Oracle正则表达式汇总
oracle正则表达式

POSIX 正则表达式由标准的元字符(metacharacters)所构成:
'^' 表示字符串的开始
'$' 表示字符串的结束
'.' 表示任何字符
字符的范围,比如说'[a-z]',表示任何ASCII 小写字母,与字符类"[[:lower:]]"" 等价
'?' 允许一个后继字符匹配零次或一次
REGEXP_LIKE 与LIKE 操作符相似。如果第一个参数匹配正则表达式它就解析为TRUE。例如Where REGEXP_LIKE(ENAME,'^J[AO]','i') 将在ENAME 以JA 或JO 开始的情况下返回一行数据。'I' 参数指定正则表达式是大小写敏感的。另外还可以在CHECK 约束和函数索引中指定REGEXP_LIKE。例如:
Oracle 8 和Oracle 9i中缺乏灵活性的SQL 正则表达式最终在Oracle 10g中得到了解决。Oracle 数据库目前内建了符合POSIX 标准的正则表达式。
四个新的函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和EGEXP_REPLACE。它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
REGEXP_INSTR 与INSTR 函数类似。它返回一个字符串中匹配一个正则表达式的第一个子串的开始位置。例如:
Select REGEXP_INSTR('The total is $400 for your purchase.','$[[:digit:]] ')
Oracle正则表达式汇总

oracle的正则表达式oracle的正则表达式(regular expression)简单介绍目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境。
Oracle 10g正则表达式提高了SQL灵活性。
有效的解决了数据有效性,重复词的辨认, 无关的空白检测,或者分解多个正则组成的字符串等问题。
Oracle 10g支持正则表达式的四个新函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和REGEXP_REPLACE。
它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
特殊字符:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了RegExp 对象的Multiline 属性,则$ 也匹配'\n' 或'\r'。
'.' 匹配除换行符\n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
\num 匹配num,其中num 是一个正整数。
对所获取的匹配的引用。
正则表达式的一个很有用的特点是可以保存子表达式以后使用,被称为Backreferencing. 允许复杂的替换能力如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,缓冲区从左到右编号, 通过\数字符号访问。
orcl正则

Oracle正则表达式语法基于Perl语言的正则表达式语法,区分大小写(case sensitive)。
以下是一些基本语法:
1. 字符匹配:`.` 匹配除了换行外的任意一个字符;`\d` 匹配任何数字,相当于`[0-9]`;`\D` 匹配任何非数字字符,相当于`[^0-9]`;`\w` 匹配任何字母数字字符或下划线,相当于`[a-zA-Z0-9_]`;`\W` 表示匹配任何非字母数字字符或下划线,相当于`[^a-zA-Z0-9_]`。
2. 限定符:`*` 匹配前一个字符出现0次或多次;`+` 匹配前一个字符出现1次或多次;`?` 匹配前一个字符出现0次或1次;`{n}` 匹配前一个字符出现n次;`{n,}` 匹配前一个字符出现n次或更多;`{n,m}` 匹配前一个字符出现n~m次。
`|` 指两项之间的一个选择。
例如,`^([a-z]+|[0-9]+)$` 表示所有小写字母或数字组合成的字符串。
3. 边界匹配:`^` 匹配开始位置;`$` 匹配结束位置;`\b` 匹配单词边界,即单词的开头或结尾位置;`\B` 匹配非单词边界,即不是单词的开头或结尾位置。
4. 分组和引用:括号`()` 分组,标记一个子表达式的开始和结束位置;`\num` 引用第num个子表达式,num从1开始。
5. 字符集合:`[]` 表示一组字符中的任意一个。
6. 转义符:`\\` 表示转义一个字符。
Oracle正则表达式还支持贪婪匹配、非贪婪匹配、零宽断言(zero-width assertion)、后向引用(backreference)、捕获组等高级语法。
Oracle数据库正则表达式

Oracle数据库正则表达式正则表达式:⽆论是在前端还是后台正则表达式都是⼀个⾄关重要的知识点,例如判断⼀个⼿机号码输⼊是否正确,如果使⽤Java、C或者其他语⾔进⾏字符串进⾏判断,也许写⼏⼗⾏代码都不⼀定能解决,⽽且漏洞百出,⽽使⽤正则表达式,⼀⾏代码则可轻易解决,下⾯是举例说明正则表达式的⽤法:1: \d 代表⼀个(阿拉伯数字)任意数字 例如:判断⽤户输⼊的是否为11位数字(当然⼿机号码是不能这么简答的表达,只是解释⼀下\d的⽤法)1select'ok'2from dual3where regexp_like('188****5678','\d\d\d\d\d\d\d\d\d\d\d')2: . 代表⼀个(任意字母)任意字母 这⾥需要注意的是,如果输⼊的数字确实需要字母 . 的话,不能直接输 . 要转换⼀下格式,输⼊ \. 即可,这个需要注意。
3: [[:number:]] ⼀个任意数字(可以使⼗六进制) 这个⽤的并不多,如果现实⼗六进制,可以使⽤如下⽅式即可1select'ok'2from dual3where regexp_like('str','[0-9a-fA-F]')4: [[:alpha:]] ⼀个任意⼤⼩写字母5: [ ] 匹配到⽅括号内的其中⼀个字母 ⽅括号中只能匹配到其中的任意⼀个字母,或者是7 或者是8或者是9,只能是1个1select'ok'2from dual3where regexp_like('8','[379]') 例如下⾯的就是ASCII码中,数字3到ASCII码⼩写的 a 其中的任意⼀个字符的匹配1select'ok'2from dual3where regexp_like('9','[3-a]') 当然如果是12345678这样的连续的数字可以这么写1select'ok'2from dual3where regexp_like('str','[1-8]') 如果是要匹配 12345678 中的其中⼀个,或者是字母 a也⾏,就可以这么写,a可以写到前边,也可以写到后⾯,这并⽆所谓,因为只匹配⼀个⽽已1select'ok'2from dual3where regexp_like('str','[a1-8]')6: () 单词匹配 单词匹配,⼀般⽤竖线隔开,例如:⼩明喜欢吃苹果或者⾹蕉或者樱桃,此时就应该是⽤单词的匹配,在圆括号中任选⼀个。
oracle的正则表达式语法

