2011-JSCUT-基于文档重要度的静态索引剪枝方法
搜索剪枝常见方法与技巧

搜索剪枝常见方法与技巧关键字搜索方法,剪枝摘要搜索是计算机解题中常用的方法,它实质上是枚举法的应用。
由于它相当于枚举法,所以其效率是相当地的。
因此,为了提高搜索的效率,人们想出了很多剪枝的方法,如分枝定界,启发式搜索等等。
在竞赛中,我们不仅要熟练掌握这些方法,而且要因地制宜地运用一些技巧,以提高搜索的效率。
正文搜索的效率是很低的,即使剪枝再好,也无法弥补其在时间复杂度上的缺陷。
因此,在解题中,除非其他任何方法都行不通,才可采用搜索。
既然采用了搜索,剪枝就显得十分的必要,即使就简简单单的设一个槛值,或多加一两条判断,就可对搜索的效率产生惊人的影响。
例如N后问题,假如放完皇后再判断,则仅仅只算到7,就开始有停顿,到了8就已经超过了20秒,而如果边放边判断,就算到了10,也没有停顿的感觉。
所以,用搜索就一定要剪枝。
剪枝至少有两方面,一是从方法上剪枝,如采用分枝定界,启发式搜索等,适用范围比较广;二是使用一些小技巧,这类方法适用性虽不如第一类,有时甚至只能适用一道题,但也十分有效,并且几乎每道题都存在一些这样那样的剪枝技巧,只是每题有所不同而已。
问题一:(最短编号序列)表A和表B各含k(k<=20)个元素,元素编号从1到k。
两个表中的每个元素都是由0和1组成的字符串。
(不是空格)字符串的长度<=20。
例如下表的A和B两个表,每个表都含3个元素(k=3)。
表A 表B对于表A和表B,存在一个元素编号的序列2113,分别用表A中的字符串和表Array对表A和表B,具有上述性质的元素编号序列称之为S(AB)。
对于上例S(AB)=2113。
编写程序:从文件中读入表A和表B的各个元素,寻找一个长度最短的具有上述性质的元素编号序列S(AB)。
(若找不到长度<=100的编号序列,则输出“No Answer”。
对于这道题,因为表A和表B不确定,所以不可能找到一种数学的方法。
因为所求的是最优解,而深度优先搜索很容易进入一条死胡同而浪费时间,所以必须采用广度优先搜索的方法。
成电求实专技网2021年度公需科目信息检索

成电求实专技网2021年度公需科目信息检索1、(单选,4分)所有检索策略都包含三个要素。
以下不属于这三个元素的选项之一是()a、匹配函数b、排序函数c、文档表示d、查询表示答案:b2.(单选,4分)在向量模型中,不可以通过()来衡量文档和查询之间的相似度。
a、向量之间的距离B,向量内积C,向量之间的角度D,向量之间的切线值答案:D3、(单选,4分)T1、T2和T3表示特征项,D1、D2、D3和D4表示文档向量,Q表示查询向量,其中D1=4T1+2t2+3T3,D2=T1+4T2+2t3,D3=5t1+2t3,D4=T2+3T3,Q=T1+0t2+2t3。
Q最有可能与上述文件相关的是()a、d1b、d2c、d3d、d4答案:a4.(单选,4分)以下选项中属于概率模型的优点的是()a、该模型有一个内部相关反馈机制,根据相关概率降序排列文档。
B.该模型最初将文档分为相关集和不相关集。
C.模型中的所有权重都是二进制的。
D.该模型假设索引词彼此独立。
答:a5、(单选,4分)神经模型中的信息检索()a、布尔模型b、向量模型c、概率模型d、结构化模型回答:B以下关于网络爬虫的描述中,错误的一项是()a、在爬虫程序的开头,您需要向爬虫程序发送一个URL列表,作为爬虫程序的起始位置。
B.根据特定的爬网策略对新发现的URL进行爬网,并重复此操作。
C.爬虫程序将对所有网页进行爬网,以确保搜索的正确性。
D.对于商业搜索引擎,分布式爬虫是必须采用的技术。
回答:C7、(单选,4分)在实际的搜索引擎系统中,文档信息是通过存储()a、文档地址b、文档简化序号c、文档编号d、文件编号差异回答:d8、(单选,4分)在以下方法中,不是索引构建方法的方法是()a、两边文档遍历法b、排序法c、归并法d、hits答案:d9.(单选,4分)关于pagerank标准算法与简化算法正确的是()a、对于G中的每个节点n,PageRank简化算法将其初始值设置为1/Nb。
计算机专业英语大全

