并行进位运算器实验报告
运算器实验报告

运算器实验报告实验背景运算器是计算机中一种重要的基本逻辑电路,用于进行算术和逻辑运算。
本次实验旨在设计一个基于逻辑门的4位二进制加法器,以实现两个4位二进制数的加法运算。
实验设备与材料1. 逻辑门:AND门、OR门、XOR门、NOT门2. 电路连接线3. 电压源4. 实验板5. 4个开关、8个LED灯实验原理在二进制数的加法中,我们需要对每一位进行逐个相加,并考虑进位的情况。
对于两个4位二进制数的加法,我们可以将其划分为4个单独的位加法运算,再结合进位的情况进行计算。
实验步骤1. 连接电路:根据逻辑门的真值表和逻辑方程,使用电路连接线将逻辑门按照设计要求连接在一起。
2. 设计输入:使用4个开关分别表示两个4位二进制数的每一位输入。
3. 设计输出:使用8个LED灯分别表示两个4位二进制数的每一位输出和进位。
4. 进行实验:按照设计的输入情况,观察LED灯的亮灭情况,验证加法器的正确性。
5. 记录结果:将实验结果记录在实验报告中。
实验结果与分析实验中,我们设计的4位二进制加法器成功实现了两个4位二进制数的加法运算。
通过观察LED灯的亮灭情况,我们可以判断出加法器的计算是否正确。
在实验过程中,我们发现在某些情况下,LED灯的亮灭可能存在短暂的闪烁现象,这是因为逻辑门的切换速度限制导致的,不会影响加法器的正常运算结果。
实验总结通过本次实验,我们深入理解了运算器的工作原理,并成功设计并实现了一个基于逻辑门的4位二进制加法器。
在实验中,我们熟悉了逻辑门的连接方法,并通过观察LED灯的亮灭情况验证了加法器的正确性。
此外,在实验中我们也发现了逻辑门的切换速度限制会导致LED 灯的闪烁现象。
在实际应用中,我们需要根据逻辑门的性能要求选择适当的门延迟时间,以保证运算器的稳定工作。
总体而言,本次实验对于我们理解运算器的工作原理,掌握逻辑门的应用具有重要意义。
我们相信通过进一步的学习和实践,我们能够设计出更加复杂和高效的运算器,为计算机的发展做出更大的贡献。
并行实验快速排序实验报告完整版

华南师范大学实验报告学生姓名学 号专 业计算机科学与技术年级、班级课程名称并行计算实验项目快速排序的并行算法实验时间 2011 年 6 月 10 日实验类型实验指导老师实验评分3.1实验目的与要求1.熟悉快速排序的串行算法2.熟悉快速排序的并行算法3.实现快速排序的并行算法3.2 实验环境及软件单台或联网的多台PC机, Linux操作系统, MPI系统。
3.3实验内容1.快速排序的基本思想2.单处理机上快速排序算法3.快速排序算法的性能4.快速排序算法并行化5.描述了使用2m个处理器完成对n个输入数据排序的并行算法。
6.在最优的情况下并行算法形成一个高度为logn的排序树7、完成快速排序的并行实现的流程图8、完成快速排序的并行算法的实现3.4实验步骤3.4.1.快速排序(Quick Sort)是一种最基本的排序算法, 它的基本思想是: 在当前无序区R[1, n]中取一个记录作为比较的“基准”(一般取第一个、最后一个或中间位置的元素), 用此基准将当前的无序区R[1, n]划分成左右两个无序的子区R[1, i-1]和R[i, n](1≤i≤n), 且左边的无序子区中记录的所有关键字均小于等于基准的关键字, 右边的无序子区中记录的所有关键字均大于等于基准的关键字;当R[1, i-1]和R[i, n]非空时, 分别对它们重复上述的划分过程, 直到所有的无序子区中的记录均排好序为止。
3.4.2.单处理机上快速排序算法输入: 无序数组data[1,n]输出: 有序数组data[1,n]Begincall procedure quicksort(data,1,n)Endprocedure quicksort(data,i,j)Begin(1) if (i<j) then(1.1)r = partition(data,i,j)(1.2)quicksort(data,i,r-1);(1.3)quicksort(data,r+1,j);end ifEndprocedure partition(data,k,l)Begin(1) pivo=data[l](2) i=k-1(3) for j=k to l-1 doif data[j]≤pivo theni=i+1exchange data[i] and data[j]end ifend for(4) exchange data[i+1] and data[l](5) return i+1End3.4.3.快速排序算法的性能主要决定于输入数组的划分是否均衡, 而这与基准元素的选择密切相关。
运算器实验实验报告(计算机组成原理)

