【优选推荐】统计学第9章分类数据分析
贾俊平《统计学》(第7版)考研真题与典型题详解 第9章~第10章【圣才出品】

这个表格是( )。 A.4×3 列联表 B.3×2 列联表 C.2×3 列联表 D.3×4 列联表 【答案】B 【解析】表中的行是态度变量,这里划分为三类,即赞成、中立和反对;表中的列是单 位变量,这里划分为两类,即男同学和女同学,因此这个表格是 3×2 列联表。
2 / 60
圣才电子书
十万种考研考证电子书、题库视频学习平台
第 9 章 分类数据分析
一、单项选择题 1.列联分析是利用列联表来研究( )。 A.两个数值型变量的关系 B.两个分类变量的关系 C.两个数值型变量的分布 D.一个分类变量和一个数值型变量的关系 【答案】B 【解析】列联表是由两个或以上的变量进行交叉分类的频数分布表,列联分析是利用列 联表来研究两个分类变量之间的关系。
10.某大学为了解男女毕业生对开设《职业规划》这门课程的看法,分别抽取了 500 名男学生和 500 名女学生进行调查,得到的结果如表 9-7 所示。
表 9-7 关于开设《职业规划》课子书、题库视频学习平台
如果要检验男女毕业生对开设《职业规划》这门课程的看法是否相同,即检验假设 H0: π1=π2=850/1000=0.85,χ2 检验统计量的自由度是( )。
表 9-5
根据这个列联表计算的χ2 统计量的值为( )。 A.0.6176 B.1.2352 C.2.6176 D.3.2352 【答案】B 【解析】非参数检验中的χ2 拟合优度检验和可以应用于列联表的独立性检验来测定两 个分类变量之间的相关程度。用 fo 表示观察值频数,用 fe 表示期望值频数,则χ2 统计量为:
4 / 60
圣才电子书 十万种考研考证电子书、题库视频学习平台
【解析】赞成研究生奖学金制度改革的行百分比分别为:(90/174)×100%=51.7%; (84/174)×100%=48.3%。
贾俊平《统计学》配套题库 【课后习题】详解 第9章~第10章【圣才出品】
第9章分类数据分析一、思考题1.简述列联表的构造与列联表的分布。
答:列联表是由两个以上的变量进行交叉分类的频数分布表。
列联表的分布可以从两个方面看,一个是观察值的分布,又称为条件分布,每个具体的观察值就是条件频数;一个是期望值的分布。
2.用一张报纸、一份杂志或你周围的例子构造一个列联表,说明这个调查中两个分类变量的关系,并提出进行检验的问题。
答:对三个生产厂甲、乙、丙提供的学习机的A、B、C 三种性能进行质量检验,欲了解生产厂家同学习机性能的质量差异是否有关系。
抽查了450部学习机次品,整理成为如表9-2所示的3×3列联表。
表9-2A B C 总计甲乙丙204015459065357070100200150总计75200175450根据抽查检验的数据表明:次品类型与厂家(即哪一个厂)生产是无关的(即是相互独立的)。
建立假设:H 0:次品类型与厂家生产是独立的,H 1:次品类型与厂家生产不是独立的。
次品类型生产厂可以计算各组的期望值,如表9-3所示(表中括号内的数值为期望值)。
表9-3各组的期望值计算表A B C 总计甲乙丙20(17)40(33)15(25)45(44)90(89)65(67)35(39)70(78)70(58)100200150总计75200175450所以2222(2017)(4033)(7058)9.821173358χ---=+++=…。
而自由度等于(R -1)(C -1)=(3-1)×(3-1)=4,若以0.01的显著性水平进行检验,查χ2分布表得20.01(4)13.277χ=。
由于220.019.821(4)13.277χχ=<=,故接受原假设H 0,即次品类型与厂家生产是独立的。
3.说明计算2χ统计量的步骤。
