Coarse-gradient Langevin algorithms for dynamic data integration and uncertainty quantifica
兰姆达演算法

兰姆达演算法兰姆达演算法(Lambda Calculus)是一种基于数学逻辑的形式系统,用于描述和研究计算过程。
它由逻辑学家阿隆佐·邱奇(Alonzo Church)在20世纪30年代提出,被认为是计算机科学的基础之一。
兰姆达演算法具有简洁而强大的表达能力,被广泛应用于函数式编程语言、类型理论以及计算机科学理论研究中。
1. 什么是兰姆达演算法?兰姆达演算法是一种形式系统,它描述了一种抽象的计算模型。
与图灵机不同,兰姆达演算法没有存储器或状态的概念,它仅通过对表达式进行变换来进行计算。
这使得兰姆达演算法成为一个非常简单且优雅的计算模型。
在兰姆达演算法中,所有的计算都通过函数应用来实现。
它由三个基本元素组成:变量、抽象和应用。
变量表示一个符号或名字;抽象定义了一个函数;应用表示函数对参数的调用。
2. 兰姆达演算法的基本语法在兰姆达演算法中,表达式由变量、抽象和应用构成。
下面是一些基本的语法规则:•变量:一个变量由一个字母或字符串表示,例如x、y或foo。
•抽象:抽象定义了一个函数。
它由一个λ符号后跟一个变量和一个点组成,然后是函数体。
例如λx.x表示一个接受参数x并返回x的函数。
•应用:应用表示函数对参数的调用。
它由两个表达式连在一起组成,左边是函数,右边是参数。
例如(λx.x) y表示将y作为参数传递给函数λx.x。
3. 兰姆达演算法的基本操作兰姆达演算法通过一系列的规则进行计算和变换。
这些规则定义了如何对表达式进行求值和简化。
3.1 β-归约β-归约是兰姆达演算法中最重要的操作之一。
它描述了如何将函数应用到参数上,并将其简化为结果。
β-归约规则如下:(λx.E) V → E[x:=V]其中,(λx.E)表示一个抽象,V表示一个值(可以是变量或其他表达式),E[x:=V]表示将E中的所有自由出现的变量x替换为V。
这个规则表示,当一个函数应用到参数上时,它的函数体中的变量将被替换为参数,从而得到一个新的表达式。
fine-to-coarse reconstruction算法-概述说明以及解释

fine-to-coarse reconstruction算法-概述说明以及解释1.引言1.1 概述:在计算机视觉领域,图像重建是一项重要的任务,其目的是从输入的低分辨率图像中生成高质量的高分辨率图像。
Fine-to-Coarse Reconstruction算法是一种常用的图像重建算法,它通过逐渐增加图像的分辨率级别,从粗到细地重建图像,以获得更加清晰、细节丰富的图像。
Fine-to-Coarse Reconstruction算法在图像处理和计算机视觉中有着广泛的应用,能够有效地提高图像质量和细节信息的还原程度。
本文将详细介绍Fine-to-Coarse Reconstruction算法的原理、应用和优势,希望能为读者提供深入了解和应用该算法的指导。
1.2 文章结构本文主要分为引言、正文和结论三部分。
在引言部分中,我们将对Fine-to-Coarse Reconstruction算法进行概述,并介绍文章的结构和目的。
在正文部分,我们将详细介绍Fine-to-Coarse Reconstruction算法的原理以及其在实际应用中的表现。
我们将重点讨论该算法在图像处理、计算机视觉等领域的应用,并探讨其优势和局限性。
最后,在结论部分,我们将对整篇文章进行总结,展望Fine-to-Coarse Reconstruction算法的未来发展方向,并留下一些思考和结束语。
整个文章结构清晰,层次分明,将帮助读者全面了解和理解Fine-to-Coarse Reconstruction算法的重要性和价值。
1.3 目的Fine-to-Coarse Reconstruction算法的目的是通过逐步从细节到整体的重建过程,实现对图像或模型的高效重建。
通过逐步迭代的方式,算法能够在保持细节的同时,提高重建的速度和准确性。
本文旨在深入探讨Fine-to-Coarse Reconstruction算法的原理、应用和优势,以期能够为相关研究和应用提供更多的启发和帮助。
fluent操作界面中英

fluent 操作界面中英文对照Read 读取文件:scheme 方案journal 日志profile 外形 Write 保存文件Import :进入另一个运算程序 Interpolate :窜改,插入 Hardcopy : 复制, Batch options 一组选项 Save layout 保存设计Grid 网格Check 检查Info 报告:size 尺寸 ;memory usage 内存使用 情况;zones 区域;partitions 划分存储区 Polyhedral 多面体:Convert domain 变换范围Convert skewed cells 变换倾斜的单元Merge 合并 Separate 分割Fuse (Merge 的意思是将具有相同条件的边界合 并成一个;Fuse 将两个网格完全贴合的边界融合 成内部(interior)来处理,比如叶轮机中,计算多 个叶片时,只需生成一个叶片通道网格,其他通 过复制后,将重合的周期边界Fuse 掉就行了。
注意两个命令均为不可逆操作,在进行操作时注 意保存case) Zone 区域: append case file 添力口 case 文档 Replace 取代;delete 删除;deactivate 使复 位; Surface mesh 表面网孔Reordr 追加,添加:Domain 范围;zones 区域; Print bandwidth 打印 Scale 单位变换 Translate 转化Rotate 旋转 smooth/swap 光滑/交换CheckInfo ► Polyhedra►Merge...Separate ► Fuse...Zone►Surface Mesh... Reorder►Scale...Translate...Rotate...Smooth/Swap...ieGrid ] Define Solvea:w 1E3 SolverSolver* Pressure Based 'Density Based Space「2DL Axisymmetric 广 Axcsymmetric Swirl m 3DVelgty Formulatiqn • Absolute RelativeGradient Option区 Implicit「Explicit Time# SteadyUnsteadyPorous Formulation• Superficial VelocityPhysical Veiccity6K | Cancel] Help |Pressure based 基于压力 Density based 基于密度Models 模型:solver 解算器Formulation # Green-Gauss Cell Oased Green-Gauss N 。
卡尔曼滤波算法的程序实现和推导过程

卡尔曼滤波算法的程序实现和推导过程---蒋海林(QQ:280586940)---卡尔曼滤波算法由匈牙利裔美国数学家鲁道夫·卡尔曼(Rudolf Emil Kalman)创立,这个数学家特么牛逼,1930年出生,现在还能走能跳,吃啥啥麻麻香,但他的卡尔曼滤波算法已经广泛应用在航空航天,导弹发射,卫星在轨运行等很多高大上的应用中。
让我们一边膜拜一边上菜吧,下面就是卡尔曼滤波算法的经典程序,说是经典,因为能正常运行的程序都长得差不多,在此向原作者致敬。
看得懂的,帮我纠正文中的错误;不太懂的,也不要急,让我慢慢道来。
最后希望广大朋友转载时,能够保留我的联系方式,一则方便后续讨论共同进步,二则支持奉献支持正能量。
void Kalman_Filter(float Gyro,float Accel)///角速度,加速度{///陀螺仪积分角度(先验估计)Angle_Final = Angle_Final + (Gyro - Q_bias) * dt;///先验估计误差协方差的微分Pdot[0] = Q_angle - PP[0][1] - PP[1][0];Pdot[1] = - PP[1][1];Pdot[2] = - PP[1][1];Pdot[3] = Q_gyro;///先验估计误差协方差的积分PP[0][0] += Pdot[0] * dt;PP[0][1] += Pdot[1] * dt;PP[1][0] += Pdot[2] * dt;PP[1][1] += Pdot[3] * dt;///计算角度偏差Angle_err = Accel - Angle_Final;///卡尔曼增益计算PCt_0 = C_0 * PP[0][0];PCt_1 = C_0 * PP[1][0];E = R_angle + C_0 * PCt_0;K_0 = PCt_0 / E;K_1 = PCt_1 / E;///后验估计误差协方差计算t_0 = PCt_0;t_1 = C_0 * PP[0][1];PP[0][0] -= K_0 * t_0;PP[0][1] -= K_0 * t_1;PP[1][0] -= K_1 * t_0;PP[1][1] -= K_1 * t_1;Angle_Final += K_0 * Angle_err; ///后验估计最优角度值Q_bias += K_1 * Angle_err; ///更新最优估计值的偏差Gyro_Final = Gyro - Q_bias; ///更新最优角速度值}我们先把卡尔曼滤波的5个方程贴上来:X(k|k-1)=A X(k-1|k-1)+B U(k) ……… (1)//先验估计 P(k|k-1)=A P(k-1|k-1) A ’+Q ……… (2)//协方差矩阵的预测Kg(k)= P(k|k-1) H ’ / (H P(k|k-1) H ’ + R) ……… (3)//计算卡尔曼增益 X(k|k)= X(k|k-1)+Kg(k) (Z(k) - H X(k|k-1)) ……… (4)通过卡尔曼增益进行修正 P(k|k)=(I-Kg(k) H )P(k|k-1) ……… (5)//更新协方差阵这5个方程比较抽象,下面我们就来把这5个方程和上面的程序对应起来。
对抗样本方法分类

