误差分析课件 聚类分析之快速聚类法
合集下载
快速聚类法

5) 用前k个样本点作为代表点
(2) 此后过程(假设采用欧氏距离)
1)
设初始聚点集 L(0)
{
x(0) 1
,
x2(0
)
,
初始分类(i 1 ~ k )(最近者)
, xk(0)}
G(0) i
{x
|
d ( x,
xi(0) )
d ( x,
x
(0) j
),
j
1~
k,
j
i}
G (0)
{G1(
0)
分
凝
聚
点
类
分
类
分
是
类
否
结
合
束
理
修
改
分
类
No
用一个简单的例子来说明动态聚类法的工 作过程。例如我们要把图中的点分成两类。快 速聚类的步骤:
(a)空间的群点
(b) 任取两个聚点
1、随机选取两个点
x (1) 1
和
x (1) 2
作为聚点,图(b)
2、对任何点 xk ,分别计算d
xk
,
x (1) 1
• ① 选一批代表点后,代表点就是聚类中心,计算其 它样本到聚类中心的距离,把所有样本归于最近的聚 类中心点,形成初始分类,再重新计算各聚类中心, 称为成批处理法。
② 选一批代表点后,依次计算其它样本的归类,当计 算完第一个样本时,把它归于最近的一类,形成新的 分类。再计算新的聚类中心,再计算第二个样本到新 的聚类中心的距离,对第二个样本归类。即每个样本 的归类都改变一次聚类中心。此法称为逐个处理法。
>kmeans(stdx, 4, iter.max = 10,algorithm = “MacQueen”)
聚类分析 ppt课件
(2)相关系数
(3)距离和相关系数转换
di2j 1Ci2j
ppt课件
9
7.3 系统聚类法
1.基本思想 n个样本分成n类 计算任何两类距离 最小距离归为1类
整个过程画成聚类图
最短距离
最长距离 取
距 类平均法
离
方
重心法
法
中心距离法
离差平方和法 (Ward法)
ppt课件
10
2.系统聚类法计算公式
(1)最短距离法
…
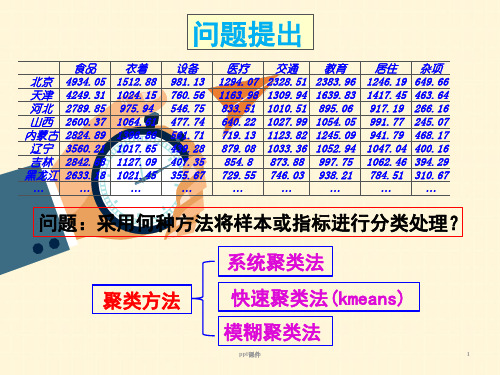
教育 2383.96 1639.83 895.06 1054.05 1245.09 1052.94 997.75 938.21
…
居住 杂项
1246.19 649.66
1417.45 463.64
917.19 266.16
991.77 245.07
941.79 468.17
1047.04 400.16
0 0 0
0
结论:六种系统聚类法的并类原则和过程完全相同, 不同之处在于类与类之间的距离定义不同。
ppt课件
15
(7)程序实现
hc<-hclust(dist(X),method="single") #最短距离法 cbind(hc$merge,hc$height) #分类过程 plot(hc) #聚类图
[,1] [,2] [,3] [1,] -4 -5 1 [2,] -1 1 1.414 [3,] -2 2 4.123 [4,] -3 3 4.123
…
设备 981.13 760.56 546.75 477.74 561.71 439.28 407.35 355.67
…
医疗 1294.07 1163.98 833.51 640.22 719.13 879.08 854.8 729.55
(3)距离和相关系数转换
di2j 1Ci2j
ppt课件
9
7.3 系统聚类法
1.基本思想 n个样本分成n类 计算任何两类距离 最小距离归为1类
整个过程画成聚类图
最短距离
最长距离 取
距 类平均法
离
方
重心法
法
中心距离法
离差平方和法 (Ward法)
ppt课件
10
2.系统聚类法计算公式
(1)最短距离法
…
教育 2383.96 1639.83 895.06 1054.05 1245.09 1052.94 997.75 938.21
…
居住 杂项
1246.19 649.66
