超链接检测
网站检测报告

1.对图片增加alt属性描述。
以这种格式alt=”{品牌词}{产品系列}-{产品型号}”
2.无用的二级域名太多
3.没有友情链接, 且友情链接不可以连自己的站
4.出现违规关键字(官方)
5.标题<title>中的关键字用_链接
6.以下是链接错误
首页——我要看——品味连连看。
首页——网站导航
首页——搜索栏下——热闹搜索没有内容
首页——所有商量分类——热门品牌没有内容
首页——公告资讯——没有该文章
首页——购物指南——如何购物, 链接内图片不显示
首页——家购特色——开店优势死链
首页——项目合作——功能不可用
首页——托管服务——功能不可
首页——电子营业执照无链接
首页——冀ICP备12006697号重复
二级页面——友情链接要么是首页的链接, 要么是错误链接
二级页面——客服服务——QQ、和我联系有错
二级页面——商家信息——正品保障, 优质商家, 七天退货, 都是死链
1.关键词密度不够
2.缺少一下网站地图
3.主关键字太多(5个左右)
4.三级页面底部可适当添加一些加入关键字的文字介绍
5.没有长尾关键字
6.网站这样的标题都应加上超链接。
【普及贴】知网、万方、paperpass等论文重复率检测软件介绍

淘宝搜索:双赢文笔---- 人大经济论坛普及贴每个即将毕业的学生或在岗需要评职称、发论文的职场人士,论文检测都是必不可少的一道程序。
面对市场上五花八门的检测软件,到底该如何选择?选择查重后到底该如何修改?现在就做一个知识的普及。
一、关于检测软件分类1 知网知网是使用率最广的一套检测系统,其使用率广,其实是在于这套系统背后的资源支持及平台支持,如同方依靠的学校背景及咱们下载文章的知网平台。
知网随着使用对象的不同,又划分为以下几个分类:①知网学术不端检测。
现在的知网学术不端检测已发展到了VIP5.0,大多数学校毕业检测都用的这套系统。
针对的主要对象是硕士研究生和博士研究生。
当然我们需要注意一点,知网学术不端VIP5.0的系统会不定时更新,(淘宝搜索:双赢文笔)所以随着系统内容的不端丰富,你当时重复率检测只有2%的文章,可能过一段时间会变成5%,对于那些重复率控制的马马虎虎的同学,尽量早作打算。
②知网TMLC2,实际上这套系统的检测范围可能较VIP5.0稍微小一点,但一般情况下与VIP5.0的检测结果相同。
现在高校一般都用TMLC2,尽管如此,(淘宝搜索:双赢文笔)学生毕业检测的时候一般都用VIP5.0检测。
③科技期刊学术不端文献检测系统(AMLC)/社科期刊学术不端文献检测系统(SMLC)。
这两种都是用来检测期刊论文的。
④知网CNKI小分解,其实是学术不端5.0中的一种,其专门针对大学本科的毕业生论文检测。
2.万方万方论文检测比较简单,更多的是一种网络数据库,检测相对最不严格,可适合任何群体的初稿检测。
3.paperpass检测(简称PP检测)这个软件检测的比较严格,可以说达到变态的地步,有时候自己写的一句话都有可能标红。
所以,经过多年的论文检测经验,无论是初稿还是终稿,只要PP检测通过了,可以说知网的任何系统检测都有99.99...%的(淘宝搜索:双赢文笔)把握能通过。
所以各位如果实在不放心自己的检测结果,那就PP检测挑战一把吧。
电脑超链接操作流程

电脑超链接操作流程Using hyperlinks on a computer can be a simple yet effective way to navigate through websites and documents. 超链接是电脑上一种简单而有效的方式,可以用来在网站和文件之间进行导航。
By clicking on a hyperlink, users can quickly access related information or jump to different sections of a page. 通过点击超链接,用户可以快速访问相关信息或跳转到页面的不同部分。
