计量经济学第二次作业异方差检验
《计量经济学》上机实验答案过程步骤
实2:我国1978-2001年的财政收入(y )和国民生产总值(x )的数据资料如表2所示:表2 我国1978-2001年财政收入和国民生产总值数据试根据资料完成下列问题:(1)给出模型t t t u x b b y ++=10的回归报告和正态性检验,并解释回归系数的经济意义; (2)求置信度为95%的回归系数的置信区间;(3)对所建立的回归方程进行检验(包括估计标准误差评价、拟合优度检验、参数的显著性检验); (4)若2002年国民生产总值为亿元,求2002年财政收入预测值及预测区间(05.0=α)。
参考答案:(1) t t x y133561.06844.324ˆ+= =)ˆ(i b s =)ˆ(ib t 941946.02=R 056.1065ˆ==σSE 30991.0=DW 9607.356=F 133561.0ˆ1=b ,说明GNP 每增加1亿元,财政收入将平均增加万元。
(2))ˆ()2(ˆ02/00b s n t b b ⋅-±=α=±⨯ )ˆ()2(ˆ12/11b s n t b b ⋅-±=α=±⨯ (3)①经济意义检验:从经济意义上看,0133561.0ˆ1〉=b ,符合经济理论中财政收入随着GNP 增加而增加,表明GNP 每增加1亿元,财政收入将平均增加万元。
②估计标准误差评价: 056.1065ˆ==σSE ,即估计标准误差为亿元,它代表我国财政收入估计值与实际值之间的平均误差为亿元。
③拟合优度检验:941946.02=R ,这说明样本回归直线的解释能力为%,它代表我国财政收入变动中,由解释变量GNP 解释的部分占%,说明模型的拟合优度较高。
④参数显著性检验:=)ˆ(1b t 〉0739.2)22(025.0=t ,说明国民生产总值对财政收入的影响是显著的。
(4)6.1035532002=x , 41.141556.103553133561.06844.324ˆ2002=⨯+=y根据此表可计算如下结果:102221027.223)47.32735()1()(⨯=⨯=-⋅=-∑n x x x tσ92220021002.5)47.327356.103553()(⨯=-=-x x ,109222/1027.21002.52411506.10650739.241.14155)()(11ˆ)2(ˆ⨯⨯++⨯⨯±=--++⋅⋅-±∑x x x x n n t yt f f σα=实验内容与数据3:表3给出某地区职工平均消费水平t y ,职工平均收入t x 1和生活费用价格指数t x 2,试根据模型t t t t u x b x b b y +++=22110作回归分析报告。
计量经济学异方差实验报告及心得体会

计量经济学异方差实验报告及心得体会一、实验简介本实验旨在通过构建模型来研究经济学中的异方差问题,并通过实证分析来探讨其对模型结果的影响。
实验数据采用随机抽样方法自真实经济数据中获取,共包括两个自变量和一个因变量。
在实验中,我将对模型进行两次回归分析,一次是假设无异方差问题,一次是考虑异方差问题,并比较两个模型的结果。
二、实验过程1.数据准备:根据实验设计,我根据随机抽样方法,从真实经济数据中抽取了一部分样本数据。
2.模型建立:我将自变量Y和X1、X2进行回归分析。
首先,我假设模型无异方差问题,得到回归结果。
然后,我将检验异方差性,若存在异方差问题,则建立异方差模型继续回归分析。
3.模型估计:利用最小二乘法进行参数估计,并计算回归结果的标准差和假设检验。
4.模型比较:对比两个模型的回归结果,分析异方差对模型拟合程度和参数估计的影响。
三、实验结果1.无异方差假设模型回归结果:回归方程:Y=0.9X1+0.5X2+2.1标准差:0.3显著性水平:0.05拟合优度:0.852.考虑异方差问题模型回归结果:回归方程:Y=0.7X1+0.4X2+1.9标准差:0.6显著性水平:0.05拟合优度:0.75四、实验心得体会通过本次实验,我对计量经济学中的异方差问题有了更深入的了解,并进一步认识到其对模型结果的影响。
1.异方差问题的存在会对统计推断结果产生重要影响。
在本次实验中,考虑异方差问题的模型相较于无异方差模型,参数估计值差异较大,并且拟合优度也有所下降。
因此,我们在实证分析中应尽可能考虑异方差问题。
2.在实际应用中,异方差问题可能较为普遍。
经济学中的许多变量存在异方差性,例如,个体收入、消费支出等。
因此,在进行经济学研究时,我们应当警惕并尽量排除异方差问题。
3.针对异方差问题,我们可以采用多种方法进行调整,例如,利用异方差稳健标准误、加权最小二乘法等。
在本次实验中,我们采用了异方差模型进行调整,并得到了相对较好的结果。
计量经济学试题异方差性与加权最小二乘法

计量经济学试题异方差性与加权最小二乘法计量经济学试题:异方差性与加权最小二乘法一、引言计量经济学作为经济学的一个重要分支,通过运用数理统计和经济理论的方法,旨在分析经济现象并进行经济政策的评估。
在实证分析中,经常会遇到异方差性的问题,而加权最小二乘法是处理异方差性的一种重要方法。
本文将探讨异方差性的来源、加权最小二乘法的原理与应用。
二、异方差性的来源异方差性是指随着自变量的变化,随机误差的方差也会发生变化。
异方差性可能会导致经验结果不准确、偏离真实情况,并影响对经济现象的解释和预测。
