solr4.1+tomcat6.0集群
tomcat集群

用apache和tomcat搭建集群,实现负载均衡一、集群和负载均衡的概念(一)集群的概念集群(Cluster)是由两台或多台节点机(服务器)构成的一种松散耦合的计算节点集合,为用户提供网络服务或应用程序(包括数据库、Web服务和文件服务等)的单一客户视图,同时提供接近容错机的故障恢复能力。
集群系统一般通过两台或多台节点服务器系统通过相应的硬件及软件互连,每个群集节点都是运行其自己进程的独立服务器。
这些进程可以彼此通信,对网络客户机来说就像是形成了一个单一系统,协同起来向用户提供应用程序、系统资源和数据。
除了作为单一系统提供服务,集群系统还具有恢复服务器级故障的能力。
集群系统还可通过在集群中继续增加服务器的方式,从内部增加服务器的处理能力,并通过系统级的冗余提供固有的可靠性和可用性。
(二)集群的分类1、高性能计算科学集群:以解决复杂的科学计算问题为目的的IA集群系统。
是并行计算的基础,它可以不使用专门的由十至上万个独立处理器组成的并行超级计算机,而是采用通过高速连接来链接的一组1/2/4 CPU的IA服务器,并且在公共消息传递层上进行通信以运行并行应用程序。
这样的计算集群,其处理能力与真正超级并行机相等,并且具有优良的性价比。
2、负载均衡集群:负载均衡集群为企业需求提供更实用的系统。
该系统使各节点的负载流量可以在服务器集群中尽可能平均合理地分摊处理。
该负载需要均衡计算的应用程序处理端口负载或网络流量负载。
这样的系统非常适合于运行同一组应用程序的大量用户。
每个节点都可以处理一部分负载,并且可以在节点之间动态分配负载,以实现平衡。
对于网络流量也如此。
通常,网络服务器应用程序接受了大量入网流量,无法迅速处理,这就需要将流量发送给在其它节点。
负载均衡算法还可以根据每个节点不同的可用资源或网络的特殊环境来进行优化。
3、高可用性集群:为保证集群整体服务的高可用,考虑计算硬件和软件的容错性。
如果高可用性群集中的某个节点发生了故障,那么将由另外的节点代替它。
Tomcat、TongWeb5.0、TongWeb6.0部署solr

Tomcat、TongWeb5.0、TongWeb6.0部署solr将solr,solr-4.7.2复制到某⼀路径下,⽐如F盘根⽬录。
1、tomcat中进⾏配置,配置如下:<Context docBase="F:/solr" reloadable="true" ><Environment name="solr/home" type="ng.String" value="F:/solr-4.7.2/example/solr" override="true" /></Context>将tomcat启动,启动solr服务器,就可以进⾏索引创建及查询了。
2、东⽅通TongWeb5.0中进⾏配置。
配置如下:a、东⽅通安装⽬录下 **\TongWeb5.0\config\twns.xml 的<deployments></deployments>标签中间添加<web-app context-root="solr" name="solr" source-path="F:\solr" />b、solr主⽬录配置: F:\solr\WEB-INF\web.xml 中加⼊<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>F:\solr-4.7.2\example\solr</env-entry-value><env-entry-type>ng.String</env-entry-type></env-entry>3、东⽅通TongWeb6.0中进⾏配置,配置如下:a、把solr1\solr-4.7.2\dist\solr-4.7.2.war包复制到TongWeb6.0\autodeploy⽬录下b、在TongWeb6.0\bin\tongweb.xml⽂件⾥添加:<web-app name="solr-4.7.2" original-location="D:\TongWeb6.0\autodeploy\solr-4.7.2.war"location="${tongweb.app}\solr-4.7.2" context-root="/solr-4.7.2" vs-names="server" is-directory="false" enabled="true" description="autodeploy---solr-4.7.2.war" deploy-order="100" object-type="user" jsp- compile="false" dtd-validate="false" is-autodeploy="true" version="" retire-state="none" retire-strategy="nature" retire-timeout="0" version-serial-number="1"/>指定war位置和系统访问路径。
Solr搜索技术应用实战

