统计学贾俊平_第四版课后习题答案
统计学贾俊平第四版课后习题答案
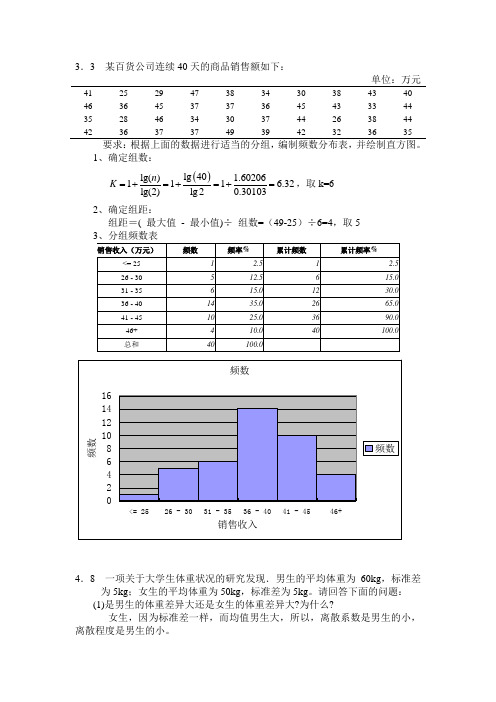
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取54.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg ,标准差为5kg ;女生的平均体重为50kg ,标准差为5kg 。
请回答下面的问题: (1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。
(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg ×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。
(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。
(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。
最新统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学课后习题答案(第四版)贾俊平(第4、5、7、10章)

《统计学》第四版 第四章练习题答案众数:M o =1O;中位数:中位数位置=n+1/2=5.5 , M e =10 ;平均数:(2) Q L 位置=n/4=2.5, Q L =4+7/2=5.5 ; Q u 位置=3n/4=7.5 , Q u =12(4) 4.2 和 M O =23。
将原始数据排序后,计算中位数的位置为:中位数位置=n+1/2=13,第13个位置上的数值为23,所以中位数为 M e =23(2)Q L 位置=n/4=6.25, Q L ==19 ; Q u 位置=3n/4=18.75,Q u =26.5茎 叶 频数 5 5 1 6 6 7 8 3 71 3 4 8 85(3)第一种排队方式: 离散程度大于第二种排队方式。
(4 )选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方 式。
_ Z X i4.4 ( 1)X8223/30=274.14.1 ( 1 ) 二X i X =n96.9,6 102' (X i-X ) _156.4 42n -1, 9由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
(1)从表中数据可以看出,年龄出现频数最多的是 19和23,故有个众数,即 M O =19(3)⑶平均数-A =600/25=24,标准差—(XLX)\ n —1210626.6525-1n(4) 偏态系数SK=1.08,峰态系数K=0.77(5) 分析:从众数、中位数和平均数来看,网民年龄在 23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数 1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
(1)茎叶图如下: 大于 4.3 —2'(X 一 X ) 4.080.714nn -1■ 8由于两种排队方式的平均数不同,所以用离散系数进行比较。
(2) X 二一^ =63/9=7, S = ■■n中位数位置=n+1/2=15.5 , M e=272+273/2=272.5(2) Q L位置=n/4=7.5, Q L==(258+261)/2=259.5 ; Q u 位置=3n/4=22.5 , Q u=(284+291)/2=287.5' (^-X ^ /3002-7 = 21.17 I n —1 \ 30—12100 +3000 +15004.5 (1)甲企业的平均成本=总成本/总产量=-2100 3000---- + ----- 15 20乙企业的平均成本=总成本/总产量=3255150015006255=18.293255 1500 1500 342____ + _____ + _____152030原因:尽管两个企业的单位成本相同, 但单位成本较低的产品在乙企业的产量中所占比重较 大,因此拉低了总平均成本。
统计学 贾俊平第四版第四章课后答案(目前最全)

第四章统计数据的概括性描述4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:(1)(2)(3)(4)说明汽车销售分部的特征答:10名销售人员的在5月份销售的汽车数量较为集中。
4.2 随机抽取25个网络用户,得到他们的年龄数据如下:单位:周岁19 15 29 25 2423 21 38 22 1830 20 19 19 1623 27 22 34 2441 20 31 17 23要求;(1)计算众数、中位数:1、排序形成单变量分值的频数分布和累计频数分布:网络用户的年龄从频数看出,众数Mo有两个:19、23;从累计频数看,中位数Me=23。
