第五讲 受限因变量时间序列以及panel模型
离散因变量和受限因变量模型

E ( yi ) P( yi 1) pi xi β
(7.1.3)
5
式(7.1.3)只有当xi 的取值在(0,1)之间时才成立,否则就会
产生矛盾,而在实际应用时很可能超出这个范围。因此,线性
概率模型常常写成下面的形式:
xi β, pi 1, 0,
0 xi β 1 xi β 1 xi β 0
* i * i
(7.1.9)
其中:F是ui*的分布函数,要求它是一个连续函数,并且是
单调递增的。因此,原始的回归模型可以看成如下的一个回
归模型:
yi 1 F xi β ui
即yi关于它的条件均值的一个回归。
(7.1.10)
8
分布函数的类型决定了二元选择模型的类型,根据分布函 数F的不同,二元选择模型可以有不同的类型,常用的二元选择 模型如表7.1所示: 表7.1 常用的二元选择模型
在离散选择模型中,最简单的情形是在两个可供选择的 方案中选择其一,此时被解释变量只取两个值,称为二元选 择模型(binary choice model)。在实际生活中,我们经常 遇到二元选择问题。例如,在买车与不买车的选择中,买车
记为1,不买记为0。是否买车与两类因素有关系:一类是车
本身所具有的属性,如价格、型号等;另一类是决策者所具 有的属性如收入水平、对车的偏好程度等。如果我们要研究 是否买车与收入之间的关系,即研究具有某一收入水平的个 体买车的可能性。因此,二元选择模型的目的是研究具有给
令pi = P ( yi =1) ,那么 1 - pi = P ( yi =0) ,于是
E ( yi ) 1 P( yi 1) 0 P( yi 0) pi
(7.1.2)
第五讲 面板数据模型

1.面板数据定义 对于面板数据 yi t, i = 1, 2, …, N; t = 1, 2, … , T,如果每个个体在相同的时期 内都有观测值记录,则称此面板数据为平衡面板数据( balanced panel data) 。 若面板数据中的个体在相同时期内缺失若干个观测值,则称此面板数据为非平 衡面板数据( unbalanced panel data) 。 案例 1( file:5panel02) :1996-2002 年中国东北、华北、华东 15 个省级地 区的居民家庭固定价格的人均消费( CP)和人均收入( IP)数据。数据是 7 年 的,每一年都有 15 个数据,共 105 组观测值。 人均消费和收入两个面板数据都是平衡面板数据,各有 15 个个体。
图 6 对数的人均消费对收入的面板数据散点图 图 7 对数的人均消费对收入的面板数据散点图
本例用对数研究更合理
面板数据模型与应用
1.面板数据定义 为了观察得更清楚,图 8 给出北京和内蒙古 1996-2002 年消费对收入散点图。从图中 可以看出,无论是从收入还是从消费看内蒙古的水平都低于北京市。内蒙古 2002 年的收 入与消费规模还不如北京市 1996 年的大。图 9 给出该 15 个省级地区 1996 和 2002 年的 消费对收入散点图。 6 年之后 15 个地区的消费和收入都有了相应的提高。
IP_I 14000
1.面板数据定义
11000 10000 9000 8000 7000 6000 5000 4000 3000 IP 2000 2000 4000 6000 8000 IPCROSS 10000 12000 14000 CP1996 CP1997 CP1998 CP1999 CP2000 CP2001 CP2002
面板数据的模型(panel data model)

面板数据的模型(panel data model)王志刚 2004年11月11日一. 混合数据模型和面板数据模型如果扰动项it ε服从独立同分布假定,而且和解释变量不相关,那么就可以采用混合最小二乘法估计(Pooled OLS ),但是这里要注意POLS 暗含着一个假定就是,截距项和解释变量的系数是相同的,不随着个体和时间而变化。
我们一般采用单因子(one-way effects )模型,假定截距项具有个体异质性,也就是:这种模型是最常见的面板模型(又称为纵列数据longitudinal data ),因为面板数据往往要求个体纬度 N>>T(时间纬度),下面我们基本上以这种模型为例。
it u 是独立同分布,而且均值为0,方差为2u σ。
如对截距项和解释变量系数均有个体的异质性,那么要采用随机系数模型(Random coefficient model ),stata 的xtrchh 过程提供了相应的估计。
双因子模型(two-way ):it t i it u ++=γαε二. 固定效应(Fixed effects ) vs 随机效应(Random effects)如果个体效应i α是一个均值为0,方差为2ασ的独立同分布的随机变量,也就是()0,cov =it i x α,该模型就称为随机效应模型(又称为error component model );如果相关,则称为固定效应模型。
1.在随机效应模型中,it ε在每个个体内部存在着一阶自相关,因为他们都包含着相同的个体效应;此时OLS 无效,而且标准差也失真,应该采用广义最小二乘估计(GLS)其中:是个体按时间的均值;有待估计;我们可以通过对组内和组间估计得到相应的残差,从而可以计算出方差;T k n e e e e nnk nT ubetween between between between within within u 22222,,ˆˆ1σσσσσα-=-'='--=;组间估计:εβ+=..i i x y ;组内估计如下;2.如果个体效应和解释变量相关,OLS 和GLS 都将失效,此时要采用固定效应模型。
离散因变量和受限因变量模型课件

离散因变量模型的建立与实现
离散因变量模型的建立过程
确定研究问题
明确研究目的,确定因变量和自变量, 并了解相关背景知识。
数据收集
收集适合研究问题的数据,确保数据 质量和完整性。
变量选择
根据研究目的和背景知识,选择合适 的自变量和因变量。
模型构建
根据离散因变量的特点,选择合适的 模型进行拟合,如逻辑回归、多项式 逻辑回归等。
THANKS
感谢观看
离散因变量与受限因变量模型的适用范围
离散因变量模型
适用于分析分类数据或计数数据,如性别、婚姻状况、职业等。这类模型可以帮 助我们了解不同类别之间的差异和关联。
受限因变量模型
适用于分析连续变量,但在特定情境下取值受到限制的数据。这类模型可以帮助 我们预测变量的取值范围和了解变量之间的关系。例如,在经济学中常用的截尾 回归模型就属于受限因变量模型。
离散因变量和受 限因变量模型课 件
• 离散因变量模型概述 • 受限因变量模型概述 • 离散因变量模型的建立与实现 • 受限因变量模型的建立与实现 • 离散因变量与受限因变量模型的比较与选
择 • 案例分析
01
CATALOGUE
离散因变量模型概述
离散因变量的定义
离散因变量
在回归分析中,因变量(即被解释变 量)的值只能取有限个离散值,而不 能取连续值。这些离散值通常是整数 或分类数据。
05
CATALOGUE
离散因变量与受限因变量模型的比较与选 择
离散因变量与受限因变量的比较
定义
离散因变量是指因变量的取值是离散的,通常只有有限个可 能的值;而受限因变量是指因变量的取值受到某些限制,例 如在某个范围内取值。
2024年度李子奈计量经济学课件