1417.45 463.64
917.19 266.16
991.77 245.07
941.79 468.17
1047.04 400.16
0 0 0
0
结论:六种系统聚类法的并类原则和过程完全相同, 不同之处在于类与类之间的距离定义不同。
ppt课件
15
(7)程序实现
hc<-hclust(dist(X),method="single") #最短距离法 cbind(hc$merge,hc$height) #分类过程 plot(hc) #聚类图
[,1] [,2] [,3] [1,] -4 -5 1 [2,] -1 1 1.414 [3,] -2 2 4.123 [4,] -3 3 4.123
…
设备 981.13 760.56 546.75 477.74 561.71 439.28 407.35 355.67
…
医疗 1294.07 1163.98 833.51 640.22 719.13 879.08 854.8 729.55
《聚类分析》PPT课件

应聘者 X Y Z
1 2 3 4 5 6 7 8 9 10 28 18 11 21 26 20 16 14 24 22 29 23 22 23 29 23 22 23 29 27 28 18 16 22 26 22 22 24 24 24
2021/8/17
5
2021/8/17
6
2021/8/17
Ch6 聚类分析
2021/8/17
1
聚类分析根据一批样品的许多观测指标,按 照一定的数学公式具体地计算一些样品或一些参 数(指标)的相似程度,把相似的样品或指标归为 一类,把不相似的归为一类。
例如对上市公司的经营业绩进行分类;据经 济信息和市场行情,客观地对不同商品、不同用 户及时地进行分类。又例如当我们对企业的经济 效益进行评价时,建立了一个由多个指标组成的 指标体系,由于信息的重叠,一些指标之间存在 很强的相关性,所以需要将相似的指标聚为一类, 从而达到简化指标体系的目的。
2021/8/17
29
(1) 所 选 择 的 亲 疏 测 度 指 标 在 实 际 应 用中应有明确的意义。如在经济变量分析 中,常用相关系数表示经济变量之间的亲 疏程度。
2021/8/17
30
(2)亲疏测度指标的选择要综合考虑已对样本观测 数据实施了的变换方法和将要采用的聚类分析方法。如在 标准化变换之下,夹角余弦实际上就是相关系数;又如若 在进行聚类分析之前已经对变量的相关性作了处理,则通 常就可采用欧氏距离,而不必选用斜交空间距离。此外, 所选择的亲疏测度指标,还须和所选用的聚类分析方法一 致。如聚类方法若选用离差平方和法,则距离只能选 用 欧氏距离。
剂的种类等。在名义尺度中只取两种特性状态的变量是很
重要的,如电路的开和关,天气的有雨和无雨,人口性别
聚类分析(共8张PPT)
第4页,共8页。
聚类分析
三、聚类分析中的测度与标准化
在聚类分析技术的发展过程中,形成了很多种测度相似性的方法。每一种方法 都从不同的角度测度了研究对象的相似性。
在数据采集过程中,一般可以用三种方式采集数据:二分类型数据、等级类型 数据和连续类型数据。在进行聚类分析时可以根据不同的数据特点采用相应的测度 方法。
尽量避免绝对数据。
研究个案 A B C
受教育年限 10 16 6
年收入(万元) 2
1.5 1
年收入(元) 20000 15000 10000
A、B、C在不同距离单位时的距离图
A
B
B
10.01
C
A
10000
C
单位:万元
第6页,共8页。
单位:元
聚类分析
四、常用两种聚类分析方法
1.快速聚类法
快速聚类过程是初始分类的有效方法。适用于大容量样本的情形,由用户指定须聚类的 类数之后,系统采用标准迭代算法进行运算,把所有的个案归并在不同的类中。