oracle的正则表达式语法Oracle的正则表达式语法正则表达式在计算机编程中是非常重要的,它可以帮助我们轻松地匹配、查找和替换文本中的特定字符序列。
Oracle数据库也支持正则表达式,因此,本文将介绍Oracle的正则表达式语法。
1. 字符类:正则表达式中的字符类可以表示一组字符中的任何一个字符。
在Oracle中,我们可以使用方括号([])来表示字符类,如下所示:[abc]:表示a、b或c中的任何一个字符。
[^abc]:表示除a、b或c以外的任何一个字符。
[a-z]:表示从a到z中的任何一个小写字母。
[A-Z]:表示从A到Z中的任何一个大写字母。
[0-9]:表示从0到9中的任何一个数字。
2. 元字符:正则表达式中的元字符有特殊的含义,可以用来表示空格、数字、特殊字符等。
在Oracle中,我们可以使用以下元字符:\d:表示任何一个数字,等效于[0-9]。
\D:表示除数字以外的任何一个字符,等效于[^0-9]。
\s:表示任何一个空格字符,等效于[ \t\n\r\f\v]。
\S:表示除空格字符以外的任何一个字符。
\w:表示任何一个字母、数字或下划线字符,等效于[a-zA-Z0-9_]。
\W:表示除字母、数字和下划线以外的任何一个字符。
.:表示除换行符以外的任何一个字符。
3. 重复符号:正则表达式中的重复符号可以表示重复出现的字符或字符序列。
在Oracle中,我们可以使用以下重复符号:*:表示重复0次或多次。
+:表示重复1次或多次。
:表示重复0次或1次。
{n}:表示重复n次。
{n,}:表示重复n次或多次。
{n,m}:表示重复n到m次。
4. 边界符号:正则表达式中的边界符号可以表示待查找字符串的边界,如单词的开头或结尾。
在Oracle中,我们可以使用以下边界符号:^:表示字符串的开头。
$:表示字符串的结尾。
\b:表示单词边界,例如字母和空格之间的边界。
\B:表示除单词边界以外的任何一个位置。
5. 分组和反向引用:正则表达式中的分组可以一组字符视为一个整体,并对整个字符组进行操作。
oracle regexp用法

oracle regexp用法Oracle数据库中的正则表达式(Regexp)函数提供了强大的模式匹配功能,可以在字符串中搜索、替换和提取特定模式的数据。
1. REGEXP_LIKE函数:用于检查一个字符串是否与指定的模式匹配。
例如,我们可以使用REGEXP_LIKE函数来检查一个字符串是否是有效的电子邮件地址:SELECT emailFROM usersWHERE REGEXP_LIKE(email, '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}$');这将返回所有符合指定电子邮件地址模式的用户。
2. REGEXP_SUBSTR函数:用于从一个字符串中提取满足指定模式的子字符串。
例如,我们可以使用REGEXP_SUBSTR函数从一个字符串中提取出所有的数字字符:SELECT REGEXP_SUBSTR('abc123def456', '[0-9]+') AS resultFROM dual;这将返回字符串中所有满足模式[0-9]+(即连续的数字字符)的子字符串。
3. REGEXP_REPLACE函数:用于将一个字符串中满足指定模式的部分替换为新的字符串。
例如,我们可以使用REGEXP_REPLACE函数将一个字符串中的所有数字字符替换为“#”:SELECT REGEXP_REPLACE('abc123def456', '[0-9]+', '#') AS resultFROM dual;这将返回字符串中所有的数字字符被替换为“#”后的结果。
这只是Oracle Regexp的一些常见用法示例,实际上,Oracle还提供了许多其他强大的Regexp函数和操作符,可以用于更复杂的模式匹配和处理需求。
在使用Regexp函数时,需要熟悉Regexp的语法规则和各种模式匹配表达式,以便灵活运用于实际场景中。
oracle regex 正则表达式

