clementine使用手册
第5章 Clementine使用简介

第5章 Clementine使用简介5.1Clementine 概述Clementine数据挖掘平台是一个可视化的、强大的数据分析平台。
用户可以通过该平台进行与商业数据操作相关的操作。
数据流区域:它是Clementine窗口中最大的区域,这个区域的作用是建立数据流,或对数据进行操作。
选项板区域:它是在Clementine的底部,每个选项卡包含一组相关的可以用来加载到数据流区域的节点组成。
它包括:数据源、记录选项、字段选项、图形、建模和输出。
管理器:它位于Clementine的右上方,包括流、输出和模型三个管理器。
项目区域:它位于Clementine的右下方,主要对数据挖掘项目进行管理。
并且,它提供CRISP-DM和类两种视图。
另外,Clementine还包括类似于其他windows软件的菜单栏、工具栏和状态栏。
Clementine非常容易操作,包含很多经典数据挖掘算法和一些较新的数据挖掘算法通常,大多数数据挖掘工程都会经历以下过程:检查数据以确定哪些属性可能与相关状态的预测或识别有关。
保留这些属性(如果已存在),或者在必要时导出这些属性并将其添加到数据中。
使用结果数据训练规则和神经网络。
使用独立测试数据测试经过训练的系统。
Clementine的工作就是与数据打交道。
最简单的就是“三步走”的工作步骤。
首先,把数据读入Clementine中,然后通过一系列的操作来处理数据,最后把数据存入目的文件。
Clementine数据挖掘的许多特色都集成在可视化操作界面中。
可以运用这个接口来绘制与商业有关的数据操作。
每个操作都会用相应的图标或节点来显示,这些节点连接在一起,形成数据流,代表数据在操作间的流动。
Clementine用户界面包括6个区域。
数据流区域(Stream canvas):数据流区域是Clementine窗口中最大的区域,在这个区域可以建立数据流,也可以对数据流进行操作。
每次在Clementine中可以多个数据流同时进行工作,或者是同一个数据流区域有多个数据流,或者打开一个数据流文件。
如何使用数据挖掘工具Clementine——以我国图书情报类期刊学术影响力评价为例

T k n hn s irr n nom d n Ju as A a e c a igC iee Lbaya dIfr a o o r l ’ c d mi n
I a tE au t n a n Emprc sa c mp c v l ai s A o i a Re e rh il
以我 国图书情报 类期 刊学术 影 响力评 价 为例
李 许 扬 阳 培
( 北京协 和 医学院 医学信 息研 究所 ,北 京 102) 000
( 摘 要)本文首 先简要介绍了数据挖掘工具 geel 的特 点及若干基本功能 ( l nn m te 即若干模块) ,然后 以基 于 《 中国期刊 高
D : 0.9 9 i n.0 8—0 2 .0 2. 1 0 5 OI1 3 6 s 1 0 s 8 1 2 1 O .3
[ 中图分类号]G5 . ( 215 文献标识码) [ A 文章编号]10 — 81( 1) 1 04 0 08 02 2 2 O — 1 0 6— 4
Ho t e Clme t e a Da a l n n o w o Us e n i sA t n t g To l n v
lg yce d ̄ o hns u a 2 1 e i )pbse yITC h ae vl t e cdmcipc b s g II t i e f i e or l 00vro ulhdb / ,t ppr a a dt iaae i m at yui id id n C e j n s( sn i S e e ue hr n
该软件将一系列数据处理程序或技术整合成相互独立的模块例如将聚类决策树神经网络关联规则等多种数据挖掘技术集成在直观的可视化图形界面中并采用图形用户交互式界面因此对于不谙编程但又经常面临大量数据处理任务的用户来说它的确要比excel更易用更高效而且处理方法有重用性即这次构建的数据流经保存后可在下一个类似任务中稍做修改便可使用或者一条数据流可以支持相似数据的分析不需要再翻看复杂的编程手册在excel里频繁使用各种函数整理数据等
clementine新手入门手册

clementine新手入门手册作为一款将高级建模技术与易用性相结合的数据挖掘工具,Clementine 可帮助您发现并预测数据中有趣且有价值的关系。
可以将 Clementine 用于决策支持活动,如:•创建客户档案并确定客户生命周期价值。
•发现和预测组织内的欺诈行为。
•确定和预测网站数据中有价值的序列。
•预测未来的销售和增长趋势。
•勾勒直接邮递回应和信用风险。
•进行客户流失预测、分类和细分。
•自动处理大批量数据并发现其中的有用模式。
这些只是使用 Clementine 从数据中提取有价值信息的众多方式的一部分。
只要有数据,且数据中正好包含所需信息,Clementine 基本上都能帮您找到问题的答案。
连接到服务器服务器,服务器,服务器登录,登录,登录登录到Clementine Server,登录到Clementine Server,登录到Clementine Server连接,连接,连接到Clementine Server,到Clementine Server,到Clementine ServerClementine Server,Clementine Server,Clementine Server主机名称,主机名称,主机名称端口号,端口号,端口号用户ID,用户ID,用户ID密码,密码,密码域名(Windows),域名(Windows),域名(Windows)主机名,主机名,主机名Clementine Server,Clementine Server,Clementine Server端口号,端口号,端口号Clementine Server,Clementine Server,Clementine Server用户ID,用户ID,用户IDClementine Server,Clementine Server,Clementine Server密码,密码,密码Clementine Server,Clementine Server,Clementine Server域名(Windows),域名(Windows),域名(Windows)Clementine Server,Clementine Server,Clementine ServerClementine 既可以作为独立的应用程序运行,也可以作为连接到 Clementine Server 的客户端运行。
2_Clementine简介

