数据的概括性度量
【统计学】4.数据的概括性度量

【统计学】4.数据的概括性度量【统计学】4.数据的概括性度量4.1 集中趋势的度量4.2 离散程度的度量4.3 偏态与峰态的度量学习⽬标1.集中趋势各测度值的计算⽅法2.集中趋势各测度值的特点及应⽤场合3.离散程度各测度值的计算⽅法4.离散程度各测度值的特点及应⽤场合5.偏态与峰态的测度⽅法6.⽤excel 计算描述统计量并进⾏统计4.1 集中趋势的度量集中趋势(central tendency )1.⼀组数据向其中⼼值靠拢的倾向和程度,反映了⼀组数据中⼼点位置所在2.测度集中趋势就是寻找数据⽔平的代表值或中⼼值3.不同类型的数据不同的集中趋势测度值4.低层次数据的测度值适⽤于⾼层次的测量数据,但⾼层次的数据的测度值并不适⽤于低层次的测量数据4.1.1 分类数据:众数众数(mode )1.⼀组数据中出现次数最多的变量值2.⼀般仅适合数据量较多时使⽤3.不受极端值得影响4.⼀组数据可能没有众数或有⼏个众数(众数可能不唯⼀也可能不存在)5.主要⽤于分类数据(分类数据只对应分类的频数),也可⽤于顺序数据和数值型数据4.1.2 顺序数据:中位数和分位数中位数(median )1.⼀组数据排序后处于中间位置上的值2.中位数不受极端值的影响3.中位数主要⽤于顺序数据,也可⽤于数值型数据,但不适⽤于分类数据中位数(位置和数值的确定)排序位置确定n +12数值确定M e =x (n +12),n 为奇数12[x (n2)+x (n2+1)],n 为偶数因此中位数不⼀定是原数据中的某个变量值四分位数(quartile)1.排序后处于25%和75%位置上的值2.不受极端值的影响3.计算公式Q L 位置=n4,Q U 位置=3n4,4.如果是在0.25或0.75的位置上,则四分位数等于该位置的下侧值加上按⽐例分摊位置两侧数值的差值(加权平均数概念){{4.1.3 数值型数据:平均数平均数(mean )1.也称为均值2.集中趋势的最常⽤测度值3.⼀组数据的均衡点所在4.体现了数据的必然性5.易受极端值的影响6.有简单平均数和加权平均数之分7.根据总体数据计算,称为平均数,即为µ,根据样本数据计算的,称为样本平均数,即为x 简单平均数(算数平均数)设⼀组数据为:x 1,x 2,...x n (总体数据x N )样本平均数¯x =x 1+x 2+...+x n n =∑n i =1x i n 总体平均数µ=x 1+x 2+...+x N N =∑Ni =1x iN加权平均数(Weighted mean )设各组的组中值为:M 1,M 2,...,M k 相应的频数为:f 1,f 2,...f k 样本加权平均¯x =M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑k i =1M i f in总体加权平均µ=M 1f 1+M 2f 2+...M k f kf 1+f 2+...+f k=∑⼏何平均数(geometric mean )1. n 个变量值乘积的n 次⽅根2. 适⽤于对⽐率数据的平均3. 主要⽤于计算平均增长率4. 计算公式为G =nx 1×x 2×...×x n =nn∏i =1xi4.1.4众数、中位数和平均数的⽐较1. 众数不受极端值影响具有不唯⼀性数据量较⼤时众数才有意义数据分布偏斜程度较⼤且有明显峰值时应⽤2. 中位数不受极端值影响数据分布偏斜程度较⼤时应⽤3. 平均数利⽤了全部数据信息,数学性质优良易受极端值影响数据对称分布或接近对称分布时应⽤4.2 离散程度的度量离中趋势1.数据分布的⼀个重要特征2.反映各变量值远离其中⼼值的程度(离散程度)3.从另⼀个侧⾯说明了集中趋势测度值的代表程度4.不同类型的数据有不同的离散程度测度值4.2.1 分类数据:异众⽐率异众⽐率(variation ratio )1. 对分类数据离散程度的测度2. ⾮众数组的频数占总频数的⽐例3. 计算公式v r =∑f i −f m ∑f i=1−f m∑f i4.⽤于衡量众数是否具有代表性4.2.2 顺序数据:四分位差四分位差(quartile deviation )1. 对顺序数据离散程度的测度2. 也称为内距或四分间距3. 上四分位数与下四分位数之差Q d =Q U −Q L4. 反映了中间50%数据的离散程度5. 不受极端值影响√√6. ⽤于衡量中位数是否具有代表性4.2.3 数值型数据:⽅差和标准差极差(range)1. ⼀组数值型数据的最⼤值和最⼩值之差2. 离散程度的最简单测度值3. 易受极端值影响4. 未考虑数据的分布,数据利⽤率低5. 计算公式为R=max(x i)−min(x i)标准差(mean deviation)1. 各变量值与其平均数离差绝对值的平均数2. 能全⾯反映⼀组数据的离散程度3. 数学性质差,实际应⽤较少4. 计算公式未分组数据M d=∑n i=1|x i−¯x|n组距分组数据Md=∑k i=1|M i−¯x|fin⽅差和标准差(variance and standard deviation)1. 各变量与其平均数离差平⽅的平均数2. 数据离散程度的最常⽤测度值3. 反映了各变量与均值的平均差异4. 根据总体数据计算的,称为总体⽅差(标准差)σ2(σ)根据样本数据计算的,称为样本⽅差(标准差)s2(s)⽅差的计算公式未分组数据s2=∑n i=1(x i−¯x)2n−1组距分组数据s2=∑k i=1(M i−¯x)2fin−1标准差的计算公式未分组数据s=∑n i=1(x i−¯x)2n−1组距分组数据s=∑k i=1(M i−¯x)2fin−1为什么是除以n-1⽽不是n?⾃由度(degree of freedom)1. ⾃由度是指数据个数与附加给独⽴观测值的约束或限制的个数之差2. 从字⾯涵义看,⾃由度是指⼀组数据中可以⾃由取值的个数3. 当样本数据的个数为n时,若样本平均数确定后,则附加给n个观测值的约束个数就是1个,因此只有n-1个数据可以⾃由取值,其中必有⼀个数据不能⾃由取值。
数据的概括性度量数据特征的描述

