验证性因子分析..
amos_验证性因子分析报告步步教程
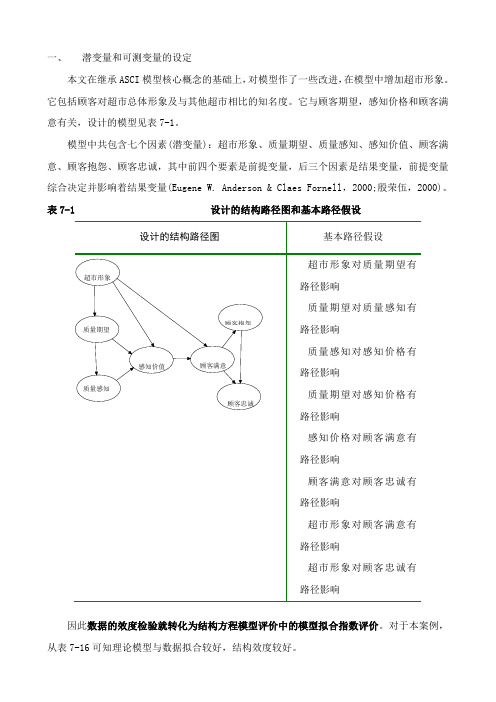
一、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表7-1 设计的结构路径图和基本路径假设超市形象对质量期望有路径影响质量期望对质量感知有路径影响质量感知对感知价格有路径影响质量期望对感知价格有路径影响感知价格对顾客满意有路径影响顾客满意对顾客忠诚有路径影响超市形象对顾客满意有路径影响超市形象对顾客忠诚有路径影响因此数据的效度检验就转化为结构方程模型评价中的模型拟合指数评价。
对于本案例,从表7-16可知理论模型与数据拟合较好,结构效度较好。
二、结构方程模型建模构建如图的初始模型。
超市形象质量期望质量感知a1e111a2e21a3e31a5e511a4e41a6e61a7e71a8e81a10e1011a9e91a11e111a12e121a13e131顾客满意感知价格a18e1811a16e161a17e171a15e1511a14顾客忠诚a24e24a22e22a23e231111z21z41z51z31z11e141图7-3 初始模型结构图7-4 Amos Graphics初始界面图第一节Amos实现1一、Amos模型设定操作1.模型的绘制在使用Amos进行模型设定之前,建议事先在纸上绘制出基本理论模型和变量影响关系路径图,并确定潜变量与可测变量的名称,以避免不必要的返工。
相关软件操作如下:第一步,使用建模区域绘制模型中的七个潜变量(如图7-6)。
AMOS做验证性因子分析

AMOS做验证性因子分析验证性因子分析(Confirmatory factor analysis, CFA)是一种统计方法,用于检验研究者构建的理论或假设模型是否与实际数据相吻合。
它是一种多变量分析方法,用于测量和验证潜在因子对观察指标的关系。
在本文中,将介绍如何使用AMOS软件进行验证性因子分析,并说明其步骤和解释结果的方法。
验证性因子分析的步骤如下:1.准备数据:首先,需要准备清洁和格式化的数据集。
确保变量的测量是连续的,并检查是否存在缺失值。
如果存在缺失值,可以选择删除缺失值或使用合适的方法进行缺失值处理。
2.建立模型:在AMOS软件中,创建新项目并选择“新模型”的选项。
在模型中添加指标和潜变量,并指定它们之间的因子关系。
可以使用路径图或列表方式指定模型。
3. 参数估计:在参数估计部分,选择适当的估计方法,如最大似然估计(Maximum Likelihood, ML)或广义最小二乘估计(Generalized Least Squares, GLS)。
这些方法可以根据数据集的特点来选择。
4. 模型拟合度检验:进行模型拟合度检验是确认模型的重要步骤。
通过比较实际数据与模型预测数据的吻合程度来评估模型的拟合度。
常用的拟合度指标包括卡方检验值(chi-square)、规范拟合指数(NFI)、增量拟合指数(IFI)和根均方误差逼近指数(RMSEA)。
5.修正模型:如果模型拟合度不佳,需要对模型进行修正。
可以根据修正指标的建议来调整模型,例如删除不明显或不显著的路径,增加或修改潜变量之间的关系。
6.解释结果:解释模型结果是验证性因子分析的重要任务之一、通过对模型参数和估计值的解读来解释实际数据与模型之间的关系。
还可以进行模型比较,比较不同模型之间的差异和优劣。
验证性因子分析的结果通常包括了对模型拟合度的评估和模型参数的解释。
模型拟合度指标可以告诉我们模型与实际数据的吻合程度,例如卡方检验值的显著性、NFI、IFI和RMSEA等指标。
数学模型中的因子分析法

数学模型中的因子分析法因子分析是一种常用的数学模型,用于解释多个变量之间的关系和发现潜在的因素。
它是一种降维技术,旨在将众多变量转化为较少数量的无关因子。
因子分析在统计学、心理学和市场研究等领域广泛应用,可用于数据降维、消除多重共线性、提取潜在特征、构建模型等等。
在因子分析中,有两种主要类型:探索性因子分析(Exploratory Factor Analysis,EFA)和验证性因子分析(Confirmatory Factor Analysis,CFA)。
探索性因子分析用于发现数据中的潜在因素,而验证性因子分析则用于验证已经提出的因素模型是否符合实际数据。
探索性因子分析的步骤如下:1.提出假设:确定为什么要进行因子分析以及预期结果,用于指导后续的数据分析。
2.数据准备:收集和整理要进行因子分析的数据,确保数据的可用性和准确性。
