Hierarchical MPI+OpenMP implementation of parallel PIC applications on clusters of Symmetri
openmpi跨节点执行命令参数

openmpi跨节点执行命令参数【原创版】目录1.openmpi 概述2.openmpi 跨节点执行的命令参数3.实例说明正文1.openmpi 概述OpenMPI(Open-source MPI)是一个开源的并行计算框架,可以用于构建高性能计算(HPC)系统。
MPI(Message Passing Interface)是一种并行计算的通信协议,OpenMPI 是 MPI 的一种实现。
OpenMPI 提供了一种在分布式系统上实现并行计算的方法,它的设计目标是为了提供高性能、可移植性和易用性。
在 OpenMPI 中,可以通过 mpirun 命令来执行并行任务,这个命令可以跨节点分配任务和资源。
2.openmpi 跨节点执行的命令参数openmpi 跨节点执行的命令参数主要包括以下几个:- "-n":指定并行度,即并行处理的节点数目。
- "-l":指定每个节点上的进程数。
- "-o":指定输出文件。
- "-f":指定输入文件。
- "- Host":指定主机名,用于与主机进行通信。
- "- Port":指定端口号,用于与主机进行通信。
3.实例说明假设我们有一个名为“example.mpi”的并行计算程序,我们希望在两台节点(node1 和 node2)上执行它。
那么,我们可以使用以下命令:```mpirun -n 2 -l 2 -o output -f input example.mpi```这条命令的含义如下:- "-n 2":指定并行度为 2,即在两台节点上执行任务。
- "-l 2":指定每台节点上运行 2 个进程。
- "-o output":指定输出文件名为“output”。
- "-f input":指定输入文件名为“input”。
openmp语言标准

openmp语言标准
OpenMP(Open Multi-Processing)是一种支持共享内存并行编程的API,由OpenMP Architecture Review Board牵头提出,并已被广泛接受,用于共享内存并行系统的多处理器程序设计的一套指导性编译处理方案(Compiler Directive)。
OpenMP支持的编程语言包括C、C++和Fortran;而支持OpenMp 的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。
OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。
当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
OpenMP标准由一些具有国际影响力的软件和硬件厂商共同定义和提出,是一种在共享存储体系结构上的可移植编程模型,广泛应用于UNIX、Linux、Windows等多种平台上。
以上信息仅供参考,如有需要,建议您查阅相关网站。
MPI编程简单介绍

MPI编程简单介绍MPI编程简单介绍多线程是⼀种便捷的模型,当中每⼀个线程都能够訪问其他线程的存储空间。
因此,这样的模型仅仅能在共享存储系统之间移植。
⼀般来讲,并⾏机不⼀定在各处理器之间共享存储,当⾯向⾮共享存储系统开发并⾏程序时,程序的各部分之间通过来回传递消息的⽅式通信。
要使得消息传递⽅式可移植,就须要採⽤标准的消息传递库。
这就促成的消息传递接⼝(Message Passing Interface, MPI)的⾯世,MPI是⼀种被⼴泛採⽤的消息传递标准[1]。
与OpenMP并⾏程序不同,MPI是⼀种基于消息传递的并⾏编程技术。
消息传递接⼝是⼀种编程接⼝标准,⽽不是⼀种详细的编程语⾔。
简⽽⾔之,MPI标准定义了⼀组具有可移植性的编程接⼝。
各个⼚商或组织遵循这些标准实现⾃⼰的MPI软件包,典型的实现包含开放源码的MPICH、LAM MPI以及不开放源码的Intel MPI。
因为MPI提供了统⼀的编程接⼝,程序猿仅仅须要设计好并⾏算法,使⽤对应的MPI库就能够实现基于消息传递的并⾏计算。
MPI⽀持多种操作系统,包含⼤多数的类UNIX和Windows系统。
3.1.1怎样实现MPI3.1.2 MPI程序的特点MPI程序是基于消息传递的并⾏程序。
消息传递指的是并⾏运⾏的各个进程具有⾃⼰独⽴的堆栈和代码段,作为互不相关的多个程序独⽴运⾏,进程之间的信息交互全然通过显⽰地调⽤通信函数来完毕。
的安装和配置我使⽤的MPICH2安装⽂件是mpich2-1.0.6p1-win32-ia32.msi,在Windows下安装MPICH2⽐較简单,可是要有Microsoft .NET Framework 2.0的⽀持。
安装基本上仅仅要单击“Next”就可以。
在安装过程中会提⽰输⼊进程管理器的password,这个password被⽤来訪问全部的程序,这⾥使⽤的password为admin。
安装完毕后,安装⽂件夹下的include⼦⽂件夹包括了编程所须要的全部头⽂件,lib⼦⽂件夹包括了对应的程序库,⽽⼦⽂件夹bin则包括了MPI在Windows以下必须的执⾏程序。
mpi程序编译运行指令

mpi程序编译运行指令MPI(Message Passing Interface)是一种用于并行计算的编程模型。
下面将介绍MPI程序的编译和运行指令。
编译MPI程序通常需要使用MPI编译器,常见的MPI编译器有MPICH、OpenMPI等。
在编译MPI程序之前,需要确保已经正确安装了MPI编译器和相关的库文件。
编译MPI程序的指令通常为:```mpiicc -o program program.c```其中,`mpiicc`是MPI编译器的命令,`-o program`指定输出的可执行文件名为`program`,`program.c`是要编译的MPI程序源代码文件。
运行MPI程序的指令通常为:```mpiexec -n <进程数> ./program```其中,`mpiexec`是MPI程序运行的命令,`-n <进程数>`指定运行时的进程数,`./program`指定要运行的MPI可执行文件。
在MPI程序中,可以使用MPI库中的函数来实现进程间的通信和协调。
常用的MPI函数包括`MPI_Init`、`MPI_Finalize`、`MPI_Comm_size`、`MPI_Comm_rank`、`MPI_Send`、`MPI_Recv`等。
这些函数可以实现进程的初始化、获取进程数和进程编号、发送和接收消息等功能。
MPI程序的运行流程一般为:1. 所有进程调用`MPI_Init`进行初始化。
2. 调用`MPI_Comm_size`获取进程总数,调用`MPI_Comm_rank`获取当前进程编号。
3. 根据进程编号的不同,执行不同的代码逻辑。
4. 进程间需要通信时,使用`MPI_Send`和`MPI_Recv`进行消息的发送和接收。
5. 所有进程执行完毕后,调用`MPI_Finalize`进行清理工作。
MPI程序的并行计算模型是基于消息传递的,即进程之间通过发送和接收消息来实现数据的交换和协同计算。
mpi基本用法 -回复

