SPSS中逐步回归分析的应用
介绍SPSS中逐步回归分析的应用

介绍SPSS中逐步回归分析的应用2009-04-20 12:30:45| 分类:默认分类阅读2037 评论0 字号:大中小订阅杨应红张马兵卢逢刚(安庆市气象局246001)引言SPSS(Statistical Package for the Social Science)社会科学应用软件包是世界上著名的统计分析软件之一。
它和SAS(Statistical Analysis System,统计分析系统)、BMDP(Biomedical Programs,生物医学程序)并称为国际上最有影响的三大统计软件。
SPSS名为社会学统计软件包,这是为了强调其社会科学应用的一面(因为社会科学研究中的许多现象都是随机的,要使用统计学和概率论的定理来进行研究),而实际上它在社会科学、自然科学的各个领域都能发挥巨大作用,并已经应用于经济学、生物学、教育学、心理学、医学以及体育、工业、农业、林业、商业和金融等各个领域。
回归分析是目前气象统计分析中最为常用的一种方法之一。
例如目前台站常用的MOS(模式输出统计量)方法中,回归分析是最基本的方法之一。
逐步回归能够帮我们建立最优的回归模型,但过程较复杂。
Spss软件功能强大,且操作简单。
我们用该软件对气象资料作逐步回归分析,对于Spss软件用于气象统计的便利亦可见一斑。
下面以安庆市1951-1971年6~8月降水及相关资料(表一)为例。
1 数据格式表中1971年因子值留作预报时使用,不参加到样本中进行统计,表中符号意义如下:y:安庆市整个地区6~8月降水量(mm)。
X1:1月500hPa高度距平和(50°~20°W,60°N;45°~25°W,55°N)。
X2:2~3月500hPa高度距平和(70°~100°E,30°N)。
X3:4月500hPa高度距平和(25°N,105°~115°E;20°N,100°~120°E;15°N,105°~115°E)。
SPSS的Logistics回归

SPSS的Logistics回归实验⽬的学会使⽤SPSS的简单操作,Logistic回归。
实验要求使⽤SPSS。
实验内容实验步骤 (1)⼆项分类Logistic回归SPSS分析,使⽤Hosmer和Lemeshow于1989年研究低出⽣体重婴⼉的影响因素作为演⽰例⼦。
结果变量为“是否娩出低出⽣体重⼉”,考虑影响因素有8个,详见Logistics_step.sav⽂件。
本例题主要演⽰“⾃变量的筛选与逐步回归”。
操作如下:点击【分析】→【回归】→【⼆元Logistics回归】,在打开的对话框中,把待结果变量LOW选⼊【因变量】中,将变量LWT,AGE,SMOKE,PTL,HT,UI,FTV,RACE选⼊【协变量】中。
点击【分类】,把RACE选⼊【分类协变量】→【第⼀个】→【变化量】→【继续】,【块】⾥的【⽅法(M)】选【向前:LP】,【选项】→【Exp(B)的置信区间】→【继续】,单击【运⾏】。
主要分析结果如下:分类变量编码频率参数编码(1)(2)种族⽩⼈96.000.000⿊⼈26 1.000.000其他种族67.000 1.000 上表输出race在产⽣哑变量时的编码情况,以⽩⼈为参照⽔平。
未包括在⽅程中的变量得分⾃由度显著性步骤 0变量产妇体重 4.6161.032产妇年龄 2.4071.121产妇在妊娠期间是否吸烟 4.9241.026本次妊娠前早产次数7.2671.007是否患有⾼⾎压 4.3881.036应激性 4.2051.040随访次数.9341.334种族 5.0052.082种族(1) 1.7271.189种族(2) 1.7971.180总体统计29.1409.001 输出的是拟合包含常数项和任⼀⾃变量的Logistics回归模型检验统计量、⾃由度及P值。
其中race产⽣两个哑变量,因此其总⾃由度为2。
由上表可以发现,本次妊娠前早产次数(ptl)的score统计量最⼤,P=0.007,⼩于SPSS默认选⼊变量的标准(0.05)因此下⼀步将它⾸先选⼊模型。
SPSS在教师考评中的应用——回归分析

SPSS在教师考评中的应用——回归分析现行教师考评指标体系,没有反映出教师劳动的本质特征及其运动规律,还存在定性指标多,定量指标少,考评指标内涵缺乏,考评指标多而乱的问题.所以必须抓住众多指标中,起关键作用的指标,以遵循全面考评与重点考评相结合等原则。
采用回归分析的方法,借用SPPS 统计软件对各种指标进行分析。
标签:教师考评考评指标回归分析一、当前教师考评的现状及存在的问题自1978年我国恢复教师考评工作以来,坚持对教师年度和任期教学工作考评就日益显得重要。
而为了做好对教师的考评工作,自上世纪80年代中,后期,全国各省,市,自治区先后都制定出了相关的考核指标体系,不少学校还在次基础上,结合自身工作实际研究制定了本校教师教学工作考评指标体系。
所有这些,对加强中小学教师队伍建设特别是对规范中小学教师日常工作管理,促进教师综合素质的提高,无疑发挥了重要的作用。
但据对诸多中小学校教师开展日常教学工作考评实践情况的调查研究来看,结果发现:现行的中小学及教师考评指标体系仍存在诸多亟待解决的问题。
其主要表现:第一,从总体上看,没有反映出中小学教师工作的本质特征及其客观规律。
教师劳动明显具有劳动经济学中揭示的“潜在”,“流动”和“凝结”三种表现形态的本质特征。
这也就是说,若想对教师日常工作情况做出真实的考评,必须同时考评其综合素质,工作投入和工作绩效三个方面。
并依据其建构起相应的考评指标体系,都是模仿国家公务员按德,能,勤,绩四个方面来建构的,因此无法反映出中小学教师工作的本质特征,继而也就无法对教师工作做出最合理,科学的考评。
第二,定性指标多,定量指标少。
以我省中小学教师考评指标体系为例,除“出勤率”和“工量”为定量指标外,其余几乎都是定性描述性指标。
其结果是不仅考评实践中可操作性差,而且考评的区分度很低。
第三,考评指标内涵模糊甚至缺失。
如我省中小学教师考评指标体系,除一,二级考评指标外,对二级考评指标的任何一项的内涵界定都没有。
数据统计分析软件SPSS的应用(五)——相关分析与回归分析

数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS的应用(五)——相关分析与回归分析数据统计分析软件SPSS是目前应用广泛且非常强大的数据分析工具之一。
在前几篇文章中,我们介绍了SPSS的基本操作和一些常用的统计方法。
本篇文章将继续介绍SPSS中的相关分析与回归分析,这些方法是数据分析中非常重要且常用的。
一、相关分析相关分析是一种用于确定变量之间关系的统计方法。
SPSS提供了多种相关分析方法,如皮尔逊相关、斯皮尔曼相关等。
在进行相关分析之前,我们首先需要收集相应的数据,并确保数据符合正态分布的假设。
下面以皮尔逊相关为例,介绍SPSS 中的相关分析的步骤。
1. 打开SPSS软件并导入数据。
可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备相关分析的变量。
选择菜单栏中的“Analyze”选项,然后选择“Correlate”子菜单中的“Bivariate”。
在弹出的对话框中,选择要进行相关分析的变量,并将它们添加到相应的框中。
3. 进行相关分析。
点击“OK”按钮后,SPSS会自动计算所选变量之间的相关系数,并将结果输出到分析结果窗口。
4. 解读相关分析结果。
SPSS会给出相关系数的值以及显著性水平。
相关系数的取值范围为-1到1,其中-1表示完全负相关,1表示完全正相关,0表示没有相关关系。
显著性水平一般取0.05,如果相关系数的显著性水平低于设定的显著性水平,则可以认为两个变量之间存在相关关系。
二、回归分析回归分析是一种用于探索因果关系的统计方法,广泛应用于预测和解释变量之间的关系。
SPSS提供了多种回归分析方法,如简单线性回归、多元线性回归等。
下面以简单线性回归为例,介绍SPSS中的回归分析的步骤。
1. 打开SPSS软件并导入数据。
同样可以通过菜单栏中的“File”选项来导入数据文件,或者使用快捷键“Ctrl + O”。
2. 准备回归分析的变量。
《2024年数据统计分析软件SPSS的应用(五)——相关分析与回归分析》范文

《数据统计分析软件SPSS的应用(五)——相关分析与回归分析》篇一数据统计分析软件SPSS的应用(五)——相关分析与回归分析一、引言在当今的大数据时代,数据统计分析已成为科研、商业决策和日常生活中的重要工具。
SPSS(Statistical Package for the Social Sciences)作为一款广泛使用的数据统计分析软件,其强大的功能为各类数据分析提供了有力支持。
本文将重点介绍SPSS中相关分析与回归分析的应用,探讨其在实际研究中的应用价值。
二、相关分析的应用1. 相关分析的基本概念相关分析是研究两个或多个变量之间关系密切程度的一种统计方法。
