共享内存使用方法
python多进sharedmemory用法

python多进sharedmemory用法(最新版)目录1.共享内存的概念与作用2.Python 多进程的共享内存实现方法3.使用 sharedmemory 的实例与注意事项正文一、共享内存的概念与作用共享内存是多进程或多线程之间共享数据空间的一种技术。
在多进程或多线程程序中,共享内存可以实现进程或线程之间的数据交换和同步,从而提高程序的运行效率。
Python 提供了 sharedmemory 模块来实现多进程之间的共享内存。
二、Python 多进程的共享内存实现方法在 Python 中,可以使用 multiprocessing 模块创建多进程,并使用 sharedmemory 模块实现进程间的共享内存。
以下是一个简单的示例:```pythonimport multiprocessing as mpimport sharedmemorydef func(shm):shm.write(b"Hello, shared memory!")if __name__ == "__main__":shm = sharedmemory.SharedMemory(name="my_shared_memory", size=1024)p = mp.Process(target=func, args=(shm,))p.start()p.join()print(shm.read(0, 1024))```在这个示例中,我们首先导入 multiprocessing 和 sharedmemory 模块。
然后,定义一个函数 func,该函数接收一个共享内存对象 shm 作为参数,并将字节串"Hello, shared memory!"写入共享内存。
在主进程中,我们创建一个共享内存对象 shm,并启动一个子进程 p,将 func 函数和共享内存对象 shm 作为参数传递给子进程。
simulink的shared memory模块具体使用方法

simulink的shared memory模块具体使用方法Simulink的Shared Memory模块是一种用于在不同的模型之间传递数据的工具。
这个模块可以允许不同的模块或系统在同一进程中相互通信,而无需通过繁琐的外部接口。
下面将介绍Shared Memory模块的具体使用方法。
首先,在Simulink模型中引入Shared Memory模块。
在模块库浏览器中选择FPGA & ASIC Design,然后选择HDLC和Memory部分,找到Shared Memory模块。
将该模块拖动到模型中适当的位置。
接下来,配置Shared Memory模块的参数。
双击Shared Memory模块,弹出模块参数对话框。
在这里,你可以设置共享内存的名称、大小和访问权限等。
确保选择一个唯一的名称,以便其他模型可以识别和使用共享内存。
然后,在发送数据的模型中,将要共享的数据连接到Shared Memory模块的信号输入端口。
你可以使用常规的数据源模块(如Constant或Signal Generator)来生成要传递的数据。
将输出信号连接到Shared Memory模块的Data In输入端口。
在接收数据的模型中,将Shared Memory模块的Data Out输出端口连接到相应的信号处理模块,以处理接收到的数据。
确保在模型中的其他部分由相应的时钟或触发信号驱动,以确保数据在正确的时刻传输和接收。
你可以使用时钟源模块或者Trigger模块来提供时基信号。
最后,进行模型的编译和仿真。
保存并编译模型,然后运行仿真以验证Shared Memory模块的功能。
你可以在仿真结果中检查发送和接收数据是否正确。
总结一下,通过Simulink的Shared Memory模块,我们可以在不同的模型之间实现数据的共享和通信。
只需简单配置参数和连接信号,就能方便地在同一进程中传递数据,提高模型的灵活性和效率。
希望这篇文章对你了解Shared Memory模块的具体使用方法有所帮助。
python读取共享内存的几种方法

共享内存是指多个进程之间可以共同访问的内存空间,通常用于进程之间的通讯。
Python作为一种广泛应用的编程语言,在处理共享内存时也有多种方法。
本文将介绍Python读取共享内存的几种方法,希望能对读者有所帮助。
1. 使用Python标准库multiprocessing中的Value和ArrayPython的multiprocessing库提供了Value和Array两种数据结构,它们可以在多个进程之间共享。
Value用于共享一个单一的值,而Array则用于共享一个数组。
下面是一个使用Value和Array读取共享内存的简单示例:```pythonimport multiprocessingimport ctypesdef worker1(shared_value):print("Worker 1: ", shared_value.value)def worker2(shared_array):for i in shared_array:print("Worker 2: ", i)if __name__ == "__m本人n__":shared_value = multiprocessing.Value(ctypes.c_int, 5)shared_array = multiprocessing.Array(ctypes.c_int, [1, 2, 3, 4, 5])p1 = multiprocessing.Process(target=worker1,args=(shared_value,))p2 = multiprocessing.Process(target=worker2,args=(shared_array,))p1.start()p2.start()p1.join()p2.join()```2. 使用Python第三方库multiprocess除了使用Python标准库中的multiprocessing,还可以使用第三方库multiprocess实现共享内存的读取。
python多进sharedmemory用法

