oracle 判断字段是否为是数字 regexp_like用法 正则表达式
oraclesql语言模糊查询--通配符like的使用教程

oraclesql语⾔模糊查询--通配符like的使⽤教程oracle在Where⼦句中,可以对datetime、char、varchar字段类型的列⽤Like⼦句配合通配符选取那些“很像...”的数据记录,以下是可使⽤的通配符:% 零或者多个字符_ 单⼀任何字符(下划线)\ 特殊字符oracle10g以上⽀持正则表达式的函数主要有下⾯四个:1,REGEXP_LIKE :与LIKE的功能相似2,REGEXP_INSTR :与INSTR的功能相似3,REGEXP_SUBSTR :与SUBSTR的功能相似4,REGEXP_REPLACE :与REPLACE的功能相似POSIX 正则表达式由标准的元字符(metacharacters)所构成:'^' 匹配输⼊字符串的开始位置,在⽅括号表达式中使⽤,此时它表⽰不接受该字符集合。
'$' 匹配输⼊字符串的结尾位置。
如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。
'.' 匹配除换⾏符之外的任何单字符。
'?' 匹配前⾯的⼦表达式零次或⼀次。
'+' 匹配前⾯的⼦表达式⼀次或多次。
'*' 匹配前⾯的⼦表达式零次或多次。
'|' 指明两项之间的⼀个选择。
例⼦'^([a-z]+|[0-9]+)$'表⽰所有⼩写字母或数字组合成的字符串。
'( )' 标记⼀个⼦表达式的开始和结束位置。
'[]' 标记⼀个中括号表达式。
'{m,n}' ⼀个精确地出现次数范围,m=<出现次数<=n,'{m}'表⽰出现m次,'{m,}'表⽰⾄少出现m次。
\num 匹配 num,其中 num 是⼀个正整数。
Oracle数据库正则表达式

Oracle数据库正则表达式正则表达式:⽆论是在前端还是后台正则表达式都是⼀个⾄关重要的知识点,例如判断⼀个⼿机号码输⼊是否正确,如果使⽤Java、C或者其他语⾔进⾏字符串进⾏判断,也许写⼏⼗⾏代码都不⼀定能解决,⽽且漏洞百出,⽽使⽤正则表达式,⼀⾏代码则可轻易解决,下⾯是举例说明正则表达式的⽤法:1: \d 代表⼀个(阿拉伯数字)任意数字 例如:判断⽤户输⼊的是否为11位数字(当然⼿机号码是不能这么简答的表达,只是解释⼀下\d的⽤法)1select'ok'2from dual3where regexp_like('188****5678','\d\d\d\d\d\d\d\d\d\d\d')2: . 代表⼀个(任意字母)任意字母 这⾥需要注意的是,如果输⼊的数字确实需要字母 . 的话,不能直接输 . 要转换⼀下格式,输⼊ \. 即可,这个需要注意。
3: [[:number:]] ⼀个任意数字(可以使⼗六进制) 这个⽤的并不多,如果现实⼗六进制,可以使⽤如下⽅式即可1select'ok'2from dual3where regexp_like('str','[0-9a-fA-F]')4: [[:alpha:]] ⼀个任意⼤⼩写字母5: [ ] 匹配到⽅括号内的其中⼀个字母 ⽅括号中只能匹配到其中的任意⼀个字母,或者是7 或者是8或者是9,只能是1个1select'ok'2from dual3where regexp_like('8','[379]') 例如下⾯的就是ASCII码中,数字3到ASCII码⼩写的 a 其中的任意⼀个字符的匹配1select'ok'2from dual3where regexp_like('9','[3-a]') 当然如果是12345678这样的连续的数字可以这么写1select'ok'2from dual3where regexp_like('str','[1-8]') 如果是要匹配 12345678 中的其中⼀个,或者是字母 a也⾏,就可以这么写,a可以写到前边,也可以写到后⾯,这并⽆所谓,因为只匹配⼀个⽽已1select'ok'2from dual3where regexp_like('str','[a1-8]')6: () 单词匹配 单词匹配,⼀般⽤竖线隔开,例如:⼩明喜欢吃苹果或者⾹蕉或者樱桃,此时就应该是⽤单词的匹配,在圆括号中任选⼀个。
oracle模糊查询中的like和regexp_like用法介绍

