edu-exam-c-tables-normal-dist
机器学习设计知识测试 选择题 53题

1. 在机器学习中,监督学习的主要目标是:A) 从无标签数据中学习B) 从有标签数据中学习C) 优化模型的复杂度D) 减少计算资源的使用2. 下列哪种算法属于无监督学习?A) 线性回归B) 决策树C) 聚类分析D) 支持向量机3. 在机器学习模型评估中,交叉验证的主要目的是:A) 增加模型复杂度B) 减少数据集大小C) 评估模型的泛化能力D) 提高训练速度4. 下列哪项不是特征选择的方法?A) 主成分分析(PCA)B) 递归特征消除(RFE)C) 网格搜索(Grid Search)D) 方差阈值(Variance Threshold)5. 在深度学习中,卷积神经网络(CNN)主要用于:A) 文本分析B) 图像识别C) 声音处理D) 推荐系统6. 下列哪种激活函数在神经网络中最为常用?A) 线性激活函数B) 阶跃激活函数C) ReLUD) 双曲正切函数7. 在机器学习中,过拟合通常是由于以下哪种情况引起的?A) 模型过于简单B) 数据量过大C) 模型过于复杂D) 数据预处理不当8. 下列哪项技术用于处理类别不平衡问题?A) 数据增强B) 重采样C) 特征选择D) 模型集成9. 在自然语言处理(NLP)中,词嵌入的主要目的是:A) 提高计算效率B) 减少词汇量C) 捕捉词之间的语义关系D) 增加文本长度10. 下列哪种算法不属于集成学习方法?A) 随机森林B) AdaBoostC) 梯度提升机(GBM)D) 逻辑回归11. 在机器学习中,ROC曲线用于评估:A) 模型的准确性B) 模型的复杂度C) 模型的泛化能力D) 分类模型的性能12. 下列哪项不是数据预处理的步骤?A) 缺失值处理B) 特征缩放C) 模型训练D) 数据标准化13. 在机器学习中,L1正则化主要用于:A) 减少模型复杂度B) 增加特征数量C) 特征选择D) 提高模型精度14. 下列哪种方法可以用于处理时间序列数据?A) 主成分分析(PCA)B) 线性回归C) ARIMA模型D) 决策树15. 在机器学习中,Bagging和Boosting的主要区别在于:A) 数据处理方式B) 模型复杂度C) 样本使用方式D) 特征选择方法16. 下列哪种算法适用于推荐系统?A) K-均值聚类B) 协同过滤C) 逻辑回归D) 随机森林17. 在机器学习中,A/B测试主要用于:A) 模型选择B) 特征工程C) 模型评估D) 用户体验优化18. 下列哪种方法可以用于处理缺失数据?A) 删除含有缺失值的样本B) 使用均值填充C) 使用中位数填充D) 以上都是19. 在机器学习中,偏差-方差权衡主要关注:A) 模型的复杂度B) 数据集的大小C) 模型的泛化能力D) 特征的数量20. 下列哪种算法属于强化学习?A) Q-学习B) 线性回归C) 决策树D) 支持向量机21. 在机器学习中,特征工程的主要目的是:A) 减少数据量B) 增加模型复杂度C) 提高模型性能D) 简化数据处理22. 下列哪种方法可以用于处理多分类问题?A) 一对多(One-vs-All)B) 一对一(One-vs-One)C) 层次聚类D) 以上都是23. 在机器学习中,交叉熵损失函数主要用于:A) 回归问题B) 分类问题C) 聚类问题D) 强化学习24. 下列哪种算法不属于深度学习?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 长短期记忆网络(LSTM)25. 在机器学习中,梯度下降算法的主要目的是:A) 减少特征数量B) 优化模型参数C) 增加数据量D) 提高计算速度26. 下列哪种方法可以用于处理文本数据?A) 词袋模型(Bag of Words)B) TF-IDFC) 词嵌入D) 以上都是27. 在机器学习中,正则化的主要目的是:A) 减少特征数量B) 防止过拟合C) 增加数据量D) 提高计算速度28. 下列哪种算法适用于异常检测?A) 线性回归B) 决策树C) 支持向量机D) 孤立森林(Isolation Forest)29. 在机器学习中,集成学习的主要目的是:A) 提高单个模型的性能B) 结合多个模型的优势C) 减少数据量D) 增加模型复杂度30. 下列哪种方法可以用于处理高维数据?A) 主成分分析(PCA)B) 特征选择C) 特征提取D) 以上都是31. 在机器学习中,K-均值聚类的主要目的是:A) 分类B) 回归C) 聚类D) 预测32. 下列哪种算法适用于时间序列预测?A) 线性回归B) ARIMA模型C) 决策树D) 支持向量机33. 在机器学习中,网格搜索(Grid Search)主要用于:A) 特征选择B) 模型选择C) 数据预处理D) 模型评估34. 下列哪种方法可以用于处理类别特征?A) 独热编码(One-Hot Encoding)B) 标签编码(Label Encoding)C) 特征哈希(Feature Hashing)D) 以上都是35. 在机器学习中,AUC-ROC曲线的主要用途是:A) 评估分类模型的性能B) 评估回归模型的性能C) 评估聚类模型的性能D) 评估强化学习模型的性能36. 下列哪种算法不属于监督学习?A) 线性回归B) 决策树C) 聚类分析D) 支持向量机37. 在机器学习中,特征缩放的主要目的是:A) 减少特征数量B) 提高模型性能C) 增加数据量D) 简化数据处理38. 下列哪种方法可以用于处理文本分类问题?A) 词袋模型(Bag of Words)B) TF-IDFC) 词嵌入D) 以上都是39. 在机器学习中,决策树的主要优点是:A) 易于理解和解释B) 计算效率高C) 对缺失值不敏感D) 以上都是40. 下列哪种算法适用于图像分割?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 支持向量机41. 在机器学习中,L2正则化主要用于:A) 减少模型复杂度B) 增加特征数量C) 特征选择D) 提高模型精度42. 下列哪种方法可以用于处理时间序列数据的季节性?A) 移动平均B) 季节分解C) 差分D) 以上都是43. 在机器学习中,Bagging的主要目的是:A) 减少模型的方差B) 减少模型的偏差C) 增加数据量D) 提高计算速度44. 下列哪种算法适用于序列数据处理?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 支持向量机45. 在机器学习中,AdaBoost的主要目的是:A) 减少模型的方差B) 减少模型的偏差C) 增加数据量D) 提高计算速度46. 下列哪种方法可以用于处理文本数据的情感分析?A) 词袋模型(Bag of Words)B) TF-IDFC) 词嵌入D) 以上都是47. 在机器学习中,支持向量机(SVM)的主要优点是:A) 适用于高维数据B) 计算效率高C) 对缺失值不敏感D) 以上都是48. 下列哪种算法适用于推荐系统中的用户行为分析?A) 协同过滤B) 内容过滤C) 混合过滤D) 以上都是49. 在机器学习中,交叉验证的主要类型包括:A) K-折交叉验证B) 留一法交叉验证C) 随机划分交叉验证D) 以上都是50. 下列哪种方法可以用于处理图像数据?A) 卷积神经网络(CNN)B) 循环神经网络(RNN)C) 随机森林D) 支持向量机51. 在机器学习中,梯度提升机(GBM)的主要优点是:A) 适用于高维数据B) 计算效率高C) 对缺失值不敏感D) 以上都是52. 下列哪种算法适用于异常检测中的离群点检测?A) 线性回归B) 决策树C) 支持向量机D) 孤立森林(Isolation Forest)53. 在机器学习中,特征提取的主要目的是:A) 减少特征数量B) 提高模型性能C) 增加数据量D) 简化数据处理答案:1. B2. C3. C4. C5. B6. C7. C8. B9. C10. D11. D12. C13. C14. C15. C16. B17. D18. D19. C20. A21. C22. D23. B24. C25. B26. D27. B28. D29. B30. D31. C32. B33. B34. D35. A36. C37. B38. D39. D40. A41. A42. D43. A44. B45. B46. D47. A48. D49. D50. A51. D52. D53. B。
可视化学生成绩管理系统(QT)