absence 缺席access 访问存取通路进入achieve 实现完成acquire 获得adjacency list method 邻接表表示法adjacency matrix method 邻接矩阵表示法algorithm 算法allocate 留下分配[h2][/h2]analog 推论append 添加archive 档案归档array 数组assign 分配assume 假设assurance 确信信任A TM(asynchronous transfer mode) 异步传输模式b.. real programs kernels 实程序核心程序b.. toy benchmark synthetic benchmark 简单基准程序复合基准程序balance 平衡bandwidth 带宽batch 一批一组benchmark 基准测试程序best-fit algorithm 最佳适应算法BFS(breadth first search) 广度优先搜索法binary 二进制binary relation 二元关系binary tree 二叉树bit series 比特序列black-box white-box 黑盒白盒block miss 块失效blocked 阻塞(等待状态也称阻塞或封锁状态)boundary 界线分界bridge 网桥bubble sort 冒泡排序calculation 计算candidate key 候选键(辅键)capability 能力才能capacity 容量cartesian product 笛卡尔积CASE(com.. aided sof.. engineering) 计算机辅助软件工程CCP(communication control processor) 通信控制处理机cell 信元characteristic 特征特性circuit switching 线路交换circular wait 循环等待CISC(complex instruction set computer) 复杂指令集计算机class 类Client/Server 客户机/服务器clock cycle clock rate 时钟周期时钟频率coaxial cable 同轴电缆cohesion coupling 内聚耦合coincidental logical procedural functional 偶然内聚逻辑内聚过程内聚功能内聚combination 联合配合common 公用的共同的communication 通信complement number 补码component 成分concept 概念观念condition 情况状况conform 符合consist 组成存在constrain 约束contain 包含correspond (corresponding) 相符合(相应的一致的)CPETT 计算机性能评价工具与技术CPI 每条指令需要的周期数CSMA/CD 带冲突检测的载波监听多路访问cursor 游标cyclic redundency check 循环冗余检校database: integrity consistency restory 完整性一致性可恢复性database: security efficiency 数据库设计的目标: 安全性效率deadlock: mutual exclusion 死锁条件: 互斥deadlock: circular wait no preemption 死锁条件: 循环等待无优先权decimal 十进位的decision 决定判断decomposition 双重的混合的decrease 减少definition 定义definition phase 定义阶段demonstrate 证明design phase 设计阶段determine 限定development phase 开发阶段DFS(depth first search) 深度优先搜索法diagram 图表Difference Manchester 差分曼彻斯特directed graph undirected graph 有向图无向图distinguish 辩认区别distributed system 分布式系统divide division 分开除除法divide union intersection difference 除并交差document 文件文档DQDB(distributed queue dual bus) 分布队列双总线draw 绘制dual 二元的双的dynamic design process 动态定义过程element 元素要素elevator (scan) algorithm 电梯算法又称扫描算法encapsulation inheritance 封装(压缩) 继承(遗传) encode 译成密码entity 实体entity integrity rule 实体完整性规则equal 相等的equation 方程式等式estimate 估计判断Ethernet 以太网evolution 发展演化exceed 超过exchange sort 交换排序exclusive locks 排它锁(简记为X 锁)execute 实现执行exhibit 表现展示陈列existence 存在发生expertise 专门技术external(internal) fragmentation 外(内)碎片fault page fault 中断过错页中断FDDI(fiber distributed data interface) 光纤分布式数据接口FDM(frequency division multiplexing 频分多路复用fiber optic cable 光缆FIFO replacement policy 先进先出替换算法figure 数字图形final 最后的最终的first normal form 第一范式floppy 活动盘片(软盘)foreign key domain tuple 外来键值域元组form 形状形式formula 公式表达式foundation 基础根据基金frame page frame 帧结构页结构frequency 频率FTP 文件传送服务function 函数functionally dependent 函数依赖gateway 网间连接器gather 聚集采集推测general-purose registers 通用寄存器generate 产生grade 等级标准graph (graphic) 图Gropher 将用户的请求自动转换成FTPguarantee 保证确定hash table hash function collision 哈希表哈希函数(散列函数) 碰撞HDLC 面向比特型数据链路层协议hit rate 命中率host 主计算机host language statement 主语言语句hypertext 超级文本illustrate 举例说明independent 独立的index 索引indirect 间接的influence 有影响的initially 最初开头insertion sort 插入排序instruction format 指令格式instruction set 指令集interface 接口分界面连接体internal 内部的内在的interrupt 中断IPC 工业过程控制ISAM VSAM 索引顺序存取方法虚拟存储存取方法join natural join semijoin 连接自然连接半连接judgment 判断kernel executive supervisor user 核心执行管理用户kernels 核心程序key comparison 键(码)值比较LAN(local area network) 局域网load 负载载入logical functional 逻辑内聚功能内聚longitudinal 水平的loop 圈环状maintain 维护保养供给maintanence phase 维护(保养)阶段MAN(metropclitan area network) 城域网Manchester 曼彻斯特map 地图映射图matrix 矩阵点阵memory reference 存储器参量message switching 报文交换method 方法技巧MFLOP(million floating point operate p s 每秒百万次浮点运算minimum 最小的MIPS(millions of instructions per second 每秒百万条指令module 单位基准monitor (model benchmark physcal) method 监视(模型基准物理)法multilevel data flow chart 分层数据流图multiple 复合的多样的multiple-term formula 多项式multiplexing 多路复用技术multiplication 乘法mutual exclusion 互相排斥non-key attributes 非码属性null 零空Nyquist 奈奎斯特object oriented 对象趋向的使适应的object oriented analysis 面向对象的分析object oriented databases 面向对象数据库object oriented design 面向对象的设计object oriented implementation 面向对象的实现obtain 获得occupy 占有居住于occurrence 事件odd 奇数的one-dimensional array 一维数组OODB(object oriented data base) 面向对象数据库OOM(object oriented method) 面向对象的方法oom: information object message class 信息对象消息类oom: instance method message passing 实例方法消息传递open system 开放系统operand 操作数optimized 尽量充分利用optional 任选的非强制的organize 组织overflow 溢出overlapping register windows 重叠寄存器窗口packet switching 报文分组交换page fault 页面失效page replacement algorithm 页替换算法paged segments 段页式管理PCB(process control block) 进程控制块peer entites 对等实体perform 表演执行period 时期周期permit 许可准许phase 阶段局面状态physical data link network layer 物理层数据链路层网络层pipeline 管道platter track cluster 面磁道簇predicate 谓语preemption 有优先权的prefix (Polish form) 前缀(波兰表达式)preorder inorder postorder 前序中序后序presentation application layer 表示层应用层primary key attributes 主码属性principle 原则方法procedural coincidental 过程内聚偶然内聚process 过程加工处理proficient 精通program debugging 程序排错projection selection join 投影选择连接proposition 主张建议陈述protocal 协议prototype 原型样板prototyping method (model) 原型化周期(模型)pseudo-code 伪码(又称程序设计语言PDL) punctuation 标点purpose 目的意图quality 质量品质queue 队列ready blocked running 就绪阻塞(等待) 运行real page number 实页数real programs 实程序redirected 重定向redundency 冗余reference integrity rule 引用完整性规则referred to as 把.....当作regarde 关于register(registry) 寄存器登记注册挂号regularly 定期的常规的relation 关系relay 中继reliability 可信赖的repeater 中继器replacement 替换represent 代表象征request indication response confirm 请求指示响应确认resource 资源respon 回答响应RISC(reduced instruction set computer) 精简指令集计算机robustness 健壮性router 路由器scheme 计划图表sector head cylinder 扇区磁头柱面selection sort 选择排序semaphores 信号sequence 序列顺序Shanon 香农share locks 共享锁(简记为S 锁)short path critical path 最短路径关键路径signal 信号signal-to-noise ratio 信噪比B/Nsimilar 相似的SISD SIMD MISD MIMD * 指令流* 数据流SMDS 交换多兆位数据服务software development phase 软件开发阶段software engineering 软件工程software portability 软件可移植性software requirements specification 软件需求说明书solve 解决sort 种类方式分类排序spanning tree 跨越树(生成树)specify 指定说明speedup 加速比SSTF(shortest-seek-time-first) 最短寻道时间优先(磁盘调度算法) stack strategy non-stack strategy 堆栈型非堆栈型starvation 饥饿匮乏statement 陈述storage 贮藏库store procdures 存储过程strategy 战略兵法计划strict 严密的styles 文体风格subgroup 循环的subset 子集子设备superclass subclass abstract class 超类子类抽象类suppose 假定symbolic 象征的符号的synthetic benchmark 复合基准程序system testing 系统测试Systolic 脉动阵列table 表表格桌子TDM(time division multiplexing) 时分多路复用technology 工艺技术terminal 终端testing phase 测试阶段theta select project theta join θ选择投影θ连接time complexity 时间复杂度timestamping 时标技术Token Bus 令牌总线Token Ring 令牌环toy benchmark 简单基准程序transaction 事务记录transmite 传送transport layer session layer 传输层会话层traversal method 遍历方法triggers store procedures 触发器存储过程(ORACLE 系统)underflow 下溢unique 唯一的unit system acceptance testing 单元测试系统测试确认测试universe 宇宙全世界update 更新value [数]值variable 变量vertical 垂直的vertice edge 顶点(结点) 边via 经过virtual memory system 虚拟存储系统WAN(wide area network) 广域网waterfall model 瀑布模型white noise 白噪声write-back(copy-back) 写回法write-through(store-through) 写直达法WWW(world wide web) 万维网。
(2021年)安徽省阜阳市全国计算机等级考试网络技术真题(含答案)

(2021年)安徽省阜阳市全国计算机等级考试网络技术真题(含答案) 学校:________ 班级:________ 姓名:________ 考号:________一、单选题(10题)1.2.下列关于SNMP操作的描述中,正确的是()。
A.只有团体字的访问模式是read的条件下才能实现Set操作B.当出现自陷情况时,代理会向管理站发出包含团体字和SetResponsePDU的报文C.当管理站需要查询时,就向某个代理发出包含团体字和SetResponsePDU的报文D.代理使用Inform方式执行Notification操作时需要收到管理站发出的一条确认消息3.关于目录索引搜索引擎,下列哪种说法是不正确的()。
A.目录索引搜索引擎的缺点是需要人工介入、维护量大、信息量少、信息更新不及时B.目录索引搜索引擎是真正的搜索引擎C.目录索引搜索引擎是以人工方式或半自动方式搜集、编辑、分类、归档信息,以便查询D.目录索引搜索引擎因为加入了人的智能,所以信息准确、导航质量高4.按照ITU-T标准,传输速度为622.080Mbps的标准是()。
A.OC-3B.OC-12C.OC-48D.OC-1925.下列关于网络接入技术和方法的描述中,错误的是()。
A.“三网融合”中的三网是指计算机网络、电信通信网和广播电视网B.宽带接入技术包括xDSL、HFC、SDH、无线接入等C.无线接入技术主要有WLAN、WMAN等D.Cable Modem的传输速率可以达到10一36Mbps6.下列对VLAN的描述中,错误的是()。
A.VLAN IDl—1005是标准范围,1025—4096是扩展范围B.可用于Ethernet的VLAN ID为l一1000C.VLAN name用32个字符表示D.IEEE 802.1 Q标准规定,VLAN ID用16比特表示7.千兆以太网的传输速率是传统的10Mbps以太网的100倍,但是它仍然保留着和传统的以太网相同的( )。
操作系统-第六章 文件系统习题(有答案)

