有序样品聚类法
使用有序聚类的方法确定分级标准

使用有序聚类的方法确定分级标准使用有序聚类的方法确定分级标准一、引言分级标准在各个领域中起着至关重要的作用,它能够帮助我们对事物进行分类和评估。
然而,确定一个合适的分级标准并不容易,特别是当涉及到大量数据和复杂事物时。
在本文中,我们将探讨使用有序聚类的方法来确定分级标准的有效性和可行性。
二、有序聚类方法的介绍有序聚类是一种将数据进行分组的方法,与传统的聚类方法相比,它能够对数据进行更加精确和细致的分类。
有序聚类基于相似性和差异性的度量,在同一组数据中表现出相似性更高,而与其他组数据的相似性较低。
这种分组的方式能够帮助我们更好地理解数据的结构和关系。
三、有序聚类方法在确定分级标准中的应用1. 数据准备:在确定分级标准之前,我们需要对数据进行准备和清洗。
这包括数据的收集、整理和处理等。
确保数据的准确性和完整性对于有序聚类方法的应用至关重要。
2. 聚类过程:有序聚类方法的关键在于确定合适的相似度度量和聚类算法。
相似度度量可以基于距离、相关性等指标进行计算。
聚类算法的选择可以根据数据的特性和目标来确定。
常见的聚类算法包括K-means、层次聚类等。
3. 分级标准的确定:确定合适的分级标准是根据聚类结果进行的。
根据聚类的中心点和数据分布情况,可以将数据分为不同的级别。
可以将数据分为高、中、低三个级别,或者根据具体需求进行更加详细的划分。
4. 评估和调整:确定分级标准后,需要进行评估和调整。
评估的目的是确定分级标准的准确性和有效性。
如果发现标准不合理或者不符合实际情况,需要进行调整和优化。
四、有序聚类方法的优势和局限性1. 优势:- 精确性:有序聚类方法能够对数据进行更加精确和准确的分类。
- 细致性:有序聚类方法能够将数据分成多个级别,可以更全面地描述数据的特征和属性。
- 可解释性:有序聚类方法能够给出分类的解释和依据,便于理解和应用。
2. 局限性:- 数据要求:有序聚类方法需要大量高质量的数据来支持分类的准确性和可靠性。
数学建模-聚类分析

满足输出;不满足循环;
(7)重复;
初始聚类中心的选择
初始聚类中心的选取决定着计算的迭代 次数,甚至决定着最终的解是否为全局最优, 所以选择一个好的初始聚类中心是很有必要 的。
(1)方法一:选取前k个样品作为初始凝聚点。
(2)方法二: 选择第一个样本点作为第一个聚类 中心。然后选取距离第一个点最远的点作为第二个 聚 类中心。……
数据变换:进行[0,1]规格化得到
初始类个数的选择; 初始类中心的选择;
设k=3,即将这15支球队分成三个集团。现抽取日 本、巴林和泰国的值作为三个类的种子,即初始化三 个类的中心为 A:{0.3, 0, 0.19}; B:{0.7, 0.76, 0.5}; C:{1, 1, 0.5};
样品到类中心的距离; 归类;
计算所有球队分别对三个中心点的欧氏 距离。下面是用程序求取的结果:
第一次聚类结果: A:日本,韩国,伊朗,沙特; B:乌兹别克斯坦,巴林,朝鲜; C:中国,伊拉克,卡塔尔,阿联酋,泰 国,越南,阿曼,印尼。
重新计算类中心;
下面根据第一次聚类结果,采用k-均值法调整各个类的 中心点。
A类的新中心点为:{(0.3+0+0.24+0.3)/4=0.21,
数据变换
(5)极差正规化变换:
x*ij
=
xij
min 1t n
xij
Rj
i 1,,2,...,,n; j 1,..., m
(6)对数变换x*:ij = log xij
i 1,,2,...,,n; j 1,..., m
k
样品间的距离
(1)绝对值距离:
m
dij
xit x jt
t 1
聚类分析