以下是可能导致异方差性的原因:1. 条件异方差性:数据的方差可能与自变量之间的关系存在相关性。
例如,在研究家庭收入对教育支出的影响时,高收入家庭的支出方差可能比低收入家庭更大。
2. 记忆效应:在纵向数据分析中,随着时间的推移,个体经济行为可能受到过去观测结果的影响,进而导致异方差性的存在。
3. 测量误差:数据收集中的测量误差可能会导致异方差性。
例如,对于某些变量,测量误差可能更大,从而导致随机误差的方差不一致。
三、加权最小二乘法的原理加权最小二乘法(Weighted Least Squares, WLS)是一种用于处理异方差性的回归方法,其原理是通过给不同观测值分配不同的权重,以减小异方差的影响。
具体来说,加权最小二乘法的目标是最小化加权残差平方和。
在加权最小二乘法中,权重的选择是关键。
常见的权重选择方法包括:1. 方差稳定化权重:根据方差与自变量的关系,将观测值的权重设置为方差的倒数,以减小方差变化带来的影响。
2. 广义最小方差法权重:将权重设置为具有稳定方差的函数形式,例如Huber权重函数、Andrews权重函数等。
3. 经验权重:根据经验判断,给不同观测值分配权重,以反映其重要性。
四、加权最小二乘法的应用加权最小二乘法在计量经济学中有广泛的应用。
以下是一些常见的应用领域:1. 金融经济学:在金融领域中,异方差性往往普遍存在。
异方差检验结果解读

异方差检验结果解读
异方差检验(Heteroscedasticity test)是一种用于检验不同组之间是否存在方差
差异的统计方法。
该检验通常用于回归分析中,以确定回归模型的合理性和精确性。
异方差性可能导致回归模型的预测能力下降,因此解读异方差检验结果对于正确分析数据非常重要。
在异方差检验中,常用的检验方法包括Park、White、Goldfeld-Quandt等。
检
验结果通常以显著性水平为基准进行判断。
检验结果显示显著性水平小于或等于设定的阈值(通常为0.05),则可以认为不存在异方差;反之,如果显著性水平大于阈值,则可以认为存在异方差。
异方差检验的结果还提供了其他有用的信息,如异方差性的模式或形式。
一种
常用的方法是绘制残差图,通过观察残差与预测值的关系,可以初步判断异方差性的模式。
常见的异方差性模式包括上升或下降斜线、漏斗形状等。
在图形分析的基础上,可以进一步使用更专业的统计方法,如白噪声检验(White noise test)或Breusch-Pagan检验,来验证异方差性的模式。
在回归分析中,若检验结果显示存在异方差,需要采取相应的纠正措施。
常用
的纠正方法包括回归模型的转换、加权最小二乘法等。
这些方法可以有效地纠正异方差性,提高模型的准确性和稳定性。
总结来说,异方差检验结果的解读需要关注显著性水平、残差图以及其他专业
统计方法的检验结果。
通过综合分析这些信息,我们能够确定回归模型是否受到异方差性的影响,进而采取相应的纠正措施。
正确解读异方差检验结果对于准确分析数据和得出可靠的结论至关重要。
计量经济学实验二
实验二〔一〕异方差性【实验目的】掌握异方差性的检验及处理方法【实验内容】建立并检验我国制造业利润函数模型【实验步骤】【例1】表1列出了1998年我国主要制造工业销售收入与销售利润的统计资料,请利用统计软件Eviews建立我国制造业利润函数模型。
一、检验异方差性⒈图形分析检验⑴观察销售利润〔Y〕与销售收入〔X〕的相关图(图1):SCAT X Y图1 我国制造工业销售利润与销售收入相关图从图中可以看出,随着销售收入的增加,销售利润的平均水平不断提高,但离散程度也逐步扩大。
这说明变量之间可能存在递增的异方差性。
⑵残差分析首先将数据排序〔命令格式为:SORT 解释变量〕,然后建立回归方程。
在方程窗口中点击Resids按钮就可以得到模型的残差分布图〔或建立方程后在Eviews工作文件窗口中点击resid对象来观察〕。
图2 我国制造业销售利润回归模型残差分布图2显示回归方程的残差分布有明显的扩大趋势,即说明存在异方差性。
⒉Goldfeld-Quant检验⑴将样本安解释变量排序〔SORT X〕并分成两部分〔分别有1到10共11个样本合19到28共10个样本〕⑵利用样本1建立回归模型1〔回归结果如图3〕,其残差平方和为。
SMPL 1 10LS Y C X图3 样本1回归结果⑶利用样本2建立回归模型2〔回归结果如图4〕,其残差平方和为。
SMPL 19 28 LS Y C X图4 样本2回归结果⑷计算F 统计量:12/RSS RSS F ==,21RSS RSS 和分别是模型1和模型2的残差平方和。
取05.0=α时,查F 分布表得44.3)1110,1110(05.0=----F ,而44.372.2405.0=>=F F ,所以存在异方差性⒊White 检验⑴建立回归模型:LS Y C X ,回归结果如图5。
图5 我国制造业销售利润回归模型⑵在方程窗口上点击View\Residual\Test\White Heteroskedastcity,检验结果如图6。
计量经济学--异方差性讲解

图1:我国税收和GDP
图2:1998年我国制造工业和利润
X-GDP Y-税收
X-销售收入 Y-销售利润
两个散点图有共同的特征,随着自变量增加,因变量也 增加,但是图2中,当X比较小时,数据点相对集中,随 着X增大,数据点变得相对分散。而图1中数据分布却没 有出现这一特征。
异方差的性质
