spss曲线拟合与回归分析
spss中的回归分析

7、Plots(图)对话框 单击“Plots”按钮,对话框如下图所示。Plots可帮助分析
资料的正态性、线性和方差齐性,还可帮助检测奇异值或异常值。
(1)散点图:可选择如下任何两个变量为Y(纵轴变量)与X (横轴变量)作图。为 获得更多的图形,可单击“Next”按钮来重 复操作过程。
Variables
Model
Entered
1
INCOMEa
Variables
Removed
Method
. Enter
a. All requested variables entered.
b. Dependent Variable: FOODEXP
输 入 / 移 去 的 变 量b
模型 1
输入的变量 移去的变量
DEPENDENT:因变量。 *ZPRED:标准化预测值。 *ZRESID: 标准化残差。 *DRESID:删除的残差。 *ADJPRED:调整残差。 *SRESID:Student氏残差。 *SDRESID: Student氏删除残差。 (2)Standardized Residual Plots:标准化残差图。 Histogram:标准化残差的直方图,并给出正态曲线。 Normal Probality Plot:标准化残差的正态概率图(P-P图)。 (3)Produce all Partial plots:偏残差图。
Coefficie nts Beta
.923
系 数a
t -.781 12.694
Sig. .441 .000
模型
1
(常量)
非标准化系数
B
标准误
spss曲线拟合与回归分析
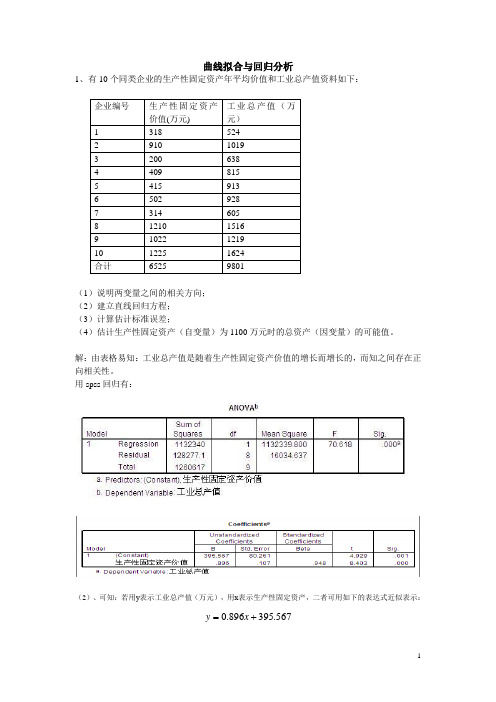
曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。
SPSS回归分析过程详解

线性回归的假设检验
01
线性回归的假设检验主要包括拟合优度检验和参数显著性 检验。
02
拟合优度检验用于检验模型是否能够很好地拟合数据,常 用的方法有R方、调整R方等。
1 2
完整性
确保数据集中的所有变量都有值,避免缺失数据 对分析结果的影响。
准确性
核实数据是否准确无误,避免误差和异常值对回 归分析的干扰。
3
异常值处理
识别并处理异常值,可以使用标准化得分等方法。
模型选择与适用性
明确研究目的
根据研究目的选择合适的回归模型,如线性回 归、逻辑回归等。
考虑自变量和因变量的关系
数据来源
某地区不同年龄段人群的身高 和体重数据
模型选择
多项式回归模型,考虑X和Y之 间的非线性关系
结果解释
根据分析结果,得出年龄与体 重之间的非线性关系,并给出 相应的预测和建议。
05 多元回归分析
多元回归模型
线性回归模型
多元回归分析中最常用的模型,其中因变量与多个自变量之间存 在线性关系。
非线性回归模型
常见的非线性回归模型
对数回归、幂回归、多项式回归、逻辑回归等
非线性回归的假设检验
线性回归的假设检验
H0:b1=0,H1:b1≠0
非线性回归的假设检验
H0:f(X)=Y,H1:f(X)≠Y
检验方法
残差图、残差的正态性检验、异方差性检验等
非线性回归的评估指标
判定系数R²
回归分析spss