oracle模糊查询中的like和regexp_like用法介绍like常用用法:1.%代表任意数量的某一或某些字符。
select * from tmp_table t where like '%Bob'(查询tmp_table表中name列最后三位是BOb的记录,eg:BBob)select * from tmp_table t where like 'Bob%'(查询tmp_table表中name列开始三位是BOb的记录,eg:Bobm)select * from tmp_table t where like '%Bob%'(查询tmp_table表中name列中包含BOb的记录,eg:aBObm,aaBobmm)2._代表某一字符select * from tmp_table t where like '_Bob'(查询tmp_table表中name列为四位且最后三位是BOb的记录,eg:aBob,bBob)select * from tmp_table t where like 'B_ob'(查询tmp_table表中name列为四位且第二位是任意字符的记录,eg:Bnob,Bmob)select * from tmp_table t where like 'Bob_'(查询tmp_table表中name列为四位且最后一位是任意字符的记录,eg:Bobm,Bobn)regexp_like适用于查询某一列包含多个字符串的时候,常用用法:select * from tmp_table t where regexp_like(,'Bob|Jane|marry' )(查询tmp_table表中name 列中包含Bob或Jane或marry的记录,eg:Bob Smith,Jane Green)等同于:select * from tmp_table t where like '%Bob%' or like '%Jane%' or like '%marry%'这里顺便说下in、exists的用法:select * from tmp_table t where in ('Bob','Jane','marry' )等同于select * from tmp_table t where exists ('Bob','Jane','marry' )等同于select * from tmp_table t where ='Bob' or ='Jane' or ='marry'注:这里“等同于”指的是查询结果一样,并不包括语句的执行效率。
oracle like的用法

oracle like的用法Oraclelike法是一种在Oracle据库中使用相似查询功能的查询语法,它可以找出与指定值相似的行。
在 Oracle 中,有 2 Like法Simple Like Regular Expression Like,它们可以用来实现相似的功能,但是却有着本质的不同。
Simple Like Oracle 中最常用的 Like法,它使用 % _ 两种字符来表示字符范围,其中 % 代表 0多个字符,_ 代表一个字符。
例如,要查询现有数据库中所有以 abc头的字符串,可以使用这样的SQL:SELECT * FROM tablename WHERE like abc%此外,Simple Like可以用于模糊查询,也就是在查找字符串时不需要完全匹配,只需要满足某个简单的规则即可,如:SELECT * FROM tablename WHERE like %abc%此外,Simple Like可以用于排除满足某个条件的所有字符串,如:SELECT * FROM tablename WHERE NOT LIKE %abc%Regular Expression Like Oracle另一种 Like法,它使用正则表达式来确定字符范围,其中 [ ]示一组字符,{m}示有 m 个重复,{m,n}示有 m n 个重复,?示 0 1 个重复,+示 1多个重复,*示 0多个重复,^示不匹配,.示任意单个字符,例如:SELECT * FROM tablename WHERE REGEXP_LIKE(column1, A-Z]+ 这里的 `column1`示在查询中要使用的列,`[A-Z]+`示要查询的字符串必须是一个大写字母,其中 `[A-Z]`示字母A到字母Z,而 `+`示有至少一个这样的字母。
在使用 Oracle Like法时,除了要注意关键字的使用,还要考虑数据库索引类型和索引大小,否则会使查询效率降低,造成性能问题。
oracle正则表达式用法

Oracle正则表达式基于Perl语言的正则表达式语法,其基本语法和使用方法如下:1. 字符匹配:* .:匹配除了换行外的任意一个字符。
* \d:匹配任何数字,相当于[0-9]。
* \D:匹配任何非数字字符,相当于[^0-9]。
* \w:匹配任何字母数字字符或下划线,相当于[a-zA-Z0-9_]。
* \W:表示匹配任何非字母数字字符或下划线,相当于[^a-zA-Z0-9_]。
2. 限定符:* *:匹配前一个字符出现0次或多次。
* +:匹配前一个字符出现1次或多次。
* ?:匹配前一个字符出现0次或1次。
* {n}:匹配前一个字符出现n次。
* {n,}:匹配前一个字符出现n次或更多。
* {n,m}:匹配前一个字符出现n~m次。
3. 边界匹配:* ^:匹配开始位置。
* $:匹配结束位置。
* \b:匹配单词边界,即单词的开头或结尾位置。
* \B:匹配非单词边界,即不是单词的开头或结尾位置。
4. 分组和引用:* ( ):分组,标记一个子表达式的开始和结束位置。
* \num:引用第num个子表达式,num从1开始。
5. 字符集合:[]表示一组字符中的任意一个。
6. 转义符:\表示转义一个字符。
7. 其他高级语法支持:贪婪匹配、非贪婪匹配、零宽断言(zero-width assertion)、后向引用(backreference)、捕获组等。
另外,Oracle 10g支持正则表达式的四个新函数分别是REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR和REGEXP_REPLACE,它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
请注意,具体使用方法可能因不同的数据库版本或应用场景而有所不同。
建议查阅Oracle官方文档或相关教程以获取更详细和准确的信息。
ORACLE正则表达式查询