数据收集与处理 变量选择与测量 实证分析
评价环境污染治理政策的 效果及其影响因素。
采用环境经济学理论模型 ,如环境污染与经济增长 关系模型、环境规制效果 评价模型等。
收集相关地区和行业的环 境污染和治理数据,如污 染物排放量、治理投资额 等,并进行必要的处理。
选择环境污染治理效果作 为被解释变量,选择治理 投资额、污染物排放量、 环保政策等作为解释变量 ,并进行测量。
27
实证研究设计思路及步骤
构建理论模型
根据研究问题,选择合适的理 论或模型,构建实证研究的理 论框架。
变量选择与测量
选择合适的变量,并对其进行 测量,以便后续分析。
确定研究问题
明确研究目的和研究问题,是 实证研究的出发点。
2024/3/24
数据收集与处理
根据理论模型的要求,收集相 关数据,并进行必要的处理, 如数据清洗、转换等。
运用计量经济学方法,如 面板数据分析、倾向得分 匹配等,对收集的数据进 行实证分析,评价环境污 染治理政策的效果及其影 响因素。
2024/3/24
30
THANKS
感谢观看
2024/3/24
31
空间杜宾模型(SDM)
估计方法
同时考虑了因变量和自变量的空间滞后效 应,以及误差项的空间相关关系,更为全 面地揭示了空间效应的作用机制。
包括最大似然估计法、广义最小二乘法、 工具变量法等,用于对空间计量模型进行 参数估计和假设检验。
2024/3/24
26
07
实证研究与案例分析
Chapter
2024/3/24
面板数据定义
指包含若干个截面个体成员在一段时间内的样本数据集合,其每 一个成员都有多个观测值。
第5章 PanelData计量经济学模型

• 在具体模型方法方面,采用Panel Data比单纯采 用横截面数据或时间序列数据也有许多优势。例 如:
– 可以显著地增加自由度,使得统计推断更加有效; – 可以降低变量之间的共线性,使得参数估计量更具有 效性; – 可以有助于从不同的经济理论出发建立的互相竞争的 模型中识别出正确的模型; – 可以减少甚至消除模型估计偏差;等等。
• 模型6:截面个体和时点变截距模型。
Yit i t Xit β it
i 1,, n t 1,, T
该模型表示,在横截面个体之间,存在个体影响,同时 在不同的时点之间,存在个体影响,但是不存在变化的 经济结构,因而结构参数在不同横截面个体上是相同的。 这是一类在实际应用中常见的模型。从应用的角度,人们 希望既控制截面个体影响,也控制时点影响,然后求得平 均意义上的不变的结构参数。 该模型的估计方法与模型2并无大的差别。
3、回归残差平方和的计算
1 T y i y it T t 1
T
1 T xi xit T t 1
第i群的残差平方和
Wxx,i ( xit xi )( xit xi )
t 1 T
Wxy,i ( xit xi )( yit yi )
t 1
yit i xit i uit
受限因变量模型

用计量经济模型反映选择行为
行为主体从事的每项活动都可以看作是一种选择; 行为主体有其偏好; 人们的行为有其规则; 在经济分析中,通常认为选择基于效用最大化标准。 研究中需要考虑:
行为理论基础 计量经济学模型方法
模型设定 统计理论和数据 估计方法
应用分析
行为假定
就可以选择的活动而言,行为主体的偏好具有传递 性和完备性。 每项选择都有其相应的效用水平Uijt 每个行为主体都试图获得最大效用,当Ui1t > Ui2t 时, 行为主体会选择第一项活动。 然而我们无法观测效用本身,我们只有通过观察行 为主体做出的选来揭示其偏好
LR = -2(Lr– Lur )~ c2q 如果未受约束似然值与受约束似然值相等,说明模型效果差,未通过 检验;相反,如果未约束似然值远大于约束似然值,说明所设自变 量通过检验,模型总体效果较好。它对应于线性模型中的F值。
拟合优度
对于线性概率模型,可以直接用得到R2来判断拟合优度; Probit 模型和Logit模型没有R2,因而需要利用其他方法来反 映拟合优度。 一种方法是利用对数似然值计算伪R2(pseudo R2)或 McFadden R2,该值也被称作似然值比值指数,定义为1 – Lur/Lr
必要时给出选项 得到估计结果
用EVIEWS估计有限因变量模型
得到结果后可以在VIEW子菜单下调用:
Coefficient tests各种对系数的统计检验 Residual tests对残差的统计检验 Expectation-Prediction Table 可以得到正确和错 误推断的比例 Goodness-of-Fit Tests检验拟合优劣
得到的参数不会相同 但分析结论不会有大的差别 因而通常基于模型的统计表现和经验来决定取舍
第六章_受限因变量模型__颜莹

Chapter 6 受限因变量模型本章讨论的一类模型是因变量的取值受到限制,有时候这种限制不需要特别的处理,但有时候这种限制却另有含义。
特别,y 取有限个离散值,如1y =(表示赞成),0y =(表示反对)。
于是,()E Y X 用线性回归模型来表示就不合适了,我们将依据y 受不同限制的情况处理几类不同的非线性模型,并只给非线性模型的估计检验方法——极大似然方法一、离散响应模型有时,我们只观察到y 处于某种状态,用1表示;用0表示不出于该状态,如,1y =(就业),0y =(失业),或y 仅有几种很少的状态可供选择,我们把y 仅取有限的离散值情况称为离散响应模型。
同样,影响y 的状态的因素称为解释变量或相关变量,X 可能包括有关个体的各种情况,如表示教育程度,年龄,性别……他们都有可能影响y 的状态。
关心的问题:j X 多大程度上影响了y 的状态。
设1()(1)(1.......)k P X P y X P y X X ==== 那么对连续变量1X(1)()j jP y X P X X X ∂=∂=∂∂ 对二元变量k X (取0,1)1111(.......,1)(.......,0)k k P X X P X X ---以上两式,如果()P X 已知,就近的反映了j X 对于y 的状态的影响, 如何确定()P X ? (一)二元响应的线性概率模型最简单,将()(1)P X P y X ==改写成01122(1).......k k P y X X X X X βββββ==++++= ∵(1)()P y X P X ==,则(0)1()P y X P X ==- ∴()()E y X P X =且()()[1()]Var y X P X P X =-∴()E y X X β=,且()(1)Var y X X X ββ=-这说明,如果用线性投影来拟合()E y X ,存在条件异方差(与样本有关) 注意:1、当j X 取连续值:(1)j jP y X X β∂==∂2、当j X 取离散值,(1,(0,j j j P X P X β==-=其余不变)其余不变)如果参数β未知,由()E y X X β=可知,利用y X βε=+,给定样本,y ,1,1.......k X X ,可得β的一致估计OLS β∧。
受限因变量模型颜莹