G2={ 2 }
G3={ 6 }
G4={ 8 }
G5={ 11 }
0 1 2 3 4
从上直观来看,分两类较合适。
一.最短距离法 ( nearest neighbor )
D p q m in { d | j G p ,l Gq }
jl
递推公式 Dk r = min { Dp k , Dq k } Gr={ Gp , Gq }
程度的统计量、确定分类数目、建立一种
分类方法,并按亲近程度对观测对象给出
合理的分类。这种问题正是聚类分析所要 解决的问题。
聚类分析及可以对样品进行分类,也 可以对变量进行分类。对样品的分类常称 为Q型聚类分析,对变量的分类常称为R型 聚类分析。
聚类分析同回归分析、判别分析一起
被称为多元分析的三大方法。
分类的问题可以分两种: 一种是对当前所研究的问题已知它的 类别数目,且知道各类的特征(如分布规律 等),目的是将另一些未知类别的个体正确 归属于其中某一类,这是前面判别分析所 要解决的问题。
另一种是事先不知道研究的问题应分
为几类,更不知道观测到的个体的具体分
类情况,目的正是需要通过对观测数据所
进行的分析处理,选定一种度量个体接近
,
i 1 , 2 , ..., n , j 1 , 2 , ..., p
1 n1
n
xj
1 n
i1
n
x ij
sj
i1
( x ij x j )
2
极差标准化:
* x ij
x ij x j Rj
,
i 1 , 2 , ..., n , j 1 , 2 , ..., p
有序聚类过程
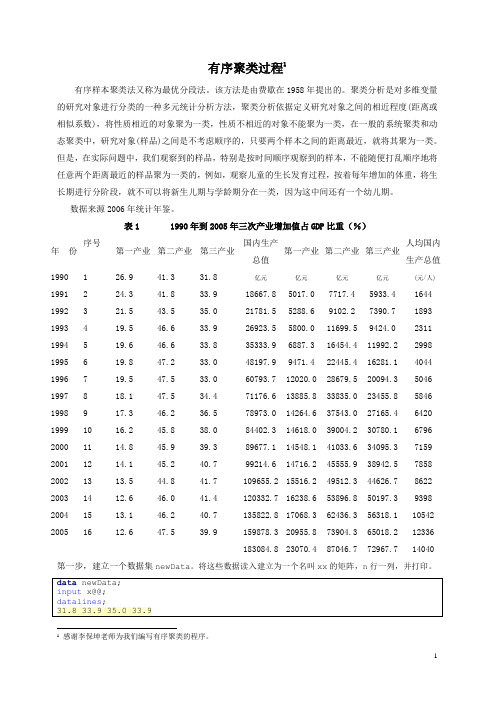
有序聚类过程1有序样本聚类法又称为最优分段法。
该方法是由费歇在1958年提出的。
聚类分析是对多维变量的研究对象进行分类的一种多元统计分析方法,聚类分析依据定义研究对象之间的相近程度(距离或相似系数),将性质相近的对象聚为一类,性质不相近的对象不能聚为一类,在一般的系统聚类和动态聚类中,研究对象(样品)之间是不考虑顺序的,只要两个样本之间的距离最近,就将其聚为一类。
但是,在实际问题中,我们观察到的样品,特别是按时间顺序观察到的样本,不能随便打乱顺序地将任意两个距离最近的样品聚为一类的,例如,观察儿童的生长发育过程,按着每年增加的体重,将生长期进行分阶段,就不可以将新生儿期与学龄期分在一类,因为这中间还有一个幼儿期。
数据来源2006年统计年鉴。
表1 1990年到2005年三次产业增加值占GDP比重(%)年份序号第一产业第二产业第三产业国内生产总值第一产业第二产业第三产业人均国内生产总值1990 1 26.9 41.3 31.8 亿元亿元亿元亿元 (元/人) 1991 2 24.3 41.8 33.9 18667.8 5017.0 7717.4 5933.4 1644 1992 3 21.5 43.5 35.0 21781.5 5288.6 9102.2 7390.7 1893 1993 4 19.5 46.6 33.9 26923.5 5800.0 11699.5 9424.0 2311 1994 5 19.6 46.6 33.8 35333.9 6887.3 16454.4 11992.2 2998 1995 6 19.8 47.2 33.0 48197.9 9471.4 22445.4 16281.1 4044 1996 7 19.5 47.5 33.0 60793.7 12020.0 28679.5 20094.3 5046 1997 8 18.1 47.5 34.4 71176.6 13885.8 33835.0 23455.8 5846 1998 9 17.3 46.2 