生成树的关键概念
生成树的计数

生成树的计数郑艺容;周雪【摘要】In this paper, we explored the possibility of counting spanning tree in a combinatorial approach. We got three combinatorial identifies applying the inclusion-exclusion principle. Based on these identifies and mathematics induction, we gave an easy proof for the Cayley’s formula using a combinatorial argument. The approach combines the problem of graphical enumeration with classical problems in combinatorial mathematics and reveals the essence of the problem of counting spanning trees with better effect.%从组合数学的角度研究生成树的计数。
先利用容斥原理,得到3个组合恒等式,再从组合数学的角度出发,并利用数学归纳法给出了Cayley’s 公式的又一简便证明。
该计数方法将图的计数问题与组合数学中的经典问题联系起来,更好地揭示了生成树计数的本质。
【期刊名称】《厦门理工学院学报》【年(卷),期】2015(000)001【总页数】3页(P95-97)【关键词】Cayley’s 公式;生成树;容斥原理;数学归纳法【作者】郑艺容;周雪【作者单位】厦门理工学院应用数学学院,福建厦门361024; 福州大学离散数学中心,福建福州350003;福州大学离散数学中心,福建福州350003【正文语种】中文【中图分类】O157计算图的不同生成树的个数是图的计数问题中的一个重要研究课题.1857年,Cayley [1] 在研究给定碳原子数n的饱和碳氢化合物(CnH2n+2)的同分异构体的数目时,提出“树”的概念,即不含圈的连通图.如果连通图G的一个子图T是一棵树,且包含G的所有顶点,则该子图T称为G的生成树(Spanning Tree).设G 是一个图,t(G)表示G中不同生成树的个数.Cayley于1889年给出计算n阶完全图的不同生成树个数的公式,即著名的Cayley’s 公式.定理1 [2] (Cayley’s 公式) n阶完全图的不同生成树的个数Cayley’s 公式有很多不同的证明方法,参见文献[2-5].本文又给出Cayley’s 公式的又一简单证明.首先介绍一些基本概念和结论.容斥原理是组合数学中一个非常重要的定理,其内容如下:定理2[6 ] (容斥原理) 设A是有限集,Ai⊆A(i=1,2,…,n,n≥2),则设N={1,2,…,n},M={1,2,…,m},A表示N上所有p维数组构成的集合,其中p<m≤n.因为p<m,那么对A中的任意一个p维数组s,存在M中的元素i∉s.令Ai(i=1,2,…,m)表示A中不含有i的p维数组构成的集合,易知A=A1∪A2∪…∪Am.引理m.定理3 设n,m,p∈N+,p<m≤n,则以下组合恒等式成立证明A,Ai(i=1,2,…,m)定义如上.首先,由乘法原理可知.又A=A1∪A2∪…∪Am,根据容斥原理、对称性及引理1可得:特别地,当p=n-2时可得以下推论:推论(n≥3).以下给出Cayley’s 公式的另一简单证明.设T表示所有n阶生成树构成的集合,tn表示所有n阶生成树的个数,即.Ti(i=1,2,…,n)表示顶点i为树叶的所有n阶生成树构成的集合.引理2 集合T1∩T2∩…∩Tk满足:.证明由上述定义可知:T1∩T2∩…∩Tk那么表示顶点1,2,…,k(1≤k≤n)均为树叶的n阶生成树构成的集合,这样的任意一棵树可经过下述两个步骤得到.(i)由顶点k+1,k+2,…,n导出的子图T是一棵树,易知恰好有tn-k个这样的T;(ii)把顶点1,2,…,k添加到T中得到树T,使得顶点i(1,2,…,k)为T的树叶,即顶点i 恰好与顶点k+1,k+2,…,n中的某一个顶点相邻,这样的方式共有(n-k)k种,根据乘法计数原理可得:=(n-k)ktn-k .引理3 n阶不同生成树的个数tn满足:tn=1(n=1,2);(n≥3).证明T表示所有n阶生成树构成的集合,Ti(i=1,2,…n)表示所有n阶生成树中顶点i为树叶的生成树构成的集合,由于每棵非平凡树至少有两片树叶,故T=T1∪T2∪…∪Tn,由容斥原理、对称性及引理2可知:以下给出Cayley’s 公式的另一证明.定理4 所有不同n阶生成树的个数tn=nn-2 ( Cayley’s 公式)证明用数学归纳法(i)易知t1=t2=1,t3=3 结论显然成立.(ⅱ)假设定理对小于n的正整数都成立.(ⅲ)以下证明对n结论成立.根据引理3Cayley’s 公式是图计数中的经典公式,已有很多不同的证明方法,本文利用由容斥原理得到的组合恒等式并借助数学归纳法给出Cayley’s 公式的又一简单证明.接下来可进一步研究Cayley’s 公式的不同证明方法,特别是能将图的其它经典问题与图的计数问题联系起来证明Cayley’s 公式,更好地揭示图论中的一些本质联系.2【相关文献】[1]CAYLEY A.On the theory of the analytical forms called trees[J].Philophical Magazine,1857,13(4):172-176.[2]CAYLEY A.A theorem on trees[J].Quart J Math,1989,23:376-378.[3]SHOR P W.A new proof of Cayley’s formula for counting l abeled trees[J].J Combin Theory:Series A,1995,71:154-158.[4]ARIANNEJAD M,EMAMI M.A new proof of Cayley’s formula for counting labeled spanning trees[J].Electronic Notes in Discr Math,2014,45:99-102.[5]GODSIL C,ROYLE G.Algebraic graph theory[M].New York:Springer-Verlag,2001.[6]曹汝成.组合数学[M].广州:华南理工大学出版社,2000.。
生成树协议原理

