初级计量经济学复习整理
计量经济学复习笔记

2023计量经济学笔记PERSONAL NOTES计量经济学笔记目录CH1导论 (3)CH2简单线性回归模型 (5)CH3多元线性回归模型 (11)CH4多重共线性 (14)CH5异方差 (16)CH6自相关 (19)CH1导论1、计量经济学:以经济理论和经济数据的事实为依据,运用数学、统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
研究主体是经济现象及其发展变化的规律。
2、运用计量分析研究步骤:●模型设定——确定变量和数学关系式●估计参数——分析变量间具体的数量关系●模型检验——检验所得结论的可靠性●模型应用——做经济分析和经济预测3、模型(1)变量A.解释变量:表示被解释变量变动原因的变量,也称自变量,回归元,X。
B.被解释变量:表示分析研究的对象,变动结果的变量,也成应变量,Y。
C.内生变量:其数值由模型所决定的变量,是模型求解的结果。
D.外生变量:其数值由模型意外决定的变量。
(外生变量数值的变化能够影响内生变量的变化,而内生变量却不能反过来影响外生变量。
)E.前定内生变量:过去时期的、滞后的或更大范围的内生变量,不受本模型研究范围的内生变量的影响,但能够影响我们所研究的本期的内生变量。
F.前定变量:前定内生变量和外生变量的总称。
(2)数据●时间序列数据:按照时间先后排列的统计数据(t)。
●截面数据:发生在同一时间截面上的调查数据(i)。
●面板数据:时间序列数据和截面数据结合的数据(t,i)。
●虚拟变量数据:表征政策,条件等,一般取0或1(d).4、估计评价统计性质的标准无偏:E(^β)=β有效:最小方差性一致:N趋近无穷时,β估计越来越接近真实值5、检验经济意义检验:所估计的模型与经济理论是否相等统计推断检验:检验参数估计值是否抽样的偶然结果,是否显著计量经济检验:是否符合计量经济方法的基本假定预测检验:将模型预测的结果与经济运行的实际对比6、计量经济学的研究过程CH2简单线性回归模型一、相关知识点:1、变量间的关系分为函数关系与相关关系(相关系数是对变量间线性相关程度的度量。
计量经济学复习笔记要点

计量经济学 总复习第一部分:统计基础知识均值的概念:通常人们所说的均值就是“平均数”,统计意义上的均值是“期望值”。
方差:变量的每个样本与均值的距离大小的概念。
标准差:对方差开根号就是标准差。
数学期望值与方差的数学性质总体方差: 1.常量aE (a )=a 2σ(a)=0抽样方差: 2.变量 y=a+bxE(y)=a+bE(x)总体标准偏差: 2σ(y)=b^2 * 2σ(x)抽样标准偏差:假设检验的定义:事先做一个假设,然后再用统计方法来检验这个假设是否有统计意义。
假设检验的步骤:第一步,设定假设条件。
原定假设,H0:u=u0,和替代假设,Ha:u ≠u0。
第二步,决定用哪种检验, 如果n ≥30,用Z 检验,如果n<30, 用t 检验。
第三步,找出临界值, 根据给定的定义域的大小,即α=1%、α=5%、或 α=10% 从概率分布表中查出Zc 值,或tc 值。
第四步,计算统计值, 或者第五步,比较统计值与临界值而得出结论。
如果统计值的绝对值大于临界值,那么我们就否定原定假设; 如果统计值的绝对值小于临界值,那么我们就不能否定原定假设。
第二部分 最小二乘法最小二乘法的假设条件:(1) (2) (3) (4) (5) 文字解释:Nu x Ni ∑-=22)(σ1)(22--=∑n x xs ni2σσ=2s s =nux Z σ0*-=n s u x t 0*-=)(=X E i ε∞<=22,)(σσεi Var 0),(=j i Cov εε0),(=i i X Cov ε1),(±≠j i X X Cov(1)每个误差必须是随机的,其误差的期望值是零;(2)误差都是雷同的,其方差相等,同时其方差的变化量必须是有限的; (3)每个误差之间必须是相互独立的; (4)误差项与方程式中的自变量是无关的; (5)自变量之间无直接的线性关系。
通用最小二乘法的步骤:第一步:求出误差项:第二步:求误差的平方和最小。
计量经济学复习资料

计量经济学复习资料一、引言计量经济学是研究经济现象的数量关系和经济变量之间相互影响的学科。
它通过运用统计学和数学方法,以实证的方式分析经济模型和数据,以期为经济理论的验证和决策制定提供科学依据。
计量经济学作为经济学的重要分支,在经济学领域里起着举足轻重的作用。
本文将为大家提供一个关于计量经济学的复习资料,以便大家更好地复习和理解这门学科。
二、计量经济学基础1. 理论基础:回顾计量经济学的理论基础,包括经济学中的基本原理、假设和模型,以及计量经济学方法的发展演变过程。
2. 计量经济学的基本概念:介绍计量经济学中的一些基本概念,如变量、参数、模型、数据等,帮助读者建立对计量经济学基础概念的理解和认知。
三、计量经济模型1. 线性回归模型:介绍线性回归模型的基本原理和假设,包括最小二乘估计法、截距项、解释变量的选择和回归结果的解释等。
2. 多元线性回归模型:介绍多元线性回归模型的基本原理、假设和参数估计方法,包括多重共线性、异方差和自相关等问题的处理方法。
3. 非线性回归模型:介绍非线性回归模型,如对数线性模型、二项式模型和估计方法等。
4. 时间序列模型:介绍时间序列模型的基本原理、假设和参数估计方法,包括平稳性、季节性和趋势性等问题的处理方法。
四、计量经济学常用方法1. 模型诊断:介绍计量经济学中的模型诊断方法,包括残差分析、异方差检验和自相关检验等。
2. 假设检验:介绍计量经济学中的假设检验方法,包括参数显著性检验、模型拟合优度检验和模型比较等。
3. 预测方法:介绍计量经济学中的预测方法,包括时间序列分析、回归分析和面板数据分析等。
4. 因果推断:介绍计量经济学中的因果推断方法,包括工具变量法、自然实验和计量分析的注意事项等。
五、计量经济学在实际应用中的案例研究1. 劳动经济学:介绍计量经济学在劳动经济学领域的实际应用,包括劳动力市场分析、教育回报率和人力资本投资等。
2. 金融经济学:介绍计量经济学在金融经济学领域的实际应用,包括资本市场分析、投资组合选择和风险管理等。
(完整)计量经济学考试重点整理

