算术编码报告
算数编码上机实验报告

一、实验目的1. 理解算数编码的基本原理。
2. 掌握算数编码的实现方法。
3. 分析算数编码的优缺点,并与其他编码方法进行比较。
4. 提高编程能力和算法实现能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 编译器:Python 解释器4. 输入数据:文本文件三、实验内容本次实验主要涉及以下内容:1. 算数编码的基本原理。
2. 算数编码的算法实现。
3. 算数编码的性能分析。
四、实验步骤1. 数据预处理首先,读取输入文本文件,并将文本转换为字符序列。
然后,统计每个字符出现的频率,并按照频率从高到低进行排序。
2. 算数编码实现(1)初始化:创建一个闭区间 [0, 1],该区间表示所有可能的编码。
(2)编码过程:a. 对于待编码的字符,根据其频率将其对应的概率分配到编码区间上。
b. 计算该字符对应的概率区间 [p1, p2]。
c. 将编码区间 [0, 1] 分成 [0, p1] 和 [p1, p2] 两个子区间。
d. 根据字符对应的概率区间,选择其中一个子区间作为新的编码区间。
e. 重复步骤 b、c、d,直到编码区间缩小到只有一个字符的区间。
(3)解码过程:a. 初始化解码区间为 [0, 1]。
b. 遍历编码后的数据,根据每个数据对应的概率区间,逐步缩小解码区间。
c. 当解码区间缩小到只有一个字符的区间时,输出该字符。
3. 性能分析(1)编码长度:比较算数编码与其他编码方法(如Huffman编码、LZ77编码等)的编码长度。
(2)编码时间:比较算数编码与其他编码方法的编码时间。
(3)解码时间:比较算数编码与其他编码方法的解码时间。
五、实验结果与分析1. 编码长度通过实验结果,我们发现算数编码的编码长度明显优于Huffman编码和LZ77编码。
在相同的数据量下,算数编码的编码长度更短,有利于数据压缩。
2. 编码时间算数编码的编码时间略长于Huffman编码,但短于LZ77编码。
实验一 算数编码实验报告

实验一算数编码实验报告一、实验目的算数编码是一种无损数据压缩算法,本实验的目的在于深入理解算数编码的原理和实现方法,通过实际编程和实验数据的分析,掌握算数编码在数据压缩中的应用,并评估其压缩效果和性能。
二、实验原理算数编码的基本思想是将整个输入消息表示为一个0, 1)区间内的一个实数。
消息中的每个符号根据其出现的概率映射到这个区间的子区间。
随着消息中符号的不断输入,子区间不断缩小,最终得到的区间范围就代表了整个消息。
具体来说,假设要编码的消息由字符集合{A, B, C}组成,它们出现的概率分别为{P(A) = 04, P(B) = 03, P(C) = 03}。
首先,将区间0, 1)划分为三个子区间:0, 04)表示 A,04, 07)表示 B,07, 1)表示 C。
当输入第一个字符为 A 时,编码区间缩小为0, 04)。
接着,根据后续输入的字符继续细分区间,直到整个消息编码完成。
三、实验环境本次实验使用的编程语言为 Python,开发环境为 PyCharm。
同时,使用了一些常用的数学计算库,如 NumPy 等。
四、实验步骤1、定义字符集和其对应的概率```pythonchar_set ='A','B','C'probability = 04, 03, 03```2、初始化编码区间```pythonlow = 0high = 1```3、输入消息并进行编码```pythonmessage ="ABAC"for char in message:index = char_setindex(char)range_length = high lowhigh = low + range_length sum(probability:index + 1)low = low + range_length sum(probability:index)```4、输出编码结果```pythonencoded_value =(low + high) / 2print("编码结果:", encoded_value)```五、实验结果与分析对于输入的消息"ABAC",经过算数编码后得到的编码结果约为0235。
视频编码算术编码实验报告