答:计算2χ统计量的步骤:(1)用观察值o f 减去期望值e f ;(2)将(o f -e f )之差平方;(3)将平方结果2)(e o f f -除以e f ;(4)将步骤(3)的结果加总,即得:22()o e ef f f χ-=∑。
《分类数据分析》PPT课件 (2)

精选课件ppt
2
分类数据分析的应用范围
政治学领域:研究政治立场是否影响政治派别。 社会学和心理学领域:分析不同类别的人不同的心理
特征。 公共政策分析领域:研究不同政策在不同地区产生的
效果。 文化传播领域:研究人们对媒体的看法。 分类数据分析是社会科学中最重要的课题之一。一方
面因为它的用途广泛,另一方面因为它解决的是基本 问题
PRE是不对称的,即需要区分自变量和 因变量。
在样本高度不均匀时,会出现不独立但 是结果为0的情况。
精选课件ppt
31
Goodman and Kruskal’s Lambda
Lambda方法是PRE方法的一种,原理是分别计算在 两种情况下预测错误的比例,然后进行比较。
X
c
d
Totals
Y
a
0.3 0.1 0.4
民主党
X:党派 独立党
共和党
革命的
Y:
场 立
中立的
保守的
33% (193)
41% (241)
26% (153)
100% (587)
30% (161)
37% (199)
34% (182)
100% (542)
11% (46)
33% (134)
56% (229)
100% (409)
400 574 564 1538
y
j1
(1Pm)
j1 (1Pm)
J
J
(1Pm)(1 Pim ) 1 (1Pm)
J
( nmj ) nm
ˆy
j 1
(n nm )
精选课件ppt
33
Lambda的方差
J
统计学第9章 相关分析和回归分析

回归模型的类型
回归模型
一元回归
线性回归
10 - 28
多元回归
线性回归 非线性回归
非线性回归
统计学
STATISTICS (第二版)
一元线性回归模型
10 - 29
统计学
STATISTICS (第二版)
一元线性回归
1. 涉及一个自变量的回归 2. 因变量y与自变量x之间为线性关系
被预测或被解释的变量称为因变量 (dependent variable),用y表示 用来预测或用来解释因变量的一个或多个变 量称为自变量 (independent variable) ,用 x 表示
统计学
STATISTICS (第二版)
3.相关分析主要是描述两个变量之间线性关 系的密切程度;回归分析不仅可以揭示 变量 x 对变量 y 的影响大小,还可以由 回归方程进行预测和控制 4.回归系数与相关系数的符号是一样的,但 是回归系数是有单位的,相关系数是没 有单位的。
10 - 27
统计学
STATISTICS (第二版)
10 - 19
统计学
STATISTICS (第二版)
相关系数的经验解释
1. 2. 3. 4.
|r|0.8时,可视为两个变量之间高度相关 0.5|r|<0.8时,可视为中度相关 0.3|r|<0.5时,视为低度相关 |r|<0.3时,说明两个变量之间的相关程度 极弱,可视为不相关
10 - 20
10 - 6
统计学
STATISTICS (第二版)
函数关系
(几个例子)
某种商品的销售额 y 与销售量 x 之间的关系 可表示为 y = px (p 为单价)
贾俊平《统计学》(第5版)课后习题-第9章 分类数据分析【圣才出品】

第9章 分类数据分析一、思考题1.简述列联表的构造与列联表的分布。
答:列联表是由两个以上的变量进行交叉分类的频数分布表。
列联表的分布可以从两个方面看,一个是观察值的分布,又称为条件分布,每个具体的观察值就是条件频数;一个是期望值的分布。
2.用一张报纸、一份杂志或你周围的例子构造一个列联表,说明这个调查中两个分类变量的关系,并提出进行检验的问题。
