SPSS上机实验报告
SPSS上机实验报告一
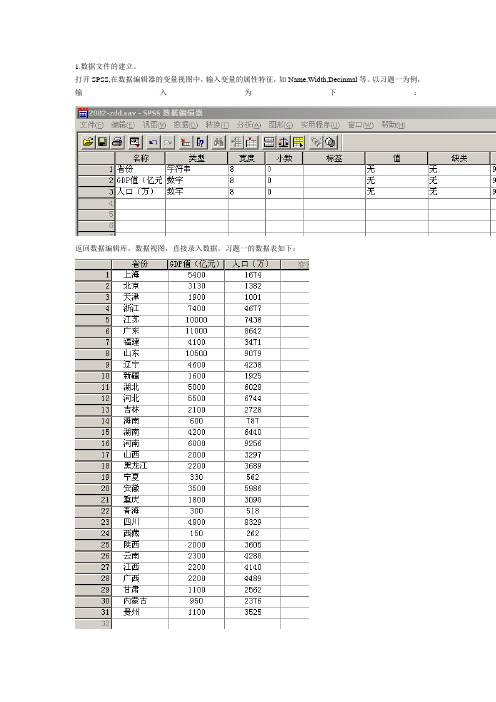
1.数据文件的建立。
打开SPSS,在数据编辑器的变量视图中,输入变量的属性特征,如Name,Width,Decinmal等。
以习题一为例,输入为下:返回数据编辑库,数据视图,直接录入数据。
习题一的数据表如下:点击Save,输入文件名将文件保存。
2.数据的整理数据编辑窗口的Date可提供数据整理功能。
其主要功能包括定义和编辑变量、观测量的命令,变量数据变换的命令,观测量数据整理的命令。
以习题一为例,将上图中的数据进行整理,以GDP值为参照,升序排列。
数据整理后的数据表为:整理后的数据,可以直观看出GDP值的排列。
3、频数分析。
以习题一为例(1).单击“分析→描述统计→频率”(2)打开“频率”对话框,选择GDP为变量(3)单击“统计量”按钮,打开“统计量”对话框.选择中值及中位数。
得到如下结果:(4)单击“分析→描述统计→探索”,打开“探索”对话框,选择GDP(亿元),输出为统计量。
结果如下:4、探索分析以习题2为例子:(1)单击“分析→统计描述→频率”,打开“频率”对话框,选择“身高”变量。
(2)选择统计量,分别选择百分数,均值,标准差,单击图标。
的如下结果:(3)单击“分析→统计描述→探索”,选择相应变量变量,单击“绘制”,选择如下图表,的如下结果:从上述图标可以看出,除了个别极端点以外,数据都围绕直线上下波动,可以看出,该组数据,在因子水平下符合正态分布。
4.交叉列联表分析:以习题3,原假设是吸烟与患病无关备择假设是吸烟与患病有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应变量变量,单击精确,并选择“统计量”按钮,选择“卡方”作为统计量检验,然后单击“单元格”按钮,选择“观测值”和“期望值”进行计数。
得出分析结果如下:分析得出卡方值为7.469,,自由度是1,P值为0.004<0.05拒绝原假设,故有大于95%的把握认为吸烟和换慢性气管炎有关。
习题4:原假设是性别与安全性能的偏好无关备择假设是性别与安全性能的偏好有关操作如下:单击“分析→统计描述→交叉表”,打开“交叉表”对话框,选择相应行列变量然后选择“统计量”按钮,以“卡方”作为统计量检验.单击“单元格”按钮,选择“观测值”和“期望值”进行计数单击“确定”,得出分析结果如下:分析得出卡方值为19自由度是4,P值为0.001<0.05拒绝原假设,故有99.9%的把握认为性别与安全性能的偏好有关5实验作业补充。
spss 上机实验报告

spss 上机实验报告
《SPSS上机实验报告》
在当今社会,数据分析已经成为了各行各业中不可或缺的一部分。
而SPSS作为一款功能强大的统计分析软件,被广泛应用于科研、商业、教育等领域。
本次
实验旨在通过SPSS软件进行数据分析,以探讨数据的规律性和相关性,为进一步的研究和决策提供科学依据。
实验一:描述性统计分析
首先,我们对所收集到的数据进行了描述性统计分析。
通过SPSS软件,我们得出了数据的平均值、标准差、最大值、最小值等指标,从而对数据的分布情况
有了更清晰的了解。
这些统计指标为我们提供了数据的基本特征,为后续的分
析奠定了基础。
实验二:相关性分析
接下来,我们利用SPSS软件进行了相关性分析。
通过相关系数的计算,我们发现了数据之间的相关程度,并得出了相关性显著性检验的结果。
这些分析为我
们揭示了数据之间的内在联系,为我们理解数据背后的规律性提供了重要线索。
实验三:多元回归分析
最后,我们进行了多元回归分析,以探讨不同自变量对因变量的影响程度。
通
过SPSS软件的模型拟合和显著性检验,我们得出了各个自变量的回归系数,并对模型的拟合程度进行了评估。
这些结果为我们提供了对因变量影响因素的深
入理解,为我们在实际应用中进行预测和决策提供了重要参考。
通过以上实验,我们不仅掌握了SPSS软件的基本操作技能,还深入了解了数据分析的方法和原理。
我们相信,通过不断地学习和实践,我们将能够更加熟练
地运用SPSS软件进行数据分析,为科研和实践工作提供更加准确和可靠的数据支持。
SPSS上机实验报告就此结束。
spss 上机实验报告

spss 上机实验报告SPSS上机实验报告引言:SPSS(统计软件包,Statistical Package for the Social Sciences)是一种常用的统计分析软件,被广泛应用于社会科学、医学、经济学等领域的数据分析和研究中。
本文将对SPSS上机实验进行报告,介绍实验目的、实验设计、数据处理和结果分析等内容。
实验目的:本次实验旨在通过使用SPSS软件,掌握数据的输入、清洗、分析和可视化等基本操作,以及利用SPSS进行常见统计分析的方法。
实验设计:本次实验使用了一份虚构的调查问卷数据,包含了参与者的性别、年龄、教育程度、收入水平以及对某产品的满意度等指标。