SPSS Inc.大纲第二讲 Clementine简介Clementine软件及应用介绍 Clementine操作介绍 应用Clementine进行数据挖掘的一个实例—— 药物选择决策支持系统Copyright 2003, SPSS Inc.1Copyright 2003, SPSS Inc.2Clementine产品构成•Clementine是服务器/客户端结构的产品 •Clementine产品: • (1)Clementine Standalone/Client • (2)SPSS Data Access Pack • (3)Clementine Server • 其它,如Clementine Solution Publisher runtime •SPSS Data Access Pack用于和数据库进行连接并获取数据Clementine的结构示意图1. 把很多操作放在 数据库层面上执行 2. 不能在数据库中执行的操作 放在强有力的Server上执行4. 数据不必在网络上进行 大量无效的传输.3. 客户端只用于观察 结果和发出分析挖掘 指令Copyright 2003, SPSS Inc.3Copyright 2003, SPSS Inc.5Clementine的界面和设计思路• • • • 可视化界面 四个区域分别是建模区、结点区、模型描述区、项目管理区 通过连接结点构成数据流建立模型 Clementine通过6类结点的连接完成数据挖掘工作,它们是: ♦ Source(源结点):Database、Var. Files等 ♦ Record Ops (记录处理结点):Select、Sample等` ♦ Field Ops(字段处理结点):Type、Filter等 ♦ Graphs(图形结点):Plot、Distribute等 ♦ Modeling(模型结点):Neural Net、C5.0等 ♦ Output(输出结点):Table、Matrix等Clementine操作基本知识鼠标应用 三键与双键鼠标 左键 选择节点或图标置于流区域 右键 激活浮动菜单 中键 连接或断开两个节点 帮助Copyright 2003, SPSS Inc.7Copyright 2003, SPSS Inc.8Copyright 2003, SPSS Inc.1SPSS Inc.Clementine操作基本知识节点的增加,以 为例 Click “Sources”,Click ,Click “流区域” Click “Sources”,Double Click Click “Sources”,Drag to “流区域” 节点的删除 Click , Delete Right Click ,Click “Delete” 节点的移动:DragClementine操作基本知识节点的编辑 Double Click Right Click ,Click “Edit” 节点的重命名和解释 Right Click ,Click “Edit”,Click “Annotations” Double Click ,Click “Annotations” Right Click ,Click “Rename and Annotations” 拷贝、粘贴Copyright 2003, SPSS Inc.9Copyright 2003, SPSS Inc.10Clementine操作基本知识构建流时节点的连接 Highlight ,Add to the Canvas Right Click ,Click “Connect”,Click Drag the middle mutton from to 构建流时节点连接的删除 Right Click or , Click “Disconnect” Right Click “Connection”,Click “Delete Connection” Double Click orClementine操作基本知识流的执行 Highlight “Stream”,Click Right Click ,Click “Execute” In the Edit Window of the , Click “Execute” 流的保存 帮助 Help Menu Dialogue WindowCopyright 2003, SPSS Inc.11Copyright 2003, SPSS Inc.12药物选择决策支持系统主要内容通过一个数据挖掘实例说明数据挖掘的流程 了解数据挖掘过程中可能遇到的问题 了解结果发布的几种形式药物选择决策支持系统如何通过数据挖掘实现医院医生选择治疗手段 的决策支持系统 某医院治疗某种疾病可以选择5种药物,分别 是drugA、drugB 、drugC、drugX、drugY,每 种药物根据病人的情况不同疗效也会不同,医 院有很多历史的病历作为参考,如何从这些历 史数据中发现病人特征和推荐药物的关系?Copyright 2003, SPSS Inc.13Copyright 2003, SPSS Inc.14Copyright 2003, SPSS Inc.2SPSS Inc.数据描述变量名称 Age Sex BP Cholesterol Na K DrugCopyright 2003, SPSS Inc.遵循CRISP-DM的数据挖掘过程数据理解(数据流) 商业理解(文档)变量含义 年龄 性别 血压 胆固醇含 量 钠含量 钾含量 最适合药 物备注分为高(high)、低(low)和正常(normal) 三种 分为高(high)、低(low)和正常(normal) 三种数据准备(数据流) 结果发布(数据流) 建立模型(数据流)以下五种之一: drugA、drugB 、drugC、drugX、drugY15Copyright 2003, SPSS Inc.模型评估(数据流)16在进行数据挖掘过程中应该注意的几 个问题商业经验的作用 数据的拆分——训练集与检验集 不同模型的印证与比较模型发布推荐药物静态列表 推荐药物写回数据库Copyright 2003, SPSS Inc.17Copyright 2003, SPSS Inc.18Copyright 2003, SPSS Inc.3。
SPSS-Clementine和KNIME数据挖掘入门
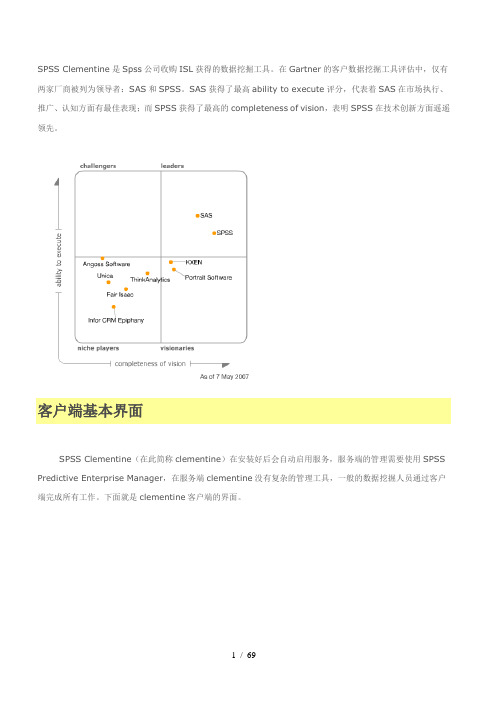
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:)。
Clementine1(基础)

