指令格式本题目标CPU以能实现部分MIPS指令为目标,具体指令如下表1:(slti)无条件跳跳转(jL)J转空操作空操作(nop)表1 目标CPU指令集1.2 从指令具体行为反推设计方案CPU要执行一条指令,不外乎需要完成以下几个过程:取指令,指令译码,将译码出的指令放到算术逻辑运算部件ALU上执行运算,根据ALU算得的访存地址进行访存和将访存的结果写回寄存器等。
当然,不同的指令类型(R、I、J)可能经过的过程稍有不同,即它们的数据通路有所不同,以下将具体介绍:1、R格式指令数据通路:1)从指令寄存器Instr MEM中取出指令,同时PC增值(即加1等待下个CLK到来);2.)寄存器单元rs1和rs2的内容从寄存器堆Reg File中读出;3.)ALU根据功能码Opcoder确定操作方式,对从寄存器堆读出的数据进行计算;4.)ALU运算结果被写入寄存器堆,由rd确定写入的寄存器堆存储单元地址。
图1 R指令数据通路2. I 指令(除lw、sw和分支指令)数据通路如图2:1.)从指令寄存器Instr Mem中取出指令,同时PC增值(即加1等待下个CLK到来);2.)寄存器单元rs1的内容从寄存器堆Reg File中读出;3.)ALU将从寄存器堆rs1单元中读出的数据与符号扩展后的指令低16位值相加;4.)ALU的运算结果被写入寄存器堆,由rt确定写入的寄存器堆存储单元地址。
图2 I 指令(除lw、sw和分支指令)数据通路3、Lw指令数据通路如图3:1.)从指令寄存器Instr Mem中取出指令,同时PC增值(即加1等待下个CLK到来);2.)寄存器单元rs1的内容从寄存器堆Reg File中读出;3.)ALU将从寄存器堆rs1单元中读出的数据与符号扩展后的指令低16位值相加;4.)将ALU的运算结果作为数据存贮器的地址读出相应单元的内容;5)把从数据存储单元取出的数据写入寄存器堆,由rt确定写入的寄存器存储单元地址。
电子科技大学CPU设计:精简指令集(RISC)32位单周期cpu设计
精简指令集(RISC)32位单周期cpu设计电气513摘要:该作品为一个精简指令集的32位单周期cpu,具有18条基本的指令,可以实现数据的存取、运算等基本功能。
测试程序执行过程中,CPU各部件的具体数据可以显示到FPGA的数码管上。
目录1.CPU的整体电路设计;2.CPU的指令格式;3.基本功能部件的设计;4.主要功能部件的设计;5.CPU的封装;6.FPGA测试。
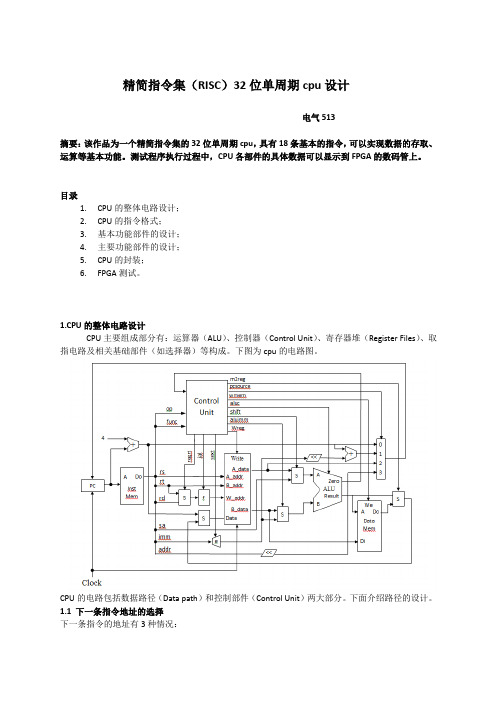
1.CPU的整体电路设计CPU主要组成部分有:运算器(ALU)、控制器(Control Unit)、寄存器堆(Register Files)、取指电路及相关基础部件(如选择器)等构成。
下图为cpu的电路图。
CPU的电路包括数据路径(Data path)和控制部件(Control Unit)两大部分。
下面介绍路径的设计。
1.1 下一条指令地址的选择下一条指令的地址有3种情况:1.程序不转移时下一条指令的地址为PC+4;2.执行beq和bne指令发生转移时,下一条指令的地址是PC加4,再加上符号扩展的偏移量左移2位的和;3.执行j指令时转移的目标地址是指令中的低26位地址左移2位,再与PC+4的高4位拼接在一起。
下一条指令地址的产生和选择电路如图所示。
图中控制器(Control Unit)根据op、func和zero(对于beq和bne指令)信号产生相应的转移控制选择信号pcsource。
1.2 ALU的输入端ALU的输入端有2个:A输入端和B输入端。
A、B输入端分别有2种输入情况。
对于A输入端,有寄存器堆的A_data和移位数sa输入。
对于B输入端,有寄存器堆的B_data和符号扩展后的立即数imm输入。
其输入数据路径如图所示。
ALU的A、B端具体输入哪路数据由控制器(Control Unit)根据指令译码产生控制信号shift和aluimm 来选择。
1.3寄存器堆的输入端寄存器堆的A_addr和B_addr的输入来自指令,分别只有一种输入,W_addr有2种,而Data有4种输入。
risc v rv32i 指令

risc v rv32i 指令