mpi基本用法-回复「MPI基本用法」是一种用于并行计算的编程模型和库。
MPI是Message Passing Interface的缩写,它提供了一系列的函数和语义,用于在多个进程之间进行通信和同步。
MPI的主要目标是提高并行计算的速度和效率,并使得并行计算程序易于开发和维护。
本文将逐步回答关于MPI基本用法的问题,并介绍如何使用MPI进行并行计算。
1. 什么是MPI?MPI是一种用于并行计算的编程模型和库。
它由一组函数和语义组成,用于在多个进程之间进行通信和同步。
MPI旨在提高并行计算的速度和效率,并使得并行计算程序易于开发和维护。
2. MPI的基本概念是什么?MPI的基本概念是进程和通信。
每个并行计算程序都由多个进程组成,这些进程在不同的处理器上独立运行。
MPI提供了一种机制,使得这些进程能够在执行过程中进行通信和同步,以实现并行计算的目标。
3. MPI的基本通信模式有哪些?MPI提供了多种基本通信模式,包括点对点通信和集体通信。
点对点通信是指两个进程之间的直接通信,例如发送和接收消息。
集体通信是指多个进程之间的协作通信,例如广播和归约操作。
4. 如何在MPI程序中发送和接收消息?MPI提供了一对发送和接收函数,用于在进程之间发送和接收消息。
发送函数将数据从一个进程发送给另一个进程,而接收函数用于接收来自其他进程的数据。
要发送消息,可以使用MPI_Send函数,而要接收消息,可以使用MPI_Recv函数。
5. MPI如何进行同步操作?MPI提供了多种同步操作,包括阻塞和非阻塞操作。
阻塞操作意味着进程将被阻塞,直到某个操作完成。
非阻塞操作允许进程在操作进行的同时执行其他操作。
要进行阻塞同步,可以使用MPI_Barrier函数;而要进行非阻塞同步,可以使用MPI_Ibarrier函数。
6. 如何在MPI程序中使用集体通信?MPI提供了一系列的集体通信函数,用于实现多个进程之间的协作通信。
其中,广播操作将一个进程的数据发送给所有其他进程,而归约操作将多个进程的数据合并为一个结果。
openmp和mpi环境配置
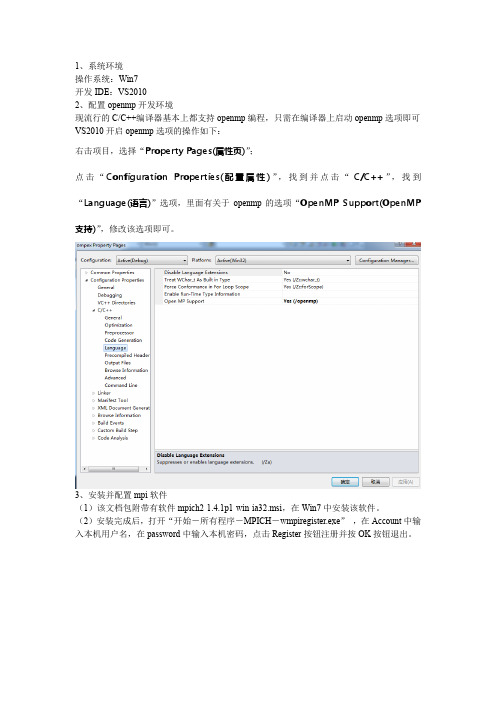
1、系统环境操作系统:Win7开发IDE:VS20102、配置openmp开发环境现流行的C/C++编译器基本上都支持openmp编程,只需在编译器上启动openmp选项即可VS2010开启openmp选项的操作如下:右击项目,选择“Property Pages(属性页)”;点击“Configuration Properties(配置属性)”,找到并点击“C/C++”,找到“Language(语言)”选项,里面有关于openmp的选项“OpenMP Support(OpenMP 支持)”,修改该选项即可。
3、安装并配置mpi软件(1)该文档包附带有软件mpich2-1.4.1p1-win-ia32.msi,在Win7中安装该软件。
(2)安装完成后,打开“开始-所有程序-MPICH-wmpiregister.exe”,在Account中输入本机用户名,在password中输入本机密码,点击Register按钮注册并按OK按钮退出。
(3)在VS2010中,配置VC++ Directories选项。
在VS2010中,VC++ Directories在Solution Explorer中,在项目名称上右键选择Properties,即进入Property Pages窗口。
(4)展开左边Configuration Properties,选中其中的VC++ Directories,在右边Include Directories加入“C:\Program Files\MPICH2\include;”(mpi安装目录里)(5)展开左边Configuration Properties,选中其中的VC++ Directories,在右边Library Directories加入“C:\Program Files\MPICH2\lib;”(6)展开左边Configuration Properties中的C/C++,选中其中的Preprocessor,在右边的Preprocessor Definitions中加入“MPICH_SKIP_MPICXX;”(7)同样展开C/C++,选中Code Generation,把右边的Runtime Library更改为“Multi-threaded Debug (/MTd)”(此外有下拉菜单可选到它)(8)展开左边的Linker,选中Input,在右边Additional Dependencies中加入“mpi.lib;”(9)运行MPI程序打开“开始-所有程序-MPICH-wmpiexec.exe”,在Applicationd右边浏览找到你在VS2010中生成的exe文件,设置Number of processes(即进程数目,用来模拟并行计算的CPU数目)。
并行编程——MPIOPENMP混合编程

