快速生成大量随机文件的方法
excel随机生成指定数量的数据的函数

题目:Excel中随机生成指定数量数据的函数1.引言在日常工作中,我们经常需要处理大量数据,有时候需要生成一定数量的随机数据来模拟实际情况或者测试程序的性能。
Excel作为一款强大的办公软件,其中提供了丰富的函数和工具来帮助我们处理数据。
本文将介绍如何在Excel中使用函数来随机生成指定数量的数据。
2.RAND函数在Excel中,我们可以使用RAND函数来生成一个0到1之间的随机数。
具体的函数格式为:=RAND()。
每次计算或输入其它数据时,RAND函数都会随机生成一个新的数值。
但是,这样的随机数并不一定符合我们的要求,因为我们需要生成指定的数量的随机数。
3.ROUND和INT函数为了生成指定数量的随机数,我们可以结合使用ROUND和INT函数来实现。
先来介绍一下ROUND函数。
ROUND函数的作用是将一个数四舍五入到指定的位数。
具体的函数格式为:=ROUND(数值, 位数)。
假设我们需要生成100个0到100之间的随机整数,可以使用=ROUND(RAND()*100,0)来实现。
这样就能生成0到100之间的随机整数了。
另外,INT函数的作用是向下取整,具体的函数格式为:=INT(数值)。
结合INT函数,我们可以生成指定范围内的随机整数。
4.RANDBETWEEN函数RANDBETWEEN函数是Excel中提供的专门用于生成指定范围内的随机整数的函数。
具体的函数格式为:=RANDBETWEEN(下限, 上限)。
=RANDBETWEEN(1,100)就会生成1到100之间的随机整数。
5.数组公式除了上述提到的函数之外,还可以使用数组公式来生成指定数量的随机数。
数组公式是Excel中一个强大且灵活的功能,能够对一组数据进行复杂的操作。
下面是一个使用数组公式生成指定数量随机数的示例:假设我们需要生成100个0到100之间的随机整数,可以使用如下的数组公式来实现:={ROUND(RAND()*100,0),ROUND(RAND()*100,0),…}注意,这是一个数组公式,需要按下Ctrl+Shift+Enter键来确认输入,而不是单纯的回车键。
Word文档批量处理大师 用户手册【精】
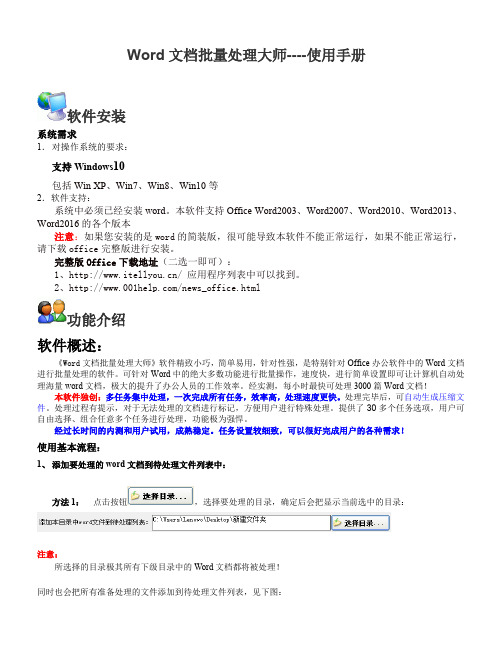
Word文档批量处理大师----使用手册软件安装系统需求1.对操作系统的要求:支持Windows10包括Win XP、Win7、Win8、Win10等2.软件支持:系统中必须已经安装word。
本软件支持Office Word2003、Word2007、Word2010、Word2013、Word2016的各个版本注意:如果您安装的是word的简装版,很可能导致本软件不能正常运行,如果不能正常运行,请下载office完整版进行安装。
完整版Office下载地址(二选一即可):1、/ 应用程序列表中可以找到。
2、/news_office.html功能介绍软件概述:《Word文档批量处理大师》软件精致小巧,简单易用,针对性强,是特别针对Office办公软件中的Word文档进行批量处理的软件。
可针对Word中的绝大多数功能进行批量操作,速度快,进行简单设置即可让计算机自动处理海量word文档,极大的提升了办公人员的工作效率。
经实测,每小时最快可处理3000篇Word文档!本软件独创:多任务集中处理,一次完成所有任务,效率高,处理速度更快。
处理完毕后,可自动生成压缩文件。
处理过程有提示,对于无法处理的文档进行标记,方便用户进行特殊处理。
提供了30多个任务选项,用户可自由选择、组合任意多个任务进行处理,功能极为强悍。
经过长时间的内测和用户试用,成熟稳定。
任务设置较细致,可以很好完成用户的各种需求!使用基本流程:1、添加要处理的word文档到待处理文件列表中:方法1:点击按钮,选择要处理的目录,确定后会把显示当前选中的目录:注意:所选择的目录极其所有下级目录中的Word文档都将被处理!同时也会把所有准备处理的文件添加到待处理文件列表,见下图:提示:当该目录下的子目录或者word文档数量特别大时,可能会占用您较长的时间。