python多进sharedmemory用法(最新版)目录1.Python 多进程共享内存的使用方法2.共享内存的优势与局限性3.实例:使用 Python 多进程和共享内存实现一个简单的计算任务正文在 Python 多进程编程中,共享内存是一种重要的通信方式,可以让多个进程之间共享数据,从而实现进程间的协作。
本文将介绍 Python 多进程共享内存的使用方法,并结合一个实例来说明如何使用共享内存实现一个简单的计算任务。
一、Python 多进程共享内存的使用方法Python 提供了`multiprocessing`模块来支持多进程编程。
在`multiprocessing`模块中,可以使用`SharedMemory`类来创建一个共享内存对象。
下面是一个简单的示例:```pythonimport multiprocessing as mp# 创建一个共享内存对象shared_memory = mp.SharedMemory("shared_memory", size=100) # 在子进程中访问共享内存def child(shared_memory):shared_memory.append("Hello, shared memory!")# 启动子进程p = mp.Process(target=child, args=(shared_memory,))p.start()p.join()# 在主进程中访问共享内存print(shared_memory.getvalue())```二、共享内存的优势与局限性共享内存的优势在于可以让多个进程之间直接共享数据,从而降低通信的开销。
这对于那些需要频繁访问共享数据的进程来说,可以提高程序的运行效率。
然而,共享内存也有其局限性。
首先,共享内存的数据是多个进程共享的,因此需要考虑数据的同步问题。
当多个进程同时访问共享内存时,需要保证数据的一致性。
共享内存在Java中的实现和应用

共享内存在Java中的实现和应用共享内存是一种用于进程间通信的机制,它允许多个进程共享同一块内存区域。
在Java中,共享内存主要通过以下几种方式实现和应用:Java内存映射、并发集合类、Java共享数据模型和进程间通信。
首先,Java内存映射是Java提供的一种共享内存的机制。
通过Java 的NIO(New Input/Output)库中的MappedByteBuffer类,我们可以将文件或内存映射到内存中,并通过同一个文件或内存来实现进程之间的通信。
这种方式可以提高进程间通信的效率,并且方便地处理大量数据。
例如,一些进程可以将数据写入共享内存,而其他进程可以直接从共享内存中读取数据,避免了不必要的数据拷贝和通信开销。
其次,Java提供了一系列的并发集合类,如ConcurrentHashMap、ConcurrentLinkedQueue等,它们内部使用了共享内存实现多线程之间的安全访问。
这些集合类通过使用非阻塞算法和锁分离等技术,实现了高效地共享内存访问。
这样,多个线程可以同时读写共享内存,而无需显式地进行同步操作。
这种方式在并发编程中得到广泛应用,例如多线程的生产者-消费者模型、线程池等场景。
此外,Java还提供了一种共享数据模型,即Java内存模型(Java Memory Model,JMM)。
JMM定义了多线程之间如何共享数据的规范,通过使用volatile、synchronized等关键字来保证共享内存的可见性和一致性。
JMM提供了一种方便的方式来实现多线程之间的共享数据访问,使得开发者可以更容易地编写并发程序。
例如,多个线程可以通过共享变量来进行状态同步、线程间的通信等操作。
最后,Java中的进程间通信也可以使用共享内存来实现。
通过操作系统的底层API,Java可以创建共享内存区域,并在不同的进程之间共享该内存区域。
例如,Java提供了一种称为JNI(Java Native Interface)的机制,允许Java程序通过调用本地代码来访问操作系统的底层功能。
android sharedmemory用法