并⾏编程——MPIOPENMP混合编程在⼤规模节点间的并⾏时,由于节点间通讯的量是成平⽅项增长的,所以带宽很快就会显得不够。
所以⼀种思路增加程序效率线性的⽅法是⽤MPI/OPENMP混合编写并⾏部分。
这⼀部分其实在了解了MPI和OPENMP以后相对容易解决点。
⼤致思路是每个节点分配1-2个MPI进程后,每个MPI进程执⾏多个OPENMP线程。
OPENMP部分由于不需要进程间通信,直接通过内存共享⽅式交换信息,不⾛⽹络带宽,所以可以显著减少程序所需通讯的信息。
Fortran:Program hellouse mpiuse omp_libImplicit NoneInteger :: myid,numprocs,rc,ierrInteger :: i,j,k,tidCall MPI_INIT(ierr)Call MPI_COMM_RANK(MPI_COMM_WORLD,myid,ierr)Call MPI_COMM_SIZE(MPI_COMM_WORLD,numprocs,ierr)!$OMP Parallel private(tid)tid=OMP_GET_THREAD_NUM()write(*,*) 'hello from',tid,'of process',myid!$OMP END PARALLELCall MPI_FINALIZE(rc)StopEnd Program helloC++:# include <cstdlib># include <iostream># include <ctime># include "mpi.h"# include "omp.h"using namespace std;int main ( int argc, char *argv[] );//****************************************************************************80int main ( int argc, char *argv[] ){int myid;int nprocs;int this_thread;MPI::Init();myid=MPI::COMM_WORLD.Get_rank();nprocs=MPI::COMM_WORLD.Get_size();#pragma omp parallel private(this_thread){this_thread=omp_get_thread_num();cout <<this_thread<<" thread from "<<myid<<" is ok\n";}MPI::Finalize();return0;}这⾥值得要注意的是,似乎直接⽤mpif90/mpicxx编译的库会报错,所以需要⽤icc -openmp hello.cpp -o hello -DMPICH_IGNORE_CXX_SEEK -L/Path/to/mpi/lib/ -lmpi_mt -lmpiic -I/path/to/mpi/include其中-DMPICH_IGNORE_CXX_SEEK为防⽌MPI2协议中⼀个重复定义问题所使⽤的选项,为了保证线程安全,必须使⽤mpi_mt库对于intel的mpirun,必须在mpirun后加上-env I_MPI_PIN_DOMAIN omp使得每个mpi进程会启动openmp线程。
openmp的使用

openmp的使用OpenMP是一种用于并行编程的编程模型,它可以帮助开发人员在共享内存系统中并行化程序。
它是一种基于指令集架构的并行编程模型,因此可以在多种平台上使用。
OpenMP的主要目标是通过利用多核处理器的并行计算能力来提高程序的性能。
在OpenMP中,程序员使用指令集来标识并行区域,并指定如何将工作分配给不同的线程。
通过使用指令集,程序员可以指定哪些部分的代码应该并行执行,以及应该有多少线程参与并行计算。
OpenMP提供了一套指令和库函数,用于管理线程的创建、同步和通信。
在使用OpenMP进行并行编程时,程序员可以使用不同的指令来指定并行区域。
例如,可以使用#pragma omp parallel指令来标识一个并行区域,其中的代码将由多个线程并行执行。
可以使用#pragma omp for指令来指定一个循环应该以并行方式执行。
还可以使用其他指令来指定线程之间的同步和通信操作。
OpenMP还提供了一些库函数,用于处理线程的创建、同步和通信。
例如,可以使用omp_get_num_threads函数来获取当前并行区域中线程的数量。
可以使用omp_get_thread_num函数来获取当前线程的编号。
还可以使用omp_barrier函数来同步线程的执行。
OpenMP还提供了一些环境变量和编译器选项,用于控制并行程序的行为。
例如,可以使用OMP_NUM_THREADS环境变量来设置并行计算时使用的线程数。
可以使用OMP_SCHEDULE编译器选项来指定循环调度策略。
这些环境变量和编译器选项可以帮助程序员优化并行程序的性能。
使用OpenMP进行并行编程时,程序员需要注意一些问题。
首先,程序员需要确保并行化的代码是可重入的,即不依赖于全局状态。
其次,程序员需要避免竞争条件,即多个线程同时访问共享数据时可能导致不确定的结果。
为了避免竞争条件,可以使用锁、原子操作或其他同步机制。
程序员还可以使用OpenMP的一些高级特性来进一步优化程序的性能。
MPI的搭建及OpenMP的配置实验指导书

MPI的搭建及OpenMP的配置实验指导书1.MPI简介消息传递接口(Message Passing Interface,MPI)是目前应用较广泛的一种并行计算软件环境,是在集群系统上实现并行计算的软件接口。
为了统一互不兼容的的用户界面,1992年成立了MPI委员会,负责制定MPI的新标准,支持最佳的可移植平台。
MPI不是一门新的语言,确切地说它是一个C和Fortran的函数库,用户通过调用这些函数接口并采用并行编译器编译源代码就可以生成可并行运行的代码。
MPI的目标是要开发一个广泛用于编写消息传递程序的标准,要求用户界面实用、可移植,并且高效、灵活,能广泛应用于各类并行机,特别是分布式存储的计算机。
每个计算机厂商都在开发标准平台上做了大量的工作,出现了一批可移植的消息传递环境。
MPI吸收了它们的经验,同时从句法和语法方面确定核心库函数,使之能适用于更多的并行机。
MPI在标准化过程中吸收了许多代表参加,包括研制并行计算机的大多数厂商,以及来自大学、实验室与工业界的研究人员。
1992年开始正式标准化MPI,1994年发布了MPI的定义与实验标准MPI 1,相应的MPI 2标准也已经发布。
MPI吸取了众多消息传递系统的优点,具有很好的可以执行、易用性和完备的异步通信功能等。
MPI事实上只是一个消息传递标准,并不是软件实现并行执行的具体实现,目前比较著名的MPI具体实现有MPICH、LAM MPI等,其中MPICH是目前使用最广泛的免费MPI系统,MPICH2是MPI 2标准的一个具体实现,它具有较好的兼容性和可扩展性,目前在高性能计算集群上使用非常广泛。
MPICH2的使用也非常简单,用户只需在并行程序中包含MPICH的头文件,然后调用一些MPICH2函数接口将计算任务分发到其他计算节点即可,MPICH2为并行计算用户提供了100多个C和Fortran函数接口,表1-1列出了一些常用的MPICH2的C语言函数接口,用户可以像调用普通函数一样,只需要做少量的代码改动就可以实现程序的并行运行,MPICH并行代码结构如图1-1所示。
mpi基本用法 -回复

