spss第五讲回归分析报告
SPSS多元线性回归分析报告实例操作步骤

SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1.open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method 选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals(残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表Variables Entered/Removed aModel Variables Entered Variables Removed Method1 城市人口密度(人/平方公里) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).2 城市居民人均可支配收入(元) . Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >=.100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
spss多元回归分析的报告怎么做

spss多元回归分析的报告怎么做:怎么做回归报告分析s pss 多元线性回归spss操作spss回归分析结果解释spss多元线性回归结果篇一:SPSS多元线性回归分析实例操作步骤SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件1. open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise.进入如下界面:2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue.4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals (残差)选项组中的Unstandardized;点击Continue.5.点击右侧Options,默认,点击Continue.6.返回主对话框,单击OK.输出结果分析:1.引入/剔除变量表该表显示模型最先引入变量城市人口密度(人/平方公里),第二个引入模型的是变量(转载于: 写论文网:spss 多元回归分析的报告怎么做)城市居民人均可支配收入(元),没有变量被剔除。
《SPSS数据分析教程》 ——回归分析..共43页

36、如果我们国家的法律中只有某种 神灵, 而不是 殚精竭 虑将神 灵揉进 宪法, 总体上 来说, 法律就 会更好 。—— 马克·吐 温 37、纲纪废弃之日,便是暴政兴起之 时。— —威·皮 物特
38、若是没有公众舆论的支持,法律 是丝毫 没有力 量的。 ——菲 力普斯 39、一个判例造出另一个判例,它们 迅速累 聚,进 而变成 法律。 ——朱 尼厄斯
39、勿问成功的秘诀为何,且尽全力做你应该做的事吧。——美华纳
40、学而不思则罔,思而不学则殆。——孔子
40、人类法律,事物有规律,这是不 容忽视 的。— —爱献 生
谢谢!
36、自己的鞋子,自己知道紧在哪里。——西班牙
37、我们唯一不会改正的缺点是软弱。——拉罗什福科
xiexie! 38、我这个人走得很慢,但是我从不后退。——亚伯拉罕·林肯
spss回归分析报告怎么写

spss回归分析报告怎么写引言回归分析是一种统计分析方法,用于研究自变量与因变量之间的关系。
在社会科学研究中,SPSS是常用的统计分析软件之一,可以进行回归分析并生成回归分析报告。
本文将详细介绍如何使用SPSS生成回归分析报告,并对其中的关键内容进行详细解释。
数据收集与处理在进行回归分析之前,首先需要收集相关的数据,并进行必要的数据处理。
数据收集可以采用问卷调查、实验观测等方式。
数据处理包括数据清洗、缺失值处理、异常值处理等步骤,旨在提高数据的质量和可靠性。
描述性统计分析在进行回归分析之前,可以先进行描述性统计分析,对所研究的变量进行初步了解。
描述性统计分析可以包括计算变量的均值、标准差、最大值、最小值等指标,绘制柱状图、箱线图等图表。
这些统计指标和图表可以帮助我们对数据的分布情况、异常值等情况进行初步判断。
回归分析步骤回归分析的基本步骤包括建立模型、估计参数、模型检验和解释结果。
下面将详细介绍每个步骤。
1. 建立模型在SPSS中,可以通过选择回归分析功能,将自变量和因变量输入模型中。
通常情况下,将因变量放在因变量框中,并将自变量放在预测框中。
可以选择的参数包括常数项、线性项、交互项等。
2. 估计参数在建立模型后,SPSS会自动进行参数估计,并生成相应的结果。
估计参数主要是通过最小二乘法进行计算,得出自变量对因变量的回归系数和截距项的估计值。
3. 模型检验模型检验是分析回归模型的拟合程度和可靠性。
SPSS会给出很多统计指标来评估模型的适应度,例如F统计量、R方、调整的R方等。
此外,还可以检验回归系数的显著性,判断自变量是否对因变量有显著影响。
4. 解释结果在报告中,需要对模型的结果进行解释和详细分析。
可以对回归系数逐个进行讨论,解释每个自变量对因变量的影响程度和方向。
同时,也可以利用图表展示模型的结果,例如画出散点图、拟合直线图等,直观地展示自变量和因变量之间的关系。
结论与建议在回归分析报告的最后,需要对研究结果进行总结,并给出相应的建议。
SPSS学习系列27.回归分析报告