运算器实验实验报告(计算机组成原理)西安财经学院信息学院《计算机组成原理》实验报告实验名称运算器实验实验室实验楼 418实验日期第一部分8 位算术逻辑运算实验一、实验目的 1、掌握算术逻辑运算器单元 ALU(74LS181)的工作原理。
2、掌握简单运算器的数据传送通路组成原理。
3、验证算术逻辑运算功能发生器 74LSl8l 的组合功能。
4、按给定数据,完成实验指导书中的算术/逻辑运算。
二、实验内容 1 、实验原理实验中所用的运算器数据通路如图 1-1 所示。
其中运算器由两片 74LS181以并/串形成 8 位字长的 ALU 构成。
运算器的输出经过一个三态门 74LS245(U33)到内部数据总线 BUSD0~D7 插座 BUS1~2 中的任一个(跳线器JA3 为高阻时为不接通),内部数据总线通过 LZD0~LZD7 显示灯显示;运算器的两个数据输入端分别由二个锁存器 74LS273(U29、U30)锁存,两个锁存器的输入并联后连至内部总线BUS,实验时通过 8 芯排线连至外部数据总线 E_D0~D7 插座E_J1~E_J3 中的任一个;参与运算的数据来自于 8 位数据开并KD0~KD7,并经过一三态门 74LS245(U51)直接连至外部数据总线 E_D0~E_D7,通过数据开关输入的数据由 LD0~LD7 显示。
图 1-1 中算术逻辑运算功能发生器 74LS181(U31、U32)的功能控制信号S3、S2、S1、S0、CN、M 并行相连后连至 6 位功能开关,以手动方式用二进制开关 S3、S2、S1、S0、CN、M 来模拟74LS181(U31、U32)的功能控制信号S3、S2、S1、S0、CN、M;其它电平控制信号 LDDR1、LDDR2、ALUB`、SWB`以手动方式用二进制开关 LDDR1、LDDR2、ALUB、SWB 来模拟,这几个信号姓名学号班级年级指导教师李芳有自动和手动两种方式产生,通过跳线器切换,其中ALUB`、SWB`为低电平有效,LDDR1、LDDR2 为高电平有效。
并行程序设计实验报告

并行程序设计实验报告实验报告:并行程序设计一、实验目的本实验旨在通过并行程序设计,提高程序的执行效率和性能,减少串行程序在处理大规模数据时出现的效率瓶颈。
二、实验原理1.任务划分:将大规模的任务划分成多个可并行执行的子任务。
2.任务分配:将各个子任务分配给不同的计算单元(如多线程、多进程、多核)进行处理。
3.任务合并:将各个子任务的计算结果进行合并,得到最终的结果。
三、实验内容本次实验主要涉及多线程编程和数据并行编程。
1.多线程编程多线程编程是指在一个单独的程序中同时运行多个线程,利用系统的多核资源来提高程序的执行效率。
多线程编程可以通过线程的创建、启动、运行和同步等操作来实现。
在本实验中,我们将使用C++编程语言,并利用其提供的多线程库来实现多线程编程。
具体步骤如下:(1)使用pthread库创建并启动多个线程。
(2)利用线程同步机制(如互斥锁、信号量等)保证线程的正确执行顺序和数据的正确性。
(3)通过编写并行程序,将大规模任务划分成多个子任务,并分配给不同的线程进行处理。
2.数据并行编程数据并行编程是指将大规模的数据划分成多个小块,并分配给多个计算单元(如GPU)进行并行处理。
每个计算单元都执行相同的计算操作,但操作的数据不同。
在本实验中,我们将使用CUDA平台进行数据并行编程。
(1)利用CUDA编程模型,将计算任务划分成多个线程块,并分配给不同的计算单元执行。
(2)通过编写并行程序,实现数据的划分和映射、任务的分配和协调。
四、实验结果经过多次实验,我们发现并行程序设计在处理大规模数据时能够显著提高程序的执行效率和性能。
相比于串行程序,多线程编程和数据并行编程分别提高了X%和Y%的执行速度。
同时,我们也发现在设计并行程序时,要考虑到数据的划分和映射、任务的分配和协调、线程的同步和通信等方面的问题。
这些问题对于程序的性能和正确性都有着重要的影响。
五、实验总结通过本次实验,我们了解到并行程序设计的基本原理和技术,以及它在优化程序性能和提高执行效率方面的重要作用。
并行计算实验报告一