计量经济学考试重点整理第一章:P1:什么是计量经济学?由哪三组组成?定义:“用数学方法探讨经济学可以从好几个方面着手,但任何一个方面都不能和计量经济学混为一谈。
计量经济学与经济统计学绝非一码事;它也不同于我们所说的一般经济理论,尽管经济理论大部分具有一定的数量特征;计量经济学也不应视为数学应用于经济学的同义语。
经验表明,统计学、经济理论和数学这三者对于真正了解现代经济生活的数量关系来说,都是必要的,但本身并非是充分条件。
三者结合起来,就是力量,这种结合便构成了计量经济学。
”P9:理论模型的设计主要包含三部分工作,即选择变量,确定变量之间的数学关系,拟定模型中待估计参数的数值范围。
P12:常用的样本数据:时间序列,截面,虚变量数据P13:样本数据的质量(4点)完整性;准确性;可比性;一致性P15-16:模型的检验(4个检验)1、经济意义检验2、统计检验拟合优度检验总体显著性检验变量显著性检验3、计量经济学检验异方差性检验序列相关性检验共线性检验4、模型预测检验稳定性检验:扩大样本重新估计预测性能检验:对样本外一点进行实际预测P16计量经济学模型成功的三要素:理论、方法和数据。
P18-20:计量经济学模型的应用1、结构分析经济学中的结构分析是对经济现象中变量之间相互关系的研究.结构分析所采用的主要方法是弹性分析、乘数分析与比较静力分析。
计量经济学模型的功能是揭示经济现象中变量之间的相互关系,即通过模型得到弹性、乘数等。
2、经济预测计量经济学模型作为一类经济数学模型,是从用于经济预测,特别是短期预测而发展起来的。
计量经济学模型是以模拟历史、从已经发生的经济活动中找出变化规律为主要技术手段。
对于非稳定发展的经济过程,对于缺乏规范行为理论的经济活动,计量经济学模型预测功能失效。
模型理论方法的发展以适应预测的需要。
3、政策评价政策评价是指从许多不同的政策中选择较好的政策予以实行,或者说不同的政策对经济目标所产生的影响的差异。
计量经济学复习知识点重点难点

计量经济学复习知识点重点难点计量经济学知识点第一章导论1、计量经济学的研究步骤:模型设定、估计参数、模型检验、模型应用。
2、计量经济学是统计学、经济学和数学的结合。
3、计量经济学作为经济学的一门独立学科被正式确立的标志:1930年12月国际计量经济学会的成立。
4、计量经济学是经济学的一个分支学科。
第二章简单线性回归模型1、在总体回归函数中引进随机扰动项的原因:①作为未知影响因素的代表;②作为无法取得数据的已知因素的代表;③作为众多细小影响因素的综合代表;④模型的设定误差;⑤变量的观测误差;⑥经济现象的内在随机性。
2、简单线性回归模型的基本假定:①零均值假定;②同方差假定;③随机扰动项和解释变量不相关假定;④无自相关假定;⑤正态性假定。
3、OLS回归线的性质:①样本回归线通过样本均值;②估计值的均值等于实际值的均值;③剩余项ei的均值为零;④被解释变量的估计值与剩余项不相关;⑤解释变量与剩余项不相关。
4、参数估计量的评价标准:无偏性、有效性、一致性。
5、OLS估计量的统计特征:线性特性、无偏性、有效性。
6、可决系数R2的特点:①可决系数是非负的统计量;②可决系数的取值范围为[0,1];③可决系数是样本观测值的函数,可决系数是随抽样而变动的随机变量。
第三章多元线性回归模型1、多元线性回归模型的古典假定:①零均值假定;②同方差和无自相关假定;③随机扰动项和解释变量不相关假定;④无多重共线性假定;⑤正态性假定。
2、估计多元线性回归模型参数的方法:最小二乘估计、极大似然估计、矩估计、广义矩估计。
3、参数最小二乘估计的性质:线性性质、无偏性、有效性。
4、可决系数必定非负,但是根据公式计算的修正的可决系数可能为负值,这时规定为0。
5、可决系数只是对模型拟合优度的度量,可决系数越大,只是说明列入模型中的解释变量对被解释变量的联合影响程度越大,并非说明模型中各个解释变量对被解释变量的影响程度也大。
6、当R2=0时,F=0;当R2越大时,F值也越大;当R2=1时,F→∞。
计量经济学考试复习资料

计量经济学1. 外生变量和滞后变量统称为前定变量。
2. 设消费函数为,其中虚拟变量,当统计检验表明下列哪项成立时,表示城镇家庭与农村家庭有一样的消费行为,。
3. 当模型存在序列相关现象时,适宜的参数估计方法是广义差分法。
4. 设某商品需求模型为,其中Y 是商品的需求量,X是商品的价格,为了考虑全年12个月份季节变动的影响,假设模型中引入了12个虚拟变量,则会产生的问题为完全的多重共线性。
5. 计量经济模型的基本应用领域有结构分析、经济预测、政策评价。
6. 完全多重共线性时,可以计算模型的拟合程度的判断是不正确的。
7. 当质的因素引进经济计量模型时,需要使用虚拟变量。
8. 半对数模型中,参数β1的含义是X的相对变化,引起Y的期望值绝对量变化。
9. 存在严重的多重共线性时,参数估计的标准差变大。
10. 在由n=30的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定系数为0.8500,则调整后的多重决定系数为0.8327。
11. 对于模型,为了考虑“地区”因素(北方、南方),引入2个虚拟变量形成截距变动模型,则会产生完全多重共线性。
12. 模型中引入实际上与解释变量有关的变量,会导致参数的OLS估计量方差增大。
13. u t=ρu t-1+v t序列相关可用DW检验(v t为具有零均值,常数方差且不存在序列相关的随机变量)。
14. 关于经济计量模型进行预测出现误差的原因,正确的说法是既有随机因素,又有系统因素。
15. Goldfeld-Quandt方法用于检验异方差性。
16.判定系数R2的取值范围是0≤R2≤1。
17.经济计量模型的被解释变量一定是内生变量。
18.用OLS估计经典线性模型,则样本回归直线通过点。
19. 消费函数模型,其中I为收入,则当期收入I t对未来消费C t+2的影响是:I t增加一单位,C t+2增加0.1个单位。
20. 回归模型中,关于检验所用的统计量,说法正确的是服从21. 如果模型y t=b0+b1x t+u t存在序列相关,则cov(u t, u s) ≠0(t≠s)。
(完整版)计量经济学重点知识归纳整理

1.普通最小二乘法(Ordinary Least Squares,OLS):已知一组样本观测值{}n i Y X i i ,2,1:),(⋯=,普通最小二乘法要求样本回归函数尽可以好地拟合这组值,即样本回归线上的点∧i Y 与真实观测点Yt 的“总体误差”尽可能地小。
普通最小二乘法给出的判断标准是:被解释变量的估计值与实际观测值之差的平方和最小。
2.广义最小二乘法GLS :加权最小二乘法具有比普通最小二乘法更普遍的意义,或者说普通最小二乘法只是加权最小二乘法中权恒取1时的一种特殊情况。
从此意义看,加权最小二乘法也称为广义最小二乘法。
3.加权最小二乘法WLS :加权最小二乘法是对原模型加权,使之变成一个新的不存在异方差性的模型,然后采用普通最小二乘法估计其参数。
4.工具变量法IV :工具变量法是克服解释变量与随机干扰项相关影响的一种参数估计方法。
5.两阶段最小二乘法2SLS, Two Stage Least Squares :两阶段最小二乘法是一种既适用于恰好识别的结构方程,以适用于过度识别的结构方程的单方程估计方法。
6.间接最小二乘法ILS :间接最小二乘法是先对关于内生解释变量的简化式方程采用普通小最二乘法估计简化式参数,得到简化式参数估计量,然后过通参数关系体系,计算得到结构式参数的估计量的一种方法。
7.异方差性Heteroskedasticity :对于不同的样本点,随机干扰项的方差不再是常数,而是互不相同,则认为出现了异方差性。
8.序列相关性Serial Correlation :多元线性回归模型的基本假设之一是模型的随机干扰项相互独立或不相关。
如果模型的随机干扰项违背了相互独立的基本假设,称为存在序列相关性。
9.多重共线性Multicollinearity :对于模型i k i i X X X Y μββββ++⋯+++=i k 22110i ,其基本假设之一是解释变量X 1,X 2,…,Xk 是相互独立的。
计量经济学考试重点总结