27. 回归分析回归分析是研究一个或多个变量(因变量)与另一些变量(自变量)之间关系的统计方法。
主要思想是用最小二乘法原理拟合因变量与自变量间的最佳回归模型(得到确定的表达式关系)。
其作用是对因变量做解释、控制、或预测。
回归与拟合的区别:拟合侧重于调整曲线的参数,使得与数据相符;而回归重在研究两个变量或多个变量之间的关系。
它可以用拟合的手法来研究两个变量的关系,以及出现的误差。
回归分析的步骤:(1)获取自变量和因变量的观测值;(2)绘制散点图,并对异常数据做修正;(3)写出带未知参数的回归方程;(4)确定回归方程中参数值;(5)假设检验,判断回归方程的拟合优度;(6)进行解释、控制、或预测。
(一)一元线性回归一、基本原理一元线性回归模型:Y=0+1X+ε其中 X 是自变量,Y 是因变量, 0, 1是待求的未知参数, 0也称为截距;ε是随机误差项,也称为残差,通常要求ε满足:① ε的均值为0; ② ε的方差为 2;③ 协方差COV(εi , εj )=0,当i≠j 时。
即对所有的i≠j, εi 与εj 互不相关。
二、用最小二乘法原理,得到最佳拟合效果的01ˆˆ,ββ值: 1121()()ˆ()niii nii x x yy x x β==--=-∑∑, 01ˆˆy x ββ=- 三、假设检验1. 拟合优度检验计算R 2,反映了自变量所能解释的方差占总方差的百分比,值越大说明模型拟合效果越好。
通常可以认为当R 2大于0.9时,所得到的回归直线拟合得较好,而当R 2小于0.5时,所得到的回归直线很难说明变量之间的依赖关系。
2. 回归方程参数的检验回归方程反应了因变量Y 随自变量X 变化而变化的规律,若 1=0,则Y 不随X 变化,此时回归方程无意义。
所以,要做如下假设检验:H 0: 1=0, H 1: 1≠0; (1) F 检验若 1=0为真,则回归平方和RSS 与残差平方和ESS/(N-2)都是 2的无偏估计,因而采用F 统计量:来检验原假设β1=0是否为真。
SPSS5-相关与回归分析

在回归方程中包括常项 缺失值的处理方式
用均值代替缺失值
一、线性回归分析( Linear Regression)
2、一元线性回归:
示例1:教材P260数据:20章_数据1.sav
识字量对阅读能力的影响有多大?
步骤:
(1)依据散点图检验线性关系 (2)操作过程:Analyze-Regression-Linear (3)结果输出观察重点:
二、双变量相关分析(Bivariate)
示例1:大学生人格(神经质、内外向程度) 与心理健康(SCL-90总分)之间有无相关?
SPSS操作:
1、绘制散点图,判定两变aphs-Scatter
2、打开Bivarite Correlations主对话框
偏相关分析的思想:控制其它变量的变化,即在剔 除其它变量影响的情况下,计算两变量之间的相 关关系。
两个变量间的线性相关关系,用偏相关系数表示。 应用条件:均为连续性变量。
Partial Correlations 对话框
分析变量
显著性检验 显示实际的显著性水平
控制变量
Options 对话框
均值及标准差 零阶相关矩阵(即:Pearson相关矩阵)
Model 1
Regression Residual Total
Sum of Squares 1845.333 899.634 2744.967
a. Predictors: (Constant), 识 字 量
b. Dependent Var iable: 阅 读 能力
ANOV Ab
df 1
28 29
解释回归平方和在总平方各中所占的比率,即解释回 归效果, r2=0.672,则表示因变量(阅读能力)的 变异中有67.2%是由自变量(识字量)而引起的。
SPSS做回归分析

