SPSS常见数据分析方法比较
SPSS统计分析方法及应用解析

SPSS统计分析方法及应用解析SPSS(统计软件包社会科学)是一种用于统计分析的软件包,广泛应用于社会科学领域,包括心理学、教育学、经济学等。
它提供了各种统计分析方法和功能,可以帮助研究人员从数据中提取有用的信息,并生成统计报告和图表。
本文将介绍一些常用的SPSS统计分析方法及其应用。
1.描述性统计分析描述性统计分析是对数据进行整体概括和描述的方法,包括计算平均值、标准差、频数和百分比等。
研究人员可以通过SPSS进行描述性统计分析,了解数据的分布情况和基本特征,为后续的统计推断提供基础。
2.t检验t检验是一种用于比较两个样本均值差异是否显著的方法。
SPSS提供了独立样本t检验和配对样本t检验两种方法。
研究人员可以根据实际研究设计选择适当的方法,通过SPSS计算得出t值和p值,以判断两组样本均值差异是否显著。
3.方差分析方差分析是一种用于比较两个或多个样本均值差异是否显著的方法。
SPSS提供了单因素方差分析和多因素方差分析两种方法。
研究人员可以通过SPSS计算得出方差分析表和p值,以判断不同组别之间的均值差异是否显著。
4.相关分析相关分析是一种用于研究两个或多个变量之间关系强度和方向的方法。
SPSS提供了皮尔逊相关系数和斯皮尔曼相关系数两种方法。
研究人员可以通过SPSS计算得出相关系数和p值,以判断变量之间的关系是否显著。
5.回归分析回归分析是一种用于研究自变量与因变量之间关系的方法。
SPSS提供了线性回归、多元回归和逐步回归等方法。
研究人员可以通过SPSS计算得出回归方程和回归系数,以预测因变量的值,并评估自变量对因变量的影响程度。
6.因子分析因子分析是一种用于降维和归纳分析多个变量之间的相关性的方法。
SPSS提供了主成分分析和因子分析两种方法。
研究人员可以通过SPSS计算得出因子载荷和因子得分,以解释变量之间的共性和变异。
此外,SPSS还提供了聚类分析、判别分析、生存分析等其他统计分析方法,以满足研究人员对不同问题的需求。
SPSS常见数据分析方法比较

SPSS常见数据分析方法比较SPSS(Statistical Package for the Social Sciences)是一种流行的统计分析软件,被广泛应用于社会科学研究和商业分析领域。
SPSS提供了各种数据分析方法,帮助用户从数据中提取有用的信息和洞察。
本文将介绍SPSS中常见的数据分析方法,并进行比较。
一、描述性统计分析描述性统计分析是在数据收集和处理阶段非常重要的一步。
通过计算变量的均值、中位数、标准差、最大值、最小值等指标,了解数据的基本分布情况。
SPSS提供了丰富的描述性统计分析方法,包括频数分析、分布分析、交叉报表等。
这些方法可以帮助用户对数据进行初步的分析和认识,为后续的数据分析提供基础。
二、假设检验假设检验是统计分析中常用的方法,用于判断样本数据与总体参数之间的差异是否显著。
SPSS提供了多种假设检验方法,包括t检验、方差分析(ANOVA)、卡方检验等。
这些方法可以帮助用户进行单样本或多样本的假设检验,判断不同组别的数据是否存在显著差异,从而提供统计依据。
三、相关分析相关分析用于研究两个或多个变量之间的关系。
SPSS提供了多种相关分析方法,包括Pearson相关系数分析、Spearman相关系数分析、回归分析等。
这些方法可以帮助用户判断两个变量之间的线性或非线性关系,揭示变量之间的相互关联。
四、回归分析回归分析是一种用于研究因变量与自变量之间关系的统计方法。
SPSS提供了多种回归分析方法,包括线性回归、逻辑回归、多元回归等。
这些方法可以帮助用户建立数学模型,预测因变量的取值,并判断自变量对因变量的影响程度。
五、因子分析因子分析是一种用于探索性因素之间关系的统计方法。
SPSS提供了多种因子分析方法,包括主成分分析、因子旋转等。
这些方法可以帮助用户降维处理多个相关变量,提取出共同因子,并理解变量之间的结构关系。
六、聚类分析聚类分析是一种将个体或对象进行分类的方法,将相似的个体或对象归为一类,不相似的个体或对象归为不同类。
SPSS软件中常用统计分析方法