对抗样本方法分类一、引言随着深度学习的广泛应用,其安全性问题也日益受到关注。
对抗样本(Adversarial Examples)作为深度学习领域的一个重要研究方向,旨在通过生成与原始样本相似但能使模型产生错误预测的样本,来评估和提高模型的鲁棒性。
本文将对对抗样本方法进行分类,并介绍各类方法的特点和应用场景。
二、对抗样本方法分类1. 基于梯度的方法基于梯度的方法是最早被提出的一类对抗样本生成方法,其核心思想是利用模型的梯度信息来生成对抗样本。
这类方法主要包括FGSM(Fast Gradient Sign Method)和PGD(Projected Gradient Descent)等。
FGSM是一种简单而有效的对抗样本生成方法,它通过计算模型对输入样本的梯度,并沿着梯度的反方向添加一个小的扰动来生成对抗样本。
这种方法生成的对抗样本具有较高的攻击成功率,但缺点是生成的对抗样本往往与原始样本差异较大,容易被人类识别出来。
PGD是一种更强大的对抗样本生成方法,它在FGSM的基础上进行了改进,通过多次迭代计算梯度并更新扰动来生成对抗样本。
这种方法可以生成更小且更难以被人类察觉的对抗样本,但需要较长的计算时间。
2. 基于优化的方法基于优化的方法是一类更为复杂的对抗样本生成方法,它们通过定义一个优化问题来求解对抗样本。
这类方法主要包括C&W(Carlini & Wagner)攻击和EAD (Elastic-net Attacks to Deep neural networks)等。
C&W攻击是一种基于优化的对抗样本生成方法,它通过定义一个包含模型预测概率和扰动大小的优化问题,并使用梯度下降等优化算法来求解对抗样本。
这种方法可以生成更小且更难以被检测的对抗样本,但需要较长的计算时间和较高的计算资源。
EAD是一种针对深度学习模型的基于优化的对抗样本生成方法,它结合了弹性网络正则化和C&W攻击的思想,通过同时优化模型的预测概率和扰动大小来生成对抗样本。
常用的相似准则数

常用的相似准则数相似性准则是一种用于测量或衡量两个或多个对象之间的相似性或相关性的方法或模型。
在不同领域和应用中,存在许多常用的相似性准则,以下是其中一些常见的准则。
1. 欧几里德距离(Euclidean Distance):欧几里德距离是空间中两个点之间的直线距离,根据勾股定理计算。
2. 曼哈顿距离(Manhattan Distance):曼哈顿距离是两个点在坐标系上的绝对差值之和,通常用于城市街区距离的度量。
3. 余弦相似度(Cosine Similarity):余弦相似度是向量空间中两个向量的夹角余弦值,可用于衡量文本、图像等数据的相似性。
4. 杰卡德相似系数(Jaccard Similarity Coefficient):杰卡德相似系数用于衡量两个集合的相似度,计算两个集合交集的大小与并集的大小之比。
5. 皮尔逊相关系数(Pearson Correlation Coefficient):皮尔逊相关系数是一种用于衡量两个连续变量之间线性相关程度的方法,取值范围为-1到16. 汉明距离(Hamming Distance):汉明距离是用于衡量两个等长字符串之间的差异度量,计算相同位置不同字符的个数。
7. K-L散度(Kullback-Leibler Divergence):K-L散度是一种度量两个概率分布之间差异的方法,用于衡量一个概率分布相对于另一个分布的不确定性。
10. 汉明重量(Hamming Weight):汉明重量是二进制数中非零位的个数,用于衡量两个二进制数的相似性。
11. 简化模式(Simplification Metric):简化模式是一种度量模型简化程度的方法,通常用于优化问题解的复杂度。
这些相似性准则在数据挖掘、机器学习、自然语言处理、图像处理等领域中得到广泛应用。
它们可以帮助我们理解和比较不同对象之间的相似性、相关性或差异性,从而为我们提供洞察和决策支持。
基于余弦代价函数的双模盲均衡算法

黑塞矩阵的迭代和优化算法

黑塞矩阵的迭代和优化算法在数值计算当中,黑塞矩阵的迭代和优化算法是一个重要的研究方向。
黑塞矩阵是非常重要的一个工具,它可以用来描述计算机程序的性能,也可以用来优化计算机程序的运行速度。
黑塞矩阵由于其复杂性,在计算机程序中是比较难以处理的。
然而,在很多数值计算的算法中,黑塞矩阵扮演了非常重要的角色。
为了更好地处理黑塞矩阵,很多研究者提出了很多不同的算法。
其中,最流行的算法是Newton-Raphson算法,它可以用来解决非线性最小二乘问题,非线性方程组和非线性方程求解等问题。
不过,在实际应用中,Newton-Raphson算法有一定的限制。
首先,它需要求解黑塞矩阵的逆矩阵,从而需要进行大量的计算,并且在矩阵非常大的时候,这个计算量会变得非常庞大。
其次,Newton-Raphson算法需要较好的初始值,而在实际应用中,初始值往往不是很容易获得。
为了解决这些问题,研究者们提出了很多相对于Newton-Raphson算法的优化算法。
其中,最流行的算法是Broyden-Fletcher-Goldfarb-Shanno算法(BFGS算法),它是一种无约束最优化算法,不需要计算黑塞矩阵的逆,而是通过更新黑塞矩阵的逆矩阵来近似计算黑塞矩阵的逆。
实际上,BFGS算法不仅仅可以用来处理黑塞矩阵,还可以用来处理一般性的非线性优化问题。
在实际应用中,研究者们也对BFGS算法进行了很多改进。
其中,最流行的算法是Limited-memory BFGS算法(L-BFGS算法),它采用了一种相对于BFGS 算法更高效的内存使用方式。
L-BFGS算法是一种使用有限存储空间来近似计算黑塞矩阵的逆矩阵的方法。
L-BFGS算法是一个迭代算法,每次迭代需要计算一个梯度向量和一个搜索方向。
一般来说,L-BFGS算法的搜索方向是由一个近似的黑塞矩阵和当前梯度向量计算得到的.总之,黑塞矩阵的迭代和优化算法是一个非常重要的研究领域。
通过使用这些算法,我们可以更加高效地处理黑塞矩阵,从而优化计算机程序的运行速度。
《计算机视觉》题集