结果:
y 0.0472 0.3389 x
0.0019
2
F 117.1282 F0.01 (1, 8) 11.26 R 0.9675 R0.01 (8) 0.765
检验说明线性关系显著
操作步骤:Analyze→Regression →Linear… →Statistics→Model fit Descriptives
广告心理统计SPSS
多元线性回归
一、简介 在现实生活中,客观事物常受多种因素影响,我 们记录下相应数据并加以分析,目的是为了找出对我 们所关心的指标(因变量)Y有影响的因素(也称自变 量或回归变量)x1、x2、…、xm,并建立用x1、x2、…、 xm预报Y的经验公式:
ˆ f ( x , x ,, x ) b b x b x b x Y 1 2 m 0 1 1 2 2 m m
为了求得经验公式, 可通过如下步骤进 行:
当自变量和 因变量选好 后,点击 OK 键
结果说明——常用统计量:
P (1 R 2 ) R R N P 1 ( P为 自 变 量 个 数 , N为 样 本 数 )
2 a 2
1. Model为回归方程模型编号(不同方法对应不同模型) 2. R为回归方程的复相关系数 3. R Square即R2系数,用以判断自变量对因变量的影响有 多大,但这并不意味着越大越好——自变量增多时,R2 系数会增大,但模型的拟合度未必更好 4. Adjusted R Square即修正R2,为了尽可能确切地反映模 型的拟合度,用该参数修正R2系数偏差,它未必随变量 个数的增加而增加 5. Std. Error of the Es2说明该预报 模型高度显著,可用于该地区大春 粮食产量的短期预报
中南财大-SPSS-实验报告-5

《统计分析软件》实验报告图1数据视图2.选择“分析”→“相关”→“双变量”命令,在“双变量相关”对话框的左侧列表框中,同时选中“GDP”和“INV”并单击中间的向右箭头,使之进入“变量”列表框。
图2 双变量相关对话框3.选择相关系数。
在“双变量相关”对话框内“相关系数”选项组中选择Pearson,此处为系统默认值。
4.设定显著性检验的类型。
在“显著性检验”选项组中,我们选择“双侧检验”单选按钮,此处亦为系统默认值。
5.选择是否标记显著性相关。
此处选择默认值,即“标记显著性相关”复选框。
6.选择相关性统计量输出和缺失值的处理方法。
单击“双变量相关”对话框中的“选项”按钮,在“统计量”选项组中首先选中“均值和标准差”,然后选中“叉积偏差和标准差”,输出各对变量的交叉积以及协方差阵。
在“缺失值”选项组中选中“按对排除个案”。
如图3所示:图3 双变量相关性7.设置完毕,单击确定完成相关性分析的操作步骤。
8.选择“分析”→“回归”→“线性”命令,在“线性回归”对话框的左侧列表中,选中“GDP”并单击使之进入“因变量”列表框,选中“INV”使之进入“自变量”列表框。
如图4所示:图4 线性回归其他设置采用系统默认值。
单击“确定”完成所有设置,等待输出结果。
【结果分析】1.描述性统计量表从表1中可以看出参与相关分析的两个变量的样本数据都是16,GDP的均值是,标准差是;INV的均值是,标准差是.表1 描述性统计量表2.相关分析结果表如表2所示,GDP和INV的相关系数是,显著性水平小于,因此小于.所以GDP和INV的相关关系为正向,且相关性极强。
表2 相关分析结果表3.模型拟合情况如表3所示,模型的调整R方为,说明模型的解释能力非常强。
表3 模型汇总表4.回归方程的系数以及系数的检验结果如表4所示,回归方程的系数是各个变量的回归方程中的系数值,sig值表示回归系数的显著性,越小越显著。
一般将其与作比较,如果小于,即为显著。
spss回归分析报告

SPSS回归分析报告1. 引言本报告旨在使用SPSS软件进行回归分析,并对分析结果进行解释和总结。
回归分析是一种用于探索自变量与因变量之间关系的统计方法。
通过对相关变量的分析,我们可以了解自变量对因变量的影响程度和方向。
2. 数据描述我们使用的数据集包含了X和Y两个变量的观测值。
X代表自变量,Y代表因变量。
数据集总共包含了N个观测值。
3. 数据处理在进行回归分析之前,我们需要对数据进行处理,包括数据清洗和变量转换。
数据清洗的目的是去除异常值和缺失值,确保数据的质量和完整性。
变量转换可以根据需要对变量进行归一化、对数化等操作,以满足回归分析的前提条件。
4. 模型建立我们选择了线性回归模型来研究自变量X对因变量Y的影响。
线性回归模型的表达式如下:Y = β0 + β1*X + ε其中,Y代表因变量,X代表自变量,β0和β1是回归系数,ε是误差项。
我们希望通过对数据进行回归分析,得到最佳的回归系数估计值。
5. 回归结果经过回归分析,我们得到了以下结果:回归方程:Y = a + b*X回归系数a的估计值为x,回归系数b的估计值为y。
回归方程可以用来预测因变量Y在给定自变量X的情况下的取值。
6. 模型评估为了评估我们建立的回归模型的拟合程度,我们使用了一些统计指标。
其中,R方(R^2)是衡量模型拟合优度的指标,它的取值范围在0到1之间,越接近1说明模型的拟合度越好。
我们得到的R方为r。
另外,我们还计算了回归系数的显著性检验。
显著性检验可以帮助我们判断回归系数是否具有统计学意义。
我们得到的显著性水平为p。
通过对这些统计指标的分析,我们可以评估回归模型的有效性和可靠性。
7. 结论通过SPSS软件进行回归分析,我们得到了自变量X对因变量Y的影响程度和方向。
根据我们的回归方程和回归系数,我们可以预测因变量Y在给定自变量X 的情况下的取值。
然而,需要注意的是,回归分析只能显示自变量和因变量之间的关系,并不能确定因果关系。
SPSS数据分析教程 ——回归分析课件

