第1次作业数据
第1次作业

int fun(int a,int b)
{
int r,t;
if(a<b)
{
t=a;
/**********FOUND**********/
b=a;a=b;
/**********FOUND**********/
8.在C语言中,要求运算数必须是整型的运算符是()。B
A:^B:%C:!D:>
9.以下程序的运行结果是()。A
main()
{ int n;
for(n=1;n<=10;n++)
{
if(n%3==0) continue;
printf("%d",n);
}
}
A:12457810B:369C:12D:1234567890
程序填空
下面的程序是求1!+3!+5!+……+n!的和,程序中有4个空,填空使程序完整。
main()
{
long int f,s;
int i,j,n;
/***********SPACE***********/
【?】S=0;
scanf("%d",&n);
/***********SPACE***********/
A:预处理是指完成宏替换和文件包含中指定的文件的调用
B:预处理指令只能位于C源文件的开始
C:C源程序中凡是行首以#标识的控制行都是预处理指令
D:预处理就是完成C编译程序对C源程序第一遍扫描,为编译词法和语法分析作准备
7.C语言中,char类型数据占()。A
上海交通大学数据库第一次作业

题目1正确获得1.00分中的1.00分标记题目题干在关系数据库中,表的一行称为___。
一列称为____。
()选择一项:a. 字段,记录b. 向量,分量c. 变量,值d. 记录,字段反馈你的回答正确正确答案是:记录,字段题目2正确获得1.00分中的1.00分标记题目题干在一个关系表中,关于码(Key,又称键)下面说法正确的是。
()选择一项:a. 一个表中,码可以有重复的值b. 码只由一个字段构成c. 一个表只允许一个码d. 码唯一标识其对应的记录。
反馈你的回答正确正确答案是:码唯一标识其对应的记录。
题目3正确获得1.00分中的1.00分标记题目题干选择一项:a. ①~③b. ①~②c. ①~④d. ①反馈你的回答正确正确答案是:①~④题目4正确获得1.00分中的1.00分标记题目题干下面不属于...应用与数据库连接的软件组件为()。
选择一项:a. ADOb. JDBCc. ODBCd. ActiveX反馈你的回答正确正确答案是:ActiveX题目5正确获得1.00分中的1.00分标记题目题干应用与数据管理系统的组成结构()。
选择一项:a. 只能采用B/S(浏览器-服务器)模式b. 不能采用C/S(客户-服务器)模式或B/S(浏览器-服务器)模式中的任意一种c. 可以采用C/S(客户-服务器)模式或B/S(浏览器-服务器)模式d. 只能采用C/S(客户-服务器)模式反馈你的回答正确正确答案是:可以采用C/S(客户-服务器)模式或B/S(浏览器-服务器)模式题目6不正确获得1.00分中的0.00分标记题目题干E-R图中,表示m:n的联系及实体,至少需要建立()个关系模式(即表)。
选择一项:a. 3b. 1c. 2d. 4反馈你的回答不正确正确答案是:3题目7正确获得1.00分中的1.00分标记题目题干在一个关系表中,关于码(Key,又称键)下面说法正确的是()。
选择一项:a. 一个表中,码可以有重复的值。
数据结构(C++)第一次作业参考答案

数据结构第一次作业数据结构第一次作业一.单项选择题(20分)( )1.已知一算术表达式的后缀形式为ABC *+DE-/,则其中缀形式为 _________。
a、(A+B *C)/(D-E)b、A+B*C /D-Ec、(A+B*C)/D-Ed、A+B*C/(D-E)( )2.若某链表中最常用的操作是在最后一个结点之后插入一个结点和删除第一个结点,则采用________存储方式最节省运算时间(假设链表仅设有一个first指针)。
a. 单链表b. 带头结点的双循环链表c. 单循环链表d. 双链表( )3.设一个栈的输入序列为A,B,C,D,则所得到的输出序列不可能是_______。
a. A,B,C,Db. D,C,B,Ac. A,C,D,Bd. D,A,B,C( )4.若线性表最常用的操作是存取第i个元素及其直接前驱的值,则采用_____存储方式节省时间。
a.顺序表 b.双链表 c.单循环链表 d.单链表( )5.若长度为n的线性表采用顺序存储结构,在其第i个位置插入一个新元素的算法的时间复杂度为_______。
(1≤i≤n+1)a、O(0)b、O(1)c、O(n)d、O(n2)( )6.若指针L指向一带头结点的循环单链表的头结点,该表为空表的条件是_______为真值;a. !( L -> link );b. L == (L -> link) -> link;c. L -> link;d. L == L -> link;( )7.用数组A[0..N-1]存放一个循环队列,一元素出队时,其队头指针front的修改方法是________:a. front = (front + 1) mod N;b. front = (front - 2)mod N;c. front = front + 1;d. front = front – 2;( )8.若用Head()和Tail()分别表示取广义表的表头和表尾,广义表A=(1,2,(3,4),(5,(6,7))),则Head(Tail(Head(Tail(Tail(A))))) 。
数据结构第一次作业

第一行为第一个链表的各结点值,以空格分隔。
第二行为第二个链表的各结点值,以空格分隔。
【输出形式】
合并好的链表,以非降序排列,值与值之间以空格分隔。
【样例输入】
4 7 10 34
1 4 6 29 34 34 52
【样例输出】
1 4 6 7 10 29 34 52
【评分标准】