已建节点连接A-B-C,绕开节点B直连节点C(拖动A、B之间的有 向线段到节点C)
指定节点A为当前节点,按住Alt键同时拖动A、B之间的有向线 段到节点C(结果同上)
关于源节点
源节点是连接到初始数据源的节点 源节点只能发送数据,不能从其他节点连接到一个源 节点不能连接,来自关于输出节点
浏览模型
“模型”选项卡以规则集的形式显示详细信息, 规则集实际上是可根据不同预测变量的值将各 个记录分配给子节点的一组规则。
浏览模型
模型块中的“查看器”选项卡以树的形式显示相同的模型,每个决策 点上都有一个节点。可以使用工具栏上的缩放控件放大特定节点,或 缩小节点以查看更完整的树。
放大树的左上部分
项目管理窗口
多条数据流组成一个数据挖掘项目(*.cpj) 将流管理窗口的数据流分别存放到不同目录中, 分别对应于数据挖掘的各阶段,以形成一个完 整的数据挖掘项目。 加粗黑色显示为当前目录。
客户端和服务器端
Clementine 可运行在 客 户端和服务器端两种模 式下 默认模式:客户端 在菜单 “工具” 中选 择 “服务器登录” 注意 Clementine 客户端 和服务器端版本必须匹 配
例如,包括其当前不是您的客户但您计划将其包括 到促销邮件中的人。
对新记录评分
更新 SPSS 源节点,使它指向其他数据文件 也可以添加一个新的源节点,从它读取要评分 的数据。
不管采用哪种方式,新数据集包含的预测变量字段 必须与模型所使用的相同(年龄、收入范围等), 但不包含目标字段 NEWSCHAN。
选中旧数据源节点A。右击:数据映射——选择替 换节点——选中新数据源节点B,弹出新老数据(A, B节点)对应窗口,系统匹配或用户指定,实现映射。
Clementine完整教程

Clementine教程1. 概要资料采矿使用Clementine系统主要关注通过一系列节点来执行资料的过程,这被称作一个数据流(stream)。
这一系列的节点代表了将在资料上执行的操作,而在这些节点之间的联系表明了数据流(stream)的方向。
使用者的数据流包括四个节点:一个变量文件节点,用来从资料源读取资料。
一个导出节点,向资料集中增加新的,通过计算得到的字段。
一个选择节点,用来建立选择标准,从数据流中去除记录。
一个表节点,用来显示使用者操作后得到的结果。
2.建立数据流使用者可以使用下列步骤来建立一个数据流:●向数据流区域中增加节点●连接节点形成一个数据流●指明任一节点或数据流的选项●执行这个数据流图2-1 在数据流区域上的一个完整数据流2.1节点的操作工作区域中的各种节点代表了不同的目标和操作。
把节点连接成数据流,当使用者执行的时候,让使用者可以看到它们之间的联系并得出结论。
数据流(stream)就像脚本(scripts),使用者能够保存它们,还可以在不同的数据文件中使用它们。
节点选项板(palette)在Clementine系统窗口底部的选项板(palette)中包含了用来建立数据流的所有可能的节点。
图2-2 在节点选项板上的记录选项项目(Record Ops tab)每一个项目(tab)包含了一系列相关的节点用于一个数据流(stream)操作的不同阶段,例如:●来源(Sources)。
用来将资料读进系统的节点。
●记录选项(Record Ops)。
用来在资料记录上进行操作的节点,例如选择、合并和增加。
●建模。
在Clementine系统中可用的代表有效建模算法的节点,例如类神经网络、决策树、聚类算法和资料排序。
定制常用项在节点选项板(palette)上的Favorites项目能够被定义成包含使用者对Clementine系统的习惯用法。
例如,如果使用者经常分析一个数据库中的时间序列资料,就可能想确保数据库来源节点和序列建模节点这两个都可以从Favorites项目中获得。
Clementine上机操作实验指导