3.因子提取:通过主成分分析或最大似然法等方法,提取出能够解释数据变异最大的因子。
4.因子旋转:因子旋转是为了使提取出的因子更易于解释和理解。
常用的旋转方法有正交旋转和斜交旋转等。
5.因子解释和命名:对于每个提取出的因子,需要根据变量的载荷矩阵和旋转后的载荷矩阵进行解释和命名。
载荷矩阵表示每个因子与每个变量之间的关系。
6.结果评估:对于提取出的因子,需要进行信度和效度的评估。
信度评估包括内部一致性和稳定性等指标;效度评估包括构造效度和相关效度等指标。
验证性因子分析通常用于验证已经提出的因子模型是否符合实际数据。
其步骤包括:1.提出假设:确定已存在的因子模型,并对其进行理论和实际的验证。
2.选择分析方法:确定适合验证性因子分析的模型拟合方法,如最大似然法或广义最小二乘法等。
3.构建模型:将因子模型转化为测量模型,并建立测量方程。
4.模型拟合:对构建的测量模型进行拟合,评估模型的拟合度,如χ²检验、准则拟合指数(CFI)等。
5.修正模型:根据拟合域冒去改进模型的拟合,如剔除不显著的路径、修正测量方程等。
amos验证性因子分析步步教程

应用案例1第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。
一、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。
二、潜变量和可测变量的设定本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相比的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
表2.1、顾客满意模型中各因素的具体范畴参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据文件“处理后的数据.sav”。
表三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某大学校内的各类学生(包括全日制本科生、全日制硕士和博士研究生),并且近一个月内在校内某超市有购物体验的学生。
调查采用随机拦访的方式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进行控制。
问卷内容包括7个潜变量因子,24项可测指标,7个人口变量,量表采用了Likert10级量度,如对四、缺失值的处理4正向的,采用Likert10级量度从“非常低”到“非常高”采用表列删除法,即在一条记录中,只要存在一项缺失,则删除该记录。
验证性因子分析

验证性因子分析验证性因子分析(Confirmatory Factor Analysis, CFA)是一种统计方法,用于检验和验证一个已经构建的多维量表的因子结构和因子载荷是否与预测一致。
其基本原理是在预设的因子结构前提下,通过对观察数据进行分析,确定相关因子的因子载荷是否显著,从而确定因子结构的准确性。
验证性因子分析需要先有理论基础并构建出一个已经测试过的多维量表,然后使用CFA模型对观察数据进行分析。
在该分析中,先构建一个因子模型,并设定各个因子与测量变量之间的关系,然后通过最大似然估计或贝叶斯估计等方法,根据数据对模型的适配度进行统计检验,判断模型是否能够很好地解释数据。
在验证性因子分析中,通常通过以下指标来评估模型的适配度:1. 卡方检验(Chi-Square Test):检验观察数据与模型之间的拟合程度,通常考虑的是卡方值和自由度的比值。
较小的卡方值和较大的自由度比值表示较好的拟合程度。
2. 均方根误差逼近指标(Root Mean Square Error of Approximation, RMSEA):此指标反映模型误差的程度,一般认为RMSEA值在0.05以下表示较好的拟合程度。
3. 标准化拟合指数(Comparative Fit Index, CFI)和增量拟合指数(Incremental Fit Index, TLI):这两个指标反映模型与数据的拟合程度,值越接近1表示拟合效果越好。
4. 标准化残差(Standardized Residuals):这个指标可以用来检验模型的统计显著性,较小的标准化残差表示模型比较合理。
通过分析以上指标,我们可以根据验证性因子分析的结果来评估模型的适配度,并判断因子结构是否与预期一致。
如果模型的适配度较好,即各个指标都在接受范围内,说明构建的因子结构是恰当的;如果拟合度较差,我们可能需要重新考虑因子结构或修改测量工具。
验证性or探索性因子分析傻傻分不清?