第六章文件系统一.单项选择题1.操作系统对文件实行统一管理,最基本的是为用户提供( )功能。
A.按名存取 B.文件共享 C.文件保护 D.提高文件的存取速度2.按文件用途分类,编译程序是( )。
A.系统文件 B.库文件 C.用户文件 D.档案文件3.( )是指将信息加工形成具有保留价值的文件。
A.库文件 B.档案文件 C.系统文件 D.临时文件4.把一个文件保存在多个卷上称为( )。
A.单文件卷 B.多文件卷 C.多卷文件 D.多卷多文件5.采取哪种文件存取方式,主要取决于( )。
A.用户的使用要求 B.存储介质的特性C.用户的使用要求和存储介质的特性 D.文件的逻辑结构6.文件系统的按名存取主要是通过( )实现的。
A.存储空间管理 B.目录管理 C.文件安全性管理 D.文件读写管理7.文件管理实际上是对( )的管理。
A.主存空间 B.辅助存储空间 C.逻辑地址空间 D.物理地址空间8.如果文件系统中有两个文件重名,不应采用( )结构。
A.一级目录 B.二级目录 C.树形目录 D.一级目录和二级目录9.树形目录中的主文件目录称为( )。
A.父目录 B.子目录 C.根目录 D.用户文件目录10.绝对路径是从( )开始跟随的一条指向制定文件的路径。
A.用户文件目录 B.根目录 C.当前目录 D.父目录11.逻辑文件可分为流式文件和( )两类。
A.索引文件 B.链接文件 C.记录式文件 D.只读文件12.由一串信息组成,文件内信息不再划分可独立的单位,这是指( )。
A.流式文件 B.记录式文件 C.连续文件 D.串联文件13.记录式文件内可以独立存取的最小单位是由( )组成的。
A.字 B.字节 C.数据项 D.物理块14.在随机存储方式中,用户以( )为单位对文件进行存取和检索。
A.字符串 B.数据项 C.字节 D.逻辑记录15.数据库文件的逻辑结构形式是( )。
A.链接文件 B.流式文件 C.记录式文件 D.只读文件16.文件的逻辑记录的大小是( )。
数据结构与算法分析c语言描述中文答案

数据结构与算法分析c语言描述中文答案【篇一:数据结构(c语言版)课后习题答案完整版】选择题:ccbdca6.试分析下面各程序段的时间复杂度。
(1)o(1)(2)o(m*n)(3)o(n2)(4)o(log3n)(5)因为x++共执行了n-1+n-2+??+1= n(n-1)/2,所以执行时间为o(n2)(6)o(n)第2章线性表1.选择题babadbcabdcddac 2.算法设计题(6)设计一个算法,通过一趟遍历在单链表中确定值最大的结点。
elemtype max (linklist l ){if(l-next==null) return null;pmax=l-next; //假定第一个结点中数据具有最大值 p=l-next-next; while(p != null ){//如果下一个结点存在if(p-data pmax-data) pmax=p;p=p-next; }return pmax-data;(7)设计一个算法,通过遍历一趟,将链表中所有结点的链接方向逆转,仍利用原表的存储空间。
void inverse(linklist l) { // 逆置带头结点的单链表 l p=l-next; l-next=null; while ( p) {q=p-next; // q指向*p的后继p-next=l-next;l-next=p; // *p插入在头结点之后p = q; }}(10)已知长度为n的线性表a采用顺序存储结构,请写一时间复杂度为o(n)、空间复杂度为o(1)的算法,该算法删除线性表中所有值为item的数据元素。
[题目分析] 在顺序存储的线性表上删除元素,通常要涉及到一系列元素的移动(删第i个元素,第i+1至第n个元素要依次前移)。
本题要求删除线性表中所有值为item的数据元素,并未要求元素间的相对位置不变。
因此可以考虑设头尾两个指针(i=1,j=n),从两端向中间移动,凡遇到值item的数据元素时,直接将右端元素左移至值为item的数据元素位置。
基于后验概率制导的B-KNN文本分类方法

[ e o d lt t a g r a o ; ot i o a i y B y s n l s i ; e et e h o( N ) e o ; — N e o K y r s x ct oi t n p s r r rbbl ; a e a a ie K N a sN i b r N m t d B K N m t d w e e zi e op i t i c sfr r g K h h
Z H0U n - a , U Y n ・a g Ho gj n Z o gR n u
( c o l f o ue & I fr t n Hee ie s yo e h oo y H fi 3 0 9 Chn ) S h o mp tr no mai , fi v r t f c n lg , e e 2 0 0 , ia oC o Un i T
口 _ 旦_
U
间层类型结点仅保存其孩子类型结点的 I , D 而底层类型结点
则直接存储该 类型 训练样本 的位置信息。 对于带文本类型层 次的先验信息 的文本数据库或带 有多 重类型标 记的文本数据库 , 应用 H s 表技术 , ah 只需扫描一遍 数据库 , 即可构建多路静态搜索树拓扑结构并收集 后验概率 。
本分布 的不均匀性也会给分类准确率造成一 定的影 响。降低 K N 的计算量主要有 2种方法 :1对原 始训练样 本集进行抽 N ()
测试文本 d ,通过计算它与训练集中每个样本文本的相似性
来寻找其 个最近 的邻居 ;然后在 个最近邻 中,采用投票 或积分 的策略统计 出它与各个文本类型的相似度 ,返回相似 度最大 的类型作为 d的类型标签。
K NN分类 是一种基于要求的或懒惰的学 习方法 , 它存放 所有 的训练样本 ,直到测试样本需要分类时才建立分类 ,这
利用快速索引根据关键词快速定位文档中的特定内容

利用快速索引根据关键词快速定位文档中的特定内容文档索引是一种非常有用的工具,它可以帮助我们在大量文档中快速找到所需的特定内容。
不论是在学术研究、技术手册、法律文件还是其他领域,索引都可以提供高效的查询和定位功能。
本文将讨论如何利用快速索引根据关键词快速定位文档中的特定内容,并介绍一些实用技巧和注意事项。
一、什么是快速索引快速索引是一种按照关键词对文档内容进行分类和标记的方法。
索引通常位于文件的末尾,它以字母顺序排列,并提供了与关键词相关内容的页码或章节号。
通过查阅索引,读者可以快速找到特定关键词所在的位置,从而节省时间和精力。
二、创建快速索引的方法1. 选择关键词:在创建索引之前,首先需要确定文档中与所需内容相关的关键词。
这些关键词通常是文档的核心概念、重要术语或经常被提及的名词短语。
2. 定位关键词:阅读整篇文档,找到每个关键词所在的页码或章节号,并记录下来。
一些文档处理软件如Microsoft Word提供了自动生成索引的功能,可以更加便捷地定位关键词。
3. 整理索引:按照字母顺序整理关键词列表,同时确保每个关键词后面都有正确的页码或章节号。
可以使用电子表格软件或索引生成工具来帮助整理和格式化索引。
三、如何使用快速索引1. 首先,打开文档并跳转到索引所在位置。
索引通常在文档末尾,可以通过滚动页面或使用书签功能快速到达。
2. 在索引中找到目标关键词,并记住对应的页码或章节号。
3. 切换回文档正文,在页面上使用查找功能(通常是Ctrl + F快捷键)输入关键词,并定位到所需内容所在的位置。
4. 阅读或提取所需内容,并根据需要进行保存或处理。
四、快速索引的注意事项1. 确保关键词的准确性:在创建索引时,务必保证关键词的准确性和全面性。
如果索引中漏掉了某个关键词,将会影响到后续的查询和定位。
2. 及时更新索引:如果文档内容发生了修改或者添加了新内容,需要及时更新索引。
一个过时的索引可能导致找不到所需内容,降低查询效率。
压缩语句之提取关键词

03 关键词提取的实践
关键词提取的步骤
确定主题
首先明确文章的主题或话题,以便确定需要 提取哪些关键词。
精读文章
仔细阅读文章,理解其内容,并找出与主题 相关的关键词。
筛选关键词
从文章中筛选出最能代表主题和内容的关键 词,排除无关紧要的词汇。
整理关键词
将筛选出的关键词进行整理,形成有逻辑关 系的关键词列表。
利用人工智能技术
利用人工智能技术,如深度学习、神 经网络等,可以自动学习和识别关键 词,提高提取的效率和准确性。
05 关键词提取的应用前景
关键词提取在信息检索中的应用
搜索引擎优化
关键词提取技术可以帮助搜索引 擎更准确地理解网页内容,提高 搜索结果的准确性和相关性。
个性化推荐
通过关键词提取,可以分析用户 搜索和浏览行为,为其提供个性 化的内容推荐和广告服务。
以确定关键词。
基于机器学习的方法
03
利用训练数据,通过机器学习算法训练关键词提取模型,实现
对新文本的关键词提取。
关键词提取的算法
TF-IDF算法
计算每个词在文本中的出现频率和逆向文档频 率,以评估其重要性。
TextRank算法
利用图算法和排序理论,对文本进行关键词提 取。
LSA算法
利用潜在语义分析,通过矩阵分解和降维,提取文本中的关键词。
关键词提取在自然语言处理中的应用
文本分类与聚类
关键词提取可以用于对文本进行分类 和聚类,将相似的文本归为一类,便 于信息组织和检索。
情感分析
通过关键词提取,可以分析文本中所 表达的情感倾向,用于舆情监控、产 品评价等领域。
关键词提取在社交媒体分析中的应用
用户行为分析
如何使用剪枝技术优化算法