1、简述计量经济学:是以经济理论和经济数据为事实依据,运用数学统计学的的方法建立数学模型,来研究经济数量关系和和规律的一门经济学科。
2、计量经济模型有哪些应用:①结构分析。
②经济预测。
③政策评价。
④检验和发展经济理论。
3、计量经济学研究的主要步骤:①确定变量和数学关系式——模型设定;②分析变量间具体的数量关系式——估计参数;③检验所的结论的可靠性——模型检验;④作经济分析和经济预测——模型应用。
5.计量经济学数据的分类:①时间序列数据;②截面数据;③面板数据;④虚拟变量数据。
6.在计量经济模型中,为什么会存在随机误差项:随机误差项是计量经济模型中不可缺少的一部分。
产生随机误差项的原因有以下几个方面:①模型中被忽略掉的影响因素造成的误差;②模型的设定误差;③变量的测量误差;④随机因素。
7、总体回归函数中,引进随机误差想的原因:①作为位置影响因素的代表;作为无法取得数据的已知因素的代表;作为众多细小影响因素的综合代表;②模型设定的误差;③变量测定的误差;③经济现象内在的随机性。
8、古典线性回归模型的基本假定:①零均值假定。
即在给定xt的条件下,随机误差项的数学期望为0;②同方差假定。
误差项的方差与t无关,为一个常数。
③无自相关假定。
即不同的误差项相互独立。
④解释变量与随机误差项不相关假定。
(1分)⑤正态性假定,即假定误差项服从均值为0,方差为的正态分布。
9、总体回归模型与样本回归模型的区别:①描述的对象不同。
总体回归模型描述总体中变量y与x的相互关系,而样本回归模型描述所观测的样本中变量y与x的相互关系。
②建立模型的不同。
总体回归模型是依据总体全部观测资料建立的,样本回归模型是依据样本观测资料建立的。
③模型性质不同。
总体回归模型不是随机模型,样本回归模型是随机模型,它随着样本的改变而改变。
联系:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是用来估计总体回归模型。
10.在满足古典假定条件下,一元线性回归模型的普通最小二乘估计量的统计性质:①线性,是指参数估计量和分别为观测值和随机误差项的线性函数或线性组合。
(完整word版)计量经济学复习笔记

计量经济学复习笔记CH1导论1、计量经济学:以经济理论和经济数据的事实为依据,运用数学、统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
研究主体是经济现象及其发展变化的规律。
2、运用计量分析研究步骤:模型设定一一确定变量和数学关系式估计参数一一分析变量间具体的数量关系模型检验一一检验所得结论的可靠性模型应用一一做经济分析和经济预测3、模型变量:解释变量:表示被解释变量变动原因的变量,也称自变量,回归元。
被解释变量:表示分析研究的对象,变动结果的变量,也成应变量。
内生变量:其数值由模型所决定的变量,是模型求解的结果。
外生变量:其数值由模型意外决定的变量。
外生变量数值的变化能够影响内生变量的变化,而内生变量却不能反过来影响外生变量。
前定内生变量:过去时期的、滞后的或更大范围的内生变量,不受本模型研究范围的内生变量的影响, 但能够影响我们所研究的本期的内生变量。
前定变量:前定内生变量和外生变量的总称。
数据:时间序列数据:按照时间先后排列的统计数据。
截面数据:发生在同一时间截面上的调查数据。
面板数据:虚拟变量数据:表征政策,条件等,一般取0或1.4、估计评价统计性质的标准无偏:E (人3 )= 3 随机变量,变量的函数?有效:最小方差性一致:N趋近无穷时,3估计越来越接近真实值5、检验经济意义检验:所估计的模型与经济理论是否相等统计推断检验:检验参数估计值是否抽样的偶然结果,是否显著计量经济检验:是否符合计量经济方法的基本假定预测检验:将模型预测的结果与经济运行的实际对比CH2 CH3线性回归模型模型(假设)一一估计参数一一检验一一拟合优度一一预测1、模型(线性)(1)关于参数的线性模型就变量而言是线性的;模型就参数而言是线性的。
Yi = 3 1+ 3 2lnX i+u线性影响随机影响Y i=E (Y|X i) +u E (Y|X i) =f(X i)= 3 1+3 2lnX 引入随机扰动项,(3)古典假设A零均值假定 E ( U i |X i) =0B同方差假定Var(u i|XJ=E(u i2)=2(TC无自相关假定Cov(u i ,u j)=0D随机扰动项与解释变量不相关假定Cov(u i ,X i )=0E正态性假定u~N(0, d 2)F无多重共线性假定Rank(X)=k2、估计在古典假设下,经典框架,可以使用OLS方法:OLS 寻找min Ee i2人B iois = (Y均值)-人B 2(X均值)人B 2ois = Ex i y〃Ex i23、性质OLS回归线性质(数值性质)(1)回归线通过样本均值(X均值,Y均值)(2)估计值人Y的均值等于实际值Y的均值(3)剩余项e i的均值为0(4)被解释变量估计值人Y与剩余项8不相关Cov(人Y,ej=0(5)解释变量X与剩余项8不相关Cov(e i,X i)=0在古典假设下,OLS的统计性质是BLUE统计最佳线性无偏估计4、检验(1) Z检验Ho: B 2=0原假设验证B 2是否显著不为0标准化:Z= (A B 2- B 2) /SE (A B 2)〜N( 0,1 ) 在方差已知,样本充分大用Z检验拒绝域在两侧,跟临界值判断,是否B2显著不为0(2) t检验一一回归系数的假设性检验方差未知,用方差估计量代替 A d 2=Ee i2/(n-k) 重点记忆t =(人卩2- B 2) / A SE (A B 2)〜t (n-2)拒绝域:|t|>=t 2/a( n-2)拒绝,认为对应解释变量对被解释变量有显著影响。
计量经济学复习要点