RISC-V是一个完全开放、免费的指令集架构(ISA),被广泛应用于各种领域的处理器设计中。
RISC-V被设计为一个简化的指令集,支持高度优化的实现,同时仍然能够提供足够的功能来支持现代处理器的多样化需求。
在RISC-V指令集中,RV32I被认为是基础指令集。
它是一个32位指令集,包含了简单、基础的指令来支持RISC-V基础指令集的大部分操作。
这些指令可以被理解为一个简单的基础,用于构建更高级的指令集。
下面是RISC-V RV32I指令的详细内容:
一、基本指令
1.ADD指令:用于加法运算,将两个寄存器中的值相加并将结果存储在第三个寄存器中。
opcode:0110011
funct7:0000000
funct3:000
rd:目标寄存器(0~31)
rs1:加数1寄存器(0~31)
rs2:加数2寄存器(0~31)
6.SLT指令:用于有符号比较运算,如果rs1的值小于rs2的值,则将1存储在目标寄存器中,否则将0存储在目标寄存器中。
8.SRL指令:用于逻辑右移运算,将rs1的值向右移动rs2指定的位数并将结果存储在目标寄存器中,同时将左侧空出的位置设为0。
二、加载/存储指令
1.LW指令:用于从内存中加载一个32位的值到目标寄存器中。
三、分支指令
1.BEQ指令:用于进行有符号比较,如果条件成立,则将PC修改为当前地址加上偏移量的值。
四、跳转指令
opcode:1101111
rd:目标寄存器(0~31)
imm:立即数偏移量(-1048576~1048575)。
CPU架构讲解X86、ARM、RISC、MIPS

CPU架构讲解X86、ARM、RISC、MIPS一、当前CPU的主流架构:1.X86架构采用CISC指令集(复杂指令集计算机),程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。
2.ARM架构是一个32位的精简指令集(RISC)架构。
3.RISC-V架构是基于精简指令集计算(RISC)原理建立的开放指令集架构。
4.MIPS架构是一种采取精简指令集(RISC)的处理器架构,可支持高级语言的优化执行。
CPU架构是CPU厂商给属于同一系列的CPU产品定的一个规范,是区分不同类型CPU的重要标示。
二、目前市面上的CPU分类主要分有两大阵营:1.intel、AMD为首的复杂指令集CPU;2.IBM、ARM为首的精简指令集CPU。
两个不同品牌的CPU,其产品的架构也不相同,例如,Intel、AMD的CPU是X86架构的,而IBM的CPU是PowerPC架构,ARM是ARM架构。
三、四大主流CPU架构详解(X86、ARM、RISC、MIPS)1.X86架构X86是微处理器执行的计算机语言指令集,指一个Intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合。
1978年6月8日,Intel 发布了新款16位微处理器8086,也同时开创了一个新时代:X86架构诞生了。
X86指令集是Intel为其第一块16位CPU(i8086)专门开发的,IBM 1981年推出的世界第一台PC机中的CPU–i8088(i8086简化版)使用的也是X86指令。
采用CISC(Complex Instruction Set Computer,复杂指令集计算机)架构。
与采用RISC不同的是,在CISC处理器中,程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。
顺序执行的优点是控制简单,但计算机各部分的利用率不高,执行速度慢。
随着CPU技术的不断发展,Intel陆续研制出更新型的i80386、i80486直到今天的Pentium 4系列,但为了保证电脑能继续运行以往开发的各类应用程序以保护和继承丰富的软件资源,所以Intel所生产的所有CPU仍然继续使用X86指令集。
Cortex-M3 处理器_fromARM

Cortex-M3 处理器ARM Cortex™- M3 处理器是行业领先的 32 位处理器,适用于具有高确定性的实时应用,已专门开发为允许合作伙伴为范围广泛的设备(包括微控制器、汽车车体系统、工业控制系统以及无线网络和传感器)开发高性能低成本的平台。