Chapter 6 受限因变量模型本章讨论的一类模型是被关注的因变量的取值受到限制.有时候这种限制不需要特别的处理,但有时候这种限制却是实质性的.从条件期望的角度看,如果限制的信息是确定的,例如,y 只取有限个离散值,如1y =(表示赞成),0y =(表示反对).于是,()E Y X 用线性回归模型的方式来表示就不合适了.我们将依据y 受不同限制的情况处理几类不同的非线性模型,并给出非线性模型的常用估计检验方法—极大似然方法.按理,非线性模型是下篇的内容,之所以要介绍受限因变量模型是因为它的背景与多元回归模型有关. 另外,本章的附录部分简单的介绍非线性理论,这是伍书的第12章. §1.离散响应模型有时,我们只能观察到y 处于某种状态,用1表示,用0表示不处于该状态.如1y =(就业),0y =(失业),或y 仅有几种很少的状态可供选择,我们把y 仅取有限的离散值情况称为离散响应模型.特别,y 仅取0、1为值称为二元响应模型.同样,影响y 的状态的因素称为解释变量或相关变量,X 可能包括有关个体的各种情况,如教育程度,年龄,性别…等,它们都有可能影响y 的就业状态.关注的问题:X 中j X 多大程度上影响了y 的状态? 这个问题准确的表达是,设1()(1)(1)k p x P y X P y X X ====,是一个条件概率.解释变量j X 可以是连续型的也可以是离散型的.那么对连续变量j X ,就用边际效应(1)()j jP y X p x X X ∂=∂=∂∂反映j X 对y 状态的影响,对二元变量k X ,(取0,1为值.)就用差分效应 1111(.......,1)(.......,0)k k p x x p x x ---反映K X 对y 状态的影响.以上两式,如果()p x 已知就没有问题了.问题是如何确定()p x ? (1)二元响应的线性概率模型最简单的是认为()(1)p x P y X ==仍是X 的线性函数,改写成:01122(1)k k P y X X X X X βββββ==++++=.∵(1)()P y X p x ==,则(0)1()P y X p x ==-.y 是一个二元分布. ∴()()E y X p x =,且()()[1()]Var y X p x p x =-. ∴()E y X X β=,且()(1)Var y X X X ββ=-.这说明,如果用线性投影来拟合()E y X ,则存在条件异方差.(方差与样本X 有关)注意:采用线性概率模型,未知参数β的含义,当j X 取连续值(1)j jP y X X β∂==∂;当jX 取离散值,(1,(0,j j j P X P X β==-=其余不变)其余不变). 由()E y X X β=,利用y X βε=+,给定样本y ,1k X X .可得β的一致估计OLS β∧.又由()Var y X 存在条件异方差,故OLS β∧不是有效的,再改用加权最小二乘(WLS )加以修正,做法是,对所有满足条件ˆ01i y <<的样本,定义标准差ˆi σ=然后ˆ/i i y σ对ˆ1/i σ,1ˆˆ, 1i i ik i x x i N σσ=.做回归,得WLS β∧,可增加有效性.关于检验,所有关于β的t 检验、F 检验以及部分参数为0的检验,用稳健的异方差协差矩阵和标准差都是有效的.但是线性概率模型在理论上是有欠缺的,因为拟合值有可能不在[0,1]区间内,即使都在[0,1]中,但预测值y 随着其解释变量i X 不断增加或减少,终将导致y 不在[0,1]区间内,这与概率的意义是不相符的.尽管如此,如果主要目的是估计X 中每个解释变量对y 影响的平均概率,那么一些预测值不在[0,1]中影响不大,线性概率模型不必对X 取极端值给出一个好的估计. (2) 二元响应的指数(Index )模型(probit 和 logit 模型)考虑二元响应的概率有形式:(1)()()P y X G X p x β===. 这里z R ∀∈,0()1G z <<.1(1,)k X X X =,0()K βββ'=.特别()G Z Z =就是线性概率模型.因为先把X β理解成一个指数(Index ),函数G 再把指数X β映射成一个响应函数()p x .故称模型为指数模型,在实践中G 一般取累积分布函数的形式.如果G 是某一随机变量的分布函数,那么二元响应的指数模型可以从存在潜在变量的线性模型中得到解释:设*y X e β=+,且*1(0)y y =>.*y 不可观测,但如果*0y >则可观测1y =,e 是关于原点对称与X 不相关的连续型随机变量.如果G 是e 的分布函数,那么()()G z P e z =<, 且1()(),G z G z z R --=∀∈.因此,*(1)(0)()()1()()P y X P y X P e X X G X G X p x βββ==>=>-==--=.注:没有特别的理由要求e 是关于原点对称的.但为了方便,对二元响应模型已作为一种习惯限制.没有此限制二元响应模型就不能看成是存在潜在变量的模型.二元响应不采用存在潜在变量的说法是因为无法准确定义潜在变量的含义和测量单位,从而参数i β的大小也没有特定的意义.另外,一般对G 的要求也不非要是分布函数,只要满足()G z 在[0,1]区间即可,但在实际应用时,有两个常用的选择,一个是e 服从标准正态分布,称Probit 模型;另一个是e 服从标准Logistic 分布,称为Logit 模型.1.当e 服从标准正态分布,则G 的分布函数形式为()()()zG z z v dv φ-∞=Φ=⎰2.当e 服从Logistic 的分布,则exp()()()1exp()z G z z z λ==+,有性质()()[1()]Z Z Z λλλ'=-.于是,在指数模型中,i β的含义就不如线性概率模型那样明显. 因为当i X 连续时,()()i ip x g X x ββ∂=∂,且()()dG Z g Z dZ =. ∴如果G 是分布函数,则()0g z >,z ∀.故i β的符号给出了对y 的正影响和负影响,而i β的大小则没有太大的增量意义.另外,当G 的密度g 关于原点对称时,0X β=,g 取得最大值,从而i X 在0X β=时对y 有最大影响.其次当K X 是二元解释变量,那么当0K X =改变到1,其他变量不变,对y 产生的偏效应就是011220112211(.......)(.......)k k k k G X X X G X X X ββββββββ--++++-++++该值是依赖于其他解释变量i X 取值,不过k β的符号同样能决定k X 对y 产生的偏效应是正还是负.一般的,当1K k X c =改变到2k c ,其他变量不变,那么对y 产生的偏效应就是011221011222(.......)(.......)k k k k G X X c G X X c ββββββββ++++-++++. 由()()i ip x g X x ββ∂=∂,有时也常用()/100i g X ββ表示i X 改变百分之一对y 产生的偏效应.偏效应比:()()ii j jp x p x x x ββ∂∂=∂∂,当i X 和j X 是连续型时,则不依赖G 的分布函数. (3)二元响应的极大似然估计和检验给定样本观测值,1,t t X x t n ==(0 1)t t t Y y y or ==,要求极值:11max (,,, 1.....)n n t P Y y Y y X t n β===. ∵1111{0}{1}(,1)[1()][()]n n t i i y y Prob Y y Y y X t n G X G X ββ======∏-∏,∴11()()[1()]i inyy i i i L G X G X βββ-==∏-.11ln ()ln ()(1)ln[1()]nni i i i i i L y G X y G X βββ===+--∑∑.由一阶条件,()0L ββ∂=∂,即ln ()0jL ββ∂=∂ 1j K =.