回归和相关分析
• 回归分析是在相关分析的基础上,确定了变量之间的相互影响关 系之后,准确的确定出这种关系的数量方法。因此,一般情况下, 相关分析要先于回归分析进行,确定出变量间的关系是线性还是 非线性,然后应用相关的回归分析方法。在应用回归分析之前, 散点图分析是常用的探索变量之间相关性的方法。
SPSS数据分析教程 ——回归分析
• Y = ¯0 +¯1 X +² • 其中变量X为预测变量,它是可以观测和控制的;Y为因变量或响应变量,
它为随机变量; ²为随机误差。 • 通常假设²~N(0,¾2),且假设与X无关。
SPSS数据分析教程 ——回归分析
回归模型的主要问题
• 进行一元线性回归主要讨论如下问题:
(1) 利用样本数据对参数¯0, ¯1和¾2,和进行点估计,得到经验回归方程 (2) 检验模型的拟合程度,验证Y与X之间的线性相关的确存在,而不是由
用回归方程预测
• 在一定范围内,对任意给定的预测变量取值,可以利用求得的拟 合回归方程进行预测。其预测值为:
ˆ0 ˆ0ˆ1x0PSS数据分析教程 ——回归分析
简单线性回归举例
• 一家计算机服务公司需要了解其用电话进行客户服务修复的计算 机零部件的个数和其电话用的时间的关系。经过相关分析,认为 二者之间有显著的线性关系。下面我们用线性回归找到这两个变 量之间的数量关系。
• F检验的 被拒绝,H 0并不能说明所有的自变量都对因变量Y有显著 影响,我们希望从回归方程中剔除那些统计上不显著的自变量, 重新建立更为简单的线性回归方程,这就需要对每个回归系数做 显著性检验。
• 即使所有的回归系数单独检验统计上都不显著,而F检验有可能 显著,这时我们不能够说模型不显著。这时候,尤其需要仔细对 数据进行分析,可能分析的数据有问题,譬如共线性等。
Spss线性回归分析讲稿ppt课件

察其与因变量之间是否具有线性关系。然后,
将自变量进行组合,生成若干自变量的子集,再
针对每一个自变量的子集生成回归分析报告。
比较调整后的R2值,挑选最优的自变量子集,
生成回归分析模型。
火灾袭来时要迅速疏散逃生,不可蜂 拥而出 或留恋 财物, 要当机 立断, 披上浸 湿的衣 服或裹 上湿毛 毯、湿 被褥勇 敢地冲 出去
①一元线性回归:y=a+bx (有一个自变量)
②多元线性回归:
(有两个或两个以上的自变量)
(2)按回归曲线的形态分
①线性(直线)回归
②非线性(曲线)回归
火灾袭来时要迅速疏散逃生,不可蜂 拥而出 或留恋 财物, 要当机 立断, 披上浸 湿的衣 服或裹 上湿毛 毯、湿 被褥勇 敢地冲 出去
回归分析
(二)回归分析的主要内容
即销售量的95%以上的变动都可以被该模型所解释,拟和优度较高。
表3
火灾袭来时要迅速疏散逃生,不可蜂 拥而出 或留恋 财物, 要当机 立断, 披上浸 湿的衣 服或裹 上湿毛 毯、湿 被褥勇 敢地冲 出去
一元线性回归分析
表4给出了回归模型的方差分析表,可以看到,F统计量为
734.627,对应的p值为0,所以,拒绝模型整体不显著的
图1
奖金-销售量表
火灾袭来时要迅速疏散逃生,不可蜂 拥而出 或留恋 财物, 要当机 立断, 披上浸 湿的衣 服或裹 上湿毛 毯、湿 被褥勇 敢地冲 出去
一元线性回归
以奖金-销售量表图1做回归分析
2、绘制散点图
打开数据文件,选择【图形】-【旧对话框】-【散点/点状】
图2
火灾袭来时要迅速疏散逃生,不可蜂 拥而出 或留恋 财物, 要当机 立断, 披上浸 湿的衣 服或裹 上湿毛 毯、湿 被褥勇 敢地冲 出去
spss回归分析报告怎么写

