编译实验报告+源代码
编译linux实验报告

编译linux实验报告
编译Linux实验报告
在计算机科学领域,Linux操作系统一直被广泛使用。
它是一个开放源代码的操作系统,具有稳定性和安全性。
在本次实验中,我们将学习如何编译Linux内核,并撰写实验报告以记录我们的实验过程和结果。
实验目的:
1. 了解Linux内核的编译过程
2. 熟悉编译工具和技术
3. 掌握编译过程中可能遇到的问题和解决方法
实验步骤:
1. 下载Linux内核源代码
2. 解压源代码并配置编译环境
3. 使用make命令编译内核
4. 安装编译后的内核
5. 测试新内核的稳定性和功能
实验结果:
经过一系列的操作,我们成功地编译了Linux内核,并将其安装到我们的计算机上。
新内核的稳定性和功能得到了验证,证明我们的编译过程是成功的。
实验总结:
通过本次实验,我们不仅了解了Linux内核的编译过程,还学习了如何使用编译工具和技术。
在实验过程中,我们遇到了一些问题,但通过查阅资料和尝试不同的解决方法,最终成功地完成了编译过程。
这次实验为我们提供了宝贵的
经验,也增强了我们对Linux操作系统的理解和掌握。
总的来说,编译Linux内核的实验是一次有意义的学习过程,我们通过实践提升了自己的技能和知识水平。
希望在未来的学习和工作中,能够运用这些经验和技能,为我们的计算机科学之路增添更多的成就和贡献。
编译原理实验参考原代码
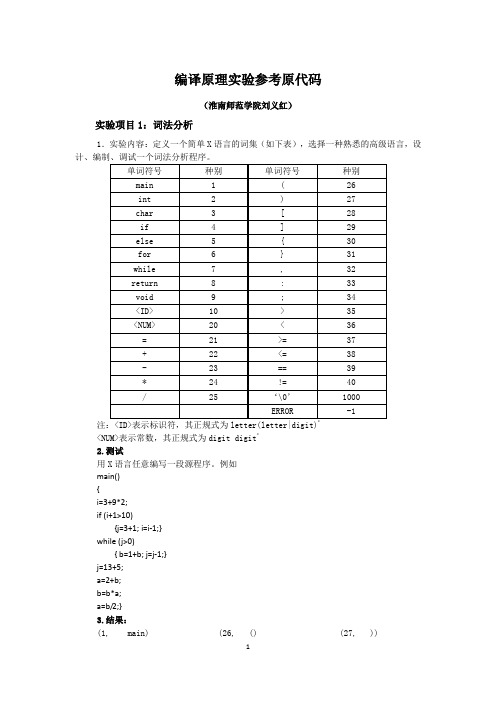
"Waiting for your expanding."
SCAN.C //词法分析器源程序
#include "globals.h" #include "scan.h"
void Do_Tag(char *strSource); void Do_Digit(char *strSource); void Do_EndOfTag(char *strSource); void Do_EndOfDigit(); void Do_EndOfEqual(char *strSource); void Do_EndOfPlus(char *strSource); void Do_EndOfSubtraction(char *strSource); void Do_EndOfMultiply(char *strSource); void Do_EndOfDivide(char *strSource); void Do_EndOfLParen(char *strSource); void Do_EndOfRParen(char *strSource); void Do_EndOfLeftBracket1(char *strSource); void Do_EndOfRightBracket1(char *strSource); void Do_EndOfLeftBracket2(char *strSource); void Do_EndOfRightBracket2(char *strSource); void Do_EndOfColon(char *strSource); void Do_EndOfComma(char *strSource); void Do_EndOfSemicolon(char *strSource); void Do_EndOfMore(char *strSource); void Do_EndOfLess(char *strSource); void Do_EndOfEnd(char *strSource); void Do_EndOfNEqual(char *strSource); void PrintError(int nColumn,int nRow,char chInput); void scaner(void);
文本编辑器c++实验报告附源代码

四川大学软件学院实验报告学号:1043111051 姓名:王金科专业:软件工程班级:2010级5班课程名称数据结构实验课时8实验项目文本编辑器实验时间12到14周实验目的了解c++类的封装和KMP算法。
Windows平台 VC6.0++实验环境实验内容(算法、程序、步骤和方法)部分函数创建思想:创建过程如下:a、定义LinkList指针变量*temp: LinkList *temp;b、定义文本输入变量ch,记录文本行数变量j,记录每行字符数变量i;c、申请动态存储空间:head->next=(LinkList *)malloc(sizeof(LinkList));d、首行头指针的前驱指针为空:head->pre=NULL;首行指针:temp=head->next;首行指针的前驱指针也为空:temp->pre=NULL;定义没输入字符时文章长度为0:temp->length=0;初始化为字符串结束标志,防止出现乱码:for(i=0;i<80;i++)temp->data[i]='\0';e、利用循环进行文本输入for(j=0;j<LINK_INIT_SIZE;j++)// 控制一页{ for(i=0;i<80;i++) //控制一行{ ch=getchar(); //接收输入字符temp->data[i]=ch; //给temp指向的行赋值····temp->length++;//行中字符长度加1if(ch=='#'){NUM=j; break; //文章结束时,Num来记录整个文章的行数}}}在字符输入的过程中,如果在单行输入的字符超过了80个字符,则需要以下操作:输入字符数大于80,重新分配空间建立下一行temp->next=(LinkList *)malloc(sizeof(LinkList)) ;给temp的前驱指针赋值:temp->next->pre=temp;temp指向当前行:temp=temp->next;将下一行初始化为字符串结束标志,防止出现乱码:for(i=0;i<80;i++)temp->data[i]='\0';记录整个文章的行数:temp->row=NUM+1;返回指向最后一行指针:return temp;文本输入部分到此结束。
编译原理实验报告——词法分析器(内含源代码)

编译原理实验(一)——词法分析器一.实验描述运行环境:vc++2008对某特定语言A ,构造其词法规则。
该语言的单词符号包括:12状态转换图3程序流程:词法分析作成一个子程序,由另一个主程序调用,每次调用返回一个单词对应的二元组,输出标识符表、常数表由主程序来完成。
二.实验目的通过动手实践,使学生对构造编译系统的基本理论、编译程序的基本结构有更为深入的理解和掌握;使学生掌握编译程序设计的基本方法和步骤;能够设计实现编译系统的重要环节。
同时增强编写和调试程序的能力。
三.实验任务编制程序实现要求的功能,并能完成对测试样例程序的分析。
四.实验原理char set[1000],str[500],strtaken[20];//set[]存储代码,strtaken[]存储当前字符char sign[50][10],constant[50][10];//存储标识符和常量定义了一个Analyzer类class Analyzer{public:Analyzer(); //构造函数 ~Analyzer(); //析构函数int IsLetter(char ch); //判断是否是字母,是则返回 1,否则返回 0。
int IsDigit(char ch); //判断是否为数字,是则返回 1,否则返回 0。
void GetChar(char *ch); //将下一个输入字符读到ch中。
void GetBC(char *ch); //检查ch中的字符是否为空白,若是,则调用GetChar直至ch进入一个非空白字符。
void Concat(char *strTaken, char *ch); //将ch中的字符连接到strToken之后。
int Reserve(char *strTaken); //对strTaken中的字符串查找保留字表,若是一个保留字返回它的数码,否则返回0。
void Retract(char *ch) ; //将搜索指针器回调一个字符位置,将ch置为空白字符。
编译链接执行实验报告(3篇)