得,1()1[]0()1()ni i ii j i i G X y y G X G X ββββ=∂--=∂-∑ 1j K =.这是一个关于β的非线性方程组,采用非线性方程算法可求得β的极大似然估计量ˆβ. 注:一般情况下,上述方程要有解,要求样本容量是n 和自变量个数k 及y 的均值y 满足条件min{,(1)}ny n y k -≥.含义是,y 取1的个数和取0的个数都必须大于k .例如t y 都取1,则方程无解.∴当G 取标准正态公布,()()t tj t jG X X X βφββ∂=∂ 1j K =,2(2)()x x φ-=.∴一阶条件就是表示成11[]()0()1()nt ttj t t t t y y X X X X φβββ=--=Φ-Φ∑ 1j K =.又当G 取Logistic 分布,exp()()()1exp()z G z z z λ==+,()()[1()]t tj t t jX X X X λβλβλββ∂∴=-∂1j K =.∴一阶条件就是表示成11[1()](1)()0nntjt t tj t t t t Xy X X y X λβλβ==---=∑∑ 1j K =.简化成1[()]0ntjt t t Xy X λβ=-=∑ 1j K =.故Logit 模型在算法上要方便些.进一步可以求得,极大似然估计ˆβ的协方差矩阵的估计为: 121ˆ[()]ˆ()ˆˆ()[1()]n i i i t i i g X X X Avar G X G X ββββ-=⎛⎫'= ⎪ ⎪-⎝⎭∑. 有了估计、渐近方差和标准差,我们就可以做各种假设检验.特别,部分系数为零的检验,在有极大似然函数的前提下,又可以方便的增加似然比检验LR.考察(1,)()(,)P y X Z G X Z p x z βγ==+=. 欲检验0:0H γ=.除了用Wald 检验和LM 检验外,用似然比检验LR.2ˆˆ2[ln ()ln ()]ur r QLR L L ββχ=-.ˆur β是无约束下的极大似然估计,ˆrβ是带约束的极大似然估计,Q 是0γ=的个数. 又当Z 的维数很大,用Wald 检验和LR 检验计算量很大,采用LM 方法更为可取.记ˆˆ()i i G G X β=,ˆˆ()i i g g X β=,ˆˆi i i u y G =-.已从极大似然估计中获得.i i on X ,得非中心决定系数2u R .0:0H γ=真下,22u QLM NR χ=.(该方法还可以推广到检验00:H γγ=.) 接下来讨论Probit 、Logit 和线性概率LP 结果的比较.因为Probit 、Logit 和LP 施加不同的变换()G X β,所以得到的极大似然估计ˆβ不能简单的进行比较.因为对j X 的一个微小变化而言,ˆˆˆ(1)[()]j j P y X g X X ββ∆=≈∆,所以,为了比较j X 增加一个单位的偏效应,我们调整ˆ()g X β归“1”.因此,如果Probit 、Logit 、LP 而言,ˆX β接近于0,那么,对Probit ,(0)0.4g ≈;对Logit ,(0)0.25g ≈;对LP ,(0)1g =.所以,0.250.40.625=,用log ˆ0.625it β与ˆprobit β相比.同理,ˆ2.5LP β与ˆprobit β相比;ˆ4LP β与log ˆitβ相比.一般的,j X 连续,用11ˆˆ[()]Nj i i N g X ββ-=∑作为总体上的平均值代替(0)g ,然后再调整,进行比较.另外,二元响应模型也存在解释变量X 有内生性的问题,以及类似二阶段极大似然估计方法.也可以把二元响应模型扩大到面板数据模型上,(1,)()it it i i i P y X c G X c β==+. 这涉及到更多非线性估计和检验的理论,这是下学期的内容,不再深入讨论下去了. (参见伍书第15章) §2.截取回归模型简介因变量y 可能受到客观条件的限制,使其在某一范围外的数据无法得到,或是有意不取.由于结果的数据受到限制,且解释变量是在结果受限条件下获得的数据,此意味着样本i X 和i y 不再独立.从条件期望的角度看,即使()E Y X X β=是正确设定,但如果要限制0y >,本质上会产生(,0)E y X y >对模型中未知参数β的非线性依赖.导致OLS 方法一致性不成立,不再是一个好的估计,只能改用极大似然方法保证大样本下估计的一致性.因变量受限的截取回归模型通俗的说法是,因变量“掐头”或“去尾”.例如,调查个人收入只能在一定范围内得到;又例如调查寿命大于80岁以上的一般用80岁代替.另一种说法是所谓角点解,问题不再是因变量部分不可观测,而是结果依赖于最优选择,且最优选择的特征是y 以正的概率取0值.因为(0)0P y X =>,从而我们关注0y >时的()E y X 就不再是线性的了.例如,慈善捐赠,关注的是捐赠了0y >的那部分.我们把截取Tobit 模型写成:设*i i i y X u β=+是正确设定,且*i y 不能完全观测.但可观测的i y ,*max(,)i i i y y c =为“去尾”或*min(,)i i i y y c =为“掐头”.且i u 在给定i X 、i c 条件下,2,(0,)i i i u X c N σ.特别0i c =,则*max(,0)i i y y =表示非负观测限制.也称为标准截取Tobit 模型.所以,()(0)0(0)(,0)(0)(,0)E y X P y X P y X E y X y P y X E y X y ==+>>=>>*(0)(0)()([/][/])(/)P y X P y X P u X X P u X X X βσβσβσ>=>=>-=>-=Φ (/)(,0)(,0)(/)u u X X E y X y E X u X y X E X X βφβσβββσσσσβσ⎡⎤⎛⎫>=+>=+>-=+ ⎪⎢⎥Φ⎝⎭⎣⎦注:(0,1)zN ,那么,()()1(). E z z c c c c R φ>=-Φ∀∈.()()() c c c c R λφ=Φ∀∈称为逆米尔斯比.所以,(/)()(/)()(/)(/)(/)X E y X X X X X X X φβσβσβσβσβσφβσβσ⎡⎤=Φ+=Φ+⎢⎥Φ⎣⎦.()(0)(,0)(,0)(0)(/)j jjjE y X P y X E y X y E y X y P y X X X X X βσβ∂>>=>+>=Φ∂∂∂.称(/)X βσΦ为标度因子.ˆˆˆ(/)(0)X P y X βσΦ=>,它是给定X 和ˆβ时正响应的概率.ˆˆ(/)X βσ∴Φ接近于1,截取Tobit 模型与多元回归就没有太多区别. 截取Tobit 模型的估计与检验涉及到麻烦的非线性计算,这是下学期的内容,略.需要提出的是,截取Tobit 模型有二种变形.我们知道,截取Tobit 模型对解释变量X 是没有任何限制的.一种变形是,因变量y 的受限导致了X 的样本i X 受限,甚至是有意不取.我们将此处理成Probit 的响应形式. 模型:1111y X u β=+,且2221[0]y X u δ=+>.假定:2y 是一个二元选择变量,当220X u δ+>时等于1.1y 受限于2y ,只有21y =时才是可观测的.1X 是X 的子集,且2y 和X 可观测.又,X 与1u 、2u 不相关,2(0,1)u N ,且1212()E u u u γ=.注:这里关注的模型尽管是线性多元回归,1111y X u β=+,但样本1i y 和1i X 都受到限制. 另一种变形是Tobit 的响应形式.模型:1111y X u β=+,且222max[,0]y X u δ=+.假定:2y 是一个截取选择变量,1y 受限于2y ,只有当2220y X u δ=+>时才是可观测的.1X 是X 的子集,且2y 和X 可观测.又,X 与1u 、2u 不相关,但222(0,)u N τ,且1212()E u u u γ=. 关于模型的背景、估计和检验都是下学期的内容,不再讨论下去了.要提醒的是,这些非线性模型都是多元回归模型受到约束变形而来.。
stata第五讲【山大陈波】