要使用链表实现,否则不能得分。
3.设n为大于1的正整数,计算机执行下面的语句时,带#语句的执行次数为n。
i=1;
j=0;
while(i+j<=n){
# if(i>j)
j++;
else
i++;
}
4.在具有n个链结点的链表中查找一个链结点的时间复杂度为O(n)。
5.下面程序段的时间复杂度为O(mn)。
for ( i = 0; i < n; i++ )
D.每个链结点有多少个直接后继结点,它就应该设置多少个指针域
8.将长度为m的线性链表链接在长度为n的线性链表之后的过程的时间复杂度若采用大O形式表示,则应该是B。
A.O(m) B.O(n) C.O(m+n) D.O(m-n)
9.在一个单链表中,若要在p所指向的结点之后插入一个新结点,则需要相继修改__个指针域
int time (int n) {
int count=0, x=2;
while ( x < n/2 ) {
x=2x;
count++;
}
return (count);
}
时间复杂度:O(logn)
count值:logn-2
JZX高等数值分析第一次实验作业
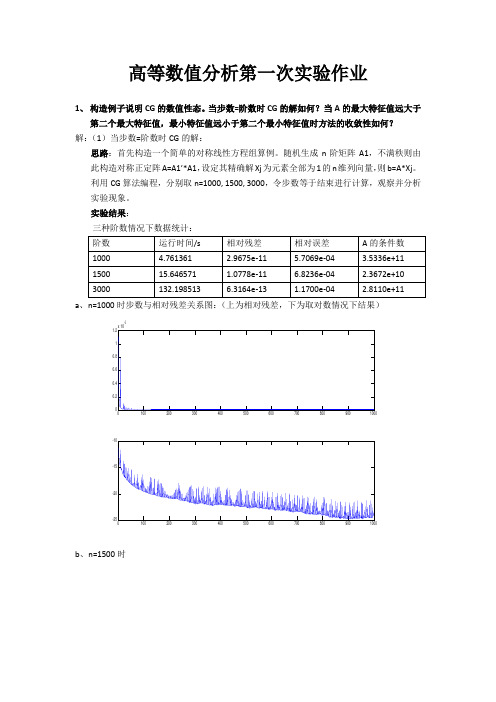
相对残差 6.1302e-16 8.7797e-09 8.0295e-09 8.5677e-09 9.1433e-09
a、 m=1 (左为相对残差,右为取对数情况)
1 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1
0 1
1.5
0
-5
-10
-15
-20
-25
-30
-35
-40
1000
4.761361
2.9675e-11
5.7069e-04
3.5336e+11
1500
15.646571
1.0778e-11
6.8236e-04
2.3672e+10
3000
132.198513
6.3164e-13
1.1700e-04
2.8110e+11
a、n=1000 时步数与相对残差关系图:(上为相对残差,下为取对数情况下结果)
(2)当 A 最大特征值远大于第二个特征值,最小特征值远小于第二个最小特征值时收敛
性情况。
思路:构造题目要求的矩阵 A。首先随机生成 n 阶矩阵 B,B 不满秩,构造对角阵 A1(最
大特征值远大于第二个最大特征值,最小特征值远小于第二个最小特征值),则由此构
造出对称正定矩阵 A: b1=B’*B; A=b1’*A1*b1。同样设定精确解 Xj 为元素全部为 1 的 n
5、 构造对称不定的矩阵,验证 Lanczos 方法的近似中断,观察收敛曲线中的峰点个数和特
征值的分布关系;观察当出现峰点时,MINRES 方法的收敛性态怎样。
解:思路:类似前两题,首先构造出一个 n 阶对角阵 D,其对角线上有 m 个负值,再对随
数据结构 第一次作业 测验答案 慕课答案 作业一 UOOC优课 课后练习 深圳大学

数据结构第一次作业一、单选题 (共100.00分)1. 已知栈S为空,数据1、2、3、4依次逐个进入栈S,则栈顶数据为()A. 1B. 2C. 3D. 4正确答案:D2. 栈的最大特点是()A. 先进先出B. 后进先出C. 无限递归D. 有限递归正确答案:B3. 队列的最大特点是()A. 先进先出B. 后进先出C. 无限递归D. 有限递归正确答案:A4. 已知栈包含10元素,其中存放在栈底是第1号元素,则第10号元素可以通过()进行访问A. 栈底B. 栈中C. 栈尾D. 栈顶正确答案:D5. 以下结构中,哪一个是属于物理结构()A. 栈B. 队列C. 链队列D. 线性表正确答案:C6. 使用长度为10的数组实现循环队列,则该队列最多存储数据个数为()A. 1B. 9C. 11.D.5正确答案:B7. 已知顺序表包含1000个数据,现在第88号位置插入新的数据,需要移动的数据个数为()A. 88B. 87C. 912D. 913正确答案:D8. 若线性表最常用的操作是存取第i个元素及其后继的值,则最节省操作时间的存储结构是()A. 单链表B. 双链表C. 单循环链表D. 顺序表正确答案:D9. 以下结构中,哪一个是属于物理结构()A. 线性表B. 栈C. 单链表D. 队列正确答案:C10. 已知顺序表包含100个数据,现在要删除第99号位置的数据,需要移动的数据个数为()A. 99B. 100C. 1D. 2正确答案:C已知指针p指向单链表L的某个结点,判断p指向的结点是尾结点的条件是()A. if (p->next>p)B. if (p->next==NULL)D. if (p->data==0)正确答案:B12. 以下描述哪个是正确的()A. 线性表的数据元素的存储位置一定是连续的B. 顺序表的数据元素的存储位置一定是连续的C. 链表的数据元素的存储位置一定不是连续的D. 线性表的数据元素的存储位置一定不是连续的正确答案:B已知顺序表包含100个数据,先在第15号位置插入1个新数据,接着删除第3号位置的数据,需要移动的数据总个数为()A. 18B. 84C. 184D. 188正确答案:C在数据结构概念中,数据的基本单位是()A. 数据段B. 数据项C. 数据表D. 数据元素D在数据结构概念中,结构是描述()A. 数据项的类型B. 数据元素之间的关系C. 数据成员的先后顺序D. 数据对象的取值范围正确答案:B在算法设计中,要求算法便于理解和修改是属于算法要求的()A. 正确性B. 可读性C. 健壮性D. 效率高正确答案:B以下关于算法的描述,哪个是正确的()A. 算法可以没有输入B. 算法可以包含无限个执行步骤C. 算法可以没有输出D. 算法的每个步骤允许带有歧义的正确答案:抽象数据类型ADT通过三方面描述,包括数据关系、数据操作和()A. 数据对象B. 数据来源C. 数据范围D. 数据判断正确答案:A设n为问题规模,以下程序的时间复杂度为()for (i=1; i<=10000; i++) for (j=1; j<=n; j++) a = a + 1;A. O(1)B. O(n)C. O(10000n)D. O(n2)正确答案:B20.设n为问题规模,以下程序的时间复杂度为() for (i=1; i< POW(2, n); i++) //POW(x, y)函数表示x的y次幂a = a+100;A. O(n)B. O(2n)C. O(n!)D. O(2n)正确答案:D。