数据流的基本操作
向数据流区域添节点
双击选项板区中待添加的节点; 左键按住待添加节点,将其拖入数据流区域内; 先选中选项板区中待添加的节点,然后将鼠标放入数据
流区域,在鼠标变为十字形时单击数据流区域的任何空 白处。
向数据流区域删节点
左键单击待删除的节点,按键盘上的delete键删除; 右键单击待删除的节点,在快捷菜单中选择delete。
管理器窗口
管理器窗口中共包含了“流”、“输出”、“模 型”三个栏。
工程管理区
工程管理区含有两个选项栏,一个是“CRISPDM”,一个是“类”。
数据流的基本操作
生成数据流的基本过程
向数据流区域增添新的节点; 将这些节点连接到数据流中; 设定数据节点或数据流的功能; 运行数据流。
调节因子η
点击“执行”按钮,即可在管理器窗口的“模型” 标签下显示生成的K-Means模型节点。
右键单击管理器窗口“模型”标签下生成的K-Means模型节点,在快 捷菜单中选择“浏览”,打开“K-Means”对话框,在“模型”标签 下会显示划分出来的三个聚类,点击“全部展开”,则可以显示每个 簇的一些统计信息
SmallSampleComma.txt
字段实例化 将ID字段的类型修改为
无类型
字段方向
输入:输入或者预测字 段
输出:输出或者被预测 字段字段
两者:既是输入又是输 出,只在关联规则中用 到
无:建模过程中不使用 该字段
分区:将数据拆分为训 练、测试(验证)部分
字段方向设置只有在建 模时才起作用
如果数据是列界定的(字段未被分隔,但是 始于相同的位置并有固定长度),应该使用固 定文本文件导入固定文件节点
实验四 Clementine数据挖掘

实验四 数据挖掘实验指导一、目的掌握数据挖掘工具Clementine 的基本方法与操作。
二、任务利用Clementine 对药物数据进行简单的数据挖掘操作,熟悉数据挖掘的基本步骤。
三、要求了解数据挖掘的基本步骤,完成针对给定数据的决策树挖掘/关联规则分析/聚类分析,并写出实验报告。
四、实验内容利用Clementine 对Drug.txt 中药物研究数据进行决策树、关联规则分析,观察挖掘的结果,比较这些方法挖掘结果的异同,根据观察的结果写出实验报告。
注:药物研究数据来源于对治疗同一疾病病人的处方,这些病人服用不同药物,取得了相同效果。
其中所含数据项如下:Age: 年龄 Sex: 性别(M\F) Drug: 病人所服药物种类(A/B/C/X/Y) BP: 血压(High\Normal\Low)Cholesterol: 胆固醇(Normal\High) Na: 唾液中钠元素含量 K: 唾液中钾元素含量 希望通过数据挖掘发现这些处方中隐藏的规律,给出不同临床特征病人更适合服务哪种药物的建议,为未来医生填写处方提供参考。
五、实验环境1、 硬件:P4/256MB 台式计算机2、 软件:Windows 2000 Professional/SQL Server 2000/Clementine 8.1及以上3、 数据:Drugs 数据 (文件Drug.txt) 六、步骤(一) 启动clementine双击桌面数据挖掘工具“clementine 8.1” 图标或C:\Clementine 8.1\bin\Clementine.exe ,即可启动该挖掘工具,界面如图4-1所示。
主工作区结果输出区(二)数据挖掘操作1.挖掘流(stream)操作(1)新建:File菜单→New Stream命令(2)保存/另存:File菜单→Save Stream /Save Stream As…命令→指定保存位置、文件名称→保存按钮(3)打开:File菜单→Open Stream…命令→指定要打开流的位置、文件名称→打开按钮2.挖掘步骤(1)建立连接数据源1)在挖掘工具区选项卡“Sources”中将“Var. File”节点拖入到主工作区。
实验二Clementine12购物篮分析(关联规则)

实验⼆Clementine12购物篮分析(关联规则)实验⼆Clementine12购物篮分析(关联规则)⼀、[实验⽬的]设计关联规则分析模型,通过模型演⽰如何对购物篮分析,并根据细分结果对采取不同的营销策略。
体验以数据驱动的模型计算给科学决策带来的先进性。
⼆、[知识要点]1、购物蓝分析概念;2、管来呢规则算法原理;3、购物蓝分析⼯具;4、Clementine12.0关联规则分析流程。
三、[实验要求和内容]1、初步了解使⽤⼯作流的⽅式构建分析模型;2、理解智能数据分析流程,主要是CRISP-DM⼯业标准流程;3、理解关联规则模型原理;4、设计关联规则分流;5、运⾏该流,并将结果可视化展⽰;6、得出模型分析结论7、运⾏结果进⾏相关营销策略设计。
四、[实验条件]Clementine12.0挖掘软件。
五、[实验步骤]1、启动Clementine12.0软件;2、在⼯作区设计管来呢规则挖掘流;3、执⾏模型,分析计算结果;4、撰写实验报告。
六、[思考与练习]1、为什么要进⾏关联规则分析?它是如何⽀持客户营销的?实验内容与步骤⼀、前⾔“啤酒与尿布”的故事是营销届的神话,“啤酒”和“尿布”两个看上去没有关系的商品摆放在⼀起进⾏销售、并获得了很好的销售收益,这种现象就是卖场中商品之间的关联性,研究“啤酒与尿布”关联的⽅法就是购物篮分析,购物篮分析曾经是沃尔玛秘⽽不宣的独门武器,购物篮分析可以帮助我们在门店的销售过程中找到具有关联关系的商品,并以此获得销售收益的增长!“啤酒与尿布”的故事产⽣于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理⼈员分析销售数据时发现了⼀个令⼈难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫⽆关系的商品会经常出现在同⼀个购物篮中,这种独特的销售现象引起了管理⼈员的注意,经过后续调查发现,这种现象出现在年轻的⽗亲⾝上。
在美国有婴⼉的家庭中,⼀般是母亲在家中照看婴⼉,年轻的⽗亲前去超市购买尿布。
clementine的中文教程