方法2:在电脑中打开任意目录,选中要处理的word文件,使用鼠标拖拽就可以把要处理的文件添加到待处理文件列表。
fuzz测试原理

Fuzz测试原理什么是Fuzz测试?Fuzz测试是一种自动化的软件测试技术,通过向目标系统输入大量的随机、无效或异常数据来触发潜在的错误和漏洞。
Fuzz测试可以在软件开发过程中发现和修复各种安全漏洞、软件缺陷和崩溃问题,以提高软件的质量和安全性。
Fuzz测试的基本原理Fuzz测试的基本原理是通过不断地生成、变异和应用随机或半随机输入数据来执行目标程序,并监控程序运行时是否发生了异常或错误。
下面是Fuzz测试的基本流程:1.选择目标程序:首先需要确定要进行Fuzz测试的目标程序,可以是一个独立的应用程序、库文件或网络服务等。
2.生成输入数据:使用Fuzz工具生成大量的随机、无效或异常数据作为输入。
这些输入数据可能包括文件、网络包、命令行参数等。
3.变异输入数据:对生成的输入数据进行变异操作,以生成更多不同类型和结构的数据。
常见的变异操作包括插入、删除、替换、重排等。
4.执行目标程序:将变异后的输入数据传递给目标程序,并监控程序运行时是否出现异常情况,如崩溃、错误信息或不正常的行为等。
5.记录运行结果:记录目标程序在不同输入数据下的运行结果,包括崩溃堆栈、错误日志等。
这些信息可以帮助开发人员定位和修复问题。
6.分析结果:对运行结果进行分析,找出引发错误或异常的输入数据和程序路径,以便进一步调试和修复问题。
7.持续测试和修复:根据分析结果,修复目标程序中的漏洞和缺陷,并进行新一轮的Fuzz测试,直到没有新的问题出现。
Fuzz测试的优势Fuzz测试相比传统的手动测试和静态代码分析有以下几个优势:1.自动化:Fuzz测试是一种自动化测试技术,可以大大减少人工测试的工作量。
只需编写一个Fuzz工具,并设置好输入数据生成规则,即可自动执行大量的测试用例。
2.广泛覆盖:Fuzz测试能够生成各种随机、无效或异常数据作为输入,从而能够广泛覆盖目标程序可能遇到的边界情况和异常情况。
这可以帮助发现开发人员未考虑到的潜在问题。
如何利用深度学习算法进行音乐生成

如何利用深度学习算法进行音乐生成一、介绍音乐是人类文化的重要组成部分,它能够表达情感、激发想象力,并且给生活带来美妙的体验。
近年来,随着深度学习算法的快速发展,研究者们开始将其应用于音乐生成领域。
利用深度学习算法进行音乐生成具有巨大潜力,可以创造出新颖的、富有艺术性的音乐作品。
本文将介绍如何利用深度学习算法进行音乐生成。
首先,我们将简要介绍深度学习和神经网络的基础知识。
接着,我们将详细阐述如何使用循环神经网络(Recurrent Neural Network, RNN)进行音乐生成。
最后,我们还会讨论一些应对挑战和提高音乐生成质量的方法。
二、深度学习和神经网络简介1. 深度学习深度学习是机器学习领域中一个重要分支,通过构建多层次的神经网络结构来模拟人类大脑的工作原理。
其核心思想是通过大量数据训练模型,从而实现高级抽象和复杂模式的学习。
2. 神经网络神经网络是深度学习的基本组成单位,它由多个神经元(或称节点)组成,并通过权重来连接不同的层。
神经网络可以分为前馈神经网络和循环神经网络两大类。
前者主要用于图像识别、语言处理等领域,而后者适用于序列数据建模,如音乐生成。
三、使用循环神经网络进行音乐生成1. 数据准备在利用深度学习算法进行音乐生成前,我们首先需要准备一些训练数据。
这些数据可以是 MIDI 文件或者其他形式的音频文件。
我们可以将 MIDI 文件转换为符号序列,其中每个元素表示一个音符、和弦或节奏信息。
2. 构建模型循环神经网络(RNN)是一种常用于序列数据建模的神经网络结构,在音乐生成领域表现良好。
通常,我们采用长短时记忆网络(Long Short-Term Memory, LSTM)作为RNN的基本单元。