ivregress 2sls lw80 expr80 tenure80 (s80 iq=med kww mrt age), first estat firststage
过度识别检验
检验工具变量是否与干扰项相关,即工具变量是否 为外生变量。目前仅限于在过度识别的情况下,进 行过度识别检验。 2SLS 2SLS根据Sargan统计量进行过度识别检验 ,GMM Sargan GMM 使用Hansen J Test进行过度识别检验。 命令均为: estat overid 检验工具变量的外生性 H0:所有工具变量都是外生的。 H1:至少有一个工具变量不是外生的,与扰动项相 关。
弱工具变量检验
工具变量Z与 X 的相关性较低时,2SLS 估计 量存在偏误,Z 称为“弱工具变量”。 检验方法: estat firststage 1。初步判断可以用偏R2(partial R2) (剔除掉模型中原有外生变量的影响)。 2。 Minimum eigenvalue statistic(最小特征 值统计量),经验上此数应该大于10。
几点注意事项: 1。2SLS只能通过stata完成,利用定义手动计算的 结果是错误的,因为残差序列是错误的。 2。不可能单独为每个内生变量指定一组特定的工 具变量, 所有外生变变量都作为自己的工具变量。 3。在大样本下,IV 估计是一致的,但在小样本下, IV 估计并非无偏估计量,有些情况下偏误可能很严 重。
invest2004
kstock2002
kstock2003
kstock2004
1 2 3 4 5 6
18.9 17.4 19 20 18.1 19.6 18.8 20.1 20.3 18.4 19.9
19.6 18.1 20.2 20.4 18.5 17.2
第五讲 描述性时间序列分析

