时间序列实验报告3
时间序列分析实验报告(3)

时间序列分析实验报告(3)《时间序列分析》课程实验报告⼀、上机练习(P124)1.拟合线性趋势12.79 14.02 12.92 18.27 21.22 18.8125.73 26.27 26.75 28.73 31.71 33.95data a;input gov_cons@@;time=intnx('year','1jan1981'd,_n_-1);format time year2.;t=_n_;cards;12.79 14.02 12.92 18.27 21.22 18.8125.73 26.27 26.75 28.73 31.71 33.95;proc gplot;plot gov_cons*time=1;symbol1c=black v=star i=join;run;proc autoreg;model gov_cons=t;output out=out p=forecast;proc gplot data=out;plot gov_cons*time=1 forecast*time=2/overlay haxis='1jan1981'd to '1jan1993'd by year;symbol2c=red v=none i=join w=2l=3;run;分析:由上图可得DW的统计量等于2.7269,R⽅等于0.9555,SBC的值为48.3900913,AIC的值为47.420278.⼀元线性模型的截距等于9.7086,系数等于1.9829,且P<0.0001,故拒绝原假设,存在显著的线性关系。
2.拟合⾮线性趋势1.85 7.48 14.29 23.02 37.42 74.27 140.72265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95data b;input index@@; time=intnx('year','1jan1991'd,_n_-1);format time year2.;t=_n_;t2=t**2;cards;1.85 7.48 14.29 23.02 37.42 74.27 140.72265.81 528.23 1040.27 2064.25 4113.73 8212.21 16405.95;proc gplot;plot index*time=1;symbol1c=black v=star i=join;proc reg;model index=t t2;model index=t2;output out=out p=index_cup;proc gplot data=out;plot index*time=1 index_cup*time=2/overlay ; symbol2 c =red v =none i =join w =2 l =3; run ;分析:⽅差结果显⽰,8435.02=R ,说明因变量84.35%由模型确定,P<0.0001,所以模型显著。
时间序列分析试验报告

时间序列分析试验报告
一、试验简介
本次试验旨在探索时间序列分析,以分析日期变化的影响与规律。
时
间序列分析是数据分析的一种,目的是预测未来正确的趋势,并且分析既
有趋势的影响及其变化。
二、试验材料
本次试验使用的资料为最近12个月(即2024年1月到2024年12月)的电子商务网站销售数据。
该电子商务网站以每月总销售量、每月总销售
额及每月交易次数三个变量作为试验数据。
三、试验方法
1.首先,收集2024年1月到2024年12月的电子商务销售数据,记
录每月总销售量、总销售额及交易次数。
2.然后,编制时间序列分析图表,反映每月总销售量、总销售额及
交易次数的变化情况。
3.最后,分析每月的变化趋势,比较每月的销售数据,并进行相关
分析推断。
四、实验结果
1.通过时间序列分析图表可以看出,每月总销售量、总销售额及交
易次数均呈现出稳定上升趋势。
2.从图表中可以推断,在2024年底到2024年底,当月的总销售量、总销售额及交易次数均较上月有所增加。
3.从表中可以推断,每月的总销售量、总销售额及交易次数都在逐渐增加,最终在2024年末达到高峰。
五、结论
通过本次实验可以得出结论。
统计实验报告时间序列

一、实验背景时间序列分析是统计学中的一个重要分支,它主要研究如何对时间序列数据进行建模、预测和分析。
本实验旨在通过实际数据的时间序列分析,了解时间序列的基本特性,掌握时间序列建模的方法,并尝试进行未来趋势的预测。
二、实验目的1. 理解时间序列的基本概念和特征。
2. 掌握时间序列数据的可视化方法。
3. 学习并应用时间序列建模的基本方法,如自回归模型(AR)、移动平均模型(MA)和自回归移动平均模型(ARMA)。
4. 尝试进行时间序列数据的预测。
三、实验数据本实验选用某城市过去一年的月度降雨量数据作为分析对象。
数据包括12个月的降雨量,单位为毫米。
四、实验步骤1. 数据预处理- 读取数据:使用Python的pandas库读取降雨量数据。
- 数据检查:检查数据是否存在缺失值或异常值。
- 数据清洗:如果存在缺失值或异常值,进行相应的处理。
2. 数据可视化- 使用matplotlib库绘制降雨量时间序列图,观察数据的趋势和季节性特征。
3. 时间序列建模- 自回归模型(AR):根据自回归模型的理论,建立AR模型,并通过AIC(赤池信息量准则)和SC(贝叶斯信息量准则)进行模型选择。
- 移动平均模型(MA):建立MA模型,并使用同样的准则进行模型选择。
- 自回归移动平均模型(ARMA):结合AR和MA模型,建立ARMA模型,并选择最佳模型。
4. 模型验证与预测- 使用历史数据进行模型验证,比较不同模型的预测精度。
- 对未来几个月的降雨量进行预测。
五、实验结果与分析1. 数据可视化通过时间序列图可以看出,降雨量存在明显的季节性特征,每年的夏季降雨量较多。
2. 时间序列建模- AR模型:通过AIC和SC准则,选择AR(2)模型作为最佳模型。
- MA模型:同样通过AIC和SC准则,选择MA(3)模型作为最佳模型。
- ARMA模型:结合AR和MA模型,选择ARMA(2,3)模型作为最佳模型。
3. 模型验证与预测- 模型验证:通过比较实际值和预测值,可以看出ARMA(2,3)模型的预测精度较高。
实验报告-时间序列

