本科《医学统计学》作业题
本科医学统计学-作业题(A~)

本科医学统计学-作业题(A~)本科《医学统计学》作业题(A)班别:姓名:学号:⼀、选择题:(50*1分)1. 医学统计学研究的对象是A. 医学中的⼩概率事件B. 各种类型的数据C. 动物和⼈的本质D. 疾病的预防与治疗E.有变异的医学事件2. ⽤样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体D.⽤配对⽅法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值B.脉搏数C.住院天数D.病情程度E.四种⾎型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差6. 某医学资料数据⼤的⼀端没有确定数值,描述其集中趋势适⽤的统计指标是A. 中位数B. ⼏何均数C. 均数D.P百分位数95E. 频数分布7. 算术均数与中位数相⽐,其特点是A.不易受极端值的影响B.能充分利⽤数据的信息C.抽样误差较⼤D.更适⽤于偏态分布资料E.更适⽤于分布不明确资料8. ⼀组原始数据呈正偏态分布,其数据的特点是A. 数值离散度较⼩B. 数值离散度较⼤C. 数值分布偏向较⼤⼀侧D. 数值分布偏向较⼩⼀侧E. 数值分布不均匀9. 将⼀组计量资料整理成频数表的主要⽬的是A.化为计数资料 B. 便于计算C. 形象描述数据的特点D. 为了能够更精确地检验E. 提供数据和描述数据的分布特征10. 6⼈接种流感疫苗⼀个⽉后测定抗体滴度为1:20、1:40、1:80、1:80、1:160、1:320,求平均滴度应选⽤的指标是A. 均数B. ⼏何均数C. 中位数D. 百分位数E. 倒数的均数11. 变异系数主要⽤于A.⽐较不同计量指标的变异程度 B. 衡量正态分布的变异程度C. 衡量测量的准确度D. 衡量偏态分布的变异程度E. 衡量样本抽样误差的⼤⼩12. 对于近似正态分布的资料,描述其变异程度应选⽤的指标是A. 变异系数B. 离均差平⽅和C. 极差D. 四分位数间距E. 标准差13. 某项指标95%医学参考值范围表⽰的是A. 检测指标在此范围,判断“异常”正确的概率⼤于或等于95%B. 检测指标在此范围,判断“正常”正确的概率⼤于或等于95%C. 在“异常”总体中有95%的⼈在此范围之外D. 在“正常”总体中有95%的⼈在此范围E. 检测指标若超出此范围,则有95%的把握说明诊断对象为“异常”14.应⽤百分位数法估计参考值范围的条件是A.数据服从正态分布B.数据服从偏态分布C.有⼤样本数据D.数据服从对称分布E.数据变异不能太⼤15.已知动脉硬化患者载脂蛋⽩B的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使⽤A.全距B.标准差C.变异系数D.⽅差E.四分位数间距16. 样本均数的标准误越⼩说明A. 观察个体的变异越⼩B. 观察个体的变异越⼤C. 抽样误差越⼤D. 由样本均数估计总体均数的可靠性越⼩E. 由样本均数估计总体均数的可靠性越⼤17. 抽样误差产⽣的原因是A. 样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当18. 对于正偏态分布的的总体, 当样本含量⾜够⼤时, 样本均数的分布近似为A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布19. 假设检验的⽬的是A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为⼩概率20. 根据样本资料算得健康成⼈⽩细胞计数的95%可信区间为7.2×109/L~9.1×109/L,其含义是A. 估计总体中有95%的观察值在此范围内B. 总体均数在该区间的概率为95%C. 样本中有95%的观察值在此范围内D. 该区间包含样本均数的可能性为95%E. 该区间包含总体均数的可能性为95%21. 两样本均数⽐较,检验结果05P说明.0A. 两总体均数的差别较⼩B. 两总体均数的差别较⼤C. ⽀持两总体⽆差别的结论D. 不⽀持两总体有差别的结论E. 可以确认两总体⽆差别22. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指A. 两样本均数的差别具有实际意义B. 两总体均数的差别具有实际意义C. 两样本和两总体均数的差别都具有实际意义D. 有理由认为两样本均数有差别E. 有理由认为两总体均数有差别23. 两样本均数⽐较,差别具有统计学意义时,P值越⼩说明A. 两样本均数差别越⼤B. 两总体均数差别越⼤C. 越有理由认为两样本均数不同D. 越有理由认为两总体均数不同E. 越有理由认为两样本均数相同24. 减少假设检验的Ⅱ类误差,应该使⽤的⽅法是A. 减少Ⅰ类错误B. 减少测量的系统误差C. 减少测量的随机误差D. 提⾼检验界值E. 增加样本含量25.两样本均数⽐较的t检验和u检验的主要差别是A. t检验只能⽤于⼩样本资料B. u检验要求⼤样本资料C. t检验要求数据⽅差相同D. t检验的检验效能更⾼E. u检验能⽤于两⼤样本均数⽐较26. ⽅差分析的基本思想和要点是A.组间均⽅⼤于组内均⽅B.组内均⽅⼤于组间均⽅C.不同来源的⽅差必须相等D.两⽅差之⽐服从F分布E.总变异及其⾃由度可按不同来源分解27. ⽅差分析的应⽤条件之⼀是⽅差齐性,它是指A. 各⽐较组相应的样本⽅差相等B. 各⽐较组相应的总体⽅差相等C. 组内⽅差=组间⽅差D. 总⽅差=各组⽅差之和E. 总⽅差=组内⽅差+ 组间⽅差28. 完全随机设计⽅差分析中的组间均⽅反映的是A. 随机测量误差⼤⼩B. 某因素效应⼤⼩C. 处理因素效应与随机误差综合结果D. 全部数据的离散度E. 各组⽅差的平均⽔平29. 对于两组资料的⽐较,⽅差分析与t检验的关系是A. t检验结果更准确B. ⽅差分析结果更准确C. t检验对数据的要求更为严格D. 近似等价E. 完全等价30.多组均数⽐较的⽅差分析,如果0.05P ,则应该进⼀步做的是A.两均数的t检验B.区组⽅差分析C.⽅差齐性检验D.q检验E.确定单独效应31. 如果⼀种新的治疗⽅法能够使不能治愈的疾病得到缓解并延长⽣命,则应发⽣的情况是A. 该病患病率增加B. 该病患病率减少C. 该病的发病率增加D. 该病的发病率减少E. 该疾病的死因构成⽐增加32. 计算⼄肝疫苗接种后⾎清学检查的阳转率,分母为A. ⼄肝易感⼈数B. 平均⼈⼝数C. ⼄肝疫苗接种⼈数D. ⼄肝患者⼈数E. ⼄肝疫苗接种后的阳转⼈数33. 计算标准化死亡率的⽬的是A. 减少死亡率估计的偏倚B. 减少死亡率估计的抽样误差C. 便于进⾏不同地区死亡率的⽐较D. 消除各地区内部构成不同的影响E. 便于进⾏不同时间死亡率的⽐较34. 影响总体率估计的抽样误差⼤⼩的因素是A. 总体率估计的容许误差B. 样本率估计的容许误差C. 检验⽔准和样本含量D. 检验的把握度和样本含量E. 总体率和样本含量35. 研究某种新药的降压效果,对100⼈进⾏试验,其显效率的95%可信区间为0.862~0.926,表⽰A. 样本显效率在0.862~0.926之间的概率是95%B. 有95%的把握说总体显效率在此范围内波动C. 有95%的患者显效率在此范围D. 样本率估计的抽样误差有95%的可能在此范围E. 该区间包括总体显效率的可能性为95% 36. 利⽤2χ检验公式不适合解决的实际问题是A. ⽐较两种药物的有效率B. 检验某种疾病与基因多态性的关系C. 两组有序试验结果的药物疗效D. 药物三种不同剂量显效率有⽆差别E. 两组病情“轻、中、重”的构成⽐例37.进⾏四组样本率⽐较的2χ检验,如220.01,3χχ>,可认为A. 四组样本率均不相同B. 四组总体率均不相同C. 四组样本率相差较⼤D. ⾄少有两组样本率不相同E. ⾄少有两组总体率不相同38. 两样本⽐较的秩和检验,如果样本含量⼀定,两组秩和的差别越⼤说明A. 两总体的差别越⼤B. 两总体的差别越⼩C. 两样本的差别可能越⼤D. 越有理由说明两总体有差别E. 越有理由说明两总体⽆差别39. 两数值变量相关关系越强,表⽰A. 相关系数越⼤B. 相关系数的绝对值越⼤ B. 回归系数越⼤C. 回归系数的绝对值越⼤ E. 相关系数检验统计量的t 值越⼤ 40. 回归分析的决定系数2R 越接近于1,说明A. 相关系数越⼤B. 回归⽅程的显著程度越⾼C. 应变量的变异越⼤D. 应变量的变异越⼩E.⾃变量对应变量的影响越⼤41.统计表的主要作⽤是A. 便于形象描述和表达结果B. 客观表达实验的原始数据C. 减少论⽂篇幅D. 容易进⾏统计描述和推断E. 代替冗长的⽂字叙述和便于分析对⽐42.描述某疾病患者年龄(岁)的分布,应采⽤的统计图是A.线图B.条图C.百分条图D.直⽅图E.箱式图43.⾼⾎压临床试验分为试验组和对照组,分析考虑治疗0周、2周、4周、6周、8周⾎压的动态变化和改善情况,为了直观显⽰出两组⾎压平均变动情况,宜选⽤的统计图是A.半对数图B.线图C.条图D.直⽅图E.百分条图44.研究三种不同⿇醉剂在⿇醉后的镇痛效果,采⽤计量评分法,分数呈偏态分布,⽐较终点时分数的平均⽔平及个体的变异程度,应使⽤的图形是A. 复式条图B. 复式线图C. 散点图D. 直⽅图E. 箱式图45. 研究⾎清低密度脂蛋⽩LDL与载脂蛋⽩B-100的数量依存关系,应绘制的图形是A. 直⽅图B. 箱式图C. 线图D. 散点图E. 条图46. 实验研究随机化分组的⽬的是A.减少抽样误差B.减少实验例数C.保证客观D.提⾼检验准确度E.保持各组的⾮处理因素均衡⼀致47. 关于实验指标的准确度和精密度,正确的说法是A.精密度较准确度更重要B.准确度较精密度更重要C.精密度主要受随机误差的影响D.准确度主要受随机误差的影响E.精密度包含准确度48. 在临床试验设计选择对照时,最可靠的对照形式是A. 历史对照B. 空⽩对照C. 标准对照D. 安慰对照E. ⾃⾝对照49. 两名医⽣分别阅读同⼀组CT⽚诊断某种疾病,Kappa值越⼤说明A. 观察个体的变异越⼤B. 观察个体的变异越⼩C. 观察⼀致性越⼤D. 机遇⼀致性越⼤E. 实际⼀致性越⼤50. 下列叙述正确的有A. 特异度⾼说明测量的稳定性好B. 灵敏度必须⼤于特异度才有实际意义C. 增⼤样本含量可以同时提⾼灵敏度和特异度D. 特异度⾼说明假阳性率低E. 阳性预测值⾼说明患病的概率⼤⼆. 名词解释:1.总体与样本2.抽样误差3.直线回归与相关4 ⽅差分析基本思想5、标准正态分布:三. 问答题:1. 常见的三类误差是什么?应采取什么措施和⽅法加以控制?2. 现测得10名乳腺癌患者化疗后⾎液尿素氮的含量(mmol/L)分别为3.43,2.96,4.43,3.03,4.53,5.25,5.64,3.82,4.28,5.25,试计算其均数和中位数。
医学统计学习题集(打印)

