中文分词和词性标注的在线重排序方法
汉语分词中未登录词识别及词性标注的研究与实现的开题报告

汉语分词中未登录词识别及词性标注的研究与实现的开题报告一、选题背景和意义随着大数据和自然语言处理的发展,汉语分词和词性标注技术在各种应用中得到了广泛应用。
然而,由于新词、专有名词等未登录词的存在,现有的分词算法难以完全识别这些词,影响了分词效果和应用效果。
因此,未登录词识别和词性标注是当前汉语分词和自然语言处理研究中的重要问题。
二、研究内容本课题将研究未登录词识别和词性标注的方法和技术,提出一种基于深度学习的未登录词识别和词性标注算法,并进行实现和评估。
具体研究内容包括:1.未登录词的概念和分类2.现有未登录词识别和词性标注算法的分析和比较3.基于深度学习的未登录词识别和词性标注算法的设计和实现4.实验设计和数据集准备,对比实验结果分析三、研究方法本课题将采用文献调研、方案设计、算法实现和实验评估等方法。
具体方法包括:1.搜集相关文献,了解现有未登录词识别和词性标注的研究成果2.设计基于深度学习的未登录词识别和词性标注算法,并结合实际应用场景进行优化3.使用Python等编程语言实现算法,并进行性能和效果评估4.选取适当的数据集,进行对比实验,获取实验数据,分析实验结果四、预期成果本课题预期达到以下成果:1.深入研究现有的未登录词识别和词性标注算法,总结其优缺点2.提出一种针对于未登录词的基于深度学习的识别和标注算法,并进行实现3.进行实验评估,得到实验数据,分析算法性能和效果4.撰写开题报告和毕业论文,发表相关学术论文五、工作计划1.文献调研和方案设计,预计时间 2 周2.算法实现和数据集准备,预计时间4周3.实验评估和实验数据分析,预计时间4周4.写作和论文修改,预计时间2周六、参考文献1. 张鹏程, 王飞跃. 基于隐马尔可夫模型和 CRF 的未登录词识别研究[J]. 计算机科学, 2018, 45(05):213-217.2. 喻红婵, 石义章. 一种基于深度学习的未登录词发现方法[J]. 河南大学学报(自然科学版), 2018, 48(03):269-273.3. 干绍龙, 朱国伟, 黄瑞娟,等. 基于标注规则和统计模型相结合的汉语分词方法[J]. 计算机研究与发展, 2018, 55(06):1185-1196.4. 李辽, 范春代, 范旭东. CRF 处理未登录词分词[J]. 计算机科学和探索, 2019, 13(05):824-829.。
手工分词和词性标注的问题

手 工 分 词 和 词 性 标 凌 的 问 题
口李海波
摘 要 :本文在对 老屋 窗口 一 文进行手 工分词和词性标 注的基础 上 ,归纳总结 了手工分词和词性标注存 在 的问题 ,为中文信 息处理 中的分词与词性标 注提供一定的参考价值 。 关键词:手 工分词 词性标注 老屋 窗口
二 、离 合 词 的 标 注 问 题 离 合 词 , 主 要 指 那 些 由 两 个 字 组 成 的合 成 词 ,尤 其 是
形 式 固 定 , 是 句 法 结 构 中最 小 的 独 立 运 用 的 单 位 ” ; 短 语 们 的 数 量 居 多 , 比 如 “ 仗 、 睡 觉 ” 之 类 由 两 个 字 组 合 而 打 的 定 义 是 “ 思 不 专 一 , 表 复 合 的 概 念 , 结 构 松 散 ,在 句 成 的双 音 节 合 成 词 , 这 些 词 语 兼 有 词 和 短 语 的 双 重 特 征 。 意 子 中 不 是 最 小 的 运 用 单 位 , 还 可 以 从 中 再 分 析 为 词 的 单 简 言之 ,离合 词 是 指横 跨 在 词和 短语 之 问 的一 个语 词 群 位 ” 。 从 上 述 定 义 中 , 我 们 可 以发 现 , 汉 语 中对 词和 短 语 体 。关 于 离 合 词 的 形 式 标 注 问 题 , 一 般 认 为 它 们 既 是 词 , 的 区分 , 是 不 能 从 词 的语 法 形 式 直 接 判 断 出 来 的 , 必 须 借 又 是 词 组 。合 在 一 起 时 是 词 , 分 开 时 则 是 词 组 。 但 词 性 标 助 语 法 意 义 的 分 析 来 判 断 。 现 代 汉 语 词 汇 里 , 由两 个 不 定 注 的 实 践 却 向 这 种 观 点 提 出 了 挑 战 。 词 性 标 注 的 原 则 是 位 语 素 构 成 的 合 成 词 占绝 大 数 , 其 中 有 些 语 素 独 立 起 来 “ 果 是 词 就 标 注 词 性 , 如 果 不 是 词 就 必 须 再 往 下 切 分 到 如 也 就 是 一 个 词 ; 同 时 , 它 们 的 构 成 方 式 又 同 词 组 的构 成 方 词 为 止 ” 。 离 合 词 标 上 词 性 就 意 味 着 它 是 一 个 词 ,不 标 上 式 很相近 ,这使得有 些词和 短语很容 易相混 。例如 : “ 黑 词 性 则 意 味 着 它 不 是 一 个 词 , 我 们 当 然 也 不 可 能 承 认 它 们 板 ”和 “白花 ” , “ 痛 ” 和 “ 痛 ” , “ 家 ”和 “ 头 手 回 回 既 是 词 又 不 是 词 。 也 就 是 说 ,正 是 词 性 标 注 存 在 的 问 题 需 要 我 们 给 离 合 词 一 个 明 确 的 定 性 ,绝 不 能 采 取 “ 是 词 又 既 味 ” 该 如 何 标 注 词 性 , 往 往 容 易 出错 。 词 和 短 语 的 区 别 , 如 果 从 词 所 表 达 的概 念 角 度 进 行 判 断 , 往 往 不 能 直 接 作 出 是 词 组 ” 的模 糊 态 度 。 分 词 和 标 注 。 例 如 : “ 板 ”所 表 达 的 概 念 比较 单 纯 、 比 黑 《 屋 窗 口 》 一 文 出 现 了 大 量 的 离 合 词 。 例 如 : 动 老 较 固 定 , 因 此 是 一 个 词 ,在 分 词 时应 把 它 作 为 一 个 独 立 的 补 离 合 词 : “ 掉 ” “ 去 ” “出来 ” “ 上 ” “ 着 ” 卖 回 装 挑 单 位 ,应 表 示 为 : 黑板 / 。 而 “ N 白花 ”所 表 示 的 概 念 不 够 等 ;动 宾 离 合 词 : “ 面 ” “ 床 ” “ 心 ”等 。 应 该 把 见 起 放 紧 密 , 可 以 拆 分 为 “白色 的花 ” ,意 思 并 没 有 像 “ 板 ” 黑 离 合 词 看 作 一 个 词 来 标 注 ,还 是 作 为 一 个 短 语 进 行 切 分 , 那 样 融 合 在 一 起 ,应 看 作 一 个 短 语 ,标 注 为 : 白/ 花 / 。 A N 学 术 界 存 在 很 大 的 争 议 。 笔 者 认 为 把 离 合 词 看 作 一 个 短 语 从 上述 分 析 可 以看 出 , 词 和 短 语 的 差 异 非 常 小 , 概 念 的 融 来标注 ,往往不 会 出错 。对双音 节单位 而言 ,结 构的凝 固 合 程 度 高 低 也 无 明确 的 界 限 , 所 以在 词 性 标 注 时 ,可 能 会 性 应 该 是 成 词 的 最 主 要 条 件 , 多 数 离 合 词 既 然 可 以 相 对 自 出 现 这 样 的 错 误 : 把 “ 板 ”标 成 “黑 / 板 / ” , 而 把 由 地 扩 展 , 两 个 成 分 一 般 又 各 有 意 义 ,而 且 这 个 意 义 还 是 黑 A N
中文分词与词性标注技术研究与应用