在构建模型时,我们需要定义输入和输出层的结构以及模型中间层之间的连接方式。
输入层通常是一个独热编码的向量表示当前时间步长的输入符号序列,输出层则可以是一个概率分布,指示下一个时间步长的输出。
DNAMAN的使用方法

文件菜单中选择“打开”或通过快捷键Ctrl+O,打开存储在计算机中的DNA序列文件。
保存文件
文件菜单中选择“保存”或通过快捷键Ctrl+S,将更改后的DNA序列存储到硬盘或其他存储设 备中。
文件格式要求
只支持常见的序列文件格式如FASTA、GenBank等,可以选择单个文件或批量导入。
D N A 序列的导入和编辑
分析序列统计学
序列长度分布
序列特征统计图
DNAMAN可以为所有序列生成序 列长度分布图,从而确定序列长 度最常见的地方,并且甚至可以 根据自己的喜好来更改分布参数。
这是用于比较DNA序列中各类特 征的常用工具。统计图通常是以 直方图的形式出现,幸运的是 DNAMAN可以自动生成这种统计 图并轻松进行定位和分析。
D N A 序列编辑
D N A 序列导入
D N A 序列统计信息
DNAMAN提供多种序列编辑工具, 例如添加碱基、删除碱基、反转 序列和互补序列等。
DNAMAN支持多种序列格式导入, 例如FASTA、GenBank等。
在编辑界面右侧的信息面板中, DNAMAN会自动生成序列的碱基 组成、止旋镇性能力等信息。
多样性分析
发现多样性和图形化分组模型对 于了解疾病的分布和传播至关重 要,DNAMAN通过比对分析大量 的DNA序列,可以进行多样性分 析并演示图形化分组模型。
D N A M A N 在植物和动物遗传学中的应用
BA C分析
通过资料库查询和选择BAC、 BIBAC、Cosmid等载体中的 DNA,进行序列分析和匹配 以获得目标DNA序列。
常见问题解答
1 D N A M A N 支持哪些文件格式?
便携式数据格式(PDF)、HTML网页、Microsoft Word和图像文件(PNG、JPEG、GIF)等。
功能测试中的随机数据生成

功能测试中的随机数据生成功能测试是软件开发中不可或缺的环节,它通过验证软件系统的各个功能是否正常运作来确保软件质量。
而在功能测试中,随机数据生成是一项重要的技术手段,它能够帮助测试人员有效地发现潜在的问题和漏洞。
本文将从随机数据生成的原理和方法入手,探讨在功能测试中如何利用随机数据生成工具进行测试。
一、随机数据生成的原理和方法随机数据生成是指根据一定的规则和算法,生成具有随机性的测试数据。
它可以模拟真实环境中的各种场景和情况,从而更好地检验软件系统的鲁棒性和稳定性。
在功能测试中,常用的随机数据生成方法包括以下几种:1.随机数生成法:通过生成随机数来模拟各种数据类型的取值范围。
例如,在测试一个登录功能时,可以通过随机生成不同长度的用户名和密码来覆盖各种可能的情况。
2.随机字符串生成法:通过生成随机字符串来模拟不同的输入数据。
例如,在测试一个搜索功能时,可以生成包含不同字符和长度的搜索词,以验证系统对于各种输入的处理能力。
3.随机日期生成法:通过生成随机日期来模拟不同时间点的数据。
例如,在测试一个日历功能时,可以生成过去、现在和未来各种时间的日期,以验证系统对于日期处理的准确性。
4.随机文件生成法:通过生成随机文件来模拟不同类型和大小的文件。
例如,在测试一个文件上传功能时,可以生成各种格式和大小的文件,以验证系统对于文件上传的处理能力。
以上仅是随机数据生成的一些基本方法,实际测试中,根据不同的需求和场景,还可以结合其他技术手段进行更加复杂的数据生成。
二、随机数据生成工具的选择与使用在进行功能测试时,可以选择合适的随机数据生成工具来辅助测试工作。
目前市场上有许多成熟的数据生成工具,如JFairy、Mockaroo、Faker等,它们可以帮助测试人员快速生成各种类型和格式的随机数据。
选择合适的随机数据生成工具时,需要考虑以下几个因素:1.数据类型和格式支持:工具是否支持需要的数据类型和格式,例如整型、字符串、日期等。
方方格子到期了?不用再找pòjiě版了,这里有个免费还好超用的!