➢经典线形回归模型的一个重要假定是同方差性:
PRF的干扰项 u i 是同方差的(homoscedastic)
即: E(ui2) 2
i 1, 2, , n (3.3.1)
➢异方差性是指,ui 的条件方差(= Yi 的条件方差)
随着X的变化而变化,用符号表示为:
E (ui2
)
2 i
(3.3.2)
Var(Yi ) Var(ui )
异方差产生的主要原因
——这就是GLS方法,得到的是GLS估计量
•模型函数形式存在设定误差 •模型中遗漏了一些重要的解释变量 •随机因素本身的影响
异方差较之 同方差更为
常见
7
异方差的具体理由
➢按照边错边改学习模型(error—learning models),人 们的行为误差随时间而减少。
➢随着收入的增长,人们在支出和储蓄中有更大的灵活
性。在做储蓄对收入的回归中, i2与收入俱增
此时如果仍采用
计算斜率参数的方差,将会
产生估计偏误,偏误的大小取决与因子值的大小。
17
3.t检验的可靠性降低
由于异方差的存在,无法正确估计参数的方差和标 志误差,因此也影响到t检验的效果
4.模型的预测误差增大
模型的预测区间和随机误差项的方差有着紧密联 系,随着随机误差项方差的增大,模型的预测区 间也随之增大,模型的预测误差也会相应增加。
计量经济学:异方差性

计量经济学:异方差性异方差性在现实经济活动中,最小二乘法的基本假定并非都能满足,上一章介绍的多重共线性只是其中一个方面,本章将讨论违背基本假定的另一个方面——异方差性。
虽然它们都是违背了基本假定,但前者属于解释变量之间存在的问题,后者是随机误差项出现的问题。
本章将讨论异方差性的实质、异方差出现的原因、异方差的后果,并介绍检验和修正异方差的若干方法。
第一节异方差性的概念一、异方差性的实质第二章提出的基本假定中,要求对所有的i (i=1,2,…,n )都有2)(σ=i u Var (5.1)也就是说i u 具有同方差性。
这里的方差2σ度量的是随机误差项围绕其均值的分散程度。
由于0)(=i u E ,所以等价地说,方差2σ度量的是被解释变量Y 的观测值围绕回归线)(i Y E =ki k i X X βββ+++ 221的分散程度,同方差性实际指的是相对于回归线被解释变量所有观测值的分散程度相同。
设模型为n i u X X Y iki k i i ,,2,1221 =++++=βββ (5.2)如果其它假定均不变,但模型中随机误差项i u 的方差为).,,3,2,1(,)(22n i u Var i i ==σ (5.3)则称i u 具有异方差性。
由于异方差性指的是被解释变量观测值的分散程度是随解释变量的变化而变化的,如图5.1所示,所以进一步可以把异方差看成是由于某个解释变量的变化而引起的,则)()(222i i i X f u Var σσ== (5.4)图5.1二、产生异方差的原因由于现实经济活动的错综复杂性,一些经济现象的变动与同方差性的假定经常是相悖的。
所以在计量经济分析中,往往会出现某些因素随其观测值的变化而对被解释变量产生不同的影响,导致随机误差项的方差相异。
通常产生异方差有以下主要原因:1、模型中省略了某些重要的解释变量异方差性表现在随机误差上,但它的产生却与解释变量的变化有紧密的关系。
计量经济学:异方差

(1)布罗施-帕甘(Breusch-Pagan)检验
例4.2 使用BP检验对例4.1的回归模型进行异方差检验。 解:EViews中进行BP检验的结果如下:
从中可以看出,无论是使用F检验还是LM检验,在5%的显著性水 平下,均可拒绝随机误差项不存在异方差的原假设
2)怀特(White)检验
20000 X
30000
40000
(2)用 X e%i2 的散点图进行判断
第三节 异方差的检验
方法2:作X-ei2散点图
从图中可以看出,随着居 民可支配收入X的提高,随 机误差项平方ei2呈递增趋 势。表明随机误差项存在 递增型异方差。
ESQU
320000 280000 240000 200000 160000 120000
概 率 密 度
X1 X2 X3
同方差
概
率
Y
密
Y
度
E(Y|X) = β0 + β 1X
X
X1 X2 X3 异方差
E(Y|X) = β 0 + β 1X
X
异方差的矩阵表示
2 1
Var(u)
0 M
0
2 2
M
L L M
0
0
0
0
0
L
2 n
2、异方差的类型
•同方差性假定的意义是:每个ui围绕其零均值的离差,并不随解释 变量X的变化而变化,不论解释变量X的观测值是大还是小,每个ui
E(ˆ )(ˆ ) E ( X X )1 X Y ( X X )1 X Y
E ( X X )1 X X U ( X X )1 X X U
计量经济学实验报告-异方差问题white分析

4.运用对数方法,消除异方差问题。进行多元线性回归分析并呈现结果,并解释相关变量。
5.运用WLS方法,消除异方差问题。进行多元线性回归分析并呈现结果,并解释相关变量。
实验内容\步骤
1.打开eviews,点击Open a Foreign file,选择桌面上保存好的练习数据,点击选择Quick-Generate Series菜单命令,在弹出的对话框中输入e=resid,生成残差序列。然后选择Quick-Graph菜单命令,在弹出的对话框中输入变量名x e^2,得到散点图。
Std. Error
t-Statistic
Prob.