36.5 78973.0 14264.6 37543.0 27165.4 6420 1999 10 16.2 45.8 38.0 84402.3 14618.0 39004.2 30780.1 6796 2000 11 14.8 45.9 39.3 89677.1 14548.1 41033.6 34095.3 7159 2001 12 14.1 45.2 40.7 99214.6 14716.2 45555.9 38942.5 7858 2002 13 13.5 44.8 41.7 109655.2 15516.2 49512.3 44626.7 8622 2003 14 12.6 46.0 41.4 120332.7 16238.6 53896.8 50197.3 9398 2004 15 13.1 46.2 40.7 135822.8 17068.3 62436.3 56318.1 10542 2005 16 12.6 47.5 39.9 159878.3 20955.8 73904.3 65018.2 12336183084.8 23070.4 87046.7 72967.7 14040 第一步,建立一个数据集newData。
聚类分析

•即为类平均法的递推公式
•组间联结法
•在计算距离时只考虑两类之间样 品之间距离的平均
类平均法 在计算距离时把两组所有个案之间 的而距离都考虑在内
•组内联结法
• 另外一种类平均法: 类与类之间的距离定义
1.4.4 分类数的确定
聚类分析的目的是要对研究对象进行分类,因此,如何 选择分类数成为各类聚类方法中的主要问题之一。 确定分类数主要的障碍是对类你的结构和内容很难给出 一个统一的定义,这样就不能给出在理论上和实践中 都可行的虚无假设。 德穆曼曾提出根据树状结构图来分类的准则: 准则1:任何类都必须在邻近各类中突出的,即各类重 心之间距离必须大。 准则2:各类所包含的元素都不应过多。 准则3:分类的数目应该应该符合使用的目的。 准则4:若采用几种不同的聚类方法处理,则在各自的 聚类图上应发现相同的类。
(5)离差平方和法 若采用直径的第一种定义方法,用Dp,Dq 分别表示类Gp和类Gq的直径,用Dp+q表示大类 Dp+q的直径。
Dp
Dpq
iG p
( xi x p ) ' ( xi x p ) Dq
jGq
(x
j
xq ) ( x j xq
'
jG p Gq
L t
(x
i 1
nt
it
xt ) ' ( xit xt )
•整个类内平方和是
L ( xit xt ) ' ( xit xt )
nt
k
t 1
i 1
当k固定时,要选择使L达到极小的分类,n个样品分成k类,一切可能的分法有
有序样品聚类分析方法在花开左组划分中的应用

有序样品聚类分析方法在花开左组划分中的应用李守奎;杨柳扬;赵庆红;王明明【摘要】本文根据云南云龙县凤代中侏罗统花开左组(J2h)剖面上系统获得的地球化学分析数据,采用多变量最优分割法,对花开左组进行了化学地层划分的应用研究,发现了该地层地球化学元素特征显著变化面,找到沉积环境变化层位,从而为岩石地层划分提供辅助依据.取得了与野外岩石地层观察情况较为一致的结果,为组级以下地层单位的划分以及沉积环境的解释提供辅助和补充资料.【期刊名称】《云南地质》【年(卷),期】2017(036)003【总页数】5页(P327-331)【关键词】有序样品聚类分析;最优分割法;化学地层;花开左组;云南云龙地区【作者】李守奎;杨柳扬;赵庆红;王明明【作者单位】云南省地质矿产勘查院大理地质矿产所,云南大理 671000;云南省地质矿产勘查院大理地质矿产所,云南大理 671000;云南省地质矿产勘查院大理地质矿产所,云南大理 671000;云南省地质矿产勘查院大理地质矿产所,云南大理671000【正文语种】中文【中图分类】P539.7在目前的区域地质调查中,地层划分研究主要采用岩石地层、生物地层和年代地层等三种地层单位。