'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的
字符串。
-- 也可以这样实现,使用字符集。
select * from fzq where regexp_like(value,'1[[:digit:]]{4}60');
-- 查询value中不是纯数字的记录
select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
--查询以12或者1b开头的记录.区分大小写。
select * from fzq where regexp_like(value,'^1[。
select * from fzq where regexp_like(value,'[[:space:]]');
select * from fzq where regexp_like(value,'1....60');
--查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录。
--使用like就不是很好实现了。
select * from fzq where regexp_like(value,'1[0-9]{4}60');
oracle中like的用法

oracle中like的用法是什么一、我们可以在where子句中使用like关键字来达到Oracle 模糊查询的效果;在Where子句中,可以对datetime、char、varchar字段类型的列用Like关键字配合通配符来实现模糊查询,以下是可使用的通配符:(1)% :零或者多个字符,使用%有三种情况字段like ‘%关键字%’字段包含”关键字”的记录字段like ‘关键字%’字段以”关键字”开始的记录字段like ‘%关键字’字段以”关键字”结束的记录例子:搜索结果:“张三”,“小三”、“三脚猫”,“猫三脚”有“三”的记录全找出来。
搜索结果:“张三”,“小三”另外,如果需要找出uname中既有“三”又有“猫”的记录,请使用and条件若使用SELECT * FROM [user] WHERE uname LIKE ‘%三%猫%’,虽然能搜索出“三脚猫”,但不能搜索出“猫三脚”。
(2)_:单一任何字符(下划线)常用来限制表达式的字符长度语句:例子:搜索结果:“猫三脚”这样uname为三个字符且中间一个是“三”的;搜索结果:“三脚猫”这样uname为三个字符且第一个是“三”的;(3)[]:在某一范围内的字符,表示括号内所列字符中的一个(类似正则表达式)。
指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
例子:搜索结果:“张三”、“李三”、“王三”(而不是“张李王三”);如[ ]内有一系列字符(01234、abcde之类的)则可略写为“0-4”、“a-e”搜索结果:“老1”、“老2”、……、“老9”;(4)[^]:不在某范围内的字符,用法与[ ]相反。
二、在Oracle中提供了instr(strSource,strTarget)函数,比使用’%关键字%’的模式效率高很多。
instr函数也有三种情况:instr(字段,’关键字’)>0相当于字段like ‘%关键字%’instr(字段,’关键字’)=1相当于字段like ‘关键字%’instr(字段,’关键字’)=0相当于字段not like ‘%关键字%’例子:用法参照上面的Like 即可特殊用法:它等价于。
Oracle中正则表达式的使用实例教程

Oracle中正则表达式的使⽤实例教程前⾔正则表达式已经在很多软件中得到⼴泛的应⽤,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境。
本⽂主要介绍了关于Oracle中正则表达式的使⽤⽅法,下⾯话不多说了,来⼀起看看详细的介绍。
Oracle使⽤正则表达式离不开这4个函数:regexp_like、regexp_substr、regexp_instr、regexp_replace。
regexp_like该函数只能⽤于条件表达式,和 like 类似,但是使⽤的正则表达式进⾏匹配//查询所有包含⼩写字母或者数字的记录。
select * from fzq where regexp_like(value,'^([a-z]+|[0-9]+)$');regexp_substr该函数和 substr 类似,⽤于拾取合符正则表达式描述的字符⼦串,该函数的定义如下function REGEXP_SUBSTR(String, pattern, position, occurrence, modifier)- String 输⼊的字符串- pattern 正则表达式- position 标识从第⼏个字符开始正则表达式匹配。
(默认为1)- occurrence 标识第⼏个匹配组。
(默认为1)- modifier 取值范围:i:⼤⼩写不敏感;c:⼤⼩写敏感;n:点号 . 不匹配换⾏符号;m:多⾏模式;x:扩展模式,忽略正则表达式中的空⽩字符。
下⾯是⼀些实例--检索中间的数字SELECT REGEXP_SUBSTR(a,'[0-9]+') FROM test_reg_substr WHERE REGEXP_LIKE(a, '[0-9]+');--检索中间的数字(从第⼀个字母开始匹配,找第2个匹配项⽬)SELECT NVL(REGEXP_SUBSTR(a,'[0-9]+',1, 2), '-') AS a FROM test_reg_substrWHERE REGEXP_LIKE(a, '[0-9]+');regexp_instr该函数和 instr 类似,⽤于标定符合正则表达式的字符⼦串的开始位置,Oracle数据库中的REGEXP_INSTR函数的语法是REGEXP_INSTR (source_char, pattern [, position [, occurrence[, return_option [, match_parameter ] ] ] ] )- source_char 搜索值的字符表达式- pattern 正则表达式- position 可选。
racle regexp_like的相关知识及使用示例