第1篇一、实验目的1. 理解编译、链接和执行的基本概念和过程。
2. 掌握使用编译器、链接器和执行器完成程序编译、链接和执行的基本操作。
3. 学习调试程序,解决编译、链接和执行过程中出现的问题。
二、实验环境1. 操作系统:Windows 102. 编译器:Microsoft Visual Studio 20193. 链接器:Microsoft Visual Studio 20194. 执行器:Windows 10自带三、实验内容1. 编译程序2. 链接程序3. 执行程序4. 调试程序四、实验步骤1. 编译程序(1)创建一个名为“HelloWorld.c”的源文件,内容如下:```cinclude <stdio.h>int main() {printf("Hello, World!\n");return 0;}```(2)打开Microsoft Visual Studio 2019,创建一个控制台应用程序项目。
(3)将“HelloWorld.c”文件添加到项目中。
(4)在项目属性中设置编译器选项,选择C/C++ -> General -> Additional Include Directories,添加源文件所在的目录。
(5)点击“生成”按钮,编译程序。
2. 链接程序(1)在Microsoft Visual Studio 2019中,点击“生成”按钮,生成可执行文件。
(2)查看生成的可执行文件,路径通常在项目目录下的“Debug”或“Release”文件夹中。
3. 执行程序(1)双击生成的可执行文件,或在命令行中运行。
(2)查看输出结果,应为“Hello, World!”。
4. 调试程序(1)在Microsoft Visual Studio 2019中,点击“调试”按钮。
(2)程序进入调试模式,可以设置断点、观察变量等。
(3)运行程序,观察程序执行过程,分析问题原因。
计算机编译原理实验报告

编译原理实验报告实验一词法分析设计一、实验功能:1、对输入的txt文件内的内容进行词法分析:2、由文件流输入test.txt中的内容,对文件中的各类字符进行词法分析3、打印出分析后的结果;二、程序结构描述:(源代码见附录)1、分别利用k[],s1[],s2[],s3[]构造关键字表,分界符表,算术运算符表和关系运算符表。
2、bool isletter(){} 用来判断其是否为字母,是则返回true,否则返回false;bool isdigit(){} 用来判断其是否为数字,是则返回true,否则返回false;bool iscalcu(){} 用来判断是否为算术运算符,是则返回true,否则返回false;bool reserve(string a[]){} 用来判断某字符是否在上述四个表中,是则返回true,否则返回false;void concat(){} 用来连接字符串;void getn(){} 用来读取字符;void getb(){} 用来对空格进行处理;void retract(){}某些必要的退格处理;int analysis(){} 对一个单词的单词种别进行具体判断;在主函数中用switch决定输出。
三、实验结果四、实验总结词法分析器一眼看上去很复杂,但深入的去做就会发现并没有一开始想象的那么困难。
对于一个字符的种别和类型可以用bool函数来判断,对于关键字和标示符的识别(尤其是3b)则费了一番功夫,最后对于常数的小数点问题处理更是麻烦。
另外,这个实验要设定好时候退格,否则将会导致字符漏读甚至造成字符重复读取。
我认为,这个实验在程序实现上大体不算困难,但在细节的处理上则需要好好地下功夫去想,否则最后的程序很可能会出现看上去没有问题,但实际上漏洞百出的状况。
将学过的知识应用到实际中并不简单,只有自己不断尝试将知识转化成程序才能避免眼高手低,对于知识的理解也必将更加深刻。
实验二LL(1)分析法一、实验原理:1、写出LL(1)分析法的思想:当一个文法满足LL(1)条件时,我们就可以为它构造一个不带回溯的自上而下的分析程序,这个分析程序是有一组递归过程组成的,每个过程对应文法的一个非终结符。
源代码编译

源代码编译【实验名称】:源代码编译【实验环境】:RedhatA:192.168.18.1 255.255.255.0Windows Xp:192.168.18.100 255.255.255.0 网关:192.168.18.1 【实验目标】:1. 重新编译安装2.iptables编译安装【实验步骤】:重新编译安装RedhatA:1.修改内存为512MB2..取消多余模块(nfslock)-----ntsysv3.挂载光盘:Layer7.isoMount /dev/cdrom /media/4.跳转到src下解压文件释放内核源码包,Cd /usr/srctar zxvf /media/linux-2.6.28.10.tar.gztar zxvf /media/netfilter-Laryer7-v2.22.tar.gz5. 合并并打补丁Cd linux-2.6.28.10/patch -p1 < ../netfilter-layer7-v2.22/kernel-2.6.25-2.6.28-layer7-2.22.patch6.配置内核编译参数cp /boot/config-2.6.18-164.el5 .config7.在源码目录中执行―make menuconfig‖命令⑴选择networking support -→⑵选择networking options-→⑶选择networking packet filtering framwork -→⑷选择Core netfilter configuration-→①<M>netfilter connection traceking support②<M>laryer7③<M>―time‖ match support④<M>"string" match support⑤<M>"connlimit" match support"⑥<M>―iprange‖ address range match support⑦<M>―state‖ match support⑧<M>"mac" address match support⑨选择exit后退⑸选择IP netfilter configuration①选择<M>IPv4 connection tracking support (require for NAT)”②<M>Full NAT③选择exit退出并保存(YES)8.编译内核的模块文件、执行程序--------make9.安装编译好的模块文件-----执行make modules__install 命令查看配置:ll /lib/ modulesll /lib/ modules/2.6.28.10/ll /boot10.安装编译好的内核执行程序-----执行make install 命令11.查看配置----cat /etc/grup.conf12.重启(reboot)长按“↓”选择linux-2.6.28.1013.以root登录,用命令:uname –r 查看版本重新编译安装iptables工具RedhatA:1.挂载光盘Layer7.iso拷贝iptables文件和layer7文件到根下cp /media/iptables-1.4.7.tar.bz2 。
C语言实验报告参考源代码

printf("last: %d\n",n);} /*最后出局者的编号*/
实验 7 函数及其应用
第二个错误:if( fabs(x1-x0)<=0.00001 ) 应改为:if( fabs(x1-x0)>=0.00001 ) 因只有 fabs(x1-x0)>=0.00001 才须递归。 4.设计一个程序,判断一个整数n 是否是素数。 具体要求如下: (1)编制一个函数int prime(number),判断整数number 是否是素数。 (2)编制主函数,由键盘输入整数number,调用(1)中的函数,若返回值为真则是素 数,否则不是素数。 (3)分别用以下数据运行该程序:103,117。
printf("\n");
}
/*打印处理后矩阵,此时第 1 列上的元素为每行的最大数*/
}
5.猴子选大王问题:n 个人围坐一圈,并顺序编号 1~n,从 1 号开始数,每数到 m 个 就让其出局,重复...。求最后出局者的编号。当 n=50,m=3 时 ,答案为 11
具体要求如下: (1)使用一维数组存放每个人的编号,每数到 m 个数就让其出局,出局者编号为 0。 (2)使用 for 循环嵌套实现。 【程序源代码】 #include "stdio.h" main() {int a[51],i,j,m=0,n; for(i=1;i<=50;i++)a[i]=i;/*为了符合习惯,数组下标从 1 开始,下标就是编号*/ for(j=1;j<=50/3;j++) /*外层循环最多循环 50/3 次*/
编译原理实验 (词法语法分析报告 附源代码