中文分词与词性标注技术研究与应用中文分词和词性标注是自然语言处理中常用的技术方法,它们对于理解和处理中文文本具有重要的作用。
本文将对中文分词和词性标注的技术原理、研究进展以及在实际应用中的应用场景进行综述。
一、中文分词技术研究与应用中文分词是将连续的中文文本切割成具有一定语义的词语序列的过程。
中文具有词汇没有明确的边界,因此分词是中文自然语言处理的基础工作。
中文分词技术主要有基于规则的方法、基于词典的方法和基于机器学习的方法。
1.基于规则的方法基于规则的中文分词方法是根据语法规则和语言学知识设计规则,进行分词操作。
例如,按照《现代汉语词典》等标准词典进行分词,但这种方法无法处理新词、歧义和未登录词的问题,因此应用受到一定的限制。
2.基于词典的方法基于词典的中文分词方法是利用已有的大规模词典进行切分,通过查找词典中的词语来确定分词的边界。
这种方法可以处理新词的问题,但对未登录词的处理能力有所限制。
3.基于机器学习的方法基于机器学习的中文分词方法是利用机器学习算法来自动学习分词模型,将分词任务转化为一个分类问题。
常用的机器学习算法有最大熵模型、条件随机场和神经网络等。
这种方法具有较好的泛化能力,能够处理未登录词和歧义问题。
中文分词技术在很多自然语言处理任务中都起到了重要的作用。
例如,在机器翻译中,分词可以提高对齐和翻译的质量;在文本挖掘中,分词可以提取关键词和构建文本特征;在信息检索中,分词可以改善检索效果。
二、词性标注技术研究与应用词性标注是给分好词的文本中的每个词语确定一个词性的过程。
中文的词性标注涉及到名词、动词、形容词、副词等多个词性类别。
词性标注的目标是为后续的自然语言处理任务提供更精确的上下文信息。
1.基于规则的方法基于规则的词性标注方法是根据语法规则和语境信息,确定每个词语的词性。
例如,根据词语周围的上下文信息和词语的词义来判断词性。
这种方法需要大量的人工制定规则,并且对于新词的处理能力较差。
自然语言处理考试题

自然语言处理考试题自然语言处理(Natural Language Processing, NLP)是一门涉及人类语言和计算机之间交互的学科,主要研究如何使计算机能够理解、解析、生成和处理人类语言。
NLP技术被广泛应用于机器翻译、信息检索、情感分析、自动问答等领域。
以下是关于NLP的一些常见考试题及其相关参考内容:1. 什么是分词?请简要介绍中文和英文分词的区别。
参考内容:分词是将连续的文本序列分割成有意义的词语的过程。
在中文分词中,一个词通常由一个汉字组成,而英文分词则是按照空格或者标点符号进行分割。
中文分词面临的主要挑战是汉字没有明确的边界,而英文分词则相对较简单。
2. 请简述词性标注的作用和方法。
参考内容:词性标注是将分词后的词语标注为其在句子中所属的词性的过程。
词性标注的作用是为后续的语义分析、句法分析等任务提供基础。
词性标注的方法包括基于规则的方法和基于统计的方法。
基于规则的方法依赖于专家编写的语法规则,而基于统计的方法则是根据大量标注好的语料库学习得到的模型进行标注。
3. 请简要描述语义角色标注的任务和方法。
参考内容:语义角色标注是为句子中的谓词识别出该谓词所携带的语义角色的过程。
谓词表示一个动作或者状态,而语义角色描述动作或状态的参与者、受事者、时间等概念。
语义角色标注的方法可以使用基于规则的方法,也可以使用基于机器学习的方法。
基于机器学习的方法通常使用已标注的语料库进行训练,例如通过支持向量机(Support Vector Machines, SVM)或者条件随机场(Conditional Random Fields, CRF)等算法进行模型训练。
4. 请简要介绍机器翻译的基本原理和方法。
参考内容:机器翻译是使用计算机自动将一种语言翻译成另一种语言的过程。
机器翻译的基本原理是建立一个模型,将源语言句子映射到目标语言句子。
机器翻译的方法包括基于规则的方法、基于统计的方法和基于神经网络的方法。
基于深度学习方法的中文分词和词性标注研究

基于深度学习方法的中文分词和词性标注研究中文分词和词性标注是自然语言处理中的重要任务,其目的是将输入的连续文字序列切分成若干个有意义的词语,并为每个词语赋予其对应的语法属性。
本文将基于深度学习方法对中文分词和词性标注进行研究。
一、深度学习方法介绍深度学习是一种基于神经网络的机器学习方法,在自然语言处理领域中应用广泛。
经典的深度学习模型包括卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)、长短时记忆网络(LongShort-Term Memory, LSTM)和门控循环单元(Gated Recurrent Unit, GRU)等。
在对中文分词和词性标注任务的研究中,CNN、RNN以及LSTM均被采用。
CNN主要用于序列标注任务中的特征提取,RNN及LSTM则用于序列建模任务中。
GRU是LSTM的一种简化版本,在应对大规模文本序列的过程中更为高效。
二、中文分词中文分词是将一段连续的汉字序列切分成有意义的词语。
传统的中文分词方法主要包括基于词典匹配的分词和基于统计模型的分词。
基于词典匹配的分词方法基于预先构建的词典,将待切分文本与词典进行匹配。
该方法精度较高,但需要较为完整的词典。
基于统计模型的分词方法则通过学习汉字之间的概率关系来进行分词。
该方法不依赖于完整的词典,但存在歧义问题。
深度学习方法在中文分词任务中也有较好的表现,通常采用基于序列标注的方法。
具体步骤如下:1. 以汉字为单位对输入文本进行编码;2. 使用深度学习模型进行序列标注,即对每个汉字进行标注,标记为B(词的开头)、M(词的中间)或E(词的结尾),以及S(单字成词);3. 将标注后的序列按照词语切分。
其中,深度学习模型可以采用CNN、RNN、LSTM或GRU等模型。
三、中文词性标注中文词性标注是为每个词语赋予其对应的语法属性,通常使用含有标注数据的语料库进行训练。
词语排序将词语按照一定的顺序进行排列

