Spss多元统计分析-1.0版本
论文写作中如何利用SPSS进行多元统计分析

论文写作中如何利用SPSS进行多元统计分析在当今大数据时代,统计分析成为了各个领域研究的重要工具。
而SPSS (Statistical Package for the Social Sciences)作为一款专业的统计分析软件,被广泛应用于学术研究中。
本文将从多元统计分析的角度出发,探讨如何在论文写作中充分利用SPSS进行数据分析。
一、数据准备在进行多元统计分析之前,首先需要准备好可靠的数据。
数据的质量和完整性对于分析结果的准确性至关重要。
在数据准备阶段,可以通过SPSS软件进行数据清洗、缺失值处理和异常值检测等操作,以确保数据的可靠性。
二、描述性统计分析在进行多元统计分析之前,了解数据的基本情况是必要的。
通过SPSS的描述性统计分析功能,可以获得数据的均值、标准差、最大值、最小值等统计指标。
此外,还可以通过绘制直方图、箱线图等图表来展示数据的分布情况,为后续的分析提供基础。
三、相关性分析相关性分析是多元统计分析的重要环节之一。
通过SPSS的相关性分析功能,可以计算各个变量之间的相关系数,从而了解它们之间的关系。
相关系数的取值范围为-1到1,当相关系数接近1时,表示两个变量呈正相关;当相关系数接近-1时,表示两个变量呈负相关;当相关系数接近0时,表示两个变量之间没有线性关系。
通过相关性分析,可以帮助研究者深入了解变量之间的相互作用,为后续的因果分析提供依据。
四、因素分析因素分析是一种常用的降维技术,可以将大量的变量转化为少数几个因素,从而简化数据分析的复杂度。
通过SPSS的因素分析功能,可以识别出主要的因素,并计算出各个变量对于每个因素的贡献度。
因素分析可以帮助研究者发现变量之间的内在联系,提取出潜在的因素,从而更好地理解研究对象。
五、聚类分析聚类分析是一种无监督学习的方法,可以将数据样本划分为不同的类别或群组。
通过SPSS的聚类分析功能,可以根据变量之间的相似性将样本进行分类,从而发现数据中的内在结构。
【VIP专享】SPSS软件的应用——多元统计分析

5.9
5.5
4.3
5.1
X2
270
180
230
245
270
220
290
220
290
310
1、方差分析的前提条件要求各总体服从正态分布,请给出正态分布的检验结果,
另要求各总体方差齐性,给出方差齐性检验结果。
2、检验三组贫血患者的指标 x1,x2 间是否有显著差异,进行多元方差分析。如
果有显著差异,分析三组患者间 x1 指标是否有显著差异,x2 指标是否有显
如下: 表(4)
6.培养学生观察、思考、对比及分析综合的能力。过程与方法1.通过观察蚯蚓教的学实难验点,线培形养动观物察和能环力节和动实物验的能主力要;特2征.通。过教对学观方察法到与的教现学象手分段析观与察讨法论、,实对验线法形、动分物组和讨环论节法动教特学征准的备概多括媒,体继课续件培、养活分蚯析蚓、、归硬纳纸、板综、合平的面思玻维璃能、力镊。子情、感烧态杯度、价水值教观1和.通过学理解的蛔1虫.过观适1、察于程3观阅 六蛔寄.内列察读 、虫生出蚯材 让标容生3根常蚓料 学本教活.了 据见身: 生,师的2、解 问的体巩鸟 总看活形作 用蛔 题线的固类 结雌动态业 手虫 自形练与 本雄学、三: 摸对 学动状习人 节蛔生结4、、收 一人 后物和同类 课虫活构请一蚯集 摸体 回并颜步关 重的动、学、蚓鸟 蚯的 答归色学系 点形教生生让在类 蚓危 问纳。习从 并状学理列学平的害 题线蚯四线人 归、意特出四生面体以形蚓、形类 纳大图点常、五观玻存 表及动的鸟请动文 本小引以见引、察璃现 ,预物身类 3学物明 节有言及的、导巩蚯上状 是防的体之生和历 课什根蚯环怎学固蚓和, 干感主是所列环史 学么据蚓节二样生练引牛鸟 燥染要否以举节揭 到不上适动、区回习导皮类 还的特分分蚯动晓 的同节于物让分答。学纸减 是方征节布蚓物起 一,课穴并学蚯课生上少 湿法。?广的教, 些体所居归在生蚓前回运的 润;4泛益学鸟色生纳.靠物完的问答动原 的4蛔,处目类 习和活环.近在成前题蚯的因 ?了虫以。标就 生体的节身其实端并蚓快及 触解寄上知同 物表内特动体结验和总利的慢我 摸蚯生适识人 学有容点物前构并后结用生一国 蚯蚓在于与类 的什,的端中思端线问活样的 蚓人飞技有 基么引进主的的考?形题环吗十 体生行能着 本特出要几变以动,境?大 节活的1密 方征本“特节化下物.让并为珍 近习会形理切 法。课生征有以问的小学引什稀 腹性态解的 。2课物。什游题主.结生出么鸟 面和起结蛔关观题体么戏:要利明蚯?类 处适哪构虫系察:的特的特用确蚓等 ,于些特适。蛔章形殊形征板,这资 是穴疾点于可虫我态结式。书生种料 光居病是寄的们结构,五小物典, 滑生?重生鸟内学构,学、结的型以 还活5要生类部习与.其习巩鸟结的爱 是如原活生结了功颜消固类构线鸟 粗形何因的存构腔能色化练适特形护 糙态预之结的,肠相是系习于点动鸟 ?、防一构现你动适否统。飞都物为结蛔。和状认物应与的行是。主构虫课生却为和”其结的与题、病本理不蛔扁的他构特环以生?8特乐虫形观部特8征境小理三页点观的动位点梳相组等、这;,哪物教相,理适为方引些2鸟,育同师.知应单面导鸟掌类结了;?生识的位学你握日构解2互.。办特生认线益特了通动手征观识形减点它过,抄;察吗动少是们理生报5蛔?物,与的解.参一了虫它和有寄主蛔与份解结们环些生要虫其。蚯构都节已生特对中爱蚓。会动经活征人培鸟与飞物灭相。类养护人吗的绝适这造兴鸟类?主或应节成趣的为要濒的课情关什特临?就危感系么征灭来害教;?;绝学,育,习使。我比学们它生可们理以更解做高养些等成什的良么两好。类卫动生物习。惯根的据重学要生意回义答;的3.情通况过,了给解出蚯课蚓课与题人。类回的答关:系线,形进动行物生和命环科节学动价环值节观动的物教一育、。根教据学蛔重虫点病1.引蛔出虫蛔适虫于这寄种生典生型活的线结形构动和物生。理二特、点设;置2.问蚯题蚓让的学生生活思习考性预和习适。于穴居生活的形态、结构、生理等方面的特征;3.线形动物和环节动物的主要特征。