视频编码技术实验报告-----算术编码算法的程序实现学院:班级:姓名:学号:本实验通过编程实现简单的算术编码解码过程,加深对视频编码中熵编码原理及过程的理解,锻炼理论与实践相联系能力。
二、实验原理算术编码是另一种常用的变字长编码,它也是利用信源概率分布特性、能够趋近熵极限的编码方法。
它与Huffman 一样,也是对出现概率大的符号赋予短码,对概率小的符号赋予长码。
但它的编码过程与Huffman 编码却不相同,而且在信源概率分布比较均匀的情况下其编码效率高于Huffman 编码。
它和Huffman 编码最大的区别在于它不是使用整数码。
Huffman 码是用整数长度的码字来编码的最佳方法,而算法编码是一种并不局限于整数长度码字的最佳编码方法。
算术编码是把各符号出现的概率表示在单位概率[0,1] 区间之中,区间的宽度代表概率值的大小。
符号出现的概率越大对应于区间愈宽,可用较短码字表示;符号出现概率越小对应于区间愈窄,需要较长码字表示。
三、实验过程1.给定二进制符号序列:0101101011111001101111001000111111111101001011011011011012.采用二元二进制算术编码进行编码,输出编码的结果。
3.采用自适应二元算术编码进行编码,输出编码结果。
4. 解码刚才编码的符号序列。
算术编码的C++实现#include <iostream>#include <string>#include <cstring>#include <vector>using namespace std;#define N 50 //输入的字符应该不超过50个struct L //结构用于求各字符及其概率{char ch; //存储出现的字符(不重复)int num; //存储字符出现的次数double f;//存储字符的概率};//显示信息void disp();//求概率函数,输入:字符串;输出:字符数组、字符的概率数组;返回:数组长度;int proba(string str,char c[],long double p[],int count);//求概率的辅助函数int search(vector<L> arch,char,int n);//编码函数,输入:字符串,字符数组,概率数组,以及数组长度;输出:编码结果long double bma(char c[],long double p[],string str,int number,int size);//译码函数,输入:编码结果,字符串,字符数组,概率数组,以及它们的长度;输出:字符串//该函数可以用于检测编码是否正确void yma(string str,char c[],long double p[], int number,int size,long double input);int main(){string str; //输入要编码的String类型字符串int number=0,size=0; //number--字符串中不重复的字符个数;size--字符串长度char c[N]; //用于存储不重复的字符long double p[N],output; //p[N]--不重复字符的概率,output--编码结果disp();cout<<"输入要编码的字符串:";getline(cin,str); //输入要编码的字符串size=str.length(); //字符串长度number=proba(str,c,p,size);//调用求概率函数,返回不重复字符的个数cout.setf(ios::fixed); //“魔法配方”规定了小数部分的个数cout.setf(ios::showpoint); //在此规定编码结果的小数部分有十个cout.precision(10);output=bma( c, p, str, number, size);//调用编码函数,返回编码结果yma(str,c, p, number, size, output); //调用译码函数,输出要编码的字符串,//以验证编码是否正确return 0;}//显示信息void disp(){cout<<endl;cout<<"********************算术编码*********************\n";cout<<endl;cout<<"此程序只需要输入要编码的字符串,不需要输入字符概率\n";cout<<endl;}//求概率函数int proba(string str,char c[],long double p[], int count){cout.setf(ios::fixed); //“魔法配方”规定了小数部分位数为三位cout.setf(ios::showpoint);cout.precision(3);vector<L>pt; //定义了结构类型的向量,用于同时存储不重复的字符和其概率L temp; //结构类型的变量temp.ch = str[0]; //暂存字符串的第一个字符,它的个数暂设为1 temp.num=1;temp.f=0.0;pt.push_back(temp); //将该字符及其个数压入向量for (int i=1;i<count;i++)//对整个字符串进行扫描{temp.ch=str[i]; //暂存第二个字符temp.num=1;temp.f=0.0;for (int j=0;j<pt.size();j++) //在结构向量中寻找是否有重复字符出现{ //若重复,该字符个数加1,并跳出循环int k; //若不重复,则压入该字符,并跳出循环k=search(pt,str[i],pt.size());if(k>=0){pt[k].num++;break;}else{pt.push_back(temp);break;}}}for (i=0;i<pt.size();i++) //计算不重复字符出现的概率{pt[i].f=double(pt[i].num)/count;}int number=pt.size(); //计算不重复字符出现的次数cout<<"各字符概率如下:\n";for (i=0;i<number;i++) //显示所得的概率,验证是否正确{if (count==0){cout<<"NO sample!\n";}else{c[i]=pt[i].ch;p[i]=pt[i].f;cout<<c[i]<<"的概率为:"<<p[i]<<endl;}}return number; //返回不重复字符的个数}//求概率的辅助函数//若搜索发现有重复字符返回正数//否则,返回-1int search(vector<L> arch,char ch1,int n){for (int i=0;i<n;i++)if(ch1==arch[i].ch) return i;return -1;}//编码函数long double bma(char c[],long double p[],string str,int number,int size){long double High=0.0,Low=0.0,high,low,range;//High--下一个编码区间的上限,Low--下一个编码区间的下限;//high--中间变量,用来计算下一个编码区间的上限;//low--中间变量,用来计算下一个编码区间的下限;//range--上一个被编码区间长度int i,j=0;for(i=0;i<number;i++)if(str[0]==c[i]) break; //编码第一个字符while(j<i)Low+=p[j++]; //寻找该字符的概率区间下限range=p[j]; //得到该字符的概率长度High=Low+range; //得到该字符概率区间上限for(i=1;i<size;i++) //开始编码第二个字符for(j=0;j<number;j++) //寻找该字符在c数组中的位置{if(str[i]==c[j]){if(j==0) //若该字符在c数组中的第一个字符{low=Low; //此时该字符的概率区间下限刚好为零high=Low+p[j]*range;High=high;range*=p[j]; //求出该字符的编码区间长度}else //若该编码字符不是c数组中的第一个{float proba_next=0.0;for(int k=0;k<=j-1;k++)proba_next+=p[k]; //再次寻找字符的概率区间下限low=Low+range*proba_next; //编码区间下限high=Low+range*(proba_next+p[j]);//编码区间上限Low=low; //编码区间下限High=high; //编码区间上限range*=p[j]; //编码区间长度}}else continue; //i++,编码下一个字符}cout<<endl;cout<<"输入字符串的编码为:"<<Low<<endl;return Low;}//译码函数void yma(string str,char c[],long double p[], int number,int size,long double input) {vector<char> v; //定义char类型向量vlong double temp; //中间变量long double sum[N]; //存储不重复字符概率区间的下限sum[0]=0.0; //数组第一个元素为0for (int i=1;i<number+1;i++) //计算数组各元素的值{sum[i]=sum[i-1]+p[i-1];}for (int j=0;j<size;j++){for (int k=0;k<number;k++){ //确定被编码字符的下限属于【0,1】之间的哪一段if ((input>sum[k])&&(input<sum[k+1])) //发现在哪就将属于该段的字符压入向量v{v.push_back(str[j]);temp=(input-sum[k])/(sum[k+1]-sum[k]);//计算下一个被编码字符的下限input=temp;break;}elsecontinue;}}cout<<endl;cout<<"译码输出为:"; //将译码结果输出for (int m=0;m<v.size();m++){cout<<v[m];}cout<<endl;}五、实验结果六、实验总结此次实验运用的是C++软件实现的编程,主要是收获了有关于编码和解码的思想,掌握了编码的原理。
第四章:算术编码..(修改版)

6 P x ki i 1
6 i 1
P x1
k,
x2
i
P
x1
k
6P
i 1
x2
i
P
x1
k
,
where x x1x2
F (2) X
32
P( x1
1)
P( x1
2)
P(x
31)
P(x
32)
FX
(2)
P(x
31)
P(x
32)
P(x 31) P(x 32) P(x1 3) P(x2 1) P(x2 2) P(x1 3)FX (2)
FX (k) 0, k 0, FX (1) 0.8, FX (2) 0.82, FX (3) 1, FX (k) 1, k 3 l (0) 0, u(0) 1
1
l (1) l (0) u(0) l (0) FX (0) 0 u(1) l (0) u(0) l (0) FX (1) 0.8
l (3) l (2) u(2) l (2) FX (1) 0.7712
u(3) l (2) u(2) l (2) FX (2) 0.77408
13 t* 0.772352 0.7712 0.4 0.77408 0.7712
FX (0) 0 t* 0.8 FX (1)
TX
x
u(n) l(n) 2
只需知道信源的cdf,即信源的概率模型
算术编码:编码和解码过程都只涉及算术运算(加、减、乘、除)
产生标识:例
考虑随机变量X(ai) = i
对序列1 3 2 1编码:
u(k ) l (k1) u(k1) l (k1) FX (xk ) l (k ) l (k1) u(k1) l(k1) FX (xk 1)
编码仿真实验报告(3篇)

第1篇实验名称:基于仿真平台的编码算法性能评估实验日期:2023年4月10日实验地点:计算机实验室实验目的:1. 了解编码算法的基本原理和应用场景。
2. 通过仿真实验,评估不同编码算法的性能。
3. 分析编码算法在实际应用中的优缺点。
实验环境:1. 操作系统:Windows 102. 编译器:Visual Studio 20193. 仿真平台:MATLAB 2020a4. 编码算法:Huffman编码、算术编码、游程编码实验内容:1. 编写Huffman编码算法,实现字符序列的编码和解码。
2. 编写算术编码算法,实现字符序列的编码和解码。
3. 编写游程编码算法,实现字符序列的编码和解码。
4. 在仿真平台上,分别对三种编码算法进行性能评估。
实验步骤:1. 设计Huffman编码算法,包括构建哈夫曼树、编码和解码过程。
2. 设计算术编码算法,包括编码和解码过程。
3. 设计游程编码算法,包括编码和解码过程。
4. 编写仿真实验代码,对三种编码算法进行性能评估。
5. 分析实验结果,总结不同编码算法的优缺点。
实验结果及分析:一、Huffman编码算法1. 编码过程:- 对字符序列进行统计,计算每个字符出现的频率。
- 根据频率构建哈夫曼树,叶子节点代表字符,分支代表编码。
- 根据哈夫曼树生成编码,频率越高的字符编码越短。
2. 解码过程:- 根据编码,从哈夫曼树的根节点开始,沿着编码序列遍历树。
- 当遍历到叶子节点时,输出对应的字符。
3. 性能评估:- 编码长度:Huffman编码的平均编码长度最短,编码效率较高。
- 编码时间:Huffman编码算法的编码时间较长,尤其是在构建哈夫曼树的过程中。
二、算术编码算法1. 编码过程:- 对字符序列进行统计,计算每个字符出现的频率。
- 根据频率,将字符序列映射到0到1之间的实数。
- 根据映射结果,将实数序列编码为二进制序列。
2. 解码过程:- 对编码的二进制序列进行解码,得到实数序列。
实验2 算术编码