《计算机视觉》题集大题一:选择题1.下列哪项不属于计算机视觉的基本任务?A. 图像分类B. 目标检测C. 语音识别D. 语义分割2.在卷积神经网络(CNN)中,以下哪项操作不是卷积层的主要功能?A. 局部感知B. 权重共享C. 池化D. 特征提取3.下列哪个模型在图像分类任务中首次超过了人类的识别能力?A. AlexNetB. VGGNetC. ResNetD. GoogleNet4.以下哪个算法常用于图像中的特征点检测?A. SIFTB. K-meansC. SVMD. AdaBoost5.在目标检测任务中,IoU (Intersection over Union)主要用于衡量什么?A. 检测框与真实框的重叠程度B. 模型的检测速度C. 模型的准确率D. 模型的召回率6.下列哪项技术可以用于提高模型的泛化能力,减少过拟合?A. 数据增强B. 增加模型复杂度C. 减少训练数据量D. 使用更大的学习率7.在深度学习中,批归一化 (Batch Normalization)的主要作用是什么?A. 加速模型训练B. 提高模型精度C. 减少模型参数D. 防止梯度消失8.下列哪个激活函数常用于解决梯度消失问题?A. SigmoidB. TanhC. ReLUD. Softmax9.在进行图像语义分割时,常用的评估指标是?A. 准确率B. 召回率C. mIoU(mean Intersection over Union)D. F1分数10.下列哪个不是深度学习框架?A. TensorFlowB. PyTorchC. OpenCVD. Keras大题二:填空题1.计算机视觉中的“三大任务”包括图像分类、目标检测和______。
2.在深度学习模型中,为了防止梯度爆炸,常采用的技术是______。
3.在卷积神经网络中,池化层的主要作用是进行______。
4.YOLO算法是一种流行的______算法。
5.在进行图像增强时,常用的技术包括旋转、缩放、______和翻转等。
量化共轭梯度算法

量化共轭梯度算法量化共轭梯度算法(Conjugate Gradient Algorithm)是一种用于求解线性方程组的迭代算法。
它的特点是每次迭代都在共轭方向上进行,从而加快了迭代的收敛速度。
下面将详细介绍量化共轭梯度算法的原理、步骤和应用。
1.原理:量化共轭梯度算法是基于共轭梯度法(Conjugate Gradient Method)发展而来的。
共轭梯度法是一种用于求解对称正定线性方程组的优化算法。
它利用了线性方程组的特殊性质,通过选择恰当的方向,将问题转化为一系列独立的一维优化问题,从而获得线性方程组的近似解。
2.步骤:(1)初始化:给定一个初始点x0和一个初始方向d0。
(2)迭代更新:根据共轭方向的性质,依次求解近似问题的解。
更新公式为:αk = (rk^T * rk) / (dk^T * A * dk)xk+1 = xk + αk * dkrk+1 = rk - αk * A * dkβk+1 = (r k+1^T * rk+1) / (rk^T * rk)dk+1 = rk+1 + βk+1 * dk其中,A表示线性方程组的系数矩阵,rk表示当前残差,dk表示方向,αk表示步长。
(3)重复步骤(2)直到满足收敛条件。
3.应用:(1)线性方程组的求解:量化共轭梯度算法可以高效地求解对称正定线性方程组,特别适用于大规模稀疏线性方程组求解。
(2)优化问题的求解:量化共轭梯度算法可以用于求解凸优化问题,例如最小二乘问题、最大似然估计等。
(3)机器学习算法的训练:量化共轭梯度算法可以用于训练一些机器学习算法,如逻辑回归、支持向量机等,提高算法的收敛速度。
(4)图像处理:量化共轭梯度算法在图像处理领域有广泛应用,例如图像恢复、图像分割和图像压缩等。
总结:量化共轭梯度算法是一种用于求解线性方程组的迭代算法,它利用了共轭方向的特性,加速了收敛速度。
它的原理和步骤相对简单,但在实际应用中具有广泛的用途。
纹理物体缺陷的视觉检测算法研究--优秀毕业论文

摘 要
在竞争激烈的工业自动化生产过程中,机器视觉对产品质量的把关起着举足 轻重的作用,机器视觉在缺陷检测技术方面的应用也逐渐普遍起来。与常规的检 测技术相比,自动化的视觉检测系统更加经济、快捷、高效与 安全。纹理物体在 工业生产中广泛存在,像用于半导体装配和封装底板和发光二极管,现代 化电子 系统中的印制电路板,以及纺织行业中的布匹和织物等都可认为是含有纹理特征 的物体。本论文主要致力于纹理物体的缺陷检测技术研究,为纹理物体的自动化 检测提供高效而可靠的检测算法。 纹理是描述图像内容的重要特征,纹理分析也已经被成功的应用与纹理分割 和纹理分类当中。本研究提出了一种基于纹理分析技术和参考比较方式的缺陷检 测算法。这种算法能容忍物体变形引起的图像配准误差,对纹理的影响也具有鲁 棒性。本算法旨在为检测出的缺陷区域提供丰富而重要的物理意义,如缺陷区域 的大小、形状、亮度对比度及空间分布等。同时,在参考图像可行的情况下,本 算法可用于同质纹理物体和非同质纹理物体的检测,对非纹理物体 的检测也可取 得不错的效果。 在整个检测过程中,我们采用了可调控金字塔的纹理分析和重构技术。与传 统的小波纹理分析技术不同,我们在小波域中加入处理物体变形和纹理影响的容 忍度控制算法,来实现容忍物体变形和对纹理影响鲁棒的目的。最后可调控金字 塔的重构保证了缺陷区域物理意义恢复的准确性。实验阶段,我们检测了一系列 具有实际应用价值的图像。实验结果表明 本文提出的纹理物体缺陷检测算法具有 高效性和易于实现性。 关键字: 缺陷检测;纹理;物体变形;可调控金字塔;重构
Keywords: defect detection, texture, object distortion, steerable pyramid, reconstruction
II
光谱分类的算法

光谱分类的算法光谱分类是一种通过分析光谱数据将待分类样本分到已知类别中的任务。
下面是一些常见的光谱分类算法:1. 支持向量机(Support Vector Machine, SVM):SVM是一种监督学习算法,通过构建最优分离超平面将不同类别的样本分开。
在光谱分类中,SVM常用于线性分类和非线性分类。
2. 随机森林(Random Forest):随机森林是一种集成学习算法,通过同时构建多个决策树进行分类。
在光谱分类中,随机森林能够有效处理高维数据和处理样本不平衡的问题。
3. 朴素贝叶斯分类器(Naive Bayes Classifier):朴素贝叶斯是一种基于贝叶斯定理和特征条件独立假设的概率模型。
在光谱分类中,朴素贝叶斯分类器能够根据样本的光谱特征及其类别的先验概率进行分类。
4. 人工神经网络(Artificial Neural Network, ANN):ANN是一种模仿人脑神经网络的计算模型。
在光谱分类中,ANN可以通过通过训练和调整权重来实现从光谱数据到类别的映射。
5. 卷积神经网络(Convolutional Neural Network, CNN):CNN是一种特殊的神经网络结构,对图像和光谱数据有较好的处理能力。
在光谱分类中,CNN能够从输入的光谱数据中提取出更具有区分性的特征。
6. 遗传算法(Genetic Algorithm):遗传算法是一种模拟自然进化过程的优化算法。
在光谱分类中,遗传算法可以用于特征选择、参数优化等问题,提高分类模型的性能。
以上仅是一些常见的光谱分类算法,实际应用中还有很多其他算法和方法,如K近邻算法、决策树、深度学习等,根据具体的问题和数据特征选择合适的算法进行光谱分类。
最相似近邻法-概述说明以及解释