Hm
Mi fi Mi fi
Mi
Mi fi fi
2024/9/29
30
例题分析:调和平均数
【例4.10】某蔬菜批发市场三种蔬菜旳日成交数 据如下表,计算三种蔬菜该日旳平均批发价格.
解:由公式
Hm
M i fi Mi fi Mi
Mi fi fi
所以H m
成交额
成交额 批发价格
n
lg Gm
1 n
(lg
x1
lg
x2
lg xn )
lg xi
i 1
n
2024/9/29
32
例题分析
【例4.11】某水泥生产企业1999年旳水 泥产量为100万吨,2023年与1999年相比 增长率为9%,2023年与2023年相比增长 率为16%,2023年与2023年相比增长率为 20%。求各年旳年平均增长率。
7
集中趋势(Central tendency)
集中趋势:一组数据向其中心值靠拢旳倾 向和程度.测度趋势就是寻找数据水平旳 代表值或中心值。
注意:不同类型旳数据用不同旳集中趋势测 度值;低层次数据旳测度值合用于高层次 旳测量数据,但高层次数据旳测度值并不 合用于低层次旳测量数据。
2024/9/29
8
位置 n 1 9 1 5 Me 1080
22
2024/9/29
17
2)10个家庭旳人均月收入数据
排 序: 660 750 780 850 960 1080
1250 1500 1630 2023
位 置: 1 2 3 4 5
6
7 8 9 10
位置 n 1 10 1 5.5
2
Gm n x1 x2 xn
统计学第4章学习指导
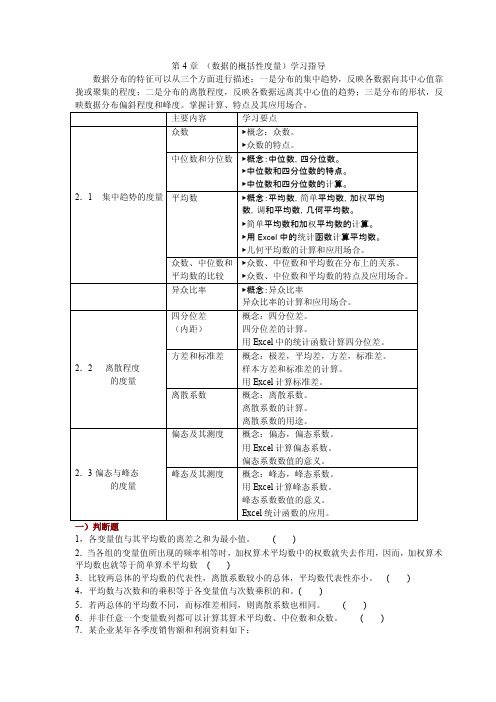
第4章(数据的概括性度量)学习指导数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。
掌握计算、特点及其应用场合。
主要内容学习要点2.1 集中趋势的度量众数▶概念:众数。
▶众数的特点。
中位数和分位数▶概念:中位数,四分位数。
▶中位数和四分位数的特点。
▶中位数和四分位数的计算。
平均数▶概念:平均数,简单平均数,加权平均数,调和平均数,几何平均数。
▶简单平均数和加权平均数的计算。
▶用Excel中的统计函数计算平均数。
▶几何平均数的计算和应用场合。
众数、中位数和平均数的比较▶众数、中位数和平均数在分布上的关系。
▶众数、中位数和平均数的特点及应用场合。
异众比率▶概念:异众比率异众比率的计算和应用场合。
2.2离散程度的度量四分位差(内距)概念:四分位差。
四分位差的计算。
用Excel中的统计函数计算四分位差。
方差和标准差概念:极差,平均差,方差,标准差。
样本方差和标准差的计算。
用Excel计算标准差。
离散系数概念:离散系数。
离散系数的计算。
离散系数的用途。
2.3偏态与峰态的度量偏态及其测度概念:偏态,偏态系数。
用Excel计算偏态系数。
偏态系数数值的意义。
峰态及其测度概念:峰态,峰态系数。
用Excel计算峰态系数。
峰态系数数值的意义。
Excel统计函数的应用。
一)判断题1,各变量值与其平均数的离差之和为最小值。
( )2.当各组的变量值所出现的频率相等时,加权算术平均数中的权数就失去作用,因而,加权算术平均数也就等于简单算术平均数( )3.比较两总体的平均数的代表性,离散系数较小的总体,平均数代表性亦小。
( )4,平均数与次数和的乘积等于各变量值与次数乘积的和。
( )5.若两总体的平均数不同,而标准差相同,则离散系数也相同。
( )6.并非任意一个变量数列都可以计算其算术平均数、中位数和众数。
统计学第四章-数据的概括性度量