Whether you are a student doing research, a professional creating a presentation, or simply browsing the internet, understanding how to use hyperlinks can enhance your productivity and make your interaction with the computer more efficient. 无论您是学生做研究,专业人士创建演示文稿,还是仅仅浏览互联网,了解如何使用超链接可以提高您的工作效率,使您与电脑的交互更加高效。
One of the most common uses of hyperlinks is in web browsers when navigating websites. 超链接最常见的用途之一是在网络浏览器中导航网站。
When you click on a hyperlink, it takes you to a different webpage or a specific section within the same page. 当您点击超链接时,它会将您带到不同的网页或同一网页内的特定部分。
超链接实验报告

一、实验目的1. 了解超链接的概念和作用;2. 掌握超链接的创建方法;3. 熟悉超链接在网页中的应用。
二、实验环境1. 操作系统:Windows 102. 浏览器:Chrome3. 网页制作软件:Dreamweaver CC三、实验内容1. 超链接的概念及作用超链接(Hyperlink)是一种在网页中实现链接跳转的技术。
通过超链接,用户可以轻松地从一个页面跳转到另一个页面,实现信息资源的快速检索和浏览。
超链接在网页中具有以下作用:(1)提高用户体验:通过超链接,用户可以方便地浏览相关内容,提高网页的可用性;(2)增强网页互动性:超链接可以让网页更具互动性,吸引用户参与;(3)优化搜索引擎排名:合理运用超链接,可以提高网页在搜索引擎中的排名。
2. 超链接的创建方法在Dreamweaver中创建超链接的方法如下:(1)选中需要设置超链接的文本或图片;(2)在“属性”面板中,找到“链接”字段;(3)点击“链接”字段右侧的文件夹图标,弹出“选择文件”对话框;(4)在对话框中选择要链接的文件,点击“确定”;(5)在“目标”下拉菜单中选择链接目标窗口;(6)在“替换”字段中,可以设置当鼠标悬停在超链接上时显示的替代文本;(7)在“访问键”字段中,可以设置键盘快捷键,方便用户快速访问超链接;(8)点击“保存”按钮,完成超链接的设置。
3. 超链接在网页中的应用以下是一些超链接在网页中的应用实例:(1)导航栏:在网页顶部或左侧设置导航栏,包含网站各个页面的超链接,方便用户浏览;(2)友情链接:在网页底部设置友情链接,与其他网站进行互链,提高网站知名度;(3)相关阅读:在文章底部设置相关阅读的超链接,引导用户阅读其他相关内容;(4)广告链接:在网页中设置广告链接,吸引用户点击,提高广告收益。
四、实验步骤1. 打开Dreamweaver,创建一个新的网页;2. 在网页中输入以下文本:“点击这里访问我的博客”;3. 选中文本,按照上述步骤设置超链接,链接到你的博客地址;4. 保存网页,并在浏览器中预览效果。
网页近似重复检测算法研究

・
(n 。 《 易<b 24 ,] b 。 《 ^S. i 。l iI . , 1 i . 2 ̄ 1 ,
能。 参考文献: [ ht: n w .e rfc m/r ie ct oywe —evr 。 1 t / e s ta. ] p/ n c t o ac vs a g r/ b sre~ h / e
和基手语义 (em 两类, Tr ) 其中Y。 e对各种基于S ige hn l的算法
进行 了实验分析 , h w h r 的IM t h算法在基于T r s Coduy —ac。 em 方面
尤为突 。 ( )S ig e算法 一 hnl
S ig e是指文档 中连续 的子序 列,S i g e的长度为该 hnl hn l 连续 的子序 列所 包含 的词的个 数。定义 s D ) (,w 为文档 D中长 度 为 w 的 S ig e 所组成 的集合 。每个文档 被分 为多重的 hnl
内容方面 的检测算法 。 orsi将 网页 内容 的重复定为 4 : Lpet。 种 内容格式一致 、 内容相 同但格式存在 差异 、 部分 内容相同且格 式一致和部分 内容相 同但格式存在 差异 。 以我们的关注点不 所