词语排序将词语按照一定的顺序进行排列词语排序字数:1500字在日常生活中,我们常常需要对一些词语进行排序,以便更好地组织信息或者进行比较。
本文将介绍一些常见的词语排序方法。
一、按字母顺序排序按字母顺序排序是最常见的排序方法之一。
无论是汉字还是英文单词,按照字母的先后顺序进行排列,可以使词语更加井然有序,方便查找和对比。
下面是一个例子:1. 英文字母排序:applebananacatdogelephant2. 汉字按拼音排序:苹果香蕉猫狗大象二、按照大小、重要性排序除了按字母顺序排序,我们还可以根据一些具体的指标进行排序,例如大小、重要性等。
这种排序方法适用于需要根据某种特定标准进行优先级排列的场景。
1. 按大小排序:小中大2. 按重要性排序:一级二级三级三、按照时间或顺序排序有时候,我们需要按照时间或者特定的顺序来排列词语。
这种排序方法适用于故事情节、时间线等需要按照特定次序展开的场景。
1. 按照时间排序:早晨上午中午下午晚上2. 按顺序排序:第一第二第三第四四、按照频率排序按照词语的频率进行排序,可以帮助我们更好地了解一些事物的出现次数或者重要程度。
这种排序方法适用于统计学、调查研究等领域。
1. 按照频率排序:最高频高频中频低频最低频五、按照空间位置排序如果我们需要描述某个地方或者某个空间内的事物,可以按照空间位置进行排序。
这种排序方法适用于地理学、建筑设计等领域。
1. 按照空间位置排序:东南西北六、按照属性排序最后,我们可以按照某些属性对词语进行排序,以便更好地分类和分析。
以下是一个例子:1. 按照颜色排序:红色蓝色绿色黄色通过以上的介绍,我们可以看到不同的排序方法适用于不同的场景和需求。
无论是按字母顺序、大小、重要性、时间顺序、频率、空间位置还是属性进行排序,都能帮助我们更好地组织信息、进行比较和分析。
在实际运用中,我们可以根据具体情况选择适合的排序方法,以便更好地表达和传达我们想要表达的意思。
基于深度学习的中文自动分词与词性标注模型研究

基于深度学习的中文自动分词与词性标注模型研究1. 引言中文自动分词与词性标注是中文文本处理和语义分析的重要基础任务。
传统方法在处理中文自动分词和词性标注时,通常采用基于规则或统计的方法,并且需要大量的特征工程。
然而,这些传统方法在处理复杂语境、歧义和未知词汇等问题时存在一定的局限性。
随着深度学习的发展,基于神经网络的自然语言处理方法在中文自动分词和词性标注任务上取得了显著的成果。
深度学习方法通过利用大规模的文本数据和端到端的学习方式,避免了传统方法中需要手动设计特征的问题,能够更好地解决复杂语境和未知词汇等挑战。
本文将重点研究基于深度学习的中文自动分词与词性标注模型,探讨这些模型在中文文本处理中的应用和效果,并对未来的研究方向进行展望。
2. 相关工作在深度学习方法应用于中文自动分词和词性标注之前,传统的方法主要基于规则或统计模型。
其中,基于规则的方法采用人工定义的规则来处理中文分词和词性标注任务,但这种方法需要大量人力投入且难以适应不同语境。
另一方面,基于统计模型的方法则依赖于大规模的语料库,通过统计和建模的方式进行分词和词性标注。
然而,这些方法在处理复杂语境和未知词汇时效果有限。
近年来,随着深度学习的兴起,基于神经网络的中文自动分词和词性标注模型逐渐成为研究热点。
其中,基于循环神经网络(RNN)的模型如BiLSTM-CRF(双向长短时记忆网络-条件随机场)模型被广泛使用并取得了令人瞩目的效果。
该模型利用LSTM单元来捕捉输入序列的上下文信息,并利用条件随机场模型来建模序列标注问题。
此外,基于注意力机制的模型如Transformer也在中文自动分词和词性标注任务中取得了优异的表现。
3. 深度学习方法在中文自动分词中的应用中文自动分词是将连续的汉字序列划分为具有独立语义的词组的任务。
传统的基于规则或统计的方法在处理未知词汇和复杂语境时存在一定的限制。
而基于深度学习的方法通过端到端的学习方式,可以更好地捕捉上下文信息,并通过大规模的语料库进行训练,从而提高分词的准确性和鲁棒性。
中文信息处理与挖掘知到章节答案智慧树2023年山东交通学院

中文信息处理与挖掘知到章节测试答案智慧树2023年最新山东交通学院第一章测试1.本课程将详细介绍的自然语言处理应用有哪些()。
参考答案:自动问答;情感分析;机器翻译;自动摘要2.下列那个概念与自然语言处理无关。
()参考答案:Computer Vision3.黏着型语言比较有代表性的语言是日语。
()参考答案:对4.自然语言中最小的有意义的构成单位是()。
参考答案:词5.中文信息处理的第一步是()。
参考答案:分词6.如果打开校正功能,对于一些典型的语法错误、拼写错误以及用词错误就可以自动检测出来。
( )参考答案:对7.就分词来讲,主要有三类分词方法()。
参考答案:基于规则的分词方法;基于词典的分词方法;基于统计的分词方法8.基于词典的分词方法从匹配的方法来讲,一般使用最大匹配法,而最匹配法又包括()。
参考答案:逆向最大匹配算法;双向最大匹配算法;正向最大匹配算法9.词性标注的主要方法主要有()。
参考答案:统计与规则相结合的词性标注方法;基于规则的词性标注方法;基于统计的词性标注方法10.命名实体识别事实上就是识别出以下三类命名实体。
()参考答案:人名;组织机构名;地名第二章测试1.概率论作为统计语言模型的数学基础,应用到自然语言处理领域,是由于:统计语言处理技术已经成为自然语言处理的主流,而在统计语言处理的步骤中,收集自然语言词汇(或者其他语言单位)的分布情况、根据这些分布情况进行统计推导都需要用到概率论。
()参考答案:对2.设E为随机试验,Ω是它的样本空间,对于E的每一个事件A赋予一个实数,记为P ( A ),如果集合函数P ( ⋅ )满足下列哪些条件,则实数P ( A )为事件A的概率。
()参考答案:规范性;非负性;可列可加性3.设A、B是两个事件,且P(B)>0,则称P(A|B)为在已知事件B发生的条件下,事件A发生的()。
参考答案:条件概率4.某一事件B的发生有各种可能的原因n个,B发生的概率是各原因引起B发生概率的总和,也就是()。
stanfordcorenlp中文分词