编译原理实验报告******************************************************************************* ******************************************************************************* PL0语言功能简单、结构清晰、可读性强,而又具备了一般高级程序设计语言的必须部分,因而PL0语言的编译程序能充分体现一个高级语言编译程序实现的基本方法和技术。
PL/0语言文法的EBNF表示如下:<程序>::=<分程序>.<分程序> ::=[<常量说明>][<变量说明>][<过程说明>]<语句><常量说明> ::=CONST<常量定义>{,<常量定义>};<常量定义> ::=<标识符>=<无符号整数><无符号整数> ::= <数字>{<数字>}<变量说明> ::=VAR <标识符>{, <标识符>};<标识符> ::=<字母>{<字母>|<数字>}<过程说明> ::=<过程首部><分程序>{; <过程说明> };<过程首部> ::=PROCEDURE <标识符>;<语句> ::=<赋值语句>|<条件语句>|<当循环语句>|<过程调用语句>|<复合语句>|<读语句><写语句>|<空><赋值语句> ::=<标识符>:=<表达式><复合语句> ::=BEGIN <语句> {;<语句> }END<条件语句> ::= <表达式> <关系运算符> <表达式> |ODD<表达式><表达式> ::= [+|-]<项>{<加法运算符> <项>}<项> ::= <因子>{<乘法运算符> <因子>}<因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’<加法运算符> ::= +|-<乘法运算符> ::= *|/<关系运算符> ::= =|#|<|<=|>|>=<条件语句> ::= IF <条件> THEN <语句><过程调用语句> ::= CALL 标识符<当循环语句> ::= WHILE <条件> DO <语句><读语句> ::= READ‘(’<标识符>{,<标识符>}‘)’<写语句> ::= WRITE‘(’<表达式>{,<表达式>}‘)’<字母> ::= a|b|…|X|Y|Z<数字> ::= 0|1|…|8|9【预处理】对于一个pl0文法首先应该进行一定的预处理,提取左公因式,消除左递归(直接或间接),接着就可以根据所得的文法进行编写代码。
编译实验二的源代码

void pro_process(char *);
void concat(char [],char);
char reserve(char []);
code_val scanner(char *);
void main()
{char buf[4048]={'\0'};
bool in_comment=false; //false表示当前字符未处于注释中
while(cinf.read(&cur_c,sizeof(char))) //从文件读一个字符
{
switch(in_comment)
{case false:
concat(token,buf[i++]);
t.code='y';
}
else
t.code='x';
strcpy(t.val,token);
return t; //返回当前单词整常数或实常数的二元式
}//识别实常数(以小数点起始)//关注淘宝店530213
exit(0); //程序终止运行
}
}
switch(buf[i]) {
case ',':
t.code=',';break;
case ';':
t.code=';';break;
case '(':
#include<fstream.h>
#include<iostream.h>
#include<conio.h>
编译原理实验报告——词法分析器(内含源代码)

#include "string.h"
#include "iostream"
using namespace std;
char set[1000],str[500],strtaken[20]; char sign[50][10],constant[50][10];
//int Words[500][10]; char ch;//当前读入字符int sr,to=0;//数组str, strtaken int st=0,dcount=0;
{
printf( "cannot open file.\n");
void input();//向存放输入结果的字符数组输入一句语句。
void display();//输出一些程序结束字符显示样式
int analyzerSubFun();//词法分析器子程序,为了实现词法分析的主要功能。
五. 代码实现
//cifa.cpp:定义控制台应用程序的入口点
//#include "stdafx Nhomakorabeah"
3.实验任务
编制程序实现要求的功能,并能完成对测试样例程序的分析。
四. 实验原理
int Reserve(char *strTaken);//对strTaken中的字符串查找保留字表,若是一个保留
字返回它的数码,否则返回0。
void Retract(char *ch); //将搜索指针器回调一个字符位置,将ch置为空白字符。
};
typedef struct keytable{
char name[20]; int kind;
c++第三版实验4源代码及实验结果