该处理器提供出色的计算性能和对事件的卓越系统响应,同时可以应对低动态和静态功率限制的挑战。
该处理器是高度可配置的,可以支持范围广泛的实现(从那些需要内存保护和强大跟踪技术的实现到那些需要极小面积的对成本非常敏感的设备)。
为什么选择 Cortex-M3提供更高的性能和更丰富的功能于 2004 年引进、最近通过新技术进行了更新并更新了可配置性的 Cortex-M3,是专门针对微控制器应用开发的主流 ARM 处理器。
性能和能效具有高性能和低动态能耗,Cortex-M3 处理器提供领先的功效:在 90nmG 基础上为 12.5 DMIPS/mW。
将集成的睡眠模式与可选的状态保留功能相结合,Cortex-M3 处理器确保对于同时需要低能耗和出色性能的应用不存在折衷。
全功能该处理器执行Thumb®-2 指令集以获得最佳性能和代码大小,包括硬件除法、单周期乘法和位字段操作。
Cortex-M3 NVIC 在设计时是高度可配置的,最多可提供 240 个具有单独优先级、动态重设优先级功能和集成系统时钟的系统中断。
丰富的连接功能和性能的组合使基于 Cortex-M3 的设备可以有效处理多个 I/O 通道和协议标准,如USB OTG (On-The-Go)。
Cortex-M3 功能Cortex-M3 功能体系结构ARMv7-M(哈佛)ISA 支持Thumb® / Thumb-2管道 3 阶段 + 分支预测Dhrystone 1.25 DMIPS/MHz内存保护带有子区域和后台区域的可选 8 区域 MPU 中断不可屏蔽的中断 (NMI) + 1 到 240 个物理中断中断延迟12 个周期中断间延迟 6 个周期中断优先级8 到 256 个优先级唤醒中断控制器最多 240 个唤醒中断睡眠模式集成的 WFI 和 WFE 指令和“退出时睡眠”功能。
中山大学计算机组成原理实验单周期CPU设计

中⼭⼤学计算机组成原理实验单周期CPU设计《计算机组成原理实验》实验报告(实验三)学院名称:数据科学与计算机学院专业(班级):学⽣姓名:学号:时间:2019 年11 ⽉8 ⽇成绩:实验三:单周期CPU设计与实现⼀.实验⽬的(1) 掌握单周期CPU数据通路图的构成、原理及其设计⽅法;(2) 掌握单周期CPU的实现⽅法,代码实现⽅法;(3) 认识和掌握指令与CPU的关系;(4) 掌握测试单周期CPU的⽅法。
⼆.实验内容设计⼀个单周期CPU,该CPU⾄少能实现以下指令功能操作。
指令与格式如下:==> 算术运算指令加“加”运算。
加“加”运算。
==> 逻辑运算指令加“与”运算。
功能:GPR[rt] ←GPR[rs] or zero_extend(immediate)。
==>移位指令==>⽐较指令==> 存储器读/写指令==> 分⽀指令else pc ←pc + 4特别说明:offset是从PC+4地址开始和转移到的指令之间指令条数。
offset符号扩展之后左移2位再相加。
为什么要左移2位?由于跳转到的指令地址肯定是4的倍数(每条指令占4个字节),最低两位是“00”,因此将offset放进指令码中的时候,是右移了2位的,也就是以上说的“指令之间指令条数”。
else pc ←pc + 4(16)bltz rs, offsetelse pc ←pc + 4。
==>跳转指令(17)j addr说明:由于MIPS32的指令代码长度占4个字节,所以指令地址⼆进制数最低2位均为0,将指令地址放进指令代码中时,可省掉!这样,除了最⾼6位操作码外,还有26位可⽤于存放地址,事实上,可存放28位地址,剩下最⾼4位由pc+4最⾼4位拼接上。
==> 停机指令功能:停机;不改变PC的值,PC保持不变。
三.实验原理单周期CPU指的是⼀条指令的执⾏在⼀个时钟周期内完成,然后开始下⼀条指令的执⾏,即⼀条指令⽤⼀个时钟周期完成。
关于RiscV的一些资料整理