并行计算实验报告一江苏科技大学计算机科学与工程学院实验报告评定成绩指导教师实验课程:并行计算宋英磊实验名称:Java多线程编程学号: 姓名: 班级: 完成日期:2014年04月22日1.1 实验目的(1) 掌握多线程编程的特点;(2) 了解线程的调度和执行过程;(3) 掌握资源共享访问的实现方法。
1.2 知识要点1.2.1线程的概念(1) 线程是程序中的一个执行流,多线程则指多个执行流;(2) 线程是比进程更小的执行单位,一个进程包括多个线程;(3) Java语言中线程包括3部分:虚拟CPU、该CPU执行的代码及代码所操作的数据。
(4) Java代码可以为不同线程共享,数据也可以为不同线程共享; 1.2.2 线程的创建(1) 方式1:实现Runnable接口Thread类使用一个实现Runnable接口的实例对象作为其构造方法的参数,该对象提供了run方法,启动Thread将执行该run方法;(2) 方式2:继承Thread类重写Thread类的run方法;1.2.3 线程的调度(1) 线程的优先级, 取值范围1,10,在Thread类提供了3个常量,MIN_PRIORITY=1、MAX_ PRIORITY=10、NORM_PRIORITY=5;, 用setPriority()设置线程优先级,用getPriority()获取线程优先级; , 子线程继承父线程的优先级,主线程具有正常优先级。
(2) 线程的调度:采用抢占式调度策略,高优先级的线程优先执行,在Java 中,系统按照优先级的级别设置不同的等待队列。
1.2.4 线程的状态与生命周期说明:新创建的线程处于“新建状态”,必须通过执行start()方法,让其进入到“就绪状态”,处于就绪状态的线程才有机会得到调度执行。
线程在运行时也可能因资源等待或主动睡眠而放弃运行,进入“阻塞状态”,线程执行完毕,或主动执行stop方法将进入“终止状态”。
1.2.5 线程的同步--解决资源访问冲突问题(1) 对象的加锁所有被共享访问的数据及访问代码必须作为临界区,用synchronized加锁。
并行计算实验报告

分析 :这样的加速比 , 是符合预测 , 很好的 . 附 :(实验 源码 ) 1 pi.cpp #include <cstdio> #include <cstdlib> #include <cstring> #include <cctype> #include <cmath> #include <ctime> #include <cassert>
#include <climits> #include <iostream> #include <iomanip> #include <string> #include <vector> #include <set> #include <map> #include <queue> #include <deque> #include <bitset> #include <algorithm> #include <omp.h> #define MST(a, b) memset(a, b, sizeof(a)) #define REP(i, a) for (int i = 0; i < int(a); i++) #define REPP(i, a, b) for (int i = int(a); i <= int(b); i++) #define NUM_THREADS 4 using namespace std; const int N = 1e6; double sum[N]; int main() { ios :: sync_with_stdio(0); clock_t st, ed; double pi = 0, x; //串行 st = clock(); double step = 1.0 / N; REP(i, N) { x = (i + 0.5) * step; pi += 4.0 / (1.0 + x * x); } pi /= N; ed = clock(); cout << fixed << setprecision(10) << "Pi: " << pi << endl; cout << fixed << setprecision(10) << "串行用时: " << 1.0 * (ed - st) / CLOCKS_PER_SEC << endl; //并行域并行化 pi = 0; omp_set_num_threads(NUM_THREADS); st = clock(); int i; #pragma omp parallel private(i) { double x; int id; id = omp_get_thread_num();
并行进位运算器实验报告

并行进位运算器实验一、实验目的:了解并行进位运算器的工作原理和过程,利用多个芯片采用扩展的方式设计出16位并行进位运算器功能部件,并封装调试。
在基于Max+plus II平台的计算机主机系统选择芯片设计寄存器,设计输入信号,分析输出波形。
二、实验仪器:一台装有MAX+plus II环境的计算机、计算机组成原理实践教程三、实验原理:1、74181芯片实现了组内四位的并行进位,即第0位的进位输入Cn可以直接传送到最高进位位上去。
那么16位并行进位运算器则需要四片74181芯片。
2、要实现组间的并行进位,则需要一片74182芯片将四片74181芯片组合起来。
四、实验步骤与方案:1、在草稿纸上设计寄存器的逻辑电路图。
将四片74181芯片与一片74182芯片连好。
2、74181芯片和74182芯片如下图所示,A0N至A3N和B0N至B3N都是输入端。
CN是初始进位端,M控制选择逻辑运算还是算术运算,S0、S1、S2、S3都是控制端。
F0N、F1N、F2N、F3N都是输出端,P、G为本组先行进位输出端。
则74182中的PN、GN为成组进位发生输出。
3、双击打开MAX+plus II软件,新建一个项目,命名后再新建一个图形编辑文件,即可出现电路设计编辑窗口。
4、在symbol窗口中选取实验中所要用到的材料,有74181芯片(4片),74182芯片(1片),若干个输入及输出等。
5、将芯片按照逻辑图进行连接,并注意对相应的Input和Output命名。
6、连线完毕后,使用MAX+plus II中的Compiler进行逻辑图的连接检查,查看是否有逻辑连线上的错误,逻辑图如下图所示。
7、逻辑图连线检查通过后,新建一个波形文件,将逻辑设计图中的所有输入/输出引脚导入波形图中。
8、设计输入端A[15..0]、B[15..0]、控制端M、S0--S3的波形,初始进位端S0,设计好以后,选择Simulator选项,设置开始时间和结束时间,选择Start,模拟器开始模拟当前项目,模拟结束,得到如下图所示的输出波形。
运算器的实验报告