C
-15.32732
1.507305
-10.16869
0.0000
LOG(X)
2.224390
0.151781
14.65526
0.0000
R-squared
0.881039
Mean dependent var
6.740001
Adjusted R-squared
实验结果分析及讨论(续)
4.运用对数方法,消除异方差结果如下:
Dependent Variable: LOG(Y)
Method: Least Squares
Date: 10/12/21 Time: 20:18
Sample: 1 31
Included observations: 31
Variable
Coefficient
Dependent Variable: Y
Method: Least Squares
Date: 10/12/21 Time: 20:25
计量经济学原理 第六章异方差性

项具有同方差性。
异方差性修正后的回归分析
加权最小二乘法(WLS):通过构造一个权重矩阵来修正异方差性,使得修正后的估计量具有更小的 方差和更高的有效性。
异方差稳健标准误(Heteroskedasticity-Robust Standard Errors):通过调整标准误的计算方式来 修正异方差性对假设检验的影响,这种方法不需要对模型进行任何修改。
相关性。
影响
异方差性主要影响估计量的效 率,而自相关性则会导致估计
量的偏误和不一致性。
检验方法
异方差性通常通过残差图、 White检验等方法进行检验, 而自相关性则可以通过DW检 验、LM检验等方法进行检验
。
异方差性与多重共线性
概念差异
异方差性关注误差项的方差变化 ,而多重共线性则是指解释变量 之间存在高度线性相关关系。
异方差性的定义和类型
异方差性是指误差项的方差随自变量的变化 而变化,包括条件异方差性和无条件异方差 性。
异方差性的检验方法
介绍了图示检验法、Goldfeld-Quandt检验、 White检验等方法,用于判断模型是否存在异方差 性。
异方差性的处理方法
针对异方差性问题,可以采用加权最小二乘 法、广义最小二乘法等方法进行修正,使模 型满足同方差性假设。
04
异方差性在回归分析中的应用
异方差性对回归结果的影响
估计量无偏性
01
在异方差性存在的情况下,普通最小二乘法(OLS)估计量仍
然是无偏的,即估计量的期望值等于真实值。
估计量有效性
02
异方差性会导致OLS估计量的方差增大,从而使得估计量的有
效性降低。
假设检验失效
03
异方差性会使得t检验和F检验失效,因为这些检验都假设误差
计量经济学异方差的检验与修正实验报告

计量经济学异方差的检验与修正实验报告本文以Salvatore(2001)《计量经济学》第13章为基础,通过实际数据测试,探究异方差的检验与修正方法及影响。
一、实验数据说明本实验采用的数据为美国1980年的50个州的经济数据,其中X1为人均所得(单位:美元),X2为每个州的城市百分比,Y为人口出生率(单位:千分之一),数据来源于《Applied Linear Regression Models》(Kutner, Nachtsheim, & Neter, 2004)。
二、实验原理当数据呈现异方差性时,传统的OLS估计方法将会失效,此时需要使用其他的估计方法。
其中常用的是加权最小二乘(WLS)估计方法。
WLS估计方法的思想是对存在异方差(方差不相等)的观测值进行权重调整,使得加权后的平方残差最小。
本实验将通过检验异方差条件、使用原有OLS估计进行对比以及应用WLS修正方法的实现来说明异方差对实证分析的影响。
三、实验内容及结果首先,为了检验异方差条件是否成立,可以采用Breusch-Pagan检验。
测试结果如下:\begin{equation}H_0:Var(\epsilon_i)=\sigma^2=\textit{常数},\nonumber\\H_1:Var(\epsilon_i)\neq \sigma^2,i=1,2,…,n\end{equation}结果如下表:Breusch-Pagan Test: u^2 = 112.208 Prob > chi2 = 0.0000通过检验结果可知,Breusch-Pagan检验统计量的p值为0.0000,小于0.05的水平,因此拒绝原假设,认为方差存在异方差。
接下来,我们将使用传统的OLS估计方法进行回归分析(OLS 1),并与WLS估计方法(WLS 1)进行对比。
OLS 1结果如下:\begin{equation}Y=0.0514X1+1.0871X2-58.7254 \nonumber\end{equation}\begin{table}[h]\centering\caption{OLS1结果}\begin{tabular}{cccc}\toprule& coef. & std. err. & t \\\midruleconst & -58.7254 & 23.703 & -2.477 \\X1 & 0.0514 & 0.027 & 1.895 \\X2 & 1.0871 & 0.402 & 2.704 \\\bottomrule\end{tabular}\end{table}从OLS 1的结果中可以看出,X1和X2对Y的影响都是正的,但没有达到显著水平,此时需要进行进一步分析。