中国地质大学计算机高级语言课程设计报告(QT设计)——学生成绩管理系统班级:191142班学号:姓名:日期:2015年7月2日一课程设计题目与要求(包括题目与系统功能要求)【实习内容】C++语言,面向对象的分析与设计。
然后改成QT语言。
【基本要求】学生成绩管理是高等学校教务管理的重要组成部分,主要包括学生成绩的录入、删除、查找及修改、成绩的统计分析等等。
请设计一个系统实现对学生成绩的管理。
系统要求实现以下功能:(1)增加记录:要求可以连续增加多条记录。
(2)删除一个学生的记录:要求可以先查找,再删除。
删除前,要求用户确认。
(3)成绩修改:若输入错误可进行修改;要求可以先查找,再修改。
(4)查找:可以根据姓名(或学号)查找某个学生的课程成绩,查找某门课程成绩处于指定分数段内的学生名单等等。
(5)统计分析:对某个班级学生的单科成绩进行统计,求出平均成绩;求平均成绩要求实现函数的重载,既能求单科的平均成绩,又能求三科总分的平均成绩。
求出一门课程标准差和合格率;(6)排序功能:要求按总分进行排序(从高到低),若总分相同,则按数学排序;若总分和数学相同,则按物理排序;若总分和各科成绩都相同,则按学号排序;(7)文件操作:可以打开文件,显示班级的所有学生信息;可以将增加或修改后的成绩重新写入文件;可以将排序好的信息写入新的文件。
【较高要求】查找可以实现模糊查询,即输入名字的一部分,可以列出满足条件的所有记录。
再从这个记录中进行二次选择。
二需求分析【问题描述】在编写过程中,主要的困难有:1.模糊搜索(不能使用string中的find函数)需要自定义一个函数。
2.排序,需要自己学习算法。
【系统环境】Qt5.4.1三概要设计【类的设计】:类Student:#ifndef STUDENT_H#define STUDENT_H#include<iostream>#include<vector>#include<fstream>#include<string>#include<iomanip>#include<cmath>using namespace std;class student{private:string m_id,m_name;int m_math,m_eng,m_phy;public:student();student(string,string,int,int,int);//构造函数student(const student&);//复制构造函数~student(){};//析构函数string getId();//自定义接口string getName();int getMath();int getEng();int getPhy();int total();student operator=(const student&);//=号重载};#endif//STUDENT_H#define MANAGEMENT#include"student.h"#include"QString"#include<QFileDialog>#include<QFile>#include<qtextstream.h>class management{private:vector<student>stu;public:vector<student>deletetxt(const string&m);//删除记录vector<student>findtxt(const string&m);//模糊搜索vector<student>findtxt1(int,int,const string&);//分数段搜索vector<student>itxt();//文件写入vector<student>getstu(){return stu;}vector<double>ttxt(vector<double>);//统计分析vector<student>ptxt();//排序void addtxt();//增加记录void changetxt();//成绩修改void otxt();//文件输出void show();//输出};#endif//MANAGEMENT类mainwindow#ifndef MAINWINDOW_H#define MAINWINDOW_H#include<QMainWindow>#include"management.h"namespace Ui{class MainWindow;}class MainWindow:public QMainWindow{Q_OBJECTpublic:explicit MainWindow(QWidget*parent=0);~MainWindow();private slots:void on_pushButton_clicked();void on_ok_clicked();void on_pushButton_2_clicked();void on_ok_2_clicked();void on_ss_clicked();void on_ss_2_clicked();void on_pushButton_3_clicked();void on_pushButton_4_clicked();private:Ui::MainWindow*ui;};#endif//MAINWINDOW_H【主界面设计】:主机面主要以一个do-while循环使得系统能够多次查询。
及格率的函数

及格率的函数一、函数的介绍及格率是指在一个考试中,获得及格分数的人数与参加考试总人数之比。
及格率是一个重要的考试指标,可以反映出学生的学习情况和教育教学质量。
本文将介绍如何编写一个计算及格率的函数。
二、函数的参数计算及格率需要知道两个参数:总人数和及格分数线。
因此,我们需要定义两个变量来存储这两个参数。
在本文中,我们将使用以下变量:total:表示总人数passing_score:表示及格分数线三、函数的返回值计算出及格率后,我们需要将其返回给调用者。
在本文中,我们将使用以下变量:passing_rate:表示及格率四、函数的实现接下来,我们将详细介绍如何实现一个计算及格率的函数。
1. 定义函数名和参数列表首先,我们需要定义一个函数名和参数列表。
在本文中,我们将使用以下代码:def calculate_passing_rate(total, passing_score):2. 计算及格人数接下来,我们需要计算出获得及格分数的人数。
可以通过循环遍历所有成绩,并统计出大于等于及格分数线的成绩数量来实现。
具体实现如下:passing_count = 0for score in scores:if score >= passing_score:passing_count += 13. 计算及格率有了及格人数后,我们就可以计算出及格率了。
具体实现如下:passing_rate = passing_count / total4. 返回及格率最后,我们需要将计算出的及格率返回给调用者。
具体实现如下:return passing_rate五、完整代码示例下面是一个完整的计算及格率的函数示例:def calculate_passing_rate(total, passing_score):passing_count = 0for score in scores:if score >= passing_score:passing_count += 1passing_rate = passing_count / totalreturn passing_rate六、函数使用示例使用上述函数非常简单。
学生成绩管理系统数据流程图及数据字典

学生成绩管理系统数据流程图及数据字典一、数据流程图学生成绩管理系统是一个用于管理学生考试成绩的系统。
下面是该系统的数据流程图,展示了数据的流动和处理过程。
1. 输入流程a. 学生信息输入:学生的基本信息包括学号、姓名、性别、年龄等,通过学生信息输入界面输入,并存储到学生信息数据库中。
b. 课程信息输入:课程的基本信息包括课程编号、课程名称、学分等,通过课程信息输入界面输入,并存储到课程信息数据库中。
c. 成绩信息输入:学生的成绩信息包括学号、课程编号、成绩等,通过成绩信息输入界面输入,并存储到成绩信息数据库中。
2. 处理流程a. 学生信息管理:包括学生信息的增加、修改、删除和查询等操作。
管理员可以通过学生信息管理界面对学生信息进行管理,包括添加新的学生信息、修改学生信息、删除学生信息和查询学生信息。
b. 课程信息管理:包括课程信息的增加、修改、删除和查询等操作。
管理员可以通过课程信息管理界面对课程信息进行管理,包括添加新的课程信息、修改课程信息、删除课程信息和查询课程信息。
c. 成绩信息管理:包括成绩信息的录入、修改、删除和查询等操作。
管理员可以通过成绩信息管理界面对成绩信息进行管理,包括录入学生的成绩、修改学生的成绩、删除学生的成绩和查询学生的成绩。
d. 成绩统计分析:根据学生的成绩信息进行统计和分析。
管理员可以通过成绩统计分析界面查看各个课程的平均成绩、最高成绩、最低成绩等统计数据。
3. 输出流程a. 学生信息输出:管理员可以通过学生信息输出界面将学生的基本信息导出为Excel或PDF等格式的文件。
b. 课程信息输出:管理员可以通过课程信息输出界面将课程的基本信息导出为Excel或PDF等格式的文件。
c. 成绩信息输出:管理员可以通过成绩信息输出界面将学生的成绩信息导出为Excel或PDF等格式的文件。
二、数据字典数据字典是对系统中使用的数据元素进行定义和说明的工具。
下面是学生成绩管理系统的数据字典,包括了系统中使用的各个数据元素及其属性。
R语言习题
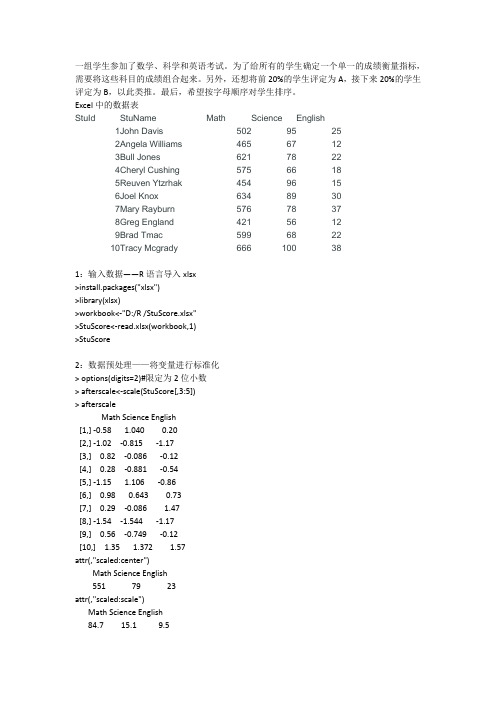
7:把name分成Firstname和LastName,加入到StuScore中
> FirstName<-sapply(name,"[",1)
> LastName<-sapply(name,"[",2)
> StuScore<-cbind(FirstName,LastName,StuScore[,-1])
一组学生参加了数学、科学和英语考试。为了给所有的学生确定一个单一的成绩衡量指标,需要将这些科目的成绩组合起来。另外,还想将前20%的学生评定为A,接下来20%的学生评定为B,以此类推。最后,希望按字母顺序对学生排序。
Excel中的数据表
StuId
StuName
Math
Science
English
1
John Davis
1 1 John Davis 502 95 25 0.22
2 2 Angela Williams 465 67 12 -1.00
3 3 Bull Jones 621 78 22 0.21
4 4 Cheryl Cushing 575 66 18 -0.38
5 5 Reuven Ytzrhak 454 96 15 -0.30
10 Tracy Mcgrady Mcgrady Tracy Mcgrady 666 100 38 1.43 B
8:order排序
> StuScore[order(LastName,FirstName),]
FirstName LastName LastNameStuName Math Science English score grade
python超详细实现完整学生成绩管理系统