SPSS软件中常用统计分析方法:均值比较与检验方差分析(参数检验)非参数检验相关分析回归分析聚类分析与判别分析因子分析与对应分析时间序列分析生存分析尺度分析(心理学)多响应变量分析常用统计图形条形图、线图和面积图圆图高低图帕累托图控制图箱图和误差条图散点图直方图P-P和Q-Q图序列图时间序列图审计抽样所谓审计抽样,是指注册会计师在实施审计程序时,从审计对象总体中选取一定数量的样本进行测试,并根据测试结果,推断审计对象总体特征的一种方法。
目录审计抽样,是指注册会计师对某类交易或账户余额中低于百分之百的项目实施审计程序,使所有抽样单元都有被选取的机会。
审计抽样,是指内部审计人员在内部审计活动中,采用适当的抽样方法从被审查和评价的审计总体中抽取一定数量有代表性的样本进行测试,以样本审查结果推断总体特征并作出相应结论的过程。
1、抽样审计不同于详细审计。
详细审计是指百分百地审计对象总体中的全部项目,并根据审计结果形成审计意见。
而抽样审计是从审计对象总体根据统计原理选取部分样本进行审计,并根据样本推断总体并发表审计意见。
2、审计抽样不能等同于抽查。
抽查作为一种技术,可以用于审前调查、确定审计重点、取得审计证据,在使用中无严格要求。
而审计抽样作为一种审计方法,需运用统计原理,并严格按规定的程序和抽样方法的要求实施。
3、抽样审计一般可用于逆查、顺查、函证等审计程序,也可用于符合性测试和实质性测试;但审计师在进行询问、观察、分析性复核时则不宜运用审计抽样。
(1)统计抽样和非统计抽样。
审计抽样统计抽样和非统计抽样的相同点:A、都需合理运用专业判断;B、都可以提供审计所要求的充分、适当的证据;C、都存在某种程度的抽样风险和非抽样风险。
统计抽样和非统计抽样的根本区别:统计抽样时利用概率法则来量化控制抽样风险;非统计抽样中,注册会计师全凭主观标准和个人经验确定样本规模和评价样本结果。
只要设计得当,非统计抽样也可达到统计抽样一样的效果。
spss常用分析方法操作步骤

SPSS常用分析方法操作步骤一、单变量单因素方差分析例题:某个年级有三个班,现在对他们的一次数学考试成绩进行随机抽(见下表),试在显著性水平0.005下检验各班级的平均分数有无显著差异(数据文件:数学考试成绩.sav)。
(1)建立数学成绩数据文件。
(2)选择“分析”→“比较均值”→“单因素方差”,打开单因素方差分析窗口,将“数学成绩”移入因变量列表框,将“班级”移入因子列表框。
(3)单击“两两比较”按钮,打开“单因素ANOV A两两比较”窗口。
(4)在假定方差齐性选项栏中选择常用的LSD检验法,在未假定方差齐性选项栏中选择Tamhane’s检验法。
在显著性水平框中输入0.05,点击继续,回到方差分析窗口。
(5)单击“选项”按钮,打开“单因素ANOV A选项”窗口,在统计量选项框中勾选“描述性”和“方差同质性检验”。
并勾选均值图复选框,点击“继续”,回到“单因素ANOV A选项”窗口,点击确定,就会在输出窗口中输出分析结果。
二、单变量多因素方差分析研究不同温度与不同湿度对粘虫发育历期的影响,得试验数据如表5-7。
分析不同温度和湿度对粘虫发育历期的影响是否存在着显著性差异(数据文件:粘虫.sav)。
(1)建立数据文件“粘虫.sav”。
(2)选择“分析”→“一般线性模型”→“单变量”,打开单变量设置窗口。
(3)分析模型选择:此处我们选用默认;(4)比较方法选择:在窗口中单击“对比”按钮,打开“单变量:对比”窗口进行设置,单击“继续”返回;(5)均值轮廓图选择:单击“绘制”按钮,设置比较模型中的边际均值轮廓图,单击“继续”返回;(6)“两两比较”选择,用于设置两两比较检验,本例中设置为“温度”和“湿度”。
三、相关分析调查了29人身高、体重和肺活量的数据见下表,试分析这三者之间的相互关系。
(1)建立数据文件“学生生理数据.sav”。
(2)选择“分析”→“相关”→“双变量”,打开双变量相关分析对话框。
(3)选择分析变量:将“身高”、“体重”和“肺活量”分别移入分析变量框中。
SPSS数据分析教程均值的比较.完整版PPT

,选择【数据】→【拆分文件】 05,接受零假设,即没有变化。
掌握均值过程和输出结果的解释 假设随机选取了两组商务旅游人员各50人,给两个机场打分,请判断这两个机场的等级是否相同?见数据5-3 下面的分数是对测验焦虑的度量,有充分的证据支持考试题目的安排对分数有影响这一假设吗?见数据5-4 单样本T检验 实例分析: 国际航空运输协会对商务旅游人员进行了一项调查,以便确定多个国际机场的等级分数,最高10分,分数越高,等级越高。 某个航班往返票的平均折扣费3月份是258元。 医生为检验某种饮食方案是否对有家庭心脏病史的病人有效,对16个病人进行了了试验,记录他们在实行饮食方案前后的体重(磅) 以及甘油三酸酯的水平(mg/100ml)。 两独立样本T检验实例分析: 打开数据文件brakes. 可以先计算配对样本的差值变量,然后进行单样本的T检验。 两个样本所来自的总体应服从正态分布(大样本情况下,T检验较为稳健) 即受试对象的年龄、性别、体重等非处理因素都相同或相似;
因而假设检验有可能犯两类错误:
第一类错误:原假设正确,而错误地拒绝了它,即“拒真” 的错误,其发生的概率为犯第一类错误的概率。
第二类错误:原假设不正确,而错误地没有拒绝它,即“受 伪”错误,其发生的概率为犯第二类错误的概率。
三、显著性值
假设检验一般先对总体的比例、均值或分布做 某种假设,称为原假设;然后计算在该假设 成立条件下出现该事件的概率,称为p值,或 显著性值。
01,并假设通勤时间服从正态分布,这位研究者能得到什么结论? 选择【分析】→【比较均值】→【单样本T检验】 如果该事件发生的概率(或可能性)较大,即 p> ,则不拒绝原假设。 打开数据文件brakes. 第二类错误:原假设不正确,而错误地没有拒绝它,即“受伪”错误,其发生的概率为犯第二类错误的概率。 掌握单样本T检验方法、应用条件和输出结果 sav是对护士工资的调查,它调查了不同岗位的护士,记录了他们的小时工资、工作经验、年龄等指标。
数据分析方法大全SPSS数据分析方法详解