class), or two or more modes (or modal class). 数据集可能有一个众数(组),或两(多)个众数
(组)。
The modal class 众数组
(计算公式)
Me
1X2NX21N2
XN21
当N为奇数时 当N为偶数时
数值型未分组数据的中位数
(5个数据的算例)
位 置 N1513 22
中位数 22
数值型未分组数据的中位数
(6个数据的算例)
原始数据: 10 5 9 12 6 8 排 序: 5 6 8 9 10 12 位 置: 1 2 3 4 5 6
零
n
(xi x) 0
i1
2). 各变量值与均值的离差平方和最小
n
(xi x)2 min
i1
(二)、调
和平均数 是总体各单位标志值倒数的算术平
harmean (harmonic mean)
均数的倒数,又叫倒数平均数
【例】 设X=(2,4,6,8),则其调和平 均数可由定义计算如下:
⒈求各标志值的倒数 : 1 ,1 ,1 ,1
第四章 数据的概括性度量
4.1 集中趋势度量 4.2 离散程度的度量 4.3 偏态与峰态的度量
数据分布的特征
集中趋势 (位置)
离中趋势 (分散程度) 偏态和峰度 (形状)
4.1 集中趋势的度量
4.1.1. 分类数据:众数 4.1.2. 顺序数据:中位数和分位数 4.1.3. 数值型数据:均值 4.1.4. 众数、中位数和均值的比较
2. 相邻两组的频数相等时,众不相等时,众数采用 下列近似公式计算
统计学各章计算题公式及解题方法

统计学各章计算题公式及解题方法第四章数据的概括性度量1.组距式数值型数据众数的计算:确定众数组后代入公式计算:下限公式:;上限公式:,其中,L为众数所在组下限,U为众数所在组上限,为众数所在组次数与前一组次数之差,为众数所在组次数与后一组次数之差,d为众数所在组组距2.中位数位置的确定:未分组数据为;组距分组数据为3.未分组数据中位数计算公式:4.单变量数列的中位数:先计算各组的累积次数(或累积频率)—根据位置公式确定中位数所在的组-对照累积次数(或累积频率)确定中位数(该公式假定中位数组的频数在该组内均匀分布)5.组距式数列的中位数计算公式:下限公式:;上限公式:,其中,为中位数所在组的频数,为中位数所在组前一组的累积频数,为中位数所在组后一组的累积频数6.四分位数位置的确定:未分组数据:;组距分组数据:7.简单均值:8.加权均值:,其中,为各组组中值统计学各章计算题公式及解题方法9.几何均值(用于计算平均发展速度):10.四分位差(用于衡量中位数的代表性):11.异众比率(用于衡量众数的代表性):12.极差:未分组数据:;组距分组数据:13.平均差(离散程度):未分组数据:;组距分组数据:14.总体方差:未分组数据:;分组数据:15.总体标准差:未分组数据:;分组数据:16.样本方差:未分组数据:;分组数据:17.样本标准差:未分组数据:;分组数据:18.标准分数:19.离散系数:第七章参数估计1.的估计值:置信水平α90%0.1 0。
05 1.65495% 0。
05 0.025 1.9699% 0.01 0。
005 2。
58统计学各章计算题公式及解题方法2.不同情况下总体均值的区间估计:总体分布样本量σ已知σ未知大样本(n≥30)正态分布小样本(n<30)非正态分布大样本(n≥30)其中,查p448 ,查找时需查n—1的数值3.大样本总体比例的区间估计:4.总体方差在置信水平下的置信区间为:5.估计总体均值的样本量:,其中,E为估计误差6.重复抽样或无限总体抽样条件下的样本量:,其中π为总体比例第八章假设检验1.总体均值的检验(已知或未知的大样本)[总体服从正态分布,不服从正态分布的用正态分布近似]假设双侧检验左侧检验右侧检验假设形式已知统计量未知拒绝域值决策,拒绝2.总体均值检验(未知,小样本,总体正态分布)假设双侧检验左侧检验右侧检验统计学各章计算题公式及解题方法假设形式已知统计量未知拒绝域值决策,拒绝注:已知的拒绝域同大样本3.一个总体比例的检验(两类结果,总体服从二项分布,可用正态分布近似)(其中为假设的总体比例)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝4.总体方差的检验(检验)假设双侧检验左侧检验右侧检验假设形式统计量拒绝域值决策,拒绝5.统计量的参考数值0.1 0。
贾俊平《统计学》考研真题(含复试)与典型习题详解(数据的概括性度量)【圣才出品】