《1∶50000区域地质调查工作指南》(2016年)要求“沉积岩岩石地层的填图单位要划分到组,组内应根据岩性组合的变化划分到段并进行翔实填绘”。
云南地区缺乏正式命名的段级及以下的正式填图单位,这也使相当于段级及以下的填图单位(非正式)的划分标准难以统一,虽然大都以组内岩层明显不同的岩性特征来进一步细分为段及亚段,但“明显不同”往往带有经验性,并无标准,具有较大的随意性。
本文试用化学地层划分方法对组内单位细分问题进行研究。
化学地层划分是按岩层的地球化学变化特征,将岩层分割为不同的层位或者单位[1]。
沉积岩中微量元素的多元统计分析是化学地层划分广泛采用的工作手段,最常用的数理统计方法为有序样品聚类分析方法,其数学原理为最优分割法。
有序样本聚类分析在黄花槐苗高生长期划分中的应用

metI i vr otn frt r 山 ehn e e t og aateeo g ae I eti r d r gt i g wh s g. n. t s eyi r t 0 e g w n a cm n u rne nu hw t al f iz s ui h mpd m t t e mp a h 0 t r d rl e n e a Ke 0 d :C sr £m ;n thih go t ;8q et lsm l c s raayi;got htm y w r s s u e e egt rwh eu ni a pe l t n l s rwh ry l a ue s l
c s D ∞s 乩 瑚 w sdvd d it f rs g8 w t h e u ni 眦 pe c s r a ayi:S ria 8 g ( r 6 e 8 fC , a i e no 0 t e i te s q e t ls l l t n ls i u a h a ue 8 u v l t e Mac l ~ V a h
第 4 卷 第 3期 8
20 0 9年 3月
湖 北 农 业 科 学
Hu e A c l r l c e c s b i u t a S i n e u
Vo _ 8 No 3 l4 -
Ma .2 O r.O 9
有序样本聚类分析在黄花槐苗高生长期划分中的应用
唐 雪辉 , 张耀 华 , 兴乐 刘
至 8月 3 1日. 长 后 期 为 9月 1日至 9月 2 生 1日。 中 , 占全 年 生 长期 l4的速 生期 , 净 生 长 量 占全 其 只 / 其
年 总 生 长量 的 7 .3 。 以要 加 强 速 生 期 苗 木 的 水 肥 管理 。 93 % 所
聚类分析之有序样品的聚类

由于只有一个指标,所以DG ( xi x )2
i 1
m
2.评价函数:D DG1 DG2 DG3
3. 计算各分类的评价函数 2 | 3 | 7 8 12 2 | 3 7 | 8 12 2 | 3 7 8 | 12 2 3 | 7 | 8 12 2 3 | 7 8 | 12 2 3 7 | 8 | 12 D 14 D 16 D 14 D 8.5 D1 D 14
即:样品1,2一类,样品3,4一类,样品5一类
谢 谢 大 家!
i 1 m
2.定义评价函数(各类直径的和) 3.根据分类数,尝试计算所有划分方法的评价函数 (各类直径的和最小),确定最优分类方案。
例子:根据指标X的观察值将有序样品1,2,3,4,5分为 三类.