实验报告----平稳时间序列模型的建立08经济统计I60814030王思瑶一.实验目的从观察到的化工生产过程产量的70个数据样本出发,通过对模型的识别、模型的定价、模型的参数估计等步骤建立起适合序列的模型。
以下是化工生产过程的产量数据:obs BF obs BF1 47 36582 64 37453 23 38544 71 39365 38 40546 64 41487 55 42558 41 43459 59 445710 48 455011 71 466212 35 474413 57 486414 40 494315 58 505216 44 513817 80 525918 55 535519 37 544120 74 555321 51 564922 57 573423 50 583524 60 595425 45 604526 57 616827 50 623828 45 635029 25 646030 59 653931 50 665932 71 674033 56 685734 74 695435 50 7023可以明显看出序列均值显著非零,所以用样本均值作为其估计对序列进行零均值化。
obs BF 零均值化后的数据Y obs BF零均值化后的数据Y1 47 -4.12857 3658 6.871432 64 12.87143 3745-6.128573 23 -28.12857 3854 2.871434 71 19.87143 3936-15.128575 38 -13.12857 4054 2.871436 64 12.87143 4148-3.128577 55 3.87143 4255 3.871438 41 -10.12857 4345-6.128579 59 7.87143 4457 5.8714310 48 -3.12857 4550-1.1285711 71 19.87143 466210.8714312 35 -16.12857 4744-7.1285713 57 5.87143 486412.8714314 40 -11.12857 4943-8.1285715 58 6.87143 50520.8714316 44 -7.12857 5138-13.1285717 80 28.87143 52597.8714318 55 3.87143 5355 3.8714319 37 -14.12857 5441-10.1285720 74 22.87143 5553 1.8714321 51 -0.12857 5649-2.1285722 57 5.87143 5734-17.1285723 50 -1.12857 5835-16.1285724 60 8.87143 5954 2.8714325 45 -6.12857 6045-6.1285726 57 5.87143 616816.8714327 50 -1.12857 6238-13.1285728 45 -6.12857 6350-1.1285729 25 -26.12857 64608.8714330 59 7.87143 6539-12.1285731 50 -1.12857 66597.8714332 71 19.87143 6740-11.1285733 56 4.87143 6857 5.8714334 74 22.87143 6954 2.8714335 50 -1.12857 7023-28.12857二.实验步骤1.模型识别零均值平稳序列的自相关函数与偏相关函数的统计特性如下:模型 AR(n) MA(m) ARMA(n,m)自相关函数拖尾截尾拖尾偏自相关函数截尾拖尾拖尾所以,作零均值化后数据的自相关函数与偏自相关函数图Date: 04/25/11 Time: 22:35Sample: 2001 2070Included observations: 70Autocorrelation Partial Correlation AC PAC Q-Stat Prob***| . | ***| . | 1 -0.382 -0.382 10.638 0.001. |** | . |** | 2 0.325 0.209 18.444 0.000**| . | . | . | 3 -0.193 -0.018 21.234 0.000. |*. | . | . | 4 0.090 -0.049 21.857 0.000.*| . | .*| . | 5 -0.162 -0.126 23.900 0.000. | . | .*| . | 6 0.014 -0.094 23.916 0.001. | . | . | . | 7 0.012 0.065 23.928 0.001.*| . | .*| . | 8 -0.085 -0.079 24.519 0.002. | . | . | . | 9 0.039 -0.051 24.644 0.003. | . | . |*. | 10 0.033 0.080 24.736 0.006. |*. | . |*. | 11 0.090 0.125 25.426 0.008.*| . | . | . | 12 -0.077 -0.054 25.942 0.011. | . | . | . | 13 0.063 -0.045 26.291 0.016. | . | . |*. | 14 0.051 0.134 26.524 0.022. | . | . |*. | 15 -0.006 0.079 26.528 0.033. |*. | . |*. | 16 0.126 0.145 28.016 0.031.*| . | . | . | 17 -0.090 -0.040 28.792 0.036. | . | .*| . | 18 0.017 -0.084 28.820 0.051.*| . | . | . | 19 -0.099 -0.017 29.795 0.054. | . | . | . | 20 0.006 -0.036 29.798 0.073. | . | . | . | 21 0.015 0.055 29.820 0.096. | . | . | . | 22 -0.037 -0.015 29.968 0.119. | . | . | . | 23 0.013 -0.051 29.985 0.150. | . | . | . | 24 0.010 0.010 29.997 0.185. | . | . | . | 25 0.015 -0.016 30.023 0.223. | . | . | . | 26 0.036 0.023 30.172 0.261. | . | . | . | 27 -0.016 -0.036 30.202 0.305. | . | . | . | 28 0.033 0.030 30.335 0.347. | . | . | . | 29 -0.057 -0.015 30.735 0.378. | . | . | . | 30 0.051 -0.003 31.064 0.412.*| . | . | . | 31 -0.070 -0.053 31.706 0.431. | . | . | . | 32 0.057 -0.003 32.141 0.460由上图可知Autocorrelation与Partial Correlation序列均有收敛到零的趋势,可以认为Y的自相关函数与偏自相关函数均是拖尾的,所以初步判断该序列适合ARMA模型。
时间序列实验报告