实验二、算术编码一、实验目的1了解图像压缩的意义和手段;2熟悉算术编码的基本性质;3熟练掌握算术编码的方法与应用;4掌握利用MA TLAB编程实现数字图像的算术编码。
二、实验原理算术编码方法是将被编码的一则消息或符号串(序列)表示成0和1之间的一个间隔(Interval),即对一串符号直接编码成[0,1]区间上的一个浮点小数。
符号序列越长,编码表示它的间隔越小,表示这一间隔所需的位数就越多。
信源中的符号序列仍然要根据某种模式生成概率的大小来减少间隔。
可能出现的符号概率要比不太可能出现的符号减少范围小,因此,只正加较少的比特位。
在传输任何符号串之前,0符号串的完整范围设为[0,1]。
当一个符号被处理时,这一范围就依据分配给这一符号的那一范围变窄。
算术编码的过程,实际上就是依据信源符号的发生概率对码区间分割的过程三、实验报告内容1.用MATLAB编程实现对图像的算术编码2叙述实验过程;3提交实验的原始图像和结果图像。
解:1)实验程序:建立ssjm.m函数:function X = ssjm(A,p,y,n)% 算术解码m = length(A); % 不重复元素的个数L = 0;U = 1;% 分配A中各个元素的所在范围for k = 1:nfor i = 1:mif i == 1Flb(i) = L;Fub(i) = L + p(i) * (U - L);elseFlb(i) = Fub(i-1);Fub(i) = Flb(i) + p(i) * (U - L);endendtemp = max(find(Flb<=y));X(k) = A(temp);L = 0;U = 1;y = (y - Flb(temp))/(Fub(temp) - Flb(temp));% L = Flb(temp);% U = Fub(temp);end建立ssbm.m函数:function [y,A,p,n] = ssbm(x)% 算术编码:% 输入:x为一向量序列% 输出:y为编码后的数据范围下限,A为序列不重复的元素,p为A对应的元素频率n = length(x);A = unique(x); % 取出x中包含的元素m = length(A); % 不重复元素的个数s = histc(x,A); % 统计A中个元素出现的次数p = s/n; % 统计A中个元素的频率sigma = 1;% 分配A中各个元素的所在范围for i = 1:mif i == 1Flb(i) = 0;Fub(i) = p(i)*sigma;elseFlb(i) = Fub(i-1);Fub(i) = Flb(i) + p(i)*sigma;endend% 开始编码for i = 1:nif i == 1temp = find(x(i) == A);Nlb = Flb(temp);Nub = Fub(temp);len = Nub - Nlb;len = len/sigma;elsetemp = find(x(i) == A);Nlb = Nlb + len * Flb(temp);len = len * p(temp);Nub = Nlb + len;endendy = (Nlb+Nub)/2;end建立主函数main.mclear;clcI = imread('图片二.jpg');sigma = 10;[rows,cols] = size(I);x = double(I(:)');T = [];Y = [];N = floor(length(x)/sigma);S = 0;for i = 1:Nt = x((i-1)*sigma+1:i*sigma); [y,A,p,n] = ssbm(t);X = ssjm(A,p,y,n);Y = [Y y];T = [T X];S = S + sum(t==X);endt = x(N*sigma+1:end);[y,A,p,n] = ssbm(t);X = ssjm(A,p,y,n);Y = [Y y];T = [T X];T = uint8(T);II = reshape(T,rows,cols); imshow(II)运行结果:原图像:结果图像:四、思考题1.算术编码的性质?答:算术编码从另一种角度对很长的信源符号序列进行有效编码,对整个序列信源符号串产生一个唯一的标识,直接对序列进行编码而不是码字的串联;不用对该长度所有可能的序列编码,标识是[0,1)之间的一个数。
算术编码(1).

8 8
1 0.8 u
o 0.6
i 0.5
e
0.2 a
0
e 0.5 u o i
e
ea 0.26 u o i e
a 0.2
19 19
20 20
从[0.06752,0.0688)中选择一个数输出:0.06752
16 16
算术编码—译码过程
通过查看哪一个信源符号拥有已编码消息所落入的数值范 围,找到消息中的第一个信源符号,0.06752在[0,0.2)之间, 所以第一个符号为a1
从编码数值中消去第一个符号a1的影响,即首先减去a1的所 在区间的下界值,然后除以a1对应区间的宽度,即 (0.06752-0)/0.2=0.3376
实际编码是用硬件或计算机软件实现,采用递推公式进行 编码。算术编码在性能上有很多的优点,如所需的参数少, 无很大的码表,主要针对信源概率未知或非平稳情况。在 实际应用中还要考虑计算精度、存储量、近似值中Q的选 择等问题,随着这些问题的解决,它正在进入实用阶段, 但要扩大应用范围或进一步提高性能,降低造价,还需进 一步改进。
在区间[0.06752,0.0688)内的任何数字都可以表示消息 a1a2a3a3a4,例0.06752
15 15
算术编码—编码过程
步骤 1 2 3 4 5 6
输入 a1
编码间隔 [0,0.2)
a2
[0.04,0.08)
a3
[0.056,0.072)
a3
[0.0624,0.0688)
多媒体实验——算术编码(2)