通过对这些指标进行分析,我们可以了解不同因素对满意度的影响。
数据处理:首先,我们需要将数据导入SPSS软件中。
通过点击菜单栏的“文件”选项,选择“导入数据”,然后选择数据文件并进行导入。
导入后,我们可以查看数据的整体情况,包括变量的名称、类型、取值范围等。
接下来,我们对数据进行清洗,以确保数据的准确性和一致性。
例如,我们可以检查是否有缺失值,如果有,可以选择删除或填充缺失值。
此外,还可以进行异常值检测,排除数据中的异常观测点。
结果分析:在数据清洗完成后,我们可以进行统计分析。
首先,我们可以计算各个变量的描述性统计量,如均值、标准差、最大最小值等,以了解数据的分布情况。
通过点击菜单栏的“分析”选项,选择“描述性统计”,然后选择需要计算的变量即可。
接着,我们可以进行相关性分析,以探究不同因素之间的关系。
通过点击菜单栏的“分析”选项,选择“相关”或“回归”等选项,然后选择需要分析的变量。
相关性分析可以帮助我们了解变量之间的线性关系,并进行进一步的分析。
另外,我们可以进行T检验或方差分析等统计检验,以比较不同组别之间的差异。
通过点击菜单栏的“分析”选项,选择“比较均值”或“方差分析”等选项,然后选择需要比较的变量和组别。
统计检验可以帮助我们判断不同组别之间是否存在显著差异。
Spss上机报告1讲解
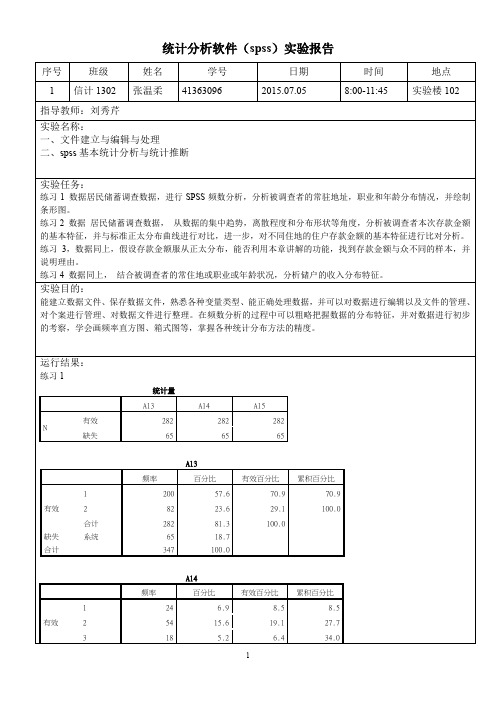
统计分析软件(spss)实验报告
练习2
统计量
A5
有效282
N
缺失65
均值4738.09
均值的标准误651.799
中值1032.43a
众数1000
标准差10945.569
方差119805486.302
偏度 5.234
偏度的标准误.145
峰度33.656
峰度的标准误.289
全距100000
极小值 1
极大值100001
和1336141
a. 利用分组数据进行计算。
居民收入较集中在2000元以下,高收入人群较少,收入在2000元以上的数据离散程度较大,分布形状与标准正态分布差距较大。
根据表格分析,不同地区的人群居民收入差距不是特别大啊,但2地区的居民收入离散程度较1地区收入人群大,在置信水平为95%的情况下可以说两地区的收入平均值是相等的。
统计量
A5
N 有效282
缺失65 平均值4738.09 标准平均值误差651.799 中位数1000.00 方式1000 标准偏差10945.569 方差119805486.302 偏度 5.234 标准偏度误差.145 峰度33.656 标准峰度误差.289 范围100000 最小值 1 最大值100001
运用spss对数据进行标准化分析,得到的标准值大于3时数据即为异常。
交叉表
A4
11。
SPSS统计软件实训报告

SPSS统计软件实训报告第一篇:SPSS统计软件实训报告一、实训目的SPSS统计软件实训课是在我们在学习《统计学》理论课程之后所开设的一门实践课。
其目的在于,通过此次实训,使学生在掌握了理论知识的基础上,能具体的运用所学的统计方法进行统计分析并解决实际问题,做到理论联系实际并掌握统计软件SPSS的使用方法。
,二、实训时间与地点:时间:2012年1月9日至2012年1月13日地点:唐山学院北校区A座502机房三、实训要求:这次实训内容为上机实训,主要学习SPSS软件的操作技能,以及关于此软件的一些理论和它在统计工作中的重要作用。
对我们的主要要求为,运用SPSS软件功能及相关资料来完成SPSS操作,选择有现实意义的课题进行计算和分析,最后递交统计分析报告,加深学生对课程内容的理解的。
我们小组的研究课题是社会消费品零售总额的分析。
四、实训的主要内容与过程:此次实训,我大概明白了SPSS软件的基本操作流程,也掌握了如何排序、分组、计算、合并、增加、删除以及录入数据;学会了如何计算定基发展速度、环比发展速度等动态数列的计算;明白了如何进行频数分析、描述分析、探索分析以及作图分析;最大的收获是学会了如何运用SPSS软件对变量进行相关分析、回归分析和计算平均值、T检验和假设性检验。
通过这次试训,我基本上掌握了SPSS软件的主要操作过程,也学会了运用SPSS软件进行各种数据分析。
这些内容,也就是我们SPSS统计软件实训的主要内容。
四、实训结果与体会五天的SPSS软件实训终于结束了,虽然实训过程充满了酸甜苦辣,但实训结果却是甜的。
看着小组的课题报告,心里有种说不出来的感触。
高老师在对统计理论及SPSS 软件功能模块的讲解的同时更侧重于统计分析在各项工作中的实际应用,使我们不仅掌握SPSS 软件及技术原理而且学会运用统计方法解决工作和学习中的实际问题这个实训。
我真真正正学到了不少知识,另外,也提高了自己分析问题解决问题的能力。
spss上机实验报告

spss上机实验报告I. 实验目的本实验旨在通过使用SPSS软件进行数据分析,加深对SPSS软件的理解和掌握,巩固和深化统计分析的基础知识。