python超详细实现完整学⽣成绩管理系统⽬录学⽣成绩管理系统简介源代码students.txtmain.pyLogin.pydb.pyMenuPage.pyview.py学⽣成绩管理系统简介⼀个带有登录界⾯具有增减改查功能的学⽣成绩管理系统(⾯向对象思想,利⽤tkinter库进⾏制作,利⽤.txt⽂件进⾏存储数据)源代码仅供学习参考,最好还是⾃⼰多敲多练习(实践是检验真理的唯⼀标准) students.txt⽤于存储数据main.pyfrom tkinter import *from Login import *import tkinter as tkroot = ()root.title('欢迎进⼊学⽣成绩管理系统')LoginPage(root)root.mainloop()Login.pyfrom tkinter import *from tkinter.messagebox import *from MenuPage import *class LoginPage(object):def __init__(self, master=None):self.root = master # 定义内部变量rootself.root.geometry('%dx%d' % (300, 180)) # 设置窗⼝⼤⼩ername = StringVar()self.password = StringVar()self.createPage()def createPage(self):self.page = Frame(self.root) # 创建Frameself.page.pack()Label(self.page).grid(row=0, stick=W)Label(self.page, text='账户: ').grid(row=1, stick=W, pady=10)Entry(self.page, textvariable=ername).grid(row=1, column=1, stick=E)Label(self.page, text='密码: ').grid(row=2, stick=W, pady=10)Entry(self.page, textvariable=self.password, show='*').grid(row=2, column=1, stick=E) Button(self.page, text='登陆', command=self.loginCheck).grid(row=3, stick=W, pady=10) Button(self.page, text='退出', command=self.page.quit).grid(row=3, column=1, stick=E) def loginCheck(self):name = ername.get()password = self.password.get()if name == 'hacker707' and password == 'admin':self.page.destroy()MenuPage(self.root)else:showinfo(title='错误', message='账号或密码错误!')db.pyimport jsonclass StudentDB(object):def __init__(self):self.students = []self._load_students_data()def insert(self, student):self.students.append(student)print(self.students)def all(self):return self.studentsdef delete_by_name(self, name): # 删除数据for student in self.students:if name == student["name"]:self.students.remove(student)breakelse:return Falsereturn True# 查询def search_by_name(self, name):for student in self.students:if name == student["name"]:return student # 姓名+成绩else:return False# 修改def update(self, stu): # 修改数据name = stu["name"]for student in self.students:if name == student["name"]:student.update(stu)return Trueelse:return False# 加载⽂件def _load_students_data(self):with open("students.txt", "r", encoding="utf-8") as f:text = f.read()if text:self.students = json.loads(text)# 保存数据def save_data(self):with open("students.txt", 'w', encoding="utf-8") as f:text = json.dumps(self.students, ensure_ascii=False)f.write(text)db = StudentDB()MenuPage.pyimport tkinter as tkfrom view import *class MenuPage(object):def __init__(self, master=None):self.root = masterself.root.geometry('%dx%d' % (600, 400))self.create_page()self.input_page = InputFrame(self.root)self.query_page = QuerryFrame(self.root)self.delete_page = DeleteFrame(self.root)self.update_page = UpdateFrame(self.root)self.about_page = AboutFrame(self.root)self.input_page.pack()def create_page(self):# 创建菜单对象menubar = tk.Menu(self.root)# add_command 添加menubar.add_command(label="录⼊", command=self.input_data) # label menubar.add_command(label="查询", command=self.query_data) # label menubar.add_command(label="删除", command=self.delete_data) # label menubar.add_command(label="修改", command=self.update_data) # label menubar.add_command(label="关于", command=self.about_data) # label # 设置菜单栏self.root.config(menu=menubar)# 切换界⾯def input_data(self):self.input_page.pack()self.update_page.pack_forget()self.delete_page.pack_forget()self.about_page.pack_forget()self.query_page.pack_forget()def query_data(self):self.input_page.pack_forget()self.query_page.pack()self.update_page.pack_forget()self.delete_page.pack_forget()self.about_page.pack_forget()def update_data(self):self.input_page.pack_forget()self.update_page.pack()self.delete_page.pack_forget()self.about_page.pack_forget()self.query_page.pack_forget()def delete_data(self):self.input_page.pack_forget()self.update_page.pack_forget()self.delete_page.pack()self.about_page.pack_forget()self.query_page.pack_forget()def about_data(self):self.input_page.pack_forget()self.update_page.pack_forget()self.delete_page.pack_forget()self.about_page.pack()self.query_page.pack_forget()view.pyimport tkinter as tkfrom db import dbfrom tkinter import ttk# 录⼊类class InputFrame(tk.Frame):def __init__(self, master=None):super().__init__(master)self.root = master = tk.StringVar()self.math = tk.StringVar()self.chinese = tk.StringVar()self.english = tk.StringVar()self.status = tk.StringVar()self.create_page()def create_page(self):bel(self).grid(row=0, stick=tk.W, pady=10)bel(self, text="姓名:").grid(row=1, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self, textvariable=).grid(row=1, column=1, stick=tk.E)bel(self, text="数学:").grid(row=2, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self, textvariable=self.math).grid(row=2, column=1, stick=tk.E)bel(self, text="语⽂:").grid(row=3, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self, textvariable=self.chinese).grid(row=3, column=1, stick=tk.E)bel(self, text="英语:").grid(row=4, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self, textvariable=self.english).grid(row=4, column=1, stick=tk.E)tk.Button(self, text="录⼊", command=self.recode_student).grid(row=5, column=1, stick=tk.E, pady=10) bel(self, textvariable=self.status).grid(row=6, column=1, stick=tk.E, pady=10)# 录⼊成绩def recode_student(self):student = {"name": .get(),"math": self.math.get(),"chinese": self.chinese.get(),"english": self.english.get(),} # ⼀个学⽣的成绩db.insert(student)# get()得到值# set()设置值self.status.set("插⼊数据成功!")self._clear_data()db.save_data()# 清空⽂本数据def _clear_data(self):.set("")self.math.set("")self.chinese.set("")self.english.set("")# 查询类class QuerryFrame(tk.Frame):def __init__(self, master=None):super().__init__(master)self.root = masterself.create_page()# 创建查询界⾯def create_page(self):self.create_tree_view()self.show_data_frame()# grid()tk.Button(self, text="刷新数据", command=self.show_data_frame).pack(anchor=tk.E, pady=5) # Treeviewdef create_tree_view(self):# 表头columns = ("name", "chinese", "math", "english")self.tree_view = ttk.Treeview(self, show='headings', columns=columns)self.tree_view.column("name", width=80, anchor='center')self.tree_view.column("chinese", width=80, anchor='center')self.tree_view.column("math", width=80, anchor='center')self.tree_view.column("english", width=80, anchor='center')self.tree_view.heading("name", text='姓名')self.tree_view.heading("chinese", text='语⽂')self.tree_view.heading("math", text='数学')self.tree_view.heading("english", text='英语')self.tree_view.pack()# 显⽰数据def show_data_frame(self):# 删除原节点 map(int,值)for i in map(self.tree_view.delete, self.tree_view.get_children("")):pass# 拿到列表⾥⾯所有值、students[]students = db.all()# 同时拿到索引跟value值for index, stu in enumerate(students):self.tree_view.insert('', index, values=(stu["name"], stu["chinese"], stu["math"], stu["english"]))class DeleteFrame(tk.Frame):def __init__(self, master=None):super().__init__(master)bel(self, text='删除数据').pack()self.status = tk.StringVar()self.de_name = tk.StringVar() # 获取删除学⽣的姓名self.create_page()# 创建界⾯def create_page(self):bel(self, text="根据姓名删除信息").pack(anchor=tk.W, padx=20)e1 = tk.Entry(self, textvariable=self.de_name)e1.pack(side=tk.LEFT, padx=20, pady=5)tk.Button(self, text='删除', command=self._delete).pack(side=tk.RIGHT)bel(self, textvariable=self.status).pack()# 删除def _delete(self):name = self.de_name.get()print(name)result = db.delete_by_name(name)if result:self.status.set(f'{name}已经被删')self.de_name.set("")else:self.status.set(f'{name}不存在')class UpdateFrame(tk.Frame):def __init__(self, master=None):super().__init__(master)self.root = masterbel(self, text='修改界⾯').pack()self.change_frame = tk.Frame(self)self.change_frame.pack() = tk.StringVar()self.math = tk.StringVar()self.chinese = tk.StringVar()self.english = tk.StringVar()self.status = tk.StringVar()self.create_page()def create_page(self):bel(self.change_frame).grid(row=0, stick=tk.W, pady=10)bel(self.change_frame, text="姓名:").grid(row=1, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self.change_frame, textvariable=).grid(row=1, column=1, stick=tk.E)bel(self.change_frame, text="数学:").grid(row=2, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self.change_frame, textvariable=self.math).grid(row=2, column=1, stick=tk.E)bel(self.change_frame, text="语⽂:").grid(row=3, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self.change_frame, textvariable=self.chinese).grid(row=3, column=1, stick=tk.E)bel(self.change_frame, text="英语:").grid(row=4, stick=tk.W, pady=10)# 单⾏⽂本框 entry,textvariable绑定变量tk.Entry(self.change_frame, textvariable=self.english).grid(row=4, column=1, stick=tk.E)# 按钮tk.Button(self.change_frame, text='查询', command=self._search).grid(row=6, column=0, stick=tk.W, pady=10) tk.Button(self.change_frame, text='修改', command=self._change).grid(row=6, column=1, stick=tk.E, pady=10) bel(self.change_frame, textvariable=self.status).grid(row=7, column=1, stick=tk.E, pady=10)# 查询def _search(self):name = .get()student = db.search_by_name(name)if student:self.math.set(student["math"])self.chinese.set(student["chinese"])self.english.set(student["english"])self.status.set(f'查询到{name}同学的信息')else:self.status.set(f'没有查询到{name}同学的信息')# 更改成绩def _change(self):name = .get()math = self.math.get()chinese = self.chinese.get()english = self.english.get()stu = {"name": name,"math": math,"chinese": chinese,"english": english,}r = db.update(stu)if r:self.status.set(f"{name}同学的信息更新完毕")else:self.status.set(f"{name}同学的信息更新失败")class AboutFrame(tk.Frame):def __init__(self, master=None):super().__init__(master)self.root = masterself.create_page()def create_page(self):bel(self, text="关于本作品(⼈⽣苦短,我⽤python)").pack(anchor=tk.W)以上就是使⽤python实现学⽣成绩管理系统,如果有改进的建议,欢迎在评论区留⾔奥~这篇⽂章参加了csdn的活动,还请⼤家多多三连⽀持⼀下博主,你们的⽀持就是我创作的动⼒到此这篇关于python超详细实现完整学⽣成绩管理系统的⽂章就介绍到这了,更多相关python 学⽣成绩管理系统内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
paddleocrtablerecognizer -回复