⽅⽅格⼦到期了?不⽤再找pòjiě版了,这⾥有个免费还好超⽤的!常使⽤Excel的⼈,可能听说过⽅⽅格⼦这款插件,⾥⾯有很多实⽤的功能,⽐如多个⼯作表的合并、多个⼯作簿⽂件的合并:还有些⽐较⼩的功能,⽐如说添加⼀些固定的前缀后缀等:但是,你必须要联⽹激活,也是订阅制的付费⽅式:虽然,⼀款好⽤的软件值得我们付费,但有时会频繁⽤到,有时⼀个⽉也⽤不了⼀回。
当然,最主要的原因还是穷。
在学习了⼀些VBA课程后,其中的⾃定义函数和动作,对我吸引⼒很⼤,我通过功能上的模仿,也开发了这样的⼀款⼩⼯具,我暂称其为「浅北表格助⼿」:究竟有多强,话不多说,直接来看!01 动作⽅⾯什么叫动作?就是可以实现不同功能的按钮,⽐如点⼀下就可以合并多个⽂件。
我⾃定义的功能有很多,⼤约有30~40个:限于篇幅原因,这⾥仅介绍⼀些你可能会经常⽤到的:单元格和⼯作簿的保护很多填表⼯作,需要协调其他部门进⾏填写,我们在制作好了填表模板时,不希望别⼈对我们的表格进⾏改动。
⽽⼀般的操作⽅法需要三步:1. 设置可编辑区域锁定为不锁定状态2. 设置不可编辑区域的单元格为锁定状态3. 设置⼯作表保护(允许编辑锁定单元格,这⾥还有⼀系列的勾选与取消勾选操作)对Excel不太熟悉的同学,看到这些专业名词,可能已经懵了。
使⽤我的⾃定义动作,只需选中允许编辑区域,点⼀下按钮,输⼊个密码即可:PS:该功能还有助于快速录⼊表格信息⽽且,使⽤其中的「⼯作簿结构保护」,你可以防⽌别⼈修改你的sheet表名称,也⽆法删除:这样,再也不怕别⼈乱改了。
数字转⽇期我们从其他系统中导出的⽂件,或者从⾝份证中提取的出⽣⽇期,格式多为下⾯这种,带有绿帽⼦的⽂本型数字:或者部分⽤“.”或“ ”分隔的错误⽇期格式:但在Excel中,这种⽅式是⽆法被识别的,⽽⼀般处理的⽅式,就是分列分列。
⽽「⽂本型⽇期转真正⽇期」这个功能,帮你⼀键处理这种“假⽇期”:另外,在其他程序中,明明是正确的⽇期格式,但复制到Excel中,却显⽰为 3000~4000 的数字。
python

xx年xx月xx日
目录
• Python概述 • Python基础 • Python进阶 • Python在数据科学中的应用 • Python在Web开发中的应用 • Python最佳实践和设计原则
01
Python概述
Python是什么
Python是一种高级编程语言
Python是一种解释型、面向对象、动态数据类型的高级编程语言,具有简洁 易懂的语法和丰富的库。
循环语句
使用for和while关键字重复执行特定的代码块。
函数和模块
函数
可以定义函数来封装具有特定功能的代码块,并通过函数名来调用。
模块
可以将代码组织成模块,并使用import关键字在其他代码中重用。
文件操作
文件读写
使用open()函数打开文件,并使用read()和write()方法读取和写入文件内容。
介绍如何使用Django框架创建 一个新的Web项目,以及项目 的目录结构和基本设置。
Flask框架基础
Flask框架的概述
Flask框架的核心组件
Flask作为Python的轻量级Web框架,简单 易学,适合小型和中型Web应用开发。
Flask框架的核心组件包括应用对象、路由 、请求和响应对象等。
介绍数据库的基本概念和分类,包括关系型数据库和非关 系型数据库等。
SQLite数据库…
介绍SQLite数据库的特点和使用方法,包括连接、表结构 和SQL语句等。
MySQL和Mon…
分别介绍MySQL和MongoDB数据库的特点和使用方法 ,包括连接、表结构和查询语句等。用方法,包括ORM工具的发展 和应用场景等。
02
数学计算
Numpy提供了大量的数学函数,可以完成各种数学计算,如算术运
《模糊测试用例的生成方法研究与应用》范文

《模糊测试用例的生成方法研究与应用》篇一一、引言在软件开发与测试过程中,确保软件的健壮性、可靠性和安全性是一个关键目标。
而模糊测试(Fuzz Testing)正是一种在输入大量无效、随机或未预期的数据时,寻找软件潜在错误和漏洞的测试方法。
本文将详细探讨模糊测试用例的生成方法及其在软件测试中的应用。
二、模糊测试用例生成方法1. 随机生成法随机生成法是模糊测试用例生成的基本方法之一。
这种方法通过随机生成大量的数据作为输入,用于检测软件在处理这些随机数据时是否出现异常或崩溃。
这种方法简单且高效,但可能无法覆盖所有可能的输入情况。
2. 基于规则的生成法基于规则的生成法是根据软件输入的特定规则和模式来生成测试用例。