写在前面:同样都是因子分析,探索性因子分析与验证性因子分析有什么不同?探索性因子分析:基于降维的思想,将错综复杂的众多变量聚合成少数几个独立的公共因子,在乎的是多个测试项是否能组成一个或多个理论变量,其理论变量是未知的,例如30 个题目里面能生成多少个理论变量,即最合适的因子个数是多少。
验证性因子分析:事前已知理论变量,强调多个测试项是否能否代表某个理论变量,例如检验购买频率、主观评估、消费比例是否真的可以反映忠诚度。
也就是我们预先的理论架构是否是好的,题目设置是否是好的,收集到的数据能否体现想要的结果,实际上也就是一种效度检验。
探索性因子分析更适合于在没有理论支持的情况下对数据的试探性分析。
验证性因子分析充分利用了先验信息,在已知因子的情况下检验所搜集的数据资料是否按事先预定的结构方式产生作用。
同时,两种因子分析缺少任何一个,因子分析都将是不完整的。
一般来说,如果研究者没有坚实的理论基础支撑,有关观测变量内部结构一般先用探索性因子分析,产生一个关于内部结构的理论,再在此基础上用验证性因子分析,这样的做法是比较科学的,但这必须要用两组分开的数据来做。
如果研究者直接把探索性因子分析的结果放到统一数据的验证性因子分析中,研究者就仅仅是拟合数据,而不是检验理论结构。
如果样本容量足够大的话,可以将数据样本随机分成两半,合理的做法就是先用一半数据做探索性因子分析,然后把分析取得的因子用在剩下的一半数据中做验证性因子分析。
今天我们主要来详细讲解一下验证性因子分析1 背景下表是理科班的100 名同学的语文、数学、英语、物理、生物、化学成绩。
研究者想要验证他们的语文、英语成绩是否可以反映理科班的文科成绩水平;他们的数学、物理、生物、化学成绩是否可以反映理科班的理科成绩水平。
2 分析步骤2.1 模型构建首先对样本进行频数统计,验证性因子分析要求总样本数据(行数)最少是全部题目(列数)的5倍以上,最好10倍以上,且一般情况下至少需要200个样本;2.2 删除不合理测量项通过因子载荷系数对因子内测量变量进行筛选,一般来说,测量变量通过显著性检验(< 0.05或0.01),并且标准化载荷系数值大于0.7,可表明测量变量符合因子要求,条件差距太大可以考虑删除变量;2.3 模型评价根据平均公因子方差抽取量(AVE)与组合信度(CR)结果可以分析因子内的测量指标的提取度,一般来说AVE要求高于0.5,且越接近1代表测量指标提取程度越高,CR要求高于0.72.4 分析总结3 软件实现3.1 案例操作3.2 结果解释3.21 因子基本汇总表样本数据集共有因子数量2 个,变量数6 个,样本数量200个,满足验证性因子分析基本数据要求。
验证性因子分析思路总结

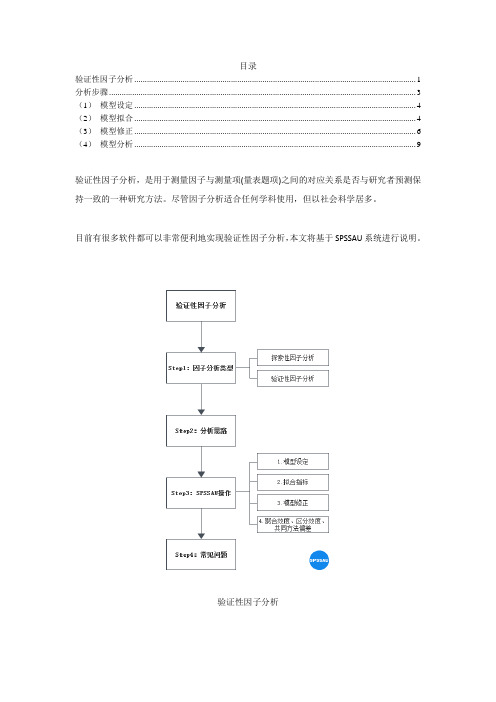
目录验证性因子分析 (1)分析步骤 (3)(1)模型设定 (4)(2)模型拟合 (4)( 3 )模型修正 (6)(4)模型分析 (9)验证性因子分析,是用于测量因子与测量项(量表题项)之间的对应关系是否与研究者预测保持一致的一种研究方法。
尽管因子分析适合任何学科使用,但以社会科学居多。
目前有很多软件都可以非常便利地实现验证性因子分析,本文将基于SPSSAU系统进行说明。
验证性因子分析Step1:因子分析类型因子分析可分为两种类型:探索性因子分析(EFA)和验证性因子分析(CFA)。
探索性因子分析,主要用于浓缩测量项,将所有题项浓缩提取成几个概括性因子,达到减少分析次数,减少重复信息的目的。
验证性因子分析与探索性因子分析相似,两者区别只在于探索性因子分析(EFA)用于探索因子与测量项之间的对应关系,验证性因子分析(CFA)用于验证结果与理论预期是否一致。
Step2:分析思路在实际研究中,验证性因子分析常会与结构方程模型、路径分析等方法联系到一起,对于不熟悉概念的研究人员容易搞混这些方法,下表对这几种方法进行简单说明:探索性因子分析(EFA)验证性因子分析(CFA )研究测量关系研究测量关系回归分析研究自变量对一个因变量的影响关系路径分析研究多个自变量与多个因变量之间的影响关系适用于非经典量表适用于经典量表y 为定量数据可先用CFA/EFA 确定因子与研究项关系,再进行路径分析结构方程模型包括两部分:结构方程模型研究影响关系及测量关系验证性因子分析和路径分析探索性因子分析:验证因子与分析项的对应关系,索性因子分析。