mpi基本用法-回复MPI基本用法MPI(Message Passing Interface)是一种常用的并行计算编程模型,它允许在分布式内存系统中进行进程间通信。
MPI被广泛应用于科学计算、高性能计算以及大规模数据处理等领域。
本文将介绍MPI的基本用法,为大家一步一步解释如何使用MPI进行并行计算。
第一步:MPI的安装和设置1.1 安装MPI库首先,要在计算机上安装MPI库。
常用的MPI库包括Open MPI、MPICH 和Intel MPI等。
根据操作系统的不同,可以选择合适的MPI库进行安装。
1.2 环境变量设置安装完成后,需要设置相应的环境变量。
将MPI的安装目录添加到系统路径(PATH)中,以便系统可以找到MPI的执行程序。
同时,还需要设置LD_LIBRARY_PATH环境变量,以指定MPI库的位置。
第二步:MPI的编程模型MPI的编程模型基于进程间的消息传递。
每个进程都有自己的地址空间,并且可以通过MPI的函数进行相互通信。
MPI定义了一系列的函数和数据类型,用于实现进程间的消息传递和同步操作。
2.1 初始化MPI环境在开始使用MPI之前,需要调用MPI的初始化函数来建立MPI的运行环境。
可以通过以下代码来完成初始化操作:c#include <mpi.h>int main(int argc, char argv) {MPI_Init(&argc, &argv);TODO: MPI代码MPI_Finalize();return 0;}在这段代码中,`MPI_Init()`函数用于初始化MPI环境,`MPI_Finalize()`函数用于关闭MPI环境。
`argc`和`argv`是命令行参数,通过它们可以传递程序运行所需的参数。
2.2 进程间通信MPI提供了一系列的通信函数,用于实现进程间的消息传递。
常用的通信函数包括`MPI_Send()`、`MPI_Recv()`、`MPI_Bcast()`和`MPI_Reduce()`等。
mpi openmp 案例

mpi openmp 案例MPI和OpenMP是并行计算中常用的编程模型,它们可以在多核和分布式系统中实现并行计算,提高计算效率。
本文将介绍一些MPI和OpenMP的案例,以展示它们在实际应用中的优势和用法。
引言概述:MPI和OpenMP是并行计算中常用的编程模型,它们分别适用于分布式和共享内存系统。
MPI(Message Passing Interface)是一种消息传递的并行编程模型,适用于分布式系统中的并行计算;而OpenMP是一种共享内存的并行编程模型,适用于多核系统中的并行计算。
下面将分别介绍它们在实际应用中的案例。
正文内容:1. MPI案例1.1 分布式矩阵乘法- 使用MPI实现矩阵乘法可以将计算任务分配给不同的进程,每个进程负责计算一部分矩阵乘法的结果。
- 使用MPI的消息传递机制,进程之间可以相互通信,将计算结果进行汇总,得到最终的矩阵乘法结果。
- 这种分布式矩阵乘法可以充分利用分布式系统的计算资源,提高计算效率。
1.2 并行排序算法- 使用MPI可以将排序任务分配给不同的进程,每个进程负责排序一部分数据。
- 进程之间可以通过消息传递机制交换数据,实现分布式的排序算法。
- 这种并行排序算法可以大大减少排序的时间复杂度,提高排序的效率。
2. OpenMP案例2.1 并行矩阵运算- 使用OpenMP可以将矩阵运算任务分配给不同的线程,每个线程负责计算一部分矩阵运算的结果。
- 多个线程可以共享内存,可以直接访问共享的数据,减少了数据的拷贝和通信开销。
- 这种并行矩阵运算可以充分利用多核系统的计算资源,提高计算效率。
2.2 并行图像处理- 使用OpenMP可以将图像处理任务分配给不同的线程,每个线程负责处理一部分图像数据。
- 多个线程可以并行地对图像进行处理,提高了图像处理的速度。
- 这种并行图像处理可以广泛应用于图像处理领域,如图像滤波、图像分割等。
总结:MPI和OpenMP是并行计算中常用的编程模型,它们分别适用于分布式和共享内存系统。
MPI+OpenMP混合编程技术总结

MPI+OpenMP混合编程一、引言MPI是集群计算中广为流行的编程平台。
但是在很多情况下,采用纯的MPI 消息传递编程模式并不能在这种多处理器构成的集群上取得理想的性能。
为了结合分布式内存结构和共享式内存结构两者的优势,人们提出了分布式/共享内存层次结构。
OpenMP是共享存储编程的实际工业标准,分布式/共享内存层次结构用OpenMP+MPI实现应用更为广泛。
OpenMP+MPI这种混合编程模式提供结点内和结点间的两级并行,能充分利用共享存储模型和消息传递模型的优点,有效地改善系统的性能。
二、OpenMP+MPI混合编程模式使用混合编程模式的模型结构图如图1在每个MPI进程中可以在#pragma omp parallel编译制导所标示的区域内产生线程级的并行而在区域之外仍然是单线程。
混合编程模型可以充分利用两种编程模式的优点MPI可以解决多处理器问的粗粒度通信而OpenMP提供轻量级线程可以和好地解决每个多处理器计算机内部各处理器间的交互。
大多数混合模式应用是一种层次模型MPI并行位于顶层OpenMP位于底层。
比如处理一个二维数组可以先把它分割成结点个子数组每个进程处理其中一个子数组而子数组可以进一步被划分给若干个线程。
这种模型很好的映射了多处理器计算机组成的集群体系结构MPI并行在结点问OpenMP并行在结点内部。
也有部分应用是不符合这种层次模型的比如说消息传递模型用于相对易实现的代码中而共享内存并行用于消息传递模型难以实现的代码中还有计算和通信的重叠问题等。
三、OpenMP+MR混合编程模式的优缺点分析3.1优点分析(1)有效的改善MPI代码可扩展性MPI代码不易进行扩展的一个重要原因就是负载均衡。
它的一些不规则的应用都会存在负载不均的问题。
采用混合编程模式,能够实现更好的并行粒度。
MPI仅仅负责结点间的通信,实行粗粒度并行:OpenMP实现结点内部的并行,因为OpenMP不存在负载均衡问题,从而提高了性能。
openmpi跨节点执行命令参数