最相似近邻法-概述说明以及解释1.引言1.1 概述最相似近邻法是一种常用的机器学习算法,也被称为k近邻算法。
它是一种基于实例的学习方法,通过计算待预测样本与训练集中样本的相似度,来进行分类或回归预测。
该算法的核心思想是利用输入样本与训练集中已有样本的特征信息进行对比,找出与输入样本最相似的k个样本,并根据它们的标签信息来对输入样本进行分类或回归预测。
这种基于相似度的方法能够很好地捕捉样本之间的关系,适用于各种不规则分布的数据集。
最相似近邻法在实际应用中具有广泛的适用性,包括图像识别、推荐系统、医学诊断等领域。
尽管该算法存在一定的计算复杂度和需要大量存储空间的缺点,但其简单直观的原理和良好的泛化能力使其成为机器学习领域中不可或缺的一部分。
1.2 文章结构本文分为引言、正文和结论三个部分。
在引言部分,将对最相似近邻法进行概述,并介绍文章的结构和目的。
在正文部分,将详细介绍什么是最相似近邻法,以及它在不同应用领域的具体应用情况。
同时,将梳理最相似近邻法的优缺点,为读者提供全面的了解。
最后,在结论部分,将总结本文的主要内容,展望最相似近邻法的未来发展前景,并给出结论性的观点和建议。
整个文章将通过逻辑清晰的结构,带领读者深入理解和认识最相似近邻法的重要性和应用。
1.3 目的最相似近邻法是一种常用的机器学习算法,其主要目的是通过比较不同数据点之间的相似度,找出与目标数据点最相似的邻居。
通过这种方法,我们可以实现数据分类、推荐系统、图像识别等多种应用。
本文旨在深入探讨最相似近邻法的原理、应用领域以及优缺点,希望读者能更全面地了解这一算法,并在实际应用中取得更好的效果。
同时,我们也将展望最相似近邻法在未来的发展前景,为读者提供对未来研究方向的参考。
通过本文的阐述,希望读者能够更深入地理解最相似近邻法,为其在实际应用中提供更好的指导。
2.正文2.1 什么是最相似近邻法最相似近邻法是一种常用的机器学习算法,它通过计算数据样本之间的相似度来进行分类或回归预测。
人工神经网络与神经网络优化算法

其中P为样本数,t j, p 为第p个样本的第j个输
出分量。
感知器网络
1、感知器模型 2、学习训练算法 3、学习算法的收敛性 4.例题
感知器神经元模型
感知器模型如图Fig2.2.1 I/O关系
n
y wipi bi
i 1
y {10
y0 y0
图2.2.1
单层感知器模型如图2.2.2
定义加权系数
10.1 人工神经网络与神经网络优化算法
③第 l 1层第 i个单元到第个单元的权值表为
; l1,l ij
④第 l 层(l >0)第 j 个(j >0)神经元的
输入定义为 , 输出定义 Nl1
x
l j
y l 1,l ij
l 1 i
为
yLeabharlann l jf (xlj )
, 其中 i0 f (•)为隐单元激励函数,
人工神经网络与神经网络优化算法
自20世纪80年代中期以来, 世界上许多国 家掀起了神经网络的研究热潮, 可以说神 经网络已成为国际上的一个研究热点。
1.构成
生物神经网
枝蔓(Dendrite)
胞体(Soma)
轴突(Axon) 胞体(Soma)
2.工作过程
突触(Synapse)
生物神经网
3.六个基本特征: 1)神经元及其联接; 2)神经元之间的联接强度决定信号传递的强
函数的饱和值为0和1。
4.S形函数
o
a+b
c=a+b/2
(0,c)
net
a
2.2.3 M-P模型
McCulloch—Pitts(M—P)模型, 也称为处理单元(PE)
x1 w1
交叉熵损失 余弦分类器

交叉熵损失余弦分类器
交叉熵损失和余弦分类器都是深度学习中常用的概念和技术。
首先,我们来谈谈交叉熵损失。
在机器学习中,交叉熵损失函
数通常用于衡量两个概率分布之间的差异性。
在分类问题中,我们
通常使用交叉熵损失来衡量模型的输出概率分布与真实标签之间的
差异。
交叉熵损失函数在训练神经网络时非常有效,因为它能够对
错误分类进行更严厉的惩罚,从而促使模型更快地收敛到最优解。
接下来,我们来谈谈余弦分类器。
余弦分类器是一种常用的文
本分类方法,它利用余弦相似度来衡量文本之间的相似程度。
在余
弦分类器中,文本被表示为向量,然后计算它们之间的余弦相似度。
余弦相似度是一种度量两个向量方向的相似程度的方法,它忽略了
向量的大小,只关注它们的方向。
余弦分类器在文本分类任务中表
现出色,尤其是在处理高维稀疏数据时效果显著。
总的来说,交叉熵损失和余弦分类器都是深度学习中非常重要
的概念和技术。
交叉熵损失在分类问题中被广泛应用,而余弦分类
器则在文本分类任务中表现出色。
深入理解和熟练运用这两个概念
对于深度学习领域的从业者来说至关重要。
希望这个回答能够帮助你更好地理解交叉熵损失和余弦分类器。
智能算法常用测试函数

智能算法常用测试函数在智能算法领域,常用测试函数用于评估和比较不同算法的性能,帮助研究人员和开发者理解算法的优劣之处。
以下是一些智能算法常用的测试函数,包括优化函数、函数和分类函数。
1.优化函数:优化函数是用来测试优化算法的性能的函数。
其中,常见的优化函数有:- 球面函数(Sphere function):f(x) = Σ x^2、球面函数是一个简单的凸函数,用于测试优化算法是否能够在高维空间中找到全局最优解。
- 罗森布洛克函数(Rosenbrock function):f(x) = Σ[100*(xi+1 - xi^2)^2 + (1 - xi)^2]。
罗森布洛克函数是一个非凸函数,在优化算法中经常用于测试算法是否能够克服局部极小值,找到全局最优解。
- 刺激函数(Ackley function):f(x) = -20 * exp(-0.2 *sqrt(1/n * Σ xi^2)) - exp(1/n * Σ cos(2πxi)) + 20 + exp(1)。
刺激函数是一个具有多个局部极小值的函数,用于测试优化算法的全局能力。
2.函数:函数是用于测试算法的性能的函数。
其中,常用的函数有:- n皇后问题(N-Queens Problem):在一个N×N的棋盘上,放置N个互不攻击的皇后。
算法要找到一种皇后的放置方式,使得所有皇后互不攻击。
- 深度优先(Depth First Search):深度优先是经典的算法,在树或图中进行全局,在过程中依次遍历每个节点,直到找到解或遍历完所有可能的节点。
- 广度优先(Breadth First Search):广度优先也是一种经典的算法,在树或图中进行全局,在过程中按层次遍历每个节点,直到找到解或遍历完所有可能的节点。
3.分类函数:分类函数是用于测试分类算法的性能的函数。
其中,常见的分类函数有:- Iris数据集分类问题:Iris数据集是一个常用的分类问题数据集,其中包含了3种不同种类的鸢尾花(Setosa、Versicolor和Virginica)的4个特征(花萼长度、花萼宽度、花瓣长度和花瓣宽度)。
强化学习算法中的最优化方法详解(五)

强化学习算法中的最优化方法详解强化学习是一种让智能体在与环境互动中学习行为策略的机器学习方法。
在强化学习中,最优化方法是非常重要的,因为它能够帮助智能体在复杂、不确定的环境中学习到最优的策略。
本文将详细介绍强化学习算法中的最优化方法,包括值函数、策略函数以及基于模型和无模型的最优化方法。
值函数值函数是强化学习中最常用的一种最优化方法。
它用来评估某个状态或行为的价值,帮助智能体做出最优的决策。
值函数可以分为状态值函数和动作值函数。
状态值函数V(s)表示在状态s下智能体能够获得的长期奖励的期望值,而动作值函数Q(s, a)表示在状态s下选择动作a后能够获得的长期奖励的期望值。
值函数的更新通常通过贝尔曼方程来进行,贝尔曼方程是强化学习中最重要的方程之一。
它描述了值函数之间的递归关系,帮助智能体在不断与环境互动中更新值函数,从而得到最优的策略。
策略函数除了值函数,策略函数也是强化学习中常用的最优化方法。
策略函数π(a|s)表示在状态s下选择动作a的概率。
在强化学习中,智能体的目标是找到一个最优的策略函数,使得在与环境互动中能够获得最大的长期奖励。
在确定性策略中,策略函数直接映射状态到动作。
而在随机性策略中,策略函数会输出一个动作的概率分布。
确定性策略通常更容易优化,但是随机性策略在某些情况下能够带来更好的探索能力。
基于模型和无模型的最优化方法在强化学习中,最优化方法可以分为基于模型和无模型的方法。
基于模型的方法通过对环境建模,预测状态转移和奖励函数,从而寻找最优的策略。
这种方法需要对环境有一定的先验知识,并且在环境模型不准确或无法建模时会出现问题。
无模型的方法则直接在与环境互动中学习策略,不需要对环境进行建模。
这种方法可以更好地适应不确定的环境,并且在一些复杂的情况下能够得到更好的效果。
无模型的方法包括值迭代、策略迭代、蒙特卡洛方法、时序差分学习等。
结语强化学习中的最优化方法是智能体学习最优策略的关键。
高斯过程分类方法