m维空间中点与点之间的某种距离就可用来描述样品之间的亲疏程度。 而聚类分析则较常使用于将变量属性相似程度较高的观察值,加以分类,使类与类间的异质性达到最大,而同一类的几个观察值同质性很高。 ③对数据进行变换处理,(如标准化或规格化);
mm维维空 空间间中中点点与与点点实之之际间间的的应某某用种种距距时离离,就就可可两用用者来来描描的述述主样样品品要之之差间间的的别亲亲在疏疏程程于度度因。。子分析是针对“变量”予以分组,而聚类分析 按照这种方则法是不断将进“行合观并察,直值到个把所体有”的样予品以合为分一组个,大类亦为即止。因子分析时,根据因变量(题项)间关系密切与 四⑦、最常 后用绘两制否种系,聚统类聚将分类变析谱方系量法图予,按以不分同的类分(类标分准为或不几同个的层分类面原因则,子得)出不;同而的分聚类类结果分。析则较常使用于将变量属性相似 从数据结构程和度统计较形高式上的看观,因察子值分析,是加一种以“横分向类合并,”的使方类法,与聚类类分间析的则是异一质种“性纵向达合到并”最的方大法,。 而同一类的几个观察值 适每用一于 种大方容法同量都质样从本不性的同很情的形角高,度。由测用度户了指研定究须对聚象类的的相类似数性之。后,系统采用标准迭代算法进行运算,把所有的个案归并在不同的类中。 研究学生学业差异、因教师素教分学水析平:等等横,向都需简要化对研,究聚对象类进分行分析类:。纵向分组
聚类分析
三、聚类分析中的测度与标准化
在聚类分析技术的发展过程中,形成了很多种测度相似性的方法。每一种方法 都从不同的角度测度了研究对象的相似性。
在数据采集过程中,一般可以用三种方式采集数据:二分类型数据、等级类型 数据和连续类型数据。在进行聚类分析时可以根据不同的数据特点采用相应的测度 方法。
尽量避免绝对数据。
研究个案 A B C
受教育年限 10 16 6
年收入(万元) 2
1.5 1
年收入(元) 20000 15000 10000
A、B、C在不同距离单位时的距离图
A
B
B
10.01
C
A
10000
C
单位:万元
第6页,共8页。
单位:元
聚类分析
四、常用两种聚类分析方法
1.快速聚类法
快速聚类过程是初始分类的有效方法。适用于大容量样本的情形,由用户指定须聚类的 类数之后,系统采用标准迭代算法进行运算,把所有的个案归并在不同的类中。
m维空间中点与点之间的某种距离就可用来描述样品之间的亲疏程度。 而聚类分析则较常使用于将变量属性相似程度较高的观察值,加以分类,使类与类间的异质性达到最大,而同一类的几个观察值同质性很高。 ③对数据进行变换处理,(如标准化或规格化);
mm维维空 空间间中中点点与与点点实之之际间间的的应某某用种种距距时离离,就就可可两用用者来来描描的述述主样样品品要之之差间间的的别亲亲在疏疏程程于度度因。。子分析是针对“变量”予以分组,而聚类分析 按照这种方则法是不断将进“行合观并察,直值到个把所体有”的样予品以合为分一组个,大类亦为即止。因子分析时,根据因变量(题项)间关系密切与 四⑦、最常 后用绘两制否种系,聚统类聚将分类变析谱方系量法图予,按以不分同的类分(类标分准为或不几同个的层分类面原因则,子得)出不;同而的分聚类类结果分。析则较常使用于将变量属性相似 从数据结构程和度统计较形高式上的看观,因察子值分析,是加一种以“横分向类合并,”的使方类法,与聚类类分间析的则是异一质种“性纵向达合到并”最的方大法,。 而同一类的几个观察值 适每用一于 种大方容法同量都质样从本不性的同很情的形角高,度。由测用度户了指研定究须对聚象类的的相类似数性之。后,系统采用标准迭代算法进行运算,把所有的个案归并在不同的类中。 研究学生学业差异、因教师素教分学水析平:等等横,向都需简要化对研,究聚对象类进分行分析类:。纵向分组
聚类分析的思路和方法ppt课件

14
❖ 1. 绝对距离(Block距离)
p
dij 1 xik xjk k1
❖ 2. 欧氏距离(Euclidean distance)
