基于改进线图分析算法的浅层汉语句法分析器的设计与实现
基于改进线图分析算法的浅层汉语句法分析器的设计与实现

第2 4卷 第 9期
2 0 年 9月 07
计 算 机 应 用 研 究
Ap l a in Re e r h o mp tr p i t s a c fCo u e s c o
Vo . 4 No 9 12 . S p .2 0 et 0 7
基 于改 进 线 图分 析 算 法 的浅层 汉 语 句 法 分 析 器 的设 计 与 实现 术
吴江 宁 ,朱 国华
( 大连 理 工大 学 系统 工程研 究所 ,辽 宁 大连 1 6 2 ) 10 4
摘
要 :针 对传 统 的汉语 句法分析 算法进 行改进 , 用 了 自 向上与 自顶 向下相 结合 的线 图分 析方 法 , 采 底 分析 、 设
A bsr c : Ba e n t r dto a ha tag rtm ,t i p rp o os d a mpr v i e e s ntxpa sn lo tm ,whih ta t s d o heta iin lc r l o i h hspa e r p e n i o ed Ch n s y a ri ga g r h i c
c mb n d b t m D a d t p d w t tge r e n a c h f ce c n ep e iin o e C i e e s n a t n l- o ie o t u n o n sr e isi o d rt e h n e t eef in y a d t rc s f h h n s y tc i a ay o o a n o i h o t c ss t a o o e ftr eman mo u e ,te r o d s g n a in mo ue b s d o h x i m o d ln t th n i.I w sc mp s do e i d ls h ywe ew r e me tt d l a e n t ema mu w r - g h mac ig h o e a g rtm ,p r o p e h tg i gmo u e b s d o t t t a t o ftan n fr lt e ̄ q e c ,a d t e s n a a sn lo h i a t fs e c a gn d l a e n sai i lmeh d o ri i g o eai sc v e u n y n h y t p r ig x mo u eb s d o h mp o e h r a a y i ag rtn .A ma l i h n s op s w s u e o v ia e t e ef in y a d d l a e n te i r v d c at n l s lo i a s h s l sz C ie e c r u a s d t a d t h f c e c n — e l i fa ii t fte i r v d a g r h e s lyo bi h mp o e o i m. l t Ke r s txu r c s ig C i e e s na t n l s ; c a t l o i m; s n a a s r y tx sr c u e y wo d : e ta p o e sn ; h n s y tc i a a y i l c s h r ag r h t y tx p r e ;s na t t r u
算法设计与分析(第2版)-王红梅-胡明-习题答案(1)

算法设计与分析(第2版)-王红梅-胡明-习题答案习题11. 图论诞生于七桥问题。
出生于瑞士的伟大数学家欧拉(Leonhard Euler ,1707—1783)提出并解决了该问题。
七桥问题是这样描述的:一个人是否能在一次步行中穿越哥尼斯堡(现在叫加里宁格勒,在波罗的海南岸)城中全部的七座桥后回到起点,且每座桥只经过一次,图 1.7是这条河以及河上的两个岛和七座桥的草图。
请将该问题的数据模型抽象出来,并判断此问题是否有解。
七桥问题属于一笔画问题。
输入:一个起点输出:相同的点1, 一次步行2, 经过七座桥,且每次只经历过一次3, 回到起点该问题无解:能一笔画的图形只有两类:一类是所有的点都是偶点。
另一类是只有二个奇点的图形。
2.在欧几里德提出的欧几里德算法中(即最初的欧几里德算法)用的不是除法而是减法。
请用伪代码描述这个版本的欧几里德算法1.r=m-n2.循环直到r=02.1 m=n图1.7 七桥问题2.2 n=r2.3 r=m-n3 输出m3.设计算法求数组中相差最小的两个元素(称为最接近数)的差。
要求分别给出伪代码和C++描述。
//采用分治法//对数组先进行快速排序//在依次比较相邻的差#include <iostream>using namespace std;int partions(int b[],int low,int high){int prvotkey=b[low];b[0]=b[low];while (low<high){while (low<high&&b[high]>=prvotkey)--high;b[low]=b[high];while (low<high&&b[low]<=prvotkey)++low;b[high]=b[low];}b[low]=b[0];return low;}void qsort(int l[],int low,int high){int prvotloc;if(low<high){prvotloc=partions(l,low,high); //将第一次排序的结果作为枢轴qsort(l,low,prvotloc-1); //递归调用排序由low 到prvotloc-1qsort(l,prvotloc+1,high); //递归调用排序由 prvotloc+1到 high}}void quicksort(int l[],int n){qsort(l,1,n); //第一个作为枢轴,从第一个排到第n个}int main(){int a[11]={0,2,32,43,23,45,36,57,14,27,39};int value=0;//将最小差的值赋值给valuefor (int b=1;b<11;b++)cout<<a[b]<<' ';cout<<endl;quicksort(a,11);for(int i=0;i!