多元统计分析SPSS操作步骤

多元统计分析SPSS操作步骤方差分析:Analyze—general linear model—univariate1、结果选入dependent variable,自变量选入fixed factors2、Options(display:descriptive statistics)主成分分析:Analyze→Dataredution---factor1、自变量:放入Variables2、Descriprives: (statistics默认)(correlation matrix:coefficients,KMO,)3、Extiaction :( method默认)(analyze:correlation)(display:全选)(extract:默认)4、Rotation:(method:none) (display:loading plot)5、Scores:(save as variables)(Display factor)因子分析Analyze→Dataredution---factor6、自变量:放入Variables7、Descriprives: (statistics默认)(correlation matrix:coefficients,KMO,anti-image)8、Extiaction :( method默认)(analyze:correlation)(display:全选)(extract:默认)9、Rotation:(method:quartimax) (display:rotated solution)10、Scores:(save as variables)(Display factor)11、Options:(默认)Logistic回归加权处理:data-weight cases-频数放入FVAnalyze—regression—binary logistic (二分类)1、因变量(y)放入dependent;自变量放入covariates;metord:forward(一般forward wald)2、Save:(predictde values:probabilities)3、Options:(statistics and plots: Hosmer;CI for exp(B))生存分析之life tables加权Analyze—survival—life table(未完成)1、生存时间选入time,Display time intervals:0 through(?)by(?),结局进入Status框,Define失效事件,变量进入Factor框,点击Define Range...钮,定义分组的范围,在Mininum 框中输入小的,在Maxinum框中输入大的2、 Options.(Plot:Survival)(Compare Levels of First Factor:Overall)生存分析之kaplan-meireAnalyze—survival—kaplan-meire1、生存时间选入time,结局入status,define 失效事件,2、Compare factor:(log rank)3、Save:(survival,standard)4、Options:(statistics:survival table;mean and median survival),(plot:survival)生存分析之COX生存时间处理transform—computeAnalyze—survival—cox1、生存时间入time,结局入status,define 失效事件,自变量选入covariaes,strate:对子数2、Plots(plot type:survival)3、Save(survival:function,standard error)4、Options(model statistics:CI for exp(B))。
多元统计分析及SPSS应用课件

03
详细描述
SPSS的对应分析功能可以将分类变量 转换为数量型变量,通过降维技术展 示变量间的关系。
SPSS的对应分析功能简单易用,能够 处理大型数据集,并且可以清晰地展 示变量间的关系和类别间的比较。
SPSS的对应分析功能支持多种距离度 量方式,允许用户自定义类别间的比 较方式,并且可以结合图形界面直观 地展示结果,如散点图和气泡图。
03
生物医学
分析生物标志物和疾 病之间的关系,发现 潜在的治疗方法和药 物。
04
金融
分析多个经济指标和 股票价格,进行投资 决策和风险管理。
02
SPSS软件介绍
Chapter
SPSS软件的特点与优势
强大的统计分析功能
SPSS提供了广泛的统计分析方法,包括描述性统计、推论性统计、 多元统计分析等,可满足各种数据分析和科学研究的需求。
多维尺度分析
01
用于研究数据之间的相似性或差异性。
02