2.统计学期中考试非常简单,为了评估简单程度,教师记录了 9 名学生交上考试试卷
的时间如下(分钟)
33 29
45 60 42 19 52 38 36[东北财经大学
2012 研]
(1)这些数据的极差为( )。
A.3.00
B.-3.00
C.41.00
D.-41.00
【答案】C
【解析】数据按从小到大排序结果如下:
A.0.38
B.0.40
C.0.54
D.2.48
【答案】A
【解析】离散系数也称为变异系数,它是一组数据的标准差与其相应的平均数之比。其
计算公式为: vs
s x
。得到 vs
22.85 0.38 。 12.45
9.已知某工厂生产的某零件的平均厚度是 2 厘米,标准差是 0.25 厘米。如果已知该 厂生产的零件厚度为正态分布,可以判断厚度在 1.5 厘米到 2.5 厘米之间的零件大约占 ( )。[浙江工商大学 2011 研]
圣才电子书 十万种考研考证电子书、题库视频学习平台
5.随机变量 X 的方差为 2,随机变量 Y=2X,那么 y 的方差是( )。[中央财经大学 2011 研]
A.1 B.2 C.4 D.8 【答案】D
【解析】Var(cX ) c2Var(X ) 22 2 8
7.设 X1,X2,…,X n 为随机样本,则哪个统计量能较好地反映样本值的分散程度( )。
[中山大学 2012 研] A.样本平均 B.样本中位数 C.样子书
【答案】C
十万种考研考证电子书、题库视频学习平台
【解析】集中趋势是指 一 组 数 据 向 某 一 中 心 值 靠 拢 的 程 度 ,它 反 映 了 一 组 数 据 中 心
第四章 数据的概括性度量

第四章数据的概括性度量第四章 数据的概括性度量一.填空题 1. 是一组数据中出现次数最多的变量值。
2.一组数据排序后处于中间位置上的变量值称 。
3.不受极端值影响的集中趋势度量指标有 . 和 。
4.一组数据的最大值与最小值之差称 。
5. 是一组数据的标准差与其相应的平均数之比。
6.Excel 中计算中位数时选用的函数为 。
7. 某工厂13名工人某日生产零件数分别为(单位:件)10.11.13.11.14.11.12.11.15.16.12.11.13 ,则中位数为 ;众数为 。
8.某百货公司连续几天的销售额如下:257.276.297.252.238.310.240.236.265,则其下四分位数是 。
9.若一组数据的e oX M M 〈〈,则其属于_______________分布(左偏.右偏)。
10.如果一组数据服从标准正态分布,则峰态系数为___________。
11.假定一个总体由5个数据组成:3.7.8.9.13,该总体的方差为。
13.某班共有25名学生,期末统计学课程的考试分数分别为:68.73.66.76.86.74.61.89.65.90.69.67.76.62.81.63.68.81.70.73.60.87.75.64.56,该班考试分数的下四分位数和上四分位数分别是和。
14.在某行业中随机抽取10家企业,第一季度的利润额(单位:万元)分别为72.63.1.54.7.54.3.29.26.9.25.23.9.23.20,该组数据的极差为。
二.单项选择题1.对于对称分布的数据,众数.中位数和平均数的关系是:()。
A.众数>中位数>平均数B.众数=中位数=平均数C.平均数>中位数>众数D.中位数>众数>平均数2.可以计算平均数的数据类型有:()。
A.分类型数据B.顺序型数据C.数据型数据D.所有数据类型3.数值型数据的离散程度测度方法中,受极端变量值影响最大的是()。
A.极差B.方差C.均方差D.平均差4.当偏态系数为正数时,说明数据的分布是()。
(04)数据概括度量

调和平均数的应用
【例】某企业某日工人的日产量资料如下:
日产量(件) 各组工人日总产量(件)
X
10 11 12 13 14
m
700 1100 4560 1950 1400 9710
合计
计算该企业该日全部工人的平均日产量。
调和平均数的应用
解:
XH m 1 Xm 9710 700 1400 10 14
求解比值的平均数的方法
mi 比值 X i fi
X
m f
Xf f
m 1 X m
己知 m、f, 己知 X、f , 采用基本平 采用加权算术 均数公式 平均数公式
己知 X、m , 采用加权调和 平均数公式
求解比值的平均数的方法
【例A】某季度某工业公司18个工业企业 产值计划完成情况如下:
STAT
第四章 数据的概括性度量
统计学家与数学家
一名统计学家遇到一位数学家,统计学家 调侃数学家说道:“你们不是说若X=Y且Y =Z,则X=Z吗!那么想必你若是喜欢一个 女孩,那么那个女孩喜欢的男孩你也会喜欢 喽!?” 数学家想也没事吧!因为它们平均的温度 不过是五十度而已!”
计划完成程度 组中值 (﹪) (﹪) 85 90以下 95 90~100 105 100~110 115 110以上 — 合计 企业数 计划产值 (个) (万元) 2 800 3 2500 10 17200 3 4400 18 24900
计算该公司该季度的平均计划完成程度。
计划完成 实际产值m 求解比值的平均数的方法 X 分析:
1 1 1 1 4 ⒉再求算术平均数: 2 4 6 8
⒊再求倒数:
1 1 1 1 4 2 4 6 8
数据的概括性度量