数据分析方法大全SPSS数据分析方法详解查看全部影响,利用历史数据进行统计分析,并对数据进行适当处理,进行趋势预测。
据报道,三个英国情报部门与亚马逊云科技签约,将其机密资料交由AWS托管。
ABC分析模型,不光可以用来划分产品和销售额,还可以划分客户及客户交易额等。
比如给企业贡献80%利润的客户是哪些,占比多少。
整体漏斗模型的核心思想其实可以归为分解和量化。
这是产品运营中比较常见的一个模型,结合产品本身的特点以及产品的生命周期位置,来关注不同的数据指标,最终制定不同的运营策略。
通过路径识别用户行为特征。
与其他分析模型配合进行深入分析后,能为找到快速用户动机,从而引领用户走向最优路径或者期望中的路径。
第三种月留存,以月度为单位的留存率,指的是每个月相对于第一个周的新增用户中,仍然还有登录的用户数。
留存率是针对新用户的,其结果是一个矩阵式半面报告,每个数据记录行是日期、列为对应的不同时间周期下的留存率。
正常情况下,留存率会随着时间周期的推移而逐渐降低。
通常,我们利用聚类分析将看似无序的对象进行分组、归类,以达到更好地理解研究对象的目的。
聚类结果要求组内对象相似性较高,组间对象相似影响 ,利用历史数据进行统计分析,并对数据进行适当处理,进行趋势预测。
数据分析的基本方法有哪些企服解答数据分析的基本方法有5种: 1、因素分析法:即对其中一指标的相关影响因素进行统计与分析。
2、比率分析法:即用相对数来表示不同项目的数据比率。
3、对比分析法:将其中一指标与选定的比较标准进行比较。
4、趋势分析法:对其中一指标进行连续多个周期的数据进行统计和分析(常用折线图)。
5、结构分析法:指对其中一项目的子项目占比进行统计和分析(常用饼图)。
相关信息谷歌拟26亿美元收购商业智能和数据分析公司Looker 36氪讯,2023年06月07日。
Alphabet旗下谷歌公司周四宣布,该公司计划以26亿美元的价格收购商业智能和数据分析公司Looker,支付方式为现金。
SPSS聚类分析中数据无量纲化方法比较_韩胜娟 - 副本

SPSS聚类分析中数据无量纲化方法比较Comparison of Undimensionalization in SPSS Cluster Analysis韩胜娟Han Shengjuan(华东交通大学,江西南昌330013)(School of Economics and Management, East China Jiaotong University, Jiangxi Nanchang330013)摘要: 聚类分析方法作为一种多指标综合评价方法,其在分析过程中数据无量纲化处理就是必不可少的。
SPSS软件聚类分析菜单提供了四大类指标数据无量纲化处理方法,不同处理方法的特点不同,适用的数据也不尽相同。
本文试图对不同的无量纲化处理方法的特点和适用数据进行分析。
关键词: SPSS ; 聚类分析; 无量纲化方法中图分类号:O212.4 文献标识码:A文章编号:1671-4792-(2008)3-0017-03Abstract: The cluster analysis is one multi-objective quality synthetic evaluation method, Undimensionalizationis essential in the analysis process. In SPSS cluster analysis menu provid four Undimensionalization methods,the different Undimensionalization's characteristic is different, the suitable data is also different, thisarticle attempts to carry on this.Keywords: SPSS; Cluster Analysis; Undimensionalization聚类分析是目前广泛使用的一种建立分类的多元统计分析方法。
SPSS统计分析—差异分析