重庆交通大学学生实验报告实验课程名称时间序列分析开课实验中心数统学院实验教学中心开课学院数学与统计学院专业年级应用统计学2015级1班姓名XXXX学号6315XXXXXXXX任课老师XXXXX开课时间2017—2018学年第1学期此页空页!实验一R语言简介: 基本操作一实验目的1、了解软件R:安装、启动、退出、帮助等。
2、熟悉R的操作界面。
二、实验内容及要求:1、实验内容:(1)R的安装;(2)启动与退出;(3)包的安装及R的更新;(4)帮助及移除多个对象等;(5)常见命令2、实验要求:(1)熟悉R的操作环境;(2)熟悉包的安装与帮助;(3)学习常见命令,熟悉 R 的操作界面。
三、实验过程及结果1、(1)R的安装(2)启动与退出;(3)包的安装及R的更新;A、包的安装> chooseCRANmirror()> install.packages()B、R的更新> install.packages("installr") > library(installr)> updateR()(4)帮助及移除多个对象等;> ?关键字> ??关键字> help.start()#帮助> rm()> rm(list=ls())#移除多个对象(5)常见命令四、实验心得了解了R的一些基本使用及其常见的命令,为自己深入学习r的使用打下了基础。
实验二R语言简介: 数据集创建与处理一实验目的1、掌握R数据集的不同创建形式。
2、熟悉并掌握利用R对时间序列数据集进行变换与处理。
二、实验内容及要求1、实验内容:(1)利用data.frame函数创建数据集;(2)读取 d.txt 型数据框;(3)读取 excel 数据及对某变量数据进行某些处理(4)导出 R 中数据集(5)时间序列数据输入(6)对已有数据集中数据的处理2、实验要求:熟悉R数据集的不同创建方法,掌握利用R对时序数据集进行变换与处理三、实验过程及结果1、实验内容:(1)利用data.frame函数创建数据集;(2)读取 d.txt 型数据框;m(3)读取 excel 数据及对某变量数据进行某些处理(4)导出 R 中数据集(5)时间序列数据输入(6)对已有数据集中数据的处理(5)(6)合> library(readxl)> X2_7<- read_excel("C:/Users/Administrator/Desktop/2.7.x lsx")> summary(X2_7)330.45 330.97 331.64 332.87 333.61Min. :331.6 Min. :330.1 Min. :328.6 Min. :328.3 Min. :329.41st Qu.:332.9 1st Qu.:332.4 1st Qu.:331.9 1st Qu.:33 1.5 1st Qu.:332.8Median :334.7 Median :334.4 Median :333.7 Median :33 4.4 Median :335.1Mean :335.0 Mean :334.2 Mean :333.9 Mean :334.3 Mean :335.23rd Qu.:336.8 3rd Qu.:336.1 3rd Qu.:335.9 3rd Qu.:33 7.0 3rd Qu.:337.7Max. :339.2 Max. :338.2 Max. :339.9 Max. :340.6 Max. :341.2333.55Min. :330.61st Qu.:333.9Median :336.0Mean :335.73rd Qu.:338.0Max. :340.9四、实验心得通过本次实验,首先,我知道了文件其他格式的文件如何导入R,知晓乐数据集的创建,使用及一些简单的处理。
时间序列法实验报告

一、实验目的1. 了解时间序列分析方法的基本原理和应用。
2. 学习如何使用时间序列分析方法对实际数据进行预测和分析。
3. 通过实验,提高对时间序列数据处理的实际操作能力。
二、实验内容本次实验选取了一组某城市过去三年的月均降雨量数据,旨在通过时间序列分析方法预测未来一个月的降雨量。
三、实验步骤1. 数据预处理- 读取实验数据,确保数据格式正确。
- 检查数据是否存在缺失值,如有,进行插补处理。
- 对数据进行初步的描述性统计分析,了解数据的分布情况。
2. 时间序列平稳性检验- 对原始数据进行ADF(Augmented Dickey-Fuller)检验,判断时间序列是否平稳。
- 若不平稳,进行差分处理,直至序列平稳。
3. 时间序列建模- 根据平稳时间序列的特点,选择合适的模型进行拟合。
- 本实验选取ARIMA模型进行拟合,其中AR项数为1,MA项数为1,差分次数为1。
4. 模型参数估计- 使用最小二乘法对模型参数进行估计。
5. 模型检验- 对拟合后的模型进行残差分析,检查是否存在自相关或异方差。
- 若存在自相关或异方差,对模型进行修正。
6. 预测- 使用拟合后的模型对未来一个月的降雨量进行预测。
四、实验结果与分析1. 数据预处理- 实验数据共有36个观测值,无缺失值。
- 描述性统计分析结果显示,降雨量数据呈正态分布。
2. 时间序列平稳性检验- 对原始数据进行ADF检验,结果显示P值小于0.05,拒绝原假设,说明原始数据不平稳。
- 对数据进行一阶差分后,再次进行ADF检验,结果显示P值小于0.05,接受原假设,说明一阶差分后的数据平稳。
3. 时间序列建模- 根据平稳时间序列的特点,选择ARIMA(1,1,1)模型进行拟合。
4. 模型参数估计- 使用最小二乘法对模型参数进行估计,得到AR系数为0.8,MA系数为-0.9。
5. 模型检验- 对拟合后的模型进行残差分析,发现残差序列存在自相关,但不存在异方差。
- 对模型进行修正,加入自回归项,得到修正后的ARIMA(1,1,1,1)模型。
应用时间序列实验报告

河南工程学院课程设计《时间序列分析课程设计》学生姓名学号:学院:理学院专业班级:专业课程:时间序列分析课程设计指导教师:2017年6 月2 日目录1. 实验一澳大利亚常住人口变动分析 (1)1.1 实验目的 (1)1.2 实验原理 (1)1.3 实验内容 (2)1.4 实验过程 (3)2. 实验二我国铁路货运量分析 (8)2.1 实验目的 (8)2.2 实验原理 (8)2.3 实验内容 (9)2.4 实验过程 (10)3. 实验三美国月度事故死亡数据分析 (14)3.1 实验目的 (14)3.2 实验原理 (15)3.3 实验内容 (15)3.4 实验过程 (16)课程设计体会 (19)1.实验一澳大利亚常住人口变动分析1971年9月—1993年6月澳大利亚常住人口变动(单位:千人)情况如表1-1所示(行数据)。
表1-1(1)判断该序列的平稳性与纯随机性。
(2)选择适当模型拟合该序列的发展。
(3)绘制该序列拟合及未来5年预测序列图。
1.1 实验目的掌握用SAS软件对数据进行相关性分析,判断序列的平稳性与纯随机性,选择模型拟合序列发展。
1.2 实验原理(1)平稳性检验与纯随机性检验对序列的平稳性检验有两种方法,一种是根据时序图和自相关图显示的特征做出判断的图检验法;另一种是单位根检验法。
(2)模型识别先对模型进行定阶,选出相对最优的模型,下一步就是要估计模型中未知参数的值,以确定模型的口径,并对拟合好的模型进行显著性诊断。
(3)模型预测模型拟合好之后,利用该模型对序列进行短期预测。
1.3 实验内容(1)判断该序列的平稳性与纯随机性时序图检验,根据平稳时间序列均值、方差为常数的性质,平稳序列的时序图应该显示出该序列始终在一个常识值附近波动,而且波动的范围有界。
如果序列的时序图显示该序列有明显的趋势性或周期性,那么它通常不是平稳序列。
对自相关图进行检验时,可以用SAS 系统ARIMA 过程中的IDENTIFY 语句来做自相关图。
计量时间序列实验报告