2度量衡单位
吨,米,立方米
3标准实物单位
拖拉机折合标准台,不同含量的化肥折合为100%含量计算,各种不同发热量的煤折合为7000大卡/千克的标准煤
4复合单位
运输业的吨公里,发电量的千瓦时
5双重或多重单位
发动机“台/千瓦”,船舶用“艘、马力、吨位”三种单位表示
⑵价值指标
以货币为单位计量
⑶劳动指标
从实际应用角度来看,在抽样估计中,当我们用样本方差Sn-1²去估计总体方差σ²时,它是σ²的无偏估计量。
2、时期指标具有可加性,时点指标不能累加。
3、时期指标是流量指标,时点指标是存量指标。
二、总量指标(按其反应的内容不同):分为总体单位总量和总体标志总量
⑴总体单位总量(单位总量):一个总体中所包含的总体单位总数,表示总体本身的规模大小。
⑵总体标志总量(标志总量):是反映统计总体中各单位某一数量标志值的总和表示总体某一数量特征的总量。
⑴时期指标:表明现象在一段时间内发展过程的总量指标
商品销售额,一定时期的产品产量,工资总额
⑵时点指标:表明现象在某一时刻(瞬间)上发展状况的总量指标
人口数,设备台数,商品库存量,储蓄存款余额
区别:
1、时期指标的数值是连续的,可以通过连续登记取得数据。
时点指标的数值是间断计数的,每隔一定时间登记一次。
比如:
要研究某市工业企业的经营情况,该是全部工业企业构成统计总体,工业企业总数是这个总体的单位总量,该市工业企业实现的商品销售额、利税总额、职工人数等就是这个统计总体的标志总量。
三、总量指标(按其采用的计量单位不同):分为实物指标,价值指标,劳动指标,统计指标。
⑴实物计分数
学生考试成绩打分
贾俊平《统计学》(第7版)考研真题与典型题详解-第4章 数据的概括性度量【圣才出品】

第4章数据的概括性度量一、单项选择题1.一组数据的峰度系数为3.5,则该数据的统计分布应具有的特征是()。
[中央财经大学2018研]A.扁平分布B.尖峰分布C.左偏分布D.右偏分布【答案】B【解析】峰度系数用来度量数据在中心的聚集程度。
在正态分布情况下,峰度系数值是3。
大于3的峰度系数说明观察量更集中,有比正态分布更短的尾部;小于3的峰度系数说明观测量不那么集中,有比正态分布更长的尾部,类似于矩形的均匀分布。
2.某企业男性职工占80%,月平均工资为450元,女性职工占20%,月平均工资为400元,该企业全部职工的平均工资为()。
[中央财经大学2015研] A.425元B.430元C.435元D.440元【答案】D【解析】企业全部职工的平均工资=男性职工比例×男性月平均工资+女性职工比例×女性月平均工资=80%×450+20%×400=440(元)。
3.15位同学的某门课程考试成绩中,70分出现3次,80分出现4次,85分出现6次,90分出现2次,则他们成绩的众数为()。
[华中农业大学2015研] A.80B.85C.81.3D.90【答案】B【解析】众数是一组数据中出现次数最多的变量值。
题中,85分出现次数最多,故成绩的众数为85分。
4.一组样本的变异系数(CV)等于10,样本均值为5,则样本方差为()。
[厦门大学2014研]A.2B.4C.0.5D.2500【答案】D【解析】变异系数是一组数据的标准差与其相应的平均数之比,因而样本标准差=样本均值×变异系数=5×10=50,样本方差=50×50=2500。
5.现抽取了10个同学,每个同学的月生活费数据排序后为:660,750,780,850,960,1080,1250,1500,1630,2000。
则中位数的位置为()。
[重庆大学2013研]A.5.5B.5C.4D.6【答案】A【解析】中位数是将样本排序后处于中间位置的数据,总共有10个样本,因此中位数的位次=(1+10)/2=5.5。
《统计学考研题库》【章节题库+名校考研真题+模拟试题】数据的概括性度量【圣才出品】