1、样本是总体中:DA、任意一部分B、典型部分C、有意义的部分D、有代表性的部分E、有价值的部分2、参数是指:CA、参与个体数B、研究个体数C、总体的统计指标D、样本的总和E、样本的统计指标3、抽样的目的是:EA、研究样本统计量B、研究总体统计量C、研究典型案例D、研究误差E、样本推断总体参数4、脉搏数(次/分)是: BA、观察单位B、数值变量C、名义变量 D.等级变量 E.研究个体5、疗效是: DA、观察单位B、数值变量C、名义变量D、等级变量E、研究个体6、抽签的方法属于 DA分层抽样 B系统抽样 C整群抽样 D单纯随机抽样E二级抽样7、统计工作的步骤正确的是 CA收集资料、设计、整理资料、分析资料 B收集资料、整理资料、设计、统计推断C设计、收集资料、整理资料、分析资料 D收集资料、整理资料、核对、分析资料E搜集资料、整理资料、分析资料、进行推断8、实验设计中要求严格遵守四个基本原则,其目的是为了:DA便于统计处理B严格控制随机误差的影响C便于进行试验D减少和抵消非实验因素的干扰E以上都不对9、对照组不给予任何处理,属 EA、相互对照B、标准对照C、实验对照D、自身对照E、空白对照10、统计学常将P≤0.05或P≤0.01的事件称 DA、必然事件B、不可能事件C、随机事件D、小概率事件E、偶然事件11.医学统计的研究内容是 EA.研究样本B.研究个体C.研究变量之间的相关关系D.研究总体E.研究资料或信息的收集.整理和分析12.统计中所说的总体是指:AA根据研究目的确定的同质的研究对象的全体 B随意想象的研究对象的全体C根据地区划分的研究对象的全体 D根据时间划分的研究对象的全体E根据人群划分的研究对象的全体13.概率P=0,则表示BA某事件必然发生B某事件必然不发生C某事件发生的可能性很小D某事件发生的可能性很大E以上均不对14.总体应该由 DA.研究对象组成B.研究变量组成C.研究目的而定D.同质个体组成E.个体组成15. 在统计学中,参数的含义是 DA.变量B.参与研究的数目C.研究样本的统计指标D.总体的统计指标E.与统计研究有关的变量16.调查某单位科研人员论文发表的情况,统计每人每年的论文发表数应属于 AA.计数资料 B.计量资料 C.总体 D.个体 E.样本17.统计学中的小概率事件,下面说法正确的是:BA.反复多次观察,绝对不发生的事件 B.在一次观察中,可以认为不会发生的事件C.发生概率小于0.1的事件D.发生概率小于0.001的事件 E.发生概率小于0.1的事件18、统计上所说的样本是指:DA、按照研究者要求抽取总体中有意义的部分B、随意抽取总体中任意部分C、有意识的抽取总体中有典型部分D、按照随机原则抽取总体中有代表性部分E、总体中的每一个个体19、以舒张压≥12.7KPa为高血压,测量1000人,结果有990名非高血压患者,有10名高血压患者,该资料属()资料。
医学统计学试题答案

医学统计学试题答案一、选择题1. 医学统计学中,用于描述数据分布集中趋势的指标是()。
A. 方差B. 标准差C. 均数D. 百分位数答案:C2. 下列哪项不是医学研究中的常见随机误差来源?()。
A. 测量误差B. 抽样误差C. 实验设计偏差D. 仪器误差答案:C3. 在医学统计分析中,卡方检验主要用于()。
A. 比较两组连续变量的均值B. 比较两组分类变量的分布C. 检验两组数据的一致性D. 评估变量间的相关性答案:B4. 回归分析的主要目的是()。
A. 确定变量间的因果关系B. 评估变量间的关系强度C. 预测未来数据的趋势D. 以上都是答案:D5. 灵敏度和特异度是评价()的重要指标。
A. 治疗效果B. 诊断试验C. 预防措施D. 病因关系答案:B二、填空题1. 在医学统计中,用于描述数据分布离散程度的指标是________和________。
答案:方差,标准差2. 医学研究中,为了减少随机误差的影响,常采用的方法有________、________和________。
答案:重复测量,随机化,盲法3. 医学统计分析中,用于评估两组连续变量间差异的非参数检验包括________、________等。
答案:Mann-Whitney U检验,Wilcoxon符号秩检验4. 逻辑回归分析可以用来处理变量间的________和________关系。
答案:线性,非线性5. 医学研究中,为了评估治疗效果的一致性,常用的统计方法是________。
答案:Meta分析三、简答题1. 请简述医学统计学在临床研究中的应用及其重要性。
医学统计学在临床研究中的应用十分广泛,它通过使用各种统计方法和技术来分析和解释临床数据,帮助研究者得出科学的结论。
其重要性体现在以下几个方面:首先,统计学可以帮助研究者设计合理的研究方案,如随机对照试验,以减少偏倚和误差。
其次,在数据收集阶段,统计学原理可以指导如何进行有效的数据采集和处理缺失数据。
医学统计学书本练习题答案

医学统计学书本练习题答案一、选择题1. 在医学统计学中,以下哪个选项不是描述数据分布的指标?A. 均数B. 标准差C. 方差D. 样本量答案:D2. 以下哪个统计量用于描述数据的集中趋势?A. 极差B. 均数C. 标准差D. 变异系数答案:B3. 假设检验中,P值小于0.05表示:A. 拒绝原假设B. 接受原假设C. 无法判断D. 需要更多数据答案:A4. 以下哪个选项是医学统计学中常用的非参数检验方法?A. t检验B. 方差分析C. 卡方检验D. 曼-惠特尼U检验答案:D5. 相关系数的取值范围是:A. (-1, 1)B. (0, 1)C. [-1, 1]D. (-∞, ∞)答案:C二、填空题6. 医学统计学中的正态分布具有两个参数,分别是________和________。
答案:均数标准差7. 医学研究中,为了控制实验误差,常常采用________设计。
答案:随机对照8. 医学统计学中,样本均数的标准误差是________除以样本量的平方根。
答案:标准差9. 医学研究中,为了减少偏倚,常常采用________方法。
答案:盲法10. 医学统计学中,卡方检验主要用于检验________。
答案:分类变量的独立性三、简答题11. 简述医学统计学中,为什么需要进行数据的正态性检验?答案:正态性检验是确保数据满足某些统计方法的前提条件,如t 检验和方差分析等。
如果数据不满足正态分布,使用这些方法可能会得到错误的结论。
12. 解释医学统计学中的“效应量”是什么,并说明其重要性。
答案:效应量是衡量实验处理效果大小的指标,它提供了实验结果的量化度量。
效应量的大小可以反映实验的临床意义或实际意义,有助于判断实验结果的显著性。
四、计算题13. 假设有一组数据:23, 25, 27, 29, 31。
请计算这组数据的均数和标准差。
答案:均数 = (23+25+27+29+31)/5 = 27;标准差 = sqrt(((23-27)^2+(25-27)^2+(27-27)^2+(29-27)^2+(31-27)^2)/5) = 2.83(保留两位小数)14. 某研究中,两组患者的平均血压分别为120mmHg和130mmHg,标准差分别为10mmHg和15mmHg,样本量分别为50和40。
医学统计学本科试题及答案