SPSS提供了多种相关系数计算方法,如皮尔逊相关系数、斯皮尔曼等级相关系数等,以帮助研究者了解变量间的关系强度和方向。
2. 相关分析在实证研究中的应用以市场营销领域为例,研究者可以通过SPSS计算消费者购买行为与产品价格、广告投入等变量之间的相关系数,从而了解各因素对消费者购买行为的影响程度。
这种分析方法有助于企业制定有效的营销策略。
三、回归分析的应用1. 回归分析的基本概念回归分析是研究一个或多个自变量与因变量之间关系的一种预测性统计方法。
通过建立回归模型,可以分析自变量对因变量的影响程度,并进行预测。
SPSS提供了多种回归分析方法,如简单线性回归、多元线性回归等。
2. 回归分析在实证研究中的应用以医学领域为例,研究者可以通过SPSS建立药物剂量与患者恢复时间之间的回归模型,分析药物剂量对患者恢复时间的影响程度,为临床治疗提供参考依据。
此外,回归分析还可以用于研究其他领域的复杂关系,如教育、经济等。
四、案例分析以某电商平台销售数据为例,通过SPSS进行相关分析与回归分析。
首先,计算商品价格、商品评价数量、商品销量等变量之间的皮尔逊相关系数,了解各因素之间的关联程度。
然后,建立商品价格与商品销量的多元线性回归模型,分析价格对销量的影响程度。
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
多元回归分析SPSS案例
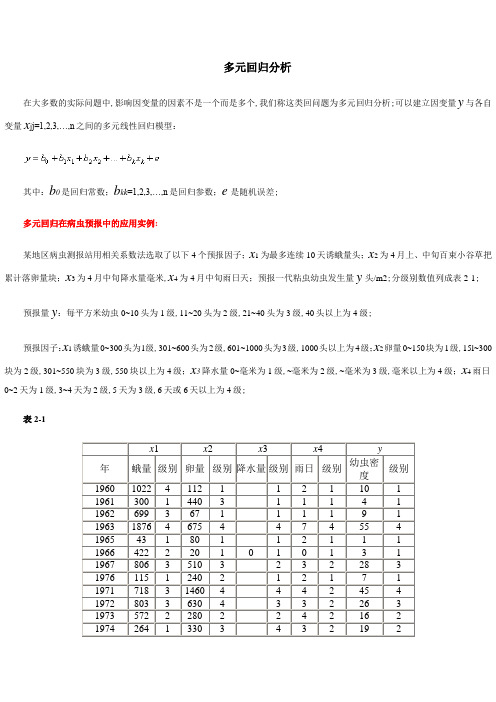
多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析;可以建立因变量y与各自变量x j j=1,2,3,…,n之间的多元线性回归模型:其中:b0是回归常数;b k k=1,2,3,…,n是回归参数;e是随机误差;多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量头;x2为4月上、中旬百束小谷草把累计落卵量块;x3为4月中旬降水量毫米,x4为4月中旬雨日天;预报一代粘虫幼虫发生量y头/m2;分级别数值列成表2-1;预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级;预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~毫米为1级,~毫米为2级,~毫米为3级,毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级;表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960 1022 4 112 1 1 2 1 10 1 1961 300 1 440 3 1 1 1 4 1 1962 699 3 67 1 1 1 1 9 1 1963 1876 4 675 4 4 7 4 55 4 1965 43 1 80 1 1 2 1 1 1 1966 422 2 20 1 0 1 0 1 3 1 1967 806 3 510 3 2 3 2 28 3 1976 115 1 240 2 1 2 1 7 1 1971 718 3 1460 4 4 4 2 45 4 1972 803 3 630 4 3 3 2 26 3 1973 572 2 280 2 2 4 2 16 2 1974 264 1 330 3 4 3 2 19 2数据保存在“”文件中;1准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据;再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生;编辑后的数据显示如图2-1;图2-1或者打开已存在的数据文件“”;2启动线性回归过程单击SPSS主菜单的“Analyze”下的“Regression”中“Linear”项,将打开如图2-2所示的线性回归过程窗口;图2-2 线性回归对话窗口3 设置分析变量设置因变量:用鼠标选中左边变量列表中的“幼虫密度y”变量,然后点击“Dependent”栏左边的向右拉按钮,该变量就移到“Dependent”因变量显示栏里;设置自变量:将左边变量列表中的“蛾量x1”、“卵量x2”、“降水量x3”、“雨日x4”变量,选移到“IndependentS”自变量显示栏里;设置控制变量: 本例子中不使用控制变量,所以不选择任何变量;选择标签变量: 选择“年份”为标签变量;选择加权变量: 本例子没有加权变量,因此不作任何设置;4回归方式本例子中的4个预报因子变量是经过相关系数法选取出来的,在回归分析时不做筛选;因此在“Method”框中选中“Enter”选项,建立全回归模型;5设置输出统计量单击“Statistics”按钮,将打开如图2-3所示的对话框;该对话框用于设置相关参数;其中各项的意义分别为:图2-3 “Statistics”对话框①“Regression Coefficients”回归系数选项:“Estimates”输出回归系数和相关统计量;“Confidence interval”回归系数的95%置信区间;“Covariance matrix”回归系数的方差-协方差矩阵;本例子选择“Estimates”输出回归系数和相关统计量;②“Residuals”残差选项:“Durbin-Watson”Durbin-Watson检验;“Casewise diagnostic”输出满足选择条件的观测量的相关信息;选择该项,下面两项处于可选状态:“Outliers outside standard deviations”选择标准化残差的绝对值大于输入值的观测量;“All cases”选择所有观测量;本例子都不选;③其它输入选项“Model fit”输出相关系数、相关系数平方、调整系数、估计标准误、ANOVA表;“R squared change”输出由于加入和剔除变量而引起的复相关系数平方的变化;“Descriptives”输出变量矩阵、标准差和相关系数单侧显著性水平矩阵;“Part and partial correlation”相关系数和偏相关系数;“Collinearity diagnostics”显示单个变量和共线性分析的公差;本例子选择“Model fit”项;6绘图选项在主对话框单击“Plots”按钮,将打开如图2-4所示的对话框窗口;该对话框用于设置要绘制的图形的参数;图中的“X”和“Y”框用于选择X轴和Y轴相应的变量;图2-4“Plots”绘图对话框窗口左上框中各项的意义分别为:•“DEPENDNT”因变量;•“ZPRED”标准化预测值;•“ZRESID”标准化残差;•“DRESID”删除残差;•“ADJPRED”调节预测值;•“SRESID”学生氏化残差;•“SDRESID”学生氏化删除残差;“Standardized Residual Plots”设置各变量的标准化残差图形输出;其中共包含两个选项:“Histogram”用直方图显示标准化残差;“Normal probability plots”比较标准化残差与正态残差的分布示意图;“Produce all partial plot”偏残差图;对每一个自变量生成其残差对因变量残差的散点图;本例子不作绘图,不选择;7 保存分析数据的选项在主对话框里单击“Save”按钮,将打开如图2-5所示的对话框;图2-5 “Save”对话框①“Predicted Values”预测值栏选项:Unstandardized 非标准化预测值;就会在当前数据文件中新添加一个以字符“PRE_”开头命名的变量,存放根据回归模型拟合的预测值;Standardized 标准化预测值;Adjusted 调整后预测值;. of mean predictions 预测值的标准误;本例选中“Unstandardized”非标准化预测值;②“Distances”距离栏选项:Mahalanobis: 距离;Cook’s”: Cook距离;Leverage values: 杠杆值;③“Prediction Intervals”预测区间选项:Mean: 区间的中心位置;Individual: 观测量上限和下限的预测区间;在当前数据文件中新添加一个以字符“LICI_”开头命名的变量,存放预测区间下限值;以字符“UICI_”开头命名的变量,存放预测区间上限值;Confidence Interval:置信度;本例不选;④“Save to New File”保存为新文件:选中“Coefficient statistics”项将回归系数保存到指定的文件中;本例不选;⑤“Export model information to XML file”导出统计过程中的回归模型信息到指定文件;本例不选;⑥“Residuals” 