这种方法需要分析软件的需求和设计,了解其输入输出的约束和规则,然后根据这些规则生成符合要求的测试用例。
这种方法可以更精确地覆盖到软件的各个部分,但需要更多的前期工作。
3. 混合生成法混合生成法是结合随机生成法和基于规则的生成法的一种方法。
它首先使用随机生成法生成大量的数据作为基础,然后根据这些数据的特性和软件的规则,进行进一步的修改和优化,从而生成更符合软件实际使用情况的测试用例。
三、模糊测试用例的应用1. 发现软件漏洞模糊测试用例可以用于发现软件中的潜在漏洞和错误。
通过大量的随机或未预期的输入,软件在处理这些输入时可能会出现异常或崩溃,从而暴露出软件的漏洞。
这些漏洞可以被进一步分析和修复,以提高软件的健壮性和安全性。
2. 提升软件质量模糊测试不仅可以发现软件的漏洞,还可以帮助开发人员了解软件的健壮性和可靠性。
通过分析模糊测试的结果,开发人员可以找出软件中容易出现错误的部分,然后进行优化和改进,从而提高软件的整体质量。
四、模糊测试用例的实践应用与案例分析以某银行的核心业务系统为例,为了确保其安全性和稳定性,我们采用了模糊测试的方法进行测试。
首先,我们根据系统的需求和设计,采用基于规则的生成法生成了大量的测试用例。
python标准库有哪些

python标准库有哪些Python标准库是Python编程语言的核心部分,它包含了大量的模块和功能,可以帮助开发者快速地实现各种功能。
本文将介绍Python标准库中一些常用的模块和功能,希望可以帮助大家更好地了解和应用Python标准库。
一、os模块。
os模块提供了丰富的方法来处理文件和目录,可以实现文件的创建、删除、重命名、文件属性的获取等操作。
同时,os模块还提供了一些与操作系统相关的功能,比如获取当前工作目录、改变工作目录、执行系统命令等。
使用os模块可以方便地进行文件和目录的管理,是Python编程中常用的模块之一。
二、sys模块。
sys模块提供了与Python解释器和系统交互的功能,可以获取Python解释器的信息、命令行参数、标准输入输出等。
通过sys模块,可以实现对Python解释器的控制和管理,比如修改模块搜索路径、退出Python解释器等。
sys模块在一些高级的应用场景中非常有用,可以帮助开发者更好地理解和控制Python解释器的行为。
三、re模块。
re模块是Python中用于处理正则表达式的模块,可以实现对字符串的模式匹配和替换。
正则表达式是一种强大的文本处理工具,可以用于字符串的匹配、查找、替换等操作。
re模块提供了丰富的方法来处理正则表达式,可以帮助开发者更好地利用正则表达式来处理文本数据。
四、datetime模块。
datetime模块提供了日期和时间的处理功能,可以实现日期时间的计算、格式化、解析等操作。
通过datetime模块,可以方便地处理日期时间相关的问题,比如计算日期之间的差值、格式化日期时间字符串、解析日期时间字符串等。
datetime模块在很多应用中都有广泛的应用,可以帮助开发者更好地处理日期时间相关的需求。
五、random模块。
random模块提供了随机数生成的功能,可以实现随机数的生成、序列的随机化、随机选择等操作。
通过random模块,可以方便地实现随机数相关的功能,比如生成随机数、打乱序列、随机选择元素等。
shell脚本生成随机数的若干方法总结

shell脚本⽣成随机数的若⼲⽅法总结shell脚本⽣成随机数的若⼲⽅法总结⽬录创建账户时我们需要配置初始随机密码,使⽤⼿机注册时会需要随机的验证码,再如俄罗斯⽅块需要随机出形状。
这都说明随机数据很重要,让我们来看看shell脚本中随机数的⽣成⽅法的⼀些案例1.使⽤字符串截取的⽅式⽣成随机密码#!/bin/bash#功能描述(Description):使⽤字串截取的⽅式⽣成随机密码.#定义变量:10个数字+52个字符.key="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"randpass(){if [ -z "$1" ];thenecho "randpass函数需要⼀个参数,⽤来指定提取的随机数个数."return 127fi#调⽤$1参数,循环提取任意个数据字符.