源代码1#include<iostream> //1调试程序using namespace std;class B{public:virtual void f1(double x){cout<<"B::f1(double)"<<x<<endl;}void f2(double x){cout<<"B::f2(double)"<<2*x<<endl;}void f3(double x){cout<<"B::f3(double)"<<3*x<<endl;}};class D:public B{public:virtual void f1(double x){cout<<"D::f1(double)"<<x<<endl;}virtual void f2(int x){cout<<"D::f2(int)"<<2*x<<endl;}virtual void f3(double x){cout<<"D::f3(double)"<<3*x<<endl;}};int main (){D d;B *pb=&d;D *pd=&d;pb->f1(1.23);pd->f1(1.23);pb->f2(1.23);pd->f2(1.23);pb->f3(1.23);pd->f3(1.23);return 0;}源代码1实验结果源代码2#include<iostream> //2编写时间类using namespace std;class Time{public:Time(int h=0,int m=0,int s=0){hour=h;minute=m;second=s;}Time operator+(Time t){Time temp;temp.hour=hour+t.hour;if(minute+t.minute>60){temp.hour++;temp.minute=(minute+t.minute)%60;}elsetemp.minute=minute+t.minute;if(second+t.second>60){temp.minute++;temp.second=(second+t.second)%60;}elsetemp.second=second+t.second;return temp;}void display(){cout<<"时间:"<<hour<<"小时"<<minute<<"分钟"<<second<<"秒"<<endl;}private:int hour;int minute;int second;};int main (){Time t1(12,34,7),t2(3,43,5),t3;t3=t1+t2;t1.display();t2.display();t3.display();return 0;}源代码2实验结果源代码3#include<iostream> //3给出抽象类containerusing namespace std;class container{protected:double radius;public:container(double radius1){radius=radius1;};virtual double surface_area()=0;virtual double volume()=0;virtual void show()=0;};class cube:public container{public:cube(double radius1):container(radius1){};double surface_area(){s=radius*radius*6;return s;}double volume(){v=radius*radius*radius;return v;}void show(){cout<<"正方形的面积为"<<s<<endl;cout<<"正方形的体积为"<<v<<endl;}private:double s;double v;};class sphere :public container{public:sphere(double radius1):container(radius1){};double surface_area(){s=4*3.14*radius*radius;return s;}double volume(){v=(4/3)*3.14*radius*radius*radius;return v;}void show(){cout<<"球的表面积为"<<s<<endl;cout<<"球的体积为"<<v<<endl;}private:double s;double v;};class cylinder:public container{public:cylinder(double radius1,double h):container(radius1) {high=h;};double surface_area(){s=2*3.14*radius*radius+2*3.14*radius*high;return s;}double volume(){v=3.14*radius*radius*high;return v;}void show(){cout<<"圆柱体的表面积为"<<s<<endl;cout<<"圆柱体的体积为"<<v<<endl;}private:double high;double v;double s;};int main (){container *p;cube c(6);sphere s(5);cylinder cy(5,6);p=&c;p->surface_area();p->volume();p->show();p=&s;p->surface_area();p->volume();p->show();p=&cy;p->surface_area();p->volume();p->show();return 0;}源代码3实验结果源代码4#include<iostream> //4编写一个可以进行集合并、差和交的运算的程序#include<string>using namespace std;#define Max 100;class Set{public:Set(){s[100]=0;lenth=0;}/* Set(int x[],int leng){s=x;lenth=leng;}*/void input(int d){s[lenth]=d;lenth++;}int getd(int i){return s[i-1];}void disp(string s1){int i;cout<<s1<<"的元素:";for(i=0;i<lenth;i++){cout<<s[i]<<" ";}cout<<endl;}void delet(int d) //d表示要删除数的在数组里的位子{if(d=lenth-1)lenth--;else{for(int i=d;i<lenth-1;i++)s[i]=s[i+1];lenth--;}}Set operator+(Set s1){int a=0;Set temp;// temp=s1;for(int b=0;b<lenth;b++)temp.s[b]=s[b];temp.lenth=lenth;for(int i=0;i<s1.lenth;i++){for(int j=0;j<lenth;j++){if(s1.s[i]==temp.s[j]){a=1;break;}}if(a==0)temp.input(s1.s[i]);elsea=0;}return temp;}Set operator-(Set s1){int i,j;int a=0;Set temp;// temp=s1;for(int b=0;b<lenth;b++) //先把this给temp temp.s[b]=s[b];temp.lenth=lenth;for( i=0;i<s1.lenth;i++){for( j=0;j<lenth;j++){if(s1.s[i]==temp.s[j]){a=1;break;}}if(a==1){temp.delet(j);a=0;}}return temp;} Set operator*(Set s1){int i,j;int a=0;Set temp;// temp=s1;// for(int b=0;b<lenth;b++) //先把this给temp // temp.s[b]=s[b];// temp.lenth=lenth;for( i=0;i<s1.lenth;i++){for( j=0;j<lenth;j++){if(s1.s[i]==s[j]){a=1;break;}}if(a==1){temp.input(s[j]);a=0;}}return temp;}Set operator=(Set s1){int i;for( i=0;i<s1.lenth;i++)s[i]=s1.s[i];lenth=s1.lenth;return *this;}private:int s[100];int lenth;};int main(){Set s1,s2,s3;for(int i=0;i<4;i++)s1.input(i); //给s1.s[]={0,1,2,3}赋值for(int j=2;j<5;j++) //给s2.s[]={2,3,4,5}赋值s2.input(j);s1.disp("s1");s2.disp("s2");s3=s1+s2; //s1和s2求并运算s3.disp("并运算后"); //结果输出s3=s1-s2; //s1和s2求差运算s3.disp("差运算后"); //结果输出s3=s1*s2; //s1和s2求交运算s3.disp("交运算后"); //结果输出return 0;}源代码4运算结果。
编译原理实验2源代码

{-1,-1,-1,106,-1,9,10,106,-1,-1,-1},
{-1,-1,-1,108,-1,9,10,108,-1,-1,-1}};
/********************从文件读一行到缓冲区**********************/
sstack[100],
ibuf[100],
stack[1000];
struct aa oth;
struct fourexp
{
char op[10];
struct aa arg1;
struct aa arg2;
int result;
}fexp[200];
{-1,106,106,106,106,-1,106,106,-1},};
/********************布尔表达式的LR分析表*********************/
static int action2[16][11]=
{{1,-1,4,-1,5,-1,-1,-1,13,7,8},
/***********************标识符和关键字的识别********************/
find(char spel[])
{
int ss1=0;
int ii=0;
while((ss1==0)&&(ii<nlength))
{
if(!strcmp(spel,ntab1[ii]))
#define S 11
#define L 12
#define tempsy 15
编译原理实验 编译器 综合报告(附源代码)

编译原理编译器综合实验---------------工程精品神刀公子一.实验背景编译器就是将“一种语言(通常为高级语言)”翻译为“另一种语言(通常为低级语言)”的程序。
一个现代编译器的主要工作流程:源代码(source code) →预处理器(preprocessor) →编译器 (compiler) →目标代码(object code) →链接器(Linker) → 可执行程序 (executables)高级计算机语言便于人编写,阅读交流,维护。
机器语言是计算机能直接解读、运行的。
编译器将汇编或高级计算机语言源程序(Source program)作为输入,翻译成目标语言(Target language)机器代码的等价程序。
源代码一般为高级语言(High-level language),如Pascal、C、C++、Java、汉语编程等或汇编语言,而目标则是机器语言的目标代码(Object code),有时也称作机器代码(Machine code)。
对于C#、VB等高级语言而言,此时编译器完成的功能是把源码(SourceCode)编译成通用中间语言(MSIL/CIL)的字节码(ByteCode)。
最后运行的时候通过通用语言运行库的转换,编程最终可以被CPU直接计算的机器码(NativeCode)。
二.算法设计典型的编译器输出是由包含入口点的名字和地址,以及外部调用(到不在这个目标文件中的函数调用)的机器代码所组成的目标文件。
一组目标文件,不必是同一编译器产生,但使用的编译器必需采用同样的输出格式,可以链接在一起并生成可以由用户直接执行的EXE,词法分析程序→语法分析程序→语义分析程序→编译器。
不断完善,不断改进。
渐变的过程。
函数。
void scanner(); //扫描void lrparser();void staBlock(int *nChain); //语句块void staString(int *nChain); //语句串void sta(int *nChain); //语句void fuzhi(); //赋值语句void tiaojian(int *nChain); //条件语句void xunhuan(); //循环语句char* E(); //Expresiion表达式char* T(); //Term项char* F(); //Factor因子char *newTemp(); //自动生成临时变量void backpatch(int p,int t); //回填int merge(int p1,int p2); //合并p1和p2void emit(char *res,char *num1,char *op,char *num2); //生成四元式截图说明:综合输入:(赋值,循环,条件。
汇编源代码-实验报告