Stanford CoreNLP是一种自然语言处理工具,它提供了一系列功能,包括分词、词性标注、命名实体识别、情感分析等。
其中,分词是自然语言处理中的基础任务之一,它将文本转化为词汇序列,为后续的语言分析和理解提供了基础。
1. Stanford CoreNLP的中文分词功能Stanford CoreNLP工具提供了专门针对中文的分词模块。
该模块采用了最新的中文分词算法,并且在准确性和速度上都有较好的表现。
通过Stanford CoreNLP中文分词功能,用户可以将中文文本进行分词处理,得到每个词汇的具体位置和内容。
2. 中文分词的重要性中文是一种词汇丰富、语法复杂的语言,其分词任务相对于英文等其他语言而言更为复杂。
正确的中文分词能够为后续的语言处理任务提供可靠的基础。
在信息检索、情感分析、机器翻译等领域中,准确的中文分词都是至关重要的。
3. Stanford CoreNLP中文分词的优势Stanford CoreNLP中文分词模块在准确性和速度上都具有一定的优势。
它采用了最新的中文分词算法,能够充分考虑词语的上下文语境,提高了分词的准确性。
Stanford CoreNLP中文分词模块还优化了算法的运行效率,能够在较短的时间内处理大规模的中文文本数据。
4. 如何使用Stanford CoreNLP进行中文分词要使用Stanford CoreNLP进行中文分词,首先需要下载并安装Stanford CoreNLP工具包。
在使用该工具时,通过简单的调用API接口即可实现中文分词的功能。
用户可以将待分词的中文文本作为输入,经过Stanford CoreNLP处理后,得到分词后的结果。
5. 应用范围Stanford CoreNLP中文分词模块能够应用于各种涉及中文文本处理的场景。
在搜索引擎中,对用户输入的搜索关键词进行分词处理,可以提高搜索结果的准确性;在情感分析中,分词能够帮助识别文本中的情感色彩,从而进行情感倾向的分析。
中文分词案例

中文分词案例中文分词是自然语言处理中的一个重要任务,其目的是将连续的中文文本切分成单个的词语。
中文分词在很多应用中都起到了关键作用,例如机器翻译、信息检索、文本分类等。
本文将以中文分词案例为题,介绍一些常用的中文分词方法和工具。
一、基于规则的中文分词方法1. 正向最大匹配法(Maximum Matching, MM):该方法从左到右扫描文本,从词典中找出最长的词进行匹配,然后将该词从文本中删除。
重复这个过程,直到文本被切分完毕。
2. 逆向最大匹配法(Reverse Maximum Matching, RMM):与正向最大匹配法相反,该方法从右到左扫描文本,从词典中找出最长的词进行匹配,然后将该词从文本中删除。
重复这个过程,直到文本被切分完毕。
3. 双向最大匹配法(Bidirectional Maximum Matching, BMM):该方法同时使用正向最大匹配和逆向最大匹配两种方法,然后选择切分结果最少的作为最终结果。
二、基于统计的中文分词方法1. 隐马尔可夫模型(Hidden Markov Model, HMM):该方法将中文分词问题转化为一个序列标注问题,通过训练一个隐马尔可夫模型来预测每个字的标签,进而切分文本。
2. 条件随机场(Conditional Random Fields, CRF):与隐马尔可夫模型类似,该方法也是通过训练一个条件随机场模型来预测每个字的标签,进而切分文本。
三、基于深度学习的中文分词方法1. 卷积神经网络(Convolutional Neural Network, CNN):该方法通过使用卷积层和池化层来提取文本特征,然后使用全连接层进行分类,从而实现中文分词。
2. 循环神经网络(Recurrent Neural Network, RNN):该方法通过使用循环层来捕捉文本的时序信息,从而实现中文分词。
四、中文分词工具1. 结巴分词:结巴分词是一个基于Python的中文分词工具,它采用了一种综合了基于规则和基于统计的分词方法,具有较高的准确性和速度。
基于词性的中文文本分类系统的研究与设计的开题报告

基于词性的中文文本分类系统的研究与设计的开题报告一、选题背景随着互联网时代的发展,大量的中文文本数据被广泛产生和传播,如何从这些数据中获得有用的信息成为了非常重要的课题。
中文文本分类是文本挖掘和自然语言处理中的一个热门研究领域,旨在将文本数据分为不同的类别,为用户和企业提供更有效地信息检索和管理平台,提高文本数据的利用价值。
传统的中文文本分类方法主要基于词汇分布假设,即假设一个文本的主题可以通过分析其中某些词在文本中的分布情况来得出。
然而,这种方法对于语言的多义性、情感倾向等因素的处理不足,导致分类的准确性有限。
近年来,随着深度学习和表示学习等技术的发展,基于神经网络的中文文本分类方法得到了广泛的应用,但由于其需要大量的数据和计算资源,对于小规模数据和简单分类任务的处理并不高效。
因此,本文基于词性标注的中文文本分类方法,旨在通过将中文文本的词语转化为其对应的词性表示,提高分类方法的准确性和效率,并且针对小数据规模和简单分类任务的场景具有一定的优势。
二、研究目的和意义本文旨在设计和实现一种基于词性标注的中文文本分类方法,该方法可以从中文文本数据中自动提取对应的词性标注特征,并将其用于分类器的训练和分类任务的处理。
该方法的实现可以有助于:1. 提高中文文本分类方法的准确性和效率;2. 针对小规模数据和简单分类任务的场景,提供高效的分类解决方案;3. 推广和应用词性标注在中文文本处理中的应用。
三、研究方法和技术路线本文将采用以下的技术和方法:1. 中文分词和词性标注技术:采用开源的中文分词和词性标注工具,将中文文本转化为对应的词语和词性序列。
2. 特征提取及表示学习技术:通过处理词性序列,提取其中的关键特征,并利用传统的机器学习算法或者神经网络模型进行训练和分类。
3. 实验设计和数据集构建:本文将从多个角度评估所提出的方法的性能,并使用公开数据集或者自行构建的数据集进行实验,对比和分析所提出方法的有效性和优劣。
fmm方法 -回复

fmm方法-回复什么是FMM方法?FMM方法,即正向最大匹配(Forward Maximum Matching)方法,是一种中文分词算法。
分词是将连续的文本切分成有意义的词语的过程,对于中文来说尤为重要。
FMM方法使用词典和规则进行切分,可以有效地解决中文分词问题。
正向最大匹配方法是指从左向右依次匹配词典中最长的词语,从而得到切分结果。
具体来说,FMM方法通过逐个匹配输入文本的每个字符,将已匹配到的字串与词典中的词语进行比对,若匹配成功则将该词切分出来,继续进行下一轮匹配。
若匹配不成功,则继续向后匹配下一个字。
一直到文本的末尾,或者切分达到预定的最大词长为止。
FMM方法的核心思想是贪心算法,即每次都选择最长的匹配,以期望能够得到准确的切分结果。
不过,FMM方法并不能保证得到最优解,因为可能会遭遇歧义或未登录词的问题。
但在实际应用中,FMM方法的效果已经被证明是很好的。
下面将详细介绍FMM方法的实现步骤:Step 1: 准备词典首先,我们需要构建一个包含常用词语的词典。
词典中的每个词条至少包含一个词语和词性标注。
词典可以通过人工抽取常见词汇,或者从大规模中文语料库中自动获取。
Step 2: 读取输入文本将待切分的文本读入内存,可以是一个字符串或一个文件。
如果是一个文件,需要逐行读取其中的文本。
Step 3: 正向匹配对于每个待切分的文本,从左至右逐个匹配字符。
首先,设置一个指针指向文本的起始位置,并定义一个滑动窗口的大小,表示当前待匹配的字串长度。
然后,从词典中找出包含该字串的最长词语和对应的词性标注。
如果找到匹配项,则将该词语切分出来,将指针向后移动该词语的长度,并将滑动窗口重置为最大词长;如果没有找到匹配项,则将滑动窗口向前滑动一个字符,并继续匹配。
Step 4: 输出切分结果重复上述步骤,直到文本的末尾。
最后,输出所有切分出的词语和对应的词性标注,或将其保存至一个文件中。
FMM方法的优点是简单易懂,实现起来较为轻松。
基于序列标注的中文分词、词性标注模型比较分析