验证性因子分析:验证因子与分析项的对应关系,性因子分析。
确认测量关系后,后续可进行路径分析系。
检验量表效度,非经典量表通常用探检验量表效度,成熟量表通常用验证/ 线性回归分析研究具体的影响关路径分析:用于研究多个自变量与多个因变量影响关系;如果因变量只有一个,可以使用线性回归分析。
结构方程模型SEM:包括测量关系和影响关系。
spssau 验证性因子分析

验证性因子分析目录1验证性因子分析基本说明 (2)2 如何使用SPSSAU进行验证性因子操作 (3)3 验证性因子不达标如何办? (9)第1点:效度不达标 (9)第2点:factor loading值过大或过小 (10)第3点:拟合指标不达标 (10)验证性因子分析(confirmatory factor analysis, CFA)是结构方程模型的一种最常见的应用。
验证性因子分析(confirmatory factor analysis, CFA)通常可用于四种用途,一是针对成熟量表进行效度分析,包括结构效度,聚合(收敛效度)和区分效度;二是验证性因子分析可用于组合信度的分析;三是验证性因子分析还可用于进行共同方法偏差CMV检验。
四是使用验证性因子分析进行权重计算;CFA的功能应用如下:验证性因子分析功能如果是使用CFA进行结构效度验证,即测量因子与对应项之间的对应关系情况是否良好,一般查看标准化factor loading即因子载荷系数值即可,如果所有的项标准化factor loading值大于0.7即说明结构效度良好。
当然,如果某项的factor loading值较小,那么可删除该项后再次分析。
如果使用CFA进行聚合效度验证,那么其是测量本应该在同一因子的项确实在该因子里面;其具体测量方式是要求A VE值大于0.5即可;如果出现A VE明显的小于0.5,此时可考虑移项一些载荷系数值较低项后再次分析。
如果使用CFA进行区分效度验证,那么其是测量不应该同一因子的项确实不在同一因子下面;测量方式有两种,第一种是看A VE平方根号值与相关系数值进行PK,如果说A VE平方根号值全部大于相关系数值,意味着聚合性明显更强,说明具有区分效度;区分效度时还有一种测量方式是使用HTMT值,该指标一般小于0.9即可,但该指标要求相对较严格,使用较少。
如果使用CFA进行信度分析,那么使用组合信度系数CR值测量即可,一般CR值大于0.7即可。
验证性因子分析实例

验证性因子分析的实例分析基本上,在应用CFA时,皆是在检验某个学者所发展的测验或量表。
CFA对测验或量表的检验可以有以下作为:(1)检验量表的面向性,或者称因子结构。
(2)检验因子的阶层关系,此种测量模式成为阶层式CFA。
(3)检验量表的信度与效度。
实例一:检验测验的面向性测验或量表的形成是由理论所建构的,可能某些学者的理论认为某个量表是一种单一面向的量表,也可能有些理论认为该量表是有多个面向,对于这种测验或量表的面向性检验,就是一种理论建构的因素效度的检验。
对CFA而言,它可以检验出哪一种面向比较符合观察数据,而决定出理论建构的最有效因子结构。
本例采用一个父母对孩子学校表现关注量表。
这个量表一共7题(X1,…,X7),资料的搜集来自于某县初中3年级学生,共有590个样本。
我们假定了三种面向性的模型:(1)此7题只建构了一个潜在因子,称为“关注”因子;(2)此7题可以建构2个潜因子,一个称为“探询”因子,一个称为“协助与督促”因子;(3)此7题可以建构成3个潜因子,第一个称为“了解”因子,第二个称为“与学校接触”因子,第三个称为“协助与督促”因子。
第一步:模型界定利用路径图呈现3种模型中变量的关系。
如图1~图3所示。