openmpi跨节点执行命令参数(原创实用版)目录1.OpenMPI 简介2.OpenMPi 参数与 mpirun 命令参数3.跨节点执行示例4.配置 Vmware 网络连接5.克隆其他主机并修改映射正文1.OpenMPI 简介OpenMPi 是一种用于并行计算的开源库,支持 Fortran 和 C/C++语言。
它可以在多台计算机上分配任务,实现高性能计算。
在 OpenMPi 中,我们需要使用 mpirun 命令来执行并行任务,而 mpirun 命令需要一些参数来进行配置。
2.OpenMPi 参数与 mpirun 命令参数OpenMPi 的参数主要包括:- host:指定主机名或 IP 地址。
- port:指定通信端口号。
- num_procs:指定并行处理的进程数。
- task_size:指定任务的大小。
- job_name:指定作业名称。
mpirun 命令的基本语法如下:```mpirun -host <host> -port <port> -num_procs <num_procs>-task_size <task_size> -job_name <job_name> <command> ```3.跨节点执行示例例如,我们有一个名为“hello_world”的简单程序,它将在每个节点上打印“Hello, World!”。
首先,我们需要创建一个名为“hello_world”的脚本文件,内容如下:```#include <mpi.h>#include <stdio.h>int main(int argc, char *argv[]) {MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &num_procs);MPI_Comm_rank(MPI_COMM_WORLD, &rank);if (rank == 0) {printf("Hello, World!");}MPI_Finalize();return 0;}```然后,我们可以使用 mpirun 命令来执行这个程序:```mpirun -host 192.168.1.10 -port 49152 -num_procs 2 -task_size 1 -job_name hello_world hello_world```在这个示例中,我们将程序运行在了两台计算机上,其中一台计算机的 IP 地址为 192.168.1.10。
mpi + openmpi混合编程的实现与性能分析

Computer Science and Application 计算机科学与应用, 2019, 9(10), 1859-1866Published Online October 2019 in Hans. /journal/csahttps:///10.12677/csa.2019.910208Implementation and Performance Analysis of MPI + Open MPI Hybrid ProgrammingPeiqin Fan, Lin Zhang, Shuai Tang, Jingyi LiuNavy Submarine Academy, Qingdao ShandongReceived: Sep. 19th, 2019; accepted: Oct. 4th, 2019; published: Oct. 11th, 2019AbstractIn order to give full play to the computing power of SMP cluster, combined with the characteristics of SMP cluster parallel system architecture, the design and implementation of multilevel hybrid parallel program based on SMP cluster are studied by using MPI + OpenMP hybrid parallel pro-gramming mode. The performance test case of hybrid parallel programming is developed by using MPI to realize the rough degree partition of tasks between nodes and OpenMP to realize the fine degree partition of tasks in nodes. The test result shows that MPI + OpenMP hybrid programming mode can effectively make use of the multi-level parallel mechanism of SMP cluster, and give full play to the advantages of the two programming models and effectively improve the computing ef-ficiency of SMP cluster.KeywordsCluster, Hybrid Programming, Parallel Computation, Performance AnalysisMPI + OpenMPI混合编程的实现与性能分析范培勤,张林,唐帅,刘敬一海军潜艇学院,山东青岛收稿日期:2019年9月19日;录用日期:2019年10月4日;发布日期:2019年10月11日摘要为充分发挥SMP集群的计算能力,结合SMP集群并行系统体系架构的特点,采用MPI + OpenMP混合并行编程模式,研究了基于SMP集群的多级混合并行程序的设计和实现方法。
openmpi 超算用例 -回复

openmpi 超算用例-回复开发人员如何在超算环境中使用OpenMPI?在这篇文章中,我们将介绍开发人员如何在超算环境中使用OpenMPI。
OpenMPI是一个开源的消息传递接口库,可以在并行计算中实现多台计算机之间的通信。
对于计算密集型应用程序和科学计算任务,OpenMPI 在超算环境中被广泛使用。
在超算环境中,我们将以中括号内的内容为主题,一步一步回答开发人员如何使用OpenMPI。
1. 登录超算节点首先,我们需要登录超算节点。
这可以通过ssh协议实现。
在命令行终端中输入以下命令,以用户名和超算IP地址替换相应的参数:ssh username@supercomputer_ip_address输入密码进行身份验证。
成功登录后,我们将进入超算节点。
2. 准备环境在超算节点上,我们需要准备OpenMPI的环境。
如果OpenMPI已经在超算中安装好,我们只需要加载相应的环境模块。
在终端中输入以下命令,加载OpenMPI环境模块:module load openmpi成功加载环境模块后,我们将能够使用OpenMPI的命令和库。
3. 编写并编译MPI应用程序接下来,我们需要编写一个使用MPI的应用程序。
可以使用任何支持MPI 的编程语言,如C,C++,Fortran等。
下面是一个简单的C语言示例,计算并行求和:c#include <stdio.h>#include <mpi.h>int main(int argc, char argv) {int size, rank, sum = 0, globalSum = 0;MPI_Init(&argc, &argv);MPI_Comm_size(MPI_COMM_WORLD, &size);MPI_Comm_rank(MPI_COMM_WORLD, &rank);每个进程计算自己的部分和for (int i = rank; i < 100; i += size) {sum += i;}所有进程将部分和汇总到一个全局和中MPI_Reduce(&sum, &globalSum, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD);打印全局和if (rank == 0) {printf("全局和:d\n", globalSum);}MPI_Finalize();return 0;}将上述代码保存为`sum.c`文件。
openmpi 超算用例 -回复