医学统计学本科试题及答案一、选择题(每题2分,共20分)1. 在医学统计学中,总体是指:A. 研究中的所有个体B. 研究中所观察到的个体C. 研究中所抽取的样本D. 研究中未观察到的个体答案:A2. 下列哪项不是医学统计学中常用的统计图表?A. 条形图B. 折线图C. 饼图D. 散点图E. 树状图答案:E3. 以下哪个指标用于描述分类变量的关联性?A. 均值B. 标准差C. 相关系数D. 卡方检验答案:D4. 医学统计学中的“误差”通常指:A. 测量误差B. 抽样误差C. 实验误差D. 所有上述情况答案:D5. 在进行两独立样本均值的比较时,应使用:A. t检验B. 方差分析C. 卡方检验D. 秩和检验答案:A6. 医学统计学中的“样本量”是指:A. 研究中观察到的个体数量B. 研究中抽取的个体数量C. 研究中所有可能的个体数量D. 研究中随机抽取的个体数量答案:B7. 以下哪个统计量用于描述数据的离散程度?A. 平均数B. 中位数C. 众数D. 方差答案:D8. 相关系数的取值范围是:A. -1 到 1B. 0 到 1C. -∞ 到+∞D. 1 到+∞答案:A9. 在医学研究中,为了减少偏倚,研究者通常会采用:A. 随机化B. 匹配C. 盲法D. A和C答案:D10. 下列哪项是生存分析中常用的统计方法?A. Kaplan-Meier法B. Cox回归C. Logistic回归D. 所有上述情况答案:D二、简答题(每题10分,共30分)1. 简述医学统计学中的“随机误差”和“系统误差”的区别。
答案:随机误差是指在测量过程中由于偶然因素引起的误差,这种误差是不可预测的,但在多次测量中会呈现正态分布,可以通过增加样本量来减少其影响。
系统误差则是由于测量方法或仪器本身的缺陷引起的误差,它是可预测的,并且会持续影响测量结果,需要通过改进测量方法或校准仪器来消除。
2. 解释医学统计学中的“95%置信区间”的含义。
医学统计学练习题及答案

练习题答案第一章医学统计中的基本概念练习题一、单向选择题1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差答案: E E D E A二、简答题1.常见的三类误差是什么?应采取什么措施和方法加以控制?[参考答案]常见的三类误差是:(1)系统误差:在收集资料过程中,由于仪器初始状态未调整到零、标准试剂未经校正、医生掌握疗效标准偏高或偏低等原因,可造成观察结果倾向性的偏大或偏小,这叫系统误差。
要尽量查明其原因,必须克服。
(2)随机测量误差:在收集原始资料过程中,即使仪器初始状态及标准试剂已经校正,但是,由于各种偶然因素的影响也会造成同一对象多次测定的结果不完全一致。
譬如,实验操作员操作技术不稳定,不同实验操作员之间的操作差异,电压不稳及环境温度差异等因素造成测量结果的误差。
对于这种误差应采取相应的措施加以控制,至少应控制在一定的允许范围内。
一般可以用技术培训、指定固定实验操作员、加强责任感教育及购置一定精度的稳压器、恒温装置等措施,从而达到控制的目的。
(3)抽样误差:即使在消除了系统误差,并把随机测量误差控制在允许范围内,样本均数(或其它统计量)与总体均数(或其它参数)之间仍可能有差异。
医学统计学作业
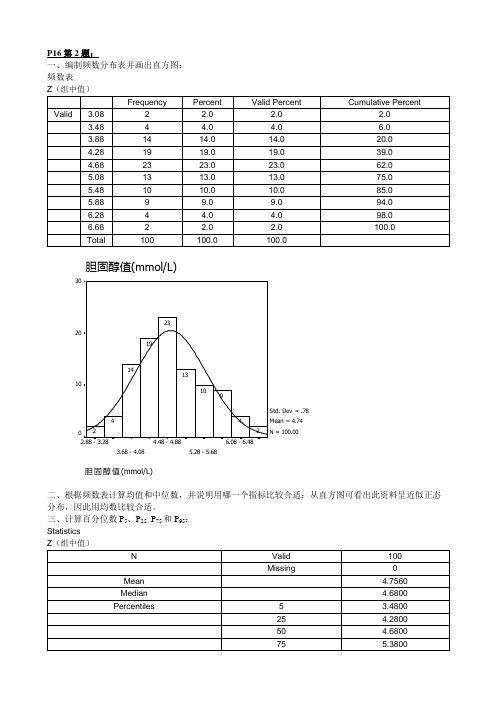
P16第2题:一、编制频数分布表并画出直方图: 频数表F r e q u e n c y二、根据频数表计算均值和中位数,并说明用哪一个指标比较合适:从直方图可看出此资料呈近似正态分布,因此用均数比较合适。
三、计算百分位数P 5、P 25、P 75和P 95:Statistics1、建立数据库文件,变量名定义为总胆固醇;2、analyze→descriptive statistics→frequencies…;3、将“总胆固醇”选入variables栏中;4、statistics…→选择quartiles、percentile(s) →输入5、25、75、95并add,并选择mean、median→continue;5、charts…→选histograms→continue→OK;6、双击output中histogram→双击数字,调整interval axis:1)custom→define…→interval width:0.4→continue;2)labels…→every 2 labels→type:range→continue→OK。
7、点击bar label styles→standard→apply all。
P16第3题:步骤:4、analyze→reports→case summaries…→variables:X。
grouping variables:Z;5、statistics…→cell statistics:geometric mean→continue →OKa Limited to first 100 cases.10名正常人的血清HBsAg平均滴度为16;10名肝癌患者的血清HBsAg平均滴度为39.4。
P27第二题:1)依题意可按正态分布法处理,由于总胆固醇值过多和过少均属异常,因此应计算两侧参考值范围。
已知μ=4.95、σ=0.85上限:μ+1.96σ=4.95+1.96*0.85=6.62下限:μ-1.96σ=4.95-1.96*0.85=3.28因此该地30-45岁成年男子血清总胆固醇的95%参考值范围为3.28~6.62mmol/L2)血清总胆固醇大于5.72mmol/L 的正常成年男子占总体的百分数即小于[4.95-(5.72-4.95)]=4.18mmol/L 的正常成年男子所占百分数 已知μ=4.95、σ=0.85、x=4.18U=(x-μ)/σ=(4.18-4.95)/0.85=-0.906 查附表1得φ(-0.906)=0.1685答:血清总胆固醇大于5.72mmol/L 的正常男子占总体的百分数为16.85%。
本科《医学统计学》试题

本科《医学统计学》试题姓名:组别:学号:成绩:一、单项选择题(40小题,每小题1分,共40分)1.抽签的方法属于A.分层抽样 B.系统抽样 C.整群抽样 D.单纯随机抽样2.测量身高、体重等指标的原始资料叫A.计数资料B.计量资料 C.等级资料 D.分类资料3.将计量资料制作成频数表的过程,属于统计工作哪个基本步骤A.统计设计 B.收集资料C.整理资料 D.分析资料4.各观察值均加(或减)同一数A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变 D.两者均改变5.用样本推论总体,具有代表性的样本指的是A.依照随机原则抽取总体中的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体6.下列观测结果属于等级资料的是()A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度7.收集资料不可避免的误差是()A. 随机误差B. 系统误差C. 过失误差D. 记录误差8.某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是()A. 中位数B. 几何均数P百分位数C. 均数D.959.算术均数与中位数相比,其特点是()A.不易受极端值的影响 B.能充分利用数据的信息C.抽样误差较大 D.更适用于偏态分布资料10.一组原始数据呈正偏态分布,其数据的特点是()A. 数值离散度较小B. 数值离散度较大C. 数值分布偏向较大一侧D. 数值分布偏向较小一侧11.变异系数主要用于()A.比较不同计量指标的变异程度 B. 衡量正态分布的变异程度C. 衡量测量的准确度D. 衡量偏态分布的变异程度12.对于近似正态分布的资料,描述其变异程度应选用的指标是()A. 变异系数B. 离均差平方和C. 标准差D. 四分位数间距13.已知动脉硬化患者载脂蛋白B的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用()A.四分位数间距 B.标准差C.变异系数 D.方差14.样本均数的标准误越小说明()A. 观察个体的变异越小B. 观察个体的变异越大C. 由样本均数估计总体均数的可靠性越大D. 由样本均数估计总体均数的可靠性越小15.正态分布是以()A. t值为中心的频数分布B. 参数为中心的频数分布C. 变量为中心的频数分布D. 均数为中心的频数分布16.对于正偏态分布的总体, 当样本含量足够大时, 样本均数的分布近似为()A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布17.下列哪个公式可用于估计医学95%正常值范围()A X±1.96SB X±1.96SXC μ±1.96SXD X±2.58S18.从一个总体中抽取样本,产生抽样误差的原因是()A总体中个体之间存在变异 B抽样未遵循随机化原则C被抽取的个体不同质 D组成样本的个体较少19.假设检验的目的是()A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同20.正态分布曲线下,横轴上,从均数到+∞的面积为( B )A.95%B.50%C.97.5%D.因标准差未知,不能确定21.6人的血清滴度为<1:20、1:20、1:40、1:80、1:160、1:320,描述其平均滴度宜采用( C )A.算术均数B.中位数C.几何均数D.平均数22.现调查20岁男大学生100名,身高标准差为4.09cm,体重标准差为4.10kg,比较两者的变异程度,结果( D )A.体重变异程度大B.身高变异程度大C.两者变异程度接近D.两者标准差不能直接比较23.反映均数抽样误差的统计指标是( B )A、标准差B、标准误C、变异系数D、全距E、方差24.以一定概率由样本均数估计总体均数,宜采用( D )A.抽样误差估计B.点估计C.参考值范围估计D.区间估计25.参数可信区间估计的可信度是指( B )A.αB.1一αC.βD.1一β二、是非题(对者打“+”,错者打“-”,20题,每题1分,共20分)( + )1.在假设检验中,所有的假设都是对总体特征的假设。
本科《医学统计学》作业题(A)