oracle regex 正则表达式Oracle正则表达式(Regex)是一种强大的工具,用于在数据库中进行模式匹配和字符串处理。
使用Oracle的正则表达式功能,可以快速、高效地提取、替换和验证数据。
本文将介绍Oracle正则表达式的基本语法和常用功能,帮助读者更好地理解和应用正则表达式。
一、正则表达式介绍正则表达式是一种描述字符模式的语言,可以通过正则表达式来匹配、查找和操作字符串。
Oracle引入了Perl风格的正则表达式,提供了丰富的模式匹配功能。
二、基本语法Oracle正则表达式的模式由各种字符和特殊字符组成。
下面是一些常用的特殊字符:1. 常用元字符:- . 匹配任意字符- \d 匹配数字- \w 匹配字母、数字、下划线- \s 匹配空白字符2. 量词:- * 匹配0个或多个字符- + 匹配1个或多个字符- ? 匹配0个或1个字符- {n} 匹配n个字符- {n,} 匹配至少n个字符- {n,m}匹配n到m个字符3. 字符类:- [] 匹配方括号内的任意字符- [^] 匹配不在方括号内的任意字符三、常用功能1. 字符串匹配:使用正则表达式可以在数据库中进行字符串匹配,从而找到符合特定模式的数据。
例如,可以通过正则表达式找到所有以"A"开头的字符串,或者找到所有包含特定字符的字符串。
2. 字符串替换:正则表达式还可以用于字符串替换。
可以使用正则表达式将字符串中的某些部分替换为其他内容。
例如,可以将所有的电话号码替换为特定的格式。
3. 字符串提取:使用正则表达式可以快速提取字符串中的特定部分。
例如,可以从邮件地址中提取出用户名和域名。
4. 数据验证:正则表达式还可以用于数据验证,确保数据符合特定的格式要求。
例如,可以使用正则表达式验证电话号码、邮件地址等数据的有效性。
四、使用示例下面是一些使用Oracle正则表达式的示例:1. 查找所有以"A"开头的字符串:SELECT column_name FROM table_name WHERE REGEXP_LIKE(column_name, '^A.*');2. 替换字符串中的数字为"X":SELECT REGEXP_REPLACE(column_name, '\d', 'X') FROM table_name;3. 提取邮件地址的用户名和域名:SELECT REGEXP_SUBSTR(email, '(\w+)@(\w+\.\w+)') FROM table_name;4. 验证电话号码的有效性:SELECT column_name FROM table_name WHERE REGEXP_LIKE(column_name, '^\d{3}-\d{4}-\d{4}$');五、总结本文介绍了Oracle正则表达式的基本语法和常用功能。
第21章 Oracle中的正则表达式

21.4
本章实例
在进行正则表达式匹配时,还可以忽略字符大小写形 式进行匹配。这是比使用LIKE判式更加灵活和方便之处。 select * from people where regexp_like(name, 'or'); select * from people where regexp_like(name, 'or', 'i');
21.2.6
Oracle中正则表达式的特殊性
[[:alnum:]]:表示任意字母和数字。 [[:space:]]:表示任意空白字符,正则表达式的一般语 法为\s。
[[:upper:]]:表示任意大写字母。
[[:punct:]]:表示任意标点符号。 [[:xdigit:]]:表示任意16进制的数字,相当于[0-9a-fAF]。
21.3 正则都提供了对正则表达式的支 持。而这种支持,主要是通过提供函数来体现的。Oracle中 共有四个正则表达式相关函数,它们分别是: regexp_like()
regexp_instr()
regexp_substr() regexp_replace()
21.6
习题
1.简述正则表达式与通配符的区别。 2.简述正则表达式匹配时的贪婪原则。 3.简述Oracle正则表达式的特殊性。
4.利用regexp_replace()函数将YYYY-MM-DD格式 的字符串,转换为MM/DD/YYYY格式。
22.1.2
正则表达式与编程语言
在各种编程语言中,可以说,正则表达式是无处不在 的。正则表达式在各种编程语言中高度统一,都遵循一致的 语法。因此,一旦熟悉了一种编程语言中的正则表达式,那 么,可以直接应用于其他编程语言。编程语言同时也是正则 表达式的载体,没有编程语言,正则表达式的作用将无从发 印
oracle正则表达式

Oracle Database 10g中的正规表达式特性是一个用于处理文本数据的强大工具Oracle Database 10g的一个新特性大大提高了您搜索和处理字符数据的能力。
这个特性就是正规表达式,是一种用来描述文本模式的表示方法。
很久以来它已在许多编程语言和大量UNIX 实用工具中出现过了。
Oracle 的正规表达式的实施是以各种SQL 函数和一个WHERE子句操作符的形式出现的。
如果您不熟悉正规表达式,那么这篇文章可以让您了解一下这种新的极其强大然而表面上有点神秘的功能。
已经对正规表达式很熟悉的读者可以了解如何在Oracle SQL 语言的环境中应用这种功能。
什么是正规表达式?正规表达式由一个或多个字符型文字和/或元字符组成。
在最简单的格式下,正规表达式仅由字符文字组成,如正规表达式cat。
它被读作字母c,接着是字母a和t,这种模式匹配cat、location和catal og之类的字符串。
元字符提供算法来确定Oracle 如何处理组成一个正规表达式的字符。
当您了解了各种元字符的含义时,您将体会到正规表达式用于查找和替换特定的文本数据是非常强大的。
验证数据、识别重复关键字的出现、检测不必要的空格,或分析字符串只是正规表达式的许多应用中的一部分。
您可以用它们来验证电话号码、邮政编码、电子邮件地址、社会安全号码、IP 地址、文件名和路径名等的格式。
此外,您可以查找如HTML 标记、数字、日期之类的模式,或任意文本数据中符合任意模式的任何事物,并用其它的模式来替换它们。
用Oracle Database 10g使用正规表达式您可以使用最新引进的Oracle SQL REGEXP_LIKE操作符和REGEXP_INSTR、REGE XP_SUBSTR以及REGEXP_REPLACE函数来发挥正规表达式的作用。
您将体会到这个新的功能如何对LIKE操作符和INSTR、SUBSTR和REPLACE函数进行了补充。
oracle正则表达式regexp_like用法