数据库原理第一次作业-答案

首页 > 课程作业作业名称数据库原理第1次作业作业总分100起止时间2016-10-11至2016-11-8 23:59:00通过分数60标准题总分100题号:1 题型:单选题(请在以下几个选项中选择唯一正确答案)本题分数:2对于学生选课关系,其关系模式为:学生(学号,,年龄,所在系);课程(课程名,课程号,先行课);选课(学号,课程号,成绩)。
表示“学过数据库和操作系统的学生和学号”的关系代数是()•A、∏,学号(σ课程名=‘数据库’(课程))•B、∏,学号(σ课程名=‘数据库’(学生∞选课∞课程))∩∏ ,学号(σ课程名=‘操作系统’(学生∞选课∞课程))•C、∏,学号(σ课程名=‘数据库’(学生))•D、∏,学号(σ课程名=‘数据库’ and课程名=‘操作系统’(学生∞选课∞ 课程))标准答案:b说明:题号:2 题型:单选题(请在以下几个选项中选择唯一正确答案)本题分数:2对于学生选课关系,其关系模式为:学生(学号,,年龄,所在系);课程(课程名,课程号,先行课);选课(学号,课程号,成绩)。
表示“学过数据库课程的学生和学号”的关系代数是()•A、∏学号(∏,(σ课程名=‘数据库’(课程))•B、∏学号(∏,(σ课程名=‘数据库’(学生))•C、∏,学号(σ课程名=‘数据库’(学生∞选课∞课程))•D、∏,学号(σ课程名=‘数据库’(学生∞课程))标准答案:c说明:案)本题分数:2设关系R与关系S具有相同的属性个数,且相对应的属性的值取自同一个域,则R-(R-S)等于()•A、R∪S•B、R∩S•C、R×S•D、R-S标准答案:b说明:题号:4 题型:单选题(请在以下几个选项中选择唯一正确答案)本题分数:2设关系R和S的元组个数分别为100和200,关系T是R和S的笛卡尔积,则T的元组个数是()•A、100•B、200•C、300•D、20000标准答案:d说明:题号:5 题型:单选题(请在以下几个选项中选择唯一正确答案)本题分数:2在数据库系统中,用户使用的数据视图是()描述,它是用户与数据库系统之间的接口。
数据结构第一次作业及答案--线性表
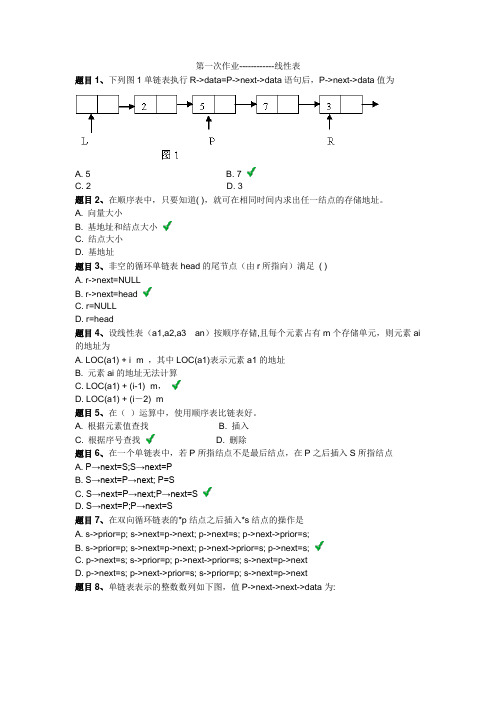
第一次作业------------线性表题目1、下列图1单链表执行R->data=P->next->data语句后,P->next->data值为A. 5B. 7C. 2D. 3题目2、在顺序表中,只要知道( ),就可在相同时间内求出任一结点的存储地址。
A. 向量大小B. 基地址和结点大小C. 结点大小D. 基地址题目3、非空的循环单链表head的尾节点(由r所指向)满足( )A. r->next=NULLB. r->next=headC. r=NULLD. r=head题目4、设线性表(a1,a2,a3···an)按顺序存储,且每个元素占有m个存储单元,则元素ai 的地址为A. LOC(a1) + i×m ,其中LOC(a1)表示元素a1的地址B. 元素ai的地址无法计算C. LOC(a1) + (i-1)×m,D. LOC(a1) + (i-2)×m题目5、在()运算中,使用顺序表比链表好。
A. 根据元素值查找B. 插入C. 根据序号查找D. 删除题目6、在一个单链表中,若P所指结点不是最后结点,在P之后插入S所指结点A. P→next=S;S→next=PB. S→next=P→next; P=SC. S→next=P→next;P→next=SD. S→next=P;P→next=S题目7、在双向循环链表的*p结点之后插入*s结点的操作是A. s->prior=p; s->next=p->next; p->next=s; p->next->prior=s;B. s->prior=p; s->next=p->next; p->next->prior=s; p->next=s;C. p->next=s; s->prior=p; p->next->prior=s; s->next=p->nextD. p->next=s; p->next->prior=s; s->prior=p; s->next=p->next题目8、单链表表示的整数数列如下图,值P->next->next->data为:A. 47B. 93C. 19D. 64题目9、在一个具有n个结点的有序单链表中插入一个新结点并仍然有序的时间复杂度是( )。
统计学作业1

统计学第一次作业〔2012年3月15日〕注意:作业全部为课后习题,请将必要的推导过程写出,不能只写答案。