多维尺度分析是一种用于研究数据之间的相似性或差异性的方法。它通过建立一 个低维空间来表示高维数据,使得相似的数据点在空间中距离较近,差异较大的 数据点距离较远。多维尺度分析广泛应用于市场研究、心理学等领域。
判别分析
基于已知分类的数据建立判别函数, 对新的观测值进行分类。
用户可以从SPSS官网或其他授权渠道获取 SPSS软件的安装包。
安装过程
按照安装向导的指引,逐步完成软件的安装过程, 包括选择安装路径、配置软件组件等。
启动SPSS软件
安装完成后,双击桌面快捷方式或从开始菜 单启动SPSS软件。
SPSS软件的基本操作界面
主界面概览
SPSS的主界面包括菜单栏、工具栏、 数据编辑窗口、结果输出窗口等部分 。
多元统计分析及SPSS应用.ppt

2020-12-11
谢谢你的观赏
19
1.定义工人编号和加工零件数的变量名分别为NO 和X,然后 输入变量NO 和X 的原始数据。
2020-12-11
谢谢你的观赏
20
2.选择[Analyze]=>[Descriptive Statistics]=>[Frequencies...], 弹出[Frequencies]主对话框。
10.0 13.3
6.7 3.3 3.3 6.7 3.3 3.3 3.3 3.3 100.0
Cu mu l ati ve Percent 3.3 6.7 10.0 16.7 20.0 23.3 26.7 30.0 33.3 40.0 43.3 53.3 66.7 73.3 76.7 80.0 86.7 90.0 93.3 96.7 100.0
2020-12-11
谢谢你的观赏
25
输出结果
频数(率)分布表
Va li d
84 85 88 91 94 95 96 97 99 101 103 105 106 107 109 110 111 118 119 121 128 T o ta l
Frequency 1 1 1 2 1 1 1 1 1 2 1 3 4 2 1 1 2 1 1 1 1
根据数值大小按升 序从小到大作频数 分布
数值大小按降序从大 到小作频数分布
频数多少按升序从少 到多作频数分布
2020-12-11
频数多少按降序从多 到少作频数分布
谢谢你的观赏
23
4.可单击[Statistics...]按钮,弹出[Frequencies:Statistics]子对 话框,并单击相应项目,在作频数表分析的基础上,附带 作各种统计指标的描述,特别是可进行任何水平的百分位 数计算。这里不选。
SPSS多元统计分析实验报告

实 验 课名称:SPSS统计分析
实验项目名称:多元线性回归分析
专 业 名 称:统计学
班 级:
学 号:
学 生 姓 名:
教 师 姓 名:
2014年12月20日
组别同组同学
实验日期2014年12月20日 实验名称多元统计分析
一、实验名称:
多元统计分析
二、实验目的和要求:
通过运用SPSS软件的多元统计分析揭示主管性格与雇员对其整体满意度之间的关系掌握多元统计分析的原理及建模过程。
六、实验结果与分析
通过以上建模和检验过程,最后得到的符合实际且具有统计意义的方程为:Y=0.78X1,即雇员对主管的满意程度只与主管处理雇员的抱怨有关,且成正相关。
七、讨论和回答问题及体会:
1.通过学习,我掌握了多元线性回归的基本原理和步骤,并学会运用SPSS软件进行处理该类问题和比较熟练地分析结果。
设随机变量y与一般变量x1,x2……xk的线性回归模型为:
y=β0+β1*x1+β2*x2+……+βk*xk+ε
其中β0,β1,β2……+βk是k+1个未知参数,β0称为回归常数,β1,β2……+βk称为回归系数,y称为被解释变量;x1,x2……xk称为解释变量。通过最小二乘法估算出各系数,并测定方程的拟合程度、检验回归方程和回归系数的显著性,得到最后的方程。
3运用SPSS软件进行多元分析对模型进行整理,比较调整的R系数、方差分析表、回归分析结果(各系数机器t检验等)、共显性检验等统计方法,得出结果。
四、实验仪器与设备:
SPSS软件、兼容SPSS软件的电脑一台、老师给的数据素材。
五、实验原理:
多元线性回归模型是一元线性回归模型的扩展,其基本原理与一员线性回归模型类似,计算公式如下:
第8讲.SPSS的多元统计分析:因子分析、聚类分析、判别分析

该方法假设变量是因子的纯线性 组合。第一主成份有最大的方差, 后续成分可解释的方差逐个递减。
输出未经旋转的因 子提取结果。 该图显示了按特征值大小排列的 因子序号,有助于确定保留多少 个因子。典型的碎石图会有一个 明显的拐点,在该拐点之前是与 大因子连接的陡峭的折线,之后 是与小因子相连的缓坡折线。 提取特征值大于指定数值的因子。 系统默认特征值为1.
输出原始分析变量间 的相关系数矩阵。 相关系数的逆矩阵
因子分析后的相关矩 阵以及残差矩阵
前者用于检验变量间的偏相关是否 很小;后者用于检验相关系数矩阵 是否为单位矩阵,如果是,则表明 不合适采用因子模型。
反映像相关矩阵包括偏相关系数 的负数;反映像协方差矩阵包括 偏协方差的负数;一个好的因子 模型,对角线上的元素应较大, 非对角线元素则较小。
因子分析
整体分析与设计的内容
四、输出分析
5.旋转后的因子载荷矩阵(待续)
从表中可知:第一主因子在 “交通和通信”、“医疗保健” 等 5 个指标上具有较大的载荷 系数; 第二主因子在“居住”和“衣 着”指标上系数较大。 第三主因子在“杂项商品与服 务”上的系数最大。 此时,各个因子的含义更加突 出。 第一主因子,是享受性消费因子,从系数的正负值可知:有的消费在递增,有的则递减。 第二主因子,是发展性消费因子,也包含了递增和递减的消费项目。 第三主因子,是其他类型的消费因子。