独立两样本t检验
定义:所谓独立样本是指两个样本之间彼此独立没有任何关联,两个独立样 本各自接受相同的测量,研究者的主要目的是了解两个样本之间是否有显著差异 存在。这个检验的前提如下:
注意: 两样本必须是独立的,即从一总体中抽取一批样本对从另一总体中抽取一
批样本没有任何影响,两组样本个案数目可以不同,个案顺序可以随意调整。 样本来自的总体要服从正态分布且变量为连续测量数据。 在进行独立两样本t检验之前,要通过F检验来看两样本的方差是否相等。
这样我们可采用一定的方法来比较组内变异和组间变异的大小如果后者远远大于前者则说明处理因素的影响确实存在如果两者相差无几则说明影响不存在这就是方差分析的基本思想
差异分析
1、均值描述—Means过程 2、t检验 3、方差分析
均值描述——Means过程
定义:Means过程是SPSS计算各种基本描述统计量的过程。 Means过程其实就是按照用户指定条件,对样本进行分组计算均 数和标准差,如按性别计算各组的均数和标准差。
• 方差分析的类型
单因素方差分析
单因素方差分析是指只单独考虑一个因素A对指标X的影响。此时其他因素都不变 或者控制在一定的范围之内。考虑因素A有k个水平,在每次水平下做ni次试验。
在方差分析中,代表变异大小,并用来进行变异分解的指标是离均差平方和。 总的变异平方和记为SST,被分解为两项:第一项是各组的离均差平方和之和,代 表组内变异(即随机变量引起的变异),称为组内平方和SSW(Within Groups); 第二项是按样本含量大小加权的各组均数与总均数的差值平方之和,代表组间变 异(由控制变量引起的变异),称为组间平方和或者处理平方和SSB(Between Groups)。
SPSS统计策略(12):多组率、构成比比较的统计方法(卡方和Fisher法)
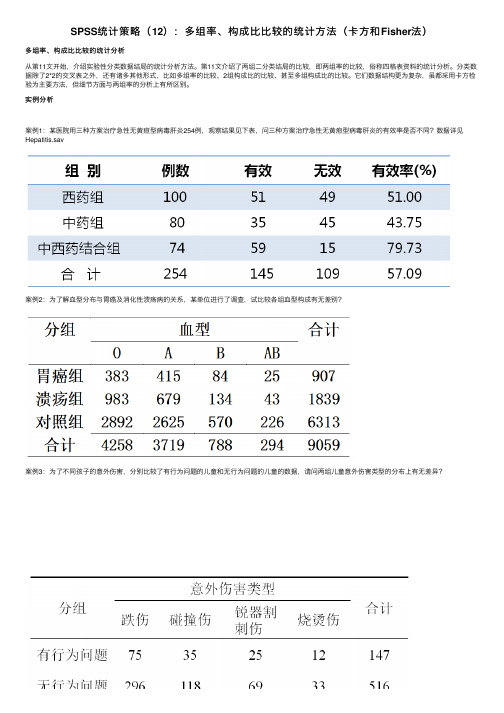
SPSS统计策略(12):多组率、构成⽐⽐较的统计⽅法(卡⽅和Fisher法)多组率、构成⽐⽐较的统计分析从第11⽂开始,介绍实验性分类数据结局的统计分析⽅法。
第11⽂介绍了两组⼆分类结局的⽐较,即两组率的⽐较,俗称四格表资料的统计分析。
分类数据除了2*2的交叉表之外,还有诸多其他形式,⽐如多组率的⽐较、2组构成⽐的⽐较、甚⾄多组构成⽐的⽐较。
它们数据结构更为复杂,虽都采⽤卡⽅检验为主要⽅法,但细节⽅⾯与两组率的分析上有所区别。
实例分析案例1:某医院⽤三种⽅案治疗急性⽆黄疸型病毒肝炎254例,观察结果见下表,问三种⽅案治疗急性⽆黄疸型病毒肝炎的有效率是否不同?数据详见Hepatitis.sav案例2:为了解⾎型分布与胃癌及消化性溃疡病的关系,某单位进⾏了调查,试⽐较各组⾎型构成有⽆差别?案例3:为了不同孩⼦的意外伤害,分别⽐较了有⾏为问题的⼉童和⽆⾏为问题的⼉童的数据,请问两组⼉童意外伤害类型的分布上有⽆差异?1案情分析案例1结局为⼆上述3个例⼦结局均为分类数据(效果、⾎型、意外伤害类型),汇总数据形成的三线表称为多⾏多列交叉表或者⾏列表多⾏多列交叉表或者⾏列表。
区别就在于,案例组多分类结局。
因此,第1个例⼦为多个率的⽐较,第2个例⼦为多个构成⽐的⽐较,第3个例⼦则是2个构分类结局,案例2为多分类结局,案例3则是2组多分类结局。
成⽐的⽐较。
2统计分析策略多⾏多列交叉表数据的分析,或者说多个率、构成⽐,乃⾄两个构成⽐的⽐较,四格表资料的分析策略⼀样,均可以考虑卡⽅和均可以考虑卡⽅和Fisher确切概率⽅法进⾏。
但是细节⽅⾯,与四格表资料的分析策略有所不同。
第⼀,多⾏多列交叉表分析没有校正卡⽅。
具体应⽤条件如下:1.不超过20%单元格的理论频数(期望频数)T < 5时,可使⽤卡⽅检验进⾏⽐较。
不超过20%的T < 5,卡⽅检验2.如果超过20%单元格的理论频数(期望频数)T < 5,或者⾄少⼀个T<1,此时采⽤的是Fisher确切概率法。
SPSS数据分析教程均值的比较讲课文档