#⽤随机数对62取余数,返回的结果为[0-61].pass=""for i in `seq $1`donum=$[RANDOM%${#key}]local tmp=${key:num:1}pass=${pass}${tmp}doneecho $pass}#randpass 8 取8个字符#randpass 16#echo $(randpass 6) 从key中随机取6个字符输出#创建临时测试账户,为账户配置随机密码,并将密码保存⾄/tmp/pass.log.useradd tomcatpasswd=$(randpass 6)echo $passwd | passwd --stdin tomcatecho $passwd > /tmp/pass.log2.使⽤命令⽣成随机数uuid的⽣成⽅法[root@localhost ~]# uuidgencc3652e3-7e54-498b-a4e3-6ff746f5cc73[root@localhost ~]# uuidgen6f5d5581-f4b4-4443-8cb3-37ad11b97d52[root@localhost ~]# uuidgenfc48a818-d323-48f1-b975-86e8f6d9046aopenssl命令来⽣成⽣成16进制的随机字符串[root@localhost ~]# openssl rand -hex 18e[root@localhost ~]# openssl rand -hex 2eeb6[root@localhost ~]# openssl rand -hex 32aefbb[root@localhost ~]# openssl rand -hex 478706e3a[root@localhost ~]# openssl rand -hex 50dfdd2bbbc[root@localhost ~]# openssl rand -hex 6e7a550493377⽣成含有特殊符号的随机字符串[root@localhost ~]# openssl rand -base64 1eQ==[root@localhost ~]# openssl rand -base64 6PdOc8SXT[root@localhost ~]# openssl rand -base64 10mHDkK/mEgITaVA==使⽤base64算法⽣成的随机数据,其最终的长度为(n/3)向上取整后在乘以4.如(1/3)=0.333333 ,向上取整为1,base64编码后长度为1×4=4位如(6/3)=2 ,向上取整为2,base64编码后长度为2×4=8位如(10/3)=3.333333 ,向上取整为4,base64编码后长度为4×4=16位[root@localhost ~]# date +%s #通过时间提取随机数字1588802225[root@localhost ~]# date +%s #1970-1-1到现在的秒数1588802231[root@localhost ~]# date +%s%N #1970-1-1到现在的纳秒数1588802237373838045#对明⽂加密⽣成随机字符串[root@localhost ~]# echo abc | openssl passwd -stdin89n8souuGpQS6[root@localhost ~]# echo 1234 | openssl passwd -stdinMhm/mQIxCm5nE#对密⽂⽤⼀段杂字⽣成随机字符串openssl passwd -1 -salt string //string⼀般为8位[root@localhost ~]# openssl passwd -1 -salt hellotomPassword:$1$hellotom$5j6sZNiOfuQiZuz421aFS.3.使⽤设备⽂件来⽣成在linux操作系统中默认提供了两个可以⽣成随机数的设备⽂件:/dev/random/dev/urandom。
批处理命令随机数random的用法及实

批处理命令随机数random的用法及实例最近研究批处理命令,偶然发现,居然还有随机数,在此之前,是未敢想过。
说到随机数,不同的软件都有随机函数的功能,使用方法大体类似,但却有着区别。
本文,给您介绍一下MS-DOS中的批处理命令random的用法及实例。