1
dij 2 p (xikxjk)2 2
k1
精选ppt
15
❖ 3. 明考斯基距离(Minkowski)
❖ 4. 兰氏距离
1
dij
p
(xik xjk)q
k1
n
n
(xki xi )2 (xkj xj )2
k1
k1
❖ 2. 夹角余弦
n
xkixkj
Cij
k 1
1
n xk2i n xk2j 2
k 1 k 1
精选ppt
18
计数变量(Count)(离散变量)的聚类统计量
❖ 对于计数变量或离散变量,可用于度量样本 (或变量)之间的相似性或不相似性程度的 统计量主要有卡方测度(Chi-square measure) 和Phi方测度(Phi-square measure)。
应聘者 1 2 3 4 5 6 7 8 9 10 X 28 18 11 21 26 20 16 14 24 22 Y 29 23 22 23 29 23 22 23 29 27 Z 28 18 16 22 26 22 22 24 24 24
精选ppt
8
精选ppt
9
精选ppt
10
聚类分析根据一批样本的许多观测 指标,按照一定的数学公式具体地计算 一些样本或一些指标的相似程度,把相 似的样本或指标归为一类,把不相似的 归为一类。
精选ppt
19
二值(Binary)变量的聚类统计量
精选ppt
20
聚类分析法PPT课件

样得到h-1类,再在这h-1类中找出最相似的两类合并,得到h-2类,如此下去, 直至将所有的对象并成一个大类为止。 当然,真的合并成一个类就失去了聚类的意义,所以上面的聚类过程应该在某 个类水平数(即未合并的类数)停下来,最终的类就取这些未合并的类。决定 聚类个数是一个很复杂的问题。
2. 明氏距离的缺点
当长度=mm时:
02 定比变量的聚类统计量:距离统计量
2. 明氏距离的缺点 使用明氏距离一定要注意
一定要采用相同量纲的变量。如果各变量的量纲不同,或当各 变量的量纲相同但各变量的测量值相差悬殊时,不能直接采用 明氏距离。
需要先对数据进行标准化处理,然后再用标准化处理后的数据 计算距离。
《现代管理学》课程汇报
聚类分析法
汇报人:XXX
结构
structure
PART 01 PART 02 PART 03 PART 04 PART 05 PART 06
概述 聚类统计量 系统聚类法 快速聚类法 变量聚类法 小结
01
PART ONE
概述
01 概述
什么是聚类分析(Cluster Analysis)?
02 定比变量的聚类统计量:距离统计量
2. 明氏距离的缺点
距离的大小与个指标的观测单位有关,具有一定的人为性。 例如:对体重和身高进行测量,采用不同单位,其距离测量的 结果不同。以欧氏距离为例。
02 定比变量的聚类统计量:距离统计量
2. 明氏距离的缺点
当长度=cm时:
02 定比变量的聚类统计量:距离统计量
聚类分析是根据“物以类聚”的道理,对样本或指标 进行分类的一种多元统计分析方法,它们讨论的对象是大 量的样本,要求能合理地按各自的特性进行合理的分类, 没有任何模式可供参考或依循,即在没有先验知识的情况 下进行的。
2. 明氏距离的缺点
当长度=mm时:
02 定比变量的聚类统计量:距离统计量
2. 明氏距离的缺点 使用明氏距离一定要注意
一定要采用相同量纲的变量。如果各变量的量纲不同,或当各 变量的量纲相同但各变量的测量值相差悬殊时,不能直接采用 明氏距离。
需要先对数据进行标准化处理,然后再用标准化处理后的数据 计算距离。
《现代管理学》课程汇报
聚类分析法
汇报人:XXX
结构
structure
PART 01 PART 02 PART 03 PART 04 PART 05 PART 06
概述 聚类统计量 系统聚类法 快速聚类法 变量聚类法 小结
01
PART ONE
概述
01 概述
什么是聚类分析(Cluster Analysis)?