oracle正则表达式regexp_like用法摘要:1.简介- Oracle 数据库- 正则表达式(Regular Expression)- regexp_like 函数2.regexp_like 函数的基本语法- 语法结构- 参数说明3.regexp_like 函数的用法- 匹配字符串- 匹配数字- 匹配日期- 匹配特殊字符4.regexp_like 函数的实例- 实例1:匹配字符串- 实例2:匹配数字- 实例3:匹配日期- 实例4:匹配特殊字符5.regexp_like 函数与like 的比较- 相似之处- 不同之处6.总结- regexp_like 函数的优势- regexp_like 函数的应用场景正文:Oracle 数据库是业界知名的关系型数据库管理系统,广泛应用于各种企业和组织的数据存储和管理。
在Oracle 数据库中,正则表达式(Regular Expression)是一种强大的文本处理工具,可以帮助用户快速进行数据查询和筛选。
regexp_like 函数是Oracle 数据库中提供的一个正则表达式匹配函数,可以对字符串进行模式匹配。
regexp_like 函数的基本语法如下:```regexp_like(string, pattern)```其中,string 是需要匹配的字符串,pattern 是正则表达式模式。
regexp_like 函数的用法非常丰富,可以匹配各种类型的数据。
以下是一些常见的用法:- 匹配字符串:可以使用通配符*和?进行字符串匹配。
例如,要匹配以"ab"开头的字符串,可以使用`regexp_like("ab*", "ab")`。
- 匹配数字:可以使用数字范围进行匹配。
例如,要匹配1 到10 之间的整数,可以使用`regexp_like(数字,"^[1-9][0-9]?$")`。
orcl中用正则表达式

orcl中用正则表达式在Oracle中,你可以使用正则表达式来执行各种字符串操作,例如搜索、替换、提取等。
Oracle的正则表达式功能主要通过`REGEXP_SUBSTR`、`REGEXP_INSTR`、`REGEXP_REPLACE`等函数提供。
以下是一些在Oracle中使用正则表达式的示例:1. 使用`REGEXP_SUBSTR`提取字符串假设你想从某个字符串中提取所有的数字:```sqlSELECT REGEXP_SUBSTR('abc123def456', '[0-9]+') FROM dual;```这会返回`123`和`456`。
2. 使用`REGEXP_INSTR`查找字符串查找某个字符串在另一个字符串中的位置:```sqlSELECT REGEXP_INSTR('abc123def456', '[0-9]+') FROM dual;```这会返回数字`4`,表示第一个数字(123)开始于位置4。
3. 使用`REGEXP_REPLACE`替换字符串替换所有匹配正则表达式的子串:```sqlSELECT REGEXP_REPLACE('abc123def456', '[0-9]+', 'XX') FROM dual;```这会返回`abcXXdefXX`。
4. 使用复杂的正则表达式例如,如果你想从字符串中提取所有由字母组成的子串:```sqlSELECT REGEXP_SUBSTR('abc123def456', '[a-zA-Z]+') FROM dual;```这会返回`abc`和`def`。
5. 分组和捕获使用括号进行分组和捕获:```sqlSELECT REGEXP_SUBSTR('abc123def456', '([a-z]+)([0-9]+)', 1, 1, NULL, 1) FROM dual;```这将返回`abc`,因为它是第一个匹配的子串。
oracle sql 年月正则表达式

Oracle SQL中的年月正则表达式是指能够匹配特定格式的年月信息的正则表达式。
在实际的数据处理中,经常需要对年月信息进行提取、比较、筛选等操作,而正则表达式正是一个强大的工具,能够帮助我们轻松地处理这些任务。
1. 年月正则表达式的基本结构在Oracle SQL中,用于匹配年月信息的正则表达式的基本结构是由数字和特定的分隔符组成的。
一般而言,年月信息的格式可以是"yyyy-mm"、"yyyy/mm"、"yyyymm"等形式,因此我们需要编写相应的正则表达式来进行匹配。
2. 匹配四位年份和两位月份如果我们需要匹配的年月信息的格式是"yyyy-mm",那么对应的正则表达式可以是"\b\d{4}-\d{2}\b"。
其中,"\b"表示单词边界,"\d"表示数字,"{4}"表示恰好匹配4个数字,"-"表示匹配连字符,"{2}"表示恰好匹配2个数字。
3. 匹配四位年份和两位月份如果我们需要匹配的年月信息的格式是"yyyy/mm",那么对应的正则表达式可以是"\b\d{4}/\d{2}\b"。
其中,"\b"表示单词边界,"\d"表示数字,"{4}"表示恰好匹配4个数字,"/"表示匹配斜杠,"{2}"表示恰好匹配2个数字。
4. 匹配六位年份和两位月份如果我们需要匹配的年月信息的格式是"yyyymm",那么对应的正则表达式可以是"\b\d{6}\d{2}\b"。
其中,"\b"表示单词边界,"\d"表示数字,"{6}"表示恰好匹配6个数字,"{2}"表示恰好匹配2个数字。
oracle正则表达式语法