关于RiscV的⼀些资料整理1. 基于RISC-V架构的开源处理器及SoC研究综述原⽂链接:在RISC-V发布之前,实际上已经有⼏种开源指令级架构,包括SPARC V8、OpenRISC,其中SUN发布的开源多核多线程处理器OpenSparcT1、OpenSparcT2,以及欧空局的LEON3采⽤的就是SPARC V8,OpenRISC也有同名的开源处理器32位架构由RV32表⽰,其每个通⽤寄存器的宽度为32⽐特;64位架构由RV64表⽰,其每个通⽤寄存器的宽度为64⽐特RV32G表⽰RV32IMAFD,RV64G表⽰RV64IMAFD,C压缩指令的指令编码长度为16⽐特,⽽普通的⾮压缩指令的长度为32⽐特E 嵌⼊式,仅需要⽀持16个通⽤整数寄存器D 必须⽀持F整数寄存器0被预留为常数0,其他的31个(I架构)或者15个(E架构)为普通的通⽤整数寄存器D/F 浮点模块,则需要另外⼀个独⽴的浮点寄存器组,包含32个通⽤浮点寄存器。
如果仅使⽤F模块的浮点指令⼦集,则每个通⽤浮点寄存器的宽度为32⽐特;如果使⽤了D模块的浮点指令⼦集,则每个通⽤浮点寄存器的宽度为64⽐特开源CPU- RISC-V 架构标量处理器——RocketRocket是采⽤Chisel(Constructing Hardware in an Scala Embedded Language)编写的UCB设计的⼀款64位、5级流⽔线、单发射顺序执⾏处理器,主要特点有:⽀持MMU,⽀持分页虚拟内存,所以可以移植Linux操作系统具有兼容IEEE 754-2008标准的FPU具有分⽀预测功能,具有BTB(Branch Prediction Buff)、BHT(Branch History Table)、RAS(Return Address Stack)超标量乱序执⾏处理器——BOOMBOOM(Berkeley Out-of-Order Machine)是UCB设计的⼀款64位超标量、乱序执⾏处理器,⽀持RV64G,也是采⽤Chisel编写,利⽤Chisel的优势,只使⽤了9000⾏代码,流⽔线可以划分为六个阶段:取指、译码/重命名/指令分配、发射/读寄存器、执⾏、访存、回写。
单周期RISC处理器KMIPS说明文档
单周期RISC处理器KMIPS说明文档作者:老邹zbzou_xy@ KMIPS下载/s/1nt2zT3r这个设计参照了网络上的一些资料,修改了设计,现在已经能够正确执行lw、sw、and、or、add、sub、addi、beq和bne九条指令,如果需要扩充部分指令,修改controler和alu 设计就可以了,比较方便。
【适合CPU设计初学者】下面就介绍一下,这个工程的设计、仿真和验证方法。
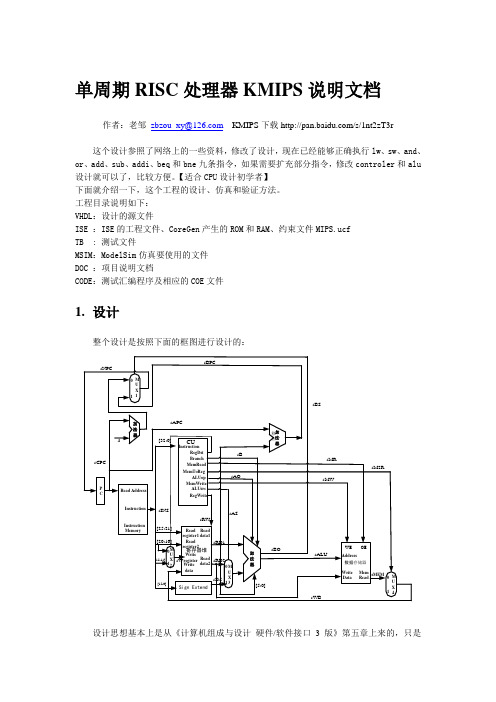
工程目录说明如下:VHDL:设计的源文件ISE :ISE的工程文件、CoreGen产生的ROM和RAM、约束文件MIPS.ucfTB : 测试文件MSIM:ModelSim仿真要使用的文件DOC :项目说明文档CODE:测试汇编程序及相应的COE文件1.设计整个设计是按照下面的框图进行设计的:设计思想基本上是从《计算机组成与设计硬件/软件接口3版》第五章上来的,只是ALU控制部分放在了ALU里面,以后有时间再改个一样的。
每个模块对应一个设计文件,对应关系如下:2.仿真2.1说明1、仿真环境使用的是ModelSimSE 6.1f。
2、仿真使用的文件放在MSIM目录中,有三个文件:compile.do、sim.do和wave.do。
compile.do设置了要编译的文件,wave.do设置了要加入波形窗口的信号及显示方式,sim.do 设置了仿真需要的命令。
3、测试要使用的文件放在目录TB中,有MIPS.vhd(顶层文件,为了便于仿真,没有使用分频模块)、myeDmem.vhd(数据存储器,加了读使能信号)、ram.vhd(可以在ISE 下综合的ram)、myeImem.vhd(指令寄存器,要执行的指令都定义在此。
因为是16进制MIPS指令代码,很难看懂,所以要了解代码对应的程序,请看CODE目录下的all_instr.asm 文件)和test_kmips.vhd(testbench)。
2.2仿真步骤1、启动ModelSim后,改变工作目录(File Change Directory)到目录KMIPS_OK\MSIM 中,在命令窗口运行do compile.do(编译工程需要的设计文件),这样需要的设计文件就加入到库WORK中,如图所示:2、在命令窗口运行do sim.do,就开始仿真,并得到相应的仿真波形。