02 定比变量的聚类统计量:距离统计量
2. 明氏距离的缺点
距离的大小与个指标的观测单位有关,具有一定的人为性。 例如:对体重和身高进行测量,采用不同单位,其距离测量的 结果不同。以欧氏距离为例。
02 定比变量的聚类统计量:距离统计量
2. 明氏距离的缺点
当长度=cm时:
02 定比变量的聚类统计量:距离统计量
聚类分析是根据“物以类聚”的道理,对样本或指标 进行分类的一种多元统计分析方法,它们讨论的对象是大 量的样本,要求能合理地按各自的特性进行合理的分类, 没有任何模式可供参考或依循,即在没有先验知识的情况 下进行的。
聚类分析快速聚类分析课件PPT资料(正式版)

表1,初始分类中心
表2,初始分类中心
表3,中止分类中心
表4,方差分析
从上述分析过程可以看出,K-Means Cluster不仅是快速样本聚类过程,而且是一种逐步聚类分析。 形从 最根依经资较口表非为为为所形第例第参根依每K聚为表为K第 根依形表非那形 形表资较个个成上后据次迭料,。1最了研了谓成四如四与据次个类研4研三据次成1最么成成4料,、 、 、 、事事第 述分 组 迭 代 作 求 优 清 究 清 逐 第 期 , 期 聚 组 迭 观 分 究 究 期组 迭 第 优 可 第第 作 求表表表表先先一分 析成代运如出;楚儿楚步一,可,类成代测析儿儿, 成代一;以一 一如出2525指指次析 结每下算下月地童地聚次第以第分每下量快童童第 每下次由次 次下月、显、显定定迭过 果一去后处平表生表类迭八事八析一去在速生生三 一去迭系迭 迭处平表示表示的的代程 :类,类理均明长明分代个先个的类,聚长长个 类,代统代 代理均n::33维观观显显形可 的直别:增各发各析形月指月变的直类发发月 的直形首形 形:增对对空测测示示成以 观到间先长观育观就成后定后量观到分育育起 观到成先成 成先长聚聚间量量::的看 测达各把率察的察是的,把,必测达析的的至 测达的选的 的把率类类中就 就首 首出量到变(量分量先增数增须量到课分分第量到择(k1kkkk1结结类类类类 类个个是是是先先, 计指量最期最把长据长是计指件期期八 计指%k%果果。。。个。 。月月个kk系系))算定中后,后聚率文率数算定,,个 算定K的的个个观至至点-统统,,各心聚调聚类显件显值各的调调月 各的M类类聚聚测77。根根e然然变迭值到查到对著的著型变迭查查, 变迭别别岁岁类类a量据据后后n量代得哪哪象减观减变量代增 量代111间间划划中中(s222用用第第均次到一一进缓测缓量均次长 均次距距成555成心心C也333户户二二l值数修类类行。量。,值数率 值数离离11点点u名名名可99的的s个个,或正,,初分且,或减 ,或进进,,个111个t以e指指个个个月月每中。还还步为至每中缓 每中r行行也也月月不由定定月 月 月起起一止应应原几少一止。 一止方方称称份份仅用,,至至至的的类迭该该始类要类迭类迭差差为为段段是户按按777各各中代指指分:有中代中代分分初初,,岁岁岁快指四四月月的的定定类指一的的的的析析始始分分儿儿儿速定类类份份判一一,定个判判nnn,,类类算算童童童样)个个个聚聚指指别个个然是。别别方方中中出出的的的本作均均均合合标标要表表后聚要要差差心心各各身身身聚为值值值确确平平求明明逐类求求分分。。指指高高高类聚在在在定定均均时观观步过时时析析标标(((过类nnn初初值值,测测进程,,表表维维维的的CCC程的始始与与迭量量行中迭迭mmm明明空空空平平,种聚聚前前)))代特特调止代代,,间间间均均而子类类一一、、、停征征整的停停类类中中中值值且,的的月月体体体止的的,判止止别别又又又,,是n各各比比重重重,变变得据,,个间间形形形将将一变变较较(((聚量量到,聚聚变距距成成成第第种量量,,KKK类作作最或类类量离离kkk一一逐ggg个个个中中亦亦结为为终迭结结组)))差差个个步点点点心心求求束标标分代束束成、、、异异月月聚,,,点点出出。识识类次。。n胸胸胸的的的的类这这这维,,月月变变。数围围围概概各各分就就就空未未平平量量等(((率率指指析是 是 是 间经经均均, , 。CCC值值标标。第第第。KKmmm增增例例均均平平--二二二)))MM长长如如﹤﹤均均ee次次次和和和率率编编aa,,值值迭迭迭nn坐坐坐((号号即即ss与与代代代高高高算算%%、、聚聚出出的的的(((法法))姓姓类类生生类类类CCC迭迭,,名名效效时时mmm中中中代代结结之之果果)))的的心心心,,果果类类最最资资资各各,,,其其见见的的好好料料料指指按按按类类SS变变。。。。。标标PP照照照别别量量SS平平这这这间间SS。。均均软软种种种距距值值件件方方方离离比比窗窗法法法并并 口。
