第一章数据挖掘概述
数据挖掘概念与技术第一章PPT课件

数据淹没,但却缺乏知识
信息技术的进化
···
数据挖掘的自动化分析的海量数据集 文件处理->数据库管理系统->高级数据库:系统高级数据分析
2021
3
定义:从大量的数据中提取有趣的(非平凡的,隐 含的,以前未知的和潜在有用的)模式或知识。
“数据中发现知识”(KDD)
2021
4
选择和变换
评估和表示
第一章 引论
2021
1
1.1 为什么进行数据挖掘 1.2 什么是数据挖掘 1.3 可以挖掘什么类型的数据 1.4 可以挖掘什么类型的模式 1.5 使用什么技术 1.6 面向什么类型的应用 1.7 数据挖掘的主要问题 1.8 小结
2021
2
数据爆炸
海量数据,爆炸式增长
来源:网络,电子商务,个人 类型:图像,文本···
设想网上购物的一次交易,其付款过程至少包括以下几步数据库操作:
一、更新客户所购商品的库存信息 二、保存客户付款信息--可能包括与银行系统的交互 三、生成订单并且保存到数据库中 四、更新用户相关信息,例如购物数量等等
2021
9
其他类型的数据
股票交易数据 文本 图像 音频视频 未知的
2021
10
1.4.1 类/概念描述:特征化与区分
类/概念
数据特征化
目标数据的一般特性或特征汇总
数据区分
将目标类数据对象的一般性与一个或多个 对比类对象的一般特性进行比较
特征化和区分
2021
11
1.4.2 挖掘频繁模式、关联和相关性
频繁模式是在数据中频繁出现的模式
1.频繁项集、频繁子序列、频繁子结构 2.挖掘频繁模式可以发现数据中的关联和相关性 例如:单维与多维关联
数据仓库与数据挖掘第一章 数据仓库和数据挖掘概述

③ 采用事件驱动和主动推送的方式为业务系统提供分析能力,例如银行的信 贷风险管理员,当审批某人的贷款请求时,关于该申请人的相关风险评级 等信息就会被主动推送过来。
1.1.2 发展历程4——数据中心
通过数据中心的构建,企业从 传统的交易系统(记录系统) 和各种差分系统(Different System)逐渐转向构建创新系 统,通过使用分析技术创造独 特的竞争优势,将分析技术慢 慢融入到企业的核心战略制定 和日常运营管理中。
1.1.1 数据仓库和数据挖掘的目标
构建数据仓库和应用数据挖掘的共同目标:
(7)构建数据治理体系,保证数据的一致性,消除信息的冗余、冲突和缺失等问题;
(8)提供高效、实时和准确的多维数据分析、报表统计、即时查询、广告版、多媒体分析、流 分析和内容分析等功能,为企业运营分析提供全面支持;
(9)提供简洁易用的数据挖掘和预测分析支撑,为企业分析提供全面支持;
。。。。。。
1.1.2 发展历程1——报表查询系统
• 随着时间的推移,这些报表查询系统越来越不能满足企业的需求。 • 例如:
① 查询访问性能比较慢 ② 报表统计相对固定难以满足企业灵活的业务需求 ③ 无法进行多维分析等
1.1.2 发展历程2——传统数据仓库技术
• 使用ETL(Extract,Transform,Load )或ETCL(Extract, Transform,Clean,Load )工具实现数据的导出、转换、清洗和装 入工具,使用操作型数据存储(Operational Data Store,ODS)存储 明细数据,使用数据集市和数据仓库技术实现面向主题的历史数据存 储,使用多维分析工具进行前端展现,以及使用数据仓库工具提供的 挖掘引擎或基于单独的数据挖掘工具进行预测分析等。相比之前的报 表查询系统。
数据挖掘基础 数据挖掘概念ppt课件

层次聚类树树状图
A
B
C
D
E
1.1 数据挖掘概述
1.1.2 数据挖掘常用算法概述
第一章 数据挖掘概念
在面对海量数据时,需要使用一定的算法,才能从中挖掘出有用的信息,下面介绍数 据挖掘中常用的算法。
1. 分类算法 (1) 决策树算法 决策树算法是一种典型的分类算法,首先利用已知分类的数据构造决策树,然后利用 测试数据集对决策树进行剪枝,每个决策树的叶子都是一种分类,最后利用形成的 决策树对数据进行分类。决策树的典型算法有ID3,C4.5,CART等。
1.1 数据挖掘概述
1.1.3 数据挖掘常用工具概述
第一章 数据挖掘概念
2. Clementine(SPSS) 软件 Clementine是SPSS所发行的一种资料探勘工具,集成了分类、聚类和关联规则
等算法,Clementine提供了可视化工具,方便用户操作。其通过一系列节点来执行 挖掘过程,这一过程被称作一个数据流,数据流上面的节点代表了要执行的操作。 Clementine的资料可视化能力包含散布图、平面图及Web分析。
1.1 数据挖掘概述
第一章 数据挖掘概念
1.1.3 数据挖掘常用工具概述
1. Weka软件
Weka(Waikato Environment for Knowledge Analysis)的全名是怀卡托智能 分析环境,是一款免费与非商业化的数据挖掘软件,基于Java环境下开源的机器学 习与数据挖掘软件。Weka的源代码可在其官方网站下载。它集成了大量数据挖掘算 法,包括数据预处理、分类、聚类、关联分析等。用户既可以使用可视化界面进行 操作,也可以使用Weka提供的接口,实现自己的数据挖掘算法。图形用户界面包括 Weka Knowledge Flow Environment和Weka Explorer。用户也可以使用Java语 言调用Weka提供的类库实现数据挖掘算法,这些类库存在于weka.jar中。
数据挖掘概论