本科《医学统计学》作业题(A)班别:姓名:学号:一、选择题:(50*1分)1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差 E.仪器故障误差6. 某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是A. 中位数B. 几何均数P百分位数C. 均数D.95E. 频数分布7. 算术均数与中位数相比,其特点是A.不易受极端值的影响 B.能充分利用数据的信息C.抽样误差较大 D.更适用于偏态分布资料E.更适用于分布不明确资料8. 一组原始数据呈正偏态分布,其数据的特点是A. 数值离散度较小B. 数值离散度较大C. 数值分布偏向较大一侧D. 数值分布偏向较小一侧E. 数值分布不均匀9. 将一组计量资料整理成频数表的主要目的是A.化为计数资料 B. 便于计算C. 形象描述数据的特点D. 为了能够更精确地检验E. 提供数据和描述数据的分布特征10. 6人接种流感疫苗一个月后测定抗体滴度为 1:20、1:40、1:80、1:80、1:160、1:320,求平均滴度应选用的指标是A. 均数B. 几何均数C. 中位数D. 百分位数E. 倒数的均数11. 变异系数主要用于A.比较不同计量指标的变异程度 B. 衡量正态分布的变异程度C. 衡量测量的准确度D. 衡量偏态分布的变异程度E. 衡量样本抽样误差的大小12. 对于近似正态分布的资料,描述其变异程度应选用的指标是A. 变异系数B. 离均差平方和C. 极差D. 四分位数间距E. 标准差13. 某项指标95%医学参考值范围表示的是A. 检测指标在此范围,判断“异常”正确的概率大于或等于95%B. 检测指标在此范围,判断“正常”正确的概率大于或等于95%C. 在“异常”总体中有95%的人在此范围之外D. 在“正常”总体中有95%的人在此范围E. 检测指标若超出此范围,则有95%的把握说明诊断对象为“异常”14.应用百分位数法估计参考值范围的条件是A.数据服从正态分布 B.数据服从偏态分布C.有大样本数据 D.数据服从对称分布 E.数据变异不能太大15.已知动脉硬化患者载脂蛋白B的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用A.全距 B.标准差C.变异系数 D.方差E.四分位数间距16. 样本均数的标准误越小说明A. 观察个体的变异越小B. 观察个体的变异越大C. 抽样误差越大D. 由样本均数估计总体均数的可靠性越小E. 由样本均数估计总体均数的可靠性越大17. 抽样误差产生的原因是A. 样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当18. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布19. 假设检验的目的是A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为小概率20. 根据样本资料算得健康成人白细胞计数的95%可信区间为×109/L~×109/L,其含义是A. 估计总体中有95%的观察值在此范围内B. 总体均数在该区间的概率为95%C. 样本中有95%的观察值在此范围内D. 该区间包含样本均数的可能性为95%E. 该区间包含总体均数的可能性为95%21. 两样本均数比较,检验结果05.0P说明A. 两总体均数的差别较小B. 两总体均数的差别较大C. 支持两总体无差别的结论D. 不支持两总体有差别的结论E. 可以确认两总体无差别22. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指A. 两样本均数的差别具有实际意义B. 两总体均数的差别具有实际意义C. 两样本和两总体均数的差别都具有实际意义D. 有理由认为两样本均数有差别E. 有理由认为两总体均数有差别23. 两样本均数比较,差别具有统计学意义时,P值越小说明A. 两样本均数差别越大B. 两总体均数差别越大C. 越有理由认为两样本均数不同D. 越有理由认为两总体均数不同E. 越有理由认为两样本均数相同24. 减少假设检验的Ⅱ类误差,应该使用的方法是A. 减少Ⅰ类错误B. 减少测量的系统误差C. 减少测量的随机误差D. 提高检验界值E. 增加样本含量25.两样本均数比较的t检验和u检验的主要差别是A. t检验只能用于小样本资料B. u检验要求大样本资料C. t检验要求数据方差相同D. t检验的检验效能更高E. u检验能用于两大样本均数比较26. 方差分析的基本思想和要点是A.组间均方大于组内均方 B.组内均方大于组间均方C.不同来源的方差必须相等 D.两方差之比服从F分布E.总变异及其自由度可按不同来源分解27. 方差分析的应用条件之一是方差齐性,它是指A. 各比较组相应的样本方差相等B. 各比较组相应的总体方差相等C. 组内方差=组间方差D. 总方差=各组方差之和E. 总方差=组内方差 + 组间方差28. 完全随机设计方差分析中的组间均方反映的是A. 随机测量误差大小B. 某因素效应大小C. 处理因素效应与随机误差综合结果D. 全部数据的离散度E. 各组方差的平均水平29. 对于两组资料的比较,方差分析与t检验的关系是A. t检验结果更准确B. 方差分析结果更准确C. t检验对数据的要求更为严格D. 近似等价E. 完全等价30.多组均数比较的方差分析,如果0.05P ,则应该进一步做的是A.两均数的t检验 B.区组方差分析C.方差齐性检验 D.q检验E.确定单独效应31. 如果一种新的治疗方法能够使不能治愈的疾病得到缓解并延长生命,则应发生的情况是A. 该病患病率增加B. 该病患病率减少C. 该病的发病率增加D. 该病的发病率减少E. 该疾病的死因构成比增加32. 计算乙肝疫苗接种后血清学检查的阳转率,分母为A. 乙肝易感人数B. 平均人口数C. 乙肝疫苗接种人数D. 乙肝患者人数E. 乙肝疫苗接种后的阳转人数33. 计算标准化死亡率的目的是A. 减少死亡率估计的偏倚B. 减少死亡率估计的抽样误差C. 便于进行不同地区死亡率的比较D. 消除各地区内部构成不同的影响E. 便于进行不同时间死亡率的比较34. 影响总体率估计的抽样误差大小的因素是A. 总体率估计的容许误差B. 样本率估计的容许误差C. 检验水准和样本含量D. 检验的把握度和样本含量E. 总体率和样本含量35. 研究某种新药的降压效果,对100人进行试验,其显效率的95%可信区间为~,表示A.样本显效率在~之间的概率是95%B. 有95%的把握说总体显效率在此范围内波动C. 有95%的患者显效率在此范围D. 样本率估计的抽样误差有95%的可能在此范围E. 该区间包括总体显效率的可能性为95%36. 利用2χ检验公式不适合解决的实际问题是A. 比较两种药物的有效率B. 检验某种疾病与基因多态性的关系C. 两组有序试验结果的药物疗效D. 药物三种不同剂量显效率有无差别E. 两组病情“轻、中、重”的构成比例37.进行四组样本率比较的2χ检验,如220.01,3χχ>,可认为A. 四组样本率均不相同B. 四组总体率均不相同C. 四组样本率相差较大D. 至少有两组样本率不相同E. 至少有两组总体率不相同38. 两样本比较的秩和检验,如果样本含量一定,两组秩和的差别越大说明A. 两总体的差别越大B. 两总体的差别越小C. 两样本的差别可能越大D. 越有理由说明两总体有差别E. 越有理由说明两总体无差别39. 两数值变量相关关系越强,表示A. 相关系数越大B. 相关系数的绝对值越大B. 回归系数越大C. 回归系数的绝对值越大E. 相关系数检验统计量的t 值越大40. 回归分析的决定系数2R 越接近于1,说明A. 相关系数越大B. 回归方程的显著程度越高C. 应变量的变异越大D. 应变量的变异越小E. 自变量对应变量的影响越大41.统计表的主要作用是A. 便于形象描述和表达结果B. 客观表达实验的原始数据C. 减少论文篇幅D. 容易进行统计描述和推断E. 代替冗长的文字叙述和便于分析对比42.描述某疾病患者年龄(岁)的分布,应采用的统计图是A.线图 B.条图C.百分条图 D.直方图E.箱式图43.高血压临床试验分为试验组和对照组,分析考虑治疗0周、2周、4周、6周、8周血压的动态变化和改善情况,为了直观显示出两组血压平均变动情况,宜选用的统计图是A.半对数图 B.线图C.条图 D.直方图E.百分条图44.研究三种不同麻醉剂在麻醉后的镇痛效果,采用计量评分法,分数呈偏态分布,比较终点时分数的平均水平及个体的变异程度,应使用的图形是A. 复式条图B. 复式线图C. 散点图D. 直方图E. 箱式图45. 研究血清低密度脂蛋白LDL与载脂蛋白B-100的数量依存关系,应绘制的图形是A. 直方图B. 箱式图C. 线图D. 散点图E. 条图46. 实验研究随机化分组的目的是A.减少抽样误差 B.减少实验例数C.保证客观 D.提高检验准确度E.保持各组的非处理因素均衡一致47. 关于实验指标的准确度和精密度,正确的说法是A.精密度较准确度更重要 B.准确度较精密度更重要C.精密度主要受随机误差的影响 D.准确度主要受随机误差的影响E.精密度包含准确度48. 在临床试验设计选择对照时,最可靠的对照形式是A. 历史对照B. 空白对照C. 标准对照D. 安慰对照E. 自身对照49. 两名医生分别阅读同一组CT片诊断某种疾病,Kappa值越大说明A. 观察个体的变异越大B. 观察个体的变异越小C. 观察一致性越大D. 机遇一致性越大E. 实际一致性越大50. 下列叙述正确的有A. 特异度高说明测量的稳定性好B. 灵敏度必须大于特异度才有实际意义C. 增大样本含量可以同时提高灵敏度和特异度D. 特异度高说明假阳性率低E. 阳性预测值高说明患病的概率大二. 名词解释:1.总体与样本2.抽样误差3.直线回归与相关4 方差分析基本思想5、标准正态分布:三. 问答题:1. 常见的三类误差是什么应采取什么措施和方法加以控制2. 现测得10名乳腺癌患者化疗后血液尿素氮的含量(mmol/L)分别为,,,,,,,,,,试计算其均数和中位数。
医学统计学练习及参考答案