(2)根据定义公式计算四分位数。
Q1位置=25/4=6.25,因此Q1=19,Q3位置=3×25/4=18.75,因此Q3=27,或者,由于25和27都只有一个,因此Q3也可等于25+0.75×2=26.5。
(3)计算平均数和标准差;Mean=24.00;Std. Deviation=6.652(4)计算偏态系数和峰态系数:Skewness=1.080;Kurtosis=0.773(5)对网民年龄的分布特征进行综合分析:分布,均值=24、标准差=6.652、呈右偏分布。
如需看清楚分布形态,需要进行分组。
为分组情况下的直方图:为分组情况下的概率密度曲线:分组:1、确定组数:()l g 25l g ()1.3981115.64l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(41-15)÷6=4.3,取53、分组频数表网络用户的年龄 (Binned)分组后的直方图:4.3 某银行为缩短顾客到银行办理业务等待的时间。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学课后习题答案_(第四版)_贾俊平

《统计学》第四版 第四章练习题答案4.1 (1)众数:M 0=10; 中位数:中位数位置=n+1/2=5.5,M e =10;平均数:6.91096===∑nxx i(2)Q L 位置=n/4=2.5, Q L =4+7/2=5.5;Q U 位置=3n/4=7.5,Q U =12 (3)2.494.1561)(2==-=∑-n i s x x (4)由于平均数小于中位数和众数,所以汽车销售量为左偏分布。
4.2 (1)从表中数据可以看出,年龄出现频数最多的是19和23,故有个众数,即M 0=19和M 0=23。
将原始数据排序后,计算中位数的位置为:中位数位置= n+1/2=13,第13个位置上的数值为23,所以中位数为M e =23(2)Q L 位置=n/4=6.25, Q L ==19;Q U 位置=3n/4=18.75,Q U =26.5(3)平均数==∑nx x i600/25=24,标准差65.612510621)(2=-=-=∑-n i s x x(4)偏态系数SK=1.08,峰态系数K=0.77(5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。
由于标准差较大,说明网民年龄之间有较大差异。
从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。
由于峰态系数为正值,所以为尖峰分布。
4.3 (1(2)==∑nxx i63/9=7,714.0808.41)(2==-=∑-n i s x x (3)由于两种排队方式的平均数不同,所以用离散系数进行比较。
第一种排队方式:v 1=1.97/7.2=0.274;v 2=0.714/7=0.102.由于v 1>v 2,表明第一种排队方式的离散程度大于第二种排队方式。
(4)选方法二,因为第二种排队方式的平均等待时间较短,且离散程度小于第一种排队方式。
4.4 (1)==∑nx x i8223/30=274.1中位数位置=n+1/2=15.5,M e =272+273/2=272.5(2)Q L 位置=n/4=7.5, Q L ==(258+261)/2=259.5;Q U 位置=3n/4=22.5,Q U =(284+291)/2=287.5(3) 17.211307.130021)(2=-=-=∑-n i s x x4.5 (1)甲企业的平均成本=总成本/总产量=41.193406600301500203000152100150030002100==++++乙企业的平均成本=总成本/总产量=29.183426255301500201500153255150015003255==++++原因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。
统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学第四版答案(贾俊平)

第1章统计和统计数据1.1 指出下面的变量类型。
(1)年龄。
(2)性别。
(3)汽车产量。
(4)员工对企业某项改革措施的态度(赞成、中立、反对)。
(5)购买商品时的支付方式(现金、信用卡、支票)。
详细答案:(1)数值变量。
(2)分类变量。
(3)数值变量。
(4)顺序变量。
(5)分类变量。
1.2 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。