如何使用剪枝技术优化算法随着数据量和模型复杂度的增加,算法的效率成为一个越来越重要的问题。
剪枝技术是一种常用的优化算法效率的方法,本文将介绍如何使用剪枝技术优化算法。
一、剪枝技术的基本概念和原理剪枝技术是指在搜索算法、分类算法、关联规则挖掘等领域中,通过剪去不需要考虑的部分来降低算法复杂度和提高效率的一种技术。
剪枝技术的基本原理是通过一定的判断条件,减少算法的搜索空间,从而达到优化算法的效果。
剪枝技术分为静态剪枝和动态剪枝两种。
静态剪枝是指在算法执行前就进行筛选,剪去不必要的分支,从而减少计算量;动态剪枝是在算法执行过程中对搜索空间进行剪枝,根据算法实际情况和需求动态地调整搜索空间。
在具体的算法实现中,剪枝技术可以采用多种方式,如减枝、约束传播、启发式剪枝等。
减枝是指根据预设的规则,剪去不需要考虑的分支,减少搜索空间。
约束传播是指根据算法中的局部约束条件,预处理出所有合法的方案,从而在搜索过程中减少计算量。
启发式剪枝是指利用启发式算法的思想,通过剪枝引导搜索过程,从而更快地找到最优解。
二、如何使用剪枝技术优化算法1. 确定优化目标在使用剪枝技术优化算法前,需要明确优化目标。
优化目标可以是算法的时间复杂度、空间复杂度、正确率等,也可以是多个因素的综合考虑。
只有明确了优化目标,才能更有针对性地进行剪枝。
2. 选择适当的剪枝策略在使用剪枝技术时,需要选择适当的剪枝策略。
不同的算法适合不同的剪枝策略。
例如,在搜索算法中,可以采用启发式剪枝、减枝等方式;在分类算法中,可以采用预剪枝、后剪枝等方式;在关联规则挖掘中,则可以采用约束传播等方式。
3. 优化剪枝条件剪枝技术的效果取决于剪枝条件的选择。
对于一个给定的算法,需要深入了解算法中各个环节的特点和规律,选取合适的剪枝条件。
另外,对于动态剪枝,还需要根据具体情况动态地调整剪枝条件。
4. 结合其他优化方式剪枝技术是一种常用的优化算法的方式,但并不是万能的。
在实际应用中,还需要结合其他优化方式,如并行计算、缓存优化、矩阵压缩等,来达到更好的优化效果。
关键词提取算法在文本分类中的使用技巧

关键词提取算法在文本分类中的使用技巧在信息时代,大量的文本数据被生成和积累,如何高效地处理和分类这些文本数据成为了重要的研究领域。
文本分类是一种将文本分配到预定义的类或类别中的任务,它对于自然语言处理、信息检索和机器学习等领域具有广泛的应用。
在文本分类任务中,关键词提取算法起着重要的作用。
关键词提取算法可以将文本中的关键信息提取出来,为文本分类模型提供重要的特征。
本文将介绍关键词提取算法在文本分类中的使用技巧,并探讨其优化策略。
一、常见的关键词提取算法1. TF-IDF算法TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的关键词提取算法。
它通过统计词频和逆文档频率来评估一个词对于文本的重要程度。
在文本分类任务中,我们可以通过计算每个词的TF-IDF值来衡量其在文本中的重要性,并将TF-IDF值高的词作为关键词提取出来。
TF-IDF算法简单易用,并且可以有效防止常见词汇的干扰。
2. TextRank算法TextRank算法是一种基于图的排序算法,在文本摘要和关键词提取任务中广泛应用。
它通过构建单词之间的图结构,并使用PageRank算法对单词进行排序,从而得到关键词。
TextRank算法可以自动发现文本中的重要词汇,并且可以捕捉单词之间的语义关系,因此在文本分类任务中有较好的效果。
3. LDA算法LDA(Latent Dirichlet Allocation)是一种生成模型,主要用于主题建模任务。
在文本分类中,LDA算法可以用来提取文本的主题特征,从而作为关键词提取的依据。
LDA算法能够发现文本中隐藏的主题,并将文本表示为主题的分布,进而提取主题关键词。
不过,LDA算法在计算上较复杂,需要充分考虑模型参数的选择和训练过程的调优。
二、关键词提取算法的使用技巧1. 数据预处理在使用关键词提取算法之前,需要对文本数据进行预处理。
常见的预处理步骤包括去除标点符号、停用词和数字,进行词干化或词形还原等。
浙江省杭州市2019届高考技术命题比赛试题7
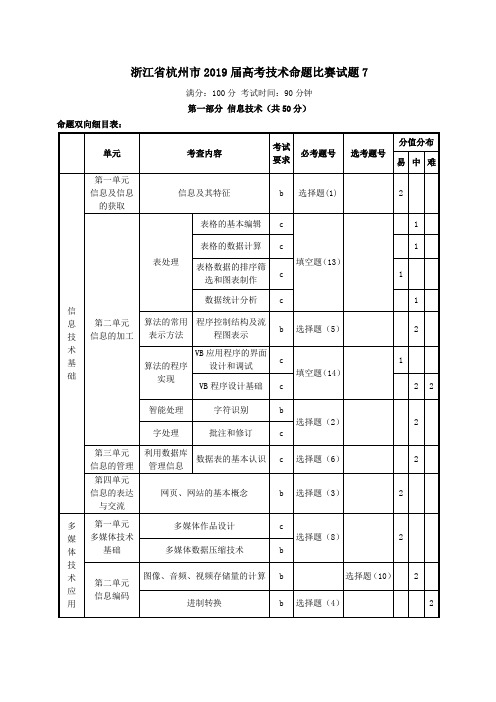
浙江省杭州市2019届高考技术命题比赛试题7满分:100分考试时间:90分钟第一部分信息技术(共50分)命题双向细目表:一、选择题(本大题共12小题,每小题2分,共24分。
每小题列出的四个备选项中只有一个是符合题目要求的,不选、多选、错选均不得分)1.【原创】浙江省已经实行了学生学费的网上缴纳功能,缴费管理平台对每个学生应缴费用都会生成一个独立二维码,只要扫描对应二维码就可利用支付宝实现缴费,对此下列说法正确..的是( ) A.平台生成的二维码是信息。
B.“扫一扫”二维码,是信息编码的过程。
C.缴费成功后,再次扫描该二维码无法进行二次缴款,体现了信息的时效性。
D.为了扫码时不受清晰度影响,二维码必须以矢量图方式存储。
参考答案:C 预设难度值:0.75命题意图与解析:本题意图联系生活实际,考核有关信息的概念和特征等基本知识。
二维码是信息的载体,扫码是信息获取的过程,缴费成功后缴费信息实现了更新是信息时效性的体现,大部分二维码都采用位图形式存储。
2.【原创】小张利用手机拍摄得到“梦与颜色.jpg ”图像,使用OCR 软件进行字符识别,然后使用Word 软件编辑识别后的文档,界面分别如下图所示:下列说法不正确...的是( ) A.字符识别过程应用了人工智能技术,图像的清晰度会影响识别率。
B.由于拍摄得到的图像倾斜过大会影响识别率,所以需先进行版面分析。
C.在进行Word 编辑时,发现有识别错误,可能是小张在导出前未进行校对工作。
D.从图2可知,小张在编辑时开启了修订功能,此处有两处修订。
参考答案:B 预设难度值:0.65命题意图与解析:本题意图考核有关OCR 识别和Word 的相关知识。
如果得到的图像倾斜过大,应在版面分析之前进行倾斜校正。
3.【原创】下列说法正确..的是()第2题-2图第2题-1图A .网页是由HTML 语言描述的,可以由IE 浏览器进行编辑和执行。
B .我们可以利用收藏夹把网页上喜欢的内容保存下来。
剪枝算法综述