oracle正则表达式语法Oracle正则表达式语法正则表达式是一种常用的文本匹配方法,它可以在文本中搜索特定的字符串、取代或者操作一些文本操作,也有利于开发者更简洁的实现一些文本过滤的需求。
Oracle正则表达式语法是Oracle数据库提供的一种文本匹配方式,在处理大量数据时能够大大提高处理效率。
下面是Oracle正则表达式语法相关内容的详细介绍:1.匹配任意字符通配符可以替代任何字符,用”%”表示。
比如:”%moon%”可以匹配moon、bluemoon、bigmoon等。
2. 匹配单个字符“_”表示匹配单个字符。
比如:”d_g”可以匹配dog、dig、dug等。
3. 简单的字符匹配直接匹配字符即可,比如:'A'可以匹配A,'B'可以匹配B。
4. 区分大小写Oracle正则表达式中区分大小写。
比如:”A”只匹配A,“a”只匹配a。
5. 匹配多个字符可以使用方括号表示多个字符。
比如:[abc123]就可以匹配a、b、c、1、2、3。
6. 匹配任意一个字符用“.”匹配任意一个字符。
比如:”3.”可以匹配31、32、33等。
7. 匹配多个字符之间的内容在[]中使用“-”语法,表示匹配两个字符之间的内容。
比如:[3-8]可以匹配3、4、5、6、7、8。
8. 匹配条件选择使用竖线 | 来表示条件选择。
比如:”java|c++”可以匹配java和c++。
9. 匹配单个字符中的某个条件使用圆括号来设定多项匹配规则。
比如:(Java|Pearl|Python)可以匹配Java或Pearl或Python。
10. 匹配一个或多个使用 + 来表示出现一次或多次,比如:”bo+t”可以匹配bot、boot、bootoot等。
使用*来表示出现零次或多次,比如:”bo*t”可以匹配bt、bot、boot、bootoot等。
使用? 来表示出现零次或一次,比如:”bo?t”可以匹配bt、bot。
oracle 匹配正则表达式

oracle 匹配正则表达式摘要:1.Oracle中正则表达式的基本概念2.Oracle中常用的正则表达式符号及功能3.实战案例:使用正则表达式进行数据匹配和提取4.总结与建议正文:随着大数据时代的到来,数据处理和分析变得愈发重要。
作为数据库管理的佼佼者,Oracle在其功能上也有着丰富的扩展。
正则表达式便是其中之一,它可以帮助我们更高效地处理和分析数据。
本文将介绍Oracle中正则表达式的基本概念、常用符号及功能,并通过实战案例来演示如何使用正则表达式进行数据匹配和提取。
一、Oracle中正则表达式的基本概念在Oracle中,正则表达式作为一种字符串匹配和查找工具,适用于各种数据处理场景。
它可以用来检查数据完整性、校验输入项格式、查找特定模式等。
为了更好地使用正则表达式,我们需要了解一些基本概念,如字符集、量词、分组、选择等。
二、Oracle中常用的正则表达式符号及功能1.字符集:用于定义匹配的字符范围,如[a-z]表示小写字母。
2.量词:用于指定匹配次数,如*表示零次或多次匹配,+表示一次或多次匹配。
3.分组:将正则表达式的一部分组合在一起,以便进行特定操作。
4.选择:使用|符号表示在两个或多个模式中选择一个进行匹配。
以下是一些常用符号的示例:- 字面字符:如"a"、"b"等。
- 字符集:如[a-z]、[0-9]等。
- 否定字符集:如[^a-z]表示匹配非小写字母。
- 量词:如*、+、?等。
- 分组:如(ab)表示匹配连续的ab字符。
- 选择:如a|b表示匹配a或b。
三、实战案例:使用正则表达式进行数据匹配和提取案例1:检查电子邮件格式```SELECT * FROM users WHERE email REGEXP "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$";```案例2:提取字符串中的数字```SELECT SUBSTR(column_name, REGEXP("[0-9]+", 1, "") AS digits FROM table_name;```四、总结与建议正则表达式在Oracle数据库中的应用极为广泛,熟练掌握正则表达式有助于提高数据处理和分析的效率。
oracle正则表达式

分类:Linux----------------------feedback@b)REGEXP_INSTRREGEXP_INSTR返回与正则表达式匹配的字符和字符串的位置。
如SQL> select regexp_instr('The zip code 80831 is for falcon, co','[[:digit:]]{5}') REGEXP_INSTR from dual;REGEXP_INSTR------------14c)REGEXP_REPLACEREGEXP_REPLACE与REPLACE函数类似,提供一种修改与所给正则表达式匹配的字符串的方法。
作用包括纠正拼写错误、格式化输入输出的文本。
如电话号码的格式为:719-111-1111。
使用REGEX_REPLACER的返回值是:SQL> select regexp_replace('Reformat the phone number 719-111-1111 ...',2 '[1]?[-.]?(\(?[[:digit:]]{3}\)?)+[- .]?'3 || '([[:digit:]]{3})[- .]?([[:digit:]]{4})',4 ' (\1) \2-\3') regexp_replace5 from dual;REGEXP_REPLACE---------------------------------------------Reformat the phone number (719) 111-1111 ...Sd)REGEXP_LIKEREGEXP_LIKE运算符与LIKE运算符相似,但是功能更强大,因为它支持使用与此正则表达式与文本进行匹配。
语法如下:REGEXP_LIKE(source_string, pattern, match_parameter)Source_string可以是文字字符串,如果前面例中的字符串,也可以是包含某些字符串的变量或列。
Oracle正则表达式