第三十六页,共43页。
案例分析
数据文件dietstudy.sav包含对“Stillman diet”的研 究结果。医生为检验某种饮食方案是否对有家 庭心脏病史的病人有效,对16个病人进行了了 试验,记录他们在实行饮食方案前后的体重( 磅)以及甘油三酸酯的水平(mg/100ml)。
别难而惊慌失措的不愉快经历,因此人们对考 试题目的安排进行了研究,以弄清它对焦虑的 影响。下面的分数是对测验焦虑的度量,有充 分的证据支持考试题目的安排对分数有影响这 一假设吗?见数据5-4
第三十四页,共43页。
5.5配对样本T检验
两配对样本T检验用来检验来自两配对总体的均 值是否在统计上有显著性差异。常见的配对设 计方法有以下几种:
第十七页,共43页。
T分布和正态分布比较
第十八页,共43页。
在大样本情况下,T分布和正态分布密度函数十 分接近
在大样本情况下,T检验和U检验是等价的
第十九页,共43页。
例子
打开数据文件brakes.sav,该数据为某工厂不同 机器生产的刹车片直径,已知符合质量标准的 刹车片直径应为322 mm,现在需要知道哪些机 器生产的刹车片直径不符合质量标准。
第四十一页,共43页。
2、减肥药的效果 为了研究一种减肥药的效果,特抽取了20名试
验者进行试验,其服用该产品一个疗程前后的 体重变化见数据5-6。试用配对样本T检验的方 法判断该药物能否引起试验者体重的明显变化 ?
第四十二页,共43页。
动手练习
数据文件GSS2004_Mod.sav中记录了男性或者女 性每周上网浏览网页的时间(变量WWWHR, 单位小时)和每天观看电视的时间(变量 TVHOURS,单位小时)。用本章学习的技巧分 析男性和女性在观看电视的时间和上网的时间 上分别就什么区别。
SPSS数据处理中常用方法PPT课件

18
多因素方差分析
LOGO
多因素方差分析中的控制变量在两个或两 个以上,它的研究目的是要分析多个控制变量 的作用、多个控制变量的交互作用以及其他随 机变量是否对结果产生了显著影响
2020/1/10
19
LOGO
将观察变量总的离差平方和分解为3个部分: 多个控制变量单独作用引起的离差平方和 多个控制变量交互作用引起的离差平方和 其他随机因素引起的离差平方和
MSb/MSw比值构成F分布,用F值与其临界值 比较,推断各样本是否来自相同的总体
2020/1/10
8
方差分析的假设检验
LOGO
零假设H0:m组样本均值都相同,即μ 1= μ2=....= μm
如果经过计算结果组间均方远远大于组内均方 ( MSb>>MSw ),F>F0.05(dfb,dfw), p<0.05, 拒绝零假设, 说明样本来自不同的正态总体, 说明处理造成均值的差异有统计意义;否则, F<F0.05((dfb,dfw), p>0.05不能拒绝零假设,说明 样本来自相同的正态总体,处理间无差异。
Compare Means
One-Way ANOVA
2020/1/10
LOGO
12
在SPSS中的实现步骤
LOGO
2020/1/10
13
2020/1/10
LOGO
14
2020/1/10
LOGO
15
2020/1/10
LOGO
16
运算结果
LOGO
2020/1/10
17
2020/1/10
运算结果
LOGO
30
在SPSS中的操作
SPSS如何实现多个条件的多重比较

SPSS如何实现多个条件的多重比较在使用SPSS进行数据分析时,我们常常需要进行多个条件下的多重比较。
SPSS提供了一些简单的策略来实现这一目标。
下面将介绍一些常见的方法。
1. 单因素方差分析(One-way ANOVA)如果我们有一个自变量(组别)和一个因变量(数值型),并且希望比较多个组之间的均值差异,我们可以使用单因素方差分析。
在SPSS中,选择“分析”菜单下的“一元方差分析”选项。
然后将因变量移至“因变量”框中,将自变量移至“因子”框中。
点击“选项”,勾选“描述性统计”和“多重比较”。
2. 重复测量方差分析(Repeated Measures ANOVA)在某些情况下,我们可能有多个因变量,并且希望比较这些因变量在多个时间点或条件下的均值差异。
这时可以使用重复测量方差分析。
在SPSS中,选择“分析”菜单下的“一元方差分析”选项。
在“因变量”框中选择所有的因变量,将自变量(时间点或条件)移至“因子”框中。
点击“选项”,勾选“描述性统计”和“多重比较”。
3. 多元方差分析(Multivariate ANOVA)在某些情况下,我们可能有多个自变量,并且想要比较这些自变量在多个因变量上的均值差异。
这时可以使用多元方差分析。
在SPSS中,选择“分析”菜单下的“一元方差分析”选项。
在“因变量”框中选择所有的因变量,将自变量移至“因子”框中。
点击“选项”,勾选“描述性统计”和“多重比较”。
4. 进一步的多重比较分析除了上述方法,SPSS还提供了更多的多重比较分析方法,如LSD(最小显著差异法)、Bonferroni法、Tukey法等。
这些方法可在上述分析的结果中找到。
需要注意的是,在进行多重比较时,我们应该根据实际情况选择最适合的方法。
在选择方法时,应综合考虑样本大小、数据分布和研究假设等因素。
以上就是在SPSS中实现多个条件的多重比较的一些基本方法。
希望对您有帮助!。
SPSS数据分析的统计方法选择