异方差性检验 计量经济学 EVIEWS建模课件

G-Q检验的步骤:
①将n对样本观察值(Xi,Yi)按观察值Xi的大 小排队;
②将序列中间的c=n/4个观察值除去,并 将剩下的观察值划分为较小与较大的相 同的两个子样本,每个子样的样本容量 均为(n-c)/2;
③对每个子样分别进行OLS回归,并计算各自 的残差平方和∑esi12 与∑esi22 ;
计量经济学模型一旦出现异方差性,如果仍采用 OLS估计模型参数,会产生下列不良后果:
1.参数估计量非有效
OLS估计量仍然具有无偏性,但不具有有效 性。因为在有效性证明中利用了 E(εε’)=2I 。
而且,在大样本情况下,尽管参数估计量具 有一致性,但仍然不具有渐近有效性。
2. 变量的显著性检验失去意义
例如以绝对收入假设为理论假设、以截面数据
为样本建立居民消费函数: Ci=0+1Yi+εi
将居民按照收入等距离分成n组,取组平均数 为样本观测值。 • 一般情况下,居民收入服从正态分布:中等收 入组人数多,两端收入组人数少。而人数多的组 平均数的误差小,人数少的组平均数的误差大。 • 所以样本观测值的观测误差随着解释变量观测 值的不同而不同,往往引起异方差性。
异方差性的检验与修正分析
一、异方差性问题 二、异方差性检验 三、异方差的修正及案例 四、条件异方差模型的建立
⒉ 在同方差情况下: 异 方 差 的 图 示 在异方差情况下: 说 明 :
异方差时
同方差:i2 = 常数 f(Xi) 异方差:i2 = f(Xi)
⒊异方差的类型
异方差一般可归结为三种类型: (1)单调递增型: i2随X的增大而增大 (2)单调递减型: i2随X的增大而减小 (3)复 杂 型: i2与X的变化呈复杂形式
变量的显著性检验中,构造了t统计量
南京财经大学计量经济学RESET检验和异方差(考试)
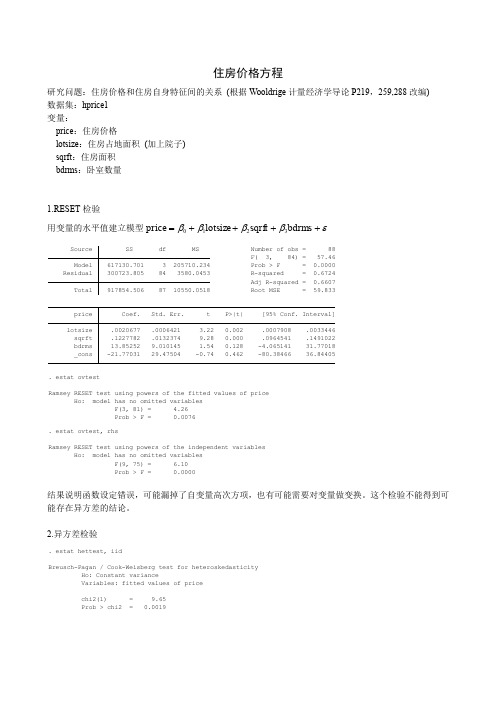
住房价格方程研究问题:住房价格和住房自身特征间的关系 (根据Wooldrige 计量经济学导论P219,259,288改编) 数据集:hprice1变量:price :住房价格lotsize :住房占地面积 (加上院子)sqrft :住房面积bdrms :卧室数量1.RESET 检验用变量的水平值建立模型εββββ++++=bdrms sqrft lotsize price 3210 _cons -21.77031 29.47504 -0.74 0.462 -80.38466 36.84405bdrms 13.85252 9.010145 1.54 0.128 -4.065141 31.77018sqrft .1227782 .0132374 9.28 0.000 .0964541 .1491022lotsize .0020677 .0006421 3.22 0.002 .0007908 .0033446price Coef. Std. Err. t P>|t| [95% Conf. Interval]Total 917854.506 87 10550.0518 Root MSE = 59.833Adj R-squared = 0.6607Residual 300723.805 84 3580.0453 R-squared = 0.6724Model 617130.701 3 205710.234 Prob > F = 0.0000F( 3, 84) = 57.46Source SS df MS Number of obs = 88Prob > F = 0.0076F(3, 81) = 4.26Ho: model has no omitted variablesRamsey RESET test using powers of the fitted values of price. estat ovtestProb > F = 0.0000 F(9, 75) = 6.10Ho: model has no omitted variablesRamsey RESET test using powers of the independent variables. estat ovtest, rhs结果说明函数设定错误,可能漏掉了自变量高次方项,也有可能需要对变量做变换。
南开大学计量经济学第2次作业答案

因为 F=196.18>3.40,所以否定 H0 总体回归方程是显著的。即可以认为劳动投入和资 本投入与美国 27 家主要金属行业 SIC33 的产出有显著的线性关系。
(7)检验该模型是否存在异方差,并将结果复制粘贴到作业上。
因为回归式中含有两个解释变量,所以 White 检验辅助回归式中应该包括 5 个解释变量。 辅助回归式为:
μ̂���2��� = α0 + α1LNK + α2LNL + α3LNK2 + α4LNL2+α5LNK ∗ LNL White 检验输出结果如下:
计量经济学(本科)第二次作业