保存残差选项:“Unstandardized”非标准化残差;“Standardized”标准化残差;“Studentized”学生氏化残差;“Deleted”删除残差;“Studentized deleted”学生氏化删除残差;本例不选;⑦“Influence Statistics” 统计量的影响;“DfBetas”删除一个特定的观测值所引起的回归系数的变化;“Standardized DfBetas”标准化的DfBeta值;“DiFit” 删除一个特定的观测值所引起的预测值的变化;“Standardized DiFit”标准化的DiFit值;“Covariance ratio”删除一个观测值后的协方差矩隈的行列式和带有全部观测值的协方差矩阵的行列式的比率;本例子不保存任何分析变量,不选择;8其它选项在主对话框里单击“Options”按钮,将打开如图2-6所示的对话框;图2-6 “Options”设置对话框①“Stepping Method Criteria”框用于进行逐步回归时内部数值的设定;其中各项为:“Use probability of F”如果一个变量的F值的概率小于所设置的进入值Entry,那么这个变量将被选入回归方程中;当变量的F值的概率大于设置的剔除值Removal,则该变量将从回归方程中被剔除;由此可见,设置“Use probability of F”时,应使进入值小于剔除值;“Ues F value”如果一个变量的F值大于所设置的进入值Entry,那么这个变量将被选入回归方程中;当变量的F值小于设置的剔除值Removal,则该变量将从回归方程中被剔除;同时,设置“Use F value”时,应使进入值大于剔除值;本例是全回归不设置;②“Include constant in equation”选择此项表示在回归方程中有常数项;本例选中“Include constant in equation”选项在回归方程中保留常数项;③“Missing Values”框用于设置对缺失值的处理方法;其中各项为:“Exclude cases listwise”剔除所有含有缺失值的观测值;“Exchude cases pairwise”仅剔除参与统计分析计算的变量中含有缺失值的观测量;“Replace with mean”用变量的均值取代缺失值;本例选中“Exclude cases listwise”;9提交执行在主对话框里单击“OK”,提交执行,结果将显示在输出窗口中;主要结果见表2-2至表2-4;10 结果分析主要结果:表2-2表2-2 是回归模型统计量:R 是相关系数;R Square 相关系数的平方,又称判定系数,判定线性回归的拟合程度:用来说明用自变量解释因变量变异的程度所占比例;Adjusted R Square 调整后的判定系数;Std. Error of the Estimate 估计标准误差;表2-3表2-3 回归模型的方差分析表,F值为,显著性概率是,表明回归极显著;表2-4分析:建立回归模型:根据多元回归模型:把表6-9中“非标准化回归系数”栏目中的“B”列系数代入上式得预报方程:预测值的标准差可用剩余均方估计:回归方程的显著性检验:从表6-8方差分析表中得知:F统计量为,系统自动检验的显著性水平为;F,4,11值为,F,4,11 值为,F,4,11 值为;因此回归方程相关非常显著;F值可在Excel中用FINV 函数获得;回代检验需要作预报效果的验证时,在主对话框图6-8里单击“Save”按钮,在打开如图3-6所示对话框里,选中“Predicted Values”预测值选项栏中的“Unstandardized”非标准化预测值选项;这样在过程运算时,就会在当前文件中新添加一个“PRE_1”命名的变量,该变量存放根据回归模型拟合的预测值;然后,在SPSS数据窗口计算“y”与“PRE_1”变量的差值图2-7,本例子把绝对差值大于视为不符合,反之则符合;结果符合的年数为15年,1年不符合,历史符合率为%;图2-7多元回归分析法可综合多个预报因子的作用,作出预报,在统计预报中是一种应用较为普遍的方法;在实际运用中,采取将预报因子和预报量按一定标准分为多级,用分级尺度代换较大的数字,更能揭示预报因子与预报量的关系,预报效果比采用数量值统计方法有明显的提高,在实际应用中具有一定的现实意义;。
多元回归分析SPSS

多元回归分析SPSS
SPSS可以进行多元回归分析的步骤如下:
1.导入数据:首先需要将所需的数据导入SPSS软件中。
可以使用SPSS的数据导入功能,将数据从外部文件导入到工作空间中。
2.选择自变量和因变量:在进行多元回归分析之前,需要确定作为自
变量和因变量的变量。
在SPSS中,可以使用变量视图来选择所需的变量。
3.进行多元回归分析:在SPSS的分析菜单中,选择回归选项。
然后
选择多元回归分析,在弹出的对话框中将因变量和自变量输入相应的框中。
可以选择是否进行数据转换和标准化等选项。
4.分析结果的解释:多元回归分析完成后,SPSS将生成一个回归模
型的结果报告。
该报告包括各个自变量的系数、显著性水平、调整R平方
等统计指标。
根据这些统计指标可以判断自变量与因变量之间的关系强度
和显著性。
5.进一步分析:在多元回归分析中,还可以进行进一步的分析,例如
检查多重共线性、检验模型的假设、进一步探索变量之间的交互作用等。
通过多元回归分析可以帮助研究者理解因变量与自变量之间的关系,
预测因变量的值,并且确定哪些自变量对因变量的解释更为重要。
在
SPSS中进行多元回归分析可以方便地进行数值计算和统计推断,提高研
究的科学性和可信度。
总结来说,多元回归分析是一种重要的统计分析方法,而SPSS是一
个功能强大的统计软件工具。
通过结合SPSS的多元回归分析功能,研究
者可以更快速、准确地进行多元回归分析并解释结果。
以上就是多元回归分析SPSS的相关内容简介。
spss多元回归分析报告案例
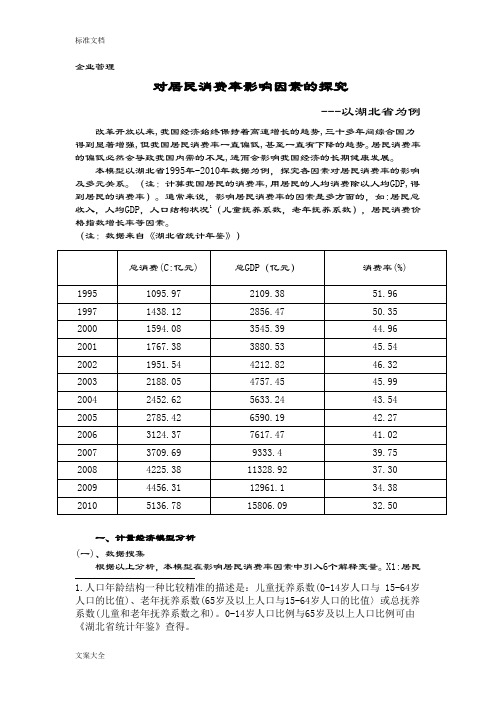
企业管理对居民消费率影响因素的探究---以湖北省为例改革开放以来,我国经济始终保持着高速增长的趋势,三十多年间综合国力得到显著增强,但我国居民消费率一直偏低,甚至一直有下降的趋势。
居民消费率的偏低必然会导致我国内需的不足,进而会影响我国经济的长期健康发展。
本模型以湖北省1995年-2010年数据为例,探究各因素对居民消费率的影响及多元关系。
(注:计算我国居民的消费率,用居民的人均消费除以人均GDP,得到居民的消费率)。
通常来说,影响居民消费率的因素是多方面的,如:居民总收入,人均GDP,人口结构状况1(儿童抚养系数,老年抚养系数),居民消费价格指数增长率等因素。
(注:数据来自《湖北省统计年鉴》)总消费(C:亿元) 总GDP(亿元)消费率(%)1995 1095.97 2109.38 51.96 1997 1438.12 2856.47 50.35 2000 1594.08 3545.39 44.96 2001 1767.38 3880.53 45.54 2002 1951.54 4212.82 46.32 2003 2188.05 4757.45 45.99 2004 2452.62 5633.24 43.54 2005 2785.42 6590.19 42.27 2006 3124.37 7617.47 41.02 2007 3709.69 9333.4 39.75 2008 4225.38 11328.92 37.30 2009 4456.31 12961.1 34.38 2010 5136.78 15806.09 32.50一、计量经济模型分析(一)、数据搜集根据以上分析,本模型在影响居民消费率因素中引入6个解释变量。
X1:居民1.人口年龄结构一种比较精准的描述是:儿童抚养系数(0-14岁人口与 15-64岁人口的比值)、老年抚养系数(65岁及以上人口与15-64岁人口的比值〉或总抚养系数(儿童和老年抚养系数之和)。
SPSS如何进行线性回归分析操作 精品

SPSS如何进行线性回归分析操作本节内容主要介绍如何确定并建立线性回归方程。
包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。
为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。
也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。
另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。
一、一元线性回归分析用SPSS进行回归分析,实例操作如下:1.单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。
从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。