=9;++i){if( (a[i+1]-a[i])<=(a[i+2]-a[i+1]) )value=a[i+1]-a[i];elsevalue=a[i+2]-a[i+1];}cout<<value<<endl;return 0;}4.设数组a[n]中的元素均不相等,设计算法找出a[n]中一个既不是最大也不是最小的元素,并说明最坏情况下的比较次数。
中文信息处理与挖掘知到章节答案智慧树2023年山东交通学院

中文信息处理与挖掘知到章节测试答案智慧树2023年最新山东交通学院第一章测试1.本课程将详细介绍的自然语言处理应用有哪些()。
参考答案:自动问答;情感分析;机器翻译;自动摘要2.下列那个概念与自然语言处理无关。
()参考答案:Computer Vision3.黏着型语言比较有代表性的语言是日语。
()参考答案:对4.自然语言中最小的有意义的构成单位是()。
参考答案:词5.中文信息处理的第一步是()。
参考答案:分词6.如果打开校正功能,对于一些典型的语法错误、拼写错误以及用词错误就可以自动检测出来。
( )参考答案:对7.就分词来讲,主要有三类分词方法()。
参考答案:基于规则的分词方法;基于词典的分词方法;基于统计的分词方法8.基于词典的分词方法从匹配的方法来讲,一般使用最大匹配法,而最匹配法又包括()。
参考答案:逆向最大匹配算法;双向最大匹配算法;正向最大匹配算法9.词性标注的主要方法主要有()。
参考答案:统计与规则相结合的词性标注方法;基于规则的词性标注方法;基于统计的词性标注方法10.命名实体识别事实上就是识别出以下三类命名实体。
()参考答案:人名;组织机构名;地名第二章测试1.概率论作为统计语言模型的数学基础,应用到自然语言处理领域,是由于:统计语言处理技术已经成为自然语言处理的主流,而在统计语言处理的步骤中,收集自然语言词汇(或者其他语言单位)的分布情况、根据这些分布情况进行统计推导都需要用到概率论。
()参考答案:对2.设E为随机试验,Ω是它的样本空间,对于E的每一个事件A赋予一个实数,记为P ( A ),如果集合函数P ( ⋅ )满足下列哪些条件,则实数P ( A )为事件A的概率。
()参考答案:规范性;非负性;可列可加性3.设A、B是两个事件,且P(B)>0,则称P(A|B)为在已知事件B发生的条件下,事件A发生的()。
参考答案:条件概率4.某一事件B的发生有各种可能的原因n个,B发生的概率是各原因引起B发生概率的总和,也就是()。
自然语言理解讲义第三讲.

CS
NP N 张三 V 是 N 县长 V 派 V’ V 来
的
de 的
自顶向下分析法(14):示例
S
NP VP NP
规则: (1) SNP VP (2) NPN (3) NPCS 的 (4) CSNP V' (5) VPV NP (6) V'V V
使用规则: NPN
CS
NP N 张三 V 是 N N 县长 V 派 V’ V 来
位置不变
自顶向下分析法(23) :一种改进方法
算法 1. 选择当前状态:从可能状态列表中选择第一个状态,并称之为 C。从可能状态表中去掉C。若表为空,在算法失败。 2. 若C的符号表为空。如果位置指向句子末尾,则算法成功;如 果位置不指向句子末尾,则goto 1(回溯)。 3. 否则(若C的符号表不为空),按下面方法产生新状态: 若C的符号表的第一个符号表示词性。如果句子的下一个词具 有该词性,则通过从C的符号表中去掉该符号并调整位置指针 来构造一新状态,然后将新状态加入可能状态列表;如果句 子的下一个词不具有该词性,则goto 1。 否则,若C的第一个符号为其他非终极符,为该符号的每条重 写规则产生一新状态,然后将所有这些新状态加入可能状态 列表。 goto 1.
使用规则: NPN
NP
N 张三 V 是 N 县长 V 派 V 来 de 的
自底向上分析法(4)
规则: (1) SNP VP (2) NPN (3) NPCS 的 (4) CSNP V' (5) VPV NP (6) V'V V
使用规则: NPN
NP
N 张三 V 是
NP N 县长 V 派 V 来 de 的
2
old
3
制图理论下汉语多重句法话题的分布

制图理论下汉语多重句法话题的分布作者:段张涛来源:《现代语文》2021年第06期摘要:汉语话题可以根据前置句首、提顿词两个方面来确定。
在句法上,汉语话题可以分为悬垂话题、左置话题与话题化话题结构。
从制图理论视角出发,汉语句法话题呈现出左缘分布的态势,即“悬垂话题>左置话题/话题化话题结构”的分布。
关键词:制图理论;左缘结构;句法话题一、引言话题是语言学中一个十分重要的概念,汉语话题也引起了学界的关注。
如Li & Thompson 将汉语视为一种“话题优先型”语言[1],陈静、高远则对这一观点提出了质疑,认为真正的“汉语式话题”只占陈述句的一小部分[2],不足以构成类型学上的意义。
尽管学界对现代汉语中的话题是否优先尚存在争议,但至少可以说明,汉语话题是具有自身特点的。
关于汉语中话题和主语的关系,学界的观点也不尽一致,大致可以分为三类:“主语话题等同说”[3]、“主语话题不同说”[1]、[4](P222)、[5]和“只有话题没有主语说”[6]、[7]。