医学统计学练习及参考答案《医学统计学》练习题及参考答案一、填空题:1、频数分布通常具有集中趋势、离散趋势两个基本特征。
P412、统计表一般需有标题、线条(横线)、标目、数字四个基本结构。
3、四格表应用基本公式进行卡方检验的条件是:n≥40 、T≥5 。
4、正态分布的两个决定参数是:位置参数μ、形状参数。
P535、正态分布中央95%的观察值的分布区间是(μ-1.96σ,μ+1.96 σ)。
P536、概率抽样三个基本原则是:随机化原则、同质性原则、 n足够大。
7、实验设计的三大原则是对照、随机化、重复。
P20二、单项选择题:1.下面的变量中,属于分类变量的是---B--.A.脉搏 B.血型 C.肺活量 D.血压2. 已知我国部分县1988年死因构成比资料如下:心脏疾病11.41%,损伤与中毒11.56%,恶性肿瘤15.04%,脑血管病16.07%,呼吸系统病25.70%,其他20.22%.为表达上述死因的构成的大小,根据此资料应绘制统计图为--D---.A.线图 B.直方图 C.直条图 D.百分条图 E.统计地图 3. 在一项研究的最初检查中,人们发现30~40岁男女两组人群的冠心病患病率均为4%,于是,认为该年龄组男女两性发生冠心病的危险相同.这个结论是---C--. A.正确的B. 不正确的,因为没有可识别的队列人群 C.不正确的,因为没有区分发病率与患病率D.不正确的,因为用百分比代替率来支持该结论 E.不正确的,因为没有设立对照组 4. sx表示---C--.A.总体均数 B. 总体均数离散程度 C. 样本均数的标准差 D.变量值x的离散程度 E.变量值x的可靠程度5.做两个总体均数比较t检验,计算t>t0.01,(n1+n2-2时,可以认为-B----.A.反复随机抽样时,出现这种大小的均数差异的可能性大于0.01B.样本均数差异是由随机抽样误差所致的可能性小于0.01,可认为两总体有差别。
《医学统计学》作业习题

《医学统计学》作业习题第一章医学统计中的基本概念一、单向选择题1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差二、简答题1.常见的三类误差是什么?应采取什么措施和方法加以控制?2.抽样中要求每一个样本应该具有哪三性?3.什么是两个样本之间的可比性?第二章集中趋势的统计描述一、单项选择题1. 某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是A. 中位数B. 几何均数P百分位数C. 均数D.95E. 频数分布2. 算术均数与中位数相比,其特点是A.不易受极端值的影响 B.能充分利用数据的信息C.抽样误差较大 D.更适用于偏态分布资料E.更适用于分布不明确资料3. 一组原始数据呈正偏态分布,其数据的特点是A. 数值离散度较小B. 数值离散度较大C. 数值分布偏向较大一侧D. 数值分布偏向较小一侧E. 数值分布不均匀4. 将一组计量资料整理成频数表的主要目的是A.化为计数资料 B. 便于计算C. 形象描述数据的特点D. 为了能够更精确地检验E. 提供数据和描述数据的分布特征5. 6人接种流感疫苗一个月后测定抗体滴度为 1:20、1:40、1:80、1:80、1:160、1:320,求平均滴度应选用的指标是A. 均数B. 几何均数C. 中位数D. 百分位数E. 倒数的均数二、计算与分析1. 现测得10名乳腺癌患者化疗后血液尿素氮的含量(mmol/L)分别为3.43,2.96,4.43,3.03,4.53,5.25,5.64,3.82,4.28,5.25,试计算其均数和中位数。
医学统计学试题和答案

〔一〕单项选择题3.抽样的目的是〔b 〕。
A.争论样本统计量 B. 由样本统计量推断总体参数C.争论典型案例争论误差 D. 争论总体统计量4.参数是指〔b 〕。
A.参与个体数 B. 总体的统计指标C.样本的统计指标 D. 样本的总和5.关于随机抽样,以下那一项说法是正确的〔 a 〕。
A.抽样时应使得总体中的每一个个体都有同等的时机被抽取B.争论者在抽样时应细心选择个体,以使样本更能代表总体C.随机抽样即随便抽取个体D.为确保样本具有更好的代表性,样本量应越大越好6.各观看值均加〔或减〕同一数后〔 b 〕。
A.均数不变,标准差转变B.均数转变,标准差不变C.两者均不变D.两者均转变7.比较身高和体重两组数据变异度大小宜承受〔 a 〕。
A.变异系数B.差C.极差D.标准差8.以下指标中〔d〕可用来描述计量资料的离散程度。
A.算术均数B.几何均数C.中位数D.标准差9.偏态分布宜用〔c〕描述其分布的集中趋势。
A.算术均数B.标准差C.中位数D.四分位数间距10.各观看值同乘以一个不等于0 的常数后,〔b〕不变。
A.算术均数 B.标准差C.几何均数D.中位数11.〔 a 〕分布的资料,均数等于中位数。
A.对称B.左偏态C.右偏态D.偏态12.对数正态分布是一种〔 c 〕分布。
A.正态B.近似正态C.左偏态D.右偏态c 〕描述其13.最小组段无下限或最大组段无上限的频数分布资料,可用〔集中趋势。
A.均数B.标准差C.中位数D.四分位数间距14.〔 c 〕小,表示用该样本均数估量总体均数的牢靠性大。
A. 变异系数B.标准差C. 标准误D.极差15.血清学滴度资料最常用来表示其平均水平的指标是〔 c 〕。
A.算术平均数B.中位数C.几何均数D. 平均数16.变异系数CV 的数值〔 c 〕。
A.肯定大于1B.肯定小于 1C. 可大于1,也可小于1D.肯定比标准差小17.数列8、-3、5、0、1、4、-1 的中位数是〔 b 〕。
本科《医学统计学》作业题(A)资料讲解