能仅局 限在完全重复 的网页上 。 本文将 在第二 部分介绍 目前主要 的网页近似 重复检测 算 法和他们 的优缺 点; 在第三部分介绍模糊 哈希 算法,提出采用 改进的模糊哈希算法 ;在第 四部分 展示 改进 算法 的实验结果, 并在第五部分总结 。 二 、网页重复检测算法 曹。 等人将文本复制检测算法分为 :基于语法 ( h n l ) S i g e
一
、
引 言
互联 网的网站成 指数 在增长,据统计 。 ,在 2 1 0 2年 4月, 互联 网中的网站数量达到 了 6 6 1 7 7个,有超过 2 . % 7990 9 3 的网 页为重复 网页或近似重 复网页。 量的重复网页造成的索引中 大 文档的大量重复 ,索引质量 的降低 ,索引空间的增加 , 索速 检 度 的降低和重复 的检测结果 的增 多无疑 降低 了用户体验 。 近几 年, 在近似 网页 的检测方面 国内外开展了诸多研究 , 如网页结 构近似性检测 。 、超链接近似性检测 。 ,而本 文强调的是在 等
网络链接安全性检测演示文档

短链接的危害
随着社交网站的普及,短链接逐渐被我们熟知。短链接主要
是通过域名重定向技术将较长的域名信息通过一定的转换算 法进行处理,用另外一个较短域名信息进行表示。当用户访 问这个较短的域名信息时,就可以直接跳转到较长的URL地址 上。早期主要应用在图片上传网站中上传图片,达到减少代 码字符数的目地。社交网站对用户的输入字符数都有限制, 而短链接正好解决了节省字数的问题,为用户留下了更多的 空间。然而每件事的出现必有两面性,它给我带来方便的同 时又会带来什么安全隐患呢?短链接的安全越来越引起了人 们的注意。 转换为短链接地址以后确实方便用户在社交网站内容的显示, 但在用户可能无法通过短链接地址直接看出点击这个短链接 地址后究竟会打开什么样的网站。通过有关测试,包含恶意 代码的链接可以通过有些杀毒软件直接检测,而转换后的短 链接杀毒软件是无法确认的。用爬虫软件SocSciBot也无法继 续爬虫,得不到链接真正的网站安全性。正因为如此,攻击 者也就会经常利用这一弱点对用户实施攻击和欺骗。
网络链接安全性检测
一、网络链接基本知识介绍
二、网络爬虫进行链接分析
一、网络链接基本知识介绍
1、网络链接的定义
2、网络链接存在的问题
3、网络链接分析原理
1、网络链接的定义
网络链接,即根据统一资源定位符,运用超文本制作语言,将网站内部网 页之间、系统内部之间或不同系统之间的超文本和超媒体进行链接。通过此 种链接技术,即可从一网站的网页连接到另一网站的网页,正是这样一种技 术,才得以使世界上数以亿万计的计算机密切联系到了一起,从而构成网络 的坚实基础。 网络链接是指从一个网页指向一个目标的连接关系,这个目标可以是另一 个网页,也可以是相同网页上的不同位置,还可以是一个图片,一个电子邮 件地址,一个文件,甚至是一个应用程序。而在一个网页中用来链接的对象, 可以是一段文本或者是一个图片。当浏览者单击已经链接的文字或图片后, 链接目标将显示在浏览器上,并且根据目标的类型来打开或运行。它是一种 允许我们同其他网页或站点之间进行连接的元素,在本质上属于一个网页的 一部分。各个网页链接在一起后,才能真正构成一个网站。互联网发展到今 天,可以毫不夸张地说,没有网络链接就没有互联网,没有网络链接互联网 就没有生命力,链接技术是互联网的坚实基础。 链接也称超级链接,超链接是指从一个网页指向一个目标的连接关系,而 在一个网页中用来超链接的对象,可以是一段文本或者是一个图片.当浏览者 单击已经链接的文字或图片后,链接目标将显示在浏览器上,并且根据目标的 类型来打开或运行。
黑链排查方法

黑链排查方法
黑链排查的方法主要包括以下几种:
1. 经常检查网站的源代码,利用Ctrl+F在搜索框里搜素<a这个标签,属于HTML代码里的超链接标签,一般查看这个就能看出哪些是一些出站链接,也就是黑链。
2. 利用站长工具里的死链接检查功能,这个工具的好处就是可以查看到网站页面上的所有链接,而且在把所有链接查找出来之后,还可以查看这些链接是否可以正常访问。
如果发现可疑的出站连接时,可以点击进去看看,如果不是有关我们网站的链接内容,那么就可以判断出这条链接是一条黑链接了。