运算器的实验报告
运算器的实验报告
一、实验目的
本实验的目的是熟悉运算器的结构及工作原理,了解运算器的基本电路,以及学习操作和编程使用运算器,并介绍运算器的基本应用。
二、实验场地
实验场地位于实验室。
三、实验内容
1、实验者先介绍运算器基本结构、工作原理以及存储单元的组织结构。
2、然后实验者进行实操,熟悉运算器的四则运算、寄存器功能以及求和等算法操作,验证实验结果。
3、最后演示运算器的应用技术,如控制器的设计,并了解相关软硬件设计原理、技术及其流程。
四、实验结果
实验者熟悉了运算器的结构及工作原理,掌握了基本的运算算法及应用技术等。
并且,实验者进行的实操验证了实验结果。
五、实验总结
本次实验使实验者熟悉了运算器的结构及工作原理,掌握了基本的运算算法及应用技术等,实验者通过实践操作、软件计算和算法求解,熟悉了运算器的操作技术,加深了对运算器的理解,提高了实验者运用运算器的能力。
并行加法器实验报告

《计算机组成原理》课程设计实验报告1 任务描述掌握运算器的原理及其设计方法的基础上,利用TD-CMA 计算机组成原理教学实验系统的CPLD单元或FPGA单元,使用Quartus II 软件,使用Verilog或VHDL语言设计方式实现一8位并行进位并行加法器,并进行验证。
2 实验设备该实验所使用的是TD-CMA实验箱及PC机一台。
3 设计原理和方法3.1 工作原理加法器是执行二进制加法运算的逻辑部件,也是CPU 运算器的基本逻辑部件(减法可以通过补码相加来实现)。
加法器又分为半加器和全加器(FA),不考虑低位的进位,只考虑两个二进制数相加,得到和以及向高位进位的加法器为半加器,而全加器是在半加器的基础上又考虑了低位过来的进位信号。
3.2 设计方法对加法器进位的逻辑表达式做推导:C0 = 0Ci+1 = AiBi + AiCi + BiCi设gi = AiBi;pi = Ai + Bi,则有Ci+1 = gi + piCi由于gi、pi 只和Ai、Bi 有关,这样Ci+1 就只和Ai、Ai-1、…、A0,Bi、Bi-1、…B0 及C0有关。
所以各位的进位Ci、Ci-1、…、C1 就可以并行地产生。
转化为VHDL语言即为:sum(n)<=ain(n) xor bin(n) xor h(n);h(n+1):=(ain(n) and bin(n)) or (h(n) and ain(n)) or (h(n) and bin(n));3.3设计思想本算法的核心思想是把8 位加法器分成两个4 位加法器,先求出低4 位加法器的各个进位,特别是向高4 位加法器的进位C4。
然后,高4 位加法器把C4 作为初始进位,使用低4 位加法器相同的方法来完成计算。
每一个4 位加法器在计算时,又分成了两个2 位的加法器。
4 设计过程(1)根据上述加法器的逻辑原理使用 Quartus II 软件编辑相应的电路原理图并进行编译,其在EPM1270 芯片中对应的引脚如图,框外文字表示I/O 号,框内文字表示该引脚的含义。
并行计算实验报告