题一
张同乐 0911275 国际经济与贸易系
多元线性回归模型 y = 0 + 1 x1 + 2 x2 +…+ k xk +u 中系数的线 性约束,可以用线性约束条件的 F 检验来检验。比如,要检验模型
中最后 m 个回归系数是否为零,在原假设k-m+1=…=k =0 成立条件 下,统计量
证明:
检验总体显著性的 F 检验的原假设为:
检验统计量为:
H0: 1 = ⋯ = ������ = 0
1
F
=
������������������⁄������ ������������������⁄(������ − ������
−
1)
~F(������,T
−
k
−
1)
(0.1)
计量经济学实验答案--第二版(张晓峒)
计量经济学张晓峒第二版实验第5章异方差2.已知我国29个省、直辖市、自治区1994年城镇居民人均生活费支出Y,可支配收入X的截面数据见下表(表略)。
(1)用等级相关系数和戈德菲尔徳- 夸特方法检验支出模型的扰动项是否存在异方差性。
支出模型是Y i =β0 +β 1 X i +u i(2)无论{u i}是否存在异方差性,用EViews练习加权最小二乘法估计模型,并用模型进行预测。
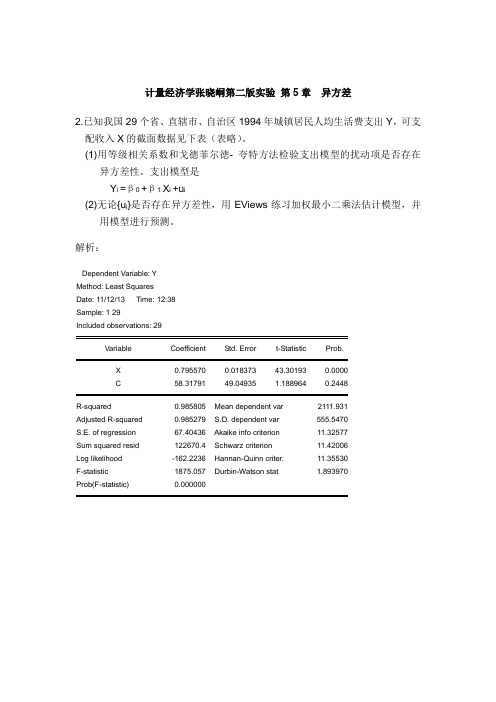
解析:Dependent Variable: YMethod: Least SquaresDate: 11/12/13 Time: 12:38Sample: 1 29Included observations: 29Variable Coefficient Std. Error t-Statistic Prob.X 0.795570 0.018373 43.30193 0.0000C 58.31791 49.04935 1.188964 0.2448R-squared 0.985805 Mean dependent var 2111.931Adjusted R-squared 0.985279 S.D. dependent var 555.5470S.E. of regression 67.40436 Akaike info criterion 11.32577Sum squared resid 122670.4 Schwarz criterion 11.42006Log likelihood -162.2236 Hannan-Quinn criter. 11.35530F-statistic 1875.057 Durbin-Watson stat 1.893970Prob(F-statistic) 0.0000001,5002,0002,5003,0003,5004,0001,0002,0003,0004,0005,000可支配收入人均生活费支出(1)略去中心9个样本观测值,将剩下的20个样本观测值分成容量相等的两个子样本,每个子样本的样本观测值个数均为10.由前面的样本回归产生的残差平方和为12363.80,后面样本产生的残差平方和为62996.26.所以F=62996.26/12363.80=5.10,自由度n=10-2=8,查F 分布表得临界值为3.44,因为F=5.10>3.44,所以支出模型的随机误差项存在异方差性。
计量经济学所有检验

一、拟合优度检验可决系数TSS RSS TSS ESS R -==12 TSS 为总离差平方和,ESS 为回归平方和,RSS 为残差平方和 该统计量用来测量样本回归线对样本观测值的拟合优度。
该统计量越接近于1,模型的拟合优度越高。
调整的可决系数)1/()1/(12----=n TSS k n RSS R 其中:n-k-1为残差平方和的自由度,n-1为总体平方和的自由度。
将残差平方和与总离差平方和分别除以各自的自由度,以剔除变量个数对拟合优度的影响。
二、方程的显著性检验(F 检验) 方程的显著性检验,旨在对模型中被解释变量与解释变量之间的线性关系在总体上是否显著成立作出推断。
原假设与备择假设:H 0:β1=β2=β3=…βk =0 H 1: βj 不全为0统计量)1/(/--=k n RSS kESS F 服从自由度为(k , n-k-1)的F 分布,给定显著性水平α,可得到临界值F α(k,n-k-1),由样本求出统计量F 的数值,通过F>F α(k,n-k-1)或F ≤F α(k,n-k-1)来拒绝或接受原假设H 0,以判定原方程总体上的线性关系是否显著成立。
三、变量的显著性检验〔t 检验〕对每个解释变量进行显著性检验,以决定是否作为解释变量被保留在模型中。
原假设与备择假设:H0:βi =0 〔i=1,2…k 〕;H1:βi ≠0给定显著性水平α,可得到临界值t α/2(n-k-1),由样本求出统计量t 的数值,通过 |t|> t α/2(n-k-1) 或 |t|≤t α/2(n-k-1)来拒绝或接受原假设H0,从而判定对应的解释变量是否应包括在模型中。
四、参数的置信区间参数的置信区间用来考察:在一次抽样中所估计的参数值离参数的真实值有多“近〞。