生成树协议原理生成树协议是一种基于链路层的协议,它通常在以太网交换机上实现,用于管理以太网局域网中的网络拓扑。
生成树协议的工作原理是通过使用一个根桥(Root Bridge)和多个非根桥(Non-Root Bridge)来建立一颗树状结构,以确保网络中没有环路存在。
生成树协议的核心算法是通过一种称为生成树算法(Spanning Tree Algorithm)来找到从根桥到每个非根桥的最短路径,从而构建一颗最小生成树。
最小生成树是一种能够连接所有节点并且没有环路的树状结构,它是生成树协议的基础,用于确定网络中数据包的传输路径。
生成树协议的工作流程包括以下几个关键步骤:1. 选择根桥:在网络中通过比较桥(Bridge)的优先级和MAC地址来确定根桥,根桥是生成树中的根节点,所有数据包都将通过根桥进行转发。
2. 计算生成树:每个非根桥通过生成树算法计算到根桥的最短路径,确定自己在生成树中的位置,并将该信息传播到整个网络中。
3. 确定端口状态:每个桥根据生成树信息确定哪些端口可以用于数据包的传输,哪些端口需要阻断以避免环路的产生。
4. 更新生成树:在网络拓扑发生变化时,生成树协议会重新计算生成树,并更新每个桥的状态,重新确定最佳路径。
5. 数据包转发:根据生成树确定的路径,数据包会被从源地址传输到目的地址,通过生成树结构保证数据包的正常传输。
生成树协议的优点是可以有效避免数据包在网络中的循环传输,提升网络通信的稳定性和可靠性。
生成树协议能够自动适应网络拓扑的变化,快速重新计算生成树,并重新确定最佳传输路径,从而保证网络快速恢复到正常状态。
然而,生成树协议也存在一些局限性。
生成树协议在网络中设置大量的桥和端口时,会造成网络拓扑复杂,生成树的计算和更新会消耗大量的网络资源。
此外,生成树协议需要在所有交换机上进行配置和管理,当网络规模较大时,配置和管理网络可能会变得困难。
为了解决生成树协议的一些局限性,IEEE制定了一系列的生成树协议标准,包括802.1D、802.1w和802.1s等。
图论中的生成树计数算法

图论中的生成树计数算法生成树是图论中重要的概念之一,它是指由给定图的节点组成的树形结构,其中包含了原图中的所有节点,但是边的数量最少。
生成树的计数问题是指在一个给定的图中,有多少种不同的生成树。
生成树计数算法是解决这个问题的关键步骤,本文将介绍一些常见的生成树计数算法及其应用。
1. Kirchhoff矩阵树定理Kirchhoff矩阵树定理是图论中经典的生成树计数方法之一。
该定理是由Kirchhoff在19世纪提出的,它建立了图的Laplacian矩阵与其生成树个数的关系。
Laplacian矩阵是一个$n\times n$的矩阵,其中$n$是图中的节点数。
对于一个连通图而言,Laplacian矩阵的任意一个$n-1$阶主子式,其绝对值等于该图中生成树的个数。
应用示例:假设我们有一个无向连通图,其中每个节点之间的边权均为1。
我们可以通过计算图的Laplacian矩阵的任意一个$n-1$阶主子式的绝对值来得到该图中的生成树个数。
2. Prufer编码Prufer编码是一种编码方法,可用于求解生成树计数问题。
它是基于树的叶子节点的度数的编码方式。
Prufer编码将一个树转换为一个长度为$n-2$的序列,其中$n$是树中的节点数。
通过给定的Prufer序列,可以构造出对应的生成树。
应用示例:假设我们有一个具有$n$个节点的有标号的无根树。
我们可以通过构造一个长度为$n-2$的Prufer序列,然后根据Prufer编码的规则构造出对应的生成树。
3. 生成函数方法生成函数方法是一种利用形式幂级数求解生成树计数问题的方法。
通过将图的生成树计数问题转化为生成函数的乘法运算,可以得到生成函数的一个闭形式表达式,从而求解生成树的个数。
应用示例:假设我们有一个具有$n$个节点的有根树,其中根节点的度数为$d$。
我们可以通过生成函数方法求解出该有根树中的生成树个数。
4. Matrix-Tree定理Matrix-Tree定理是对Kirchhoff矩阵树定理的一种扩展,适用于带权图中生成树计数的问题。
c2-3

树
树
树
树
树
进一步思考:若从 进一步思考:若从K4中任去一边 e ,其生成 树棵数是多少? 树棵数是多少?
τ ( K4 − e) = ?
τ ( Kn − e) = ?
τ ( Kn − e) = (n − 2)nn−3
树
进一步思考续….. 进一步思考续 .. 画出K 的所有非同构生成树。 画出 4的所有非同构生成树。 求如下图的所有非同构生成树。 求如下图的所有非同构生成树。
树
2 1 4
6
4 2,4, 5,5, , , , ,
5 3
7
树
2,4,5,5,4 , , , ,
2 4 1 5
4,5,5,4 , , ,
2 4 1 5
树
5,5,4 , ,
2 4 1 3 5
5,4 ,
6 2 4 1 3 5
树
4
6 2 4 1 3 5 1 3 2 4 5 6
7
树
画出K 的所有生成树。 画出 4的所有生成树。
树
§2.3 生成树 定义1 定义 生成树 每个连通图至少包含一棵生成树 生成树的构造--破圈法 生成树的构造--破圈法 -- 图G的生成树棵数计算 的生成树棵数计算
τ (G ) = τ (G − e ) + τ (G e )
树
τ(G)=
=
+
=(
+
)+(
树
+
)=
+(
+
) + (
+
) + (
+
)
树
树
更一般的呢? 更一般的呢? τ(Kn)=? ?
数据结构复习题汇总