高斯过程分类方法
高斯过程(Gaussian Process,GP)是一种基于概率模型的非参数方法,常用于回归和分类问题。
以下是几种基于高斯过程的分类方法:
1. 基于最大边缘化(Maximum Marginal)的分类方法:对于二分类问题,通过对训练数据集进行最大边缘化(Maximum Marginalization)来得到分类器。
该方法需要先估计高斯过程的超参数,然后利用最大边缘化得到后验概率密度函数,再通过概率阈值判断分类结果。
2. 基于拉普拉斯近似(Laplace approximation)的分类方法:将高斯过程的先验概率密度函数通过拉普拉斯近似转化为一个近似的正态分布,然后利用训练数据集计算出后验概率密度函数的平均值和方差。
最终分类结果通过对后验概率密度函数的平均值应用概率阈值得到。
3. 基于期望传播(Expectation Propagation,EP)的分类方法:通过近似方法得到近似的高斯分布,然后利用期望传播算法进行高斯分布的近似,并使用近似的高斯分布来计算分类器。
以上是基于高斯过程的几种分类方法,具体应用时需要根据数据集的特征和需求灵活选择。
AI之旅(5):正则化与牛顿方法
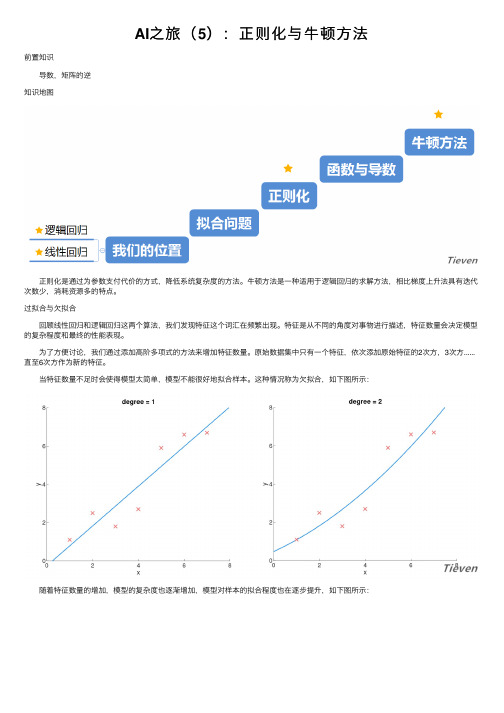
AI之旅(5):正则化与⽜顿⽅法前置知识 导数,矩阵的逆知识地图 正则化是通过为参数⽀付代价的⽅式,降低系统复杂度的⽅法。
⽜顿⽅法是⼀种适⽤于逻辑回归的求解⽅法,相⽐梯度上升法具有迭代次数少,消耗资源多的特点。
过拟合与⽋拟合 回顾线性回归和逻辑回归这两个算法,我们发现特征这个词汇在频繁出现。
特征是从不同的⾓度对事物进⾏描述,特征数量会决定模型的复杂程度和最终的性能表现。
为了⽅便讨论,我们通过添加⾼阶多项式的⽅法来增加特征数量。
原始数据集中只有⼀个特征,依次添加原始特征的2次⽅,3次⽅......直⾄6次⽅作为新的特征。
当特征数量不⾜时会使得模型太简单,模型不能很好地拟合样本。
这种情况称为⽋拟合,如下图所⽰: 随着特征数量的增加,模型的复杂度也逐渐增加,模型对样本的拟合程度也在逐步提升,如下图所⽰: 当特征数量过多时会使得模型太复杂,模型可以极好地拟合样本。
这种情况称为过拟合,如下图所⽰: 显然⽋拟合的情况是不好的,那么过拟合的情况如何呢?虽然模型很好地拟合了数据集,然⽽这不是⼀个好的模型,它对数据集过度拟合以⾄于对新样本的泛化能⼒很差。
“如⽆必要,勿增实体”。
参数是特征的权重,当参数越⼤时特征的影响越⼤,当参数越⼩时特征的影响越⼩。
如果能让参数尽量变⼩,就可以降低模型的复杂度。
为了避免出现过拟合的情况,可以在代价函数中加⼊正则化项,正则化项是关于参数的代价。
因为存在代价,算法在寻找全局最优点的过程中,必须使得参数尽量最⼩化。
正则化 线性回归原代价函数如下: 线性回归新代价函数如下: λ称为正则化参数,和学习率α⼀样,这是⼀个需要⼿动调节的参数。
正则化参数λ的作⽤是调节以下两个⽬标间的平衡关系: ⽬标⼀:使模型更好地拟合数据; ⽬标⼆:使参数θ尽量最⼩化; 当正则化参数λ减⼩时,需要为参数θ⽀付的代价变⼩,模型的复杂度提⾼,存在的风险是可能会出现过拟合。
当正则化参数λ增⼤时,需要为参数θ⽀付的代价变⼤,模型的复杂度降低,存在的风险是可能会出现⽋拟合。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
COARSE-GRADIENT LANGEVIN ALGORITHMS FOR DYNAMIC DATA INTEGRATION AND UNCERTAINTY QUANTIFICATION P.DOSTERT∗,Y.EFENDIEV†,T.Y.HOU‡,AND W.LUO§Abstract.The main goal of this paper is to design an efficient sampling technique for dynamic data integra-tion using the Langevin algorithms.Based on a coarse-scale model of the problem,we compute the proposals of the Langevin algorithms using the coarse-scale gradient of the target distribution.To guarantee a correct and efficient sampling,each proposal isfirst tested by a Metropolis acceptance-rejection step with a coarse-scale distribution.If the proposal is accepted in thefirst stage,then afine-scale simulation is performed at the second stage to determine the acceptance probability. Comparing with the direct Langevin algorithm,the new method generates a modified Markov chain by incorporating the coarse-scale information of the problem.Under some mild technical condi-tions we prove that the modified Markov chain converges to the correct posterior distribution.We would like to note that the coarse-scale models used in the simulations need to be inexpensive,but not necessarily very accurate,as our analysis and numerical simulations demonstrate.We present numerical examples for sampling permeabilityfields using two-point geostatistics.Karhunen-Lo`e ve expansion is used to represent the realizations of the permeabilityfield conditioned to the dynamic data,such as the production data,as well as the static data.The numerical examples show that the coarse-gradient Langevin algorithms are much faster than the direct Langevin algorithms but have similar acceptance rates.1.Introduction.Uncertainties in the detailed description of reservoir lithofa-cies,porosity,and permeability are major contributors to uncertainty in reservoir per-formance forecasting.Making decisions in reservoir management requires a method for quantifying rge uncertainties in reservoirs can greatly affect the production and decision making on well drilling.Better decisions can be made by reducing the uncertainty.Thus,quantifying and reducing the uncertainty is an im-portant and challenging problem in subsurface modeling.Additional dynamic data, such as the production data,can be used in achieving more accurate predictions.The previousfindings show that dynamic data can be used to improve the predictions and reduce the uncertainty.Therefore,to predict future reservoir performance,the reservoir properties,such as porosity and permeability,need to be conditioned to dynamic data.In general it is difficult to calculate this posterior probability distri-bution because the process of predictingflow and transport in petroleum reservoirs is nonlinear.Instead,we estimate this probability distribution from the outcomes of flow predictions for a large number of realizations of the reservoir.It is essential that the permeability(and porosity)realizations adequately reflect the uncertainty in the reservoir properties,i.e.,we correctly sample this probability distribution.The prediction of permeabilityfields based on dynamic data is a challenging prob-lem because permeabilityfields are typically defined on a large number of grid blocks. The Markov chain Monte Carlo(MCMC)method and its modifications have been used previously to sample the posterior distribution of the permeabilityfield.Oliver et al.[21,22]proposed the randomized maximum likelihood method,which generates unconditional realizations of the production and permeability data and then solves a deterministic gradient-based inverse problem.The solution of this minimization problem is taken as a proposal and accepted with probability one because the rig-orous acceptance probability is very difficult to estimate.In addition to the need of solving a gradient-based inverse problem,this method does not guarantee a proper sampling of the posterior distribution.Developing efficient and rigorous MCMC cal-culations with high acceptance rates remains a challenging problem.In this paper,we employ the Langevin algorithms within the context of MCMC methods for sampling the permeabilityfingevin algorithms provide efficient sampling techniques because they use the gradient information of the target distribu-tions.However,the direct Langevin algorithm is very expensive because it requires the computation of the gradients withfine-scale simulations.Based on a coarse-scale model of the problem,we propose an approach where the gradients are computed with inexpensive coarse-scale simulation.These coarse-scale gradients may not be very ac-curate and,for this reason,the computed results arefirst tested with coarse-scale distributions.If the result is accepted at thefirst stage,then afine-scale simulation is performed at the second stage to determine the acceptance probability.Thefirst stage of the method modifies the Markov chain generated by the direct Langevin al-gorithms.We can show that the modified Markov chain satisfies the detailed balance condition for the correct distribution.Moreover,we point out that the chain is ergodic and converges to the correct posterior distribution under some technical assumptions. The validity of the assumptions for our application is also discussed in the paper For sampling the permeabilityfields in two-phaseflows,we use a coarse-scale model based on multiscalefinite element methods.The multiscalefinite element methods are used to construct coarse-scale velocityfields which are further used to solve the transport equation on the coarse-grid.The multiscale basis functions are not updated throughout the simulation,which provides an inexpensive coarse-scale methodology.In this respect,the multiscalefinite element methods are conceptually similar to the single-phaseflow upscaling methods(see e.g.,[3,5]),where the main idea is to upscale the underlyingfine-scale permeabilityfield.These types of upscaling methods are not very accurate because the subgrid effects of transport