本次作业共包括前四章的14道题目,个别题目有删减:第一章统计学的性质1-3答:〔1〕对于简单随机抽样,置信度为95%的置信区间公式为:表:历年盖洛普对总统选举的调查结果〔n=1500〕年度共和党民主党民主党候选人P*(1-P)/n 95%置信度总体比例的置信区间〔%〕实际选举结果〔%〕1960 尼克松49% 肯尼迪51% 0.0001666 51±2.5298 肯尼迪50.11964 戈德沃特36% 约翰逊64% 0.0001536 ☆64±2.4291 约翰逊61.31968 尼克松57% 汉弗莱50% 0.0001634 50±2.5303 汉弗莱49.71972 尼克松62% 麦戈文38% 0.0001571 38±2.4564 麦戈文38.21976 福特49% 卡特51% 0.0001666 51±2.5298 卡特51.11980 里根52% 卡特48% 0.0001664 ☆48±2.5283 卡特44.7〔2〕注☆:实际选举结果证明错误的置信区间2-2、在中国台湾的一项《夫妻对电视传播媒介观念差距的研究》中,访问了30对夫妻,其中丈夫所受教育X(以年为单位)的数据如下:18 20 16 6 16 17 12 14 16 1814 14 16 9 20 18 12 15 13 1616 2l 2l 9 16 20 14 14 16 16第二章描述性统计学2-2答:1) 将数据分组,使组中值分别为6,9,12,15,18,21,作出X的频数分布表;解:〔1〕数据分组如下:表:丈夫所受教育年限X频数分布表〔n=30〕分组编号组下、上限组中值X值〔年〕频数〔f〕相对频率〔 f / n 〕累积频率〔%〕1 [4.5,7.5〕6 6 1 0.0333 3.332 [7.5,10.5〕9 9、9 2 0.0666 10.003 [10.5,13.5〕12 12、12、13 3 0.1000 20.004 [13.5,16.5〕15 14、14、14、14、14、15、16、16、16、16、16、16、16、16、16 15 0.5000 70.005 [16.5,19.5〕18 17、18、18、18 4 0.1333 83.006 [19.5,22.5〕21 20、20、20、21、21 5 0.1666 100.00总计463 30 1.00002) 作出频数分布的直方图;解:〔图〕丈夫所受教育年限X数据直方图〔单位:年;n=30〕3) 问10.5年的教育在第几百分位数上?13年呢?解:10.5年的教育,累积频率为10.00%,前面有10.00%个样本,所以在第10个百分位数上;13年的教育,累积频率为20.00%,前面有20.00%个样本,所以在第20个百分位数上。
试验设计及数据分析第一次作业习题答案

习题答案1.设用三种方法测定某溶液时,得到三组数据,其平均值如下:x1̅̅̅=(1.54±0.01)mol/Lx2̅̅̅=(1.7±0.2)mol/Lx3̅̅̅=(1.537±0.005)mol/L试求它们的加权平均值。
解:根据数据的绝对误差计算权重:w1=10.012,w2=10.22,w3=10.0052因为w1:w2:w3=400:1:1600所以w̅=1.54×400+1.7×1+1.537×1600400+1+1600=1.5376812.试解释为什么不宜用量程较大的仪表来测量数值较小的物理量。
答:因为用量程较大的仪表来测量数值较小的物理量时,所产生的相对误差较大。
如3.测得某种奶制品中蛋白质的含量为(25.3±0.2)g/L,试求其相对误差。
解:E w=∆ww =0.225.3=0.79%4.在测定菠萝中维生素C含量的测试中,测得每100g菠萝中含有18.2mg维生素C,已知测量的相对误差为0.1%,试求每100g菠萝中含有维生素C的质量范围。
解:E w=∆ww=0.1%,所以∆m=m×E w=18.2×0.1%=0.0182ww所以m的范围为18.1818mg<m<18.2182ww或依据公式w w=w×(1±|w w|)=18.2×(1±0.1%)mg5.今欲测量大约8kPa(表压)的空气压力,试验仪表用1)1.5级,量程0.2MPa 的弹簧管式压力表;2)标尺分度为1mm的U型管水银柱压差计;3)标尺分度为1mm的U形管水柱压差计。
求最大绝对误差和相对误差。
解:1)压力表的精度为1.5级,量程为0.2MPa,则|∆w|www=0.2×1.5%=0.003www=3wwww w=∆w w×100%=38×100%=3.75×10−1=37.5%2)1mm汞柱代表的大气压为0.133KPa,所以|∆w|www=0.133wwww w=∆w w×100%=0.1338×100%=1.6625×10−2=1.6625%3)1mm水柱代表的大气压:ρgh,其中g=9.80665m/s2,通常取g=9.8m/s2则|∆w|www=9.8×10−3wwww w=∆w w×100%=9.8×10−38×100%=1.225×10−36.在用发酵法生产赖氨酸的过程中,对产酸率(%)作6次评定。
ASPEN作业报告--1
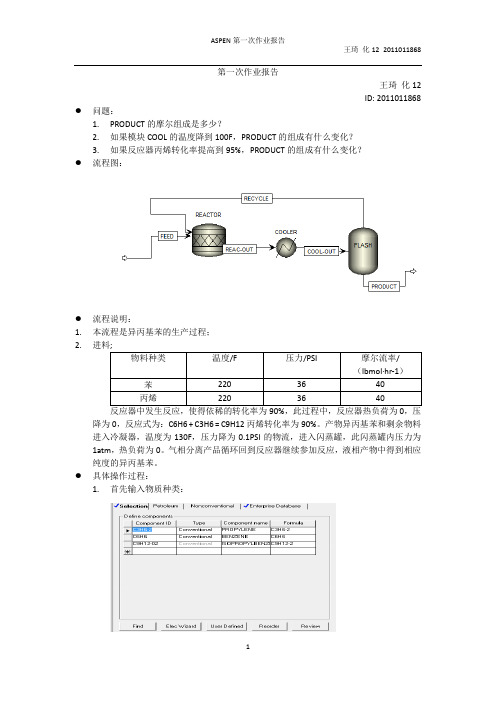
第一次作业报告王琦化12ID:2011011868●问题:1.PRODUCT的摩尔组成是多少?2.如果模块COOL的温度降到100F,PRODUCT的组成有什么变化?3.如果反应器丙烯转化率提高到95%,PRODUCT的组成有什么变化?●流程图:●流程说明:1.本流程是异丙基苯的生产过程;2.反应器中发生反应,使得依稀的转化率为90%,此过程中,反应器热负荷为0,压降为0,反应式为:C6H6 + C3H6 = C9H12丙烯转化率为90%。
产物异丙基苯和剩余物料进入冷凝器,温度为130F,压力降为0.1PSI的物流,进入闪蒸罐,此闪蒸罐内压力为1atm,热负荷为0。
气相分离产品循环回到反应器继续参加反应,液相产物中得到相应纯度的异丙基苯。
●具体操作过程:1.首先输入物质种类:2.然后确定物性,选择R-S法:3.对进料进行设置:4.再对各个模块进行设置,包括反应器、冷凝器和闪蒸罐5.在以上各种数据和生产要求输入完毕后,即可以按开始键进行模拟计算6.计算可以得到结果:7.在RESULT SUMMARY中查看结果即可:计算结果说明:1.题目中第一问是问产品PRODUCT的摩尔组成是多少:看到PRODUCT那列给出了反应物和产物的摩尔流率,经过简单的计算即可:异丙基苯的摩尔组成为90.55%2.第二问的模拟流程基本和第一问的过程一致,改变相应的参数COOL模块的温度参数从130F到100F即可,运行后得到组成变为:86.76%3.第三问将丙烯的转化率提高到95%,得到如下的计算结果:90.55%●计算结果说明,如果降低冷凝器的温度,回使得产物的摩尔组成有较明显的变化,这说明闪蒸的分离效率降低了,如果想要提高分离效率,则应该控制冷凝温度在一个较为合理的数值,这是与闪蒸过程能量衡算密切相关的。