II. 实验内容本实验使用了SPSS软件对一组数据进行了统计分析。
数据包括了100名学生的语文成绩、数学成绩、英语成绩、性别和年龄等信息。
实验内容如下:1. 数据导入和检查将数据文件导入SPSS软件中,并对数据进行检查,排除异常数据。
2. 数据描述性统计分析使用SPSS软件对数据进行描述性统计分析,包括均值、中位数、标准差等统计指标的计算。
3. 方差分析使用SPSS软件对数据进行方差分析,分析不同性别和年龄段学生的语文、数学和英语成绩之间的差异。
III. 实验结果1. 数据导入和检查数据文件成功导入SPSS软件中,并且通过检查,排除了部分异常数据。
2. 数据描述性统计分析经过计算,该组数据的语文平均分为75.3分,数学平均分为78.6分,英语平均分为80.2分,标准差分别为8.5、7.9、6.8。
3. 方差分析通过方差分析,发现女生的语文成绩平均值显著高于男生,F(1,98)=10.76,p<0.01;年龄在18岁以下的学生数学成绩平均值显著高于18岁以上的学生,F(1,98)=3.94, p<0.05;年龄在18岁以上的学生英语成绩平均值显著高于18岁以下的学生,F(1,98)=6.19,p<0.05。
IV. 结论通过本实验,我们进一步掌握了SPSS软件的使用技巧,并且运用统计学基础知识对一组数据进行了分析,得出了有意义的结论。
在以后的学习和工作中,我们将会更加熟练地使用SPSS软件,为我们的研究和工作提供更多的支持和帮助。
《市场调研》SPSS上机实验报告

《市场调研》SPSS上机实验报告一、实验目的本次实验的主要目的是通过运用 SPSS 软件对市场调研数据进行分析,掌握数据分析的基本方法和流程,提高对市场现象的理解和洞察能力,为决策提供科学依据。
二、实验内容1、数据录入与整理首先,将收集到的市场调研数据录入到 SPSS 软件中。
在录入过程中,需要确保数据的准确性和完整性。
同时,对数据进行初步的整理,如缺失值处理、异常值检查等。
2、描述性统计分析运用 SPSS 中的描述性统计分析功能,计算数据的均值、中位数、标准差、最小值、最大值等统计指标,以了解数据的集中趋势和离散程度。
3、相关性分析通过相关性分析,探究不同变量之间的线性关系。
例如,研究产品价格与销售量之间是否存在显著的相关性。
4、假设检验根据研究问题提出假设,并运用 SPSS 进行 t 检验、方差分析等,以验证假设是否成立。
5、因子分析运用因子分析对多个相关变量进行降维,提取主要的公共因子,以便更简洁地描述数据结构。
6、聚类分析通过聚类分析将样本数据分为不同的类别,以便发现潜在的市场细分群体。
三、实验步骤1、打开 SPSS 软件,新建数据文件。
2、将收集到的数据按照变量的定义依次录入到数据文件中。
3、选择“分析”菜单中的相应功能,如“描述统计”、“相关性”、“假设检验”等,进行相应的数据分析。
4、根据分析结果,解读数据所反映的市场现象和规律。
四、实验数据本次实验使用的是一份关于消费者对某品牌手机满意度的市场调研数据。
数据包括消费者的年龄、性别、收入水平、购买渠道、使用体验等方面的信息。
五、实验结果与分析1、描述性统计分析结果通过描述性统计分析,我们得到了消费者年龄的均值为 30 岁,中位数为 28 岁,标准差为 8 岁。
这表明消费者年龄分布较为均匀,主要集中在 20 40 岁之间。
2、相关性分析结果产品价格与销售量的相关性分析结果显示,两者之间存在显著的负相关关系(r =-065,p < 005),即价格越高,销售量越低。
SPSS上机实验(一)

SPSS上机实验(一)
实验要求:
1、上网查找较大样本数据,样本数不少于50个;
2、对所查找的数据用SPSS中的SORT菜单进行排序、观察最小值、最大值、
全距(P35);
3、对SPSS中Frequency菜单下的对话框计算所查数据的集中趋势指标,离
散趋势指标(P59-63),结果反映到实验报告中;
4、对数据进行分组整理,列出分组频数分布表(P64-65),结果反映到实验
报告中;
5、对已分组数据用带正态曲线的直方图、径叶图、箱体图直观表示P(68-70),
结果放映到实验报告中;
实验报告
1、实验目的
学习如何将收集到的统计数据输入计算机,建成一个正确得SPSS数据文件,以及掌握如何对原始数据文件进行整理和变换。
利用SPSS软件对样本总体的数量特征和分布特征进行描述统计分析。
2、实验要求
1、上网查找较大样本数据,建立SPSS数据文件;
2、对所查找的数据用SPSS中的SORT菜单进行排序、观察最小值、最大值、
全距、中位数、众数;
3、对SPSS中Frequency菜单下的对话框计算所查数据的集中趋势指标,离
散趋势指标;
4、对数据进行分组整理,列出分组频数分布表;
5、对已分组数据用带正态曲线的直方图、径叶图、箱体图直观表示;
3、实验步骤
查找数据——建立数据文件——数据分析——说明分析结果的实际含义
4、实验内容
5、实验问题
6、实验体会