a n d s p e e d a r e c o n s i d e r e d d u r i n g t h e c o mp a r i s o n .Fi r s t o f t h e s e t h r e e mo d e l s a r e p i p e l i n e s e q u e n t i a 1 mo d e 1 . Th e s e c —
t h e s t a c k e d l e a r n i n g mo d e l a c h i e v e s t h e h i g h e s t a c c u r a c y .Fi n a l l y ,we c o mp a r e o u r s t a c k e d l e a r n i n g mo d e l wi t h s t a t e -
第 2 7 卷 第 4期 2 0 1 3年 7月
中文 信息 学报
J OURNA L OF CH I NE S E I NFORM ATI ON P ROCES S I NG
Vo l I 2 7 ,No .4
J u 1 . ,2 0 1 3
文章 编号 : 1 0 0 3 — 0 0 7 7 ( 2 0 1 3 ) 0 4 — 0 0 3 0 — 0 7
第一届古代汉语分词和词性标注国际评测

05
结论和建议
结论总结
01
02
03
本次评测的参赛者普遍表现出色,整 体上对古代汉语分词和词性标注任务 有较深入的理解和掌握。
在分词方面,大多数参赛者能够正确 处理常见词汇和语法结构,但在处理 复杂语句和特定领域词汇时仍存在一 定挑战。
在词性标注方面,大多数参赛者能够 较好地标注出词汇的基本词性,但在 标注多义词和复杂句子的词性时仍需 进一步提高准确性。
可以考虑引入更多的复杂句子和特定 领域词汇作为评测难点,以进一步考 察参赛者的技术和能力。
展望未来,随着自然语言处理技术的 发展,相信古代汉语分词和词性标注 技术将不断提升,为相关领域的研究 和应用提供更好的支持。
感谢您的观看
THANKS
第一届古代汉语分词和词性 标注国际评测
2023-11-04
目录
• 评测背景和目标 • 评测任务和数据集 • 参赛系统和评测结果 • 分析和讨论 • 结论和建议
01
评测背景和目标
古代汉语分词和词性标注的重要性
理解古代文献
对古代汉语进行分词和词性标注是理解古代文献的关键步骤,有助于提高理 解的准确性和完整性。
总结词
词性标注是对每个词语进行语义分类的过 程,有助于深入理解句子的含义和结构。
VS
详细描述
词性标注准确率评测的任务是基于人工标 注的词性结果,评估算法对古代汉语文本 进行预处理
总结词
本评测使用的数据集包含多种古代汉语语料库,涵盖了多个历史时期和语言风格。
任务A:分词准确率评测
总结词
分词是古代汉语处理中的重要任务之一,旨在将句子拆分成 单独的词语,为后续的词性标注和句法分析等任务提供基础 。
详细描述
中文文本关键词抽取的三种方法(TF-IDF、TextRank、word2vec)
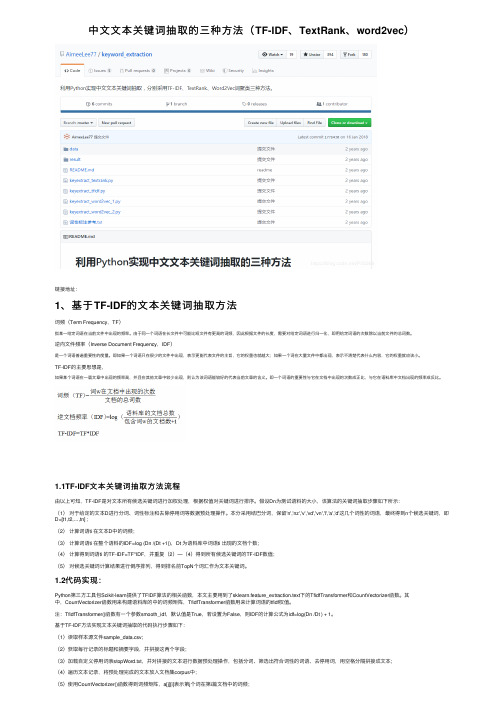
中⽂⽂本关键词抽取的三种⽅法(TF-IDF、TextRank、word2vec)链接地址:1、基于TF-IDF的⽂本关键词抽取⽅法词频(Term Frequency,TF)指某⼀给定词语在当前⽂件中出现的频率。
由于同⼀个词语在长⽂件中可能⽐短⽂件有更⾼的词频,因此根据⽂件的长度,需要对给定词语进⾏归⼀化,即⽤给定词语的次数除以当前⽂件的总词数。
逆向⽂件频率(Inverse Document Frequency,IDF)是⼀个词语普遍重要性的度量。
即如果⼀个词语只在很少的⽂件中出现,表⽰更能代表⽂件的主旨,它的权重也就越⼤;如果⼀个词在⼤量⽂件中都出现,表⽰不清楚代表什么内容,它的权重就应该⼩。
TF-IDF的主要思想是,如果某个词语在⼀篇⽂章中出现的频率⾼,并且在其他⽂章中较少出现,则认为该词语能较好的代表当前⽂章的含义。
即⼀个词语的重要性与它在⽂档中出现的次数成正⽐,与它在语料库中⽂档出现的频率成反⽐。
1.1TF-IDF⽂本关键词抽取⽅法流程由以上可知,TF-IDF是对⽂本所有候选关键词进⾏加权处理,根据权值对关键词进⾏排序。
假设Dn为测试语料的⼤⼩,该算法的关键词抽取步骤如下所⽰:(1)对于给定的⽂本D进⾏分词、词性标注和去除停⽤词等数据预处理操作。
本分采⽤结巴分词,保留'n','nz','v','vd','vn','l','a','d'这⼏个词性的词语,最终得到n个候选关键词,即D=[t1,t2,…,tn] ;(2)计算词语ti 在⽂本D中的词频;(3)计算词语ti 在整个语料的IDF=log (Dn /(Dt +1)),Dt 为语料库中词语ti 出现的⽂档个数;(4)计算得到词语ti 的TF-IDF=TF*IDF,并重复(2)—(4)得到所有候选关键词的TF-IDF数值;(5)对候选关键词计算结果进⾏倒序排列,得到排名前TopN个词汇作为⽂本关键词。
基于BiLSTM-CRF的中文分词和词性标注联合方法