实验四算术编码算法的实现一、实验目的1、学习Matlab软件的使用和编程;2、进一步深入理解算术编码算法的原理;二、实验内容1、用Matlab软件对文本文件“seq1.txt”实现整数型的算术编码。
三、实验原理1、编码器在开始时将“当前间隔”[L,H)设置为[0,1)。
2、对每一事件,编码器按步骤(a)和(b)进行处理。
a、编码器将“当前间隔”分为子间隔,每一个事件一个。
b、编码器选择子间隔应与下一个确切发生的事件相对应,并使它成为新的“当前间隔”。
3、最后输出的“当前间隔”的下边界就是该给定事件序列的算术编码。
四、算术编码的Matlab源程序及运行结果function arithscale()clc;fid=fopen('seq1.txt','r');seq=fread(fid,'*char');fclose(fid);seq=reshape(seq,1,length(seq));[alpha prob]=probmodel(seq);if~isempty(alpha)[tag mnm]=arithscalecod(alpha,prob,seq);disp(strcat('Tag=',tag));seq=arithscaledecod(tag,alpha,prob,length(seq),mnm);disp('Sequence=');disp(seq);elsedisplay('Empty Sequence....');endendfunction[alpha prob]=probmodel(seq)if~isempty(seq)alpha(1)=seq(1);prob(1)=1;l=length(seq);k=2;for i=2:lidx=find(seq(i)==alpha);if isempty(idx)alpha(k)=seq(i);prob(k)=1;k=k+1;elseprob(idx)=prob(idx)+1;endendprob=prob./l;elsealpha=[];prob=[];endendfunction[tag mnm]=arithscalecod(alpha,prob,seq)ls=length(seq);l=0;u=1;Fx(1)=0;for i=1:length(prob)Fx(i+1)=Fx(i)+prob(i);endtag=[];dif=[];while~isempty(seq)dif(end+1)=u-l;if l>=0&u<0.5tag=strcat(tag,'0');l=2*l;u=2*u;elseif l>=0.5&u<1tag=strcat(tag,'1');l=2*(l-0.5);u=2*(u-0.5);elsep=find(seq(1)==alpha);l1=l+(u-l)*Fx(p);u=l+(u-l)*Fx(p+1);l=l1;seq(1)='';endendwl=8;b=numb2bin(u,wl);tag=strcat(tag,b);mnm=min(dif);endfunction b=numb2bin(l,wl)b=[];for i=1:wlv=l*2;f=floor(v);b=strcat(b,num2str(f));l=v-f;endendarithscaledecod函数function seq=arithscaledecod(tag,alpha,prob,lgt,mnm) l=0;u=1;Fx(1)=0;for i=1:length(prob)Fx(i+1)=Fx(i)+prob(i);endseq='';k=ceil(log2(1/mnm));k=2*k;ln=length(tag);if k>lnk=ln;endwhile lgt>0if l>=0&u<0.5tag(1)='';tag(end+1)='0';l=2*l;u=2*u;elseif l>=0.5&u<1tag(1)='';tag(end+1)='0';l=2*(l-0.5);u=2*(u-0.5);elseb=tag(1:k);tg=bin2numb(b);t=(tg-l)/(u-l);for j=1:length(prob)if t>=Fx(j)&t<Fx(j+1)breakendendseq=[seq alpha(j)];l1=l+(u-l)*Fx(j);u=l+(u-l)*Fx(j+1);l=l1;lgt=lgt-1;endendendfunction d=bin2numb(b)d=0;for i=1:length(b)bt=str2num(b(i));d=d+bt*2^(-i);endend五、运行结果:Tag=1010011110000000001000001000110001000110010110Sequence= ABCAAAACCCCAAAAACCCCAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA。
算术编码

算术码之例(4)
译码:若C-P(S)<p0 p(S),译出0,≧译出1。 0.1101010>0.01 1 0.11 0.01 0.1101001>0.0011 1 0.1001 0.0111 0.1100011>0.001001 ………………………………………… 0 ……………………………<………..
24
一般马氏链的算术编码(7)
可见不移位时,进位只能影响整数的末 位。若当前的P(A)是 y-Qy–Q+1…y0 . y1y2… 若y0=0, 以前各位均可输出,因这位可吸 收进位。 若y0=1,向前找第一个零,设为y-Q,其前均 可输出,并将Q存入一存储器。
25
一般马氏链的算术编码(8)
若有进位,可令y0=0, 存储器置零,以前 100…可输出。 若有移位,可按进位后的y0值照前述法 则处理。 4.多元信源的简化问题。 要避免乘法运算,可用几个k值来逼近 实际的概率值。p=2-k1+2-k2+….+2-kr
N! r p( N 0 r ) p0 p1N r r!( N r )!
30
自适应算术编码(3)
以r/N作为0的概率编算术码,这一帧的 代码长度为 l=r log(N/r)+(N-r)log[N/(N-r)] 则每二元符号的平均码长为
N! r N r l L p0 p1 r!( N r )! N
23
一般马氏链的算术编码(6)
3.进位引入差错的防止 [P(Aar)+p(Aar)]2-L(Aar) =[P(A)+p(A)∑P(ar|S)]W2-L(A) +[p(A)P(ar|S)]2-L(A)≦[P(A)+p(A)]2-L(A), 递推至加一序列B, [P(AB)+p(AB)]2-L(AB)≦[P(A)+p(A)]2-L(A), 若加B过程内未移位,则P(AB)-P(A)<1
算术编解码实验报告

一、实验目的1.进一步学习C++语言概念和熟悉VC 编程环境。
2.学习算术编码基本流程, 学会调试算术编码程序。
3. 根据给出资料,自学自适应0 阶算术编、解码方法。
二、实验要求:(1)实验前编写源程序、准备测试数据。
(2)在Turbo C下完成程序的编辑、编译、运行,获得程序结果。
如果结果有误,应找出原因,并设法更正之。
三、实验内容编程实现任给n个概率和为1的随机分布字符,对任意排列的字符序列进行算术编码,计算平均码长。
得到编码结果并进行解码#include<iostream.h>#include"math.h" //定义所需要用到的变量及数组char S[100], A[10];float P[10],f[10],gFs;//编码程序void bianma(int a,int h){ int i,j;float fr;float ps=1;float Fs=0;float Sp[100],b[100],F[100]; //以待编码的个数和字符个数为循环周期,将待编码的字符所对应的概率存入到Fs中for(i=0;i<h;i++){ for(j=0;j<a;j++){ if(S[i]==A[j]){ Sp[i]=P[j];fr=f[j];//将划分好的[0,1)区间的对应点赋值给fr}}Fs=Fs+ps*fr;//从选择的子区间中继续进行下一轮的分割。
不断的进行这个过程,直到所有符号编码完毕。
ps*=Sp[i]; //求Ps}cout<<"Fs="<<Fs<<endl;//显示最终的算术编码gFs=Fs;float l=log(1/ps)/log(2);//计算算术编码的码字长度lif(l>(int)l)l=(int)l+1;else l=int(l); //将Fs转换成二进制的形式int d[20];int m=0;while(l>m){ Fs=2*Fs;if(Fs>1){ Fs=Fs-1;d[m]=1;}else if(Fs<1)d[m]=0;else {d[m]=1;break;}m++;}int z=m;//解决有关算术编码的进位问题,给二进制数加1if(m>=l){ while(1){ d[m-1]=(d[m-1]+1)%2;//最后位加1if(d[m-1]==1)break;else m--;}}cout<<"s=";for(int e=0;e<z;e++)cout<<d[e];cout<<endl;}//解码程序void jiema(int a,int h){ int i,j;float Ft,Pt;float Fs=0,Ps=1;for(i=0;i<h;i++)//以编码个数和符号个数为循环周期,对其进行解码 { for(int j=a-1;j>-1;j--){ Ft=Fs;Pt=Ps;Ft+=Pt*f[j];//对进行逆编码Pt*=P[j];if(gFs>=Ft)//对其进行判断,并且将值存入到数组A中{ Fs=Ft;Ps=Pt;cout<<A[j];break;}}}cout<<endl;}void main(){ cout<<"输入所要编码的符号的个数,并按回车跳转:"<<endl;int a,i,h=0;cin>>a;cout<<"请输入符号及其相对应的概率值,并按回车跳转:"<<endl;for(i=0;i<a;i++){ char x;float y;cin>>x;A[i]=x;//将字符依次存入数组A中cin>>y;P[i]=y;//将字符所对应的概率依次存入到数组P中}for(i=1;i<a;i++){ f[0]=0;f[i]=f[i-1]+P[i-1];//将要编码的数据映射到一个位于[0,1)的实数区间中}cout<<"请输入所要编码的符号序列,并以*结尾:"<<endl;while(1)//这个while语句的作用是将要编码的字符存入到数组S中{ char ss;cin>>ss;if(ss=='*')break;//在以“*”为结尾的时候结束存储S[h++]=ss;}cout<<"输入的字符经过算术编码之后为:"<<endl;bianma(a,h);cout<<"由上述所对应的解码为:"<<endl;jiema(a,h);}四、实验数据记录及分析实验取a、b、c、d四个字符,概率分别为0.4、0.3、0.2、0.1;对字符序列abcdadb进行算术编码。
实验五算术编码