答:对三个生产厂甲、乙、丙提供的学习机的A、B、C三种性能进行质量检验,欲了解生产厂家同学习机性能的质量差异是否有关系。
抽查了450部学习机次品,整理成为如表9-2所示的3×3列联表。
表9-2根据抽查检验的数据表明:次品类型与厂家(即哪一个厂)生产是无关的(即是相互独立的)。
建立假设:H0:次品类型与厂家生产是独立的,H1:次品类型与厂家生产不是独立的。
可以计算各组的期望值,如表9-3所示(表中括号内的数值为期望值)。
表9-3 各组的期望值计算表所以2222(2017)(4033)(7058)9.821173358χ---=+++=…。
而自由度等于(R -1)(C -1)=(3-1)×(3-1)=4,若以0.01的显著性水平进行检验,查χ2分布表得20.01(4)13.277χ=。
由于220.019.821(4)13.277χχ=<=,故接受原假设H 0,即次品类型与厂家生产是独立的。
3.说明计算2χ统计量的步骤。
答:计算2χ统计量的步骤:(1)用观察值o f 减去期望值e f ;(2)将(o f -e f )之差平方;(3)将平方结果2)(e o f f -除以e f ;(4)将步骤(3)的结果加总,即得:22()o e ef f f χ-=∑。
4.简述ϕ系数、c 系数、V 系数的各自特点。
答:(1)ϕ相关系数是描述2×2列联表数据相关程度最常用的一种相关系数。
它的计算公式为:ϕ,式中,∑-=ee of f f 22)(χ;n 为列联表中的总频数,也即样本量。
统计学(第六版)第九章分类数据分析(课后习题答案)
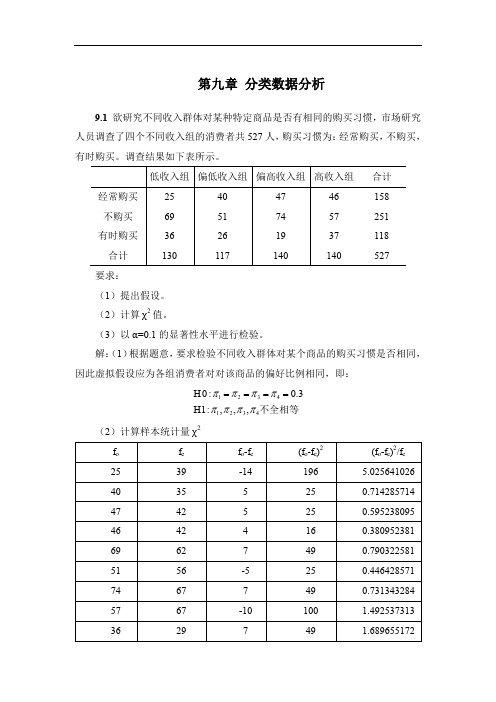
H 0 : 1 2 3 4 0.3 H1: 1 , 2 , 3 , 4不全相等
(2)计算样本统计量 χ2 fo 25 40 47 46 69 51 74 57 36 fe 39 35 42 42 62 56 67 67 29 fo-fe -14 5 5 4 7 -5 7 -10 7 (fo-fe)2 196 25 25 16 49 25 49 100 49 (fo-fe)2/fe 5.025641026 0.714285714 0.595238095 0.380952381 0.790322581 0.446428571 0.731343284 1.492537313 1.689655172
9.2 从总体中随机抽取了 n=200 的样本,调查后按不同属性归类,得到如下 结果: n1=28,n2=56,n3=48,n4=36,n5=32 依据经验数据,各类别在总体中的比例分别为: π1=0.1,π2=0.2,π3=0.3,π4=0.2,π5=0.2 以 α=0.1 的显著性水平进行检验, 说明现在的情况与经验数据相比是否发生 了变化(用 P 值) 解:虚拟假设 H0:样本数据的各类数据的比例与总体中各类数据的比例相同 H1:样本数据的各类数据的比例与总体中各类数据的比例不同 计算样本统计量 χ2 fo 28 56 48 36 32 fe 20 40 60 40 40 fo-fe 8 16 -12 -4 -8 (fo-fe)2 64 256 144 16 64 (fo-fe)2/fe 3.2 6.4 2.4 0.4 1.6 14 χ2 的自由度为(5-1)=4,P=0.007 远小于显著性水平 α=0.1,故拒绝 H0,现 在的情况与经验数据相比已经发生了变化(显著差异) 。
26 19 37
贾俊平《统计学》(第五版)考研真题(含复试)与典型习题详解 分类数据分析

合计
赞成
35
30
65
反对
15
20
35
合计
50
50
100
如果要检验男女教师对教师体制改革的看法是否相同,提出的原假设为( )。