计量经济学复习要点164590(总20页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--计量经济学复习要点第1章 绪论数据类型:截面、时间序列、面板用数据度量因果效应,其他条件不变的概念 习题:C1、C2第2章 简单线性回归回归分析的基本概念,常用术语现代意义的回归是一个被解释变量对若干个解释变量依存关系的研究,回归的实质是由固定的解释变量去估计被解释变量的平均值。
简单线性回归模型是只有一个解释变量的线性回归模型。
回归中的四个重要概念1. 总体回归模型(Population Regression Model ,PRM)t t t u x y ++=10ββ--代表了总体变量间的真实关系。
2. 总体回归函数(Population Regression Function ,PRF )t t x y E 10)(ββ+=--代表了总体变量间的依存规律。
3. 样本回归函数(Sample Regression Function ,SRF )tt t e x y ++=10ˆˆββ--代表了样本显示的变量关系。
4. 样本回归模型(Sample Regression Model ,SRM )tt x y 10ˆˆˆββ+=---代表了样本显示的变量依存规律。
总体回归模型与样本回归模型的主要区别是:①描述的对象不同。
总体回归模型描述总体中变量y 与x 的相互关系,而样本回归模型描述所关的样本中变量y 与x 的相互关系。
②建立模型的依据不同。
总体回归模型是依据总体全部观测资料建立的,样本回归模型是依据样本观测资料建立的。
③模型性质不同。
总体回归模型不是随机模型,而样本回归模型是一个随机模型,它随样本的改变而改变。
总体回归模型与样本回归模型的联系是:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是用来估计总体回归模型。
线性回归的含义线性:被解释变量是关于参数的线性函数(可以不是解释变量的线性函数) 线性回归模型的基本假设简单线性回归的基本假定:对模型和变量的假定、对随机扰动项u 的假定(零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定) 普通最小二乘法(原理、推导)最小二乘法估计参数的原则是以“残差平方和最小”。
计量经济学复习笔记

第一章统计概念1.什么是计量经济学计量经济学是对经济的测度,利用经济理论、数学、统计推断等工具对经济现象进行分析的一门社会科学。
2.计量经济学的方法论(计量经济分析步骤)(1)建立理论假说。
(2)收集数据。
(3)假定数学模型。
(4)设立统计或计量模型。
(5)估计经济模型参数(6)核查模型的适用性:模型设定检验。
(7)检验源自模型的假定(8)利用模型进行预测4.数据类型(1)时间序列数据:按时间跨度获得的数据。
特征是一般变量如 Y t、X t下标为t。
(2)截面数据:同一时点上的一个或多个变量的数据集合。
如:各地区2002年人口普查数据。
(3)合并数据:既包括时间序列数据有包括截面数据。
例:20年间10个国家的失业数据。
20年失业数据是时间序列,10个国家又是截面数据。
(4)面板数据:同一个横截面的单位的跨期调查数据。
例:对相同的家庭数量在几个时间间隔内进行的财务状况调查。
5.理解回归关系回归关系是一种统计上的相关关系,并不意味着自变量和因变量之间存在着因果关系。
第二章线性回归的基本思想1.回归分析的含义: 回归分析是反映的自变量和因变量之间的统计关系,回归分析是在自变量给定条件下的因变量的变化,是一种条件回归分析E(Y i|X i)=B1+B2X i2.随机误差项的性质(为什么要引入随机误差项)(1)随机误差项代表着未纳入模型变量对因变量的影响(2)即使模型包括了影响因变量的所有因素,模型也有不可避免的随机性。
(3)μ还代表着度量误差(4)模型设定应该尽可能简单,只要不遗漏重要变量,把因变量的次要影响因素归于随机项 μ 。
(奥卡姆剃刀原则)3.参数估计方法———普通最小二乘法的基本思想 选择参数使得残差平方和最小——Min ∑e i 2=Min ∑(Y i −Yi ̌)2=Min ∑(Y i −b 1−b 2X i )^24.根据Ols 法得出参数 b 1 b 2 称为最小二乘估计量,最小二乘估计量的性质: (1)Ols 方法获得样本回归直线过样本均值点(X ,Y ) (2)残差的均值总为0,(3)残差项与解释变量的乘积求和为0,即残差项与解释变量不相关。
计量经济学复习笔记(注释)

计量经济学复习笔记CH1导论1、计量经济学:以经济理论和经济数据的事实为依据,运用数学、统计学的方法,通过建立数学模型来研究经济数量关系和规律的一门经济学科。
研究主体是经济现象及其发展变化的规律。
2、运用计量分析研究步骤:模型设定——确定变量和数学关系式估计参数——分析变量间具体的数量关系模型检验——检验所得结论的可靠性模型应用——做经济分析和经济预测3、模型变量:解释变量:表示被解释变量变动原因的变量,也称自变量,回归元。
被解释变量:表示分析研究的对象,变动结果的变量,也成应变量。
内生变量:其数值由模型所决定的变量,是模型求解的结果。
外生变量:其数值由模型意外决定的变量。
外生变量数值的变化能够影响内生变量的变化,而内生变量却不能反过来影响外生变量。
前定内生变量:过去时期的、滞后的或更大范围的内生变量,不受本模型研究范围的内生变量的影响,但能够影响我们所研究的本期的内生变量。
前定变量:前定内生变量和外生变量的总称。
数据:时间序列数据:按照时间先后排列的统计数据。
截面数据:发生在同一时间截面上的调查数据。
面板数据:虚拟变量数据:表征政策,条件等,一般取0或1.4、估计评价统计性质的标准无偏:E(^β)=β 随机变量,变量的函数?有效:最小方差性一致:N趋近无穷时,β估计越来越接近真实值5、检验经济意义检验:所估计的模型与经济理论是否相等统计推断检验:检验参数估计值是否抽样的偶然结果,是否显著计量经济检验:是否符合计量经济方法的基本假定预测检验:将模型预测的结果与经济运行的实际对比CH2 CH3 线性回归模型模型(假设)——估计参数——检验——拟合优度——预测1、模型(线性)(1)关于参数的线性 模型就变量而言是线性的;模型就参数而言是线性的。
Y i =β1+β2lnX i +u i线性影响 随机影响Y i =E (Y i |X i )+u i E (Y i |X i )=f(X i )=β1+β2lnX i引入随机扰动项,(3)古典假设A 零均值假定 E (u i |X i )=0B 同方差假定 Var(u i |X i )=E(u i 2)=σ2C 无自相关假定 Cov(u i ,u j )=0D 随机扰动项与解释变量不相关假定 Cov(u i ,X i )=0E 正态性假定u i ~N(0,σ2)F 无多重共线性假定Rank(X)=k2、估计在古典假设下,经典框架,可以使用OLS方法:OLS 寻找min ∑e i2 ^β1ols = (Y 均值)-^β2(X 均值)^β2ols = ∑x i y i /∑x i 23、性质OLS 回归线性质(数值性质)(1)回归线通过样本均值 (X 均值,Y 均值)(2)估计值^Y i 的均值等于实际值Y i 的均值(3)剩余项e i 的均值为0(4)被解释变量估计值^Y i 与剩余项e i 不相关 Cov(^Y i ,e i )=0(5)解释变量X i 与剩余项e i 不相关 Cov(e i ,X i )=0在古典假设下,OLS 的统计性质是BLUE 统计 最佳线性无偏估计4、检验(1)Z 检验Ho:β2=0 原假设 验证β2是否显著不为0标准化: Z=(^β2-β2)/SE (^β2)~N (0,1) 在方差已知,样本充分大用Z 检验拒绝域在两侧,跟临界值判断,是否β2显著不为0(2)t 检验——回归系数的假设性检验方差未知,用方差估计量代替 ^σ2=∑e i 2/(n-k) 重点记忆t =(^β2-β2)/^SE (^β2)~t (n-2)拒绝域:|t|>=t 2/a (n-2)拒绝,认为对应解释变量对被解释变量有显著影响。
计量经济学重点总结