一,Clementine数据挖掘的基本思想数据挖掘(Data Mining)是从大量的,不完全的,有噪声的,模糊的,随机的实际应用数 据中,提取隐含在其中的,人们事先不知道的,但又是潜在有用的信息和知识的过程,它是一 种深层次的数据分析方法.随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法. 它结合了人工智能(AI)和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些 高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于 自己所要解决的问题. Clementine为我们提供了大量的人工智能,统计分析的模型(神经网络,关联分析,聚类分 析,因子分析等) ,并用基于图形化的界面为我们认识,了解,熟悉这个软件提供了方便.除了 这些Clementine还拥有优良的数据挖掘设计思想, 正是因为有了这个工作思想, 我们每一步的工 作也变得很清晰. (如图一所示)图一CRISP-DM process model如图可知,CRISP-DM Model包含了六个步骤,并用箭头指示了步骤间的执行顺序.这些顺 序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行.通 过对这些步骤的执行,我们也涵盖了数据挖掘的关键部分. Business understanding:商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段 里我们需要明确商业目标,评估商业环境,确定挖掘目标以及产生一个项目计划. Data understanding:数据是我们挖掘过程的"原材料",在数据理解过程中我们要知道都有些什么数据,这些 数据的特征是什么,可以通过对数据的描述性分析得到数据的特点. Date preparation:在数据准备阶段我们需要对数据作出选择,清洗,重建,合并等工作. 选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作. Modeling:建模过程也是数据挖掘中一个比较重要的过程.我们需要根据分析目的选出适 合的模型工具,通过样本建立模型并对模型进行评估. Evaluation: 并不是每一次建模都能与我们的目的吻合, 评价阶段旨在对建模结果进行评估, 对效果较差的结果我们需要分析原因,有时还需要返回前面的步骤对挖掘过程重新定义. Deployment:这个阶段是用建立的模型去解决实际中遇到的问题,它还包括了监督,维持, 产生最终报表,重新评估模型等过程.二,Clementine的基本操作方法1,操作界面的介绍图二 Clementine操作界面 1.1数据流程区 Clementine在进行数据挖掘时是基于数据流程形式,从读入数据到最后的结果显示都是由 流程图的形式显示在数据流程区内.数据的流向通过箭头表示,每一个结点都定义了对数据的 不同操作,将各种操作组合在一起便形成了一条通向目标的路径. 数据流程区是整个操作界面中最大的部分,整个建模过程以及对模型的操作都将在这个区 域内执行.我们可以通过File-new stream新建一个空白的数据流,也可以打开已有的数据流. 所有在一个运行期内打开的数据流都将保存在管理器的Stream栏下. 1.2选项面板 选项面板横跨于Clementine操作界面的下部, 它被分为Favorites, Sources, Record Ops, Fields Ops,Graphs,Modeling,Output七个栏,其中每个栏目包含了具有相关功能的结点. 结点是数据流的基本组成部分,每一个结点拥有不同的数据处理功能.设置不同的栏是为了将 不同功能的结点分组,下面我们介绍各个栏的作用. Sources:该栏包含了能读入数据到Clementine的结点.例如Var. File结点读取自由格式的文 本文件到Clementine,SPSS File读取spss文件到Clementine. Record Ops: 该栏包含的结点能对数据记录进行操作. 例如筛选出满足条件的记录 (select) , 将来自不同数据源的数据合并在一起(merge) ,向数据文件中添加记录(append)等. Fields Ops:该栏包含了能对字段进行操作的结点.例如过滤字段(filter)能让被过滤的字段不作为模型的输入,derive结点能根据用户定义生成新的字段,同时我们还可以定义字段的数 据格式. Graphs:该栏包含了纵多的图形结点,这些结点用于在建模前或建模后将数据由图形形式 输出. Modeling:该栏包含了各种已封装好的模型,例如神经网络(Neural Net) ,决策树(C5.0) 等. 这些模型能完成预测 (Neural Net, Regression, Logistic ) 分类 , (C5.0, C&R Tree, Kohonen, K-means,Twostep) ,关联分析(Apriori,GRI,Sequece)等功能. Output:该栏提供了许多能输出数据,模型结果的结点,用户不仅可以直接在Clementine 中查看输出结果,也可以输出到其他应用程序中查看,例如SPSS和Excel.Favorites:该栏放置了用户经常使用的结点,方便用户操作.用户可以自定义其Favorites 栏,操作方法为:选中菜单栏的Tools,在下拉菜单中选择Favorites,在弹出的Palette Manager 中选中要放入Favorites栏中的结点. 图三 Favorites栏的设置 1.3管理器管理器中共包含了Streams,Outputs,Models三个栏.其中Streams中放置了运行期内打开的 所有数据流,可以通过右键单击数据流名对数据流进行保存,设置属性等操作.Outputs中包含 了运行数据流时所有的输出结果,可以通过双击结果名查看输出的结果.Models中包含了模型 的运行结果,我们可以右键单击该模型从弹出的Browse中查看模型结果,也可以将模型结果加入到数据流中.图四 管理器窗口中对stream的设置 1.4项目窗口的介绍 项目窗口含有两个选项栏,一个是CRISP-DM,一个是Classes.CRISP-DM的设置是基于CRISP-DM Model的思想,它方便用户存放在挖掘各个阶段形成的 文件.由右键单击阶段名,可以选择生成该阶段要拥有的文件,也可以打开已存在的文件将其 放入该阶段.这样做的好处是使用户对数据挖掘过程一目了然,也有利于对它进行修改.图五 将各阶段的文件归类 Classes窗口具有同CRISP-DM窗口相似的作用,它的分类不是基于挖掘的各个过程,而是 基于存储的文件类型.例如数据流文件,结点文件,图表文件等.2,数据流基本操作的介绍2.1生成数据流的基本过程数据流是由一系列的结点组成,当数据通过每个结点时,结点对它进行定义好的操作.我 们在建立数据流是通常遵循以下四步: ①,向数据流程区增添新的结点; ②,将这些结点连接到数据流中; ③,设定数据结点或数据流的功能; ④,运行数据流. 2.2向数据流程区添/删结点 当向数据流程区添加新的结点时,我们有下面三种方法遵循: ①,双击结点面板中待添加的结点; ②,左键按住待添加结点,将其拖到数据流程区内; ③,选中结点面板中待添加的结点,将鼠标放入数据流程区,在鼠标变为十字形时单击数 据流程区. 通过上面三种方法我们都将发现选中的结点出现在了数据流程区内. 当我们不再需要数据流程区内的某个结点时,可以通过以下两种方法来删除: ①左键单击待删除的结点,用delete删除; ②右键单击待删除的结点,在出现的菜单中选择delete. 2.3将结点连接到数据流中 上面我们介绍了将结点添加到数据流程区的方法,然而要使结点真正发挥作用,我们需要 把结点连接到数据流中.以下有三种可将结点连接到数据流中的方法: ①,双击结点 左键选中数据流中要连接新结点的结点(起始结点) ,双击结点面板中要连 接入数据流的结点(目标结点) ,这样便将数据流中的结点与新结点相连接了; 图六 双击目标结点以加入数据流 ②,通过鼠标滑轮连接在工作区内选择两个待连接的结点,用左键选中连接的起始结点,按住鼠标滑轮将其拖曳 到目标结点放开,连接便自动生成. (如果鼠标没有滑轮也选用alt键代替) 图七 由滑轮连接两结点 ③,手动连接 右键单击待连接的起始结点,从弹出的菜单栏中选择Connect.选中Connect后鼠标和起始 结点都出现了连接的标记,用鼠标单击数据流程区内要连接的目标结点,连接便生成.图八 选择菜单栏中的connect 图九 点击要连入的结点 注意:①,第一种连接方法是将选项面板中的结点与数据流相连接,后两种方法是将已在 数据流程区中的结点加入到数据流中 ②,数据读取结点(如SPSS File)不能有前向结点,即在 连接时它只能作为起始结点而不能作为目标结点. 2.4绕过数据流中的结点 当我们暂时不需要数据流中的某个结点时我们可以绕过该结点.在绕过它时,如果该结点 既有输入结点又有输出结点那么它的输入节点和输出结点便直接相连;如果该结点没有输出结 点,那么绕过该结点时与这个结点相连的所有连接便被取消.方法:用鼠标滑轮双击需要绕过的结点或者选择按住alt键,通过用鼠标左键双击该结点来 完成.图十 绕过数据流中的结点 2.5将结点加入已存在的连接中 当我们需要在两个已连接的结点中再加入一个结点时,我们可以采用这种方法将原来的连 接变成两个新的连接.方法:用鼠标滑轮单击欲插入新结点的两结点间的连线,按住它并把他拖到新结点时放手, 新的连接便生成. (在鼠标没有滑轮时亦可用alt键代替) 图十一 将连线拖向新结点图十二 生成两个新的连接 2.6删除连接 当某个连接不再需要时,我们可以通过以下三种方法将它删除: ①,选择待删除的连接,单击右键,从弹出菜单中选择Delete Connection; ②,选择待删除连接的结点,按F3键,删除了所有连接到该结点上的连接;③,选择待删除连接的结点,从主菜单中选择Edit Node Disconnect. 图十三 用右键删除连接 2.7数据流的执行 数据流结构构建好后要通过执行数据流数据才能从读入开始流向各个数据结点.执行数据 流的方法有以下三种:①,选择菜单栏中的按钮,数据流区域内的所有数据流将被执行;②,先选择要输出的数据流,再选择菜单栏中的按钮,被选的数据流将被执行; ③,选择要执行的数据流中的输出结点,单击鼠标右键,在弹出的菜单栏中选择Execute选项,执行被选中的数据流.图十四 执行数据流的方法三,模型建立在这部分我们将介绍五种分析方法的建立过程, 它们分别是因子分析, 关联分析, 聚类分析, 决策树分析和神经网络.为了方便大家练习,我们将采用Clementine自带的示例,这些示例在 demos文件夹中均可找到,它们的数据文件也在demos文件夹中.在模型建立过程中我们将介绍 各个结点的作用.1,因子分析(factor. str)示例factor.str是对孩童的玩具使用情况的描述,它一共有76个字段.过多的字段不仅增添了 分析的复杂性,而且字段之间还可能存在一定的相关性,于是我们无需使用全部字段来描述样 本信息.下面我们将介绍用Clementine进行因子分析的步骤: Step一:读入数据Source栏中的结点提供了读入数据的功能,由于玩具的信息存储为toy_train.sav,所以我们 需要使用SPSS File结点来读入数据.双击SPSS File结点使之添加到数据流程区内,双击添加到数据流程区里的SPSS File结点,由此来设置该结点的属性. 在属性设置时,单击Import file栏右侧的按钮,选择要加载到数据流中进行分析的文件,这 里选择toy_train.sav.单击Annotations页,在name栏中选择custom选项并在其右侧的文本框中输 入自定义的结点名称.这里我们按照原示例输入toy_train. Step二:设置字段属性进行因子分析时我们需要了解字段间的相关性,但并不是所有字段都需要进行相关性 分析,比如"序号"字段,所以需要我们将要进行因子分析的字段挑选出来.Field Ops栏中 的Type结点具有设置各字段数据类型,选择字段在机器学习中的的输入/输出属性等功能, 我们利用该结点选择要进行因子分析的字段.首先,将Type结点加入到数据流中,双击该 结点对其进行属性设置: 由上图可看出数据文件中所有的字段名显示在了Field栏中,Type表示了每个字段的数 据类型. 我们不需要为每个字段设定数据类型, 只需从Values栏中的下拉菜单中选择<Read> 项,然后选择Read Value键,软件将自动读入数据和数据类型;Missing栏是在数据有缺失 时选择是否用Blank填充该字段;Check栏选择是否判断该字段数据的合理性;而Direction 栏在机器学习模型的建立中具有相当重要的作用,通过对它的设置我们可将字段设为输入/ 输出/输入且输出/非输入亦非输出四种类型.在这里我们将前19个字段的Direction设置为 none,这表明在因子分析我们不将这前19个字段列入考虑,从第20个字段起我们将以后字 段的direction设置为In,对这些字段进行因子分析. Step三:对数据进行因子分析 因子分析模型在Modeling栏中用PCA/Factor表示.在分析过程中模型需要有大于或等 于两个的字段输入,上一步的Type结点中我们已经设置好了将作为模型输入的字段,这里 我们将PCA/Factor结点连接在Type结点之后不修改它的属性,默认采用主成分分析方法.在建立好这条数据流后我们便可以将它执行.右键单击PCA/Factor结点,在弹出的菜 单栏中选择Execute执行命令.执行结束后,模型结果放在管理器的Models栏中,其标记为 名称为PCA/Factor的黄色结点.右键单击该结果结点,从弹出的菜单中选择Browse选项查看输出结果.由结果可知参 与因子分析的字段被归结为了五个因子变量,其各个样本在这五个因子变量里的得分也在 结果中显示. Step四:显示经过因子分析后的数据表 模型的结果结点也可以加入到数据流中对数据进行操作.我们在数据流程区内选中 Type结点,然后双击管理器Models栏中的PCA/Factor结点,该结点便加入到数据流中. 为了显示经过因子分析后的数据我们可以采用Table结点,该结点将数据由数据表的形式输 出. 4.1为因子变量命名 在将PCA/Factor(结果)结点连接到Table结点之前,用户可以设置不需要显示的字段, 也可以更改因子变量名,为了达到这个目的我们可以添加Field Ops栏中的filter结点.在对filter结点进行属性设置时,Filter项显示了字段的过滤与否,如果需要将某个字段过滤,只需用鼠标单击Filter栏中的箭头,当箭头出现红“×”时该字段便被过滤。
Clementine12.0操作