1970s
层次数据库 网状数据库
1980s晚期
高级数据库系统 【扩展的关系数据库】 【面向对象数据库】
2000s
流数据管理和挖掘 基于应用的数据挖掘
XML数据库
3
三、什么是数据挖掘
• 数据挖掘 (从数据中发现知识)
• 从大量的数据中挖掘那些令人感兴趣的、有用的、隐含的、先前未知的和可能 有用的模式或知识
• 例:
age (X , "30...39") income (X , &#uter") [sup port 20%,confidence 70%]
9
四、挖掘的数据类型
• 分类和预测
• 根据训练集中的数据属性和类标号,构建模型来分类现有数据,并用来分类新数据, 或预测类型标志未知的对象类
• 区分:提供两个或多个数据集的比较描述
• 例:
Status Graduate Undergraduate
Birth_country Canada Canada
Age_range 25-30 25-30
Gpa Good Good
Count 90 210
8
四、挖掘的数据类型
• 关联规则挖掘
从事务数据库、关系数据库和其他信息存储中的大量数据的项集之间发现有趣的、 频繁出现的模式、关联和相关性
• 数据挖掘的替换词
• 数据库中的知识挖掘(KDD) • 知识提炼 • 数据/模式分析 • 数据考古 • 数据捕捞
4
三、什么是数据挖掘
• 数据库中的知识挖掘(KDD)
模式评估
数据挖掘
任务相关数据
数据仓库
选择
数据清理 数据集成
数据库
5
数据挖掘第一与第二章概述数据收集讲解学习

2022年3月12日星期六
数据挖掘导论
25
数据集的重要特性
• 维度(Dimensionality) – 数据集的维度是数据集中的对象具有的属性数目 – 维灾难(Curse of Dimensionality) – 维归约(dimensionality reduction)
• 稀疏性(Sparsity) – 具有非对称特征的数据集,一个对象的大部分属性上的值都为 0 – 只存储和处理非零值
数据
– 数据中的联系
• 如时间和空间的自相关性、图的连通性、半结构化文本和XML文 档中元素之间的父子联系
2022年3月12日星期六
数据挖掘导论
9
挑战4
• 数据的所有权与分布
– 数据地理上分布在属于多个机构的资源中
• 需要开发分布式数据挖掘技术
– 分布式数据挖掘算法面临的主要挑战包括
• (1) 如何降低执行分布式计算所需的通信量? • (2) 如何有效地统一从多个资源得到的数据挖掘结果? • (3) 如何处理数据安全性问题?
Single 70K
No
Married 120K No
Divorced 95K
Yes
Married 60K
No
Divorced 220K No
Single 85K
Yes
Married 75K
No
Single 90K
Yes
2022年3月12日星期六
数据挖掘导论
28
记录数据: 数据矩阵
• 如果一个数据集族中所有数据对象都具有相同的数 值属性值,则数据对象可以看做多维空间中的点, 每个维代表对象的一个不同属性。
2.1 数据类型
• 数据集的不同表现在很多方面。例如, 某些数据集包含时间序列或者彼此之间具 有明显联系的对象。毫不奇怪,数据的类 型决定我们应使用何种工具和技术来分析 数据。此外,数据挖掘研究常常是为了适 应新的应用领域和新的数据类型的需要而 展开的。
简述说明数据挖掘的步骤。

简述说明数据挖掘的步骤。
数据挖掘的步骤第一章:引言数据挖掘是一种通过发现和分析大量数据中潜在规律和模式来提取有价值信息的过程。
它在各个领域中都扮演着重要角色,帮助人们做出决策、预测趋势和优化业务流程。
本文将详细介绍数据挖掘的步骤,并阐述每个步骤的核心内容。
第二章:问题定义在进行数据挖掘之前,首先需要明确定义需要解决的问题。
这个步骤的关键是准确理解业务需求,并将其转化为可量化的问题。
例如,一个电商公司想提高销售额,问题定义可以是“预测某个产品的销售量”。
第三章:数据收集与整理在数据挖掘的过程中,数据的质量和可用性至关重要。
因此,在进行数据收集之前,需要确定需要的数据类型和数据来源。
然后,通过各种方法,如网络爬虫或调查问卷,收集所需数据。
接下来,对收集到的数据进行清洗和整理,包括去除重复数据、处理缺失值和异常值等。
第四章:数据探索与可视化在数据整理完成后,需要对数据进行探索和可视化分析。
通过使用统计方法和数据可视化工具,可以从数据中发现潜在的关联、趋势和异常值。
这能够帮助我们更好地理解数据,并为后续的模型建立提供指导。
第五章:特征选择与特征工程在进行数据挖掘之前,需要选择合适的特征进行建模。
特征选择是指从大量的特征中选择最相关和最有用的特征。
而特征工程则是对原始特征进行变换和组合,以提取更多的信息。
通过这两个步骤,可以减少维度灾难的影响,并提高模型的准确性和可解释性。
第六章:模型选择与训练在数据预处理完成后,需要选择合适的模型进行训练。
根据问题的特性和数据的类型,可以选择不同的机器学习算法,如决策树、神经网络和支持向量机等。
通过训练数据,模型可以学习到数据的模式和规律,并用于未知数据的预测和分类。
第七章:模型评估与调优在模型训练完成后,需要对模型进行评估和调优。
通过使用评估指标,如准确率、召回率和F1分数等,可以评估模型的性能。
如果模型表现不佳,可以通过调整模型参数、增加训练数据或改进特征工程等方法进行调优,以提高模型的准确性和泛化能力。
数据挖掘与商业智能实战