android sharedmemory用法全文共四篇示例,供读者参考第一篇示例:Android SharedMemory是一种用于在多个进程之间共享数据的机制。
它允许不同应用程序之间共享大块内存,这对于需要高性能数据交换的应用程序非常有用,比如多媒体应用程序或游戏。
在Android系统中,每个进程都有自己的独立地址空间,因此默认情况下进程之间不能直接共享内存。
但是Android SharedMemory 提供了一种方法让不同进程之间可以共享内存块。
这种共享内存块创建的共享内存区域可以由不同进程映射到自己的地址空间中,从而实现数据共享。
SharedMemory的用法非常简单,首先需要创建一个SharedMemory对象,然后使用该对象创建一个共享内存区域,并将数据写入其中。
接着,其他进程可以通过SharedMemory对象来访问共享内存区域,即可以将这个内存区域映射到自己的地址空间,并读取其中的数据。
在Android中,可以使用SharedMemory API来实现SharedMemory的功能。
下面是一个基本的SharedMemory用法示例:1. 创建SharedMemory对象SharedMemory sharedMemory =SharedMemory.create("shared_memory_name", 1024);这行代码创建了一个名为"shared_memory_name",大小为1024字节的共享内存区域。
2. 写入数据这段代码将"Hello, SharedMemory!"这个字符串写入了共享内存区域中。
3. 读取数据SharedMemory sharedMemory =SharedMemory.create("shared_memory_name", 1024);ByteBuffer byteBuffer = sharedMemory.mapReadOnly();byte[] data = new byte[1024];byteBuffer.get(data);通过上面的示例,我们可以看到SharedMemory的基本用法。
CUDA共享内存的使用示例
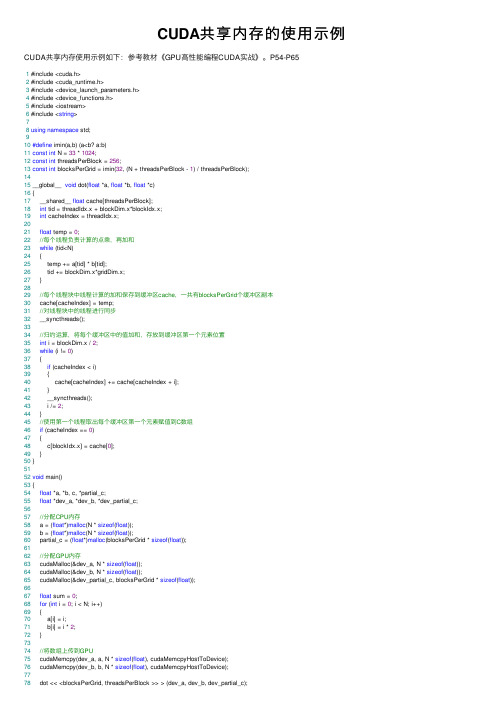
CUDA共享内存的使⽤⽰例CUDA共享内存使⽤⽰例如下:参考教材《GPU⾼性能编程CUDA实战》。
P54-P651 #include <cuda.h>2 #include <cuda_runtime.h>3 #include <device_launch_parameters.h>4 #include <device_functions.h>5 #include <iostream>6 #include <string>78using namespace std;910#define imin(a,b) (a<b? a:b)11const int N = 33 * 1024;12const int threadsPerBlock = 256;13const int blocksPerGrid = imin(32, (N + threadsPerBlock - 1) / threadsPerBlock);1415 __global__ void dot(float *a, float *b, float *c)16 {17 __shared__ float cache[threadsPerBlock];18int tid = threadIdx.x + blockDim.x*blockIdx.x;19int cacheIndex = threadIdx.x;2021float temp = 0;22//每个线程负责计算的点乘,再加和23while (tid<N)24 {25 temp += a[tid] * b[tid];26 tid += blockDim.x*gridDim.x;27 }2829//每个线程块中线程计算的加和保存到缓冲区cache,⼀共有blocksPerGrid个缓冲区副本30 cache[cacheIndex] = temp;31//对线程块中的线程进⾏同步32 __syncthreads();3334//归约运算,将每个缓冲区中的值加和,存放到缓冲区第⼀个元素位置35int i = blockDim.x / 2;36while (i != 0)37 {38if (cacheIndex < i)39 {40 cache[cacheIndex] += cache[cacheIndex + i];41 }42 __syncthreads();43 i /= 2;44 }45//使⽤第⼀个线程取出每个缓冲区第⼀个元素赋值到C数组46if (cacheIndex == 0)47 {48 c[blockIdx.x] = cache[0];49 }50 }5152void main()53 {54float *a, *b, c, *partial_c;55float *dev_a, *dev_b, *dev_partial_c;5657//分配CPU内存58 a = (float*)malloc(N * sizeof(float));59 b = (float*)malloc(N * sizeof(float));60 partial_c = (float*)malloc(blocksPerGrid * sizeof(float));6162//分配GPU内存63 cudaMalloc(&dev_a, N * sizeof(float));64 cudaMalloc(&dev_b, N * sizeof(float));65 cudaMalloc(&dev_partial_c, blocksPerGrid * sizeof(float));6667float sum = 0;68for (int i = 0; i < N; i++)69 {70 a[i] = i;71 b[i] = i * 2;72 }7374//将数组上传到GPU75 cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice);76 cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice);7778 dot << <blocksPerGrid, threadsPerBlock >> > (dev_a, dev_b, dev_partial_c);7980 cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost); 8182//CPU 完成最终求和83 c = 0;84for (int i = 0; i < blocksPerGrid; i++)85 {86 c += partial_c[i];87 }8889#define sum_squares(x) (x*(x+1)*(2*x+1)/6)90 printf("does GPU value %.6g = %.6g?\n", c, 2 * sum_squares((float)(N - 1)));9192 cudaFree(dev_a);93 cudaFree(dev_b);94 cudaFree(dev_partial_c);9596free(a);97free(b);98free(partial_c);99 }我的博客即将同步⾄腾讯云+社区,邀请⼤家⼀同⼊驻。
cuda共享内存使用方法

cuda共享内存使用方法CUDA共享内存是一种特殊的内存类型,它位于多个线程块之间共享的内存区域。
使用共享内存可以提高线程块之间的数据传输速度,从而加速CUDA程序的执行。
在本文中,我们将介绍如何使用CUDA共享内存以及一些最佳实践方法。
首先,让我们来看一下如何在CUDA中声明共享内存。
在CUDA 中,可以使用`__shared__`关键字来声明共享内存。
例如,下面的代码演示了如何在CUDA中声明一个共享内存数组:cuda.__shared__ int sharedArray[128];在这个例子中,我们声明了一个包含128个整数的共享内存数组。
在每个线程块中,都会有一个这样的共享内存数组实例。
接下来,让我们看一下如何在CUDA内核函数中使用共享内存。
在内核函数中,可以使用共享内存来临时存储数据,以便线程块中的线程可以快速访问。
下面是一个简单的示例,展示了如何在CUDA内核函数中使用共享内存:cuda.__global__ void myKernel()。
{。
__shared__ int sharedArray[128];// 在共享内存中进行数据操作。
sharedArray[threadIdx.x] = threadIdx.x; // 等待所有线程完成共享内存操作。
__syncthreads();// 使用共享内存中的数据进行计算。
int result = sharedArray[threadIdx.x] 2;}。
在这个示例中,我们首先声明了一个共享内存数组`sharedArray`,然后在内核函数中使用了这个共享内存数组来存储线程索引,并进行一些简单的计算。
除了上述基本的使用方法外,还有一些最佳实践方法可以帮助我们更好地使用CUDA共享内存。
首先,要注意共享内存的大小限制,不要超出设备的限制。
其次,尽量避免使用过多的共享内存,因为它可能会降低线程块的并行性。
最后,要确保正确同步共享内存的访问,可以使用`__syncthreads()`函数来确保所有线程都已经完成对共享内存的操作。
python多进sharedmemory用法