剪枝算法综述
x
介绍
剪枝算法是一类从评价值最优化问题中获得最优解的算法,是机器学习和搜索引擎的重要基础,其结果可以用于优化计算机程序、算法以及计算机系统的性能。
它的本质是探索检索空间以找到最优解的方法。
剪枝算法的主要功能是消减搜索空间,通过消减搜索空间来获取最优解。
它通过对搜索树进行搜索,避免了在不必要的节点上浪费资源,最后得到更好的搜索效果。
剪枝算法分为两类。
一类是前剪枝算法,它的原理是在搜索树中寻找最佳点,在搜索到最佳点时,舍弃比它低的点,从而减小搜索空间;另一类是后剪枝算法,它的原理是在所有子树被访问完后,删除没有影响最终结果的节点,从而减小搜索空间。
剪枝算法的典型应用如下:
1.最优组合搜索:可以使用剪枝算法找出给定数据集中可能存在的最优解。
2.图像特征提取:可以使用剪枝算法从图像中提取最有价值的特征集合。
3.机器学习:可以使用剪枝算法减少模型的复杂度,从而提高模型的精度和效率。
剪枝算法具有计算效率高、性能优良以及易于实现等特点,广泛
应用于计算机科学中的优化问题处理中。
其结果可以有效提升计算机系统的性能,实现极致优化。
llama index 切割文本段 建索引原理 提供索引

llama index 切割文本段建索引原理提供索引【实用版】目录一、引言二、llama index 的原理和作用三、切割文本段四、建索引原理五、提供索引六、结论正文一、引言在知识爆炸的时代,有效地管理和检索信息变得尤为重要。
为了提高信息检索的效率,我们通常需要对大量的文本进行处理。
llama index 作为一种高效的文本处理工具,可以快速地对文本进行切割、建索引和提供索引。
本文将从这三个方面详细介绍 llama index 的原理和应用。
二、llama index 的原理和作用llama index,全称为“Log-linear Linguistic Modeling with Added Memory”,即带记忆的逻辑线性语言建模,是一种基于统计模型的文本处理方法。
它的主要作用是对大量文本进行有效的分析和处理,为信息检索提供便利。
llama index 通过对文本进行建模,可以有效地提取文本的关键信息,从而为检索系统提供索引。
三、切割文本段在构建 llama index 之前,首先需要对原始文本进行处理。
llama index 采用一种基于词频的切割方法,将原始文本切分成为若干个文本段。
在这个过程中,llama index 会根据预先设定的词频阈值,将文本中出现频率较高的词汇作为切割点,从而将文本切分成为多个有意义的文本段。
四、建索引原理在建立索引的过程中,llama index 采用了一种基于统计模型的方法。
它首先会对每个文本段进行建模,通过计算词汇的概率分布,得到每个词汇在文本段中的重要程度。
然后,llama index 会根据这些重要程度,为每个词汇建立一个索引。
在这个过程中,llama index 还会利用一些记忆机制,如“added memory”,来提高索引的效率和准确性。
五、提供索引在建立索引之后,llama index 可以提供基于关键词的检索功能。
用户可以通过输入关键词,快速地定位到相关文本段。
搜索引擎关键技术——文本处理

按照扫描方向的不同,可分为正向匹 配和逆向匹配;按照不同长度优先匹配的 情况,可分为最大匹配和最小匹配;按照 是否与词性标注过程相结合,可分为单纯 分词方法和分词与标注相结合的一体化方 法。
于“网络机器人”,但其收集信息的效率及全 面性低于“网络机器人”。
2.信息预处理技术
信息预处理系统的主要工作是从抓取的网页 中提取能够代表网页的属性,并将这些属性组成 网页的对象,然后根据一定的相关度算法进行计 算,得到每一个网页针对页面内容及链接每一个 关键词的相关度,并用这些信息建立索引数据库。
c. 基于统计的分词方法
从形式上看,词是稳定的字的组合, 因此在上下文中,相邻的字同时出现的次 数越多,就越有可能构成一个词。因此字 与字相邻共现的频率或概率能够较好地反 映成词的可信度。
于是可以对语料中相邻共现的各个字 的组合的频度进行统计,计算它们的互现 信息。互现信息体现了汉字之间结合关系 的紧密程度。当紧密程度高于某一个阈值 时,便可认为此字组可能构成了一个词。
•词干提取方法
a. 查表法 b. 词缀删除法 c. 后继变化数 d. N个字符列
应用最多的,最实际的词干提取方法 是去除词缀法。
Porter算法是最著名的词缀去除方法。
5.索引词选择
并不一定对文档中出现的所有词条都 建立索引,而是选择一些比较重要的词条 来建立索引。
• 科技文献一般由专家来选择索引词汇,方 法准确,但需消耗大量人力;
现在常用的做法是保留一些专门指出 的(通过与正规表达式的匹配)数字,而 将其他数字过滤掉。
• 连字符
国科大自然语言处理作业 词语切分 (2)

国科大自然语言处理作业词语切分引言概述:自然语言处理是人工智能领域的一个重要分支,而词语切分是其中的一个基础任务。
国科大自然语言处理作业中,词语切分是一个重要的实践项目。
本文将从五个大点出发,详细阐述词语切分的相关内容。
正文内容:1. 词语切分的定义和意义1.1 词语切分的定义:词语切分是将连续的文本序列切分成有意义的词语的过程。
它是自然语言处理中的基础任务,对于后续的语义分析、机器翻译等任务具有重要意义。
1.2 词语切分的意义:词语切分可以提取文本中的重要信息,帮助理解文本的含义。
对于机器翻译等任务,准确的词语切分可以提高翻译的质量和准确性。
2. 词语切分的方法和技术2.1 基于规则的方法:基于规则的方法是通过定义一系列规则来切分词语,例如根据空格、标点符号等进行切分。
这种方法简单直观,但对于复杂的语言现象处理效果有限。
2.2 基于统计的方法:基于统计的方法利用统计模型来学习词语切分的规律,例如使用隐马尔可夫模型(HMM)等。
这种方法可以处理复杂的语言现象,但需要大量的标注数据和计算资源。
2.3 基于深度学习的方法:基于深度学习的方法利用神经网络模型来学习词语切分的规律,例如使用循环神经网络(RNN)等。
这种方法可以自动学习特征,并在大规模数据上取得较好的效果。
3. 词语切分的挑战和问题3.1 歧义性:词语切分中存在歧义性,即一个文本序列可以有多种切分方式。
如何解决歧义性成为一个挑战。
3.2 未登录词:未登录词是指在训练数据中未出现的词语,如何准确切分未登录词也是一个问题。
3.3 外文词语:在中英文混合的文本中,如何准确切分外文词语也是一个挑战。
4. 词语切分的评价指标4.1 准确率:准确率是指切分结果中正确切分的词语数量与总切分词语数量的比例。
4.2 召回率:召回率是指切分结果中正确切分的词语数量与标准切分结果中的词语数量的比例。
4.3 F1值:F1值是准确率和召回率的调和平均值,综合考虑了切分结果的准确性和完整性。
信息技术(第一册)试题及答案

