模糊聚类实例
模糊聚类分析实验报告
实验报告(一)一、实验内容模糊聚类在土地利用分区中的应用二、实验目的本次上机实习主要以指导学生掌握“如何应用模糊聚类方法进行土地利用规划分区”为目标。
三、实验方法本次试验是在Excel中实现。
利用《土地利用规划学》P114页数据,使用“欧氏距离法”、建模糊相似矩阵,并进行模糊聚类分析实现土地利用分区。
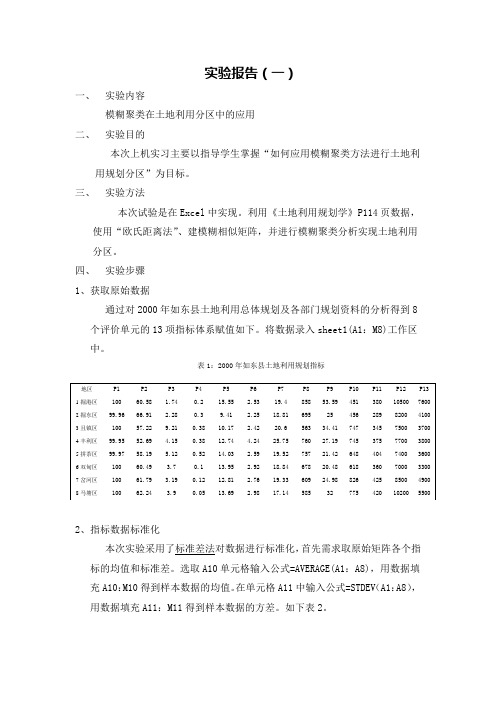
四、实验步骤1、获取原始数据通过对2000年如东县土地利用总体规划及各部门规划资料的分析得到8个评价单元的13项指标体系赋值如下。
将数据录入sheet1(A1:M8)工作区中。
表1:2000年如东县土地利用规划指标2、指标数据标准化本次实验采用了标准差法对数据进行标准化,首先需求取原始矩阵各个指标的均值和标准差。
选取A10单元格输入公式=AVERAGE(A1:A8),用数据填充A10:M10得到样本数据的均值。
在单元格A11中输入公式=STDEV(A1:A8),用数据填充A11:M11得到样本数据的方差。
如下表2。
表2:13个指标值得均值和标准差选取A13单元格输入公式=(A1-A$10)/A$11,并用数据填充A13:M20区域得到标准化矩阵如下表3。
表3:标准化数据矩阵3、求取模糊相似矩阵本次试验是通过欧氏距离法求取模糊相似矩阵。
其数学模型为:mr ij=1−c√∑(x ik−x jk)2k=1选取A23单元格输入公式=SQRT((A$13-A13)^2+(B$13-B13)^2+(C$13-C13)^2+(D$13-D13)^2+(E$13-E13)^2+(F$13-F13)^2+(G$13-G13)^2+(H$13-H13)^2+(I$13-I13)^2+(J$13-J13)^2+(K$13-K13)^2+(L$13-L13)^2+(M$13-M13)^2)求的d11,B23中输入公式=SQRT((A$14-A13)^2+(B$14-B13)^2+(C$14-C13)^2+(D$14-D13)^2+(E$14-E13)^2+(F$14-F13)^2+(G$14-G13)^2+(H$14-H13)^2+(I$14-I13)^2+(J$14-J13)^2+(K$14-K13)^2+(L$14-L13)^2+(M$14-M13)^2)q 求的d12。
模糊聚类分析在生活中的运用

模糊聚类分析在生活中的运用
模糊聚类分析是一种基于模糊数学技术的数据分析方法,它能够有效地将数据分类,让用户能够更加清楚的获得信息。
自20世纪70年代以来,模糊聚类分析在许多学科和行业中都得到了广泛的应用,其中包括社会学、医学、金融、商业等多个领域。
模糊聚类分析在生活中也有非常多的运用,下面就让我们来看看模糊聚类分析在生活中的运用。
首先,模糊聚类分析在精准医疗领域中有着重要的应用。
例如,数据挖掘技术可以利用模糊聚类分析,从海量的医疗数据中快速分析出病人的病变模式。
对于上述模式的发现,可以帮助医生更有针对性地采取临床治疗方法,为病人提供更加靶向性的治疗,从而提高治疗效果。
其次,模糊聚类分析还在社会调查领域占据了重要的地位。
比如,社会学家可以利用模糊聚类分析对大量的调查结果进行分析,对社会现象进行归纳概括,分出不同的群体,如性别、年龄等。
这有助于社会学家们把握社会现象的发展趋势,从而更好地为政府提供决策依据,给社会发展提供建议。
此外,模糊聚类分析还在智能推荐系统中得到了广泛的运用。
比如,当我们在电商网站上购买商品时,模糊聚类分析可以根据用户的浏览记录、购买记录等进行分析,为用户推荐商品,从而提高购买效率。
以上就是模糊聚类分析在生活中的运用。
可以看出,模糊聚类分
析是一种强大的数据分析工具,能够有效地提取出大量的信息,为各个领域的发展提供有力的支撑。
未来,模糊聚类分析将在更多领域发挥作用,为人类社会作出更大的贡献。
fcm聚类算法例题

fcm聚类算法例题FCM(模糊C均值)聚类算法是一种常用的聚类算法,它通过将每个数据点与聚类中心之间的模糊隶属度来划分数据点所属的聚类。
下面我将为你提供一个FCM聚类算法的例题。
假设我们有一组数据集,包含10个数据点,每个数据点有2个特征。
我们的目标是将这些数据点划分为3个聚类。
数据集如下:数据点1: (2, 3)。
数据点2: (4, 6)。
数据点3: (3, 8)。
数据点4: (2, 5)。
数据点5: (1, 7)。
数据点6: (6, 2)。
数据点7: (7, 4)。
数据点8: (8, 5)。
数据点9: (9, 4)。
数据点10: (7, 6)。
现在我们来应用FCM聚类算法来进行聚类。
首先,我们需要初始化聚类中心。
假设我们将聚类中心初始化为:聚类中心1: (2, 3)。
聚类中心2: (5, 5)。
聚类中心3: (8, 4)。
接下来,我们计算每个数据点与聚类中心之间的距离,并计算每个数据点对于每个聚类中心的隶属度。
这里我们可以使用欧氏距离来衡量距离。
通过计算距离和隶属度,我们可以更新聚类中心的位置。
具体的更新过程是通过最小化目标函数来进行的,目标函数是每个数据点与聚类中心的距离的加权和。
重复以上步骤直到聚类中心的位置不再改变或者达到预定的迭代次数。
最后,我们将每个数据点分配到具有最高隶属度的聚类中心,从而完成聚类。
以上就是一个FCM聚类算法的例题。
在实际应用中,我们可以根据数据的特点和需求,调整聚类的个数和初始聚类中心的位置,以得到更好的聚类结果。
同时,FCM算法还可以用于处理模糊数据和噪声数据。
模糊聚类分析实验报告