样品 X 1 2 2 3
m
3 7
4 8
5 12
1.定义直径:DG ( xi x )( xi身高 25 (cm)
1.9 1.7
12.2 8.4 7.5
根据这些数据,试将男孩的发育分为3个阶段。
有序样品:样品是有先后关系,不能随意改变先后 关系,例如:与时间有关的样品。 有序样品聚类的过程: 1.定义类的直径,包含m个样品的类的直径
DG ( xi x )( xi x )
数学模型与数学建模之
聚类分析之 (简单)有序样品聚类
于晶贤
E-mail: yujingxian@
例:为了了解儿童的生长发育规律,现在统计了男 孩从出生到11岁每年平均增长的重量和身高如下:
年龄 1 2 1.8 3 4 5 1.5 7.1 6 1.3 6.4 7 1.4 5.9 8 2.0 6.0 9 1.9 5.6 10 2.3 6 11 2.1 6.5
有序样品的聚类

一个好的分类方法就是应该使处于同一类事物之间的差别尽 可能地小,而使类与类之间的差别尽可能地大。为了表示类 内部事物与事物的差别,我们借用统计中全距(直径)的计 算方法, 以 4,5,6,7,8 、9,10,11这个分类为例来说 1,2,3 、 明计算类内差别的方法: 1,2,3 对应的数据为9.3、1.8、1.9,最大值为 其中第一类 9.3,最小值为1.8,这一类的差异我们用全距 9.3-1.8=7.5 第二类 4,5,6,7,8 中最大值为2.0,最小值为1.3,则 2.0-1.3=0.7 第三类 9,10,11 中的最大值为2.3,最小值为1.9,则 2.3-1.9=0.4 为衡量上述分类方法的优劣,我们计算此种分类方法中的三 个类内的平 0.4 K 2.87 3
以同样的方法分析,可知把这11个数据分成 两类的最好分类方法是
1, 2,3,4,5,6,7,8,9,10,11
这时的优劣指标K为 0.5
那么这11个数据分成几类为宜呢? 为此.我们分别找到把11个数据分成1类、2类、…、11类 的最好的分类法,计算出各最好分类方法的优劣指标,列 表如下:
由表可看到,如果把1至11岁的数据只分成一类时,K=8, 优劣指标值太大;而对n大于4时的K值相差不多;而当n =3或n=4时,K值已降为0.30和0.20.而n=5及其以上时, K相差太小,而类分得太多无意义,因此分成3类或4类为 宜。
对于另一种分类方法 {1.、2、3、4} 、{5、6}、{7、 8、9、10、11} 其第一类的类内差异为7.6,第二类的类内差异为 0.2.第三类的类内差异为0.9。该分类方法的优劣指 标K为2.9。相比之下,此分类方法不如前一种分类方 法好。 试问:分三类最好的分类方法应怎么分?
聚类分析

聚类算法聚类分析根据分类对象不同分为Q型聚类分析和R型聚类分析。
Q型聚类是指对样品进行聚类;R型聚类是指对变量进行聚类。
根据处理方法的不同又分为:系统聚类法、有序样品聚类法、动态聚类法、模糊聚类法、图论聚类法等。
算法原理:对于样品(变量)进行分类,就需要研究样品之间的关系。
性质越接近的样品(变量),它们的相似系数绝对值越接近1,而彼此无关的样品(变量),它们相似系数的绝对值接近于0.比较相似的样品(变量)归为一类,不怎么相似的样品归为不同的类。
一、数据类型在实际问题中,遇到的变量有的是定量的(如长度、重量等),有的是定性的(如性别、职业等),因此将变量的类型分为以下三种尺度:间隔尺度:变量是用实数来表示的,如长度、重量、压力和速度等等。
有序尺度:变量度量时没有明确的数量表示,而是划分一些等级,等级之间有次序关系,如产品分为上、中、下三等,此三等有次序关系,但没有数量关系。
名义尺度:变量度量时既没有数量表示,也没有次序关系,而用不同状态来表示,如性别变量有男、女两种状态;某物体有红、黄、白三种颜色等。
二、对于数据具有不同的量纲以及不同的数量级单位,为了使不同量纲及不同数量级的数据能放在一起比较,一般在具体运用多元统计各种方法之前,先对数据进行变换处理。
(一)间隔尺度变量变换方法1、中心化处理变换:变换后数值=变换前数值-该变量的均值称为中心化变换,即平移变换,该变换可以使新坐标的原点与样品点集合的重心重合,而不会改变样本间的相互位置,也不会改变变量的相关性。
2、标准化变换变换:变换后数值=(变换前数值-该变量的均值)/该变量标准差称为标准化变换,变换后的数据,每个变量的样本均值为0,标准差为1,而且标准化变换后的数据与量纲无关。