1、两个多位十进制数相加的实验CRLF MACRO ;定义宏,用CRLF表示回车换行MOV DL,0DH;回车MOV AH,02H;2号调用显示回车INT 21HMOV DL,0AH;换行MOV AH,02H;2号调用换行INT 21HENDM ;宏定义结束DATA SEGMENT;定义两个加数DATA1 DB 33H,39H,31H,37H,34H ;一个加数为47193DATA2 DB 36H,35H,30H,38H,37H ;一个加数为28056DATA ENDS;数据段定义结束STACK SEGMENT stack 'stack';堆栈段定义STA DB 20 DUP(?);定义从STA开始20个单元作为堆栈使用TOP EQU LENGTH STA;TOP等于堆栈段单元数STACK ENDS;堆栈定义结束CODE SEGMENT;代码段定义ASSUME CS:CODE,DS:DATA,SS:STACK,ES:DATASTART: MOV AX,DATA ;数据段首地址存在DS中MOV DS,AX ;设置数据段MOV AX,STACK ;堆栈段首地址存在SS中MOV SS,AX ;设置堆栈段MOV AX,TOP ;堆栈段堆栈指针地址存在SP中MOV SP,AXMOV SI,OFFSET DATA2 ;SI存放data2偏移量MOV BX,05 ;循环5次CALL DISPL ;调用子程序输出CRLF ;调用回车换行MOV SI,OFFSET DATA1 ;同上MOV BX,05CALL DISPLCRLF ;回车换行MOV DI,OFFSET DATA2CALL ADDA ;调用函数ADDA计算两个10进制数相加MOV SI,OFFSET DATA1;将使用加法运算程序MOV BX,06;显示结束CALL DISPL ;计算完毕,输出结果CRLF;回车换行MOV AX,4C00H; 返回系统提示符INT 21HDISPL PROC NEAR ;子程序,实现倒序从SI开始输出BX位字符DS1: MOV AH,02;显示功能号MOV DL,[SI+BX-1];显示字符串中一字符INT 21H;DOS的中断调用DEC BX;BX减1,修改偏移量JNZ DS1;如果BX未减到零跳到DSL执行指令RET;返回DISPL ENDP;完成子功能程序定义ADDA PROC NEAR ;子程序,实现5位十进制加法MOV DX,SIMOV BP,DIMOV BX,5 ;转换5次AD1: SUB byte ptr [SI+BX-1],30H ;转换为16进制数SUB BYTE PTR [DI+BX-1],30H;;转换为16进制DEC BX;修改偏移量JNZ AD1 ;循环BX次MOV SI,DXMOV DI,BPMOV CX,05;包括进位共五位CLC;清进位AD2: MOV AL,[SI] ;两个10进制数相加MOV BL,[DI]ADC AL,BL;进行带进位加法AAA;非组合BCD码得的加法调整MOV [SI],AL;结果送被加数区INC SIINC DI;指向下一位LOOP AD2;循环JNC ABC ;若最后一位产生进位,额外输出1AND BYTE PTR DATA1+5,00HADD BYTE PTR DATA1+5,31HMOV SI,DXMOV DI,BPMOV BX,05JMP AD3ABC: ;没有进位则不执行AND BYTE PTR DATA1+5,00HMOV SI,DXMOV DI,BPMOV BX,05AD3: ADD BYTE PTR [SI+BX-1],30H ;转换为ASCII码DEC BX;16进制的数字串转化JNZ AD3RETADDA ENDP;加法程序结束CODE ENDS;代码段结束END START;整个程序结束2、字符串匹配实验DATA SEGMENTCH1 DB 100CONT1 DB ?S1 DB 100 DUP('$')CH2 DB 100CONT2 DB ?S2 DB 100 DUP('$');定义提示信息字符串INFO1 DB 'INPUT STRING1',0DH,0AH,'$'INFO2 DB ' INPUT STRING2',0DH,0AH,'$'MA DB 'MATCH',0DH,0AH,'$'NM DB 'NO MATCH',0DH,0AH,'$'CRLF DB 0DH,0AH,'$'DATA ENDSCODE SEGMENT 'code'ASSUME CS:CODE,DS:DATASTART: MOV AX,DATA ;数据段存入DS,ESMOV DS,AXMOV ES,AXMOV AH,9 ;输出提示信息1LEA DX,INFO1INT 21HMOV AH,10 ;字符串输入s1LEA DX,CH1INT 21HLEA DX,CRLF ;回车换行MOV AH,9INT 21HLEA DX,INFO2 ;输出提示信息2INT 21HMOV AH,10 ;字符串输入s2LEA DX,CH2INT 21HLEA DX,CRLF ;回车换行MOV AH,9INT 21HMOV SI,OFFSET S1 ;把s1的偏移地址放入siMOV DI,OFFSET S2 ;把s2偏移地址放入diMOV CL,CONT1 ;s1的长度放入clXOR CH,CH ;高位清0CLD ;DF=0,确定地址改变方向OL: ;匹配字符串MOV DX,DIMOV BX,CXPUSH CX ;cx压入栈以保留状态MOV AL,[SI] ;si中的字符内容放入al,被比较项MOV CL,CONT2 ;cl中存放比较次数,即s2长度XOR CH,CH ;高位清0REPNZ SCASB ;比较字符串,SI与DI指向字符比较,比较之后自动各自向后移动1位JZ MATCH ;均比较成功则匹配成功MOV DI,DXMOV CX,BX ;更新循环次数INC SILOOP OLJMP NMATCHMATCH:LEA DX,MA ;输出匹配成功MOV AH,9INT 21HJMP EXNMATCH:LEA DX,NM ;输出匹配不成功MOV AH,9INT 21HEX: MOV AX,4C00H ;返回DOSINT 21HCODE ENDSEND START3、从键盘输入数据并显示的实验DATA SEGMENT ;定义数据段STRING1 DB 'Please input a number :', 0DH, 0AH, '$'STRING2 DB 5, 0, 5 DUP(?)STRING3 DB 'Input ERROR.', 0DH, 0AH, '$'DATA ENDSCODE SEGMENT ;定义代码段ASSUME CS:CODE, DS:DATASTART:MOV AX, DATAMOV DS, AXMOV DX, OFFSET STRING1 ;输出STRING1的内容MOV AH, 09HINT 21HMOV DX, OFFSET STRING2 ;输入STRING2的内容即四位16进制数MOV AH, 0AHINT 21HMOV CL, 4MOV CH, CLMOV SI, OFFSET STRING2ADD SI, 2CLDXOR AX, AXXOR DX, DXDDD1: LODSB ;将一个字节装入AL ,输入的数为0~9 CMP AL, '0'JB ERRORCMP AL, '9'JA DDD2SUB AL, 30H;JMP DDD3DDD2: CMP AL, 'A' ;输入的数为A~FJB ERRORCMP AL, 'F'JA DDD4SUB AL, 37H;JMP DDD3DDD4: CMP AL, 'a';输入的数为a~fJB ERRORCMP AL, 'f'JA ERRORSUB AL, 57H;DDD3: ROL DX, CLOR DL, ALDEC CHJNZ DDD1 ;将ASCII码全部转为对应的16进制数MOV AH, 2MOV BX, DXMOV DL, 13INT 21HMOV DL, 10INT 21HMOV CX, 16LP1: MOV DL, '0'ADD BX, BX ;左移一位JNC ZZZINC DLZZZ: INT 21H ;输出字符'0'或'1'LOOP LP1JMP EXITERROR:MOV DX, OFFSET STRING3 ;产生错误MOV AH, 09HINT 21HEXIT: MOV AH, 4CH ;退出INT 21HCODE ENDSEND START4、排序实验DATAS SEGMENTARRAY DB 32H,22H,10H,55H,18H,68H,75H,13H,20H,38H ;定义存放数的数组COUNT EQU 10 ;定义数据个数COUNTSTR DB 'AFTER SORT IS: ',0DH,0AH,'$'DATAS ENDSSTACKS SEGMENTSTACKS ENDSCODES SEGMENTASSUME CS:CODES,DS:DATAS,SS:STACKSSTART: MOV AX,DATASMOV DS,AXMOV CX,COUNTDEC CX ;CX中的数据为循环次数OUTLP: MOV DX,CXMOV BX,OFFSET ARRAYINLP: MOV AL,[BX] ;取前一个数CMP AL,[BX+1] ;将这个数和下一个数比较JNA NEXT ;若不大于则不进行交换,转移到NEXTXCHG AL,[BX+1] ;若这个数比下一个数大,则两数交换MOV [BX],ALNEXT: INC BX ;下一对元素DEC DXJNZ INLP ;内循环尾LOOP OUTLP ;外循环尾MOV BX,OFFSET ARRAYMOV CX,COUNTLEA DX,STRMOV AH,09H ;输出提示字符串INT 21HOUTPUT: MOV AL,[BX] ;先输出数字的高位SHR AL,1SHR AL,1SHR AL,1SHR AL,1 ;左移四位ADD AL,30H ;将ASCII码改为对应的数字再输出MOV DL,ALMOV AH,02H ;输出高位数字INT 21H ;再输出数字的低位MOV AL,[BX]AND AL,0FH ;屏蔽高位,保留低位以输出ADD AL,30HMOV DL,ALMOV AH,02H ;输出低位数字INT 21HMOV DL,' ' ;输出一个空格MOV AH,02HINT 21HINC BX ;输出下一个数值LOOP OUTPUTMOV AH,4CHINT 21HCODES ENDSEND START5、DOS、BIOS调用DATAS SEGMENTDATAS ENDSTACKS SEGMENTSTACKS ENDSCODES SEGMENTASSUME CS:CODES,DS:DATAS,SS:STACKSSTART: MOV AX,DATASMOV DS,AXMOV AH,2 ;显示单个字符MOV CX,16 ;设置循环次数MOV BL,00Hloop1: MOV BH,16;第一层循环,共输出16行字符loop2: CMP BL,7 ;判断是否是特殊字符,下同,第二层循环,每次输出一行字符JZ SPECIALCMP BL,8JZ SPECIALCMP BL,9JZ SPECIALCMP BL,0AHJZ SPECIALCMP BL,0DHJZ SPECIALMOV DL,BL ;显示当前字符INT 21HMOV DL,20H ;空格INT 21HJMP NEXT ;不是特殊字符,准备进入下一次循环SPECIAL: ;若是特殊字符,输出两个空格PUSH DXXOR DX,DXINT 21HINT 21HPOP DXNEXT:INC BLDEC BHCMP BH,0JNE loop2MOV DL,0AH ;换行INT 21MOV DL,0DH ;回车INT 21H loop loop1 EXIT:MOV AH,4CHINT 21H CODES ENDS END START。
编译学原理实验报告