openmpi 超算用例-回复什么是openmpi?OpenMPI是一种高性能计算中常用的并行计算工具,全称为Open Message Passing Interface。
它是为了帮助应用程序能够充分利用并行计算环境而开发的一套标准接口和工具。
OpenMPI提供了一套并行计算模型,使得程序能够在多个计算节点上并行地执行,从而大大提高计算能力。
在超级计算机以及其他高性能计算平台上,OpenMPI是非常受欢迎的一种并行计算框架。
超级计算机的发展与使用超级计算机是具有极高计算能力的计算设备,通常由数千个计算节点组成,并采用大规模并行计算的方式工作。
超级计算机广泛应用于科学研究、气象预测、金融风险管理、可视化以及其他需要大规模计算能力的领域。
然而,超级计算机的使用具有一定的复杂性,需要面对许多挑战,如任务划分、数据通信、负载均衡等。
并行计算的挑战和解决方案在超级计算机上运行一个并行计算程序需要解决一系列的挑战。
首先,需要将计算任务划分为多个子任务,并将这些子任务分配到不同的计算节点上。
其次,需要进行节点间的数据通信和同步,以保证各个子任务之间的协作。
最后,还需要考虑负载均衡的问题,确保各个计算节点的计算能力得到充分利用。
OpenMPI的应用OpenMPI作为一种高性能计算工具,具备并行计算的必备功能。
它提供了一套标准接口,使得程序员能够方便地在超级计算机上开发并行计算程序。
OpenMPI支持多种计算模式,如共享内存模式和分布式内存模式,以适应不同类型的并行计算需求。
此外,OpenMPI还提供了丰富的工具和库,如机器学习、数据挖掘和可视化等,帮助开发者更加高效地开发并行计算程序。
OpenMPI的使用步骤要在超级计算机上使用OpenMPI,需要经过以下几个步骤:1.准备环境:在使用OpenMPI之前,需要先安装并配置OpenMPI的软件包。
使用OpenMPI时,需要确保每个计算节点上都已正确安装OpenMPI,并进行相应的环境配置。
4 OpenMP、MPI多线程编程

运行时库函数
OpenMP运行时函数库主要用以设置和获取执行环境相关 的信息 它们当中也包含一系列用以同步的API
编译指导语 句
运行时函数库
环境变量
使用Visual Studio 2005编写OpenMP程序
当前的Visual Studio .Net 2005完全支持OpenMP 2.0 标准,通过新的编译器选项 /openmp来支持OpenMP程 序的编译和链接。
编译指导语句
在编译器编译程序的时候,会识别特定的注释,而这些特定的注 释就包含着OpenMP程序的一些语义。
#pragma omp <directive> [clause[ [,] clause]…] 其中directive部分就包含了具体的编译指导语句,包括parallel, for, parallel for, section, sections, single, master, critical, flush, ordered和atomic。
openmp与openmpi区别