在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。
所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。
具体如下图所示:2.请单击Statistics…按钮,可以选择需要输出的一些统计量。
如RegressionCoefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。
Model fit 项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。
上述两项为默认选项,请注意保持选中。
设置如图7-10所示。
设置完成后点击Continue返回主对话框。
回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。
由于此部分内容较复杂而且理论性较强,所以不在此详细介绍,读者如有兴趣,可参阅有关资料。
3.用户在进行回归分析时,还可以选择是否输出方程常数。
SPSS多元统计论文-回归分析

回归分析在商品的需求量分析中的运用摘要:本文结合多元统计分析理论中关于多元线性回归分析的应用,对商品需求量与商品价格和人均月收入的关系的线性方程进行探索研究。
回归分析的基本思想是描述若干个变量间的统计关系,以研究一个或多个自变量与因变量之间的内在联系。
而回归分析研究又包括线性回归和非线性回归。
本文就是运用线性回归来分析商品需求量和商品价格,人均月收入之间的关系的。
关键词:线性回归线性方程商品需求量一.引言随着我国经济的快速发展,人们的物质生活条件越来越好,各种各样的商品出现在人们的日常生活中。
随着人们收入水平的不断变化,随着商品价格的不断变化,人们对某种商品的需求量也不同。
如果生产的商品量大于商品的需求量,则会导致资源浪费,商品的价格下降;反之如果商品的生产量少于商品的需求量,则会导致商品供应不足,价格上涨。
以上两种情况都会对经济发展造成不利的影响。
因此,对商品需求量的预测是必要的。
那么,应该如何预测商品的需求量呢?为此,本文在参阅相关文献的基础上,根据东方财富网所提供的某地1996~2995年10年间对某品牌的手表需求量和商品价格,人均月收入的数据采用线性回归的方法进行回归分析,并对模型进行检验,预测。
二.经济理论分析、所涉及的经济变量(1)经济理论分析:1.需求:是指在各种不同价格水平下,消费者愿意且能够购买的商品或服务的数量;2.需求与价格之间存在这需求规律,即“在其它条件不变的条件下,一种商品的价格上升会引起该商品的需求量减少,价格下降会引起该商品的需求量增多”;由此我们引出需求的价格弹性的概念,它是指需求量对价格变动的反应程度,是需求量变化的百分比除以价格变化 的百分比,即公式:价格变动率需求量变得率需求的价格弹性系数=3.同理,需求与收入的关系可以用需求的收入弹性分析,它表示某一商品的需求量对收入变化的反应程度,即公式: 收入变动率需求量变得率需求的收入弹性系数=(2)变量的设定:在经济生活中,我们不难发现价格和收入水平的高低对商品需求量有着直接且密切的影响,故所建立的模型是一个回归模型!其中“商品价格”与“消费者平均收入”分别是自变量x1、x2,“商品需求量”是因变量y 。
用SPSS做logistic回归分析解读

如何用SPSS做logistic回归分析解读————————————————————————————————作者:————————————————————————————————日期:如何用进行二元和多元logistic回归分析一、二元logistic回归分析二元logistic回归分析的前提为因变量是可以转化为0、1的二分变量,如:死亡或者生存,男性或者女性,有或无,Yes或No,是或否的情况。
下面以医学中不同类型脑梗塞与年龄和性别之间的相互关系来进行二元logistic回归分析。
(一)数据准备和SPSS选项设置第一步,原始数据的转化:如图1-1所示,其中脑梗塞可以分为ICAS、ECAS和NCAS三种,但现在我们仅考虑性别和年龄与ICAS的关系,因此将分组数据ICAS、ECAS和NCAS转化为1、0分类,是ICAS赋值为1,否赋值为0。
年龄为数值变量,可直接输入到spss中,而性别需要转化为(1、0)分类变量输入到spss当中,假设男性为1,女性为0,但在后续分析中系统会将1,0置换(下面还会介绍),因此为方便期间我们这里先将男女赋值置换,即男性为“0”,女性为“1”。
图 1-1第二步:打开“二值Logistic 回归分析”对话框:沿着主菜单的“分析(Analyze)→回归(Regression)→二元logistic(Binary Logistic)”的路径(图1-2)打开二值Logistic 回归分析选项框(图1-3)。
如图1-3左侧对话框中有许多变量,但在单因素方差分析中与ICAS 显著相关的为性别、年龄、有无高血压,有无糖尿病等(P<),因此我们这里选择以性别和年龄为例进行分析。
在图1-3中,因为我们要分析性别和年龄与ICAS的相关程度,因此将ICAS选入因变量(Dependent)中,而将性别和年龄选入协变量(Covariates)框中,在协变量下方的“方法(Method)”一栏中,共有七个选项。
SPSS Logistic回归分析及其应用 图文

gi
ln(
p(y i) ) p(y J)
bi0
bi1x1
bi2 x2
bip xp
•而对于参考类别, 其模型中的所有系数均为0。
•最后,求得第i类的概率值:
p( yi )
exp( gi )
J
exp( gk )
k 1
•另:参数估计表(Parameter Estimates) 中的Exp(B) 表示某 因素(自变量) 内该类别是其相应参考类别具有某种倾向性的 倍数。
分析的一般步骤
• 变量的编码 • 哑变量的设置和引入(设置参照类) • 各个自变量的单因素分析 • 变量的筛选 • 交互作用的引入 • 建立多个模型 • 选择较优的模型 • 模型应用条件的评价 • 输出结果的解释
Logistic回归的分类
• 二项Logistic回归 (Binary Regression)
•
log it( p)
ln( p ) 1 p
b0
b1x1
bpxp
ez
eb0 b1x1 bp x p
p 1 e z 1 eb0 b1x1 bp x p
建立回归模型:
ln( p 1
p
)
b0
b1x
其中,p=p(y=1)
1 拥有住房 y=
0 其它情况
5
4.909
4
5.548
5
4.281
6
4.406
2
1.816
0
1.313
1
1.011
1
.537
0
.179
住房Y = 1
spss 回归标准化残差

spss 回归标准化残差SPSS回归标准化残差。
在SPSS中,回归分析是一种常用的统计方法,用于研究自变量和因变量之间的关系。
在进行回归分析时,我们经常会关注残差,因为残差可以帮助我们评估模型的拟合程度和预测能力。
本文将介绍如何在SPSS中进行回归分析,并重点讨论回归标准化残差的计算和解释。
首先,让我们回顾一下回归分析的基本概念。
回归分析用于研究因变量(也称为预测变量)和一个或多个自变量之间的关系。
在SPSS中,我们可以通过“回归”菜单来进行回归分析。
在建立回归模型后,我们可以查看残差的统计信息,包括标准化残差。
回归标准化残差是指残差除以其标准差后得到的值。
标准化残差可以帮助我们评估每个观测值在模型中的相对位置,从而识别异常值和影响值。
在SPSS中,我们可以通过在回归分析结果中选择“保存标准化残差”来计算和保存标准化残差。
接下来,让我们看看如何解释回归标准化残差。
标准化残差的绝对值大于2.0通常被认为是异常值或离群点。
这意味着该观测值在模型中的表现与其他观测值有明显差异,可能对模型的拟合和预测产生影响。
因此,我们需要对这些观测值进行进一步的分析,了解其产生的原因,并考虑是否需要将其排除在模型之外。
此外,标准化残差还可以用来检测异方差性。
如果残差的方差随着自变量或因变量的水平而发生变化,就会出现异方差性。
在回归分析中,异方差性会影响参数估计的准确性和假设检验的结果。
通过检查标准化残差的图形模式和方差的变化趋势,我们可以初步判断是否存在异方差性,并在需要时对模型进行修正。
除了用于识别异常值和检测异方差性外,标准化残差还可以用来评估模型的预测能力。
我们可以通过比较实际观测值和预测值之间的差异来评估模型的拟合程度。
如果标准化残差的绝对值较大,说明模型对该观测值的预测存在较大偏差,需要对模型进行修正或改进。
总之,回归标准化残差在回归分析中起着重要的作用。
通过计算和解释标准化残差,我们可以评估模型的拟合程度、识别异常值和离群点,检测异方差性,并评估模型的预测能力。
3.多个多变量(指标)平均数的检验,SPSS应用:逐步回归、线性回归、聚类分析、因素分析综述

• DV’s are English and Math.