are neglected. We would like to note that upscaled models are used in MCMC simulations in pre-viousfindings.In a pioneering work([12]),Glimm and Sharp employed error models between coarse-andfine-scale simulations to quantify the uncertainty.Numerical results for sampling permeabilityfields using two-point geostatistics are presented in the ing the Karhunen-Lo`e ve expansion,we can represent the high dimensional permeabilityfield by a small number of parameters.Further-more,the static data(the values of permeabilityfields at some sparse locations)can be easily incorporated into the Karhunen-Lo`e ve expansion to further reduce the dimen-sion of the parameter space.Imposing the values of the permeability at some locations restricts the parameter space to a subspace(hyperplane).Numerical results are pre-sented for both single-phase and two-phaseflows.In all the simulations,we show that the gradients of the target distribution computed using coarse-scale simulations provide accurate approximations of the actualfine-scale gradients.Furthermore,we present the uncertainty assessment of the production data based on sampled perme-abilityfields.Our numerical results show that the uncertainty spread is much larger if no dynamic data information is used.However,the uncertainty spread decreases if more information is incorporated into the simulations.The paper is organized as follows.In the next section,we briefly describe the model equations and their upscaling.Section3is devoted to the analysis of the Langevin MCMC method and its relevance to our particular application.Numerical results are presented in Section4.22.Fine and coarse models.In this section we briefly introduce a coarse-scale model used in the simulations.We consider two-phaseflows in a reservoir(denoted byΩ)under the assumption that the displacement is dominated by viscous effects;i.e.,we neglect the effects of gravity,compressibility,and capillary pressure.Porosity will be considered to be constant.The two phases will be referred to as water and oil, designated by subscripts w and o,respectively.We write Darcy’s law for each phase as follows:v j=−k rj(S)∂t+v·∇f(S)=0,(2.3)whereλis the total mobility,h is the source term,f(S)is theflux function,and v is the total velocity,which are respectively given by:λ(S)=k rw(S)µo,(2.4)f(S)=k rw(S)/µwFPVIFig.2.1.Typicalfine and coarse scale fractionalflowsdiscussion)is defined as the fraction of oil in the producedfluid and is given by q o/q t, where q t=q o+q w,with q o and q w theflow rates of oil and water at the production edge of the model.More specifically,F(t)=1− ∂Ωout f(S)v n dlV p T0q t(τ)dτ,with V p the total pore volume of the system.PVI provides the dimensionless time for the displacement.ngevin algorithm using coarse-scale models.3.1.Problem setting.The problem under consideration consists of sampling the permeabilityfield given fractionalflow measurements.Typically,the prior infor-mation about the permeabilityfield consists of its covariance matrix and the values of the permeability at some sparse locations.Since the fractionalflow is an integrated response,the map from the permeabilityfield to the fractionalflow is not one-to-one. Hence this problem is ill-posed in the sense that there exist many different permeabil-ity realizations for the given production data.From the probabilistic point of view,this problem can be regarded as conditioning the permeabilityfields to the fractionalflow data with measurement errors.Conse-quently,our goal is to sample from the conditional distribution P(k|F),where k is thefine-scale permeabilityfield and F is the fractionalflow ing the Bayes formula we can writeP(k|F)∝P(F|k)P(k).(3.1) In the above formula,P(k)is the unconditioned(prior)distribution of the permeabil-ityfield.In practice,the measured fractionalflow contains measurement errors.In this paper,we assume that the measurement error satisfies a Gaussian distribution, thus,the likelihood function P(F|k)takes the formP(F|k)∝exp − F−F k 2where F is the reference fractionalflow,F k is the fractionalflow for the permeability field k,andσf is the measurement precision.In practice,F k is computed by solving the nonlinear PDE system(2.1)-(2.3)for the given k on thefine-grid.Since both F and F k are functions of time(denoted by t),the norm F−F k 2is defined as the L2 normF−F k 2= T0[F(t)−F k(t)]2dt.Denote the sampling target distribution asπ(k)=P(k|F)∝exp − F−F k 2q(Y|k n)π(k n) ,(3.4)i.e.take k n+1=Y with probability p(k n,Y),and k n+1=k n with probability1−p(k n,Y).The MCMC algorithm generates a Markov chain{k n}whose stationary distribution isπ(k).A remaining question is how to choose an efficient proposal distribution q(Y|k n).An important type of proposal distribution can be derived from the Langevin diffusion,as proposed by Grenander and Miller[13].The Langevin diffusion is defined by the stochastic differential equation1dk(τ)=√2∇logπ(k n)+the Metropolis acceptance-rejection step(3.4).Consequently,we choose the proposal generator q(Y|k n)in Algorithm I asY=k n+∆τ∆τǫn.(3.6)Sinceǫn are independent Gaussian vectors,the transition distribution of the proposal generator(3.6)isq(Y|k n)∝exp − Y−k n−∆τ2∆τ ,q(k n|Y)∝exp − k n−Y−∆τ2∆τ .(3.7)The scheme(3.6)can be regarded as a problem-adapted random walk.The gra-dient information of the target distribution is included to enforce a biased random walk.The use of the gradient information in inverse problems for subsurface char-acterization is not new.In their original work,Oliver et al[21,22]developed the randomized maximum likelihood method,which uses the gradient information of the target distribution.This approach uses unconditional realizations of the production and permeability data and solves a deterministic gradient-based minimization prob-lem.The solution of this minimization problem is taken as a proposal and is accepted with probability one,since the acceptance probability is very difficult to estimate. In addition to the need of solving a gradient-based inverse problem,this method does not guarantee a proper sampling of the posterior distribution.Thus,develop-ing efficient and rigorous MCMC calculations with high acceptance rates remains a challenging problem.Though the Langevin formula(3.6)resembles the randomized maximum likelihood method,it is more efficient and rigorous,and one can compute the acceptance probability easily.The Langevin algorithms also allow us to achieve high acceptance rates.However,computing the gradients of the target distribution is very expensive.In this paper,we propose to use the coarse-scale solutions in the computation of the gradients to speed up the Langevin algorithms.ngevin MCMC method using coarse-scale models.The major computational cost of Algorithm I is to compute the value of the target distribu-tionπ(k)at different permeabilities.Since the map between the permeability k and the fractionalflow F k is governed by the PDE system(2.1)-(2.3),there is no explicit formula for the target distributionπ(k).To compute the functionπ(k),we need to solve the nonlinear PDE system(2.1)-(2.3)on thefine scale for the given k.For the same reason,we need to compute the gradient ofπ(k)in(3.6)numerically(by finite differences),which involves solving the nonlinear PDE system(2.1)-(2.3)multi-ple times.To compute the acceptance probability(3.4),the PDE system(2.1)-(2.3) needs to be solved one more time.As a