(1)这一研究的总体是什么?样本是什么?样本量是多少?(2)“月收入”是分类变量、顺序变量还是数值变量?(3)“消费支付方式”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。
(2)数值变量。
(3)分类变量。
1.3 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。
(1)这一研究的总体是什么?(2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量?详细答案:(1)总体是“所有的网上购物者”。
(2)分类变量。
1.4 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。
(1)这种抽样方式是分层抽样、系统抽样还是整群抽样?(2)样本量是多少?详细答案:(1)分层抽样。
(2)100。
第3章用统计量描述数据为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.7 6.87.1 7.3 7.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。
(2)比两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。
详细答案:(1)(岁);(岁)。
(2);。
第一中排队方式的离散程度大。
(3)选方法二,因为平均等待时间短,且离散程度小。
统计学第四章、第十章课后练习答案 贾俊平第四版

0.05 2
=1.96
由于总体标准差已知,所以总体均值μ的95%的置信区间为:
x ± zα 2
σ
n
=104560 ± 1.96*
85414 100
= 104560±16741.144即(87818.856,121301.144)
7.4(1)已知n=100,x =81,s=12,
α=0.1,z 0.1 2 =1.645
由于n=100为大样本,所以总体均值μ的90%的置信区间为:
x ± zα 2
s n
=81 ± 1.645*
12 100
= 81±1.974,即(79.026,82.974)
(2)已知α=0.05,
z
0.05 2
=1.96
由于n=100为大样本,所以总体均值μ的95%的置信区间为:
x ± zα 2
s n
∑x (3)平均数x =
n
i
= 600/25=24,标准差s =
∑( xi ? x )
n ?1
2
=
1062 = 6.65 25 ? 1
(4)偏态系数SK=1.08,峰态系数K=0.77(5)分析:从众数、中位数和平均数来看,网民年龄在23-24岁的人数占多数。由于标准差较大,说明网民年龄之间有较大差异。从偏态系数来看,年龄分布为右偏,由于偏态系数大于1,所以,偏斜程度很大。由于峰态系数为正值,所以为尖峰分布。4.3(1)茎叶图如下:茎5 6 7叶5 678 13488频数1 3 5
第五章练习题答案
5.1(1)平均分数是范围在0-100之间的连续变量,Ω=[0,100] (2)已经遇到的绿灯次数是从0开始的任意自然数,Ω=N(3)之前生产的产品中可能无次品也可能有任意多个次品,Ω=[10,11,12,13…….] 5.2设订日报的集合为A,订晚报的集合为B,至少订一种报的集合为A∪B,同时订两种报的集合为A∩B。P(A∩B)=P(A)+ P(B)-P(A∪B)=0.5+0.65-0.85=0.3 5.3 P(A∪B)=1/3,P(A∩B )=1/9, P(B)= P(A∪B)- P(A∩B )=2/9 5.4 P(AB)= P(B)P(A∣B)=1/3*1/6=1/18 P( A∪B )=P( AB )=1- P(AB)=17/18
统计学贾俊平第四版课后习题测验答案

3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学第四版答案(贾俊平)

40 30 20 10 0
25
30
35
40
●4. 为了确定灯泡的使用寿命(小时) ,在一批灯泡中随机抽取 100 只进行测试,所得结果 如下: 700 706 708 668 706 694 688 701 716 715 729 710 692 690 689 671 728 712 694 693 691 736 683 718 719 722 681 697 747 689 685 707 685 691 695 674 699 696 702 683 709 708 685 658 682 651 741 717 691 690 706 698 698 673 698 733 684 692 661 666 700 749 713 712 705 707 735 696 710 708 676 683 718 701 665 698 722 727 702 692