paddleocrtablerecognizer -回复什么是PaddleOCR表格识别器PaddleOCR表格识别器是一种基于深度学习的技术,用于自动识别和提取图像中的表格内容。
它是飞桨(PaddlePaddle)开源项目中的一个子模块,通过使用深度学习算法,能够自动解析表格中的文字信息,并将其转换为结构化的数据,方便进一步的数据分析和处理。
PaddleOCR表格识别器的原理PaddleOCR表格识别器的原理基于深度学习中的目标检测和文字识别技术。
首先,它使用目标检测算法检测出图像中可能存在的表格区域,然后通过文字识别模型将表格中的文字内容进行识别。
具体来说,PaddleOCR 表格识别器使用了Faster RCNN作为目标检测模型,它能够有效地定位出图像中的表格区域。
接着,它使用了基于CRNN(卷积循环神经网络)的文字识别模型,该模型能够将表格中的文字内容转化为易读的文本。
PaddleOCR表格识别器的使用方法使用PaddleOCR表格识别器可以分为以下几个步骤:1. 安装PaddleOCR:首先,需要安装PaddleOCR的Python库。
可以通过pip命令进行安装:pip install paddlepaddle paddleocr2. 导入PaddleOCR:在Python脚本中导入PaddleOCR库:pythonimport paddleocrfrom paddleocr import PaddleOCR3. 创建OCR实例:使用PaddleOCR类创建一个OCR实例:pythonocr = PaddleOCR()4. 加载表格识别模型:通过使用OCR实例的`add_tableocr`方法,加载表格识别模型:pythonocr.add_tableocr()5. 识别表格:使用OCR实例的`table_ocr`方法,对待识别的图像进行表格识别:pythonresult = ocr.table_ocr(image)6. 处理识别结果:通过对识别结果进行处理,可以将表格中的文字信息提取出来,并将其转换为结构化的数据。
学生成绩管理系统数据流程图及数据字典

学生成绩管理系统数据流程图及数据字典一、数据流程图数据流程图是一种图形化工具,用于描述系统内部的数据流动和处理过程。
在学生成绩管理系统中,数据流程图可以清晰地展示信息的输入、处理和输出过程,有助于理解系统的功能和流程。
1. 整体数据流程图整体数据流程图展示了学生成绩管理系统的总体流程,包括主要的数据流和处理过程。
以下是一个简化的整体数据流程图示例:[图1 整体数据流程图]2. 子系统数据流程图学生成绩管理系统可以划分为多个子系统,每一个子系统负责不同的功能模块。
以下是几个常见的子系统数据流程图示例:2.1 学生信息管理子系统数据流程图[图2 学生信息管理子系统数据流程图]学生信息管理子系统负责学生信息的录入、查询、修改和删除等操作。
数据流程图中的主要流程包括学生信息的录入、查询和修改。
2.2 课程管理子系统数据流程图[图3 课程管理子系统数据流程图]课程管理子系统负责课程信息的录入、查询、修改和删除等操作。
数据流程图中的主要流程包括课程信息的录入、查询和修改。
2.3 成绩管理子系统数据流程图[图4 成绩管理子系统数据流程图]成绩管理子系统负责学生成绩的录入、查询、修改和统计等操作。
数据流程图中的主要流程包括成绩信息的录入、查询、修改和统计。
二、数据字典数据字典是对系统中使用的数据项进行定义和描述的文档,包括数据项的名称、含义、数据类型、长度、取值范围等信息。
在学生成绩管理系统中,数据字典可以匡助开辟人员和用户理解各个数据项的含义和属性。
以下是学生成绩管理系统中常见的数据字典示例:1. 学生信息表(Student)数据项含义数据类型长度取值范围学生ID 学生惟一标识字符串 10 100000001-999999999姓名学生姓名字符串 20 任意字符性别学生性别字符串 2 男、女年龄学生年龄整数 3 10-100班级学生所在班级字符串 20 任意字符2. 课程信息表(Course)数据项含义数据类型长度取值范围课程ID 课程惟一标识字符串 10 1001-9999课程名称课程名称字符串 50 任意字符学分课程学分浮点数 - 大于0的数字教师ID 教师惟一标识字符串 10 1000001-99999993. 成绩信息表(Grade)数据项含义数据类型长度取值范围学生ID 学生惟一标识字符串 10 100000001-999999999课程ID 课程惟一标识字符串 10 1001-9999成绩学生成绩浮点数 - 0-100以上是学生成绩管理系统数据流程图及数据字典的示例,可以根据实际需求进行调整和扩展。
findclusers函数

findclusers函数
findClusters函数通常用于数据挖掘和机器学习的聚类分析中。
这个函数的目标是识别数据集中的聚类或集群,即数据中的相似或相关点。
具体来说,findClusters函数可能会执行以下步骤:
1.数据预处理:清理和标准化数据,以便消除异常值、缺失值或其他无关因素。
2.选择聚类算法:例如K-means、DBSCAN、层次聚类等。
3.执行聚类:根据所选算法对数据进行聚类。
4.评估聚类:通过各种指标(如轮廓系数、Calinski-Harabasz 指数等)评估聚类的质量。
5.返回结果:通常,findClusters函数会返回一个聚类结果的表示,可能是一个每个点的聚类标签,或者是每个聚类的中心点。
在使用findClusters函数时,需要注意以下几点:
•参数调整:不同的聚类算法可能需要不同的参数。
确保调整这些参数以获得最佳结果。
•数据量与维度:对于非常大的数据集或高维数据,聚类可能会变得困难。
在这种情况下,可能需要采用降维或采样技术。
•算法选择:根据数据的性质和问题类型选择合适的聚类算法。
•结果解释:解释聚类结果时要小心,确保它们有意义并满足业务或研究需求。
在Python中,许多库提供了findClusters或类似的函数,例如scikit-learn、sklearn、mlxtend 等。
使用这些库时,请查阅相关文档以了解如何正确使用这些函数。
巧用Excel函数实现学生成绩统计及查询