计量经济学重点总结计量经济学的研究方法可以分成以下几个步骤:建立模型、收集数据、估计参数、模型检验和模型运用。
上个一学期课,觉得初级计量经济学课程主要关注估计参数和模型检验这两个部分。
话不多说,先开始吧。
因为一元和多元很相似,所以放在一起总结了。
1.估计参数1.1回归方程1.1.1 一元回归线性模型总体回归方程(PRF)E(Y|Xi)=f(Xi)=β0+β1Xi ( β0 、β1 为回归系数,是要估计的参数)设μi=Yi−E(Y|Xi) ,上式代入,可求得总体回归模型为Yi=β0+β1Xi+μi样本回归模型(SRF)和总体回归模型的差别在于样本回归模型是由于取的是样本,所以β0 、β1 、Yi 都是估计值因此,可以建立样本回归方程Y^i=β^0+β^1Xi 。
设残差ei=Yi−Y^i ,原方程带入可求得样本回归模型为Yi=β^0+β^1Xi+ei1.1.2 多元回归线性模型一样的道理,构建总体回归方程与样本回归模型,解释变量为k个。
总体回归方程(PRF),,,E(Y|Xi1,Xi2,……,Xik))=β0+β1Xi1+β2Xi2+……+βkXik所以总体回归模型为Yi=E(Y|Xi1,……+Xik)+μi=β0+β1Xi1+……+βkXik+μi样本回归方程同理样本观察值带入总体回归模型得Y1=β0+β1X11+……+βkX1k+μ1Y2=β0+β1X21+……+βkX2k+μ2可以得到总体回归模型的矩阵表示为Y=Xβ+U样本回归模型的矩阵表示为Y=Xβ^+e1.2 基本假定1)模型假设正确2)解释变量具有变异性,方差趋向于一个非零常数(所以多元函数的列满秩)3)随机误差项零均值、条件同方差、不同随机误差项彼此独立,是零均值同方差的正态分布1.3 OLS估计法1.3.1 一元回归线性方程样本回归方程中残差为ei=Yi−Y^i=Yi−β^0−β^1Xi因此残差平方和为(Q=Σei2=Σ(Yi−Y^i=Yi−β^0−β^1Xi)2分别对β0 、β1 求偏导。
计量经济学基础知识梳理(超全)
然对数,或简称为对数函数,记为
y logx
还有几种不同符号可以表示自然对数,最常用的是 lnx
或 loge x 。当对数使用几个不同的底数时,这些不同的
都用 logx 表示自然对数。
符号是有作用的。目前,只有自然对数最重要,因此我们
2.自然对数
y
y logx
x
图2.1.4 y=log(x) 的图形
是非常重要的。在许多情况下,使用一个常弹性模型都很
方便,而对数函数能帮助我们设定这样的模型。如果我们 对x和y都使用对数近似计算,弹性就近似等于
log y logx
因此,一个常弹性模型可近似描述为方程
1 为y对x的弹性(假定x,y>0)。 式中,
log y 0 1 logx
2.自然对数
在经验研究工作中还经常出现使用对数函数的其他可 能性。假定y>0,且
则 log y 1x ,从而 100 log y 100 1 x。 由此可知,当y和x有上述方程所示关系时,
log y 0 1 x
%y 100 1x
换言之,对数“解除了”指数,反之亦然。对数函数和指数 函数互为反函数。
指数函数的两个有用性质是
exp(x1+x2)=exp(x1)exp(x2) 和 exp﹝c· log(x)﹞=xc
4.微分学
记忆:经济学中常用的一些函数及其导数有
y 0 1x 2 x2 ; dy dx 1 22 x y 0 1 x ; dy dx 1 x2
第一章
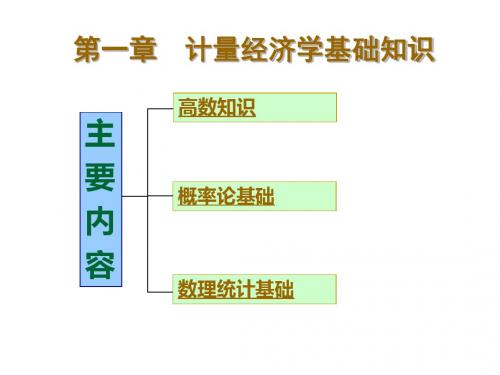
计量经济学基础知识
高数知识
主 要 内 容
概率论基础
数理统计基础
第一节 高数知识
计量经济学必备知识点总结

计量经济学必备知识点总结一、基本概念1. 变量与参数:在计量经济学中,经济模型通常会涉及到各种变量和参数,其中变量是指可以随着时间或其他因素而变化的量,而参数是指在模型中不变的常量。
2. 线性关系与非线性关系:线性关系是指两个变量之间的关系可以用一条直线来表示,而非线性关系则不符合这一特点。
3. 动态关系与静态关系:动态关系是指变量之间的关系随着时间的推移而变化,而静态关系则在一个时间点上成立。
二、假设检验1. 假设检验的基本逻辑:假设检验是计量经济学中最基本的一种统计推断方法,其基本逻辑是通过对样本数据进行分析,判断某一经济理论假设的合理性。
2. 一类和二类错误:在假设检验中,如果我们拒绝了一个实际上是真实的假设,就犯了一类错误;而如果我们接受了一个实际上是错误的假设,就犯了二类错误。
三、最小二乘法1. 最小二乘估计的基本原理:最小二乘法是一种常用的参数估计方法,其基本原理是选择使得残差平方和最小的参数值作为估计值。
2. 普通最小二乘法和加权最小二乘法:普通最小二乘法是指在残差的平方和最小化的情况下对参数进行估计,而加权最小二乘法则是在普通最小二乘法的基础上引入了加权因素。
3. 最小二乘估计的性质:最小二乘估计具有无偏性、有效性和一致性等重要性质。
四、多元回归分析1. 多元回归模型的建立:在多元回归分析中,我们通常会建立包括多个自变量和一个因变量的回归模型,用来描述自变量对因变量的影响。
2. 多元回归模型的识别:在多元回归分析中,识别问题是指通过样本数据估计出的回归系数能否代表总体数据中的真实关系。
五、时间序列分析1. 时间序列数据的特点:时间序列数据是指在一段时间内观察到的一系列数据,其特点包括趋势、季节性和周期性等。
2. 平稳性的检验:在时间序列分析中,平稳性是一个重要的假设,其检验包括单位根检验和差分平稳性检验等方法。
3. ARMA模型和ARCH模型:ARMA模型是时间序列数据的经典模型,用来描述时间序列数据的自回归和移动平均关系;而ARCH模型则是用来描述时间序列数据的异方差性。
计量经济学知识点汇总