数据结构复习题汇总黄⽼师:题型结构如下:单项选择题,15⼩题,30分;填空题,5⼩题,10分;综合应⽤题,50分(树、图、查找)算法设计与分析,2选1,10分(线性结构)试卷中⼀些算法只给英⽂名称;考查范围(⿊体字为建议的重点考查内容;红字为备注;蓝字为拟纳⼊的考研⼤纲内容)⼀、绪论(⼀)算法、数据结构基本概念(⼆)算法分析中O(f(n))符号的含义(三)时间复杂度简单分析表⽰⼆、线性表(⼀)线性表的定义和基本操作(⼆)线性表的实现1.顺序存储2.链式存储3.线性表的应⽤三、栈、队列(⼀)栈和队列的基本概念(⼆)栈和队列的顺序存储结构(三)栈和队列的链式存储结构(四)栈和队列的应⽤四、树与⼆叉树(⼀)树的概念(⼆)⼆叉树1.⼆叉树的定义及其主要特征2.⼆叉树的顺序存储结构和链式存储结构3.⼆叉树的遍历及应⽤(三)树、森林1. 森林与⼆叉树的转换2. 树的存储结构;3.树和森林的遍历4.线索⼆叉树的基本概念和构造(四)⼆叉树的应⽤1.哈夫曼(Huffman)树和哈夫曼编码2.⼆叉排序树五、图(⼀)图的基本概念(⼆)图的存储及基本操作1.邻接矩阵法2.邻接表法(三)图的遍历1.深度优先搜索2.⼴度优先搜索(四)图的基本应⽤1.最⼩(代价)⽣成树2.最短路径3.拓扑排序4.关键路径六、查找(⼀)查找的基本概念(⼆)顺序查找法(三)折半查找法(四)⼆叉查找树及其基本操作(只考察基本概念)(五)平衡⼆叉树(只考察基本概念)(六)散列(Hash)表(七)查找算法的分析及应⽤七、排序(⼀)排序的基本概念(⼆)直接插⼊排序(三)⽓泡排序(bubble sort)(四)简单选择排序(五)希尔排序(shell sort)(六)快速排序(七)堆排序(⼋)⼆路归并排序(merge sort)(九)各种排序算法的⽐较(⼗)排序算法的应⽤选择题1、顺序队列的出队操作,正确修改队⾸指针的是( B )(A)sq.front = (sq.front+1)%maxsize; (B)sq.front = sq.front+1;(C)sq.rear = (sq. rear +1)%maxsize; (D)sq.rear = sq. rear +1;2、⾮空的循环单链表head的尾结点(由指针p指)满⾜( C )(A)p->next = NULL (B)p = NULL (C)p->next = head (D)p = head3、在单键表中,删除p所指结点的直接后继,其中指针修改为( A )(A)p->next = p->next ->next; (B)p = p->next; p->next = p->next->next;(C)p->next = p->next; (D)p = p->next ->next;4、通常要求同⼀逻辑结构中的所有数据元素具有相同的特性,这意味着( B )(A)数据元素具有同⼀特点(B)不仅数据元素所包含的数据项的个数要相同,⽽且对应数据项的类型也要⼀致(C)每个数据元素都⼀样(D)数据元素所包含的数据项的个数要相等5、关于线性表,下列说法正确的是( D )(A)每个元素都有⼀个直接前驱和直接后继(B)线性表中⾄少要有⼀个元素(C)表中诸元素的排列顺序必须是由⼩到⼤或由⼤到⼩的(D)除第⼀元素和最后⼀个元素外,其余每个元素都有⼀个且仅有⼀个直接前驱和直接后继6、带头结点的单链表,其表头指针为head,则该单链表为空的判断条件是( B )(A)head == NULL (B)head->next == NULL(C)head->next == head (D)head !== NULL7、含n个顶点的连通图中的任意⼀条简单路径,其长度不可能超过(C )(A)1 (B)n/2 (C)n-1 (D)n8、设有⼀个顺序栈S,元素S1, S2, S3, S4, S5, S6依次进栈,如果6个元素出栈的顺序是S2, S3, S4, S6, S5, S1,则栈的容量⾄少应该是( B )(A)2 (B)3 (C)5 (D)69、设深度为k的⼆叉树上只有度为0和度为2的结点,则这类⼆叉树上所含结点的总数最少为( C )个(A)k+1 (B)2k (C)2k -1 (D)2k +110、从具有n个结点的单链表中查找指定结点时,若查找每个结点的概率相等,在查找成功的情况下,平均需要⽐较( D )个结点。
stp生成树协议的原理和应用

Stp生成树协议的原理和应用1. 概述STP(Spanning Tree Protocol)是一种用于构建和维护割除冗余链路的树状拓扑结构的链路层协议。
它能够避免网络环路以及广播风暴的发生,确保数据在网络中的可靠传输。
2. 原理STP的原理基于以下几个关键概念:2.1 网桥(Bridge)网桥是连接不同网络的设备,它有多个网口用于接收和转发数据帧。
2.2 网桥标识(Bridge Identifier)每个网桥都有一个唯一的标识,用于在网络中区分不同的网桥。
网桥标识由优先级和MAC地址组成。
2.3 端口状态每个网桥端口都有不同的状态,包括: - Disabled(禁用):端口不参与生成树计算。
- Blocking(阻塞):端口不转发数据帧,只接收配置和STP BPDU (Bridge Protocol Data Units)帧。
- Listening(监听):端口仅接收配置和STP BPDU帧。
- Learning(学习):端口接收和转发数据帧,并学习源MAC地址。
- Forwarding(转发):端口接收和转发所有数据帧。
2.4 根桥(Root Bridge)生成树中的起始点,用于确定整个网络的拓扑结构。
根桥的网桥标识具有最小优先级。
2.5 生成树生成树是一种无环的树状拓扑结构,其中只有一条路径可用于发送数据帧。
其它路径被阻塞以避免网络环路的发生。
生成树的构建是通过选择根桥和确定端口状态来实现的。
2.6 BPDU帧BPDU帧是STP协议使用的消息格式,用于实现生成树的构建和维护。
BPDU 帧包含了网桥标识、优先级、路径代价等信息。
3. 应用STP协议在网络中的应用主要有以下几个方面:3.1 网络环路的割除在复杂的网络中,往往存在多条路径连接不同的网桥。
如果没有STP协议进行环路割除,数据帧可能会在环路中不断转发,导致广播风暴和网络拥塞。
STP协议通过选择一条最短路径,将其它路径阻塞,确保网络中不存在环路。
数据结构与算法课程总结