3、极差正规化变换(规格化变换)变换:变换后数值=(变换前数值-该变量最小值)/极差称为极差正规化变换,变换后的数据在0到1之间;也是与量纲无关。
4、对数变换变换:变换后数值=log(变换前数值)称为对数变换,要求该变量所有值均大于0,它可以将具有指数特征的数据结构变换为线性数据结构。
有序聚类分析法

有序聚类分析法
有序聚类分析法是聚类分析的方法之一。
在通常的聚类分析中样品之间彼此是
平等的,聚类时是将样品混在一起按照距离或相似系数的标准来进行分类,但是有些客观现象在聚类时不能打乱原来样品的排列顺序。
例如要对儿童生长发
育的规律划分成几个阶段,或对我国解放以后经济的发展速度划分成几个阶段,同一个阶段的样品要求是互相连接的,也就是说聚类时要求必须是次序相邻的
样品才能在一类。
这种聚类的方法称作有序样品聚类法。
有序样本聚类方法在城市轨道交通运营时段划分中的应用

有序样本聚类方法在城市轨道交通运营时段划分中的应用曾小旭;汪林;罗贤迪;张宁;赵圣娜【期刊名称】《都市快轨交通》【年(卷),期】2017(030)002【摘要】为合理划分轨道交通运营时段并指导其开行方案,提出一种基于有序样本聚类技术的运营时段划分方法.根据统计时段内客流数据,引入单向OD(origin-destination)概率矩阵,并给出单向OD概率矩阵的时序模型和提取方法;利用有序样本聚类方法,以最优分割法量化站间客流转移规律,求解聚类方案.最后以某一轨道交通线路为例,提取时间间隔为20 min的上行OD概率矩阵时间序列,以最优分割法进行聚类,将站间客流转移规律相近的统计时段归为一类,提出目标线路运营时段划分方案.【总页数】5页(P108-112)【作者】曾小旭;汪林;罗贤迪;张宁;赵圣娜【作者单位】天津市地下铁道运营有限公司,天津300222;东南大学ITS研究中心轨道交通研究所,南京210018;北京城建设计发展集团股份有限公司,北京100045;东南大学成贤学院,南京210088;东南大学ITS研究中心轨道交通研究所,南京210018;东南大学ITS研究中心轨道交通研究所,南京210018【正文语种】中文【中图分类】F530.7【相关文献】1.有序样本聚类方法在水土保持分区中的应用 [J], 张建勋;朱景春;王东云2.大数据技术在城市轨道交通运营管理中的应用 [J], 张凌亮3."城轨云"技术在城市轨道交通运营中的应用分析 [J], 崔嘉4.基于岗位能力的分层次教学在城市轨道交通运营管理专业中的应用初探 [J], 姜玲芝5.BOPPPS模式在"城市轨道交通运营"课程教学中的应用 [J], 韦强;李晨蕾;唐小小因版权原因,仅展示原文概要,查看原文内容请购买。
地震序列的有序样品聚类方法研究

地震序列的有序样品聚类方法研究
许俊奇
【期刊名称】《华南地震》
【年(卷),期】1995(015)001
【摘要】在应用最优分割法对地震活动性分类研究的基础上引进线性模型,扩大最优分割法在地震活动性分类中的应用范围,并将聚类问题与建模问题有机地结合起来,以揭示地震活动的某种内在规律,这对于探索地震预报和地震的发生规律有一定实际意义。
【总页数】5页(P38-42)
【作者】许俊奇
【作者单位】无
【正文语种】中文
【中图分类】P315.5
【相关文献】
1.基于有序样品聚类和模糊理论发动机状态监测研究 [J], 刘玉兵;杨川;王晓东
2.基于有序样品聚类最优二分割算法的滑坡演化阶段划分 [J], 黄丽;樊孝菊;罗文强
3.基于有序样品聚类最优二分割算法的滑坡演化阶段划分 [J], 黄丽;樊孝菊;罗文强;
4.用有序样品聚类法建立蒙古族7~18岁学生腰围的参考值 [J], 赵宏林;王风英;王丽梅;孙红;钟宏伟
5.有序样品聚类分析方法在花开左组划分中的应用 [J], 李守奎;杨柳扬;赵庆红;王
明明
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
������ ������ − ������������ ′ |(1.2)
������ ������ =1 ������ (������������
, ������������ +1 − 1)(1.3)