SPSS数据分析的统计方法选择SPSS(Statistical Package for the Social Sciences)是一款广泛应用于社会科学领域的统计分析软件。
在进行数据分析时,选择合适的统计方法非常重要,因为不同的问题需要不同的统计方法来解决。
下面是一些常用的统计方法及其在SPSS中的应用。
1.描述统计:描述统计是对数据的基本特征进行汇总和整理的方法。
SPSS提供了丰富的描述统计方法,如变量的均值、中位数、标准差、最小值、最大值、分位数等。
2.t检验:t检验用于比较两个群体均值是否有显著差异。
SPSS中提供了独立样本t检验和配对样本t检验两种方式来进行t检验。
3.方差分析:方差分析用于比较多个群体均值是否有显著差异。
SPSS 中的一元方差分析可以用于比较一个因变量在一个自变量有多个水平时的均值差异。
4. 相关分析:相关分析用于研究两个变量之间的关系。
在SPSS中,可以通过计算Pearson相关系数或Spearman等级相关系数来进行相关分析。
5.回归分析:回归分析用于研究因变量与自变量之间的关系和预测。
SPSS中提供了多种回归方法,包括线性回归、逐步回归、逐级回归等。
6.卡方检验:卡方检验用于检验观察频数与期望频数之间的差异。
SPSS中提供了卡方检验方法,包括卡方独立性检验和卡方拟合度检验。
7.方差分析:方差分析(ANOVA)是一种用于比较多个组均值的统计方法。
在SPSS中,可以进行一元方差分析或多元方差分析来评估组间差异的显著性。
8. 非参数检验:非参数检验用于在不满足正态分布假设的情况下比较群体差异。
SPSS中提供了一些非参数检验方法,如Wilcoxon符号秩检验、Mann-Whitney U检验、Kruskal-Wallis H检验等。
9.因素分析:因素分析用于降维和提取潜在变量。
在SPSS中,可以进行主成分分析或因子分析来研究变量之间的相关结构。
10.聚类分析:聚类分析用于将相似的个体或因素分组。
SPSS数据分析

SPSS数据分析0SPSS⼀、基本功能及操作介绍(⼀)数据1.个案排序对数据视图中的某个个案进⾏排序,具体排序规则可以点进去选择。
2.变量排序对变量视图中某个变量进⾏排序,具体规则可以点进去选择。
3.转置⾏列互转。
4.合并⽂件有两种⽂件的合并,添加个案可以实现两个⽂件的纵向合并,添加变量可以两个⽂件的横向合并。
5.重构实现把⼀个表格的若⼲个变量变为同⼀个变量等进⾏表格的合适转换6.汇总对数据按照类别进⾏汇总,⽐如三个班级的学⽣成绩表格,可以按照班级把学⽣成绩的平均值等等汇总到另外⼀个表格,该表格就会显⽰⽐如按班级显⽰各个班级的成绩平均值等7.拆分⽂件实现输出图形表格的合理拆分,⽐如⼀个公司有8个部门,现要求分男⼥⽐较各个部门的⼈员⼯资情况,理论上我们⽤选择个案(见下条),逐个选择男⼥与部门需要操作2*8次,由此画出2*8张图表。
利⽤拆分⽂件,这个时候可以选择⽐较组或者按组来组织输出,然后分组依据就是部门与性别,在利⽤下⾯会讲到的数据描述就可以实现预期效果。
8.选择个案实现选择表格中符合条件的个案然后对其进⾏相应操作,点击进去后会有各种选择⽅式,⽐如如果满⾜什么条件才选择,随机选择百分之多少等等1.重新编码为不同变量可以把原来的变量或者变量的范围重新定义为新的变量,⽐如现有⼀个班级的学⽣成绩,要求分⼼50-70分,70-90分90-100分的同学所占⽐例,平均值等,现在就可以利⽤重新编码为不同变量,把上述范围重新编码为新的变量(名字可以⾃⼰任意选取),具体操作点击进去之后⽐较清楚。
2.计算变量实现对原来变量的重新计算从⽽产⽣新的变量,⽐如对原来变量进⾏乘以10操作产⽣新的变量等等,产⽣的变量名都是可以⾃⼰选择的1.描述统计:实现对表格中变量的各种类型的描述统计1.1 频率实现某⼀变量的频率统计,统计显⽰可以显⽰其平均值等等,可以选择⽤条形图或者什么其他图形进⾏描述,⽐如对于各个部门的⼯资可以进⾏分部门描述各个部门⼯资平均值或者其所占整体⽐率。
SPSS数据分析的统计方法选择