回归分析spss回归分析是一种常用的统计方法,用于探究变量之间的关系。
它通过建立一个数学模型,通过观察和分析实际数据,预测因变量与自变量之间的关联。
回归分析可以帮助研究者得出结论,并且在决策制定和问题解决过程中提供指导。
在SPSS(统计包括在社会科学中的应用)中,回归分析是最常用的功能之一。
它是一个强大的工具,用于解释因变量与自变量之间的关系。
在进行回归分析之前,我们需要收集一些数据,并确保数据的准确性和可靠性。
首先,我们需要了解回归分析的基本概念和原理。
回归分析基于统计学原理,旨在寻找自变量与因变量之间的关系。
在回归分析中,我们分为两种情况:简单回归和多元回归。
简单回归适用于只有一个自变量和一个因变量的情况,多元回归适用于多个自变量和一个因变量的情况。
在进行回归分析之前,我们需要确定回归模型的适用性。
为此,我们可以使用多种统计性检验,例如检验线性关系、相关性检验、多重共线性检验等。
这些检验可以帮助我们判断回归模型是否适用于收集到的数据。
在SPSS中进行回归分析非常简单。
首先,我们需要打开数据文件,然后选择“回归”功能。
接下来,我们需要指定自变量和因变量,并选择适当的回归模型(简单回归或多元回归)。
之后,SPSS将自动计算结果,并显示出回归方程的参数、标准误差、显著性水平等。
在进行回归分析时,我们需要关注一些重要的统计指标,例如R方值、F值和P值。
R方值表示自变量对因变量的解释程度,它的取值范围在0到1之间,越接近1表示模型的拟合效果越好。
F值表示回归模型的显著性,P值则表示自变量对因变量的影响是否显著。
我们通常会将P值设定为0.05作为显著性水平,如果P值小于0.05,则我们可以认为自变量对因变量有显著影响。
此外,在回归分析中,我们还可以进行一些额外的检验和分析。
比如,我们可以利用残差分析来检查回归模型的拟合优度,以及发现可能存在的异常值和离群点。
此外,我们还可以进行变量选择和交互效应的分析。
SPSS 10.0高级教程十二:多元线性回归与曲线拟合

SPSS 10.0高级教程十二:多元线性回归与曲线拟合回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。
回归分析就是用于说明这种依存变化的数学关系。
§10.1Linear过程10.1.1 简单操作入门调用此过程可完成二元或多元的线性回归分析。
在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。
例10.1:请分析在数据集Fat surfactant.sav中变量fat对变量spovl的大小有无影响?显然,在这里spovl是连续性变量,而fat是分类变量,我们可用用单因素方差分析来解决这个问题。
但此处我们要采用和方差分析等价的分析方法--回归分析来解决它。
回归分析和方差分析都可以被归入广义线性模型中,因此他们在模型的定义、计算方法等许多方面都非常近似,下面大家很快就会看到。
这里spovl是模型中的因变量,根据回归模型的要求,它必须是正态分布的变量才可以,我们可以用直方图来大致看一下,可以看到基本服从正态,因此不再检验其正态性,继续往下做。
10.1.1.1 界面详解在菜单中选择Regression==>liner,系统弹出线性回归对话框如下:除了大家熟悉的内容以外,里面还出现了一些特色菜,让我们来一一品尝。
【Dependent框】用于选入回归分析的应变量。
【Block按钮组】由Previous和Next两个按钮组成,用于将下面Independent框中选入的自变量分组。
由于多元回归分析中自变量的选入方式有前进、后退、逐步等方法,如果对不同的自变量选入的方法不同,则用该按钮组将自变量分组选入即可。
下面的例子会讲解其用法。
【Independent框】用于选入回归分析的自变量。
【Method下拉列表】用于选择对自变量的选入方法,有Enter(强行进入法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)五种。
《SPSS统计分析》第11章 回归分析