巧用Excel函数实现学生成绩统计及查询作者:于宁来源:《电脑知识与技术》2011年第01期摘要:电子表格软件Excel具有强大的数据处理和分析功能,其中函数是Excel数据计算和处理的核心工具。
该文利用Excel中的不同函数功能,实现对学生成绩的统计、课程分析及信息查询。
关键词:Excel;函数;公式中图分类号:TP311文献标识码:A文章编号:1009-3044(2011)01-0209-02Score Statistics and Query Using Excel FunctionsYU Ning(Department of Computer Science of College of Arts and Science of Beijing Union University, Beijing 100190, China)Abstract: Excel spreadsheet software has powerful data processing and analysis capabilities, and the Excel function is the core tool for data calculating and processing. In this paper, score statistics, curriculum analysis and information inquiries were achieved with different Excel functions.Key words: Excel; function; formula在学校的日常教学管理中,经常遇到需要汇总、统计或查询学生学期成绩的问题,借助Microsoft Office系列办公软件中的电子表格Excel,可以帮助我们方便、快速地完成数据表中的统计、分析,特别是灵活地运用Excel中的公式和函数,不仅能提高工作效率,还能帮助我们完成一些特殊的功能。
学生成绩管理系统数据流程图及数据字典

学生成绩管理系统数据流程图及数据字典数据流程图:学生成绩管理系统是一个用于管理学生学习成绩的系统。
下面是该系统的数据流程图,展示了数据的流动和处理过程。
1. 学生信息录入流程:- 学生信息管理员将学生个人信息录入系统。
- 系统验证学生信息的有效性,包括学号、姓名、性别、出生日期等。
- 验证通过后,学生信息被存储到学生信息数据库中。
2. 课程信息录入流程:- 课程管理员将课程信息录入系统。
- 系统验证课程信息的有效性,包括课程编号、课程名称、学分等。
- 验证通过后,课程信息被存储到课程信息数据库中。
3. 学生成绩录入流程:- 教师将学生的课程成绩录入系统。
- 系统验证学生和课程的有效性,确保学生和课程都存在于对应的数据库中。
- 验证通过后,成绩信息被存储到成绩信息数据库中。
4. 学生成绩查询流程:- 学生、教师或管理员通过系统界面选择查询学生成绩。
- 系统根据用户的选择,从成绩信息数据库中检索相应的学生成绩信息。
- 系统将查询结果显示给用户。
5. 学生成绩统计流程:- 管理员选择进行学生成绩统计。
- 系统从成绩信息数据库中获取所有学生成绩。
- 系统根据统计要求,计算学生的平均成绩、最高分、最低分等统计指标。
- 统计结果被显示给管理员。
数据字典:下面是学生成绩管理系统的数据字典,定义了系统中使用的数据对象及其属性。
1. 学生信息:- 学号(学生的唯一标识符)- 姓名- 性别- 出生日期- 年级- 班级2. 课程信息:- 课程编号(课程的唯一标识符)- 课程名称- 学分3. 成绩信息:- 学号(学生的唯一标识符)- 课程编号(课程的唯一标识符)- 成绩4. 统计结果:- 平均成绩- 最高分- 最低分系统中的数据对象之间存在以下关系:- 学生信息与成绩信息之间是一对多的关系,一个学生可以有多个成绩记录。
- 课程信息与成绩信息之间也是一对多的关系,一个课程可以有多个成绩记录。
通过学生成绩管理系统的数据流程图和数据字典,可以清晰地了解系统中数据的流动和处理过程,以及各个数据对象之间的关系。
《spss统计软件》练习题库及答案

华中师范大学网络教育学院《SPSS统计软件》练习题库及答案(本科)一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:A Insert Variable;B Insert Case;C Go to Case;D Weight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute;D Categorize Variables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C 对数据进行行列转置;D 按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B. 三种城市身高没有差别的可能性是0.043;C. 三种城市身高有差别的可能性是0.043;D. 说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
统计建模与R试题