Oracle中的支持正则表达式的函数,主要有下面四个:1,REGEXP_LIKE :与LIKE的功能相似。
2,REGEXP_INSTR :与INSTR的功能相似。
3,REGEXP_SUBSTR :与SUBSTR的功能相似。
4,REGEXP_REPLACE :与REPLACE的功能相似。
它们在用法上与Oracle SQL函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成: '$' 匹配输入字符串的结尾位置。
如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的 '( )' 标记一个子表达式的开始和结束位置。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
\num 匹配 num,其中 num 是一个正整数。
对所获取的匹配的引用。
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
oracle的正则表达式

oracle的正则表达式(regular expression)简单介绍目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP等操作系统,PHP,C#,Java等开发环境。
Oracle 10g正则表达式提高了SQL灵活性。
有效的解决了数据有效性,重复词的辨认, 无关的空白检测,或者分解多个正则组成的字符串等问题。
Oracle 10g支持正则表达式的四个新函数分别是:REGEXP_LIKE、REGEXP_INSTR、REGEXP_SUBSTR、和REGEXP_REPLACE。
它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
特殊字符:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配'\n' 或'\r'。
'.' 匹配除换行符 \n之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'*' 匹配前面的子表达式零次或多次。
'+' 匹配前面的子表达式一次或多次。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
\num 匹配 num,其中 num 是一个正整数。
对所获取的匹配的引用。
正则表达式的一个很有用的特点是可以保存子表达式以后使用,被称为Backreferencing. 允许复杂的替换能力如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,缓冲区从左到右编号, 通过\数字符号访问。
oracle regexp_like的复杂用法 -回复