本科《医学统计学》作业题(A)班别:姓名:学号:一、选择题:(50*1分)1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值B.脉搏数C.住院天数D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差E.仪器故障误差6. 某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是A. 中位数B. 几何均数C. 均数D.P百分位数95E. 频数分布7. 算术均数与中位数相比,其特点是A.不易受极端值的影响B.能充分利用数据的信息C.抽样误差较大D.更适用于偏态分布资料E.更适用于分布不明确资料8. 一组原始数据呈正偏态分布,其数据的特点是A. 数值离散度较小B. 数值离散度较大C. 数值分布偏向较大一侧D. 数值分布偏向较小一侧E. 数值分布不均匀9. 将一组计量资料整理成频数表的主要目的是A.化为计数资料 B. 便于计算C. 形象描述数据的特点D. 为了能够更精确地检验E. 提供数据和描述数据的分布特征10. 6人接种流感疫苗一个月后测定抗体滴度为1:20、1:40、1:80、1:80、1:160、1:320,求平均滴度应选用的指标是A. 均数B. 几何均数C. 中位数D. 百分位数E. 倒数的均数11. 变异系数主要用于A.比较不同计量指标的变异程度 B. 衡量正态分布的变异程度C. 衡量测量的准确度D. 衡量偏态分布的变异程度E. 衡量样本抽样误差的大小12. 对于近似正态分布的资料,描述其变异程度应选用的指标是A. 变异系数B. 离均差平方和C. 极差D. 四分位数间距E. 标准差13. 某项指标95%医学参考值范围表示的是A. 检测指标在此范围,判断“异常”正确的概率大于或等于95%B. 检测指标在此范围,判断“正常”正确的概率大于或等于95%C. 在“异常”总体中有95%的人在此范围之外D. 在“正常”总体中有95%的人在此范围E. 检测指标若超出此范围,则有95%的把握说明诊断对象为“异常”14.应用百分位数法估计参考值范围的条件是A.数据服从正态分布B.数据服从偏态分布C.有大样本数据D.数据服从对称分布E.数据变异不能太大15.已知动脉硬化患者载脂蛋白B的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用A.全距B.标准差C.变异系数D.方差E.四分位数间距16. 样本均数的标准误越小说明A. 观察个体的变异越小B. 观察个体的变异越大C. 抽样误差越大D. 由样本均数估计总体均数的可靠性越小E. 由样本均数估计总体均数的可靠性越大17. 抽样误差产生的原因是A. 样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当18. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布19. 假设检验的目的是A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为小概率20. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109/L~9.1×109/L,其含义是A. 估计总体中有95%的观察值在此范围内B. 总体均数在该区间的概率为95%C. 样本中有95%的观察值在此范围内D. 该区间包含样本均数的可能性为95%E. 该区间包含总体均数的可能性为95%21. 两样本均数比较,检验结果05P说明.0A. 两总体均数的差别较小B. 两总体均数的差别较大C. 支持两总体无差别的结论D. 不支持两总体有差别的结论E. 可以确认两总体无差别22. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指A. 两样本均数的差别具有实际意义B. 两总体均数的差别具有实际意义C. 两样本和两总体均数的差别都具有实际意义D. 有理由认为两样本均数有差别E. 有理由认为两总体均数有差别23. 两样本均数比较,差别具有统计学意义时,P值越小说明A. 两样本均数差别越大B. 两总体均数差别越大C. 越有理由认为两样本均数不同D. 越有理由认为两总体均数不同E. 越有理由认为两样本均数相同24. 减少假设检验的Ⅱ类误差,应该使用的方法是A. 减少Ⅰ类错误B. 减少测量的系统误差C. 减少测量的随机误差D. 提高检验界值E. 增加样本含量25.两样本均数比较的t检验和u检验的主要差别是A. t检验只能用于小样本资料B. u检验要求大样本资料C. t检验要求数据方差相同D. t检验的检验效能更高E. u检验能用于两大样本均数比较26. 方差分析的基本思想和要点是A.组间均方大于组内均方B.组内均方大于组间均方C.不同来源的方差必须相等D.两方差之比服从F分布E.总变异及其自由度可按不同来源分解27. 方差分析的应用条件之一是方差齐性,它是指A. 各比较组相应的样本方差相等B. 各比较组相应的总体方差相等C. 组内方差=组间方差D. 总方差=各组方差之和E. 总方差=组内方差+ 组间方差28. 完全随机设计方差分析中的组间均方反映的是A. 随机测量误差大小B. 某因素效应大小C. 处理因素效应与随机误差综合结果D. 全部数据的离散度E. 各组方差的平均水平29. 对于两组资料的比较,方差分析与t检验的关系是A. t检验结果更准确B. 方差分析结果更准确C. t检验对数据的要求更为严格D. 近似等价E. 完全等价30.多组均数比较的方差分析,如果0.05P ,则应该进一步做的是A.两均数的t检验B.区组方差分析C.方差齐性检验D.q检验E.确定单独效应31. 如果一种新的治疗方法能够使不能治愈的疾病得到缓解并延长生命,则应发生的情况是A. 该病患病率增加B. 该病患病率减少C. 该病的发病率增加D. 该病的发病率减少E. 该疾病的死因构成比增加32. 计算乙肝疫苗接种后血清学检查的阳转率,分母为A. 乙肝易感人数B. 平均人口数C. 乙肝疫苗接种人数D. 乙肝患者人数E. 乙肝疫苗接种后的阳转人数33. 计算标准化死亡率的目的是A. 减少死亡率估计的偏倚B. 减少死亡率估计的抽样误差C. 便于进行不同地区死亡率的比较D. 消除各地区内部构成不同的影响E. 便于进行不同时间死亡率的比较34. 影响总体率估计的抽样误差大小的因素是A. 总体率估计的容许误差B. 样本率估计的容许误差C. 检验水准和样本含量D. 检验的把握度和样本含量E. 总体率和样本含量35. 研究某种新药的降压效果,对100人进行试验,其显效率的95%可信区间为0.862~0.926,表示A. 样本显效率在0.862~0.926之间的概率是95%B. 有95%的把握说总体显效率在此范围内波动C. 有95%的患者显效率在此范围D. 样本率估计的抽样误差有95%的可能在此范围E. 该区间包括总体显效率的可能性为95% 36. 利用2χ检验公式不适合解决的实际问题是A. 比较两种药物的有效率B. 检验某种疾病与基因多态性的关系C. 两组有序试验结果的药物疗效D. 药物三种不同剂量显效率有无差别E. 两组病情“轻、中、重”的构成比例37.进行四组样本率比较的2χ检验,如220.01,3χχ>,可认为A. 四组样本率均不相同B. 四组总体率均不相同C. 四组样本率相差较大D. 至少有两组样本率不相同E. 至少有两组总体率不相同38. 两样本比较的秩和检验,如果样本含量一定,两组秩和的差别越大说明A. 两总体的差别越大B. 两总体的差别越小C. 两样本的差别可能越大D. 越有理由说明两总体有差别E. 越有理由说明两总体无差别39. 两数值变量相关关系越强,表示A. 相关系数越大B. 相关系数的绝对值越大 B. 回归系数越大C. 回归系数的绝对值越大 E. 相关系数检验统计量的t 值越大 40. 回归分析的决定系数2R 越接近于1,说明A. 相关系数越大B. 回归方程的显著程度越高C. 应变量的变异越大D. 应变量的变异越小E.自变量对应变量的影响越大41.统计表的主要作用是A. 便于形象描述和表达结果B. 客观表达实验的原始数据C. 减少论文篇幅D. 容易进行统计描述和推断E. 代替冗长的文字叙述和便于分析对比42.描述某疾病患者年龄(岁)的分布,应采用的统计图是A.线图B.条图C.百分条图D.直方图E.箱式图43.高血压临床试验分为试验组和对照组,分析考虑治疗0周、2周、4周、6周、8周血压的动态变化和改善情况,为了直观显示出两组血压平均变动情况,宜选用的统计图是A.半对数图B.线图C.条图D.直方图E.百分条图44.研究三种不同麻醉剂在麻醉后的镇痛效果,采用计量评分法,分数呈偏态分布,比较终点时分数的平均水平及个体的变异程度,应使用的图形是A. 复式条图B. 复式线图C. 散点图D. 直方图E. 箱式图45. 研究血清低密度脂蛋白LDL与载脂蛋白B-100的数量依存关系,应绘制的图形是A. 直方图B. 箱式图C. 线图D. 散点图E. 条图46. 实验研究随机化分组的目的是A.减少抽样误差B.减少实验例数C.保证客观D.提高检验准确度E.保持各组的非处理因素均衡一致47. 关于实验指标的准确度和精密度,正确的说法是A.精密度较准确度更重要B.准确度较精密度更重要C.精密度主要受随机误差的影响D.准确度主要受随机误差的影响E.精密度包含准确度48. 在临床试验设计选择对照时,最可靠的对照形式是A. 历史对照B. 空白对照C. 标准对照D. 安慰对照E. 自身对照49. 两名医生分别阅读同一组CT片诊断某种疾病,Kappa值越大说明A. 观察个体的变异越大B. 观察个体的变异越小C. 观察一致性越大D. 机遇一致性越大E. 实际一致性越大50. 下列叙述正确的有A. 特异度高说明测量的稳定性好B. 灵敏度必须大于特异度才有实际意义C. 增大样本含量可以同时提高灵敏度和特异度D. 特异度高说明假阳性率低E. 阳性预测值高说明患病的概率大二. 名词解释:1.总体与样本2.抽样误差3.直线回归与相关4 方差分析基本思想5、标准正态分布:三. 问答题:1. 常见的三类误差是什么?应采取什么措施和方法加以控制?2. 现测得10名乳腺癌患者化疗后血液尿素氮的含量(mmol/L)分别为3.43,2.96,4.43,3.03,4.53,5.25,5.64,3.82,4.28,5.25,试计算其均数和中位数。
医学统计学练习题与答案

一、单向选择题1. 医学统计学研究的对象是 E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是 D.病情程度4. 随机误差指的是 E. 由偶然因素引起的误差5. 收集资料不可避免的误差是 A.随机误差1.某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是A. 中位数2. 算术均数与中位数相比,其特点是 B.能充分利用数据的信息3. 一组原始数据呈正偏态分布,其数据的特点是 D.数值分布偏向较小一侧4. 将一组计量资料整理成频数表的主要目的是E.提供数据和描述数据的分布特征1. 变异系数主要用于 A .比较不同计量指标的变异程度2. 对于近似正态分布的资料,描述其变异程度应选用的指标是E. 标准差3.某项指标95%医学参考值范围表示的是D.在“正常”总体中有95%的人在此范围4.应用百分位数法估计参考值范围的条件是B .数据服从偏态分布5.已知动脉硬化患者载脂蛋白B 的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用 E .四分位数间距1.样本均数的标准误越小说明 E.由样本均数估计总体均数的可靠性越大2. 抽样误差产生的原因是D.个体差异3.对于正偏态分布的的总体,当样本含量足够大时,样本均数的分布近似为C.正态分布4. 假设检验的目的是 D.检验总体参数是否不同5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109/L ~9.1×109/L ,其含义是 E.该区间包含总体均数的可能性为95%1. 两样本均数比较,检验结果05.0 P 说明 D.不支持两总体有差别的结论2. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指E. 有理由认为两总体均数有差别3. 两样本均数比较,差别具有统计学意义时,P 值越小说明 D.越有理由认为两总体均数不同4. 减少假设检验的Ⅱ类误差,应该使用的方法是 E.增加样本含量5.两样本均数比较的t 检验和u 检验的主要差别是B.u 检验要求大样本资料1. 利用2χ检验公式不适合解决的实际问题是C.两组有序试验结果的药物疗效2.欲比较两组阳性反应率, 在样本量非常小的情况下(如1210,10n n <<), 应采用C.Fisher 确切概率法二、简答题1.抽样中要求每一个样本应该具有哪三性?从总体中抽取样本,其样本应具有“代表性”、“随机性”和“可靠性”。
医学统计学作业题