实验五算术编码班级学号姓名实验组别实验⽇期室温报告⽇期成绩报告内容:(⽬的和要求、原理、步骤、数据、计算、⼩结等)实验名称:实验五算术编码⼀、实验⽬的1.掌握算数编码原理;2.学习算术编码基本流程,学会调试算术编码程序;3.根据给出资料,⾃学⾃适应0阶算术编码⽅法。
⼆、实验内容1.利⽤MATLAB编写程序实现算数编码;2.对⽂件符号进⾏概率统计,⽣成编码表;3.对⽂件进⾏压缩编码;3.(选做)对⽂件进⾏解压缩,⽐较原始数据和解压后的数据之间是否有损耗。
三实验仪器、设备1.计算机-系统最低配置256M内存、P4CPU;2.MATLAB编程软件。
四、实验原理算术编码的编码对象是⼀则消息或⼀个字符序列,其编码思路是将该消息或字符序列表⽰成0和1之间的⼀个间隔(Interval)上的⼀个浮点⼩数。
在进⾏算术编码之前,需要对字符序列中每个字符的出现概率进⾏统计,根据各字符出现概率的⼤⼩,将每个字符映射到[0,1]区间上的某个⼦区间中。
然后,再利⽤递归算法,将整个字符序列映射到[0,1]区间上的某个Interval中。
在进⾏编码时,只需从该Interval中任选⼀个⼩数,将其转化为⼆进制数。
符号序列越长,编码表⽰它的Interval的间隔就越⼩,表⽰这⼀间隔所需的⼆进制位数就越多,编码输出的码字就越长。
五、实验步骤项⽬⽂件建⽴步骤同实验⼆,下⾯列出对给定序列的算术编码步骤:1.编码器在开始时将“当前间隔”[L,H)设置为[0,1);2.对每⼀事件,编码器按步骤(a)和(b)进⾏处理;(a)编码器将“当前间隔”分为⼦间隔,每⼀个事件⼀个;(b)⼀个⼦间隔的⼤⼩与下⼀个将出现的事件的概率成⽐例,编码器选择⼦间隔对应于下⼀个确切发⽣的事件相对应,并使它成为新的“当前间隔”。
3.最后输出的“当前间隔”的下边界就是该给定事件序列的算术编码。
六、实验注意事项1.编码概论累加分布;2.编码区间上限和下限迭代算法;3.⾃适应模型0阶的编码原理。
信息论算术编码实验报告

实验三算术编码一、实验目的1.进一步学习C++语言概念和熟悉VC 编程环境。
2.学习算术编码基本流程, 学会调试算术编码程序。
3. 根据给出资料,自学自适应0 阶算术编、解码方法。
二、实验内容与原理(一)实验原理:1.算术编码基本原理这是将编码消息表示成实数0 和1 之间的一个间隔,消息越长,编码表示它的间隔就越小,表示这一间隔所需的二进制位就越多。
算术编码用到两个基本的参数:符号的概率和它的编码间隔。
信源符号的概率决定压缩编码的效率,也决定编码过程中信源符号的间隔,而这些间隔包含在0到1之间。
编码过程中的间隔决定了符号压缩后的输出。
首先借助下面一个简单的例子来阐释算术编码的基本原理。
考虑某条信息中可能出现的字符仅有a b c 三种,我们要压缩保存的信息为bccb。
在没有开始压缩进程之前,假设对a b c 三者在信息中的出现概率一无所知(采用的是自适应模型),暂认为三者的出现概率相等各为1/3,将0 - 1 区间按照概率的比例分配给三个字符,即a 从0.0000 到0.3333,b 从0.3333 到0.6667,c 从0.6667 到1.0000。
进行第一个字符b编码,b 对应的区间0.3333 -0.6667。
这时由于多了字符b,三个字符的概率分布变成:Pa = 1/4,Pb = 2/4,Pc = 1/4。
按照新的概率分布比例划分0.3333 - 0.6667 这一区间,划分的结果可以用图形表示为:+-- 0.6667 Pc = 1/4 | +-- 0.5834 | | Pb = 2/4 | | | +-- 0.4167 Pa = 1/4 | +-- 0.3333 接着拿到字符c,现在要关注上一步中得到的c 的区间0.5834 -0.6667。
新添了c 以后,三个字符的概率分布变成Pa = 1/5,Pb = 2/5,Pc = 2/5。
用这个概率分布划分区间0.5834 - 0.6667:+-- 0.6667 | Pc = 2/5 | +-- 0.6334 | Pb = 2/5 || +-- 0.6001 Pa = 1/5 | +-- 0.5834 输入下一个字符c,三个字符的概率分布为:Pa = 1/6,Pb = 2/6,Pc = 3/6。
实验三算术编码
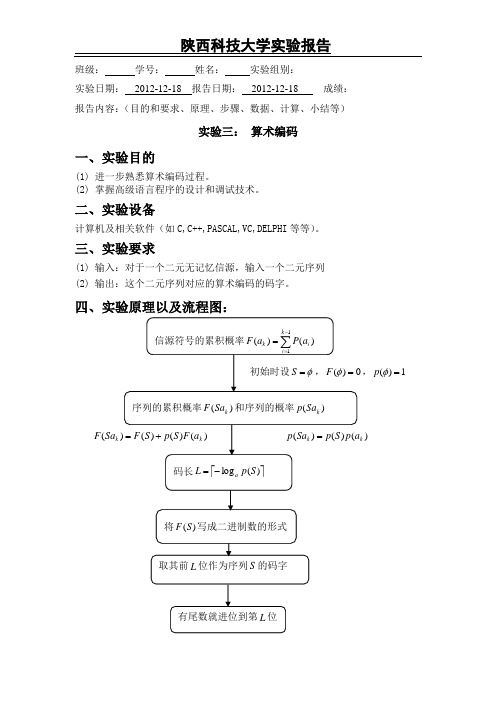
陕西科技大学实验报告 班级: 学号: 姓名: 实验组别:实验日期: 2012-12-18 报告日期: 2012-12-18 成绩: 报告内容:(目的和要求、原理、步骤、数据、计算、小结等)实验三: 算术编码一、实验目的(1) 进一步熟悉算术编码过程。
(2) 掌握高级语言程序的设计和调试技术。
二、实验设备计算机及相关软件(如C,C++,PASCAL,VC,DELPHI 等等)。
三、实验要求(1) 输入:对于一个二元无记忆信源,输入一个二元序列(2) 输出:这个二元序列对应的算术编码的码字。
四、实验原理以及流程图:,1)(=φp(k Sa F )k1: procedure Huffman({i s }; {i p })2: if q = = 2 then3: return 00s →,11s →4: else5: 降序排序{i p }6: 缩减信源:创建一个符号's 以取代2q s -,1q s -,其概率为'21q q p p p --=+ 7: 递归调用Huffman 算法以得到'03,...,,q s s s - 的编码:'03,...,,q w w w -,相应的概率分布为'03,...,,q p p p -8: return ''003321,...,,0,1q q q q s w s w s w s w ----→→→→9: end if10: end procedure五、程序代码#include<stdio.h>#include<string.h>#include<math.h>double qiup(char s[],double p[],int n){ double temp=1;for(int i=0;i<n;i++){if(s[i]=='1'){temp*=p[1];}else {temp*=p[0];}}return temp;}void qiuf(char s[],double f[],double p[],int n){ if(n==1){f[0]=0;f[1]=p[0];}else{double ps=qiup(s,p,n-1);qiuf(s,f,p,n-1);if(s[n-1]=='1'){f[n]=f[n-1]+f[1]*ps;}else{f[n]=f[n-1]+f[0]*ps;}}}void convert(double ps,char s[],int n){int i=0;while(i<n){int t=ps*2;ps=ps*2-t;s[i]=t;i++;}i=n-1;if(ps!=0){s[n-1]=s[n-1]+1;while (i>=1){ if(s[i]==2){s[i]=0;s[i-1]+=1;i--;}else i--;}for(i=0;i<n;i++)s[i]=s[i]+48;}}int main(){char s[100];double p[2];printf("请输入的信源0的概率:");scanf("%lf",&p[0]);printf("请输入的信源1的概率:");scanf("%lf",&p[1]);printf("请输入要进行的算术编码的二元序列:"); scanf("%s",s);int n=strlen(s);double f[100];qiuf(s,f,p,n);printf("该码的累计概率是%lf\n",f[n]);double ps=qiup(s,p,n);int l=log(1/ps)/log(2)+1;char r[100];convert(f[n],r,l);printf("算术编码后的二元序列:");for(int i=0;i<l;i++)printf("%c",r[i]);printf("\n");}六、程序运行结果:七.实验总结通过本次实验了解了算术编码原理,经过编码调试后,更深一步加深了对算术编码的理解,也提高了自己的编程能力。
算术编码实验报告信息论与编码实验报告