数据挖掘与商业智能实战第一章:数据挖掘概述数据挖掘是一种从大规模的数据中自动发现隐藏模式、关系和规律的技术。
它结合了机器学习、统计学和数据库技术,可以帮助企业发现有价值的信息,从而支持业务决策和资源优化。
数据挖掘的主要步骤包括问题定义、数据收集和清洗、特征选择和转换、模型构建和评估。
第二章:商业智能基础商业智能是一种通过分析企业内部和外部数据,提供关键指标和业务洞察的方法。
它包括数据仓库、数据集成、分析报告和数据可视化等组成部分。
商业智能的应用可以帮助企业快速准确地了解市场动态、竞争态势,从而制定有效的市场策略和决策。
第三章:数据收集与清洗数据挖掘的第一步是数据收集与清洗。
数据可以来自多个来源,包括企业内部的数据库、外部的市场调研数据、社交媒体数据等。
数据清洗是为了解决数据质量问题,包括去除重复数据、缺失数据的处理、异常点的排查等。
数据清洗的目的是确保后续的数据分析和建模过程的准确性和可靠性。
第四章:特征选择与转换特征选择是指从原始数据中选择最相关、最具预测能力的特征。
特征转换是将原始数据转化为适合特定算法的形式。
常用的特征选择方法包括过滤式、包裹式和嵌入式等。
特征转换方法包括主成分分析、因子分析和线性判别分析等。
通过特征选择和转换,可以降低数据维度,提高模型的简洁性和性能。
第五章:模型构建与评估在数据挖掘中,常用的建模方法包括分类、回归、聚类和关联规则等。
建模过程涉及算法选择、模型训练、模型参数调优和模型评估等步骤。
模型评估的指标包括准确率、召回率、F1值等,可以用来评估模型的性能和稳定性。
通过不断的迭代和优化,可以构建更准确、更可靠的数据挖掘模型。
第六章:商业智能应用案例商业智能的应用场景非常广泛。
以零售行业为例,可以通过分析销售数据和顾客行为数据,获取销售趋势、商品流行度、顾客偏好等信息,从而制定优化的销售策略和促销活动。
在定价方面,可以通过分析市场价格和竞争对手的定价策略,制定合理的定价策略。
模式识别与数据挖掘期末总结

模式识别与数据挖掘期末总结第一章概述1.数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当地描述,提取出有用的信息的过程。
2.数据挖掘(Data Mining,DM) 是指从海量的数据中通过相关的算法来发现隐藏在数据中的规律和知识的过程。
3.数据挖掘技术的基本任务主要体现在:分类与回归、聚类、关联规则发现、时序模式、异常检测4.数据挖掘的方法:数据泛化、关联与相关分析、分类与回归、聚类分析、异常检测、离群点分析、5.数据挖掘流程:(1)明确问题:数据挖掘的首要工作是研究发现何种知识。
(2)数据准备(数据收集和数据预处理):数据选取、确定操作对象,即目标数据,一般是从原始数据库中抽取的组数据;数据预处理一般包括:消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换。
(3)数据挖掘:确定数据挖掘的任务,例如:分类、聚类、关联规则发现或序列模式发现等。
确定了挖掘任务后,就要决定使用什么样的算法。
(4)结果解释和评估:对于数据挖掘出来的模式,要进行评估,删除冗余或无关的模式。
如果模式不满足要求,需要重复先前的过程。
6.分类(Classification)是构造一个分类函数(分类模型),把具有某些特征的数据项映射到某个给定的类别上。
7.分类过程由两步构成:模型创建和模型使用。
8.分类典型方法:决策树,朴素贝叶斯分类,支持向量机,神经网络,规则分类器,基于模式的分类,逻辑回归9.聚类就是将数据划分或分割成相交或者不相交的群组的过程,通过确定数据之间在预先指定的属性上的相似性就可以完成聚类任务。
划分的原则是保持最大的组内相似性和最小的组间相似性10.机器学习主要包括监督学习、无监督学习、半监督学习等1.(1)标称属性(nominal attribute):类别,状态或事物的名字(2):布尔属性(3)序数属性(ordinal attribute):尺寸={小,中,大},军衔,职称【前面三种都是定性的】(4)数值属性(numeric attribute): 定量度量,用整数或实数值表示●区间标度(interval-scaled)属性:温度●比率标度(ratio-scaled)属性:度量重量、高度、速度和货币量●离散属性●连续属性2.数据的基本统计描述三个主要方面:中心趋势度量、数据分散度量、基本统计图●中心趋势度量:均值、加权算数平均数、中位数、众数、中列数(最大和最小值的平均值)●数据分散度量:极差(最大值与最小值之间的差距)、分位数(小于x的数据值最多为k/q,而大于x的数据值最多为(q-k)/q)、说明(特征化,区分,关联,分类,聚类,趋势/跑偏,异常值分析等)、四分位数、五数概括、离群点、盒图、方差、标准差●基本统计图:五数概括、箱图、直方图、饼图、散点图3.数据的相似性与相异性相异性:●标称属性:d(i,j)=1−m【p为涉及属性个数,m:若两个对象匹配为1否则p为0】●二元属性:d(i,j)=p+nm+n+p+q●数值属性:欧几里得距离:曼哈顿距离:闵可夫斯基距离:切比雪夫距离:●序数属性:【r是排名的值,M是排序的最大值】●余弦相似性:第三章数据预处理1.噪声数据:数据中存在着错误或异常(偏离期望值),如:血压和身高为0就是明显的错误。
数据仓库与数据挖掘教程(第2版)陈文伟版课后答案

第一章数据仓库与数据挖掘概述1.数据库与数据仓库的本质差别是什么?答:数据库用于事务处理,数据仓库用于决策分析;数据库保持事务处理的当前状态,数据仓库既保存过去的数据又保存当前的数据;数据仓库的数据是大量数据库的集成;对数据库的操作比较明确,操作数据量少,对数据仓库操作不明确,操作数据量大。
数据库是细节的、在存取时准确的、可更新的、一次操作数据量小、面向应用且支持管理;数据仓库是综合或提炼的、代表过去的数据、不更新、一次操作数据量大、面向分析且支持决策。
6.说明OLTP与OLAP的主要区别。
答:OLTP针对的是细节性数据、当前数据、经常更新、一次性处理的数据量小、对响应时间要求高且面向应用,事务驱动; OLAP针对的是综合性数据、历史数据、不更新,但周期性刷新、一次处理的数据量大、响应时间合理且面向分析,分析驱动。
8.元数据的定义是什么?答:元数据(metadata)定义为关于数据的数据(data about data),即元数据描述了数据仓库的数据和环境。
9.元数据与数据字典的关系什么?答:在数据仓库中引入了“元数据”的概念,它不仅仅是数据仓库的字典,而且还是数据仓库本身信息的数据。
18.说明统计学与数据挖掘的不同。
答:统计学主要是对数量数据(数值)或连续值数据(如年龄、工资等),进行数值计算(如初等运算)的定量分析,得到数量信息。
数据挖掘主要对离散数据(如职称、病症等)进行定性分析(覆盖、归纳等),得到规则知识。
19.说明数据仓库与数据挖掘的区别与联系。
答:数据仓库是一种存储技术,它能适应于不同用户对不同决策需要提供所需的数据和信;数据挖掘研究各种方法和技术,从大量的数据中挖掘出有用的信息和知识。
数据仓库与数据挖掘都是决策支持新技术。
但它们有着完全不同的辅助决策方式。
在数据仓库系统的前端的分析工具中,数据挖掘是其中重要工具之一。
它可以帮助决策用户挖掘数据仓库的数据中隐含的规律性。
数据仓库和数据挖掘的结合对支持决策会起更大的作用。
数据挖掘中的名词解释