本课程的先修可称为离散数学和高级语言程序设计,后续课程为操作系统、数据库系统 原理和编译原理等。
数据结构中的存储结构及基本运算的实现需要程序设计的基本知识和编程能力和经验, 本课程大部分实例和实验均是用 C 语言实现的,故要求叫熟练地掌握 C 语言。 三、选用的教材及参考书
教材选用《数据结构与算法》,大连理工大学出版社,作者郭福顺、廖明宏等。参考书 为《数据结构(C 语言版》,清华大学出版社出版,严蔚敏、吴伟民编著。 四、教学内容
第六章 树 教学要求: 本章目的是二元树的定义、性质、存储结构、遍历、线索化,树的定义、存储结构、 遍历、树和森林与二元树的转换,哈夫曼树及其应用(优化判定过程和哈夫曼编码)等内容。 要求在熟悉这些内容的基础上,重点掌握二元树的遍历算法及其有关应用,难点是使用本章 所学到的有关知识设计出有效算法,解决与树或二元树相关的应用问题。 教学内容 1.树的概念(领会) 1.1 树的逻辑结构特征。 1.2 树的不同表示方法。 1.3 树的常用术语及含义。
斯坦纳树解法-概述说明以及解释

斯坦纳树解法-概述说明以及解释1.引言1.1 概述概述部分是文章的开篇部分,用于介绍主题和问题背景。
下面是一个示例:概述斯坦纳树(Steiner Tree)是图论中的一个经典问题,旨在找到一个具有最小总权重的联通子图,以连接给定一组节点。
斯坦纳树问题在实际生活中有着广泛的应用,例如通信网络设计、电力系统规划和生物信息学等领域。
本文将详细介绍斯坦纳树的概念、应用领域以及解法的基本原理。
首先,我们将给出斯坦纳树的定义和问题描述,以便读者对该问题有一个清晰的认识。
然后,我们将探讨斯坦纳树在不同领域中的应用,以展示它在实际问题中的重要性。
接下来,我们将介绍一些经典的斯坦纳树解法,包括近似算法和精确算法,并详细讨论它们的基本原理和优缺点。
通过本文的阅读,读者将能够了解斯坦纳树问题的背景和意义,掌握不同领域中的应用案例,并对斯坦纳树解法的基本原理有一定的了解。
此外,我们还将对斯坦纳树解法的优点和局限性进行讨论,并展望未来在这一领域的发展方向。
接下来,在第二节中,我们将开始具体介绍斯坦纳树的概念和应用领域。
1.2 文章结构【文章结构】本文主要分为引言、正文和结论三个部分。
下面将对每个部分进行详细介绍。
1. 引言引言部分主要包括概述、文章结构和目的三个方面的内容。
在概述部分,将简要介绍斯坦纳树解法的背景和重要性。
2. 正文正文部分是文章的核心部分,主要包括斯坦纳树的概念、应用领域和解法的基本原理三个方面的内容。
2.1 斯坦纳树的概念在本小节中,将详细解释什么是斯坦纳树,斯坦纳树的定义和特点。
2.2 斯坦纳树的应用领域本小节将介绍斯坦纳树的应用领域,包括网络通信、电力系统、交通规划等方面的应用案例。
2.3 斯坦纳树解法的基本原理在本小节中,将详细介绍斯坦纳树解法的基本原理和算法,包括构建斯坦纳树的思路和具体步骤。
同时,可以提及一些经典的斯坦纳树解法算法和优化方法。
3. 结论结论部分对斯坦纳树解法的优点和局限性进行总结,并对未来的发展方向进行展望。
6-4-数据结构——从概念到C++实现(第3版)-王红梅-清华大学出版社

数 据 结
构
(
从
012345
概 念
到
adjvex[n] = 0 0 0 0 0 0
实 现 )
清
华
lowcost[n] = 0 34 46 ∞ ∞ 19
大 学 出
版
社
Prim算法——存储结构
每一次迭代,设数组lowcost[n]中的最小权值是lowcost [j],则
令lowcost[j] = 0,表示将顶点 j 加入集合U中;
从 概 念
到
实
如何存储候选最短边集(连接U和V-U的候选最短边)?
现 ) 清
华
例如:{(v0 , v1)34,(v0 , v2)46,(v0, v3)∞,(v0 , v4)∞,(v0, v5 )19}
大 学 出
版
社
数组adjvex[n]:表示候选最短边的邻接点
adjvex[i] = j
数组lowcost[n]:表示候选最短边的权值
v4)26}
数 据
V-U={v1 , v3 , v4 }
结 构 ( 从
cost ={(v0 , v1)34, (v2, v3)17, (v5 , v4)26}
概 念 到
实
现
)
清
第三次迭代:
华 大 学
出
U={v0 , v5, v2 , v3 }
版 社
V-U={v1 , v4}
cost={(v0 , v1)34, (v5 , v4)26}
学 出 版
社
U:涂色
V-U:尚未涂色
方法:一个顶点涂色、另一个顶点尚未涂色的最短边
Prim算法——运行实例
34
v1
v0 19 v5
解决最小生成树的算法