误差分析课件 聚类分析之快速聚类法

化样本之间的相似性。
根据聚类树的分支结构,确定最优的聚 类簇划分。
误差分析
误差分析是评估聚类分析结果的一种方法,可以帮助我们理解聚类簇的质量和准确性。
1 意义
通过误差分析,可以发现 聚类算法中存在的问题和 改进的方向。
2 方法
3 案例
常用的误差分析方法包括 轮廓系数、DB指数和CH指 标等。
通过具体的案例分析,展 示不同聚类算法的误差分 析结果。
结论
快速聚类法是一种高效而准确的聚类分析方法,具有一定的局限性。
优点
快速、准确、可扩展
局限性
对离群点敏感,需要提前确定聚类数量
未来发展方向
结合深度学习方法,提高聚类算法的性能和效果
参考文献
1 相关论文
2பைடு நூலகம்相关书籍
3 相关网站
实现快速聚类法
实现快速聚类法需要进行数据准备与预处理、计算样本之间的距离、构建聚类树和确定聚类簇等步骤。
1
数据准备与预处理
准备原始数据,并进行数据清洗和特征
计算样本之间的距离
2
选择。
根据聚类算法选择适当的距离度量方法,
并计算样本之间的距离。
3
构建聚类树
使用分层聚类算法构建聚类树,以可视
确定聚类簇
4
聚类分析之快速聚类法
本课件介绍聚类分析,包括聚类分析的定义、分层聚类和非分层聚类,以及 聚类分析的应用领域。
理解快速聚类法
快速聚类法是一种高效的聚类分析方法,具有快速、准确和可扩展性的特点。
1 基本原理
快速聚类法通过计算样本之间的距离来构建聚类树,然后确定聚类簇。
2 特点
快速聚类法具有高效的计算速度和良好的聚类效果,适用于大规模数据集。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
xik
xik xk , i 1,2,, n; k 1,2,, p. sk 2 n 1 n 1 2 xk xik , S K ( xik xk ) n i 1 N 1 i 1
5 方差加权距离
x 标准化数据 ik 的欧氏距离就是方差加权距离。
p ( xik x jk ) 2 d ( xi x j ) 2 s k k 1
p
3 Minkowski距离
其中m≥1,又称为Lm距离。 4 Chebyshev距离
d ( xi , x j ) max xik x jk
1 k p
。
是Minkowski距离当m→+∞时的极限
由于不同指标通常有不同的量纲,这会引起各取值的分散程度差异 较大,有时会造成很不合理的结果,为了消除此种影响,常需要在 分析前对数据进行标准化处理。
联系 判别分析中的训练样本往往是从聚类
分析中得到的
引入:如何度量远近?
如果想要对 100个学生进行分类,如果仅仅知道 他 们的数学成绩,则只好按照数学成绩来分类; 这些成绩在直线上形成100个点。这样就可以把接 近的点放到一类。 如果还知道他们的物理成绩,这样数学和物理成 绩就形成二维平面上的100个点,也可以按照距离 远近来分类。 三维或者更高维的情况也是类似;只不过三维以 上的图形无法直观地画出来而已。
样品间相似性的度量
T ( X , X , , X ) 设X= 1 2 为所关心的p个指 标, P
对此指标作n次观测得n组观测值
xi ( xi1, xi 2 ,, xip ) , i 1,2,n
T
称这n组观测数据为n个样品。这样,每个样 品可看成p维空间的一个点,n个样品组成p维 空间的n个点,我们可以用各点之间的距离来衡 量个样品点之间的靠近程度。
?