第五讲描述性时间序列分析11 时间序列成分分析1.1 时间序列的构成因素时间序列中的数据(也称为观测值),总是由各种不同的影响因素共同作用所至;换一句话说,时间序列中的数据,总是包含着不同的影响因素。
我们可以将这些影响因素合并归类为几种不同的类型,并对各种类型因素的影响作用加以测定。
对时间序列影响因素的归类,最常见的是归为3类:21、长期趋势T(SPSS的名称为Smoothed Trend-Cycle,缩写stc),长期趋势是一种对事物的发展普遍和长期起作用的基本因素。
受长期趋势因素的影响,事物表现出在一段相当长的时期内沿着某一方向的持续发展变化。
2、季节周期因子S(SPSS的名称为Season Factors Component), 缩写saf,季节周期也称为季节变动,是一种现象以一定时期(如一年、一月、一周等)为一周期呈3现较有规律的上升、下降交替运动的影响因素。
3、不规则变动因子I(SPSS的名称为Irregular Component, 缩写err)。
不规则变动是一种偶然性、随机性、突发性因素。
受这种因素影响,现象呈现时大时小、时起时伏、方向不定、难以把握的变动。
这种变动不同于前三种变动,它完全无规律可循,无法控制和消除,例如战争、自然灾害等。
【例】1993年1月至2000年12月社会消费品月零售4总额的各成分图如下。
图1 1993年1月至2000年12月社会消费品月零售总额曲线图5图2 长期趋势成分6图3 不规则变动因子图7图4 季节因子图81.2 时间序列的组合模型若以Y代表时间序列中的数据(观测值),则Y由上述四类因素所决定的组合模型为:=++(加法模型)Y T S I在加法模型中,各种影响因素是相互独立的,均为与Y同计量单位的绝对量。
加法模型中,各因素的分解是根据减法进行(如Y T S I-=+)。
Y T S I=⨯⨯(乘法模型)9在乘法模型中,只有长期趋势是与Y同计量单位的绝对量;其余因素均为以长期趋势为基础的比率,表现为对于长期趋势的一种相对变化幅度,通常以百分数表示。
第十章-定性选择模型与受限因变量模型-课件PPT