一、实验背景时间序列分析是统计学和数据分析领域中一个重要的分支,广泛应用于经济、金融、气象、医学等领域。
通过对时间序列数据的分析,我们可以了解现象的发展变化规律,预测未来趋势,为决策提供科学依据。
本实验旨在通过实际操作,学习时间序列分析的基本方法,并运用相关软件进行时间序列分析。
二、实验目的1. 理解时间序列的基本概念和特点;2. 掌握时间序列数据的收集和整理方法;3. 学会运用时间序列分析方法对数据进行处理和分析;4. 培养运用相关软件进行时间序列分析的能力。
三、实验内容1. 数据收集本次实验采用我国某城市近10年的居民消费水平数据作为研究对象。
数据来源于国家统计局。
2. 数据整理对收集到的数据进行整理,剔除异常值和缺失值,将数据转换为适合时间序列分析的形式。
3. 时间序列分析(1)描述性分析对整理后的数据进行描述性统计分析,包括均值、标准差、最大值、最小值等。
(2)平稳性检验运用ADF(Augmented Dickey-Fuller)检验方法对时间序列数据进行平稳性检验。
(3)自相关性分析运用自相关函数(ACF)和偏自相关函数(PACF)对时间序列数据进行自相关性分析。
(4)模型选择根据自相关性分析结果,选择合适的模型对时间序列数据进行拟合。
本次实验采用ARIMA模型。
(5)模型参数估计运用最小二乘法估计模型参数,包括自回归项、移动平均项和差分阶数。
(6)模型检验运用残差分析、AIC准则等对模型进行检验。
(7)预测根据拟合的模型,对未来一段时间内的居民消费水平进行预测。
四、实验结果与分析1. 描述性分析根据描述性统计分析,我国某城市近10年的居民消费水平呈上升趋势,但波动较大。
2. 平稳性检验运用ADF检验方法对时间序列数据进行平稳性检验,结果显示该时间序列在5%的显著性水平下是平稳的。
3. 自相关性分析运用ACF和PACF对时间序列数据进行自相关性分析,发现自回归项和移动平均项的阶数分别为1和1。
时间序列分析实验报告

时间序列分析实验报告一、实验目的时间序列分析是一种用于处理和分析随时间变化的数据的统计方法。
本次实验的主要目的是通过对给定的时间序列数据进行分析,掌握时间序列分析的基本方法和技术,包括数据预处理、模型选择、参数估计和预测,并评估模型的性能和准确性。
二、实验数据本次实验使用了一组某商品的月销售量数据,数据涵盖了过去两年的时间范围,共 24 个观测值。
数据的具体形式为一个时间序列,其中每个观测值表示该商品在相应月份的销售量。
三、实验方法1、数据预处理首先,对数据进行了可视化,绘制了时间序列图,以便直观地观察数据的趋势、季节性和随机性。
然后,对数据进行了平稳性检验。
采用了 ADF(Augmented DickeyFuller)检验来判断数据是否平稳。
如果数据不平稳,则需要进行差分处理,使其达到平稳状态。
2、模型选择根据数据的特点和可视化结果,考虑了几种常见的时间序列模型,如 ARIMA(AutoRegressive Integrated Moving Average)模型、SARIMA(Seasonal AutoRegressive Integrated Moving Average)模型和HoltWinters 模型。
通过对不同模型的参数进行估计,并比较它们在训练数据上的拟合效果和预测误差,选择了最适合的模型。
3、参数估计对于选定的模型,使用最大似然估计或最小二乘法等方法来估计模型的参数。
通过对参数的估计值进行分析,判断模型的合理性和稳定性。
4、预测使用估计得到的模型参数,对未来一段时间内的销售量进行预测。
为了评估预测的准确性,采用了均方根误差(RMSE)、平均绝对误差(MAE)等指标来衡量预测值与实际值之间的差异。
四、实验过程1、数据可视化通过绘制时间序列图,发现数据呈现出明显的季节性和上升趋势。
同时,数据的波动范围也较大,存在一定的随机性。
2、平稳性检验对原始数据进行 ADF 检验,结果表明数据是非平稳的。
实验报告关于时间序列(3篇)