专业:信息与计算科学 姓名: 学号:实验一 模糊聚类分析实验目的:掌握数据文件的标准化,模糊相似矩阵的建立方法,会求传递闭包矩阵;会使用数学软件MATLAB 进行模糊矩阵的有关运算实验学时:4学时实验内容:⑴ 根据已知数据进行数据标准化.⑵ 根据已知数据建立模糊相似矩阵,并求出其传递闭包矩阵.⑶ (可选做)根据模糊等价矩阵绘制动态聚类图.⑷ (可选做)根据原始数据或标准化后的数据和⑶的结果确定最佳分类. 实验日期:20017年12月02日实验步骤:1 问题描述:设有8种产品,它们的指标如下:x 1 = (37,38,12,16,13,12)x 2 = (69,73,74,22,64,17)x 3 = (73,86,49,27,68,39)x 4 = (57,58,64,84,63,28)x 5 = (38,56,65,85,62,27)x 6 = (65,55,64,15,26,48)x 7 = (65,56,15,42,65,35)x 8 = (66,45,65,55,34,32)建立相似矩阵,并用传递闭包法进行模糊聚类。
2 解决步骤:2.1 建立原始数据矩阵设论域},,{21n x x x X 为被分类对象,每个对象又有m 个指标表示其性状, im i i i x x x x ,,,21 ,n i ,,2,1 由此可得原始数据矩阵。
于是,得到原始数据矩阵为323455654566356542155665482615645565276285655638286384645857396827498673176422747369121316123837X 其中nm x 表示第n 个分类对象的第m 个指标的原始数据,其中m = 6,n = 8。
2.2 样本数据标准化2.2.1 对上述矩阵进行如下变化,将数据压缩到[0,1],使用方法为平移极差变换和最大值规格化方法。
(1)平移极差变换:111min{}max{}min{}ik ik i n ik ik ik i n i n x x x x x ,(1,2,,)k m L显然有01ikx ,而且也消除了量纲的影响。
模糊聚类的原理和应用

模糊聚类的原理和应用1. 简介模糊聚类是一种聚类分析方法,它通过考虑数据点属于不同聚类的程度,使得数据点可以同时属于多个聚类。
与传统的硬聚类方法不同,模糊聚类能够更好地处理实际问题中的复杂性和不确定性。
本文将介绍模糊聚类的原理和应用。
2. 模糊聚类的原理在传统的硬聚类方法中,每个数据点只能隶属于一个聚类,而在模糊聚类中,每个数据点可以属于多个聚类,且属于不同聚类的程度可以从0到1之间的任意值。
这种程度被称为隶属度,用来表示数据点与聚类的关联程度。
模糊聚类的原理可以通过以下步骤来解释:1.初始化聚类中心:首先随机选择一些数据点作为聚类中心。
2.计算隶属度:计算每个数据点与每个聚类中心的隶属度,可以使用模糊C均值(FCM)算法来计算。
3.更新聚类中心:根据隶属度计算出每个聚类的中心点,更新聚类中心。
4.重复步骤2和3,直到聚类中心不再变化或达到预设的迭代次数。
模糊聚类的核心是通过计算隶属度来确定每个数据点对每个聚类的归属程度,从而实现多类别的聚类。
3. 模糊聚类的应用模糊聚类在许多领域中具有广泛的应用,包括数据挖掘、模式识别、图像处理和生物信息学等。
以下是几个常见的应用领域:3.1 数据挖掘在数据挖掘中,模糊聚类可以帮助找到数据集中的隐藏模式和关联规则。
通过将数据点划分到不同的聚类中,可以更好地理解数据的结构和特征。
模糊聚类还可以用作预测分析和聚类分析的基础。
3.2 模式识别在模式识别中,模糊聚类可以帮助将输入数据分类到模式类别中。
通过考虑隶属度,模糊聚类可以更好地处理模糊和不确定性的输入数据。
这在人脸识别、手写体识别等任务中非常有用。
3.3 图像处理在图像处理中,模糊聚类被广泛应用于图像分割和图像压缩等任务。
通过将图像像素划分到不同的聚类中,可以实现图像的分割和压缩。
模糊聚类还可以用于图像特征提取和图像检索等应用。
3.4 生物信息学在生物信息学中,模糊聚类被用于处理基因表达数据和蛋白质序列数据等。
模糊数学作业

模糊聚类分析班级:信计10-1班 姓名:万丽 学号:201011011011题目:设有四种产品,给它们的指标如下: u1=(37,38,12,16,13,12) u2=(69,73,74,22,64,17) u3=(73,86,49,27,68,39) u4=(57,58,64,84,63,28)试用最大最小法建立相似矩阵,并用传递闭包法,最大树法及编网法进行模糊聚类。
并求最佳聚类。
解:一、构造模糊相似矩阵⎪⎪⎪⎪⎪⎭⎫⎝⎛=286384645857396827498673176422747369121316123837U *为由题设知特性指标矩阵采用最大值规格化法,.6).,...,max (,21'===n u u u M M u u nj j j j jij ij此处其中:采用最大值规格化法,.39,68,84,74,86,73654321======M M M M M M 显然,此处只写出'12u 的做法,其他元素同理可得。
44.08638212'12===M u u .⎪⎪⎪⎪⎪⎭⎫⎝⎛=72.092.000.186.067.078.000.100.132.066.000.100.144.094.026.000.185.095.031.019.019.016.044.051.0U 为数据规格化后,矩阵变用最大最小法构造模糊相似矩阵:6,)()(11=∨∧=∑∑==m u uu u r mk jk ikmk jk ikij 此处,41.044.48.144.094.026.000.185.095.031.019.019.016.044.051.0)()(6121612112==++++++++++=∨∧=∑∑==k k kk k ku uu u r ,其他元素求法相同。
于是,模糊相似矩阵为:⎪⎪⎪⎪⎪⎭⎫⎝⎛=169.072.036.069.0177.036.072.077.0141.036.036.041.01R二、进行模糊聚类1、利用传递闭包法进行模糊聚类 利用平方法合成传递闭包:R R R R ⊇⎪⎪⎪⎪⎪⎭⎫ ⎝⎛==172.072.041.072.0177.041.072.077.0141.041.041.041.012 , 2224172.072.041.072.0177.041.072.077.0141.041.041.041.01RR R R =⎪⎪⎪⎪⎪⎭⎫ ⎝⎛== 。
模糊熵聚类公式 csdn