解决最小生成树的算法一、最小生成树是什么?最小生成树,听名字就有点拗口对吧?它就是在一个图中找到一棵“树”,让你能够连接所有的节点,但又不能浪费太多的“钱”——就像你去买菜,怎么挑最便宜的菜而又不浪费时间跑到其他地方。
简单来说,最小生成树就是连接所有节点的最省钱的方式。
想象一下,如果你有好多小镇,想要铺设道路,怎么才能让这些小镇都互通而花的钱最少呢?这时候,最小生成树就派上用场了。
嗯,可能有的朋友要问了:“什么是图呢?”其实就是一种数据结构,用来表示一些物体之间的关系。
比如你和朋友之间的联系方式,城市和城市之间的交通网络,都是图的典型例子。
图里面有“点”和“边”,点代表物体,边代表物体之间的关系。
最小生成树就是要找出一条最省钱的路线,连接所有点而且不能有冗余。
二、为什么要解决最小生成树的问题?有没有想过,你怎么找到一个城市到另一个城市最短的道路,或者是把一堆电线连接成最短的电网,或者是设计一个无线网络覆盖的最佳路径?这些问题,背后都有一个共同点——图,而且是“最小生成树”。
如果你不想被一堆无聊的线路和高昂的费用搞得头大,那你得学会怎么找到最优的路径。
解决最小生成树问题,就像是为这个世界节省资源,优化效率。
所以,最小生成树不仅仅是在计算机上能派得上用场,实际上,它跟我们的生活息息相关。
想想看,飞机航线设计、电力传输网络、甚至是社交网络的优化,背后不都是这样一个“省钱”的问题吗?你看,这个问题,看似简单,实际上却能带来巨大的改变,真的是又贴近生活又有深度。
三、最小生成树的算法讲完了最小生成树的概念,接下来就是怎么计算它了。
大家是不是有点急了,想知道这其中的“秘诀”?放心,告诉你哦,这里有几种算法可以帮你搞定。
最常见的两种算法就是普里姆算法和克鲁斯卡尔算法。
说到这,可能有的小伙伴开始抓耳挠腮了,普里姆?克鲁斯卡尔?听起来像是两个古怪的名字,但其实它们也没那么可怕。
说白了,普里姆就像是你从一个点开始,逐步扩展,找到最小的边,跟着边走,最后把所有点都串起来;克鲁斯卡尔呢,是你把所有的边都列出来,按照权重从小到大排序,然后一点一点地选边,避免形成环,直到所有的点都被连接起来。
最小生成树 课程思政

最小生成树课程思政最小生成树是图论中的一个重要概念,也是计算机科学中的常用算法之一。
它在实际应用中有着广泛的意义,不仅可以用于网络设计、通信传输等领域,也可以用于社交网络分析、物流规划等问题的求解。
本文将以“最小生成树”为主题,探讨其概念、应用和算法实现等方面。
第一部分:概念介绍最小生成树是指在一个连通无向图中,找出一个子图,使得该子图包含原图的所有顶点,且边的权重之和最小。
换言之,最小生成树是连接所有顶点的一棵树,并且树的边的权重之和最小。
第二部分:应用领域最小生成树在实际应用中有着广泛的用途。
首先,它可以用于网络设计。
在计算机网络中,最小生成树可以帮助我们选择一些关键节点,以便构建一个高效的网络拓扑结构,从而提高网络的传输效率和稳定性。
其次,最小生成树还可以用于物流规划。
在物流领域,我们需要确定一些关键的物流节点,以便降低物流成本和提高物流效率。
此外,最小生成树还可以用于社交网络分析。
通过构建一个社交关系的图模型,并应用最小生成树算法,我们可以找出社交网络中的核心节点,从而更好地理解和分析社交关系的结构和特征。
第三部分:算法实现在实际应用中,我们可以使用多种算法来求解最小生成树问题,如Prim算法和Kruskal算法等。
这些算法的基本思想是通过不断地选择权重最小的边,并保证边的选择不会形成环路,最终得到最小生成树。
具体而言,Prim算法是一种贪心算法,它从一个初始节点开始,逐步扩展最小生成树的边,直到包含所有节点为止。
Kruskal 算法则是基于边的排序和并查集等数据结构来实现的,它按照边的权重从小到大的顺序逐个选择边,并保证边的选择不会形成环路。
第四部分:最小生成树的优势和局限性最小生成树作为一种图论中的重要概念和算法,具有以下优势:首先,它能够帮助我们找到一个连通图的最优子图,从而减少了冗余的边和节点,使得网络更加紧凑和高效。
其次,最小生成树可以帮助我们发现网络中的关键节点和连接关系,为网络优化和改进提供了重要的参考依据。
(完整word版)离散数学复习提纲(完整版)

《离散数学》期末复习大纲(完整版)(含例题和考试说明)一、命题逻辑[复习知识点]1、命题与联结词(否定¬、析取∨、合取∧、蕴涵→、等价↔),复合命题2、命题公式与赋值(成真、成假),真值表,公式类型(重言、矛盾、可满足),公式的基本等值式3、范式:析取范式、合取范式,极大(小)项,主析取范式、主合取范式4、公式类型的判别方法(真值表法、等值演算法、主析取/合取范式法)5、命题逻辑的推理理论本章重点内容:命题与联结词、公式与解释、(主)析取范式与(主)合取范式、公式类型的判定、命题逻辑的推理[复习要求]1、理解命题的概念;了解命题联结词的概念;理解用联结词产生复合命题的方法.2、理解公式与赋值的概念;掌握求给定公式真值表的方法,用基本等值式化简其它公式,公式在解释下的真值。
3、了解析取(合取)范式的概念;理解极大(小)项的概念和主析取(合取)范式的概念;掌握用基本等值式或真值表将公式化为主析取(合取)范式的方法.4、掌握利用真值表、等值演算法和主析取/合取范式的唯一性判别公式类型和公式等价方法。
5、掌握命题逻辑的推理理论。
[疑难解析]1、公式类型的判定判定公式的类型,包括判定公式是重言的、矛盾的或是可满足的。
具体方法有两种,一是真值表法,二是等值演算法。
2、范式求范式,包括求析取范式、合取范式、主析取范式和主合取范式。
关键有两点:一是准确理解掌握定义;另一是巧妙使用基本等值式中的分配律、同一律和互补律(排中律、矛盾律),结果的前一步适当使用幂等律,使相同的短语(或子句)只保留一个.3、逻辑推理掌握逻辑推理时,要理解并掌握12个(除第10,11)推理规则和3种证明法(直接证明法、附加前提证明法和归谬法). 例1.试求下列公式的主析取范式:(1)))()((P Q Q P P ⌝∨⌝⌝∧→→;(2))))((R Q Q P P →⌝∨→⌝∨())()(())()((:)1P Q Q P Q P P P Q Q P P ∧∧∨∧∧⌝∨⌝=∧∧∨⌝∨⌝=原式解Q P P P Q P P Q P ∨⌝=∨⌝∧∨⌝=∧∨⌝=)()()())(())((Q P P Q Q P ∧∨⌝∨∨⌝∧⌝=)()()(Q P Q P Q P ∧∨∧⌝∨⌝∧⌝=)))((()))(((:)2R Q Q P P R Q Q P P ∨∨∨∨=→⌝∨→⌝∨解)()()()(R Q P R Q P R Q P R Q P R Q P ∧⌝∧∨∧∧⌝∨⌝∧∧⌝∨∧⌝∧⌝=∨∨=)()()(R Q P R Q P R Q P ∧∧∨⌝∧∧∨⌝∧⌝∧∨)2.用真值表判断下列公式是恒真?恒假?可满足?(1)(PP )Q (2)(P Q)Q (3)((P Q)(Q R ))(P R) 解:(1) 真值表 P QP P P (P P)Q 0 01 0 1 0 11 0 0 1 00 0 1 1 1 0 0 0因此公式(1)为可满足.(2) 真值表P Q P Q (P Q) (P Q)Q0 0 1 0 00 1 1 0 01 00 1 01 1 1 0 0因此公式(2)为恒假。
(一)《机器学习》(周志华)第4章决策树笔记理论及实现——“西瓜树”