oracle regexp_like的复杂用法-回复Oracle的正则表达式函数regexp_like可以用于在字符串中检索符合特定模式的子字符串。
它是非常强大和灵活的工具,可以处理各种复杂的模式匹配需求。
在本文中,我们将逐步介绍regexp_like的复杂用法,并给出一些示例,以便更好地理解和使用这个函数。
regexp_like函数的基本语法如下:regexp_like(source_string, pattern)其中,source_string是要进行匹配的源字符串,而pattern是要匹配的模式。
首先,我们来了解一些基本的模式匹配符号:1. '\': 转义符号,可以用于转义特殊字符。
例如,'\.'可以匹配一个点号(.)。
2. '*': 匹配前一个字符0次或多次。
例如,'a*'可以匹配零个或多个连续的小写字母a。
3. '+': 匹配前一个字符1次或多次。
例如,'a+'可以匹配一个或多个连续的小写字母a。
4. '?': 匹配前一个字符0次或1次。
例如,'a?'可以匹配一个或零个小写字母a。
5. ' ': 匹配两个模式之一。
例如,'a b'可以匹配小写字母a或b。
6. '[]': 匹配方括号内的任意一个字符。
例如,'[abc]'可以匹配小写字母a、b或c。
7. '[^]': 匹配不在方括号内的任何字符。
例如,'[^abc]'可以匹配任何不是小写字母a、b或c的字符。
8. '()': 用于分组,可以通过' '或括号嵌套实现复杂的模式匹配。
下面我们将使用这些模式匹配符号来演示regexp_like的复杂用法。
1. 匹配一个特定的字符串:可以直接将特定的字符串作为模式传递给regexp_like函数。
Oracle中如何判断字符串是否全为数字
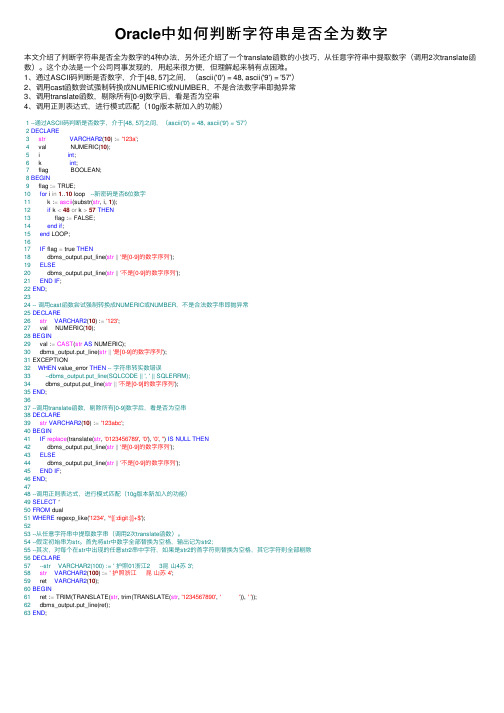
Oracle中如何判断字符串是否全为数字本⽂介绍了判断字符串是否全为数字的4种办法,另外还介绍了⼀个translate函数的⼩技巧,从任意字符串中提取数字(调⽤2次translate函数)。
这个办法是⼀个公司同事发现的,⽤起来很⽅便,但理解起来稍有点困难。
1、通过ASCII码判断是否数字,介于[48, 57]之间,(ascii('0') = 48, ascii('9') = '57')2、调⽤cast函数尝试强制转换成NUMERIC或NUMBER,不是合法数字串即抛异常3、调⽤translate函数,剔除所有[0-9]数字后,看是否为空串4、调⽤正则表达式,进⾏模式匹配(10g版本新加⼊的功能)1--通过ASCII码判断是否数字,介于[48, 57]之间,(ascii('0') = 48, ascii('9') = '57')2DECLARE3str VARCHAR2(10) :='123a';4 val NUMERIC(10);5 i int;6 k int;7 flag BOOLEAN;8BEGIN9 flag := TRUE;10for i in1..10 loop --新密码是否6位数字11 k :=ascii(substr(str, i, 1));12if k <48or k >57THEN13 flag := FALSE;14end if;15end LOOP;1617IF flag = true THEN18 dbms_output.put_line(str||'是[0-9]的数字序列');19ELSE20 dbms_output.put_line(str||'不是[0-9]的数字序列');21END IF;22END;2324-- 调⽤cast函数尝试强制转换成NUMERIC或NUMBER,不是合法数字串即抛异常25DECLARE26str VARCHAR2(10) :='123';27 val NUMERIC(10);28BEGIN29 val :=CAST(str AS NUMERIC);30 dbms_output.put_line(str||'是[0-9]的数字序列');31 EXCEPTION32WHEN value_error THEN-- 字符串转实数错误33--dbms_output.put_line(SQLCODE || ', ' || SQLERRM);34 dbms_output.put_line(str||'不是[0-9]的数字序列');35END;3637--调⽤translate函数,剔除所有[0-9]数字后,看是否为空串38DECLARE39str VARCHAR2(10) :='123abc';40BEGIN41IF replace(translate(str, '0123456789', '0'), '0', '') IS NULL THEN42 dbms_output.put_line(str||'是[0-9]的数字序列');43ELSE44 dbms_output.put_line(str||'不是[0-9]的数字序列');45END IF;46END;4748--调⽤正则表达式,进⾏模式匹配(10g版本新加⼊的功能)49SELECT*50FROM dual51WHERE regexp_like('1234', '^[[:digit:]]+$');5253--从任意字符串中提取数字串(调⽤2次translate函数)。
oracle中like用法(一)

oracle中like用法(一)Oracle中Like的用法Like是Oracle数据库中的一个关键字,用于在比较时以模式匹配的方式搜索数据。
以下是Like的几种用法和详细讲解。
普通模式匹配使用Like可以搜索包含特定字符模式的数据。
其中包括以下符号:•%:表示任意字符序列(包括空字符)•_:表示任意单个字符以下是Like的几个示例:1.SELECT * FROM table_name WHERE column_name LIKE'%abc%':表示在column_name列中搜索包含”abc”的任意字符序列的数据。
2.SELECT * FROM table_name WHERE column_name LIKE'a%':表示在column_name列中搜索以字母”a”开头的数据。
3.SELECT * FROM table_name WHERE column_name LIKE'_bc':表示在column_name列中搜索以任意单个字符加上”bc”结尾的数据。
注意:Like默认情况下是不区分大小写的,但可以通过修改数据库设置来实现大小写敏感的搜索。
使用转义字符有时候需要搜索特殊字符本身,而不是作为通配符。
这时可以使用转义字符来实现。
1.SELECT * FROM table_name WHERE column_name LIKE'%\%%' ESCAPE '\':表示在column_name列中搜索包含百分号字符的数据。
在Like中,百分号(%)是特殊字符,所以需要使用转义字符()进行转义。
使用字符范围除了使用通配符外,还可以使用字符范围进行模式匹配。
可以使用方括号([])表示字符的范围,或者使用连字符(-)表示连续的字符范围。
1.SELECT * FROM table_name WHERE column_name LIKE'[abc]%':表示在column_name列中搜索以字母”a”、“b”或”c”开头的数据。
Oracle 10g正则表达式REGEXP_LIKE简介