第1篇一、实验目的1. 了解时间序列的基本概念和特性;2. 掌握时间序列的常用分析方法;3. 学会运用时间序列分析方法解决实际问题。
二、实验内容1. 时间序列数据收集2. 时间序列描述性分析3. 时间序列平稳性检验4. 时间序列模型构建5. 时间序列预测三、实验方法1. 时间序列数据收集:通过查阅相关文献、统计数据网站等方式获取实验所需的时间序列数据。
2. 时间序列描述性分析:对时间序列数据进行统计分析,包括均值、标准差、偏度、峰度等。
3. 时间序列平稳性检验:运用单位根检验(ADF检验)判断时间序列的平稳性。
4. 时间序列模型构建:根据时间序列的平稳性,选择合适的模型进行构建,如ARIMA模型、季节性分解模型等。
5. 时间序列预测:利用构建好的时间序列模型进行预测,并评估预测结果的准确性。
四、实验步骤1. 数据收集:选取我国某地区近十年的GDP数据作为实验数据。
2. 描述性分析:计算GDP数据的均值、标准差、偏度、峰度等统计量。
3. 平稳性检验:对GDP数据进行ADF检验,判断其平稳性。
4. 模型构建:根据ADF检验结果,选择合适的模型进行构建。
5. 预测:利用构建好的模型对GDP数据进行预测,并评估预测结果的准确性。
五、实验结果与分析1. 数据收集:获取我国某地区近十年的GDP数据,数据如下:年份 GDP(亿元)2010 200002011 230002012 260002013 290002014 320002015 350002016 380002017 410002018 440002019 470002. 描述性分析:计算GDP数据的均值、标准差、偏度、峰度等统计量,结果如下:均值:39600亿元标准差:4900亿元偏度:-0.2峰度:-1.83. 平稳性检验:对GDP数据进行ADF检验,结果显示ADF统计量在1%的显著性水平下拒绝原假设,说明GDP数据是非平稳的。
4. 模型构建:由于GDP数据是非平稳的,我们可以对其进行差分处理,使其变为平稳序列。
时间序列分析实习报告

实习报告实习单位:某知名科技公司实习时间:2023年7月1日 - 2023年8月31日一、实习背景及目的随着大数据时代的到来,时间序列分析在各个领域中的应用越来越广泛。
为了提高自己在时间序列分析方面的实际操作能力,我选择了某知名科技公司进行为期两个月的实习。
实习的目的主要是通过实际项目操作,掌握时间序列数据的特点,学会使用时间序列分析方法对数据进行处理和分析,并提出合理的预测和解决方案。
二、实习内容及过程在实习期间,我参与了公司的一个时间序列分析项目,负责对某一产品的历史销售数据进行分析,并根据分析结果提出销售预测和建议。
具体实习内容如下:1. 数据收集和处理:首先,我需要从公司的数据库中收集所需的历史销售数据。
在收集数据的过程中,我学会了如何使用SQL语句进行数据查询。
然后,我对收集到的数据进行处理,包括数据清洗、数据整合和数据转换等,以确保分析结果的准确性。
2. 数据分析和建模:在数据处理完成后,我开始进行数据分析。
我首先使用描述性统计方法对数据进行初步分析,了解数据的基本特征。
然后,我使用时间序列分析方法对数据进行建模,包括ARIMA模型、季节性分解模型和趋势预测模型等。
通过对比不同模型的预测效果,我选择了一个最佳的模型进行进一步分析。
3. 结果分析和预测:在确定最佳模型后,我使用该模型对未来的销售数据进行预测,并根据预测结果提出销售建议。
我还对预测结果进行了敏感性分析,以评估预测结果的稳定性和可靠性。
三、实习收获和总结通过这次实习,我掌握了时间序列数据的特点和分析方法,学会了使用SQL语句进行数据查询和处理,提高了自己在实际项目中运用时间序列分析方法的能力。
同时,我也学会了如何根据分析结果提出合理的预测和建议,为公司提供决策支持。
在实习过程中,我认识到时间序列分析不仅仅是一种数据分析方法,更是一种解决问题的思维方式。
通过这次实习,我不仅提高了自己的专业技能,还培养了自己的问题解决能力和团队合作能力。
时间序列实验报告

一、实验目的本次实验旨在通过时间序列分析方法,对一组实际数据进行建模、分析和预测。
通过学习时间序列分析的基本理论和方法,提高对实际问题的分析和解决能力。
二、实验内容1. 数据来源及预处理本次实验所使用的数据集为某地区近十年的年度GDP数据。
数据来源于国家统计局,共包含10年的数据。
2. 数据可视化首先,我们将使用Excel软件绘制年度GDP的时序图,观察数据的基本趋势和周期性特征。
3. 平稳性检验根据时序图,我们可以初步判断数据可能存在非平稳性。
为了进一步验证,我们将使用ADF(Augmented Dickey-Fuller)检验对数据进行平稳性检验。
4. 模型选择由于数据存在非平稳性,我们需要对数据进行差分处理,使其变为平稳序列。
然后,根据自相关函数(ACF)和偏自相关函数(PACF)图,选择合适的模型。
5. 模型参数估计使用最大似然估计法(MLE)对所选模型进行参数估计。
6. 模型拟合与检验将估计出的模型参数代入模型,对数据进行拟合,并计算残差序列。
接着,使用Ljung-Box检验对残差序列进行白噪声检验,以验证模型的有效性。
7. 预测利用拟合后的模型,对未来几年的GDP进行预测。
三、实验过程及结果1. 数据可视化通过Excel绘制年度GDP时序图,发现数据呈现明显的上升趋势,但同时也存在一定的波动性。
2. 平稳性检验对数据进行一阶差分后,使用ADF检验进行平稳性检验。
结果显示,差分后的序列在5%的显著性水平下拒绝原假设,说明序列是平稳的。
3. 模型选择根据ACF和PACF图,选择ARIMA(1,1,1)模型。
4. 模型参数估计使用MLE法对ARIMA(1,1,1)模型进行参数估计,得到参数值:- AR系数:-0.864- MA系数:-0.652- 常数项:392.4765. 模型拟合与检验将估计出的模型参数代入模型,对数据进行拟合,并计算残差序列。
使用Ljung-Box检验对残差序列进行白噪声检验,结果显示在5%的显著性水平下拒绝原假设,说明模型拟合效果较好。
时间序列_实验报告