第 54 卷第 8 期2023 年 8 月中南大学学报(自然科学版)Journal of Central South University (Science and Technology)V ol.54 No.8Aug. 2023基于BiLSTM-CRF 的中文分词和词性标注联合方法袁里驰(江西财经大学 软件与物联网工程学院,江西 南昌,330013)摘要:针对中文分词、词性标注等序列标注任务,提出结合双向长短时记忆模型、条件随机场模型和马尔可夫族模型或树形概率构建的中文分词和词性标注联合方法。
隐马尔可夫词性标注方法忽略了词本身到词性的发射概率。
在基于马尔可夫族模型或树形概率的词性标注中,当前词的词性不但与前面词的词性有关,而且与当前词本身有关。
使用联合方法有助于使用词性标注信息实现分词,有机地将两者结合起来有利于消除歧义和提高分词、词性标注任务的准确率。
实验结果表明:本文使用的中文分词和词性标注联合方法相比于通常的双向长短时记忆模型−条件随机场分词模型能够大幅度提高分词的准确率,并且相比于传统的隐马尔可夫词性标注方法能够大幅度提高词性标注的准确率。
关键词:双向长短时记忆模型;中文分词;词性标注;马尔可夫族模型;树形概率中图分类号:TP391.1 文献标志码:A 文章编号:1672-7207(2023)08-3145-09A joint method for Chinese word segmentation and part-of-speech tagging based on BiLSTM-CRFYUAN Lichi(School of Software and Internet of Things Engineering, Jiangxi University of Finance and Economics,Nanchang 330013,China)Abstract: For sequence tagging tasks such as Chinese word segmentation and part-of-speech tagging, a joint method for Chinese word segmentation and part-of-speech tagging that combines BiLSTM(bi-directional long-short term memory model), CRF(conditional random field model), Markov family model(MFM) or tree-like probability(TLP) was proposed. Part-of-speech tagging method based on HMM(hidden markov model) ignores the emission probability of the word itself to the part-of-speech. In part-of-speech tagging based on MFM or TLP, the part-of-speech of the current word is not only related to the part-of-speech of the previous word, but also related to the current word itself. The use of the joint method helps to use part-of-speech tagging information to achieve word segmentation, and organically combining the two is beneficial to eliminate ambiguity and improve the收稿日期: 2023 −02 −20; 修回日期: 2023 −03 −24基金项目(Foundation item):国家自然科学基金资助项目(61962025,61562034) (Projects(61962025, 61562034) supported by theNational Natural Science Foundation of China)通信作者:袁里驰,博士,教授,从事自然语言处理研究;E-mail :*****************DOI: 10.11817/j.issn.1672-7207.2023.08.018引用格式: 袁里驰. 基于BiLSTM-CRF 的中文分词和词性标注联合方法[J]. 中南大学学报(自然科学版), 2023, 54(8): 3145−3153.Citation: YUAN Lichi. A joint method for Chinese word segmentation and part-of-speech tagging based on BiLSTM-CRF[J]. Journal of Central South University(Science and Technology), 2023, 54(8): 3145−3153.第 54 卷中南大学学报(自然科学版)accuracy of word segmentation and part-of-speech tagging tasks. The results show that the joint method of Chinese word segmentation and part-of-speech tagging used in this paper can greatly improve the accuracy of word segmentation compared with the usual word segmentation model based on BiLSTM-CRF, and it can also greatly improve the accuracy of part-of-speech tagging compared with the traditional part-of-speech tagging method based on HMM.Key words: bi-directional long-short term memory model; Chinese word segmentation; part-of-speech tagging; Markov family model; tree-like probability分词的目的是将一个完整的句子切分成词语级别。
中文nlp的基本流程

中文nlp的基本流程自然语言处理(NLP)是一项涉及计算机科学、人工智能和语言学等多个领域的交叉学科。
它旨在使计算机能够理解、处理和生成自然语言,以便与人类进行有意义的交流。
中文NLP作为NLP的一个分支,其研究对象是中文语言,其基本流程包括文本预处理、分词、词性标注、命名实体识别、句法分析、语义分析等多个步骤。
本文将详细介绍中文NLP的基本流程。
一、文本预处理文本预处理是NLP的第一步,其目的是将原始文本转换为可供后续处理的文本格式。
中文NLP中的文本预处理包括以下几个方面:1. 文本清洗:删除文本中的HTML标签、特殊符号、停用词等无用信息,保留文本中的有用信息。
2. 文本分段:将文本按照段落进行分段,以便后续处理。
3. 文本分句:将文本按照句子进行分句,以便后续处理。
4. 繁简转换:将繁体中文转换为简体中文,以便后续处理。
二、分词分词是中文NLP的重要一环,其目的是将中文文本按照词语进行划分。
中文分词的难点在于中文词语没有明显的分隔符,因此需要使用专门的分词工具进行处理。
中文分词的常用工具包括jieba、THULAC、HanLP等。
例如,对于下面这句话:“我喜欢中文NLP”,使用jieba进行分词后,可以得到以下结果:我喜欢中文 NLP三、词性标注词性标注是将分词后的词语赋予相应的词性标记。
中文的词性标记包括名词、动词、形容词、副词、介词、连词、助词、叹词等。
中文词性标注的常用工具包括jieba、THULAC、HanLP等。
例如,对于下面这句话:“我喜欢中文NLP”,使用jieba进行分词和词性标注后,可以得到以下结果:我/r 喜欢/v 中文/n NLP/eng四、命名实体识别命名实体识别是将文本中的具有特定意义的实体(如人名、地名、组织机构名等)进行识别和分类。
命名实体识别是中文NLP中的一个重要任务,其应用广泛,如信息抽取、机器翻译、问答系统等。
中文命名实体识别的常用工具包括jieba、THULAC、HanLP等。
ictclas 标记法

ictclas 标记法ICTCLAS标记法是一种中文分词和词性标注的方法,它可以将一段中文文本按照词汇的语义进行切分,并为每个词汇添加相应的词性标记。
本文将介绍ICTCLAS标记法的基本原理和应用。
ICTCLAS标记法是基于统计模型的一种分词和词性标注方法。
它的基本原理是通过训练大量的中文语料库,学习中文词汇的出现概率和词性的分布规律。
在这个过程中,ICTCLAS会根据词汇的上下文语境,对每个词进行分词,并为每个词汇添加相应的词性标记。
ICTCLAS标记法的应用非常广泛。
首先,在自然语言处理领域,ICTCLAS可以作为中文分词的基础工具。
通过将一段中文文本进行分词,可以为后续的文本处理任务提供准备。
其次,在信息检索和文本挖掘领域,ICTCLAS可以用来对大规模的中文文本进行分析和处理。
通过将文本进行分词和词性标注,可以为后续的信息检索和文本挖掘任务提供更加准确和精细的特征表示。
此外,在机器翻译和自动问答等任务中,ICTCLAS也可以用来提高系统的性能和效果。
ICTCLAS标记法的使用非常简单。
只需要将待处理的中文文本输入ICTCLAS系统,系统会自动对文本进行分词和词性标注,并输出分词结果和词性标记。
用户可以根据自己的需要,选择不同的参数设置和输出格式。
总结起来,ICTCLAS标记法是一种基于统计模型的中文分词和词性标注方法。
它可以将一段中文文本按照词汇的语义进行切分,并为每个词汇添加相应的词性标记。
ICTCLAS标记法在自然语言处理、信息检索、文本挖掘、机器翻译和自动问答等领域都有广泛的应用。
通过使用ICTCLAS标记法,可以提高系统的性能和效果,实现更加准确和精细的文本处理和分析。
Word文档中的文字排序和筛选技巧