信息技术(第一册)试题及答案信息技术试题(第一册)选择1.下面做列出的游戏中,属于鼠标点击内容的游戏是(),属于鼠标拖拽内容的游戏是()。
A、扫雷B、蜘蛛纸牌、三维弹球D、超级玛丽2.以下光标形式中,代表系统忙的是()A、B、、D、3.金山画王图库中的“背景”默认风格是()A、水彩风格B、油彩风格、漫画风格D、矢量风格4.金山画王默认的画笔是()A、喷笔B、水彩笔、蜡笔D、铅笔+E、粉笔.在文本文档中输入上档字符时,需要先点住一下哪个按键()A、EnterB、Shift、AltD、trlE、apsL6.下面有计算机自动组词功能的拼音输入法是()A、智能ABB、微软拼音输入法、紫光华宇输入法D、全拼输入法7.一下按键,在输入文本时有另起一行功能的是()A、BaSpaeB、Shift、DeleteD、trlE、Enter8.文本文档中删除光标左面的字符应该用下面哪个按键()A、DelB、Delete、BaspaeD、Shift9.键盘上哪个按键替代了汉语拼音方案中的“ü"()A、UB、Shift+U、VD、trl+U10.以下网址中,不是搜索引擎的是()A、http://ailzxxedunB、http://gglen、http://baiduD、http://shu填空1.用金山画王绘制作品,首先要插入背景,首先应该点击()按钮,再选择()按钮,然后再选择背景的风格以及具体背景。
2.金山画王中,插入角色之后,因为角色图片并不能完全适合背景,所以需要对角色图片进行调整,调整按钮中的作用是(),的作用是(),的作用是(),的作用是()。
3.金山画王“画板"工具中的“区域"及“操纵器",能够对整个图层或某个范围内的图层进行()、()、()等操作。
4.键盘上的“基准键"一共有()个,分别是()。
.智能AB输入状态下,在输入框输入拼音之后并不出现选字框,这时候需要点击一下()键,就能出现选字框。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
华南理工大学学报(自然科学版)第39卷第4期Journal of South China University of TechnologyVol.39No.42011年4月(Natural Science Edition )April 2011文章编号:1000-565X (2011)04-0001-06收稿日期:2011-01-09*基金项目:国家自然科学基金资助项目(60933004);广东省计算机网络重点实验室资助项目(CCNL200601);“核心电子器件、高端通用芯片及基础软件产品”国家科技重大专项项目(2011ZX01042-001-001)作者简介:李晓明(1957-),男,教授,主要从事网络信息搜索与挖掘研究.E-mail :lxm@pku.edu.cn 基于文档重要度的静态索引剪枝方法*李晓明单栋栋(北京大学信息科学技术学院,北京100871)摘要:针对网页质量参差不齐、重要程度差别巨大的问题,提出了按照网页重要程度确定其剪枝幅度的静态索引剪枝方法,并在GOV2数据集上进行了验证.实验结果表明:这种方法体现了静态索引剪枝能极大降低存储需求、提高查询效率的优点;当剪枝后的索引大小是原始大小的13%时,P@10、P@20值能达到甚至超过使用完整索引时的结果;在相同的剪枝幅度下,P@10、P@20和MAP 都明显好于以往的剪枝方法.关键词:搜索引擎;倒排索引;静态索引剪枝;文档重要度中图分类号:TP391doi :10.3969/j.issn.1000-565X.2011.04.001自万维网诞生以来,网页数量呈指数趋势增长[1].搜索引擎为了保持其索引网页信息的全面性,需要爬取的信息量越来越大,从而导致支持用户查询的网页索引越来越大,对存储和性能都形成了越来越大的压力.这对搜索引擎提出了一个新的挑战:一方面,由于搜索引擎索引网页数量的增加,其需要更多的资源或者时间来处理用户提交的查询;另一方面,用户希望搜索引擎能在非常短的时间内返回高质量的结果.随着搜索引擎用户数量的不断增长,搜索引擎通常会在检索的效果与效率上做一个折中,使其能既快又好地服务大量用户.通常用户在使用搜索引擎时,往往只关心其返回的前若干条结果,这样搜索引擎不需要完整地给出与用户查询相关的所有信息,而只需要找出那些最相关的信息.搜索引擎通常使用索引剪枝技术来提升查询的处理速度,通过剪枝;留下那些与用户查询最相关的信息,从而快速响应用户的查询.另外,由于互联网的开放式特点以及所蕴含的巨大商业利益,在其信息不断增加的同时,信息的质量也变得越来越参差不齐,从很有权威性和信誉度,到商业竞争的“灌水”,质量跨度很大.将它们都搜集并索引起来,不仅会使上述资源消耗、查询效率等问题更严重,而且也会影响查询的效果(即用户对返回信息的满意度).因此,若能通过索引剪枝剪掉那些垃圾网页的信息,使它们不出现在索引中、不能返回给用户,也就隐含着搜索引擎质量的提高.如果每篇文档有一个重要度指标(例如来自权威和信誉好的网站的网页重要度高,垃圾网页重要度低),那么在索引剪枝的时候参考这个指标(重要的网页多保留一些信息,不重要的少保留一些信息),就有可能在提高访问效率的同时也改善查询效果.基于上述出发点,文中在构建索引的过程中,利用文档的重要度(包含网页的权威性及其内容的有用性两个方面)来决定每篇文档保留在索引中的信息量,并通过大规模数据实验来验证这种方法的有效性.1相关工作与背景知识倒排文件,或称倒排索引,是搜索引擎的核心数据结构,它是文档“词袋子”模型的一种具体体现[2].为了便于后面的阐述,首先介绍若干关键术语和概念.D :文档集合,D ={d 1,d 2,…};其中每个文档d i 被看成是一组词语(term ,word )的集合(“词袋子”模型假设);∑:所有文档的词语集合的并集,∑=∪d i ,亦称为词典.于是,对于每一个索引词语t !∑,对应有D 的一个子集,D (t )={d !D t !d },亦称为“posting list ”.这样,所谓“倒排索引”则可看成是由D 、∑和所有D (t )(t !D )构成的一个系统.这些概念及其关系的示意图如图1所示.图1倒排索引结构示意图Fig.1Schematic diagram of invert index structure文中着重关注这样一个结构在计算机中存放的代价问题,因为它既涉及空间资源的占用,也影响查询访问时间的长短.现代搜索引擎需要索引的文档数在百亿量级(1010),若一篇文档平均包含102个不同的词语,则这个系统所需的存储在1012量级(姑且不考虑存储单位);如果词项总数在千万量级(107),则图中每条链的长度平均为105量级(在实际典型系统中,这个长度符合Zipf 定律).所谓索引剪枝,就是要合理地从这个结构中去掉一些内容(信息),以缩小其存储规模.索引剪枝方法通常可以分成两类:静态索引剪枝[3-7]与动态索引剪枝[6-10].静态索引剪枝是在索引的构建过程中,去除那些在查询处理过程中很可能不会被用户关心或者说对用户不重要的信息,从而得到较小的索引结构,这样既节省了存储空间,又提高了访问速度.显然,由于静态索引剪枝是在索引构建阶段完成的,对用户查询信息的先验知识较少,难以很好地区分信息的重要程度,因而若剪枝幅度较大的话会对检索效果有一定的影响.通常,从提高访问速度的要求出发,人们希望剪枝后的结果最好能放到内存中,因此剪枝幅度会比较大,例如保留下来的内容不到未剪枝的20%.因此,争取留下比较重要的20%的内容就是一个关键问题.动态索引剪枝技术又称为查询提前截断,其要点是:索引存储的内容并不减少,但在处理查询的过程中,当满足一些属性条件后,查询就会被认为已经处理完毕,因此不需要处理与查询相关的所有信息.动态索引剪枝的优点是剪枝过程发生在查询处理阶段,这时知道的查询信息比较多,容易计算信息的重要度,一般不会影响最终查询的效果;缺点是依赖于倒排索引的结构,例如要求倒排索引中的倒排链按特定属性有序排列[10],才能根据属性值的变化趋势决定何时做截断.从查询速度的要求来看,动态剪枝往往只能用较少的属性作为剪枝的条件,而返回结果的排序算法往往会使用很多属性,特别是使用查询词之间的关联信息(例如查询词在文档中的接近程度)时,动态剪枝的效果并不是很好.另外,文档相关性计算公式中参数的改变对动态剪枝的速度影响也比较大.文中主要讨论静态索引剪枝的方法.静态索引剪枝主要有3种方法:以词语为中心的剪枝(TCP )方法[3],以文档为中心的剪枝(DCP )方法[4]和以倒排项为中心的剪枝(PCP )方法[5].这些方法的目的都是要缩短图1中倒排链(倒排表)的长度,不同之处在于其关注的角度.参考图1,能够容易地理解它们的要点.TCP 法关注的是一个个索引词语(t ),要缩短图中与词语对应的链的长度,也就是要减小集合D (t )的大小.核心思想是以t 为出发点,按照某种方法给D (t )中的每篇文档针对t 打分(即量化t 在D (t )中的相对重要性),保留若干分数较高的,对不同的词语保留的文档个数可以不一样.DCP 法也是要缩短倒排链的长度,但出发点是每篇文档.核心思想是看一篇文档中不同词语的相对重要性(也是按某种方式打分),保留若干分数较高的词语,其数量对于每个文档可以是一个固定值或者是与文档长度相关的值.PCP 法有些不同,它直接对每个倒排项做全局的重要性判断(也是按某种方式打分),取前J 个倒排项放入剪枝后的索引系统中.这种方法的主要问题是倒排项的全局分数比较难计算,另外,实验表明[5]PCP 效果与TCP 和DCP 相近.还有一些比较简单的剪枝方法,例如直接把高频词从索引中去除等[11].2华南理工大学学报(自然科学版)第39卷综上分析可见,这3类方法都没有考虑每一篇文档(d)在总体文档集合(D)中的相对重要性,这在传统信息检索环境下(例如图书馆的图书文献检索)可能是合理的,因为很难说图书馆中哪本书就不重要.但在互联网环境下,网页文档质量跨度很大,有些如同经典一样权威和重要,另一些则根本就是垃圾(从而在任何情况下都不应该被检索出来).