实验报告课程名称并行计算机体系结构实验名称并行计算机体系结构实验指导教师纪秋实验日期 _ 2011.4 ______学院计算机学院专业计算机科学与技术学生姓名 _______查隆冬_______ 班级/学号计科0804 /2008011183 成绩 ________ _________并行计算机体系结构实验报告⒈安装Mpich、配置文件、小组互相ping通网络的过程和指令(一)安装Mpich(1)本机插入MPICH光盘,双击桌面的计算机图标->CD-RW/DVD-ROM Drive图标;系统自动挂载cdrom到/media下。
(桌面出现新光盘图标XCAT-MPICH2.即挂载成功)(2)Cp /media/cdrecorder/mpich2-1.0.6.tar.gz /usr;本机拷贝mpich2-1.0.6.tar.gz到/usr目录下(3)Cd /usr ;进入usr目录下(4)Tar zxvf mpich2-1.0.6.tar.gz ;解压mpich2-1.0.6.tar.gz到当前目录(5)cd mpich2-1.0.6 ;进入mpich2-1.0.6目录(6)./configure –enable–f90 –prefix=/opt/mpich ;生成mpi的makefile 和设置mpich路径启用f90编译器(7)make ; 编译(8)make install ;将编译好的文件安装,安装结束后在/opt下生成mpich文件夹(9) which mpdboot ; 查找文件(二)配置环境变量(1)打开终端,输入 vi/etc/bashrc(2)在最后一行与倒数第2行之间输入(用insert键输入)export PATH=/opt/mpich/bin:$PATHexport PATH=/opt/intel/cc/10.0.026/bin:$PATHexport PATH=/opt/intel/fc/10.0.026/bin:$PATHexport LD_LIBRARY_PATH=/opt/intel/cc/10.0.026/lib:$LD_LIBRARY_PATH LD_LIBRARY_PATH=/opt/intel/fc/10.0.026/lib:$LD_LIBRARY_PATH按esc键退出;输入:wq (保存退出文件)cat /etc/bashrc ;查看文件(三)小组互相ping通网络的过程和指令(1)设置一个MPD节点配置文件在/root下新建 mpd.hosts文件,打开终端输入:cd /rootvim mpd.hosts ;使用vim文本编辑器(按insert键插入)s06 ;本机的主机号s02s12s17s18按esc键退出;按shift键和输入:wq (保存退出文件)cat /root/mpd.hosts ;查看文件(2)将主机名与相应的IP地址绑定打开终端输入:vi /etc/hosts (输入与保存退出步骤同上) 10.10.10.106 s0610.10.10.102 s0210.10.10.112 s1210.10.10.117 s1710.10.10.118 s18(3)设置两个MPD密码配置文件打开终端输入:(输入与保存退出步骤同上) cd /rootvi mpd.confMPD_SECRETWORD=123456cd /etcvi mpd.confMPD_SECRETWORD=123456(4)用绝对模式修改以下3个文件的权限打开终端输入:cd /etcls –l mpd.confchmod 600 mpd.conf ;修改该文件权限为本机可读、可写,同组和其他人没有任何权限cd /rootls –l mpd.confchmod 600 mpd.conf ;修改该文件权限为本机可读、可写,同组和其他人没有任何权限ls –l mpd.hostschmod 600 mpd.hosts ;修改该文件权限为本机可读、可写,同组和其他人没有任何权限(5)检查本组IP是否已互相连通打开终端输入:ping s02 ;s12、 s17 、s18 同上如连通,则输入ctrl+c 退出(6)启动参与与运算的节点1)首先启动本机mpdboot –n 1 –f mpd.hosts ;1为本机2)查看本机是否已启动s06 10.10.10.106若以启动则退出,输入:mpdallexit⒉编译pi.c小组并行计算π值。
运算器实验报告

运算器实验报告
运算器实验报告是指将实验过程中使用的运算器的各项性能参数和结果,以文字、图表等形式详细记录下来,以便更好地了解其特性和性能。
一般来说,运算器实验报告应包括以下几个方面:
1. 实验仪器和材料:记录所使用的运算器型号,操作系统,机器配置,以及其他相关设备和材料。
2. 实验目的:记录实验的目的,即要测量运算器的哪些性能参数。
3. 实验环境:记录实验所处的环境,如室温,湿度等。
4. 实验步骤:记录实验的执行步骤,如加/减法测试,乘/除法测试,浮点数测试,内存读写测试等。
5. 实验数据:记录实验得到的数据,如加减法耗时,乘除法耗时,浮点数运算速度,内存读取速度等。
6. 实验结论:根据实验得到的数据,对运算器的性能进行总结和分析,并得出实验结论。
并行计算实验三实验报告参考模板
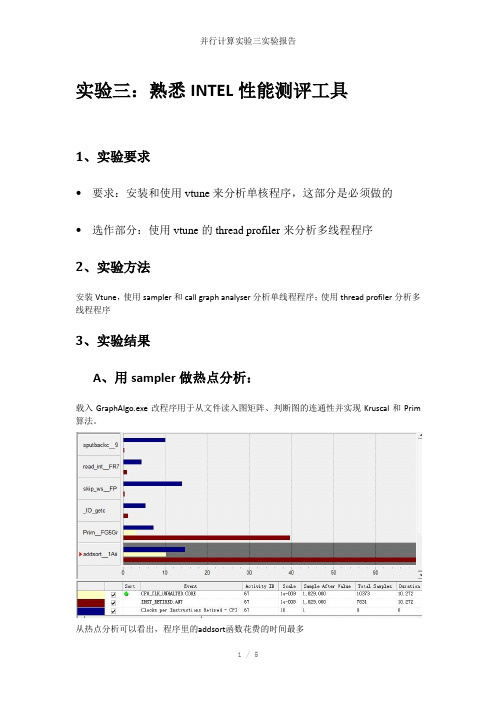
实验三:熟悉INTEL性能测评工具1、实验要求•要求:安装和使用vtune来分析单核程序,这部分是必须做的•选作部分:使用vtune的thread profiler来分析多线程程序2、实验方法安装Vtune,使用sampler和call graph analyser分析单线程程序;使用thread profiler分析多线程程序3、实验结果A、用sampler做热点分析:载入GraphAlgo.exe改程序用于从文件读入图矩阵、判断图的连通性并实现Kruscal和Prim 算法。
从热点分析可以看出,程序里的addsort函数花费的时间最多进入代码中查看,可以看出while……该语句占用时钟数最多,究其原因是A.h中定义的是链表操作,addsort函数用于按从小到大的顺序插入元素,由于链表检索效率相对较低,加上在判断条件中调用了另一个类(图)中的数据结构(图矩阵),因此效率较低。
可以考虑使用更多的空间存放索引,以此实现优化。
以下分析另一个程序(聊天服务器和客户端)首先该程序作为一个多线程程序,测试时我打开了两个客户端。
服务器端侦测到两个连接,因此也创建两个进程进行通讯,加上服务器原有的主进程,一共五个进程。
从表中可以看到,其中一对服务器——客户端进程是热点,原因是因为该连接通讯量较大。
点开客户端进程,发现reset函数占用时间最多。
Reset被用于清除缓存,为了同步需要,缓存在每次通讯前后都会被清除,因此reset重复调用次数比较多。
为了优化程序,应该减少不必要的reset调用。
B、callgraph分析通过调用图的分析,我们可以看到函数依赖性和热点的关系,通过优化关键环节,可以实现热点路径的有效缩短。
首先对银行排队系统程序进行分析,现在是对主进程DistributerWork进行的分析可以看到从主线程开始到NtDelayException为一条热路径,因为程序中使用了sleep函数对柜台工作进行模拟,因此该路径占用的cpu周期最多。
四位并行加法器实验报告