统计建模与R考试题
1、请在R环境中加载ISRL包,分析ISRL包里面的Carseats数据
集:
(1)分别计算1、2、3、4、5、6、8、9列的均值、方差和总和。
(2)请分别计算ShelveLoc列中的三个类别Bad、Good、Medium 所对应的income、price的均值、方差和总和。
(3)提示:首先取出ShelveLoc等于Bad的数据子集,然后再进行计算。
2、读取temp.csv文件,该文件为中国某城市一天的温度数据,请
你分析该温度是否服从正态分布。
3、要求采用作图的方法、正态性W检验、Kolmogorov-Smirnov
检验和Pearson拟合度卡方检验。
提示:作图方法可以采用QQ图、经验分布图等。
4、请在R环境中加载ISRL包,分析ISRL包里面的Auto数据集:
请对数据集进行回归分析,其中mpg为因变量,其余的为自变量。
5、读取temp.csv文件,请画出温度的直方图和核密度估计图,并
且和正态分布的概率密度函数进行比较。
你能得到什么结果?
6、分别从读取5个文件junzhi.txt,max.txt,max_min.txt,var.txt,
zengliang.txt中的第一列,然后合成一个矩阵,保存为hecheng.txt 文件。
保存完之后用折线图对hecheng.txt文件中的每一行分别进行可视化,总共有905个折线图,并且将这些图片保存为jpg格式。
HSDPA test setting related
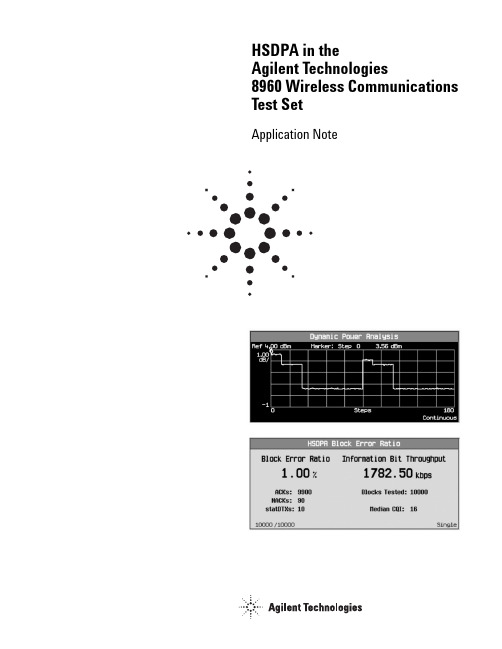
HSDPA in theAgilent Technologies8960 Wireless Communications Test SetApplication NoteTest Set Connection TypesThere are several types of connections available in the test set; each involving different protocol entities and layers,and varying amounts of signaling. Three main connection types are discussed below: FDD test mode, RB (radio bearer)test mode, and packet data connection.FDD test modeFDD test mode is an Agilent-proprietary test mode.It is based on the 3GPP RB test mode, but without Layer 3 signaling. FDD test mode allows you to test the parametric performance of your user equipment’s (UE’s) transmitter and receiver without upper layer signaling.In FDD test mode, the test set does not send any signaling information on the downlink. Rather, itcontinuously generates a downlink signal and searches for a corresponding uplink signal. The UE must synchronize to the downlink signal and send an appropriate uplink signal, which the test set uses to measure the UE’s transmitter and receiver performance. Any changes to the UE configuration must be accomplished by directly sending commands to the UE from a system controller through a proprietary digital interface.IntroductionThe W-CDMA applications in the Agilent 8960 test set are being evolved to include HSDPA test functionality. This paper contrasts the various HSDPA connection types and provides details of the test set’s HSDPA frequency division duplex (FDD) test mode and HSDPA measurements.2Packet data connectionRB test modeFDD test modeRB test modeRB test mode uses signaling to establish a Layer 3 test control connection between the test set and UE, allowing you to test the parametric performance of your UE’s transmitter and receiver.In RB test mode, the test set provides signaling toestablish a connection with the UE. The test set can use Layer 3 commands to alter the UE’s uplink radio bearer configuration. The test set measures the uplink signal to determine the UE’s transmitter and receiver performance.Packet data connectionA packet data connection allows you to performfunctional verification of your UE to validate real network operation and signaling. The test set provides signaling to establish a packet data connection with the UE, which provides an end-to-end packet-switched data channel over which IP-based applications can transfer data.The HSDPA FDD test mode implementation in the test set is an extension of the existing (non-HSDPA) FDD test mode. When Channel Type is set to 12.2k RMC + HSDPA , the test set continues to transmit and receive the 12.2k RMC and common channels, but can also be configured to include up to four HS-SCCHs and five HS-PDSCHs (as determined by the FRC Type setting.) When the HSDPA channels are active, the test set generates a six-channel OCNS as defined in 3GPP TS 34.121 E.5, rather than the OCNS defined in E.3.The test set includes a fully-operational MAC-hs layer (conforming to 3GPP Release 5 December 2004)that contains up to eight active HARQ processes.FDD Test Mode DetailsIn (non-HSDPA) FDD test mode, the test set continuously transmits a downlink signal, which consists of a dedicated physical channel (DPCH) configured as a symmetrical reference measurement channel (RMC), CPICH, and SCH/P-CCPCH channels to allow the UE to synchronize to the test set and decode the downlink data, OCNS(as defined in 3GPP TS 34.121 E.3), AWGN if desired, and a PICH channel with fixed data. The UE must be manually configured to transmit the same RMC as is transmitted in the downlink, and to enable (non-HSDPA) receiver testing the UE must loop back the data bits it receives on the RMC from the test set.3The data source for the HARQ processes is a single PRBS generator operating at the MAC-d level. Each time aHARQ process is ready to transmit a new block it requestsa single MAC-d block from the PRBS generator. If MAC-hsHeader is set to Present, the size of the requested MAC-dblock matches the MAC-hs transport block size minus the MAC-hs header. If MAC-hs header is set to Data, the MAC-d block matches the MAC-hs transport block size (whichis determined by the FRC Type setting.) The MAC-d block from the PRBS generator is pure data; it does not contain any MAC-d header information (nor does it include any headers from upper layers.)When a HARQ process transmits a block of data on theHS-DSCH transport channel, the test set’s Layer 1 transmits an associated HS-SCCH physical control channel. Thiscarries HARQ process information (new data indicator, TFRI, etc.) and HS-PDSCH physical channel configuration information (modulation type, number of codes, etc.) for that HS-DSCH transport block. This allows the UE tocorrectly receive the HS-PDSCHs and transmit appropriate acknowledgement information on its HS-DPCCH.The test set schedules new blocks and retransmissions based on the acknowledge/negative acknowledge (ACK/NACK) information on the uplink HS-DPCCH. If a NACK isreceived and the block has not been retransmitted more than the Number of Transmissions setting allows, the HARQ process retransmits the block using the next redundancy version (RV) from the RV Sequence list. If a NACK isreceived and the block has been retransmitted themaximum number of allowed times, or if an ACK isreceived, the MAC-hs layer transmits a new blockusing the first RV in the list. If the expected HS-DPCCH transmission is not received on the uplink at theappropriate time, the test set reacts according to thestatDTX Reception Behavior setting. The test set records the number of ACKs, NACKs, and statDTXs for use by theHSDPA BLER measurement.During TTIs where data is not transmitted to the UE (i.e.when inter-TTI is greater than one), the test set transmits dummy data using the Alternate H-RNTI.Test Set ConfigurationAs there is no Layer 3 signaling between the test set and UE, you must use proprietary control mechanisms todirectly configure the UE to match the test set’s HSDPA configuration. This configuration is based on the following test set settings:HS-SCCH, HS-PDSCH, and H-RNTI configuration•HS-SCCH1-4: State, level, channelization code•HS-PDSCHs: Sum of levels, channelization codes (you can specify the channelization code of the firstHS-PDSCH, the others are assigned to the adjacentchannelization codes)•FRC Type:H-Set 1-3 (QPSK and 16QAM), 4-5 (QPSK)4•Primary H-RNTI:Identifier used on HS-SCCH1 to transmit information to the UE under test •Alternate H-RNTI:Identifier used on HS-SCCH2-4 and when the test set is transmitting information onHS-SCCH1 that is not directed to the UE under test MAC-hs parameters•Number of Transmissions:The number of times a MAC-hs HARQ process will attempt to transmit a particulardata block (one to eight)•RV Sequence:Indicates the sequence of RV parameters to be used by the test for block transmissions. You may specify up to eight integer values (between zero andseven), but the number of RV parameters actuallyused by the test set is determined by the Numberof Transmissions setting•MAC-hs Transmit Window Size:This setting is only used when MAC-hs Header is set to Present. It can be set to 4, 6, 8, 12, 16, 24, or 32 MAC-hs PDUs•HS-DSCH Data Pattern:Data pattern sent in each HS-DSCH transport block (CCITT PRBS15, CCITT PRBS9, allzeros, all ones, incrementing, alternating)•MAC-hs Header•Present: When MAC-hs Header is set to Present, each MAC-hs block contains a valid MAC-hs headerformatted with the following values:The TSN field is incremented each time a new block is sent by a HARQ process.•Data: The header space is filled with HS-DSCH Data Pattern data•statDTX Reception Behavior:You can configure how the test set responds to astatDTX from the UE (the options are as defined in3GPP TS 34.121 Table 9.2.1.2)•Handle as ACK:The test set transmits a new block from the MAC-hs transmit queue using the first entry in the RV sequence and resets the transmission counter to one. If you would like the test set to continuouslytransmit new data regardless of the uplink HS-DPCCH presence (to allow you to measure BER in an externalprogram, for example), set statDTX ReceptionBehavior to Handle as ACK, set Number of Transmissionsto 1, HS-DSCH Data Pattern to CCITT PRBS15or CCITT PRBS9, and MAC-hs Header to Data.•Handle as NACK: If the transmission counter is less than the Number of Transmissions setting, the test settransmits the same block using the next entry in the RV sequence and increments the transmissioncounter by one. (If the transmission counter equalsthe Number of Transmissions setting, then theHandle as ACK process is followed instead.) •Handle as statDTX: The test set transmits the same block using the same entry in the RV sequence anddoes not increment the transmission counter.VF = 0Queue ID = 0TSN = [incrementing]SID1= 0N1= 1 F =0or no signal if the UE was not scheduled for a transmission or if the UE failed to decode the HS-SCCH of a scheduled transmission. Slots 1 and 2 may or may not contain the channel quality indicator (CQI). The presence of CQI data isdetermined by the CQI repetition factor specified by the network; it is independent of the scheduling of the data packets and associated ACK/NACK transmissions. The power levels the UE must use for ACK, NACK, and CQI transmissions is signaled to the UE by the network, and are independent of one another. Thus, the power of the HS-DPCCH may differ greatly between slots.The UE’s composite power is simultaneously controlled by inner loop power control (via TPC commands). These power changes (which occur on DPCH slot boundaries) may or may not be aligned to the HS-DPCCH slot boundary power changesbecause the uplink DPCH may be offset in time from the fixed position of the uplink HS-DPCCH. The downlink and uplink DPCH timing offset is controlled by the τDPCH parameter in 0.1 slot (256 chip) increments. For example, when τDPCH =0, the uplink DPCH will be 0.1 slot behind the uplink HS-DPCCH. This timing offset adds furthercomplexity as the UE’s composite power may differ even within a slot. This is shown in the following diagram from 3GPP TS 25.101 Figure 6.6:HSDPA Test Requirements OverviewTests for the new HSDPA UE performancerequirements are currently being drafted by 3GPP RAN WG5. As of the June 2005 release of 34.121,several tests have been drafted, but there remains a number of issues still to be resolved including the exact composition of the test signals. The main UE transmitter and receiver tests under development include:•3GPP TS 34.121 5.2A Maximum Output Power with HS-DPCCH•3GPP TS 34.121 5.7A HS-DPCCH (Transmit ON/OFF Power)•3GPP TS 34.121 5.9A Spectrum Emission Mask with HS-DPCCH•3GPP TS 34.121 5.10A Adjacent Channel Leakage Power Ratio (ACLR) with HS-DPCCH•3GPP TS 34.121 5.13.1A Error Vector Magnitude (EVM) with HS-DPCCH•3GPP TS 34.121 6.3A Maximum Input Level for HS-PDSCH Reception (16QAM) The addition of the new uplink HS-DPCCH code channel to the existing UL DPCH adds complexity to the power versus time profile of the UE, and is worthy of further explanation.The HS-DPCCH is not always transmitted continuously. Rather, slot 0 of the HS-DPCCH sub-frame contains ACK/NACK information,5HS-DPCCH 2560 chip slot boundaries* = step due to inner loop power control The power step due to HS-DPCCH transmission is the difference between the mean powers tranmitted before and after an HS-DPCCH slot boundary. The mean power evaluation period excludes a 25 µsperiod before and after any DPCCH or HS-DPCCH slot boundary.When Channel Type is set to an RMC that does not include HSDPA, the full suite of test set measurements is available.When Channel Type is set to 12.2k RMC + HSDPA, the following measurements are available:Transmitter measurementsThe transmitter measurements rely on the use of the new HS-DPCCH Trigger Source selection andHS-DPCCH Trigger Alignment setting. These settings allow you to specify the HS-DPCCH HARQsub-frame to which the measurement interval is aligned (by default the measurement interval is aligned to the uplink HS-DPCCH sub-frame for HARQ0). Additionally, you can specify a Trigger Delay of up to ±12 ms to position the measurement interval within any sub-frame. The Channel Power and Dynamic Power Analysis measurements feature a Measurement Interval setting that can be set as small as 10 µs to allow measurements of sub-slot intervals.For example, to measure the Channel Power of the CQI transmission circled below (the CQI data in the sub-frame corresponding to HARQ1 when inter-TTI interval=3), set HS-DPCCH Trigger Alignment to Subframe 3, set Trigger Delay to 666.7 µs(one timeslot) and Measurement Interval to 1.333 µs(two timeslots).Note also if you set HS-DPCCH Trigger Alignmentto subframe 1, 2, 4, or 5 (in this example theseare the subframes in which the uplink HS-DPCCH is not transmitting) you can perform standardW-CDMA measurements on just the RMC portionof the uplink signal to reduce your overall (W-CDMA and HSDPA) UE test time.HSDPA Measurements in the 8960 Test Set The test set includes several measurements capable of testing an uplink HSDPA signal. The UE must be able to decode the test set’s HS-SCCH and use the information on that channel to decode the corresponding HS-PDSCHs. The UE must also transmit a valid HS-DPCCH on the uplink which includes ACK/NACK data derived from theHS-DSCH decode.6DL HS-SCCHDL HS-PDSCH(s)UL HS-DPCCHInter-TII = 3Sub-frame:012345012 Table 1. HSDPA measurementsMeasurement3GPP performance requirementTransmitter measurementsChannel power 3GPP TS 34.121 5.2A Maximum Output Power with HS-DPCCH3GPP TS 34.121 5.7A HS-DPCCH (Transmit ON/OFF Power) Spectrum emission mask 3GPP TS 34.121 5.9A Spectrum Emission Mask with HS-DPCCHAdjacent channel leakage ratio 3GPP TS 34.121 5.10A Adjacent Channel Leakage Power Ratio (ACLR) with HS-DPCCH Dynamic power analysis 3GPP TS 34.121 5.2A Maximum Output Power with HS-DPCCH3GPP TS 34.121 5.7A HS-DPCCHComing soon:Waveform quality 3GPP TS 34.121 5.13.1A Error Vector Magnitude (EVM) with HS-DPCCHReceiver measurementsHSDPA BLER 3GPP TS 34.121 6.3A Maximum Input Level for HS-PDSCH Reception (16QAM)Also available: Audio Generator, Audio Analyzer,Spectrum Monitor, and Frequency Stability.ConclusionThe 8960’s HSDPA FDD test mode allows you to test the parametric performance of your UE’s transmitter and receiver without the overhead of upper layer signaling. For production test engineers developing test plans for W-CDMA and HSDPA devices, the 8960 provides the most complete test functionality for 3GPP TS 34.121 sections 5 and 6,with fast, accurate, and repeatable results.The Dynamic Power Analysis measurement’s Step Length can be set as low as 10 µs to allow evaluation of up to 200 0.1 slot intervals (steps).While on an HSDPA channel you can also route the downlink HARQ0 trigger to the rear panel to enable additional UE measurements using external test equipment.Receiver measurementsYou can set the Number of Blocks to Test for the HSDPA BLER measurement between 1 and 99000blocks. The HSDPA BLER measurement returns the following:•Block Error Ratio:As specified in 3GPP TS 34.121 F.6.3.2•Information Bit Throughput (R) in kb/s •Number of ACKs counted •Number of NACKs counted •Number of statDTXs counted •Blocks Tested •Median CQITo speed testing of both the HSDPA and W-CDMA functionality in your UE, you can run HSDPA Block Error Ratio concurrently with the (W-CDMA) Loopback BER or Block Error Ratio measurements.7/find/emailupdatesGet the latest information on the products and applications you select.Agilent Email UpdatesAgilent Technologies’ Test and Measurement Support, Services, and Assistance Agilent Technologies aims to maximize the value you receive, while minimizing your risk and problems. We strive to ensure that you get the test and measurement capabilities you paid for and obtain the support you need. Our extensive support resources and services can help you choose the right Agilent products for your applications and apply them successfully. Every instrument and system we sell has a global warranty. Two concepts underlie Agilent’s overall support policy: “Our Promise” and “Your Advantage.”Our PromiseOur Promise means your Agilent test and measurement equipment will meet its advertised performance and functionality. When you are choosing new equipment, we will help you with product information, including realistic performance specifications and practical recommendations from experienced test engineers. When you receive your new Agilent equipment, we can help verify that it works properly and help with initial product operation.Your AdvantageYour Advantage means that Agilent offers a wide range of additional expert test and measurement services, which you can purchase according to your unique technical and business needs. Solve problems efficiently and gain a competitive edgeby contracting with us for calibration, extra-cost upgrades, out-of-warranty repairs,and onsite education and training, as well as design, system integration, project management, and other professional engineering services. Experienced Agilent engineers and technicians worldwide can help you maximize your productivity, optimize the return on investment of your Agilent instruments and systems, and obtain dependable measurement accuracy for the life of those products./find/openAgilent Open simplifies the process of connecting and programming test systems to help engineers design, validate and manufacture electronic products. Agilent offers open connectivity for a broad range of system-ready instruments, open industry software, PC-standard I/O and global support, which are combined to more easily integrate test system development.United States:Korea:(tel) 800 829 4444(tel) (080) 769 0800(fax) 800 829 4433(fax) (080)769 0900Canada:Latin America:(tel) 877 894 4414(tel) (305) 269 7500(fax) 800 746 4866Taiwan :China:(tel) 0800 047 866(tel) 800 810 0189(fax) 0800 286 331(fax) 800 820 2816Other Asia Pacific Europe:Countries:(tel) 31 20 547 2111(tel) (65) 6375 8100Japan:(fax) (65) 6755 0042(tel) (81) 426 56 7832Email: tm_ap@(fax) (81) 426 56 7840Contacts revised: 05/27/05For more information on Agilent Technologies’ products, applications or services,please contact your local Agilent office. The complete list is available at:/find/contactusProduct specifications and descriptions in this document subject to change without notice.© Agilent Technologies, Inc. 2005Printed in USA, July 21, 20055989-3444ENAgilent Open。
r语言期末考试题及答案