python多进sharedmemory用法摘要:1.Python 共享内存的概念与作用2.Python 共享内存的适用场景3.Python 共享内存的实现方法a.使用`shm`模块b.使用`multiprocessing`模块4.Python 共享内存的使用示例a.使用`shm`模块实现共享内存b.使用`multiprocessing`模块实现共享内存5.总结与展望正文:Python 共享内存是指多个进程或线程可以访问同一块内存区域的数据,从而实现进程或线程间的数据交换与同步。
共享内存是多进程/线程编程中一种高效的通信方式,可以有效减少进程/线程间的数据拷贝,提高程序运行效率。
Python 共享内存适用于以下场景:- 多个进程/线程需要访问同一份数据,如全局变量、中间结果等。
- 进程/线程间需要进行高效的同步操作,如信号量、互斥锁等。
在Python 中,可以通过`shm`模块或`multiprocessing`模块实现共享内存。
1.使用`shm`模块实现共享内存首先,需要安装`shm`模块,通过命令行安装:```pip install python-sharedmemory```然后,可以使用`shm`模块创建共享内存区域,并设置访问权限。
以下是一个简单的示例:```pythonimport shmimport os# 创建共享内存区域shm_area = shm.SharedMemory(size=10)# 获取共享内存的地址shm_addr = shm_area.fd# 设置共享内存的访问权限os.fchmod(shm_addr, 0o666)# 访问共享内存data = shm_area.read()print(data)```2.使用`multiprocessing`模块实现共享内存`multiprocessing`模块是Python 自带的多进程支持库,可以方便地实现共享内存。
以下是一个简单的示例:```pythonimport multiprocessingdef worker(shm_area):data = shm_area.valueprint(data)if __name__ == "__main__":# 创建共享内存区域shm_area = multiprocessing.SharedMemory(size=10)# 启动子进程p = multiprocessing.Process(target=worker, args=(shm_area,))p.start()# 设置共享内存的值shm_area.value = b"hello"# 等待子进程结束p.join()```总结:Python 共享内存是一种高效的多进程/线程通信方式,可以通过`shm`模块或`multiprocessing`模块实现。
windows下共享内存的使用(c语言版本)

windows下共享内存的使⽤(c语⾔版本)共享内存就是说⽩了就是⼀种映射。
我参考了以及⽹易“开⼼⼀族的博客”的东西。
在(winXP+vs2008环境下编译通过)共享内存在 Windows 中是⽤ FileMapping 实现的。
HANDLE CreateFileMapping( //返回File Mapping Object的句柄HANDLE hFile, // 想要产⽣映射的⽂件的句柄LPSECURITY_ATTRIBUTES lpAttributes, // 安全属性(只对NT和2000⽣效)DWORD flProtect, // 保护标致DWORD dwMaximumSizeHigh, // 在DWORD的⾼位中存放File Mapping Object // 的⼤⼩DWORD dwMaximumSizeLow, // 在DWORD的低位中存放File Mapping Object // 的⼤⼩(通常这两个参数有⼀个为0)LPCTSTR lpName // File Mapping Object的名称。
);我们可以⽤ CreateFileMapping 创建⼀个内存⽂件映射对象, CreateFileMapping 这个 API 将创建⼀个内核对象,⽤于映射⽂件到内存。
这⾥,我们并不需要⼀个实际的⽂件,所以,就不需要调⽤ CreateFile 创建⼀个⽂件, hFile 这个参数可以填写INVALID_HANDLE_VALUE 。
但是,⽂件长度是需要填的。
Windows ⽀持长达 64bit 的⽂件,但是这⾥,我们的需求⼀定不会超过4G , dwMaximumSizeHigh ⼀定是 0 ,长度填在 dwMaximumSizeLow 即可。
然后调⽤ MapViewOfFile 映射到当前进程的虚拟地址上即可。
⼀旦⽤完共享内存,再调⽤ UnmapViewOfFile 回收内存地址空间。
以下有2个进程,A.c⽣成A进程,B.c⽣成b进程。
CUDA——了解和使用共享内存