值得注意的是,Rizzi曾提出Split-CP假说,意在解决话题、焦点等分布的问题[8]。
由于本文主要是以制图理论为指导,因此,更认同话题、主语不同这一观点。
需要说明的是,本文讨论的话题句式限于多项名词句NPNP……VP,并进一步探讨汉语中多重话题的句法分布。
二、制图理论与左缘结构左缘结构(Left Periphery)是由Rizzi首先提出的,它指的是标句词短语CP (Complementizer Phrase)和屈折层短语IP(Inflectional Phrase)之间的区域。
Rizzi的“Split-CP”假说将CP划分为四类,其中,标注有定无定的为限定短语FinP(Finiteness Phrase),专管陈述、疑问、虚拟等语气功能的为语势短语ForceP(Force Phrase),专管话题功能的是话题短语TopP(Topic Phrase),专管焦点功能的是焦点短語FocP(Focus Phrase)。
句法分析I[1]
![句法分析I[1]](https://img.taocdn.com/s3/m/9192354ec850ad02de804132.png)
2013年7月21日11时18分
中文信息处理--句法分析
31
自顶向下分析法-示例16
2013年7月21日11时18分
中文信息处理--句法分析
32
自顶向下分析法-示例17
2013年7月21日11时18分
中文信息处理--句法分析
33
自顶向下分析法-示例18
2013年7月21日11时18分
中文信息处理--句法分析
11
另一个例子-分析结果
2013年7月21日11时18分
中文信息处理--句法分析
12
句法分析的基本策略
句法分析通常采用的策略有:
自顶向下分析法; 自底向上分析法; 左角分析法; 其他策略。
2013年7月21日11时18分
中文信息处理--句法分析
13
上下文无关语法的分析算法
常见的上下文无关语法的句法分析算法:
中文信息处理--句法分析 6
2013年7月21日11时18分
句法结构的歧义消解(续)
我是县长。 我是县长派来的。 咬死了猎人的狗跑了。 就是这条狼咬死了猎人的狗。 小王和小李的妹妹结婚了。 小王和小李的妹妹都结婚了。
中文信息处理--句法分析 7
2013年7月21日11时18分
例子-语法
小王和小李的妹妹结婚了
中文信息处理--句法分析
16
自顶向下分析法-示例1
2013年7月21日11时18分
中文信息处理--句法分析
17
自顶向下分析法-示例2
2013年7月21日11时18分
中文信息处理--句法分析
18
自顶向下分析法-示例3
(完整版)自然语言处理

自然语言处理技术课程总结自然语言信息处理技术产生于上个世纪40年代末期,它是通过采用计算机技术来对自然语言进行加工处理的一项技术.该技术主要是为了方便人与计算机之间的交流而产生的.由于计算机严密规范的逻辑特性与自然语言的灵活多变使得自然语言处理技术较复杂.通过多年的发展,该项技术已取得了巨大的进步。
其处理过程可归纳为:语言形式化描述、处理算法设计、处理算法实现和评估。
其中,语言形式化描述就是通过对自然语言自身规律进行研究,进而采用数学的方法将其描述出来,以便于计算机处理,也可认为是对自然语言进行数学建模.处理的算法设计就是将数学形式化描述的语言变换为计算机可操作、控制的对象。
处理算法实现和评估就是通过程序设计语言(如C语言)将算法实现出来,并对其性能和功能进行评估。
它主要涉及到计算机技术、数学(主要是建模)、统计学、语言学等多个方面。
自然语言处理技术是所有与自然语言的计算机处理有关的技术的统称,其目的是使计算机理解和接受人类用自然语言输入的指令,完成从一种语言到另一种语言的翻译功能。
自然语言处理技术的研究,可以丰富计算机知识处理的研究内容,推动人工智能技术的发展。
下面我们就来了解和分析自然语言处理的关键技术。
一、常用技术分类1、模式匹配技术模式匹配技术主要是计算机将输入的语言内容与其内已设定的单词模式与输入表达式之间的相匹配的技术。
例如计算机的辅导答疑系统,当用户输入的问题在计算机的答疑库里找到相匹配的答案时,就会完成自动回答问题的功能。
但是不能总是保证用户输入的问题能得到相应的回答,于是很快这种简单匹配式答疑系统有了改进.答疑库中增加了同义词和反义词,当用户输入关键词的同义词或反义词时,计算机同样能完成答疑,这种改进后的系统被称为模糊匹配式答疑系统。
2、语法驱动的分析技术语法驱动的分析技术是指通过语法规则,如词形词性、句子成分等规则,将输入的自然语言(完整版)自然语言处理转化为相应的语法结构的一种技术。
自然语言处理的关键技术

自然语言处理的关键技术自然语言处理技术是所有与自然语言的计算机处理有关的技术的统称,其目的是使计算机理解和接受人类用自然语言输入的指令,完成从一种语言到另一种语言的翻译功能。
自然语言处理技术的研究,可以丰富计算机知识处理的研究内容,推动人工智能技术的发展。
下面我们就来了解和分析自然语言处理的关键技术。
一、常用技术分类1、模式匹配技术模式匹配技术主要是计算机将输入的语言内容与其内已设定的单词模式与输入表达式之间的相匹配的技术。
例如计算机的辅导答疑系统,当用户输入的问题在计算机的答疑库里找到相匹配的答案时,就会完成自动回答问题的功能。
但是不能总是保证用户输入的问题能得到相应的回答,于是很快这种简单匹配式答疑系统有了改进。
答疑库中增加了同义词和反义词,当用户输入关键词的同义词或反义词时,计算机同样能完成答疑,这种改进后的系统被称为模糊匹配式答疑系统。
2、语法驱动的分析技术语法驱动的分析技术是指通过语法规则,如词形词性、句子成分等规则,将输入的自然语言转化为相应的语法结构的一种技术。
这种分析技术可分为上下文无关文法、转换文法、ATN文法。