第一章1,数据挖掘(Data Mining),就是从存放在数据库,数据仓库或其他信息库中的大量的数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
2,人工智能(Artific ial Intelli gence)它是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。
3,机器学习(Machine Learnin g)是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
4,知识工程(Knowled ge Enginee ring)是人工智能的原理和方法,对那些需要专家知识才能解决的应用难题提供求解的手段。
5,信息检索(Informa tion Retriev al)是指信息按一定的方式组织起来,并根据信息用户的需要找出有关的信息的过程和技术。
6,数据可视化(Data Visuali zation)是关于数据之视觉表现形式的研究;其中,这种数据的视觉表现形式被定义为一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。
7,联机事务处理系统(OLTP)实时地采集处理与事务相连的数据以及共享数据库和其它文件的地位的变化。
在联机事务处理中,事务是被立即执行的,这与批处理相反,一批事务被存储一段时间,然后再被执行。
8, 联机分析处理(OLAP)使分析人员,管理人员或执行人员能够从多角度对信息进行快速一致,交互地存取,从而获得对数据的更深入了解的一类软件技术。
8,决策支持系统(decisio n support)是辅助决策者通过数据、模型和知识,以人机交互方式进行半结构化或非结构化决策的计算机应用系统。
政府行业数据挖掘与决策支持方案

行业数据挖掘与决策支持方案第一章数据挖掘概述 (3)1.1 数据挖掘的定义与意义 (3)1.2 行业数据挖掘的重要性 (3)1.3 数据挖掘技术发展现状 (3)第二章行业数据资源梳理 (4)2.1 行业数据资源分类 (4)2.2 数据资源整合与清洗 (4)2.3 数据质量评估与优化 (5)第三章数据预处理 (5)3.1 数据清洗 (5)3.1.1 异常值检测与处理 (5)3.1.2 数据缺失处理 (5)3.1.3 数据重复处理 (6)3.2 数据转换 (6)3.2.1 数据标准化 (6)3.2.2 数据归一化 (6)3.2.3 数据离散化 (6)3.3 数据集成 (6)3.3.1 数据源识别与整合 (6)3.3.2 数据属性匹配与转换 (7)3.3.3 数据一致性检查 (7)第四章数据挖掘方法与应用 (7)4.1 描述性分析 (7)4.2 预测性分析 (7)4.3 关联性分析 (8)第五章决策支持系统设计 (8)5.1 系统架构设计 (8)5.2 功能模块划分 (8)5.3 系统安全与稳定性 (9)第六章数据挖掘在行业的应用案例 (9)6.1 公共安全领域 (9)6.1.1 案例背景 (9)6.1.2 案例描述 (10)6.2 财政税收领域 (10)6.2.1 案例背景 (10)6.2.2 案例描述 (10)6.3 教育卫生领域 (11)6.3.1 案例背景 (11)6.3.2 案例描述 (11)第七章数据挖掘与决策支持策略 (11)7.1 数据挖掘策略 (11)7.1.1 数据来源与整合 (11)7.1.2 数据预处理与清洗 (12)7.1.3 数据挖掘方法选择与应用 (12)7.1.4 模型评估与优化 (12)7.2 决策支持策略 (12)7.2.1 决策支持系统构建 (12)7.2.2 决策模型与方法 (12)7.2.3 决策流程优化 (12)7.2.4 决策评估与反馈 (12)7.3 政策制定与优化 (13)7.3.1 政策制定原则 (13)7.3.2 政策制定流程 (13)7.3.3 政策优化策略 (13)第八章数据挖掘与决策支持技术框架 (13)8.1 技术框架构建 (13)8.1.1 框架概述 (13)8.1.2 数据采集与预处理 (13)8.1.3 数据存储与管理 (14)8.1.4 数据挖掘与分析 (14)8.1.5 决策支持系统 (14)8.2 技术选型与评估 (14)8.2.1 技术选型 (15)8.2.2 技术评估 (15)8.3 技术实施与推广 (15)8.3.1 技术实施 (15)8.3.2 技术推广 (15)第九章数据挖掘与决策支持项目管理 (15)9.1 项目管理流程 (15)9.1.1 项目立项 (15)9.1.2 项目规划 (16)9.1.3 项目实施 (16)9.1.4 项目验收与交付 (16)9.2 项目风险管理 (16)9.2.1 风险识别 (16)9.2.2 风险评估 (16)9.2.3 风险应对策略 (17)9.3 项目评估与优化 (17)9.3.1 项目评估 (17)9.3.2 项目优化 (17)第十章数据挖掘与决策支持的未来展望 (17)10.1 技术发展趋势 (17)10.2 政策法规完善 (18)10.3 数据挖掘与决策支持的融合创新 (18)第一章数据挖掘概述1.1 数据挖掘的定义与意义数据挖掘(Data Mining)是指从大量数据集中通过算法和统计分析方法,挖掘出有价值的信息和知识的过程。
[理学]厦门大学数据挖掘之第1章 数据挖掘概述PPT课件
![[理学]厦门大学数据挖掘之第1章 数据挖掘概述PPT课件](https://img.taocdn.com/s3/m/b36211b0856a561252d36f9a.png)
11.08.2020
3
教学目的
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模 糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又 是潜在有用的信息和知识的过程。它是涉及机器学习、模式识别、统 计学、人工智能、数据库管理及数据可视化等学科的边缘学科。
用统计的观点看,它可以看成是通过计算机对大量的复杂数据 集的自动探索性分析。作为一种独立于应用的技术,一经出现立即受 到广泛的关注。
第七章理解一些其它的数据挖掘技术。模糊聚类、神 经网络、时序稠密数据集的挖掘技术等。
为了满足实际的需要,我们将利用所讲授的方法, 对某地区中国移动通讯用户消费数据库、某大学大学生 隐形教育调查资料和上证指数收盘价信息进行剖析,以 便让学生充分地领悟到数据挖掘的理论和实际价值。
11.08.2020
11.08.2020
7
第六章介绍挖掘大型数据库中的关联规则。讲授关 联规则的意义和量度,维布尔关联规则,多层关联规则, 由关联规则到相关分析。另外,引入相应分析作为数据 挖掘中关联规则的提升,介绍相应分析适应性检验的基 本思想及方法,及相应分析适应性的分层量度方法。利 用可视化方法对所多度相应分析方法进行了验证。
第四章介绍Rough集的基本模型及有关概念。这一章讲授知识的分 类观点和概念的边界观点,知识的约简和决策表的约简。以统计 思想与Rough集理论相结合,介绍对事务性数据库的统计描述,对 事务性数据库事务项及属性项压缩的方法,构建事务性数据库列 联表示的模型的思想。并利用所介绍的方法进行实证分析。
第五章重点介绍数据挖掘中的聚类问题。讲授数据的排序与有向 聚类问题。介绍聚类分析数据类型衍生的思想,并对聚类分析方 法进行了比较和检验。让学生在实际应用中认识到其方法的可靠 性与稳定性。
大数据高职系列教材之数据挖掘基础PPT课件:第1章 数据挖掘概念