安徽大学计科院《计算机组成原理》课程设计实验设计报告设计题目:四位并行加法器设计班级:08软件二班小组成员:黄德宏(E20814116)胡从建(E20814110)指导老师:周勇完成日期:2011-3-15一.任务概述1.1设计题目概述:四位并行加法器采用“超前进位产生电路”来同时形成各位进位,从而实现快速加法。
超前进位产生电路是根据各位进位的形成条件来实现的。
它不需要依靠低位进位来到后在进行高位进位,而是根据各位输入同时产生进位,改变了进位逐位传送的方式,明显提高了加法器的工作速度。
1.2设计任务:通过小组合作讨论,利用MuxPlus2软件设计画出四位并行加法器原理图,在实验箱上连线,实现4位二进制数相加并得到正确的结果.1.3设计目的:○1掌握MaxPlus2软件的使用方法,并以此为工具进行设计电路原理图.○2了解加法器的工作原理,掌握超前进位产生电路的设计方法.○3正确将电路原理图下载到试验箱中.○4正确通过实验箱连线实现4位二进制数的相加并得到正确结果.○5增强小组协作的能力以及对知识探求的兴趣。
○6完成设计实验报告.1.4设计思路:加法器是计算机的基本运算部件之一。
若不考虑进位输入,两数码Xn,Yn相加称为半加,如下图为半加其功能表:(b)半加器逻辑图(c)用异或门实现半加器将Xn Yn以及进位输入Cn-1相加称为全价,其功能表如下图:a.(全加器功能表)(b)全加器的逻辑图(c)全加器的全加和Fn也可用异或门表示由功能表可得全加和Fn和进位输出Cn表达式:F n=X n Y n C n-1+ X n Y n C n-1+ X n Y n C n-1+ X n Y n C n-1C n= X n Y n C n-1+ X n n C n-1+n Y n C n-1+ X n Y n C n-1F n还可以用两个半加器来形成:F n=X n○+Y n○+C n-1如此,将n个全加器相连可得n位加法器,如图:但加法时间较长,只是因为其位间进位使串行的传送的,本位全加和Fi必须等低位进位Ci-1来到后才能进行,加法时间与位数有关,只有改变进位逐位传送,才能提高加法器的工作速度。
并行计算实验报告

并行计算实验报告并行计算实验报告引言:并行计算是一种有效提高计算机性能的技术,它通过同时执行多个计算任务来加速计算过程。
在本次实验中,我们将探索并行计算的原理和应用,并通过实验验证其效果。
一、并行计算的原理并行计算是指将一个计算任务分成多个子任务,并通过多个处理器同时执行这些子任务,以提高计算速度。
其原理基于两个关键概念:任务划分和任务调度。
1. 任务划分任务划分是将一个大的计算任务划分成多个小的子任务的过程。
划分的目标是使得每个子任务的计算量尽可能均衡,并且可以并行执行。
常见的任务划分方法有数据划分和功能划分两种。
- 数据划分:将数据分成多个部分,每个处理器负责处理其中一部分数据。
这种划分适用于数据密集型的计算任务,如图像处理和大规模数据分析。
- 功能划分:将计算任务按照功能划分成多个子任务,每个处理器负责执行其中一个子任务。
这种划分适用于计算密集型的任务,如矩阵运算和模拟仿真。
2. 任务调度任务调度是将划分后的子任务分配给不同的处理器,并协调它们的执行顺序和通信。
任务调度的目标是最大程度地减少处理器之间的等待时间和通信开销,以提高整体计算效率。
二、并行计算的应用并行计算广泛应用于科学计算、大数据处理、人工智能等领域。
它可以加速计算过程,提高计算机系统的性能,并解决一些传统计算方法难以处理的问题。
1. 科学计算并行计算在科学计算中起到至关重要的作用。
例如,在天气预报模型中,通过将地球划分成多个网格,每个处理器负责计算其中一个网格的气象数据,可以加快模型的计算速度,提高预报准确性。
2. 大数据处理随着大数据时代的到来,传统的串行计算方法已经无法满足大规模数据的处理需求。
并行计算可以将大数据分成多个部分,通过多个处理器同时处理,提高数据的处理速度。
例如,谷歌的分布式文件系统和MapReduce框架就是基于并行计算的思想。
3. 人工智能人工智能算法通常需要大量的计算资源来进行模型训练和推理。
并行计算可以在多个处理器上同时执行算法的计算任务,加快模型的训练和推理速度。
并行计算实验报告