SPSS回归分析报告怎么写引言回归分析是一种重要的统计方法,可用于探索变量之间的关系,并预测因变量的数值。
SPSS是一种常用的统计软件,能够进行回归分析并生成相应的报告。
本文将介绍如何撰写SPSS回归分析报告,包括报告的结构、内容和格式。
报告结构一个完整的SPSS回归分析报告通常包括以下几个部分:1. 标题在报告的开头,应写上简明扼要的标题,概括研究的主题和目的。
2. 引言在引言中,介绍研究的背景和目的。
说明为什么选择回归分析方法,并列出研究所使用的自变量和因变量。
还可以介绍一下所使用的数据集和样本情况。
3. 方法在方法部分,详细描述回归分析所使用的方法和步骤。
包括数据的预处理、变量的选择和模型的建立。
还可说明所使用的统计假设和显著性水平。
4. 结果结果部分应该以清晰明了的方式呈现回归分析的结果。
可以包括相关系数矩阵、回归方程、参数估计值和统计显著性等。
同时,还可以使用可视化工具如柱状图、散点图或折线图来展示数据。
5. 讨论在讨论部分,对回归分析的结果进行解释和分析。
可以讨论自变量对因变量的影响程度、显著性以及变量之间的相互作用关系。
还可以比较不同模型的效果,讨论模型的优劣之处,并与已有的研究进行对比。
6. 结论在结论部分,总结回归分析的结果,并回答研究的问题。
可以强调研究的重要性和结果对实际应用的意义。
7. 参考文献在报告的最后,列出所有引用的参考文献。
确保引用格式符合规范,如APA格式。
报告内容和格式在撰写SPSS回归分析报告时,要注意以下几点:1. 清晰明了的语言使用简洁明了的语言,避免使用过于专业的术语,使报告易于理解。
2. 表格和图表的使用使用表格和图表来展示数据和结果,使报告更具可读性。
表格和图表应有清晰的标题和标注,便于读者理解。
3. 结果解释对回归分析的结果进行详细解释,包括回归方程的含义、参数估计值的解释和显著性的判断。
4. 讨论和分析在讨论和分析部分,对结果进行深入的探讨,解释自变量对因变量的影响机制、模型的合理性以及其他可能的解释。
SPSS多元线性回归分析报告实例操作步骤