● 2. 某行业管理局所属 40 个企业 2002 年的产品销售收入数据如下(单位:万元) : 152 124 129 116 100 103 92 95 127 104
105 119 114 115 87 103 118 142 135 125 117 108 105 110 107 137 120 136 117 108 97 88 123 115 119 138 112 146 113 126 (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率; (2)如果按规定:销售收入在 125 万元以上为先进企业,115 万~125 万元为良好企业, 105 万~115 万元为一般企业,105 万元以下为落后企业,按先进企业、良好企业、一般 企业、落后企业进行分组。 解 :(1)要求对销售收入的数据进行分组, 全部数据中,最大的为 152,最小的为 87,知数据全距为 152-87=65; 为便于计算和分析,确定将数据分为 6 组,各组组距为 10,组限以整 10 划分; 为使数据的分布满足穷尽和互斥的要求,注意到,按上面的分组方式,最小值 87 可能落在最小组之下,最大值 152 可能落在最大组之上,将最小组和最大组设计成开口形
统计学第四版(贾俊平)课后所有题答案很全期末考试必备

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别姆鞘中褪荩嵌允挛锝蟹掷嗟慕峁荼硐治啾穑梦淖掷幢硎觯唬ǘㄐ允荩┧承蚴荩褐荒芄橛谀骋挥行蚶啾鸬姆鞘中褪荨K彩怯欣啾鸬模庑├啾鹗怯行虻摹#渴荩┦敌褪荩喊词殖叨炔饬康墓鄄熘担浣峁硐治咛宓氖怠?统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同 1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
1.8 统计应用实例人口普查,商场的名意调查等。
统计学贾俊平_第四版课后习题答案2

统计学贾俊平_第四版课后习题答案23.3 某百货公司连续40天的商品销售额如下:单位:万元41 46 35 4225 36 28 3629 45 46 3747 37 34 3738 37 30 4934 36 37 3930 45 44 4238 43 26 3243 33 38 3640 44 44 35要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数:K 1lg 4 0lgn()1.***** ,取1 1 6.32k=6lg(2)lg20.*****2、确定组距:组距=( 最大值- 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995―20XX年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15 要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量NValid MissingMean Median Mode Std. Deviation Percentiles25 50 7510 0 9.60 10.00 10 4.169 6.25 10.00 12.50种是所有颐客都进入一个等待队列:另―种是顾客在三千业务窗口处列队3排等待。
统计学(贾俊平 第四版)课后习题答案
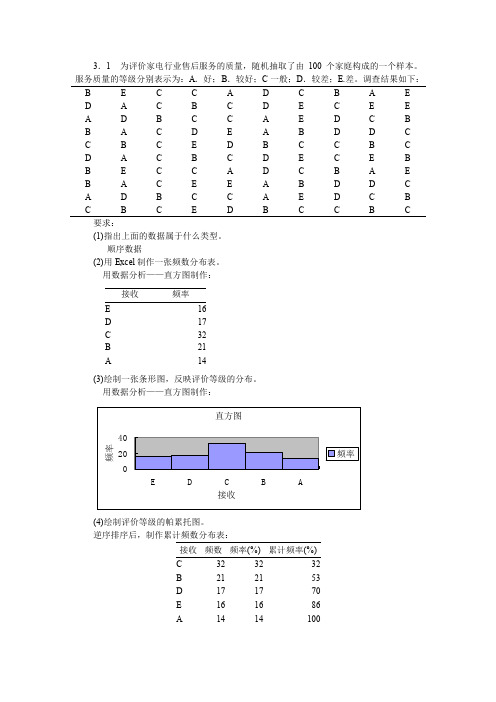
频数
2 3 9 12 7 4 2 1 40
频率%
5.0 7.5 22.5 30.0 17.5 10.0 5.0 2.5 100.0
要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
K 1
l g 4 0 l gn ( ) 1.60206 ,取 1 1 6.3 2 k=6 lg(2) lg 2 0.30103
2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取 5 3、分组频数表
要求: (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。 1、确定组数:
K 1
l g 4 0 l gn ( ) 1.60206 ,取 1 1 6.3 2 k=6 lg(2) lg 2 0.30103
2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(152-87)÷6=10.83,取 10 3、分组频数表 销售收入
直方图:
组距4,小于等于
40
30
Frequency
20
10