返回目录
多元逻辑斯谛回归
返回目录
多元逻辑斯谛回归的概念
回归模型
log( P(event) ) 1 P(event)
b0
b1 x1
b2 x2
bp xp
返回目录
多元逻辑斯谛回归过程
主对话框
返回目录
多元逻辑斯谛回归过程
参考类别对话框
保存对话框
返回目录
多元逻辑斯谛回归过程
收敛条件选择对话框
创建和选择模型对话框
返回目录
曲线估计
返回目录
曲线回归概述
1. 一般概念 线性回归不能解决所有的问题。尽管有可能通过一些函数
的转换,在一定范围内将因、自变量之间的关系转换为线性关 系,但这种转换有可能导致更为复杂的计算或失真。 SPSS提供了11种不同的曲线回归模型中。如果线性模型不能确 定哪一种为最佳模型,可以试试选择曲线拟合的方法建立一个 简单而又比较合适的模型。 2. 数据要求
线性回归分析实例1输出结果2
方差分析
返回目录
线性回归分析实例1输出结果3
逐步回归过程中不在方程中的变量
返回目录
线性回归分析实例1输出结果4
各步回归过程中的统计量
返回目录
线性回归分析实例1输出结果5
当前工资变量的异常值表
返回目录
线性回归分析实例1输出结果6
残差统计量
返回目录
线性回归分析实例1输出结果7
返回目录
习题2答案
使用线性回归中的逐步法,可得下面的预测商品流通费用率的回归系数表:
将1999年该商场商品零售额为36.33亿元代入回归方程可得1999年该商场 商品流通费用为:1574.117-7.89*1999+0.2*36.33=4.17亿元。
数据统计分析软件SPSS的应用(五)——相关分析与回归分析

数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS是目前应用广泛且非常强大的数据分析工具之一。
在前几篇文章中,我们介绍了SPSS的基本操作和一些常用的统计方法。
本篇文章将继续介绍SPSS中的相关分析与回归分析,这些方法是数据分析中非常重要且常用的。
一、相关分析相关分析是一种用于确定变量之间关系的统计方法。
SPSS提供了多种相关分析方法,如皮尔逊相关、斯皮尔曼相关等。
在进行相关分析之前,我们首先需要收集相应的数据,并确保数据符合正态分布的假设。
下面以皮尔逊相关为例,介绍SPSS 中的相关分析的步骤。
1. 打开SPSS软件并导入数据。
可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备相关分析的变量。
选择菜单栏中的“Analyze”选项,然后选择“Correlate”子菜单中的“Bivariate”。
在弹出的对话框中,选择要进行相关分析的变量,并将它们添加到相应的框中。
3. 进行相关分析。
点击“OK”按钮后,SPSS会自动计算所选变量之间的相关系数,并将结果输出到分析结果窗口。
4. 解读相关分析结果。
SPSS会给出相关系数的值以及显著性水平。
相关系数的取值范围为-1到1,其中-1表示完全负相关,1表示完全正相关,0表示没有相关关系。
显著性水平一般取0.05,如果相关系数的显著性水平低于设定的显著性水平,则可以认为两个变量之间存在相关关系。
二、回归分析回归分析是一种用于探索因果关系的统计方法,广泛应用于预测和解释变量之间的关系。
SPSS提供了多种回归分析方法,如简单线性回归、多元线性回归等。
下面以简单线性回归为例,介绍SPSS中的回归分析的步骤。
1. 打开SPSS软件并导入数据。
同样可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备回归分析的变量。
spss曲线拟合与回归分析

曲线拟合与回归分析1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:(1)说明两变量之间的相关方向;(2)建立直线回归方程;(3)计算估计标准误差;(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:=x.0+y.567395896(3)、用spss回归知标准误差为80.216(万元)。
(4)、当固定资产为1100时,总产值可能是(0.896*1100+395.567-80.216~0.896*1100+395.567+80.216)即(1301.0~146.4)这个范围内的某个值。
另外,用MATLAP也可以得到相同的结果:程序如下所示:function [b,bint,r,rint,stats] = regression1x = [318 910 200 409 415 502 314 1210 1022 1225];y = [524 1019 638 815 913 928 605 1516 1219 1624];X = [ones(size(x))', x'];[b,bint,r,rint,stats] = regress(y',X,0.05);display(b);display(stats);x1 = [300:10:1250];y1 = b(1) + b(2)*x1;figure;plot(x,y,'ro',x1,y1,'g-');industry = ones(6,1);construction = ones(6,1);industry(1) =1022;construction(1) = 1219;for i = 1:5industry(i+1) =industry(i) * 1.045;construction(i+1) = b(1) + b(2)* construction(i+1);enddisplay(industry);display( construction);end运行结果如下所示:b =395.56700.8958stats =1.0e+004 *0.0001 0.0071 0.0000 1.6035industry =1.0e+003 *1.02201.06801.11601.16631.21881.2736construction =1.0e+003 *1.2190 0.3965 0.3965 0.3965 0.3965 0.3965200400600800100012001400生产性固定资产价值(万元)工业总价值(万元)2、设某公司下属10个门市部有关资料如下:(1)、确定适宜的 回归模型; (2)、计算有关指标,判断这三种经济现象之间的紧密程度。
SPSS数据分析—非线性回归