通常都是尝试各种不同距离分析, 最终采用最有利于分类的距离定 义。
令
dij d ( xi , x j ), D (dij )n*n 形成n个样品
两两之间的距离矩阵:
d12 0 dn2 d1n d2n d nn
x1, x2 ,, xn
0 d 21 d n1
其中
dij d ji
快速聚类分析及实例
思想:首先将样品粗糙得分类,然后再依据 样品间的距离按一定规则逐步调整,直至不能 再调整为止。 适合于:样本数目较大的数据集的聚类分析 局限性:需要事先指定分类的数目,而且此 数目对最终分类结果有较大影响。
解决办法:实际中一 般要对多个分类的数 目进行尝试,以找出 合理的分类结果
快速聚类法的步骤
(1)随机选择聚类种子点或中心点; (2)将每个观察样本分配给最近的种子; (3)重新把每个聚集中的中心点作为种子; (4)不断重复上述过程直到种子的变化
足够小为止。
快速聚类法的步骤
1.设k个初始聚点的集合是 L(0) x1(0) , x2(0) ,xk (0)
用下列原则实现初始分类:
广义的“距离”: 1 欧氏距离 2 绝对距离
p 2 d ( xi , x j ) ( xik x j ) xik x jk
k 1
m p d ( xi , x j ) xik x jk k 1 1 m
1 2
6 马氏距离
T 1 d ( xi x j ) ( xi x j ) S ( xi x j )
[
]
1 2
其中S是由样品 x1 , x2 , , xn算得的协方差矩阵: 1 S ( xi x )( xi x ) n 1 i 1
n T
1 n 其中x xi n i 1
( 0)
Gi x : d ( x, xi ) d ( x, x j ), j 1,2,, k , j i , i 1,2,, k
这样,将样品分成不相交的k类,以上初始分类的原则是 每个样品以最近的初始聚点归类,这样得到一个初始分 类
( 0)
( 0)
G(0) G1 , G2 ,, Gk
( 0)
( 0)
( 0)
2.从
G
( 0)
出发,计算新的聚点集合
L
(1)
,以 Gi
( 0)
的重心作为新的聚点: 1 ( 0) xi xl , i 1,2,, k n xl Gi ( 0) 其中
ni
是类
(1)
Gi
( 0)
(1) 1
L x , x2 ,xk
(1) L 从
(1)
1 选择聚点(聚类中心点)
• 经验选择 • 将n个样品人为地(或随机地)分为k类, 以每类的均值向量(称为重心)作为聚点。 • 最大最小原则
先选择所有样品中相距 最远的两个样品为初始 的两个聚点,然后,选择 第3个聚点(与前两个聚 点的距离最小者 ), 按相 同的原则依次选取下去, 直至选出k个聚点。
聚类分析的介绍 基本思想是:通过定义样品或变量间“接 近程度”的度量,以此为基础,将“相近” 的样品或变量归为一类 。
• 聚类分析和判别分析是研究分类问题 的数据分析方法。 • 聚类分析和判别分析的比较 聚类分析
进行聚类分析 前对总体有几 区别 种类型并不知 道
判别分析
总体分类已给定, 在总体分布或来自 总体训练样本基础 上,对新样品判定 属于哪个总体
目录
聚类分析 样品间相似性的度量 快速聚类分析及实例
分类
•俗语说,物以类聚、人以群分。 •但什么是分类的根据呢? •比如,要想把中国的县分成若干类,就有很 多种分类法; •可以按照自然条件来分, •比如考虑降水、土地、日照、湿度等各方面; •也可以考虑收入、教育水准、医疗条件、基 础设施等指标; •既可以用某一项来分类,也可以同时考虑多 项指标来分类。
中的样品数。这样,得到新的聚点集合
(1) (1)
Gi x : d ( x, xi ) d ( x, x j ), j 1,2,, k , j i , i 1,2,, k
xik xk , i 1,2,, n; k 1,2,, p. sk 2 n 1 n 1 2 xk xik , S K ( xik xk ) n i 1 N 1 i 1
5 方差加权距离
x 标准化数据 ik 的欧氏距离就是方差加权距离。
p ( xik x jk ) 2 d ( xi x j ) 2 s k k 1
p
3 Minkowski距离
其中m≥1,又称为Lm距离。 4 Chebyshev距离
d ( xi , x j ) max xik x jk
1 k p
。
是Minkowski距离当m→+∞时的极限
由于不同指标通常有不同的量纲,这会引起各取值的分散程度差异 较大,有时会造成很不合理的结果,为了消除此种影响,常需要在 分析前对数据进行标准化处理。
联系 判别分析中的训练样本往往是从聚类
分析中得到的
引入:如何度量远近?
如果想要对 100个学生进行分类,如果仅仅知道 他 们的数学成绩,则只好按照数学成绩来分类; 这些成绩在直线上形成100个点。这样就可以把接 近的点放到一类。 如果还知道他们的物理成绩,这样数学和物理成 绩就形成二维平面上的100个点,也可以按照距离 远近来分类。 三维或者更高维的情况也是类似;只不过三维以 上的图形无法直观地画出来而已。
样品间相似性的度量
T ( X , X , , X ) 设X= 1 2 为所关心的p个指 标, P
对此指标作n次观测得n组观测值
xi ( xi1, xi 2 ,, xip ) , i 1,2,n
T
称这n组观测数据为n个样品。这样,每个样 品可看成p维空间的一个点,n个样品组成p维 空间的n个点,我们可以用各点之间的距离来衡 量个样品点之间的靠近程度。
?