3. 查看网站文件修改日期,如果网站是安全的,那么文件的修改日期是按照创建的日期来显示的。
如果是网站被挂了黑链接之后,这个时候网站后台的文件就会显示和最近日期差不多的时间段,那这时就应要提高警惕了。
排查方法并不限于以上三种,您还可以咨询专业技术人士,获取更多方法。
同时要注意的是,在排查后若发现黑链存在,一定要及时处理并加强防范措施。
网站的链接测试技巧
网站的链接测试技巧网站上的网页是互相链接的,单击被称为超链接的文本或图形就可以链接到其他页面。
整个网站的链接犹如一张庞大的蜘蛛网,稍不留神就会有所遗漏。
尽管网站的链接测试看起来似乎没有比较高深的技术含量,但同时,特别是对于一个较大的网站的,涉及到上百甚至上千个页面,链接测试需要较大的测试量,因此,提高测试的效率成了网站链接测试的一个重要方面。
进行链接测试时,我们需要重点把握以下几个原则:链接的正确性,即单击某个地址之后,应该能够达到正确的页面;要测试所链接的页面是否存在;要保证系统中没有孤立的页面,也就是说,网站中的页面彼此之间应该有联系,而不是独立在整个系统之外。
链接测试可以手动进行,也可以自动进行。
链接测试必须在Web网站的所有页面开发完成之后进行测试。
为了提高链接测试的效率,这里主要介绍几款链接测试的软件,希望能对各位站长在网站的链接测试中,有所帮助,提高链接测试效率。
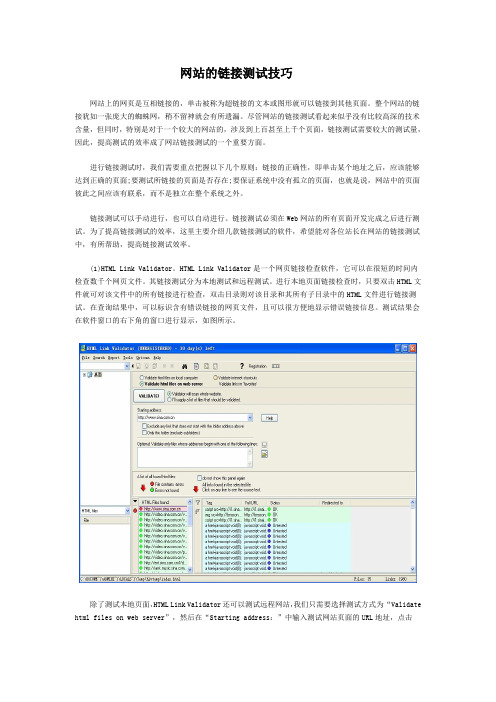
(1)HTML Link Validator。
HTML Link Validator是一个网页链接检查软件,它可以在很短的时间内检查数千个网页文件。
其链接测试分为本地测试和远程测试。
进行本地页面链接检查时,只要双击HTML文件就可对该文件中的所有链接进行检查,双击目录则对该目录和其所有子目录中的HTML文件进行链接测试。
在查询结果中,可以标识含有错误链接的网页文件,且可以很方便地显示错误链接信息。
测试结果会在软件窗口的右下角的窗口进行显示,如图所示。
除了测试本地页面,HTML Link Validator还可以测试远程网站,我们只需要选择测试方式为“Validate html files on web server”,然后在“Starting address:”中输入测试网站页面的URL地址,点击“Validate”按钮即可对指定页面进行测试。
测试完成后,单击“HTML Files found”左侧的小红点,就会显示出错的地方,如图所示。
网络安全测试中的恶意链接检测技术

网络安全测试中的恶意链接检测技术在网络安全测试中,恶意链接检测技术扮演着至关重要的角色。
随着互联网的普及,恶意链接的数量也呈指数级增长,给用户的网络安全带来了极大的威胁。
恶意链接可以是钓鱼网站、恶意软件下载链接等,一旦用户点击了这些链接,就有可能导致个人敏感信息被盗取,计算机系统被入侵等安全问题。
因此,有效的恶意链接检测技术显得尤为重要。
一、恶意链接的特征恶意链接通常具有以下几个特征:1. 虚假目标:恶意链接常常伪装成看似正规的网站,诱导用户点击。
2. 诱人内容:恶意链接常常伴随着具有高吸引力的内容,如免费软件下载、折扣优惠等,以吸引用户点击。
3. 隐藏性:恶意链接通常使用缩写、特殊符号等方式隐藏真实链接地址,让用户很难辨别。
二、常见的恶意链接检测技术为了应对恶意链接的威胁,研究人员和安全公司开发了多种恶意链接检测技术,下面介绍几种常见的技术:1. 黑名单技术:黑名单技术通过维护一个恶意链接的黑名单数据库,对用户访问的链接进行快速匹配,从而判断链接是否为恶意链接。
这种技术能够快速识别已知的恶意链接,但对于未知的新型恶意链接无法有效检测。
2. 白名单技术:白名单技术相对于黑名单技术而言,它维护的是合法链接的数据库,只有当用户访问的链接在白名单中才被认为是合法的。
这种技术虽然能够有效避免误报,但是对于未知的恶意链接无法进行检测。
3. 基于特征的检测技术:该技术通过对恶意链接的特征进行分析和提取,构建特征模型来进行检测。
常见的特征包括URL长度、域名的注册年限、域名的语义特征等。
这种技术可以有效识别未知的恶意链接,但是容易受到恶意链接的变种和伪装的干扰。
4. 机器学习技术:机器学习技术可以通过大量的数据样本进行训练,从而学习到恶意链接的模式和规律,实现自动化的恶意链接检测。