r语言期末考试题及答案# R语言期末考试题及答案一、选择题(每题2分,共20分)1. 在R语言中,以下哪个是正确的向量创建方式?A. vector(1, 2, 3)B. c(1, 2, 3)C. vector(1, 2, 3, mode = "numeric")D. list(1, 2, 3)答案:B2. 下列哪个函数可以用来计算数据集的均值?A. mean()B. median()C. sum()D. range()答案:A3. 如果要对数据进行排序,应该使用哪个函数?A. sort()B. order()C. arrange()D. rank()答案:A4. R语言中,以下哪个是正确的数据框(data frame)创建方式?A. data_frame(a = 1:5, b = letters[1:5])B. data_frame(a = 1:5, b = letters[1:5], s = 1:5)C. data.frame(a = 1:5, b = letters[1:5])D. dataframe(a = 1:5, b = letters[1:5])答案:C5. 下列哪个选项是R语言中读取CSV文件的正确方法?A. read.csv()B. read.table()C. read.data()D. load.csv()答案:A...(此处省略其他选择题,共10题)二、简答题(每题10分,共20分)1. 简述R语言中列表(list)和向量(vector)的区别。
答案:向量是R语言中最基本的数据结构,它是一个一维数组,可以包含相同类型的元素。
向量的操作通常是向量化的,即对向量中的每个元素应用函数。
而列表是一种更复杂的数据结构,可以包含不同类型的元素,并且可以是多维的。
列表中的每个元素可以是一个向量、矩阵或其他列表,甚至可以是函数。
2. 解释R语言中条件语句if-else的用法。
stable difussion

stable difussionStable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。
它使用来自LAION-5B 数据库子集的512x512图像进行训练。
使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它,如下图所示。
如果你足够聪明和有创造力,你可以创造一系列的图像,然后形成一个视频。
例如,Xander Steenbrugge使用它和上图所示的输入提示创建了下面这段令人惊叹的《穿越时间》视频。
以下是他用来创作这幅创造性艺术作品的灵感和文本:本文首先介绍什么是Stable Diffusion,并讨论它的主要组成部分。
然后我们将使用模型以三种不同的方式创建图像,这三种方式从更简单到复杂。
Stable DiffusionStable Diffusion是一种机器学习模型,它经过训练可以逐步对随机高斯噪声进行去噪以获得感兴趣的样本,例如生成图像。
扩散模型有一个主要的缺点就是去噪过程的时间和内存消耗都非常昂贵。
这会使进程变慢,并消耗大量内存。
主要原因是它们在像素空间中运行,特别是在生成高分辨率图像时。
Latent diffusion通过在较低维度的潜空间上应用扩散过程而不是使用实际的像素空间来减少内存和计算成本。
所以Stable Diffusion引入了Latent diffusion的方式来解决这一问题计算代价昂贵的问题。
1、Latent diffusion的主要组成部分Latent diffusion有三个主要组成部分:自动编码器(VAE)自动编码器(VAE)由两个主要部分组成:编码器和解码器。
编码器将把图像转换成低维的潜在表示形式,该表示形式将作为下一个组件U_Net 的输入。
解码器将做相反的事情,它将把潜在的表示转换回图像。
在Latent diffusion训练过程中,利用编码器获得正向扩散过程中输入图像的潜表示(latent)。
学生成绩管理系统数据流程图及数据字典