(⼀)《机器学习》(周志华)第4章决策树笔记理论及实现——“西⽠树”参考书籍:《机器学习》(周志华)说明:本篇内容为读书笔记,主要参考教材为《机器学习》(周志华)。
详细内容请参阅书籍——第4章决策树。
部分内容参考⽹络资源,在此感谢所有原创者的⼯作。
=================================================================第⼀部分理论基础1. 纯度(purity)对于⼀个分⽀结点,如果该结点所包含的样本都属于同⼀类,那么它的纯度为1,⽽我们总是希望纯度越⾼越好,也就是尽可能多的样本属于同⼀类别。
那么如何衡量“纯度”呢?由此引⼊“信息熵”的概念。
2. 信息熵(information entropy)假定当前样本集合D中第k类样本所占的⽐例为p k(k=1,,2,...,|y|),则D的信息熵定义为:Ent(D) = -∑k=1 p k·log2 p k (约定若p=0,则log2 p=0)显然,Ent(D)值越⼩,D的纯度越⾼。
因为0<=p k<= 1,故log2 p k<=0,Ent(D)>=0. 极限情况下,考虑D中样本同属于同⼀类,则此时的Ent(D)值为0(取到最⼩值)。
当D中样本都分别属于不同类别时,Ent(D)取到最⼤值log2 |y|.3. 信息增益(information gain)假定离散属性a有V个可能的取值{a1,a2,...,a V}. 若使⽤a对样本集D进⾏分类,则会产⽣V个分⽀结点,记D v为第v个分⽀结点包含的D中所有在属性a上取值为a v的样本。
不同分⽀结点样本数不同,我们给予分⽀结点不同的权重:|D v|/|D|, 该权重赋予样本数较多的分⽀结点更⼤的影响、由此,⽤属性a对样本集D进⾏划分所获得的信息增益定义为:Gain(D,a) = Ent(D)-∑v=1 |D v|/|D|·Ent(D v)其中,Ent(D)是数据集D划分前的信息熵,∑v=1 |D v|/|D|·Ent(D v)可以表⽰为划分后的信息熵。
详解图的应用(最小生成树、拓扑排序、关键路径、最短路径)
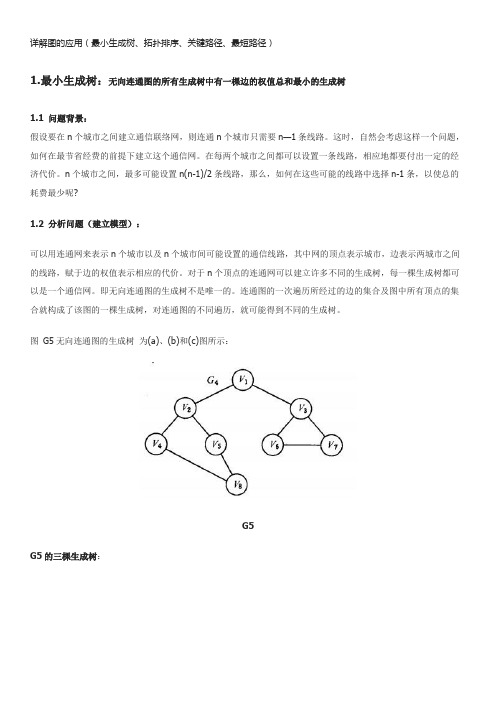
详解图的应用(最小生成树、拓扑排序、关键路径、最短路径)1.最小生成树:无向连通图的所有生成树中有一棵边的权值总和最小的生成树1.1 问题背景:假设要在n个城市之间建立通信联络网,则连通n个城市只需要n—1条线路。
这时,自然会考虑这样一个问题,如何在最节省经费的前提下建立这个通信网。
在每两个城市之间都可以设置一条线路,相应地都要付出一定的经济代价。
n个城市之间,最多可能设置n(n-1)/2条线路,那么,如何在这些可能的线路中选择n-1条,以使总的耗费最少呢?1.2 分析问题(建立模型):可以用连通网来表示n个城市以及n个城市间可能设置的通信线路,其中网的顶点表示城市,边表示两城市之间的线路,赋于边的权值表示相应的代价。
对于n个顶点的连通网可以建立许多不同的生成树,每一棵生成树都可以是一个通信网。
即无向连通图的生成树不是唯一的。
连通图的一次遍历所经过的边的集合及图中所有顶点的集合就构成了该图的一棵生成树,对连通图的不同遍历,就可能得到不同的生成树。
图G5无向连通图的生成树为(a)、(b)和(c)图所示:G5G5的三棵生成树:可以证明,对于有n 个顶点的无向连通图,无论其生成树的形态如何,所有生成树中都有且仅有n-1 条边。
1.3最小生成树的定义:如果无向连通图是一个网,那么,它的所有生成树中必有一棵边的权值总和最小的生成树,我们称这棵生成树为最小生成树,简称为最小生成树。
最小生成树的性质:假设N=(V,{ E}) 是个连通网,U是顶点集合V的一个非空子集,若(u,v)是个一条具有最小权值(代价)的边,其中,则必存在一棵包含边(u,v)的最小生成树。
1.4 解决方案:两种常用的构造最小生成树的算法:普里姆(Prim)和克鲁斯卡尔(Kruskal)。
他们都利用了最小生成树的性质1.普里姆(Prim)算法:有线到点,适合边稠密。
时间复杂度O(N^2)假设G=(V,E)为连通图,其中V 为网图中所有顶点的集合,E 为网图中所有带权边的集合。
图论中几个典型问题的求解