Lammps Mac 的并行之路openmp与openmpi区别openmp比较简单,修改现有的大段代码也容易。
基本上openmp只要在已有程序基础上根据需要加并行语句即可。
而mpi有时甚至需要从基本设计思路上重写整个程序,调试也困难得多,涉及到局域网通信这一不确定的因素。
不过,openmp虽然简单却只能用于单机多CPU/多核并行,mpi才是用于多主机超级计算机集群的强悍工具,当然复杂。
(1)MPI=message passing interface:在分布式内存(distributed-memory)之间实现信息通讯的一种规范/标准/协议(standard)。
它是一个库,不是一门语言。
可以被fortran,c,c++等调用。
MPI允许静态任务调度,显示并行提供了良好的性能和移植性,用 MPI 编写的程序可直接在多核集群上运行。
在集群系统中,集群的各节点之间可以采用 MPI 编程模型进行程序设计,每个节点都有自己的内存,可以对本地的指令和数据直接进行访问,各节点之间通过互联网络进行消息传递,这样设计具有很好的可移植性,完备的异步通信功能,较强的可扩展性等优点。
MPI 模型存在一些不足,包括:程序的分解、开发和调试相对困难,而且通常要求对代码做大量的改动;通信会造成很大的开销,为了最小化延迟,通常需要大的代码粒度;细粒度的并行会引发大量的通信;动态负载平衡困难;并行化改进需要大量地修改原有的串行代码,调试难度比较大。
(2)MPICH和OpenMPI:它们都是采用MPI标准,在并行计算中,实现节点间通信的开源软件。
各自有各自的函数,指令和库。
Reference:They are two implementations of the MPI standard. In the late 90s and early 2000s, there were many different MPI implementations, and the implementors started to realize they were all re-inventing the wheel; there wassomething of a consolidation. The LAM/MPI team joined with the LA/MPI, FT-MPI, and eventually PACX-MPI teams to develop OpenMPI. LAM MPI stoppedbeing developed in 2007. The code base for OpenMPI was completely new, butit brought in ideas and techniques from all the different teams.Currently, the two major open-source MPI implementation code-bases are OpenMPI andMPICH2.而MPICH2是MPICH的一个版本。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hierarchical MPI+OpenMP implementation of parallel PIC applications on clusters ofSymmetric MultiProcessorsSergio Briguglio1,Beniamino Di Martino2,Giuliana Fogaccia1and Gregorio Vlad11Associazione EURATOM-ENEA sulla Fusione,C.R.Frascati,C.P.65,00044,Frascati,Rome,Italy{briguglio,fogaccia,vlad}@frascati.enea.it2Dip.Ingegneria dell’Informazione,Second University of Naples,Italybeniamino.dimartino@unina.itAbstract.The hierarchical combination of decomposition strategies forthe development of parallel Particle-in-cell simulation codes,targeted tohierarchical distributed-shared memory architectures,is discussed in thispaper,along with its MPI+OpenMP implementation.Particular empha-sis is given to the devised dynamic workload balancing technique.1IntroductionParticle-in-cell(PIC)simulation consists[1]in evolving the coordinates of a set of N part particles in certainfluctuatingfields computed(in terms of particle contributions)only at the points of a discrete spatial grid and then interpolated at each particle(continuous)position.Two main strategies have been developed for the workload decomposition related to porting PIC codes on parallel systems: the particle decomposition strategy[5]and the domain decomposition one[7,6]. Domain decomposition consists in assigning different portions of the physical domain and the corresponding portions of the grid to different processes,along with the particles that reside on them.Particle decomposition,instead,stati-cally distributes the particle population among the processes,while assigning the whole domain(and the grid)to each process.As a general fact,the par-ticle decomposition is very efficient and yields a perfect load balancing,at the expenses of memory overheads.Conversely,the domain decomposition does not require a memory waste,while presenting particle migration between different portions of the domain,which causes communication overheads and the need for dynamic load balancing[3,6].Such workload decomposition strategies can be applied both for distributed-memory parallel systems[6,5]and shared-memory ones[4].They can also becombined,when porting a PIC code on a hierarchical distributed-shared memory system(e.g.,a cluster of SMPs),in two-level strategies:a distributed-memory level decomposition(among the n node computational nodes),and a shared-memory one(among the n proc processors of each node).In previous papers we have investigated some of these two-level strategies ap-plied to a specific application domain,namely the simulation of thermonuclear plasma confinement.In particular,we have designed and implemented the hier-archically combined particle-particle and particle-domain decomposition strate-gies,with the integrated use of HPF and OpenMP[2].The task of a good scalability of the domain size with n node,requires,how-ever,to avoid the replication of the grid data proper of the particle decomposition at the distributed-memory level.The scenario of hierarchically-combined decom-position strategies has then to be completed by developing the domain-particle combination and,specially,the domain-domain one.A high-level data-parallel language like HPF is not suited,in these cases,to face problems like the inter-process particle migration and the related dynamic workload unbalance.We have then to resort to explicit message-passing libraries,such as MPI.Aim of this paper is discussing the MPI+OpenMP implementation of the integrated domain-particle and domain-domain decomposition strategies,with particular emphasis to the dynamic workload balancing technique we have devised and its MPI-based implementation.In Sect.2we describe the inter-node,domain-decomposition strategy,adopted in the distributed-memory context,along with its MPI implementation,while the integration of such inter-node strategy with both intra-node particle and domain decomposition strategies is discussed in Sect.3.2MPI implementation of the inter-node domain decompositionThe typical structure of a PIC code for plasma particle simulation can be repre-sented as follows.At each time step,the code i)computes the electromagnetic fields only at the points of a discrete spatial grid(field solver phase);ii)in-terpolates thefields at the(continuous)particle positions in order to evolve particle phase-space coordinates(particle pushing phase);iii)collects particle contribution to the pressurefield at the grid points to close thefield equations (pressure computation phase).We can schematically represent the structure of this time-iteration by the following code excerpt:call field_solver(pressure,field)call pushing(field,x_part)call compute_pressure(x_part,pressure)Here,pressure,field and xIn implementing a parallel version of the code,according to the distributed-memory domain-decomposition strategy,different portions of the physical do-main and of the corresponding grid are assigned to the n node different nodes, along with the particles that reside on them.This approach yields benefits and problems that are complementary to those yielded by the particle-decomposition one[5]:on the one hand,the memory resources required to each node are ap-proximately reduced by the number of nodes;an almost linear scaling of the attainable physical-space resolution(i.e.,the maximum size of the spatial grid) with the number of nodes is then obtained.On the other hand,inter-node com-munication is required to update thefields at the boundary between two different portions of the domain,as well as to transfer those particles that migrate from one domain portion to another.Such a particle migration possibly determines a severe load unbalancing of the different processes,then requiring a dynamic balancing,at the expenses of further computations and communications.Three additional procedures then characterize the structure of the parallel code:at each time step–the number of particles managed by a process has to be checked,in order to avoid excessive load unbalancing among the processes(if such an unbalancing is verified,the load-balancing procedure must be invoked);–particles that moved from one subdomain to another because of particle pushing must be transferred from the original process to the new one;–the values of the pressure array at the boundaries between two neighbor subdomains must be corrected,because their local computation takes into account only those particles which belong to the subdomain,neglecting the contribution of neighbor subdomain’s particles.Let us report here the schematic representation of the time iteration per-formed by each process,before giving some detail on the implementation of such procedures:call field_solver(pressure,field)call check_loads(i_check,n_part,n_part_left_v,&n_part_right_v)if(i_check.eq.1)thencall load_balancing(n_part_left_v,&n_part_right_v,&n_cell_left,n_cell_right,&n_part_left,n_part_right)n_cell_new=n_cell+n_cell_left+n_cell_rightif(n_cell_new.gt.n_cell)thenallocate(field_aux(n_cell))field_aux=fielddeallocate(field)allocate(field(n_cell_new))field(1:n_cell)=field_aux(1:n_cell)deallocate(field_aux)endifn_cell=max(n_cell,n_cell_new)n_cell_old=n_cellcall