并行计算实验报告《并行计算实验报告》摘要:本实验报告旨在介绍并行计算的基本概念和原理,并通过实验结果展示并行计算在提高计算效率和性能方面的优势。
实验采用了不同的并行计算技术和工具,并对比了串行计算和并行计算的性能表现,以验证并行计算在处理大规模数据和复杂计算任务时的优越性。
1. 引言并行计算是一种利用多个处理器或计算节点同时进行计算任务的技术。
它可以显著提高计算效率和性能,特别是在处理大规模数据和复杂计算任务时。
本实验报告将通过一系列实验来展示并行计算的优势和应用场景。
2. 实验设计本次实验采用了多种并行计算技术和工具,包括MPI(Message Passing Interface)、OpenMP和CUDA。
实验分为两个部分:第一部分是对比串行计算和并行计算的性能表现,第二部分是针对特定应用场景的并行计算实验。
3. 实验结果在第一部分实验中,我们对比了串行计算和MPI并行计算的性能表现。
实验结果显示,随着计算规模的增加,MPI并行计算的性能优势逐渐显现,尤其在处理大规模数据时表现更为明显。
而在第二部分实验中,我们针对图像处理任务使用了OpenMP和CUDA进行并行计算,实验结果显示,这两种并行计算技术都能够显著提高图像处理的速度和效率。
4. 结论通过实验结果的对比和分析,我们可以得出结论:并行计算在处理大规模数据和复杂计算任务时具有明显的优势,能够显著提高计算效率和性能。
不同的并行计算技术和工具适用于不同的应用场景,选择合适的并行计算方案可以最大程度地发挥计算资源的潜力。
5. 展望未来,随着计算资源的不断增加和并行计算技术的不断发展,我们相信并行计算将在更多领域得到应用,为我们解决更多复杂的计算问题提供强大的支持和帮助。
综上所述,本实验报告通过实验结果展示了并行计算在提高计算效率和性能方面的优势,为并行计算技术的应用和发展提供了有力的支持和验证。
实验二COP2000运算器实验报告

实验二 COP2000运算器实验【实验目的】1 了解运算方法和运算器的组成2 掌握行波进位加法器设计方法。
3 讨论并行进位加法器4本实验为设计性实验。
【实验要求】1 74LS181、74LS182级联方法和运算种类。
2 认识乘法阵列乘法器。
3 COP2000实验箱的算术逻辑单元。
【实验步骤】1 设计十六位行波进位加法器(用全加器)。
2 用74LS181、74LS182实现十六位运算器。
3 运算器实现算术运算验证。
【实验内容】一设计十六位行波进位加法器(用全加器)。
二用74LS181、74LS182实现十六位运算器。
三运算器实现算术运算验证。
将55H写入A寄存器置控制信号为:按住CLOCK脉冲键,CLOCK由高变低,这时寄存器A的黄色选择指示灯亮,表明选择A 寄存器。
放开CLOCK键,CLOCK由低变高,产生一个上升沿,数据55H被写入A寄存器。
将33H写入W寄存器按住CLOCK脉冲键,CLOCK由高变低,这时寄存器W的黄色选择指示灯亮,表明选择W 寄存器。
放开CLOCK键,CLOCK由低变高,产生一个上升沿,数据33H被写入W寄存器。
观察到:运算器在加上控制信号及数据(A,W)后, 立刻给出结果, 不须时钟.【心得体会】本实验主要是对运算器的相关操作进行练习,手法是将数据写入累加器A和数据缓存寄存器w,然后通过相应的控制线和数据线将数据传入ALU,ALU将计算结果输出。
通过本次试验懂得了运算器在计算机内部的运行原理,并更深刻的理解了其运行机制及工作过程,通过实验把课堂知识得到更好的运用。
并行编程实验报告