图是一种直观形象地描述已知信息的方 式,它使事物之间的关系简洁明了,是分 析问题的有用工具,很多实际问题可以用 图来描述。
一、图的定义
图论是以图为研究对象的数学分支,在图论 中,图由一些点和点之间的连线所组成.
称图中的点为顶点(节点),称连接顶点的 没有方向的线段为边,称有方向的线段为弧.
具有n个顶点的无向连通图是树的充分必要条 件是它有n-1条边.连通图G的子图T,如果它的 顶点集与G的顶点集相同,且T为树,则称T是图 G的生成树,又称支撑树。如果图的边有权(对 应于边的实数),则生成树上各边权的总和称为
生成树的权,生成树并不唯一,权达到最小的生
成树称为最小生成树(Minimal Spanning Tree, 简称MST),最小生成树不一定唯一.
end
%以上循环调整候选边集合,入选该集合的 边数等于当前白点数,对每一个白点入选一条边, 该边通过比较连接该白点到红点的边的权值大小 确定,小者入选。该循环是程序的关键和核心部 分。
end
T,e 以上程序以文件名prim.m存盘。
例2 以2007年研究生数学建模竞赛C题为例, 已知县邮政局X1和16个邮政支局的初始距离矩 阵,求该运输图的最小生成树。
for j=2:n
b(1,j-1)=1;
b(2,j-1)=j;
b(3,j-1)=a(1,j);
end %以上一段程序生成3行n-1列的矩阵,存储初 始候选边及其权值信息,该矩阵的第一行都是1, 表示第一个红色点是1号顶点,第二行表示白色 点依次为2,3,…,n,第三行表示所有连接红点和 白点的边的权值
while size(T,2)<n-1 %只要最小生成树的边数 小于n-1就循环
数据结构习题集

7
对于一个具有 n 个结点的单链表,在已知的结点*p 后插入一个新结点的时间复杂度 为 ,在给定值为 x 的结点后插入一个新结点的时间复杂度为 ___。
8. 在顺序表中访问任意一结点的时间复杂度均为 的数据结构。
9、线性链表不具有的特点是( ) 。 A.随机访问 C.插入与删除时不必移动元素
,因此顺序表也称为
17.双循环链表中,任意一结点的后继指针均指向其逻辑后继。(对还是错)
18、线性表L在
情况下适用于使用链式结构实现。 B、需不断对L进行删除插入 D、L中结点结构复杂 )
A、需经常修改L中的结点值 C、L中含有大量的结点
19 若某线性表中最常用的操作是取第 i 个元素和找第 i 个元素的前趋元素, 则采用 ( 存储方式最节省时间。 ①单链表 ②双链表 ③单向循环 ④顺序表
3. 在双向链表指针 p 的结点前插入一个指针 q 的结点操作是( A. p->Prior=q;q->Next=p;p->Prior->Next=q;q->Prior=p->Prior; B. p->Prior=q;p->Prior->Next=q;q->Next=p;q->Prior=p->Prior; C. q->Next=p;q->Prior=p->Prior;p->Prior->Next=q;p->Prior=q; D. q->Prior=p->Prior;q->Next=p;p->Prior=q;p->Prior->Next=q;
第 4 章 数组 知识点:二维数组的存储、特殊矩阵
1. 假设有二维数组 A6×8,每个元素用相邻的 6 个字节存储,存储器按字节编址。 已知 A 的起始存储位置 (基地址) 为 1000, 则数组 A 的体积 (存储量) 为 ; 末尾元素 A57 的第一个字节地址为 ;若按行存储时,元素 A14 的第一 个字节地址为 ;若按列存储时,元素 A47 的第一个字节地址 为 。
生成树算法的三个步骤

生成树算法的三个步骤生成树算法是图论中一种重要的算法,用于从一个连通图中找到一棵包含所有顶点的子图。
生成树算法主要分为三个步骤:选择、连接和更新。
第一步,选择:在生成树算法中,选择一条边是非常关键的。
常用的选择方法有两种:Prim算法和Kruskal算法。
Prim算法是基于顶点的选择,从一个初始顶点开始,逐步选择与当前生成树相连的边中权值最小的边,直到生成树包含所有顶点。
Kruskal算法是基于边的选择,将图中的所有边按权值从小到大排序,然后依次选择权值最小的边,并判断是否与已选的边构成回路,直到生成树包含所有顶点。
第二步,连接:在选择了一条边之后,需要将这条边连接到生成树上。
连接的方式有两种:添加顶点和添加边。
添加顶点是指将边的另一个顶点加入到生成树中,而添加边是指将选择的边加入到生成树的边集合中。
在Prim算法中,选择的边连接的方式是添加边,即将选择的边加入到生成树的边集合中。
而在Kruskal算法中,选择的边连接的方式是添加顶点,即将边的另一个顶点加入到生成树中。
第三步,更新:在连接了一条边之后,需要更新生成树中的相关信息。
更新的内容主要包括:顶点集合、边集合和权值。
在Prim算法中,每次选择边之后,需要更新当前生成树包含的顶点集合和边集合,同时更新生成树的权值。
在Kruskal算法中,每次选择边之后,需要判断是否构成回路,如果不构成回路,则将选择的边加入到生成树的边集合中,并更新生成树的权值。
生成树算法包括三个步骤:选择、连接和更新。
选择是根据一定的规则选择一条边,连接是将选择的边连接到生成树上,更新是根据连接的结果更新生成树的相关信息。
不同的生成树算法在选择和连接的方式上有所不同,但都遵循这三个基本步骤。
生成树算法在实际应用中有很广泛的应用,例如网络设计、电路布线等领域。
通过理解和掌握生成树算法的基本原理和步骤,可以更好地应用于实际问题的解决中。
《数据结构》课程教学大纲