上下文无关文法是最简单并且应用最为广泛的语法,其规则产生的语法分析树可以翻译大多数自然语言,但由于其处理的词句无关上下文,所以对于某些自然语言的分析是不合适的。
转换文法克服了上下文无关文法中存在的一些缺点,其能够利用转换规则重新安排分析树的结构,即能形成句子的表层结构,又能分析句子的深层结构。
但其具有较大的不确定性。
ATN文法扩充了转移网络,比其他语法加入了测试集合和寄存器,它比转移文法更能准确地分析输入的自然语言,但也具有复杂性、脆弱性、低效性等缺点。
3、语义文法语义文法的分析原理与语法驱动相似,但其具有更大的优越性。
语义文法中是对句子的语法和语义的共同分析,能够解决语法驱动分析中单一对语法分析带来的不足。
它能够根据句子的语义,将输入的自然语言更通顺地表达出来,除去一些语法正确但不合语义的翻译。
nach 空间句法

nach 空间句法NaCh(Nucleus-arcus Complex)是大脑中的一个重要的空间句法结构,它在理解句子的语义和语法关系方面起着重要的作用。
NaCh空间句法是由Jonas Kuhn等人于2017年提出的一种基于神经网络的句法分析方法,它具有较高的准确性和鲁棒性。
下面将介绍NaCh空间句法的一些关键特点和应用。
1. NaCh空间句法的基本原理NaCh空间句法是一种基于依存句法的分析方法,它通过建立词语之间的依存关系来表示句子的语法结构。
与传统的依存句法不同,NaCh空间句法将依存关系表示为一种空间结构,即NaCh图。
在NaCh图中,每个词语都表示为一个节点,节点之间的连线表示依存关系。
通过对NaCh图的分析,可以获得句子的语义和语法信息。
2. NaCh空间句法的网络结构NaCh空间句法使用了一种基于神经网络的模型来进行句法分析。
该模型由多层感知机(MLP)和长短期记忆网络(LSTM)组成。
MLP用于提取句子中每个词语的特征,LSTM用于学习句子的语法和语义信息。
通过这种网络结构,NaCh空间句法可以有效地捕捉句子中的语法和语义关系。
3. NaCh空间句法的应用NaCh空间句法在自然语言处理领域具有广泛的应用价值。
首先,它可以用于句法分析,即将句子中的词语组织成树形结构,以便于后续的语义分析和语言生成。
其次,NaCh空间句法还可以用于语义角色标注,即将句子中的词语与其在句子中所扮演的语义角色进行关联。
此外,NaCh空间句法还可以用于问答系统、机器翻译、信息检索等任务。
4. NaCh空间句法的优势与传统的基于规则或统计的句法分析方法相比,NaCh空间句法具有以下几个优势。
首先,它可以利用深度学习的方法来学习句子的语法和语义信息,从而获得更准确的句法分析结果。
其次,NaCh空间句法可以自动学习句子中的依存关系,而无需手工定义规则。
最后,NaCh空间句法还具有较强的鲁棒性,可以处理复杂的句子结构和各种类型的错误。
湖北省教育厅办公室关于公布省级大学生创新创业训练计划项目的通知

湖北省教育厅办公室关于公布省级大学生创新创业训练计划项目的通知文章属性•【制定机关】湖北省教育厅•【公布日期】2013.11.12•【字号】鄂教高办[2013]14号•【施行日期】2013.11.12•【效力等级】地方规范性文件•【时效性】现行有效•【主题分类】高等教育正文湖北省教育厅办公室关于公布省级大学生创新创业训练计划项目的通知(鄂教高办〔2013〕14号)各普通本科高校:根据《省教育厅省财政厅关于“十二五”期间实施“湖北省高等学校本科教学质量与教学改革工程”的意见》(鄂教高〔2012〕7号)和《省教育厅办公室关于做好2013年省级和国家级大学生创新创业训练计划项目申报工作的通知》(鄂教高办函〔2013〕5号)精神,省教育厅组织专家对申报参加省级大学生创新创业训练计划高校的工作方案、项目管理办法及项目进行了审定,确定湖北大学“甲醇氧化羰基化反应催化剂合成与性能研究”等1412个项目(其中,创新训练项目1097项,创业训练项目186项,创业实践项目129项)为2013年度省级大学生创新创业训练计划项目。
经教育部审核通过的我省高校1980项(其中部委属高校1235项,省属高校745项)2012度国家级大学生创新创业训练计划项目,一并认定为2012年度省级大学生创新创业训练计划项目并予以公布。
大学生创新创业训练计划是实施素质教育的重要方式,是人才培养模式改革的重要方面,是提升大学生综合能力的重要途径。
各高校要高度重视大学生创新创业训练计划对推动人才培养模式改革的重要意义,进一步理顺校内管理机制,加强项目过程管理,保障经费投入,切实提高学生创新创业能力。
已入选国家级大学生创新创业训练计划项目的,要按照教高函〔2012〕5号要求开展科学研究和创业训练,切实落实经费投入,确保按期完成研究内容。
项目结束后,由学校组织项目验收。
各高校应对本校实施计划的整体工作情况进行年度总结,连同验收结果于每年12月报我厅。
浅层句法分析方法概述

浅层句法分析方法概述孙宏林俞士汶一、引言浅层句法分析(shallow parsing),也叫部分句法分析(partial parsing)或语块分析(chunk parsing),是近年来自然语言处理领域出现的一种新的语言处理策略。
它是与完全句法分析相对的,完全句法分析要求通过一系列分析过程,最终得到句子的完整的句法树。
而浅层句法分析则不要求得到完全的句法分析树,它只要求识别其中的某些结构相对简单的成分,如非递归的名词短语、动词短语等。
这些识别出来的结构通常被称作语块(chunk),语块和短语这两个概念通常可以换用。
浅层句法分析的结果并不是一棵完整的句法树,但各个语块是完整句法树的一个子图(subgraph),只要加上语块之间的依附关系(attachment),就可以构成完整的句法树。
所以浅层句法分析将句法分析分解为两个子任务:(1)语块的识别和分析;(2)语块之间的依附关系分析。