模糊熵聚类公式csdn摘要:1.模糊熵聚类公式的概念和原理2.模糊熵聚类公式的应用领域3.模糊熵聚类公式的实例解析4.模糊熵聚类公式的优缺点分析正文:一、模糊熵聚类公式的概念和原理模糊熵聚类公式是一种基于模糊熵理论的聚类方法,用于对数据进行分类和聚类。
模糊熵是模糊信息理论的一个重要概念,它反映了模糊集合的不确定性和模糊程度。
在聚类分析中,模糊熵聚类公式通过对数据集合的模糊熵进行计算,找出数据集合中的内在结构和规律,从而实现对数据的分类和聚类。
二、模糊熵聚类公式的应用领域模糊熵聚类公式在许多领域都有广泛的应用,如数据挖掘、模式识别、机器学习、图像处理等。
在这些领域中,模糊熵聚类公式可以帮助研究者更好地理解数据、挖掘数据中的潜在信息和规律,为决策提供支持。
三、模糊熵聚类公式的实例解析以一个简单的例子来说明模糊熵聚类公式的应用。
假设有如下五个数据点:(1,1),(2,2),(3,3),(4,4),(5,5)。
首先计算每个数据点的模糊熵,然后根据模糊熵值将数据点分为两类。
在这个例子中,数据点(1,1)和(5,5)的模糊熵最小,说明它们最接近,可以归为同一类;数据点(2,2),(3,3),(4,4)的模糊熵较大,说明它们之间的距离较远,可以归为另一类。
四、模糊熵聚类公式的优缺点分析模糊熵聚类公式的优点在于它能够较好地处理模糊和不确定的数据,适应性较强。
同时,模糊熵聚类公式具有较高的聚类精度和稳定性。
然而,模糊熵聚类公式也存在缺点,如计算复杂度较高,对初始聚类中心的选择敏感等。
在实际应用中,需要根据问题的具体情况选择合适的聚类方法。
综上所述,模糊熵聚类公式是一种基于模糊熵理论的聚类方法,具有较强的适应性和较高的聚类精度。
模糊聚类算法的原理和实现方法

模糊聚类算法的原理和实现方法模糊聚类算法是一种数据分类和聚类方法,它在实际问题中有着广泛的应用。
本文将介绍模糊聚类算法的原理和实现方法,包括模糊C均值(FCM)算法和模糊神经网络(FNN)算法。
一、模糊聚类算法的原理模糊聚类算法是基于模糊理论的一种聚类方法,它的原理是通过对数据进行模糊分割,将每个数据点对应到多个聚类中心上,从而得到每个数据点属于各个聚类的置信度。
模糊聚类算法的原理可以用数学公式进行描述。
设有n个数据样本点X={x1, x2, ..., xn},以及m个聚类中心V={v1, v2, ..., vm}。
对于每个数据样本点xi,令uij为其属于第j个聚类中心的置信度,其中j=1,2,..., m,满足0≤uij≤1,且∑uij=1。
根据模糊理论,uij的取值表示了xi属于第j个聚类中心的隶属度。
为了达到聚类的目的,我们需要对聚类中心进行调整,使得目标函数最小化。
目标函数的定义如下:J = ∑∑(uij)^m * d(xi,vj)^2其中,m为模糊度参数,d(xi,vj)为数据点xi与聚类中心vj之间的距离,常用的距离度量方法有欧氏距离和曼哈顿距离。
通过不断调整聚类中心的位置,最小化目标函数J,即可得到模糊聚类的结果。
二、模糊C均值(FCM)算法的实现方法模糊C均值算法是模糊聚类算法中最经典的一种方法。
其具体实现过程如下:1. 初始化聚类中心:随机选取m个数据点作为初始聚类中心。
2. 计算隶属度矩阵:根据当前聚类中心,计算每个数据点属于各个聚类中心的隶属度。
3. 更新聚类中心:根据隶属度矩阵,更新聚类中心的位置。
4. 判断是否收敛:判断聚类中心的变化是否小于设定的阈值,如果是则停止迭代,否则返回第2步。
5. 输出聚类结果:将每个数据点分配到最终确定的聚类中心,得到最终的聚类结果。
三、模糊神经网络(FNN)算法的实现方法模糊神经网络算法是一种基于模糊理论和神经网络的聚类方法。
其实现过程和传统的神经网络类似,主要包括以下几个步骤:1. 网络结构设计:确定模糊神经网络的层数和每层神经元的个数。
模糊聚类算法(FCM)

模糊聚类算法(FCM)伴随着模糊集理论的形成、发展和深化,RusPini率先提出模糊划分的概念。
以此为起点和基础,模糊聚类理论和⽅法迅速蓬勃发展起来。
针对不同的应⽤,⼈们提出了很多模糊聚类算法,⽐较典型的有基于相似性关系和模糊关系的⽅法、基于模糊等价关系的传递闭包⽅法、基于模糊图论的最⼤⽀撑树⽅法,以及基于数据集的凸分解、动态规划和难以辨别关系等⽅法。
然⽽,上述⽅法均不能适⽤于⼤数据量的情况,难以满⾜实时性要求较⾼的场合,因此实际应⽤并不⼴泛。
模糊聚类分析按照聚类过程的不同⼤致可以分为三⼤类:(1)基于模糊关系的分类法:其中包括谱系聚类算法(⼜称系统聚类法)、基于等价关系的聚类算法、基于相似关系的聚类算法和图论聚类算法等等。
它是研究⽐较早的⼀种⽅法,但是由于它不能适⽤于⼤数据量的情况,所以在实际中的应⽤并不⼴泛。
(2)基于⽬标函数的模糊聚类算法:该⽅法把聚类分析归结成⼀个带约束的⾮线性规划问题,通过优化求解获得数据集的最优模糊划分和聚类。
该⽅法设计简单、解决问题的范围⼴,还可以转化为优化问题⽽借助经典数学的⾮线性规划理论求解,并易于计算机实现。
因此,随着计算机的应⽤和发展,基于⽬标函数的模糊聚类算法成为新的研究热点。
(3)基于神经⽹络的模糊聚类算法:它是兴起⽐较晚的⼀种算法,主要是采⽤竞争学习算法来指导⽹络的聚类过程。
在介绍算法之前,先介绍下模糊集合的知识。
HCM聚类算法⾸先说明⾪属度函数的概念。
⾪属度函数是表⽰⼀个对象x ⾪属于集合A 的程度的函数,通常记做µA(x),其⾃变量范围是所有可能属于集合A 的对象(即集合A 所在空间中的所有点),取值范围是[0,1],即0<=µA(x),µA(x)<=1。
µA(x)=1 表⽰x 完全⾪属于集合A,相当于传统集合概念上的x∈A。
⼀个定义在空间X={x}上的⾪属度函数就定义了⼀个模糊集合A,或者叫定义在论域X={x}上的模糊⼦集A’。
第三章 模糊关系与聚类分析