Word文档中的文字排序和筛选技巧在日常工作和学习中,我们经常需要对文档中的文字进行排序和筛选,以便更好地组织和管理信息。
Word作为一个功能强大的文档处理工具,提供了多种方法来实现文字的排序和筛选。
本文将介绍几种常用的技巧,帮助您在Word文档中高效地进行文字排序和筛选。
一、文字排序技巧1. 升序排序:按照字母或数字的顺序对文本进行升序排序是一种常见的需求。
在Word中,您可以通过以下方法实现文字的升序排序:(1)选中需要排序的文字。
(2)点击“开始”选项卡中的“排序”按钮。
(3)在弹出的对话框中选择“升序”方式,并点击“确定”按钮即可。
2. 降序排序:与升序排序相反,降序排序是按照字母或数字的逆序对文本进行排序。
在Word中,您可以按照以下步骤实现降序排序:(1)选中需要排序的文字。
(2)点击“开始”选项卡中的“排序”按钮。
(3)在弹出的对话框中选择“降序”方式,并点击“确定”按钮即可。
3. 多级排序:有时候我们需要按照多个标准对文本进行排序,比如先按照字母排序,再按照数字排序。
Word提供了多级排序功能,您可以按照以下步骤实现多级排序:(1)选中需要排序的文字。
(2)点击“开始”选项卡中的“排序”按钮。
(3)在弹出的对话框中选择“自定义排序”选项卡。
(4)点击“添加级别”按钮,添加排序标准,并设置升序或降序方式。
(5)点击“确定”按钮进行排序。
4. 按列排序:在Word中,您还可以按照表格列来进行排序。
只需选中需要排序的列,然后执行上述排序步骤即可。
二、文字筛选技巧1. 条件筛选:Word提供了强大的条件筛选功能,可以根据指定的条件对文本进行筛选。
具体操作如下:(1)选中需要筛选的文字。
(2)点击“开始”选项卡中的“条件筛选”按钮。
(3)在弹出的下拉菜单中选择“自定义筛选”。
(4)根据需要设置筛选条件,并点击“确定”按钮。
2. 文本筛选:有时候我们需要找到并显示文档中特定的文字,比如某个单词或短语。
自然语言处理中语料预处理的方法