浅层句法分析的主要任务是语块的识别和分析。
这样就使句法分析的任务在某种程度上得到简化,同时也利于句法分析技术在大规模真实文本处理系统中迅速得到利用。
90年代以来,国外在英语的浅层句法方面做了不少工作,国内也有一些学者采用英语中的方法探索汉语的浅层句法分析。
本文主要就在英语浅层句法分析中所应用的一些技术进行简要的介绍,并简单介绍汉语的有关研究。
其中有些方法虽然是面向完全句法分析的,但由于其对完全句法分析的任务进行了分解,所以其技术也可以归入浅层分析的范畴。
概括起来,句法分析的方法基本上可以分成两类:基于统计的方法和基于规则的方法。
当然也可以采用规则和统计相结合的混合方法。
下面第2节介绍基于统计的方法,第3节介绍基于规则的方法,第4节简要介绍汉语的有关研究,最后是结束语。
二、基于统计的方法随着语料库技术的发展,近10年来许多统计方法被用在短语识别和分析方面。
这些方法的理论主要来自概率统计和信息论。
以下将介绍其中具有代表性的几种方法:(1)基于隐马尔科夫模型的方法;(2)互信息方法;(3) 2统计方法;(4)基于中心词依存概率的方法。
线图算法在中文句法分析中的应用
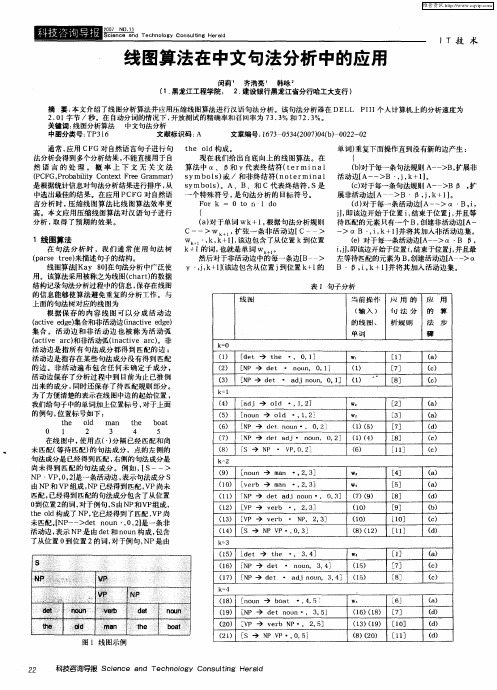
T 技 术
线 图算法在 中文句法 分析 中的应 用
闵莉 ’ 齐浩亮 ’ 韩咏 (. 1 黑龙 江工程学院 ; 2 建设银行 黑龙江省分行哈工大支行 ) .
摘 要 : 文介绍 了线图分析算 法并应用 压缩线 图算法进行 汉语句 法分析 。该句法 分析器在 DE L I1 人计算机上 的分析速 度为 本 L P I 个
te l h od构成 。 单词 ) 重复 下面操作 直到没有 新的边产 生 : 现在 我 们给 出 自底 向上的 线 图算 法 。在 { 算 法中 0、 D v代表 终结 符 ( e mi al 【 和 t r n () b对于每一条句 法规 则 A一 >B 扩展非 - , s mb l ) /和非 终结 符 ( t r na 活动边 【 y o S或 no e mi l A一一 >B ・j k 】 , , +1。 s mb l) y os 。A、B、和 C代 表终 结符 , s是 () c对于每 一条句法规 则 A一 >B D , 一 扩 个特 殊符号 , 句法 分析 的 目标 符号 。 是 展非活 动边【 >B ・D,, +1。 A jk 】 F r k = 0 t l d o o n o ( ) 于每一 条活动 边【 d对 A一~ 0 ・ i > 【 B, , { j, 即该边开始 于位置 i结束于位 置 j并且等 J , , () a 对于单 词 wk , +l 根据 句法分 析规则 待 匹配的 元素只有 一个 B, 创建非活动 边【 A— C一一>W , 扩张 一 条非 活 动边 【 > +, C 一 0B ・ik 】 > 【 , , +1并将 其加入 非活 动边集 。 1线图算法 w ・ k k 】 该边包 含 了从位 置 k到位置 , , +l , () e 对于 每一条活动边 【 一 【・ D, A一 >0 B 在 句 法 分 析 时 ,我 们通 常 使 用 句 法 树 k 的词 , +1 也就 是单 词 w… 。 ij 即该边开始于位置 i结束于位置 j并且最 ,, 】 , , (as re来描述 句子的结构 。 p re te ) 然后 对于非 活动边 中的每一 条边【 > B 左等 待匹配的元素为 B, 创建活动边【 一 【 A >0 线 图算法[ y 8 l 句法 分析 中广泛 使 v ・jk 该边包含从 位置 j Ka O在 ,,+1 J ( 到位置 k 的 B ・D, , +l ik+l并 将其加 入活 动边集 。 】 用 。该算法采用 被称之为 线图(h r) c a t的数 据 结构 记录句法分析过程 中的信息 , 保存在线 图 表 l句子分析 的 信息能 够使算 法避 免重 复的分 析工作 。 与 线 圈 当前操 作 用 的 应 用 上面 的句法树 对应的线 图为 ( /) 输 X { 法 分 的 算 . J l 根 据 保 存 的 内 容线 图可 以分 成 活 动 边 (c v d e集合和非活动边 ( at eeg ) at eeg ) i i c v d e n i 的线 圈 、 析 规 则 法 步 集 合 。 活动 边 和 非 活 动 边 也 被称 为 活 动 弧 单 侧 骤 (ci e a c 和非活动 弧( a t e a c。非 at r) v i ci r) n v k =O 活动 边是 指所 有句 法成 分都 得到 匹 配的边 ; () 1 [ e d t t e ・。 0 1 h ,] W I [] 1 () a 活动边 是指 存在 某些 句法 成 分没有 得到 匹配 的边 。非 活 动遍 布 包含 任 何未 确定 子 成分 , () [P 2 N d t ・ n l , 0 1 e oi n ,1 () 1 [] 7 () c 活 动边 保存 了分析过 程 中到 目前为止 已推 倒 () [P 3 N d t ・ a jn u , 0 1 () e d on 。 ] 1 ’ [] 8 () c 出来的成 分 , 同时 还保 存 了待 匹配规 则部分 。 k =i 为 了方便清楚的表 示在线 图中边 的起 始位置 , () 4 d j o d ・, , 3 l 1 2 W a [] 2 () a 我们给 句子 中的单词加 上位置标号 , 对于 上面 的 例句 , 位置标号 如下 : () 5 [o n n u o d ・, , l 12 W [] 3 () a
HowNet

汉语词语W1和W2,如果W1有n个义项(概念):S11、