A.H0:π1=π2=35 B.H0:π1=π2=50 C.H0:π1=π2=65
6 / 19
圣才电子书
D.H0:π1=π2=0.65
十万种考研考证电子书、题库视频学习平台
156 162
圣才电子书
A.0.6176
十万种考研考证电子书、题库视频学习平台
B.1.2352
C.2.6176
D.3.2352
【答案】B
【解析】 2 检验可以用于变量间拟合优度检验和独立性检验,可以用于测定两个分类 变量之间的相关程度。用 fo 表示观察值频数,用 fe 表示期望值频数,则 2 统计量为:
圣才电子书
十万种考研考证电子书、题库视频学习平台
第 9 章 分类数据分析
一、单项选择题
1.列联分析是利用列联表来研究( )。
A.两个数值型变量的关系
B.两个分类变量的关系
C.两个数值型变量的分布
D.一个分类变量和一个数值型变量的关系
【答案】B
【解析】列联表是由两个以上的变量进行交叉分类的频数分布表,列联分析是利用列联
【解析】表中的行是态度变量,这里划分为三类,即赞成,中立和反对;表中的列是单 位变量,这里划分为两类,即男同学和女同学,即 3×2 列联表。
5.一所大学为了解男女学生对后勤服务质量的评价,分别抽取了 300 名男学生和 240
名女学生进行调查,得到的结果如表 9-2 所示。
表 9-2 关于后勤服务质量评价的调查结果
分类数据分析

赞成 反对
合计
男学生 45 105 150
女学生 42 78 120
合计 87 183 270
9 - 18
c 统计量
统计学
STATISTICS (第四版)
概述
c2检验(Chi-square test)是现代统计 学的创始人之一,英国人K . Pearson( 1857-1936)于1900年提出的一种具有广 泛用途的统计方法,因此又称为Pearson c2检验。可用于两个或多个率或构成比间 的比较,定性资料的关联度分析,拟合 优度检验等等。
一分公司
二分公司 三分公司 四分公司
赞成该方 案
反对该方 案
实际频数 期望频数 实际频数 期望频数
68
75
57
79
100*66.4%=66
150*66.4%=80
90*66.4%=6 0
110*66.4%=73
32
75
33
31
100*33.6%=34
150*33.6%=40
90*33.6%=3 0
110*33.6%=37
n
9 -9
统计学
STATISTICS (第四版)
列联表的结构
(r c 列联表的一般表示)
列(cj)
列(cj)
行(ri)
j =1
j =2
…
i =1
f11
f12
…
i=2
f21
f22
…
:
:
:
:
合计
c1
c2
…
fij 表示第 i 行第 j 列的观察频数
合计
r1 r2
:
n
9 - 10
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 测度2?2列联表中数据相关程度
2. 对于2?2 列联表,? 系数的值在0~1之间 3. ? 相关系数计算公式为
? ? c2
n
式中:c 2 ?
r ?
c ?
(fij
?
eij)2
i?1j?1 e
ij
n为实际频数的总个数即,样本容量
9 - 21
作者:贾俊平,中国人民大学统计学院
9.1.1 分类数据 9.1.2 c 2统计量
9 -4
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
分类数据
9 -5
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
分类数据
1. 分类变量的结果表现为类别
? 例如:性别 (男, 女)
2. 各类别用符号或数字代码来测度
3. 使用分类或顺序尺度
? 你吸烟吗?
? 1.是;2.否
? 你赞成还是反对这一改革方案?