计算机组成原理-第11章 MIPS处理器设计(单周期、多周期)1 [兼容模式]
![计算机组成原理-第11章 MIPS处理器设计(单周期、多周期)1 [兼容模式]](https://img.taocdn.com/s3/m/72c9d32567ec102de2bd89a3.png)
llxx@
12
A conceptual view – computational instructions
• Both source
operands and
Read data 2
Register File
Datapath Control Points
RegWrite (“write enable” control point)
寄存器号 Instruction
R-type指令的执行
Read
register 1
Read
Read
data 1
register 2
– beq为相对寻址:以npc为基准,指令中的 target为16位,进行32位有符号扩展后左移两 位(补“00”,字对准)。
– jump为pseudodirect:指令中的target为26位, 而PC为32位。将target左移2位拼装在PC的低 28位上,PC高4位保持不变。
J-type
op(6 bits) rs(5 bits) rt(5 bits) op(6 bits)
data
16 Sign 32 extend
I-type
MemRead
R-type
llxx@
22
Instruction
条件转移beq
PC + 4 from instruction datapath
Add Sum
Branch target
Read
register 1
Read
Read
rt:ld的目的,sw的源
服务器CPU架构-RISC篇

服务器CPU架构一、SUN SPARC二、IBM PowerPC三、Intel Itanium四、SGI MIPS五、Compaq Digital Alpha六、HP PA-RISC七、AMD SledgeHammer服务器用处理器几乎都是清一色的RISC(精简指令集)架构,用在高端的工作站或服务器中。
据市场分析机构IDC报告,2000年的美国服务器市场,Sun荣居榜首,IBM屈居老二,Compaq 名列第三。
随着Intel与AMD纷纷介入这块获利市场,使高端服务器市场形成百花齐放、百家争鸣的新格局。
下面我们就来认识这些真正的服务器CPU。
一、SUN SPARC Sun是世界上第一个将RISC架构给以量产的厂商。
为了推动SPARC成为业界标准,并提高全球广泛供应来源,SUN也授权多家半导体厂生产自己的SPARC芯片。
SPARC的性能超强,价格也较高,公认在UNIX上的表现杰出。
早期的RISC处理器也是32位,直到六年多前的Alpha诞生后,才把RISC推进64位。
就SUN的SPARC而言,其64位处理器是1995年的SPARC-v9架构,产品则称为Ultra SPARC。
目前最高端的SPARC产品是64位的Ultra SPARC III,采用了Uptime Bus的技术。
Ultra SPARC III的工作频率有900MHz、750MHz和600MHz三种。
与以前的UltraSPARC II相比,UltraSPARC III运行程序的速度要快一倍。
近几年来,Intel进军高端市场的企图明显,一些拥有RISC处理器大厂已逐渐向Intel的IA-64方向发展,而SUN仍坚持发展自己的Ultra SPARC处理器,成为阻挡Intel来犯的中流砥柱。
Sun公司还将在今年推出基于MAJC架构设计的1.2GHz的Ultra Space 4处理器,它将是Sun公司在高端服务器市场竞争中的希望所在。
二、IBM PowerPC 虽然RISC这个名词是80年初由柏克莱大学Patterson教授所创造并率先使用,并成为后来的统称。
riscv32 汇编指令

RISC-V是一种开源的指令集架构(ISA),其设计目标是提供简单、高效和可定制的指令集。
RISC-V 32位(也称为RISC-V I子集)是指使用32位指令集的RISC-V实现。