Rk Rk Rn .
k 2 k 1
n 1
由传递性定义知, R Biblioteka 是传递的。n 125
(2) 显然有
R Rn 。
n 1
(3) 若有 R’ 使 R R’且 R’是传递的,则由 R R’ 有 R2 (R’)2 R’, R3 = R ◦ R2 R ◦ R’ (R’)2 R’, …… 一般有 从而 Rn R’,
(R1◦ R1) (R1◦ R2) (R2◦ R1) (R2◦ R2)
20
R12 R22 。 因为,R1、R2 是传递的,即 R12 R1、R22 R2, 则有 (R1 R2 )2 R1 R2 , 所以,R1 ⋂ R2 是传递的。
21
模糊传递闭包和等价闭包
16
证明
(1) 先证():设 u,vU,tU,令
t = R(u, t) R(t, v) ,
则 R(u,t) t ,R(t,v) t 。由于 R 是传递的, 故
R(u, v)t (tU),于是
R 2 u, v R u, t R t , v t R u, v tU tU
vV vV vV
Q u , v S v, w R u , v S v , w vV vV Q S u, w R S u , w Q S R S u, w
8
3 4 5
推论
T T R U R R U R 1 2 1 2 , T T T R I R R I R 1 2 1 2 , T
基于实例的模糊聚类法在磨床设计方案评价中的应用

机 床 。 这 些 产 品 具 有 相 同 的 结 合 面 , 用 大 致 相 同 采 的子 结 构 , 般 是 在 机 床 的 结 构 尺 寸 , 机 功 率 等方 一 电 面进行 改动 , 以满 足 不 同 的 加 工需 要 。 因 此 , 开 发 在 新 品过 程 中 , 行 的 虚 拟 设 计 与 虚 拟 计 算 得 到 的 那 进 些 满 足 设 计 要 求 的 设 计 方 案 , 后 面 的 系 列 产 品 开 对
计 算 出 的 频 率 比 已 有 的 另 一 方 案 的 相 应 的 频 率 都 低 , 应 的相 对 位 移 比此 方 案 都 大 , 可 以判 定 此 方 相 则 案为 劣 解 , 汰 ; 若 有 某 种 设 计 , 算 出 的频 率 比 淘 而 计 所 有 的 方 案 的 相 应 的频 率 都 高 , 应 的 相 对 位 移 比 相 其 他 所 有 的方 案 都 小 , 可 以 判 定 此 方 案 为 优 解 , 则 直 接 选用 此 设 计 方 案 。 在 大 多 数 情 况 下 , 方 案 的 计 各 算结果 中, 阶频率和相应 的相对位移各 有高低 , 各 必 须给出一个评价标准 。
维普资讯
20 0 2年 第 4期 ( 总第 12期 ) 5
一 一
基 于 实 例 的 模 糊 聚 类 法
在 磨 床 设 计 方 案 评 价 中 的 应 用
东 南大 学
摘要
( 10 6 卢 熹 孙庆 鸿 张建 润 陈 南 209 )
发具 有 重 要 的指 导 意 义 。
在 实 际 的机 床方 案 的 选 择 中 , 是 希 望 各 阶 频 率 尽 总
可 能 的 大 , 阶模 态 , 应 的磨 头 与 工 件 之 间相 对 位 各 对
模糊聚类实现鸢尾花(iris)分类实验报告

模糊聚类实现鸢尾花(iris)分类实验报告实验报告:模糊聚类实现鸢尾花(iris)分类一、实验目的本实验旨在通过模糊聚类算法对鸢尾花(iris)数据集进行分类,并比较其分类效果与传统的硬聚类算法。
二、实验原理模糊聚类是一种基于模糊集合理论的聚类分析方法。
与传统的硬聚类算法不同,模糊聚类能够为每个样本赋予一个隶属度,表示该样本属于某个簇的程度。
常用的模糊聚类算法包括模糊C-均值聚类(FCM)和概率模糊C-均值聚类(PFCM)。
三、实验步骤1. 数据准备:加载鸢尾花数据集,将数据分为特征和标签两部分。
2. 数据预处理:对特征数据进行归一化处理,使其满足模糊聚类的要求。
3. 构建模糊矩阵:根据给定的模糊参数,构建模糊矩阵。
4. 执行模糊聚类:使用模糊聚类算法对数据进行聚类,得到每个样本的隶属度矩阵。
5. 分类结果输出:根据隶属度矩阵和阈值,将样本分为不同的类别。
6. 评估分类效果:计算分类准确率、召回率等指标,评估分类效果。
四、实验结果以下是使用模糊C-均值聚类算法对鸢尾花数据集进行分类的结果:样本实际类别预测类别隶属度1 setosa setosa2 versicolor versicolor3 virginica virginica... ... ... ...150 setosa setosa151 versicolor versicolor152 virginica virginica通过观察上表,我们可以发现大多数样本被正确地分类到了所属的类别,且具有较高的隶属度。
具体分类准确率如下:setosa: 97%,versicolor: 94%,virginica: 95%。
可以看出,模糊聚类算法在鸢尾花数据集上取得了较好的分类效果。
五、实验总结本实验通过模糊聚类算法对鸢尾花数据集进行了分类,并得到了较好的分类效果。
与传统硬聚类算法相比,模糊聚类能够为每个样本赋予一个隶属度,更准确地描述样本属于各个簇的程度。
模糊聚类算法在图像分割中的应用实践