图1 父母对孩子学校表现关注量表单因子CFA模型图2 父母对孩子学校表现关注量表一级二因子CFA模型图3 父母对孩子学校表现关注量表一级三因子CFA模型接着是把路径图转换成方程式,就可以用LISREL程序编写出来。
图1的方程式如下:X1=λ1ξ1+δ1X2=λ2ξ1+δ2X3=λ3ξ1+δ3X4=λ4ξ1+δ4X5=λ5ξ1+δ5X6=λ6ξ1+δ6X7=λ7ξ1+δ7图2的方程式如下:X1=λ1ξ1+δ1X2=λ2ξ1+δ2X3=λ3ξ1+δ3X4=λ4ξ1+δ4X5=λ5ξ1+δ5X6=λ6ξ2+δ6X7=λ7ξ2+δ7cov(探询,协助与督促)图3的方程式如下:X1=λ1ξ1+δ1X2=λ2ξ1+δ2X3=λ3ξ1+δ3X4=λ4ξ2+δ4X5=λ5ξ2+δ5X6=λ6ξ3+δ6X7=λ7ξ3+δ7cov(了解,与学校接触)cov(了解,协助与督促)cov(与学校接触,协助与督促)3个假设模型就此界定完成。
验证性因子分析思路总结
目录验证性因子分析 (1)分析步骤 (3)(1)模型设定 (4)(2)模型拟合 (4)(3)模型修正 (6)(4)模型分析 (9)验证性因子分析,是用于测量因子与测量项(量表题项)之间的对应关系是否与研究者预测保持一致的一种研究方法。
尽管因子分析适合任何学科使用,但以社会科学居多。
目前有很多软件都可以非常便利地实现验证性因子分析,本文将基于SPSSAU系统进行说明。
验证性因子分析Step1:因子分析类型因子分析可分为两种类型:探索性因子分析(EFA)和验证性因子分析(CFA)。
探索性因子分析,主要用于浓缩测量项,将所有题项浓缩提取成几个概括性因子,达到减少分析次数,减少重复信息的目的。
验证性因子分析与探索性因子分析相似,两者区别只在于探索性因子分析(EFA)用于探索因子与测量项之间的对应关系,验证性因子分析(CFA)用于验证结果与理论预期是否一致。
Step2:分析思路在实际研究中,验证性因子分析常会与结构方程模型、路径分析等方法联系到一起,对于不熟悉概念的研究人员容易搞混这些方法,下表对这几种方法进行简单说明:探索性因子分析(EFA)研究测量关系适用于非经典量表验证性因子分析(CFA)研究测量关系适用于经典量表回归分析研究自变量对一个因变量的影响关系y为定量数据路径分析研究多个自变量与多个因变量之间的影响关系可先用CFA/EFA确定因子与研究项关系,再进行路径分析结构方程模型研究影响关系及测量关系结构方程模型包括两部分:验证性因子分析和路径分析●探索性因子分析:验证因子与分析项的对应关系,检验量表效度,非经典量表通常用探索性因子分析。
●验证性因子分析:验证因子与分析项的对应关系,检验量表效度,成熟量表通常用验证性因子分析。
确认测量关系后,后续可进行路径分析/线性回归分析研究具体的影响关系。
●路径分析:用于研究多个自变量与多个因变量影响关系;如果因变量只有一个,可以使用线性回归分析。
●结构方程模型SEM:包括测量关系和影响关系。
验证性因子分析报告

验证性因子分析报告引言验证性因子分析(CFA)是一种统计方法,用于评估测量模型的适配性和建立因子与观测变量之间的关系。
本报告旨在介绍CFA的步骤和思考过程,以及如何解释和应用CFA结果。
步骤一:确定研究目的和假设在进行CFA之前,首先需要明确研究目的和假设。
研究目的可以是验证一个已有的理论模型,或者建立一个新的测量模型。
假设可以是具体的关系假设或者差异假设。
步骤二:选择合适的测量工具和样本第二步是选择合适的测量工具和样本。
测量工具可以是问卷调查、观察或者其他形式的测量工具。
样本的选择应该具有代表性,并且具备足够的样本量以支持结果的可靠性。
步骤三:建立测量模型建立测量模型是CFA的核心步骤。
首先,确定要测量的潜在因子,并选择合适的观测变量。
然后,建立一个初始模型,将观测变量与潜在因子进行关联。
在建立模型时,需要考虑因子间的相关性以及观测变量的量表信度。
步骤四:评估模型适配性一旦建立了测量模型,接下来需要评估模型的适配性。
常用的适配性指标包括卡方检验、比较合适度指数(CFI)、增量合适度指数(IFI)和根均方误差逼近指数(RMSEA)。