1.1 数据挖掘概述
1.1.2 数据挖掘常用算法概述
第一章 数据挖掘概念
(3) 支持向量机 支持向量机(Support Vector Machine,SVM)是建立在统计学理论的VC维理论和
结构风险最小原理基础上的,它在解决小样本、非线性及高维模式识别中表现出许 多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。支持向量机算 法将在后面章节做详细介绍。
第一章 数据挖掘概念
1. 什么是测量误差和数据收集误差 测量误差是测量中测量结果与实际值之间的差值叫误差。 数据收集误差是指收集数据时遗漏数据对象或属性值,或包含了其他数据对象等情况。
2. 什么是噪声 噪声是从物理角度而言,噪声是波形不规则的声音。
1.2 数据探索
1.2.2 数据质量
第一章 数据挖掘概念
第一章 数据挖掘概念
1.3 数据挖掘的应用
第一章 数据挖掘概念
1. 算法延展性
算法延展性即为算法弹性,随着数据产生、采集技术的快速进步,以GB、TB、PB(1GB=1024MB, 1TB=1024GB,1PB=1024TB)为单位的数据集越来越普遍。
2. 高维性
在以前的数据库构成中只有少量属性的数据集,现在大数据集群构成中是具有成百上千属性的数据集。
1.2 数据探索
1.2.1 数据概述
1. 属性 (1)区分属性可通过属性可能取值的个数来判断。 (2)非对称的属性 2. 数据集的一般特性
数据集一般具有三个特性,分别是维度、稀疏性、 分辨率三个,它们对数据挖掘有重要影响。 3. 较常见的数据类型
第一章 数据挖掘概念
1.2 数据探索
1.2.2 数据质量
1.3 数据挖掘的应用
1.3.3 数据挖掘的应用场景
网络数据的挖掘与分析技术

网络数据的挖掘与分析技术第一章网络数据挖掘技术概述网络数据的挖掘与分析技术,是指通过对网络上的大量数据进行收集、整理、分析和挖掘,从中提取有用信息的一种技术手段。
随着互联网的普及和数据的爆炸增长,网络数据挖掘技术的应用越来越广泛。
网络数据挖掘技术可以应用于各个领域,比如商业分析、市场营销、金融风控以及社交网络分析等。
通过挖掘网络数据,我们可以获得一些隐藏在海量数据背后的有价值的信息,为决策提供参考。
第二章网络数据挖掘流程网络数据挖掘的流程主要包括数据收集、数据预处理、特征提取、模型构建与评估以及结果展示等几个步骤。
首先,需要对网络中的数据进行收集。
这些数据可以是网页、日志、社交媒体内容、用户行为轨迹等。
接下来,对收集到的数据进行预处理,包括数据清洗、去噪、归一化等。
这一步是为了消除数据中的噪音和不一致性,提高后续分析的准确性和可靠性。
然后,需要对预处理后的数据进行特征提取。
特征提取是将原始数据转换为计算机可处理的形式,常常使用文本挖掘、图像处理、自然语言处理等技术。
在特征提取之后,可以构建模型进行数据挖掘。
常用的数据挖掘技术包括关联规则挖掘、分类与预测、聚类分析、时序分析等。
最后,对模型进行评估,并将挖掘结果进行展示和解释。
评估模型的准确度和可信度非常重要,同时,将挖掘的结果以可视化的形式展示可以更容易理解和应用。
第三章网络数据挖掘技术应用网络数据挖掘技术可以应用于各个领域,以下将介绍几个典型的应用案例。
1. 商业分析网络数据挖掘技术可以帮助企业了解消费者行为和需求,为产品定价、市场推广、客户关系管理等方面提供数据支持和决策依据。
2. 市场营销通过挖掘网络数据,可以分析用户的购买行为、喜好偏好等信息,从而制定个性化的营销策略,提高销售转化率。
3. 金融风控网络数据挖掘技术可以分析用户的金融交易行为、信用记录等数据,检测和预测风险,从而帮助金融机构进行风险评估和欺诈检测。
4. 社交网络分析通过挖掘社交网络中的数据,可以分析人际关系、社区结构等,帮助社交媒体平台改进用户推荐、社交关系分析等功能。
数据挖掘理论基础