CPA的系数估计值0.4意味着家庭收入不变的情 况下,一个学生的增加一个点(如从3.0到4.0),该 生决定去读研的概率的估计值增加0.4。 INCOME的系数估计值0.002表明,一个学生的 成绩不变,而家庭收入增加1000美元(单位为千美 元),该生决定去读研的概率的估计值增加0.002。 LPM模型中,解释变量的变动与虚拟因变量值为 1的概率线性相关,因而称为线性概率模型。
第十章 定性选择模型和 受限因变量模型
1
对于被解释变量而言,很多情况也会对其取值有所 限制。有时,因变量描述的是微观个体的某种选择、 特征或所属等,即因变量为定性变量,相应的模型称 为定性选择模型或定性响应模型;
另一些情况是,因变量的取值被限定在某个特殊范 围,一般我们称这类取值范围受到限制的因变量为受 限因变量,相应的模型称为受限因变量模型。
C A N D 1 i 0 1 I N C O M E i 2 A G E i 3 M A L E i u i
其中:
1 如果第i个选民投候选人甲的票
C A N D1i
0
如果第i个选民不投候选人甲票 的
I NCO i M 第 iE 个选民的家庭 位收 :入 千( 美单 元)
5
尽管因变量在这个二元选择模型中只能取两个 值:0或1,可是该学生的的拟合值或预测值为0.8。 我们将该拟合值解释为该生决定读研的概率的估计值。 因此,该生决定读研的可能性或概率的估计值为0.8。 需要注意的是,这种概率不是我们能观测到的数字, 能观测的是读研还是不读研的决定。
对斜率系数的解释也不同了。在常规回归中, 斜率系数代表的是其他解释变量不变的情况下,该解 释变量的单位变动引起的因变量的变动。而在线性概 率模型中,斜率系数表示其他解释变量不变的情况下, 该解释变量的单位变动引起的因变量等于1的概率的 变动。
5.2 变系数和动态Panel模型

α i = y i γy i , 1
i = 1,L, n
在包含外生解释变量的情况下,类似地,首先采用 在包含外生解释变量的情况下,类似地, 工具变量方法估计差分方程模型,得到γ和 的估计 工具变量方法估计差分方程模型,得到 和β的估计 然后求得α 的估计量。 量,然后求得 i的估计量。
2.随机影响模型 2.随机影响模型
Data计量经济学模型 计量经济学模型( §5.2Panel Data计量经济学模型(二) —变系数模型和动态模型 变系数模型和动态模型 变系数
一、变系数模型 二、动态模型 关于Panel Data模型的总结 三、关于 模型的总结
一、变系数模型
要点
变系数模型的表达式 固定影响模型 固定影响模型——随机干扰项在不同横截面个体 随机干扰项在不同横截面个体 之间不相关——OLS估计 之间不相关 估计 固定影响模型——随机干扰项在不同横截面个体 随机干扰项在不同横截面个体 固定影响模型 之间相关——GLS估计 之间相关 估计 随机影响模型的复合误差项 随机影响模型的 随机影响模型的GLS估计 估计
显然,如果随机干扰项在不同横截面个体之间不 显然, 相关,上述模型的参数估计极为简单, 相关,上述模型的参数估计极为简单,即以每个 截面个体的时间序列数据为样本, 截面个体的时间序列数据为样本,采用经典单方 程模型的估计方法分别估计其参数。 程模型的估计方法分别估计其参数。即使采用 GLS估计同时得到的 估计同时得到的GLS估计量,也是与在每个 估计量, 估计同时得到的 估计量 横截面个体上的经典单方程估计一样。 横截面个体上的经典单方程估计一样。 条件: 条件:
Eu it = 0
2 σ u Eu it u js = 0
i = j且t = s 否则
计量经济学前沿限制因变量模型和估计

处理方法2:用抵押贷款申请是否被拒绝作为因变量建立多元回归模 型,探讨保持其他条件不变(相同)旳条件下,种族旳 差别对贷款申请是否被拒绝旳影响。
* 问题3: 方法2 能回答下列问题1 所提出旳问题吗?
6
Copyright © 2003 Prentice-Hall, ቤተ መጻሕፍቲ ባይዱnc.
(0.083)
Pr( y | P / I ratio,black) F (4.13 5.37P / I ratio 1.27black)
(0.35) (0.96)
(0.15)
22
Copyright © 2003 Prentice-Hall, Inc.
23
Copyright © 2003 Prentice-Hall, Inc.
13
Copyright © 2003 Prentice-Hall, Inc.
处理LPM不足思绪
定义: Pr( y 1| X ) G(0 1X i1 2 X i2 ) G(zi ) (3)
其中, G 是一种取值范围严格介于0 ~ 1之间旳函数,
对全部实数 z , 都有
0 G(z) 1
当
z
二值因变量模型
* 问题1:除种族不同外,两个条件完全相同旳人走进一家银行申请一
笔抵押贷款,目旳是购置一套房子,两套房子旳条件也完全相同,他 们是否有同等可能性让他们旳抵押贷款申请被接受?
怎样精确地检验种族歧视旳统计证据?
处理方法1 :用抵押贷款申请被拒绝旳比重来比较不同种 族旳人是否受到同等旳待遇.
P(Y 1| X ) jx j
▪ 回归系数能够用OLS 措施进行估计,而且一般旳(异方差 稳健旳)OLS原则误能够用来假设检验和构造置信区间
离散因变量和受限因变量模型

目录
• 引言 • 离散因变量模型 • 受限因变量模型 • 模型估计与检验 • 实证分析与应用举例 • 研究结论与展望
01
引言
目的和背景
1
探究离散因变量和受限因变量的模型选择和应用
2
分析离散因变量和受限因变量模型的优缺点
3
为实际数据分析提供理论支持和指导
离散因变量和受限因变量的定义与特点
步骤
首先,根据模型设定和观测数据构建似然函数;然后,通过对似然函数求导并令其等于零,得到 参数的最大似然估计值;最后,利用数值优化算法求解最大似然估计值。
优点
最大似然估计法具有一致性、有效性和渐近正态性等优良性质,且适用于多种类型的离散因变量 和受限因变量模型。
拟合优度检验
1
目的
拟合优度检验用于评估模型对数据的拟 合程度,即检验模型是否能够充分解释 观测数据的变异。
研究不足与局限性分析
当前研究主要集中在模型的应用和比较方面, 对模型的理论性质和统计推断的深入研究相对 较少。
在处理复杂数据和实际问题时,现有模型可能 存在局限性,如无法处理高维数据、非线性关 系等。
在实际应用中,模型的假设条件可能难以满足, 如随机抽样、误差项独立同分布等,这可能影 响模型的估计结果和解释力度。
03
适用于因变量为有序分类的情况,如评级、满意度等。
计数模型
Poisson回归
适用于计数数据,假设事件发生的次数服从泊松分布。
负二项回归
当计数数据的方差大于均值时,使用负二项回归,考虑了数据的 过度分散。
零膨胀模型
适用于存在过多零计数的情况,通过零膨胀参数对零计数进行建 模。
03
受限因变量模型
第五章受限因变量模型3