Mean =4.06 Std. Dev. =1.221 N =100 0 0 2 4 6 8
组距4,小于等于
组距 5,上限为小于等于 频数 有效 <= 45.00 46.00 - 50.00 51.00 - 55.00 56.00 - 60.00 61.00+ 合计 12 37 34 16 1 100 百分比 12.0 37.0 34.0 16.0 1.0 100.0 累计频数 12.0 49.0 83.0 99.0 100.0 累积百分比 12.0 49.0 83.0 99.0 100.0
统计学贾俊平_第四版课后习题答案

统计学贾俊平_第四版课后习题答案3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数:()lg 40lg() 1.60206111 6.32lg(2)lg 20.30103n K =+=+=+=,取k=6 2、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取54.8 一项关于大学生体重状况的研究发现.男生的平均体重为60kg,标准差为5kg;女生的平均体重为50kg,标准差为5kg。
请回答下面的问题:(1)是男生的体重差异大还是女生的体重差异大?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小,离散程度是男生的小。
(2)以磅为单位(1ks=2.2lb),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg×2.21=132.6磅,标准差为5kg ×2.21=11.05磅;女生的平均体重为50kg×2.21=110.5磅,标准差为5kg×2.21=11.05磅。
(3)粗略地估计一下,男生中有百分之几的人体重在55kg一65kg之间?计算标准分数:Z1=x xs-=55605-=-1;Z2=x xs-=65605-=1,根据经验规则,男生大约有68%的人体重在55kg一65kg之间。
(4)粗略地估计一下,女生中有百分之几的人体重在40kg~60kg之间?计算标准分数:Z1=x xs-=40505-=-2;Z2=x xs-=60505-=2,根据经验规则,女生大约有95%的人体重在40kg一60kg之间。
贾俊平统计学第四版课后答案
第三章节:数据的图表展示…………………………………………………1 第四章节:数据的概括性度量……………………………………………….15 第六章节:统计量及其抽样分布……………………………………………26 第七章节:参数估计………………………………………………. …………28 第八章节:假设检验……………………………………………….. …………38 第九章节:列联分析……………………………………………….. …………41 第十章节:方差分析……………………………………………….. …………43 3. 要求:(1)指出上面的数据属于什么类型。
顺序数据 3.31、确定组数: ()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取53、分组频数表销售收入(万元)频数频率%累计频数累计频率%<= 25 1 2.5 1 2.5 26 - 30 5 12.5 6 15.0 31 - 35 6 15.0 12 30.0 36 - 40 14 35.0 26 65.0 41 - 45 10 25.0 36 90.0 46+ 4 10.0 40100.0总和40100.0频数246810121416<= 2526 - 3031 - 3536 - 4041 - 4546+销售收入频数频数3.4data605040302010data Stem-and-Leaf PlotFrequency Stem & Leaf3.00 1 . 889 5.00 2 . 01133 7.00 2 . 6888999 2.00 3 . 13 3.00 3 . 569 3.00 4 . 123 3.00 4 . 667 3.00 5 . 012 1.00 5 . 7Stem width: 10 Each leaf: 1 case(s)3.6解:(1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计学贾俊平_第四版课后习题答案3. 3某百货公司连续40天的商品销售额如下:单位:万元4125294738343038434046364537373645433344 3528463430374426384442363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1确定组数:K 1 硼1 止1 1.60206 632,取k=6lg(2) lg 2 0.301032、确定组距:组距二(最大值-最小值)-组数=(49-25)十6=4,取53频数销售收入4. 8 一项关于大学生体重状况的研究发现•男生的平均体重为 60kg ,标准差为5kg ;女生的平均体重为50kg ,标准差为5kg 。