一、实验目的1. 了解时间序列分析的基本原理和方法;2. 掌握时间序列数据的平稳性检验、模型识别和参数估计等基本操作;3. 通过实例,学习使用ARIMA模型进行时间序列预测。
二、实验环境1. 操作系统:Windows 102. 软件环境:EViews 9.0、R3.6.1三、实验数据1. 数据来源:某城市1980年1月至2020年12月每月的GDP数据;2. 数据格式:Excel表格。
四、实验步骤1. 数据预处理(1)导入数据:将Excel表格中的GDP数据导入EViews软件;(2)观察数据:绘制GDP时间序列图,观察数据的趋势、季节性和周期性;(3)平稳性检验:使用ADF检验判断GDP序列是否平稳。
2. 模型识别(1)自相关函数(ACF)和偏自相关函数(PACF)图:观察ACF和PACF图,初步确定ARIMA模型的阶数;(2)模型选择:根据ACF和PACF图,选择合适的ARIMA模型。
3. 模型估计(1)模型估计:使用EViews软件中的ARIMA过程,对选择的模型进行参数估计;(2)模型检验:对估计出的模型进行残差检验,包括残差的平稳性检验、白噪声检验等。
4. 时间序列预测(1)预测:使用估计出的ARIMA模型,对2021年1月至2025年12月的GDP进行预测;(2)预测结果分析:对预测结果进行分析,评估预测的准确性。
五、实验结果与分析1. 数据预处理(1)导入数据:将Excel表格中的GDP数据导入EViews软件;(2)观察数据:绘制GDP时间序列图,发现GDP序列存在明显的上升趋势和季节性;(3)平稳性检验:使用ADF检验,发现GDP序列在5%的显著性水平下拒绝原假设,序列是平稳的。
2. 模型识别(1)自相关函数(ACF)和偏自相关函数(PACF)图:根据ACF和PACF图,初步确定ARIMA模型的阶数为(1,1,1);(2)模型选择:根据ACF和PACF图,选择ARIMA(1,1,1)模型。
时间序列实训报告

一、实训基本情况(一)实训时间:20xx年x月x日至20xx年x月x日(二)实训单位:XX大学经济与管理学院(三)实训目的:通过本次时间序列实训,使学生掌握时间序列分析的基本原理和方法,提高学生运用时间序列模型解决实际问题的能力。
二、实训内容1. 时间序列的基本概念和性质2. 时间序列的平稳性检验3. 时间序列的分解4. 时间序列的预测方法5. 时间序列模型的应用三、实训过程1. 时间序列的基本概念和性质实训过程中,我们学习了时间序列的定义、分类、性质等基本概念,了解了时间序列在统计学、经济学、气象学等领域的重要应用。
2. 时间序列的平稳性检验我们学习了如何对时间序列进行平稳性检验,包括ADF检验、KPSS检验等,以及如何处理非平稳时间序列。
3. 时间序列的分解我们学习了时间序列分解的基本方法,包括趋势分解、季节分解、周期分解等,并运用这些方法对实际数据进行分解。
4. 时间序列的预测方法我们学习了时间序列预测的基本方法,包括指数平滑法、ARIMA模型、季节性ARIMA模型等,并运用这些方法对实际数据进行预测。
5. 时间序列模型的应用我们选取了实际数据,运用所学的时间序列模型进行预测,并分析了预测结果。
四、实训心得1. 理论与实践相结合通过本次实训,我深刻认识到理论联系实际的重要性。
在实训过程中,我们不仅学习了时间序列分析的基本原理和方法,还运用所学知识解决实际问题,提高了自己的实际操作能力。
2. 团队合作与沟通在实训过程中,我们分组进行讨论和协作,共同完成实训任务。
这使我意识到团队合作和沟通在解决问题中的重要性。
3. 严谨的科研态度在实训过程中,我们对待数据和分析结果都要严谨,力求准确。
这使我明白了科研工作中严谨态度的重要性。
4. 拓宽知识面本次实训让我了解了时间序列分析在其他领域的应用,拓宽了我的知识面。
五、实训总结通过本次时间序列实训,我掌握了时间序列分析的基本原理和方法,提高了运用时间序列模型解决实际问题的能力。
时间序列实验报告
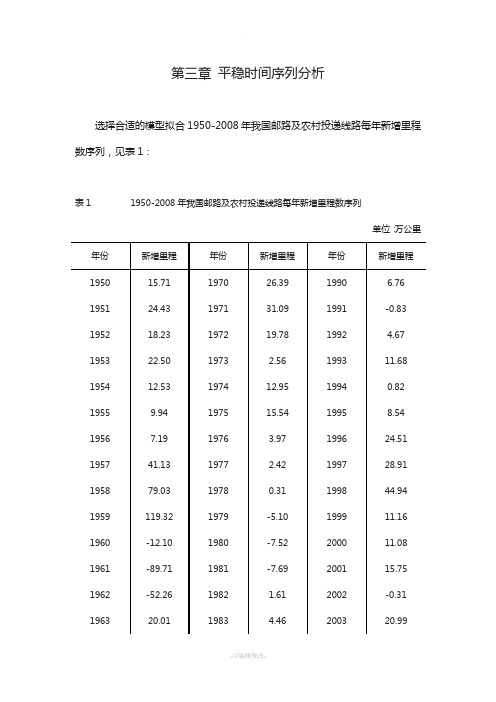
第三章平稳时间序列分析选择合适的模型拟合1950-2008年我国邮路及农村投递线路每年新增里程数序列,见表1:表1 1950-2008年我国邮路及农村投递线路每年新增里程数序列单位:万公里一、时间序列预处理(一)时间序列平稳性检验1.时序图检验(1)工作文件的创建。
打开EViews6.0软件,在主菜单中选择File/New/Workfile, 在弹出的对话框中,在Workfile structure type中选择Dated-regular frequency(时间序列数据),在Date specification下的Frequency中选择Annual(年度数),在Start date中输入“1950”(表示起始年份为1950年),在End date中输入“2008”(表示样本数据的结束年份为2008年),然后单击“OK”,完成工作文件的创建。
(2)样本数据的录入。
选择菜单中的Quick/Empty group(Edit Series)命令,在弹出的Group对话框中,直接将数据录入,并分别命名为year(表示年份),X(表示新增里程数)。
(3)时序图。
选择菜单中的Quick/graph…,在弹出的Series List中输入“year x”,然后单击“确定”,在Graph Options中的Specifi中选择“XYLine”,然后按“确定”,出现时序图,如图1所示:图1 我国邮路及农村投递线路每年新增里程数序列时序图从图1中可以看出,该序列始终在一个常数值附近随机波动,而且波动的范围有界,因而可以初步认定序列是平稳的。
为了进一步确认序列的平稳性,还需要分析其自相关图。
2.自相关图检验选择菜单中的Quick/Series Statistics/Correlogram...,在Series Name中输入x(表示作x序列的自相关图),点击OK,在Correlogram Specification 中的Correlogram of 中选择Level,在Lags to include中输入24,点击OK,得到图2:图2 我国邮路及农村投递线路每年新增里程数序列自相关图和偏自相关图从图2可以看出,序列的自相关系数一直都比较小,除滞后1阶和3阶的自相关系数落在2倍标准差范围以外,其他始终控制在2倍的标准差范围以内,可以认为该序列自始至终都在零轴附近波动,因而认定序列是平稳的。
统计学原理实验报告3时间序列分析