Oracle正则表达式Oracle正则表达式正则表达式具有强⼤、便捷、⾼效的⽂本处理功能。
能够添加、删除、分析、叠加、插⼊和修整各种类型的⽂本和数据。
Oracle从10g开始⽀持正则表达式。
下⾯通过⼀些例⼦来说明使⽤正则表达式来处理⼀些⼯作中常见的问题。
1.REGEXP_SUBSTRREGEXP_SUBSTR 函数使⽤正则表达式来指定返回串的起点和终点,返回与source_string 字符集中的VARCHAR2 或CLOB 数据相同的字符串。
语法:--1.REGEXP_SUBSTR与SUBSTR函数相同,返回截取的⼦字符串REGEXP_SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]])注:srcstr 源字符串pattern 正则表达式样式position 开始匹配字符位置occurrence 匹配出现次数match_option 匹配选项(区分⼤⼩写)1.1 从字符串中截取⼦字符串SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+') FROM dual;Output: 1PSN[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符。
SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+', 1, 2) FROM dual;Output: 231与上⾯⼀个例⼦相⽐,多了两个参数1 表⽰从源字符串的第⼀个字符开始查找匹配2 表⽰第2次匹配到的字符串(默认值是“1”,如上例)select regexp_substr('@@/231_3253/ABc','@*[[:alnum:]]+') from dual;Output: 231@* 表⽰匹配0个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符注意:需要区别“+”和“*”的区别select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]*') from dual;Output: @@+ 表⽰匹配1个或者多个@[[:alnum:]]* 表⽰匹配0个或者多个字母或数字字符select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]+') from dual;Output: Null@+ 表⽰匹配1个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符select regexp_substr('@1PSN/231_3253/ABc125','[[:digit:]]+$') from dual;Output: 125[[:digit:]]+$ 表⽰匹配1个或者多个数字结尾的字符select regexp_substr('@1PSN/231_3253/ABc','[^[:digit:]]+$') from dual;Output: /ABc[^[:digit:]]+$ 表⽰匹配1个或者多个不是数字结尾的字符select regexp_substr('Tom_Kyte@','[^@]+') from dual;Output: Tom_Kyte[^@]+ 表⽰匹配1个或者多个不是“@”的字符select regexp_substr('1PSN/231_3253/ABc','[[:alnum:]]*',1,2)from dual;Output: Null[[:alnum:]]* 表⽰匹配0个或者多个字母或者数字字符注:因为是匹配0个或者多个,所以这⾥第2次匹配的是“/”(匹配了0次),⽽不是“231”,所以结果是“Null”1.2 匹配重复出现查找连续2个⼩写字母SELECT regexp_substr('Republicc Of Africaa', '([a-z])\1', 1, 1, 'i')FROM dual;Output: cc([a-z]) 表⽰⼩写字母a-z\1 表⽰匹配前⾯的字符的连续次数1 表⽰从源字符串的第⼀个字符开始匹配1 第⼀次出现符合匹配结果的字符i 表⽰区分⼤⼩写查找连续3个6,7,8,9中的数字SELECT CASEWHEN regexp_like('Patch 10888 applied', '([6-9])\1\1') THEN'Match Found'ELSE'No Match Found'1.3 其他⼀些匹配样式查找⽹页地址信息FROM dual其中:([[:alnum:]]+\.?) 表⽰匹配1次或者多次字母或数字字符,紧跟0次或1次逗号符{3,4} 表⽰匹配前⾯的字符最少3次,最多4次/? 表⽰匹配⼀个反斜杠字符0次或者1次提取csv字符串中的第三个值SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, 3) AS outputFROM dual;Output: Japan其中:[^,]+ 表⽰匹配1个或者多个不是逗号的字符1 表⽰从源字符串的第⼀个字符开始查找匹配3 表⽰第3次匹配到的字符串注:这个通常⽤来实现字符串的列传⾏--字符串的列传⾏SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, LEVEL) AS output FROM dualCONNECT BY LEVEL <= length('1101,Yokohama,Japan,1.5.105') -length(REPLACE('1101,Yokohama,Japan,1.5.105', ',')) + 1;Output: 1101YokohamaJapan1.5.105这⾥通过LEVEL来循环截取匹配到的字符串。
oracle sql 正则 -回复