一、实验目的1. 理解编译原理的基本概念和编译过程。
2. 掌握编译器各个阶段的功能和实现方法。
3. 通过实际操作,加深对编译原理的理解和应用。
二、实验环境1. 操作系统:Windows 102. 编译器:C++编译器3. 开发环境:Visual Studio三、实验内容1. 词法分析2. 语法分析3. 语义分析4. 中间代码生成5. 代码优化6. 目标代码生成四、实验步骤1. 词法分析(1)设计词法分析器:根据实验要求,设计一个词法分析器,能够将源代码中的字符序列转换成一个个词法符号。
(2)实现词法分析器:使用C++编写词法分析器代码,实现字符序列到词法符号的转换。
(3)测试词法分析器:编写测试用例,验证词法分析器的正确性。
2. 语法分析(1)设计语法分析器:根据实验要求,设计一个语法分析器,能够识别源代码中的语法结构。
(2)实现语法分析器:使用C++编写语法分析器代码,实现语法结构的识别。
(3)测试语法分析器:编写测试用例,验证语法分析器的正确性。
3. 语义分析(1)设计语义分析器:根据实验要求,设计一个语义分析器,能够对源代码中的语义进行验证。
(2)实现语义分析器:使用C++编写语义分析器代码,实现语义验证。
(3)测试语义分析器:编写测试用例,验证语义分析器的正确性。
4. 中间代码生成(1)设计中间代码生成器:根据实验要求,设计一个中间代码生成器,能够将源代码转换成中间代码。
(2)实现中间代码生成器:使用C++编写中间代码生成器代码,实现源代码到中间代码的转换。
(3)测试中间代码生成器:编写测试用例,验证中间代码生成器的正确性。
5. 代码优化(1)设计代码优化器:根据实验要求,设计一个代码优化器,能够对中间代码进行优化。
(2)实现代码优化器:使用C++编写代码优化器代码,实现中间代码的优化。
(3)测试代码优化器:编写测试用例,验证代码优化器的正确性。
6. 目标代码生成(1)设计目标代码生成器:根据实验要求,设计一个目标代码生成器,能够将优化后的中间代码转换成目标代码。
汇编语言实验报告源代码

