32位浮点数开平方设计仿真实验报告
vivado cordic ip核计算平方根

Vivado Cordic IP核计算平方根一、背景介绍在数字信号处理领域中,计算平方根是一个非常重要的运算。
在FPGA设计中,使用Cordi c算法来计算平方根是一种非常高效的方法。
Cordic算法是一种迭代算法,可以用于计算三角函数、指数函数、对数函数等。
二、Cordic算法原理Cordic算法是一种旋转算法,它使用一系列的旋转向量将一个向量旋转到另一个向量。
在计算平方根时,我们可以将一个数表示为一个向量(x,0),然后使用Cordic算法将它旋转到向量(1,0),这样就可以得到这个数的平方根。
Cordic算法的核心是旋转向量的选择。
对于计算平方根,我们可以使用以下旋转向量:K(i) = 2^(-i)theta(i) = arctan(2^(-i))在每一次迭代中,我们将向量旋转一个角度theta(i),然后将向量的长度缩小一个因子K(i)。
这样,经过多次迭代,向量就会被旋转到向量(1,0),这时向量的长度就是原数的平方根。
三、Vivado Cordic IP核Vivado是Xilinx公司推出的一款FPGA设计软件,它包含了很多IP核,其中就包括了Cordic IP核。
使用Vivado Cordic IP核来计算平方根非常简单,只需要按照以下步骤操作:1. 打开Vivado软件,创建一个新的工程。
2. 在工程中添加Cordic IP核。
可以在IP目录中找到Cordic IP核,然后将它添加到工程中。
3. 配置Cordic IP核。
在配置界面中,选择计算平方根,并设置输入数据的位宽和精度。
可以选择使用定点数或浮点数进行计算。
4. 运行仿真。
在仿真中,可以输入一个数,然后观察输出结果是否正确。
五、实例演示下面是一个使用Vivado Cordic IP核计算平方根的实例演示。
假设我们要计算数值9的平方根,我们可以按照以下步骤操作:1. 打开Vivado软件,创建一个新的工程。
2. 在工程中添加Cordic IP核。
32位程序 double类型计算处理

标题:32位程序中的double类型计算处理随着计算机科学技术的不断发展,双精度浮点数(double)类型在32位程序中的计算处理成为了关注的焦点之一。
本文将就此话题进行探讨,介绍双精度浮点数在32位程序中的计算处理方法和注意事项。
1. 双精度浮点数的定义和特点双精度浮点数是一种用于表示实数的数据类型,通常占据64位的存储空间,其中52位用于表示尾数,11位用于表示指数,1位用于表示符号位。
这使得双精度浮点数在表示范围和精度上都比单精度浮点数更加优越,因此在科学计算和工程领域得到广泛应用。
2. 双精度浮点数在32位程序中的计算处理双精度浮点数在32位程序中的计算处理需要特别注意,因为在32位系统中,CPU通常只能一次处理32位的数据。
在进行双精度浮点数的计算处理时,需要借助CPU的特殊指令集或者使用软件模拟的方式来完成。
3. 特殊指令集的利用对于支持双精度浮点数计算的32位系统,通常会提供一些特殊的指令集来加速双精度浮点数的计算处理。
Intel的SSE(Streaming SIMD Extensions)指令集就提供了对双精度浮点数进行快速计算的指令,可以大大提高计算速度。
4. 软件模拟的处理方法对于不支持双精度浮点数计算的32位系统,可以通过软件模拟的方式来实现双精度浮点数的计算处理。
这种方法虽然速度较慢,但可以在不支持硬件加速的系统上实现双精度浮点数的计算。
5. 精度和舍入误差的问题双精度浮点数的计算处理中,由于计算机内部二进制表示和十进制实数的差异,常常会出现精度损失和舍入误差。
因此在对双精度浮点数进行计算处理时,需要特别注意精度问题,避免因为舍入误差而影响计算结果的准确性。
6. 结论在32位程序中进行双精度浮点数的计算处理,需要结合特殊指令集和软件模拟的方法来实现。
同时要注意精度和舍入误差的问题,保证计算结果的准确性。
希望本文能够对读者有所帮助,谢谢!通过以上的内容,应该可以帮助你写出一篇高质量的、流畅易读的文章。
基于FPGA的32位浮点运算单元的设计及其VHDL代码的MATLAB验证.(IJIEEB-V6-N1-1)