分割,如将样本分为训练集合测试集。
图形(Graphs)选项卡中的Plot节点和Multiplot节点。 Plot节点指定X和Y轴的变量(每个坐标轴只能指定一个变量),描画相应的散点图; Multiplot节点指定X和Y轴的变量,Y轴变量可以是多个,描画相应的折线图。
2015/10/8
9
总体介绍
41
建模指导-回归
智慧数据 财富未来
第二步:创建流
2015/10/8
42
建模指导-回归 第三步:设置参数
智慧数据 财富未来
2015/10/8
43
建模指导-回归
智慧数据 财富未来
2015/10/8
44
建模指导-回归 第四步:生成模型
智慧数据 财富未来
2015/10/8
45
建模指导-回归
智慧数据 财富未来
13
建模指导-分类
智慧数据 财富未来
输入项:购买量、保养情况、车门数、 座位数、底盘、安全性
输出项:汽车类别
2015/10/8
14
建模指导-分类 第一步:导入数据
智慧数据 财富未来
2015/10/8
15
建模指导-分类
智慧数据 财富未来
第二步:创建流
2015/10/8
16
建模指导-分类 第三步:设置参数
3.设置节点参数。
节点是用来处理数据的,需要对某些节点针对数据处理的方式设置参数。双击相应节点,或者右击 相应节点,选择弹出菜单中的Edit即可。
4.执行数据流。
当数据流建立完成后,若要得到数据分析结果,则需要执行数据流。选择主菜单Tools->Execute,
或右击会得结果的节点,选择弹出菜单中的Execute。
Clementine7.0版的新功能