当 n,k 固定时,L[b(n , k)]越小表示各类的离差平方和越小,分类是合理的。因此要寻找 一种分法b(n , k),使分类损失函数 L 达最小。记 P(n , k)是使 L 达到极小的分类法。 3. ������[������(������ , ������)]的递推公式 Fisher 算法最核心的部分是利用以下两个递推公式: L[P n , 2 = min2≤������ ≤������ {������ 1, ������ − 1 + ������(������, ������)} (1.4) L[P n , k = min������≤������ ≤������ {������[������ (������ − 1, ������ − 1)] + ������(������, ������)} 以上两个公式由定义即可证明。 第二个公式表明,若要找将 n 个样品分为 k 类的最优分割,应建立在将 j-1 个样品分为 k-1 类的最优分割基础上(这里 j=2,3,· · · ,n) 4. 最优解的求法 若分类数 k(1<k<n)已知,求分类法 P(n , k),使它在损失函数意义下达最小.其求法如下: 首先找分点 jk,使(1.4)达极小,即 L[P(n ,k)= L[P(jk-1 , k-1)] + D(jk, n). 于是得第 k 类 Gk = {jk, jk+1 ,· · · , n}. 然后找 jk-1,使它满足 L[P(jk-1 ,k-1)= L[P(jk-1-1 , k-2)] + D(jk-1, jk-1),得到第 k-1 类 Gk-1 = {jk-1, jk-1+1 ,· · · , jk-1},类似的方法依次可得到所有类 G1,G2,· · · Gk,这就是我们欲 求的最优解,即 P(n , k)={G1,G2,· · · Gk}。 总之,为了求最优解,主要是计算{D(i ,j);1≤i<j≤n}和{L[P(i ,j)];1≤i≤n,i≤j≤n}. 三.应用举例 下面通过一个例子来说明最优解的具体求法。 【例】为了了解儿童的生长发育规律,今统计了男孩从出生到十一岁每年平均增长的重 量如下: 年龄 1 2 3 4 5 6 7 8 9 10 2.3 11 2.1 增加重量 9.3 (kg) 1.8 1.9 1.7 1.5 1.3 1.4 2.0 1.9
有序样品聚类法--最优分割法 一. 最优分割法简介
1958 年 Fisher 提出 处理资料:有序资料 任务:寻找最优分割点 聚类统计量:离均差平方和 基本思想:先将 n 个样品看成一类,然后依据分类的误差函数逐渐增加分类。 二. 聚类步骤
设有序样品依次为 X(1) ,X(2) ,· · · ,X(n) (X(i)为 m 维向量). 用 b(n, k)表示将 n 个有序样品分为 k 类的某一种方法.常记分法 b(n, k)为: G1={i1,i1+1,· · · ,i2-1}, G2 = {i2, i2+1, · · · , i3-1}, · · ·· · ·· · ·· · ·· · · Gk = {ik, ik+1, · · · , n}, 其中分点为 1 = i1<i2<i3 <· · · <ik< n = ik+1 -1 (即 ik+1= n+1) 。 1. 定义类的直径 设某一类 G 包含的样品有{X(i),X(i+1), · · · ,X(j)}(j> i) ,记为 G= {i, i+1,· · · , j}. 该类的均值向量 XG 为 1 ������������ = ������ − ������ + 1 用 D(i , j)表示这一类的直径,常用的直径有: D(i , j) =
������ ������ =������ ������
������(������ )
������ =������
(������(������ ) �(������ ) − ������������ )(1.1)
当 m=1 时,也可以定义直径为 D(i , j) = 其中,������������ ′是这一类数据中的中位数。 2. 定义误差函数(损失函数) 定义这种分类法的损失函数为 L[b(n , k)] =
试问男孩发育可分为几个阶段?
③
④
K=3 G1={9.3}; G2={1.8,1.9,1.7,1.5,1.3,1.4}; G3={2.0,1.9,2.3,2.1} K=4
G1={9.3}; G2={1.8,1.9,1.7,
};
G3={1.5,1.3,1.4}; G4={2.0,1.9,2.3,2.1}