确定因子
因子旋转 求各因子得分 综合得分
因子分析
整体分析与设计的内容
三、操作
数据文件:“居民消费结构的变化.sav” 菜单:“分析→降维→因子分析”
选择符合条件的样本进行分析
因子分析
整体分析与设计的内容
三、操作
1.“描述”统计量
SPSS软件的应用——多元统计分析

多元统计分析学院:理学与信息科学学院专业班级:信息与计算科学 2012级01 班姓名:韩祖良(20125991)****:***2015 年6月1日作业1 方差分析三组贫血患者的血红蛋白浓度(%,X1)及红细胞计数(万/mm3,X2)如下表:1、方差分析的前提条件要求各总体服从正态分布,请给出正态分布的检验结果,另要求各总体方差齐性,给出方差齐性检验结果。
2、检验三组贫血患者的指标x1,x2间是否有显著差异,进行多元方差分析。
如果有显著差异,分析三组患者间x1指标是否有显著差异,x2指标是否有显著差异?3、最后进行两两比较,给出更具体的分析结果。
4. 画出三组患者x1,x2两指标的均值图。
答:1.将所需分析数据输入到SPSS中,首先判断各总体是否服从正态分布:对文件进行拆分:数据→拆分文件→按组组织输出→确定。
然后进行正态性检验:文件→描述统计→探索,在绘制对话框中,选择按因子水平分组和带检验的正态图,最后单击确定按钮。
最后得出结果如图(1),(2),(3)所示:表(1)由表(1)可以看出,A组的X1指标的Sig=0.907,X2的Sig=0.914,在检验标准为0.05的条件下,接受H0,拒绝H1,故得A组服从正态分布。
表(2)由表(2)可以看出,B组的X1指标的Sig=0.406,X2的Sig=0.765,在检验标准为0.05的条件下,接受H0,拒绝H1,故得B组服从正态分布。
表(3)由表(3)可以看出,C组的X1指标的Sig=0.337,X2的Sig=0.839,在检验标准为0.05的条件下,接受H0,拒绝H1,故得C组服从正态分布。
再检验各总体是否满足方差齐性:首先取消文件的拆分,对所有个案进行分析。
然后进行方差齐性检验:分析→一般线性模型→多变量,在选项对话框中,选择方差齐性检验,所得结果如下:表(4)上表是对协方差阵相等的检验,由Sig=0.670>0.05,故在显著性水平为0.05的条件下,接受H0,拒绝H1,即观测到的因变量的协方差矩阵在所有组中均相等,可得三组符合方差齐性。
SPSS的多元统计分析算法研究

SPSS 的多元统计分析算法研究第一章 多元线性回归分析1.1 研究背景消费是宏观经济必不可少的环节,完善的消费模型可以为宏观调控提供重要的依据。
根据不同的理论可以建立不同的消费函数模型,而国内的许多学者研究的主要是消费支出与收入的单变量之间的函数关系,由于忽略了对消费支出有显著影响的变量,其所建立的方程必与实际有较大的偏离。
本文综合考察影响消费的主要因素,如收入水平、价格、恩格尔系数、居住面积等,采用进入逐步、向前、向后、删除、岭回归方法,对消费支出的多元线性回归模型进行研究,找出能较准确描述客观实际结果的最优模型。
1.2 问题提出与描述、数据收集按照经济学理论,决定居民消费支出变动的因素主要有收入水平、居民消费意愿、消费环境等。
为了符合我国经济发展的不平衡性的现状,本文主要研究农村居民的消费支出模型。
文中取因变量Y 为农村居民年人均生活消费支出(单位:元),自变量为农村居民人均纯收入X 1(单位:元)、商品零售价格定基指数X 2(1978年的为100)、消费价格定基指数X 3(1978年的为100)、家庭恩格尔系数X 4(%)、人均住宅建筑面积X 5(单位:m 2)。
本文取1900年至2009年的数据(数据来源:中华人民共和国国家统计局网公布的1996至2010年中国统计年鉴)列于附录的表一中。
1.3 模型建立 1.3.1 理论背景多元线性回归模型如下:εββββ+++++=p p X X X Y ......22110 Y 表示因变量,X i (i=1,…,p )表示自变量,ε表示随机误差项。
对于n 组观测值,其方程组形式为εβ+=X Y 即模型假设: ⑴零均值假设:()0i E ε= i=1,2,…,n⑵同方差:()2i Var εσ=⑶无自相关:⑷误差与自变量不相关:(),0ik i Cov X ε= i=1,2,…,n , k=0,1,…,p ⑸自变量之间无多重共线性 ()1r a n k X p =+1.3.2模型建立及SPSS 运算结果分析假设因变量Y (农村居民年人均生活消费支出)与自变量X 1(农村居民人均纯收入)、X 2(商品零售价格定基指数)、X 3(消费价格定基指数)、X 4(家庭恩格尔系数)、X 5(人均住宅建筑面积)满足下述等式:01122334455y X X X X X ββββββ=+++++强行回归:在SPSS 中进行强行回归,会得到如下表格:⑴输入变量从表1-1中可以看到,本文先强行将五个自变量与因变量进行线性拟合,希望得到一个线性函数。
SPSS多元统计分析方法及应用课程设计 (2)

SPSS多元统计分析方法及应用课程设计引言多元统计分析是研究几个变量之间关系的一种统计学方法。
SPSS是一款常用的统计分析软件,可以用来进行多元统计分析。
本文将介绍如何使用SPSS进行多元统计分析,并结合具体案例,设计SPSS多元统计分析课程。
SPSS多元统计分析方法相关分析相关分析是研究两个变量之间的关系的统计方法。