I.J. Information Engineering and Electronic Business, 2014, 1, 1-14Published Online February 2014 in MECS (/)DOI: 10.5815/ijieeb.2014.01.01Design of FPGA based 32-bit Floating Point Arithmetic Unit and verification of its VHDLcode using MATLABNaresh Grover, M.K.SoniFaculty of Engineering and Technology, Manav Rachna International University, Faridabad, Indiagrovernr@, dr_mksoni@Abstract —Most of the algorithms implemented in FPGAs used to be fixed-point. Floating-point operations are useful for computations involving large dynamic range, but they require significantly more resources than integer operations.With the current trends in system requirements and available FPGAs, floating-point implementations are becoming more common and designers are increasingly taking advantage of FPGAs as a platform for floating-point implementations. The rapid advance in Field-Programmable Gate Array (FPGA) technology makes such devices increasingly attractive for implementing floating-point arithmetic. Compared to Application Specific Integrated Circuits, FPGAs offer reduced development time and costs. Moreover, their flexibility enables field upgrade and adaptation of hardware to run-time conditions. A 32 bit floating point arithmetic unit with IEEE 754 Standard has been designed using VHDL code and all operations of addition, subtraction, multiplication and division are tested on Xilinx. Thereafter, Simulink model in MAT lab has been created for verification of VHDL code of that Floating Point Arithmetic Unit in Modelsim.Index Terms—Floating Point, Arithmetic Unit, VHDL, Modelsim, Simulink.1. IntroductionThe floating point operations have found intensive applications in the various fields for the requirements for high precious operation due to its great dynamic range, high precision and easy operation rules. High attention has been paid on the design and research of the floating point processing units. With the increasing requirements for the floating point operations for the high-speed data signal processing and the scientific operation, the requirements for the high-speed hardware floating point arithmetic units have become more and more exigent. The implementation of the floating point arithmetic has been very easy and convenient in the floating point high level languages, but the implementation of the arithmetic by hardware has been very difficult. With the development of the very large scale integration (VLSI) technology, a kind of devices like Field Programmable Gate Arrays (FPGAs) have become the best options for implementing floating hardware arithmetic units because of their high integration density, low price, high performance and flexible applications requirements for high precious operation.Floating-point implementation on FPGAs has been the interest of many researchers. The use of custom floating-point formats in FPGAs has been investigated in a long series of work [1, 2, 3, 4, 5]. In most of the cases, these formats are shown to be adequate for some applications that require significantly less area to implement than IEEE formats [6] and to run significantly faster than IEEE formats. Moreover, these efforts demonstrate that such customized formats enable significant speedups for certain chosen applications. The earliest work on IEEE floating-point [7] focused on single precision although found to be feasible but it was extremely slow. Eventually, it was demonstrated [8] that while FPGAs were uncompetitive with CPUs in terms of peak FLOPs, they could provide competitive sustained floating-point performance. Since then, a variety of work [2, 5, 9, 10] has demonstrated the growing feasibility of IEEE compliant, single precision floating point arithmetic and other floating-point formats of approximately same complexity. In [2, 5], the details of the floating-point format are varied to optimize performance. The specific issues of implementing floating-point division in FPGAs have been studied [10]. Early implementations either involved multiple FPGAs for implementing IEEE 754 single precision floating-point arithmetic, or they adopted custom data formats to enable a single-FPGA solution. To overcome device size restriction, subsequent single-FPGA implementations of IEEE 754 standard employed serial arithmetic or avoided features, such as supporting gradual underflow, which are expensive to implement.In this paper, a high-speed IEEE754-compliant 32-bit floating point arithmetic unit designed using VHDL code has been presented and all operations of addition, subtraction, multiplication and division got tested on Xilinx and verified successfully. Thereafter, the new feature of creating Simulink model using MAT lab for verification of VHDL code of that 32-bit Floating Point Arithmetic Unit in Modelsim has been explained. The si mu lat io n r esu lts o f ad d itio n, su b tr actio n, multiplication and division in Modelsim wave windowhave been demonstrated.The rest of the paper is organized as follows. Section 2 presents the general floating point architecture. Section 3 explains the algorithms used to write VHDL codes for implementing 32 bit floating point arithmetic operations: addition/subtraction, multiplication and division. The Section 4 of the paper details the VHDL code and behaviour model for all above stated arithmetic operation. The section 5 explains the design steps along with experimental method to create Simulink model in MAT lab for verification of VHDL code in Modelsim and the results are shown and discussed in its section 6 while section 7 concludes the paper with further scope of work.2. Floating Point ArchitectureFloating point numbers are one possible way of representing real numbers in binary format; the IEEE 754 [11] standard presents two different floating point formats, Binary interchange format and Decimal interchange format. This paper focuses only on single precision normalized binary interchange format. Figure 1 shows the IEEE 754 single precision binary format representation; it consists of a one bit sign (S), an eight bit exponent (E), and a twenty three bit fraction (M) or Mantissa.32 bit Single Precision Floating Point Numbers IEEE standard are stored as:S EEEEEEEE MMMMMMMMMMMMMMMMMMMMMMS: Sign – 1 bitE: Exponent – 8 bitsM: Mantissa – 23 bits Fraction32 bitsFigure.1: IEEE 754 single precision binary format representation The value of number V:If E=255 and F is nonzero, then V= Nan ("Not a Number")If E=255 and F is zero and S is 1, then V= - InfinityIf E=255 and F is zero and S is 0, then V= InfinityIf 0<E<255 then V= (-1) **S * 2 ** (E-127) * (1.F) (exponent range = -127 to +128)If E=0 and F is nonzero, then V= (-1) **S * 2 ** (-126) * (0.F) ("un-normalized" values”)If E=0 and F is zero and S is 1, then V= - 0If E=0 and M is zero and S is 0, then V = 0An extra bit is added to the mantissa to form what is called the significand. If the exponent is greater than 0 and smaller than 255, and there is 1 in the MSB of the significand then the number is said to be a normalized number; in this case the real number is represented by (1)V = (-1s) * 2 (E - Bias) * (1.M) (1)Where M = m22 2-1+ m21 2-2+ m20 2-3+…+ m1 2-22+m0 2-23; Bias = 127.3. Algorithms for Floating Point Arithmetic UnitThe algorithms using flow charts for floating point addition/subtraction, multiplication and division have been described in this section, that become the base for writing VHDL codes for implementation of 32-bit floating point arithmetic unit.3.1 Floating Point Addition / SubtractionThe algorithm for floating point addition is explained through flow chart in Figure 2. While adding the two floating point numbers, two cases may arise. Case I: when both the numbers are of same sign i.e. when both the numbers are either +ve or –ve. In this case MSB of both the numbers are either 1 or 0. Case II: when both the numbers are of different sign i.e. when one number is +ve and other number is –ve. In this case the MSB of one number is 1 and other is 0.Case I: - When both numbers are of same signStep 1:- Enter two numbers N1 and N2. E1, S1 and E1, S2 represent exponent and significand of N1 and N2 respectively.Step 2:- Is E1 or E2 =‟0‟. If yes; set hidden bit of N1 or N2 is zero. If not; then check if E2 > E1, if yes swap N1 and N2 and if E1 > E2; contents of N1 and N2 need not to be swapped.Step 3:- Calculate difference in exponents d=E1-E2. If d = …0‟ then there is no need of shifting the significand. If d is more than …0‟ say …y‟ then shift S2 to the right by an amount …y‟ and fill the left most bits by zero. Sh ifting is done with hidden bit.Step 4:- Amount of shifting i.e. …y‟ is added to exponent of N2 value. New exponent value of E2= (previous E2) + …y‟. Now result is in normalize form because E1 = E2. Step 5:- Check if N1 and N2 have different sign, if …no‟; Step 6:- Add the significands of 24 bits each including hidden bit S=S1+S2.Step 7:- Check if there is carry out in significand addition. If yes; then add …1‟ to the exponent value of either E1 or new E2. After addition, shift the overall result of significand addition to the right by one by making MSB of S as …1‟ a nd dropping LSB of significand.Step 8:- If there is no carry out in step 6, then previous exponent is the real exponent.Step 9:- Sign of the result i.e. MSB = MSB of either N1 or N2.Step 10:- Assemble result into 32 bit format excluding 24th bit of significand i.e. hidden bit.Case II: - When both numbers are of different sign Step 1, 2, 3 & 4 are same as done in case I.Step 5:- Check if N1 and N2 have different sign, if …Yes‟;Step 6:- Take 2‟s complement of S2 and then add it to S1 i.e. S=S1+ (2‟s co mplement of S2).Step 7:- Check if there is carry out in significand addition. If yes; then discard the carry and also shift the result to left until there is …1‟ in MSB and also count the amount of shifting say …z‟.Step 8:- Subtract …z‟ from exponent val ue either from E1 or E2. Now the original exponent is E1-…z‟. Also append the …z‟ amount of zeros at LSB.Step 9:- If there is no carry out in step 6 then MSB must be …1‟ and in this case simply replace …S‟ by 2‟s complement.Step 10:- Sign of the result i.e. MSB = Sign of the larger number either MSB of N1or it can be MSB of N2. Step 11:- Assemble result into 32 bit format excluding 24th bit of significand i.e. hidden bit.Figure. 2: Flow Chart for floating point Addition/SubtractionIn this algorithm three 8-bit comparators, one 24-bit and two 8-bit adders, two 8-bit subtractors, two shift units and one swap unit are required in the design.First 8-bit comparator is used to compare the exponent of two numbers. If exponents of two numbers are equal then there is no need of shifting. Second 8-bit comparator compares exponent with zero. If the exponent of any number is zero set the hidden bit of that number zero. Third comparator is required to check whether the exponent of number 2 is greater than number 1. If the exponent of number 2 is greater than number 1 then the numbers are swapped.One subtractor is required to compute the difference between the 8-bit exponents of two numbers. Second subtractor is used if both the numbers are of different sign than after addition of the significands of two numbers if carry appears. This carry is subtracted from the exponent using 8-bit subtractor.One 24-bit adder is required to add the 24-bit significands of two numbers. One 8-bit adder is required if both the numbers are of same sign than after addition of the significands of two numbers if carry appears. This carry is added to the exponent using 8-bit adder. Second 8-bit adder is used to add the amount of shifting to the exponent of smaller number.One swap unit is required to swap the numbers if N2 is greater than N1. Swapping is normally done by taking the third variable. Two shift units are required one is shift left and second is shift right.3.2 Floating Point MultiplicationThe algorithm for floating point multiplication is explained through flow chart in Figure 3. Let N1 and N2 are normalized operands represented by S1, M1, E1 and S2, M2, E2 as their respective sign bit, mantissa (significand) and exponent. Basically following four steps are used for floating point multiplication.1. Multiply signifcands, add exponents, and determine signM=M1*M2E=E1+E2-BiasS=S1XORS22. Normalize Mantissa M (Shift left or right by 1) and update exponent E3. Rounding the result to fit in the available bits4. Determine exception flags and special values for overflow and underflow.Figure. 3: Flow Chart for floating point MultiplicationSign Bit Calculation: The result of multiplication is a negative sign if one of the multiplied numbers is of a negative value and that can be obtained by XORing the sign of two inputs.Exponent Addition is done through unsigned adder for adding the exponent of the first input to the exponent of the second input and after that subtract the Bias (127) from the addition result (i.e. E1+E2 - Bias). The result of this stage can be called as intermediate exponent. Significand Multiplication is done for multiplying the unsigned significand and placing the decimal point in the multiplication product. The result of significand multiplication can be called as intermediate product (IP). The unsigned significand multiplication is done on 24 bit.The result of the significand multiplication (intermediate product) must be normalized to have a leading …1‟ just to the left of the decimal point (i.e. in the bit 46 in the intermediate product). Since the inputs are normalized numbers then the intermediate product has the leading one at bit 46 or 47. If the leading one is at bit 46 (i.e. to the left of the decimal point) then the intermediate product is already a normalized number and no shift is needed. If the leading one is at bit 47 then the intermediate product is shifted to the right and the exponent is incremented by 1.Overflow/underflow means that the result‟s exponent is too large/small to be represented in the exponent field. Themust be between 1 and 254 otherwise the value is not anormalized one .An overflow may occur while adding the two exponents or during normalization. Overflow due to exponent addition can be compensated during subtraction of the bias; resulting in a normal output value (normal operation). An underflow may occur while subtracting the bias to form the intermediate exponent. If the intermediate exponent < 0 then it is an underflow that can never be compensated; if the intermediate exponent = 0 then it is an underflow that may be compensated during normalization by adding 1 to it .When an overflow occurs an overflow flag signal goes high and the result turns to ±Infinity (sign determined according to the sign of the floating point multiplier inputs). When an underflow occurs an underflow flag signal goes high and the result turns to ±Zero (sign determined according to the sign of the floating point multiplier inputs). 3.3 Floating Point DivisionThe algorithm for floating point multiplication is explained through flow chart in Figure 4. Let N1 and N2 are normalized operands represented by S1, M1, E1 and S2, M2, E2 as their respective sign bit, mantissa (significand) and exponent. If let us say we consider x=N1 and d=N2 and the final result q has been taken as “x/d”. Again the following four steps are used for floating point division.Figure. 4: Flow Chart for floating point Division (q = x/d; N1=x and N2=d)1. Divide signifcands, subtract exponents, and determine signM=M1/M2E=E1-E2S=S1XORS22. Normalize Mantissa M (Shift left or right by 1) and update exponent E3. Rounding the result to fit in the available bits4. Determine exception flags and special valuesThe sign bit calculation, mantissa division, exponent subtraction (no need of bias subtraction here), rounding the result to fit in the available bits and normalization is done in the similar way as has been described for multiplication.4. VHDL CodeThis section illustrates the main steps of VHDL code that has been used to implement the 32-bit floating point arithmetic functions: addition/subtraction, multiplication and division. It includes the arithmetic structure followed by behavior model for different arithmetic functions for 32-bit floating point format following IEEE 754 standards.ARITHMETIC UNIT STRUCTUREentity fp_alu isport(in1,in2:in std_logic_vector(31 downto 0);clk:in std_logic;sel:in std_logic_vector(1 downto 0);output1:out std_logic_vector(31 downto 0));end fp_alu;architecture fp_alu_struct of fp_alu iscomponent divider isport(clk : in std_logic;res : in std_logic;GO : in std_logic;x : in std_logic_vector(31 downto 0);y : in std_logic_vector(31 downto 0);z : out std_logic_vector(31 downto 0);done : out std_logic;overflow : out std_logic);end component;component fpa_seq isport(n1,n2:in std_logic_vector(32 downto 0);clk:in std_logic;sum:out std_logic_vector(32 downto 0));end component;component fpm isport(in1,in2:in std_logic_vector(31 downto 0);out1:out std_logic_vector(31 downto 0));end component;signal out_fpa: std_logic_vector(32 downto 0);signal out_fpm,out_div: std_logic_vector(31 downto 0); signal in1_fpa,in2_fpa: std_logic_vector(32 downto 0); beginin1_fpa<=in1&'0';in2_fpa<=in2&'0';fpa1:fpa_seq port map(in1_fpa,in2_fpa,clk,out_fpa); fpm1:fpm port map(in1,in2,out_fpm);fpd1:divider port map(clk,'0','1',in1,in2,out_div); process(sel,clk)beginif(sel="01")thenoutput1<=out_fpa(32 downto 1);elsif(sel="10")thenoutput1<=out_fpm;elsif(sel="11")thenoutput1<=out_div;end if;end process;end fp_alu_struct;FPA BEHAVIOURentity fpa_seq isport(n1,n2:in std_logic_vector(32 downto 0);clk:in std_logic;sum:out std_logic_vector(32 downto 0));end fpa_seq;architecture Behavioral of fpa_seq is--signal f1,f2:std_logic_vector(23 downto0):="000000000000000000000000";signal sub_e:std_logic_vector(7 downto0):="00000000";--signal addi:std_logic_vector(34 downto 0);signal c_temp:std_logic:='0';--_vector(34 downto 0); signal shift_count1:integer:=0;signal num2_temp2: std_logic_vector(32 downto 0):="000000000000000000000000000000000"; signal s33:std_logic_vector(23 downto0):="000000000000000000000000";signal s2_temp :std_logic_vector(23 downto0):="000000000000000000000000";signal diff:std_logic_vector(7 downto 0):="00000000"; ----------sub calling-----------------------------------------------------------------sub(e1,e2,d);if(d>="00011100")thensum<=num1;elsif(d<"00011100")thenshift_count:=conv_integer(d);shift_count1<=shift_count;num2_temp2<=num2;--s2_temp<=s2;--------------shifter calling---------------------------------------------------------shift(s2,shift_count,s3);--s33<=s3;------------sign bit checking------if (num1(32)/=num2(32))thens3:=(not(s3)+'1');------2's complementadder23(s1,s3,s4,c_out);if(c_out='1')thenshift_left(s4,d_shl,ss4);sub(e1,d_shl,ee4);sum<=n1(32)& ee4 & ss4;elseif(s4(23)='1')thens4:=(not(s4)+'1');------2's complementsum<=n1(32)& e1 & ss4;end if;end if; elses3:=s3;-- end if;---------------------same sign start---------------adder 8 calling--------------- adder8(e2,d,e3);sub_e<=e3;num1_temp:=n1(32)& e1 & s1;num2_temp:=n2(32)& e3 & s3;---------------adder 23 calling--------------- adder23(s1,s3,s4,c_out);--s2_temp<=s4;c_temp<=c_out;if(c_out='1')then--shift1(s4,s_1,s5);--s2_temp<=s5;s33<=s4;s5:='1' & s4(23 downto 1);s2_temp<=s5;adder8(e3,"00000001",e4);e3:=e4;--sub_e<=e4;sum<=n1(32)& e3 & s5;elsesum<=n1(32)& e3 & s4;end if;end if;end if;end if;----same sign endend if;------final result assembling------------sum_temp<=n1(32)& e1 & s4;--sum<=n1(32)& e3 & s4;end process;end Behavioral;FPM BEHAVIOURentity fpm isport(in1,in2:in std_logic_vector(31 downto 0);out1:out std_logic_vector(31 downto 0));end fpm;architecture Behavioral of fpm isprocedure adder( a,b:in std_logic_vector(7 downto 0); sout : out STD_LOGIC_VECTOR (8 downto 0))isvariable g,p:std_logic_vector(7 downto 0);variable c:std_logic_vector(8 downto 0);variable sout1 :STD_LOGIC_VECTOR (7 downto 0); beginc(0):='0';for i in 0 to 7 loopg(i):= a(i) and b(i);p(i):= a(i) xor b(i);end loop;for i in 0 to 7 loopc(i+1):=(g(i) or (c(i) and p(i)));end loop;for i in 0 to 7 loopsout1(i):=c(i) xor a(i) xor b(i);end loop;sout:=c(8) & sout1;end adder;-------------------------------------------multiplier-------------------------------procedure multiplier ( a,b : in STD_LOGIC_VECTOR (23 downto 0);y : out STD_LOGIC_VECTOR (47 downto 0))is variable temp,prod:std_logic_vector(47 downto 0); begintemp:="000000000000000000000000"&a;prod:="000000000000000000000000000000000000000 000000000";for i in 0 to 23 loopif b(i)='1' thenprod:=prod+temp;end if;temp:=temp(46 downto 0)&'0';end loop;y:=prod;end multiplier; --------------------------end multipier-----------------------------------------------beginprocess(in1,in2)variable sign_f,sign_in1,sign_in2: std_logic:='0'; variable e1,e2: std_logic_vector(7 downto0):="00000000";variable add_expo:std_logic_vector(8 downto0):="000000000";variable m1,m2: std_logic_vector(23 downto0):="000000000000000000000000";variable mantisa_round: std_logic_vector(22 downto 0):="00000000000000000000000";variable prod:std_logic_vector(47 downto0):="00000000000000000000000000000000000000000 0000000";variable mul_mantisa :std_logic_vector(47 downto 0):="00000000000000000000000000000000000000000 0000000";variable bias:std_logic_vector(8 downto0):="001111111";variable bias_sub:std_logic_vector(7 downto0):="00000000";variable inc_bias:std_logic_vector(8 downto0):="000000000";variable bias_round:std_logic_vector(8 downto0):="000000000";beginsign calculationsign_in1:=in1(31);sign_in2:=in2(31);sign_f:=sign_in1 xor sign_in2;FPD BEHAVIOURentity divider isport(clk : in std_logic;res : in std_logic;GO : in std_logic;x : in std_logic_vector(31 downto 0);y : in std_logic_vector(31 downto 0);z : out std_logic_vector(31 downto 0);done : out std_logic;overflow : out std_logic);end divider;architecture design of divider issignal x_reg : std_logic_vector(31 downto 0);signal y_reg : std_logic_vector(31 downto 0);signal x_mantissa : std_logic_vector(23 downto 0); signal y_mantissa : std_logic_vector(23 downto 0); signal z_mantissa : std_logic_vector(23 downto 0); signal x_exponent : std_logic_vector(7 downto 0); signal y_exponent : std_logic_vector(7 downto 0); signal z_exponent : std_logic_vector(7 downto 0); signal x_sign : std_logic;signal y_sign : std_logic;signal z_sign : std_logic;signal sign : std_logic;signal SC : integer range 0 to 26;signal exp : std_logic_vector(9 downto 0);signal EA : std_logic_vector(24 downto 0);signal B : std_logic_vector(23 downto 0);signal Q : std_logic_vector(24 downto 0);type states is (reset, idle, s0, s1, s2, s3, s4);signal state : states;beginx_mantissa <= '1' & x_reg(22 downto 0);x_exponent <= x_reg(30 downto 23);x_sign <= x_reg(31);y_mantissa <= '1' & y_reg(22 downto 0);y_exponent <= y_reg(30 downto 23);y_sign <= y_reg(31);process(clk)beginif clk'event and clk = '1' thenif res = '1' thenstate <= reset;exp <= (others => '0');sign <= '0';x_reg <= (others => '0');y_reg <= (others => '0');z_sign <= '0'; z_mantissa <= (others => '0');z_exponent <= (others => '0');EA <= (others => '0');Q <= (others => '0');B <= (others => '0');overflow <= '0';done <= '0';elsecase state iswhen reset => state <= idle;when idle =>if GO = '1' thenstate <= s0;x_reg <= x;y_reg <= y;end if;when s0 => state <= s1;overflow <= '0';SC <= 25;done <= '0';sign <= x_sign xor y_sign;EA <= '0' & x_mantissa;B <= y_mantissa;Q <= (others => '0');exp <= ("00" & x_exponent) + not ("00" & y_exponent) + 1 + "0001111111";when s1 => if (y_mantissa = x"800000" andy_exponent = x"00") thenoverflow <= '1';z_sign <= sign;z_mantissa <= (others => '0');z_exponent <= (others => '1');done <= '1';state <= idle;elsif exp(9) = '1' or exp(7 downto 0) = x"00" or(x_exponent = x"00" and x_mantissa = x"00") or(y_exponent = x"FF" and y_mantissa = x"00") then z_sign <= sign;z_mantissa <= (others => '0');z_exponent <= (others => '0');done <= '1';state <= idle;elseEA <= EA + ('0' & not B) + 1;state <= s2;end if;when s2 =>if EA(24) = '1' thenQ(0) <= '1';elseQ(0) <= '0';EA <= EA + B;end if;SC <= SC - 1;state <= s3;when s3 => if SC = 0 thenif Q(24) = '0' thenQ <= Q (23 downto 0) & '0';exp <= exp - 1;end if;state <= s4;elseEA <= EA(23 downto 0) & Q(24); Q <= Q(23 downto 0) & '0';state <= s1; end if;when s4 => if exp = x"00" thenz_sign <= sign;z_mantissa <= (others => '0');z_exponent <= (others => '0');elsif exp(9 downto 8) = "01" thenz_sign <= sign;z_mantissa <= (others => '0');z_exponent <= (others => '1');elsez_sign <= sign;z_mantissa <= Q(24 downto 1);z_exponent <= exp(7 downto 0);end if;done <= '1';state <= idle;end case;end if;end if;end process;z <= z_sign & z_exponent & z_mantissa(22 downto 0); end design;The VHDL code written has been tested and verified on Xilinx ISE 8.1i for all operation. The design utilization summary has been shown in Figure 5.Figure. 5: Design Utilization Summary of Floating Point Arithmetic Unit on FPGA5. Generation and verification of HDL code using MATLABGeneration and verification of HDL code using MATLAB requires compatible versions of MATLAB (Simulink) and HDL Simulator …Modelsim‟ to be loaded on the same system [13, 14, 15]. The basic design steps to create Simulink model for verification of VHDL code in Modelsim HDL Simulator is shown in the flow chart of Fig. 6.Figure. 6: Design steps to create Simulink model for verification ofVHDL code in ModelsimThe Simulink Model to generate and verify Floating Point arithmetic created is shown in Figure 7. Input 1 and Input 2 are the two 32 bit floating point inputs to the model and …Select‟ is set to …01‟ for Adder, …11‟ for Divider and …10‟ for Multiplier. It also has a scope to view the output. A sub-system is created to launch the Modelsim Simulator from Simulink as shown in Fig. 8.Figure. 7: Simulink model to generate and verify Floating PointarithmeticFigure. 8: Simulink sub-system to launch HDL Simulator6. RESULTSDouble clicking the …Launch HDL Simulator‟ in the Simulink model loads the test bench for simulation. The ModelSim Simulator opens a display window for monitoring the simulation as the test bench runs. The wave window in Figure 9 shows the simulation of two exponential inputs and Select set to …01‟for …adder‟ result as HDL waveform. Figure 10 shows the simulation of two decimal inputs for …adder‟. Figure 11 and 12 show the simulation of two decimal inputs for …divider‟. Figure 13 and 14 show the simulation of two decimal inputs for …multiplier‟.。
计算机32位浮点数编码实验C描述