这种技术具有较高的准确率和覆盖率,但是需要大量的训练数据,并且对于新型恶意链接的检测会存在一定的滞后性。
三、优化恶意链接检测技术的方法为了进一步提升恶意链接检测技术的准确性和效率,还可以采取以下几个方法:1. 多维度特征提取:结合URL的文本特征、结构特征、语义特征等多个维度的特征,从而提升恶意链接的识别率。
《第7节 制作网页》学历案-初中信息技术北师大版八年级上册自编模拟

《制作网页》学历案(第一课时)一、学习主题本课学习主题为“制作网页”,是初中信息技术课程的重要组成部分。
通过本课的学习,学生将初步了解网页制作的基本概念、网页的基本构成元素及制作工具的使用方法。
本课时的重点任务是掌握网页制作的基本知识和基本技能,为后续深入学习打下坚实基础。
二、学习目标1. 知识与技能:(1)了解网页的基本概念、组成要素及作用。
(2)熟悉网页制作的基本工具及操作方法。
(3)学会使用简单的HTML语言编写网页结构。
2. 过程与方法:(1)通过观看教学视频,掌握网页制作的基本流程。
(2)通过实践操作,掌握网页制作工具的使用技巧。
3. 情感态度与价值观:(1)培养学生对信息技术课程的兴趣和热爱。
(2)提高学生的创新意识和实践能力。
(3)引导学生树立正确的网络使用观念,养成良好的网络道德素养。
三、评价任务1. 课堂表现评价:观察学生在课堂上的学习态度、参与程度以及实际操作能力。
2. 作品评价:评价学生制作的网页作品,包括页面布局、色彩搭配、内容组织等方面。
3. 知识掌握评价:通过课后小测验,检查学生对网页制作基本概念和工具的掌握情况。
四、学习过程1. 导入新课(5分钟)通过展示几个精美的网页作品,激发学生的兴趣,引导学生了解网页制作的重要性和应用领域。
2. 新课讲解(15分钟)(1)讲解网页的基本概念、组成要素及作用。
(2)介绍网页制作的基本工具和操作方法。
(3)演示使用简单的HTML语言编写网页结构。
3. 实践操作(20分钟)学生根据教师提供的素材和指导,使用网页制作工具进行实践操作,教师巡回指导,及时解答学生疑问。
4. 课堂小结(5分钟)总结本课学习的重点内容,强调网页制作的基本步骤和注意事项。
五、检测与作业1. 课后小测验:检查学生对网页制作基本概念和工具的掌握情况。
2. 作业:学生自行设计并制作一个简单的网页作品,要求包括页面布局、色彩搭配、内容组织等要素。
六、学后反思1. 教师反思:总结本课教学过程中的优点和不足,针对学生反馈及时调整教学策略,提高教学效果。
《第8课 设置超链接》学历案-小学信息技术人教版三起01五年级上册

《设置超链接》学历案(第一课时)一、学习主题本节课的学习主题是“设置超链接”,是小学信息技术课程中的重要一环。
通过本课的学习,学生将掌握在网页或文档中设置超链接的基本方法和技巧,提升信息检索和知识整合的能力。
二、学习目标1. 知识与理解:了解超链接的概念及作用,掌握设置超链接的基本步骤。
2. 技能与操作:学会在网页或文档中插入、编辑和删除超链接。
3. 情感态度与价值观:培养学生对信息技术的兴趣,以及规范操作、注重细节的良好习惯。
三、评价任务1. 课堂表现评价:观察学生在课堂上的操作过程,评价其是否掌握超链接的设置方法,以及操作的规范性。
2. 作品评价:学生完成一个包含超链接设置的简单网页或文档作品,教师根据作品的完成情况、超链接的设置效果及创意进行评价。
3. 小组互评:小组内成员互相评价设置超链接的步骤和结果,提升同伴间的交流与学习。
四、学习过程1. 导入新课(5分钟)通过展示几个含有超链接的网页或文档实例,引导学生了解超链接的作用和意义,激发学习兴趣。
2. 新课讲解(10分钟)教师讲解超链接的概念、作用及设置方法,重点讲解插入和编辑超链接的步骤。
3. 操作示范(5分钟)教师进行超链接设置的示范操作,展示每个步骤的具体操作过程。
4. 学生操作(15分钟)学生根据教师示范的操作步骤,自主完成超链接的设置。
教师巡回指导,及时解答学生疑问。
5. 课堂小结(5分钟)总结本节课的学习内容,强调超链接设置的重要性和操作要点。
五、检测与作业1. 课堂检测:教师通过提问的方式,检测学生对超链接设置方法的掌握情况。
2. 作业布置:布置一个实践性的作业,要求学生自行设计一个简单的网页或文档,并在其中设置至少三个超链接。