oracle sql 正则-回复问题:如何在Oracle SQL中使用正则表达式?引言:正则表达式是一种强大的文本匹配工具,可以在字符串中查找、匹配和提取满足特定模式的文本。
在Oracle SQL中,正则表达式可以通过正则表达式函数和操作符来实现。
本文将为您介绍如何在Oracle SQL中使用正则表达式,以及一些常见的正则表达式用例。
正文:一、正则表达式函数Oracle SQL提供了丰富的正则表达式函数,可以在查询中使用。
以下是一些常见的正则表达式函数及其用法:1. REGEXP_LIKE:判断字符串是否满足特定模式。
语法:REGEXP_LIKE(column, pattern, match_parameter)示例:SELECT * FROM employees WHEREREGEXP_LIKE(last_name, 'Pat[rt]on', 'i');查询姓氏为"Patton"或"Patton"的所有员工记录。
2. REGEXP_SUBSTR:从字符串中提取满足特定模式的子字符串。
语法:REGEXP_SUBSTR(column, pattern, position, occurrence,match_parameter)示例:SELECT REGEXP_SUBSTR(email,'(^[A-Za-z0-9]+)[A-Za-z0-9]+\.[A-Za-z]{2,4}') AS domainFROM employees;提取邮箱字段中的域名部分。
3. REGEXP_INSTR:返回满足特定模式的字符串在另一个字符串中的位置。
语法:REGEXP_INSTR(column, pattern, position, occurrence, return_option, match_parameter)示例:SELECT last_name, REGEXP_INSTR(phone_number,'[0-9]{3}', 1, 1, 0, 'c') AS area_codeFROM employees;查询员工电话号码中的区号部分。
ORACLE SQL 正则表达式
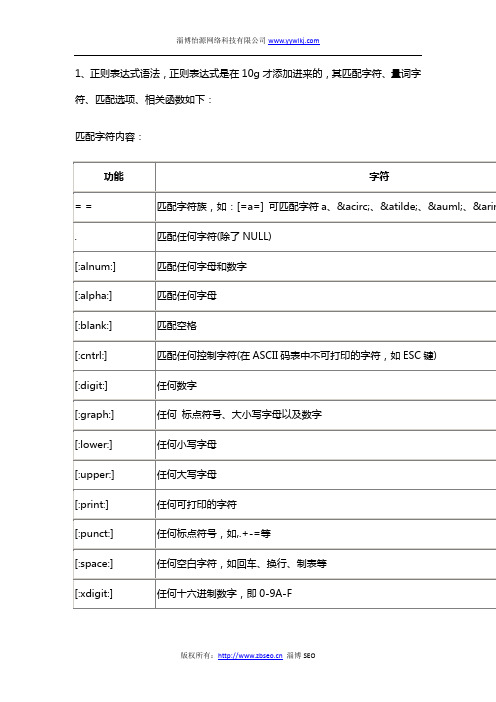
1、正则表达式语法,正则表达式是在10g才添加进来的,其匹配字符、量词字符、匹配选项、相关函数如下:匹配字符内容:匹配字符位置和条件:匹配字符数量:匹配选项:函数:REGEXP_LIKE 是LIKE语句的正则表达式版本语法:REGEXP_LIKE(源字符串, 匹配表达式[,匹配选项])REGEXP_INSTR 返回源字符串中首次匹配正则表达式的起始位置语法:REGEXP_INSTR(srcstr, pattern [, position [, occurrence[,return_option [, match_option]]]])srcstr:源字符串pattern:正则表达式position:搜索开始位置occurrence:返回第几个匹配项return_option:返回选项,0表示开始位置,1表示返回匹配的结束位置match_option:匹配选项REGEXP_SUBSTR 返回源串中匹配正则表达式的子字符串语法:SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]]) srcstr:源字符串pattern:正则表达式position:搜索的开始位置occurrence:返回第几个匹配的字符串match_option:匹配选项REGEXP_REPLACE 用执行字符串替换源文本中与正则表达式匹配的字符串语法:REGEXP_REPLACE(srcstr, pattern [,replacestr [, position[, occurrence [, match_option]]]])srcstr:源字符串pattern:正则表达式replacestr:新的字符串position:搜索起始位置occurrence:第几个匹配项match_option:匹配选项例题说明:Evaluate the following expression using meta. character for regular expression:'[^Ale|ax.r$]'Which two matches would be returned by this expression? (Choose two.)A. AlexB. AlaxC. AlxerD. AlaxendarE. AlexenderAnswer: DE'[^Ale|ax.r$]'中^表示只匹配不在集合{'A','l','e','|','a','x','.','r','$'}中的字符, 此处的'|'、'.'、'$'只是表示普通的字符,而非匹配符本文由淄博SEO(),淄博网站优化()整理发布,转载请注明出处。
Oracle中的正则表达式

Oracle中的正则表达式Oracle使⽤正则表达式离不开这4个函数:1 、regexp_like2 、regexp_substr3、 regexp_instr4 、regexp_replace2.1、REGEXP_SUBSTRREGEXP_SUBSTR函数使⽤正则表达式来指定返回串的起点和终点。
语法:regexp_substr(source_string,pattern[,position[,occurrence[,match_parameter]]])source_string:源串,可以是常量,也可以是某个值类型为串的列。
position:从源串开始搜索的位置。
默认为1。
occurrence:指定源串中的第⼏次出现。
默认值1.match_parameter:⽂本量,进⼀步订制搜索,取值如下:'i' ⽤于不区分⼤⼩写的匹配。
'c' ⽤于区分⼤⼩写的匹配。
'n' 允许将句点“.”作为通配符来匹配换⾏符。
如果省略改参数,句点将不匹配换⾏符。
'm' 将源串视为多⾏。
即将“^”和“$”分别看做源串中任意位置任意⾏的开始和结束,⽽不是看作整个源串的开始或结束。
如果省略该参数,源串将被看作⼀⾏来处理。
如果取值不属于上述中的某个,将会报错。
如果指定了多个互相⽭盾的值,将使⽤最后⼀个值。
如'ic'会被当做'c'处理。
省略该参数时:默认区分⼤⼩写、句点不匹配换⾏符、源串被看作⼀⾏。
例⼦:1. select regexp_substr('MY INFO: Anxpp,23,and boy','[[:digit:]]',1,2) from users;结果:此处会返回3。
注意这⾥同时⽤到了“[]”和“[:digit:]”。
2.2、REGEXP_INSTRREGEXP_INSTR函数使⽤正则表达式返回搜索模式的起点和终点(整数)。
Oracle 正则表达式