统计量)1(~1ˆˆˆ----'--=k n t k n c S t iiii i i ie e βββββ在(1-α)的置信水平下βi 的置信区间是( , ) ββααββi i t s t s ii-⨯+⨯22,其中,t α/2为显著性水平为α、自由度为n-k-1的临界值。
计量经济学课后答案——张龙版

计量经济学第一次作业第二章P858.用SPSS软件对10名同学的成绩数据进行录入,分析得r=,这说明学生的课堂练习和期终考试有密切的关系,一般平时练习成绩较高者,期终成绩也高。
9.(1)一元线性回归模型如下:Y i=ß0+ß1X i+u i其中,Yi 表示财政收入,Xi表示国民生产总值,ui为随机扰动项,ß0 ß1为待估参数。
由Eviews软件得散点图如下图:(2)Ýi=+SÊ:t:R2=0.958316 F= df=28斜率ß1=表示国民生产总值每增加1亿元,财政收入增加亿元。
(3)可决系数R2=表示在财政收入Y的总变差中由模型作出的解释部分占%,即有%由国民生产总值来解释,同时说明样本回归模型对样本数据的拟合程度较高。
R2=ESS/(ESS+RSS)ESS=RSS*R2/(1-R2)=+08)*=+08F=(n-2)ESS/RSS,ESS=F*RSS/(n-2)=*E09(4)SÊ(ß0)= SÊ(ß1)=ß1的95%的置信区间是:[ß(28)S Ê(ß1),ß1+(28)S Ê(ß1)] 代入数值得: [即:[,]同理可得,ß0的95%置信区间为[,] (5)①原假设H 0:ß0=0 备择假设:H 1:ß0≠0则ß0的t 值为:t 0=当ɑ=时t ɑ/2(28)=|t 0|=>t ɑ/2(28)= 故拒绝原假设H 0,表明模型应保留截距项。
②原假设H 0:ß1=0 备择假设:H 1:ß1≠0当ɑ=时t ɑ/2(28)= 因为|t 1|=>t ɑ/2(28)=故拒绝原假设H 0表明国民生产总值的变动对国家财政收入有显著影响.计量经济学第二次作业第二章9.(10) 、建立X 与t 的趋势模型,其回归分析结果如下:Dependent Variable: X Method: Least Squares Date: 04/19/10 Time: 22:03 Sample: 1978 2008Included observations: 31Dependent Variable: Y Method: Least Squares Date: 04/10/10 Time: 17:31 Sample: 1978 2007Included observations: 30VariableCoefficien t Std. Error t-StatisticProb.C XR-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid +08 Schwarz criterionLog likelihood F-statistic Durbin-Watson statProb(F-statistic)VariableCoefficien t Std. Error t-StatisticProb.T CR-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid +10 Schwarz criterionLog likelihood F-statistic Durbin-Watson statProb(F-statistic)令t=2008,其预测结果X=再根据X 对Y 进行预测,其预测结果为Y= X 2008= Y 2008=(S Ê(e 0))2—(S Ê(Y0))2=ó2 所以S Ê(e 0)= 在95%的置信度下,Y 2008的预测区间为: [Y 0-t α/2S Ê(e 0),Y 0+t α/2S Ê(e 0)]=[,]第三章P124,6. 该家庭在衣着用品方面的开支(Y )对总开支(X 1)以及衣着用品价格(X 2)的最小二乘估计结果如下:Dependent Variable: Y Method: Least Squares Date: 04/20/10 Time: 09:24 Sample: 1991 2000Included observations: 10VariableCoefficien t Std. Error t-StatisticProb.C X1 X2R-squaredMean dependent var Adjusted R-squared . dependent var . of regression Akaike info criterionSum squared resid Schwarz criterion Log likelihoodF-statisticDurbin-Watson stat Prob(F-statistic)12- 3.755455 + 0.183866 + 0.301746 i i i Y X X = :SE (2.679575) (0.028973) (0.167644) :t (-1.401511) (6.346071) (1.799923) :P (0.2038) (0.0004) (0.1149) 20.960616R = 2 0.949364R = :F (85.36888) ():(0.000012)P F :(2.725104)DW 7df =在=5%α的显著性水平下,对解释变量的估计参数1ˆβ、2ˆβ进行检验: 0111:0,:0H H ββ=≠,1{ 6.346071}0.0004<=0.05P t t α>==,1t 落入拒绝域,接受备择假设1H ,1ˆβ不显著为0,即就单独而言,总开支(X 1)对衣着用品方面的开支(Y )影响显著。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三章13题 下表列出了中国某年按行业分的全部制造业国有企业及规模以上制造业非国有企业