要求学生注意超链接的合理性和有效性。
六、学后反思1. 教师反思:教师在课后反思本节课的教学过程,总结学生的掌握情况,找出教学中存在的问题和不足,为今后的教学提供改进方向。
2. 学生反思:学生回顾本节课的学习过程,总结自己的收获和不足,思考如何在今后的学习中更好地掌握超链接的设置方法。
如何应用自动化测试进行易用性和可靠性测试

如何应用自动化测试进行易用性和可靠性测试自动化测试已经成为软件开发过程中必不可少的一环。
它可以减少测试时间,提高测试效率,更好地保障软件的质量。
而在自动化测试技术中,易用性测试和可靠性测试也是必不可少的环节。
那么,如何应用自动化测试进行易用性和可靠性测试呢?一、易用性测试的自动化易用性测试是指测试软件的人机交互界面是否友好、直观,是否符合用户操作习惯,在使用过程中是否能够让用户感到舒适。
易用性测试通常需要进行大量的手动测试和用户体验反馈。
但是,通过自动化测试,可以更好地测试软件的易用性。
1.界面测试界面测试是易用性测试中最重要的一部分。
通过自动化测试工具可以模拟用户对软件界面的操作,比如点击按钮、输入文本、选择下拉菜单等。
这样可以快速地测出软件中存在的易用性问题,比如功能定位不明确、操作过程繁琐等。
2.超链接测试许多软件中都存在超链接跳转的情况。
通过自动化测试工具可以模拟用户点击超链接后跳转到其他页面的流程,检测超链接的跳转是否正确、目标页面是否能够正常加载等问题。
3.表单测试表单测试包括输入文本、选择下拉菜单、勾选多选框等场景。
通过自动化测试工具可以进行这些操作,测试表单的正确性是否符合设计要求,以及是否容易操作等。
二、可靠性测试的自动化可靠性测试是指检测软件在长时间运行过程中是否稳定、可靠。
对于许多大型软件,可以通过自动化测试手段进行可靠性测试。
1.压力测试压力测试是可靠性测试的重要部分。
通过自动化工具,可以同时模拟多个用户对软件进行压力测试,以测试软件的稳定性和容错性。
压力测试可以检测软件承受多大的负载能力,并定位软件的性能瓶颈。
2.功能测试功能测试是可靠性测试中必不可少的部分。
通过自动化测试工具,可以测试软件中各个功能是否能够正常运行、是否符合设计要求等。
功能测试可以帮助开发人员找出软件中的潜在缺陷,提高软件的稳定性和可靠性。
3.时序测试时序测试主要是测试软件中各个模块之间的时序关系是否正确。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程设计III设计说明书网页中超链检测程序设计学生姓名学号班级成绩指导教师数学与计算机科学学院2014 年 3 月 7 日课程设计任务书2013 —2014 学年第一学期课程设计名称:课程设计三课程设计课程设计题目:网页中超链检测程序设计完成期限:自2014 年9 月2日至2014 年9 月13日共 2 周设计内容:1. 任务说明设计一个程序,给一个指定URL,分析该URL所在域中所有网页中的超链接情况:本域内链接、外域链接、页内链接、死链(链接目标不存在)等情况。
2.要求(1)了解网络爬虫的架构和工作原理,实现网络爬虫的基本框架;(2)开发平台采用JDK 1.60 eclipse集成开发环境。
(3)要求按时按量完成所规定的实验内容;(4)界面设计要求通用性强、具有实用性;指导教师:教研室负责人:课程设计评阅摘要设计了一个基于宽度优先的爬虫程序,本程序采用java编程语言,开发平台采用JDK 1.60 eclipse集成开发环境。
可实现检测网页中超链接,是一种自动搜集互联网信息的程序,可以搜集某一站点的URL,并将搜集到的URL存入文件。
关键词:网络爬虫;JAVA;超链接目录1 绪论 (1)2 网络爬虫 (2)3 对URL的认识 (4)4 通过URL抓取网页 (5)5 算法分析及程序实现 (7)6 总结 (14)1 绪论随着网络的迅速发展,万维网成为大量信息的载体,万维网已经成为人们获取信息的重要渠道,如何高效地提取并利用这些信息成为一个巨大的挑战。
搜索引擎(Search Engine),例如传统的通过搜索引擎百度,Yahoo和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