result,the direct(full)MCMC simulations with Langevin samples are prohibitively expensive.To bypass the above difficulties,we design a coarse-grid Langevin MCMC algo-rithm where most of thefine scale computations are replaced by the coarse scale ones. Based on a coarse-grid model of the distributionπ(k),wefirst generate samples from (3.6)using the coarse-scale gradient ofπ(k),which only requires solving the PDE system(2.1)-(2.3)on the coarse-grid.Then we furtherfilter the proposals by an ad-ditional Metropolis acceptance-rejection test on the coarse-grid.If the sample does6not pass the coarse-grid test,the sample is rejected and no furtherfine-scale test is necessary.The argument for this procedure is that if a proposal is not accepted by the coarse-grid test,then it is unlikely to be accepted by thefine scale test either. By eliminating most of the“unlikely”proposals with cheap coarse-scale tests,we can avoid wasting CPU time simulating the rejected samples on thefine-scale.To modelπ(k)on the coarse-scale,we define a coarse-grid map F∗k between the permeabilityfield k and the fractionalflow F.The map F∗k is determined by solving the PDE system(2.1)-(2.3)on a coarse-grid.Consequently,the target distribution π(k)can be approximated byπ∗(k)∝exp − F−F∗k 2√2∇logπ∗(k n)+2∇logπ∗(k n) 22∇logπ∗(Y) 2q∗(Y|k n)π∗(k n) ,whereπ∗(k)is the coarse-scale target distribution(3.8),q∗(Y|k n)and q∗(k n|Y)are the coarse-scale proposal distributions given by(3.10).Combining all the discussion above,we have the following revised MCMC algorithm.Algorithm II(Preconditioned coarse-gradient Langevin algorithm)•Step1.At k n,generate a trial proposal Y from the coarse Langevin algorithm(3.9).•Step2.Take the proposal k ask= Y with probability g(k n,Y),k n with probability1−g(k n,Y),7whereg (k n ,Y )=min 1,q ∗(k n |Y )π∗(Y )Q (k |k n )π(k n ) ,(3.12)i.e.,k n +1=k with probability ρ(k n ,k ),and k n +1=k n with probability 1−ρ(k n ,k ).The step 2screens the trial proposal Y by the coarse-grid distribution before passing it to the fine-scale test.The filtering process changes the proposal distribution of the algorithm from q ∗(Y |k n )to Q (k |k n )and serves as a preconditioner to the MCMC method.This is why we call it the preconditioned coarse-gradient Langevin algorithm.We note that testing proposals by approximate target distributions is not a very new idea.Similar strategies have been developed previously in [17,2].Note that there is no need to compute Q (k |k n )and Q (k n |k )in (3.12)by formula (3.11).The acceptance probability (3.12)can be simplified asρ(k n ,k )=min 1,π(k )π∗(k n )π∗(k )min q (k n |k )π∗(k ),q (k |k n )π∗(k n )=q (k |k n )π∗(k n )π∗(k )Q (k |k n ).Substituting the above formula into (3.12),we immediately get (3.13).In Algorithm II,the proposals generated by (3.9)are screened by the coarse-scale acceptance-rejection test to reduce the number of unnecessary fine-scale simulations.One can skip that preconditioning step and get the following algorithm.Algorithm III (Coarse-gradient Langevin algorithm)•Step 1.At k n ,generate a trial proposal Y from the coarse Langevin algorithm (3.9).•Step 2.Accept Y as a sample with probability ρ(k n ,Y )=min 1,q ∗(k n |Y )π(Y )We will demonstrate numerically that Algorithm II is indeed more efficient than Algorithm III.In a previous work[10],we studied preconditioning the MCMC algorithms by coarse-scale models,where the independent sampler and random walk sampler are used as the instrumental distribution.In this paper,our goal is to show that one can use coarse-scale models in Langevin algorithms.In particular,we can use coarse-scale gradients instead offine-scale gradients in these algorithms.Our numerical experiments show that the coarse-scale distribution somewhat regularizes(smooths) thefine-scale distribution,which allows us to take larger time steps in the Langevin algorithm(3.9).In addition,we employ the preconditioning technique from[10]to increase the acceptance rate of the coarse-gradient Langevin algorithms.3.3.Analysis of the coarse-gradient Langevin algorithms.In this section, we will briefly discuss the convergence property of the preconditioned coarse-grid Langevin algorithm.DenoteE= k;π(k)>0 ,E∗= k;π∗(k)>0 ,D= k;q∗(k|k n)>0for any k n∈E .(3.15) The set E is the support of the posterior(target)distributionπ(k).E contains all the permeabilityfields k which have a positive probability of being accepted as a sample.Similarly,E∗is the support of the coarse-scale distributionπ∗(k),which contains all the k acceptable by the the coarse-scale test.D is the set of all possible proposals which can be generated by the Langevin distribution q∗(k|k n).To make the coarse-gradient Langevin MCMC methods sample properly,the conditions E⊆D and E⊆E∗must hold(up to a zero measure set)simultaneously.If one of these conditions is violated,say,E⊆E∗,then there will exist a subset A⊂(E\E∗)such thatπ(A)= Aπ(k)dk>0andπ∗(A)= Aπ∗(k)dk=0,which means no element of A can pass the coarse-scale test and A will never be visited by the Markov chain{k n}.For Langevin algorithms,E⊂D is always satisfied since D is the whole space.By choosing the parameterσc inπ∗(k)properly,the condition E⊂E∗can also be satisfied.A typical choice would beσc≈σf.More discussions on the choice ofσc can be found in[10],where a two-stage MCMC algorithm is discussed. Denote by K the transition kernel of the Markov chain{k n}generated by Algo-rithm II.Since its effective instrumental proposal is Q(k|k n),the transition kernel K has the formK(k n,k)=ρ(k n,k)Q(k|k n),k=k n,K(k n,{k n})=1− k=k nρ(k n,k)Q(k|k n)dk.(3.16)That is,the transition kernel K(k n,·)is continuous when k=k n and has a positive probability at the point k=k n.First we show that K(k n,k)satisfies the detailed balance condition,that isπ(k n)K(k n,k)=π(k)K(k,k n)(3.17)9for all k,k n.The equality is obvious when k=k n.If k=k n,thenπ(k n)K(k n,k)=π(k n)ρ(k n,k)Q(k|k n)=min Q(k|k n)π(k n),Q(k n|k)π(k) =min Q(k|k n)π(k n)NNn=1h(k n)= h(k)π(k)dk.(3.19)Moreover,the distribution of k n converges toπ(k)in the total variation normlim n→∞supA∈B(E) K n(k0,A)−π(A)=0(3.20)for any initial state k0,where B(E)denote all the measurable subsets of E.104.Numerical Setting and Results.In this section we discuss the implemen-tation details of Langevin MCMC method and present some representative numerical results.Suppose the permeabilityfield k(x)is defined on the unit squareΩ=[0,1]2. We assume that the permeabilityfield k is known at some spatial locations,and the covariance of log(k)is also known.We discretize the domainΩby a rectangular mesh, hence the permeabilityfield k is represented by a matrix(thus k is a high dimensional vector).As for the boundary conditions,we have tested various boundary conditions and observed similar performance for the Langevin MCMC method.In our numerical experiments we will assume p=1and S=1on x=0and p=0on x=1and noflow boundary conditions on the lateral boundaries y=0and y=1.We have chosen this type of boundary conditions because they provide a large deviation between coarse-andfine-scale simulations for permeabilityfields considered in the paper.We will consider both single-phase and two-phaseflow displacements.Using the Karhunen-Lo`e ve expansion[19,24],the permeabilityfield can be ex-panded in terms of an optimal L2basis.By truncating the expansion we can represent the permeability matrix by a small number