SPSS多元线性回归分析报告实例操作步骤步骤1:导入数据首先,打开SPSS软件,并导入准备进行多元线性回归分析的数据集。
在菜单栏中选择"File",然后选择"Open",在弹出的窗口中选择数据集的位置并点击"Open"按钮。
步骤2:选择变量在SPSS的数据视图中,选择需要用于分析的相关自变量和因变量。
选中的变量将会显示在变量视图中。
确保选择的变量是数值型的,因为多元线性回归只适用于数值型变量。
步骤3:进行多元线性回归分析在菜单栏中选择"Analyze",然后选择"Regression",再选择"Linear"。
这将打开多元线性回归的对话框。
将因变量移动到"Dependent"框中,将自变量移动到"Independent(s)"框中,并点击"OK"按钮。
步骤4:检查多元线性回归的假设在多元线性回归的结果中,需要检查多元线性回归的基本假设。
这些假设包括线性关系、多重共线性、正态分布、独立性和等方差性。
可以通过多元线性回归的结果来进行检查。
步骤5:解读多元线性回归结果多元线性回归的结果会显示在输出窗口的回归系数表中。
可以检查各个自变量的回归系数、标准误差、显著性水平和置信区间。
同时,还可以检查回归模型的显著性和解释力。
步骤6:完成多元线性回归分析报告根据多元线性回归的结果,可以编写一份完整的多元线性回归分析报告。
报告应包括简要介绍、研究问题、分析方法、回归模型的假设、回归结果的解释以及进一步分析的建议等。
下面是一个多元线性回归分析报告的示例:标题:多元线性回归分析报告介绍:本报告基于一份数据集,旨在探究x1、x2和x3对y的影响。
通过多元线性回归分析,我们可以确定各个自变量对因变量的贡献程度,并检验模型的显著性和准确性。
研究问题:本研究旨在探究x1、x2和x3对y的影响。
如何用SPSS做logistic回归分析报告解读汇报
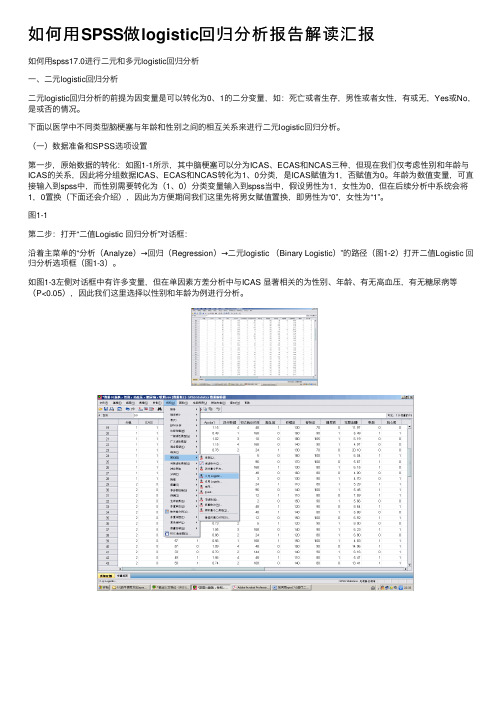
如何⽤SPSS做logistic回归分析报告解读汇报如何⽤spss17.0进⾏⼆元和多元logistic回归分析⼀、⼆元logistic回归分析⼆元logistic回归分析的前提为因变量是可以转化为0、1的⼆分变量,如:死亡或者⽣存,男性或者⼥性,有或⽆,Yes或No,是或否的情况。
下⾯以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进⾏⼆元logistic回归分析。
(⼀)数据准备和SPSS选项设置第⼀步,原始数据的转化:如图1-1所⽰,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输⼊到spss中,⽽性别需要转化为(1、0)分类变量输⼊到spss当中,假设男性为1,⼥性为0,但在后续分析中系统会将1,0置换(下⾯还会介绍),因此为⽅便期间我们这⾥先将男⼥赋值置换,即男性为“0”,⼥性为“1”。
图1-1第⼆步:打开“⼆值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→⼆元logistic (Binary Logistic)”的路径(图1-2)打开⼆值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素⽅差分析中与ICAS 显著相关的为性别、年龄、有⽆⾼⾎压,有⽆糖尿病等(P<0.05),因此我们这⾥选择以性别和年龄为例进⾏分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选⼊因变量(Dependent)中,⽽将性别和年龄选⼊协变量(Covariates)框中,在协变量下⽅的“⽅法(Method)”⼀栏中,共有七个选项。
采⽤第⼀种⽅法,即系统默认的强迫回归⽅法(进⼊“Enter”)。
接下来我们将对分类(Categorical),保存(Save),选项(Options)按照如图1-4、1-5、1-6中所⽰进⾏设置。
《2024年数据统计分析软件SPSS的应用(五)——相关分析与回归分析》范文