但是,这些通用性搜索引擎也存在着一定的局限性,如:(1)统一的返回不能满足不同用户的检索需求。
(2)搜索引擎提高覆盖面的目标与膨胀的网络信息之间的矛盾日益加深。
(3)搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的主题爬虫应运而生。
主题爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
本文通过JAVA语言实现了一个基于宽度优先遍历算法的爬虫程序。
通过实现此爬虫程序可以定点搜集某一站点的URL,可以分析出网页中的超链接情况:本域内链接、外域链接、页内链接、死链(链接目标不存在)等情况2 网络爬虫2.1 基本原理爬虫从一个或若干初始网页的URL 开始,通过分析该URL 的源文件,提取出新的网页链接,继而通过这些链接继续寻找新的链接,这样一直循环下去,直到抓取并分析完所有的网页为止。
当然这是理想状态下爬虫的执行过程,但是实际上要抓取Internet上所有的网页是不可能完成的。
从目前公布的数据来看,最好的搜索引擎也只不过抓取了整个Internet40%的网页。
这有两个原因,其一是网络爬虫设计时的抓取技术瓶颈造成的,无法遍历所有的网页,很多网页链接不能从其他网页中得到。
其二是存储技术和处理技术造成的,如果按照每个页面的平均的大小是20K,那么100亿个页面的大小就是200000G,现在的存储技术来说是个挑战。
2.2爬行策略深度优先搜索策略是一种在开发Spider 的早期使用得较多的方法,是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。
当不再有其他超链可选择时,说明搜索已经结束。
图 2.1 宽度优先遍历图2.1所示的宽度优先遍历的访问顺序为:A->B->C->D->E->F->H->G->I把互联网看成一个“超图”,以采用宽度优先遍历的方式进行访问。
实际的爬虫项目是从一系列的种子链接开始的。
所谓种子链接,就好比宽度优先遍历中的种子节点(如图2.1中的 A 节点)一样。
实际的爬虫项目中种子链接可以有多个,而宽度优先遍历中的种子节点只有一个。
整个的宽度优先爬虫过程就是从一系列的种子节点开始,把这些网页中的“子节点”(也就是超链接)提取出来,放入队列中依次进行抓取。
被处理过的链接需要放入一张表(通常称为 Visited 表)中。
每次新处理一个链接之前,需要查看这个链接是否已经存在于Visited 表中。
如果存在,证明链接已经处理过,跳过,不做处理,否则进行下一步处理。
实际的过程如图 2.2 所示。
图 2.2 宽度优先遍历开始的 URL 地址是爬虫系统中提供的种子 URL(一般在系统的配置文件中指定)。
当解析这些种子URL 所表示的网页时,会产生新的URL(比如从页面中的<a href=“”中提取出 这个链接)。
然后,进行以下工作:(1) 把解析出的链接和 Visited 表中的链接进行比较,若 Visited 表中不存在此链接,表示其未被访问过。
(2) 把链接放入 TODO 表中。
(3) 处理完毕后,再次从 TODO 表中取得一条链接,直接放入 Visited 表中。
(4) 针对这个链接所表示的网页,继续上述过程。
如此循环往复。
3 对URL的认识爬虫最主要的处理对象就是URL,它根据URL地址取得所需要的文件内容,然后对它进行进一步的处理。
因此,准确地理解URL对理解网络爬虫至关重要。
URL:统一资源定位符,是Internet 上描述信息资源的字符串。
URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL 的格式由三部分组成:第一部分访问资源的命名机制;第二部分存放资源的主机名;第三部分资源自身的名称,由路径表示。
第一部分和第二部分用“://”符号隔开,第二部分和第三部分用“/”符号隔开。
第一部分和第二部分是不可缺少的,第三部分有时可以省略。
3.1 HTTP 协议的URL 示例使用超级文本传输协议HTTP,提供超级文本信息服务的资源。
例:/channel/welcome.htm。
其计算机域名为。
超级文本文件(文件类型为.html)是在目录/channel 下的welcome.htm。
这是中国人民日报的一台计算机。