大提高 内核 的性能。如果每个多处理器可用 的寄存器或共
享 内存 不 足 以处 理 至 少 一 个 块 ,内 核 将 无 法 启 动 。
每个活动块被分 割成 线程SI ( MD 单指令 多数据 )群 , 称 为Wap 每个 Wap包含 同样 数 量的线程 ,称 为Wap r; r r
s e 被 多 处 理 器 以 SI i , z MD方 式 执 行 。 这 意 味 着 Wap中 r
起 某些 问题 。
每个 多处理器 ,见上 图的块 (, ) 0 0 和块 (, ) 1 0,均包含
以下 四 种 内 存 类 型 :
● 每线程一组本地寄存器 。 ● 一个并行数据缓存或共享 内存 。被所有线程共享 ; 能实现共享内存空间。 ● ~ 个只读 的 常量 缓存 。被 所有 线程共 享; 能加快 读取 常量内存空间的速 度;被实现 为设备 内存 的只读 区。 ● 一个只读 的纹理 缓存 。被 所有 处理器 共享 ;能加 快读取纹理 内存 空间的速度;被 实现 为设备 内存 的只读 区。 不要被上图 中的多处理器 中标有 “ 地内存”的块所 本
CU A 执行模型 D
为了尽 可能提 高性能,每个硬 件多处理器都可 以同时 积极处理 多个块 。能处理多少则取决于每个线程有 多少个 寄存器 和某一内核需要每个块 的多少共享 内存 。一个 多处 理器 同时处 理的块被 称为活动块 。具有最少资源需 求的内
的是快速的本地多处理器内存是很昂贵的。我们都同意廉
一
个块里 的其他线 程读取 ,但 不能被 不同块 的线程读取 。
具 有这些特 征的共享 内存可 以在硬件 中非常有效地 实现 ,
并转化 为CU A开发人员所需的快速内存访问。 D 现在我们有办 法让支持 CUD A的硬件设计 师在价格和 CU A软 件开发人 员需 求之间取 得平衡 。作为开 发人 员, D 我们希 望有大量的本地多处理器资源 ,例如 寄存器 和共享 内存 。这会使 工作 更轻松,也让我们的软件更有效率 。而 另一方面 ,硬件 设计 师需要提供价格低廉 的硬件 ,但不幸
共享内存使用注意事项

共享内存使用注意事项1. 避免并发写入:共享内存区域应该尽量避免多个进程同时写入,否则可能导致数据混乱和不一致。
2. 同步访问:为了确保共享内存的一致性,进程在访问共享内存时应该使用同步机制,如信号量、互斥锁等。
3. 内存泄漏:需要确保在使用完共享内存后能够及时释放,避免内存泄漏问题。
4. 避免频繁的访问:频繁的读写会增加锁的竞争,造成性能下降,应该尽量减少对共享内存的访问。
5. 缓冲区大小:在设计共享内存时,需要考虑合理的缓冲区大小,以免出现数据溢出或性能下降。
6. 垃圾数据:共享内存中可能存在垃圾数据或不可预料的数据,需要做好数据校验和清理工作。
7. 进程崩溃处理:在多进程共享内存的情况下,一旦某个进程崩溃可能导致共享内存中的数据不一致,需要做好进程崩溃的处理机制。
8. 锁的粒度:锁的粒度应该尽量合理,避免因锁的持有时间过长而降低性能。
9. 内存对齐:在设计共享内存时,需要考虑内存对齐的问题,以免出现因为内存对齐导致的性能问题。
10. 数据一致性:共享内存中的数据一致性问题需要特别重视,需要考虑如何确保数据的一致性。
11. 写时复制:对于大块的共享内存,可以考虑使用写时复制(Copy-On-Write)机制,减少内存拷贝的开销。
12. 内存映射:在使用共享内存时,可以考虑使用内存映射(mmap)来提高性能和方便管理。
13. 内存访问控制:在设计共享内存时,需要考虑如何进行访问控制,确保只有授权的进程能够访问共享内存。
14. 数据序列化:在共享内存中存储复杂的数据结构时,需要考虑如何进行数据序列化和反序列化。
15. 数据边界:需要考虑数据边界对齐的问题,以免出现由于数据边界导致的性能问题。
16. 共享内存的生命周期:需要考虑共享内存的生命周期管理,包括创建、销毁等操作。
17. 内存保护:在设计共享内存时,需要考虑如何进行内存保护,防止因意外操作导致数据损坏。
18. 内存污染:需要考虑如何避免共享内存被恶意程序污染,确保共享内存数据的安全性。
显卡共享内存

显卡共享内存
显卡共享内存是指计算机中的显卡(也称为显卡)中分配给系统内存的一部分内存。
在传统的计算机系统中,显卡用于处理图形和视频数据,它通过使用自己的内存来存储和处理这些数据。
然而,随着计算机越来越多地用于处理图形密集型任务,例如游戏和视频编辑,显卡内存的需求也越来越大。
为了解决这个问题,一些计算机制造商开始在显卡中增加共享内存的功能。
共享内存是计算机内存的一部分,可以被多个硬件组件共享使用。
通过将一部分系统内存分配给显卡,系统可以将显存和系统内存结合起来使用,从而提供更大的内存容量和更好的图形和视频处理性能。
显卡共享内存的具体分配方法和大小取决于显卡的型号和制造商。
一些显卡可以通过BIOS设置来配置共享内存的大小,而其他显卡则自动根据系统的需要动态分配内存。
在许多计算机系统中,显卡共享内存的大小通常会根据系统内存的总量进行动态分配。
例如,如果系统内存为8GB,则可以分配一部分内存(例如1GB或2GB)给显卡作为共享内存。
然而,显卡共享内存并不是没有缺点的。
由于共享内存会减少系统内存的可用空间,它可能会对系统整体的性能产生一定影响。
此外,显卡共享内存的处理速度可能不如显存,因为它是通过计算机的系统总线进行访问的,而显存则直接连接到显卡的图形处理单元。
尽管如此,显卡共享内存仍然是一个有用的功能,尤其是对于
一些日常办公和轻度娱乐的计算机用户来说。
它可以提供足够的图形和视频处理能力,而不需要额外的显存芯片。
对于那些需要更高性能的用户,他们可能仍然需要购买具有独立显存的显卡,以获得更好的图形处理能力。
simulink的shared memory模块具体使用方法