●总结:这是第一次使用ASPEN进行化工生产过程的模拟计算,做这次作业的目的除了了解ASPEN的基本操作方法以外,同时也体会到了这种计算软件对于分析生产过程的关键作用。
海致大数据建模第一次作业中级

海致大数据建模第一次作业中级一、作业要求与目标在海致大数据建模课程中,第一次作业的目标是帮助学员掌握大数据分析的基本流程和方法。
本作业要求学员对给定的数据进行处理和分析,通过数据建模实现对数据特征的挖掘,从而达到对现实问题进行预测或解释的目的。
二、数据准备与处理1.收集数据:学员需要从给定的数据源中选取合适的数据集。
数据集应具有现实意义,以便能更好地应用于实际问题。
2.数据预处理:对收集到的数据进行清洗,包括去除重复记录、缺失值处理、数据类型转换等。
此外,还需对数据进行归一化或标准化处理,以消除数据量纲对分析结果的影响。
3.数据拆分:将数据集分为训练集、验证集和测试集,以便进行模型训练、参数调整和模型性能评估。
三、数据可视化与探索1.描述性统计分析:通过绘制柱状图、箱线图、散点图等,对数据进行初步可视化分析,了解数据的分布、相关性等特点。
2.数据探索:利用数据探索方法,如聚类、关联规则挖掘等,发现数据中的潜在规律和关联关系。
四、数据建模与优化1.选择模型:根据实际问题和数据特点,选取合适的建模方法,如线性回归、逻辑回归、决策树、支持向量机等。
2.模型训练:利用训练集对所选模型进行训练,通过调整模型参数提高模型性能。
3.模型优化:根据验证集的性能指标,对模型进行优化,如调整权重、学习率等。
五、结果评估与分析1.模型评估:利用测试集对模型进行评估,计算各项性能指标,如准确率、召回率、R方等。
2.结果分析:对建模结果进行解读,分析模型在实际问题中的应用价值,并提出改进措施。
六、总结与展望本次作业旨在帮助学员掌握大数据建模的基本方法和技巧。
通过完成作业,学员应能独立完成数据处理、可视化、建模和评估等环节,为解决现实问题提供数据支持。
数据结构作业题目

一、第一次作业
①写一个函数find,实现从数组a[n]查找元素x,返回x在数组中的序号,如果找不到则返回-1。
②当a[n]递增有序时,有没有高效的算法?
③以Niklus Wirth的观点,程序是什么?
④算法有什么特性?
⑤好算法应该满足哪些标准?
⑥数据结构主要在哪些层面上讨论问题?
⑦按增长率由小至大的顺序排列下列各函数(严蔚敏题集1.10)
⑧试写一算法,自大至小依次输出顺序读入的三个整数X,Y和Z 的值(严蔚敏题集1.16)
二、第二次作业
1)题集2.2(严蔚敏)
2)题集2.10(严蔚敏)
3)题集2.12(严蔚敏)
4)题集2.7(严蔚敏)
5)题集2.15(严蔚敏)
三、第三次作业
第二章题集1、9、10(于津、陈银冬)
四、第四次作业
第三章题集1、2、3、4、5(于津、陈银冬)
五、第五次作业
①第四章题集2、5(于津、陈银冬)
②实现以下C库函数:
(1)strlen(cs)
(2)strcpy(s, ct)
(3)strcmp(cs, ct)
③完成对称矩阵、三角矩阵、对角矩阵在压缩存储下的输入输出算法
④第五章题集1、2、3(于津、陈银冬)
六、第六次作业
第六章题集1、2、10(于津、陈银冬)
七、第七次作业
第六章题集3、8、12、13(于津、陈银冬)
八、第八次作业
第六章题集6、7、9、15(于津、陈银冬)
九、第九次作业
第七章题集1、7(另加上“十字链表”存储)(于津、陈银冬)。
数据结构第一次作业

1判断题(对)1. 数据的逻辑结构与数据元素本身的内容和形式无关。
(错)2. 线性表的逻辑顺序与物理顺序总是一致的。
(对)3. 若有一个叶子结点是二叉树中某个子树的前序遍历结果序列的最后一个结点,则它一定是该子树的中序遍历结果序列的最后一个结点。
(对)4. 对于同一组待输入的关键码集合,虽然各关键码的输入次序不同,但得到的二叉搜索树都是相同的。
(对)5. 最优二叉搜索树的任何子树都是最优二叉搜索树。
(对)6. 在二叉搜索树上插入新结点时,不必移动其它结点,仅需改动某个结点的指针,使它由空变为非空即可。
(对)7. 有n(n≥1)个顶点的有向强连通图最少有n条边。
(错)8. 连通分量是无向图中的极小连通子图。
(错)9. 二叉树中任何一个结点的度都是2。
(错)10. 单链表从任何一个结点出发,都能访问到所有结点。
二、单选题1 向一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动( B )个元素。
A.8 B. 63.5 C. 63 D. 72 设有一个二维数组A[m][n],假设A[0][0]存放位置在644(10),A[2][2]存放位置在676(10),每个元素占一个空间,则A[3][3]在( A )位置,(10)表明用10进数表示。
A.692(10) B. 626(10) C. 709(10) D. 724(10)3 N个顶点的连通图至少有( A )条边。
A.N-1 B. N C. N+1 D. 04 下面程序的时间复杂度为( C )。
for(int i=0; i<m;i++)for(int j=0; j<n;j++)a[i][j]=i*j;A.O(m2) B. O(n2) C. O(m*n) D. O(m+n)5 设单链表中结点的结构为(data, link)。
已知指针q所指结点是指针p所指结点的直接前驱,若在*q与*p之间插入结点*s,则应执行下列哪一个操作( B )。
数据库第一次作业1.4数据独立性包括哪两个方面,含义具体是什么...