• Each school has a sample size of twenty students each.
Applying in SPSS
• First open SPSS software, using the analyze tab you will find the multivariate section. Multivariate tab will open listing School as the IV and drag it over to the “Fixed” side. As for Math and English you will need to drag them to the DV’s category. Next open the “Plots” tab and move the IV over to the “Horizontal Axis”
Results!
In the test between subjects we can see the difference between the English and Math scores.
In the next table compares the three schools. The table shows a difference between School A and School B, and School A and School C but not a significant difference between School B and School C.
多个多变量(指标)平均数的 检验、
基于SPSS的多元回归分析模型选取的应用毕业论文

毕业论文题目基于SPSS的多元回归分析模型选取的应用基于SPSS的多元回归分析模型选取的应用摘要本文不仅对于复杂的统计计算通过常用的计算机应用软件SPSS来实现,同时通过对两组数据的实证分析,来研究统计学中多元回归分析中的变量选取,让大家对统计学中的多元回归分析中模型的选取以及变量的选取和操作方法有更深层次的了解. 一组数据是对于淘宝交易额的未来发展趋势的研究,一组数据时对于我国财政收入的研究. 本文通过两个实证即淘宝交易额研究和财政收入研究从不同程度上对非线性回归模型和变量选取的研究运用通俗的语言和浅显的描述将SPSS在多元回归分析中的统计分析方法呈现在大家面前,让大家对多元回归分析以及SPSS软件都可以有更深一步的了解. 通过SPSS软件对数据进行分析,对数据进行处理的方法进行总结,找出SPSS对于数据处理和分析的优缺点,最后得在对变量的选取和软件的操作提出建议.关键词:统计学,SPSS,变量选取,多元回归分析AbstractThis article not only for complex statistical calculations done by the commonly used computer application software of SPSS, through the empirical analysis of the two groups of data at the same time, to study the statistics of the variables in the multivariate regression analysis, let everybody in the multiple regression analysis of statistical model selection as well as the selection of variables and operation methods have a deeper understanding. Is a set of data for the future development trend of research taobao transactions, a set of data for the research of our country's fiscal revenue. In this paper, through two empirical taobao transactions and fiscal revenue research from different degree of the study of nonlinear regression model and variable selection using a common language and plain the SPSS statistical analysis method in multiple regression analysis of present in front of everyone, let everyone to multiple regression analysis and SPSS software can have a deeper understanding. Through SPSS software to analyze data, and summarizes method of data processing, find out the advantages and disadvantages of SPSS for data processing and analysis, finally had to put forward the proposal to the operation of the selection of variables and software.Keywords: Statistical, SPSS, The selection of variables, multiple regressionanalysis目录第一章引言 (3)第二章多元回归模型的选取 (4)2.1 多元回归分析概述 (4)2.2 相关系数概述 (5)2.3 非线性回归模型概述 (5)2.4 多元线性回归模型自变量的选取 (6)第三章非线性回归模型案例:淘宝交易额模型的研究 (7)3.1 回归模型变量的确定 (7)3.1.1 数据来源 (7)3.1.2 复相关系数 (8)3.1.3 散点图看线性关系 (9)3.1.4 回归分析看拟合度 (11)3.1.5 确定回归模型变量 (11)3.2 调整后的变量的相关分析 (12)3.2.1 散点图 (12)3.2.2 计算相关系数 (14)3.3 多元线性回归分析 (16)3.4 小结 (18)第四章线性回归分析变量选取案例:财政收入模型的研究 (18)4.1 数据来源及变量选取 (18)4.2 相关分析 (20)4.2.1 散点图 (20)4.2.2 计算相关系数 (21)4.3 线性回归分析 (24)4.4 逐步回归 (26)4.5 小结 (27)第五章总结 (28)参考文献 (30)第一章引言随着社会的发展,统计的运用围越来越广泛,统计学作为高等院校经济类专业和工商管理类专业的核心课程,不管是在经济管理领域,或是在军事、医学等领域的研究中对于数量分析与统计分析都需要更高的要求,需要用到的数学知识较多,应用方面的灵活性也较强,计算量大且复杂.然而科学研究的深入,研究的对象也日益变得复杂,复杂系统的研究问题更是成为当今研究的热点. 为了更好的描述一个复杂的现象,就需要大量的数据和信息,如何高效、准确地利用已知的信息便成为当今社会研究的一项重要课题.在科学技术飞速发展的今天,统计学通过不断吸收和融合相关学科的新理论,开发应用新技术和新方法,拓展新的领域的同时不断深化和丰富了统计学传统领域的理论与方法. 在我国,社会主义市场经济体制的逐步建立,实践发展的需要对统计学提出了新的更多、更高的要求. 随着我国社会主义市场经济的成长和不断完善,统计学的潜在功能将得到更充分更完满的开掘. 从20世纪60年代开始,关于回归自变量的选择成为统计学中研究的热点问题,统计学家提出了许多回归选元的准则,并提出了许多行之有效的选元方法. 在应用回归分析去处理实际问题时,回归自变量选择是首先要解决的重要问题. 通常在做回归分析时,人们根据所研究问题的目的,结合经济理论罗列出对因变量可能有影响的的一些因素作为自变量引进回归模型,把一些对因变量影响很小的,有些甚至是没有影响的自变量,不但使得计算量变大,估计和预测的精度也下降了. 此外,如果遗漏了某些重要变量,回归方程的效果肯定不好. SPSS软件作为当今国际上运用广泛的统计分析软件,其功能齐全带有各种特点,在各个领域都得到了迅速普及,并成为各个行业提高管理水平、形成科学决策的重要手段. 