计量经济学知识点汇总1. 计量经济学概念
- 定义和作用
- 理论基础和研究方法
2. 数据处理
- 数据收集和探索性分析
- 异常值处理和缺失值处理
- 数据转换和规范化
3. 回归分析
- 简单线性回归
- 多元线性回归
- 回归假设和诊断
4. 时间序列分析
- 平稳性和单位根检验
- 自相关和偏自相关
- ARIMA模型和Box-Jenkins方法
5. 面板数据分析
- 固定效应模型和随机效应模型
- hausman检验
- 动态面板数据模型
6. 内生性和工具变量
- 内生性问题及其检验
- 工具变量法
- 两阶段最小二乘法
7. 离散选择模型
- 二项Logit/Probit模型
- 多项Logit/Probit模型
- 计数数据模型
8. 模型评估和选择
- 模型适合度检验
- 信息准则
- 交叉验证和预测评估
9. 计量经济学软件应用
- R/Python/Stata/EViews等软件使用 - 数据导入和清洗
- 模型构建和结果解释
10. 实证研究案例分析
- 经典文献阅读和评析
- 实证研究设计和实施
- 结果分析和政策建议
以上是计量经济学的主要知识点汇总,每个知识点都包含了相关的理论基础、模型方法和实践应用,可根据具体需求进行深入学习和研究。
计量经济学复习重点资料讲解

计量经济学复习重点一、1、列举计量经济分析过程的几个要素:1、数据;2、计量模型。
3、解释变量;4、被解释变量;5、相关影响。
2、计量经济分析过程基本围绕着四类值。
例如要预测一个硬币被抛1000次出现正面的次数,第一步: 从理论上研究,出现正面的概率是1/2, 这个概率是真值;第二步:做实验,例如抛硬币100次,观察出现正面的次数,那么这个次数为观察值;第三步:估计概率,用观察的次数除以100作为概率的估计值;第四步:用估计的概率乘以1000作为硬币被抛1000次出现正面的预测值。
3、估计量一般都采用哪三种评选标准:1、无偏性;2、有效性;3、一致性.4、无偏估计量的概念:若估计量的数学期望存在且等于其对应真值,即()E θθ=。
4估计量的有效性:设1θ与2θ均为θ的无偏估计量,若对于任意θ,有1θ的方差小于等于2θ的方差,则1θ较2θ有效。
5、列举计量经济分析的三种数据类型:1、横截面数据;2、时间序列数据;3、面板数据。
6、虚拟变量即一种二值变量,是对解释变量的一种定性描述。
二、:1、简述多元线性回归中('i i i y x βε=+)的高斯-马科夫假设(Gauss – Markov assumption )?若要求得到无偏估计量需满足其中的哪(些)项?112{}0,1,2,...,{,...,}{,...,}{}1,2,...,{,}0i N N i i j E i N x x V i NCov εεεεσεε=====与相互独立,若想得到无偏估计量,需满足{}0,1,2,...,i E i N ε==,和11{,...,}{,...,}N N x x εε与相互独立 某种元件的寿命X(以小时计)服从正态分布N(),均未知.现测得16只元件的寿命如下(已知 t 0.05(15) =1.7531) :159 280 101 212 224 379 179 264222 362 168 250 149 260 485 170 问是否有理由认为元件的平均寿命大于225(小时)?2:解 按题意需检验: =225, :取a =0.05.此检验问题的拒绝域为t=t a (n-1).现在n=16, t 0.05(15) =1.7531.又根据 ,s=算得 =241.5, s=98.7259,即有 t ==0.66851.7531.t没有落在拒绝域中,故接受,即认为元件的平均寿命不大于225小时.3、在平炉上进行一项试验以确定改变操作方法的建议是否会增加钢的得率,试验是在同一只平炉上进行的,每炼一炉钢时除操作方法外,其他条件都尽可能做到相同.先用标准方法炼一炉,然后用建议的方法炼一炉,以后交替进行,各炼成了10炉,其得率分别为(1) 标准方法 78.1 72.4 76.2 74.3 77.4 78.476.0 75.5 76.7 77.3(2) 新方法 79.1 81.0 77.3 79.1 80.0 79.179.1 77.3 80.2 82.1设这两个样本相互独立,且分别来自正态总体N()和N(),,均未知.问建议的新操作方法能否提高得率?(取 a=0.05,已知 t0.05(18)=1.7341)3:解需要检验假设: -0,: -0分别求出标准方法和新方法下的样本均值和样本方差如下:根据 ,s==10, =76.23, =3.325,根据,s= =10, =79.43, =2.225.又,==2.775, t 0.05(18)=1.7341, 故拒绝域为 t =-t 0.05(18)=-1.7341.现在由于样本观察值t = -4.295-1.7341,所以拒绝,即认为建议的新操作方法较原来的方法为优.4、时间序列过程t Y 为平稳过程需要满足哪些条件?若121.20.32t t t t Y Y Y ε--=-+,试问这个过程是一个平稳过程吗?解:平稳过程需满足三个条件:1、{}t E Y μ=,期望为有限常数与时间t 无关。
(完整word版)计量经济学知识点总结