Solr搜索技术应用实战Solr是一个开源的搜索平台,它基于Apache Lucene构建,提供丰富的API和可扩展性,已经成为了许多开发者选择的搜索引擎。
随着数据量的增加和业务场景的多样化,Solr的应用越来越广泛。
本文将从Solr的实战应用入手,为开发者提供一些技巧和经验。
一、Solr集群搭建Solr的性能和可靠性与硬件配置和部署状态密切相关。
在生产环境中建议使用集群部署,可以分布式处理查询请求,增加搜索并发能力和容错性。
Solr集群中每个节点可以作为独立的搜索服务器,提供相同的搜索服务。
一个完整的Solr集群由多个节点组成,分为SolrCloud和非SolrCloud两种模式,SolrCloud是集群管理的一种模式,在SolrCloud模式下,Solr 集群可以更方便地进行扩容和管理。
以下是SolrCloud集群的简要步骤:1. 准备ZooKeeper,SolrCloud使用ZooKeeper进行集群管理。
2. 启动Solr节点,并与ZooKeeper进行连接。
3. 使用Solr控制台创建集合,集合分片在所有节点之间平均分配。
4. 访问SolrCloud集群的URL,进行搜索等操作。
二、Solr数据导入Solr并不能直接从数据库或文件中获取数据,需要使用数据导入扩展来实现数据导入。
Solr数据导入流程大致如下:1. 配置数据源和数据目标,Solr支持多种数据源,包括数据库、文件、RSS等。
2. 配置数据导入的转换器和分词器,将数据源的数据转化为Solr需要的格式。
3. 配置数据导入的定时策略,Solr可以定时从数据源获取数据并导入。
以下是一个Solr数据导入的示例配置文件:```<dataConfig><dataSource name=\"jdbcDataSource\" type=\"JdbcDataSource\" driver=\"com.mysql.jdbc.Driver\"url=\"jdbc:mysql:\/\/localhost:3306\/test\" user=\"root\" password=\"123456\"\/><document><entity name=\"book\" query=\"SELECT * FROM book\"><field column=\"id\" name=\"id\"\/><field column=\"title\" name=\"title\"\/><field column=\"author\" name=\"author\"\/><field column=\"description\" name=\"description\"\/><\/entity><\/document><\/dataConfig>```以上配置会将MySQL数据库中的book表的所有数据导入Solr,并映射到Solr的id、title、author和description字段中。
服务器集群 方案

服务器集群方案服务器集群方案随着互联网的快速发展和信息技术的飞速进步,越来越多的企业和组织开始意识到服务器集群的重要性。
服务器集群是将多台服务器组合在一起,形成一个高可用、高性能的系统,能够满足用户对于稳定性和响应速度的要求。
本文将介绍服务器集群的基本概念、设计原则以及常见的方案。
1. 什么是服务器集群服务器集群是指将多台服务器连接在一起,通过负载均衡、容错技术和数据同步等手段实现高可用性的系统架构。
集群中的每台服务器被称为节点,节点之间通过网络互相通信、共享资源和负载均衡,从而提高系统的整体性能和可靠性。
2. 设计原则在设计服务器集群方案时,需要考虑以下几个原则:2.1 可用性服务器集群的主要目标之一是提供高可用的服务。
为了实现这一点,可以通过增加冗余节点、设置冗余备份系统、使用容错技术等手段来降低系统出错的概率。
当集群中的某个节点发生故障时,其他节点可以接替其工作,保证服务的连续性。
2.2 扩展性随着业务的不断扩张,服务器集群需要能够方便地扩展。
可以采取水平扩展(增加节点)或垂直扩展(增加服务器的计算能力和存储容量)的方式来满足业务的需求。
2.3 性能服务器集群需要能够为用户提供高性能的服务。
可以利用负载均衡技术将用户请求分发到不同的节点上,避免单个节点过载,从而提高系统的并发处理能力和响应速度。
2.4 数据一致性在服务器集群中,数据一致性是一个重要的考虑因素。
为了保证各节点上的数据一致性,可以采用数据复制和同步技术,保持数据的实时更新和互相备份。
3. 常见的服务器集群方案根据不同的业务需求和技术要求,可以选择不同的服务器集群方案。
以下是几种常见的方案:3.1 负载均衡集群负载均衡集群是最常见的服务器集群方案之一。
它通过在集群中设置负载均衡器,将用户请求分发到不同的节点上,实现请求的分流和负载均衡。
常见的负载均衡算法有轮询、最少连接和IP散列等。
负载均衡集群能够提高系统的并发处理能力和响应速度,提高用户的访问体验。
服务器集群解决方案