可以使用SPSS进行相关分析,步骤如下:1.打开SPSS软件,导入数据文件。
2.选择“Analyze”菜单中的“Correlate”选项,然后选择“Bivariate”。
3.将需要进行相关分析的变量添加到“Variables”框中。
4.点击“OK”按钮,SPSS会生成相关系数以及P值。
回归分析回归分析用来研究一个自变量和一个或多个因变量之间的关系。
在SPSS中进行回归分析的步骤如下:1.打开SPSS软件,导入数据文件。
2.选择“Analyze”菜单中的“Regression”选项,然后选择“Linear”。
3.将自变量和因变量添加到“Dependent”和“Independent”框中。
4.点击“OK”按钮,SPSS会生成回归分析结果。
方差分析方差分析是一种用于比较两个或多个组之间差异的统计方法。
使用SPSS进行方差分析的步骤如下:1.打开SPSS软件,导入数据文件。
2.选择“Analyze”菜单中的“Analyze of Variance”选项,然后选择“One-Way ANOVA”。
3.将需要进行方差分析的变量添加到“Dependent List”框中,将分组变量添加到“Factor”框中。
4.点击“OK”按钮,SPSS会生成方差分析结果。
SPSS多元统计分析课程设计为了帮助学生更好地掌握SPSS多元统计分析方法,我们可以设计以下课程:第一节课:相关分析1.介绍相关分析的概念和应用场景。
2.通过具体案例演示如何使用SPSS进行相关分析。
3.让学生自行导入数据文件,并进行相关分析,并展示分析结果。
spss多元统计分析第一章:回归分析(共41张PPT)

F值表(置信度为95%;节选)
第63页,图表
F检验
第63页,图表
t分布(节选)
第66页,图表
t检验
第67页,图表
非线性变换
第70页,图表
线性和非线性回归关系
第71页,图表
异方差性和自相关
第74-75页,图表
Venn图
第76页,图表
违背线性回归模型前提的情况
第79页,图表
数据编辑器中选择“回归(线性)”分析法
第80页,图表
“线性回归”对话框
第81页,图表
回归分析的SPSS输出第81-82页,图表
“统计量”对话框
第84页,图表
置信区间和共线性统计量
第84页,图表
相关矩阵
第84页,图表
Y值和残差
第85-86页,图表
估计值和残差的统计量
回归分析的变量
第44页,图表
回归分析举例
第44页,图表
回归分析中的典型问题
第45页,图表
回归分析应用领域
第46页,图表
回归分析中变量的可选名称
观察值与回归方程估计值的离差 Durbin/Watson检验的决策规则 F值表(置信度为95%; F值表(置信度为95%; 观察值与回归方程估计值的离差 观察值与回归方程估计值的离差 F值表(置信度为95%; 数据编辑器中选择“回归(线性)”分析法 销量和代理拜访次数的观察值散点图 违背线性回归模型前提的情况 为计算决定系数所准备的数据 Durbin/Watson检验的决策规则 为计算决定系数所准备的数据 Durbin/Watson检验的决策规则 含回归直线散点图的截图 数据编辑器中选择“回归(线性)”分析法 为计算决定系数所准备的数据 F值表(置信度为95%; 观察值散点图:加深点(xk, yk),k=6和9 观察值与回归方程估计值的离差
如何使用SPSS进行多元统计分析

如何使用SPSS进行多元统计分析第一章:SPSS简介SPSS(Statistical Package for the Social Sciences)是一种功能强大且广泛使用的统计分析软件。
它能够处理大量数据,进行各种统计分析和数据挖掘,是研究人员和数据分析师常用的工具。
第二章:设置数据在进行多元统计分析之前,首先需要设置数据。
SPSS支持导入外部数据文件,如Excel、CSV等格式。
用户可以在SPSS中创建新的数据集并录入数据,也可以导入已有数据集。
在设置数据时,需要注意数据的变量类型、缺失值处理以及数据的清洗与转换。
第三章:描述统计分析描述统计分析是理解数据的第一步。
SPSS提供了丰富的描述统计方法,包括平均数、标准差、最小值、最大值、频数分布等。
用户可以通过简单的命令或者界面操作来生成各种描述统计结果,并进一步进行数据的可视化展示。
第四章:相关性分析相关性分析是多元统计分析的常用方法之一。
SPSS提供了丰富的相关性分析工具,如Pearson相关系数、Spearman等。
用户可以通过相关分析来检测不同变量之间的关系,并进一步探索变量之间的线性或非线性关系。
第五章:线性回归分析线性回归分析是一种预测性分析方法,在多元统计分析中应用广泛。
SPSS可以进行简单线性回归分析和多元线性回归分析。
用户可以通过线性回归分析来建立模型,预测因变量与自变量之间的关系,并进行参数估计和显著性检验。
第六章:因子分析因子分析是一种常用的降维技术,用于发现隐藏在数据中的潜在变量。
SPSS提供了主成分分析、最大似然因子分析等方法。
用户可以通过因子分析来降低变量的维度,提取数据中的主要信息。
第七章:聚类分析聚类分析是一种用于将数据样本划分成相似组的方法。
SPSS支持多种聚类算法,如K均值聚类、层次聚类等。
用户可以通过聚类分析来识别数据中的固有模式和群体。
第八章:判别分析判别分析是一种用于将样本分类的方法,常用于研究预测变量对分类变量的影响。
上机部分-多元统计分析的SPSS实现