数据分析的统计方法选择小结目录数据分析的统计方法选择小结 (1)目录 (1)●资料1 (2)完全随机分组设计的资料 (2)配对设计或随机区组设计 (3)变量之间的关联性分析 (4)●资料2 (5)1.连续性资料 (5)1.1两组独立样本比较 (5)1.2两组配对样本的比较 (5)1.3多组完全随机样本比较 (6)1.4多组随机区组样本比较 (6)2.分类资料 (6)2.1四格表资料 (6)2.2 2×C表或R×2表资料的统计分析 (7)2.3 R×C表资料的统计分析 (7)2.4 配对分类资料的统计分析 (7)●资料3 (8)一、两个变量之间的关联性分析 (8)二、回归分析 (9)●资料4 (9)一.统计方法抉择的条件 (9)1.分析目的 (10)2.资料类型 (10)3.设计方法 (11)4.分布特征及数理统计条件 (12)二.数据资料的描述 (12)1.数值变量资料的描述 (13)2.分类变量资料的描述 (13)三.数据资料的比较 (14)1.假设检验的基本步骤 (14)2.假设检验结论的两类错误 (15)3.假设检验的注意事项 (15)4.常用假设检验方法 (16)四.变量间的相关分析 (17)1.数值变量(计量资料)的关系分析 (18)2.无序分类变量(计数资料)的相关分析 (18)3.有序分类变量(等级资料)等级相关 (18)●资料1完全随机分组设计的资料一、两组或多组计量资料的比较1.两组资料:1)大样本资料或服从正态分布的小样本资料(1)若方差齐性,则作成组t检验(2)若方差不齐,则作t’检验或用成组的Wilcoxon秩和检验2)小样本偏态分布资料,则用成组的Wilcoxon秩和检验2.多组资料:1)若大样本资料或服从正态分布,并且方差齐性,则作完全随机的方差分析。
如果方差分析的统计检验为有统计学意义,则进一步作统计分析:选择合适的方法(如:LSD检验,Bonferroni检验等)进行两两比较。
SPSS多重比较常用方法总结

S P S S多重比较常用方法总结-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN1. 1LSD法最小显着差异法,公式为:它其实只是t检验的一个简单变形,并未对检验水准做出任何校正,只是在标准误的计算上充分利用了样本信息, 为所有组的均数统一估计出了一个更为稳健的标准误,其中MS误差是方差分析中计算得来的组内均方,它一般用于计划好的多重比较。
由于单次比较的检验水准仍为α,因此可认为LSD法是最灵敏的。
1. 2 Bonferroni法该法又称Bonferroni t检验,由Bonferroni提出。
用t检验完成各组间均值的配对比较,但通过设置每个检验的误差率来控制整个误差率。
若每次检验水准为α′,共进行m 次比较,当H0 为真时,犯Ⅰ类错误的累积概率α不超过mα′,既有Bonferroni不等式α≤mα′成立。
α′=αm=αC2k=2αk ( k - 1), t =( …XA - …XB )S… dAB,S… dAB = MS误差1nA+1nB但是该方法在样本组数较小时效果较好,当比较次数m 较多时,结论偏于保守。
1. 3Sidak法它实际上就是Sidak校正在LSD法上的应用,即通过Sidak校正降低每两次比较的Ⅰ类错误概率,以达到最终整个比较的Ⅰ类错误概率为α的目的。
即α′= 1 - (1 -α) 2 / k ( k - 1) ; t =( …XA - …XB )S… dAB,S… dAB = MS误差1nA+1nB。
计算t统计量进行多重配对比较。
可以调整显着性水平,比Bofferroni方法的界限要小。
1. 4Student2Newman2Keuls法( SNK法)q = ( …XA - …XB ) /MS误差21nA+1nB,它实质上是根据预先制定的准则将各组均数分为多个子集, 利用Studentized Range分布来进行假设检验,并根据所要检验的均数的个数调整总的Ⅰ类错误概率不超过α。
数据分析方法大全SPSS数据分析方法详解

数据分析方法大全SPSS数据分析方法详解SPSS(Statistical Package for the Social Sciences)是一种常用的数据分析软件,广泛应用于各个领域的研究和统计分析。
下面是一些常用的数据分析方法和技术,以及如何在SPSS中进行实施。
1.描述性统计分析:SPSS可以计算各种描述性统计指标,如平均数、中位数、标准差、百分位数等。
可以使用“统计”菜单下的“描述统计”选项完成。
2.相关分析:相关分析用于研究两个或多个变量之间的关系。
SPSS提供了许多方法来计算相关系数,如皮尔逊相关系数、斯皮尔曼等级相关系数等。
可以使用“分析”菜单下的“相关”选项进行分析。
3.回归分析:回归分析用于研究一个或多个自变量与因变量之间的关系。
SPSS提供了多种回归模型,如线性回归、多元回归、逐步回归等。
可以使用“分析”菜单下的“回归”选项进行分析。
4.方差分析:方差分析用于比较两个或多个组之间的平均值是否显著不同。
SPSS提供了单因素方差分析、二因素方差分析、协方差分析等多种方法。
可以使用“分析”菜单下的“方差”选项进行分析。
5.t检验和方差齐性检验:t检验用于比较两个样本平均值是否显著不同,而方差齐性检验用于检验两个样本方差是否相等。
SPSS提供了独立样本t检验、配对样本t检验、方差齐性检验等多种方法。
可以使用“分析”菜单下的“比较均值”选项进行分析。
6.散点图和箱线图:散点图用于可视化两个变量之间的关系,箱线图用于可视化不同组之间的差异。
可以使用“图表”菜单下的“散点图”和“箱线图”选项进行绘制。
7.因子分析和聚类分析:因子分析用于将多个变量归纳为较少的无关连的维度,聚类分析用于将相似的对象归为同一组。
SPSS提供了因子分析和聚类分析的功能,可以使用“分析”菜单下的“因子”和“聚类”选项进行分析。
8.生存分析:生存分析用于研究事件发生的时间和概率。
SPSS提供了生存分析的方法,如卡普兰-迈尔曲线、生存函数、风险比等。
SPSS常见数据分析方法比较