RISC-V 32位汇编指令集包含许多不同的指令,用于执行各种操作,例如算术、逻辑、移位、比较和跳转等。
以下是一些常见的RISC-V 32位汇编指令示例:
1. 算术指令:
* ADD:加法
* SUB:减法
* MUL:乘法
* DIV:除法
* MOD:取模
2. 逻辑指令:
* AND:按位与
* OR:按位或
* XOR:按位异或
* NOT:按位取反
3. 移位指令:
* SLL:逻辑左移
* SRL:逻辑右移
* SRA:算术右移
4. 比较指令:
* CMP:比较两个值
5. 跳转指令:
* JAL:跳转到指定地址并保存返回地址
* JMP:无条件跳转到指定地址
6. 控制流指令:
* BEQ:等于则跳转
* BNE:不等于则跳转
* BLT:小于则跳转
* BGE:大于等于则跳转
7. 数据加载和存储指令:
* LW:加载字(32位)到寄存器
* SW:存储字(32位)到内存
8. 系统调用指令:
* SCALL:调用系统服务(软件中断)
9. 其他指令:
* NOP:无操作(空操作)
* MOV:移动数据到寄存器或从寄存器移动数据到内存等。
这些只是一些常见的RISC-V 32位汇编指令示例,实际上RISC-V指令集非常丰富,还包括许多其他指令和功能。
基于MIPS指令集的32位RISC处理器逻辑设计

本科生毕业论文题目:基于MIPS指令集的32位RISC处理器逻辑设计院系:信息科学与技术学院专业:计算机科学与技术学生姓名:***学号:********指导教师:李国桢副教授二〇〇九年四月摘要CPU是计算机系统的核心部件,在各类信息终端中得到了广泛的应用。
处理器的设计及制造技术也是计算机技术的核心之一。
MIPS是世界上很流行的一种RISC 处理器。
MIPS的意思是“无内部互锁流水级的微处理器”(Microprocessor without interlocked piped stages),其机制是尽量利用软件办法避免流水线中的数据相关问题。
本文在详细研究32位MIPS处理器体系结构的基础之上,在Quartus II 7.2环境中,完全依靠自己的研发设计能力,采用硬件描述语言VHDL完成了拥有自主知识产权的基于MIPS指令集的32位RISC处理器的逻辑设计。
共开发出单周期、多周期、五级流水线等3个不同版本的32位RISC处理器,均通过Quartus II进行了时序仿真和性能比较分析。
本文的首先概述了MIPS指令集的重要特征,为讨论CPU的具体设计奠定基础。
本文设计的3个版本的CPU均实现了一个共包含59条指令的32位MIPS指令子集。
本文的主体部分首先详细描述了处理器各个独立功能模块的设计,为后续的整体设计实现提供逻辑功能支持。
随后按照单周期、多周期、流水线的顺序,循序渐进的围绕着指令执行过程中需经历的五个阶段,详细描述了3个版本的处理器中各阶段的逻辑设计。
在完成了各个版本的CPU的整体逻辑设计后,通过Quartus II时序仿真软件在所设计的CPU上运行了测试程序,测试输出波形表明了处理器逻辑设计的正确性。
本文还通过Quartus II 7.2中的Quartus II Time Quest Timing Analyzer软件,基于Altra公司的FPGA器件比较分析了所设计的3个版本CPU的性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
0DH
Null or
I
nபைடு நூலகம்ri lw
0BH 23H
Null nor Null add
sw
2BH
Null add
beq
04H
Null sub
bne
05H
Null sub
slti 0AH
Null sub
J
JL
02H
Null null
nop nop
3FH
0
ALU 控制输入
ALU opcoder
0010 0110 0000 0001 0111 1100 0010 0110 0000 0001 1100 0010 0010 0110 0110 0111 null
数据写入数据存储器中。
图 4 SW 指令数据通路
3