卫生统计学作业题年级:专业:姓名:学号:一、名词解释1、计量资料2、计数资料3、等级资料4、总体5、样本6、抽样误差7、算术均数8、中位数9、标准差10、变异系数11、统计推断12、随机区组13、标准误14、可信区间15、参数估计16、检验效能17、相关系数18、医学正常值范围二、单项选择题1.观察单位为研究中的( )。
A.样本B.全部对象C.影响因素D.个体2.总体是由()。
A.个体组成B.研究对象组成C.同质个体组成D.研究指标组成3.抽样的目的是()。
A.研究样本统计量B.由样本统计量推断总体参数C.研究典型案例研究误差D.研究总体统计量4.参数是指()。
A.参与个体数B.总体的统计指标C.样本的统计指标D.样本的总和5.关于随机抽样,下列那一项说法是正确的()。
A.抽样时应使得总体中的每一个个体都有同等的机会被抽取B.研究者在抽样时应精心挑选个体,以使样本更能代表总体C.随机抽样即随意抽取个体D.为确保样本具有更好的代表性,样本量应越大越好6.各观察值均加(或减)同一数后()。
A.均数不变,标准差改变B.均数改变,标准差不变C.两者均不变D.两者均改变7.比较身高和体重两组数据变异度大小宜采用()。
A.变异系数B.方差C.极差D.标准差8.以下指标中()可用来描述计量资料的离散程度。
A.算术均数B.几何均数C.中位数D.标准差9.血清学滴度资料最常用来表示其平均水平的指标是()。
A.算术平均数B.中位数C.几何均数D.平均数10.两样本均数的比较,可用()。
A.方差分析B.t检验C.两者均可D.方差齐性检验11.完全随机设计方差分析的检验假设是()。
A.各处理组样本均数相等B.各处理组总体均数相等C.各处理组样本均数不相等D.各处理组总体均数不全相等12.非参数统计应用条件是()。
A.总体是正态分布B.若两组比较,要求两组的总体方差相等C.不依赖于总体分布D.要求样本例数很大13.下述哪些不是非参数统计的特点()。
医学统计学作业

医学统计作业一、论述题某种菌苗通过皮下注射,对20名观察对象进行免疫,21天后观察结果,分别采用三种原始记录形式,结果如下表:1 以上三种记录各属何种类型的统计资料?2 怎样对这些资料进行合理的分组整理,以有助于进一步的统计分析? 用某菌苗对20名对象作皮下注射免疫结果二、简答题1 一组计量数据,应如何整理,并从哪几个方面来反映资料的基本特征。
2 计量资料频数表的组段是否越细越好?3 均数、中位数和几何均数的适用范围有何异同?三 计算题1某地测得9名健康人的血清白蛋白分别为46,47,51,45,44,39,42,48,43(g/l )求:(1)平均白蛋白;(2)标准差;(3)变异系数;(2 8名某种传染病人的潜伏期分别为13,11,15,12,17,19,21,180(天)。
应用哪一种平均数指标表示其潜伏期,试计算之。
3测量某地120名成年男子血红蛋白值(g/l )数据如下表。
(1)列频数表,绘制频数分布图(2)求均数;(3)求标准差;4 某省地方病防治所测得某地133名中学生尿碘值水平见下表。
(1)它是什么分布资料。
(2)用什么指标表示其平均水平为宜,试计算之;(3)碘缺乏病防治尿碘监测要求尿碘值≥100ug/l,133名中学生中未达到要求的占百分之几。
133名中学生尿碘值水平分布5 检查某市健康成年女性744人血红蛋白含量的均数为122.39 g/l,标准差为9.98g/l,该资料的分布是近似正态分布,制订其正常值范围.6 某省医院肛肠科测定正常成年人外科学肛管(直肠末端提肛肌至肛缘)长度见下表,其分布呈正态。
检验男、女的外科学平均肛管长度有否差别?成年男女的外科学肛管长度(cm)性别例数平均数标准差男889 3.94 0.58女311 4.30 0.537某地测定191名正常人尿氟(mmol/L)含量,结果如下表。
试制订正常值范围尿氟(mmol/L) 频数(f)累计频数0.01~ 14 140.02~ 41 550.03~ 47 1020.04~ 40 1420.05~ 17 1590.06~ 12 1710.07~ 6 1770.08~ 6 1830.09~ 4 1870.10~ 20.11~ 00.12~ 10.13~ 1合计1918. 某医院对9例慢性苯中毒患者用中草药抗苯一号治疗,得下列白细胞总数(千/mm3),问该药是否对患者的白细胞总数有影响?病人号 1 2 3 4 5 6 7 8 9治疗前 6.0 4.8 5.0 3.4 7.0 3.8 6.0 3.5 4.3治疗后 4.2 5.4 6.3 3.8 4.4 4.0 5.9 8.0 5.09将病情类似的滴虫患者随机分为两组,分别用A、B两药治疗,其结果如下,试推断两药疗效有无差异。
医学统计学作业题

实践一、数值变量的整理与描述题1 在某市做调查获得102名7岁男童坐高资料如下图所示:(1)计算平均数与标准差;(2)计算中位数与四分位数间距。
实践二正态分布理论与应用题1抽样调查某市45-55岁健康男性居民的血脂水平,184名45-55岁健康男性居血清总胆固醇(TC)的X=4. 84 mmol/L, S=0.96 mmol/L.(健康人的血清总胆固醇服从正态分布)。
(1)估计该市45 ~55岁健康男性居民的血清总胆固醇的95%参考值范围;(2)估计该市45 ~55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范围内的比例;(3)估计该市45 ~55岁健康男性居民中,血清总胆固醇低于3.80 mrnoUL所占的比例。
实践三率的标准化在医学研究中的应用题1:对某地不同年龄、性别人群的HBsAg阳性率进行检测,结果如下表所示,试着对该地男、女HBsAg阳性率进行率的标准化。
提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组表某地不同年龄、性别人群的HBsAg阳性率(%)年龄组男性女性检查数阳性数阳性率检查数阳性数阳性率0~ 521 12 2.30 560 13 2.3220~ 516 14 2.71 957 26 2.7240~ 710 43 6.06 836 54 6.4660~ 838 63 7.52 570 49 8.60合计2585 132 5.11 2923 142 4.86实验四 总体均数估计在医学研究中的运用题1 从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h )的均数为9.15,标准差为2.13。
假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。
()()某实验随机测定了100名正常人血浆内皮素ET 含量ng /L , 得均数X =81.0标准差S =18.2, (1)计算抽样误差指标( 2)估计正常人血浆内皮素的95%总体均数可题 2 信区间。
医学统计学十套题