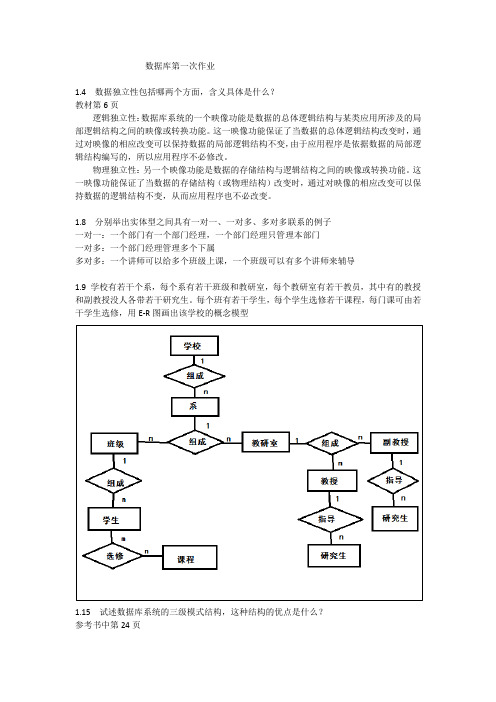
数据库第一次作业1.4 数据独立性包括哪两个方面,含义具体是什么?教材第6页逻辑独立性:数据库系统的一个映像功能是数据的总体逻辑结构与某类应用所涉及的局部逻辑结构之间的映像或转换功能。
这一映像功能保证了当数据的总体逻辑结构改变时,通过对映像的相应改变可以保持数据的局部逻辑结构不变,由于应用程序是依据数据的局部逻辑结构编写的,所以应用程序不必修改。
物理独立性:另一个映像功能是数据的存储结构与逻辑结构之间的映像或转换功能。
这一映像功能保证了当数据的存储结构(或物理结构)改变时,通过对映像的相应改变可以保持数据的逻辑结构不变,从而应用程序也不必改变。
1.8 分别举出实体型之间具有一对一、一对多、多对多联系的例子一对一:一个部门有一个部门经理,一个部门经理只管理本部门一对多:一个部门经理管理多个下属多对多:一个讲师可以给多个班级上课,一个班级可以有多个讲师来辅导1.9 学校有若干个系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授和副教授没人各带若干研究生。
每个班有若干学生,每个学生选修若干课程,每门课可由若干学生选修,用E-R图画出该学校的概念模型1.15 试述数据库系统的三级模式结构,这种结构的优点是什么?参考书中第24页第二次作业2.6 关系代数的基本运算有哪些,如何用这些基本运算来表示其他的关系基本运算?基本运算:并、差、笛卡尔积、投影和选择交:R∩S=R−(R−S)或 S−(S−R)连接:等值连接:R⋈A=B S=σA=B (R×S)自然连接:R⋈S=⨅(σR.A=S.B (R×S))除:R÷S =∏X(R)-∏X(∏X(R)×∏Y(S)-R)其中R(X,Y) S(Y,Z)2.7 设有下列四个关系模式:S(SNO,SNAME,CITY)P(PNO,PNAME,COLOR,WEIGHT);J(JNO,JNAME,CITY)SPJ(SNO,PNO,JNO,QTY)用关系代数语言完成下列操作:(1)求供应工程J1零件的供应号SNO;(2)求供应工程J1零件P1的供应商号SNO;(3)求供应工程J1红色零件的供应商号SNO;(4)求没有使用天津供应商生成的红色零件的工程号JNO;(5)求至少用了S1供应商所供应的全部零件的工程号JNO;(1)⊓SNO(σJNO=′J1′(SPJ))(2)⊓SNO(σJNO=′J1 ′∧PNO=′P1′(SPJ))(3)⊓SNO(σJNO=′J1′∧COLOR=′红′(⊓PNO,COLOR(P)⋈SPJ))(4)⊓JNO(J)−⊓JNO(⊓PNO(σCOLOR=′红′(P))⋈SPJ⋈⊓SNO(σCITY=′天津′(S)))(5)⊓SNO,JNO,PNO(SPJ)÷⊓SNO,PNO(σSNO=S1(SPJ))。
大数据分析第一次作业_

科技的不断发展,深深改变了传统的商业模式。
基于物品交换的供应链模式已经逐渐被淘汰,随着互联网用户的不断增多,越来越多的人开始“触网”,同时也在网上留下了大量数据,比如浏览记录,购买记录,出行记录等。
数据的不断积累,为商业变革打下了基础。
而大数据技术的浮现,则点燃了商业变革的导火索。
越来越多的企业通过大数据分析技术重塑商业模式,进行服务创新。
商业策略这一概念,最早是由BCG 的创始人布鲁斯亨德森和哈佛大学商学院的教授迈克尔波特提出。
亨德森理论的核心是集中优势力量对付敌人的弱点,他认为,在商业领域,包含许多被经济学家成为报酬递增的现象,比如:产业规模,投入越大,产出越大。
波特认可这一理论,但是也提出来一些限制性理论,他指出,亨德森的理论的确成立,但是从商业上来说,需要更多的步骤,一个公司或者经济模式可能在一些活动中占有优势,但可能并不合用于其他活动。
他提出来“价值链”这一概念。
基于亨德森和波特的理论,整个商业策略大厦逐渐建立起来。
但是在大数据时代,这一理论已经不在成立。
随着互联网技术的发展,信息的获取变得十分便捷,交易成本在不断降低。
交易成本的下降,导致可利用资源减少了,对垂直机构的整合也就会随之减少,价值链也会随之断裂,也可能不会断裂,但是对于同一商业中的竞争者来说,他们就可能利用其在价值链的位置,以此对竞争对手进行渗透、攻击。
英国出版的百科全书曾经是世界上最畅销的书籍之一,随着光盘和网络的流行,知识传播和更新的成本在不断下降,百科书行业随之倒闭。
维基百科随之兴起,和百科全书不同的是,维基百科的内容是由用户撰写的,并且非常专业,价格也非常便宜。
再比如2000 年,人类基因图谱的绘制,主要由专业的科研机构和科学家完成,耗费了2 亿美金和10 年的时间,才绘制出一个人的基因图谱。
而现在只需要不到1000 美元,甚至立等可取,这个行业甚至成为了零售业,以后当你去看医生的时候,可能会被要求先做一个基因绘制,然后医生会根据基因信息,找出致病基因,给你开出基因药物。
第一次作业

第三个会员获得的第32,50,80
第四个会员获得的第7,18,41
第五个会员获得的第11,66,68
第六个会员获得的第19,53,66
第七个会员获得的第26,66,81
第九个会员获得的第53,78,100
第十个会员获得的第41,55,85
第十一个会员获得的第59,63,66
解:
Lingo求解为:当a=0.95时DVD最小购买量min z=1781.25
Lingo程序为:
model:
sets:
si/1..1000/:z;
sj/1..100/:y;
lij(si,sj):c,x;
endsets
data:
c=@file('E:\a2.txt');
a=0.95;
enddata
min=@sum(sj(j):y(j));
第二十九个会员获得的第26,30,55
第三十个会员获得的第37,62,98
Lingo程序如下:
model:
sets:
si/1..1000/:z;
sj/1..100/:n;
lij(si,sj):c,x;
endsets
data:
n=@file('E:\a1.txt');
c=@file('E:\a2.txt');
a<=1/27000*@sum(lij(i,j):c(i,j)*x(i,j));
@for(si(i):@sum(sj(j):x(i,j))-3*z(i)=0);
@for(sj(j):@sum(si(i):x(i,j))<1.6*y(j));
@for(lij(i,j):x(i,j)<c(i,j));
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