• 货物销售之间的相互联系和相关性,以及基于这种联系上的预测
• 数据从那里来?
5
三、数据挖掘的应用
1、客户分析与管理 • 顾客分析
• 哪类顾客购买那种商品 (聚类分析或分类预测)
• 客户需求分析
• 确定适合不同顾客的最佳商品 • 预测何种因素能够吸引新顾客
• 提供概要信息
• 多维度的综合报告 • 统计概要信息 (数据的集中趋势和变化)
6
三、数据挖掘的应用
2、公司分析和风险管理
• 财务计划
• 现金流转分析和预测 • 交叉区域分析和时间序列分析(财务资金比率,趋势分析等等)
• 资源计划
• 总结和比较资源和花费
• 竞争
• 对竞争者和市场趋势的监控 • 将顾客按等级分组和基于等级的定价过程 • 将定价策略应用于竞争更激烈的市场中
7
三、数据挖掘的应用
3、欺诈行为检测和异常模式的发现
• 对欺骗行为进行聚类和建模,并进行孤立点分析 • 应用:卫生保健、信用卡服务、电信等
• 医疗保险
• 职业病人、 医生以及相关数据分析 • 不必要的或相关的测试
• 洗钱: 发现可疑的货币交易行为 • 电信: 电话呼叫欺骗行为
• 电话呼叫模型: 呼叫目的地,持续时间,日或周呼叫次数. 分析模型发现与期待标准的偏差
第一章 数据挖掘概论
第二节 理论基础
1
一、数据挖掘中用到的技术
• 数据挖掘:多个学科的融合
数据库系统
统计学
机器学习
数据挖掘
可视化
算法
其他学科
2
一、数据挖掘中用到的技术
• 统计学:统计模型、统计描述、假设检验 • 机器学习:监督学习、无监督学习、半监督学习 • 数据库:数据库系统、数据仓库、OLAP • 信息检索:语言模型、主题模型、自然语言处理
韩家炜-数据挖掘:概念与技术-第1章PPT课件

• 描述性的挖掘任务是描述目标数据集的数 据属性。
• 预测性的挖掘任务是归纳现有数据以用来 做预测。
2021
20
1.4.1 类别/概念描述:特征化和区
分
对于一个电商企业,销售商品可分为计算机和 打印机,客户可分为大客户和节约型客户。对这些 单个的类别和概念使用总结、概要或者精确的术语 进行描述非常有用。这种对类别或者概念的描述称 为类别/概念描述。 描述可以通过:
2021
22
举例如,总结每年在AllElectronics 花掉 5000美元以上的客户特征。
描述结果可能是这些客户的一般信息, 如他们是40-50岁之间的,有工作的,有很高 信用度的。
2021
23
数据区分
数据区分是比较目标类别数据对象和一个或者一 组对象的一般特征。
举例如,用户想比较去年的销售额增长了10%的 软件产品和销售额下降了30%的产品的一般特征。
2021
11
• 1.1 Why Data Mining? • 1.2 What is Data Mining? • 1.3 What kinds of Data Can be Mined?
– 1.3.1 Database Data – 1.3.2 Data Warehouse – 1.3.3 Transactional Data – 1.3.4 Other Kinds of Data
– 举个例子,谷歌的Flu Trends使用一些特定的词语作为流 感的指示器。它能够发现搜索流感信息的人群的数量与真 正有流感症状的人群的数量之间的紧密关系。当所有的关 于流感的信息聚集在一起时,就能呈现某种模式。使用聚 集的谷歌搜索数据,Flu Trends能比传统系统提早两周估 计到流感的发生。
数据仓库与数据挖掘技术 第一章 概述
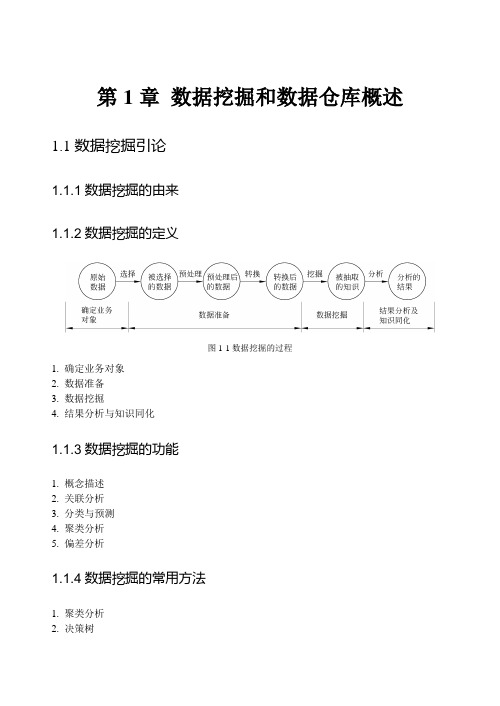
第1章数据挖掘和数据仓库概述1.1数据挖掘引论1.1.1数据挖掘的由来1.1.2数据挖掘的定义图1-1数据挖掘的过程1. 确定业务对象2. 数据准备3. 数据挖掘4. 结果分析与知识同化1.1.3数据挖掘的功能1. 概念描述2. 关联分析3. 分类与预测4. 聚类分析5. 偏差分析1.1.4数据挖掘的常用方法1. 聚类分析2. 决策树数据仓库与数据挖掘技术3. 人工神经网络4. 粗糙集5. 关联规则挖掘6. 统计分析1.2数据仓库引论1.2.1数据仓库的产生与发展1.2.2数据仓库的定义1.2.3数据仓库与数据挖掘的联系与区别1. 数据仓库与数据挖掘的联系2. 数据仓库与数据挖掘的区别1.3数据挖掘的应用1.3.1数据挖掘的应用领域1. 金融业2. 保险业3. 科学研究4. 市场营销5. 客户关系管理6. 其他领域1.3.2数据挖掘案例1. 竞技运动中的数据挖掘2. 超市中的数据挖掘3. 站点访问量分析中的数据挖掘4. 通过数据挖掘进行个性化服务数据仓库与数据挖掘技术5. “体育精品”体育用品公司1.4常用数据挖掘工具1.4.1数据挖掘工具的种类1. 按使用方式分类2. 按数据挖掘技术分类3. 按应用范围分类1.4.2评价数据挖掘工具优劣的指标1.4.3常用数据挖掘工具1. SPSS图1-2SPSS界面2. SAS数据仓库与数据挖掘技术图1-3SAS界面3. SQL Sever 2005图1-4Microsoft SQL Server 2005数据挖掘平台界面4. Weka数据仓库与数据挖掘技术图1-5Weka界面5. MA TLAB图1-6MATLAB的界面习题11. 数据挖掘技术涉及哪些技术领域?2. 数据挖掘的源数据是否必须是数据仓库的数据?可以有哪些来源?数据仓库与数据挖掘技术3. 数据挖掘的具体功能有哪些?4. 数据挖掘技术主要包含哪几种?5. 数据挖掘的过程包括哪些步骤,每一步具体包括哪些内容?6. 数据挖掘可以应用在哪些领域?7. 数据库与数据仓库的本质区别是什么?8. 举例说明数据挖掘与数据仓库的关系。
数据挖掘概念与技术(第三版)课后答案——第一章