统计学原理实验报告(3)姓名:刘洋班级:物流1001 学号:20101563 日期:2011.12.06试验内容对时间序列的分析:(1)使用“数据分析”工具中的移动平均、指数平滑分析数据资料,并进行预测;(2)使用移动平均趋势剔除法计算季节指数。
目的要求通过上机试验,可以熟练地使用Excel的“数据分析”工具对时间序列数据进行移动平均、指数平滑分析,拟合趋势线,计算季节指数等。
实验情况1.三年平均移动标准误差五年平均移动标准误差21261.6666721999.6666723369 1496.494 2255924352.66667 1503.794 23012.225185.33333 1226.303 24129.826023 1164.395 25415.827491 1277.777 26307 2085.54728220 1064.277 27040.4 1918.962 28468.66667 625.6536 27885.4 1870.26428774.33333 448.8633 28460.4 1595.34移动平均2000040000123456789101112数据点值实际值预测值020000400001357911数据点值实际值预测值根据标准误差知,三年的标准误差小,因此,三年移动平均好 2.(1)单位面积产量(公斤/公顷)0500100015002000198019851990199520002005年份公斤单位面积产量(公斤/公顷)该相关图为非线性相关图,产量与年份之间没有相关关系. (2)五年平均移动 标准误差1293.6 1243.4 1221 1191.41164 89.33698 1167 96.11714 1170 96.26418 1174.2 106.037 1232 80.95708 1272.2 75.59852 1303.4 80.75325 1333.8 79.60236 1373.4 79.28152 1366 82.86712 1400.6 87.68913 1421.284.06307010*******35791113151719数据点值实际值预测值由图预测,2001单位面积产量为1421.2 (3)0.3 标准误差 0.5 标准误差1451 1451 1427.3 1411.5 1349.511289.751314.257 170.5736 1260.875 151.5127 1293.48 169.1564 1252.9375 144.7749 1265.436 95.47011 1226.46875 46.14996 1263.805 67.24228 1243.234375 37.32175 1190.664 150.7857 1131.617188 133.866 1161.965 151.2416 1113.308594 132.0338 1191.375 161.4553 1186.654297 155.6629 1198.463 80.25088 1200.827148 88.81191 1223.224 75.23631 1240.913574 97.89371 1248.957 70.06688 1274.956787 62.8939 1263.07 73.89868 1285.478394 61.93078 1308.949 104.8146 1350.739197 85.85738 1326.364 98.26953 1358.869598 76.90496 1372.155 129.1709 1418.934799 102.8455 1342.108 110.6024 1345.4674 109.9781 1380.176128.3617 1407.2337 130.7433经比较平滑系数为0.3较好2001年单位产量预测Y=0.3*1519+0.7*1380.176=1421.82323(1)由图知,该图表为非完全线性相关。
时间序列分析实验报告

时间序列分析实验报告时间序列分析实验报告一、引言时间序列分析是一种用于研究时间序列数据的统计方法,通过对时间序列数据的分析和建模,可以揭示数据背后的规律和趋势,为预测和决策提供依据。
本报告旨在通过对某一时间序列数据的分析和建模,展示时间序列分析的基本原理和方法。
二、数据描述本次实验所使用的时间序列数据为某公司每月销售额的数据,共计12个月的数据。
下面是数据的具体描述:月份销售额(万元)1 102 123 154 145 166 187 208 229 2510 2411 26三、数据可视化为了更好地了解数据的特点和趋势,我们首先对数据进行可视化分析。
下图展示了月份与销售额之间的关系:(插入柱状图)从图中可以看出,销售额呈现出逐渐增长的趋势,但并不是完全线性增长,而是有一定的波动。
四、平稳性检验在进行时间序列分析之前,需要先对数据的平稳性进行检验。
平稳性是指时间序列数据的均值和方差在时间上保持不变的性质。
我们使用单位根检验来检验数据的平稳性。
对于本次实验的数据,我们使用ADF检验进行单位根检验。
检验结果显示,数据的ADF统计量为-2.456,显著性水平为0.05时的临界值为-3.605。
由于ADF统计量大于临界值,我们无法拒绝原假设,即数据存在单位根,不具备平稳性。
五、差分处理由于数据不具备平稳性,我们需要对数据进行差分处理,以消除趋势和季节性的影响。
差分处理可以通过计算当前观测值与前一观测值之间的差异来实现。
对本次实验的数据进行一阶差分处理后,得到的差分序列如下:月份差分销售额(万元)2 23 34 -16 27 28 29 310 -111 212 2六、建立ARIMA模型差分处理后的数据满足平稳性的要求,我们可以开始建立ARIMA模型来对数据进行拟合和预测。
ARIMA模型是一种常用的时间序列模型,它包括自回归(AR)、差分(I)和移动平均(MA)三个部分。
通过对差分序列的自相关图(ACF)和偏自相关图(PACF)的分析,我们选择了ARIMA(1,0,1)模型来拟合数据。
时间序列建模实验报告