华侨大学工学院实验报告课程名称:信息论与编码实验项目名称:算术编码学院:工学院专业班级:11级信息工程姓名:学号:1195111016指导教师:傅玉青2013年11月25日一、实验目的(1)进一步熟悉算术编码算法(2)掌握MATLAB语言程序设计和调试过程中数值的进制转换、数值与字符串之间的转换等技术。
二、实验仪器(1)计算机(2)编程软件MATLAB三、实验原理算术编码是图像压缩的主要算法之一。
是一种无损数据压缩方法,也是一种熵编码的方法。
和其它熵编码方法不同的地方在于,其他的熵编码方法通常是把输入的消息分割为符号,然后对每个符号进行编码,而算术编码是直接把整个输入的消息编码为一个数,一个满足(0.0 ≤ n < 1.0)的小数n。
当所有的符号都编码完毕,最终得到的结果区间即唯一的确定了已编码的符号串行。
任何人使用该区间和使用的模型参数即可以解码重建得到该符号串行。
实际上我们并不需要传输最后的结果区间,实际上,我们只需要传输该区间中的一个小数即可。
在实用中,只要传输足够的该小数足够的位数(不论几进制),以保证以这些位数开头的所有小数都位于结果区间就可以了。
四、实验内容及步骤(1)计算信源符号的个数n(2)将第i (i=1~n )个信源符号变换成二进制数(3)计算i (i=1~n )个信源符号的累加概率Pi 为()11i i k k P p a -==∑(4)预先设定两个存储器,起始时令()()1,0A C φφ==,φ表示空集(5)按以下公式迭代求解C 和A()()()()(),,r rC S r C S A S P A S r A S p =+=对于二进制符号组成的序列,r=0,1。
注意事项:计算C (S ,r )时的加法运用的是二进制加法(6)计算序列S 编码后的码长度L 为()21log L p S ⎡⎤=⎢⎥⎢⎥ (7)如果C 在第L 位后没有尾数,则C 的小数点后L 位即为序列S 的算术编码;如果C 在第L 位后有尾数,则取C 的小数点后L 位,再进位到第L 位,即为序列S 的算术编码。
python算术编码

python算术编码## 简介这篇原创文档将会介绍算术编码的基本原理和实现。
算术编码是一种无损数据压缩算法,在信息论领域得到广泛应用。
通过使用算术编码,可以将数据压缩成更短的编码序列,从而减少存储空间的需求。
## 基本原理算术编码的基本原理是将输入序列映射到一个实数区间中,并将该区间的特定部分表示为输出序列。
其实质是将较常见的序列映射为较短的编码,而较不常见的序列映射为较长的编码。
通过这种方式,可以实现数据的高度压缩。
具体而言,算术编码的过程如下:1. 将输入序列划分为不同的符号,并为每个符号分配一个概率。
2. 计算每个符号出现的概率区间(其实也可以是累积概率)。
3. 将整个区间根据各个符号的概率进行划分,并将输入序列映射到对应的子区间中。
4. 重复步骤3,直到得到一个唯一的编码序列。
## 实现步骤下面将介绍算术编码的实现步骤。
1. 初始化区间:将整个区间初始设置为[0, 1)。
2. 计算符号概率区间:针对每个输入符号,根据其出现的概率计算对应的区间。
可以通过累积概率或离散概率来计算。
3. 映射到区间:根据符号概率区间,将输入序列映射到对应的子区间中。
例如,如果输入序列为"ABBC",对应的符号概率区间为[0.2, 0.4),则将当前区间更新为子区间[0.2, 0.3)。
4. 缩小区间:重复步骤3,不断缩小区间,直到得到一个唯一的编码序列。
5. 输出编码序列:将最终的区间映射到一个编码序列中,并输出。
## 优缺点算术编码的优点在于其高度压缩的能力,能够将数据压缩到接近信息熵的程度。
另外,算术编码对于任意概率分布的符号集都能进行有效的编码。
然而,算术编码也存在一定的缺点。
首先,算术编码的实现相对复杂,需要进行精确的浮点数计算。
其次,算术编码对输入数据的顺序敏感,即输入序列的顺序不同,得到的编码序列也会不同。
## 总结算术编码是一种强大的数据压缩算法,其利用符号出现的概率将输入序列映射到一个实数区间中,并通过缩小区间来得到一个唯一的编码序列。
算术码实验报告