《数据统计分析软件SPSS的应用(五)——相关分析与回归分析》篇一数据统计分析软件SPSS的应用(五)——相关分析与回归分析一、引言在当今的大数据时代,数据统计分析成为了科学研究、市场调研、社会统计等众多领域的重要工具。
SPSS(Statistical Package for the Social Sciences)作为一款功能强大的数据统计分析软件,被广泛应用于各类数据分析中。
本文将重点介绍SPSS 中相关分析与回归分析的应用,以帮助读者更好地理解和掌握这两种分析方法。
二、相关分析1. 相关分析的概念与目的相关分析是研究两个或多个变量之间关系密切程度的一种统计方法。
其目的是通过计算相关系数,了解变量之间的线性关系强度和方向,为后续的回归分析提供依据。
2. SPSS中的相关分析操作步骤(1)导入数据:将数据导入SPSS软件中,建立数据文件。
(2)选择分析方法:在SPSS菜单中选择“分析”->“相关”->“双变量”,进行相关分析。
(3)设置变量:在弹出的对话框中,设置需要进行相关分析的变量。
(4)计算相关系数:点击“确定”后,SPSS将自动计算两个变量之间的相关系数,并显示在结果窗口中。
3. 相关分析的注意事项(1)选择合适的相关系数:根据研究目的和数据特点,选择合适的相关系数,如Pearson相关系数、Spearman相关系数等。
(2)控制混淆变量:在进行相关分析时,要控制可能影响结果的混淆变量,以提高分析的准确性。
三、回归分析1. 回归分析的概念与目的回归分析是研究一个或多个自变量与因变量之间关系的一种预测建模方法。
其目的是通过建立自变量和因变量之间的数学模型,预测因变量的值或探究自变量对因变量的影响程度。
2. SPSS中的回归分析操作步骤(1)导入数据:同相关分析一样,将数据导入SPSS软件中。
(2)选择分析方法:在SPSS菜单中选择“分析”->“回归”->“线性”,进行回归分析。
spss第五讲回归分析报告