of random parameters.To impose the hard constraints(the values of the permeability at prescribed locations),we willfind a lin-ear subspace of our parameter space(a hyperplane)which yields the corresponding values of the permeabilityfield.First,we briefly recall the facts of the Karhunen-Lo`e ve expansion.Denote Y(x,ω)=log[k(x,ω)],where the random elementωis included to remind us that k is a randomfield.For simplicity,we assume that E[Y(x,ω)]=0. Suppose Y(x,ω)is a second order stochastic process with E ΩY2(x,ω)dx<∞, where E is the expectation operator.Given an orthonormal basis{φk}in L2(Ω),we can expand Y(x,ω)as a general Fourier seriesY(x,ω)=∞k=1Y k(ω)φk(x),Y k(ω)= ΩY(x,ω)φk(x)dx.We are interested in the special L2basis{φk}which makes the random variables Y k uncorrelated.That is,E(Y i Y j)=0for all i=j.Denote the covariance function of Y as R(x,y)=E[Y(x)Y(y)].Then such basis functions{φk}satisfyE[Y i Y j]= Ωφi(x)dx ΩR(x,y)φj(y)dy=0,i=j.Since{φk}is a complete basis in L2(Ω),it follows thatφk(x)are eigenfunctions of R(x,y):ΩR(x,y)φk(y)dy=λkφk(x),k=1,2,...,(4.1) whereλk=E[Y2k]>0.Furthermore,we haveR(x,y)=∞k=1λkφk(x)φk(y).(4.2)Denoteθk=Y k/√λkθk(ω)φk(x),(4.3)11whereφk andλk satisfy(4.1).We assume that the eigenvaluesλk are ordered as λ1≥λ2≥....The expansion(4.3)is called the Karhunen-Lo`e ve expansion(KLE). In the KLE(4.3),the L2basis functionsφk(x)are deterministic and resolve the spatial dependence of the permeabilityfield.The randomness is represented by the scalar random variablesθk.After we discretize the domainΩby a rectangular mesh,the continuous KLE(4.3)is reduced tofinite terms.Generally,we only need to keep the leading order terms(quantified by the magnitude ofλk)and still capture most of the energy of the stochastic process Y(x,ω).For an N-term KLE approximation Y N= N k=1√= N k=1λkE Y 2|x2−y2|22L21−λkθkφk(x j)=αj,(4.5)whereαj(j=1,...,9)are prescribed constants.For simplicity,we setαj=0for all j=1,...,9.In the simulations we propose elevenθi and calculate the rest ofθi by solving the linear system(4.5).In all the simulations,we test5000samples.Because the direct Langevin MCMC simulations are very expensive,we only select a61×61fine-scale model for single-phaseflow and a37×37fine-scale model for two-phase flow.Here61and37refer to the number of nodes in each direction,since we use afinite element based approach.Typically,we consider6or10times coarsening in each direction.In all the simulations,the gradients of the target distribution are computed usingfinite-difference differentiation rule.The time step size∆τof the Langevin algorithm is denoted byδ.Based on the KLE,the parameter space of the target distributionπ(k)will change from k toθin the numerical simulations,and the Langevin algorithms can be easily rewritten in terms ofθ.12θ1θ2−3−2−10123−3−2−101230.20.40.60.811.21.41.61.82−3−2−10123−3−2−101230.20.40.60.811.21.41.61.82Fig.4.1.Left:Coarse-scale response surface π∗(defined by (3.8))restricted to a 2-D hyper-plane.Right:Fine-scale response surface π(defined by 3.3))restricted to the same 2-D hyperplane.Our first set of numerical results are for single-phase flows.First,we present a comparison between the fine-scale response surfaces πand the coarse-scale response surface π∗defined by (3.3)and (3.8),respectively.Because both πand π∗are scalar functions of 11parameters,we plot the restriction of them to a 2-D hyperplane by fixing the values of 9θ.In Figure 4.1,π∗(left figure)and π(right figure)are depicted on such a 2-D hyperplane.It is clear from these figures that the overall agreement between the fine-and coarse-scale response surfaces is good.This is partly because the fractional flow is an integrated response.However,we notice that the fine-scale response surface πhas more local features and varies on smaller scales compared to π∗.In Figure 4.2,we compare the acceptance rates of the Algorithms I,II and III with different coarse-scale precision σc .The acceptance rate is defined as the ratio between the number of accepted permeability samples and the number of fine-scale acceptance-rejection test.Since the Algorithm I does not depend on the coarse-scale precision,its acceptance rate is the same for different σc .As we can see from the figure,Algorithm II has higher acceptance rates than Algorithm III.The gain in the acceptance rates is due to the Step 2of the Algorithm II,which filters unlikely acceptable proposals.To compare the effect of different degrees of coarsening,we plot in Figure 4.2the acceptance rate of Algorithm II using both 7×7coarse models and 11×11coarse models.Since 11×11coarse models are more accurate,its acceptance rate is higher.In Figure 4.3,we present the the numerical results where larger time step δis used in the Langevin paring with Figure 4.2,we find that that the acceptance rates for all the three methods decrease as δincreases.In all the numerical results,the Algorithm I,which uses the fine-scale Langevin method (3.6),gives a slightly higher acceptance rate than both Algorithm II and III.However,Algorithm I is more expensive than Algorithm II and III since it uses the fine-scale gradients in computing the Langevin proposals.In Figure 4.4,we compare the CPU time for the different Langevin methods.From the left plot we see that Algorithm I is several times more expensive than Algorithm II and III.In the middle and right plots,we compare the Algorithm II and III when a different coarse-model and a different time step size δare used respectively.We observe that the preconditioned coarse-gradient Langevin algorithm is slightly faster than the coarse Langevin algorithm without preconditioning.13a c c e p t a n c e r a t eFig.4.2.Acceptance rate comparison between the direct fine-scale Langevin,preconditioned coarse-gradient Langevin and coarse-gradient Langevin algorithms for single-phase flow;δ=0.05,σ2f=0.003.In the left plot,the coarse-grid 11×11is used in the simulation.Fig.4.3.Acceptance rate comparison for the direct fine-scale Langevin,preconditioned coarse-gradient Langevin and coarse-gradient Langevin algorithms for single-phase flow,δ=0.1,σ2f=0.003.In all the above numerical simulations,we choose the fine-scale error precision σ2f=0.003.The scaling of the error precision depends on the norm used in (3.3).If one choses σf to be very large,then the precision is very low,and consequently,most proposals will be accepted in the direct Langevin algorithm as well as in the coarse-gradient Langevin algorithms.In this case,the acceptance rate of the coarse-gradient Langevin algorithms is still similar to the acceptance rate of the direct Langevin algorithms.Consequently,the speed-up will remain the same.For very large σf ,the preconditioning step in Algorithm II may not help to improve the acceptance rate,since most proposals will pass the preconditioning step.Next we compare the fractional flow errors for the preconditioned coarse-gradient Langevin method and the direct fine-scale Langevin method in Figure 4.5.Our ob-jective is two-fold.First,we would like to compare the convergence rates of the preconditioned coarse-gradient Langevin algorithm with that of the fine-scale (direct)Langevin algorithm.Second,we would like to show that the sampled permeabil-ity fields give nearly the same fractional flow response as the reference fractional flow data.We see from the left plot that both methods converge to the steady state within14。