\s 任一空白字符,包括制表符,换行符,回车符,换页符和垂直制表符 匹配在HTML,XML和其他标准定义中的所有传统空白字符
\S 任一非空白字符 空白字符以外的任意字符,如A%&g3;等
. 任一字符 匹配除换行符以外的任意字符除非设置了MultiLine先项
正则表达式为:.*ing
它将实现一次匹配――单词trusting。“.”匹配任意字符,当然也匹配“ing”。所以,Regex引擎回溯一位并在第2个“t”停止,然后匹配指定的模式“ing”。但是,如果禁用回溯操作:(?>.*)ing
它将实现0次匹配。“.”能匹配所有的字符,包括“ing”――不能匹配,从而匹配失败
第2次匹配:lastName group=Benes
第3次匹配:lastName group=Kramer
第4次匹配:lastName group=Costanza
不管是否设置了选项ExplictCapture,组都将被捕获
(?=) 正声明。声明的右侧必须是括号中指定的模式。此模式不构成最终匹配的一部分 正则表达式\S+(?=.NET)要匹配的输入字符串为:The languages were Java,C#.NET,,C,,Pascal
Oracle 正则表达式
Oracle 正则表达式
就是由普通字符(例如字符a到z)以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
本文详细地列出了能在正则表达式中使用,以匹配文本的各种字符。当你需要解释一个现有的正则表达式时,可以作为一个快捷的参考。更多详细内容,请参考:Francois Liger,Craig McQueen,Pal Wilton[刘乐亭译] C#字符串和正则表达式参考手册北京:清华大学出版社2003.2
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
oracle的正则表达式oracle的正则表达式(regular expression)简单介绍目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境。
Oracle 10g正则表达式提高了SQL灵活性。
有效的解决了数据有效性,重复词的辨认, 无关的空白检测,或者分解多个正则组成的字符串等问题。
Oracle 10g支持正则表达式的四个新函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和REGEXP_REPLACE。
它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
特殊字符:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了RegExp 对象的Multiline 属性,则$ 也匹配'\n' 或'\r'。
'.' 匹配除换行符\n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
\num 匹配num,其中num 是一个正整数。
对所获取的匹配的引用。
正则表达式的一个很有用的特点是可以保存子表达式以后使用,被称为Backreferencing. 允许复杂的替换能力如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,缓冲区从左到右编号, 通过\数字符号访问。
下面的例子列出了把名字aa bb cc 变成cc, bb, aa.Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '\3, \2, \1') FROM dual;REGEXP_REPLACE('ELLENHILDISMITcc, bb, aa'\' 转义符。
字符簇:[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[unct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
各种操作符的运算优先级\ 转义符(), (?, (?=), [] 圆括号和方括号*, +, ?, {n}, {n,}, {n,m} 限定符^, $, \anymetacharacter 位置和顺序| “或”操作--测试数据create table test(mc varchar2(60));insert into test values('112233445566778899');insert into test values('22113344 5566778899');insert into test values('33112244 5566778899');insert into test values('44112233 5566 778899');insert into test values('5511 2233 4466778899');insert into test values('661122334455778899');insert into test values('771122334455668899');insert into test values('881122334455667799');insert into test values('991122334455667788');insert into test values('aabbccddee');insert into test values('bbaaaccddee');insert into test values('ccabbddee');insert into test values('ddaabbccee');insert into test values('eeaabbccdd');insert into test values('ab123');insert into test values('123xy');insert into test values('007ab');insert into test values('abcxy');insert into test values('The final test is is is how to find duplicate words.');commit;一、REGEXP_LIKEselect * from test where regexp_like(mc,'^a{1,3}');{}的意思是连续几个的匹配上面的sql的意思是开头有1个到3个连续aselect * from test where regexp_like(mc,'a{1,3}');有连续3个aselect * from test where regexp_like(mc,'^a.*e$');以a开头以e结尾的字符之所以有.是因为如果写成^a*e$就变成以a开头中间都是a以e结尾的字符拉*的意思是匹配它前面的字符^ab*e$可否查出以a开头以e结尾的字符呢?答案是否定的因为*虽然是可以匹配前面的b0次或者多次但是它也仅仅是匹配以a开头中间可以有b并且都是b,或者中间没有字符,以e结尾的字符.'^[[:alpha:]]+$'的意思是以字母从开头到结尾都包含字母的字符select * from test where regexp_like(mc,'^[[:lower:]]|[[:digit:]]');小写字母或者数字开头的字符select * from test where regexp_like(mc,'^[[:lower:]]');小写字母开头的字符select mc FROM test Where REGEXP_LIKE(mc,'[^[:digit:]]');"^"就是一个有多种意义的字符元,主要看语意环境如果"^"是字符列中的第一个字符,就表示对这个字符串取反,因此, [^[:digit:]]就是表示查找非数字的模式即字符中不都是数字Select mc FROM test Where REGEXP_LIKE(mc,'^[^[:digit:]]');以非数字开头的字符二、REGEXP_INSTRSelect REGEXP_INSTR(mc,'[[:digit:]]$') from test;Select REGEXP_INSTR(mc,'[[:digit:]]+$') from test;Select REGEXP_INSTR('The price is $400.','\$[[:digit:]]+') FROM DUAL;Select REGEXP_INSTR('onetwothree','[^[[:lower:]]]') FROM DUAL;Select REGEXP_INSTR(',,,,,','[^,]*') FROM DUAL;Select REGEXP_INSTR(',,,,,','[^,]') FROM DUAL;三、REGEXP_SUBSTRSELECT REGEXP_SUBSTR(mc,'[a-z]+') FROM test;SELECT REGEXP_SUBSTR(mc,'[0-9]+') FROM test;SELECT REGEXP_SUBSTR('aababcde','^a.*b') FROM DUAL;四、REGEXP_REPLACESelect REGEXP_REPLACE('Joe Smith','( ){2,}', ',') AS RX_REPLACE FROM dual;Select REGEXP_REPLACE('aa bb cc','(.*) (.*) (.*)', '\3, \2, \1') FROM dual;。