Oracle中支持正则表达式的函数主要有以下四个:1,REGEXP_LIKE :与LIKE的功能相似。
2,REGEXP_INSTR :与INSTR的功能相似。
3,REGEXP_SUBSTR :与SUBSTR的功能相似。
4,REGEXP_REPLACE :与REPLACE的功能相似。
它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。
如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 '\n' 或 '\r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。
例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的字符串。
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少出现m次。
\num 匹配 num,其中 num 是一个正整数。
对所获取的匹配的引用。
字符簇:[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
oracle判断是否含有非数字

oracle判断是否含有⾮数字⼀、regexp_like函数
1、语法
regexp_like(字段,正则表达式)
2、正则表达式
(1)、[] 元字符表⽰范围
①[.0-9] 表⽰⼩数点和0⾄9范围内的字符
②[^.0-9] 表⽰⾮⼩数点和0⾄9范围内的字符
(2)、^ 元字符有两种含义
①^[.0-9]匹配以 .0-9开头的字符,^ 匹配字符的开始位置
②[^.0-9]匹配⾮ .0-9的字符
(3)、* 运算符表⽰匹配前⾯的⼦表达式0次或多次
(4)、+ 运算符表⽰匹配前⾯的⼦表达式1次或多次
(5)、? 运算符表⽰匹配前⾯的⼦表达式0次或1次
(6)、$ 运算符表⽰匹配字符的结束位置,[.0-9]$ 匹配 .0-9结尾的字符
3、测试
(1)、匹配⾮数字
select (case when regexp_like ('.11','([^.0-9])+') then 1else0 end)test from dual
//匹配 .0-9 范围内的字符,返回1表⽰是⾮数字,0表⽰是数字。
.11可以当做是数字
(2)、测试⼩数点开头
select5*'.11' test from dual。
在Oracle中使用正则表达式

在Oracle中使⽤正则表达式Oracle使⽤正则表达式离不开这4个函数:1。
regexp_like2。
regexp_substr3。
regexp_instr4。
regexp_replace看函数名称⼤概就能猜到有什么⽤了。
regexp_like 只能⽤于条件表达式,和 like 类似,但是使⽤的正则表达式进⾏匹配,语法很简单:regexp_substr 函数,和 substr 类似,⽤于拾取合符正则表达式描述的字符⼦串,语法如下:regexp_instr 函数,和 instr 类似,⽤于标定符合正则表达式的字符⼦串的开始位置,语法如下:regexp_replace 函数,和 replace 类似,⽤于替换符合正则表达式的字符串,语法如下:这⾥解析⼀下⼏个参数的含义:1。
source_char,输⼊的字符串,可以是列名或者字符串常量、变量。
搜索字符串。
可以是任意的数据类型char,VARCHAR2,nchar,CLOB,NCLOB类型2。
pattern,正则表达式。
3。
match_parameter,匹配选项。
取值范围: i:⼤⼩写不敏感; c:⼤⼩写敏感;n:点号 . 不匹配换⾏符号;m:多⾏模式;x:扩展模式,忽略正则表达式中的空⽩字符。
4。
position,标识从第⼏个字符开始正则表达式匹配。
可选。
搜索在字符串中的开始位置。
如果省略,默认为1,这是第⼀个位置的字符串。
5。
occurrence,标识第⼏个匹配组。
可选。
它是模式字符串中的第n个匹配位置。
如果省略,默认为1。
6。
replace_string,替换的字符串。
值描述^匹配⼀个字符串的开始。
如果与“m” 的match_parameter⼀起使⽤,则匹配表达式中任何位置的⾏的开头。
$匹配字符串的结尾。
如果与“m” 的match_parameter⼀起使⽤,则匹配表达式中任何位置的⾏的末尾。
*匹配零个或多个。
+匹配⼀个或多个出现。
?匹配零次或⼀次出现。
oracle中regexp_like的使用
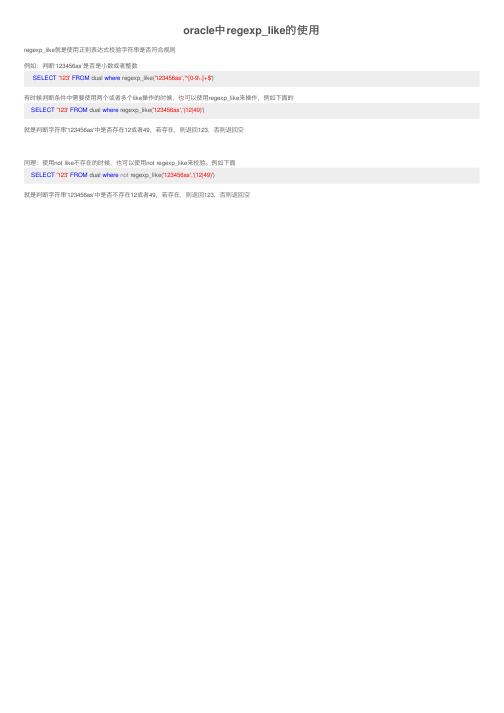
同理:使用not like不存在的时候,也可以使用not regexp_like来校验。例如下面 SELECT '123' FROM dual where not regexp_like('123456as','(12|49)')
有时候判断条件中需要使用两个或者多个like操作的时候也可以使用regexplike来操作例如下面的
oracle中 regexp_like的使用
regexp_like就是使用正则表达式校验字符串是否符合规则 例如:判断‘123456as’是否是小数或者整数
SELECT '123' FROM dual where regexp_like('123456as','^[0-9\.]+$') 有时候判断条件中需要使用两个或者多个like操作的时候,也可以使用regexp_like来操作,例如下面的
就是判断字符串'123456as'中是否不存在12或者49,
Oracle正则表达式使用介绍