SSS21im2m、,(…我A…,们BS规)1n=定,l,WolgoW2g有p1(p和md(eWc个soc2义m的rim项p相ot(i似n概o(n度念A( A,为)B:,各B))S)个2)1、概S念22的、相…似…
度绝对值的之最大值,W1和W2相式度计算如公式2:
关键词 知网;词语相似度;义原相似度;字典结构;句子相似度
1 引言
相似度的计算是中文信息处理中最为基础和重 度,并在词语定义词典的存储方式做了改进,利用汉
要的工作,它直接决定着某些领域的研究和发展。如 字的编码来组织词典。实验表明:一些区别词的相似
机器翻译、信息检索、自动文摘、自动问答系统等领 度更加合理,且提高了词语的查找速度。本文在计算
本文第2节对相似度进行简单介绍;第3节介绍基 于HowNet的词语相似度的计算;第4节对字典的设计 的改进进行讨论;第5节介绍句子相似度的计算;第6 节实验结果与分析;第7节对全文进行总结与展望。
2 相似度简介
同义词词林、知网、WordNet等);另一类是基于统 计的相似度计算方法(如TF-IDF等)。目前国内,以《知
32 depth(p1) − depth(p2 )
p1, p2 depth (p1) dist(p1,p2 )
Sim( p1, p2 ) = ±
α
,
基于HowNet句子相似度的计算
的词相似度仍然很大。文献[4] 在文献[2]论文的基础 上,进一步考虑了义原的深度信息,并利用《知网》 义原间的反义、对义关系和义原的定信息来计算词语 相似度。本文借鉴文献[2]、[4]的词语相似度计算方 法,在计算词语的相似度时考虑单义元的否定(义元相 似度取反)、加大符号义元”^”和”~ ” 的权植、对 第一义原有符号”^”的词语相似度的值取反。把词 语相似度的取值范围规定为[-1,+1]之间。若词语的 定义一样,则语义相似度为1;若两个词语的定义相 反,那么其相似度为-1。
线图分析法的一种改进方法

t c n q e .t e s se a e n c a tp ri g a e awa s ‘o e h i u s h y t ms b s d o h r ̄ a sn l l y t y’s se e a s f t e r lw f c e c . 1i a e u o wa d a me h d t a s y tms b c u e o h i o e i i n y 1 1s p p r p t f r r t o h t i a mi g t n a c e e c e c e c a t a s r. i n e h n e t f i n y o t h r p r e s o h i f h
。 一
as g。部分句法分析是通过牺牲分析的深度来换取 系统的效 率, i 所 2 议 程 表fgn a: 来记 录 刚 得 到 的重 写 规 则 的左 部 。 于议 程 P rn ) ) A ed)用 对 表 有 两 种 处理 策 略 , 先 出或 先进 后 出。 先进 以部分分析技术只能确定一个句子的某些部分时正确的 。 并不能确定 3 活 动 边 集 ( ci r)活 动 边 集 用 来 保 存 只 匹 配 了一 部 分 的 整 个 的 句 子是 否 正 确 。 ) A 5 8 0 ) 2 3 0
句法分析

2019年9月21日9时16分
22
自顶向下分析法-示例7
2019年9月21日9时16分
23
自顶向下分析法-示例8
2019年9月21日9时16分
24
自顶向下分析法-示例9
2019年9月21日9时16分
25
自顶向下分析法-示例10
2019年9月21日9时16分
26
自顶向下分析法-示例11
2019年9月21日9时16分
角的那个符号 • 比较:
2019年9月21日9时16分
53
左角分析法-示例1
2019年9月21日9时16分
54
左角分析法-示例2
2019年9月21日9时16分
55
左角分析法-示例3
2019年9月21日9时16分
56
左角分析法-示例4
2019年9月21日9时16分
57
左角分析法-示例5
2019年9月21日9时16分
分析成功,结束 – 拒绝:句子中所有词语都已移进栈中,栈中并非只有一个符号S,
48
自底向上分析法-示例13
2019年9月21日9时16分
49
自底向上分析法-示例14
2019年9月21日9时16分
50
自底向上分析法-示例15
2019年9月21日9时16分
51
自底向上分析法-示例16
2019年9月21日9时16分
52
左角分析法-概述
• 左角分析法是一种自顶向下和自底向上相结合的方法 • 所谓“左角(Left Corner)”是指任何一个句法子树中左下
108
左角分析法-示例56
2019年9月21日9时16分
109
计算机专业毕业设计题目

西北大学现代学院计算机科学与技术专业毕业设计题目注:每位导师限报不超过8名学生(无论导师给出多少题目)1. 刘伟明:1)《危险品安全管理》统计管理系统;(2人)2)单片机支持的广告显示;2人3)近距离的无线数据采集。
2人2.郭小群:1)软件工程在现考试系统:2人2)软件工程论坛:2人3.王冰张仲选课题研究领域:图像处理和分析,中文信息处理1)信息隐藏技术研究2)数字水印技术3)机密信息的化分隐藏与传输4)机动车牌的分割与识别5)汉字、词频度统计及相应的汉字输入方法6)图像拼接技术及软件7)彩票选号软件开发8)快速算法研究题目要求:熟悉相关领域的研究状况和进展,学习、研究相应的算法和方法,用计算机语言编程实现题目要求,写出研究报告或研究论文。
4.邢为民:设计题材一1、题目《单位组网实施方案设计》某单位需要构建5个分布于不同地点的局域网络,其中有4个网络各约有20台主机,有1个网络中约有60台主机(其中有40台主机集中在计算机中心),该公司向NIC 申请了一个C类的网络ID号,其号码为202.204.60。