聚类分析(组别)
一个定量变量 独立样本T检验 单因子方差分析 多因子方差分析 协方差分析
多个定量变量 多变量方程分析 多变量方程分析 多变量方程分析 多变量协方差分析
简单相关分析、 简单回归分析
复回归分析或虚拟变量复 规则相关分析、路径分
回归分析
析、结构方程模型
主成分分析(一成分)因 主成分分析(多成分)
自变量 A X A(两群) A(两群以上) A,B,…… A,B,协变量X A,B,…… A,B,协变量X
X1,X2,…… X1,X2,……, A,B,……
因变量 B Y Y Y(多重比较) Y(互动效果) Y Y1,Y2,…… Y1,Y2,……
Y Y
中文名称
英文名称
自变量
因变量
规则相关分析(无 CANCORR 因果)
因子分析 主成分分析
多元量表法
Factor(转轴) V1,V2,.....,Vn →F1,F2,……Fi(i<n)
Factor(为转 V至少为顺序量表,F为等距量表 轴)
MDS
点间的定量或非定量量表-空间构型
注:理论模型中变量通常很难测得,这类变量成为潜变量,如绩效、满意度、忠 诚度等。
路径分析(有因果) PATH
结构方程模型
SEM
判别分析
Discrim
Logistic回归
Logit
聚类分析
Cluster
X1,X2,……,A,B,…… Y1,Y2,……
X1,X2,……(显变量) Y1,Y2,…… X1,X2,……(潜变量) Y1,Y2,…… X1,X2,……,A,B,…… A X1,X2,……,A,B,…… A(两群以上) V1,V2,.....,Vn →A(V1,V2可为定量或定性)
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一 SPSS常用多变量分析技术比较汇总表
自 变量 因变量 一个分类变量 卡方分析 卡方分析 分层卡方检验 一个定量变量 独立样本T检验 单因子方差分析 多因子方差分析 协方差分析 多个定量变量 多变量方程分析 多变量方程分析 多变量方程分析 多变量协方差分析
一个分组变量(2群) 一个分组变量(多群) 两个分组变量 N个分组变量 一个定量变量 一个定量变量
复回归分析
虚拟变量回归分析
REGRESSION
Dummy Reg
X1,X2,……
X1,X2,……, A,B,……
Y
Yபைடு நூலகம்
中文名称 规则相关分析(无 因果)
英文名称 CANCORR
自变量 X1,X2,……,A,B,……
因变量 Y1,Y2,……
路径分析(有因果) PATH
结构方程模型 SEM
X1,X2,……(显变量)
多个定量变量(或包含 虚拟变量) 多个定量变量
注 • 卡方分析:定量两个定性变量的关联程度 • 简单相关分析:计量两个计量变量的相关程度 • 独立样本T检验:比较两组平均数是否相等 • ONEWAY ANOVA:比较三组以上的平均数是否相等,并 进行多重比较检验 • TWOWAY ANOVA:比较两因素的平均数是否相等,并检 验主效应和交互效应 • 判别分析与Logistic回归:检验一组计量的自变量(可含 虚拟变量)是否可以正确区别一个定性的因变量 • 多维量表发(MDS):试图将个体中的变异数据,经过转 维为一个多维度的空间图,且转化的个体在空间中的相对 关系仍与原始数据尽量配合一致
二SPSS常用统计技术(变量个数与 测量量表)比较汇总表
中文名称 卡方分析 简单相关分析 独立样本T检验 单因素方差分析 方差分析 协方差分析 多变量方差分析 多变量协变量方差 分析 英文名称 CROSSTABS CORRELATE T-TEST ONEWAY ANOVA ANCOVA MANOVA MANCOVA 自变量 A X A(两群) A(两群以上) A,B,…… A,B,协变量X A,B,…… A,B,协变量X 因变量 B Y Y Y(多重比较) Y(互动效果) Y Y1,Y2,…… Y1,Y2,……
区别分析、 Logistic回归 区别分析、 Logistic回归 聚类分析(组别)
简单相关分析、 简单回归分析 复回归分析或虚拟变量复 回归分析 主成分分析(一成分)因 子分析(一分子)MDS (一维) 规则相关分析、路径分 析、结构方程模型 主成分分析(多成分) 因子分析(多因子) MDS(多维)
X1,X2,……(潜变量)
Y1,Y2,……
Y1,Y2,……
判别分析
Logistic回归 聚类分析 因子分析 主成分分析 多元量表法
Discrim
Logit Cluster
X1,X2,……,A,B,……
X1,X2,……,A,B,……
A
A(两群以上)
V1,V2,.....,Vn →A(V1,V2可为定量或定性)
Factor(转轴) V1,V2,.....,Vn →F1,F2,……Fi(i<n) Factor(为转 轴) MDS V至少为顺序量表,F为等距量表 点间的定量或非定量量表-空间构型
注:理论模型中变量通常很难测得,这类变量成为潜变量,如绩效、满意度、忠 诚度等。