Karl Gauss的最小化图
y
(xn , yn)
(x2 , y2)
(x1 , y1)
ei = yi^-yi
(xi , yi)
yˆ bˆ0 bˆ1x
x
参数的最小二乘估计
(
bˆ
和
0
bˆ
1
的计算公式)
根据最小二乘法,可得求解
bˆ
和
0
bˆ
1
的
公式如下:
bˆ0
(三) 回归直线的拟合优度
一、变差 1、因变量 y 的取值是不同的,y 取值的这种波动称为变
第一部分 回归分析
什么是回归分析?
1、重点考察一个特定的变量(因变量),而 把其他变量(自变量)看作是影响这一变 量的因素,并通过适当的数学模型将变 量间的关系表达出来
2、利用样本数据建立模型的估计方程 3、对模型进行显著性检验 4、进而通过一个或几个自变量的取值来估
计或预测因变量的取值
回归分析的模型
线性影响后,y随机波动大小的一个估计量 4、反映用估计的回归方程预测y时预测误差的大小 5、计算公式为(k为自变量个数)
n
y yˆ 2
i
s i1
i
SSE MSE
e
n k 1
n k 1
(四) 显著性检验
线性关系的检验 1、检验自变量与因变量之间的线性关系是否显著; 2、将回归均方(MSR)同残差均方(MSE)加以比较,
3 、误差项 满足条件
误差项 满足条件
正态性。 是一个服从正态分布的随机变量,
且期望值为0,即 ~N(0 , 2 ) 。对于一个给定的 x 值,y 的期望值为E(y)=b0+ b1x
方差齐性。对于所有的 x 值, 的方差一个特定
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
n
n
i 1
i 1
注:用最小二乘法拟合的直线来代表x与y之间的 关系与实际数据的误差比其他任何直线都小。
Karl Gauss的最小化图
y
(xn , yn)
ˆ ˆx ˆ y 0 1
回归分析的模型
一、分类 按是否线性分:线性回归模型和非线性回归模型 按自变量个数分:简单的一元回归和多元回归 二、基本的步骤
利用SPSS得到模型关系式,是否是我们所要的? 要看回归方程的显著性检验(F检验) 回归系数的显著性检验(T检验) 拟合程度R2 (注:相关系数的平方,一元回归用R Square,多元回归 用Adjusted R Square)
误差项 满足条件
正态性。 是一个服从正态分布的随机变量,
且期望值为0,即 ~N(0 , 2 ) 。对于一个给定的 x 值,y 的期望值为E(y)=0+ 1x
方差齐性。对于所有的 x 值, 的方差一个特定
的值,的方差也都等于 2 都相同。同样,一个特定 的x 值, y 的方差也都等于2
注:线性部分反映了由于 x的变化而引起的 y的变 化;误差项 反映了除 x和 y之间的线性关系之 外的随机因素对 y的影响,它是不能由 x和y之 间的线性关系所解释的变异性。
一元线性回归模型(基本假定) 1、因变量x与自变量y之间具有线性 关系 2、在重复抽样中,自变量x的取值 是固定的,即假定x是非随机的 3 、误差项 满足条件
第二部分 线性回归
线性回归分为一元线性回归和多元线性回归。 一、一元线性回归:
1、涉及一个自变量的回归 2、因变量y与自变量x之间为线性关系 被预测或被解释的变量称为因变量(dependent variable) , 用y表示 用来预测或用来解释因变量的一个或多个变量称为自变量 (independent variable),用x表示 3、因变量与自变量之间的关系用一个线性方程来表示
线性回归的过程
一元线性回归模型确定过程 一、做散点图(Graphs ->Scatter->Simple) 目的是为了以便进行简单地观测(如: Salary与Salbegin的关系)。 二、建立方程 若散点图的趋势大概呈线性关系,可以建立线性方 程,若不呈线性分布,可建立其它方程模型,并比较 R2 (-->1)来确定一种最佳方程式(曲线估计)。 多元线性回归一般采用逐步回归方法-Stepwise。
第五讲
回归分析、线性回归和曲线估计
第一部分 回归分析 第二部分 线性回归
第三部分 曲线估计
第一部分 第十讲回顾
在对其他变量的影响进行控制 的条件下,衡量多个变量中某两个 变量之间的线性相关程度的指标称 为偏相关系数。
偏相关分析的公式表达 r01 r02r12 r01.2 2 2 1 r 1 r 02 12
回归分析的过程
在回归过程中包括:
Liner:线性回归 Curve Estimation:曲线估计
Binary Logistic: 二分变量逻辑回归 Multinomial Logistic:多分变量逻辑回归; Ordinal 序回归;Probit:概率单位回归; Nonlinear:非线性回归; Weight Estimation:加权估计; 2-Stage Least squares :二段最小平方法; Optimal Scaling 最优编码回归 我们只讲前面2个简单的(一般教科书的讲法)
r01.23
r0i .12L (i 1)(i 1)L p
r02 r03.2r13.2
1 r2 03.2
1 r2 3.2
r0i .12L (i 1)(i 1)L ( p 1) r0 p.12L ( p 1)rip.12L (i 1)(i 1)L ( p 1)
1 r2 1 r2 0 p.12L ( p 1) ip.12L ( i 1)( i 1)L ( p 1)
独立性。独立性意味着对于一个特定的 x 值,
它所对应的ε与其他 x 值所对应的ε不相关;对于一 个特定的 x 值,它所对应的 y 值与其他 x 所对应的 y 值也不相关
估计的回归方程
(estimated regression equation)
1. 总体回归参数β0和β1是未知的,必须利用样本数 据去估计 ˆ0 和 ˆ1 代替回归方程中的未知参 2. 用样本统计量 数β0和β1 ,就得到了估计的回归方程 3. 一元线性回归中估计的回归方程为
(一) 一元线性回归模型
(linear regression model)
1、描述因变量 y 如何依赖于自变量 x 和误差项 的方程称为回归模型 2、一元线性回归模型可表示为
Y是x 的线性函数 (部分)加上误差项
y = 0 1 x
0 和 1 称为模
型的参数
误差项 是随机 变量
第一部分 回归分析
什么是回归分析?
1、重点考察一个特定的变量(因变量),而 把其他变量 ( 自变量 ) 看作是影响这一变 量的因素,并通过适当的数学模型将变 量间的关系表达出来 2、利用样本数据建立模型的估计方程 3、对模型进行显著性检验 4、进而通过一个或几个自变量的取值来估 计或预测因变量的取值
(x2 , y2)
ei = yi^ -yi
(x1 , y1)Leabharlann (xi , yi)
x
参数的最小二乘估计
( ˆ 0和 ˆ 1 的计算公式) 根据最小二乘法,可得求解 ˆ 0和 ˆ 1 的 公式如下:
ˆ0 ˆ1 x ˆ y ˆ0是估计的回归直线在 y 轴上的截距, ˆ1是直线的 其中: 斜率,它表示对于一个给定的 x 的值, y ˆ 是 y 的估计值, 也表示 x 每变动一个单位时, y 的平均变动值
(二) 参数的最小二乘估计
德国科学家Karl Gauss(1777—1855)提出用最 小化图中垂直方向的误差平方和来估计参数 使因变量的观察值与估计值之间的误差平方和 ˆ0和 ˆ1的方法。即 达到最小来求得