send_receive_cells(field,x_part,&n_cell_left,n_cell_right,&n_part_left,n_part_right)if(n_cell_new.lt.n_cell_old)thenallocate(field_aux(n_cell_old))field_aux=fielddeallocate(field)allocate(field(n_cell_new))field(1:n_cell_new)=field_aux(1:n_cell_new)deallocate(field_aux)endifn_cell=n_cell_newn_part=n_part+n_part_left+n_part_rightendifcall pushing(field,x_part)call transfer_particles(x_part,n_part)allocate(pressure(n_cell))call compute_pressure(x_part,pressure)call correct_pressure(pressure)In order to avoid continuous reallocation of particle arrays(here represented by xpart around this optimal size are allowed within a certain band of oscillation(e.g.,±10%).This band is defined in such a way to prevent,under normal conditions,index overflows and,at the same time,to avoid excessive load unbalancing.One of the processes(the MPI rank-0process)collects,in subroutine checkpart v,n rightcheck is set equal to1.Then, such informations are scattered to the other processes.These communications are easily performed with MPI by means of the collective communication primitives MPI Scatter and MPIbalancing)by each process accord-ing to their belonging to the units(e.g.,the ncell celln left,n right.Series of MPIaux),when their size is modified.Portions of the array field have now to be exchanged between neighbor pro-cesses,along with the elements of the array xreceiveSend and MPIcellpart corresponding to particles to be transferred are identified on the basis of the labelling procedure performed in subroutine loadpart(remember that such an array is overdimensioned).After rearranging the subdomain,subroutine pushing is executed,producing the new particle coordinates,xparticles.First,particles to be transferred are identified,and the corresponding elements of xpart are compacted in order tofill holes.Each process sends to the other processes the corresponding chunks of the auxiliary buffer,and receives the new-particle coordinates in the higher-index portion of the array xAlltoallv call the tool of choice.Finally,after reallocating the array pressure,subroutine compute pressure),by means of MPI Recv calls.The true value is obtained by adding the two partial values.The array pressure can now be yielded to the subroutine field3Integration of the inter-node domain decomposition with intra-node particle and domain decompositionstrategiesThe implementation of particle and domain decomposition strategies for a PIC code at the shared-memory level in a high-level parallel programming environ-ment like OpenMP has been discussed in Refs.[4,2].We refer the reader to those papers for the details of such implementation.Let us just recall the main dif-ferences between the two intra-node approaches,keeping in mind the inter-node domain-decomposition context.In order to avoid race conditions between differ-ent threads in updating the array pressure,the particle-decomposition strat-egy introduces a private auxiliary array with same rank and size of pressure, which can be privately updated by each thread;the updating of pressure is then obtained by a reduction of the different copies of the auxiliary array.The domain-decomposition strategy consists,instead,in further decomposing the node subdomain and assigning a pair of the resulting portions(we will refer to them as to“intervals”,looking at the subdivision along one of the dimensions of the subdomain)along with the particles residing therein to each thread.This requires labelling particles according to the interval subdivision.The loop over particles in subroutine pressure can be restructured as follows.A pair of paral-lel loops are executed:one over to the odd intervals,the other over the even ones.A loop over the interval particles is nested inside each of the interval loops.Race conditions between threads are then removed from the pressure computation, because particles treated by different threads,will update different elements of pressure as they belong to different,not adjacent,intervals.Race conditions can still occur,however,in the labelling phase,in which each particle is assigned, within a parallel loop over particles,to its interval and labelled by the incre-mented value of a counter:different threads can try to update the counter of a certain interval at the same time.The negative impact of such race conditions on the parallelization efficiency can be contained by avoiding to execute a complete labelling procedure for all the particles at each time step,while updating such indexing“by intervals”only in correspondence to particles that have changed interval in the last time step[4].The integration of the inter-node domain-decomposition strategy with the intra-node particle-decomposition one does not present any relevant problem. The only fact that should be noted is that,though the identification of particles to be transferred from one subdomain to the others can be performed,in sub-routine transfer1/12/13/14/1d-p0.14 4.257.489.60d-d0.13 4.877.9511.0Pushing8.58 4.28 2.78 2.118.52 4.26 2.77 2.10d-p0.430.210.150.11d-d0.680.360.240.19Pressure9.82 4.82 3.16 2.407.82 3.85 2.51 1.92particles will then include,in addition to the check on inter-subdomain particle migration,the check on inter-interval migra-tion.Particles that left the subdomain will affect the internal ordering of the original interval only;particles who came into the subdomain will be assigned to the proper interval,then affecting only the internal ordering of the new interval; particles that changed interval without leaving the subdomain will continue to affect the ordering of both the original and the new interval.The analysis aimed to identify,in subroutine transfer1/22/23/24/20.92 1.83 2.78 3.71d-d 1.88 3.54 5.847.56Table2.Speed-up values for the3-D skeleton-code implementations of the domain-particle and the domain-domain decomposition strategies at different pairs n node/n proc.strategies are shown in Table1.The elapsed time(in seconds)for the different procedures are reported for different pairs n node/n proc.Note that the“Pressure”procedure includes both compute pressure subroutines.A case with a spatial grid of128×32×16cells and N part=1048576particles has been considered.The overall speed-up values,defined as the ratio between the serial-execution elapsed times and the parallel execution ones,are reported in Table2.These results have been obtained by running the code on an IBM SP parallel system,equipped with four2-processors SMP Power3nodes,with clock frequency of200MHz and1GB RAM.We note that,for the considered case,the elapsed times decrease with the total number of processors for pushing,particle transfer and pressure procedures, while it increases for the load balancing procedure.This result can strongly depend,as far as the particle transfer procedure is concerned,on the rate of particle migration(which,in turn,depends on the specific dynamics considered).Finally,we note that the domain-domain decomposition strategy comes out to be,for this case,more efficient than the domain-particle one.This is due to the need of reducing,in the framework of the latter decomposition strategy,the private copies of the array pressure.References1.Birdsall,C.K.,Langdon,A.B.:Plasma Physics via Computer Simulation.(McGraw-Hill,New York,1985).2.Briguglio,S.,Di Martino,B.,Vlad,G.:Workload Decomposition Strategies forHierarchical Distributed-Shared Memory Parallel Systems and their Implementation with Integration of High Level Parallel Languages.Concurrency and Computation: Practice and Experience,Wiley,Vol.14,n.11,(2002)933–956.3.Cybenko,G.:Dynamic Load Balancing for Distributed Memory Multiprocessors.J.Parallel and Distributed Comput.,7,(1989)279–391.4.Di Martino,B.,Briguglio,S.,Vlad,G.,Fogaccia,G.:Workload DecompositionStrategies for Shared Memory Parallel Systems with OpenMP.Scientific Program-ming,IOS Press,9,n.2-3,(2001)109–122.5.Di Martino,B.,Briguglio,S.,Vlad,G.,Sguazzero,P.:Parallel PIC Plasma Sim-ulation through Particle Decomposition Techniques.Parallel Computing27,n.3, (2001)295–314.6.Ferraro,R.D.,Liewer,P.,Decyk,V.K.:Dynamic Load Balancing for a2D Concur-rent Plasma PIC Code,put.Phys.109,(1993)329–341.7.Fox,G.C.,Johnson,M.,Lyzenga,G.,Otto,S.,Salmon,J.,Walker,D.:SolvingProblems on Concurrent Processors(Prentice Hall,Englewood Cliffs,New Jersey, 1988).。