请回答下面的问题: (1) 是男生的体重差异大还是女生的体重差异大 ?为什么?女生,因为标准差一样,而均值男生大,所以,离散系数是男生的小, 离散程度是男生的小。
(2) 以磅为单位(1ks = 2. 21b),求体重的平均数和标准差。
都是各乘以2.21,男生的平均体重为60kg X 2.21=132.6磅,标准差为5kg X2.21=11.05磅;女生的平均体重为 50kg X 2.21=110.5磅,标准差为 5kg X 2.21=11.05 磅。
(3) 粗略地估计一下,男生中有百分之几的人体重在 55kg 一 65kg 之间? 计算标准分数:Z1= _ =55 60=-1; Z2= _ = 65 60 =1,根据经验规贝U ,男生大约 s 5 s 5有68%的人体重在55kg 一 65kg 之间。
(4) 粗略地估计一下,女生中有百分之几的人体重在 40kg 〜60kg 之间? 计算标准分数:Z1= -_- = 40 50 =-2; Z2= -―- = 60 50 =2,根据经验规则,女生大约 s 5 s 5有95%的人体重在40kg 一 60kg 之间。
4. 9 一家公司在招收职员时,首先要通过两项能力测试。
在 A 项测试中,其平均分数是100分,标准差是15分;在B 项测试中,其平均分数是 400 分,标准差是50分。
一位应试者在A 项测试中得了 115分,在B 项测试 中得了 425分。
与平均分数相比,该应试者哪一项测试更为理想 ? 解:应用标准分数来考虑问题,该应试者标准分数高的测试理想。
因此,A 项测试结果理想。
4. 13在金融证券领域,一项投资的预期收益率的变化通常用该项投资的风险 来衡量。
预期收益率的变化越小,投资风险越低;预期收益率的变化越大, 投资风险就越高。
下面的两个直方图,分别反映了 200种商业类股票和200 种高科技类股票的收益率分布。
在股票市场上,高收益率往往伴随着高风 险。
但投资于哪类股票,往往与投资者的类型有一定关系。
(1) 你认为该用什么样的统计量来反映投资的风险 ? 标准差或者离散系数。
(2) 如果选择风险小的股票进行投资,应该选择商业类股票还是高科技类股 票?选择离散系数小的股票,则选择商业股票。
(3) 如果进行股票投资,你会选择商业类股票还是高科技类股票 ? 考虑高收益,则选择高科技股票;考虑风险,则选择商业股票。
Z A = 辽亜卫°=1 s 15 Z B = 425 400 50 =0.5闾商业类股票少)奇科技类股票解:(1)方差或标准差;(2)商业类股票;(3)(略)。
7.1从一个标准差为5的总体中抽出一个容量为40的样本,样本均值为25。
(1) 样本均值的抽样标准差 叹等于多少?(2)在95%的置信水平下,允许误差是多少?解:已知总体标准差c =5,样本容量n= 40,为大样本,样本均值x =25,(2)已知置信水平1 — a =95%,得 乙/2 =1.96,于是,允许误差是 E : =Z a /2 命=1.96X 0.7906= 1.5496。
7.2某快餐店想要估计每位顾客午餐的平均花费金额。
在为期3周的时间里选取49名顾客组成了一个简单随机样本。
(1)假定总体标准差为15元,求样本均值的抽样标准误差。
(2)在95%的置信水平下,求边际误差x,由于是大样本抽样,因此样本均值服从正态分布,因此概率度t=z 2因此,x t x z ..-2 次 Z 0.025x=1.96X 2.143=4.2(3) 如果样本均值为120元,求总体均值 的95%的置信区间。
置信区间为:x x ,x x = 120 4.2,120 4.2 = (115.8,124.2)7.10(1)样本均值的抽样标准差(T=—=x.n5 .40=0.790615.49=2.1437J(& ( I > 已知:n=36. x=l495t a =0.05,由于n=36为人样木*所以零件平均长度的95锯的置信区间为:14K 硏」50.13 |(2) *上和的估计屮,便用了统计中的屮心极限定理.谬定理表附’从均值为“、方晋为(7’的总体中,抽取了界慷为(1們随机样木 3n 充分人时(通常n > 30).样木均代的捕样分布id 似戢从均肺为fi .方< h ① 的正态分布・7. 11某企业生产的袋装食品采用自动打包机包装,每袋标准重量为 lOOg 。
现从某天生产的一批产品中按重复抽样随机抽取 50包进行检查,测得每包重量(单位:g)如下:每包重量(g ) 包数 96〜98 2 98〜100 3 100〜102 34 102〜104 7 104〜106 4 合计50已知食品包重量服从正态分布,要求:(1)确定该种食品平均重量的95%的置信区间。