SPSS数据分析—非线性回归
线性回归的关键条件是因变量与自变量之间呈线性关系。
如果存在非线性关系,就需要使用非线性回归进行分析。
在SPSS中,非线性回归有两个过程可供调用:回归曲线估计和
非线性回归。
这两种方法的思路不同,前者通过变量转换将曲线线性化,再使用线性回归进行拟合;后者则直接按照非线性模型进行拟合。
使用变量转换的方法简单易行,但只适用于拟合比较简单的非线性关系。
此外,变量转换可能会改变残差的分布和独立性等性质,导致拟合结果不一定是最优解。
当曲线关系复杂时,无法通过变量转换进行直线化。
因此,非线性回归模型可以很好地解决这些问题。
非线性回归模型提出了一个基本模型框架,期望函数可以为任意形式,甚至没有表达式。
在参数估计上,由于是曲线,无法直接使用最小二乘法进行估计,需要使用XXX-牛顿法进行估计,这一方法比较依赖于初始值的设定。
为了比较两种方法的效果,我们使用同一组数据来进行拟合。
使用回归曲线估计进行拟合时,需要进行变量转换,只能
拟合比较简单的非线性关系。
而使用非线性回归进行拟合时,直接按照非线性模型进行拟合,可以拟合更为复杂的非线性关系。
因此,非线性回归在处理复杂非线性关系时更为有效。
用spss软件进行一元线性回归分析

step2:做散点图
给散点图添加趋势线的方法: • 双击输出结果中的散点图 • 在“图表编辑器”的菜单中依次点击“元素”—“总计拟合线”,由此“属性”中加载了 “拟合线” • 拟合方法选择“线性”,置信区间可以选95%个体,应用
step3:线性回归分析
从菜单上依次点选:分析—回归—线性 设置:因变量为“年降水量”,自变量为“纬度” “方法”:选择默认的“进入”,即自变量一次全部进入的方法。 “统计量”:
step4:线性回归结果
【Anova】 (analysisofvariance方差分析) • 此表是所用模型的检验结果,一个标准的方差分析表。 • Sig.(significant )值是回归关系的显著性系数,sig.是F值的实际显著性概率即P值。 当sig. <= 0.05的时候,说明回归关系具有统计学意义。如果sig. > 0.05,说明二者 之间用当前模型进行回归没有统计学意义,应该换一个模型来进行回归。 • 由表可见所用的回归模型F统计量值=226.725 ,P值为0.000,因此我们用的这个回 归模型是有统计学意义的,可以继续看下面系数分别检验的结果。 • 由于这里我们所用的回归模型只有一个自变量,因此模型的检验就等价与系数的检验, 在多元回归中这两者是不同的。
• 勾选“模型拟合度”,在结果中会输出“模型汇总”表 • 勾选“估计”,则会输出“系数”表 “绘制”:在这一项设置中也可以做散点图 “保存”: • 注意:在保存中被选中的项目,都将在数据编辑窗口显示。 • 在本例中我们勾选95%的置信区间单值,未标准化残差 “选项”:只需要在选择方法为逐步回归后,才需要打开
利用spss进行一元线性回归
step1:建立数据文件 打开spss的数据编辑器,编辑变量视图
用SPSS做回归分析

结果说明——回归系数分析:
1. Model 为回归方程模型编号 2. Unstandardized Coefficients 为非标准化系数,B为系数值, Std.Error为系数的标准差 3. Standardized Coefficients 为标准化系数 4. t 为t检验,是偏回归系数为0(和常数项为0)的假设检验 5. Sig. 为偏回归系数为0 (和常数项为0)的假设检验的显著性 水平值 6. B 为Beta系数,Std.Error 为相应的标准差
结果:
y 0.0472 0.3389 x 2 0.0019
F 117.1282 F0.01 (1, 8) 11.26 R 0.9675 R0.01 (8) 0.765
检验说明线性关系显著
操作步骤:Analyze→Regression →Linear… →Statistics→Model fit Descriptives
162 150 140 110 128 130 135 114 116 124 158 144 130 125 175
以年龄为自变量x, 血压为因变量y,可 作出如下散点图:
SPSS数据分析—非线性回归