© ISL 2000
15
2.3 從Clementine6.5以來的變化
批次處理模式的改良,詳情可見第十七章。
輸出的改進,Clementine中右上方的輸出管理器視窗
能構幫助使用者了解資料流程的輸出,無須開啟多個 視窗而耗費電腦記憶體資源。
© ISL 2000
16
2.3 從Clementine6.5以來的變化
●産生三維圖表 ●可得到多層重疊的圖表,包括選項板和動畫直觀顯示
●附加的顯示選項
●準確的複製和貼上功能 ●以HTML形式輸出
© ISL 2000
11
欄位選擇器
在某些節點的對話 方塊中,如填充、 分類和導出節點等, 點擊欄位選擇器, 可以在節點和 Clementine運算式 中更快速、更容易 的選擇欄位。
Chapter2 Clementine7.0版的新功能
Agenda
2.1 歡迎 2.2 新特徵 2.3 從Clementine6.5以來的變化
© ISL 2000
1
2.1 歡迎
此版本中的具體變動請閱讀相關資訊。如果是 Clementine的老使用者,請參見“從Clementine 6.5以來的變化”部分以獲取關於充分使用此版 本中增強功能的更多資訊。
腳本的改進,使Clementine操作自動化已經成爲了一個
更加統一和徹底的特點。
更為靈活的超級節點。
●超級節點能夠被嵌套。 ●一個超級節點可以包含資料流程片斷和額外的資料流程。 ●在一個超級節點中執行也是本版本的一個新特點。 ●以前在超級節點中不允許的節點(如:Merge和Append)
現在都能夠被嵌套了。
© ISL 2000
12
樹型閱讀器
Clementine教材应用范例