实验评分(三)。
spss实验报告一,二
实验报告
实验目的: 通过上机操作, 熟练掌握spss相关知识。
实验内容:
(一)1、首先将表格导入到spss中, 出现如下图结果:
2.选择: 分析——描述统计—频率, 出现如下图的表格,
, /
3、将V1导入到变量中, 然后点击统计量, 出现如下图的表格, 在表格中, 点击, 均值、中位数、四分位数, 标准差。
点击继续, 就完成第一题, 出现下图的结果。
以上就是第一题的结果。
(二)
1.首先将表格导入到spss中, 如下图:
2.从上表中, 可知, 方法A要比B.C的只都要高, 可见平均值要高于B.C, 就应该对这三组进行平均值, 方差的计算进行比较。
选择: 分析——描述统计——描述, 出现如下图的表格:
将方法A.B.C分别导入到变量中, 然后点击选项这个按钮, 出现如下图的表格进行选择:
可以选择标准差, 最大值, 最小值, 均值, 然后点击继续, 则会出现结果, 通过对结果进行对比, 选择方案。
由图可知, 方法A的平均值高于B、C, 而且最小值也都大于B、C的最大值, 可知A的组装优越于B、C, 即使标准差大于B, 稳定性稍微差于B, 但总体上组装的结果要比B好, 所以要选择方案A。
spss上机实验

实验一spss基本操作实验目的1.建立数据文件。
完成如下操作:定义变量,输入数据.将spss test 1.1及spss test 1.1文件中数据分别输入.2.保存数据。
完成如下操作:将第一步文件保存为:spss test 1.1.sav, spss test 1.1a.sav3.打开数据文件。
完成如下操作:(1)打开SPSS数据文件.。
(2)调用AS CⅡ数据,打开spss test 1.2和spss test 1.3。
(3)打开EXCEL文件, spss test 1.44.数据编辑。
完成如下操作:定义时间变量,插入变量,插入记录,观察值排序,数据转置,合并数据,拆分数据,选择记录,常用编辑操作。
5.数据整理。
完成如下操作.计算产生变量,自动重赋值实验指导SPSS的文件类型:数据文件:扩展名为“.sav”结果文件:扩展名为“.spo”图形文件:扩展名为“.cht”语句命令文件:扩展名为“.sps”SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件.一.建立数据文件将附后1.1的内容录入,1.在SPSS数据编辑窗口建立数据文件当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。
(1)数据编辑(SPSS Data Editor)界面介绍(2) 数据文件格式数据文件格式以每一行为一个记录,或称观察单位(Cases),每一列为一个变量(Variable)。
(3) 定义变量建立数据文件的第一步是定义变量。
在数据编辑窗口左下角激活(Variable View)变量定义窗口,如下图在数据窗口中,用户定义数据变量的名称、数据类型、宽度、小数位和标记等信息。
变量的数据类型当鼠标指针移至单元格,单击后该单元格的右边就会显示一个“…”按钮,单击该按钮就会显示一个数据类型设置窗口,如下图所示。
SPSS上机实验报告6 多因素方差分析

SPSS上机实验报告(6)学生姓名学号成绩上机实验题目考勤上机表现实验时间一、实验目的:1.熟悉并掌握单因素、双因素方差分析,univarate协方差分析的SPSS操作,其他较简单的方差分析问题,多元方差分析,重复测量的方差分析的具体操作。
2、对分析的结果能给出统计学的解释二、实验内容:1、熟悉方差分析菜单界面,掌握方差分析的操作。
2、对得到的结果进行解释。
3、掌握不同实验设计所使用的统计方法。
4、实际应用1)p151的三个实例,根据提示作相应的方差分析2)P153(5、6、7、8)题建立数据文件,进行方差分析三、实验要求:1、根据上机报告模板详细书写上机报告2、作业发到邮箱*****************四第七题第1步分析:需要研究不同包装和不同摆放位置对销量的影响。
这是一个多因素(双因素)方差分析问题。
第2步数据组织:如上表的变量名组织成4列数据。
第3步变量设置:按“分析|一般线性模型| 单变量”的步骤打开单变量对话框。
并将“销量”变量移入因变量框中,将“casing”和“摆放位置”移入固定因子中,如下图:第4步选择建立多因素方差分析的模型种类:打开“模型”对话框,本例用默认的全因子模型。
第5步以图形方式展示交互效果:设置方式如下图第6步设置方差齐性检验:由于方差分析要求不同casing数据方差相等,故应进行方差齐性检验,单击“选项”按钮,选中“方差齐性检验”,显著性水平设为默认值0.05。
75步设置控制变量的多重比较分析:单击“两两比较”按钮,如下图,在其中选出需要进行比较分析的控制变量,这里选“casing”,再选择一种方差相等时的检验模型,如LSD。