服务器集群解决方案随着互联网的迅猛发展,以及企业对大数据、高性能计算、云计算等需求的增加,服务器的稳定性和性能已成为企业重要的关注点。
为了解决这些问题,越来越多的企业开始采用服务器集群解决方案。
服务器集群是由多台服务器组成的一个网络系统,旨在提高网络服务的可靠性、可扩展性和性能。
它通过将工作负载分配到多台服务器上,从而实现负载均衡,增加服务器的容错能力。
服务器集群解决方案可以根据需求的不同而采用不同的架构,下面是一些常见的服务器集群解决方案:1. 高可用性集群:这种解决方案采用双机热备模式,主服务器负责处理用户请求,而备用服务器将监控主服务器的状态。
一旦主服务器发生故障,备用服务器会立即接管请求,以保持服务的连续性。
这种集群方案对于对服务可用性要求高的企业非常适用。
2. 负载均衡集群:这种解决方案通过将用户请求均匀地分布到集群中的多台服务器上,以最大程度地提高整个系统的处理能力和性能。
常见的负载均衡技术包括基于DNS的负载均衡、反向代理负载均衡和应用层负载均衡等。
3. 分布式集群:分布式集群是一种将大型计算任务分解成多个小任务,分配给多台服务器并行处理的解决方案。
这种集群方案可以大大提高计算速度和数据处理能力,特别适用于大数据分析和科学计算等领域。
4. 数据库集群:这种解决方案通过将数据库分布到多台服务器上,实现数据的复制和同步,从而提高数据库的可用性和性能。
常见的数据库集群技术包括主从复制、主主复制和数据库分片等。
5. 容器集群:容器集群是一种将应用程序打包成独立的容器,并在多台服务器上运行的解决方案。
容器集群可以实现快速部署、弹性扩展和资源隔离等功能,提供灵活而高效的应用程序管理方式。
以上只是一些常见的服务器集群解决方案,实际上还有很多其他的解决方案,可以根据企业的需求和预算来选择适合自己的方案。
无论选择哪种方案,企业都应该注意以下几点:首先,选择高性能和可靠性好的服务器硬件。
服务器硬件的稳定性和性能对整个集群的效果至关重要。
linux下配置tomcat集群的负载均衡

linux下配置tomcat集群的负载均衡一、首先了解下与集群相关的几个概念集群:集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台。
在客户端看来,一个集群就象是一个服务实体,但事实上集群由一组服务实体组成。
与单一服务实体相比较,集群提供了以下两个关键特性:·可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。
·高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。
在集群中,同样的服务可以由多个服务实体提供。
如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。
集群提供的从一个出错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。
为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力:·负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
·错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。
这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。
集群分类:Linux集群主要分成三大类( 高可用集群,负载均衡集群,科学计算集群)高可用集群( High Availability Cluster)常见的就是2个节点做成的HA集群,有很多通俗的不科学的名称,比如"双机热备", "双机互备", "双机".高可用集群解决的是保障用户的应用程序持续对外提供服务的能力。
(请注意高可用集群既不是用来保护业务数据的,保护的是用户的业务程序对外不间断提供服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度)。
Solr集群配置方案说明书

Solr集群配置方案说明书Solr集群配置方案说明书Jboss应用服务器由于版本不同,集群配置方式也不同,由于目前我们采用jboss7做为应用服务器,因此solr的服务集群方式采用jboss7的集群配置。
我们采用jboss+apache集群方式。
1.Jboss7+apache集群1.1Jboss主从服务器设置:1)下载jboss7解压后找到打开目录,找到domain/configuration/host.xml文件,如图所示:2)编辑host.xml,如果是主服务器的话,如同所示:将后面的ip改为当前机器的ip.3)从服务器的设置方式,除上述方式外,需要增加主控服务器的ip 配置,如图所示4)在配置好主从服务器的ip后,需要设置安全策略,我们增加几个用户,做主从访问控制,进入cmd模式,进入jboss安装目录下的bin目录键入add-uer命令,一个是主服务器用户名和密码,一个是从服务器用户和密码。
如下图所示:5)配好用户后我们也要将用户名策略加入到从应用服务器主控制配置中:注:value的值是base64加密1.2apache相关的配置1)编辑domain.xml,增加下面内容2)增加端口设置3)Apache配置建议采用mod_jk,配置方式跟tomcat相同.2.Solr集群配置2.1solr分发设置solr分布式部署的原理与jboss相同都是采用主从结构,下面介绍主从服务1)主服务器配置修改下面部分:注:replicateAfter : SOLR会自行在以下操作行为发生后执行复制:'commit', 'startup' 'optimize',这里我们选择commit , 即SOLR每一次接受到commit请求后,会执行复制策略。
confFiles : 待分发的配置文件,solr 也会将主服务器上的字段配置文件:schema.xml和stopwords.txt,固排文件:elevate.xml同步到辅服务器上。
solr集群搭建