例:/talk/talk1.htm。
其计算机域名为。
超级文本文件(文件类型为.html)是在目录/talk 下的talk1.htm。
3.2 文件的URL用URL表示文件时,服务器方式用file表示,后面要有主机IP 地址、文件的存取路径(即目录)和文件名等信息。
有时可以省略目录和文件名,但“/”符号不能省略。
例:file:///pub/files/foobar.txt。
代表存放在主机 上的pub/files/目录下的一个文件,文件名是foobar.txt。
例:file:///pub。
代表主机 上的目录/pub。
例:file:///。
代表主机 的根目录。
4 通过URL抓取网页所谓网页抓取,就是把 URL 地址中指定的网络资源从网络流中读取出来,保存到本地。
类似于使用程序模拟 IE 浏览器的功能,把 URL 作为 HTTP 请求的内容发送到服务器端,然后读取服务器端的响应资源。
Java 语言是为网络而生的编程语言,它把网络资源看成是一种文件,它对网络资源的访问和对本地文件的访问一样方便。
它把请求和响应封装为流。
因此我们可以根据相应内容,获得响应流,之后从流中按字节读取数据。
构造一个url对象,可以通过获得的 URL 对象来取得网络流,进而像操作本地文件一样来操作网络资源。
在实际的项目中,网络环境比较复杂,需要处理 HTTP 返回的状态码,设置 HTTP 代理,处理 HTTPS协议等工作。
为了便于应用程序的开发,实际开发时常常使用 Apache 的HTTP 客户端开源项目——HttpClient。
它完全能够处理 HTTP 连接中的各种问题,使用起来非常方便。
只需在项目中引入 HttpClient.jar 包,就可以模拟 IE 来获取网页内容。
串方式获取返回的内容。
这也是网页抓取所需要的内容。
通常需要把返回的内容写入本地文件并保存。
最后还要关闭网络连接,以免造成资源消耗。
HTTP 状态码表示 HTTP 协议所返回的响应的状态。
比如客户端向服务器发送请求,如果成功地获得请求的资源,则返回的状态码为 200,表示响应成功。
如果请求的资源不存在,则通常返回 404 错误。
HTTP 状态码通常分为 5 种类型,分别以 1~5 五个数字开头,由 3 位整数组成。
1XX 通常用作实验用途。
这一节主要介绍 2XX、3XX、4XX、5XX 等常用的几种状态码,如表 4.1 所示。
图 4.1 HTTP状态码说明当返回的状态码为 5XX 时,表示应用服务器出现错误,采用简单的丢弃处理就可以解决。
当返回值状态码为 3XX 时,通常进行转向,读取新的 URL 地址。
当响应状态码为 2XX 时,根据表 1.1 的描述,我们只需要处理 200 和 202 两种状态码,其他的返回值可以不做进一步处理。
200 的返回状态码是成功状态码,可以直接进行网页抓取。
202 的响应状态码表示请求已经接受,服务器再做进一步处理5 算法分析及程序实现爬虫过程中使用一个集合,根据宽度优先算法遍历网页中所有的节点,通过过滤,得到所有的超链接节点,然后将链接节点放入集合中,再遍历整个集合,依次显示到界面、保存到文件中作为索引。
图5.1 程序流程图程序实现:首先,定义图5.1中所描述的“URL 队列”,这里使用一个LinkedList 来实现这个队列。
public class Queue {//使用链表实现队列private LinkedList queue = new LinkedList();//入队列public void enQueue(Object t) {queue.addLast(t);}//出队列public Object deQueue() {return queue.removeFirst();}//判断队列是否为空public boolean isQueueEmpty() {return queue.isEmpty();}//判断队列是否包含tpublic boolean contians(Object t) {return queue.contains(t);}public boolean empty() {return queue.isEmpty();}}除了URL 队列之外,在爬虫过程中,还需要一个数据结构来记录已经访问过的URL。