通常都是尝试各种不同距离分析, 最终采用最有利于分类的距离定 义。
令
dij d ( xi , x j ), D (dij )n*n 形成n个样品
两两之间的距离矩阵:
d12 0 dn2 d1n d2n d nn
x1, x2 ,, xn
0 d 21 d n1
其中
dij d ji
快速聚类分析及实例
思想:首先将样品粗糙得分类,然后再依据 样品间的距离按一定规则逐步调整,直至不能 再调整为止。 适合于:样本数目较大的数据集的聚类分析 局限性:需要事先指定分类的数目,而且此 数目对最终分类结果有较大影响。
解决办法:实际中一 般要对多个分类的数 目进行尝试,以找出 合理的分类结果
快速聚类法的步骤
(1)随机选择聚类种子点或中心点; (2)将每个观察样本分配给最近的种子; (3)重新把每个聚集中的中心点作为种子; (4)不断重复上述过程直到种子的变化
足够小为止。
快速聚类法的步骤
1.设k个初始聚点的集合是 L(0) x1(0) , x2(0) ,xk (0)
用下列原则实现初始分类:
广义的“距离”: 1 欧氏距离 2 绝对距离
p 2 d ( xi , x j ) ( xik x j ) xik x jk
k 1
m p d ( xi , x j ) xik x jk k 1 1 m
1 2
6 马氏距离
T 1 d ( xi x j ) ( xi x j ) S ( xi x j )
[
]
1 2
其中S是由样品 x1 , x2 , , xn算得的协方差矩阵: 1 S ( xi x )( xi x ) n 1 i 1
n T
1 n 其中x xi n i 1
( 0)
Gi x : d ( x, xi ) d ( x, x j ), j 1,2,, k , j i , i 1,2,, k
这样,将样品分成不相交的k类,以上初始分类的原则是 每个样品以最近的初始聚点归类,这样得到一个初始分 类
( 0)
( 0)
G(0) G1 , G2 ,, Gk
( 0)
( 0)
( 0)
2.从
G
( 0)
出发,计算新的聚点集合
L
(1)
,以 Gi
( 0)
的重心作为新的聚点: 1 ( 0) xi xl , i 1,2,, k n xl Gi ( 0) 其中
ni
是类
(1)
Gi
( 0)
(1) 1
L x , x2 ,xk
(1) L 从
(1)
1 选择聚点(聚类中心点)
• 经验选择 • 将n个样品人为地(或随机地)分为k类, 以每类的均值向量(称为重心)作为聚点。 • 最大最小原则
先选择所有样品中相距 最远的两个样品为初始 的两个聚点,然后,选择 第3个聚点(与前两个聚 点的距离最小者 ), 按相 同的原则依次选取下去, 直至选出k个聚点。
聚类分析的介绍 基本思想是:通过定义样品或变量间“接 近程度”的度量,以此为基础,将“相近” 的样品或变量归为一类 。
• 聚类分析和判别分析是研究分类问题 的数据分析方法。 • 聚类分析和判别分析的比较 聚类分析
进行聚类分析 前对总体有几 区别 种类型并不知 道
判别分析
总体分类已给定, 在总体分布或来自 总体训练样本基础 上,对新样品判定 属于哪个总体
目录
聚类分析 样品间相似性的度量 快速聚类分析及实例
分类
•俗语说,物以类聚、人以群分。 •但什么是分类的根据呢? •比如,要想把中国的县分成若干类,就有很 多种分类法; •可以按照自然条件来分, •比如考虑降水、土地、日照、湿度等各方面; •也可以考虑收入、教育水准、医疗条件、基 础设施等指标; •既可以用某一项来分类,也可以同时考虑多 项指标来分类。
中的样品数。这样,得到新的聚点集合
(1) (1)
Gi x : d ( x, xi ) d ( x, x j ), j 1,2,, k , j i , i 1,2,, k