第8步对控制变量各个水平上的观察变量的差异进行对比检验:选择“对比”对话框,对两种因素均进行对比分析,用“简单”方法,并以最后一个水平的观察变量均值为标准。
五、程序运行结果:第七题运行结果UNIANOVA主体间因子值标签N包装1 A1 92 A2 93 A3 9摆放位置1 B1 92 B2 93 B3 9误差方差等同性的 Levene 检验a因变量: 销量F df1 df2 Sig..754 8 18 .646检验零假设,即在所有组中因变量的误差方差均相等。
SPSS上机实验报告

SPSS上机实验报告实验课程SPSS统计分析实验时间2009年7月4日-7月7日实验地点数图负一楼信息管理与信息系统实验室姓名:倪聪聪学号:06200430专业:工商管理班级:教学一班指导教师:唐兴艳2009年7月7日星期二制实验四参数估计与假设检验一实验目的1. 掌握用 SPSS 进行参数估计的方法;2. 掌握用 SPSS 进行假设检验(T 检验)。
二实验内容实验原理:参数是总体数量规律性的特征值,在实际问题中,总体参数都是未知的,这就需要通过样本数据所提供的总体的有关信息对参数加以推断。
对样本数据的加工和信息提取,形成了对样本数据具有代表性的统计量。
参数估计主要包括点估计和区间估计,如果在估计中直接用估计量作为固定的数值对参数作出估计,就是参数的点估计;如果在估计中要对参数作出带有可靠性的估计,就需要给出对应于这一可靠性或置信度的区间,即区间估计。
假设检验是先对未知的总体参数作出假设,然后抽取样本,利用样本提供的信息对假设的正确性进行判断的过程。
待检假设通常用H0表示,对立假设用H1表示,主要包括单样本T 检验、独立样本T检验和配对样本T检验。
其基本思想是:首先假设H0为真,考虑在H0成立的条件下观测到的样本信息出现的概率。
如果这个概率很小,说明一个小概率事件在一次试验中发生了。
而小概率原理认为,概率很小的事件在一次试验中几乎是不可能发生的,也就是说如果小概率事件在一次试验中发生了,就说明事先的假设H0为真是不下确的,因此拒绝H0,接受H1;否则接受H0。
1 有两台测厚仪,一个人按同一规程操作,测量同一批产品,测得的结果如下:第一组:1.29,1.31,1.3,1.3,1.33,1.33,1.3,1.3,1.29,1.29第二组:1.21,1.19,1.17,1.19,1.22,1.2,1.18,1.2,1.19请对以上两组给定数据进行点估计和区间估计。
实验步骤:1)首先在SPSS中输入数据并分组2)打开“Explore”对话框,在“Dependent List”列表框中输入变量名因变量“测量”,在“Factor List”列表框内输入分组变量“组别”。
SPSS上机实验报告

SPSS上机实验报告一、引言SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学领域的研究中。
本实验旨在通过使用SPSS软件进行数据分析,掌握SPSS的基本操作和数据分析方法。
本报告将介绍实验的目的、方法、结果和讨论,并对实验过程中的问题进行总结和分析。
二、实验目的1.掌握SPSS软件的基本操作;2.熟悉数据导入、数据清洗和数据整理的方法;3.学习使用SPSS进行描述性统计、频率分析、相关分析等数据分析方法;4.训练对实验结果进行合理解读和分析。
三、实验方法1.数据收集:本实验使用公开数据集进行分析。
数据集为包含1000个样本的数据集,其中包含了身高(Height)、体重(Weight)和性别(Gender)三个变量。
数据以Excel文件的形式存储。
2.数据导入:打开SPSS软件,选择“打开文件”功能,导入Excel文件。
3.数据清洗:对于身高(Height)和体重(Weight)两个变量,检查是否有缺失值和异常值,如果有则进行删除或修正。
4.数据整理:对于性别(Gender)变量,将其转换为数值型变量(例如1表示男性,2表示女性),以便后续分析。
5.数据分析:进行描述性统计,计算身高和体重的均值、标准差、最大值和最小值,了解数据的整体情况。
进行频率分析,计算性别的分布情况,并绘制柱状图展示。
进行相关分析,计算身高和体重之间的相关系数,了解二者之间的关系。
四、实验结果1.描述性统计:身高的均值为170.5cm,标准差为10.2cm,最大值为190cm,最小值为150cm;体重的均值为65kg,标准差为8.5kg,最大值为80kg,最小值为50kg。
2.频率分析:男性占样本的50%,女性占样本的50%。
柱状图展示了男女性别在样本中的分布情况。
3.相关分析:身高和体重之间的相关系数为0.8,表示二者有较强的正相关关系。
spss软件上机实训报告8页word

上机实训报告前言中国汽车行业现状中国车市异军突起,北汽控股收购萨博整车平台等技术、保时捷收购不成反被收购大众收购保时捷49.9%股份、长安与中航合并央企首例汽车业重组诞生长安跻身前三甲、中国汽车2009第1000万辆在一汽隆重下线、汽车振兴规划细则公布1.6升及以下排量减收购置税、吉利收购沃尔沃。