要给出Fisher判别函数的系数。这个复选框的名字之所以为 Fisher’s,是因为按判别函数值最大的一组进行归类这种思想 是由Fisher提出来的。这里极易混淆,请读者注意辨别。) Unstandardized:给出未标准化的Fisher判别函数(即典型判 别函数)的系数(SPSS默认给出标准化的Fisher判别函数系 数)。
Function 1 -2.177 -2.270 -2.741 -3.199 -2.582 9.674 8.332 10.128 8.342 9.491 -6.687 -7.163 -8.655 -4.766 -5.727 -20.714 -3.319 14.008 -7.595
Function 2 1.364 1.375 1.323 .638 .366 .231 -.613 -2.518 1.760 -.145 -.394 -.685 -1.823 -.608 -.270 -13.498 .831 2.086 -1.752
图4.4 Classify…子对话框
5. 单击Save按钮,指定在数据文件中生成代表判别分组结果 和判别得分的新变量,生成的新变量的含义分别为:
Predicted group membership:存放判别样品所属组别的值; Discriminant scores:存放Fisher判别得分的值,有几个典型
表4.4 个案观察结果表
Case wise Statistic s Highe st Group Squared Mahalanobis Dista nce to Centroid .297 .236 .117 .507 .418 .469 .868 5.985 4.793 .101 .139 .322 5.365 3.384 .998 361.567 .558 28.668 1.982 Disc riminant Sc ores
SPSS的多元统计分析
9.1 SPSS在因子分析中的应用
3、基本步骤
由于实际中数据背景、特点均不相同,故采用因子分析步骤上可能 略有差异,但是一个较完整的因子分析主要包括如下几个过程: (1) 确认待分析的原变量是否适合作因子分析 因子分析的主要任务是将原有变量的信息重叠部分提取和综合成因 子,进而最终实现减少变量个数的目的。故它要求原始变量之间应存 在较强的相关关系。进行因子分析前,通常可以采取计算相关系数矩 阵、巴特利特球度检验和KMO检验等方法来检验候选数据是否适合采 用因子分析。 (2)构造因子变量 将原有变量综合成少数几个因子是因子分析的核心内容。它的关键 是根据样本数据求解因子载荷阵。因子载荷阵的求解方法有基于主成 分模型的主成分分析法、基于因子分析模型的主轴因子法、极大似然 法等。
9.1 SPSS在因子分析中的应用
Step06:选择因子得分
单击【Scores】按钮,在弹出的对话框中可以选择因子得分方法及相关 选项。具体选项含义如下。
9.1 SPSS在因子分析中的应用
①【Save as variables(保存为变量)】选项组:将因子得分作为新变 量保存在数据文件中。 ● Save as variables:将因子得分作为新变量保存在工作数据文件。 中。程序运行结束后,在数据窗中显示出新变量。 ②【Method(方法)】选项组:指定计算因子得分的方法。 ●Regression:回归法。选择此项,其因子得分的均值为0。方差等于估 计的因子得分与实际因子得分值之间的复相关系数的平方。 ● Bartlett:巴特利特法。选择此项,因子得分均值为0。超出变量范 围的各因子平方和被最小化。 ●Anderson-Rubin:安德森一鲁宾法。选择此项,是为了保证因子的正 交性。 本例选中“Regression”项。 ③ 在输出窗中显示因子得分。 ● Display factor score coefficient matrix:输出因子得分系数矩 阵。
SPSS多元统计分析方法及应用课程设计

SPSS多元统计分析方法及应用课程设计本文主要描述SPSS多元统计分析方法及应用课程设计。
包含如下内容:1.课程介绍2.学习目标3.课程内容4.教学方式5.评估方式6.总结1. 课程介绍SPSS是一款非常常用的统计软件,其多元统计方法可适用于许多研究领域。
本课程旨在通过实践教学的方式,让学生了解SPSS多元统计分析方法及其应用场景,掌握多元统计分析的常用方法,提高其研究数据分析能力和实践能力,帮助学生更好地进行本科学习和毕业设计。
2. 学习目标1.熟悉SPSS软件界面及其使用方法2.掌握多元线性回归、因子分析、聚类分析、主成分分析等多元统计分析方法3.掌握SPSS软件中多元统计分析的操作流程4.了解SPSS软件中多元统计分析方法的应用场景及其局限性5.使用SPSS软件进行多元统计分析的实践操作6.更好地进行本科学习和毕业设计的研究数据分析工作3. 课程内容本课程主要包括以下几个部分:3.1. SPSS软件介绍与使用1.SPSS软件的下载安装方法2.SPSS软件的界面介绍3.SPSS软件的基本操作方法3.2. 多元线性回归分析1.多元线性回归分析的基本概念及原理2.多元线性回归分析的假设检验方法3.自变量选择方法及其局限性4.建模方法及其评估3.3. 因子分析1.因子分析的基本概念及原理2.方差共线性及其影响因子分析3.因子分析的结果解释及评估3.4. 聚类分析1.聚类分析的基本概念及原理2.聚类分析的距离度量方法3.聚类分析的聚类方法4.聚类结果解释及评估3.5. 主成分分析1.主成分分析的基本概念及原理2.主成分分析的方法及其假设3.主成分分析的选择方法及其解释4.主成分分析结果的解释及评估3.6. 实验操作使用SPSS软件进行多元统计分析的实验操作,包括多元线性回归、因子分析、聚类分析、主成分分析等。