? 1.赞成;2.反对
4. 对分类数据的描述和分析通常使用列联表
5. 可使用?c?检验
9 -6
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
c ? 统计量
9 -7
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
9.2 拟合优度检验
9 - 10
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
拟合优度检验
(例题分析)
【例】 1912年4月15日,豪华巨轮泰坦尼
克号与冰山相撞沉没。当时船上共有共 2208人,其中男性 1738人,女性 470人。 海难发生后,幸存者为 718人,其中男性 374人,女性 344人,以的显著性水平检验 存活状况与性别是否有关。 (? ?0.05)
11
i=2
f
21
:
:
列(c ) j
j=2
f
12
f
22:合计cc1
2
f 表示第 i 行第 j 列的观察频数
ij
9 - 16
合计 …
…
r
1
…
r
2
:
:
…
n
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
独立性检验
(例题分析)
【例】一种原料来自三个不同的地区,原料质量被分成三个不 同等级。从这批原料中随机抽取500件进行检验,结果如表9-3 所示,要求检验各个地区和原料质量之间是否存在依赖关系? (? ?0.05)
9 - 11
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
拟合优度检验
(例题分析)
解:要回答观察频数与期望频数是否一致,检验 如下假设:
H0:观察频数与期望频数一致 H :观察频数与期望频数不一致
1
9 - 12
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
ij
5. 表中列出了行变量和列变量的所有可能的组 合,所以称为列联表
6. 一个 r 行 c 列的列联表称为 r ? c 列联表
9 - 15
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
列联表的结构
(r ? c 列联表的一般表示)
列(c ) j
行(r )
j =1
i
i =1
f
1. 品质相关
? 对品质数据 (分类和顺序数据 )之间相关程 度的测度
2. 列联表变量的相关属于品质相关
3. 列联表相关测量的统计量主要有
? ? 相关系数
? 列联相关系数 ? V 相关系数
9 - 20
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
? 相关系数
(correlation coefficient)
统计学 第 9 章 分类数据分析
STATISTICS (第五版)
9 -1
作者:中国人民大学统计学院 贾俊平
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
第 9 章 分类数据分析
9.1 分类数据与c 2统计量 9.2 拟合优度 检验 9.3 列联分析:独立性检验 9.4 列联分析中应注意的问题
独立性检验
(例题分析)
9 - 18
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
9.4 列联表中的相关测量
9.4.1 ? 相关系数
9.4.2 列联相关系数 9.4.3 V 相关系数
9 - 19
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
列联表中的相关测量
9 -2
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
学习目标
1. 理解分类数据与c 2 统计量
2. 掌握拟合优度检验及其应用 3. 掌握独立性检验及其应用 4. 掌握测度列联表中的相关性
9 -3
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
9.1 分类数据与列联表
拟合优度检验
(例题分析)
自由度的计算为 df=R-1,R为分类变量类型的
个数。在本例中,分类变量是性别,有男 女两个类别 ,故 R=2 ,于是自由度 df=2-
1=1,经查分布表, c ?(0.1)(1)=2.706,故
拒绝H0,说明存活状况与性别显著相关
9 - 13
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
c ? 统计量
1. 用于检验分类变量拟合优度 2. 计算公式为
? c 2 ?
( f ? f )2
o
e
f
e
9 -8
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
c ? 统计量
分布与自由度的关系
9 -9
作者:贾俊平,中国人民大学统计学院
统计学 9.3 列联分析:独立性检验
STATISTICS (第五版)
9.3.1 列联表
9.3.2 独立性检验
9 - 14
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)
列联表
(contingency table)
1. 由两个以上的变量交叉分类的频数分布表
2. 行变量的类别用 r 表示, ri 表示第 i 个类别 3. 列变量的类别用 c 表示, cj 表示第 j 个类别 4. 每种组合的观察频数用 f 表示
解:H0:地区和原料等级之间是独立的(不存在依赖关系) H :地区和原料等级之间不独立 (存在依赖关系)
1
c? 0.05(4)=9.488故拒绝H0,接受H1 ,即地区和原 料等级之间存在依赖关系,原料的质量受地区的影响
9 - 17
作者:贾俊平,中国人民大学统计学院
统计学
STATISTICS (第五版)