浮点数编码实验1、提要本篇讲解浮点数的编码,先介绍浮点数的编码规格,最后用C程序来实现将给定的整数编码转换成浮点数编码。
2、浮点数编码在计算机中浮点数采用V = (-1)s×M×2E的形式来表示,在计算机中单精度浮点数是32位,双精度浮点数是64位,我们仅仅对单精度浮点数做说明。
就单精度浮点数而言,计算机中保存了S,M和E 的编码,其中S表示符号位,0表示正数,1表示负数;M是学名叫尾数;E是阶码,它是指数加上一个偏置数,单精度浮点数的偏置数是127,之所以加上这个偏置数是为了便于浮点数的运算。
在单精度浮点数中,符号位占最高位1位,阶码占用紧接着的8位,尾数占用最后23位,如下图所示:31 30 22 0 重点说一下尾数M,M隐含了小数点前面的1,举个例子,如果M是1010000000000011110000B,那么M的实际值是1#1010000000000011110000B,其中#表示小数点的位置;然后说说阶码E,假定解码E是10001001B,十进制值位137,E需要再减去偏置127,才能得到指数137-127=10,最后假定S是0,那么这个例子中所描述的浮点数表示的值是:1.1010000000000011110000B × 210也就是:11010000000.000011110000B。
3、将一个十进制数转成浮点数表示举个例子,十进制数-12.75转换成浮点数表示,首先确定符号位是1,将12.75转成二进制表示1100.11B = 1.10011×23,可以确定尾数M是100 1100 0000 0000 0000 0000B,阶码E=3+127 = 130 = 1000 0010B,其浮点数表示为1#1000 0010#100 1100 0000 0000 0000 0000B =C14C0000H。
其中#分割S、E和M。
4、一些非规格浮点数的表示上面部分说的是浮点数的规格表示,还有一些非规格表示。
32位浮点乘法器的设计与仿真代码