据中国汽车工业协会(下称“中汽协”)发布的数据显示,去年国内汽车销售了1364.48万辆,同比增幅46.15%,中国确定成为全球第一大汽车市场,将昔日霸主美国远远甩在身后,美国去年销量为1043万辆。
由于今年政府依然实施刺激汽车消费的购置税优惠、汽车下乡补贴等政策,国内车企普遍预测,2019年国内汽车销量增幅约为15%。
,根据主要汽车企业制订的最新产销计划和目标,2019年国内汽车销量有望达到1600万辆,接近美国金融危机爆发前的每年汽车销量。
其中,上汽预计今年销量可达300万辆,北汽预计为170万辆,广汽为72万辆,比亚迪为80万辆,华晨为45万辆,吉利为40万辆。
中汽协公布的数据称,2009年国内汽车销量1364.48万辆,同比增长46.15%。
其中乘用车销量为1033.13万辆,同比增长52.93%。
商用车销量331.35万辆,同比增长28.39%。
与2019年相比,不仅乘用车市场取得惊人增长,商用车也走出谷底。
2009年国内销量前十位的汽车公司分别是上汽、一汽、东风、长安、北汽、广汽、奇瑞、比亚迪、华晨和吉利,上述十家企业共销售汽车1189.33万辆,占汽车销售总量的87%。
一个易见的事实是,国内汽车市场上目前仍是在排队加价销售状态中。
实训概述一、实训目的(1)掌握SPSS中基本的数据处理方法;(2)学会使用SPSS进行单变量多选题次数分布表的制作,能以此方式独立完成相关作业。
二、实训要求1、已学习教材相关内容,理解数据整理中的统计计算问题;理解统计表和统计图的制作方法;已阅读本次实训指导书,了解SPSS中相关的统计命令。
spss统计学上机报告

一、用两种定义变量的方法绘制直方图某学院两个专业,各抽取24名学生,他们某门课考试成绩资料如下:甲专业乙专业成绩(分)学生数成绩(分)学生数60以下7 60-70 960-70 11 70-90 1270-90 6 90以上 3合计24 合计24方法1:SPSS操作步骤:⑴定义“成绩”、“学生数”和“专业”三个变量。
⑵在定义变量窗口对“专业”做变量值标签,令1=甲专业,2=乙专业。
⑶在录入数据窗口依次录入表中数据。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选学生数。
⑸选择分析下拉菜单中的描述统计子菜单,选择频率模块。
操作结果图如下:方法2:SPSS操作步骤:⑴定义“成绩”、“专业学生数”两个变量。
⑵在录入数据窗口依次录入表中数据。
⑶根据已存在的变量产生新变量。
选择转换下拉菜单中的计算变量,计算总人数。
总人数=甲专业学生数+乙专业学生数。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选总人数。
⑸选择分析下拉菜单中的描述统计子菜单,选择频率模块。
操作结果图如下:二、一个总体均值的区间估计和两个总体均值差的假设检验某学院两个专业,各抽取24名学生,他们某门课考试成绩资料如下:甲专业乙专业成绩(分)学生数成绩(分)学生数60以下7 60-70 960-70 11 70-90 1270-90 6 90以上 3合计24 合计241、以95%的概率保证程度推断该学院所有学生该门课考试成绩为多少?2、以95%的概率保证程度推断两个专业学生的平均成绩是否有显著性差异。
第一问SPSS操作步骤:⑴定义“成绩”、“专业学生数”两个变量。
⑵在录入数据窗口依次录入表中数据。
⑶根据已存在的变量产生新变量。
选择转换下拉菜单中的计算变量,计算总人数。
总人数=甲专业学生数+乙专业学生数。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选总人数。
⑸选择分析下拉菜单中的描述统计子菜单,选择探索模块。
操作结果图如下:分析:由题可知这是一个总体方差未知时均值的区间估计,由表可知所有学生的考试成绩的置信区间为(67.9428,74.7655),所以95%的把握认为该学院所有学生该门课考试成绩为(67.9428,74.7655)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验名称:频数分布实验目的和要求:绘制频数分布表、频数分布直方图并分析集中趋势指标、差异性指标和分布形状指标实验内容:绘制频数分布表和频数分布直方图并分析实验记录、问题处理:绘制频数分布表销售额频率百分比有效百分比累积百分比有效79.00 1 3.3 3.3 3.380.00 1 3.3 3.3 6.7 82.00 1 3.3 3.3 10.0 85.00 2 6.7 6.7 16.7 89.00 1 3.3 3.3 20.0 93.00 1 3.3 3.3 23.395.00 1 3.3 3.3 26.796.00 2 6.7 6.7 33.397.00 