线性回归的首要满足条件是因变量与自变量之间呈线性关系,之后的拟合算法也是基于此,但是如果碰到因变量与自变量呈非线性关系的话,就需要使用非线性回归进行分析。
SPSS中的非线性回归有两个过程可以调用,一个是分析—回归—曲线估计,另一个是分析—回归—非线性,两种过程的思路不同,这也是非线性回归的两种分析方法,前者是通过变量转换,将曲线线性化,再使用线性回归进行拟合;后者则是直接按照非线性模型进行拟合。
我们按照两种方法分别拟合同一组数据,将结果进行比较。
分析—回归—曲线估计
变量转换的方法简单易行,在某些情况下是首选,但是只能拟合比较简单的(选项中有的)非线性关系,并且该方法存在一定的缺陷,例如
1.通过变量转换使用最小二乘法拟合的结果,再变换回原值之后不一定是最优解,并且变量转换也可能会改变残差的分布和独立性等性质。
2.曲线关系复杂时,无法通过变量转换进行直线化
3.曲线直线化之后,只能通过最小二乘法进行拟合,其他拟合方法无法实现
基于以上问题,非线性回归模型可以很好的解决,它和线性回归模型一样,也提出一个基本模型框架,所不同的是模型中的期望函数可以为任意形式,甚至没有表达式,在参数估计上,由于是曲线,无法直接使用最小二乘法进行估计,需要使用高斯-牛顿法进行估计,这一方法比较依赖于初始值的设定。
下面我们来直接按照非线性模型进行拟合,看看结果如何
分析—回归—非线性
以上用了两种方差进行拟合,从决定系数来看似乎非线性回归更好一点,但是要注意的是,曲线回归计算出的决定系数是变量转换之后的,并不一定能代表变换之前的变异解释程度,这也说明二者的决定系数不一定可比。
我们可以通过两种方法计算出的预测值与残差图进行比较来判断优劣,首先将相关结果保存为变量,再做图。
spss第五讲回归分析PPT课件

2、用于判断误差的假定是否成立 3、检测有影响的观测值
34
残差图
(形态及判别)
残
差
0
残
残
差
差
0
0
x
(a)满意模式
x
(b)非常数方差
x
(c)模型不合适
35
二、检验正态性 标准化残差(standardized residual)
2. E(y0) 在1-置信水平下的置信区间为
yˆ0 t 2 (n 2)se
1
n
x0 x 2
n
xi x 2
i 1
式中:se为估计标准误差
29
个别值的预测区间
1. 利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的一个个别值的估计区间,这一
区间称为预测区间(prediction interval) 2. y0在1-置信水平下的预测区间为
一、变差 1、因变量 y 的取值是不同的,y 取值的这种波动称为变
差。变差来源于两个方面
由于自变量 x 的取值不同造成的 除 x 以外的其他因素(如x对y的非线性影响、测量误差等)
的影响
2、对一个具体的观测值来说,变差的大小可以通过该 实际观测值与其均值之差y y 来表示
16
误差分解图
y
(xi , yi )
32
一、检验方差齐性
残差(residual)
1、因变量的观测值与根据估计的回归方程求 出的预测值之差,用e表示
ei yi yˆi
2、反映了用估计的回归方程去预测而引起的 误差
3、可用于确定有关误差项的假定是否成立 4、用于检测有影响的观测值
简单介绍SPSS如何做回归和相关