A.动态相对数 B.平均差 C.标准差 D.标准差系数 【答案】D 【解析】标准差系数是反映变量变动程度的相对指标。其计算公式为:标准差系数=样 本标准差/平均数,消除了平均数不相等的影响。
5.右偏分布的特征是( )。[华东师范大学 2013 研]
2.15 位同学的某门课程考试成绩中,70 分出现 3 次,80 分出现 4 次,85 分出现 6 次, 90 分出现 2 次,则他们成绩的众数为( )。[华中农业大学 2015 研]
A.80 B.85 C.81.3 D.90 【答案】B 【解析】众数是一组数据中出现次数最多的变量值。题中,85 分出现次数最多,故成 电子书 十万种考研考证电子书、题库视频学习平台
3.当变量分布呈右偏分布时,( )。[浙江工商大学 2014 研] A.应该用算术平均数来代表变量值的一般水平 B.众数比算术平均数更适合代表平均水平 C.较小变量值的频数比较大 D.较小变量值的频数比较小 【答案】C 【解析】AB 两项,在偏态分布情况下,由于变量值中出现特别大或特别小的极端数值 使其分布曲线在图形上呈现出不对称的情形。当有极大变量值出现时,为右偏分布,此时算 术平均数易受极端值影响,而众数较平均水平偏小,因此二者均不适用于代表变量值的一般 水平;CD 两项,因为在右偏分布情况下,变量的平均数接近于变量值较大的一端,众数接 近于变量值较小的一端,因此较小变量值的频数比较大。
2 / 42
圣才电子书
A.偏态系数大于 0
十万种考研考证电子书、题库视频学习平台
B.偏态系数小于 0
C.偏态系数等于 0
D.只能从直方图上判断,不能用统计量进行描述
统计学第4章数据的概括性度量

https://
REPORTING
• 引言 • 集中趋势的度量 • 离散程度的度量 • 偏态与峰态的度量 • 数据分布形态的图形表示 • Excel在概括性度量中的应用
目录
PART 01
引言
REPORTING
WENKU DESIGN
概括性度量的定义
方差和标准差能够全面反映数据的离散程度,且计算相对简单。其中标
准差具有与原始数据相同的量纲,更便于比较不同数据集之间的离散程
度。
PART 04
偏态与峰态的度量
REPORTING
WENKU DESIGN
偏态及其度量
偏态定义
偏态是指数据分布的不对称性。 在统计学中,偏态通常通过计算 偏态系数来衡量。
特点
算术平均数对极端值敏感,当数 据集中存在极端异常值时,算术
平均数可能会受到较大影响。
中位数
定义
计算公式
中位数是一组数据按照大小顺序排列后, 位于中间位置的数值,用于反映数据集中 趋势的一个统计指标。
中位数 = 第(n+1)/2项数据(n为数据个数 )适用Fra bibliotek围特点
适用于数值型数据,且数据分布呈偏态或 存在极端异常值的情况。
偏态与峰态度量
包括偏态系数和峰态系数 等,用于描述数据分布的 形态特点。
PART 02
集中趋势的度量
REPORTING
WENKU DESIGN
算术平均数
定义
算术平均数是一组数据的总和 除以数据的个数,用于反映数 据集中趋势的一个统计指标。
计算公式
算术平均数 = 数据总和 / 数据 个数
适用范围
适用于数值型数据,且数据之 间没有极端异常值的情况。
第4章 数据的概括性度量

5
利用图表展示数据,只是对数据分布的形状和特征给出一个粗略的了解,如要全 面把握数据分布的特征,还需要找到反映数据分布特征的各个代表值。 数据分布特征的测度和描述可以分解为三个方面:分布的集中趋势,反映各数据 向中心值靠拢或聚集的程度;离散程度,反映各数据远离其中心值的程度;分布 的形状,反映数据分布的偏态与峰态。
解:这里的数据为顺序数据。变 量为“回答类别” 甲城市中对住房表示不满 意的户数最多,为 108 户,因此 众数为“不满意”这一类别,即
户数 (户)
24 108 93 45 30 300
百分比 (%)
8 36 31 15 10 100.0
Mo=不满意
12
70
顺序数据:中位数和分位数
在一组数据中,可以找出处在某个位置上的数据,称为分位数。 常用的分位数主要有中位数和四分位数。
中位数(median)
13
i 1
n
xi M e min
70
中位数(位置和数值的确定)
位置确定 中位数位置 n 1
2
n为数据个数
设一组数据按从小到大的顺序排序成x(1),x(2),…,x(n), 则中位数
x n 1 2 数值确定 M e 1 x n x n 1 2 2 2
果汁 矿泉水 绿茶 其他 碳酸饮料 合计
6 10 11 8 15 50
0.12 0.20 0.22 0.16 0.30 1
12 20 22 16 30 100
Mo=碳酸饮料
11
70
顺序数据的众数(例题分析)
甲城市家庭对住房状况评价的频数分布 回答类别 非常不满意 不满意 一般 满意 非常满意 合计 甲城市
贾俊平《统计学》(第5版)章节题库-第4章 数据的概括性度量【圣才出品】