请你设计一个方案,将某单位的所有主机连接起来。
2、要求:1) 在论文中叙述网络的发展、网络技术及现阶段网络技术在经济发展中的应用、作用;2) 在论文中叙述某单位构建网络所需要解决的问题、解决方法;3) 阐述你所设计方案的原则,组网实施的方案及方案的成本核算、优缺点;4) 叙述本方案易出现的问题及处理方法;5) 要求有组网实施实物方案图;6) 论文答辨时,要求用幻灯片进行方案的阐述及答辩。
设计题材二1、题目:《Windows2000 server在局域网中的应用》目前,各学校、企业、事业单位,为实现资源的共享、数据的快速传递,同时为实现网络办公(OA系统办公),分别建立了本单位内部网络(Intranet企业内部网)。
在Intranet中服务器操作系统的选择是对整个网络的运行、管理至关重要。
2、要求:1) 在论文中叙述网络操作系统的作用,简单介绍常用的网络操作的特点;2) 在论文中叙述Windows2000 server的发展、特点及优点;3) 阐述Windows2000 server 用户、用户组管理及安全策略;4) 阐述DHCP、DNS、WWW、EMAIL 、FTP五大服务的内容,及在Windows 2000 server中如何配置和管理;5) 叙述Windows 2000 server中五大服务容易出现的问题及处理方法;6) 论文答辩时,要求用幻灯片进行介绍及答辩。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
表明利用改进的分析算法, 使得句法分析效率和分析结果的准确率均有一定程度的提高。
关键词: 文本信息处理; 汉语句法分析; 线图分析法; 句法解析器; 句法结构
中图 分类 号: TP391
文献标志码: A
文 章编 号: 1001 - 3695( 2007) 09- 0164- 04
Design and implementation of shallow Chinese syntax parser based on improved chart algorithm
b) 如果在字符间隔 i 预 测出 现点 规则 y→ α·b β, 那 么 在字符间隔 i 后有可能出现字符 b。
重复 a) b) 直到预测完所有满足情况的点规则。 改 进 算 法 的 伪 代 码 描 述 如下 :
input: Chinese character strings with word segments and parts of speech annotation
第 24 卷 第 9 期 2007 年 9 月
计算 机应用研究 Application Research of Computers
Vol. 24 No. 9 Sept. 2007
基于改进线图分析算法的浅层 汉语句法分析器的设计与实现*
吴江宁, 朱国华
( 大连 理工 大学 系统 工程 研究 所, 辽 宁 大连 116024)
elseif C matches any active edge of the form X→ X1 … Xm· C ( p0 p1 ) in ActiveArcs, add an edge X( p0 - p2 ) to agenda and add C( p1 - p2 ) to the chart endif
1. 2 传统线图分析算法的优点与不足
传 统 线 图 分 析 算 法 的 优 点表 现 在 可 以 表 示 不 相 连 的 子树 。 在自然语言分析中, 有时 局部的 结构分 析成功 了, 但 总体的 结 构分析却不好, 使得最后难以形成一棵完整的树。线图可以表 示不相连的子树, 不一定 要求最 后必须 形成一 棵完整 的树, 可 以把局部分析正确的结构以子树的形式保存下来, 而不至于将 前面 的 分 析 抛 弃 。
WU Jiang-ning, ZHU Guo-hua
( Institute of Systems Engineering, Dalian University of Technology, Dalian Liaoning 116024, China)
Abstract: Based on the traditional chart algorithm, this paper proposed an improved Chinese syntax parsing algorithm, which combined bottom up and top down strategies in order to enhance the efficiency and the precision of the Chinese syntactic analysis. It was composed of three main modules, they were word segmentation module based on the maximum word-length matching algorithm, part of speech tagging module based on statistical method of training of relative frequency, and the syntax parsing module based on the improved chart analysis algorithm. A small-size Chinese corpus was used to validate the efficiency and feasibility of the improved algorithm. Key words: textual processing; Chinese syntactic analysis; chart algorithm; syntax parser; syntax structure