实验名称:算术码编码与解码实验实验目的:1. 理解算术码的基本原理和编码方法。
2. 掌握算术码的编码和解码过程。
3. 评估算术码在数据压缩和传输中的应用效果。
实验时间:2023年X月X日实验地点:计算机实验室实验设备:计算机、实验软件实验人员:XXX、XXX、XXX实验内容:一、实验原理算术码是一种无损失的数据压缩编码方法,它将数据信息映射到某个区间内的一个概率分布上,然后用该概率分布对数据进行编码。
算术码的优点是压缩效果好,抗干扰能力强,但计算复杂度较高。
二、实验步骤1. 数据准备选择一组实验数据,如文本文件、图片等,用于进行算术码编码和解码实验。
2. 编码过程(1)计算数据中每个符号出现的概率。
(2)将数据映射到[0,1)区间内的概率分布上。
(3)根据概率分布对数据进行编码,生成算术码。
3. 解码过程(1)读取算术码。
(2)根据算术码计算每个符号出现的概率。
(3)将概率分布映射回原始数据。
4. 评估效果比较编码前后数据的长度,计算压缩比;同时,对比原始数据和解码后的数据,检查解码的正确性。
三、实验结果与分析1. 编码过程以文本文件为例,计算每个字符出现的概率,得到概率分布。
然后将文本文件映射到[0,1)区间内的概率分布上,生成算术码。
2. 解码过程读取算术码,根据概率分布计算每个字符出现的概率,将概率分布映射回原始数据。
3. 评估效果(1)压缩比:编码前文本文件长度为X,编码后长度为Y,压缩比为Y/X。
(2)解码正确性:解码后的数据与原始数据完全一致。
实验结果表明,算术码在数据压缩和传输中具有较好的效果。
在实际应用中,可以根据具体需求调整编码和解码过程,以达到更好的压缩效果。
四、实验总结1. 算术码是一种有效的数据压缩编码方法,具有较好的压缩效果和抗干扰能力。
2. 通过实验,掌握了算术码的编码和解码过程,为实际应用提供了理论基础。
3. 实验结果表明,算术码在数据压缩和传输中具有较好的效果,为相关领域的研究提供了参考。
算术指令实验报告总结(3篇)

第1篇一、实验背景算术指令实验是计算机科学领域的一项基础实验,旨在通过编程实现对基本算术运算的模拟。
本次实验主要涉及加法、减法、乘法和除法四种运算,通过编写程序来模拟这些运算过程,并分析实验结果。
二、实验目的1. 理解算术运算的基本原理;2. 掌握编程语言中算术运算的实现方法;3. 分析算术运算的精度和误差;4. 提高编程能力和问题解决能力。
三、实验内容1. 加法运算(1)使用编程语言实现两个整数的加法运算;(2)使用编程语言实现两个浮点数的加法运算;(3)分析加法运算的精度和误差。
2. 减法运算(1)使用编程语言实现两个整数的减法运算;(2)使用编程语言实现两个浮点数的减法运算;(3)分析减法运算的精度和误差。
3. 乘法运算(1)使用编程语言实现两个整数的乘法运算;(2)使用编程语言实现两个浮点数的乘法运算;(3)分析乘法运算的精度和误差。
4. 除法运算(1)使用编程语言实现两个整数的除法运算;(2)使用编程语言实现两个浮点数的除法运算;(3)分析除法运算的精度和误差。
四、实验过程1. 确定实验环境,选择合适的编程语言(如Python、C++等);2. 编写加法运算程序,测试不同类型数据的加法运算;3. 编写减法运算程序,测试不同类型数据的减法运算;4. 编写乘法运算程序,测试不同类型数据的乘法运算;5. 编写除法运算程序,测试不同类型数据的除法运算;6. 分析实验结果,记录精度和误差。
五、实验结果与分析1. 加法运算(1)整数加法运算结果与预期一致,无误差;(2)浮点数加法运算存在精度误差,但符合IEEE 754标准;(3)加法运算精度受限于编程语言和计算机硬件。
2. 减法运算(1)整数减法运算结果与预期一致,无误差;(2)浮点数减法运算存在精度误差,但符合IEEE 754标准;(3)减法运算精度受限于编程语言和计算机硬件。
3. 乘法运算(1)整数乘法运算结果与预期一致,无误差;(2)浮点数乘法运算存在精度误差,但符合IEEE 754标准;(3)乘法运算精度受限于编程语言和计算机硬件。
数字编码实验报告(3篇)