5)分支和跳转指令数据通路如图 5: 分支和跳转指令主要控制 PC 的输入来达到分支或跳转的目的。 分支指令数据通路: 1.)从指令寄存器 Instr Mem 中取出指令,同时 PC 增值(即加 1 等待下个 CLK 到来); 2.)寄存器单元 rs1 和 rs2 的内容从寄存器堆 Reg File 中读出;同时主控制单元还计算
0
0
0
1
1
andi 001 0 0 0
0
0
0
1
1
ori 101 0 0 0
0
0
0
1
1
I
nori 011 lw 000
0 0
0 0
0 0
0 1
0 0
0
1
1
1
1
1
sw 000 X 0 0
0
1
0
1
0
beq 010 X 0 1
0
0
0
0
0
bne 010 X 0 1
0
0
0
0
0
slti 110 0 0 0
0
0
0
1
1、 R 格式指令数据通路: 1)从指令寄存器 Instr MEM 中取出指令,同时 PC 增值(即加 1 等待下个 CLK 到来);
1
2.)寄存器单元 rs1 和 rs2 的内容从寄存器堆 Reg File 中读出; 3.)ALU 根据功能码 Opcoder 确定操作方式,对从寄存器堆读出的数据进行计算; 4.)ALU 运算结果被写入寄存器堆,由 rd 确定写入的寄存器堆存储单元地址。
5
格式
操作码 功能码
操作数
ALU 动作
IR(31~26) IR(5~0)
add
20H add
sub
22H sub
R
and or
00H
24H and
25H
or
slt
2AH sub
nor
27H nor
addi 08H
Null add
subi 0EH
Null add
andi 0CH
Null and
ori
图 3 LW 指令数据通路 4、Sw 指令数据通路如图 4: 1.)从指令寄存器 Instr Mem 中取出指令,同时 PC 增值(即加 1 等待下个 CLK 到来); 2.)寄存器单元 rs1 和 rs2 的内容从寄存器堆 Reg File 中读出; 3.)ALU 将从寄存器堆 rs1 单元读出的数据与符号扩展后的指令低 16 位值相加; 4.)将 ALU 的运算结果作为数据存贮器的写入地址,把从寄存器堆 rs2 单元中取出的
第一章 32 位单周期 RISC 处理器设计
要设计一款处理器,首先要选择体系结构,本题选择的是 RISC 体系结构,因为它适合 于流水线设计。然后需要选择一个标准的指令集,本题选择的 MIPS 指令集并按照常规的五 段流水的方式来实现流水线。流水线的实现过程将在第二章介绍。
1.1 目标处理器指令集与指令格式
跳转(jL)
空操作(nop)
格式 R R I I R R R I I I I I I R
I
J
表 1 目标 CPU 指令集
1.2 从指令具体行为反推设计方案
CPU 要执行一条指令,不外乎需要完成以下几个过程:取指令,指令译码,将译码出的 指令放到算术逻辑运算部件 ALU 上执行运算,根据 ALU 算得的访存地址进行访存和将访 存的结果写回寄存器等。当然,不同的指令类型( R、I、J)可能经过的过程稍有不同,即 它们的数据通路有所不同,以下将具体介绍:
跳转指令数据通路: 1.)从指令寄存器 Instr Mem 从取出指令,同时 PC 增值(即加 1 等待下个 CLK 到来); 2.)主控制单元计算各控制线应被设置的状态,状态表如表 2 所示。PC+1 的值的高 6 位[31~26]加上指令低 26 位([25~0])值组成跳转目标地址,根据主控制单元生成的 Jump 值决定是否跳转,Jump 为 1 则 PC 的值取跳转目标地址,否则取其它地址。 此外,对于空操作指令,只要把 jump、branch、memwrite、memread、regwrite 均设为 低电平,就可以保证该指令进行空操作,即执行没有任何效果的操作。 在理清各格式指令的数据通路后把它们综合在一起构成即构成目标 CPU 的总的数据 通路,具体如图 5。
如图 6 五级流水线数据通路
7