自然语言处理中语料预处理的方法一、概述语料预处理是自然语言处理中的一个重要环节,它是指对原始文本进行清洗、分词、词性标注等操作,以便于后续的文本分析和挖掘。
本文将从数据收集、数据清洗、分词和词性标注四个方面介绍语料预处理的方法。
二、数据收集1. 网络爬虫网络爬虫是一种自动化程序,可以在互联网上抓取特定网站的内容。
使用网络爬虫可以快速地获取大量的文本数据。
2. 数据库导出如果已经有了存储在数据库中的文本数据,可以通过数据库导出功能将其导出为txt或csv格式的文件。
3. 其他来源除了网络爬虫和数据库导出外,还可以从其他渠道获取文本数据,例如公开数据集或人工采集等。
三、数据清洗1. 去除HTML标签和特殊符号在从网络上抓取到文本数据时,往往会包含HTML标签和特殊符号等无用信息。
可以使用正则表达式或BeautifulSoup等工具去除这些信息。
2. 去除停用词停用词是指那些在自然语言中频繁出现但没有实际意义的单词,如“的”、“了”、“是”等。
可以使用停用词表将这些单词去除。
3. 大小写转换将文本数据中的所有字母转换为小写或大写,可以避免因大小写不一致而导致的错误。
四、分词1. 基于规则的分词基于规则的分词是指利用人工定义的规则对文本进行分词。
例如,可以根据中文单词的构成规则(如汉字和拼音)来进行分词。
2. 基于统计模型的分词基于统计模型的分词是指利用机器学习算法对文本进行自动划分。
例如,可以使用隐马尔可夫模型或条件随机场模型等算法来进行中文分词。
3. 混合式分词混合式分词是指将基于规则和基于统计模型两种方法结合起来使用,以提高分词效果。
五、词性标注1. 基于规则的标注基于规则的标注是指利用人工定义的语法规则对文本进行标注。
例如,可以根据中文句法结构(如主谓宾)来进行标注。
2. 基于统计模型的标注基于统计模型的标注是指利用机器学习算法对文本进行自动标注。
例如,可以使用隐马尔可夫模型或条件随机场模型等算法来进行中文词性标注。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本文采 用Collins (2002) 的平均感知机训练 算法 ,训练分词与词性标注分类器。算法1 描 述了感知机训练算法。我们采用“平均参数” 技术来避免过拟合。训练的过程就是学习一个 从输入 x ∈ X 映射到输出 y ∈ Y 的判别模型, X 是训练语料中的句子集合, Y 是相应的标记结 果。Jiang et al. (2009) 中使用了 GEN ( x) 函数列 举输入 x 的所有候选结果,表示每个训练实例 ( x, y ) ∈ X × Y 映射到特征向量 Φ( x, y) ∈ R d , 对于一 个特征向量, α ∈ R d 是与其对应的参数向量。对 于一个输入的汉字串 x ,目的是找到一个满足下 式的输出结果 F ( x) : F ( x) = arg max Φ ( x, y ) ⋅ α (1)
2: α ← 0 3: for 4: 5: 6: 7:
t ← 1T
感知机训练算法
1: Input: Training examples ( xi , y i )
do
for i ← 1 N do if
z i ≠ yi
z i ← arg max z∈GEN ( xi ) Φ ( xi , z ) ⋅ α
8: Output: Parameters α
训练算法
2.1
分词与词性标注特征模板
根据 Ng and Low (2004),用 C0 表示当前的 汉字, C−i 表示 C0 左边第 i 个汉字, Ci 表示 C0 右 边第 i 个汉字。 Pu (Ci ) 用于判断当前汉字 Ci 是否 为分隔符(是就返回 1,否则返回 0)。 T (Ci ) 用于 判断当前汉字 Ci 的类别:数字,日期,英文字 母,和其它(分别返回 1, 2, 3 和 4)。
摘要
用同样的语料和特征模板。在分词结果上,本 方法可以达到传统重排序方法在 nbest-100 上做 重排序的效果,略低于在压缩词图上做重排序 的效果。在联合分词与词性标注结果上,本方 法超过传统的重排序方法,相对于在 nbest-100 上做重排序的结果,本方法再次提高0.3个百分 点,错误率再次下降4.32%,并且与在压缩词图 上做重排序的方法性能相当。 接下来,我们在第2节介绍字标注分词和词 性标注方法,第3节详细阐述在线重排序方法, 第 4 节列举相关工作,第 5 节是本文实验及结果 分析,第6节是对本文的总结与展望。
cands[i − 1] 与 Ci 组合生成一定数量的 C1:i 的候 选结果,再由 cands[i − 2] 与 Ci −1Ci 组合生成一
定数量的 C1:i 的候选结果,按此依次生成所有
1 2 3 4 5 6 7 8
W0 W−1W0 S (W0 ) W0T0 W−1 T−1 T−2T−1 T−3T−2T−1
其中 Φ( x, y) ⋅ α 表示特征向量 Φ( x, y) 和参数向量
y∈GEN ( x )
的内积。本文沿用此方法。
3
在线重排序方法
Ci (i = −2...2) 1 C 2 i Ci +1 (i = −2...1) C−1C1 3 Pu (C0 ) 4 T ( C ) T ( C 5 −2 −1 )T (C0 )T (C1 )T (C2 ) 表 1 分词和词性标注的局部特征模板
p ⋅ scorelocal ←
表 2 分词与词性标注的全局特征模板
3.2
在线重排序方法
本文提出的在线重排序方法的基本思想是 利用局部字特征和全局特征共同作用,完成分 词与词性标注的解码过程。解码时,为每个字 维护一个堆栈,用来存储从第一个字到当前字 为止的候选结果集,利用这些结果计算局部特 征和全局特征分数,根据“局部特征 + 全局特 征”的总分数进行重排序。解码的过程实际上 就是为每个字构建从第一个字到当前字为止字 序列的候选结果表 的过程。算法2 是在线重排 序解码算法,详细描述了联合分词与词性标注 的在线重排序解码过程。 3-16 行考虑到了字序列 C1:n 中的每个汉字
5: 6: 7: 8: 9: 10: 11: 12: 13: 14: 15: 16:
Evallocal ( p )
for d ∈ cands[i − l ] do
pnew ← d + p
pnew ⋅ scorelocal ← p ⋅ scorelocal + d ⋅ scorelocal
pnew ⋅ score ←
对于句子 s 的 n-best 候选结果 cand ( s ) ,重 ˆ: 排序是从 cand ( s ) 中选择最好的结果 y
ˆ arg max w ⋅ f ( y ) = y
y∈cand ( s 量 f 和权重向量 w 的点积, 点积的结果用于对候选结果 cand ( s ) 重排序。
在线重排序方法利用的特征包括两部分, 一部分是局部的字特征,另一部分是全局的 词、词性特征。全局特征分数的计算方式与传 统的重排序方法类似,因此,本节首先介绍传 统的重排序方法,再介绍在线重排序方法。
3.1
传统的重排序方法
表 1 描述了分词和词性标注的局部特征模 板,假设当前分析的是“450 公里”中的“0” 字,特征模板生成的特征如下:
算法 2 在线重排序解码算法 1: Input: Character Sequence C1:n 2: cands[1...n] ← ∅ 4: 3: for i ← 1...n do cands[i ] ← ∅ for l ← 1 min(i, K ) do w = Ci −l +1:i for t ∈ POS do p ←< w, t >
了从第1个字到第 i − l 个字 Ci −l 为止的候选分词 与词性标注候选结果 d ∈ Cand [i − l ] , d 与 p 组 合成新的结果 pnew , pnew 就是从第1个字到第 i 字为止的一个候选分词与词性标注结果。构建 Ci 对 应 的 候 选 结 果 表 cands[i ] 时 , 由
中文分词和词性标注的在线重排序方法
孟凡东 谢军 刘群 中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190 {mengfandong,xiejun,liuqun}@
特征,增大解码空间,结果比单独分词、词性 标注的基线系统效果都好。 基于字标注的分词方法,通常使用的是局 当前主流的中文分词与词性标注方法将 部特征。局部特征是在一定长度的窗口范围内 分词和词性标注问题看成是序列标注问 抽取字的上下文信息,距离该字较远的信息难 题,通常利用局部特征训练判别式模 以得到充分的利用。虽然只利用局部特征已经 型。该方法取得了很好的效果,但是与 可以取得很好的结果,但是引入全局特征可以 词、词性相关的全局特征并没有被充分 进一步增强处理歧义的能力,对于分词与词性 的利用。为了更好的处理分词和词性标 标注来说是有帮助的。 注的歧义,传统的重排序方法在第一次 通常使用全局特征的方法是重排序方法。 解码的 n-best 候选结果集上,利用全局 即第一次利用局部特征训练分类器进行解码, 特征进行二次解码,重新选择一个更好 保留 n-best 候选结果表;然后利用重排序技术 的结果。该方法往往需要保留较大的候 进行第二次解码,在这 n-best 候选结果列表里 选结果集,并需要两次解码。本文提出 重新选择出最好的结果。这种方法在一定程度 了一种在线重排序方法,将重排序过程 上提高了分词、词性标注的效果,但是往往需 融合到一次解码的过程中,充分利用局 要在第一次解码时保留较大的 n-best 列表,才 部和全局特征,在一次解码时利用更多 能找到真正的最优解。 信息以减少搜索错误,选择一个更好的 本文提出中文分词与词性标注的在线重排 结果。本文在中文宾州树库 (CTB5.0) 和 序方法,将分词解码过程与重排序过程融合在 微软亚洲研究院语料(MSR)上做实验,结 一个框架下,在充分利用传统的局部特征的基 果表明,本方法相对于只用局部特征训练 础上,补充利用全局特征。利用堆栈搜索算法 的基线系统以及传统的重排序方法都有 解码。我们为每个字保留一个堆栈,存储从第 明显的效果提升。 一个字到当前字为止的最好的候选结果集,以 供在线重排序使用。相对于传统的重排序方 1 引言 法,本方法旨在一次解码过程中利用更多的信 息尽量避免错误,以便搜索到更好的结果。本 Xue and Shen (2003) 首先提出将分词问题 方法只需要为每个字保留一个很小的堆栈,效 转化为基于字的序列标注问题,当前主流的中 果就有明显的提升。 文分词方法基本上采用这个思想,利用最大 本文在CTB5.0和MSR语料上做实验,实验 熵 (Ratnaparkhi and Adwait, 1996)、 条件随机场 结果表明,本方法相对于仅用局部特征训练的 (Lafferty et al., 2001)、感知机算法 (Collins, 2002) 基线系统分词和词性标注错误率均有明显下 等训练判别式模型。相对于生成式的方法 降。相对于只用局部特征的基线系统, CTB和 (Rabiner, 1989; Fine et al., 1998),判别式方法处 MSR语料上的的分词错误率分别下降11.57%和 理未登录词的能力更强。Ng and Low (2004) 进 10.86% 。 CTB 的联合分词与词性标注错误率下 一步提出联合分词与词性标注的方法,将分词 降为5.65%。 和词性标注融合在统一的框架下,以词性作为 本文与 Jiang et al. (2008)进行对比,我们使
C1:i 的候选结果存入 cands[i ] 中。第12和13行计
算 pnew 的“局部特征”得分和“局部特征+全局 特征 ” 的总得分。第 15 行是将这个新结果存储 到字 Ci 对应的存储候选结果表 cands[i ] 中。第 16 行将 cands[i ] 中的结果根据特征总得分 s 从 大到小排序。第 17 行得到最后的结果,即最后 一个字的候选结果表 cands[n] 中得分最高的结 果 cands[n][0] 。