预测是指提出从本间隔点 出发向 右可能 接续的 所有活 跃 边的列表。尚未验证的预测保留在表中, 已经被验证或被反驳 的预测则从表中划掉。预测是根据规则进行的, 首先从字符间 隔 1 开始向右预测可能要出现一个句子, 即预测将有点规则 S→ · α出 现 。
a) 如果在字符间隔预测出点规则 y→ α·B β, B→ γ∈P, 那么从字符间隔 i 后可 能接续 点规则 B→· γ( α, β可为 空, B 为非终结符) 。
第9期
吴江宁, 等: 基于改进线图分析算法的浅层汉语句法分析器的设计与实现
· 165·
用自顶向下回溯的分析方 法。它逐个 地枚举 推导直 至找到 一 个能生成输入句子结构的 推导。自顶 向下的 分析是 从假设 出 发的, 它假定一个节点可 以替换 下面的 节点, 从根到 叶逐步 分 枝, 从抽象到具体、从整体到部分。目的很明确, 就是要找到与 叶相 适 应 的 句 法 结 构 。
目前国内很多有代表性的 句法分 析系统 中的汉 语句法 分 析模块都是通过改进已有的经典句法分析算法设计的, 不少已 在实践中取得 了良 好 的效 果[ 2] 。其 中, 传统 的 基于 规则 的 方 法占了主导地位, 这是因为基于规则的方法从汉语句子最本质 的特征 出发, 如 构词法、词组构造 法、造句 法等, 从宏观上总 结 出句法规则。无论汉语的句式结构多么自由, 其中蕴涵的最基 本的规则是相对稳定的, 而且规则易于表达汉语句子成分的构 成规律。另外的原因是, 经过长 时间的 发展和 不断改 进, 这 类
摘 要: 针 对传 统的 汉语 句法 分析 算法进 行改 进, 采用 了自 底向 上与 自顶 向下 相结 合的 线图 分 析 方法 , 分析 、设
计和 实现 了一 个汉语 句法 分析 原型 系统 。该 系统实 现了 基于 最大 词长 匹配 算法 的分 词模 块、基于 统 计 方法 的 词
性标注模块和基于改进的线图分析算法的句法分析模块。最后对系统进行小规模中文文本试验测试, 测试结果
2 改进的句法分析算法
自顶向下和自底向上分析 算法两 者均不 可避免 地会产 生 较多的冗余, 从而导 致分析 效率降 低。 为了减 少冗余、节省 时 间和空间、提高分析准确率, 本文提出一种改进策略, 在自底向 上线图分析算法中, 引入了自 顶向下 的预测 功能[ 5] , 称之为 自 底向 上 与 自 顶 向 下 相 结 合 的 改进 线 图 分 析 算 法 。
output: Chart of syntactic analysis begin for( i = 0; i < = n; i + + ) for every active edge of the form X→ X1 … · Xk… Xm( px - py ) in ActiveArcs do if Xk is a terminating symbol and p1 > py, delete this active edge from
使用线图分析算 法进行 句法分 析时, 通常采 用两种 方 式 [ 4] , 即自顶向下分析和自底向上分析。
1) 自顶向下分析 算法 在句 法 分析 中, 最 普通 的就 是 采
收 稿日期 : 2006- 0 家自 然科学 基金 资助项 目( 70271046, 70431001) 作 者简介 : 吴 江宁 ( 1964 - ) , 女, 副教 授, 博士, 主要 研究 方向为 知识 管理、文本 挖掘 、信 息检索 ( jnwu@ dlut. edu. cn) ; 朱国华 ( 1980- ) , 男 , 硕士 研 究生, 主要 研究 方向为 句法 分析、文本 信息 处理.
X1 … Xm( p1 - p2 ) to ActiveArcs and add C( p1 - p2 ) to the chart elseif C matches any active edge of the form X→ X1 … · C… Xm( p0 -
p1 ) in ActiveArcs, add an active edge X→ X1 … · C… Xm( p0 - p2 ) to ActiveArcs and add C( p1 - p2 ) to the chart
ActiveArcs endif if agenda = , put the part of speech and the left and right interval into
agenda endif choose a element from agenda which is C( p1 - p2 ) if C matches the form X→ · C X1 … Xm, add an active edge X→ C·
随着计算机和 Internet 的推广应用, 由数据处理、信息处理 发展到知识处理, 对 语 言文 字处 理 要求 的深 度 和广 度越 来 越 高。汉语句法分析在中文文本 信息处 理领域 中占有 十分重 要 的地位, 同时它也是公认的一个研究难题。不同于其他西方语 言, 汉语有许多特殊之处, 吸收 其他语 言研究 成果时 需要结 合 汉语的特点加 以研 究[ 1] 。当 前对 汉 语的 研 究主 要按 照 词、句 子和篇章三个层次开展。其中 句子的 处理在 三个层 次中起 着 承上启下的 作用, 所 以 句子 处理 是 一个 核心 课 题。就目 前 来 说, 句子处理以自动分词 为基础, 以句 法分析 和语义 分析为 核 心。本文工作围绕着句法分析方法和系统展开, 句法分析就是 应用句法规则和其他知识, 将输入句子中的词之间的线性次序 变换 成 语 法 树 形 式 的 数 据 结 构。