0到100之间的数@echo offsetlocal enabledelayedexpansionset /a h1="%random%%%100"::除以100的余数echo %h1%pause产生一个255以内的数@echo offsetlocal enabledelayedexpansionset /a h1=%random%%%255+1echo %h1%pause_______________________随机0-99 的随机数@echo off:loopset /a "a=%random%%%100"echo %a%pausegoto loop---注:%random%变量指0到32726的随机数%random%%%100是指向100求模,意指用随机数%random%除以100,然后取余数,余数就只能为0-99之间了.批处理产生四个四位不重复的随机数@echo offsetlocal enabledelayedexpansionset var=123456789set /a h1=%random%%%9+1set var=!var:%h1%=0!for /l %%i in (9,-1,7) do (set /a temp=!random!%%%%icall set h%%i=%%var:~!temp!,1%%call set var=%%var:!h%%i!=%%)echo %h1%%h9%%h8%%h7%pause批处理产生四个四位不重复的随机数@echo offsetlocal enabledelayedexpansionset /a str=123456789for /l %%i in (1 1 10) do (set /a num=!random! %% 9+1call set str=%%str:!num!=%%!num!)echo !str:~2,4!Pause@echo off&setlocal enabledelayedexpansion::生成四位的随机数100个for /l %%i in (1,1,100) do (set/a #%%i=!random!%%9000+1000)::过滤掉有重复数字的随机数for /l %%i in (0,1,100) do (for /l %%j in (0,1,9) do (set ss=!#%%i:%%j=!if !ss! lss 100 (set "#%%i=")))for /f "tokens=2 delims=#=" %%i in ('set #') do echo %%ipause一、random的取值范围要使用random,必须将其当作一个变量来使用,这样才能得到值。
VBA快速生成随机姓名与地址的实用方法

VBA快速生成随机姓名与地址的实用方法在许多情况下,我们需要在Excel电子表格或其他Microsoft Office应用程序中快速生成随机的姓名和地址。
这种需求可以是为了模拟测试数据、创建假数据集或生成样本文件。
在这篇文章中,我们将探索一种实用且高效的方法,使用VBA编程语言来实现快速生成随机姓名和地址的功能。
一、生成随机姓名在开始编写VBA代码之前,我们需要准备一个包含常用姓氏和名字的列表。
这个列表可以是一个Excel电子表格,其中每一行包含一个姓氏和名字的组合。
你可以根据实际需求,选择任意数量的姓名。
在VBA编辑器中,我们将使用Randomize函数、Rnd函数和Cells函数来实现随机生成姓名的功能。
下面是一个示例代码:```vbaSub GenerateRandomName()Dim lastRow As Long, randomIndex As LonglastRow = Sheets("姓名列表").Cells(Rows.Count,1).End(xlUp).RowrandomIndex = Int((lastRow - 1 + 1) * Rnd + 1)Dim randomName As StringrandomName = Sheets("姓名列表").Cells(randomIndex,1).Value & " " & Sheets("姓名列表").Cells(randomIndex,2).ValueMsgBox randomName, vbInformation, "随机姓名"End Sub```以上代码假设姓名列表位于名为“姓名列表”的工作表中的A列和B列。
你可以根据实际情况修改代码中的工作表名称和数据列。
执行这段代码后,将会在一个消息框中显示随机生成的姓名。
模块速度测试实验报告(3篇)

第1篇一、实验背景随着现代计算机技术的飞速发展,模块化设计在软件开发中越来越受到重视。
为了提高软件的灵活性和可维护性,模块化编程已成为一种主流的软件开发模式。
本实验旨在测试一个Node.js环境下使用fs模块读取JSON文件的速度,以评估其在实际应用中的性能表现。