这些指标可以帮助研究者判断模型是否与实际数据拟合良好。
步骤五:检验因子负荷和因子间关系一旦模型的适配性得到确认,接下来需要检验因子负荷和因子间的关系。
因子负荷指观测变量与潜在因子之间的关系强度,可以通过标准化回归系数来度量。
因子间关系可以通过检验路径系数或者相关系数来判断。
步骤六:解释和应用CFA结果最后一步是解释和应用CFA的结果。
根据因子负荷和因子间关系的方向和强度,可以对测量模型进行解释,并验证研究假设。
此外,CFA结果还可以用于改进测量工具或者探索其他相关问题。
结论验证性因子分析是一种强大的统计方法,可以用于评估测量模型的适配性和建立因子与观测变量之间的关系。
通过明确研究目的和假设,选择合适的测量工具和样本,建立测量模型,评估模型适配性,检验因子负荷和因子间关系,并解释和应用CFA结果,研究者可以得出可靠的结论,并推动理论和实践的发展。
amos验证性因子分析步步教程

amos验证性因⼦分析步步教程应⽤案例1第⼀节模型设定结构⽅程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。
下⾯以⼀个研究实例作为说明,使⽤Amos7软件2进⾏计算,阐述在实际应⽤中结构⽅程模型的构建、运算、修正与模型解释过程。
⼀、模型构建的思路本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了⼀个新的模型,并以此构建潜变量并建⽴模型结构。
根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利⽤对缺失值进⾏处理后的数据3进⾏分析,并对⽂中提出的模型进⾏拟合、修正和解释。
⼆、潜变量和可测变量的设定本⽂在继承ASCI模型核⼼概念的基础上,对模型作了⼀些改进,在模型中增加超市形象。
它包括顾客对超市总体形象及与其他超市相⽐的知名度。
它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。
模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。
1关于该案例的操作也可结合书上第七章的相关内容来看。
2本案例是在Amos7中完成的。
3见spss数据⽂件“处理后的数据.sav”。
2.1、顾客满意模型中各因素的具体范畴参考前⾯模型的总体构建情况、国外研究理论和其他⾏业实证结论,以及⼩范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。
三、关于顾客满意调查数据的收集本次问卷调研的对象为居住在某⼤学校内的各类学⽣(包括全⽇制本科⽣、全⽇制硕⼠和博⼠研究⽣),并且近⼀个⽉内在校内某超市有购物体验的学⽣。
调查采⽤随机拦访的⽅式,并且为避免样本的同质性和重复填写,按照性别和被访者经常光顾的超市进⾏控制。
问卷内容包括7个潜变量因⼦,24项可测指标,4正向的,采⽤Likert10级量度从“⾮常低”到“⾮常⾼”本次调查共发放问卷500份,收回有效样本436份。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
9
单因子模型(测量模型)
父母社 经地位
λ1 X1 δ1 λ2 X2 δ2 λ3 X3 δ3
观测变量 潜在变量 路 相 径 关
10
Table 1 相关系数矩阵
X1 X2 X3 Y1 Y2
X1 1.0000 0.5902 0.5461 0.2852 0.2701
X2
X3
Y1
Y2
1.0000 0.4509 1.0000 0.2377 0.2349 1.0000 0.2269 0.2203 0.6759 1.0000
13
Slight ____
Slight ____
Quite ____
Exremely ____ Limited Selection
2 验证性因子分析的基本过程
理论构建 模型设定 模型识别 模型估计 模型评价 模型修正
14
φ12
ξ1
ξ2
X1
x2
x3
y2