于是文中提出如下两点假设:(1)对于大规模网页文档集合D={d1,d2,…},若要求只保留每篇文档的部分信息以减少存储,则按照文档相对重要性确定每篇文档保留的信息量,要比只考虑词语在文档中的重要性确定保留的信息量得到的结果具有更高的查询价值.(2)对于大规模网页文档集合D={d1,d2,…},若按照文档相对重要性来确定保留每篇文档的部分信息量,得到的结果不仅存储需求大大减少,而且也比原始文档集合具有更高的查询价值.2文档重要度的计算本研究的核心观点是考虑利用文档的重要度来决定其保留的信息量.所谓每一篇文档包含的信息,按照“词袋子”模型,就是它所包含的词语的集合,信息量则可以看成是该集合的大小,“剪枝”即为从该集合中去掉一些词语.对于一个网页文档的重要度估算,可以从文档之间的链接关系、文档内容以及用户使用文档的方式这3个角度来衡量,分别称之为文档的权威性、内容的有用性和用户的关注度.用户倾向于相信权威性高的网页包含的信息.通常认为一个被较多重要网页链向的网页具有较高权威性,可用PageRank、HITS、SpamRank等算法来计算.文中使用PageRank算法[12],即每一网页(p i)的PageRank值(PR)由式(1)得到:PR(pi )=1-"C+"∑p j!In(p i)PR(pj)Out(pj)(1)式中:In(pi )为所有链向页面pi的网页的集合;Out(pj)为页面pj链出网页的集合;C为文档集合中网页的总数;"为随机游走因子,在这里取0.85.对于网页内容的有用性,用单个页面与整个网页集合的相似度来表示.一种观点认为,一个文档与整个数据集越相似,就越能代表整个数据集.因此,那些相似度高的文档在数据集中的重要性就较高.鉴于此,认为一篇文档与数据集的相似度是它在整个数据集中重要度的体现.当然,也可能有相反的观点,即认为一篇文档越是与集合中其他的不一样,其价值(新颖性)对于集合就越大.但这对本研究影响不大,文中只需要找到一种能支持上述两个假设的方法,而不一定要找到最优的方法.相似度的计算方法有很多,例如TF*IDF、语言模型等.文中用KL散度来计算.KL散度是衡量两个分布之间差异的一个指标,差异越大,其值也越大.为每篇文档和整个文档集建立语言模型P和Q,那么文档与文档集的KL散度值可以通过式(2)计算:KL D(d,D)=KL D(P,Q)=∑t!TP(t)·(lg P(t)Q(t))(2)式中:T为整个文档集中的词集合;P为文档d对应的语言模型;Q为文档集D对应的语言模型.用户对网页的关注度是另一个衡量网页重要度的指标.一个网页被越多用户关注,其重要性往往越高于一个没人访问的网页.在计算用户关注度时,可以利用搜索引擎中的查询点击日志,一个被经常点击的网页得到的关注往往比很少被点击的网页要高.另外,还可以从网站自身的访问日志中获取用户访问网页的信息.所以,可以定义用户的点击频率或访问次数为网页被关注的程度.3实验过程与结果分析本节的目的是希望验证前文提出的两个假设.其中,“查询价值”是一个关键概念,需要在实验设计中予以体现.给定一个代表着某些文档集合的信息集合,什么是它的“查询价值”?比较容易考虑的,就是在其上建立一个搜索引擎,用该搜索引擎对用户查询满足的程度来代表集合的查询价值,这也就是本研究的出发点.这样做的一个最大好处,除了比较容易理解外,实验可以利用公认的评测数据集以及采用经典的查询效果评价指标,例如P@N、MAP等.3.1实验步骤使用GOV2数据集作为实验数据[13].GOV2数据集包含2004年初美国政府域名下的2500万网页,其主要用于2004—2006年Terabyte TREC任务,数据规模为426G.同时,使用与GOV2数据集一起提供的查询集(701-850)以及对应的文档相关性标注来评测索引剪枝的效果.实验的基准系统是在完整索引上采用BM25来[14]计算一个查询q={q1,q2,…,qn}与一篇文档d的相关性,即3第4期李晓明等:基于文档重要度的静态索引剪枝方法SBM25(q,d)=∑ni=1lgN-n(qi)+0.5n(qi)+0.5·f(qi,d)·(k1+1)f(qi,d)(+k(11-b+b·l d avg(l d)))(3)式中:N为总的文档数;n(qi )为出现查询词qi的文档的个数;f(qi ,d)为查询词qi在文档d中的出现次数;ld 为文档d的长度;avg(ld)为整个文档集中文档的平均长度;k1和b为可调的参数.在基准系统中,当k1=1.2、b=0.4时检索效果最好.文中使用TREC信息检索评测中经常使用的评测指标P@10、P@20和MAP来衡量系统的检索效果.在这3个指标上,基准系统在查询集(701-850)上分别能达0.5550、0.5319和0.3106,其值与TREC公布的其他参加评测的系统具有可比性.Büttcher等[4]发现,在GOV2数据集上,同等剪枝幅度下,采用DCP法剪枝后查询的效果比采用TCP法的好.因此,文中主要与DCP法进行对比.DCP法对索引剪枝的过程可分为4步:(1)对每篇文档与整个文档集建立一元语言模型P与Q;(2)利用式(2)计算文档与文档集的相似度;(3)对文档中的词按其对KL散度贡献度(式(2)中的每一个求和项对应一个词语,其大小则对应该词语对KL散度的贡献度)排序;(4)对每篇文档取前K个词,参与剪枝后的索引.当K固定,例如K=10时,表示每篇文章的前10个词参与索引,这种方法记为DCP_ const;K也可以是百分比,例如10%,表示取前10%词参与索引,这种方法记为DCP_rel.Büttcher等发现DCP_rel的效果优于DCP_const.实验中,使用DCP_rel作为对比.由于文中提出的方法也是针对文档的,要考虑在一篇文档中留下哪些词,因此可以参照DCP法的步骤,但需要对DCP法的第1步与第4步进行修改.在第1步中,首先去除了20个最频繁的词,实现表明去除这些词对检索效果基本没有影响;其次,在构建语言模型的过程中,由于存在数据稀疏问题,只对在文档集中出现频率最高的前100万个词建立语言模型,对于其他词,认为其出现频次很少,不需要对其进行剪枝;这些不需要剪枝的词占总索引大小的3.6%,因此,剪枝后产生的索引大小最小是原始大小的3.6%;实验中,对DCP_rel也做这样的处理,发现其效果比原始的方法好.在第4步中,利用文档的重要度决定为每篇文档保留多少词语,而不是像DCP_rel那样采用一个固定比例.由于文档不同方面(权威性,有用性,关注度等)的重要度值的分布是不一样的,因此,使用了sigmoid函数公式来对这些值进行转换.P(v)=k1+e-(v-m)/s(4)式中:v对应于一个文档的某一方面的重要度;m为坐标的偏离值;k用于控制保留的最大比例;s用于控制函数的平滑性.文献[4]表明,DCP_rel方法在文档中保留10%的词,就能取得非常好的检索效果.所以文中实验限定每篇文档最多可以保留文档中20%的词,最少可以不保留任何信息.文中只使用了文档权威性与内容有用性来衡量文档的重要度,而用户的关注度在GOV2测试集中比较难获得,所以没有具体的体现.对于文档的权威性,利用PageRank计算公式为每个文档计算其重要度,其均值是1.因此在sigmoid函数中,m=1,k= 0.2,参数s主要控制剪枝后索引的大小,这种剪枝方法记为DCP_imp_PR.对于文档内容的有用性,利用式(2)计算出文档的KL散度值.对于KL散度值,文档与文档集越相似,其值越小,当两个分布相同时,KL散度值取得最小值0.因此,取KL散度值的相反数来衡量文档内容的有用性.对于KL散度值的转换,取m=0,k=0.4,同样参数s用于控制剪枝后索引的大小,这种剪枝方法记为DCP_imp_KL.此外,这两种计算文档重要度的方法可以结合以得到文档的综合重要度,相应的方法记为DCP_imp_ comb,其可由式(5)计算:P(d)=αP(PR)+βP(KL)(5)其中:P(PR)是对PageRank值的转换值;P(KL)是对KL散度值的转换值;实验中取α=0.5,β=0.5.3.2结果分析搜索引擎索引结构的大小可自然地用倒排项的个数来衡量.所谓“倒排项”,就是图1中“倒排项”所指的那些实体,它们不是文档本身,但对应一篇文档,包含一些相关信息,需要一定的空间存放.各种不同的索引剪枝方法在不同索引剪枝粒度下的P@10、P@20、MAP的取值如图2-4所示.图2各种剪枝方法在不同保留信息比例下的P@10取值Fig.2P@10values at different pruning levels with different pruning methods4华南理工大学学报(自然科学版)第39卷图3各种剪枝方法在不同保留信息比例下的P@20取值Fig.3P@20values at different pruning levels with different pruningmethods图4各种剪枝方法在不同保留信息比例下的MAP 取值Fig.4MAP values at different pruning levels with different pruning methods由图2可见,DCP_imp 方法对P@10指标的改进很大.当保留10%的信息时,DCP_imp 方法在P@10指标上就能超越使用完整索引的基准系统(P@10=0.5550),这支持了文中的假设2.其原因是排序算法往往会把重要度高的文档排在较前面的位置,例如,BM25算法会把与查询相似的页面排在前面.在DCP_imp 方法下,重要的文档保留的信息较多,而对于不重要的文档,为其保留信息少.这样不重要的文档对整体文档排序的干扰会比使用完整信息索引时小,从而其产生的前10条结果的质量就比较高.同时,图2所示结果表明,在保留相同信息比例的情况下,DCP_imp 方法整体上优于传统的DCP_rel 方法,这是对假设1的支持.由图3可见,DCP_imp 方法的P@20值随着保留信息比例的增大而增大,与使用完整索引的效果相近.特别是DCP_imp_comb 方法,在保留13%的信息时,P@20值基本达到使用完整索引时的效果.但与P@10的改进效果相比,这些剪枝方法都没有超过使用完整信息时达到的效果.