分支程序设计-字母字符转换-源码:.386.MODEL FLATExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORDINCLUDE io.h ; header file for input/outputcr EQU 0dh ; carriage return characterLf EQU 0ah ; line feed.STACK 4096 ; reserve 4096-byte stack.DATApromot BYTE "Enter a char of letter ",cr,Lf,0warning BYTE "The char isn't a letter,enter again ",0answerLtoU BYTE "The char is a lowercase,it's uppercase is "BYTE cr,Lf,0answerUtoL BYTE "The char is a uppercase,it's lowercase is "BYTE cr,Lf,0char BYTE 1 DUP(?).CODE_start:output promot ;输出提示语句input char,1 ;输入数据doGo:mov bl,charinput char,1cmp char,0dh ;与0dh比较je doWhCMP ;若相等,跳转到doWhCMPjmp doGo ;重新输入数据doWhCMP:cmp bl,41h ;与41h(A)比较jl inputAgain ;若char<A,提示重新输入cmp bl,5Ahjle endUppertoL ;若char<=Z,跳转到大写字母转换为小写字母部分cmpLower:cmp bl,61h ;与61h(a)比较jl inputAgain ;若char<a,跳转到重新输入cmp bl,7Ah ;与7Ah(z)比较jg inputAgain ;若char>z,跳转到重新输入jmp endLowertoU ;跳转到小写字母转换为大写字母部分inputAgain:output warning ;输出错误信息提示语句input char,1 ;输入数据mov bl,charjmp doGo ;跳转到比较部分endUppertoL:mov al,bladd al,32 ;ASCII码加32mov char,aloutput answerUtoL ;输出结果提示语句output char ;输出结果jmp endMain ;跳转到结束部分endLowertoU:mov al,blsub al,32 ;ASCII码减32mov char,aloutput answerLtoU ;输出结果提示语句output char ;输出结果endMain:INVOKE ExitProcess, 0 ; exit with return code 0 PUBLIC _start ; make entry point public END ; end of source code循环程序设计-显示九九乘法表-源码:.386.MODEL FLATExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORDINCLUDE io.hcr EQU 0dhLf EQU 0ah.STACK 4096.DATAcome BYTE "Welcome to multiplication table!",cr,Lf,0sum BYTE 6 DUP (?),0first BYTE 6 DUP (?),0second BYTE 6 DUP (?),0row WORD ?lie WORD ?prompt1 BYTE "*", 0prompt2 BYTE "=",0prompt3 BYTE cr, Lf,0prompt4 BYTE " ",0.CODE_start:output come ;输出欢迎语句output prompt3 ;换行mov row, 1 ;将行数初始值赋值为1mov lie, 1 ;将列数初始值赋值为1fo:cmp row,9 ;行数与9相比较jg quit ;若行数等于9则退出循环mov bx,row ;bx寄存器中存储行数itoa first,bx ;将bx的值转换为ASCII码值存储到first中output first+5 ;输出行数output prompt1 ;输出乘号mov cx,lie ;cx寄存器中存储列数itoa second,cx ;将cx的值转换为ASCII码值存储到second中output second+5 ;输出列数output prompt2 ;输出等号mov ax,cx ;将cx寄存器中的列数移到ax寄存器为乘法做准备imul bx ;做乘法bx*ax即行数*列数itoa sum,ax ;将结果转换为ASCII码值存储到sum中output sum+4 ;输出乘积运算结果output prompt4 ;输出空格cmp bx,cx ;行数与列数值进行比较je to ;若相等则跳转到换行输出部分inc lie ;列数自增jmp fo ;继续循环to:output prompt3 ;输出换行inc row ;行数自增mov lie,1 ;列数初始化为1jmp fo ;进入循环quit:INVOKE ExitProcess, 0 ; exit with return code 0 PUBLIC _start ; make entry point public END ; end of source code子程序设计-求给定整数的所有素因子-源码:.386.MODEL FLATExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORD INCLUDE io.h ; header file for input/outputcr EQU 0dh ; carriage return characterLf EQU 0ah ; line feed.STACK 4096 ; reserve 4096-byte stack.DATA ; reserve storage for dataflai DWORD ?temp DWORD ?crlf BYTE "*",0eqll BYTE "=",0prompt BYTE "Enter a number to find all the prime factors",cr,Lf,0fl DWORD ?value BYTE 11 DUP(?),0char BYTE 1 DUP(?)PUBLIC _start.CODE ; start of main program code_start:output prompt ;输出提示语句input value,11 ;输入数据atod value ;ASCII码转换为数字push eax ;eax寄存器的值压入堆栈call byteInput ;调用byteInput子程序add esp,4output eqll ;输出等号push eax ;eax寄存器的值压入堆栈call findPfactor ;调用findPfactor子程序add esp,4INVOKE ExitProcess, 0 ; exit with return code 0findPfactor PROC NEAR32 ;寻找素因子子程序push ebp ;ebp内的值压入堆栈mov ebp,espmov eax,[ebp+8]mov flai,eaxmov ecx,2mov ebx,ecxdoFind:mov ecx,ebxcmp ecx,flai ;while循环的条件比较je endFind ;如果ecx的值与flai相等则退出循环doFactor:mov temp,eaxcdq ;为除法做准备idiv ecx ;除法eax=eax/ecxcmp edx,0 ;eax符号位与0进行比较jne endFactor ;若不相等跳转到endFactor部分push ecx ;ecx值压入堆栈output crlf ;输出换行call byteInput ;调用byteInput子程序add esp,4jmp doFactorendFactor:mov eax,tempinc ebx ;ebx值自增jmp doFind ;跳转到doFind部分endFind:pop ebp ;ebp弹出堆栈ret ;返回指令findPfactor ENDP ;findPfactor子程序结束byteInput PROC NEAR32 ;byteInput子程序push ebp ;ebp压入堆栈mov ebp,esppush ebx ;ebx压入堆栈push eax ;eax压入堆栈push edx ;edx压入堆栈mov fl,0mov ebx,10mov eax,[ebp+8]doWh:cdq ;为除法做准备idiv ebx ;除法eax=eax/ebxpush edx ;edx压入堆栈inc fl ;fl值自增cmp eax,0 ;eax与0比较je enddoWh ;若相等则退出循环jmp doWhenddoWh:doPrint:cmp fl,0 ;fl值与0作比较je enddoPrint ;若相等则退出输出循环dec fl ;fl值自减pop edx ;edx弹出堆栈mov char,dladd char,'0'output char ;输出charjmp doPrint ;继续循环enddoPrint:pop edx ;edx弹出堆栈pop eax ;eax弹出堆栈pop ebx ;ebx弹出堆栈pop ebp ;ebp弹出堆栈ret ;返回指令byteInput ENDP ;byteInput子程序结束END ; end of source code位运算指令的使用-双字型数的高低字转换-源码:.386.MODEL FLATExitProcess PROTO NEAR32 stdcall, dwExitCode:DWORD INCLUDE io.h ; header file for input/outputcr EQU 0dh ; carriage return characterLf