y2
δ1
δ2
δ3
δ4
δ5
RMR 残差平方根
反应理论假设模型 整体残差
<0.05, 越接近0越好
CFA可计算模型拟合优度指标,以验证因子模型是否 适合样本资料的相关结构; 通过CFA,可检查因子结构与可靠度 (测量信度); CFA可提供信度及效度(收敛效度与区分效度)分析。 如上例:相关系数高,可知测量结果应具有一致性。
11
(二)评价信度与构念效度
CFA可以使用模型拟合优度统计量(如χ2)与相关拟 合优度指标(GFI、AGFI)来衡量变量的信度与 (reliability)与效度(validity)。
0.5461 corr ( X 1 , X 3 ) corr (111 1 , 311 3 ) 1131 0.714
corr ( X 1 , Y X 1 4 ) corr (111 1 , 42 2 4 ) 11corr (1 , 2 ) 42 .. 1112 42 0.203 0.2852 corr ( X 1 , Y X 2 5 ) corr (111 1 , 52 2 5 ) 11corr (1 , 2 )52 .. 1112 52 0.2701 0.095 corr ( X 2 , X 3 ) corr (211 2 , 321 3 ) 2131 0.4509 0.685
图2 两因子模型的路径图 父母社会经济地位与学生业绩
15
2.1 Intuition
验证性因子分析时应优先采用“协方差矩 阵”,而非相关系数矩阵。
1.0000 0.5902 0.5461 0.2852 0.2701 1.0000 0.4509 1.0000 0.2377 0.2349 1.0000 0.2269 0.2203 0.6759 1.0000
17
CFA模型的尺度不定性 (scaling indeterminancy)
Var(ξi)与所有的λij的值不能同时决 定,两者有抵换关系 尺度不定性的解决方法: 1. 令每个因子的方差为1; 2. 将每个因子与因子载荷在之上的变量间 的λ值任选一个,并固定为1
18
λ11 λ21
0 0 0 λ42 λ52
corr ( X 3 , Y X 2 5 ) corr (311 3 , 52 2 5 ) 31corr (1 , 2 )52
corr(X 1 , X 1 ) 11 1,
2 11
corr(X 2 , X 2 ) 22 1,
0.2377 .. 2112 42 0.246
corr ( X 2 , Y X 1 4 ) corr ( 211 2 , 42 2 4 ) 21corr (1 , 2 )42
corr ( X 2 , Y X 2 5 ) corr (211 2 , 52 2 5 ) 21corr (1 , 2 )52 .. 2112 52 0.181 0.2269 .. 3112 42 0.2349 0.170 .. 3112 52 0.2203 0.113
20 Y14 , Y corr ( X X 0.585 2 5 ) corr (42 2 4 , 52 2 5 ) 42 52 0.6759
corr ( X 3 , Y X 1 4 ) corr ( 311 3 , 42 2 4 ) 31corr (1 , 2 )42
信度:观测变量与潜变量之间的相关程度(>0.70) 效度:可分下列两种
收敛效度(convergent validity):对相同特性 (construct, concept, or research variables)使用 不同衡量方法(Likert scale, Stapel scale, or semantic differential),所得结果高度相关。 区分效度(discriminant validity):不同构念 (construct) 彼此之间确实不相同。
验证性因子分析
Confirmatory Factor Analysis
张岩波
Dept. of health statistics Shanxi medical university
1
内容提要