2 6.7 6.7 40.0 99.00 2 6.7 6.7 46.7 105.00 2 6.7 6.7 53.3 106.00 1 3.3 3.3 56.7 109.00 1 3.3 3.3 60.0 110.00 1 3.3 3.3 63.3 112.00 2 6.7 6.7 70.0 113.00 1 3.3 3.3 73.3 114.00 1 3.3 3.3 76.7 115.00 1 3.3 3.3 80.0 124.00 1 3.3 3.3 83.3 129.00 2 6.7 6.7 90.0 130.00 2 6.7 6.7 96.7 190.00 1 3.3 3.3 100.0 合计30 100.0 100.0频数分布直方图集中趋势指标、差异性指标和分布形状指标统计量销售额有效30N缺失0均值106.8333均值的标准误 3.97755中值105.0000众数85.00a标准差21.78592方差474.626偏度 1.915偏度的标准误.427峰度 6.297峰度的标准误.833全距111.00极小值79.00极大值190.00实验结果分析:从统计量表可以看出有效样本数有30个,没有缺失值。
平均销售额是106.8333,标准差为21.78592。
从频数分布表可以看出样本值、频数占总数的百分比、累计百分比。
从带正态曲线的直方图可以看出销售额集中在110实验名称:列联表成绩:实验目的和要求:绘制频数表、相对频数表并进行显著性检验和关系强度分析实验内容:绘制频数表、相对频数表并分析实验记录、问题处理:满意度* 性别交叉制表性别合计男性女性满意度不满意计数19 8 27 满意度中的 % 70.4% 29.6% 100.0% 性别中的 % 35.2% 17.4% 27.0%和3205.00 a. 存在多个众数。
显示最小值总数的 % 19.0% 8.0% 27.0%一般计数23 21 44 满意度中的 % 52.3% 47.7% 100.0% 性别中的 % 42.6% 45.7% 44.0% 总数的 % 23.0% 21.0% 44.0%满意计数12 17 29 满意度中的 % 41.4% 58.6% 100.0% 性别中的 % 22.2% 37.0% 29.0% 总数的 % 12.0% 17.0% 29.0%合计计数54 46 100 满意度中的 % 54.0% 46.0% 100.0% 性别中的 % 100.0% 100.0% 100.0% 总数的 % 54.0% 46.0% 100.0%卡方检验值df 渐进 Sig. (双侧)Pearson 卡方 4.825a 2 .090 似然比 4.931 2 .085 线性和线性组合 4.650 1 .031 有效案例中的 N 100a. 0 单元格(0.0%) 的期望计数少于 5。
最小期望计数为12.42。
对称度量值近似值 Sig.按标量标定φ.220 .090Cramer 的 V .220 .090有效案例中的 N 100a. 不假定零假设。
b. 使用渐进标准误差假定零假设。
实验结果分析:从卡方检验看出sig>0.05,不显著。
所以男生女生对满意与否评价没有差异实验名称:方差分析成绩:实验目的和要求:单因子方差分析、多因子方差和协方差分析实验内容:进行单因子方差分析并输出方差分析表、显著性检验及解释结果、多因子方差和协方差分析并输出方差分析表和协方差分析表、显著性检验及解释结果。
实验记录、问题处理:单因子方差分析分析——比较均值,单因素——键入销售额为因变量,键入促销力度为因子——两两比较打钩L检验,选项方差齐性检验打钩得:多因子方差分析分析——一般线性模型,单变量——键入店内促销和赠券状态为固定因子,销售额为因变量——两两比较打钩L检验,选项方差齐性检验协方差分析分析——一般线性模型,单变量——键入店内促销和赠券状态为固定因子,销售额为因变量,键入客源排序为协变量——两两比较打钩L 检验,选项方差齐性检验打钩,得:实验结果分析:单因子:组间显著性为0.000,小于0.05,显著影响。
多因子:店内促销和赠券状态显著性分别都为0.000,小于0.05,显著影响。
但是店内促销和赠券状态交互作用的显著性为0.206,大于0.05,不显著。
协方差:经协变量客源排序的显著性为0.363,对销售额影响不显著。
店内促销的显著性为0.000,小于0.05,对销售额影响显著。
赠券状态的显著性为0.000,小于0.05,对销售额影响显著。
店内促销和赠券状态的交互作用显著性为0.208,大于0.05,对销售额影响不显著实验名称:相关分析成绩:实验目的和要求:计算Pearson相关系数和简单相关系数并分析实验内容:计算Pearson相关系数和简单相关系数并分析实验记录、问题处理:分析——相关,双变量——添加收、家庭人口、受教育程度、汽车保有量——默认pearson分析——确定,得:实验结果分析:1、收入对受教育年数,相关系数为0.327,显著性为0.001,小于0.01,所以收入和受教育年为正向相关,且相关性很强。