数据挖掘概念与技术(第三版)课后答案——第⼀章1.1 什么是数据挖掘?在你的回答中,强调以下问题:(a)它是⼜⼀种⼴告宣传吗?(b)它是⼀种从数据库、统计学、机器学习和模式识别发展⽽来的技术的简单转换或应⽤吗?(c)我们提出了⼀种观点,说数据挖掘是数据库技术进化的结果。
你认为数据挖掘也是机器学习研究进化的结果吗?你能基于该学科的发展历史提出这⼀观点吗?针对统计学和模式识别领域,做相同的事。
(d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。
答:数据挖掘不是⼀种⼴告宣传,它是⼀个应⽤驱动的领域,数据挖掘吸纳了诸如统计学习、机器学习、模式识别、数据库和数据仓库、信息检索、可视化、算法、⾼性能计算和许多应⽤领域的⼤量技术。
它是从⼤量数据中挖掘有趣模式和知识的过程。
数据源:包括数据库、数据仓库、Web、其他信息存储库或动态的流⼊系统的数据等。
当其被看作知识发现过程时,其基本步骤主要有:1. 数据清理:清楚噪声和删除不⼀致数据;2. 数据集成:多种数据源可以组合在⼀起;3. 数据选择:从数据库中提取与分析任务相关的数据;4. 数据变换:通过汇总或者聚集操作,把数据变换和统⼀成适合挖掘的形式;5. 数据挖掘:使⽤智能⽅法或者数据挖掘算法提取数据模式;6. 模式评估:根据某种兴趣度量,识别代表知识的真正有趣的模式。
7. 知识表⽰:使⽤可视化和知识表⽰技术,向⽤户提供挖掘的知识。
1.2 数据仓库与数据库有什么不同?它们有哪些相似之处?答:不同:数据仓库是多个异构数据源在单个站点以统⼀的模式组织的存储,以⽀持管理决策。
数据仓库技术包括数据清理、数据集成和联机分析处理(OLAP)。
数据库系统也称数据库管理系统,由⼀组内部相关的数据(称作数据库)和⼀组管理和存取数据的软件程序组成,是⾯向操作型的数据库,是组成数据仓库的源数据。
它⽤表组织数据,采⽤ER数据模型。
相似:它们都为数据挖掘提供了源数据,都是数据的组合。
数据挖掘第一章