第4章 数据的概括性度量一、单项选择题1.一组数据中出现频数最多的变量值称为( )。
A.众数B.中位数C.四分位数D.平均数【答案】A【解析】众数是一组数据中出现次数最多的变量值。
众数主要用于测度分类数据的集中趋势。
一般情况下,只有在数据量较大的情况下,众数才有意义。
2.下列关于众数的叙述,不正确的是( )。
A.一组数据可能存在多个众数B.众数主要适用于分类数据C.一组数据的众数是唯一的D.众数不受极端值的影响【答案】C【解析】众数是一组数据中出现次数最多的变量值。
众数主要用于测度分类数据的集中趋势,当然也适用于作为顺序数据以及数值型数据集中趋势的测度值。
一般情况下,只有在数据量较大的情况下,众数才有意义。
一组数据可能存在多个众数,由于众数是一个位置代表值,因此它不受数据中极端值的影响。
3.一组数据排序后处于中间位置上的变量值称为( )。
A.众数B.中位数C.四分位数D.平均数【答案】B【解析】中位数是一组数据排序后处于中间位置上的变量值。
中位数将全部数据等分成两部分,每部分包含50%的数据,一部分数据比中位数大,另一部分则比中位数小。
4.一组数据排序后处于25%和75%位置上的值称为( )。
A.众数B.中位数C.四分位数D.平均数【答案】C【解析】四分位数也称四分位点,它是一组数据排序后处于25%和75%位置上的值。
四分位数是通过3个点将全部数据等分为4部分,其中每部分包含25%的数据。
5.非众数组的频数占总频数的比例称为( )。
A.异众比率B.离散系数C.平均差D.标准差【答案】A【解析】异众比率是指非众数组的频数占总频数的比例。
主要用于衡量众数对一组数据的代表程度。
6.四分位差是( )。
A.上四分位数减下四分位数的结果B.下四分位数减上四分位数的结果C.下四分位数加上四分位数D.四分位数与上四分位数的中间值【答案】A【解析】四分位差也称内距或四分间距,它是上四分位数与下四分位数之差。
四分位差反映了中间50%数据的离散程度,其数值越小,说明中间的数据越集中;其数值越大,说明中间的数据越分散。
统计学贾俊平第4章 数据的概括性度量

均值(续)
事实上,各个观察值与平均数差的总和为0
证明
( xi x ) 0
i 1
n
x x x n x
x x n
i 1 i i i
n
xi n x
All rights reserved
30
均值(续)
n
各个观察值与平均数差的平方和为最小
员工每人加薪5000元
Income 3 4 5 3 4 3.8
33
Name A B C D E Average
Raise 0.5 0.5 0.5 0.5 0.5
New income 3.5 4.5 5.5 3.5 4.5 4.3
All rights reserved
i
组中值x i 3.5 4.5 5.5 6.5
x i× f i 119 58.5 132 208 517.5
xf x
i
n
517 .5 103
28
All rights reserved
均值(续)
均值的性质
均值是要找到一平衡点
均值 Min(观察值与该点的距离 )
29
All rights reserved
i i
fi 34 13 24 32 103
xi×f i 102 52 120 192 466
n
26
n
i
f x
i
i
i
f x x n
i
All rights reserved
均值(续)
加权(weighted)问题
27
All rights reserved
统计学数据的概括性量详解