2、收入对汽车保有量,相关系数为0.208,显著性为0.038,小于0.05,所以收入对汽车保有量为正向相关。
3、家庭人口对汽车保有量,相关系数为0.576,显著性为0.000,小于0.01,所以收入对汽车保有量为正向相关,且相关性很强。
4、受教育年数对收入,相关系数为0.327,显著性为0.001,小于0.01,所以受教育年数对收入为正想相关,且相关性很强。
实验名称:回归分析成绩:实验目的和要求:掌握简单回归模型和多元回归分析的SPSS操作方法实验内容:检验简单回归模型、绘制散点图、输出回归结果并分析、残差分析;检验多元回归分析模型、输出回归结果并分析及残差分析。
实验记录、问题处理:(一)简单回归模型汇总模型R R 方调整 R 方标准估计的误差1 .754a.569 .554 1.691a. 预测变量: (常量), 促销水平。
Anova a模型平方和df 均方 F Sig.1 回归105.800 1 105.800 36.999 .000b 残差80.067 28 2.860总计185.867 29a. 因变量: 月均销售额b. 预测变量: (常量), 促销水平。
系数a模型非标准化系数标准系数t Sig.B 标准误差试用版1(常量) 10.667 .817 13.059 .000促销水平-2.300 .378 -.754 -6.083 .000 a. 因变量: 月均销售额实验结果分析:R方为0.554,拟合优度一般。
P值sig显著表达式:销售额=10.667-2.3*促销水平(二)多元线性回归得:模型汇总模型R R 方调整 R 方标准估计的误差1 .754a.569 .554 1.6912 .925b.856 .846 .995a. 预测变量: (常量), 店内促销。
b. 预测变量: (常量), 店内促销, 赠券状态。
Anova a模型平方和df 均方 F Sig.1 回归105.800 1 105.800 36.999 .000b 残差80.067 28 2.860总计185.867 292 回归159.133 2 79.567 80.360 .000c 残差26.733 27 .990总计185.867 29a. 因变量: 销售额b. 预测变量: (常量), 店内促销。
c. 预测变量: (常量), 店内促销, 赠券状态。
系数a模型非标准化系数标准系数t Sig.B 标准误差试用版1(常量) 10.667 .817 13.059 .000店内促销-2.300 .378 -.754 -6.083 .0002 (常量) 14.667 .727 20.183 .000 店内促销-2.300 .222 -.754 -10.337 .000 赠券状态-2.667 .363 -.536 -7.339 .000a. 因变量: 销售额实验结果分析:R方在第二次拟合达到0.856,说明模型的拟合的情况非常好方差分析表显示P值sig<0.05,说明模型非常显著。
表达式:销售额=14.667-2.3*店内促销-2.667*赠券状态实验名称:Logistic回归成绩:实验目的和要求:掌握Logistic回归分析的SPSS操作方法实验内容:估计和检验Logistic回归系数并解释结果。
实验记录、问题处理:得出:分类表a已观测已预测品牌忠诚百分比校正0 1步骤 1 品牌忠诚0 12 3 80.01 3 12 80.0总计百分比80.0a. 切割值为 .500方程中的变量B S.E, Wals df Sig. Exp (B)步骤 1a品牌态度 1.274 .479 7.075 1 .008 3.575 产品态度.186 .322 .335 1 .563 1.205购物态度.590 .491 1.442 1 .230 1.804常量-8.642 3.346 6.672 1 .010 .000a. 在步骤 1 中输入的变量: 品牌态度, 产品态度, 购物态度.实验结果分析:结果显示:品牌忠诚=1.274*品牌态度+0.186*产品态度+0.590*购物态度-8.462 其中品牌态度的sig小于0.05,所以品牌态度与品牌购买正向变化显著。
但是因为产品态度和购物态度的sig大于0.05,所以这两个变量与品牌购买的正向变化不显著实验名称:因子分析成绩:实验目的和要求:掌握因子分析的SPSS操作方法实验内容:KMO 和Barlett 氏检验;输出碎石图及旋转前后的因子矩阵;各因子的特征值和解释的方差比例;解释因子并命名;计算因子得分。
实验记录、问题处理: 步骤处理:分析——降维——因子分析 将度量变量键入变量框,选取描述,勾选KMO 与bartlett 球形度检验 选取抽取,勾选碎石图 选取旋转,勾选载荷图选取得分,勾选保存变量和因子得分系数矩阵 如图所示:KMO 和 Bartlett 的检验取样足够度的 Kaiser-Meyer-Olkin 度量。