解:大样本,总体方差未知,用 z 统计量样本均值=101.4,样本标准差s=1.829 置信区间:s - Z 2 n ,Xs Z 2.n亍士乙说真w 蛀149.5±0 63>1 =0.95,z .2 = Z o.025 =1.96s _ "n ,X1 829i 829101.4 1.96,101.4 1.96 = (100.89, 101.91) V50V50⑵如果规定食品重量低于l00g 属于不合格,确定该批食品合格率的 95%的置信区间。
解:总体比率的估计大样本,总体方差未知,用z 统计量样本比率=(50-5) /50=0.9 置信区间:=0.95, z .2 = Z 0.025 =1.967. 13 —家研究机构想估计在网络公司工作的员工每周加班的平均时间,为此随机抽取了 18个员工。
得到他们每周加班的时间数据如下(单位:小时):6 21 17 20 7 08 16 29 3812 11 921 2515 16假定员工每周加班的时间服从正态分布。
估计网络公司员工平均每周加班时 间的90%的置信区间。
解:小样本,总体方差未知,用t 统计量t X : t n 1 s —/均值=13.56,样本标准差s=7.801 置信区间:N 0,1P1 P,PP1P nP 1 P=0.9 1.96 J 0.9 1 0.9 ,0.9\ 501.960.9 1 0.9V 50=(0.8168, 0.9832) pnP 1 P--------- ,P z 2nssx t 2 n 1-n,X t 2 n 1"n1 =0.90,n=18,t2 n 1 = t 0.05 17 =1.7369 xs st 2 n 1?n ,x t 2 n 17n7 8011.7369 = (10.36, 16.75) 4187. 15在一项家电市场调查中•随机抽取了 200个居民户,调查他们是否拥有 某一品牌的电视机。
其中拥有该品牌电视机的家庭占23%。
求总体比例的置 信区间,置信水平分别为90%和95%。
解:总体比率的估计大样本,总体方差未知,用z 统计量:N 0,1P 1 P样本比率=0.23 置信区间:P 1 P L^,P U=(0.1811,0.2789)1=0.95, z ;2 = z 0.025 =1.960.2883)=0.90, z .2 = Z 0.025 =1.64513.56 1.7369 7.801,13.56V180.23 1.645 0.23 1 0.23r0—°231.6450.23 1 0.232000.23 1.96°231 °.23,0.23 1.96 °231 °23(0.1717,7. 28某超市想要估计每个顾客平均每次购物花费的金额。
根据过去的经验, 标准差大约为120元,现要求以95%的置信水平估计每个顾客平均购物金额 的置信区间,并要求边际误差不超过 20元,应抽取多少个顾客作为样本? 2 2 z2解:n ——,1=0.95, z ,2=Z o,o25 =1.96, x 1.962 1202=138.3,取 n=139 或者 140,或者 150。
8. 2 一种元件,要求其使用寿命不得低于 700小时。
现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。
已知该元件寿命服从正态分 布, =60小时,试在显著性水平0. 05下确定这批元件是否合格。
解:H 0: 沪700; H 1:卩<700已知:x = 680 = 60由于n=36>30,大样本,因此检验统计量:x 0 _ 680 700s 「n 60 .36当a_ 0.05,查表得z _ 1.645。
因为z v -z ,故拒绝原假设,接受备择假设,说明这批产品不合格8. 4糖厂用自动打包机打包,每包标准重量是 100千克。
每天开工后需要检验一次打包机工作是否正常。
某日开工后测得9包重量(单位:千克)如下: 99. 3 98. 7 100. 5 101. 2 98. 3 99. 7 99. 5 102. 1 100. 5 已知包重服从正态分布,试检验该日打包机工作是否正常 (a _0. 05)?解:H 0:尸 100; H 1:尸 100经计算得:x _ 99.9778 S _ 1.21221 检验统计量: _ -0.055当a_0.05,自由度n — 1_9时,查表得t 2 9 _ 2.262。
因为t v t 2,样本 统计量落在接受区域,故接受原假设,拒绝备择假设,说明打包机工作正常。
8. 5某种大量生产的袋装食品,按规定不得少于 250克。
今从一批该食品中任意抽取50袋,发现有6袋低于250克。
若规定不符合标准的比例超过 5% 就不得出厂,问该批食品能否出厂(a _ 0. 05)? 解:解:H 0: n< 0.05; H 1: n> 0.05已知:p _ 6/50=0.12202t99.9778_100 1.21221 .9检验统计量:当a= 0.05,查表得z = 1.645。