模糊聚类算法在图像分割中的应用实践图像分割是计算机视觉领域的一个重要研究方向,其主要目的是将图像中的像素按照一定的规则划分为不同的区域,从而实现对图像内容的理解和分析。
在此过程中,模糊聚类算法是一种常用的图像分割方法,该算法通过对图像像素的聚类分析,实现对图像分割的精准和有效。
一、模糊聚类算法基础模糊聚类算法是指一类基于模糊理论的聚类算法,主要使用模糊集合和隶属度函数来描述聚类过程中数据点的归属关系。
在模糊聚类算法中,每个数据点可以被分配到多个聚类中心,而且分配的隶属度不是只有0或1,而是在0到1之间的某个值,这种灵活性使得模糊聚类算法具备更好的适应性和鲁棒性,因此适用于多种不同数据的聚类问题。
模糊聚类算法中常用的模糊集合包括模糊C均值、模糊C中心算法等,这些算法都是基于迭代优化的思想来实现聚类过程中的分类,通过不断优化每个数据点的隶属度和聚类中心的位置,最终得到高精度的数据聚类结果。
二、模糊聚类算法在图像分割中的应用模糊聚类算法在图像分割中的应用是基于其广泛适用性和高效性而得以实现的。
由于图像具有高维度和大规模的特点,传统的聚类算法很难取得较好的效果,而模糊聚类算法则具有较好的适应性和鲁棒性,可以适用于不同尺寸、不同灰度级和不同形状的图像分割问题。
在图像分割中,常用的模糊聚类算法包括基于模糊C均值的图像分割算法、基于模糊C中心的图像分割算法等。
这些算法的基本思路是将图像中的所有像素视为数据点,通过迭代优化的方式得到像素的聚类结果,最终将图像分割成多个区域,并实现对各个区域的特征提取和分析。
三、实践应用场景在实践中,模糊聚类算法在图像分割领域中应用广泛,其中涉及到医学图像分析、计算机视觉、图像处理等不同领域。
以下是一些典型的实践应用场景:1、医学图像分析模糊聚类算法在医学图像分析中具有重要的应用价值,特别是对于对比度不高、噪声较多的医学图像分割问题。
例如,利用模糊C均值算法对乳腺X光图像进行分割,可以有效地提取出乳腺的三维形态结构,实现对乳腺肿瘤的自动检测和定位。
如何在Matlab中进行模糊聚类分析

如何在Matlab中进行模糊聚类分析在数据分析领域,模糊聚类分析是一种常用的技术,它可以应用于各种领域的数据处理和模式识别问题。
而Matlab作为一种功能强大的数据分析工具,也提供了丰富的函数和工具箱,以支持模糊聚类分析的实施。
1. 引言模糊聚类分析是一种基于模糊集理论的聚类方法,与传统的硬聚类方法不同,它允许样本属于多个聚类中心。
这种方法的优势在于可以更好地应对数据中的不确定性和复杂性,对于某些模糊或模糊边界问题具有更好的解释能力。
2. 模糊聚类算法概述Matlab提供了多种模糊聚类算法的实现,其中最常用的是基于模糊C均值(Fuzzy C-Means,FCM)算法。
FCM算法的基本思想是通过最小化聚类后的模糊划分矩阵与原始数据之间的距离来确定每个样本所属的聚类中心。
3. 数据预处理与特征提取在进行模糊聚类分析之前,需要对原始数据进行预处理和特征提取。
预处理包括数据清洗、缺失值处理和异常值处理等;特征提取则是从原始数据中抽取出具有代表性和区分性的特征,用于模糊聚类分析。
4. 模糊聚类分析步骤在Matlab中,进行模糊聚类分析通常包括以下步骤:(1) 初始化聚类中心:通过随机选择或基于某种准则的方法初始化聚类中心。
(2) 计算模糊划分矩阵:根据当前的聚类中心,计算每个样本属于各个聚类中心的隶属度。
(3) 更新聚类中心:根据当前的模糊划分矩阵,更新聚类中心的位置。
(4) 判断终止条件:通过设置一定的终止条件,判断是否达到停止迭代的条件。
(5) 输出最终结果:得到最终的聚类结果和每个样本所属的隶属度。
5. 模糊聚类结果评估在进行模糊聚类分析后,需要对聚类结果进行评估以验证其有效性和可解释性。
常用的评估指标包括模糊划分矩阵的聚类有效性指标、外部指标和内部指标等。
通过这些指标的比较和分析,可以选择合适的模糊聚类算法和参数设置。
6. 模糊聚类的应用模糊聚类分析在诸多领域中都有广泛的应用。
例如,在图像处理中,可以利用模糊聚类方法对图像进行分割和识别;在生物信息学中,可以应用于基因表达数据的分类和模式识别等。
利用模糊ISODATA方法进行模糊C均值聚类python实现

利⽤模糊ISODATA⽅法进⾏模糊C均值聚类python实现不确定性计算作业⼆模糊c-均值聚类⼀.算法描述模糊c-均值聚类算法 fuzzy c-means algorithm (FCMA)或称( FCM )。
在众多模糊聚类算法中,模糊C-均值(FCM )算法应⽤最⼴泛且较成功,它通过优化⽬标函数得到每个样本点对所有类中⼼的⾪属度,从⽽决定样本点的类属以达到⾃动对样本数据进⾏分类的⽬的。
模糊聚类分析作为⽆监督机器学习的主要技术之⼀,是⽤模糊理论对重要数据分析和建模的⽅法,建⽴了样本类属的不确定性描述,能⽐较客观地反映现实世界,它已经有效地应⽤在⼤规模数据分析、数据挖掘、⽮量量化、图像分割、模式识别等领域,具有重要的理论与实际应⽤价值,随着应⽤的深⼊发展,模糊聚类算法的研究不断丰富。
⼆.数据描述使⽤给定数据glasscaled.txt三.算法参数输⼊:属性矩阵输出:分类结果四.实验流程1. 取定c (2< c < n),取初值 U (0)属于M fc (U (0)为C 模糊划分矩阵),逐步迭代2. 计算聚类中⼼()()()11()/()n n l l r l ri ij j ij j j v uxu ===∑∑3. 按如下⽅法更新U (l)4. ⽤⼀个矩阵范数⽐较()l U 与(1)l U +。
对取定的ε,若五.实验结果六.讨论模糊聚类分析作为⽆监督机器学习的主要技术之⼀,是⽤模糊理论对重要数据分析和建模的⽅法,建⽴了样本类属的不确定性描述,能⽐较客观地反映现实世界,它已经有效地应⽤在⼤规模数据分析、数据挖掘、⽮量量化、图像分割、模式识别等领域,具有重要的理论与实际应⽤价值,随着应⽤的深⼊发展,模糊聚类算法的研究不断丰富。
模糊数学2模糊聚类分析方法模糊综合评判方法