(完整word版)计量经济学知识点总结第一章:1计量经济学研究方法:模型设定,估计参数,模型检验,模型应用2.计量经济模型检验方式:①经济意义:模型与经济理论是否相符②统计推断:参数估计值是否抽样的偶然结果③计量经济学:是否复合基本假定④预测:模型结果与实际杜比3.计量经济学中应用的数据类型:①时间序列数据(同空不同时)②截面数据(同时不同空)③混合数据(面板数据)④虚拟变量数据(学历,季节,气候,性别)第二章:1.相关关系的类型:①变量数量:简单相关/多重相关(复相关)②表现形式:线性相关(散布图接近一条直线)/非线性相关(散布图接近一条直线)③变化的方向:正相关(变量同方向变化,同增同减)/负相关(变量反方向变化,一增一减不相关)2.引入随机扰动项的原因:①未知影响因素的代表(理论的模糊性)②无法取得数据的已知影响因素的代表(数据欠缺)③众多细小影响因素综合代表(非系统性影响)④模型可能存在设定误差(变量,函数形式设定)⑤模型中变量可能存在观测误差(变量数据不符合实际)⑥变量可能有内在随机性(人类经济行为的内在随机性)3.OLS回归线数学性质:①剩余项的均值为零②OLS回归线通过样本均值③估计值的均值等于实际观测值的均值④被解释变量估计值与剩余项不相关⑤解释变量与剩余项不相关4.OLS估计量”尽可能接近”原则:无偏性,有效性,一致性5.OLS估计式的统计性质/优秀品质:线性特征,无偏性特征,最小方差性特征第三章:1.偏回归系数:控制其他解释变量不变的条件下,第j个解释变量的单位变动对被解释变量平均值的影响,即对Y平均值直接或净的影响2.多元线性回归中的基本假定:①零均值②同方差③无自相关④随机扰动项与解释变量不相关⑤无多重共线性⑥正态性…一元中有123463. OLS回归线数学性质:同第二章34. OLS估计式的统计性质:线性特征,无偏性特征,最小方差性特征5.为什么用修正可决系数不用可决系数?可决系数只涉及变差没有考虑自由度,如果用自由度去校正所计算的变差,可纠正解释变量个数不同引起的对比困难第四章:1.多重共线性背景:①经济变量之间具有共同变化趋势②模型中包含滞后变量③利用截面数据建立模型可出现..④样本数据自身原因2.后果:A完全①参数估计值不确定②csgj值方差无限大B不完全①csgj量方差随贡献程度的增加而增加②对cs区间估计时,置信区间区域变大③假设检验用以出现错误判断④可造成可决系数较高,但对各cs 估计的回归系数符号相反,得出错误结论3.检验:A简单相关系数检验法:COR 解释变量.大于0.8,就严重B方差膨胀因子法:因子越大越严重;≥10,严重C直观判断法:增加或剔除一个解释变量x,估计值y发生较大变化,则存在;定性分析,重要x标准误差较大并没通过显著性检验时,则存在;x回归系数所带正负号与定性分析结果违背,则存在;x相关矩阵中,x之间相关系数较大,则存在D逐步回归检验法:将变量逐个引入模型,每引入一个x,都进行F检验,t检验,当原来引入的x由于后面引入的x不显著是,将其剔除.以确保每次引入新的解释变量之前方程种植包含显著变量.4.补救措施:①剔除变量法②增大样本容量③变换模型形式:自相关④利用非样本先验信息⑤截面数据与时序数据并用:异方差⑥变量变换第五章:1.异方差产生原因:①模型中省略了某些重要的解释变量②模型设定误差③数据测量误差④截面数据中总体各单位的差异2.后果:A参数估计统计特性:参数估计的无偏性仍然成立;参数估计方差不再是最小B参数显著性检验:t统计量进行参数检验失去意义C 预测影响:将无效3检验:A图示①相关图形分析data x y,看散点图,quick→graph→x,y→OK→scatter diagram→OK,可以看到x,y散点图②残差图形分析data x y,sort x;ls y c x;再回归结果的子菜单点resid,可以看残差分析图Bgoldfeld-quanadt:data x y;sort x;smpl 1 n1;ls y c x(RSS1);smpl n2 n;ls y c x(RSS2);计算F*=RSS2/RSS1,取α=0.05,查F分布表,得F0.05((n-c)/2,(n-c)/2),将F值与此对比.若F*>F(0.05),拒绝原假设,存在异方差Cwhite:data x y;ls y c x;在回归结果的子菜单中点击view-residual test-white heteroskedasticity,可以看到辅助回归模型的估计结果D arch;E:glejser:data x y;ls y c x;genr E1=resid;genr E2=abs(E1);genr XH=X^h;ls E2 c xh;依次根据XH的T值判断E2与XH之间是否存在异方差4.补救措施:A模型变换法:genr y1=y/根号x^h; genr x2=1/根号x^h ; genr x3=x/根号x^h;ls y1 x2 x3;B加权最小二乘法wls:权数:w1t=1/xt;w2t=1/xt^2;w3t=1/根号xt.电脑操作:genr w1=1/x;genr w2=1/(x^2);genr w3=1/sqr(x);ls (w=w1t) y c x;ls (w2=w2t) y c x;ls (w3=w3t) y c x. 第六章:1.自相关产生原因:①经济系统的惯性②经济活动的滞后效应③数据处理造成的相关④蛛网现象⑤模型设定偏误2.表现形式:自相关性质可以用自相关系数符号判断.即ρ<0为负相关, ρ>0为正相关.当|ρ|接近1时,表示相关的程度很高.自相关形式:见公式.3.后果:见公式.4.检验:A图示检验:data x y;ls y c x;再回归模型的子菜单点击resids,可以看到模型残差分布图;genr e=resid;data e e(-1);view-graph-scatter-simple scatter.B.DW检验:data x y;ls y c x;根据回归结果得出DW值,然后判断是否自相关.(正相关0~dl,无法判断dl~du,正相关du~2~4-du,无法判断4-du~4-dl,负相关4-dl~4).5.补救:A广义差分法:data x y;ls y c x;根据DW求ρ尖>(ρ尖=1-DW/2);smpl 2 n;genr yi=y-ρ尖*y(-1); genr xi=x-ρ尖*x(-1);ls y1 c x1;运用DW检验判断是否消除了自相关B:Cochrane orcutt迭代法:data x y;la y c x ar(1);运用DW检验判断C其他方法:①一阶差分法:data x y;ls y c x;smpl 2 n;genr y1=y-y(-1); genr x1=x-x(-1);ls y1 c x1; 运用DW检验判断②德宾两步法:data x y;smpl 2 n;ls y c y(-1)根据输出结果看y(-1)前系数,求出ρ尖; genr yi=y-ρ尖*y(-1); genr xi=x-ρ尖*x(-1);ls y1 c x1;运用DW检验判断第七章:1.虚拟变量0和1选取原则:0基期,比较的基础,参照物;1报告期:被比较类型2.虚拟变量数量的设置规则:①若定性因素具有m≥2个相互排斥属性,当回归模型有截距项时,只能引入m-1个变量②当回归模型无截距项时,引入m个变量3.虚拟解释变量的回归:加法截距:①解释变量只有一个分为两种相互排斥类型的定性变量而无定量变量②解释变量包含一个定量变量和一个分为两种类型的定性变量③解释变量包含一个定量变量和一个两种以上类型的定性变量④解释变量包含一个定量变量和两个定性变量.乘法斜率:①截距不变情形②结局斜率均发生变化③分段回归分析描述的精度.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
普通最小二乘法(Ordinary least squares, OLS )给出的判断标准是:二者之差的平方和最小。
称为OLS 估计量的离差形式(deviation form )。
称为样本回归函数的离差形式。
对于最大或然法,当从模型总体随机抽取n 组样本观测值后,最合理的参数估计量应该使得从模型中抽取该n 组样本观测值的概率最大。
在满足基本假设条件下,对一元线性回归模型:于是,Y 的概率函数为或然函数(likelihood function)为:∑∑+-=-=nii i n i X Y Y Y Q 121021))ˆˆ(()ˆ(ββ⎪⎪⎩⎪⎪⎨⎧∑-∑∑∑-∑=∑-∑∑∑-∑∑=2212220)(ˆ)(ˆi i i i i i i i ii i i i X X n X Y X Y n X X n X Y X Y X ββ⎪⎩⎪⎨⎧-=∑∑=XY x y x ii i 1021ˆˆˆβββi i x y 1ˆˆβ=ii i X Y μββ++=10),ˆˆ(~210σββii X N Y +2102)ˆˆ(2121)(ii X Y i eY P ββσπσ---=),,,(),ˆ,ˆ(21210n Y Y Y P L ⋅⋅⋅=σββ21022)ˆˆ(21)2(1i i nX Y neββσσπ--∑-=高斯—马尔可夫定理(Gauss-Markov theorem)在给定经典线性回归的假定下,最小二乘估计量是具有最小方差的线性无偏估计量。