solrcloud集群搭建1什么是SolrCloud1.1什么是SolrCloudSolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用SolrCloud。
当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。
1.2SolrCloud结构SolrCloud为了降低单机的处理压力,需要由多台服务器共同来完成索引和搜索任务。
实现的思路是将索引数据进行Shard(分片)拆分,每个分片由多台的服务器共同完成,当一个索引或搜索请求过来时会分别从不同的Shard的服务器中操作索引。
SolrCloud需要Solr基于Zookeeper部署,Zookeeper是一个集群管理软件,由于SolrCloud 需要由多台服务器组成,由zookeeper来进行协调管理。
下图是一个SolrCloud应用的例子:对上图进行图解,如下:1.2.1物理结构三个Solr实例(每个实例包括两个Core),组成一个SolrCloud。
1.2.2逻辑结构索引集合包括两个Shard(shard1和shard2),shard1和shard2分别由三个Core组成,其中一个Leader两个Replication,Leader是由zookeeper选举产生,zookeeper控制每个shard 上三个Core的索引数据一致,解决高可用问题。
用户发起索引请求分别从shard1和shard2上获取,解决高并发问题。
1.2.2.1c ollectionCollection在SolrCloud集群中是一个逻辑意义上的完整的索引结构。
它常常被划分为一个或多个Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个collection。
collection=shard1+shard2+....+shardX1.2.2.2C ore每个Core是Solr中一个独立运行单位,提供索引和搜索服务。
tomcat集群 - 群猫乱舞
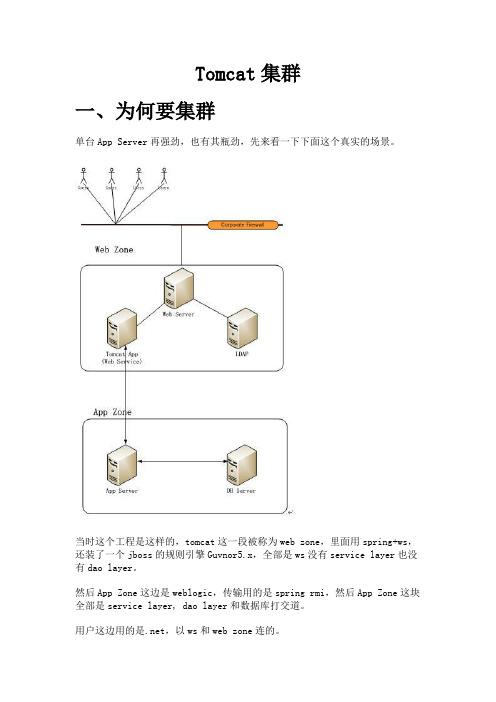
Tomcat集群一、为何要集群单台App Server再强劲,也有其瓶劲,先来看一下下面这个真实的场景。
当时这个工程是这样的,tomcat这一段被称为web zone,里面用spring+ws,还装了一个jboss的规则引擎Guvnor5.x,全部是ws没有service layer也没有dao layer。
然后App Zone这边是weblogic,传输用的是spring rmi,然后App Zone这块全部是service layer, dao layer和数据库打交道。
用户这边用的是.net,以ws和web zone连的。
时间一长,数据一多,就出问题了。
拿Loader Runner跑下来,发觉是Web Zone这块,App Server已经被用到极限了。
因为客户钱不多,所以当时的Web Zone是2台服务器,且都是32位的,内存不少,有8GB,测试下来后发觉cpu loader又不高,但是web server这边的吞吐量始终上不去,且和.net客户端那边响应越来越慢。
分析了一下原因:单台tomcat能够承受的最大负载已经到头了,单台tomcat 的吞吐量就这么点,还要负担Guvnor的运行,Guvnor内有数百条业务规则要执行。
再看了一下其它方面的代码、SQL调优都已经到了极限了,所以最后没办法,客户又不肯拿钱投在内存和新机器上或者是再买台Weblogic,只能取舍一下,搞Tomcat集群了。
二、集群分类Tomcat作集群的逻辑架构是上面这样的一张图,关键是我们的production环境还需要规划好我们的物理架构。
2.1 横向集群比如说,有两台Tomcat,分别运行在2台物理机上,好处是最大的即CPU扩展,内存也扩展了,处理能力也扩展了。
2.2 纵向集群即,两个Tomcat的实例运行在一台物理器上,充分利用原有内存,CPU未得到扩展。
2.3 横向还是纵向一般来说,广为人们接受的是横向扩展的集群,可做大规模集群布署。
Tomcat6集群和负载均衡