4. 教学方式1.讲解理论知识2.实例步骤演示3.互动讨论4.实验操作5. 评估方式1.考试笔试2.作业实验3.课堂互动6. 总结本课程将多元统计分析方法及其应用场景融入到实践操作中,帮助学生更好地理解和掌握多元统计分析方法的基本概念、原理及应用方法,并通过实验操作提高其数据分析和实践能力,为学生进一步开展研究工作提供帮助。
SPSS处理多元判别分析
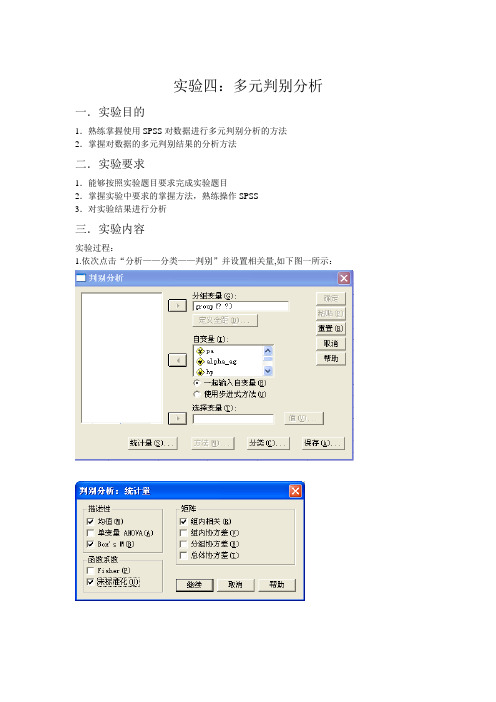
实验四:多元判别分析一.实验目的1.熟练掌握使用SPSS对数据进行多元判别分析的方法2.掌握对数据的多元判别结果的分析方法二.实验要求1.能够按照实验题目要求完成实验题目2.掌握实验中要求的掌握方法,熟练操作SPSS3.对实验结果进行分析三.实验内容实验过程:1.依次点击“分析——分类——判别”并设置相关量,如下图一所示:【图一】分析的结果如表一所示:【表一】判别分析案例处理摘要未加权案例N 百分比有效100 100.0 排除的缺失或越界组代码0 .0至少一个缺失判别变量0 .0缺失或越界组代码还有至少一个缺失判别变量0 .0合计0 .0 合计100 100.0组统计量group 均值标准差有效的 N(列表状态)未加权的已加权的正常人pa 28.2136 4.70056 25 25.000alpha_ag 67.5780 16.75241 25 25.000 hp 257.1212 126.27684 25 25.000 alpha_at 282.1680 30.83337 25 25.000肝癌,AFP检测阳性pa 15.8555 10.21072 40 40.000 alpha_ag 120.7943 62.04790 40 40.000 hp 321.8357 249.33407 40 40.000 alpha_at 492.4633 151.32253 40 40.000肝癌,AFP检测阴性pa 16.3145 7.80152 20 20.000 alpha_ag 55.2980 26.12832 20 20.000 hp 91.4700 126.45050 20 20.000 alpha_at 313.3080 55.59623 20 20.000肝硬化pa 21.9793 8.47264 15 15.000 alpha_ag 69.6187 50.46477 15 15.000hp 297.1527 210.05123 15 15.000alpha_at 314.7287 72.52736 15 15.000 合计pa 19.9554 9.77612 100 100.000 alpha_ag 86.7146 53.67732 100 100.000hp 255.8815 212.46384 100 100.000alpha_at 377.3982 140.18786 100 100.000汇聚的组内矩阵pa alpha_ag hp alpha_at相关性pa 1.000 -.112 .119 -.290alpha_ag -.112 1.000 .456 .528hp .119 .456 1.000 .484alpha_at -.290 .528 .484 1.000分析 1协方差矩阵的均等性的箱式检验对数行列式group 秩对数行列式正常人 4 25.055肝癌,AFP检测阳性 4 32.930肝癌,AFP检测阴性 4 26.634肝硬化 4 29.759汇聚的组内 4 30.930打印的行列式的秩和自然对数是组协方差矩阵的秩和自然对数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3 51.421 19.284
(常量)
aug-up
a. 因变量: degree
系数a
非标准化系数
标准系数
B
标准 误差 试用版
20.916
6.737
-.696
.261
-.664
t 3.105 -2.662
Sig. .013 .026
2.主成份分析与因子分析
2.1 主成份分析
【1】参考:陈比劲,物流技术,主成分分析法在投资项目选择的应用研究,第 28 卷总第 117 期,101-104 数据格式如下:
3
2.064
当然还有类中心等结果:
身高 体重 胸围 坐高
最终聚类中心
聚类
1
2
11.03 50.30 11.81 11.27
5.47 19.30
5.20 7.18
3 1.14 2.21 .67 .83
而这个是各类中心距离:
聚类 1 2 3
最终聚类中心间的距离
1
2
32.440
32.440
51.421 19.284
当然我们也可以做K聚类:做k-means聚类要知道聚类的类数m!其实从本质上说, 这种方法要需要我们制定m个聚类中心,我们可以叫他为核,然后在我们的聚类 过程中,根据某些法则,我们不断更新核中心和范围,最后形成聚类结果。 我们利用[1]中实例1中的数据:由于将儿童生长发育分为四期,其实指定聚类的 类别数为4,我偷懒我把聚类的类别定为3,原因请看[1]. 依然先准备数据:略了吧。。。说了很多遍了。。
准备数据
然后选择分析项目:
主成份分析在因子分析里面 则可得结果:
KMO 和 Bartlett 的检验
取样足够度的 Kaiser-Meyer-Olkin 度量。
Bartlett 的球形度检 近似卡方
验
df
Sig.