普通最小二乘估计量(ordinary least Squares Estimators )称为最佳线性无偏估计量(best linear unbiased estimator, BLUE )σ2的最小二乘估计量为它是关于σ2的无偏估计量。
2102*)ˆˆ(21)2ln()ln(ii X Y n L L ββσσπ--∑--==⎪⎪⎩⎪⎪⎨⎧∑-∑∑∑-∑=∑-∑∑∑-∑∑=2212220)(ˆ)(ˆi i i i i i i i ii i i i X X n X Y X Y n X X n X Y X Y X ββ),(~ˆ2211∑ix N σββ),(~ˆ22200σββ∑∑ii xn XN ∑=22ˆ/1ixσσβ∑∑=222ˆ0i i x n X σσβ2ˆ22-=∑n e iσ因此,σ2的最大或然估计量不具无偏性,但却具有一致性。
TSS=ESS+RSSY 的观测值围绕其均值的总离差(total variation)可分解为两部分:一部分来自回归线(ESS),另一部分则来自随机势力(RSS)。
拟合优度:回归平方和ESS/Y 的总离差TSS称R 2 为(样本)可决系数/判定系数(coefficient of determination)。
可决系数的取值范围:[0,1]R 2越接近1,说明实际观测点离样本线越近,拟合优度越高。
1ˆβ的样本方差:∑=222ˆˆ1ix S σβ1ˆβ的样本标准差:∑=2ˆˆ1ix S σβ0ˆβ的样本方差:∑∑=2222ˆˆ0i i x n X S σβ0ˆβ的样本标准差:∑∑=22ˆˆ0i ix n XS σβTSS RSSTSS ESS R -==1记2⎪⎪⎭⎫ ⎝⎛=∑∑22212ˆi i y x Rβ)2(~ˆˆ--=n t st ii i βββααα-=<<-1)(22t t t P于是得到:(1-α)的置信度下, βi 的置信区间是Ŷ0是条件均值E(Y|X=X 0)的无偏估计。
在1-α的置信度下,总体均值E(Y|X 0)的置信区间为在1-α的置信度下,Y 0的置信区间为∑-=2210/)ˆ,ˆ(i x X Cov σββ)))(1(,(~ˆ22020100∑-++ix X X n X N Y σββ022ˆ00ˆ0ˆ)|(ˆYY S t Y X Y E S t Y ⨯+<<⨯-αα),(~20100σββX N Y +)))(11(,0(~ˆ220200∑-++-ix X X n N Y Y σ0022ˆ000ˆ0ˆˆYY Y Y S t Y Y S t Y --⨯+<<⨯-αα)ˆ,ˆ(ˆˆ22ii s t s t i i ββααββ⨯+⨯-要缩小置信区间,需 (1)增大样本容量n(2)提高模型的拟合优度总体回归模型n 个随机方程的矩阵表达式为其中样本回归函数的矩阵表达:或其中:μX βY +=)1(212221212111111+⨯⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=k n kn nn k k X X X X X X X X XX 1)1(210⨯+⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=k k ββββ β121⨯⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=n n μμμ μβX Y ˆˆ=e βX Y +=ˆ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=k βββˆˆˆˆ10 β⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=n e e e 21e Y X βX)X ('='ˆ样本回归函数的离差形式其矩阵形式为其中:在离差形式下,参数的最小二乘估计结果为随机误差项μ的方差的无偏估计量为从统计检验的角度:n >30 时,Z 检验才能应用; n-k ≥8时, t 分布较为稳定 一般经验认为:当n ≥30或者至少n ≥3(k +1)时,才能说满足模型估计的基本要求。
Y X X X β''=-1)(ˆ0e X ='i ki k i i i e x x x y ++++=βββˆˆˆ2211 e βx y +=ˆ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=n y y y 21y ⎪⎪⎪⎪⎪⎭⎫⎝⎛=kn n nk k x x x x x x x x x 212221212111x ⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=k βββˆˆˆˆ21 βY x x x β''=-1)(ˆk k X X Y βββˆˆˆ110---= 11ˆ22--'=--=∑k n k n e iee σ调整的思路是:将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响:其中:n-k -1为残差平方和的自由度,n -1为总体平方和的自由度。
服从自由度为(k , n -k -1)的F 分布给定显著性水平α,可得到临界值F α(k,n-k-1),通过F >F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0或)1/()1/(12----=n TSS k n RSSR 11)1(122-----=k n n R R )1/(/--=k n RSS kESS F 12)()ˆ(-'=X X βσCov kFk n n R +----=1112)1/()1(/22---=k n R kR F以c ii 表示矩阵(X’X)-1主对角线上的第i 个元素,于是参数估计量的方差为:给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1) 来拒绝或接受原假设H 0一元线性回归中,t 检验与F 检验一致一方面,t 检验与F 检验都是对相同的原假设H 0:β1=0进行检验; 另一方面,两个统计量之间有如下关系:如何才能缩小置信区间? 增大样本容量n提高模型的拟合优度 提高样本观测值的分散度iii c Var 2)ˆ(σβ=),(~ˆ2iii i c N σββ)1(~1ˆˆˆ----'--=k n t k n c S t iiii i iie e βββββ222212221222122212212ˆ)2(ˆ)2(ˆ)2(ˆ)2(ˆt x n ex n e x n e n e x n e y F i ii iii i ii i=⎪⎪⎭⎫ ⎝⎛⋅-=⎪⎪⎪⎭⎫ ⎝⎛-=-=-=-=∑∑∑∑∑∑∑∑∑∑ββββ得到(1-α)的置信水平下E(Y 0)的置信区间:e 0服从正态分布,即给定(1-α)的置信水平下Y 0的置信区间:受约束样本回归模型为e’e 为无约束样本回归模型的残差平方和RSS U 受约束与无约束模型都有相同的TSS RSS R ≥RSS U ESS R ≤ESS U通常情况下,对模型施加约束条件会降低模型的解释能力。
),(~ˆ020X X)X (X βX 100''-σN Y )1(~ˆˆ--''--k n t )E(Y Y 00010X X)X (X σ10000100)(ˆˆ)()(ˆˆ22X X X X X X X X ''⨯+<<''⨯---σσααt Y Y E t Y )))(1(,0(~01020X X X X ''+-σN e 010000100)(1ˆˆ)(1ˆˆ22X X X X X X X X ''+⨯+<<''+⨯---σσααt Y Y t Y **ˆe βX Y +=)1,(~)1/()/()(-------=U R U U U R U U R k n k k F k n RSS k k RSS RSS F基本假定违背:不满足基本假定的情况。
主要包括:(1)随机误差项序列存在异方差性;(2)随机误差项序列存在序列相关性;(3)解释变量之间存在多重共线性;(4)解释变量是随机变量且与随机误差项相关(随机解释变量);此外:(5)模型设定有偏误(6)解释变量的方差不随样本容量的增而收敛异方差性的后果1、参数估计量非有效OLS估计量仍然具有无偏性,但不具有有效性而且,在大样本情况下,尽管参数估计量具有一致性,但仍然不具有渐近有效性。
2、变量的显著性检验失去意义其他检验也是如此。
3、模型的预测失效一方面,由于上述后果,使得模型不具有良好的统计性质;所以,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。
G-Q检验的步骤:①将n对样本观察值(X i,Y i)按观察值X i的大小排队②将序列中间的c=n/4个观察值除去,并将剩下的观察值划分为较小与较大的相同的两个子样本,每个子样样本容量均为(n-c)/2③对每个子样分别进行OLS回归,并计算各自的残差平方和实际经济问题中的序列相关性1、经济变量固有的惯性2、模型设定的偏误3、数据的“编造”序列相关性的后果 1、参数估计量非有效2、变量的显著性检验失去意义3、模型的预测失效序列相关性的检验 基本思路:然后,通过分析这些“近似估计量”之间的相关性,以判断随机误差项是否具有序列相关性。