然而,我国对于该软件的运用和理解始终处于早期应用阶段,无论是在功能的研究开发还是实际生活当中的运用都与西方发达国家相差甚远. 尤其是在管理决策方面,都因为没有进行深度分析而造成了浪费,要么就是利用SPSS软件进行简单分析而未进行深度开发,导致所得的信息有限、各信息间的关系不明确,最终导致管理者的判断出现偏差.基于以上背景,本文通过总结和吸取其他国外学者对统计学研究的,并结合我国的实际情况,本文采用了案例一对于网络购物这块的的研究,通过对2005年到2012年的居民消费水平,以及我国网络普及度,我国人人均纯收入以及我国的居民消费水平对淘宝网的未来发展趋势进行非线性回归模型的研究以及案例二对于我国财政收入的进行变量选取研究,通过对1992年到2012年的人均国生产总值,城镇居民家庭人均可支配收入,全社会固定投资,进出口总额,居民消费价格水平对我国财政收入的影响进行定量数据的研究. 通过对数据的选取,回归模型的确定以及软件的操作方法来告知读者如何在SPSS的操作中变量选取的原则、要求和方法.第二章多元回归模型的选取2.1 多元回归分析概述回归分析是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法(即寻找具有相关关系的变量减的数学表达式并进行统计推断的一种统计方法). 按照其所涉及的自变量,可分为一元回归分析和多元回归分析;线性回归分析和非线性回归分析是按照自变量和因变量之间的关系划分的.而本文运用了多元线性回归分析中的方法,多元线性回归分析就是指回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系. 多元回归分析的主要容有以下几点:(1)从一组数据出发,确定某些变量之间的定量关系式,即建立数学模型并估计其中的未知参数. 估计参数的常用方法是最小二乘法;(2)对这些关系式的可信程度进行检验;(3)在许多自变量共同影响着一个因变量的关系中,判断哪些自变量的影响是显著的,哪些自变量的影响是不显著的,将影响显著的自变量选入模型中,而剔除影响不显著的变量,通常用逐步回归等方法;(4)利用所求的关系式对某一生产过程进行预测或控制.回归分析研究的主要问题是确定Y与X间的定量关系表达式,这种表达式称为回归方程;对求得的回归方程的可信度进行检验;判断自变量X对因变量Y有无影响;利用所求得的回归方程进行预测和控制. 回归分析主要应用于研究两个变量之间到底是哪个变量受哪个变量的影响,影响程度如何,通过分析现象之间相关的具体形式,确定其因果关系,并用数学模型来表现其具体关系,并根据实测数据来求解模型的各个参数,然后评价回归模型是否能够很好的拟合实测数据;如果能够很好的拟合,则可以根据自变量作进一步预测.2.2 相关系数概述相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量. 相关关系是现象间客观存在的,但数值又是不严格及不完全确定的相互依存关系.1)复相关系数在一元回归分析中我们用相关系数r 来说明两变量之间线性相关的程度,在多元回归分析中,仍用它来表示y 与其他自变量之间的线性密切程度,此为复相关系数. 复相关是指因变量与多个自变量之间的相关关系. 复相关系数只是反映变量间表面的非本质的联系,因为变量很有可能受到其他变量的影响.2)偏相关系数在多变量的情况下,变量之间的相关系数是相当复杂的. 任意两个变量之间都有可能存在着相关关系,因此,只知道被解释变量与解释变量的总的相关程度是不够的. 如果需要了解某两个变量间的相关程度,就应在消除其他变量影响的情况下来计算他们的相关系数,这就是偏相关系数. 偏相关系数与复相关系数不同,复相关系数的取值在0-1之间,而偏相关系数则是有正有负,所以复相关系数与偏相关系数之间也有可能相差很大. 变量之间本存在错综复杂的关系,甚至可能使得符号也相反,但是偏相关系数才是变现变量之间的本质联系的.偏相关的主要用途:偏相关主要是用来研究自变量与因变量之间的关系的,其通过得到的自变量与因变量数据来进行计算,通过偏相关系数可以看出哪些自变量对因变量的影响更大一些,同时对于偏相关系数较小的变量,可以剔除.2.3 非线性回归模型概述非线性回归模型是指在众多的现象中,分析变量之间的关系时不符合解释变量线性和参数线性的一种模型. 在实际的经济活动中,经济变量的关系是相当复杂的,直接表示为线性关系的情况也并不多见. 但大多数的非线性关系是可以通过一些简单的数学处理,使之转化为线性关系,从而通过线性回归来进行计算. 而非线性回归模型又分为可化为线性模型的非线性回归模型和不可化为线性模型的非线性回归模型.本文研究的是可转化为线性模型的非线性回归模型,而可转化为线性模型的非线性回归模型又有好几种方法可以对变量进行转换.其有以下几种模型:1)多项式函数模型对于形如:k k x x x y ββββ+⋅⋅⋅+++=22110 ,的模型为多项式模型.令21122,,,k k k z x z x z x === ,原模型可化为线性形式k k z z z y ββββ+⋅⋅⋅+++=22110 ,那么就可以用多元线性回归分析的方法进行处理了.2)指数函数模型对于形如:k x k x x e e e y ββββ+⋅⋅⋅+++=21210 ,的模型为指数函数模型. 令k x k x x e z e z e z =⋅⋅⋅==,,,2121 ,原模型可化为线性形式k k z z z y ββββ+⋅⋅⋅+++=22110 ,那么就可以用多元线性回归分析的方法进行处理了.3)双曲线模型;4)半对数模型和双对数模型等.本文将对指数函数型非线性模型进行案例说明,所以对于其他类型的非线性回归模型的道理是一致的,在这里就不进行一一解释.2.4 多元线性回归模型自变量的选择在多元线性回归模型中自变量的选择实质上就是模型的选择. 现设一切可供选择的变量是t 个 ,它们组成的回归模型称为全模型(记:1+=t m ),在获得n 组观测数据后,我们有模型:⎩⎨⎧+=),0(~2n n I N X Y σεεβ , 其中:Y 是1⨯n 的观测值,β是1⨯m 未知参数向量,X 是m n ⨯结构矩阵,并假定X 的秩为m .现从t x x x ,,,21 这t 个变量中选t '变量,不妨设t x x x ',,,21 ,那么对全模型中的参数β和结构矩阵X 可作如下的分块(记:1+'=t p ):()'=q p βββ, , ()q p X X X = .我们称下面的回归模型为选模型:⎩⎨⎧+=),0(~2n p p I N X Y σεεβ ,其中:Y 是1⨯n 的观测值,p β是1⨯p 未知参数向量, p X 是p n ⨯结构矩阵,并假定p X 的秩为p .自变量的选择可以看成是这样的两个问题,一是究竟是用全模型还是用选模型,二是若用选模型,则究竟应包含多少变量最适合. 然而自变量的选择与相关系数,回归分析都有密切的关系,自变量的选择需要通过一系列的验证,剔除之后才能得到最好的变量从而得到最好的回归模型. 下面我们用两个案例来对多元回归模型的选取来进行解释和探讨.第三章 非线性回归模型案例:淘宝交易额研究3.1 回归模型变量的确定3.1.1数据来源为研究淘宝网未来发展趋势,从新浪官方微博淘宝数据魔方中获得淘宝2009年聚划算中购物群众的年龄比例作为定性数据,进行研究年龄对淘宝购物的影响. 并在新浪财经网上获得淘宝网自2003年到2012年的淘宝交易额以及淘宝注册人数的数据. 在中商情报局里获得我国近网络普及度等数据并从国家统计年鉴中选取统计指标居民消费水平.淘宝注册人数(1x )在一定程度上反应了网络购物的群众的人数,反应了当今社会网络购物的普遍性. 同时淘宝的注册人数也展现了人们对网络购物的认可度,换言之也就是说接受了网络购物并会在网上进行消费,是对网络购物很大程度上的支持. 我国网络普及度(2x )是指我国近几年网络在我国普及的围,这一块更好的反映了网络对居民网络消费的影响,因为网络是网络消费的必要条件. 我国网络普及度反映的是在我国日趋发展的经济下,人们对网络的接受程以及信任程度也是直接影响到淘宝的网络购物.居民消费水平(3x )主要通过消费的物质产品和劳务的数量和质量来反映. 居民消费水平的提高也能很好的展现在网络消费上作出的贡献.第二产业增加值(4x )是指采矿业,制造业,电力、煤气及水的生产和供应业,建筑业. 而制造业的发展也相继影响着产品的销售,所以在这里采用第二产业对淘宝交易额的影响. 通过对以上这三个定量数据的研究来其与淘宝交易额的关系,从而研究淘宝未来的发展趋势以及优劣态. 