❖ (1)单层次模糊综合评判模型 设X={x1,x2…xn}是综合评判因素所组成集合,
Y={y1,y2…yn}是评语所组成的集合。
R:X→Y rij=µR(xi,yj) 元素rij表示xi符合yj标准的程度。
A=(a1,a2…an)是各评判因素的权重分配,
则评判结果 B=A◦R.
例
我们对于某学校的校园网络一期建设情况进行评判,设包括三个因 素,即硬件建设,软件建设、人员培训,用论域U表示为:
0.38 0.8 0.67
0.49 1375 931源自0.380.80.67
0.93
0.95 0.67 0.94
0.9
0.94 0.67 0.95
1
0.99
0.99 0.45 0.55
0.99
1
0.99 0.45 0.55
0.99
0.45 0.55
0.99
0.45 0.55
1
0.45 0.55
0.45 1
0.49137 5931
0.93
0.9
1 0.67 0.94 0.38
0.38
0.38 0.95 0.94
0.67 1 0.67
0.94 0.67 1
0.8 0.67
0.8 0.67
0.8 0.67
0.67 0.94 0.67 0.95
0.49137 5931
0.38 0.8 0.67
0.49137 5931
较好
40% 30% 10%
可以
10% 20% 30%
不好
0 10% 60%
0.2 R ~
0.7
0.1
0
上表就构成模糊矩阵 R= 0
0.4 0.5 0.1
模糊聚类分析

查德 1965 年给出的定义:
定义:从论域 U 到闭区间0, 1 的任意一个映射:A :U 0, 1 ,对 任意u U ,u A Au , Au 0, 1 ,那么A 叫做 U 的一个模糊
子集, Au 叫做 u 的隶属函数,也记做A u 。
简单地可表达为:
设U是论域,称映射 A(x):U→[0,1]
39 C 以上的一人,x1 ;
如 果 规 定 37.5 C 以 下 的 不 算 发 烧 , 问 有 多 少 发 烧 病 人 ? 医 生 就 可 以 回 答 :
x1, x3, x4 , x5 ,但所谓“发烧”实际上是一个模糊概念,它存在程度上的不同,也就是
说要用隶属函数来描述。如果根据医师的经验规定,对“发烧”来说:
(1) AB AB; (2) ≤ A A; (3) (A∪B)= A∪B,(A∩B)= A∩B.
4、隶属函数的确定
1. 模糊统计方法 与概率统计类似,但有区别:若把概率
统计比喻为“变动的点”是否落在“不动的 圈”内,则把模糊统计比喻为“变动的圈” 是否盖住“不动的点”.
2. 指派方法 一种主观方法,一般给出隶属函数的解
一、模糊集及模糊关系
1、模糊问题的提出
在自然科学或社会科学研究中,存在着许多定义 不很严格或者说具有模糊性的概念。这里所谓的模 糊性,主要是指客观事物的差异在中间过渡中的不 分明性,如某一生态条件对某种害虫、某种作物的 存活或适应性可以评价为“有利、比较有利、不那 么有利、不利”;灾害性霜冻气候对农业产量的影 响程度为“较重、严重、很严重”,等等。这些通 常是本来就属于模糊的概念,为处理分析这些“模 糊”概念的数据,便产生了模糊集合论。
体温39 C 以上的隶属函数 x 1 ; 体温38.5 C 以上不到39 C 的隶属函数 x 0.9 ; 体温38 C 以上不到38.5 C 的隶属函数 x 0.7 ; 体温37.5 C 以上不到38 C 的隶属函数 x 0.4 ; 体温37.5 C 以下的隶属函数 x 0 ;
模糊聚类分析例子

1•模糊聚类分析模型环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。
设这5个环境区域的污染数据为x i=(80, 10, 6, 2), x2 =(50, 1,6, 4), X3 =(90, 6, 4, 6), X4=(40, 5, 7, 3), X5=(10, 1,2,4).试用模糊传递闭包法对X进行分类。
解:80 10 6 250 1 6 4由题设知特性指标矩阵为:X* 90 6 4 640 5 7 310 1 2 4数据规格化:最大规格化X j —iLj M j其中:M j max(X1j,X2j,…,X nj)构造模糊相似矩阵:采用最大最小法来构造模糊相似矩阵R (r j )5 5利用平方自合成方法求传递闭包t(R)依次计算R2,R4,R8,由于R8R4,所以t(R) R41 0.63 0.62 0.63 0.53 1 0.63 0.62 0.63 0.530.63 1 0.56 0.70 0.53 0.63 1 0.62 0.70 0.5320.53,R 0.62 0.62 1 0.62 0.53 = R8R 0.62 0.56 1 0.62 40.63 0.70 0.62 1 0.53 0.63 0.70 0.62 1 0.530.53 0.53 0.53 0.53 1 0.53 0.53 0.53 0.53 1选取适当的置信水平值[0,1],按截矩阵进行动态聚类。
把t(R)中的元素从大到小的顺序编排如下: 1>>>062>053. 依次取=1, , , 062, 053,得1 0 0 0 00 1 0 0 0t(R)1 00 1 0 0,此时X 被分为5类:{X i} , {X2} , {X3} , {X4} , {X5}0 0 0 1 00 0 0 0 11 0 0 0 00 1 0 1 0t (R) 0.7 0 0 1 0 0 ,此时X被分为4类:{X i},{X2 ,X4} ,{ X3} ,{ X5}0 1 0 1 00 0 0 0 11 1 0 1 01 1 0 1 0t (R) 0.630 0 1 0 0 ,此时X被分为3类:{X i ,X2,X4},{ X3 } ,{X5 }1 1 0 1 00 0 0 0 11 1 1 1 01 1 1 1 0t(R)0.62 1 1 1 1 0 ,此时X 被分为2类:{X i ,X2 ,X4,X3},{ X5} 1 1 1 1 00 0 0 0 11 1 1 111 1 1 11t (R) 0.531 1 1 11 此时X被分为1类:{x^x?,; X3,X4,X5}1 1 1 111 1 1 11Matlab程序如下:%数据规格化MATLAB 程序a=[80 10 6 250 1 6 490 6 4 640 5 7 310 1 2 4];mu=max(a)for i=1:5for j=1:4r(i,j)=a(i,j)/mu(j);endendr%采用最大最小法构造相似矩阵r=[];b=r';for i=1:5for j=1:5R(i,j)=sum(min([r(i,:);b(:,j)']))/sum(max([r(i,:);b(:,j)']));endendR%利用平方自合成方法求传递闭包t(R)矩阵合成的MATLAB 函数function rhat=hech(r);n=length(r);for i=1:nfor j=1:n rhat(i,j)=max(min([r(i,:);r(:,j)']));以对一名员end end求模糊等价矩阵和聚类的程序R=[];R1=hech (R)R2=hech (R1)R3=hech (R2)bh=zeros(5);bh(find(R2>)=12. 模糊综合评判模型某烟草公司对某部门员工进行的年终评定, 关于考核的具体操作过程,工的考核为例。
模糊数学中的模糊分类与模糊聚类