Oracle正则表达式使⽤介绍下⾯通过⼀些例⼦来说明使⽤正则表达式来处理⼀些⼯作中常见的问题。
1.REGEXP_SUBSTRREGEXP_SUBSTR 函数使⽤正则表达式来指定返回串的起点和终点,返回与source_string 字符集中的VARCHAR2 或CLOB 数据相同的字符串。
语法:--1.REGEXP_SUBSTR与SUBSTR函数相同,返回截取的⼦字符串REGEXP_SUBSTR(srcstr, pattern [, position [, occurrence [, match_option]]])注:srcstr源字符串pattern正则表达式样式position开始匹配字符位置occurrence匹配出现次数match_option匹配选项(区分⼤⼩写)1.1从字符串中截取⼦字符串SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+') FROM dual;Output: 1PSN[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符。
SELECT regexp_substr('1PSN/231_3253/ABc', '[[:alnum:]]+', 1, 2) FROM dual;Output: 231与上⾯⼀个例⼦相⽐,多了两个参数1表⽰从源字符串的第⼀个字符开始查找匹配2表⽰第2次匹配到的字符串(默认值是“1”,如上例)select regexp_substr('@@/231_3253/ABc','@*[[:alnum:]]+') from dual;Output: 231@* 表⽰匹配0个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符注意:需要注意“+”和“*”的区别select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]*') from dual;Output: @@+ 表⽰匹配1个或者多个@[[:alnum:]]* 表⽰匹配0个或者多个字母或数字字符select regexp_substr('1@/231_3253/ABc','@+[[:alnum:]]+') from dual;Output: Null@+ 表⽰匹配1个或者多个@[[:alnum:]]+ 表⽰匹配1个或者多个字母或数字字符select regexp_substr('@1PSN/231_3253/ABc125','[[:digit:]]+$') from dual;Output: 125[[:digit:]]+$ 表⽰匹配1个或者多个数字结尾的字符select regexp_substr('@1PSN/231_3253/ABc','[^[:digit:]]+$') from dual;Output: /ABc[^[:digit:]]+$ 表⽰匹配1个或者多个不是数字结尾的字符selectregexp_substr('*******************','[^@]+')fromdual;Output: Tom_Kyte[^@]+ 表⽰匹配1个或者多个不是“@”的字符select regexp_substr('1PSN/231_3253/ABc','[[:alnum:]]*',1,2)from dual;Output: Null[[:alnum:]]* 表⽰匹配0个或者多个字母或者数字字符注:因为是匹配0个或者多个,所以这⾥第2次匹配的是“/”(匹配了0次),⽽不是“231”,所以结果是“Null”1.2匹配重复出现查找连续2个⼩写字母SELECT regexp_substr('Republicc Of Africaa', '([a-z])\1', 1, 1, 'i')FROM dual;Output: cc([a-z])表⽰⼩写字母a-z\1表⽰匹配前⾯的字符的连续次数1表⽰从源字符串的第1个字符开始匹配1第1次出现符合匹配结果的字符i表⽰区分⼤⼩写1.3其他⼀些匹配样式查找⽹页地址信息SELECT regexp_substr('Go to /products and click on database', 'http://([[:alnum:]]+\.?){3,4}/?') RESULT FROM dualOutput: 其中:http://表⽰匹配字符串“http://”([[:alnum:]]+\.?) 表⽰匹配1次或者多次字母或数字字符,紧跟0次或1次逗号符{3,4}表⽰匹配前⾯的字符最少3次,最多4次/?表⽰匹配⼀个反斜杠字符0次或者1次提取csv字符串中的第三个值SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, 3) AS outputFROM dual;Output: Japan其中:[^,]+表⽰匹配1个或者多个不是逗号的字符1表⽰从源字符串的第⼀个字符开始查找匹配3表⽰第3次匹配到的字符串注:这个通常⽤来实现字符串的列传⾏--字符串的列传⾏SELECT regexp_substr('1101,Yokohama,Japan,1.5.105', '[^,]+', 1, LEVEL) AS outputFROM dualCONNECT BY LEVEL <= length('1101,Yokohama,Japan,1.5.105') -length(REPLACE('1101,Yokohama,Japan,1.5.105', ',')) + 1;Output: 1101YokohamaJapan1.5.105这⾥通过LEVEL来循环截取匹配到的字符串。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