二、实验环境1. 操作系统:Windows 102. 编程语言:Node.js3. 版本:v16.19.14. 处理器:AMD R5-6600H5. 内存:三星DDR5 8Gx26. 硬盘:海力士固态 512G,读写速度8000MB/s7. 笔记本电脑三、实验目的1. 测试fs模块读取JSON文件的速度,分析其性能表现。
2. 评估fs模块在处理大量数据时的响应速度。
3. 为实际应用中选择合适的文件存储方案提供参考。
四、实验方法1. 创建一个测试脚本,使用fs模块读取JSON文件。
2. 使用同步和异步两种方式读取JSON文件,对比其性能差异。
3. 生成一个包含大量工单数据的JSON文件,测试不同数据量下的读取速度。
4. 对测试结果进行分析,绘制图表展示速度与数据量的关系。
五、实验步骤1. 安装Node.js环境,确保版本为v16.19.1。
2. 创建一个名为test.js的测试脚本,使用fs模块读取JSON文件。
3. 编写同步和异步两种读取方式的测试代码。
4. 生成一个包含大量工单数据的JSON文件,数据量分别为10万、50万、100万、500万、1000万、5000万、10000万行。
5. 运行测试脚本,记录不同数据量下的读取时间。
6. 分析测试结果,绘制图表展示速度与数据量的关系。
六、实验结果与分析1. 同步和异步读取方式的性能对比在测试中,异步读取方式的响应速度明显优于同步读取方式。
这是由于异步读取方式不会阻塞主线程,可以在读取文件的同时执行其他任务,从而提高程序的运行效率。
2. 读取速度与数据量的关系从测试结果可以看出,随着数据量的增加,读取速度呈现下降趋势。
随机文件要求

随机资料要求一、设备仪器随机文件由安装单位立卷,向建设单位归档。
二、整理原则以单台(套)为保管单元,进行组卷整理,随机文件较多时可按部件、组件为单位进行整理。
三、案卷质量1、随机文件的书写材料应长期保存,不得用易褪色书写材料。
必须提供一份原件归档,其中部分钢材质量证明书、检测报告、设备铭牌可以为复印件或数码照片打印,但必须加盖生产厂家或供应商红章或专用章,内容清楚。
2、随机文件附带的总图或装配图应为蓝图或计算机出图,必须加盖竣工图章,零部件图也要求必须归档,附在总图后,可以不盖竣工图章。
3、进口设备必须提供进口国当地商会出具的原产地证明文件,必须是原件(如进口国应用电子签名签署原产地证明,通过原产地证明中的网址可以查询的,可以提供彩色输出件)。
同时提供质量证明、数量证明、运单、装箱单、报关清单。
如果进口设备到货后进行了商检或锅炉压力容器安全性能监督检验,应归档商检报告或锅炉压力容器安全性能监督检验报告。
4、凡有设备位号的随机文件上应标注设备位号。
5、设备制造厂家的外购产品,应在随机文件中附外购产品的合格证、质量证明文件及产品说明书等原件内容,份数应与随机文件套数相同。
6、非标设备制造厂家必须提供详细的随机文件,同一设备型号多台套,如E101A/B/C/D,应按照4台设备,分别提供质量证明文件及设备随机图纸,包括零部件图,以满足按台套组卷归档。
随机文件书写要规范,内容包括质量证明文件、设计变更通知单、工程联络单、备件清单、铭牌、图纸目录、总图、装配图、零部件图并加盖竣工图章。
7、泵设备归档除泵的本体资料外,连同对应的电动机合格证、说明书、图纸一起归档。
8、压力容器图纸盖章要求,应加盖设计出图章、特种设备设计许可印章、竣工图章。
9、卷内文件要求无错页、倒页、压字,装订前要拆除金属物,修补或裱糊破损文件,材料的载体和书写材料应符合耐久性要求,不能有热敏纸,不能有铅笔、圆珠笔、红黑墨水、纯蓝墨水、复写纸等书写的字迹。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
快速生成大量随机文件的方法
要快速生成大量随机文件,可以使用以下方法:
1. 使用Python编程语言的random模块生成随机数据,并将其写入文件中。
可以使用循环来生成多个文件。
2. 使用Linux或Unix系统的dd命令生成随机数据,然后将其写入文件中。
例如,以下命令可以生成一个1GB的随机文件:
dd if=/dev/urandom of=randomfile bs=1M count=1000
3. 使用第三方工具生成随机数据并将其写入文件中。
例如,可以使用Faker库来生成随机文本,或使用 API来获取真正的随机数据。
不管使用哪种方法,都可以通过控制生成的数据量、格式和类型来控制生成的随机文件的数量和内容。
- 1 -。