原始数据如下:表3.1为消除数据之间因单位不同产生的量纲的影响,对数据进行标准化得如下数据得到表3.23.1.2 复相关系数对表3.2 的数据进行复相关系数的研究,看变量之间的复相关关系,得到如下表3.3的复相关系数表:表3.3表3.3中有带“**”号的结果表明有关的两变量在0.01的显著性水平下显著相关,由上图可知,y 与1x 的相关系数为0.987>0,表示变量之间存在线性关系,其相关系数检验对应的概率P 值为0.000,低于显著性水平0.05,说明淘宝交易额与淘宝注册人数之间相关性显著. y 与2x e 的相关系数为0.923>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与我国网络普及度之间相关性显著.y 与3x 的相关系数为0.963>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与居民消费水平之间相关性显著. y 与4x e 的相关系数为0.919>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明我国第二产业增加值与居民消费水平之间相关性显著.综上所述通过SPSS 得出的相关系数的矩阵得到为:=1yx r 0.987 ,=2yx r 0.923 ,=3yx r 0.963 ,=4yx r 0.919 .虽然变量都通过了检验,但是可以看到2yx r 和4yx r 较另外两个复相关系数较低,因此对变量进行散点图的分析来了解自变量与因变量的相关关系.3.1.3 散点图看线性关系对y 与各个变量作出散点图(1)淘宝注册人数1x 与淘宝网交易总额y 的相关性散点图:图3.1(2)网络普及度2x 与淘宝网交易总额y 的散点图:图3.2(3)我国居民消费水平3x 与淘宝交易额y 的散点图:图3.3(4)第二产业增加值4x 对淘宝交易额y 的散点图:图3.4图3.2和3.4分别是自变量2x 和4x 与因变量的相关系数图,可以看出自变量2x 和因变量y 之间呈明显的指数线性关系,而变量4x 也是同样与因变量y 之间呈明显的指数线性关系.他们之间是非线性回归模型的关系. 所拟合的效果不理想所以我们还需要对数据进行进一步的处理和分析,得到确切的答案.3.1.4 回归分析看拟合度对数据进行回归分析:表3.4表3.4是自变量与因变量得到的回归分析,可知,因变量y 与常数项和自变量1x ,2x ,3x ,4x 的回归的标准化回归系数分别为0.01,0.660,-0.229,1.439,-0.899.而通过P 检验可以看到由上表 2.4可以看出常数项以及各自变量的P 值分别为:0.906,0.000,0.018,0.000及0.000. 可以看出原始变量所得到的P 值并没有全部通过检验. 说明常数项对因变量影响不显著. 对数据进行t 值检验,在给定的05.0=α,自由度9211=-=n 的临界值时,查表得=9025.0t 2.262,其常数项的t 值为0.123小于2.262,说明常数项不显著. 综上所述,可以初步得到一个模型为:4321899.0439.1229.0660.001.0x x x x y -+-+= .3.1.5确定回归模型变量综上通过散点图、复相关系数以及回归分析可以知道由于自变量2x 和4x 与因变量y 之间是非线性关系,是呈指数线性关系为研究之间线性关系,所以得到的模型的拟合程度并不是很理想.因此对自变量2x 和4x 进行取e 的对数即2x e 和4x e 来对变量进行研究看拟合效果得到下表.表3.5下面对表3.5进行变量分析与研究,通过对非线性模型中的变量的研究来了解多元回归分析中变量的选取与使用,同时对自变量进一步进行分析.3.2 调整后变量的相关分析3.2.1 散点图对y与各个变量作出散点图x与淘宝网交易总额y的相关性散点图:(1)淘宝注册人数1图3.5(2)e的网络普及度次方2x e与淘宝网交易总额y的相关性检验:图3.6x与淘宝交易额y的相关性检验:(3)我国居民消费水平3图3.7(4)e的第二产业增加值的次方4x e对淘宝交易额y的影响:图3.8由以上四个散点图可知,其所有的点均落在了左上至右下的一条直线上,表明了数据之间存在显著相关关系. 所以我们还需要对数据进行进一步的分析,得到确切的答案.3.2.2 计算相关系数(1)复相关系数r 是用来衡量回归直线对于观察值配合的密切程度,即用来衡量因变量y 与自变量1x ,2x e ,3x ,4x e 之间相关的密切程度. 以下是用SPSS 对数据进行相关性分析,得到如下的相关系数图表3.6图中有带“**”号的结果表明有关的两变量在0.01的显著性水平下显著相关,由上图可知,y 与1x 的相关系数为0.987>0,表示变量之间存在线性关系,其相关系数检验对应的概率P 值为0.000,低于显著性水平0.05,说明淘宝交易额与淘宝注册人数之间相关性显著. y 与2x e 的相关系数为0.979>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与我国网络普及度之间相关性显著.y 与3x 的相关系数为0.963>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与居民消费水平之间相关性显著. y 与4x e 的相关系数为0.997>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明我国第二产业增加值与居民消费水平之间相关性显著.综上所述通过SPSS 得出的相关系数的矩阵得到为:=1yx r 0.987 ,=2yx r 0.979 ,=3yx r 0.963 ,=4yx r 0.997 .由以上数据可以看出,各列之间存在正相关关系. 即淘宝网注册人数1x 、e 的我国网络普及度2x e 、我国居民消费水平3x 、e 的我国第二产业增加值次方4x e 与淘宝交易总额y 存在显著的相关关系.(2)计算偏相关系数:下面是用SPSS 作出的偏相关系数:① 消除我国网络普及度、第二产业增加值和居民消费水平的影响后,计算淘宝注册人数与淘宝交易额的偏相关系数为:表3.7由上可知,淘宝注册人数与淘宝交易额的偏相关系数为0.795.②消除淘宝交易额、第二产业增加值和居民消费水平的影响后,我国网络普及度和淘宝交易额的偏相关系数为:表3.8由上可知我国网络普及度与淘宝交易额的偏相关系数为0.733.③消除淘宝注册人数、第二产业增加值和我国网络普及度的影响后,我国居民消费水平和淘宝交易额的偏相关系数:表3.9由上可知,我国居民消费水平和淘宝交易额的偏相关系数为-0.932.④消除淘宝注册人数、我国网络普及度和居民消费水平的影响后,计算第二产业增加值与淘宝交易额的偏相关系数:表3.10由上可知,e的第二产业增加值次方与淘宝交易额的偏相关系数为0.946.⑤下表为各个变量之间的偏相关系数表,为方便,这里直接变各变量之间的偏相关系数:r y 1x 2x e3x 4x e y 0.795 0.773 -0.9320.946 1x 0.795 -0.611 0.758 -0.592x e0.773 -0.611 0.702 -0.521 3x-0.932 0.758 0.702 0.818 4x e 0.946 -0.59 -0.521 0.818表3.11这里我们对变量2x 和4x 采用的是其指数幂,是因为在对变量的相关性进行检验时,通过散点图可以看出2x 和4x 与因变量之间呈的是指数线性关系,是非线性关系所以对数据进行了处理,因为原始变量之间存在的非线性关系得出的结果不具有代表性. 可以通过散点图看到从以上的偏相关系数来看,如果2x e ,3x 和4x e 保持不变,y 与1x 之间存在相关关系,当1x ,3x 和4x e 的保持不变时,2x e 和y 之间存在相关关系,其他关系同上,在这里就不进行一一解释.我们也可以通过以上的偏相关系数表可以看出各个自变量之间也存在一定的偏相关关系,但是相对于自变量与因变量之间的偏相关关系较小,说明这些变量之间的选择比较显著.但是其关系强度较前者略低,所以经过以上系数得到的偏相关系数可以看出,其相关程度较原关系的强度低,应采用原数据的自变量和因变量. 即所采用的自变量和因变量保持不变.通过复相关系数的计算和偏相关系数的计算结果可以看出,复相关系数的取值在0-1之间,偏相关系数的取值在-1到1之间,由上数据便可看出偏相关系数与复相关系数之间的差距相差甚大,有的甚至改变了符号. 从上可以看出通过复相关系数不能很好的确定变量之间的相关关系,不能明确的解释变量,而偏回归系数可以看出变量是否符合要求. 