样本序号人口密度x 1/(人·.km -2)人均耕地面积x 2/hm 2)森林覆盖率x 3/%1363.9120.35216.1012141.503 1.68424.3013100.695 1.06765.6014143.739 1.33633.2055131.412 1.62316.607668.337 2.03276.204795.4160.80171.106862.901 1.65273.307986.6240.84168.9041091.3940.81266.5021176.9120.85850.3021251.274 1.04164.6091368.8310.83662.8041477.3010.62360.1021576.948 1.02268.0011699.2650.65460.70217118.5050.66163.30418141.4730.73754.20619137.7610.59855.90120117.612 1.24554.50321122.7810.73149.1021363.9120.352250.8362141.503 1.68428.4273100.695 1.067-12.3814143.739 1.33630.6635131.412 1.62318.336668.337 2.032-44.739795.4160.801-17.660862.901 1.652-50.175986.6240.841-26.4521091.3940.812-21.6821176.9120.858-36.1641251.274 1.041-61.8021368.8310.836-44.2451477.3010.623-35.7751576.948 1.022-36.1281699.2650.654-13.81117118.5050.661 5.42918141.4730.73728.39719137.7610.59824.68520117.612 1.245 4.53621122.7810.7319.705总计2374.59621.206 1.13687E-13平均值113.076 1.009809524 5.41366E-15开根号计算步骤:计算结果:1363.9120.35216.101 2141.503 1.68424.3013100.695 1.06765.6014143.739 1.33633.2055131.412 1.62316.607668.337 2.03276.204795.4160.80171.106862.901 1.65273.307986.6240.84168.9041091.3940.81266.5021176.9120.85850.3021251.274 1.04164.6091368.8310.83662.8041477.3010.62360.1021576.948 1.02268.0011699.2650.65460.70217118.5050.66163.30418141.4730.73754.20619137.7610.59855.90120117.612 1.24554.50321122.7810.73149.102总计2374.59621.2061155.374平均值113.076 1.00980952455.01780952开根号计算步骤:155.2875833-0.034897657同理:得:又知:得:问:变量X4与变量X1/X2/X3之间的复相关系数R4.123样本序号人口密度x 1/(人·.km -2)人均耕地面积x 2/hm 2)森林覆盖率x 3/%1363.9120.35216.1012141.5031.68424.3013100.695 1.06765.6014143.739 1.33633.2055131.412 1.62316.607668.337 2.03276.204795.4160.80171.106862.901 1.65273.307986.6240.84168.9041091.3940.81266.5021176.9120.85850.3021251.274 1.04164.6091368.8310.83662.8041477.3010.62360.1021576.948 1.02268.0011699.2650.65460.70217118.5050.66163.30418141.4730.73754.20619137.7610.59855.90120117.612 1.24554.50321122.7810.73149.102总计2374.59621.2061155.374平均值113.076 1.00980952455.01780952开根号计算步骤:-174945.6564得:-0.335600207同理:2269.0493420.644141142得:0.534266850.890087902则:0.600240548同理:10154.314120.069997017-0.1697576340.659150592-0.257539985-0.2687914450.661167624-0.406540543-0.0135178670.730741312-0.01849884计算结果:问:对三个计算结果进行显著性检验样本序号人口密度x 1/(人·.km -2)人均耕地面积x 2/hm 2)森林覆盖率x 3/%1363.9120.35216.1012141.503 1.68424.3013100.695 1.06765.6014143.739 1.33633.2055131.412 1.62316.607668.337 2.03276.204795.4160.80171.106862.901 1.65273.307986.6240.84168.9041091.3940.81266.5021176.9120.85850.3021251.274 1.04164.6091368.8310.83662.8041477.3010.62360.1021576.948 1.02268.0011699.2650.65460.70217118.5050.66163.30418141.4730.73754.20619137.7610.59855.90120117.612 1.24554.50321122.7810.73149.1021)对单相关系数进行检验由上表可知:样本数:n=21所以,根据相关系数检验表格得知:α=0.1而|R12|<R0.1=0.3687得出结论:R12的相关性不显著2)对偏相关系数R23.1的显著性检验:对偏相关系数的显著性检验,一般采用t -检验法,其统由上表可知:样本数:n=21则,带入数据得到:通过查询t的分布临界值表得知,在自由度为18时:t 0.05=1.7341t0.025=2.1009显然t0.025>|t|>t0.05得出结论:在置信度水平a=0.05上,偏相关系数R23.1是显著的3)对复相关系数R4.123的显著性检验:对复相关系数的显著性检验,一般采用F检验法。
其统计量计算公式为:由上表可知:样本数:n=21通过查询F的分布表得知,在f1为19时:F<F0.01=5.01F>F0.025=3.90得出结论:在置信度水平a=0.025上,复相关系数R4.123是显著的农民人均纯收入x 4/(元·人-1)人均粮食产量x 5 (kg·人-1)经济作物占农作物播面比例x 6/%耕地占土地面积比x 7/%192.110295.34026.72418.4921752.350452.26032.31414.4641181.540270.12018.2660.1621436.120354.26017.48611.8051405.090586.59040.68314.4011540.290216.3908.128 4.065926.350291.5208.135 4.0631501.240225.25018.352 2.645897.360196.37016.861 5.176911.240226.51018.279 5.643103.520217.09019.793 4.881968.330181.3804.005 4.066957.140194.0409.110 