模糊数学中的模糊分类与模糊聚类模糊数学是一种旨在处理模糊或不确定信息的数学分支。
在日常生活中,我们经常会遇到无法明确划分的情况,例如对于颜色、温度、评价等概念,很难用确定的数值来量化描述。
为了更好地研究和解决这些模糊问题,模糊数学提供了一种有效的工具。
本文将重点介绍模糊数学中的模糊分类与模糊聚类两个主要概念。
一、模糊分类1.1 概述模糊分类是指将对象根据其模糊属性划分为不同的类别或群组。
与传统分类不同,模糊分类允许对象被同时归属于多个类别,而不是严格地属于某一个类别。
这一特点使得模糊分类能够更好地应对现实生活中的模糊性和不确定性。
1.2 模糊分类方法模糊分类的方法主要包括模糊关联、模糊决策树和模糊聚类等。
1.2.1 模糊关联模糊关联是通过建立一个关联矩阵来进行模糊分类的方法。
关联矩阵中的每个元素表示对象与类别之间的隶属度关系,该关系通常用一个介于0和1之间的实数值来表示。
通过对关联矩阵进行模糊运算,可以得到对象所属于不同类别的隶属度,从而实现模糊分类。
1.2.2 模糊决策树模糊决策树将传统决策树中的确切节点替换为模糊节点,从而实现对对象的模糊分类。
模糊节点表示对应分支的隶属度,可以有多个分支与之对应。
通过对模糊决策树进行模糊运算,可以得到对象所属于不同类别的隶属度,从而实现模糊分类。
二、模糊聚类2.1 概述模糊聚类是指将具有相似特征的对象自动聚合到一起形成群组的过程。
与传统聚类算法不同,模糊聚类允许对象被同时归属于多个群组,而不是严格地属于某一个群组。
这一特点使得模糊聚类能够更好地处理模糊性和不确定性。
2.2 模糊聚类方法模糊聚类的方法主要包括模糊C均值聚类、模糊聚类算法和模糊关联聚类等。
2.2.1 模糊C均值聚类模糊C均值聚类是一种常用的模糊聚类方法,它通过计算对象与聚类中心之间的隶属度关系来实现聚类。
该方法假设每个对象属于不同聚类的隶属度之和为1,通过迭代计算,可以得到每个对象所属于不同聚类的隶属度。
模糊c均值聚类算法python