课程实验报告课程名称:并行编程专业班级:学号:姓名:指导教师:报告日期:计算机科学与技术学院目录实验一 (3)1. 实验目的与要求 (3)2. 实验内容 (3)3. 实验结果 (3)实验二 (4)1. 实验目的与要求 (4)2. 算法描述 (4)3. 实验方案 (4)4. 实验结果与分析 (6)实验三 (7)1. 实验目的与要求 (7)2. 算法描述 (7)3. 实验方案 (7)4. 实验结果与分析 (8)实验四 (9)1. 实验目的与要求 (9)2. 算法描述 (9)3. 实验方案 (9)4. 实验结果与分析 (12)实验五 (13)1.实验目的与要求 (13)2.算法描述 (13)3.实验方案 (13)4.实验结果与分析 (15)PROJECT2 (17)AIM: (17)HYPOTHESIS: (17)METHODS: (17)RESULT: (17)DICUSSION&CONCLUSION (18)REFERENCE (19)1.实验目的与要求become familiar with the parallel development environments, and the basic principles and methods of parallel programming and performance optimization by using tools and frameworks like pthread, OpenMP, MPI under Linux system. 2.实验内容熟悉并行开发环境,掌握并行编程用到的工具如线程、OpenMP,、MPI等。
3.实验结果通过上机操作熟悉了各种命令,编写了简单的程序熟悉开发环境。
1.实验目的与要求a)master the basic principles and methods of parallelprogramming design and performance optimization using pthreadb)understand the basic method for data partition and taskdecomposition in parallel programmingc)implement the parallel algorithm of calculating the value of piusing pthreadd)then carries on the simple analysis and summary of theprogram execution results2.算法描述采用蒙特卡洛方法计算圆周率,利用单位圆与边长为1的正方形面积之比计算圆周率的近似值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
并行进位运算器实验
一、实验目的:
了解并行进位运算器的工作原理和过程,利用多个芯片采用扩展的方式设计出16位并行进位运算器功能部件,并封装调试。
在基于Max+plus II平台的计算机主机系统选择芯片设计寄存器,设计输入信号,分析输出波形。
二、实验仪器:
一台装有MAX+plus II环境的计算机、计算机组成原理实践教程
三、实验原理:
1、74181芯片实现了组内四位的并行进位,即第0位的进位输入Cn可以直接传送到最高进位位上去。
那么16位并行进位运算器则需要四片74181芯片。
2、要实现组间的并行进位,则需要一片74182芯片将四片74181芯片组合起来。
四、实验步骤与方案:
1、在草稿纸上设计寄存器的逻辑电路图。
将四片74181芯片与一片74182芯片连好。
2、74181芯片和74182芯片如下图所示,A0N至A3N和B0N至B3N都是输入端。
CN是初始进位端,M控制选择逻辑运算还是算术运算,S0、S1、S2、S3都是控制端。
F0N、F1N、F2N、F3N都是输出端,P、G为本组先行进位输出端。
则74182中的PN、GN为成组进位发生输出。
3、双击打开MAX+plus II软件,新建一个项目,命名后再新建一个图形编辑文件,即可出现电路设计编辑窗口。
4、在symbol窗口中选取实验中所要用到的材料,有74181芯片(4片),74182芯片(1片),若干个输入及输出等。
5、将芯片按照逻辑图进行连接,并注意对相应的Input和Output命名。
6、连线完毕后,使用MAX+plus II中的Compiler进行逻辑图的连接检查,查看是否有逻辑连线上的错误,逻辑图如下图所示。
7、逻辑图连线检查通过后,新建一个波形文件,将逻辑设计图中的所有输入/输出引脚导入波形图中。
8、设计输入端A[15..0]、B[15..0]、控制端M、S0--S3的波形,初始进位端S0,设计好以后,选择Simulator选项,设置开始时间和结束时间,选择Start,模拟器开始模拟当前项目,模拟结束,得到如下图所示的输出波形。
五、实验分析:
1、在0ns至10ns时,A0至A15分别设为0、0、0、1、0、0、0、1、0、0、0、1、0、0、0、1,B0至B15则全为0,控制端M为0则进行算术运算,控制端S3、S
2、S1、S0分别为0、0、0、1则进行运算A+B。
即两个十六位数0001000100010001和0000000000000000相加得0001000100010001。
图上F的输出证明结果的正确性。
2、在20ns至30ns时,A0至A15分别设为0、0、1、0、0、0、1、0、0、0、1、
0、0、0、1、0,B0至B15的值变为0、0、0、1、0、0、0、1、0、0、0、1、0、0、0、1,M、C0值不变,仍进行算术运算。
控制端S3、S2、S1、S0分别为1、1、0、0则执行运算A+A。
即两个0010001000100010相加得0100010001000100。
图上F的输出证明结果的正确性。
六、实验总结:
一开始很容易想到要用四片74181芯片设计,但是忽略了组间并行进位直接将四片74181接成串行进位。
后在检查的过程才发现这个问题,课本上学过74182芯片可以构成第二级的先行进位逻辑,即实现小组之间的现行进位,便明白还需要加入一片74182芯片,应将题目分析清楚之后才开始在软件上连图。
画波形图图时其实不应该将M值一直保持不变,应该让它波动,这样实验结果才更具有说服性。