simulink的shared memory模块具体使用方法Simulink是一款功能强大的可视化建模和仿真环境,可以用于各种系统的设计和分析。
在Simulink中,shared memory(共享内存)是一种用于在不同模块之间传递数据的机制。
本文将介绍shared memory模块的具体使用方法,包括如何创建shared memory,如何在Simulink模型中使用shared memory,并给出一些实例来说明其使用场景和注意事项。
一、共享内存概述共享内存是一种在多进程或多线程环境中用于共享数据的机制,它允许不同的进程或线程通过读取和写入同一块内存区域来传递数据。
在Simulink中,共享内存模块允许不同模块之间通过读取和写入共享内存块来传递数据。
共享内存模块在Simulink中的应用场景非常广泛,比如在并行计算中,可以通过共享内存模块传递数据,以提高计算的效率;在多任务系统中,可以通过共享内存模块传递任务之间的状态信息;在通信系统中,可以通过共享内存模块传递数据包等。
二、创建共享内存在Simulink中创建共享内存模块非常简单。
首先,打开Simulink,选择一个模型文件或者新建一个模型文件。
然后,点击"Library Browser"按钮,在"Simulink"类别下找到"Signal Routing"子类别,点击"Shared Memory"模块。
在模型中拖拽一个共享内存模块到合适的位置。
接下来,双击共享内存模块,弹出其属性对话框。
在对话框中,可以设置共享内存块的名称、大小和数据类型等参数。
点击确认之后,共享内存模块就创建成功了。
三、在Simulink模型中使用共享内存在Simulink模型中使用共享内存非常简单。
首先,将要读取共享内存或写入共享内存的模块连接到共享内存模块。
然后,双击共享内存模块,弹出其属性对话框。
python读取共享内存数据的方法

一、什么是共享内存共享内存是一种进程间通信的方式,它允许不同的进程访问同一块内存空间。
这种通信方式可以提高进程间的数据交换速度,适用于需要频繁交换数据的场景。
在Python中,我们可以使用共享内存来实现进程间的数据共享。
二、Python中的共享内存模块Python提供了multiprocessing模块来支持进程间的通信和共享内存。
在multiprocessing模块中,有一个Value和Array类可以用于创建共享内存。
Value类用于创建单个变量的共享内存,而Array类用于创建数组类型的共享内存。
三、使用Value类读取共享内存数据1. 我们需要导入multiprocessing模块:```pythonimport multiprocessing```2. 我们可以使用Value类来创建共享内存变量:```pythonshared_value = multiprocessing.Value('i', 0)```3. 在上面的代码中,我们创建了一个共享整数变量,初始值为0。
`'i'`表示变量的数据类型为整数。
4. 要读取共享内存中的数据,我们可以直接访问Value对象的value 属性:```pythondata = shared_value.valueprint(data)```5. 通过上面的代码,我们可以读取共享内存中的数据,并将其打印出来。
四、使用Array类读取共享内存数据1. 与Value类类似,我们首先需要导入multiprocessing模块:```pythonimport multiprocessing```2. 我们可以使用Array类来创建共享内存数组:```pythonshared_array = multiprocessing.Array('i', [1, 2, 3, 4, 5])```3. 在上面的代码中,我们创建了一个包含5个整数的共享内存数组,初始值为1, 2, 3, 4, 5。
Shell脚本编写的高级技巧使用共享内存和进程间通信

Shell脚本编写的高级技巧使用共享内存和进程间通信共享内存和进程间通信是Shell脚本编写中非常重要的技巧和概念。
它们可以帮助我们实现进程之间的数据传递和通信。
本文将介绍使用共享内存和进程间通信的高级技巧,以及如何在Shell脚本中应用这些技巧。
一、共享内存1.1 什么是共享内存共享内存是一种用于进程间通信的机制,它允许不同的进程访问同一块内存区域。
通过共享内存,多个进程可以实现数据共享,从而提高程序的效率。
1.2 在Shell脚本中使用共享内存在Shell脚本中使用共享内存需要借助一些系统命令和工具,比如ipcs、ipcrm等。
下面是一个使用共享内存实现数据传递的例子:```shell#!/bin/bash# 创建共享内存shm_id=$(ipcs -m | grep "0x" | awk '{ print $2 }')if [ -z "$shm_id" ]; thenshm_id=$(ipcmk -M | awk '{ print $NF }')fi# 写入数据data="Hello, shared memory!"echo -n "$data" > /dev/shm/$shm_id# 读取数据data=$(cat /dev/shm/$shm_id)echo "Shared memory data: $data"# 删除共享内存ipcrm -M $shm_id```这个脚本首先用ipcs命令检查是否已存在共享内存,如果不存在则用ipcmk命令创建一块共享内存。
然后,它通过echo命令将数据写入共享内存,再通过cat命令读取共享内存中的数据。
最后,使用ipcrm 命令删除共享内存。
二、进程间通信2.1 什么是进程间通信进程间通信(Inter-Process Communication,简称IPC)是指不同进程之间进行数据交换和通信的机制。
Linux命令高级技巧使用ipcs和ipcrm管理共享内存和信号量