(总体) (样本)
10
Nankai University
❖ 根据分组数据计算的平均数称为加权平均数,设共分成k组, 各组组中值分别用M1,M2,…Mk表示,f1,f2,…fk表示各组频数,
式中n为样本量 n f。i
k
fiMi
X i1 n
❖ 计算加权平均数时,用各组的组中值代表各组的实际数据,使 用这一代表值时是假定各组数据在组内是均匀分布的,如果实 际数据与这一假定相吻合,计算的结果还是比较准确的,否则 误差会很大。
n
1 4
,QU
位置
3(n 1) 4
8
Nankai University
❖ 如果位置是整数,四分位数就是该位置对应的值;如果是 在0.5的位置上,则取该位置两侧值的平均数;如果是在 0.25或0.75的位置上,则四分位数等于该位置的下侧值 加上按比例分摊位置两侧数值的差值。
❖ Q1=第1四分位数,即第25百分位数 ❖ Q2=第2四分位数,即第50百分位数 ❖ Q3=第3四分数据的集中趋势测度值。
17
Nankai University
2.数据离散程度的度量
18
Nankai University
❖ 数据的离散程度是数据分布的另一个重要特征,反映的是 各变量值远离其中心值的程度。
❖ 当所平均的各比率数值相差不大时,算术平均和几何平均 的结果相差不大,否则二者的差别就很明显。
12
Nankai University
❖ 例1:调查300个人的政党背景,形成如下数据分布结果 ,请问众数是什么?
政党背景 民主党 共和党 无党派人士
频数 90 70 140
❖ 例2:随机抽取9个学生,调查得到的每位学生的人均月 花销数据如下,请计算众数、中位数、均值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
众数
(mode)
一组数据中出现次数最多的变量值 适合于数据量较多时使用 不受极端值的影响 一组数据可能没有众数或有几个众数 主要用于分类数据,也可用于顺序数据和
数值型数据 应用范围不多
众数
(不惟一性)
无众数 原始数据: 4 3 7 10 5 9 12 6 8
2017年底港府统计处发表《2016年中期人口统计》, 称本港人均居住面积中位数为161呎(约合15平方米)
四分位数
(quartile)
排序后处于25%和75%位置上的值
25% 25% 25% 25%
QL
QM
QU
不受极端值的影响
四分位数
(位置的确定)
原始数据:
分组数据:
数值型数据的四分位数
(9个数据的算例)
合计
人数
3 7 13 5 2
30
向上累积
3 10 23 28 30
——
mefm
.i
100
30 / 2 10 10 13
103.85
美国人口普查局发布报告显示,2013年美国家庭年 收入的中位数是51939美元
四口之家的年收入在23624美元以下即为贫困户。
2016年,美国家庭收入中位数增长3.2%,从2015 年的57230美元增至59039美元,创有记录以来新 高,超过1999年的前纪录58655美元。所有数字都 是经过通胀调整后的。
位 置: 1 2 3 4 5 6 7 8 9
中位数 1080(元/月)
数值型数据的中位数
(9个数据的实例)
【例1】 10个家庭的人均月生活费支出数据
原始数据: 1500 750 780 1080 850 960 2000 1250 1630 1680 排 序: 750 780 850 960 1080 1250 1500 1630 1680 2000
位 置: 1 2 3 4 5 6 7 8 9 10
中位数 (1080+1250)/2=1165(元/月)
分组数据的中位数的近似公式
me
l
n
/
2 fm
sm1
.i
在求中位数时,如果数据大量重复某一数值 ,这时的中位数未必准确,在解释时要特别 小心。
实例分析
按零件加工数分组
80-90 90-100 100-110 110-120 120-130
样本均值
k
x x1 f1 x2 f2 L xk fk i1xi fi
f1 f2 L fk
k
i1
fi
实例分析
按零件加工数分组
80-90 90-100 100-110 110-120 120-130
合计
人数
3 7 13 5 2
30
组中值
加权均值 (例题分析)
k
x
xi fi
i 1 k
fi
排 序: 660 750 780 850 960 1080 1250 1500 1630 2000
位 置: 1 2 3 4 5 6 7 8 9 10
试想一下分组数据的四分数计算近似公 式
十分位数
有几个十分位数? 十分位数的位置如何确定 如何求十分位数?
百分位数
有几个百分位数? 百分位数的位置如何确定 如何求百分位数?
均值
(mean)
1. 集中趋势的最常用测度值 2. 一组数据的均衡点所在 3. 易受极端值的影响 4. 是客观事物必然性数量特征的一种反映
简单均值
(simple mean)
总体均值 样本均值
加权均值
(weighted mean)
设一组数据为: x1 ,x2 ,… ,xk 相应的频数为: f1 , f2 ,… ,fk
一个众数 原始数据: 5 5 6 5 9 8 5 5 5
多于一个众数 原始数据:28 25 28 28 28 36 42 42 42 42
原始数据(职业):
教师 医生 公务员 教师 医生 银行职员 财务人员 医 生 教师 教师
中位数
(median)
排序后处于中间位置上的值
50%
Me
不受极端值的影响
平均增长速度等方面有很重要的作用。
计算公式
G
n
x 1
x2
L
xn
适用于特殊数据,变量值x一般为比率
9.97%
某企业最近4年产品销售收入的年增长 率分别为8%、7%、12%、13%,求该企 业这4年销售收入的年平均增长率?
50%
主要用于顺序数据,也可用数值型数据,但不能用 于分类数据
各变量值与中位数的离差绝对值之和最小。
中位数的位置
未分组数据 中位数的位置=(1+n)/2
分组数据 中位数的近似位置=n/2
数值型数据的中位数
(9个数据的实例)
【例1】 9个家庭的人均月生活费支出数据
原始数据: 1500 750 780 1080 850 960 2000 1250 1630 排 序: 750 780 850 960 1080 1250 1500 1630 2000
第四章 统计数据的概括性度量
4.1 集中趋势的度量 4.2 离散程度的度量 4.3 偏态与峰态的度量
学习目标
• 掌握集中趋势各测度值的计算方法和 应用场合
• 掌握离散程度各测度值的计算方法及 应用场合
• 了解偏态和峰态的测度方法 • 能运用EXCEL计算描述统计量并进行分
析
4.1 集中趋势的度量
85 3 95 7 105 13 115 5 125 2 30
i 1
3110 103.67 30
均值
(数学性质)
各变量值与均值的离差之和等于零
n
xi x 0
i 1
各变量值与均值的离差平方和最小
n
( xi x )2 m in i 1
几何平均数
是n个变量值乘积的n次方根,用G表示 在计算社会经济问题的平均发展速度和
【例1】:9个家庭的人均月收入数据
原始数据: 1500 750 780 1080 850 960 2000 1250 1630
排 序: 750 780 850 960 1080 1250 1500 1630 2000
位 置: 1 2 3 4 5 6 7 8 9
【例2】:10个家庭的人均月收入数据
4.1.1 众数 4.1.2 中位数和分位数 4.1.3 平均数 4.1.4 众数、中位数和平均数的比较
集中趋势
1. 一组数据向其中心值靠拢的倾向和程度 2. 测度集中趋势就是寻找数据水平的代表值或中心值 3. 不同类型的数据用不同的集中趋势测度值 4. 低层次数据的测度值适用于高层次的测量数据,但高