1 2 3 4 前言 验证性因子分析 关于样本 应用实例
2
因子分析概述 (factor analysis)
factor loadings matrix
Λ=
λ31 0 0
2 22
factor correlation matrix
1 ψ12 ψ21 1
19
corr ( X 1 , X 2 ) corr (111 1 , 211 2 ) 1121 0.5902 0.722
22
评价指标
2 2 ln L ln L R F
指标 χ2 卡方值
说明 χ2易受样本量大小影响,当样本 量较大时,易导致拒绝零假设, 因此建议与其它指标同时评价。
零假设: the proposed model fits as well as a perfect model
R =
16
X1 = λ11ξ1 + λ12ξ2 + δ1 X2 = λ21ξ1 + λ22ξ2 + δ2 X3 = λ31ξ1 + λ32ξ2 + δ3 Y1 = λ41ξ1 + λ42ξ2 + δ4 Y2 = λ51ξ1 + λ52ξ2 + δ5
探索性因子分析模型
X1 = λ11ξ1 + δ1 验证性因子分析模型 X2 = λ21ξ1 + δ2 X3 = λ31ξ1 + δ3 Y1 = +λ42ξ2 + δ4 Y2 = +λ52ξ2 + δ5 Corr(ξ1,ξ2) = φ12, var(ξ1)=φ11, var(ξ2)=φ22
提供模型拟合优度统计量 提供参数估计的标准误
8
1.1 CFA的应用
(一)检验因子模型的拟合优度
透过验证性因子分析,可针对特定的因子模型评 价拟合优度,并验证其理论构架。
例:研究者欲研究父母的社会经济地位如何影响学生在学 校和工作中的表现,采用问卷调查了3094名学生
5个指标: X1是母亲的学历等级(1~6) X2是父亲的学历等级(1~6) X3是父母的工资总收入等级(1~10) Y1是学生的大学学分等级(1~4) Y2是学生毕业5年后的工资等级(1~10)
2 21
corr(X 3 , X 3 ) 33 1,
2 31
corr(X 4 , X 4 ) 44 1,
2 42
corr(X 5 , X 5 ) 55 1
2 52
21
模型拟合优度检验
n n 1 ln( LF ) [ln S tr ( SS )] [ln S p] 2 2
用于分析影响变量或支配变量的共同因子有几个, 且各因子本质为何的一种统计方法 是一类降维相关分析技术,考察一组变量(指标) 之间的协方差或相关系数结构,并用于解释这些 变量与少数因子(潜变量)之间的关系 事先未知,确定因子的维数 ——探索性因子分析(EFA) 根据某些理论或其他先验知识对可能的个数或因 子结构作出假设 ——验证性因子分析(CFA)
n ln( LR ) ln tr S 1 2
Set α=0.2
H0: Reduced model is indifferent from full model Ha: two models are significantly different
对n极为敏感
2[ln(LR ) ln(LF )] n[ln tr(S1 ) ln S p] ~ 2
3
概念间的关系
4
探索性与验证性因子分析的比较
EFA CFA 理论构架在分 因素分析后的 須先有特定的理 析过程中所扮 产物 论观点作为基础, 演的角色 再决定该构架是 否适合 理论构架在分 析过程中所扮 事后 事前 演的检验时机
5
探索性因子分析的分析步骤
1. 收集观测变量。 2. 获得协方差阵(或相关系数矩阵) 3. 确定因子个数:Kaiser准则、Screen检验 依据具体的假设,决定因子个数; 用尽可能少的因子解释尽可能多的方差。 4. 提取因子:主成分法、最小二乘法、最大似然法 5. 因子旋转: 因子载荷阵的不唯一性,可对因子进行旋转,使因子结构 朝合理方向趋近。 旋转方法:正交、斜交旋转等,常用方差最大化正交旋转 6. 解释因子结构:依据因子载荷大小作出解释,并赋予因子特 定含义 7. 因子得分:公共因子代表原始变量,更利于描述研究对象的 特征 6