Linux命令高级技巧使用ipcs和ipcrm管理共享内存和信号量Linux命令高级技巧:使用ipcs和ipcrm管理共享内存和信号量在Linux操作系统中,共享内存和信号量是进程间通信的重要手段。
使用ipcs和ipcrm命令可以对共享内存和信号量进行管理和操作。
本文将介绍如何使用ipcs和ipcrm命令来高效管理共享内存和信号量。
一、共享内存介绍及管理共享内存是进程之间共享数据的一种方式,提高了进程间数据交换的效率。
在Linux中,使用ipcs命令可以查看当前系统中存在的共享内存情况。
```bash$ ipcs -m```上述命令将列出所有共享内存的相关信息,包括共享内存的标识符、大小、进程ID等。
通过查看这些信息,我们可以了解当前系统的共享内存使用情况。
接下来,我们可以使用ipcrm命令来删除无用的共享内存。
```bash$ ipcrm -m <共享内存标识符>```上述命令将删除指定标识符的共享内存。
需要注意的是,只有创建该共享内存的进程或具有足够权限的用户才能删除共享内存。
二、信号量介绍及管理信号量是用来协调多个进程之间对共享资源的访问的一种机制。
在Linux中,使用ipcs命令可以查看当前系统中存在的信号量。
```bash$ ipcs -s```上述命令将列出所有信号量的相关信息,包括信号量的标识符、当前值、进程ID等。
通过查看这些信息,我们可以了解当前系统的信号量使用情况。
与共享内存类似,我们可以使用ipcrm命令来删除无用的信号量。
```bash$ ipcrm -s <信号量标识符>```上述命令将删除指定标识符的信号量。
同样需要注意的是,只有创建该信号量的进程或具有足够权限的用户才能删除信号量。
三、使用案例下面以一个实际的使用案例来说明如何使用ipcs和ipcrm命令进行共享内存和信号量的管理。
假设我们有两个进程A和B,需要使用共享内存和信号量进行数据交换和同步。
用共享内存实现消息队列

用共享内存实现消息队列共享内存是一种特殊的内存区域,它允许两个或多个进程访问相同的内存空间,从而实现数据的共享。
在实际应用中,可以使用共享内存实现高效的消息队列,提高进程间通信的性能。
本文将介绍如何使用共享内存实现消息队列。
1. 创建共享内存区域:首先,需要创建一个共享内存区域,用于存储消息数据。
可以使用系统调用shmget来创建共享内存区域,并通过参数指定共享内存的大小。
```c#include <sys/ipc.h>#include <sys/shm.h>key_t key = ftok("keyfile", 'A'); // 生成一个key,用于标识共享内存区域int shm_id = shmget(key, size, IPC_CREAT , 0666); // 创建共享内存区域,并指定大小```2. 连接共享内存区域:创建共享内存区域后,需要通过指定的shm_id来连接到该区域,并获得指向该内存区域的指针。
```cvoid* shm_ptr = (void*)shmat(shm_id, NULL, 0); // 连接共享内存区域,并返回指向该区域的指针```3.定义消息结构体:在共享内存区域中,可以定义一个消息结构体,用于存储消息的内容。
```ctypedef structint type; // 消息类型char data[256]; // 消息数据} Message;```4.实现消息队列的操作:在共享内存区域中,可以定义一个变量来作为指示消息队列状态的变量,比如当前队列中的消息数量。
使用互斥锁或信号量来保护队列的并发操作。
```c#define MAX_MESSAGES 10typedef structint count; // 消息数量int front; // 队列头int rear; // 队列尾Message messages[MAX_MESSAGES]; // 消息队列数组} MessageQueue;void push(MessageQueue* queue, Message msg)//加锁//将消息添加到队列尾部//更新队列头和尾//解锁Message pop(MessageQueue* queue)//加锁//获取队列头的消息//更新队列头指针//解锁return message;```5. 使用消息队列:在多个进程中,可以使用共享内存区域实现的消息队列进行进程间通信。
cuda shared 使用方法