实现Apache,Tomcat集群和负载均衡背景介绍参考Apache tomcat文档:Clustering/Session Replication HOW-TO 1.1 术语定义服务软体是b/s或c/s结构的s部分,是为b或c提供服务的服务性软件系统。
服务硬体指提供计算服务的硬件、比如pc机、pc服务器。
服务实体通指服务软体和服务硬体。
客户端指接受服务实体服务的软件或硬件。
1.2 两大关键特性集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台。
在客户端看来,一个集群就象是一个服务实体,但事实上集群由一组服务实体组成。
与单一服务实体相比较,集群提供了以下两个关键特性:可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。
高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。
在集群中,同样的服务可以由多个服务实体提供。
如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。
集群提供的从一个出错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。
1.3 两大能力为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力:负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。
错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。
这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。
负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。
1.4 两大技术实现集群务必要有以下两大技术:集群地址--集群由多个服务实体组成,集群客户端通过访问集群的集群地址获取集群内部各服务实体的功能。
具有单一集群地址(也叫单一映像)是集群的一个基本特征。
部署高可用 Tomcat 集群

部署高可用 Tomcat 集群随着互联网应用的不断增多,单个服务器往往难以承受高并发访问的压力,因此采用集群的方式进行部署成为一种常见的解决方案。
Tomcat作为JAVA的应用服务器,也适用于集群的部署。
本文将介绍如何部署高可用Tomcat集群。
一、负载均衡器的选择在部署Tomcat集群之前,我们需要选择一款负载均衡器。
负载均衡器可以将客户端的请求分发到不同的服务器上,从而实现负载均衡。
目前比较常见的负载均衡器有Nginx、HAProxy和Apache等。
在选择负载均衡器时,需要考虑以下因素:1. 功能和性能:负载均衡器需要支持HTTP和HTTPS协议,并能够处理高并发请求。
2. 配置的难易程度:负载均衡器的配置文件需要考虑到性能和使用方便之间的平衡。
3. 社区支持和文档资料:负载均衡器的使用需要有足够的社区支持和文档资料。
综合考虑,我们选择Nginx作为负载均衡器。
二、Tomcat集群节点的设置在设置Tomcat集群节点之前,需要先确定采用的集群方式。
Tomcat集群可以采用共享存储方式或互相同步的方式。
共享存储方式:采用共享存储方式的Tomcat集群将共享同一份资源,包括代码、配置文件和缓存等。
当其中一个节点收到请求时,它将先查询本地缓存,如果不存在则从共享文件系统中读取数据。
互相同步的方式:采用互相同步的方式的Tomcat集群则每个节点都保留一份相同的资源,当其中一个节点更新相应的资源时,其他节点也会同步更新。
在本文中,我们将采用互相同步的方式。
为了实现互相同步,我们需要进行如下配置:1. 安装rsync在每个节点上都需要安装rsync,可以使用yum或apt-get等包管理器安装。
2. 创建Tomcat用户创建一个以Tomcat命名的用户,并赋予其Tomcat所在目录的读写执行权限。
3. 配置rsync在每个节点上都需要配置rsync,使其能够同步Tomcat的配置文件、程序文件和文件夹等。
IIS6.0+tomcat6.0+JK整合(8080端口和80端口共用jsp网站)

经过这么久IIS和tomcat整合实践,积累了部分经验。
从一开始整合项目需要放到tomcat的webapps下面,而且必须需要tomcat里面ROOT的index.html 的跳转;到现在的可以把项目放在服务器的任何地方上,而也不需要index.html,只需要项目本身的index.jsp就能够进行访问。
总的来说,还是有一定提高。
现将IIS6.0和tomcat6.0的完美整合整理如下:一、整合环境:Windows Service 2003、JDK1.60、IIS7.0 和tomcat6.0二、使用技术:IIS6.0和TOMCAT6.0的默认端口不用改变,使用原有的80和8080即可,采用isapi_redirect-1.2.27.dll文件作为iis和tomcat的接口,使用就能访问tomcat中的jsp网站。
三、操作步骤说明:我的项目是放在E盘下,名字为zhdr,我的域名 是和服务器绑定的,在外网上输入:8080是可以访问到网站的,输入:8080/zhdr是可以访问网站的。
1、下载isapi_redirect-版本号.dll文件作为IIS与TOMCAT的接口,我下载的是isapi_redirect-1.2.27.dll,然后将文件放在${TOMCAT_HOME}/conf下。
2、使用记事本建立如下.reg文件,保存并执行:Windows Registry Editor Version 5.00[HKEY_LOCAL_MACHINE\SOFTWARE\Apache Software Foundation\Jakarta Isapi Redirector\1.0]"log_file"="e://Program Files//Apache Software Foundation//Tomcat 6.0//logs""log_level"="info""worker_file"="e://Program Files//Apache Software Foundation//Tomcat 6.0//conf//workers.properties""worker_mount_file"="e://Program Files//Apache Software Foundation//Tomcat 6.0//conf//uriworkermap.properties""extension_uri"="/jakarta/isapi_redirect-1.2.27.dll"注意修改与tomcat相关的路径,一定要设置成为自己tomcat的路径。
tomcat集群配置