这是由以下两方面原因造成的:第一,静态索引剪枝在索引构建时会去除大部分的信息,使得在检索时找出的相关文档的数量减少;第二,随着返回文档数的增加,那些不重要的文档对排序的干扰会降低.不过从图中仍可发现DCP_imp 方法要优于DCP_rel 方法,这也是对假设1的支持.MAP 值不仅与精度相关,还与文档的召回率相关.而静态索引剪枝方法去除了一些信息,使得一些文档无法被检索到,导致召回率比使用完整索引信息时的低,从而在MAP 上比使用完整索引信息的低.实验结果显示,使用完整索引信息的MAP 可以达到0.3106,而在索引剪枝保留13%的信息时,DCP_imp_comb 只达到了0.2520,下降了近19%.但是,就搜索引擎的应用需求而言,召回率没有P@10、P@20重要.同时,从图中仍可以发现DCP_imp 方法对MAP 值的改进效果普遍比DCP_rel 方法的好,这又是对假设1的支持.4结语索引剪枝是实现大规模搜索引擎的一项基本技术.基于对网页质量参差不齐,重要程度差别巨大的观察,文中提出了按照网页重要程度确定剪枝幅度具有优越性的假设,并提出了一种具体的方法对该假设进行验证.该方法属于静态剪枝范畴,即在创建索引的阶段施行,它根据文档的重要程度来决定倒排表中保留信息的多少.在GOV2数据集上的实验结果表明,这种方法不仅体现了剪枝能极大降低存储需求、提高查询效率的优点,而且也不会降低查询的效果,在去除了近90%信息的情况下,反映查询效果的P@10、P@20值基本不受影响;同时,该方法与以往的剪枝方法相比,在保留相同信息量的情况下,P@10、P@20和MAP 都明显改进.文中提出的方法与相关实验有效地起到了验证假设的作用,但方法与实验本身还有许多待完善之处,包括文档重要性模型及其计算,文档重要度与保留信息量的关系等等,都有待于进一步的研究.参考文献:[1]李晓明.对中国曾有过静态网页数的一种估计[J ].北京大学学报:自然科学版,2003,39(3):394-398.Li Xiao-ming.An estimation of the growth of Chinese Web pages [J ].Acta Scientiarum Naturalium Universitatis Pe-kinensis ,2003,39(3):394-398.[2]李晓明,闫宏飞,王继民.搜索引擎———原理、技术与5第4期李晓明等:基于文档重要度的静态索引剪枝方法系统[M].北京:科学出版社,2010:130.[3]Carmel D,Cohen D.Static index pruning for information retrieval systems[C]∥Proceeding of the24th Annual In-ternational ACM SIGIR Conterence on Research and De-velopment in Information Retrieval.New York:ACM,2001:43-50.[4]Büttcher S,Clarke C.A document-centric approach to static index pruning in text retrieval systems[C]∥Pro-ceedings of the15th ACM International Conference on In-formation and Knowledge Management.New York:ACM,2006:182-190.[5]Nguyen L T.Static index pruning for information retrieval system:a posting-based approach[C]∥7th Workshop onLarge-Scale Distributed Systems for Information Retrieval.New York:ACM,2009:25-32.[6]De Moura E S,Dos Santos C F,Fernandes D R,et al.Im-proving web search efficiency via a locality based staticpruning method[C]∥Proceedings of the14th Interna-tional Conference on World Wide Web.New York:ACM,2005:235-244.[7]Altingovde I S,Ozcan R,Ulusoy .Exploiting query views for static index pruning in web search engines[C]∥Pro-ceeding of the18th ACM Conference on Information andKnowledge Management.New York:ACM,2009:1951-1954.[8]Persin M,Zobel J,Sacks-Davis R.Filtered document re-trieval with frequency-sorted indexes[J].Journal of theAmerican Society for Information Science,1996,47:749-764.[9]Anh V N,Moffat A.Pruned query evaluation using pre-computed impacts[C]∥Proceedings of the29th AnnualInternational ACM SIGIR Conference on Research andDevelopment in Information Retrieval.New York:ACM,2006:372-379.[10]Zhang F,Shi S,Yan H,et al.Revisiting globally sorted indexes for efficient document retrieval[C]∥Procee-dings of the Third ACM International Conference on WebSearch and Data Mining.New York:ACM,2010:371-380.[11]Skobeltsyn G,Junqueira F,Plachouras V,et al.ResIn:a combination of results caching and index pruning forhigh-performance web search engines[C]∥Proceedingsof the31th Annual International ACM SIGIR Conferenceon Research and Development in Information Retrieval.New York:ACM,2008:131-138.[12]Brin S,Page L.The anatomy of a large-scale hypertextual web search engine[J].Computer Networks and ISDNSystems,1998,30:107-117.[13]Büttcher S,Clarke C,Soboroff L.The TREC2006ter-abyte track[C]∥Proceedings of the15th Text RetrievalConference.Gaithersburg:NIST,2006:128.[14]Robertson S,Walker S,Beaulieu M.Okapi at TREC-7:automatic ad hoc,filtering,VLC and interactive track[J].Nist special Publication,1999:253-264.Static Index Pruning Based on Document ImportanceLi Xiao-ming Shan Dong-dong(School of Electronics Engineering and Computer Science,Peking University,Beijing100871,China)Abstract:As the quality and importance of Web pages are both variable,this paper proposes a static index pruning method which uses the web page importance to determine the ratio of information kept for each document.The re-sult of experiments on GOV2dataset show that(1)the proposed method greatly reduces the storage size and speeds up the search;(2)when the pruned index takes only13%of the original size,P@10and P@20reach or exceed the baseline using full index;and(3)by using the proposed method,P@10,P@20and MAP are all better than those of the traditional method at the same pruning level.Key words:search engine;inverted index;static index pruning;document importance6华南理工大学学报(自然科学版)第39卷。