第1篇一、实验目的1. 理解数字编码的基本原理和方法。
2. 掌握几种常见的数字编码技术,如BCD编码、格雷码编码等。
3. 通过实验验证数字编码的正确性和实用性。
二、实验原理数字编码是将数字信号转换成另一种数字信号的过程。
数字编码技术广泛应用于数字通信、计算机技术、工业控制等领域。
常见的数字编码有BCD编码、格雷码编码、二进制编码等。
BCD编码(Binary-Coded Decimal)是一种将十进制数转换为二进制数的编码方式。
格雷码编码(Gray Code)是一种将数字信号转换成相邻码之间只有一个二进制位差别的编码方式,具有自同步性。
三、实验设备与材料1. 实验箱:包括数字电路模块、逻辑门、计数器等。
2. 实验指导书:提供实验原理、步骤、注意事项等。
3. 实验数据记录表。
四、实验步骤1. BCD编码实验(1)将十进制数转换为BCD编码。
(2)使用实验箱中的数字电路模块,将BCD编码转换为二进制编码。
(3)观察并记录实验结果。
2. 格雷码编码实验(1)将二进制数转换为格雷码编码。
(2)使用实验箱中的数字电路模块,将格雷码编码转换为二进制编码。
(3)观察并记录实验结果。
3. 数字编码比较实验(1)将十进制数分别转换为BCD编码和格雷码编码。
(2)比较两种编码方式的优缺点。
(3)记录实验数据。
五、实验结果与分析1. BCD编码实验结果将十进制数123转换为BCD编码,得到0011 0010。
使用实验箱将BCD编码转换为二进制编码,得到0111 0010。
实验结果表明,BCD编码能够正确地将十进制数转换为二进制数。
2. 格雷码编码实验结果将二进制数1101转换为格雷码编码,得到0111。
使用实验箱将格雷码编码转换为二进制编码,得到1101。
实验结果表明,格雷码编码能够正确地将二进制数转换为格雷码编码,并且相邻码之间只有一个二进制位差别。
3. 数字编码比较实验结果将十进制数123分别转换为BCD编码和格雷码编码,得到BCD编码为0011 0010,格雷码编码为0111。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3
1/10
[0.514,
3
D
0.52]
0.51439 在间隔[0.5, 0.52)的第 7 个 1/10
[0.514,
4
A
0.5146]
0.51439 在间隔[0.514, 0.52]的第 1 个 1/10
[0.5143,
5
C
0.51442]
0.51439 在间隔[0.514, 0.5146]的第 5 个 1/10
运行结果:
7
七、实验心得体会
通过这一次算术编解码的实验,我学到了算术编解码的方法,也进一步巩固了 C 语言编程。刚开始老师讲的时候,有点蒙,不是理解的很好,后来通过跟老师同学的进 一步请教,终于搞明白了其中的奥妙,编码过程是先对一组信源符号按照符号的概率从 大到小排序,将[0,1)设为当前分析区间。按信源符号的概率序列在当前分析区间划分 比例间隔,然后锁定当前消息符号(初次检索的话就是第一个消息符号),进行放大然 后再根据比例划分间隔。重复这个过程,直到“输入消息序列”检索完毕为止。这个过 程同时懂得了十进制的小数怎么转换成为二进制。
Ft=Fs; Pt=Ps; Ft+=Pt*f[j];//对进行逆编码 Pt*=P[j]; if(gFs>=Ft)//对其进行判断,并且将值存入到数组 A 中 {
Fs=Ft; Ps=Pt; cout<<A[j]; break; } } } cout<<endl; } void main() {
cout<<"输入所要编码的符号的个数,并按回车跳转:"<<endl;
Fs=2*Fs; if(Fs>1) {
Fs=Fs-1; d[m]=1; } else if(Fs<1)d[m]=0; else {d[m]=1;break;} m++; }
5
int z=m;//解决有关算术编码的进位问题,给二进制数加 1 if(m>=l) {
while(1) { d[m-1]=(d[m-1]+1)%2;//最后位加 1 if(d[m-1]==1)break; else m--; } } cout<<"s="; for(int e=0;e<z+1;e++) cout<<d[e]; cout<<endl; } //解码程序 void jiema(int a,int h) { int i,j; float Ft,Pt; float Fs=0,Ps=1; for(i=0;i<h;i++)//以编码个数和符号个数为循环周期,对其进行解码 { for(int j=a-1;j>-1;j--) {
[0.514,0.5146] [0.514, 0.52]间隔的第一个 1/10
[0.5143,
[0.514, 0.5146]间隔的第五个 1/10 开始,
C
0.51442]
二个 1/10
[0.514384,
D
[0.5143, 0.51442]间隔的最后 3 个 1/10
0.51442]
[0.5143836, [0.514384,0.51442]间隔的 4 个 1/10,从第
实验报告书
课程名称: 实验名称:
信息论与编码实验 算术编解码
1
一、 实验内容
借助 C++编程来实现对算术编码的编码及其译码算法的实现
二、实验环境
1. 计算机 2. VC++6.0
三、实验目的
1. 进一步熟悉算术编码的原理,及其基本的算法; 2. 通过编译,充分对于算术编码有进一步的了解和掌握; 3. 掌握 C++语言编程(尤其是数值的进制转换,数值与字符串之间的转换等)
6
int a,i,h=0; cin>>a; cout<<"请输入符号及其相对应的概率值,并按回车跳转:"<<endl; for(i=0;i<a;i++) {
char x; float y; cin>>x; A[i]=x;//将字符依次存入数组 A 中 cin>>y; P[i]=y;//将字符所对应的概率依次存入到数组 P 中 } for(i=1;i<a;i++) { f[0]=0; f[i]=f[i-1]+P[i-1];//将要编码的数据映射到一个位于[0,1)的实数区间中 }
B
0.514402]
1 个 1/10 开始
从[0.5143876, 0.514402]中选择一个数作为输出:0.5143876
译码过程
步骤 1 2
间隔
译码符号
译码判决
[0.5, 0.7] C
0.51439 在间隔 [0.5, 0.7)
[0.5, 0.52] A
0.51439 在间隔 [0.5, 0.7)的第 1 个
(a)编码器将“当前间隔”分为子间隔,每一个事件一个。 (b)一个子间隔的大小与下一个将出现的事件的概率成比例,编码器选择子间隔对
应于下一个确切发生的事件相对应,并使它成为新的“当前间隔”。 (3)最后输出的“当前间隔”的下边界就是该给定事件序列的算术编码。
编码过程
假设信源符号为{A, B, C, D},这些符号的概率分别为{ 0.1, 0.4, 0.2,0.3 }, 根据这些概率可把间隔[0,1]分成 4 个子间隔:[0,0.1],[0.1,0.5],[0.5,0.7], [0.7, 1],其中[x,y]表示半开放间隔,即包含 x 不包含 y。上面的信息可综合在表 03-04-1 中。
四、实验原理
算术编码
算术编码的基本原理是将编码的消息表示成实数 0 和 1 之间的一个间隔,消息越长, 编码表示它的间隔就越小,表示这一间隔所需的二进制位就越多。 算术编码用到两个基本的参数:符号的概率和它的编码间隔。信源符号的概率决定压缩 编码的效率,也决定编码过程中信源符号的间隔,而这些间隔包含在 0 到 1 之间。编码 过程中的间隔决定了符号压缩后的输出。 给定事件序列的算术编码步骤如下: (1)编码器在开始时将“当前间隔”设置为[0,1)。 (2)对每一事件,编码器按步骤(a)和(b)进行处理
此次实验,受益匪浅,希望下次实验能有更大的收获。
8
编码和译码的全过程分别表示在下表:
编码过程
步骤 1 2 3 4 5
6
7 8
输入符号 编码间隔
编码判决
C
[0.5, 0.7]
符号的间隔范围[0.5, 0.7]
A
[5, 0.52] [0.5, 0.7]间隔的第一个 1/10
D
[0.514,0.52] [0.5, 0.52]间隔的最后一个 1/10
A
六、实验数据记录及分析
源程序:
#include<iostream.h> #include"math.h" //定义所需要用到的变量及数组 char S[100], A[10];
4
float P[10],f[10],gFs; //编码程序 void bianma(int a,int h) {
int i,j; float fr; float ps=1; float Fs=0; float Sp[100],b[100],F[100]; //以待编码的个数和字符个数为循环周期,将待编码的字符所对应的概率存入到 Fs 中 for(i=0;i<h;i++) {
cout<<"请输入所要编码的符号序列,并以*结尾:"<<endl; while(1)//这个 while 语句的作用是将要编码的字符存入到数组 S 中 { char ss; cin>>ss; if(ss=='*')break;//在以“*”为结尾的时候结束存储 S[h++]=ss; } cout<<"输入的字符经过算术编码之后为:"<<endl; bianma(a,h); cout<<"由上述所对应的解码为:"<<endl; jiema(a,h);
下表为信源符号,概率和初始编码间隔
2
符号
A
B
C
D
概率
0.1
0.4
0.2
0.3
初始编码间隔 [0, 0.1) [0.1, 0.5) [0.5, 0.7) [0.7, 1]
如果二进制消息序列的输入为:C A D A C D B。编码时首先输入的符号是 C,找 到它的编码范围是[0.5,0.7]。由于消息中第二个符号 A 的编码范围是[0, 0.1],因 此它的间隔就取[0.5, 0.7]的第一个十分之一作为新间隔[0.5,0.52]。依此类推,编 码第 3 个符号 D 时取新间隔为[0.514,0.52],编码第 4 个符号 A 时,取新间隔为[0.514, 0.5146],…。消息的编码输出可以是最后一个间隔中的任意数。整个编码过程如图 03-04-1 所示。
for(j=0;j<a;j++) {
if(S[i]==A[j]) {
Sp[i]=P[j]; fr=f[j];//将划分好的[0,1)区间的对应点赋值给 fr } } Fs=Fs+ps*fr;//从选择的子区间中继续进行下一轮的分割。不断的进行这个过程,直到所
有符号编码完毕。
ps*=Sp[i]; //求 Ps } cout<<"Fs="<<Fs<<endl;//显示最终的算术编码 gFs=Fs; float l=log(1/ps)/log(2);//计算算术编码的码字长度 l if(l>(int)l)l=(int)l+1; else l=int(l); //将 Fs 转换成二进制的形式 int d[20]; int m=0; while(l>m) {