课程教学大纲课程代号:07021021学时数:56+S16适用专业:计算机科学与技术专业一、本课程的性质、目的和任务1。
本课程的性质数据结构是高等院校计算机各专业的核心课程之一,也是重要的专业基础课,主要介绍和研究各种基本的数据结构及其应用.2。
本课程的目的通过本课程的学习,使学生获得有关数据的各种逻辑结构、在存储器上的存储结构以及相关运算的算法:并能够根据实际问题的需要选择和设计出相应运算的算法。
为《操作系统》、《数据库概论》等后续课程的学习及为应用软件特别是非数值应用软件的开发打下良好的基础和时间基础。
3.本课程的任务本课程的主要任务是培养学生:(1)熟练掌握各种数据结构的特点、存储表示,操作算法及在计算机科学中基本应用。
(2)初步掌握算法的时间分析和空间分析的技巧。
(3)培养、训练学生选用合格的数据结构和使用类C语言编写质量高、风格好的应用程序及初步评价算法程序的能力.二、教学基本内容和要求1。
绪论(1)教学目的与要求熟悉数据结构的一些基本概念;了解抽象数据类型的定义、表示和实现方法;掌握C++语言的语句及算法描述的书写规则;掌握计算语句频度和估算算法时间复杂度的方法。
(2)主要内容数据、数据元素、数据对象、数据类型、数据结构等概念;抽象数据类型的定义、表示和实现方法;描述算法的C++语言;算法设计的基本要求以及从时间和空间角度分析算法的方法。
(3)重点、难点重点:算法的时间和空间复杂性的评价;难点:算法效率的度量。
2.线性表(1)教学目的与要求掌握线性表的定义和顺序存储结构;掌握线性表的链式存储结构;掌握线性表的插入、删除、归并等基本运算;了解静态链表和一元多项式的有关知识。
(2)主要内容线性表的顺序存储结构、线性表的链式存储结构;在线性表的两类存储结构(顺序的和链式的)上实现基本操作;静态链表的存储结构和运算;一元多项式的抽象数据类型定义、表示及加法的实现。
(3)重点、难点重点:线性表的链式存储结构;难点:静态链表的存储结构和运算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
生成树的关键概念
解决循环连接的方案就是STP。
通过一定算法,STP使任意两个节点间有且只有一条路径连接,而其他的冗余链路则被自动阻塞,作为备份链路,如图8-6所示。
只有当活动链路失败时,备份链路才会被激活,从而恢复设备之间的连接,保证网络的畅通。
与EtherChannel技术不同,Spanning-Tree只能保证在两台设备间拥有一条活动链路,因此,也就无法实现带宽加倍和负载均衡。
这就好比一棵真实生长树,从树根开始长起,然后是树干、树枝,最后到树叶,从而保证任意两片树叶间只有一条路。
而链路选举的标准就是优先级值(Priority)和端口费用(Cost)。
Spanning-Tree的优点是可以在任何端口实现,而不一定是固定的双绞线端口或光纤端口。
网络环路侦测和预防(Network loop detection and prevention)的意义在于任何两个局域网之间应该只有一条路径,否则,网络中将出现环路。
如果存在着多于一条的路径,那么生成树算法将会侦测到环路的发生,并自动选择开销值(Cost)最低的那条路径作为可使用的路径(主链路),而阻断其他路径,将它们作为备用路径(备用链路)。
自动拓扑重构(Automatic topology re-configuration)是指当主链路出现故障时,生成树算法将自动启用备用链路,重构网络结构。
生成树运算在无环路逻辑拓扑时,使用3个关键概念:网桥ID(Bridge ID)、路径开销(PC)及桥接协议数据单(BPDU)通知功能。
1.网桥ID(Bridge ID)
每台网桥都有一个ID表示,Bridge ID称为BID。
它是由一个2字节加6字节,总共8字节组成的存储域组成,如图8-7所示。
低6字节MAC地址由交换机分配好,高2字节BID 为网桥优先级,范围从0~65 535,默认为32 768。
2.路径开销(Path Cost)
IEEE 802.1D早期定义采用1 000Mbps来除以实际的带宽获得的数据作为路径开销值,但由于后来实际带宽超过1 000Mbps,得到了小数,不方便计算;后来IEEE 802.1D修正了新值,目前采用新值,如表8-1所示。
表8-1 生成树路径开销值
3.桥接协议数据单元(BPDU)
生成树在运算选举中,还通过相互比较桥接协议数据单元(Bridge Protocol Data Units,BPDU)实现。
BPDU有两种类型,配置BPDU和拓扑改变通知(TCN BPDU)。
BPDU配置消息是以以太网数据帧的格式进行传递的,采用多播MAC地址
01-80-C2-00-00-00为目的MAC地址,网络中的网桥收到该地址后,能够判断出该数据帧是生成树协议的数据帧,源MAC地址域中的本网桥的MAC地址,数据帧的具体内容如表8-2
所示。
表8-2 BPDU配置消息格式
DMA:目的MAC地址,固定的组播地址,0X0180C2000000。
SMA:源MAC地址,发送BPDU配置消息的桥MAC地址。
L/T:帧长。
LLC Header:配置消息固定的链接头。
PayLoad:BPDU数据区。
IEEE 802.1D指定17个多播地址,范围从0x00180c2000000~0x00180c2000010,用于不同网桥版本,如果交换机端口开启STP,交换机CPU接收目标来地址
0x0180C2000000~0x0180C2000010,如果STP被关闭,则认为这些多播地址为未知的。
表8-2中的Payload是BPDU的核心配置部分,具体组成信息如表8-3所示。
表8-3 BPDU值域
拓扑改变BPDU(TCN BPDU),顾名思义就是拓扑改变时发出的BPDU,这是由拓扑改变的网桥发出的,与配置网桥区别在于,表8-3中的Type值为1。