cuda shared 使用方法CUDA是一种并行计算平台和编程模型,可用于利用GPU进行高性能计算。
在CUDA中,共享内存是一种特殊的内存区域,可用于在线程块中的线程之间共享数据。
本文将介绍CUDA共享内存的使用方法。
一、共享内存的定义和特点共享内存是位于GPU上的一块硬件内存,具有低延迟和高带宽的特点。
它被设计用于在线程块中的多个线程之间共享数据。
共享内存的大小是有限的,且需要在编译时进行指定。
二、共享内存的声明和初始化在CUDA中,可以使用__shared__关键字来声明共享内存。
例如,可以使用以下语句声明一个大小为256字节的共享内存:__shared__ int sharedMem[256];在CUDA中,共享内存的初始化可以在内核函数中的任何地方进行。
通常情况下,可以在每个线程块的第一个线程(线程索引为0)中进行初始化。
例如,可以使用以下语句初始化共享内存中的所有元素为0:if(threadIdx.x == 0){for(int i=0; i<256; i++){sharedMem[i] = 0;}}__syncthreads();三、共享内存的使用共享内存可以用于在线程块中的线程之间共享数据。
在使用共享内存之前,需要将全局内存中的数据复制到共享内存中。
例如,可以使用以下语句将全局内存中的数据复制到共享内存中:sharedMem[threadIdx.x] = globalMem[threadIdx.x];__syncthreads();在共享内存中的数据可以被多个线程同时访问和修改。
例如,可以使用以下语句在共享内存中进行数据的累加操作:sharedMem[threadIdx.x] += 1;__syncthreads();四、共享内存的同步在使用共享内存时,需要确保所有线程都完成其对共享内存的读写操作,以避免数据的不一致性。
在CUDA中,可以使用__syncthreads()函数来实现线程的同步。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
共享内存---shmget shmat shmdt 要使用共享内存,应该有如下步骤:
1.开辟一块共享内存shmget()
2.允许本进程使用共某块共享内存shmat()
3.写入/读出
4.禁止本进程使用这块共享内存shmdt()
5.删除这块共享内存shmctl()或者命令行下ipcrm
ftok()。
它有两个参数,一个是字符串,一个是字符。
字符串一般用当前进程的程序名,字符一般用来标记这个标识符所标识的共享内存是这个进程所开辟的第几个共享内存。
ftok()会返回一个key_t型的值,也就是计算出来的标识符的值。
shmkey = ftok( "mcut" , 'a' ); // 计算标识符
操作共享内存,我们用到了下面的函数
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget( key_t shmkey , int shmsiz , int flag );
void *shmat( int shmid , char *shmaddr , int shmflag );
int shmdt( char *shmaddr );
shmget()是用来开辟/指向一块共享内存的函数。
参数定义如下:key_t shmkey 是这块共享内存的标识符。
如果是父子关系的进程间通信的话,这个标识符用IPC_PRIV A TE来代替。
但是刚才我们的两个进程没有任何关系,所以就用ftok()算出来一个标识符使用了。
int shmsiz 是这块内存的大小.
int flag 是这块内存的模式(mode)以及权限标识。
模式可取如下值:新建:IPC_CREA T
使用已开辟的内存:IPC_ALLOC
如果标识符以存在,则返回错误值:IPC_EXCL
然后将“模式” 和“权限标识”进行“或”运算,做为第三个参数。
如:IPC_CREA T | IPC_EXCL | 0666
这个函数成功时返回共享内存的ID,失败时返回-1。
// shmid开辟共享内存
shmid = shmget( shmkey , sizeof(in_data) , IPC_CREA T | 0666 ) ;
shmat()是用来允许本进程访问一块共享内存的函数。
int shmid是那块共享内存的ID。
char *shmaddr是共享内存的起始地址
int shmflag是本进程对该内存的操作模式。
如果是SHM_RDONL Y的话,就是只读模式。
其它的是读写模式
成功时,这个函数返回共享内存的起始地址。
失败时返回-1。
char *head , *pos ,
head = pos = shmat( shmid , 0 , 0 );
// 允许本进程使用这块共享内存
shmdt()与shmat()相反,是用来禁止本进程访问一块共享内存的函数。
参数char *shmaddr是那块共享内存的起始地址。
成功时返回0。
失败时返回-1。
shmdt( head ); // 禁止本进程使用这块内存
此外,还有一个用来控制共享内存的shmctl()函数如下:
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
int shmctl( int shmid , int cmd , struct shmid_ds *buf );
int shmid是共享内存的ID。
int cmd是控制命令,可取值如下:
IPC_STA T 得到共享内存的状态
IPC_SET 改变共享内存的状态
IPC_RMID 删除共享内存
struct shmid_ds *buf是一个结构体指针。
IPC_STA T的时候,取得的状态放在这个结构体中。
如果要改变共享内存的状态,用这个结构体指定。
返回值:成功:0
失败:-1
shmctl(shmid,IPC_RMID,NULL);
struct shmid_ds buf;
... ...
shmctl( shmid , IPC_STA T , &buf ); // 取得共享内存的状态
... ...
shmctl( shmid , IPC_RMID , &buf ); // 删除共享内存
注意:在使用共享内存,结束程序退出后。
如果你没在程序中用shmctl()
删除共享内存的话,一定要在命令行下用ipcrm命令删除这块共享内存。
你要是不管的话,它就一直在那儿放着了。
简单解释一下ipcs命令和ipcrm命令。
取得ipc信息:
ipcs [-m|-q|-s]
-m 输出有关共享内存(shared memory)的信息
-q 输出有关信息队列(message queue)的信息
-s 输出有关“遮断器”(semaphore)的信息
%ipcs -m
删除ipc
ipcrm -m|-q|-s shm_id
%ipcrm -m 105
例如,我们在以0x12345678为KEY创建了一个共享内存,可以直接使用ipcrm -M 0x12345678来删除共享内存区域。