学生成绩管理系统数据流程图及数据字典一、数据流程图学生成绩管理系统是一个用于记录和管理学生各科成绩的系统。
下面是该系统的数据流程图:1. 学生信息管理流程:a. 输入学生信息:管理员或教师通过系统界面输入学生的基本信息,包括学生姓名、学号、班级等。
b. 学生信息存储:系统将输入的学生信息存储在学生信息数据库中,以便后续的成绩管理和查询。
2. 成绩录入流程:a. 输入成绩信息:教师通过系统界面选择要录入成绩的科目和学生,然后输入相应的成绩。
b. 成绩信息存储:系统将输入的成绩信息存储在成绩数据库中,与学生信息关联。
3. 成绩查询流程:a. 输入查询条件:教师或学生通过系统界面输入查询条件,如学生姓名、学号、班级等。
b. 查询成绩信息:系统根据输入的查询条件,在成绩数据库中查找匹配的成绩信息,并将结果显示在界面上。
4. 成绩统计流程:a. 统计成绩信息:系统根据学生的成绩数据进行统计分析,包括计算平均成绩、最高成绩、最低成绩等。
b. 显示统计结果:系统将统计结果显示在界面上,以便教师和学生查看。
二、数据字典下面是学生成绩管理系统的数据字典,包括各个数据流、数据存储和处理过程的详细说明:1. 学生信息数据库(Student Information Database):- 数据项:学生姓名、学号、班级2. 成绩数据库(Grade Database):- 数据项:学生姓名、学号、班级、科目、成绩3. 输入学生信息(Input Student Information):- 数据流:管理员或教师输入的学生基本信息4. 学生信息存储(Store Student Information):- 数据流:输入学生信息流程中的学生基本信息- 数据存储:学生信息数据库5. 输入成绩信息(Input Grade Information):- 数据流:教师输入的成绩信息6. 成绩信息存储(Store Grade Information):- 数据流:输入成绩信息流程中的成绩信息- 数据存储:成绩数据库7. 输入查询条件(Input Query Conditions):- 数据流:教师或学生输入的查询条件8. 查询成绩信息(Query Grade Information):- 数据流:输入查询条件流程中的查询结果- 数据存储:成绩数据库9. 统计成绩信息(Calculate Grade Statistics):- 数据流:成绩数据库中的成绩信息10. 显示统计结果(Display Statistics Results):- 数据流:统计成绩信息流程中的统计结果以上是学生成绩管理系统的数据流程图及数据字典的详细描述。
《机器学习导论》题集

《机器学习导论》题集一、选择题(每题2分,共20分)1.以下哪个选项不是机器学习的基本类型?A. 监督学习B. 无监督学习C. 强化学习D. 深度学习2.在监督学习中,以下哪个选项是标签(label)的正确描述?A. 数据的特征B. 数据的输出结果C. 数据的输入D. 数据的预处理过程3.以下哪个算法属于无监督学习?A. 线性回归B. 逻辑回归C. K-均值聚类D. 支持向量机4.在机器学习中,过拟合(overfitting)是指什么?A. 模型在训练集上表现很好,但在新数据上表现差B. 模型在训练集上表现差,但在新数据上表现好C. 模型在训练集和新数据上表现都很好D. 模型在训练集和新数据上表现都差5.以下哪个选项不是交叉验证(cross-validation)的用途?A. 评估模型的泛化能力B. 选择模型的超参数C. 减少模型的训练时间D. 提高模型的准确性6.在梯度下降算法中,学习率(learning rate)的作用是什么?A. 控制模型训练的迭代次数B. 控制模型参数的更新速度C. 控制模型的复杂度D. 控制模型的训练数据量7.以下哪个激活函数常用于神经网络中的隐藏层?A. Sigmoid函数B. Softmax函数C. ReLU函数D. 线性函数8.以下哪个选项不是决策树算法的优点?A. 易于理解和解释B. 能够处理非线性数据C. 对数据预处理的要求不高D. 计算复杂度低,适合大规模数据集9.以下哪个评价指标适用于二分类问题?A. 准确率(Accuracy)B. 召回率(Recall)C. F1分数(F1 Score)D. 以上都是10.以下哪个算法属于集成学习(ensemble learning)?A. 随机森林B. K-近邻算法C. 朴素贝叶斯D. 感知机二、填空题(每空2分,共20分)1.在机器学习中,数据通常被分为训练集、_______和测试集。
2._______是一种常用的数据预处理技术,用于将数值特征缩放到一个指定的范围。
r语言期末考试试题及答案

r语言期末考试试题及答案R语言期末考试试题一、选择题(每题2分,共20分)1. 在R语言中,以下哪个函数用于创建向量?A. c()B. vector()C. list()D. matrix()2. 如何在R中生成一个1到10的向量?A. 1:10B. c(1, 10)C. 1 + 10D. 1..103. 以下哪个命令可以计算数据集的均值?A. mean()B. average()C. sum()D. median()4. 在R中,以下哪个函数可以用于读取CSV文件?A. read.table()B. read.csv()C. load()D. source()5. R语言中,用于数据框(data frame)的子集选择的函数是?A. subset()B. select()C. filter()D. slice()二、简答题(每题5分,共20分)1. 解释R语言中向量和列表的区别。
2. 描述如何使用R语言进行线性回归分析。
3. 阐述R语言中数据框(data frame)的特点。
4. 简述R语言中循环结构的基本用法。
三、编程题(每题10分,共30分)1. 编写一个R语言函数,该函数接受一个向量作为输入,并返回向量中所有元素的平方。
2. 使用R语言编写一个脚本,该脚本读取一个CSV文件,并计算该文件中数值列的平均值。
3. 编写一个R语言程序,该程序能够生成一个100x100的矩阵,其中元素为1到10000的整数。
四、综合应用题(每题15分,共30分)1. 假设你有一个包含多个变量的数据集,描述如何使用R语言进行描述性统计分析,并绘制相应的图表。
2. 给定一个时间序列数据集,使用R语言编写一个脚本,该脚本能够识别并标记数据集中的异常值。
参考答案一、选择题1. A2. A4. B5. A二、简答题1. 向量是R语言中最基本的数据结构,它是一个一维数组,所有元素必须具有相同的类型。
列表(list)是一个更复杂的数据结构,可以包含不同类型的元素,并且可以是多维的。
stata期末考试题目及答案

stata期末考试题目及答案一、选择题(每题2分,共20分)1. 在Stata中,用于生成新变量的命令是:A. generateB. replaceC. dropD. rename答案:A2. 下列哪个命令可以用来描述数据集中的变量?A. describeB. listC. tabulateD. sum答案:A3. 若要计算变量x和y的平均值,应使用以下哪个命令?A. mean x yB. summarize x yC. average x yD. meanby x y答案:B4. 以下哪个命令可以用于回归分析?A. regressB. correlateC. tabulateD. describe答案:A5. 要将数据集保存为.dta格式,应使用哪个命令?A. saveB. exportC. writeD. saveas答案:A6. 在Stata中,如何查看当前数据集中的所有变量?A. listB. describeC. showD. display答案:B7. 要对数据集中的连续变量进行分组,应使用哪个命令?A. groupB. byC. tabulateD. collapse答案:D8. 以下哪个命令可以用来绘制散点图?A. scatterB. lineC. barD. histogram答案:A9. 若要对数据集中的变量进行标准化处理,应使用哪个命令?A. standardizeB. normalizeC. genD. replace答案:A10. 在Stata中,如何生成一个随机数序列?A. randomB. runiformC. rnormalD. genr答案:B二、简答题(每题5分,共30分)1. 解释Stata中“merge”命令的基本用法。
答案:Stata中的“merge”命令用于合并两个数据集。
基本用法是指定要合并的两个数据集的关键字(即两个数据集中共有的变量),然后使用“1:1”、“1:m”或“m:1”等比例来指示数据集之间的关系。