第一章:绪论与SAS基础第一节:数据挖掘概论一、数据挖掘的基本概念与应用现代信息社会的特征:数据泛滥、知识相对缺乏。
随着计算机技术、数据库技术的快速发展和广泛应用,各行业中积累的数据越来越多,金融行业中尤其如此。
有数据表明,进入20世纪90年代后,人类积累的数据量以每月高于15%的速度增长,原有的数据库技术不能从海量数据库中挖掘出决策有用信息或新的知识,这样就出现了数据泛滥、知识相对缺乏的状态。
为解决这个问题,从20世纪90年代起,数据挖掘技术开始兴起。
数据挖掘是从数据仓库中发掘那些潜在的、鲜为人知的数据规律和数理模式(新的决策有用知识),其目的是在过去检验的基础上预测未来的发展趋势。
例1:数据挖掘在商业管理中的应用:日本超市中啤酒与尿片的规律;英国超市中大额交易者与某种品牌的奶酪的联系;消费者视角的主要停留区域与商品布置。
例2:数据挖掘在银行中的应用:信用卡违约与欺诈预测模型构建;企业贷款的信用风险预测模型构建;反洗钱预警系统构建。
例3:数据挖掘在金融市场中的应用:趋势图与关联规则挖掘;股票自动交易模式的识别与自动交易系统构建;外资并构企业预测模型构建。
二、不同学科对数据挖掘技术的研究与开发数据挖掘是一门综合性的新兴学科,其应用前景十分广泛。
1990年代末,在对100名美国著名科学家的问卷调查中,数据挖掘被列为21世纪对人类发展影响最大、最有前途的10大高新技术的第三位。
我国对数据挖掘技术也十分重视,数据挖掘技术的开发与应用最近10年来都被列为国家873、973高科技项目,列为我国科技的一个重点发展方向。
数据挖掘是一门综合性的跨学科技术,因此对其的研究也涉及数据学科领域。
现在对数据挖掘技术的研究主要包括:数据挖掘的理论研究:各种数据挖掘技术的理论基础,理论依据研究。
从数学、统计学、人工智能、计算机图形学等领域对此展开研究。
数据挖掘的技术研究。
从计算数学、统计学、人工智能、机器学习、计算机图形学、软件工程等领域。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
息结构”或者说知识是“多个信息之间的关联”。-》
客观世
收 数分
信 深入分
知
界
集 据析
息
析
识
决策和行动
图1.1
“信息贫乏”(Information poor) “数据关在牢笼中”(data in jail),
奈斯伯特(John Naisbett)惊呼 “Wear drowning in information,but starving for
knowledge”(人类正被数据淹没,却饥渴于知识)。
面临浩渺无际的数据,人们呼唤从数据汪洋中来一 个去粗存精、去伪存真的技术,使之能从已有信息中发 现模式或规律,使之能够智能地、自动地将这些原始数 据转化处理为有用的信息和知识。
苦恼: 淹没在数据中 ; 不能制定合适的决策!
数据
知识
决策
金融 经济 政府 POS. 人口统计 生命周期
模式 趋势 事实 关系 模型 关联规则 序列
目标市场 资金分配 贸易选择 在哪儿做广告 销售的地理位置
数据爆炸,知识贫乏
银行信用卡的发放 保费的确定 商品进货量的确定 油井的加压注水措施 广告与销售之间的关联 商品的关联销售 客户群的分析 客户流失分析等等
结果,收集在大型数据库中的数据变成了 “数据坟墓”——难得再访问的数据档案。 这样,重要的决定常常不是基于数据库中信息丰富的
数据,而是基于决策者的直觉,因为决策者缺乏从海 量数据中提取有价值知识的工具
数据和信息之间的鸿沟要求系统地 开发数据挖掘工具,将数据坟墓转 换成知识“金块”。
气温的变化让购买行为发生了哪些改变? 竞争对手的新包装对销售产生了怎样的影响? 不少问题目前也可以回答,但它们更多是基于经验, 而不是基于数据。
案例2:阿迪达斯的“黄金罗盘”
案例3:数据权之争
案例4:《纸牌屋》你学不会
案例5:定制爱情
一、数据丰富与知识贫乏
数据、信息和知识 数据 是“客观事物的属性、数量、位置及相互关系等
在何种数据源上进行数据挖掘 数据挖掘所依赖的数据来源多种多样,可以是常用
的关系数据库、事物数据库、文本数据库、多媒体数 据库等,主要取决于用户的目的及所处的领域。
由以下步骤组成: 1、数据清理 消除重复的、不完全的、违反语义约束的数据 2、数据集成 多种数据源可以组合在一起
3、数据选择 从数据库中检索与分析任务相关的数据
三、数据挖掘的体系结构 基于这种观点,典型的数据挖掘系统具有以下主要
成分(见图1-5):
四、数据挖掘的学科体系
数据挖掘涉及多学科技术的集成,包括: 数据库技术、统计学、机器学习、高性能计算、模 式识别、神经网络、数据可视化、信息检索、图象 与信号处理和空间数据分析。
●根据采用的技术分类,最常用的数据挖掘技术有: 统计方法 机器学习方法 神经计算 可视化
4、数据变换 数据变换或统一成适合挖掘的形式,如通过汇总或聚集操
作
5、数据挖掘 使用智能方法提取数据模式
6、模式评估 根据某种兴趣度度量,识别表示知识的真正有趣的
模式 7、知识表示
使用可视化和知识表示技术,向用户提供挖掘的知 识
这些知识可以直接提供给决策者,用以辅助决策过程; 或者提供给领域专家,修正已有的专家体系;也可以作 为新的知识转存到应用系统的知识存储机构中,比如专 家系统、规则库等。
数据挖掘
数据仓库的产生
数据仓库技术是随着人们对大型数据库系统研究的 不断深入,在传统数据库技术基础之上发展而来的, 其主要目的就是为决策提供支持,为OLAP、数据挖 掘深层次的分析提供平台。 数据仓库是一个和实际应用密不可分的研究领 域,与传统数据库相比,数据仓库不仅引入了许多 新的概念,而且在体系结构、数据组织等方面,均 有其自身的特点。
1.2 数据挖掘基本知识
一、数据挖掘的定义 简单地说,数据挖掘是从大量数据中提取
或“挖掘”知识。
定义1:KDD就是要从大量的、不完全的、有噪声的、模糊 的、随机的实际应用数据中,提取隐含在其中的、人们 事先不知道的、但又是潜在有用的信息和知识。
二、数据挖掘的步骤
KDD定义中的“非平凡性”主要强调其搜索有一定的自动 性、智能性,而并非对数据集中的每一点都要遍历到。 它是一个多步骤的处理过程,多步骤之间相互影响、 反复调整,形成一种螺旋上升过程。如下图:
《数据仓库与数据挖掘》
主讲教师: 胡晓晖 联系方式:1085206157@
1.1-----数据挖掘的产生背景
应用驱动
从数据中挖掘“金子”
案例1:农夫山泉用大数据卖矿泉水
发挥您的想象力,选择您认为可是的答案
胡健想知道的问题包括:
怎样摆放水堆更能促进销售?
什么年龄的消费者在水堆前停留更久,他们一次购 买的量多大?
1.统计方法
统计方法是从事物的外在数量上的表现去推断该事 物可能的规律性. 最初总是从数量表现上通过统计分析看出一些线索, 然后提出一定的假说或学说,做进一步深入的理论研 究. (1)传统统计方法
传统的统计学所研究的主要是渐进理论,即当样本 趋向无穷多时的统计性质.统计方法主要考虑测试预 想的假设是否与数据模型拟合.
而计算机另一个领域---人工智能的发展,使得这 种“发现”成为可能。于是,从数据库中发现知识(KDD) 及其核心技术——数据采掘(DM)便应运而生了。
数据爆炸但知识贫乏
数据库越来越大
数据挖掘
可怕的数据
有价值的知识
二、数据挖掘的出现
数据挖掘是应用驱动的结果
近年来,数据挖掘之所以引起了信息产业界的极大关 注,其主要原因是存在大量数据,可以广泛使用,并且 迫切需要将这些数据转换成有用的信息和知识。
统计方法的处理过程分:
① 搜集数据:采样、实验设计
② 分析数据:建模、知识发现
③ 进行推理:预测,分类
④
常见的统计方法
回归分析(多元回归)
判别分析(贝叶斯判别类等)