医学统计学试卷一、选择题(每题1分,共60分) 1、A1、A2型题1. 下列选项中,通常认为不属于计量资料类型的是A. 身高资料B. 舒张压资料C. 血清总胆固醇资料D. 人体的臂长资料E.某病患病率资料2.计算某地某年肺癌的发病率,其分母应为A 该地体检人数B 该地年平均就诊人数C 该地年平均人口数D 该地平均患者人数E 该地易感人数3.比较7岁男童与17岁青年身高的变异程度,宜用: A. 极差 B. 四分位数间距 C. 方差 D. 标准差 E. 变异系数4.根据观测结果,已建立y 关于x 的回归方程ˆy=2.0-3.0x ,该回归方程表示:x 每增加1个单位,则A. y 平均增加2个单位B. y 平均减少2个单位C. y 平均增加3个单位D. y 平均减少3个单位E. y 平均减少5个单位5.某地1992年随机抽取100名健康女性,算得其血清总蛋白含量的均数为74g/L ,标准差为4 g/L ,则其95%的参考值范围A 74±4×4B 74±1.96×4C 74±2.58×4D 74±2.58×4÷10E 74±1.96×4÷106.方差分析结果,)2,1(05.0ννF F >处理,则统计结论是A 各总体均数不全相等B 各总体均数都不相等C 各样本均数不全相等D 各样本均数间差别都有显著性 D 各总体方差不全相等 7. 下列四句话有几句是正确的?标准差是用来描述随机变量的离散程度的。
标准误是用来描述统计量的变异程度的。
t 检验只用于检验两样本均数的差别。
2χ检验可用来比较两个或多个率的差别。
A. 0句B. 1句C. 2句D. 3句E. 4句8. 假定某细菌的菌落数服从Poisson 分布,经观察得平均菌落数为9,问菌落数的标准差为:A. 18B. 9C. 3D. 81E. 27 9. 公式()∑-=TT A 22χ可用于 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
班别:姓名:学号:一、选择题:(50*1分)1. 医学统计学研究的对象是A. 医学中的小概率事件B. 各种类型的数据C. 动物和人的本质D. 疾病的预防与治疗E.有变异的医学事件2. 用样本推论总体,具有代表性的样本指的是A.总体中最容易获得的部分个体 B.在总体中随意抽取任意个体C.挑选总体中的有代表性的部分个体 D.用配对方法抽取的部分个体E.依照随机原则抽取总体中的部分个体3. 下列观测结果属于等级资料的是A.收缩压测量值 B.脉搏数C.住院天数 D.病情程度E.四种血型4. 随机误差指的是A. 测量不准引起的误差B. 由操作失误引起的误差C. 选择样本不当引起的误差D. 选择总体不当引起的误差E. 由偶然因素引起的误差5. 收集资料不可避免的误差是A. 随机误差B. 系统误差C. 过失误差D. 记录误差 E.仪器故障误差6. 某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是A. 中位数B. 几何均数P百分位数C. 均数D.95E. 频数分布7. 算术均数与中位数相比,其特点是A.不易受极端值的影响 B.能充分利用数据的信息C.抽样误差较大 D.更适用于偏态分布资料E.更适用于分布不明确资料8. 一组原始数据呈正偏态分布,其数据的特点是A. 数值离散度较小B. 数值离散度较大C. 数值分布偏向较大一侧D. 数值分布偏向较小一侧E. 数值分布不均匀9. 将一组计量资料整理成频数表的主要目的是A.化为计数资料 B. 便于计算C. 形象描述数据的特点D. 为了能够更精确地检验E. 提供数据和描述数据的分布特征10. 6人接种流感疫苗一个月后测定抗体滴度为 1:20、1:40、1:80、1:80、1:160、1:320,求平均滴度应选用的指标是A. 均数B. 几何均数C. 中位数D. 百分位数E. 倒数的均数11. 变异系数主要用于A.比较不同计量指标的变异程度 B. 衡量正态分布的变异程度C. 衡量测量的准确度D. 衡量偏态分布的变异程度E. 衡量样本抽样误差的大小12. 对于近似正态分布的资料,描述其变异程度应选用的指标是A. 变异系数B. 离均差平方和C. 极差D. 四分位数间距E. 标准差13. 某项指标95%医学参考值范围表示的是A. 检测指标在此范围,判断“异常”正确的概率大于或等于95%B. 检测指标在此范围,判断“正常”正确的概率大于或等于95%C. 在“异常”总体中有95%的人在此范围之外D. 在“正常”总体中有95%的人在此范围E. 检测指标若超出此范围,则有95%的把握说明诊断对象为“异常”14.应用百分位数法估计参考值范围的条件是A.数据服从正态分布 B.数据服从偏态分布C.有大样本数据 D.数据服从对称分布 E.数据变异不能太大15.已知动脉硬化患者载脂蛋白B的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用A.全距 B.标准差C.变异系数 D.方差E.四分位数间距16. 样本均数的标准误越小说明A. 观察个体的变异越小B. 观察个体的变异越大C. 抽样误差越大D. 由样本均数估计总体均数的可靠性越小E. 由样本均数估计总体均数的可靠性越大17. 抽样误差产生的原因是A. 样本不是随机抽取B. 测量不准确C. 资料不是正态分布D. 个体差异E. 统计指标选择不当18. 对于正偏态分布的的总体, 当样本含量足够大时, 样本均数的分布近似为A. 正偏态分布B. 负偏态分布C. 正态分布D. t分布E. 标准正态分布19. 假设检验的目的是A. 检验参数估计的准确度B. 检验样本统计量是否不同C. 检验样本统计量与总体参数是否不同D. 检验总体参数是否不同E. 检验样本的P值是否为小概率20. 根据样本资料算得健康成人白细胞计数的95%可信区间为×109/L~×109/L,其含义是A. 估计总体中有95%的观察值在此范围内B. 总体均数在该区间的概率为95%C. 样本中有95%的观察值在此范围内D. 该区间包含样本均数的可能性为95%E. 该区间包含总体均数的可能性为95%21. 两样本均数比较,检验结果05P说明.0A. 两总体均数的差别较小B. 两总体均数的差别较大C. 支持两总体无差别的结论D. 不支持两总体有差别的结论E. 可以确认两总体无差别22. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指A. 两样本均数的差别具有实际意义B. 两总体均数的差别具有实际意义C. 两样本和两总体均数的差别都具有实际意义D. 有理由认为两样本均数有差别E. 有理由认为两总体均数有差别23. 两样本均数比较,差别具有统计学意义时,P值越小说明A. 两样本均数差别越大B. 两总体均数差别越大C. 越有理由认为两样本均数不同D. 越有理由认为两总体均数不同E. 越有理由认为两样本均数相同24. 减少假设检验的Ⅱ类误差,应该使用的方法是A. 减少Ⅰ类错误B. 减少测量的系统误差C. 减少测量的随机误差D. 提高检验界值E. 增加样本含量25.两样本均数比较的t检验和u检验的主要差别是A. t检验只能用于小样本资料B. u检验要求大样本资料C. t检验要求数据方差相同D. t检验的检验效能更高E. u检验能用于两大样本均数比较26. 方差分析的基本思想和要点是A.组间均方大于组内均方 B.组内均方大于组间均方C.不同来源的方差必须相等 D.两方差之比服从F分布E.总变异及其自由度可按不同来源分解27. 方差分析的应用条件之一是方差齐性,它是指A. 各比较组相应的样本方差相等B. 各比较组相应的总体方差相等C. 组内方差=组间方差D. 总方差=各组方差之和E. 总方差=组内方差 + 组间方差28. 完全随机设计方差分析中的组间均方反映的是A. 随机测量误差大小B. 某因素效应大小C. 处理因素效应与随机误差综合结果D. 全部数据的离散度E. 各组方差的平均水平29. 对于两组资料的比较,方差分析与t检验的关系是A. t检验结果更准确B. 方差分析结果更准确C. t检验对数据的要求更为严格D. 近似等价E. 完全等价30.多组均数比较的方差分析,如果0.05P ,则应该进一步做的是A.两均数的t检验 B.区组方差分析C.方差齐性检验 D.q检验E.确定单独效应31. 如果一种新的治疗方法能够使不能治愈的疾病得到缓解并延长生命,则应发生的情况是A. 该病患病率增加B. 该病患病率减少C. 该病的发病率增加D. 该病的发病率减少E. 该疾病的死因构成比增加32. 计算乙肝疫苗接种后血清学检查的阳转率,分母为A. 乙肝易感人数B. 平均人口数C. 乙肝疫苗接种人数D. 乙肝患者人数E. 乙肝疫苗接种后的阳转人数33. 计算标准化死亡率的目的是A. 减少死亡率估计的偏倚B. 减少死亡率估计的抽样误差C. 便于进行不同地区死亡率的比较D. 消除各地区内部构成不同的影响E. 便于进行不同时间死亡率的比较34. 影响总体率估计的抽样误差大小的因素是A. 总体率估计的容许误差B. 样本率估计的容许误差C. 检验水准和样本含量D. 检验的把握度和样本含量E. 总体率和样本含量35. 研究某种新药的降压效果,对100人进行试验,其显效率的95%可信区间为~,表示A.样本显效率在~之间的概率是95%B. 有95%的把握说总体显效率在此范围内波动C. 有95%的患者显效率在此范围D. 样本率估计的抽样误差有95%的可能在此范围E. 该区间包括总体显效率的可能性为95%检验公式不适合解决的实际问题是36. 利用2A. 比较两种药物的有效率B. 检验某种疾病与基因多态性的关系C. 两组有序试验结果的药物疗效D. 药物三种不同剂量显效率有无差别E. 两组病情“轻、中、重”的构成比例37.进行四组样本率比较的2χ检验,如220.01,3χχ>,可认为A. 四组样本率均不相同B. 四组总体率均不相同C. 四组样本率相差较大D. 至少有两组样本率不相同E. 至少有两组总体率不相同38. 两样本比较的秩和检验,如果样本含量一定,两组秩和的差别越大说明A. 两总体的差别越大B. 两总体的差别越小C. 两样本的差别可能越大D. 越有理由说明两总体有差别E. 越有理由说明两总体无差别39. 两数值变量相关关系越强,表示A. 相关系数越大B. 相关系数的绝对值越大B. 回归系数越大C. 回归系数的绝对值越大E. 相关系数检验统计量的t 值越大40. 回归分析的决定系数2R 越接近于1,说明A. 相关系数越大B. 回归方程的显著程度越高C. 应变量的变异越大D. 应变量的变异越小E. 自变量对应变量的影响越大41.统计表的主要作用是A. 便于形象描述和表达结果B. 客观表达实验的原始数据C. 减少论文篇幅D. 容易进行统计描述和推断E. 代替冗长的文字叙述和便于分析对比42.描述某疾病患者年龄(岁)的分布,应采用的统计图是A.线图 B.条图C.百分条图 D.直方图E.箱式图43.高血压临床试验分为试验组和对照组,分析考虑治疗0周、2周、4周、6周、8周血压的动态变化和改善情况,为了直观显示出两组血压平均变动情况,宜选用的统计图是A.半对数图 B.线图C.条图 D.直方图E.百分条图44.研究三种不同麻醉剂在麻醉后的镇痛效果,采用计量评分法,分数呈偏态分布,比较终点时分数的平均水平及个体的变异程度,应使用的图形是A. 复式条图B. 复式线图C. 散点图D. 直方图E. 箱式图45. 研究血清低密度脂蛋白LDL与载脂蛋白B-100的数量依存关系,应绘制的图形是A. 直方图B. 箱式图C. 线图D. 散点图E. 条图46. 实验研究随机化分组的目的是A.减少抽样误差 B.减少实验例数C.保证客观 D.提高检验准确度E.保持各组的非处理因素均衡一致47. 关于实验指标的准确度和精密度,正确的说法是A.精密度较准确度更重要 B.准确度较精密度更重要C.精密度主要受随机误差的影响 D.准确度主要受随机误差的影响E.精密度包含准确度48. 在临床试验设计选择对照时,最可靠的对照形式是A. 历史对照B. 空白对照C. 标准对照D. 安慰对照E. 自身对照49. 两名医生分别阅读同一组CT片诊断某种疾病,Kappa值越大说明A. 观察个体的变异越大B. 观察个体的变异越小C. 观察一致性越大D. 机遇一致性越大E. 实际一致性越大50. 下列叙述正确的有A. 特异度高说明测量的稳定性好B. 灵敏度必须大于特异度才有实际意义C. 增大样本含量可以同时提高灵敏度和特异度D. 特异度高说明假阳性率低E. 阳性预测值高说明患病的概率大二. 名词解释:1.总体与样本2.抽样误差3.直线回归与相关4 方差分析基本思想5、标准正态分布:三. 问答题:1. 常见的三类误差是什么?应采取什么措施和方法加以控制?2. 现测得10名乳腺癌患者化疗后血液尿素氮的含量(mmol/L)分别为,,,,,,,,,,试计算其均数和中位数。