模糊C均值聚类算法 Python在数据分析领域中,聚类是一种广泛应用的技术,用于将数据集分成具有相似特征的组。
模糊C均值(Fuzzy C-Means)聚类算法是一种经典的聚类算法,它能够将数据点分到不同的聚类中心,并给出每个数据点属于每个聚类的概率。
本文将介绍模糊C均值聚类算法的原理、实现步骤以及使用Python语言实现的示例代码。
1. 模糊C均值聚类算法简介模糊C均值聚类算法是一种基于距离的聚类算法,它将数据点分配到不同的聚类中心,使得各个聚类中心到其所属数据点的距离最小。
与传统的K均值聚类算法不同,模糊C均值聚类算法允许每个数据点属于多个聚类中心,并给出每个数据点属于每个聚类的概率。
模糊C均值聚类算法的核心思想是将每个数据点分配到每个聚类中心的概率表示为隶属度(membership),并通过迭代优化隶属度和聚类中心来得到最优的聚类结果。
2. 模糊C均值聚类算法原理2.1 目标函数模糊C均值聚类算法的目标是最小化以下目标函数:其中,N表示数据点的数量,K表示聚类中心的数量,m是一个常数,u_ij表示数据点x_i属于聚类中心c_j的隶属度。
目标函数由两部分组成,第一部分是数据点属于聚类中心的隶属度,第二部分是数据点到聚类中心的距离。
通过优化目标函数,可以得到最优的聚类结果。
2.2 隶属度的更新隶属度的更新通过以下公式进行计算:其中,m是一个常数,决定了对隶属度的惩罚程度。
m越大,隶属度越趋近于二值化,m越小,隶属度越趋近于均匀分布。
2.3 聚类中心的更新聚类中心的更新通过以下公式进行计算:通过迭代更新隶属度和聚类中心,最终可以得到收敛的聚类结果。
3. 模糊C均值聚类算法实现步骤模糊C均值聚类算法的实现步骤如下:1.初始化聚类中心。
2.计算每个数据点属于每个聚类中心的隶属度。
3.更新聚类中心。
4.判断迭代是否收敛,若未收敛,则返回步骤2;若已收敛,则输出聚类结果。
4. 模糊C均值聚类算法 Python 实现示例代码下面是使用Python实现模糊C均值聚类算法的示例代码:import numpy as npdef fuzzy_cmeans_clustering(X, n_clusters, m=2, max_iter=100, tol=1e-4): # 初始化聚类中心centroids = X[np.random.choice(range(len(X)), size=n_clusters)]# 迭代更新for _ in range(max_iter):# 计算隶属度distances = np.linalg.norm(X[:, np.newaxis] - centroids, axis=-1)membership = 1 / np.power(distances, 2 / (m-1))membership = membership / np.sum(membership, axis=1, keepdims=True)# 更新聚类中心new_centroids = np.sum(membership[:, :, np.newaxis] * X[:, np.newaxis], axis=0) / np.sum(membership[:, :, np.newaxis], axis=0)# 判断是否收敛if np.linalg.norm(new_centroids - centroids) < tol:breakcentroids = new_centroidsreturn membership, centroids# 使用示例X = np.random.rand(100, 2)membership, centroids = fuzzy_cmeans_clustering(X, n_clusters=3)print("聚类中心:")print(centroids)print("隶属度:")print(membership)上述代码实现了模糊C均值聚类算法,其中X是输入的数据集,n_clusters是聚类中心的数量,m是模糊指数,max_iter是最大迭代次数,tol是迭代停止的阈值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(二).模型实例分析
例:设某地区设置有11个雨量站,其分布图见图1,10年来各雨量站所测得的年降雨量列入表1中。
现因经费问题,希望撤销几个雨量站,问撤销那些雨量站,而不会太多的减少降雨信息?
图1
表1
应该撤销那些雨量站,涉及雨量站的分布,地形,地貌,人员,设备等众多因素。
我们仅考虑尽可能地减少降雨信息问题。
一个自然的想法是就10年来各雨量站所获得的降雨信息之间的相似性,对全部雨量站进行分类,撤去“同类”(所获降雨信息十分相似)的雨量站中“多余”的站。
问题求解 假设为使问题简化,特作如下假设 (1) 每个观测站具有同等规模及仪器设备; (2) 每个观测站的经费开支均等; 具有相同的被裁可能性。
分析:对上述撤销观测站的问题用基于模糊等价矩阵的模糊聚类方法进行分析,原始数据如上。
求解步骤:
1.利用相关系数法,构造模糊相似关系矩阵1111)(⨯αβr ,其中
ij r =
2
11
1
221]
)()([|
)(||)(|∑∑∑=-=-⋅---n k n
k j jk i ik n
k j jk i ik
x x x x x x x x
其中i x =∑=10
1101k ik x ,i =1,2, (11)
j x =∑=n
k jk x n 1
1,j =1,2, (11)
用C 语言编程计算出模糊相似关系矩阵1111)(⨯αβr ,具体程序如下 #include<stdio.h> #include<math.h>
double r[11][11]; double x[11]; void main()
{ int i,j,k; double fenzi=0,fenmu1=0,fenmu2=0,fenmu=0;
int year[10][11]={276,324,159,413, 292 ,258,311,303,175,243,320, 251 ,287,349,344,310,454,285,451,402,307,470, 192 ,433,290,563,479,502,221,220,320,411,232,
246 ,232,243,281,267,310,273,315,285,327,352,
291,311,502,388 ,330,410,352,267,603,290,292,
466 ,158,224,178,164,203,502,320,240,278,350,
258,327,432 ,401,361,381,301,413,402,199,421,
453,365,357 ,452,384,420,482,228,360,316,252,
158 ,271,410,308,283,410,201,179,430,342,185,
324,406,235,520 ,442,520,358,343,251,282,371};
for(i=0;i<11;i++)
{ for(k=0;k<10;k++)
{ x[i]=x[i]+year[k][i];}
x[i]=x[i]/10;
}
for(i=0;i<11;i++)
{for(j=0;j<11;j++)
{ for(k=0;k<10;k++)
{ fenzi=fenzi+fabs((year[k][i]-x[i])*(year[k][j]-x[j]));
fenmu1=fenmu1+(year[k][i]-x[i])*(year[k][i]-x[i]);
fenmu2=fenmu2+(year[k][j]-x[j])*(year[k][j]-x[j]); fenmu=sqrt(fenmu1)*sqrt(fenmu2);
r[i][j]=fenzi/fenmu;
}
fenmu=fenmu1=fenmu2=fenzi=0;
}}
for(i=0;i<11;i++)
{ for(j=0;j<11;j++)
{printf("%6.3f",r[i][j]);}
printf("\n");} getchar(); }
得到模糊相似矩阵R
1.000 0.839 0.528 0.844 0.828 0.702 0.995 0.671 0.431 0.573 0.712 0.839 1.000 0.542 0.996 0.989 0.899 0.855 0.510 0.475 0.617 0.572 0.528 0.542 1.000 0.562 0.585 0.697 0.571 0.551 0.962 0.642 0.568 0.844 0.996 0.562 1.000 0.992 0.908 0.861 0.542 0.499 0.639 0.607 0.828 0.989 0.585 0.992 1.000 0.922 0.843 0.526 0.512 0.686 0.584 0.702 0.899 0.697 0.908 0.922 1.000 0.726 0.455 0.667 0.596 0.511 0.995 0.855 0.571 0.861 0.843 0.726 1.000 0.676 0.489 0.587 0.719 0.671 0.510 0.551 0.542 0.526 0.455 0.676 1.000 0.467 0.678 0.994 0.431 0.475 0.962 0.499 0.512 0.667 0.489 0.467 1.000 0.487 0.485 0.573 0.617 0.642 0.639 0.686 0.596 0.587 0.678 0.487 1.000 0.688 0.712 0.572 0.568 0.607 0.584 0.511 0.719 0.994 0.485 0.688 1.000
对这个模糊相似矩阵用平方法作传递闭包运算,求44
2:R R R −→−
即t (R )=4R =*R
注:R 是对称矩阵,故只写出它的下三角矩阵
⎥
⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦
⎤⎢
⎢⎢
⎢⎢⎢
⎢⎢⎢
⎢⎢⎢
⎢⎢
⎢⎣⎡=1688.0697
.0688.0719
.0719
.0719
.0719
.0697
.0719
.0719
.01
697.0688.0688.0688.0688.0688.0688.0688.0688.01
676
.0697.0697.0697.0697.0962.0697.0697.01719.0719.0719.0719.0697.0719.0719.01861.0861.0861.0697.0861.0994.01922.0922.0697.0995.0861
.01992.0697
.0996
.0861.01697.0996.0861.01697.0697.01861.0000
.1*R
取λ=0.996,则
996.0R =⎥
⎥⎥⎥⎥
⎥
⎥⎥⎥⎥⎥⎥
⎥⎥⎥⎦
⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡111111*********
故第二行(列),第四行(列)完全一致,故42,x x 同属一类,所以此时可以将观测站分为9类{42,x x ,5x },{1x },{3x },{6x },{7x },{8x },{9x },{10x },{11x } 这表明,若只裁减一个观测站,可以裁42,x x 中的一个。
若要裁掉更多的观测站,则要降低置信水平λ,对不同的λ作同样分析,得到
λ=0.995时,可分为8类,即{42,x x ,5x ,6x },{1x },{3x },{7x },{8x },{9x },{10x },{11x }
λ=0.994时,可分为7类{42,x x ,5x ,6x },{1x ,7x },{3x } ,{8x },{9x },{10x },{11x }
λ=0.962时,
可分为6类{42,x x ,5x ,6x },{1x ,7x },{3x ,9x } ,{8x }, {10x },{11x } λ =0.719时,可分为5类{42,x x ,5x ,6x },{1x ,7x },{3x ,9x } ,{8x ,
11x },{10x }
再具体分析图5-1,我们可以看到6x 虽然和42,x x ,5x 分为一类,但6x 和42,x x ,
5x 观测点相距较远,撤去6x 是不太合适的,保留6x 而撤去42,x x ,5x 就更不合适
了。
因此还是将其分为6类,即{42,x x ,5x },{6x },{1x ,7x },{3x ,9x } ,{8x ,
11x },{10x },依据每类最少保留一个站的原则,最多可撤去5个站。
实际应该撤
去哪几个站就应该依据其他条件来确定了。
由本例可以看出,当需要比较聚类的数据较多时,一般采用模糊聚类法进行分析,在分析过程中,复杂的数据运算都可以在计算机上实现,从而减少繁琐的手工操作。