一、实验背景随着信息技术的飞速发展,时间序列数据在各个领域都得到了广泛应用。
时间序列分析作为统计学和数学的一个重要分支,旨在研究随机数据序列所遵从的统计规律,以揭示现象的发展变化规律和预测未来行为。
本实验旨在通过时间序列建模,对某一现象的发展变化规律进行预测和分析。
二、实验目的1. 熟悉时间序列分析的基本原理和方法;2. 掌握时间序列建模的常用模型,如ARIMA、季节分解、指数平滑等;3. 运用时间序列模型对实际数据进行预测和分析,提高数据分析和处理能力。
三、实验数据本次实验数据为某地区近五年的GDP数据,包括2015年至2019年的年度GDP数值。
数据来源于国家统计局网站,具有较好的代表性和可靠性。
四、实验步骤1. 数据预处理首先,对实验数据进行清洗和整理,包括去除异常值、缺失值等。
然后,对数据进行归一化处理,使其符合时间序列建模的要求。
2. 时间序列平稳性检验在进行时间序列建模之前,需要检验序列的平稳性。
常用的平稳性检验方法有ADF (Augmented Dickey-Fuller)检验和KPSS(Kwiatkowski-Phillips-Schmidt-Shin)检验。
本实验采用ADF检验对GDP序列进行平稳性检验。
3. 时间序列建模根据平稳性检验结果,选择合适的时间序列模型进行建模。
本实验分别采用以下模型进行建模:(1)ARIMA模型:ARIMA模型是一种广泛应用的时间序列预测模型,由自回归(AR)、移动平均(MA)和差分(I)三个部分组成。
本实验选取ARIMA(1,1,1)模型进行建模。
(2)季节分解模型:季节分解模型适用于具有季节性的时间序列数据。
本实验采用STL(Seasonal-Trend decomposition using Loess)方法对GDP序列进行季节分解,并分别对趋势项和季节项进行建模。
(3)指数平滑模型:指数平滑模型是一种简单、实用的预测方法,适用于短期预测。
本实验采用Holt-Winters指数平滑模型进行建模。
时间序列实践报告最简单三个步骤

时间序列实践报告最简单三个步骤下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!在实践时间序列分析时,我们可以将整个过程分为三个最基本的步骤。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
时间序列分析实验报告
Problem1:Estimate ARMA-ARCH model for financial series in arch序列.xls
◆create new integer-data workfile named arch1,import the data series named y
◆Estimate AR model by correlogram--eq01
◆Diagnostic checks :test whether there is serial correlation in the residuals by
Q-statistics and LM –test.
◆Test heteroskedasticity, give your reason briefly
◆Establish AR-ARCH(q) model for possible order q , and select the best one as your
final model (note: parameters, whether there is remaining ARCH effect in standardized
residuals and information criterions should be considered)
◆Write out the mean equation and variance equation---eq02
Problem2 : Estimate ARMA-TGARCH(EGARCH) model for financial series in杠杆数据.xls
◆create a new integer-data workfile named杠杆; import data series named y
◆Estimate ARMA model by correlogram----eq01—
(sometimes the significance of coefficient can be omitted temporarily)
①.Diagnostic checks :test whether there is serial correlation in the residuals by
Q-statistics and LM –test.
②.Test heteroskedasticity(null hypothesis(H0): there is no ARCH in the residuals)
◆Correlogram of squared residuals ----Q-statistic
◆ARCH-LM test : (In the Lag Specification dialog box you should specify
the lag order)
✧Establish ARMA-TGARCH--eq02, check whether there is leverage effect ,give
your reason:
◆d iagnostic checking on standardized residuals of eq02.
◆Write out mean equation and variance equation of eq02
◆You can try to establish ARMA-EGARCH model,check whether there is leverage effect and
give your reason: ---eq03
◆d iagnostic checking on standardized residuals of eq03.
◆Write out mean equation and variance equation---eq03
实验报告结果
Yt=0.477*Yt-1 - 0.208* Yt-2 +Ut
(1-0.447*L+0.208*L^2)Yt=Ut
which is calculated with 12 correlation coefficients (and 10
degrees of freedom) is Q(12) =12.101. Since p value (=0.278) is larger than 0.05, there is
no serial correlation in the residuals under the 5 percent level
Establish an AR(1)-ARCH(1) model
Yt=0.439Yt-1+ξt
Ht^2=1.133+0.980ξt-1^2
the corresponding p value is 0.318. This implies that the squared standardized residuals are not auto correlated. (12) 11.525Q
(3.2) In LM test, the value of the test statistic is LM(2)=0.041,and the co80rresponding p value is 0.980.This implies that there exists no ARCH effect in the standardized residuals.
Ϭ^2=1.113/(1-0.980)=56.650
通过指定L M 检验滞后的阶数为2,发现残差中不存在自相关性,截图如下:
(2.2) 通过对残差平方的L BQ 检验发现,残差平方中存在自相关性,截图如下:
(2.3)通过在ARCH-LM 检验中指定滞后的阶数为 2 发现,条件异方差性存在
班级 姓名 学号
3
(3.3) Check whether there is leverage effect. Please give your reason briefly.
建立 AR(1)-TARCH(1,1)模型。
(3.1) (1- 0.871L ) y t = εt , h t = 0.083 + 0.226εt -1 + 0.611εt -1d t -1 + 0.460h t -1
(3.2) 通过对标准化残差的 L BQ 检验发现,标准化残差中不存在自相关性,截图如下:
通过对标准化残差平方的 LBQ 检验发现,标准化残差平方之间不存在自相关性,截图 如下: (3.3) The TARCH(1,1) model is。