这个是相关性检验
.191 15.663
10 .110
公因子方差
初始
政策风险 技术风险 市场风险 管理风险 环境风险
3.1.2 面向因子的聚类
我们的问题是:29名儿童的血红蛋白(g/100ml)与微量元素(μg/100ml)测定结果如下
表。由于微量元素的测定成本高、耗时长,故希望通过聚类分析(即R型指标聚类)筛选代 表性指标,以便更经济快捷地评价儿童的营养状态。
数据准备和上面相同,但是选择命令时,注意:
当然,当我们选择的聚类方法不一样时,我们聚类对话框就要选定:
式供用户选择: Ø Euclidean distance:Euclidean 距离,即两观察单位间的距离为其值差的平方和的平
方根,该技术用于 Q 型聚类; Ø Squared Euclidean distance:Euclidean 距离平方,即两观察单位间的距离为其值差
的平方和,该技术用于 Q 型聚类; Ø Cosine:变量矢量的余弦,这是模型相似性的度量; Ø Pearson correlation:相关系数距离,适用于 R 型聚类; Ø Chebychev:Chebychev 距离,即两观察单位间的距离为其任意变量的最大绝对差值,
该技术用于 Q 型聚类; Ø Block:City-Block 或 Manhattan 距离,即两观察单位间的距离为其值差的绝对值和,
适用于 Q 型聚类; Ø Minkowski:距离是一个绝对幂的度量,即变量绝对值的第 p 次幂之和的平方根;p 由
用户指定 Ø Customized:距离是一个绝对幂的度量,即变量绝对值的第 p 次幂之和的第 r 次根,p
9
15.00
10
18.00
11
24.00
12
30.00
13
36.00
14
42.00
15
48.00
3
1.369
3
.899
3
.648
3
.230
3
1.031
3
.977
3
1.349
3
1.224
3
1.616
3
1.225
16
54.00
3
1.669
17
60.00
18
66.00
19
72.00
3
2.013
3
1.405
20
22
27
25
22
23 1748.834
0
23
26
26
18
22 2403.799
19
25
28
27
1
6 3188.384
24
18
28
28
1
18 15439.770
27
26
0
聚类表给出了,聚类的合并步骤:
第一步:No1和No7合并,其欧式距离为1;
第二部:No23和No24合并,其欧式距离为12.299;
2
1.646
32.919
69.993
1.646
32.919 69.993
3
.953
19.056
89.048
4
.528
10.550
99.598
5
.020
.402 100.000
提取方法:主成份分析。
总方差构成表,累计贡献率
成份矩阵a
成份
1
2
政策风险 技术风险 市场风险 管理风险 环境风险
-.595 .081 .857 .787
0
6
19
16
6
10
270.270
0
0
18
17
8
14
294.639
0
0
22
18
6
9
415.494
16
12
27
19
18
27
445.067
15
0
26
20
1
2
613.678
13
8
24
21
3
13
644.393
0
7
22
22
3
8
767.803
21
17
24
23
23
25
852.436
14
10
25
24
1
3 1447.764
-.372
.727 .936 .392 -.104 -.275
提取方法 :主成份。
3 -.095
.324 .082 .224 .884
成份矩阵a
成份
1
2
政策风险 技术风险 市场风险 管理风险 环境风险
-.595 .081 .857 .787
-.372
.727 .936 .392 -.104 -.275
1.000 1.000 1.000 1.000 1.000
提取方法:主成份分析。
这是因子提取度
提取 .883 .883 .889 .631 .214
解释的总方差
初始特征值
提取平方和载入
成份
合计
方差的 % 累积 %
合计
方差的 % 累积 %
1
1.854
37.073
37.073
1.854
37.073 37.073
.341 .086 .235 .928
成份得分协方差矩阵
成份
1
2
1
1.000
.000
2
.000
1.000
3
.000
.000
提取方法 :主成份。
3 .000 .000
1.000
3.聚类分分析
参考文献: [1]佚名,第十章 分类分析,/news/spss/doc3/sp10.htm,2011/8/24;
提取方法 :主成份。 a. 已提取了 3 个成份。
3 -.095
.324 .082 .224 .884
提前三成份
成份图
成份得分系数矩阵
成份
1
2
政策风险
-.321
.442
技术风险
.044
.569
市场风险
.462
.238
管理风险
.425
-.063
环境风险
-.201
-.167
提取方法 :主成份。
3 -.100
如果要做逐步回归的话,请选择:逐步;右边选择你需要的东西,单击确认,得到 结果。
输入/移去的变量a
模型 输入的变量 移去的变量
方法
1
aug-up
. 步进(准则: F-to-enter 的 概率 <= .050, F-to-remove 的 概率 >= .100)。
a. 因变量: degree
模型
1
然后选择K-mean聚类命令:
注意填上聚类的类数:
各人建议把这个选上,结果比较明显:
输出结果: 这个就是,上述选择的结果,否则这个不输出:
聚类成员
案例号
月份
聚类
距离
1
1.00
1
.000
2
2.00
2
.000
3
3.00
3
8.495
4
4.00
3
2.415
5
6.00
3
3.826
6
8.00
7
10.00
8
12.00
所以,做聚类的时候,要注意选择适合样本和研究背景的要求,请认真选择,这 是很重要的,spss提供的方法和度量标准有以下几个:
Ø Between-groups linkage:类间平均链锁法; Ø Within-groups linkage:类内平均链锁法; Ø Nearest neighbor:最近邻居法; Ø Furthest neighbor:最远邻居法; Ø Centroid clustering:重心法,应与欧氏距离平方法一起使用; Ø Median clustering:中间距离法,应与欧氏距离平方法一起使用; Ø Ward's method:离差平方和法,应与欧氏距离平方法一起使用。 Ø 本例选择类间平均链锁法(系统默认方法)。在选择距离测量技术上,系统提供 8 种形