4.484824.370188.09019.4095.7211255.420211.55011.102 3.1331251.030220.910 4.383 4.6151246.470242.16010.706 6.053814.210193.46011.419 6.4421124.050228.4409.5217.881805.670175.23018.106 5.7891313.110236.29026.7247.162解(一)62,918.699-0.6580.433-165.002808.0940.6740.45519.165153.2890.0570.003-0.708940.2200.3260.10610.002336.2090.6130.37611.2432,001.578 1.022 1.045-45.732311.876-0.2090.044 3.6882,517.5310.6420.412-32.222699.708-0.1690.028 4.465470.109-0.1980.039 4.2891,307.835-0.1520.023 5.4903,819.4870.0310.001-1.9281,957.620-0.1740.0307.6901,279.851-0.3870.15013.8381,305.2320.0120.000-0.440190.744-0.3560.127 4.91429.474-0.3490.122-1.894806.390-0.2730.074-7.747609.349-0.4120.170-10.16620.5750.2350.055 1.06794.187-0.2790.078-2.70682578.05668 3.770757238-182.692401 287.3639794 1.941843773-182.692401558.015954-0.327396376解(二)250.83662,918.699-0.6580.43328.427808.0940.6740.455-12.381153.2890.0570.00330.663940.2200.3260.10618.336336.2090.6130.376-44.7392,001.578 1.022 1.045-17.660311.876-0.2090.044-50.1752,517.5310.6420.412-26.452699.708-0.1690.028-21.682470.109-0.1980.039-36.1641,307.835-0.1520.023-61.8023,819.4870.0310.001-44.2451,957.620-0.1740.030-35.7751,279.851-0.3870.150-36.1281,305.2320.0120.000-13.811190.744-0.3560.1275.42929.474-0.3490.12228.397806.390-0.2730.07424.685609.349-0.4120.1704.53620.5750.2350.0559.70594.187-0.2790.0781.13687E-1382578.05668 3.770757238287.3639794 1.941843773 -5.419172762155.2875833-0.034897657-16417.21909 22980.25131 -0.714405551 -0.327396376-0.2687914450.4371426270.661167624-0.406540543解(三)192.110-0.6578095241752.35028.427808.0943290.6741904761181.540-12.381153.2891610.057190476 1436.12030.663940.2195690.326190476 1405.09018.336336.2088960.613190476 1540.290-44.7392001.578121 1.022190476 926.350-17.66311.8756-0.208809524 1501.240-50.1752517.5306250.642190476 897.360-26.452699.708304-0.168809524 911.240-21.682470.109124-0.197809524 103.520-36.1641307.834896-0.151809524 968.330-61.8023819.4872040.031190476 957.140-44.2451957.620025-0.173809524 824.370-35.7751279.850625-0.386809524 1255.420-36.1281305.2323840.012190476 1251.030-13.811190.743721-0.355809524 1246.470 5.42929.474041-0.348809524 814.21028.397806.389609-0.272809524 1124.05024.685609.349225-0.411809524 805.670 4.53620.5752960.235190476 1313.1109.70594.187025-0.278809524 22407.0182578.056681067.000476287.3639794521291.86013522.5965150.792256474145067.81140.4344795030.4371426270.5339828650.4325320560.657671693解(四)农民人均纯收入x 4/(元·人-1)人均粮食产量x 5 (kg·人-1)经济作物占农作物播面比例x 6/%耕地占土地面积比x 7/%192.110295.34026.72418.4921752.350452.26032.31414.4641181.540270.12018.2660.1621436.120354.26017.48611.8051405.090586.59040.68314.4011540.290216.3908.128 4.065926.350291.5208.135 4.0631501.240225.25018.352 2.645897.360196.37016.8615.176911.240226.51018.279 5.643103.520217.09019.793 4.881968.330181.380 4.005 4.066957.140194.0409.110 4.484824.370188.09019.409 5.7211255.420211.55011.102 3.1331251.030220.910 4.383 4.6151246.470242.16010.706 6.053814.210193.46011.419 6.4421124.050228.4409.5217.881805.670175.23018.106 5.7891313.110236.29026.7247.162-0.327396376检验法,其统计量计算公式为:(n为样本数,k为自变量个数)-0.406540543184.2426406870.8347247870.913632742-1.887854244上,偏相关系数R23.1是显著的F检验法。