02
SPSS回归分析
线性回归分析
定义:线性回 归分析是一种 通过建立数学 模型来描述因 变量和自变量 之间线性关系 的统计分析方
法。
目的:通过回 归分析,可以 确定因变量和 自变量之间的 关系强度,并 预测因变量的
未来值。
适用范围:适 用于因变量和 自变量之间存 在线性关系的
情况。
操作步骤:选 择自变量和因 变量,建立回 归模型,进行 模型拟合和检 验,解释结果 和预测未来。
YOUR LOGO
20XX.XX.XX
SPSS回归和相关分析的简单介 绍
XX,a click to unlimited possibilities
汇报人:XX
目 录
01 单 击 添 加 目 录 项 标 题 02 S P S S 回 归 分 析 03 S P S S 相 关 分 析
01
添加章节标题
THANK YOU
汇报人:XX
数据清洗和 建立回归模 模型评估和
整理
型
优化
解释结果和 预测
03
SPSS相关分析
描述性相关分析
参数相关分析
添加标题 添加标题 添加标题 添加标题
定义:参数相关分析是统计学中用于衡量两个或多个变量之间关联程度 的方法。
类型:包括Pearson相关系数、Spearman秩相关系数和Kendall秩相关 系数等。
非线性回归分析
定义:非线性回归分析是一种用于探索和描述因变量与自变量之间非线性关系的统计方法。
适用场景:当因变量与自变量之间的关系不是简单的线性关系时,可以使用非线性回归分 析。
模型形式:非线性回归分析的模型通常采用幂函数、指数函数、对数函数等形式。
参数估计:非线性回归分析的参数通常通过最小二乘法或最大似然估计等方法进行估计。
数据统计分析软件SPSS的应用相关分析与回归分析

数据统计分析软件SPSS的应用相关分析与回归分析一、本文概述随着信息技术的快速发展和大数据时代的来临,数据统计分析在各个领域的应用越来越广泛。
SPSS作为一款功能强大的数据统计分析软件,其在社会科学、商业分析、医学统计等多个领域具有广泛的应用。
本文将深入探讨SPSS在相关分析与回归分析中的应用,帮助读者更好地理解和应用这一强大的工具。
本文将简要介绍SPSS软件的基本功能和特点,使读者对其有一个初步的了解。
随后,文章将重点介绍相关分析的概念、类型及其在SPSS中的实现方法,包括皮尔逊相关系数、斯皮尔曼秩相关系数等。
文章还将详细阐述回归分析的基本原理、类型及其在SPSS中的操作步骤,如线性回归分析、逻辑回归分析等。
通过本文的学习,读者将能够掌握SPSS在相关分析与回归分析中的基本应用,提高数据处理和分析的能力,为实际工作和研究提供有力支持。
文章还将提供一些实际案例,以帮助读者更好地理解和应用所学知识,提高实际操作能力。
二、SPSS软件基础SPSS,全称为Statistical Package for the Social Sciences,即“社会科学统计软件包”,是一款广泛应用于社会科学领域的数据统计分析软件。
它提供了丰富的数据分析工具,包括描述性统计、推论性统计、探索性数据分析、回归分析、因子分析、聚类分析等,能够帮助研究者轻松处理和分析数据,挖掘数据背后的深层次信息。
在使用SPSS之前,用户需要对其基本界面和常用功能有所了解。
SPSS界面友好,主要分为菜单栏、工具栏、数据视图和变量视图等部分。
菜单栏包含了大多数统计分析功能的命令,如“分析”“描述统计”“因子分析”等。
工具栏则提供了一些常用的统计分析工具的快捷方式。
数据视图是用户输入和编辑数据的地方,而变量视图则用于定义变量的属性,如变量名、变量类型、宽度、小数位数等。
在SPSS中,数据分析的核心步骤通常包括数据准备、数据分析、结果解释和报告生成。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
曲线拟合与回归分析
1、有10个同类企业的生产性固定资产年平均价值和工业总产值资料如下:
企业编号生产性固定资产
价值(万元) 工业总产值(万元)
1 318 524
2 910 1019
3 200 638
4 409 815
5 415 913
6 502 928
7 314 605
8 1210 1516
9 1022 1219
10 1225 1624
合计6525 9801
(1)说明两变量之间的相关方向;
(2)建立直线回归方程;
(3)计算估计标准误差;
(4)估计生产性固定资产(自变量)为1100万元时的总资产(因变量)的可能值。
解:由表格易知:工业总产值是随着生产性固定资产价值的增长而增长的,而知之间存在正向相关性。
用spss回归有:
(2)、可知:若用y表示工业总产值(万元),用x表示生产性固定资产,二者可用如下的表达式近似表示:
567
.
395
896
.0x
y。