Apache Tomcat 集群配置∙Page restrictions apply∙Attachments:1∙Added by 汤超, last edited by 武翔on Aug 26, 2010 (view change)Apche /dist/httpd/binaries/win32/httpd-2.2.15-win32-x86-no_ssl.msi mod_jk/tomcat/tomcat-connectors/jk/binaries/win32/mod_jk-1.2.30-httpd-2.2.3.soapache-tomcat-5.5.23.zip /download-55.cgi下载配置及实例source我的程序分别安装到D:\webserver\ Apache Software Foundation\Apache2D:\webserver\TomcatCluster\tomcat1D:\webserver\TomcatCluster\tomcat2Apache安装完后,在右下角状态栏中可以看到Apache Service Monitor 可以控制Apache的状态。
验证Apache是否安装成功,可以访问http://localhost如果能看到Apache的预制页面显示“It works!”,说明安装成功,如果不行,可以访问http://localhost:8080试试(可能因为80端口已被占用,可以修改Apache 的配置文件httpd.conf, 修改为:Listen 8080 )1. 找到Apache安装目录下conf目录中的httpd.conf文件。
在文件最后添加一句:2.include "D:\webserver\Apache Group\Apache2\conf\mod_jk.conf"3. 在conf目录中新建文件mod_jk.conf并添加下面的内容:4.#加载mod_jk Module5.LoadModule jk_module modules/mod_jk-1.2.30-httpd-2.2.3.so6.#指定 workers.properties文件路径7.JkWorkersFile conf/workers.properties8.#指定哪些请求交给tomcat处理,"controller"为在workers.propertise里指定的负载分配控制器名9.JkMount /*.jsp controller10. 在conf目录下新建workers.properties文件并添加如下内容:(PS: AJP13是Apache JServ Protocol version 1.3)11.#server12.worker.list = controller13.#========tomcat1========14.worker.tomcat1.port=1100915.worker.tomcat1.host=localhost16.worker.tomcat1.type=ajp1317.worker.tomcat1.lbfactor = 118.#========tomcat2========19.worker.tomcat2.port=1200920.worker.tomcat2.host=localhost21.worker.tomcat2.type=ajp1322.worker.tomcat2.lbfactor = 123.24.#========controller,负载均衡控制器========25.worker.controller.type=lb26.worker.controller.balanced_workers=tomcat1,tomcat227.worker.controller.sticky_session=128. 将mod_jk-1.2.30-httpd-2.2.3.so 复制到Apache的modules目录中。
Tomcat集群配置详解

Tomcat集群配置详解在单一的服务器上执行WEB应用程序有一些重大的问题,当网站成功建成并开始接受大量请求时,单一服务器终究无法满足需要处理的负荷量,所以就有点显得有点力不从心了。
另外一个常见的问题是会产生单点故障,如果该服务器坏掉,那么网站就立刻无法运作了。
不论是因为要有较佳的扩充性还是容错能力,我们都会想在一台以上的服务器计算机上执行WEB应用程序。
所以,这时候我们就需要用到集群这一门技术了。
一、准备文件完全按照以下版本配置,至于最新版本是否可以还需要验证。
1、Apache :apache_2.2.8-win32-x86-no_ssl.msi2、JDK:jdk1.8.0_113、Tomcat:Tomcat 6.0.14 (两个)4、mod_jk-1.2.31-httpd-2.2.3.so全部安装好后,配置好JDK和Tomcat的环境变量,这个略过不讲。
二、配置Apache1、修改httpd.conf我的Apache安装在D:\Program Files\Apache Software Foundation\Apache2. 2,找到conf目录下的httpd.conf,在文件的最后一行添加include "D:\Program Files\Apache Software Foundation\Apache2.2\conf\mod _jk.conf"注意把D修改为自己的安装盘符。
2、新建mod_jk.conf文件新建mod_jk.conf文件,内容如下:没错只有这几行LoadModule jk_module modules/mod_jk-1.2.31-httpd-2.2.3.soJkWorkersFile conf/workers.properties#指定那些请求交给tomcat处理,"controller"为在workers.propertise里指定的负载分配控制器名JkMount /*.jsp controller3、将下载的JK插件mod_jk-1.2.31-httpd-2.2.3.so复制到Apache安装目录的modules目录下。
oracle在tomcat中配置数据源