select * from fzq where regexp_like(value,'^[^[:digit:]]+$');
--查询以12或者1b开头的记录.不区分大小写。
select * from fzq where regexp_like(value,'^1[2b]','i');
('8','adc de');
insert into fzq values
('9','adc,.de');
insert into fzq values
('10','1B');
insert into fzq values
('10','abcbvbnb');
insert into fzq values
('11','11114560');
insert into fzq values
('11','11124560');
--regexp_like
--查询value中以1开头60结束的记录并且长度是7位
select * from fzq where value like '1____60';
);
--数据插入
insert i9;1','1234560');
insert into fzq values
('2','1234560');
insert into fzq values
('3','1b3b560');
insert into fzq values
/*
理解它的语法就可以了。其它的函数用法类似。
*/
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]。
但是它们使用POSIX 正则表达式代替了老的百分号(%)和通配符(_)字符。
POSIX 正则表达式由标准的元字符(metacharacters)所构成:
'^' 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
'$' 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹
-- 也可以这样实现,使用字符集。
select * from fzq where regexp_like(value,'1[[:digit:]]{4}60');
-- 查询value中不是纯数字的记录
select * from fzq where not regexp_like(value,'^[[:digit:]]+$');
oracle 判断字段是否为是数字 regexp_like用法 正则表达式 .
2010-10-30 19:11 665人阅读 评论(0) 收藏 举报
oracle 判断字段是否为是数字 regexp_like用法 正则表达式
ORACLT TNND 2010-07-15 10:12:28 阅读508 评论0 字号:大中小 订阅
各种操作符的运算优先级
/转义符
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
|
*/
--创建表
create table fzq
(
id varchar(4),
value varchar(10)
配 '/n' 或 '/r'。
'.' 匹配除换行符之外的任何单字符。
'?' 匹配前面的子表达式零次或一次。
'+' 匹配前面的子表达式一次或多次。
'*' 匹配前面的子表达式零次或多次。
'|' 指明两项之间的一个选择。例子'^([a-z]+|[0-9]+)$'表示所有小写字母或数字组合成的
字符串。
select * from fzq where regexp_like(value,'1....60');
--查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录。
--使用like就不是很好实现了。
select * from fzq where regexp_like(value,'1[0-9]{4}60');
--查询以12或者1b开头的记录.区分大小写。
select * from fzq where regexp_like(value,'^1[2B]');
-- 查询数据中包含空白的记录。
select * from fzq where regexp_like(value,'[[:space:]]');
'( )' 标记一个子表达式的开始和结束位置。
'[]' 标记一个中括号表达式。
'{m,n}' 一个精确地出现次数范围,m=<出现次数<=n,'{m}'表示出现m次,'{m,}'表示至少
出现m次。
/num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
字符簇:
[[:alpha:]] 任何字母。
/*
ORACLE中的支持正则表达式的函数主要有下面四个:
1,REGEXP_LIKE :与LIKE的功能相似
2,REGEXP_INSTR :与INSTR的功能相似
3,REGEXP_SUBSTR :与SUBSTR的功能相似
4,REGEXP_REPLACE :与REPLACE的功能相似
它们在用法上与Oracle SQL 函数LIKE、INSTR、SUBSTR 和REPLACE 用法相同,
--查询所有包含小写字母或者数字的记录。
select * from fzq where regexp_like(value,'^([a-z]+|[0-9]+)$');
--查询任何包含标点符号的记录。
select * from fzq where regexp_like(value,'[[:punct:]]');
('4','abc');
insert into fzq values
('5','abcde');
insert into fzq values
('6','ADREasx');
insert into fzq values
('7','123 45');
insert into fzq values