32位浮点乘法器的设计与仿真代码一、引言随着计算机科学和技术的不断发展,浮点乘法器在科学计算、图像处理、人工智能等领域中扮演着重要的角色。
本文将详细讨论32位浮点乘法器的设计与仿真代码,并深入探讨其原理和实现方法。
二、浮点数表示在开始设计32位浮点乘法器之前,我们首先需要了解浮点数的表示方法。
浮点数由符号位、阶码和尾数组成,其中符号位表示数的正负,阶码确定数的大小范围,尾数表示数的精度。
三、浮点乘法器的原理浮点乘法器的原理基于乘法运算的基本原理,即将两个数的尾数相乘,并将阶码相加得到结果的阶码。
同时需要考虑符号位的处理和对阶的操作。
下面是32位浮点乘法器的基本原理:1.获取输入的两个浮点数A和B,分别提取出符号位、阶码和尾数。
2.将A和B的尾数相乘,得到乘积P。
3.将A和B的阶码相加,得到结果的阶码。
4.对乘积P进行规格化,即将小数点左移或右移,使其满足规定的位数。
5.对结果的阶码进行溢出判断,若溢出则进行相应的处理。
6.将符号位与结果的阶码和尾数合并,得到最终的浮点乘积。
四、浮点乘法器的设计根据浮点乘法器的原理,我们可以开始进行浮点乘法器的设计。
设计的关键是确定乘法器中各个部件的功能和连接方式。
下面是浮点乘法器的设计要点:1.输入模块:负责接收用户输入的两个浮点数,并提取出符号位、阶码和尾数。
2.乘法模块:负责将两个浮点数的尾数相乘,得到乘积P。
3.加法模块:负责将两个浮点数的阶码相加,得到结果的阶码。
4.规格化模块:负责对乘积P进行规格化操作,使其满足规定的位数。
5.溢出判断模块:负责判断结果的阶码是否溢出,并进行相应的处理。
6.输出模块:负责将符号位、阶码和尾数合并,得到最终的浮点乘积。
五、浮点乘法器的仿真代码为了验证浮点乘法器的设计是否正确,我们需要进行仿真测试。
下面是一段简单的浮点乘法器的仿真代码:module floating_point_multiplier(input wire [31:0] a,input wire [31:0] b,output wire [31:0] result);wire [31:0] mantissa;wire [7:0] exponent;wire sign;// 提取符号位assign sign = a[31] ^ b[31];// 提取阶码assign exponent = a[30:23] + b[30:23];// 尾数相乘assign mantissa = a[22:0] * b[22:0];// 规格化assign {result[30:23], result[22:0]} = {exponent, mantissa};// 处理溢出always @(*)beginif (exponent > 255)result = 32'b0; // 结果溢出为0else if (exponent < 0)result = 32'b0; // 结果溢出为0elseresult[31] = sign;endendmodule六、浮点乘法器的应用浮点乘法器在科学计算、图像处理、人工智能等领域中有着广泛的应用。
32位浮点加法器设计

32位浮点加法器设计一、基本原理浮点数加法运算是在指数和尾数两个部分进行的。
浮点数一般采用IEEE754标准表示,其中尾数部分采用规格化表示。
浮点加法的基本原理是将两个浮点数的尾数对齐并进行加法运算,再进行规格化处理。
在加法运算过程中,还需考虑符号位、指数溢出、尾数对齐等特殊情况。
二、设计方案1. 硬件实现方案:采用组合逻辑电路实现浮点加法器,以保证运算速度和实时性。
采用Kogge-Stone并行加法器、冒泡排序等技术,提高运算效率。
2.数据输入:设计32位浮点加法器,需要提供两个浮点数的输入端口,包括符号位、指数位和尾数位。
3.数据输出:设计32位浮点加法器的输出端口,输出相加后的结果,包括符号位、指数位和尾数位。
4.控制信号:设计合适的控制信号,用于实现指数对齐、尾数对齐、规格化等操作。
5.流程控制:设计合理的流程控制,对各个部分进行并行和串行处理,提高加法器的效率。
三、关键技术1. Kogge-Stone并行加法器:采用Kogge-Stone并行加法器可以实现多位数的并行加法运算,提高运算效率。
2.浮点数尾数对齐:设计浮点加法器需要考虑浮点数尾数的对齐问题,根据指数大小进行右移或左移操作。
3.溢出判断和处理:浮点加法器需要判断浮点数的指数是否溢出,若溢出需要进行调整和规格化。
4.符号位处理:设计浮点加法器需要考虑符号位的处理,确定加法结果的符号。
四、性能评价性能评价是衡量浮点加法器设计好坏的重要指标。
主要从以下几个方面进行评价:1.精度:通过与软件仿真结果进行比较,评估加法器的运算精度,误差较小的加法器意味着更高的性能。
2.速度:评估加法器的运行速度,主要考虑延迟和吞吐量。
延迟越低,意味着加法器能够更快地输出结果;吞吐量越高,意味着加法器能够更快地处理多个浮点加法运算。
3.功耗:评估加法器的功耗情况,低功耗设计有助于提高整个系统的能效。
4.面积:评估加法器的硬件资源占用情况,面积越小意味着设计更紧凑,可用于片上集成、嵌入式系统等场景。
基于FPGA单精度浮点数算术运算系统的设计与仿真

Electronic Technology •电子技术Electronic Technology & Software Engineering 电子技术与软件工程• 113●基金项目:广西自然科学基金项目(2014GXNSFAA118392);广西教育厅科研项目(YB2014209)。
【关键词】FPGA 单精度浮点运算 模块化 系统FPGA 近年来在体系结构、技术水平和持续改进的设计方面进行了提高和完善,弥补了专用处理器灵活性不足之处,FPGA 的容量、速度和资源已经有了更好的提高。
在微处理器的指令系统中,浮点数加/减和乘/除法指令都是实现2个单精度浮点数的运算,浮点数算术运算系统的设计通常采用流水线和自顶向下方式,但对于所执行的浮点数算术运算指令需要应用上一条运算指令的运算结果作为操作数的指令,则浮点数算术运算的流水线操作失去作用,影响了浮点数算术运算指令执行的速度。
本设计利用Verilog 语言,采用基于FPGA 自主设计的浮点数算术运算系统,进行浮点加减乘除运算验证和仿真,提高了运算的操作速度,具有较强的通用性和可操作性。
1 单精度浮点加减乘除运算1.1 单精度浮点数表示IEEE754标准中,一个规格化32位的浮点数表示为:X=(-1)S ×(1.M)×2e e=E-127其中用1位表示数字的符号S ,S 为0表示正数,S 为1表示负数。
IEEE754标准中规定的规格化浮点数的阶码是用移码表示,用8位来表示阶码E ,E 是带有偏移量的阶码,偏基于FPGA 单精度浮点数算术运算系统的设计与仿真文/谢四雄 李克俭 蔡启仲 潘绍明移量是127,e 是实际阶码,在计算实际阶码e 时,对阶码E 的计算采用源码的计算方式,32位浮点数的8位的阶码E 的取值范围是0到255,用23位来表示尾数M ,尾数用原码表示,其中尾数域值是1.M 。
单精度浮点数的存储格式如表1所示,因为规格化的浮点数的尾数域最左位总是1,故这一位不予存储,而认为隐藏在小数点的左边,使用的时候再恢复出来。
DSP实验(浮点处理)报告

DSP浮点处理器实验报告实验名称:DSP浮点处理器实验1姓名:班级:指导教师:完成时间:2012/05/23实验一实验系统的硬件连接以及中断控制LED一、实验系统的硬件连接1、设置仿真环境为Emulator模式;2、连接仿真器到PC和开发板;3、连接电源线,打开电源;4、进入CCS开发环境。
二、实验目的1、熟悉实验系统的硬件连接和使用方法。
2、熟悉Code Composer Studio (CCS3.3)集成开发环境及软硬件仿真方法。
3、掌握TMS320C6722的GPIO和定时中断的具体使用。
三、实验内容及原理1、使用定时中断的方式通过程序控制实验系统使LED按一定的频率闪烁。
2、TMS320C6722定时器每1/8192秒产生一次中断,每次中断时中断服务程序向计数变量加1,加满1024后程序将LED的亮灭状态改变一次。
最终实现LED以1Hz的频率闪烁(即每秒亮1次)。
四、实验要求基本要求:1、熟悉使用Code Composer Studio (CCS3.3)集成开发环境,能够进行程序的编辑、编译和硬件仿真,掌握软件的基本操作。
2、熟悉编写程序的基本结构和简单编写方法。
3、能够修改程序,使LED按照指定的频率闪烁。
扩展要求:1、修改实验参考程序,采用完全使用中断而不再在主程序循环中计数的方式控制LED闪烁,且保持闪烁频率不变。
2、继续修改程序,使LED闪烁频率为1Hz(每秒亮一次)。
五、实验系统的内部结构框图六、实验硬件连接示意图七、实验参考程序的流程图八、拓展要求程序改动思路1.拓展一:将main中的程序转到timer0中,应注意在转移main的内容前面加上一个标志如aa。
2.拓展二:由定时参数的计算公式,外部时钟频率X10/8/采样频率。
比较400h,可知将FS定义为808h同404h进行比较。
只要了解循环进行的频率和比照的频率就可以改变灯闪烁的频率。
将727h 改成8196即可。
3.总结TMS320VC33初始化内容步骤首先要对重要寄存器和总线初始化init: ldp 0,dpldi @STCK,spldi 1800h,st 状态指针寄存器ldi @MCTL,ar0ldi MBUS1,r0 主计数sti r0,*ar0MCTL .word 808064H ;;主总线控制寄存器地址单元STCK .word 809E00H ; ;堆栈寄存器地址单元MBUS1 .set 01038H ; ;0等待标志字.end定时中断初始化initt0: ldi 0,r0ldi 808h,ar0lsh 12,ar0addi 20h,ar0 ; ;指向808020单元即全局控制寄存器sti r0,*+ar0(4) ;;计数寄存器ldi FS,r0 ;sti r0,*+ar0(8) ;;周期寄存器ldi 3c1h,r0sti r0,*ar0 ;retsFS .set 727H ; ;FS的计算.data4.总结TMS320VC33定时器使用方法main:ldi @TNUM,ar0ldi *ar0,r0absi r0cmpi 400h,r0 ; ;比较判断是否循环blt mainldi 0,r0 ;;计数到则清零则进行翻转sti r0,*ar0ldi @LEDS,ar0 ; ;接着进行LED灯状态的翻转ldi *ar0,r0cmpi 0,r0ldieq 1,r0ldine 0,r0sti r0,*ar0ldi @LED,ar0sti r0,*ar0br main;------------------------------5.总结TMS320VC33中断的使用方法timer0: push st 发生中断回到此处复位回归push ar0push r0 先保存低32位pushf r0 再保存高32位ldi @TNUM,ar0 时钟中断,完成一次操作。
32位浮点加法器设计[整理版]
![32位浮点加法器设计[整理版]](https://img.taocdn.com/s3/m/c6464a9e2af90242a895e5f9.png)
32位浮点加法器设计
苦行僧宫城
摘要:运算器的浮点数能够提供较大的表示精度和较大的动态表示范围,浮点 运算已成为现代计算程序中
不可缺少的部分。浮点加法运算是浮点运算中使用频率最高的运算。因此,浮 点加法器的性能影响着整个
CPU勺浮点处理能力。文中基于浮点加法的原理,采用Verilog硬件描述语言
设计32位单精度浮点数加法
f)规格化移位:对尾数加减结果进行移位,消除尾数的非有效位,使其最高位为
1。Байду номын сангаас
g)舍入:有限精度浮点表示需要将规格化后的尾数舍入到固定结果。 由以上 基本算法可见,它包含2个全长的移位即对阶移位和规格化移位,还要包括3个全 长的有效加法,即步骤c、d、g。由此可见,基本算法将会有很大的时延。
2 32位浮点加法器设计与实现
器,并用modelsim对浮点加法器进行仿真分析,从而验证设计的正确性和可 行性。
关键词:浮点运算 浮点加法器Verilog硬件描述语言
Studying on Relation of Technology and Civilization苦行僧宫城
(School of Mechatronic Engineering and Automation, Shanghai
University, Shanghai,China)
Abstract: The floating-point arithmetic provides greater precision and greater dynamic representation indication range, with floating point calculations have become an indispensable part of the program.Floatingpoint adder is the most frequently used floating point arithmetic. Therefore, the performance of floating point adder affecting the entire CPU floating point processing capabilities. In this paper the principlebased floating-point addition, Verilog hardware description language
32位单精度浮点乘法器的FPGA实现

!!#尾数规 格 化’ 需 要 把 尾 数 相 乘 的 !Y 位 结 果 数 据 变 成 $! 位 的 数 据 ’ 分 / 步 进 行 &
图 /!/$ 位 浮 点 数 据 格 式
/$位 浮 点 数 据 格 式 &K ( !2.#8 6 N 6$12.$6 ( 其中乘法器运算操作分!步进行( !.#确 定 结 果 的 符 号’ 对 K 和 M 的 符 号 位 做 异 或 操作( !$#计算阶码’两 数 相 乘’结 果 的 阶 码 是 两 数 的 阶 码 相 加’由于 K 和M 都 是 偏 移 码’因 此 需 要 从 中 减 去 偏 移 码 值 $! 万方数据
而 4EGGEQC树$/%的 乘 法 阵 列 如 下&
.$
’ ( .’’. .(# ( !’’# ,’’. ,’’$#, !’’/ ,’’! ,’’"#, !’’1 ,’’6 ,’’Y#, !’’_ ,’’.# ,’’..#,’’.$ !Y# 加法器之间的连接关系 如 图 .’ 图 $ 所 示’ 或 者 从 公
收稿日期!$##" #Y ./
万方数据
! ! ! !’’. ( KC 6 !H$.2. ,H$. 2$H$.,."6$$.Βιβλιοθήκη !!!!!!!!. (##.#*#.$
表 8! 基 EJ1104 编 码 真 值 表
H$.,.
H$.
H$.2. QFPC
值
#
#
#
#
上海大学verilog设计32位浮点加法器设计

32位浮点加法器设计摘要:浮点数具有数值范围大,表示格式不受限制的特点,因此浮点数的应用是非常广泛的。
浮点数加法运算比较复杂,算法很多,但是为了提高运算速度,大部分均是基于流水线的设计结构。
本文介绍了基于IEE754标准的用Verilog 语言设计的32位浮点加法器,能够实现32位浮点数的加法运算。
虽然未采用流水线的设计结构但是仍然对流水线结构做了比较详细的介绍。
关键字:浮点数,流水线,32位浮点数加法运算,Verilog 语言设计32-bit floating point adder designCao Chi,Shen Jia- qi,Zheng Yun-jia(School of Mechatronic Engineering and Automation, Shanghai University, Shanghai ,China ) Abstract://沈佳琪搞定Key words :float; Assembly line; 32-bit floating-point adder 浮点数的应用非常广泛,无论是在计算机还是微处理器中都离不开浮点数。
但是浮点数的加法运算规则比较复杂不易理解掌握,而且按照传统的运算方法,运算速度较慢。
因此,浮点加法器的设计采用了流水线的设计方法。
32位浮点数运算的摄入处理采用了IEE754标准的“0舍1入”法。
1. 浮点数的介绍在处理器中,数据不仅有符号,而且经常含有小数,即既有整数部分又有小数部分。
根据小数点位置是否固定,数的表示方法分为定点表示和浮点表示。
浮点数就是用浮点表示法表示的实数。
浮点数扩大了数的表示范围和精度。
浮点数由阶符、阶码E 、数符、尾数N 构成。
任意一个二进制数N 总可以表示成如下形式:N=。
通常规定:二进制浮点数,其尾数数字部分原码的最高位为1,叫作规格化表示法。
因此,扩大数的表示范围,就增加阶码的位数,要提高精度,就增加尾数的位数。
实验1--浮点运算

北京信息科技大学自动化学院实验报告课程名称 DSP控制技术实验名称简单的浮点运算实验仪器 PC机一台专业自动化班级/学号自控1105/2011010865 学生姓名黄洁艳实验日期实验地点教七楼102 成绩指导教师艾红实验一 CCS调试环境熟悉以及简单程序的软件调试一.实验目的1.了解 F28335 简单的浮点运算。
2.熟悉浮点运算的编程。
二.实验原理TMS320F28335是一款32 位浮点通用数字信号处理芯片,它具有存储空间大、运算精度高等特点。
三.实验要求1.设置 Code Composer Studio 3.3在硬件仿真方式下运行2.启动 Code Composer Studio 3.33.打开工程文件,打开源程序Example_2833xFPU.c阅读程序,理解程序内容。
4.编译、下载程序。
5.把 y1和 y2 添加到观察窗。
6.运行程序,观察 y1和 y2结果。
7. 修改 x1 和 x2 值,重新执行程序,观察 y1和 y2结果。
8.退出 CCS。
四. 实验程序如下:#include "DSP2833x_Device.h" // DSP2833x Headerfile Include File#include "DSP2833x_Examples.h" // DSP2833x Examples Include Filefloat y1, y2;float m1, m2;float x1, x2;float b1, b2;void main(void){ // Step 1. Initialize System Control:// PLL, WatchDog, enable Peripheral Clocks// This example function is found in the DSP2833x_SysCtrl.c file.InitSysCtrl();// Step 2. Initalize GPIO:// This example function is found in the DSP2833x_Gpio.c file and// illustrates how to set the GPIO to it's default state.// InitGpio(); // Skipped for this example// Step 3. Clear all interrupts and initialize PIE vector table:// Disable CPU interruptsDINT;// Initialize the PIE control registers to their default state.// The default state is all PIE interrupts disabled and flags// are cleared.// This function is found in the DSP2833x_PieCtrl.c file.InitPieCtrl();// Disable CPU interrupts and clear all CPU interrupt flags:IER = 0x0000;IFR = 0x0000;// Initialize the PIE vector table with pointers to the shell Interrupt // Service Routines (ISR).// This will populate the entire table, even if the interrupt// is not used in this example. This is useful for debug purposes.// The shell ISR routines are found in DSP2833x_DefaultIsr.c.// This function is found in DSP2833x_PieVect.c.InitPieVectTable();// Interrupts that are used in this example are re-mapped to// ISR functions found within this file.// Step 5. User specific code, enable interrupts:// Calculate two y=mx+b equations.y1 = 0;y2 = 0;m1 = 10;m2 = .6;x1 = 7;x2 = 7.3;b1 = 4.2;b2 = 8.9;y1 = m1/x1 + b1;y2 = m2*x2 + b2;ESTOP0; // This is a software breakpoint}五.实验结果分析程序设计实现了简单的浮点乘法和加法运算,y1和y2是实验结果。
一种高性能32位浮点乘法器的ASIC设计

2004年4月第26卷 第4期系统工程与电子技术Systems Engineering and E lectronicsApr.2004V ol 126 N o 14收稿日期:2003-02-24;修回日期:2003-07-10。
作者简介:赵忠武(1977-),男,硕士,主要研究方向为模拟集成电路设计,数字ASIC 设计。
文章编号:1001Ο506X (2004)04Ο0531Ο04一种高性能32位浮点乘法器的ASIC 设计赵忠武,陈 禾,韩月秋(北京理工大学电子工程系,北京100081)摘 要:介绍了一种32位浮点乘法器的ASIC 设计。
通过采用改进Booth 编码的树状4:2列压缩结构,提高了乘法器的速度,降低了系统的功耗,且结构更规则,易于V LSI 实现。
整个设计采用Verilog H D L 语言结构级描述,用TS MC 0.25标准单元库进行逻辑综合。
采用三级流水技术,完成一次32位浮点乘法的时间为28.98ns ,系统的时钟频率可达103.52MH z 。
关键词:浮点乘法器;Booth 编码;树状列压缩中图分类号:T N492 文献标识码:ADesign of high 2perform ance 322bit floating 2point multipliers for ASICZH AO Zhong 2wu ,CHE N He ,H AN Y ue 2qiu(Department o f Electronic Engineering ,Beijing Institute o f Technology ,Beijing 100081,China )Abstract :A design of high 2per formance 322bit floating 2point multipliers for ASIC is presented.By using a structure of 4:2col 2umn com pression trees with the m odified Booth encoding ,the speed of the multipliers is im proved and the power of the system is re 2duced.Furtherm ore ,due to a m ore regular structure ad opted ,it is easy for V LSI realization of the multipliers.The wh ole design is described in Verilog H D L at structurelevel ,and synthesized using the TS MC 0.25standard cell library.W ith the techn ology of three 2stage pipeline ,28.98ns is needed to com plete a 322bit floating 2point multiplication ,and the frequency of the system can reach 103.52MH z.K ey w ords :Floating 2point multiplier ;Booth encoding ;column com pression tree1 引 言随着计算机和DSP 技术的不断发展,人们对速度快、面积小的高性能协处理器的需求也越来越大。
浮点32位并行乘法器设计与研究的开题报告

浮点32位并行乘法器设计与研究的开题报告
一、选题背景
现代计算机普遍采用浮点运算,浮点乘法是其中较为复杂的一种运算。
浮点乘法的速度和精度对计算机的性能有着至关重要的影响。
因此,设计一种快速、高效且精度高的浮点乘法器是非常有必要的。
二、研究目的
本研究旨在设计一种基于FPGA实现的浮点32位并行乘法器,并且探究其性能及精度。
具体目的包括:
1. 研究浮点乘法器的基本原理和实现方式。
2. 设计一种32位浮点乘法器的算法和数据路径。
3. 基于FPGA平台实现32位浮点乘法器,并进行性能评估和精度分析。
三、研究方法
本研究将采用以下方法:
1. 阅读相关文献,了解浮点乘法器的实现原理和算法。
2. 设计基于二进制补码的32位浮点乘法器算法和数据路径。
3. 使用Verilog语言进行32位浮点乘法器的RTL级设计。
4. 在FPGA平台上进行实现,并分析其性能和精度。
四、预期成果
完成本研究后,预期可以获得以下成果:
1. 掌握浮点乘法器的基本原理和实现方式。
2. 设计一种32位浮点乘法器的算法和数据路径。
3. 完成浮点32位并行乘法器的RTL级设计。
4. 在FPGA平台上进行实现,并得到相应性能和精度结果。
五、研究意义
1.本研究可以为浮点运算的优化和加速提供一种新的思路。
2.可以为计算机的相关领域提供更快速、高效的计算能力。
3.研究结果具有重要的教育和科研意义,可以为相关领域的学生和研究人员提供学习借鉴。
32位浮点加法器设计[整理版]
6.心得体会
实验过后,终于长长的舒了一口气,这个课程的任务终于要完成了,当然,实 验,仅仅是检验学习的一种途径,在后面,更应该多多练习,熟悉并掌握这门实用 的数字电路工具。贯穿整个实验,小组成员之间紧密配合,在团队合作,共同进步 的思想下,收获了很多个体与团队间的经验,但更多的,还是对课程知识的运用和 总结,总得说来,这次实验让大家受益匪浅。
为[1,
254],0和255表示特殊值;f有22位,再加上小数点左边一位隐含的1总共23位构成尾
数部分
1.3浮点பைடு நூலகம்算
浮点加法运算由一些单独的操作组成。在规格化的表示中,对于基为2的尾数 的第1个非0位的1是隐含的,因此,可以通过不存储这一位而使表示数的数目增 加。但在进行运算时不能忽略。浮点加法一般要用以下步骤完成:
a)指数相减:将2个指数化为相同值,通过比较2个指数的大小求出指数差的
绝对值△E。
b)对阶移位:将指数较小的操作数的尾数右移4E位。
c)尾数加减:对完成对阶移位后的操作数进行加减运算。
d)转换:当尾数相加的结果是负数时,要进行求补操作,将其转换为符号2尾数 的表示方式。
e)前导1和前导0的判定:判定由于减法结果产生的左移数量或由于加法结 果产生的右移数量。
1.设计过程总结
本次实验采用Top_down的设计思路,在弄清楚了浮点数加法的基本规则过 后,即清楚输入输出,从而拟定几个基本的输入,ia,ib,ena,reset和clk,即用 于计算的两个浮点数ia和ib根据要求,其位宽定为32位,之后就是一个重置端reset,和脉冲信号elk,最后就是使能端ena,当然,有输入肯定有输出了,综合 浮点数的两个标准,尾数和指数,即ze和zm应浮点数的一般大小,暂时把ze设为8位,zm设定为24位,即暂定为两个输出端口,但是,作为一个完整的输出 结果,在输入信号的综合完成后,明显只有一个输出数是不完整的,因此我们增加 了一个辅助输出,即driver。输入输出结束过后,就是对一些寄存器的定义了, 显然,在对输入的锁存状态有一些特别的考虑,即ia和ib暂时锁存在一个状态 中,然后通过浮点加法规则,对寄存器取值计算,最后输出结果,具体加法器算法 参考网络。
实验1 运算器设计与仿真
预做实验报告1 运算器设计与仿真一、实验目的理解并掌握运算器的基本电路结构及其设计方法,学会使用Verilog HDL 对电路进行行为建模、结构建模以及仿真测试。
二、实验内容利用Verilog HDL 设计一个运算器模型,并进行仿真测试。
要求该运算器的字长为32位,能够实现加法、减法、逻辑与、逻辑或四种运算,并产生N(结果为负)、Z(结果为零)、V(结果溢出)、C(进位)四个标志位。
要求采用层次化的建模方法,即先搭建低层模块,然后再逐级搭建高层模块。
三、实验环境PC 机1台、Modelsim 仿真软件1套。
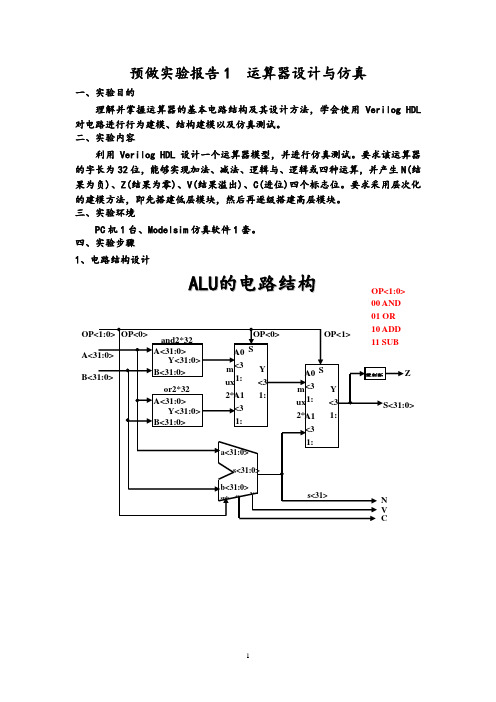
四、实验步骤 1、电路结构设计A L U 的电路结构OP<1:0> 00 AND 01 ORcc o 1位全加器逻辑表达式:S= abc i+abc i+abc i+abc i=a c iCo=abc i i+abc i+abc i=ab+ac i+bc is<3:0> 其中:S u b=0,做加法,S u b=1,做减法。
2、建立Verilog模型module fadd(a,b,s,ci,co);input a,b,ci;output s,co;reg s,co;always @ (a or b or ci)begins<=(a&~b&~ci)|(~a&b&~ci)|(~a&~b&ci)|(a&b&ci);co<=(a&b)|(a&ci)|(b&ci);endendmodulemodule add(a,b,sub,s,c,v,n);input [31:0]a;input [31:0]b;input sub;output [31:0]s;output c,v,n;wire [31:0]a;wire [31:0]b;wirec1,c2,c3,c4,c5,c6,c7,c8,c9,c10,c11,c12,c13,c14,c15,c16,c17,c18,c19,c 20,c21,c22,c23,c24,c25,c26,c27,c28,c29,c30,c31;fadd f0(a[0],b[0]^sub,s[0],sub,c1);fadd f1(a[1],b[1]^sub,s[1],c1,c2);fadd f2(a[2],b[2]^sub,s[2],c2,c3);fadd f3(a[3],b[3]^sub,s[3],c3,c4);fadd f4(a[4],b[4]^sub,s[4],c4,c5);fadd f5(a[5],b[5]^sub,s[5],c5,c6);fadd f6(a[6],b[6]^sub,s[6],c6,c7);fadd f7(a[7],b[7]^sub,s[7],c7,c8);fadd f8(a[8],b[8]^sub,s[8],c8,c9);fadd f9(a[9],b[9]^sub,s[9],c9,c10);fadd f10(a[10],b[10]^sub,s[10],c10,c11);fadd f11(a[11],b[11]^sub,s[11],c11,c12);fadd f12(a[12],b[12]^sub,s[12],c12,c13);fadd f13(a[13],b[13]^sub,s[13],c13,c14);fadd f14(a[14],b[14]^sub,s[14],c14,c15);fadd f15(a[15],b[15]^sub,s[15],c15,c16);fadd f16(a[16],b[16]^sub,s[16],c16,c17);fadd f17(a[17],b[17]^sub,s[17],c17,c18);fadd f18(a[18],b[18]^sub,s[18],c18,c19);fadd f19(a[19],b[19]^sub,s[19],c19,c20);fadd f20(a[20],b[20]^sub,s[20],c20,c21); fadd f21(a[21],b[21]^sub,s[21],c21,c22); fadd f22(a[22],b[22]^sub,s[22],c22,c23); fadd f23(a[23],b[23]^sub,s[23],c23,c24); fadd f24(a[24],b[24]^sub,s[24],c24,c25); fadd f25(a[25],b[25]^sub,s[25],c25,c26); fadd f26(a[26],b[26]^sub,s[26],c26,c27); fadd f27(a[27],b[27]^sub,s[27],c27,c28); fadd f28(a[28],b[28]^sub,s[28],c28,c29); fadd f29(a[29],b[29]^sub,s[29],c29,c30); fadd f30(a[30],b[30]^sub,s[30],c30,c31); fadd f31(a[31],b[31]^sub,s[31],c31,c); assign n=s[31];assign v=c^c31;endmodulemodule mux21_32(f,a,b,s);output[31:0] f;input[31:0] a,b;input s;reg [31:0] f;always @(s or a or b)case(s)1'd0: f=a;1'd1: f=b;endcaseendmodulemodule ALU(op,a,b,s,n,v,c,z);input [1:0]op;input [31:0]a,b;output[31:0]s;output n,v,c,z;wire [31:0]d,e,f,s1;assign d=a&b;assign e=a|b;mux21_32 u0(f,d,e,op[0]);add u2(a,b,op[0],s1,c,v,n);mux21_32 u1(s,f,s1,op[1]);assign z=~(|s);endmodule3、设计测试文件`timescale 1ns / 1nsmodule ALUtest;reg clk;reg [1:0]op;reg [31:0]a,b;wire [31:0]s;wire n,v,c,z;//op=00 AND;//op=01 OR;//op=10 ADD;//op=11 SUB;ALU A(op,a,b,s,n,v,c,z);//clock generationinitial clk = 1;always #50 clk = ~clk;initialbegin#20 a=32'b0100_0101_0100_0000_0010_0010_0101_0001;b=32'b1010_0101_0010_0000_0100_0010_0011_0010;op=2'b00;#100 a=32'b0100_0101_0100_0000_0010_0010_0101_0001;b=32'b1010_0101_0010_0000_0100_0010_0011_0010;op=2'b01;#100 a=32'b0100_0101_0100_0000_0010_0010_0101_0001;b=32'b1010_0101_0010_0000_0100_0010_0011_0010;op=2'b10;#100 a=32'b0100_0101_0100_0000_0010_0010_0101_0001;b=32'b1010_0101_0010_0000_0100_0010_0011_0010;op=2'b11;#100 a=32'b0111_1011_1101_1110_1111_1111_1111_1111;b=32'b0111_1011_1101_1110_1111_1111_1111_1111;op=2'b11;#100 a=32'd15;b=32'd9;op=2'b11;#100 a=32'd9;b=32'd15;op=2'b11;#100 $stop;endEndmodule$display("a= %b, b= %b, op= %b, s= %b,n=%b,z=%b,v=%b,c=%b\n",a,b,op,s,n,z,v,c);注意:测试的完备性。
32位单精度浮点乘法器的FPGA实现