Tomcat6.0 连接池的配置1.本人当前使用的Tomcat版本为:6.0.20,oracle为稳定的9i版本2.下文为方便起见,依习惯以%Tomcat_Home%表示Tomcat安装的目录,本人安装目录为“E:\Progr am Files\WindowsXP\tomcat6”配置步骤如下:1.Tomcat 6的配置和以前的不同了,不推荐在server.xml中进行配置,而是在%Tomcat_Home%\ webapps\yourApp\META-INF \context.xml中进行配置才是更好的方法。
而不是以前版本%Tomcat _Home%\conf下的context.xml文件。
这样就可以在不同的web应用下单独配置连接池了,且Tomc at会自动重载。
当然你也可以更改%Tomcat_Home%\conf下的context.xml文件,将所有web应用下的连接池进行统一配置。
2.将代码修改如下:view plaincopy to clipboardprint?<Context reloadable="true"><WatchedResource>WEB-INF/web.xml</WatchedResource><Resource name="jdbc/oracleds" auth="Container" type="javax.sql.DataSource"maxActive="100"maxIdle="30"maxWait="10000"username="scott"password="tiger"driverClassName="oracle.jdbc.driver.OracleDriver"url="jdbc:oracle:thin:@localhost:1521:ora9"/></Context><Context reloadable="true"><WatchedResource>WEB-INF/web.xml</WatchedResource><Resource name="jdbc/oracleds" auth="Container" type="javax.sql.DataSource"maxActive="100"maxIdle="30"maxWait="10000"username="scott"password="tiger"driverClassName="oracle.jdbc.driver.OracleDriver"url="jdbc:oracle:thin:@localhost:1521:ora9"/></Context>name 为当前数据源JNDI的名字,可以随意设定;auth 为验证方式;type 资源类型;driverClassName 为Oracle驱动引用;maxActiv 为连接池最大激活的连接数,设为0表示无限制;maxIdle 为连接池最大空闲的连接数,数据库连接的最大空闲时间。
服务器集群部署方案