指令运行时在流水线数据通路中经过的五个步骤如下: 1.)取指令(IF):利用 PC 中的地址从指令寄存器中读出数据,然后将指令存入 IF/ID 流水线寄存器中,在 IR 段即 0~31 位;同时把 PC+1 后的地址 NPC 也存入 IF/ID 流水线寄存 器中,在 NPC 段即 32~63 位。所以 IF/ID 寄存器为 64 位。 2.)指令译码与读取寄存器堆(ID):把从 IF/ID 流水线寄存器取出来的指令进行译码, 由 其 31~26 位 ( 指 令 的 操 作 码 ) 产 生 控 制 位 WB ( memtoreg/regwrite )、 M (jump/branch/memread/memwrite)和 EX(alusrc/regdst/aluop)并存入流水线寄存器 ID/EX 的 174~164 位,从寄存器堆中读取 2 个操作数据并存入 ID/EX 的 105~74 和 73~42 位,同时 把其他以后用到的数据也存入 ID/EX 中,如图 6。 3)运算模块(EX):主要执行数据运算和分支、跳转地址计算。数据运算是指 ALU 根 据 opcoder 的控制位执行相应的算术逻辑运算,同时把运算结果存入 EX 流水线寄存器 (37~69)作为下级数据存储器的地址或返回寄存器堆的运算结果;同时计算分支地址和跳 转地址并存入 EX 流水线寄存器(70~101 位 和 102~133 位),同时相应的把 M、WB 等数 据也存入 EX 流水线寄存器以便后面使用。 4)访存模块(MEM):一则起传递作用,把 ALU 运算的结果存入 MEM 流水线寄存器 (5~36);二则访存,把 ALU 运算的结果作为地址从数据寄存器中取出相应的数据并存入 MEM 流水线寄存器(37~68),同时把上一级中的信号 WB 和 WS 存入 MEM 流水线寄存器 以便流入下一级;在这一级中还要把分支地址和跳转地址连回 IF 模块。 5)写回模块(WB):以 MEM 流水线寄存器中的低 5 位 WS 为寄存器堆写入地址,根 据控制信号 memtoreg 来选择把 MEM 流水线寄存器 5~36 或 37~68 位数据存入寄存器堆中。 到此,流水线的加入工作完成,此处理器的处理速度理论上为没有流水线的处理器的 5 倍。
图 2 I 指令(除 lw、sw 和分支指令)数据通路
2
3、Lw 指令数据通路如图 3: 1.)从指令寄存器 Instr Mem 中取出指令,同时 PC 增值(即加 1 等待下个 CLK 到来); 2.)寄存器单元 rs1 的内容从寄存器堆 Reg File 中读出; 3.)ALU 将从寄存器堆 rs1 单元中读出的数据与符号扩展后的指令低 16 位值相加; 4.)将 ALU 的运算结果作为数据存贮器的地址读出相应单元的内容; 5)把从数据存储单元取出的数据写入寄存器堆,由 rt 确定写入的寄存器存储单元地址。
ALUop
100 100 100 100 100 100 000 010 001 101 011 000 000 010 010 110
100
表 3 目标处理器控制真值表
到此为止,32 位单周期 RISC 处理器整体设计基本结束。从图 5 中可以看出,该处理 器 CPI 为 1,即每条指令执行的平均时钟周期数为 1,即要求处理器要在一个时钟周期内执 行完一条指令。对于像 lw 之类的指令,执行完一条指令需要 5 步,再加上时钟 Set up 和 Hold 延迟,那么一条指令的执行时间比较长,这就严重阻碍了 CPU 频率的提高,影响 CPU 的处 理速度的提高。为解决此问题,将在下一章引入流水线处理。
1
J JL
1X
0
0
0
X
0
nop nop 100 1 0 0
0
0
0
0
0
表 2 主控制单元状态表
ALU 的控制主要由图 5 中的 ALU Logic 模块产生。由表 1 中的指令以及它们在图 5 中 数据通路可以看出,只有 R 和 I 类型指令运行需要 ALU 运算单元的参与,而且 ALU 需要 完成的功能为:加、减、与、或、或非、小于置 1 和等于置 1(Zero 端口),而小于置 1 和 等于置 1 也只需要对减法运算结果再进行一些组合控制而已,所以确切的说,ALU 只需要 能进行加、减、与、或、或非运算即可。由此得出的 ALU 控制位(ALU opcoder)和 ALUop 以及指令 R 型指令功能码之间的关系如表 3。
本题目标 CPU 以能实现部分 MIPS 指令为目标,具体指令如下表 1: