greenplum基本操作及管理命令
GreenPlum使用手册

GreenPlum数据库集群安装说明及使用手册开心十二月总结****年**月**日目录1体系结构介绍 (4)2安装 (10)2.1安装 (10)2.1.1安装准备 (10)2.1.2安装gp-db (11)2.1.3配置通讯 (13)2.1.4建立数据存储池 (17)2.1.5同步系统时间 (17)2.1.6验证安装是否成功 (17)2.1.7初始化 (17)2.1.8数据库的启停 (18)2.2Master双机热备 (19)2.3Segment节点互备 (20)3GP数据库的使用 (22)3.1pgAdminIII工具 (22)3.1.1安装和第一次使用pgAdminIII (22)3.1.2主窗体 (23)3.1.3导航菜单 (23)3.1.4工具栏介绍 (24)3.1.5数据库与表的创建 (25)3.1.6使用pgAdminIII备份数据库 (25)3.2JDBC配置 (26)3.3GP数据库两个重要概念 (27)3.3.1什么是Schema (27)3.3.2数据分布存储 (28)3.4GP的SQL语法 (28)3.4.1数据加载 (28)3.4.2SQL并行查询 (32)3.4.3聚合函数 (32)3.4.4索引 (32)3.4.5分区 (34)3.4.6函数 (35)4维护数据库 (39)4.1数据库启动gpstart (39)4.2数据库停止gpstop (41)4.3查看实例配置和状态 (41)4.4查看数据库运行状态gpstate (42)4.5查看用户会话和提交的查询等信息 (43)4.6查看数据库、表占用空间 (43)4.7查看数据分布情况 (44)4.8实例恢复gprecoverseg (44)4.9查看锁信息 (44)4.10数据库的备份与恢复 (44)5调优、排错 (44)6附件 (44)6.1DBA常用命令 (44)7Q&A (45)7.1不支持触发器 (45)7.2更新操作中的若干问题 (45)1体系结构介绍Greenplum数据库产品——下一代数据仓库引擎和分析方法Greenplum公司是企业数据云计算解决方案的创始人,为客户提供灵活的数据商业智能和分析方法。
GP常用命令整理

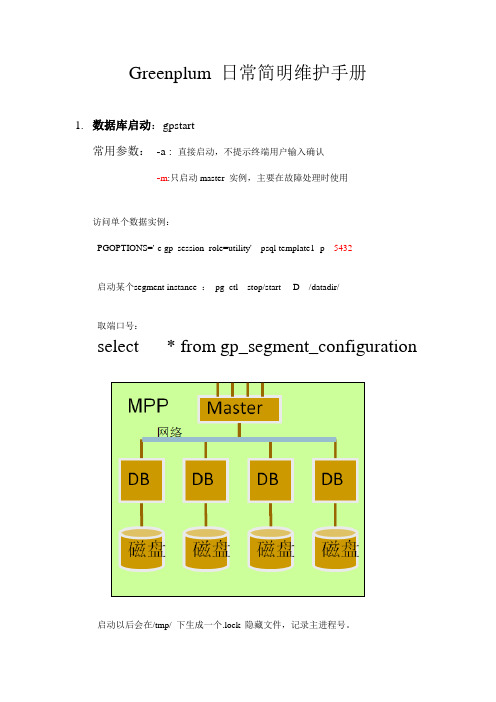
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数: -a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance : pg_ctl stop/start -D /datadir/取端口号:select * fromgp_segment_configuration启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ; select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P〔primary instance〕和M〔mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,那么说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录1.gpstate:显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和 mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
GP 常用数据库命令
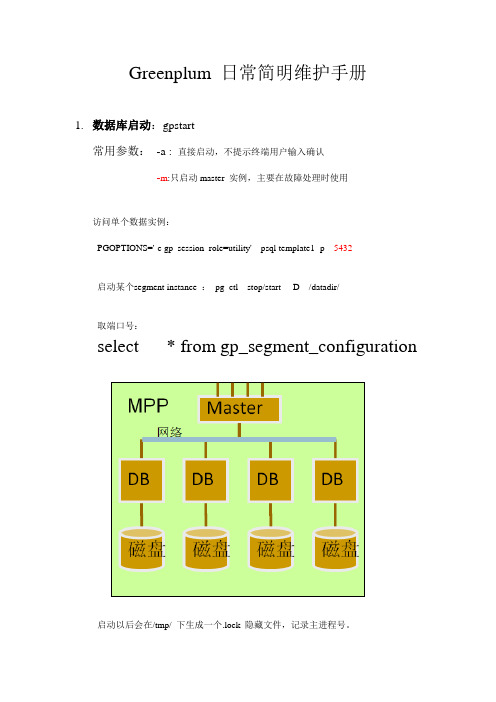
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数:-a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance :pg_ctl stop/start -D /datadir/取端口号:select * from gp_segment_configuration 启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ;select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录4.gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
GP日常维护手册-常用命令

Greenp lum 日常维护手册1.数据库启动:g pstar t常用可选参数:-a : 直接启动,不提示终端用户输入ye s确认-m:只启动mas ter 实例,主要在故障处理时使用2.数据库停止:g pstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止mas t er 实例,与gpsta rt –m 对应使用-M fast:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
-f:强制停止数据库-r:重启数据库3.查看实例配置和状态select * from gp_con figur ation orderby 1 ;select * from gp_con figur ation_hist ory orderby 1 ;主要字段说明:Conten t:该字段相等的两个实例,是一对P(primar y instan ce)和M(mirrorInstan ce)Isprim ary:实例是否作为p rimary instan ce 运行V alid:实例是否有效,如处于fal se 状态,则说明该实例已经dow n 掉。
Port:实例运行的端口Datadi r:实例对应的数据目录注 4.0后,实例配置的数据表:gp_seg ment_confi gurat ion 、pg_fil espac e_ent ry、gp_fau lt_st rateg y;其它常用的系统表:pg_cla ss,pg_att ribute,pg_database,pg_tab l es……可以用tab来匹配表名;4.gpstat e :显示Gree n plum数据库运行状态,详细配置等信息常用可选参数:-c:primary instan ce 和mirror instan ce 的对应关系-m:只列出mir ror 实例的状态和配置信息-f:显示stan dby master的详细信息-s:查看详细状态,如在同步,可显示数据同步完成百分比--versio n,查看数据库v ersio n(也可使用pg_cont roldata查看数据库版本和p ostg r esql版本)该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
GreenPlum_常用数据库命令
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数:-a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance :pg_ctl stop/start -D /datadir/取端口号:select * from gp_segment_configuration 启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ;select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录4.gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
greenplum gdfdist使用手册

greenplum gdfdist使用手册Greenplum GDFDist 使用手册概述Greenplum GDFDist 是一个用于在 Greenplum 数据库集群中进行分布式数据传输和加载的工具。
它提供了高效、可靠和并行的数据传输功能,能够加速数据导入和导出的过程。
本手册将向您介绍 GDFDist 的安装和配置方法,并提供一些常见的使用示例。
安装和配置1. 安装 GDFDistGDFDist 是作为 Greenplum 数据库分发功能的一部分提供的。
在安装 Greenplum 数据库时,GDFDist 已经被自动包括在内。
确保已正确安装 Greenplum 数据库版本来使用 GDFDist。
2. 配置 GDFDist在开始使用 GDFDist 之前,需要进行一些配置。
打开 Greenplum 数据库配置文件(通常位于 `$MASTER_DATA_DIRECTORY/gpseg-1/postgresql.conf`),找到以下配置项,并根据需要进行修改: - `gp_external_enable`:确保该配置项的值为 `on`,以启用外部表和 GDFDist 功能。
- `gp_external_max_segs`:根据您的集群规模和性能需求,适当调整此配置项的值。
它控制了能使用 GDFDist 进行数据传输的并行进程数量。
完成配置后,重新加载Greenplum 数据库配置文件以使更改生效。
使用示例以下是一些常见的 GDFDist 使用示例,展示了不同场景下如何高效地使用数据传输功能。
1. 从本地文件导入数据到 Greenplum 数据库使用 `COPY` 命令结合 GDFDist,可以将本地文件中的数据快速导入到 Greenplum 数据库中。
示例命令如下:```COPY my_table FROM PROGRAM 'gdfdist -F text -b my_file.txt' WITH (FORMAT CSV, HEADER);```在上述命令中,`my_table` 是指目标表的名称,`my_file.txt` 是指本地文件的路径名。
GREENPLUM介绍之数据库管理(四)-创建数据库和用户管理

GREENP LUM介绍之数据库管理(四)-创建数据库和用户管理上一篇/ 下一篇 2011-04-08 15:09:01 / 个人分类:G REENP LUM 查看(82 )/ 评论( 1 )/ 评分( 5 /0 ) GREEN PLUM与ORACL E一样有着完全独立于操作系统的用户管理系统,以及权限管理系统。
首先我们介绍一下GP中的数据库。
在GP初始化系统后,G P会自动创建出三个数据库pos tgre,templ ate0,templ ate1.其中p ostgr e用作系统内部数据的存放,我们既不要删除它,也不要修改它。
templ ate1是系统默认的数据,我们创建数据库时可以以t empla te1为模板,创建新的数据库。
所以,如果有不希望其它数据库继承的对象,就不要在数据库te mplat e1中进行创建。
G P中创建数据库的语法非常简单,句法如下CREA TE DA TABAS E new nameUSING TEMP LATEtmpla tedbn ame;速度非常快,这个过程中系统会生成相应的字典信息。
如果没有指定usi ng te mplat e子句,系统就使用t empla te1数据库作为模板创建新数据库。
我们也可以其它数据库为模板,创建新的数据库。
temp late0数据库是创建temp late1的模板,一般我们也不使用它创建应用对象。
GP允许在一个GP SERV ER中创建多个DAT ABASE。
但是一个DATAB ASE只能属于一个S ERVER。
一个连接在同一时间点只能访问一个数据库。
GP中也有SC HEMA的概念。
GP日常维护手册-常用命令

Greenplum 日常维护手册1. 数据库启动:gpstart常用可选参数: -a : 直接启动,不提示终端用户输入yes确认 -m:只启动master 实例,主要在故障处理时使用2. 数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-M fast:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
-f:强制停止数据库-r:重启数据库3. 查看实例配置和状态select * from gp_configuration order by 1 ;select * from gp_configuration_history order by 1 ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirrorInstance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录注4.0后,实例配置的数据表:gp_segment_configuration 、pg_filespace_entry、gp_fault_strategy;其它常用的系统表:pg_class,pg_attribute,pg_database,pg_tables……可以用tab来匹配表名;4. gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息-s:查看详细状态,如在同步,可显示数据同步完成百分比--version,查看数据库version(也可使用pg_controldata查看数据库版本和postgresql版本)该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
GreenPlum 使用指南

GreenPlum 使用指南连接数据库psql -d postgres集群部署1.安装依赖库所有节点执行# yum -y install rsync coreutils glib2 lrzsz sysstat e4fsprogs xfsprogs ntp readline-devel zlib zlib-devel openssl openssl-devel pam-devel libxml2-devel libxslt-devel python-devel tcl-devel gcc make smartmontools flex bison perl perl-devel perl-ExtUtils* OpenIPMI-tools openldap openldap-devel logrotate python-py gcc-c++ libevent-devel apr-devel libcurl-devel bzip2-devel libyaml-develeasy_install pippip install paramikopip install psutilpip install lockfile2.修改内核参数# vi /etc/sysctl.conf#dev_max_backlog = 2500->10000#add by langke install greenplumkernel.shmmni = 4096kernel.sem = 50100 64128000 50100 1280kernel.msgmni = 2048net.ipv4.conf.all.arp_filter = 1filter.ip_conntrack_max = 655360net.ipv4.tcp_keepalive_probes = 9net.ipv4.tcp_keepalive_intvl = 7vm.overcommit_memory = 2fs.file-max = 7672460fs.aio-max-nr = 1048576上面这个内核参数设置之后影响elasticsearch进程(进程自动退出,报OOM:Native memory allocation (mmap) failed to map 11314593792 bytes for committing reserved memory,可能是vm.overcommit_memory,参数影响)kernel.shmmni = 4096kernel.sem =250 32000 32 128kernel.msgmni = 32768net.ipv4.conf.all.arp_filter = 0net.ipv4.tcp_keepalive_probes = 9net.ipv4.tcp_keepalive_intvl = 75vm.overcommit_memory = 0fs.file-max = 7672460fs.aio-max-nr = 1048576# sysctl -p受内核参数影响kafka java客户端推送数据也受影响,soa_logs队列推送很慢,内核参数一直调整无效,最终迁移kafka节点:所以内核参数最好还是不要修改# rm -f /etc/security/limits.d/90-nproc.conf# vi /etc/security/limits.conf* soft nproc 204800* hard nproc 204800* soft memlock unlimited* hard memlock unlimited设置块设备预读大小/sbin/blockdev --setra 16384 /dev/sda1/sbin/blockdev --setra 16384 /dev/sdb1/sbin/blockdev --setra 16384 /dev/sdc1/sbin/blockdev --setra 16384 /dev/sdd13.初始化安装环境#切换到hadoop用户su hadoopmaster节点:mkdir -p /data/disk1/gp/masterchown -R hadoop /data/disk1/gp/masterchmod 700 /data/disk1/gp/master所有segment 节点:mkdir -p /data/disk1/gp/datamkdir -p /data/disk2/gp/datamkdir -p /data/disk3/gp/datamkdir -p /data/disk4/gp/datamkdir -p /data/disk1/gp/mirrormkdir -p /data/disk2/gp/mirrormkdir -p /data/disk3/gp/mirrormkdir -p /data/disk4/gp/mirrorchown -R hadoop /data/disk1/gp/datachmod -R 700 /data/disk1/gp/data4.安装:./greenplum-db-4.3.9.1-build-1-rhel5-x86_64.bin安装到/opt/17173_install/greenplum-db-4.3.9.1安装完成cd greenplum-db/bin./pg_configcd ..cat greenplum_path.sh添加到用户的环境变量cat greenplum_path.sh >> ~/.bash_profile. ~/.bash_profile创建主机文件,包括所有节点以及主节点本身vi hostsea2sea3sea4sea5sea6交换KEY,master 访问所有的segment不需要输入密码,master pub拷贝到所有的segment authorized_keys,安装过hadoop可以略过gpssh-exkeys -f ./host安装软件到segment hostsgpseginstall -f ./host -u hadoop5.初始化数据库配置文件cp docs/cli_help/gpconfigs/gpinitsystem_config ./chmod 644 ./gpinitsystem_configvi ./gpinitsystem_configdeclare -a DATA_DIRECTORY=(/data/disk1/gp/data /data/disk2/gp/data/data/disk3/gp/data /data/disk4/gp/data)MASTER_HOSTNAME=sea6MASTER_DIRECTORY=/data/disk1/gp/masterMIRROR_PORT_BASE=50000REPLICATION_PORT_BASE=41000MIRROR_REPLICATION_PORT_BASE=51000declare -a MIRROR_DATA_DIRECTORY=(/data/disk1/gp/mirror/data/disk2/gp/mirror /data/disk3/gp/mirror /data/disk4/gp/mirror) DATABASE_NAME=seaMACHINE_LIST_FILE=/opt/17173_install/greenplum-db/host_segment编辑主机文件,不要包含master, standby,除非master,standby节点也需要当segment node使用.vi host_segmentsea2sea3sea4sea5sea6初始化数据库gpinitsystem -c ./gpinitsystem_config6.增加standby一个gp集群只有一个master肯定会让人不放心,还好有备用,当master宕掉后,会自动启用standby作为master,下面来看一下standby怎么添加在standby服务器上执行,sea5作为standbymkdir /data/disk1/gp/masterchown hadoop /data/disk1/gp/master在master服务器上执行gpinitstandby -s sea5中间输入一次Y7.增加mirrormirror就是镜像,也叫数据备份。
greenplum基本操作及管理命令

greenplum基本操作及管理命令第1章系统管理 1.1 GP服务启停 su - gpadmingpstart #正常启动gpstop #正常关闭gpstop -M fast #快速关闭gpstop –r #重启gpstop –u #重新加载配置文件 1.2 登陆 psql gpdbpsql -d gpdb -h gphostm -p 5432 -U gpadmin 1.3 查看segment配置 select * from gp_segment_configuration; 1.4 文件系统 select * from pg_filespace_entry; 1.5 列出所有数据库 psql –l 1.6 行表库最大尺寸一个数据库最大尺寸无限制已存在有32TB 的数据库一个表的最大尺寸 32 TB一行记录的最大尺寸 1.6 TB一个字段的最大尺寸? 1 GB一个表里最大行数无限制一个表里最大列数 250-1600 与列类型有关一个表里的最大索引数量无限制当然实际上没有真正的无限制还是要受可用磁盘空间、可用内存/交换区的制约。
事实上当这些数值变得异常地大时系统性能也会受很大影响。
表的最大尺寸32 TB 不需要操作系统对大文件的支持。
大表用多个 1 GB 的文件存储因此文件系统尺寸的限制是不重要的。
如果缺省的块大小增长到32K 最大的表尺寸和最大列数还可以增加到四倍 1.7 存储空间一个 Postgres 数据库存储一个文本文件所占用的空间最多可能需要相当于这个文本文件自身大小5倍的磁盘空间。
第2章 Psql操作 2.1 创建/删除用户创建用户createuser [-a] [-A] [-d] [-D] [-e] [-P] [-h 主机名] [-p port] 用户名参数说明[-a]允许创建其他用户相当于创建一个超级用户[-A]不允许此用户创建其他用户[-d]允许此用户创建数据库[-D]不允许此用户创建数据库[-e]将执行过程显示到Shell上[-P]创建用户时同时设置密码[-h 主机名]为某个主机上的Postgres创建用户[-p port]与-h参数一同使用指定主机的端口。
greenplum 语法

greenplum 语法Greenplum是一种基于PostgreSQL的高性能、可扩展的关系型数据库管理系统。
它以并行处理和分布式架构为基础,支持大规模数据存储和查询,适用于数据仓库和商业智能应用。
下面介绍一些 Greenplum 常用的 SQL 语法:1. 创建数据库:CREATE DATABASE database_name;2. 创建表:CREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,.....);3. 插入数据:INSERT INTO table_name (column1, column2, column3,...) VALUES (value1, value2, value3,...);4. 查询数据:SELECT column1, column2,..... FROM table_name WHERE condition;5. 更新数据:UPDATE table_name SET column1 = value1, column2 =value2,.... WHERE condition;6. 删除数据:DELETE FROM table_name WHERE condition;7. 创建索引:CREATE INDEX index_name ON table_name (column1,column2,....);8. 删除索引:DROP INDEX index_name;9. 创建视图:CREATE VIEW view_name AS SELECT column1, column2,.... FROM table_name WHERE condition;10. 删除视图:DROP VIEW view_name;11. 创建函数:CREATE FUNCTION function_name (argument_type,argument_type,....) RETURNS return_type AS $$function_body;$$ LANGUAGE plpgsql;12. 删除函数:DROP FUNCTION function_name (argument_type,argument_type,....);以上是 Greenplum 常用的 SQL 语法,通过学习这些语法可以更加熟练地操作数据库。
Greenplum常用命令、函数

Greenplum常⽤命令、函数Greenplum常⽤查询命令#查看test_bd事务(即数据库)下的所有表名包含 user 的表信息SELECT UPPER(A.SCHEMANAME) AS SCHEMANAME, UPPER(A.TABLENAME) AS TABLENAME,D.ATTRELID,D.ATTRELID :: regclass,UPPER(D.ATTNAME) AS ATTNAME,REPLACE(REPLACE(REPLACE(FORMAT_TYPE(D.ATTTYPID, D.ATTTYPMOD),'numeric','NUMBER'),'character varying','VARCHAR2'),'date','DATE') AS DATA_TYPE,E.DESCRIPTIONFROM PG_TABLES AS AINNER JOIN PG_CLASS AS B ON A.TABLENAME = B.RELNAMELEFT JOIN PG_CATALOG.PG_DESCRIPTION AS E ON B.OID = E.OBJOIDLEFT JOIN PG_CATALOG.PG_ATTRIBUTE AS D ON D.ATTRELID = E.OBJOID AND D.ATTNUM = E.OBJSUBIDWHERE SCHEMANAME ='test_bd'AND A.TABLENAME LIKE'%user%'AND D.ATTNUM >0ORDER BY A .TABLENAME,D.ATTNUM select pg_size_pretty(pg_database_size('gp_db')); #查看gp数据库⼤⼩ select gp_segment_id,count(*) from db_name.tb_name group by gp_segment_id; #查看数据分布情况1.创建数据库 createdb test_db;2.删除数据库 dropdb test_db;3.创建模式 create schema myschema;4.删除模式 drop schema myschema;5.创建⽤户 create user user_name with password '123456' ;6.删除⽤户 drop user user_name;7.查看系统⽤户信息 select usename from pg_user;8.查看版本信息 select version();9.打开psql交互⼯具 psql name_db;10.执⾏sql⽂件 mydb=> \i basics.sql \i 命令从指定的⽂件中读取命令。
GreenPlum使用手册

GreenPlum数据库集群安装说明及使用手册开心十二月总结****年**月**日目录1体系结构介绍 (4)2安装 (10)2.1安装 (10)2.1.1安装准备 (10)2.1.2安装gp-db (11)2.1.3配置通讯 (13)2.1.4建立数据存储池 (17)2.1.5同步系统时间 (17)2.1.6验证安装是否成功 (18)2.1.7初始化 (18)2.1.8数据库的启停 (19)2.2Master双机热备 (19)2.3Segment节点互备 (20)3GP数据库的使用 (23)3.1pgAdminIII工具 (23)3.1.1安装和第一次使用pgAdminIII (23)3.1.2主窗体 (24)3.1.3导航菜单 (24)3.1.4工具栏介绍 (25)3.1.5数据库与表的创建 (26)3.1.6使用pgAdminIII备份数据库 (26)3.2JDBC配置 (27)3.3GP数据库两个重要概念 (28)3.3.1什么是Schema (28)3.3.2数据分布存储 (29)3.4GP的SQL语法 (29)3.4.1数据加载 (29)3.4.2SQL并行查询 (33)3.4.3聚合函数 (33)3.4.4索引 (33)3.4.5分区 (35)3.4.6函数 (36)4维护数据库 (40)4.1数据库启动gpstart (40)4.2数据库停止gpstop (42)4.3查看实例配置和状态 (42)4.4查看数据库运行状态gpstate (43)4.5查看用户会话和提交的查询等信息 (44)4.6查看数据库、表占用空间 (44)4.7查看数据分布情况 (45)4.8实例恢复gprecoverseg (45)4.9查看锁信息 (45)4.10数据库的备份与恢复 (45)5调优、排错 (45)6附件 (45)6.1DBA常用命令 (45)7Q&A (46)7.1不支持触发器 (46)7.2更新操作中的若干问题 (46)1体系结构介绍Greenplum数据库产品——下一代数据仓库引擎和分析方法Greenplum公司是企业数据云计算解决方案的创始人,为客户提供灵活的数据商业智能和分析方法。
Greenplum简明使用手册

GP服务启停su - gpadmingpstart #正常启动gpstop #正常关闭gpstop -M fast #快速关闭gpstop –r #重启gpstop –u #重新加载配置文件登陆与退出Greenplum#正常登陆psql gpdbpsql -d gpdb -h gphostm -p 5432 -U gpadmin#使用utility方式PGOPTIONS="-c gp_session_role=utility" psql -h -d dbname hostname -p port#退出在psql命令行执行\q参数查询psql -c 'SHOW ALL;' -d gpdbgpconfig --show max_connections创建数据库createdb -h localhost -p 5432 dhdw创建GP文件系统# 文件系统名gpfsdw# 子节点,视segment数创建目录mkdir -p /gpfsdw/seg1mkdir -p /gpfsdw/seg2chown -R gpadmin:gpadmin /gpfsdw# 主节点mkdir -p /gpfsdw/masterchown -R gpadmin:gpadmin /gpfsdwgpfilespace -o gpfilespace_configgpfilespace -c gpfilespace_config创建GP表空间psql gpdbcreate tablespace TBS_DW_DATA filespace gpfsdw;SET default_tablespace = TBS_DW_DATA;删除GP数据库gpdeletesystem -d /gpmaster/gpseg-1 -f查看segment配置select * from gp_segment_configuration;文件系统select * from pg_filespace_entry;磁盘、数据库空间SELECT * FROM gp_toolkit.gp_disk_free ORDER BY dfsegment;SELECT * FROM gp_toolkit.gp_size_of_database ORDER BY sodddatname;日志SELECT * FROM gp_toolkit.__gp_log_master_ext;SELECT * FROM gp_toolkit.__gp_log_segment_ext;表描述/d+ <tablename>表分析VACUUM ANALYZE tablename;表数据分布SELECT gp_segment_id, count(*) FROM <table_name> GROUP BY gp_segment_id;表占用空间SELECT relname as name, sotdsize/1024/1024 as size_MB, sotdtoastsize as toast, sotdadditionalsize as otherFROM gp_toolkit.gp_size_of_table_disk as sotd, pg_classWHERE sotd.sotdoid = pg_class.oid ORDER BY relname;索引占用空间SELECT soisize/1024/1024 as size_MB, relname as indexnameFROM pg_class, gp_toolkit.gp_size_of_indexWHERE pg_class.oid = gp_size_of_index.soioidAND pg_class.relkind='i';OBJECT的操作统计SELECT schemaname as schema, objname as table, usename as role, actionname as action, subtype as type, statime as timeFROM pg_stat_operationsWHERE objname = '<name>';锁SELECT locktype, database, c.relname, l.relation, l.transactionid, l.transaction, l.pid, l.mode, l.granted, a.current_queryFROM pg_locks l, pg_class c, pg_stat_activity aWHERE l.relation=c.oidAND l.pid=a.procpidORDER BY c.relname;队列SELECT * FROM pg_resqueue_status;加载(LOAD)数据到Greenplum数据库gpfdist外部表# 启动服务gpfdist -d /share/txt -p 8081 –l /share/txt/gpfdist.log &# 创建外部表,分隔符为’/t’drop EXTERNAL TABLE TD_APP_LOG_BUYER;CREATE EXTERNAL TABLE TD_APP_LOG_BUYER (IP text,ACCESSTIME text,REQMETHOD text,URL text,STATUSCODE int,REF text,name text,VID text)LOCATION ('gpfdist://gphostm:8081/xxx.txt')FORMAT 'TEXT' (DELIMITER E'/t'FILL MISSING FIELDS) SEGMENT REJECT LIMIT 1 percent;# 创建普通表create table test select * from TD_APP_LOG_BUYER;# 索引# CREATE INDEX idx_test ON test USING bitmap (ip);# 查询数据select ip , count(*) from test group by ip order by count(*); gpload# 创建控制文件# 加载数据gpload -f my_load.ymlcopyCOPY country FROM '/data/gpdb/country_data'WITH DELIMITER '|' LOG ERRORS INTO err_countrySEGMENT REJECT LIMIT 10 ROWS;从Greenplum数据库卸载(UNLOAD)数据gpfdist外部表# 创建可写外部表CREATE WRITABLE EXTERNAL TABLE unload_expenses( LIKE expenses )LOCATION ('gpfdist://etlhost-1:8081/expenses1.out','gpfdist://etlhost-2:8081/expenses2.out')FORMAT 'TEXT' (DELIMITER ',')DISTRIBUTED BY (exp_id);# 写权限GRANT INSERT ON writable_ext_table TO <name>;# 写数据INSERT INTO writable_ext_table SELECT * FROM regular_table;copyCOPY (SELECT * FROM country WHERE country_name LIKE 'A%') TO '/home/gpadmin/a_list_countries.out';执行sql文件psql gpdbname –f yoursqlfile.sql或者psql登陆后执行\i yoursqlfile.sqlGreenplum配置优化# 查询参数psql -c'SHOW ALL;' -d gpdbgpconfig--show max_connections# 修改参数配置命令gpconfig-c <parameter name> -v <parameter value>比如:gpconfig-c log_statement -v DDL# 使参数生效gpstop –r# 修改默认搜索路径# 默认dbtestALTERDATABASE dhgp SET search_path TO dbtest;# 设置work_mem 64MBALTERDATABASE dhgp SET work_mem TO 65536;另一种写法:SETwork_mem TO '64MB'# 设置maintenance_work_mem 128MBALTER DATABASEdhgp SET maintenance_work_mem TO 131072; # 设置max_work_mem 4GALTERDATABASE dhgp SET max_work_mem TO 4194304;# 设置statement_memALTERDATABASE dhgp SET statement_mem TO '256MB';# 12G,需要配合修改/etc/sysctl.conf kernel.shmmaxALTERDATABASE dhgp SET effective_cache_size TO 1572864;# 在各个节点的postgres.conf文件中配置,master和每个segment的可以使用的cpu个数Master:gp_resqueue_priority_cpucores_per_segment 8Segment:2# checkpoint_segments32-256(512MB-4GB)。
GreenPlum-数据存储目录迁移及常用操作

GreenPlum-数据存储⽬录迁移及常⽤操作⼀、环境介绍Greenplum5 3节点集群,Centos7.2虚拟机,⼆、需求因为/home⽬录磁盘空间已满,需要将Greenplum的数据存储⽬录转移到新的分区/opt⽬录下,虚拟机磁盘管理没有⽤LVM逻辑卷管理,⽆法动态扩容/home。
三、解决⽅案⼀般Greenplum不⽀持移动它的⽬录,但是可以通过以下两种⽅案实现Greenplum的数据存储⽬录的更改:1.移动⽬录并在其旧位置创建符号链接到新位置。
例如:#如果以前使⽤"/home/data/master"⽬录,需要移动到"/opt/data2/master",移动前备份mv /home/data/master /opt/data2/master#则可以⽤符号链接"/data/master - >/data2/master",创建软链接ln -s /opt/data2/master /home/data/master#这⾥讲解下软硬连接的区别:ln -s and ln硬连接(ln):⽂件名就相当于⼀个硬连接(指针),当为⼀个⽂件再建⽴⼀个硬连接后相当于⼜增加了⼀个指向⽂件存储地的指针,当原⽂件名⽂件删除后,新建硬连接依旧可以访问数据。
软连接(ln -s):当原⽂件名⽂件被删除后,软连接失效。
软硬连接都不会增加存储⼤⼩,这⾥使⽤软连接是因为硬连接⽆法跨分区建⽴。
2.如果为测试系统,不考虑数据。
使⽤“gpdeletesystem”删除旧系统并在新⽬录中重新初始化它四、常⽤操作重置环境:解决不能解决的⼀系列问题1.删除主节点中gpdata下的master与⽂件存储⽬录,副节点也同样删除⽂件存储⽬录。
2.切换gpadmin⽤户,配置.bash_profile环境,例如:source /opt/greenplum/greenplum-db/greenplum_path.shexport MASTER_DATA_DIRECTORY=/home/gpadmin/gpdata/gpmaster/gpseg-1export PGPORT=5432export PGDATABASE=postgres #默认进⼊的dbsource .bash_profile3.查看初始化init脚本是否正确4.初始化数据库,node4为master的备份节点,这⾥若不成功则配置有错。
greenplum实施方案

greenplum实施方案Greenplum实施方案在当今大数据时代,企业面临着海量数据的存储、管理和分析挑战。
为了更好地应对这些挑战,越来越多的企业开始采用Greenplum作为他们的大数据解决方案。
本文将介绍Greenplum实施方案,帮助企业更好地理解和应用Greenplum。
首先,要实施Greenplum,企业需要进行需求分析和规划。
在这一阶段,企业需要明确自己的数据存储和分析需求,以及未来的发展方向。
同时,还需要评估现有的IT基础设施和人员技术水平,以确定是否具备实施Greenplum的条件。
其次,企业需要进行Greenplum的部署和配置。
在部署阶段,企业需要选择合适的硬件设备,并进行相应的网络和安全设置。
在配置阶段,企业需要根据自身需求对Greenplum进行参数设置和优化,以确保系统的稳定性和性能。
接下来,企业需要进行数据迁移和导入。
在这一阶段,企业需要将现有的数据迁移到Greenplum中,并进行相应的数据清洗和转换工作。
同时,企业还需要建立数据导入的定时任务,确保数据的及时更新和同步。
然后,企业需要进行应用开发和优化。
在这一阶段,企业需要根据自身业务需求开发相应的数据分析应用,并对应用进行性能优化和调整,以提高数据分析的效率和准确性。
最后,企业需要进行监控和维护。
在这一阶段,企业需要建立完善的监控系统,对Greenplum的运行状态和性能进行实时监控,并及时进行故障排除和性能调优。
总的来说,Greenplum的实施方案涉及到需求分析、部署配置、数据迁移导入、应用开发优化以及监控维护等多个方面。
企业在实施Greenplum时,需要充分考虑自身的实际情况,合理规划和安排每个阶段的工作,以确保整个实施过程顺利进行,并达到预期的效果。
通过本文的介绍,相信读者对Greenplum的实施方案有了更深入的了解。
希望企业可以根据自身需求和实际情况,合理选择和应用Greenplum,从而更好地应对大数据挑战,提升企业的竞争力和发展潜力。
GreenPlum使用手册

GreenPlum数据库集群安装说明及使用手册开心十二月总结****年**月**日目录1体系结构介绍 (4)2安装 (12)2.1安装 (12)2.1.1安装准备 (12)2.1.2安装gp-db (14)2.1.3配置通讯 (18)2.1.4建立数据存储池 (24)2.1.5同步系统时间 (24)2.1.6验证安装是否成功 (24)2.1.7初始化 (25)2.1.8数据库的启停 (26)2.2Master双机热备 (27)2.3Segment节点互备 (29)3GP数据库的使用 (34)3.1pgAdminIII工具 (34)3.1.1安装和第一次使用pgAdminIII (34)3.1.2主窗体 (35)3.1.3导航菜单 (36)3.1.4工具栏介绍 (37)3.1.5数据库与表的创建 (38)3.1.6使用pgAdminIII备份数据库 (39)3.2JDBC配置 (40)3.3GP数据库两个重要概念 (41)3.3.1什么是Schema (41)3.3.2数据分布存储 (43)3.4GP的SQL语法 (43)3.4.1数据加载 (43)3.4.2SQL并行查询 (51)3.4.3聚合函数 (51)3.4.4索引 (51)3.4.5分区 (54)3.4.6函数 (57)4维护数据库 (63)4.1数据库启动gpstart (63)4.2数据库停止gpstop (69)4.3查看实例配置和状态 (69)4.4查看数据库运行状态gpstate (70)4.5查看用户会话和提交的查询等信息 (73)4.6查看数据库、表占用空间 (73)4.7查看数据分布情况 (73)4.8实例恢复gprecoverseg (74)4.9查看锁信息 (74)4.10数据库的备份与恢复 (74)5调优、排错 (75)6附件 (75)6.1DBA常用命令 (75)7Q&A (76)7.1不支持触发器 (76)7.2更新操作中的若干问题 (77)1体系结构介绍Greenplum数据库产品——下一代数据仓库引擎和分析方法Greenplum公司是企业数据云计算解决方案的创始人,为客户提供灵活的数据商业智能和分析方法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第1章系统管理1.1 GP服务启停su - gpadmingpstart #正常启动gpstop #正常关闭gpstop -M fast #快速关闭gpstop –r #重启gpstop –u #重新加载配置文件1.2 登陆psql gpdbpsql -d gpdb -h gphostm -p 5432 -U gpadmin 1.3 查看segment配置select * from gp_segment_configuration;1.4 文件系统select * from pg_filespace_entry;1.5 列出所有数据库psql –l1.6 行表库最大尺寸一个数据库最大尺寸?无限制(已存在有32TB 的数据库)一个表的最大尺寸?32 TB一行记录的最大尺寸?1.6 TB一个字段的最大尺寸? 1 GB一个表里最大行数?无限制一个表里最大列数?250-1600 (与列类型有关)一个表里的最大索引数量?无限制当然,实际上没有真正的无限制,还是要受可用磁盘空间、可用内存/交换区的制约。
事实上,当这些数值变得异常地大时,系统性能也会受很大影响。
表的最大尺寸32 TB 不需要操作系统对大文件的支持。
大表用多个1 GB 的文件存储,因此文件系统尺寸的限制是不重要的。
如果缺省的块大小增长到32K ,最大的表尺寸和最大列数还可以增加到四倍1.7 存储空间一个Postgres 数据库(存储一个文本文件)所占用的空间最多可能需要相当于这个文本文件自身大小5倍的磁盘空间。
第2章Psql操作2.1 创建/删除用户创建用户:createuser [-a] [-A] [-d] [-D] [-e] [-P] [-h 主机名] [-p port] 用户名参数说明:[-a]:允许创建其他用户,相当于创建一个超级用户;[-A]:不允许此用户创建其他用户;[-d]:允许此用户创建数据库;[-D]:不允许此用户创建数据库;[-e]:将执行过程显示到Shell上;[-P]:创建用户时,同时设置密码;[-h 主机名]:为某个主机上的Postgres创建用户;[-p port]:与-h参数一同使用,指定主机的端口。
createuser -h 172.28.18.51 -p 5000 -D -A -e testuser创建超级用户:createuser -P -d -a -e testuser删除用户:命令:dropuser [-i] [-h] [-p] [-e] 用户名参数说明:[ -i]:删除用户前,要求确认;[-h 主机名]:删除某个主机上的Postgres用户;[-p port]:与-h参数一同使用,指定主机的端口;[-e]:将执行过程显示到Shell上。
2.2 创建数据库createdb -p 5432 -e -U gpadmin mydb2.3 运行建库脚本psql -p 5432 -U gpadmin -d mydb -f ./mysql.sql 2.4 表描述/d+ <tablename>2.5 执行sql文件psql gpdbname –f yoursqlfile.sql或者psql登陆后执行\i yoursqlfile.sq2.6 返回查询头几行/随机几行SELECT colsFROM tabORDER BY random()LIMIT 1 ;2.7 更改字段类型ALTER TABLE ALTER COLUMN TYPE第3章数据导入导出3.1 GPload工具编写load.ymlverSION: 1.0.0.1USER: gpadminPORT: 5432GPLOAD:INPUT:- SOURCE:FILE:- /opt/gpadmin/zhonghong/testload.txt- COLUMNS:- msisdn: text- blank1: text- blank2: text- uaText: text- FORMAT: text- DELIMITER: '|'OUTPUT:- TABLE: ua_in- MODE: INSERTSQL:执行命令:gpload -f load.yml -U gpadmin -d uainfo3.2 外部表CREATE EXTERNAL TABLE ext_expenses ( name text,date date, amount float4, category text, desc text ) LOCATION (‘gpfdist://etlhost:8081/*’,‘gpfdist://etlhost1:8081/*’)FORMAT ‘TEXT’ (DELIMITER ‘,’);装载数据:1-insert方式INSERT INTO expenses_travelSELECT * from ext_expenses where category=’travel’;2-create table…as …方式CREATE TABLE expenses AS SELECT * from ext_expenses;3.3 Copy命令Copy命令装载数据并不是并行装载,而且所装载的数据文件必须放在master服务器上,例如:COPY country FROM ‘/data/gpdb/country_data’WITH DELIMITER ‘|’ LOG ERRORS INTO err_countrySEGMENT REJECT LIMIT 10 ROWS;第4章附录——命令大全输入: /copyright 获取发布信息/h 获取SQL 命令的帮助/? 获取psql 命令的帮助/g 或者以分号作为执行查询的结尾/q 退出4.1 一般选项/c[onnect] [数据库名|- [用户名称]]联接到新的数据库(当前为"test")/cd [目录名] 改变当前的工作目录/copyright 显示PostgreSQL 用法和发布信息/encoding [编码]显示或设置客户端编码/h [名字] SQL 命令的语法帮助, 用* 可以看所有命令的帮助/q 退出psql/set [名字[值]]设置内部变量, 如果没有参数就列出所有/timing 查询计时开关切换(目前是关闭)/unset 名字取消(删除)内部变量/! [命令] 在shell 里执行命令或者开始一个交互的shell4.2 查询缓冲区选项/e [文件名] 用一个外部编辑器编辑当前查询缓冲区或者文件/g [文件名] 向服务器发送SQL 命令(并且把结果写到文件或者|管道) /p 显示当前查询缓冲区的内容/r 重置(清理) 查询缓冲区/s [文件名] 打印历史或者将其保存到文件/w [文件名] 将查询缓冲区写出到文件4.3 输入/输出选项/echo [字串] 向标准输出写出文本/i 文件名执行来自文件的命令/o [文件名] 向文件或者|管道发送所有查询结果/qecho [字串]向查询输出流写出文本(见/o)4.4 信息选项/d [名字] 描述表, 索引, 序列, 或者视图/d{t|i|s|v|S} [模式] (加"+" 获取更多信息)列出表/索引/序列/视图/系统表/da [模式] 列出聚集函数/db [模式] 列出表空间(加"+" 获取更多的信息)/dc [模式] 列出编码转换/dC 列出类型转换/dd [模式] 显示目标的注释/dD [模式] 列出域/df [模式] 列出函数(加"+" 获取更多的信息)/dg [模式] 列出组/dn [模式] 列出模式(加"+" 获取更多的信息)/do [名字] 列出操作符/dl 列出大对象, 和/lo_list 一样/dp [模式] 列出表, 视图, 序列的访问权限/dT [模式] 列出数据类型(加"+" 获取更多的信息)/du [模式] 列出用户/l 列出所有数据库(加"+" 获取更多的信息)/z [模式] 列出表, 视图, 序列的访问权限(和/dp 一样)4.5 格式选项/a 在非对齐和对齐的输出模式之间切换/C [字串] 设置表标题, 如果参数空则取消标题/f [字串] 为非对齐查询输出显示或设置域分隔符/H 在HTML 输出模式之间切换(当前是关闭)/pset 变量[值]设置表的输出选项(变量:= {foramt|border|expanded|fieldsep|null|recordsep|tuples_only|title|tableattr|pager})/t 只显示行(当前是关闭)/T [字串] 设置HTML <表> 标记属性, 如果没有参数就取消设置/x 在扩展输出之间切换(目前是关闭)4.6 拷贝, 大对象选项/copy ... 执行SQL COPY, 数据流指向客户端主机/lo_export LOBOID FILE/lo_import FILE [COMMENT]/lo_list/lo_unlink LOBOID 大对象操作4.7 SQL帮助ABORT CREATE INDEX DROP TYPEALTER AGGREGATE CREATE LANGUAGE DROP USERALTER CONVERSION CREATE OPERATOR CLASS DROP VIEW ALTER DATABASE CREATE OPERATOR ENDALTER DOMAIN CREATE RULE EXECUTEALTER FUNCTION CREATE SCHEMA EXPLAINALTER GROUP CREATE SEQUENCE FETCHALTER INDEX CREATE TABLE GRANTALTER LANGUAGE CREATE TABLE AS INSERTALTER OPERATOR CLASS CREATE TABLESPACE LISTENALTER OPERATOR CREATE TRIGGER LOADALTER SCHEMA CREATE TYPE LOCKALTER SEQUENCE CREATE USER MOVEALTER TABLE CREATE VIEW NOTIFYALTER TABLESPACE DEALLOCATE PREPAREALTER TRIGGER DECLARE REINDEXALTER TYPE DELETE RELEASE SAVEPOINTALTER USER DROP AGGREGATE RESETANALYZE DROP CAST REVOKEBEGIN DROP CONVERSION ROLLBACKCHECKPOINT DROP DATABASE ROLLBACK TO SAVEPOINTCLOSE DROP DOMAIN SAVEPOINTCLUSTER DROP FUNCTION SELECTCOMMENT DROP GROUP SELECT INTOCOMMIT DROP INDEX SETCOPY DROP LANGUAGE SET CONSTRAINTSCREATE AGGREGATE DROP OPERATOR CLASS SET SESSION AUTHORIZATIONCREATE CAST DROP OPERATOR SET TRANSACTIONCREATE CONSTRAINT TRIGGER DROP RULE SHOWCREATE CONVERSION DROP SCHEMA START TRANSACTIONCREATE DATABASE DROP SEQUENCE TRUNCATECREATE DOMAIN DROP TABLE UNLISTENCREATE FUNCTION DROP TABLESPACE UPDATECREATE GROUP DROP TRIGGER VACUUM命令: ABORT描述: 终止当前事务语法:ABORT [ WORK | TRANSACTION ]命令: ALTER AGGREGATE描述: 改变一个聚集函数的定义语法:ALTER AGGREGATE 名字( 类型) RENAME TO 新名字ALTER AGGREGATE 名字( 类型) OWNER TO 新属主命令: ALTER CONVERSION描述: 改变一个转换的定义语法:ALTER CONVERSION 名字RENAME TO 新名字ALTER CONVERSION 名字OWNER TO 新属主命令: ALTER DATABASE描述: 改变一个数据库语法:ALTER DATABASE 名字SET 参数{ TO | = } { 值| DEFAULT } ALTER DATABASE 名字RESET 参数ALTER DATABASE 名字RENAME TO 新名字ALTER DATABASE 名字OWNER TO 新属主命令: ALTER DOMAIN描述: 改变一个域的定义语法:ALTER DOMAIN 名字{ SET DEFAULT 说明| DROP DEFAULT }ALTER DOMAIN 名字{ SET | DROP } NOT NULLALTER DOMAIN 名字ADD 域约束ALTER DOMAIN 名字DROP CONSTRAINT 约束名字[ RESTRICT | CASCADE ] ALTER DOMAIN 名字OWNER TO 新宿主命令: ALTER DOMAIN描述: 改变一个域的定义语法:ALTER DOMAIN 名字{ SET DEFAULT 说明| DROP DEFAULT }ALTER DOMAIN 名字{ SET | DROP } NOT NULLALTER DOMAIN 名字ADD 域约束ALTER DOMAIN 名字DROP CONSTRAINT 约束名字[ RESTRICT | CASCADE ] ALTER DOMAIN 名字OWNER TO 新宿主命令: ALTER FUNCTION描述: 改变一个函数的定义语法:ALTER FUNCTION 名字( [ 类型[, ...] ] ) RENAME TO 新名字ALTER FUNCTION 名字( [ 类型[, ...] ] ) OWNER TO 新属主命令: ALTER GROUP描述: 改变一个用户组语法:ALTER GROUP 组名称ADD USER 用户名称[, ... ]ALTER GROUP 组名称DROP USER 用户名称[, ... ] ALTER GROUP 组名称RENAME TO 新名称命令: ALTER INDEX描述: 改变一个索引的定义语法:ALTER INDEX 索引名称动作[, ... ]ALTER INDEX 索引旧名称RENAME TO 索引新名称动作为以下之一:OWNER TO 新属主SET TABLESPACE indexspace_name命令: ALTER LANGUAGE描述: 改变一个过程语言的定义语法:ALTER LANGUAGE 名字RENAME TO 新名字命令: ALTER OPERATOR CLASS描述: 改变一个操作符表的定义语法:ALTER OPERATOR CLASS 名字USING 索引方法RENAME TO 新名字ALTER OPERATOR CLASS 名字USING 索引方法OWNER TO 新属主命令: ALTER OPERATOR CLASS描述: 改变一个操作符表的定义语法:ALTER OPERATOR CLASS 名字USING 索引方法RENAME TO 新名字ALTER OPERATOR CLASS 名字USING 索引方法OWNER TO 新属主命令: ALTER OPERATOR描述: 改变一个操作符的定义语法:ALTER OPERATOR 名字( { 左边类型| NONE } , { 右边类型| NONE } ) OWNER TO 新属主命令: ALTER SCHEMA描述: 改变一个模式的定义语法:ALTER SCHEMA 名字RENAME TO 新名字ALTER SCHEMA 名字OWNER TO 新属主命令: ALTER SEQUENCE描述: 改变一个序列生成器的定义语法:ALTER SEQUENCE 名字[ INCREMENT [ BY ] 递增][ MINVALUE 最小值| NO MINVALUE ] [ MAXVALUE 最大值| NO MAXVALUE ] [ RESTART [ WITH ] 开始] [ CACHE 缓存] [ [ NO ] CYCLE ]命令: ALTER TABLE描述: 改变一个表的定义语法:ALTER TABLE [ ONLY ] 表名[ * ]action [, ... ]ALTER TABLE [ ONLY ] 表名[ * ]RENAME [ COLUMN ] 字段名TO 新字段名ALTER TABLE 表名RENAME TO 新表名action 为下面的一种:ADD [ COLUMN ] 字段名类型[ 字段约束[ ... ] ]DROP [ COLUMN ] 字段名[ RESTRICT | CASCADE ]ALTER [ COLUMN ] 字段名TYPE 类型[ USING 表达式]ALTER [ COLUMN ] 字段名SET DEFAULT 表达式ALTER [ COLUMN ] 字段名DROP DEFAULTALTER [ COLUMN ] 字段名{ SET | DROP } NOT NULLALTER [ COLUMN ] 字段名SET STATISTICS integerALTER [ COLUMN ] 字段名SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN }ADD 表约束DROP CONSTRAINT 约束名字[ RESTRICT | CASCADE ]CLUSTER ON 索引名称SET WITHOUT CLUSTERSET WITHOUT OIDSOWNER TO 新属主SET TABLESPACE 表空间名字命令: ALTER TABLESPACE描述: 改变一个表空间的定义语法:ALTER TABLESPACE 名字RENAME TO 新名字ALTER TABLESPACE 名字OWNER TO 新属主命令: ALTER TABLESPACE描述: 改变一个表空间的定义语法:ALTER TABLESPACE 名字RENAME TO 新名字ALTER TABLESPACE 名字OWNER TO 新属主命令: ALTER TRIGGER描述: 改变一个触发器的定义语法:ALTER TRIGGER 名字ON 表RENAME TO 新名字命令: ALTER TYPE描述: 改变一个类型的定义语法:ALTER TYPE 名字OWNER TO 新属主命令: ALTER USER描述: 改变一个数据库用户语法:ALTER USER name [ [ WITH ] option [ ... ] ]where option can be:CREATEDB | NOCREATEDB| CREATEUSER | NOCREATEUSER| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password'| VALID UNTIL 'abstime'ALTER USER name RENAME TO newnameALTER USER name SET parameter { TO | = } { value | DEFAULT }ALTER USER name RESET parameter命令: ANALYZE描述: 收集关于数据库的统计数字语法:ANALYZE [ VERBOSE ] [ 表[ (字段[, ...] ) ] ]命令: BEGIN描述: 开始一个事务块语法:BEGIN [ WORK | TRANSACTION ] [ 事物模式[, ...] ]事物模式为下面之一:ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }READ WRITE | READ ONLY命令: CHECKPOINT描述: 强行交易日志检查语法:CHECKPOINT命令: CLOSE描述: 关闭一个游标语法:CLOSE 名字命令: CLUSTER描述: 根据一个索引建表簇语法:CLUSTER 索引名字ON 表名CLUSTER 表名CLUSTER命令: COMMENT描述: 定义或改变一个对象的评注语法:COMMENT ON{TABLE object_name |COLUMN table_name.column_name | AGGREGATE agg_name (agg_type) |CAST (sourcetype AS targettype) | CONSTRAINT constraint_name ON table_name | CONVERSION object_name |DATABASE object_name |DOMAIN object_name |FUNCTION func_name (arg1_type, arg2_type, ...) | INDEX object_name |LARGE OBJECT large_object_oid |OPERATOR op (leftoperand_type, rightoperand_type) OPERATOR CLASS object_name USING index_method | [ PROCEDURAL ] LANGUAGE object_name |RULE rule_name ON table_name |SCHEMA object_name |SEQUENCE object_name |TRIGGER trigger_name ON table_name |TYPE object_name |VIEW object_name} IS 'text'命令: COMMIT描述: 提交当前事务语法:COMMIT [ WORK | TRANSACTION ]命令: COPY描述: 在一个文件和一个表之间拷贝数据语法:COPY 表名[ ( 字段[, ...] ) ]FROM { '文件名' | STDIN }[ [ WITH ][ BINARY ][ OIDS ][ DELIMITER [ AS ] 'delimiter' ][ NULL [ AS ] 'null string' ][ CSV [ QUOTE [ AS ] 'quote' ] [ ESCAPE [ AS ] 'escape' ][ FORCE NOT NULL column [, ...] ]COPY 表名[ ( 字段[, ...] ) ]TO { '文件名' | STDOUT }[ [ WITH ][ BINARY ][ OIDS ][ DELIMITER [ AS ] 'delimiter' ] [ NULL [ AS ] 'null string' ][ CSV [ QUOTE [ AS ] 'quote' ] [ ESCAPE [ AS ] 'escape' ][ FORCE QUOTE column [, ...] ]命令: CREATE AGGREGATE描述: 定义一个新的聚集函数语法:CREATE AGGREGATE name ( BASETYPE = input_data_type, SFUNC = sfunc,STYPE = state_data_type[ , FINALFUNC = ffunc ][ , INITCOND = initial_condition ] )命令: CREATE CAST描述: 定义一个新的类型转换语法:CREATE CAST (源类型AS 目标类型)WITH FUNCTION 函数名(参数类型)[ AS ASSIGNMENT | AS IMPLICIT ]CREATE CAST (源类型AS 目标类型)WITHOUT FUNCTION[ AS ASSIGNMENT | AS IMPLICIT ]命令: CREATE CONSTRAINT TRIGGER描述: 定义一个新的约束触发器语法:CREATE CONSTRAINT TRIGGER nameAFTER events ONtablename constraint attributesFOR EACH ROW EXECUTE PROCEDURE funcname ( args )命令: CREATE CONVERSION描述: define a new encoding conversion语法:CREATE [DEFAULT] CONVERSION 名字FOR 源编码TO 目标编码FROM 函数名命令: CREATE DATABASE描述: 创建一个新的数据库语法:CREATE DATABASE 数据库名称[ [ WITH ] [ OWNER [=] 数据库属主][ TEMPLATE [=] 模板][ ENCODING [=] 编码][ TABLESPACE [=] 表空间] ]命令: CREATE DOMAIN描述: 定义一个新的域语法:CREATE DOMAIN name [AS] data_type[ DEFAULT expression ][ constraint [ ... ] ]constraint 是:[ CONSTRAINT constraint_name ]{ NOT NULL | NULL | CHECK (expression) }命令: CREATE FUNCTION描述: 定义一个新的函数语法:CREATE [ OR REPLACE ] FUNCTION 名字( [ [ 参数名字] 参数类型[, ...] ] ) RETURNS 返回类型{ LANGUAGE 语言名称| IMMUTABLE | STABLE | VOLATILE| CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT | STRICT | [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER | AS 'definition'| AS 'obj_file', 'link_symbol'} ...[ WITH ( attribute [, ...] ) ]命令: CREATE GROUP描述: 定义一个新的用户组语法:CREATE GROUP 组名[ [ WITH ] option [ ... ] ]option 可以为:SYSID gid| USER username [, ...]命令: CREATE INDEX描述: 定义一个新的索引语法:CREATE [ UNIQUE ] INDEX 索引名称ON 表名[ USING method ]( { column | ( expression ) } [ opclass ] [, ...] )[ TABLESPACE tablespace ][ WHERE predicate ]命令: CREATE LANGUAGE描述: 定义一个新的过程语言语法:CREATE [ TRUSTED ] [ PROCEDURAL ] LANGUAGE nameHANDLER call_handler [ VALIDATOR valfunction ]命令: CREATE OPERATOR CLASS描述: 定义一个新的操作符类语法:CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type USING index_method AS{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ] | FUNCTION support_number funcname ( argument_type [, ...] )| STORAGE storage_type} [, ... ]命令: CREATE OPERATOR CLASS描述: 定义一个新的操作符类语法:CREATE OPERATOR CLASS name [ DEFAULT ] FOR TYPE data_type USING index_method AS{ OPERATOR strategy_number operator_name [ ( op_type, op_type ) ] [ RECHECK ] | FUNCTION support_number funcname ( argument_type [, ...] )| STORAGE storage_type} [, ... ]命令: CREATE OPERATOR描述: 定义一个新的操作符语法:CREATE OPERATOR name (PROCEDURE = funcname[, LEFTARG = lefttype ] [, RIGHTARG = righttype ][, COMMUTATOR = com_op ] [, NEGATOR = neg_op ][, RESTRICT = res_proc ] [, JOIN = join_proc ][, HASHES ] [, MERGES ][, SORT1 = left_sort_op ] [, SORT2 = right_sort_op ][, LTCMP = less_than_op ] [, GTCMP = greater_than_op ])命令: CREATE RULE描述: 定义一个新的重写规则语法:CREATE [ OR REPLACE ] RULE 名字AS ON 事件TO 表[ WHERE 条件]DO [ ALSO | INSTEAD ] { NOTHING | 命令| ( 命令; 命令 ... ) }命令: CREATE RULE描述: 定义一个新的重写规则语法:CREATE [ OR REPLACE ] RULE 名字AS ON 事件TO 表[ WHERE 条件]DO [ ALSO | INSTEAD ] { NOTHING | 命令| ( 命令; 命令 ... ) }test=# /h CREATE SCHEMA命令: CREATE SCHEMA描述: 定义一个新的模式语法:CREATE SCHEMA 模式名称[ AUTHORIZATION 用户名称] [ 模式元素[ ... ] ]CREATE SCHEMA AUTHORIZATION 用户名称[ 模式元素[ ... ] ]命令: CREATE SEQUENCE描述: 定义一个新的序列生成器语法:CREATE [ TEMPORARY | TEMP ] SEQUENCE name [ INCREMENT [ BY ] increment ][ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ][ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]命令: CREATE TABLE描述: 定义一个新的表语法:CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name ({ column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]| table_constraint| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ] } [, ... ])[ INHERITS ( parent_table [, ... ] ) ][ WITH OIDS | WITHOUT OIDS ][ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ][ TABLESPACE tablespace ]where column_constraint is:[ CONSTRAINT constraint_name ]{ NOT NULL |NULL |UNIQUE [ USING INDEX TABLESPACE tablespace ] |PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] |CHECK (expression) |REFERENCES reftable [ ( refcolumn ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ][ ON DELETE action ] [ ON UPDATE action ] }[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]and table_constraint is:[ CONSTRAINT constraint_name ]{ UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] | CHECK ( expression ) |FOREIGN KEY ( column_name [, ... ] ) REFERENCES reftable [ ( refcolumn [, ... ] ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] }[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]命令: CREATE TABLE AS描述: 以一个查询的结果定义一个新的表语法:CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE 表名字[ (字段名字[, ...] ) ] [ [ WITH | WITHOUT ] OIDS ]AS query命令: CREATE TABLESPACE描述: 定义一个新的表空间语法:CREATE TABLESPACE 表空间名称[ OWNER 用户名称] LOCATION '目录'命令: CREATE TRIGGER描述: 定义一个新的触发器语法:CREATE TRIGGER 名字{ BEFORE | AFTER } { 事件[ OR ... ] }ON 表[ FOR [ EACH ] { ROW | STATEMENT } ]EXECUTE PROCEDURE 函数名( 参数)命令: CREATE TYPE描述: 定义一个新的数据类型语法:CREATE TYPE name AS( attribute_name data_type [, ... ] )CREATE TYPE name (INPUT = input_function,OUTPUT = output_function[ , RECEIVE = receive_function ][ , SEND = send_function ][ , ANALYZE = analyze_function ][ , INTERNALLENGTH = { internallength | VARIABLE } ] [ , PASSEDBYVALUE ][ , ALIGNMENT = alignment ][ , STORAGE = storage ][ , DEFAULT = default ][ , ELEMENT = element ][ , DELIMITER = delimiter ])命令: CREATE USER描述: 定义一个新的数据库用户帐户语法:CREATE USER name [ [ WITH ] option [ ... ] ]where option can be:SYSID uid| CREATEDB | NOCREATEDB| CREATEUSER | NOCREATEUSER| IN GROUP groupname [, ...]| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password' | VALID UNTIL 'abstime'命令: CREATE VIEW描述: 定义一个新的视图语法:CREATE [ OR REPLACE ] VIEW 名字[ ( 字段名[, ...] ) ] AS query命令: DEALLOCATE描述: 解除一个准备好的语句语法:DEALLOCATE [ PREPARE ] 规划名称命令: DECLARE描述: 定义一个游标语法:DECLARE name [ BINARY ] [ INSENSITIVE ] [ [ NO ] SCROLL ] CURSOR [ { WITH | WITHOUT } HOLD ] FOR query[ FOR { READ ONLY | UPDATE [ OF column [, ...] ] } ]命令: DELETE描述: 删除一个表的记录语法:DELETE FROM [ ONLY ] 表[ WHERE 条件]命令: DROP AGGREGATE描述: 删除一个聚集函数语法:DROP AGGREGATE 名字( 类型) [ CASCADE | RESTRICT ]命令: DROP CAST描述: 删除一个类型转换语法:DROP CAST (源类型AS 目标类型) [ CASCADE | RESTRICT ]命令: DROP CONVERSION描述: 删除一个转换语法:DROP CONVERSION 名字[ CASCADE | RESTRICT ]命令: DROP DATABASE描述: 删除一个数据库语法:DROP DATABASE 名字命令: DROP DOMAIN描述: 删除一个域语法:DROP DOMAIN 名字[, ...] [ CASCADE | RESTRICT ]命令: DROP FUNCTION描述: 删除一个函数语法:DROP FUNCTION 名字( [ 类型[, ...] ] ) [ CASCADE | RESTRICT ]命令: DROP GROUP描述: 删除一个用户组语法:DROP GROUP 名字命令: DROP INDEX描述: 删除一个索引语法:DROP INDEX 名字[, ...] [ CASCADE | RESTRICT ]命令: DROP LANGUAGE描述: 删除一个过程语言语法:DROP [ PROCEDURAL ] LANGUAGE 名字[ CASCADE | RESTRICT命令: DROP OPERATOR CLASS描述: 删除一个操作符类语法:DROP OPERATOR CLASS name USING index_method [ CASCADE | RESTRICT ]描述: 删除一个操作符语法:DROP OPERATOR 名字( { 左边类型| NONE } , { 右边类型| NONE } ) [ CASCADE | RESTRICT ]命令: DROP RULE描述: 删除一个重写规则语法:DROP RULE 名字ON 关系[ CASCADE | RESTRICT ]命令: DROP SCHEMA描述: 删除一个模式语法:DROP SCHEMA 名字[, ...] [ CASCADE | RESTRICT ]命令: DROP SEQUENCE描述: 删除一个序列语法:DROP SEQUENCE 名字[, ...] [ CASCADE | RESTRICT ]命令: DROP TABLE描述: 删除一个表语法:DROP TABLE 名字[, ...] [ CASCADE | RESTRICT ]命令: DROP TABLESPACE描述: 删除一个表空间语法:DROP TABLESPACE 表空间名字命令: DROP TRIGGER描述: 删除一个触发器语法:DROP TRIGGER 名字ON 表[ CASCADE | RESTRICT ]命令: DROP TYPE描述: 删除一个数据类型语法:DROP TYPE 名字[, ...] [ CASCADE | RESTRICT ]命令: DROP USER描述: 删除一个数据库用户帐户语法:DROP USER 名字命令: DROP VIEW描述: 删除一个视图语法:DROP VIEW 名字[, ...] [ CASCADE | RESTRICT ]命令: END描述: 提交当前事务语法:END [ WORK | TRANSACTION ]命令: EXECUTE描述: 执行一个准备好的语句语法:EXECUTE 规划名称[ (参数[, ...] ) ]命令: EXPLAIN描述: 显示语句的执行规划语法:EXPLAIN [ ANALYZE ] [ VERBOSE ] 语句命令: FETCH描述: 恢复来自一个使用游标查询的行语法:FETCH [ direction { FROM | IN } ] cursorname direction 可以为空或下面的一种:NEXTPRIORFIRSTLASTABSOLUTE countRELATIVE countcountALLFORWARDFORWARD countFORWARD ALLBACKWARDBACKWARD countBACKWARD ALL命令: GRANT描述: 定义访问权限语法:GRANT { { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER[,...] | ALL [ PRIVILEGES ] }ON [ TABLE ] 表名称[, ...]TO { 用户名称| GROUP 组名称| PUBLIC } [, ...] [ WITH GRANT OPTION ]GRANT { { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }ON DATABASE 数据库名称[, ...]TO { 用户名称| GROUP 组名称| PUBLIC } [, ...] [ WITH GRANT OPTION ]GRANT { EXECUTE | ALL [ PRIVILEGES ] }ON FUNCTION 函数名称([类型, ...]) [, ...]TO { 用户名称| GROUP 组名称| PUBLIC } [, ...] [ WITH GRANT OPTION ]GRANT { USAGE | ALL [ PRIVILEGES ] }ON LANGUAGE 语言名称[, ...]TO { 用户名称| GROUP 组名称| PUBLIC } [, ...] [ WITH GRANT OPTION ]GRANT { { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }ON SCHEMA 模式名称[, ...]TO { 用户名称| GROUP 组名称| PUBLIC } [, ...] [ WITH GRANT OPTION ]GRANT { CREATE | ALL [ PRIVILEGES ] }ON TABLESPACE 表空间名称[, ...]TO { 用户名称| GROUP 组名称| PUBLIC } [, ...] [ WITH GRANT OPTION ]命令: INSERT描述: 在一个表中创建新行语法:INSERT INTO 表名[ ( 字段[, ...] ) ]{ DEFAULT VALUES | VALUES ( { 表达式| DEFAULT } [, ...] ) | 子查询}命令: LISTEN描述: 监听一个通知语法:LISTEN 名字命令: LOAD描述: 提取或重载一个共享库文件语法:LOAD '文件名'命令: LOCK描述: 锁定一个表语法:LOCK [ TABLE ] 名字[, ...] [ IN lockmode MODE ] [ NOWAIT ]lockmode 可以是下面的一种:ACCESS SHARE | ROW SHARE | ROW EXCLUSIVE | SHARE UPDATE EXCLUSIVE| SHARE | SHARE ROW EXCLUSIVE | EXCLUSIVE | ACCESS EXCLUSIVE命令: MOVE描述: 定位一个游标语法:MOVE [ direction { FROM | IN } ] cursorname命令: NOTIFY描述: 生成一个通知语法:NOTIFY 名字命令: PREPARE描述: 为执行准备一条语句语法:PREPARE 规划名称[ (数据类型[, ...] ) ] AS 语句命令: REINDEX描述: 重建索引语法:REINDEX { DATABASE | TABLE | INDEX } 名字[ FORCE ]命令: RELEASE SAVEPOINT描述: 删除一个以前定义的savepoint语法:RELEASE [ SAVEPOINT ] savepoint_name命令: RESET描述: 恢复运行时参数值为默认值语法:RESET 名字RESET ALL命令: REVOKE描述: 删除访问权限语法:REVOKE [ GRANT OPTION FOR ]{ { SELECT | INSERT | UPDATE | DELETE | RULE | REFERENCES | TRIGGER } [,...] | ALL [ PRIVILEGES ] }ON [ TABLE ] 表名称[, ...]FROM { 用户名称| GROUP 组名称| PUBLIC } [, ...][ CASCADE | RESTRICT ]REVOKE [ GRANT OPTION FOR ]{ { CREATE | TEMPORARY | TEMP } [,...] | ALL [ PRIVILEGES ] }ON DATABASE 数据库名称[, ...]FROM { 用户名称| GROUP 组名称| PUBLIC } [, ...][ CASCADE | RESTRICT ]REVOKE [ GRANT OPTION FOR ]{ EXECUTE | ALL [ PRIVILEGES ] }ON FUNCTION 函数名称([类型, ...]) [, ...]FROM { 用户名称| GROUP 组名称| PUBLIC } [, ...][ CASCADE | RESTRICT ]REVOKE [ GRANT OPTION FOR ]{ USAGE | ALL [ PRIVILEGES ] }ON LANGUAGE 语言名称[, ...]FROM { 用户名称| GROUP 组名称| PUBLIC } [, ...][ CASCADE | RESTRICT ]REVOKE [ GRANT OPTION FOR ]{ { CREATE | USAGE } [,...] | ALL [ PRIVILEGES ] }ON SCHEMA 模式名称[, ...]FROM { 用户名称| GROUP 组名称| PUBLIC } [, ...][ CASCADE | RESTRICT ]REVOKE [ GRANT OPTION FOR ]{ CREATE | ALL [ PRIVILEGES ] }ON TABLESPACE 表空间名称[, ...]FROM { 用户名称| GROUP 组名称| PUBLIC } [, ...][ CASCADE | RESTRICT ]命令: ROLLBACK描述: 终止当前事务语法:ROLLBACK [ WORK | TRANSACTION ]命令: ROLLBACK TO SAVEPOINT描述: 回滚到一个savepoint语法:ROLLBACK [ WORK | TRANSACTION ] TO [ SAVEPOINT ] savepoint_name命令: SAVEPOINT描述: 在当前事物中定义一个新的savepoint语法:SAVEPOINT savepoint_name命令: SELECT描述: 恢复一个表或视图的行语法:SELECT [ ALL | DISTINCT [ ON ( 表达式[, ...] ) ] ]* | 表达式[ AS output_name ] [, ...][ FROM from_item [, ...] ][ WHERE 条件][ GROUP BY 表达式[, ...] ][ HAVING 条件[, ...] ][ { UNION | INTERSECT | EXCEPT } [ ALL ] select ][ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ][ LIMIT { count | ALL } ][ OFFSET start ][ FOR UPDATE [ OF 表名[, ...] ] ]from_item 可以是下面的一种:[ ONLY ] table_name [ * ] [ [ AS ] alias [ ( column_alias [, ...] ) ] ]( select ) [ AS ] alias [ ( column_alias [, ...] ) ]function_name ( [ argument [, ...] ] ) [ AS ] alias [ ( column_alias [, ...] | column_definition [, ...] ) ]function_name ( [ argument [, ...] ] ) AS ( column_definition [, ...] )from_item [ NATURAL ] join_type from_item [ ON join_condition | USING ( join_column [, ...] ) ]命令: SELECT INTO描述: 以一个查询的结果定义一个新的表语法:SELECT [ ALL | DISTINCT [ ON ( expression [, ...] ) ] ]* | expression [ AS output_name ] [, ...]INTO [ TEMPORARY | TEMP ] [ TABLE ] new_table[ FROM from_item [, ...] ][ WHERE condition ][ GROUP BY expression [, ...] ][ HAVING condition [, ...] ][ { UNION | INTERSECT | EXCEPT } [ ALL ] select ][ ORDER BY expression [ ASC | DESC | USING operator ] [, ...] ][ LIMIT { count | ALL } ][ OFFSET start ][ FOR UPDATE [ OF tablename [, ...] ] ]命令: SET描述: 改变一个运行时参数语法:SET [ SESSION | LOCAL ] 名字{ TO | = } { 值| '值' | DEFAULT }SET [ SESSION | LOCAL ] TIME ZONE { timezone | LOCAL | DEFAULT }命令: SET CONSTRAINTS描述: 设置当前交易的约束检查模式语法:SET CONSTRAINTS { ALL | 名字[, ...] } { DEFERRED | IMMEDIATE }命令: SET SESSION AUTHORIZATION描述: 设置当前会话的会话用户确认和当前用户确认语法:SET [ SESSION | LOCAL ] SESSION AUTHORIZATION 用户名称SET [ SESSION | LOCAL ] SESSION AUTHORIZATION DEFAULTRESET SESSION AUTHORIZATION命令: SET TRANSACTION描述: 设置当前交易的属性语法:SET TRANSACTION 事物模式[, ...]SET SESSION CHARACTERISTICS AS TRANSACTION 事物模式[, ...]事物模式为下面之一:ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }READ WRITE | READ ONLY命令: SHOW描述: 显示运行时参数值语法:SHOW 名字SHOW ALL命令: START TRANSACTION描述: 开始一个事务块语法:START TRANSACTION [ 事物模式[, ...] ]事物模式为下面之一:ISOLATION LEVEL { SERIALIZABLE | REPEATABLE READ | READ COMMITTED | READ UNCOMMITTED }READ WRITE | READ ONLY命令: TRUNCATE描述: 清空一个表语法:TRUNCATE [ TABLE ] 名字命令: UNLISTEN描述: 停止监听通知语法:UNLISTEN { 名字| * }命令: UPDATE描述: 更新一个表的记录语法:UPDATE [ ONLY ] 表名SET 字段= { 表达式| DEFAULT } [, ...][ FROM fromlist ][ WHERE 条件]命令: VACUUM描述: 垃圾回收和可选择分析一个数据库语法:VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] [ 表]VACUUM [ FULL ] [ FREEZE ] [ VERBOSE ] ANALYZE [ 表[ (列[, ...] ) ] ]。