服务器集群部署方案引言随着互联网的迅猛发展,现代企业对于服务器的需求越来越大。
为了处理大量的用户请求并保证系统的高可用性,服务器集群成为了一个必不可少的解决方案。
本文将介绍一种常见的服务器集群部署方案,并提供一些建议和最佳实践。
1. 架构设计服务器集群的架构设计是非常关键的,它直接决定了系统的稳定性和扩展性。
在设计过程中,应该考虑以下几个方面:1.1. 负载均衡为了平衡各个服务器的负载,我们可以引入负载均衡器。
负载均衡器可以根据预先定义的算法,将请求分发到不同的服务器上,以达到负载均衡的目标。
常见的负载均衡算法有轮询、最少连接和源IP哈希等。
1.2. 高可用性为了确保系统的高可用性,我们可以引入冗余服务器。
当某一台服务器发生故障时,其他服务器可以接管它的工作,保证服务的连续性。
冗余服务器可以采用主备模式或者多主模式。
1.3. 数据同步当多个服务器共同处理业务时,数据的同步是一个重要的问题。
我们可以选择使用数据库集群,如MySQL主从复制或者多主复制,来实现数据的同步。
2. 服务器选型在选择服务器时,我们需要考虑以下几个方面:2.1. 性能不同的业务对服务器的性能要求不同。
在选择服务器时,需要根据业务的具体需求,选择具有足够性能的服务器。
2.2. 可靠性服务器的可靠性直接影响到系统的稳定性。
在选择服务器时,应该选择可靠性较高的品牌和型号。
2.3. 扩展性随着业务的发展,服务器的扩展性也是一个重要的考虑因素。
选择支持灵活扩展的服务器,可以方便地进行系统升级和扩展。
3. 部署流程服务器集群的部署流程包括以下几个步骤:3.1. 系统安装和配置首先,需要在每台服务器上安装操作系统,并进行基本的系统配置。
例如,调整网络配置、设置主机名和配置防火墙等。
3.2. 软件安装安装集群软件,如Nginx、MySQL等。
根据实际情况,选择合适的软件版本,并进行配置。
3.3. 配置负载均衡器根据实际需求,选择并安装合适的负载均衡器。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Lucene&&Solr
一、Lucene是一个由Java实现的成熟、自由、开源的信息检索软件包,通过Lucene你可以为应用程序添加索引和搜索功能。
最新的版本是lucene-4.1.0。
应用实例:
索引过程的核心类:
IndexWriter:用于创建一个新的索引,并把文档加到已有的索引中去,也就是说它是一个可以对索引进行写操作,不能用于读取和搜索操作的一个对象。
有FSDirectory和RAMDirectory,具体用法:StandardAnalyzer()是一个解析器
IndexWriter writer = new IndexWriter(FSDirectory.getDirectory(path,
Analyzer:解析器(分析器),负责将要被索引的文本文件中提取词汇单元,并提出剩下的无用信息
Document:可以理解为一个虚拟的文档,比如web页面,或是一个数据库中的表
Field:可理解为:上述数据库表中的一条数据
注意:这里有个方法在lucene4.1.0中不可使用了:
doc.add(Field.Text("contents", new FileReader(f)));
可以用
doc1.add(new Field("name", "lighter springside com", Field.Store.YES, Field.Index.TOKENIZED));
搜索过程核心类:
IndexSearcher:用于搜索IndexWriter类所创建的索引。
可以看作是一个以只读方式打开索引的类。
Term:用于搜索的一个基本单元,如同域对象一样。
Query:查询类
TermQuery:最基本的查询类型
Hits:相当于查询结果(放的是查询结果的指针)
Solr是基于Lucene的搜索服务器。
/apache/lucene/solr/4.1.0
下载最新的solr-4.1.0,完成后在example中有start.jar文件,双击后,打开浏览器(IE不行,有bug)ff,输入:http://localhost:8983/solr
在Solr和Lucene中,使用一个或多个Document来创建索引,一个Document包括一个或多个Field。
Field包括名称、内容以及告诉Solr如何处理内容的元数据。
Solr通过向部署在Servlet容器中的Web应用程序发送Http请求来启动索引和搜索。
Solr接收请求,确定要使用的适当的SolrRequestHandler,然后处理请求。
后通过Http方式返回响应。
默认是返回XML、响应,也可以配置格式,如:Json
Add/update允许向Solr添加文档或更新文档。
知道提交后才讷讷感搜索到这些添加和更新
Commit告诉Solr,应该使上次提交以来所做的所有更新都可以被搜索到
Optimize重构lucene文件以改进搜索性能
Delete可以通过id或查询来指定
添加索引,之后点击ff中collection1下面的query,看到搜索页面:在query中的q填写你刚添加的xhb,可以得到:
添加索引也可以直接添加对象:
进行如上查询也可以查到。
可以在ff中的fireBug中看到http请求和返回xml的详细内容。
二、Solr4.1.0+Tomcat6.0配置集群
下载包(不再赘述)
1、将solr-4.1.0包中dist目录下的solr-4.1.0.war放到tomcat的webapps下,启动tomcat,会报错说加载不到solrConfig.xml文件。
2、手动删除上述war文件,会发现在tomcat的webapps下多了一个solr4.1.0文件夹,将它改名为solr,在该文件夹下建一个solrhome文件夹。
文件结构:
3、在solrhome下建立solr文件夹,将solr4.1.0包example中的solr目录复制到该solr下。
5、单个节点配置完成。
6、接第五步,无误后即可进行集群的配置
7、以我主机为例:
在F盘下
其中mem.xml和post.jar都在solr-4.1.0\example\exampledocs文件夹下可以找到,直接copy。
同时修改tomcat端口,
cluster-m(tomat): 8008
cluster-s1(tomcat): 7070
cluster-s2(tomcat): 6006
cluster-s3(tomcat): 5005
要注意的是不仅connection的端口要改,server端口也要改。
cmd命令下netstat -an查看端口占用情况
8、进入F:\clusters\cluster_m\webapps\solr\solrhome\solr下对solr.xml文件进行配
其中的host为本机localhost,hostPort为集群中节点对应的端口,注意dataDir属性,这里专门设置一个cluster_data目录存放集群的zoo-data(临时文件),index等数据等。
9、依次配置其他三个节点。