EVIEWS包括估计单方程有限因变量模型的程序; 在录入数据和给出变量表后,调用指令:
Quick->Estimate equation
->模型选项
Binary – Binary choice (Logit, Probit, Extreme value) Ordered – Ordered choice Censored – Censored data (Tobit)
26
多元选择模型基本概念
有序模型:观察到的因变性 (ranked)排序的分类结果:
例1:教育水平分文盲、小学、初中、高中、大学、研
究生等 例2:农民就业分纯农业、兼业、非农业等 例3:收入水平分级 例4:考试成绩分优秀、良好、及格和不及格等
式中Lur和Lr分别为包括所有解释变量的对数似然值和只包括常数 项的对数似然值 当计算出的概率大于0.5时认为事件发生了,即有y = 1,反之则认 为事件未发生。 用列表的方式可以反映出正确推断的比例,在EVIEWS下可以直 接生成。
另一种方式是根据模型做出的正确推断
用EVIEWS估计有限因变量模型
行为主体选择第一项活动意味着Ui1t
> Ui2t
随机效用函数 (Random Utility Functions)
形式:Uij = j + i’xij + i’zi + eij
j为与特定选择j相联系的常数项 i为反映行为主体偏好的权重 zi xij 为选择j所具有的特性(Attributes)
有限因变量模型
(Limited dependent variable models)
第五章 选择模型与受限因变量
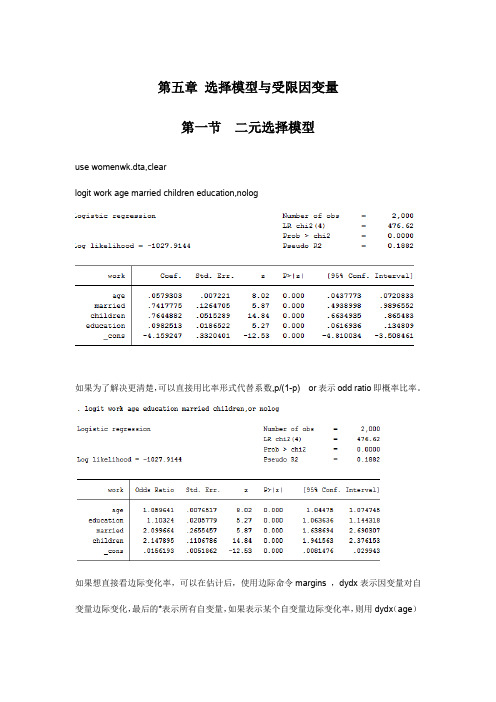
第五章选择模型与受限因变量第一节二元选择模型use womenwk.dta,clearlogit work age married children education,nolog如果为了解决更清楚,可以直接用比率形式代替系数,p/(1-p) or表示odd ratio即概率比率。
如果想直接看边际变化率,可以在估计后,使用边际命令margins ,dydx表示因变量对自变量边际变化,最后的*表示所有自变量,如果表示某个自变量边际变化率,则用dydx(age)第二节多元选择模型use nomocc2.dta,查看数据假设方案选择独立条件下,直接使用多元logit估计。
因变量是职业occ(共有五个选项低技术劳动者、手艺人、蓝领、白领、专业人士),自变量是白人、教育、经验。
其系数解释为相对于对比职业(专业),各自变量对应的概率。
如,对于一个白人来说,与选择专业化工作对比而言,更不可能选择服务与手艺人(z检验通过),但是否选择白领、蓝领则未必。
系数值随着对照方案的不同而有所差异。
可以更换对照方案:mlogit occ white ed exper,base(1) 这里的base(1)就是将第一类职业menial(服务人员)作为对照方案。
其结果如下:仍以白人为例,与成为一名服务人员相比,白人成为一名专业技术职位的可能性更大,其检验概率为0.019.但是,成为一名手工艺者的可能性却不大。
教育(ed)系数与检验结果类似。
在估计的基础上,我们可以预测一个人以后到底会选择什么样的职业,利用模型进行预测predict oc1 oc2 oc3 oc4 oc5list oc1 oc2 oc3 oc4 oc5 in 5/10 即在预测后,显示第五个至第十个对象选择某种职业的结果。
因变量不同数值代表不同的方案,各个方案概率和为 1. 多项选择是二项选择的自然推广,因无法同时识别所有系数,所以会将某方案作为“参照方案base category”,然后令其相应系数为0.然后利用最大似然法进行估计。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2. Logit 估计 —- 最大似然法估计法 我们观察不到 p (拥有住房的概率) , 而只观察到 Y 的结果 (拥有住房 Y=1, 或不拥有住房 Y=0) ,如何估计参数? 一般用最大似然法估计法估计参数。因为 Y 服从贝努里分布,我们有 Pr(Yi = 1) = pi Pr(Yi = 0) = 1 - pi 假设我们得到 n 个观测值的随机样本,令 fi(Yi)表示 Yi=1 或 Yi=0 的概率, 于是观测到 n 个 Y 值的联合分布概率(joint probability)为
ln f (Y1 , Y2 ,..., Yn ) = ∑[Yi ln pi + (1 − Yi ) ln(1 − pi )]
i =1 n
n
= ∑[Yi ln pi − Yi ln(1 − pi ) + ln(1 − pi )]
i =1 n
⎡ ⎛ p i ⎞⎤ n = ∑ ⎢Yi ln⎜ ⎟⎥ + ∑ ln(1 − pi ) ⎜1− p ⎟ i =1 ⎣ i =1 i ⎠⎦ ⎝
---------------------| yhat| 0 | 1 | Y 0 18 3 1 3 8
----------+-----------
----------------------
(2)pseudo-R2 最常用的是 McFadden(1974)提出的 pseudo-R2 McFadden pseudo R 1
T
β 2β 3 ~χ 2 5β 3β 0 (2) Nonlinear restrictions: g(β)=0 H :β β g β β β 1 W 0 g β
T
1
∂g β var β ∂βT
∂g β ∂βT
T
g β
74
W
β β
1
T
β
β
var β cov β , β β β 1
cov β , β var β
Under the null hypothesis with q exclusion restrictions,
~
2. Wald test (1) Linear restrictions:Rβ = r W Rβ Rβ Example: H : 1 0 W β 2β 5β 3β β 2 0 β 5 3 β
Y=0, 1,
0<p<1,
所以 lnf < 0,lnL 与 lnL0 均为负。 如果解释变量均无解释能力,那么|lnL| = |lnL0|, 因此 pseudo-R2 = 0 通常情况下,|lnL| < |lnL0|, 因此 pseudo-R2
0 lnL lnL0
<1
73
扩充内容: Three Asymptotically Equivalence Tests (all based on maximum likelihood estimation) 1. Likelihood Ratio (LR) test 1. Likelihood Ratio (LR) test
L L
其中 lnL 表示被估计模型的对数似然函数值 lnL0 表示只有截距项的模型的对数似然函数值
72
为何可以用 pseudo-R 刻划拟合优度? 因为 ln f (Y1 , Y2 ,..., Yn ) = ∑ [Yi ln p i + (1 − Yi ) ln(1 − p i )]
i =1 n
2
3. Lagrange Multiplier test (omitted)
四、Probit 模型 1. Probit 模型含义 累积分布函数(cumulative distribution function,CDF)为如下标准正态分布 的 CDF 的模型称为 Probit 模型:
p = p(Y = 1 | X) = Φ(β0 + β1x1 + β2 x 2 + ... + βk x k ) = p( t ≤ β0 + β1x1 + β2 x 2 + ... + βk x k ) =∫
第五讲 定性响应回归模型、时间序列模型、 以及 Panel Data 模型
第一节 定性响应回归模型(Qualitative Response Regression Models)
一、定性响应回归模型的性质 因变量 Y 是一个定性变量的模型。比如:一个家庭拥有住房(Y=1)或不拥 有住房(Y = 0) ;成年人劳动参与决定,参与(Y = 1)或不参与(Y = 0) ;夫妻 双方都参加工作(Y = 1)或只一人参加工作(Y = 0) 。 数据格式:是否拥有住房例子 Family 1 2 3 4 5 .. .. 39 40 Y = 1 if owns home, 0 otherwise 0 1 1 0 1 .. .. 0 1 X (income, 1000 dollars) 8 16 18 11 12 .. .. 7 17
Y 1
0
X
三、Logit 模型 1. Cumulative Logistic 分布函数及 Logit 模型
p = E (Y = 1 | X ) =
1 1 + e −( β 0 + β1x )
=
e ( β 0 + β1x ) 1 + e ( β 0 + β1 x )
作一变换,我们得到有意思的结果
1 p e ( β 0 + β1x ) / = = e ( β 0 + β1x ) ( β 0 + β1 x ) ( β 0 + β1 x ) 1− p 1+ e 1+ e
n i =1 n
− ∑ ln(1 + e
i =1Βιβλιοθήκη β 0 + β1 x 1,i + β 2 x 2 ,i + ...+ β k x k ,i
)
最大化以上对数似然函数,使观测到(样本中)Y 的概率尽可能的大,就可 以得到 β 的参数估计。 注意:以上似然函数是非线性的(对参数来说) ,所以需要用非线性估计方 法得到 β 的值以使似然函数最大。
β
β
T
β β
1
β var β STATA code: testnl
2β β cov β , β
β var β
~χ 1
Reference: Allan W. Gregory and Michael R. Veall, 1985. Formulating Wald Tests of Nonlinear Restrictions. Econometrica, Vol. 53, No. 6 (Nov., 1985), pp. 1465-1468.
ˆ ⎞ ⎛ p ⎟ ln⎜ ⎜1− p ⎟ = −13.0214 + 2.8261GPA + 0.0951TUCE + 2.3787PSI ⎝ ˆ⎠
如何解释估计的参数? 2.8261: 在保持其他条件不变的情况下, GPA 每增加 1 点估计的 logit (log of ; odds ratio, 对数机会比率) 将增加 2.8261; odds ratio 将增加 10.8797 (≈ e2.8261) 给定 GPA,TUCE,和 PSI,我们可以估计期中考试成绩得 A 的概率为
T
r
T
Asy. Var Rβ
T
r Rβ
Rβ r
r
r
RVar β R
3 0 3 0
β 2β 3 3β 0 5β 1 0
var β 2 0 cov β , β 5 3 cov β , β
cov β , β var β cov β , β
cov β , β cov β , β var β
1 0
2 0 5 3
2. 例子:家庭是否拥有住房与收入之间的关系 STATA 运行结果。 y= 结果解释: -0.9457 (0.1228) + 0.1021x (0.0082)
ˆ = −0.9457 表示收入为 0 家庭拥有住房的概率为-0.9457. β 0
ˆ = 0.1021 表示每增加 1 个单位收入($1000) β ,家庭拥有住房的概率增加 1
f (Y1 , Y2 ,..., Yn ) = ∏ f i (Yi ) =∏ piYi (1 − pi )1− Yi
i =1 i =1
n
n
以上联合分布概率称为似然函数(likelihood function) 。对上式两边取自然 对数,我们有对数似然函数(log likelihood function)为
e −13.0214+ 2.8261GPA + 0.0951TUCE + 2.3787 PSI ˆ= p 1 + e −13.0214+ 2.8261GPA + 0.0951TUCE + 2.3787 PSI
4. 拟合优度的测度 (1) 正确预测的百分比 Phat > 0.5, Yhat = 1 Phat < 0.5, Yhat = 0 与实际情况相比,计算出正确预测的百分比。 . table yhat y, contents(freq)
68
当 y =1 时 当y=0时
1-β0-β1x -β0-β1x
p 1-p
(2) 干扰项 ε 的异方差性,导致估计量的无效率,即 OLS 估计量不具有最小 方差; var(ε) = p(1-p) (由贝努里分布得到) 又因为 p = E(yi|xi) = β0 +β1xi, 所以 ε 的方差最终依赖于 x,即具有异方 差性。 (3) 无法保证 0 ≤ E(yi|xi)≤ 1 条件在任何 x 值情况下都成立。 比如上例中,预测 yhat 情况,有一些小于 0,有一些大于 1。