的工业总产值Y ,资产合计K 及职工人数L 。
序号 工业总产值 Y (亿元) 资产合计 K (亿元) 职工人数L (万人) 序号 工业总产值Y (亿元) 资产合计K (亿元) 职工人数 L (万人) 1 3722.7 3078.22 113 13 4429.19 3785.91 61 2 1442.52 1684.43 67 14 5749.02 8688.03 254 3 1752.37 2742.77 84 15 1781.37 2798.9 83 4 1451.29 1973.82 27 16 1243.07 1808.44 33 5 5149.3 5917.01 327 17 812.7 1118.81 43 6 2291.16 1758.77 120 18 1899.7 2052.16 61 7 1345.17 939.1 58 19 3692.85 6113.11 240 8 656.77 694.94 31 20 4732.9 9228.25 222 9 370.18 363.48 16 21 2180.23 2866.65 80 10 1590.36 2511.99 66 22 2539.76 2545.63 96 11 616.71 973.73 58 23 3046.95 4787.9 222 12 617.94 516.01 28 24 2192.63 3255.29 163
解:
⑴ 先对Y AK L e αβμ=左右两边同时取对数得:
ln ln ln ln ln Y C K L
C A e αβμ=++=+
相应的数据变为:
通过Eviews 软件进行回归分析得到如下结果:
于是得到回归方程为:
首先可决系数20.892388
R=和修正的可决系数20.882139
R=都是接近于1的,故该回归方程的模拟情况还是比较好的。
在5%的显著性水平下,自由度为(2,21)的F分布的临界值为
0.05(2,21) 3.47
F=,该回归分析的统计量87.07231
F=显著大于3.47,因此ln Y与lnK、lnL有显著
的关系;再看t分布,因为
0.05(21) 1.721
t=,其常数项µ
02,410253 1.721
β=>、lnK的系数
µ15.692170 1.721
β=>说明这两项已经通过检验,但是lnL的回归系数没有通过检验。
⑵这个题不知道怎么做,只能根据答案提示做出结果,具体不知道怎么分析。
第四章8题下表列出了某年中国部分省市城镇居民家庭平均每个全年可支配收入(X)与消费性支出(Y)的统计数据。
地区可支配收
入(X)
消费性
支出(Y)
地区
可支配
收入(X)
消费性
支出(Y)
北京10349.69 8493.49 浙江9279.16 7020.22
天津8140.5 6121.04 山东6489.97 5022
河北5661.16 4348.47 河南4766.26 3830.71
山西4724.11 3941.87 湖北5524.54 4644.5
内蒙古5129.05 3927.75 湖南6218.73 5218.79
辽宁5357.79 4356.06 广东9761.57 8016.91
吉林4810 4020.87 陕西5124.24 4276.67
黑龙江4912.88 3824.44 甘肃4916.25 4126.47
上海11718.01 8868.19 青海5169.96 4185.73
江苏6800.23 5323.18 新疆5644.86 4422.93
解:
⑴最小线性二乘估计的检验结果和回归方程为:
⑵异方差检验
X与Y散点图,从下图可以看出方差基本一致。
怀特检验结果:(这个表有些项看不懂,故也不知道怎么分析)
G-Q检验:
两个样本的估计结果为:
于是得到如下的F统计量:1
0.05
2
/4295354.3
4.09883268(4,4) 6.39
/472058.15
RSS
F F
RSS
===<=,故接受原假设,即不是异方差的。
⑶通过上面的检验是不存在异方差性的,不需要纠正异方差性的后果了。
当然,如果显著性水平再高一点的话,该回归模型就不能通过同方差的假设性检验了,此时就需要对此进行一定的修改。
权的确定这部分是看参考答案的,为什么选它目前还没完全明白。
可以得到加权最小最小二乘估计的结果为:
接下来对加权最小二乘得到的回归方程进行怀特检验,有如下结果:。