从下面的回归分析中继续对变量进行研究.3.3 多元线性回归分析对数据进行回归分析,得到如下结果:表3.12复相关系数为1,判定系数为0.999,调整系数为0.999,估计值的标准误差为0.03296.表3.13由上面结果的看其显著性检验结果为,回归平方和为9.993,残差平方和0.007,总平方和10.000, F 统计量的值为2.299E3,对应的概率P 值为0.000,小于显著性水平0.05,即:淘宝交易总额y 与淘宝网注册人数1x 、e 的我国网络普及度次方2x e 、我国居民消费水平3x 和e 的我国第二产业增加值次方4x e 之间存在线性关系,所以可认为所建立的回归方程有效.表3.14由上表可知,因变量y 与常数项和自变量1x ,2x e ,3x ,4x e 的回归的标准化回归系数分别为-1.119,0.244,0.107,-0.321,0.615. 3个回归系数B 的显著性水平均小于0.05,这里可以认为自变量1x ,2x e ,3x ,4x e 对因变量y 有显著性影响. 于是得到回归方程为:42615.0321.0107.0244.0119.131x x e x e x y +-++-= , 由上图可知对数据进行t 值检验,在给定的05.0=α,自由度9211=-=n 的临界值时,查表得=9025.0t 2.262,因为1x ,2x e ,3x ,4x e 的参数对应的t 统计量的绝对值均大于2.262,这说明%5的显著性水平下,斜率系数均显著不为0,表明淘宝网注册人数1x ,e 的我国网络普及度次方2x e ,我国居民消费水平3x ,e 的我国第二产业增加值次方4x e 等变量联合起来对该商品的消费支出有显著的影响.P 检验:由上表可以看出各自变量以及常数项的P 值分别为:0.00,0.018,0.039,0.001及0.000,可以看出其P 值均小于0.05,均通过检验综上所述,四个自变量对因变量都有显著性影响,并都通过了检验可以得到最优方程式为:。
spss多重线性回归逐步回归法操作和结果解释方法

spss多重线性回归逐步回归法操作和结果解释方法∙∙|∙浏览:16524∙|∙更新:2012-11-24 22:30∙1∙2∙3∙4∙5∙6∙7分步阅读一键约师傅百度师傅最快的到家服务,最优质的电脑清灰!spss经常用到的一个回归方法是stepwise,也就是逐步回归,它指的是每次只纳入或者移除一个变量进入模型,这个方法虽然好用,但是最后可能出现几个模型都比较合适,你就要比较这几个模型的优劣,这是个麻烦事,这里就给大家简单的分析分析。
方法/步骤1.打开spss以后,打开数据,这些都准备好了以后,我们开始拟合方程,在菜单栏上执行:analyze---regression---linear,打开回归拟合对话框2.在这里,我们将因变量放大dependent栏,将自变量都放到independent栏3.将method设置为stepwise,这就是逐步回归法4.点击ok按钮,开始输出拟合结果5.我们看到的第一个表格是变量进入和移除的情况,因为这个模型拟合的比较好,所以我们看变量只有进入没有移除,但大部分的时候变量是有进有出的,在移除的变量这一栏也应该有变量的6.第二个表格是模型的概况,我们看到下图中标出来的四个参数,分别是负相关系数、决定系数、校正决定系数、随机误差的估计值,这些值(除了随机误差的估计值)都是越大表明模型的效果越好,根据比较,第四个模型应该是最好的7.方差分析表,四个模型都给出了方差分析的结果,这个表格可以检验是否所有偏回归系数全为0,sig值小于0.05可以证明模型的偏回归系数至少有一个不为零8.参数的检验,这个表格给出了对偏回归系数和标准偏回归系数的检验,偏回归系数用于不同模型的比较,标准偏回归系数用于同一个模型的不同系数的检验,其值越大表明对因变量的影响越大。
END经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。
作者声明:本篇经验系本人依照真实经历原创,未经许可,谢绝转载。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS中逐步回归分析的应用SPSS(Statistical Package for the Social Science)社会科学应用软件包是世界上著名的统
计分析软件之一。
它和SAS(Statistical Analysis System,统计分析系统)、BMDP(Biomedical Programs,生物医学程序)并称为国际上最有影响的三大统计软件。
SPSS名为社会学统计软件包,这是为了强调其社会科学应用的一面(因为社会科学研究中的许多现象都是随机的,要使用统计学和概率论的定理来进行研究),而实际上它在社会科学、自然科学的各个领域都能发挥巨大作用,并已经应用于经济学、生物学、教育学、心理学、医学以及体育、工业、农业、林业、商业和金融等各个领域。
回归分析是目前气象统计分析中最为常用的一种方法之一。
例如目前台站常用的MOS(模式输出统计量)方法中,回归分析是最基本的方法之一。
逐步回归能够帮我们建立最优的回归模型,但过程较复杂。
Spss软件功能强大,且操作简单。
我们用该软件对气象资料作逐步回归分析,对于Spss软件用于气象统计的便利亦可见一斑。
下面以安庆市1951-1971年6~8月降水及相关资料(表一)为例。
1 数据格式
表中1971年因子值留作预报时使用,不参加到样本中进行统计,表中符号意义如下:y:安庆市整个地区6~8月降水量(mm)。
X1:1月500hPa高度距平和(50°~20°W,60°N;45°~25°W,55°N)。
X2:2~3月500hPa高度距平和(70°~100°E,30°N)。
X3:4月500hPa高度距平和(25°N,105°~115°E;20°N,100°~120°E;15°N,105°~115°E)。
X4:12月下旬一次年1月下旬安庆市地面WSW-WNW风速合计(m/s)。
2 统计步骤
2.1 做数据散点图,观察因变量和自变量关系是否具有线性关系。
2.1.1 GraPhs→Scatter→SiPle 顺序展开如图a所示的对话框:
2.1.2 将变量y(6-8月降水量)、x1(1月份500hPa高度距平和)依次选入Y Axis和X Axis,单击ok按钮。
生成的图形如图(b)所示,根据同样的操作可以作出以y(6-8月降水量)为Y Axis,分别以其他几个自变量为X Axis的散点图。
从散点图可以看出6-8月降水量和这几个自变量存在明显的线性关系,由此可以判定建立线性回归方程是非常适合的。
2.2 回归模型的建立
2.2.1 按Analyze→Regression→Linear顺序展开如图c所示的对话框:
2.2.2 左侧的源变量框中选择y(6-8月降水量)作为因变量进入DePendent框中。
选择x1、x2、x3、x4变量作为自变量进入IndePendent(s)框中。
2.2.3 在Method选择框中选择StePwise(逐步回归)作为分析方式。
2.2.4 单击Statics按钮,并打开如图d的对话框。
在Resideuals栏中选择Casewise diagnostics项要求进行奇异值判别。
并在Outliers outside standard deviation 的参数键入3,设置观测值的标准差大于3为奇异值。
选中Collinearity diagnostics复选框,要求进行共线性诊断。
单击Continue按钮返回。
2.2.5 为了从图形上检测模型的直线性和方差的齐性做散点图。
单击Plot按钮,打开Plots 对话框,将变量ZPRED与ZRESID分别选如X、Y框中。
单击Continue
按钮回到主对话框。
2.2.6 提交系统执行结果。
2.3 结果输出见表
表2-1:被引入或被从剔除回归方程中剔除的各变量
表2-2:拟合过程小结
表2-3:方差分析
表2-4:回归系数分析
表2-5:共线性诊断
3 小结
通过对上述个例的分析可以看到:运用Spss软件作逐步回归分析具有如下优点:
3.1 通过作散点图,可以直观的看出变量间是否具有线性关系。
从而大致判断可能进入回归方程的变量。
3.2 通过对变量及参数的控制作逐步回归。
Spss软件能自动剔除与预报量关系较弱的变量,为我们建立一个最优的回归模型。
3.3 通过方差分析,可以判断模型的效果。
另外,我们还可以通过对一些参数的选择,在结果中得到对方程的显著性检验分析,以判断回归模型是否达到了我们的要求。
可见,Spss软件用于气象资料的统计分析,是极为方便且有效的。
参考文献
1 黄嘉佑.《气象统计分析与预报方法》,2000,86-91.。