EQU 0ah ; line feed.STACK 4096 ; reserve 4096-byte stack.DATA ; reserve storage for dataprompt BYTE "Input a number: ",0number BYTE 20 dup (?)result BYTE cr,Lf,"The 2's complement representation is: " hexout BYTE 8 DUP(?),cr,Lf,0prompt2 BYTE cr,lf,"After the shift ",0.CODE ; start of main program code Hex PROC NEAR32push eaxlea ebx,hexout+7 ;取最后一个字符的地址mov ecx,8 ;字符个数mov esi,eaxforcount:mov edx,eaxand edx,0000000fhcmp edx,9jnle elseLetteror edx,30h ;转换为字符jmp endifDigitelseLetter:add edx,'A'-10 ;转化为字母endifDigit:mov BYTE PTR [ebx],dldec ebx ;指向下一个字符shr eax,4 ;右移位loop forcountoutput resultpop eaxretHex ENDP_start:output promptinput number,16 ;输入一个数字atod numbercall Hex ;调用子程序Hexrol eax,16 ;循环左移位output prompt2 ;输出转换后的十六进制数call HexINVOKE ExitProcess, 0 ;exit with return code 0 PUBLIC _start ; make entry point public END ; end of source code。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程设计报告( 2013-- 2014年度第1学期)名称:编译技术课程设计B题目:简单编译程序的设计与实现院系:计算机系班级:XXX学号:XXX学生姓名:XXX指导教师:XXX设计周数:XXX成绩:日期:XX 年XX 月实验一.词法分析器的设计与实现一、课程设计(综合实验)的目的与要求1.1 词法分析器设计的实验目的本实验是为计算机科学与技术专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。
通过这个实验,使学生应用编译程序设计的原理和技术设计出词法分析器,了解扫描器的组成结构,不同种类单词的识别方法。
能使得学生在设计和调试编译程序的能力方面有所提高。
为将来设计、分析编译程序打下良好的基础。
1.2 词法分析器设计的实验要求设计一个扫描器,该扫描器是一个子程序,其输入是源程序字符串,每调用一次识别并输出一个单词符号。
为了避免超前搜索,提高运行效率,简化扫描器的设计,假设该程序设计语言中,基本字(也称关键词)不能做一般标识符用,如果基本字、标识符和常数之间没有确定的运算符或界符作间隔,则用空白作间隔。
单词符号及其内部表示如表1-1所示,单词符号中标识符由一个字母后跟多个字母、数字组成,常数由多个十进制数字组成。
单词符号的内部表示,即单词的输出形式为二元式:(种别编码,单词的属性值)。
表1-1 单词符号及其内部表示二、设计(实验)正文1.词法分析器流程图2.词法分析器设计程序代码// first.cpp : 定义控制台应用程序的入口点。
//#include"stdafx.h"#include<iostream>#include<string>using namespace std;int what(char a){if((int(a)>=48)&&(int(a)<=57)){return 0;//0-9数字}elseif((int(a)>=97)&&(int(a)<=122)){return 1;//a-z的字母}else{return 2;//其他的标点符号}}void scan(char a[],int &m,char zc[100][100],int &n){char zh[100];int b=0,weizhi,r=0;int zbbm;//-----------------------------检测整形常数while(a[m]==' '){cout<<"遇到空格"<<endl;m++;}if(what(a[m])==0){while(what(a[m])==0){b=b*10+int(a[m])-48;m++;}zbbm=7;cout<<"("<<zbbm<<","<<b<<")"<<endl;}else//----------------------------------检测字符型if(what(a[m])==1){if((a[m]=='b')&&(a[m+1]=='e')&&(a[m+2]=='g')&&(a[m+3]=='i')&&(a[m+4]=='n')& &(what(a[m+5])==2)){m=m+5;zbbm=1;cout<<"("<<zbbm<<",-)"<<endl;}//=====检测beginelseif((a[m]=='i')&&(a[m+1]=='f')&&(what(a[m+2])==2)){m=m+2;zbbm=2;cout<<"("<<zbbm<<",-)"<<endl;}//检测ifelseif((a[m]=='t')&&(a[m+1]=='h')&&(a[m+2]=='e')&&(a[m+3]=='n')&&(what(a[m+4])= =2)){m=m+4;zbbm=3;cout<<"("<<zbbm<<",-)"<<endl;}//检测thenelseif((a[m]=='e')&&(a[m+1]=='l')&&(a[m+2]=='s')&&(a[m+3]=='e')&&(what(a[m+4])= =2)){m=m+4;zbbm=4;cout<<"("<<zbbm<<",-)"<<endl;}//检测elseelseif((a[m]=='e')&&(a[m+1]=='n')&&(a[m+2]=='d')&&(what(a[m+3])==2)){m=m+3;zbbm=5;cout<<"("<<zbbm<<",-)"<<endl;}//检测end//----------------------------对未知字符的检测else{int j=0;while(what(a[m])!=2){zh[j]=a[m];m++;j++;}zh[j]='#';if(n==0){j=0;while(zh[j]!='#'){zc[0][j]=zh[j];j++;}zc[0][j]='#';n=1;weizhi=1;}elseif(n>0){int k=0,y=1;while((k<n)&&(y==1)){r=0;while(zc[k][r]!='#'){r++;}if(r!=j){k++;y=1;}elseif(r==j){r=0;while((int(zc[k][r])==int(zh[r]))&&(r<j)){r++;}if(r==j){weizhi=k+1;y=0;}else{k++;y=1;}}}if(y==1){j=0;while(zh[j]!='#'){zc[n][j]=zh[j];j++;}zc[n][j]='#';n=n+1;weizhi=n;}}zbbm=6;//怎么输出地址cout<<"("<<zbbm<<","<<weizhi<<")"<<endl;}}elseif(what(a[m])==2){if(a[m]=='+'){zbbm=8;m++;cout<<"("<<zbbm<<",-)"<<endl;}//检测+elseif(a[m]=='('){zbbm=11;m++;cout<<"("<<zbbm<<",-)"<<endl;}//检测(elseif(a[m]==')'){zbbm=12;m++;cout<<"("<<zbbm<<",-)"<<endl;}//检测)elseif(a[m]=='*'){if(a[m+1]=='*'){zbbm=10;m+=2;}else{zbbm=9;m++;}cout<<"("<<zbbm<<",-)"<<endl;}}}int main(){char zc[100][100];int n=0;cout<<"begin------------1"<<endl;cout<<"if ------------2"<<endl;cout<<"then ------------3"<<endl;cout<<"else ------------4"<<endl;cout<<"end ------------5"<<endl;cout<<"标志符------------6"<<endl;cout<<"整型常数------------7"<<endl;cout<<"+------------8"<<endl;cout<<"*------------9"<<endl;cout<<"**------------10"<<endl;cout<<"(------------11"<<endl;cout<<")------------12"<<endl;cout<<"========================================================="<<endl;cout<<endl;int m=0;char a[100];cout<<"请输入测试语句:";cin.getline(a,100,'\n');cout<<"输出格式为: (种别编码,单词的属性值)"<<endl;while(a[m]!='#'){scan(a,m,zc,n);}return 0;}3.词法分析器运行结果实验二. 算符优先分析的设计与实现一、课程设计(综合实验)的目的与要求2.1 算符优先分析程序设计的实验目的本实验是为计算机科学与技术专业的学生在学习《编译技术》课程后,为加深对课堂教学内容的理解,培养解决实际问题能力而设置的实践环节。