32位单精度浮点乘法器的FPGA 实现胡侨娟,仲顺安,陈越洋,党 华(北京理工大学 北京 100081)摘 要:采用V erilog HDL 语言,在FPGA 上实现了32位单精度浮点乘法器的设计,通过采用改进型Boo th 算法和W allace 树结构,提高了乘法器的速度。
本文使用A ltera Q uartus II 411仿真软件,采用的器件是EPF 10K 100EQ 2401,对乘法器进行了波形仿真,并采用015C M O S 工艺进行逻辑综合。
关键词:浮点乘法器;Boo th 算法;W allace 树;波形仿真中图分类号:T P 33212+2 文献标识码:B 文章编号:1004373X (2005)2402302I m plem en ta tion of 32b it Si ngle Prec ision Floa ti ng Po i n tM ultipl ier Ba sed on FPGAHU Q iao juan ,ZHON G Shunan ,CH EN Yueyang ,DAN G H ua(Beijing Institute of T echno l ogy,Beijing,100081,Ch ina )Abs tra c t :U sing V erilog HDL ,a design of 32b single p recisi on floating po int m ulti p lier based on FPGA is p resented 1By using astructure of W allace trees and Boo th algo rithm ,the speed of m ulti p lier has been i m p roved 1T he softw are of A ltera Q uartus II 411is used fo r perfo r m ing the w ave si m ulati on of the m ulti p lier w ith EPF 10K 100EQ 2401device 1T he m ulti p lier is synthesized w ith 015C M O S techno logy 1Ke yw o rds :floating po int m ulti p lier ;Boo th algo rithm ;W allace trees ;w ave si m ulati on收稿日期:20050813 随着计算机和信息技术的快速发展,人们对微处理器的性能要求越来越高。
arm neon sqrt指令

arm neon sqrt指令摘要:一、arm neon sqrt 指令简介1.arm neon 指令集概述2.sqrt 指令的作用和意义二、arm neon sqrt 指令的使用1.sqrt 指令的语法和参数2.sqrt 指令的执行过程3.sqrt 指令的优化和应用场景三、arm neon sqrt 指令的发展趋势和展望1.sqrt 指令在人工智能和大数据领域的应用2.sqrt 指令的未来发展方向和挑战正文:arm neon sqrt 指令是arm neon 指令集的一个基础指令,用于对两个单精度浮点数(32 位)进行平方根运算,返回结果的高16 位和低16 位。
arm neon 指令集是arm 公司专门为高性能计算和数字信号处理而设计的扩展指令集,它通过增加新的指令来提高处理器在执行这些类型任务时的效率。
sqrt 指令在arm neon 指令集中具有重要的地位,它可以在一个时钟周期内完成两个32 位浮点数的平方根运算,这对于需要大量计算的任务来说,可以显著提高处理器的性能。
同时,由于arm neon 指令集被广泛应用于嵌入式系统、数字信号处理、图形处理器等领域,因此sqrt 指令在这些领域也有着广泛的应用。
在具体的使用过程中,arm neon sqrt 指令需要两个参数,即需要计算平方根的两个浮点数。
执行过程是先将这两个浮点数相加,然后对和进行平方根运算,最后将结果的高16 位和低16 位分别存入两个输出寄存器中。
在实际应用中,arm neon sqrt 指令常常被用于神经网络、深度学习等人工智能领域,以及大数据处理、图像处理等高性能计算领域。
随着这些领域的快速发展,对arm neon sqrt 指令的性能和效率也提出了更高的要求。
展望未来,arm neon sqrt 指令的发展趋势是更高的性能和效率,以及更广泛的应用场景。
arm 公司也在不断推出新的arm neon 指令集扩展,以满足这些需求。
高速32位浮点乘法器设计的开题报告

高速32位浮点乘法器设计的开题报告一、选题依据随着科技的快速发展,计算机在越来越多的领域中发挥着关键作用。
而在计算机的运算过程中,浮点运算是非常重要的一环。
为了能够完成更加复杂的计算任务,需要设计高精度、高效率的浮点运算器。
而高速32位浮点乘法器就是其中非常重要的一种。
因此,本课题选择研究高速32位浮点乘法器的设计。
二、研究的内容本课题研究的内容包括:1. 高速32位浮点乘法器的基本功能2. 高速32位浮点乘法器的设计原理3. 高速32位浮点乘法器的关键技术和算法4. 高速32位浮点乘法器的实现方式5. 高速32位浮点乘法器的性能评估与测试三、研究的意义高速32位浮点乘法器作为现代计算机系统的重要组成部分,其性能的高低直接影响到计算机的整体性能。
因此,研究高速32位浮点乘法器的设计,对于提升计算机的性能具有重要的意义和价值。
同时,在本课题的研究过程中,还可以深入了解现代计算机系统的内部原理和结构,具有很高的教育和研究价值。
四、研究的难点和解决方案在研究高速32位浮点乘法器的过程中,可能会面临以下难点:1. 设计原理的复杂性。
高速32位浮点乘法器的设计原理比较复杂,需要涉及到大量的数学知识。
为了解决这个问题,可以深入学习数学知识,并利用各种工具辅助分析设计。
2. 算法的高效性。
在设计高速32位浮点乘法器时,需要考虑到算法的高效性。
因此,研究合适的算法是非常重要的。
对于算法的研究,可以参考各种文献和优秀的实践经验。
3. 实现方式的可靠性。
在实现高速32位浮点乘法器时,需要考虑到实现方式的可靠性和稳定性。
为了解决这个问题,可以采用多种方案进行比较和测试,确保实现方式的可靠性。
五、预期成果本课题的预期成果包括:1. 高速32位浮点乘法器设计的详细说明和实现方式。
2. 高速32位浮点乘法器的性能评估和测试结果。
3. 研究过程中遇到的问题和解决方案的总结。
六、研究方法本课题的研究方法主要包括:1. 文献调研。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
32位浮点数开平方设计仿真实验报告名字:李磊学号:10045116 班级:10042211
32位浮点数的IEEE-754格式
单精度格式
IEEE.754标准规定了单精度浮点数共32位,由三部分组成:23位尾数f,8位偏置指数e,1位符号位s。
将这三部分由低到高连续存放在一个32位的字里,对其进行编码。
其中[22:0]位包含23位的尾数f;[30:23]位包含8位指数e;第31位包含符号s
{s[31],e[30:23],f[22:0]}
其中偏置指数为实际指数+偏置量,单精度浮点数的偏置量为128,双精度浮点数的偏置量为1024。
规格化的数:由符号位,偏置指数,尾数组成,实际值为1.f乘2的E-128次方
非规格化的数:由符号位,非偏置指数,尾数组成,实际值为0.f乘2的E次方
特殊的数:0(全为零),+无穷大(指数全为1,尾数为0,符号位为0),-无穷大(指数
全为1,尾数为0,符号位为1),NAN(指数全为1,尾数为不全为0)
浮点数开方器设计:
设计思路:
1.前端处理:
2.指数奇偶判断
3.指数开方
4.尾数开方
5.后端处理
设计全文:
module flowsqr(en,a,sqr_a,ost,clk);
input en,clk,a;
output sqr_a,ost;
wire en,ost,clk;
wire[31:0] a;
reg[31:0] sqr_a;
reg[47:0] am;
reg[24:0] sqr_am,sqr_am2;
reg[7:0] ae,sqr_ae;
reg[3:0] state;
parameter start=4'b0000,
judge_ae=4'b0010,
ae_right_move=4'b0011,
sqr_e=4'b0100,
num_std=4'b0110,
over=4'b0111,
sqr_m1=4'b0101,
sqr_m2=4'b1000,
sqr_m3=4'b1001,
sqr_m4=4'b1010,
sqr_m5=4'b1011;
always@(posedge clk)
begin
if(en)
begin
case(state)
start: //前端处理,分离指数和尾数,同时还原尾数:
begin
if(a[31]==0)
begin
am <= {1'b0,1'b1,a[22:0],23'b0};
ae <= a[30:23];
sqr_am <= {1'b0,1'b1,a[22:0]};
state <= judge_ae;
end
else
state <= over;
end
judge_ae: // 指数数奇偶判断
begin
if(ae[0]==0)
state <= sqr_e;
else
state <= ae_right_move;
end
ae_right_move: // 指数处理
begin
am <= {1'b0,am[47:1]};
sqr_am <={1'b0,sqr_am[24:1]};
ae <= ae+1;
state <= sqr_e;
end
sqr_e: //指数开方
begin
sqr_ae[7] <= ae[7];
sqr_ae[6:0]<= {1'b0,ae[6:1]};
state <= sqr_m1;
end
sqr_m1: //尾数开方,运用牛顿迭代法begin
sqr_am2 <= am/sqr_am;
state <= sqr_m2;
end
sqr_m2:
begin
if(sqr_am2>sqr_am)
begin
sqr_am2 <= sqr_am2-sqr_am;
end
else
begin
sqr_am2[23:0] <= sqr_am[23:0]-sqr_am2[23:0];
sqr_am2[24] <=1'b1;
end
state <= sqr_m3;
end
sqr_m3:
begin
sqr_am2[23:0] <= {1'b0,sqr_am2[23:1]};
state <= sqr_m4;
end
sqr_m4:
begin
if(sqr_am2[24]==0)
begin
sqr_am2=sqr_am+sqr_am2;
end
else
begin
sqr_am2[23:0]=sqr_am[23:0]-sqr_am2[23:0];
sqr_am2[24]=1'b0;
end
state <= sqr_m5;
end
sqr_m5:
begin
if(sqr_am[24:1]==sqr_am2[24:1])
begin
state <= num_std;
end
else
begin
sqr_am <= sqr_am2;
state <= sqr_m1;
end
end
num_std: //尾数规格化处理
begin
if(sqr_am[23]==0)
begin
sqr_am[23:0] <= {sqr_am[22:0],1'b0};
sqr_ae <= sqr_ae-1;
state <= num_std;
end
else
state <= over;
end
over:
begin
state <= start;
end
default:
begin
state <= start;
end
endcase
end
end
assign ost = (state == over) ? 1 : 0; //后端处理,输出规格化浮点数always@(posedge ost)
begin
sqr_a <= {1'b0,sqr_ae[7:0],sqr_am[22:0]};
end
endmodule
结果仿真
被开方数为8.25,结果约为2.87228,验证成功。