© ISL 2000
18
圖20-7 撥款申請分佈
© ISL 2000
19
爲了探索其他可能的欺詐形式,我們可以撇開多次 申請的記錄,將注意力集中到只申請過一次的記錄上來。 可以用選擇節點(Select Node)刪除相應的記錄。
圖20-8 去除多重申請
© ISL 2000 20
我們可以使用Clementine建立一個迴歸模型,以農場大小, 主要作物類型,土壤質量等爲引數來估計一個農場的收入是 多少。在建模以前,需要在導出節點Derived Node中使用 CLEM語言來生成一個新的欄位。我們用如下的運算式來估 計農場收入:
© ISL 2000 23 圖20-11 偏差百分比的直方圖
20.3.3 訓練神經網路
經過探索性資料分析,我們發現將真實值和通過一系 列因變數得到的期望值進行比較似乎是有用的。神經網路 可以用來處理此類問題。神經網路使用資料中的變數,對 目標變數或回應進行預測。使用預測的結果,我們可以探 索偏離正常值的記錄或記錄組。 在建模之前,我們首先將一個類型節點Type Node 加 到目前的流程中。因爲需要用資料中的變數來預測所申請 的貸款金額,所以將claimvalue的方向設置爲OUT。
© ISL 2000 27
20.3.4 總結
本例建立了一個預測模型將模型預測值和資料集(農場 收入)中的實際值進行比較。我們發現偏差主要出現在一種 撥款申請類型(可耕地開發)中,然後進行更深入的分析。
通過一個訓練後的神經網路模型,歸納出申請額和農場 大小、估計的收入,主要作物等等之間的關係。然後與神經 網路模型的估計值相比較,大於50%的將被認爲是需要進一 步調查的。當然,最終這些申請有可能是有效的,但是它們 與正常值的差異卻是值得注意的。
Clementine-第二讲

数据理解的其他
数据的分类汇总(Aggregate节点) 以Telephone.sav为例,目标: 第一,分别计算未流失客户和流失客户的 基本费用的平均值和标准差 第二,分别针对未流失客户和流失客户群, 计算选用不同类套餐类型的客户,其基本 费用的平均值和标准差
第19页,共40页。
Clementine的数据读入和集 成
第1页,共40页。
主要内容
变量类型 Clementine数据的读入操作 Clementine数据的集成操作
第2页,共40页。
变量类型
从数据挖掘角度看变量类型:数值型变量、分类型变量 (定类型、定序型),Clementine中的变量类型:
连续数值型(Range) 二分类型(Flag) 多分类型(Set)
Clementine的数据准备
第20页,共40页。
变量转换
变量派生
数据精简 数据筛选
主要内容
第21页,共40页。
变量转换
变量转换是对变量的原有取值进行转换处理,覆 盖变量的原来取值
CLEM表达式:(Clementine Language for Expression Manipulation)专门用于表述运 算操作,描述算术表达式和条件表达式
以Telephone.sav为例 Quality选项卡Missing value框
Count of records with valid values,计算 各变量的有效样本量;
breakdown counts of records with invalid values,计算各变量取各种无效值的样本个数
多线图( Time Plot节点)
鲜苹果出口量和出口额的线图
第37页,共40页。
Clementine 中文版

串流工作區:實際上用來建構DM 流程的所有的動作、設定…的區域
節點調色板:不同的節點(node)代表不同功能的工具,不同的活頁代表不同的資料採礦流程的工具集合
操作管理區:管理操作時期產生的串流、輸出、模型
專案管理區:以資料採礦專案的角度來管理串流、輸出、模型
可將各種檔案及流程圖分門別類整理在六個CRISP-DM步驟的資夾中,方便任何使用人員隨時取。
清楚所做過的流程,有架構不紊亂。
即使非原始的建立者也可迅速進入狀況。
可依自己需求增減資料夾
合模型。
Clementine资料采集入门

© ISL 2000
5
3.2 機器學習技術(續3)
統計模型: ●線性迴歸模型試圖在引數欄位區域中尋找一條直線或 一個面,使得預測值和觀測輸出值間差異最小。 ●Logistic迴歸模型在某種程度上是比較複雜的,主要用 來預測字元型因變數的每一個可能值的概率。 ●統計模型已經出現很長時間,而從數學角度較易理解。 它們展示了假設資料間存在簡單關係的幾種基本模型。
© ISL 2000
13
3.5 小技巧(續1)
資料是否均衡?
假設有兩種結果:低的或高的。90%的案例是低的, 只有10%是高的。類神經網路對這樣有偏資料的處理 是相當糟糕的。它們只會學習低的結果並試圖忽略高 的結果。
抽樣
利用抽樣方法可以改善上述的問題,此外,在大量資 料集基礎上開始工作前,可先抽取一個較小的樣本, 這將使你在進行較簡單的實驗性分析時執行的更快。
© ISL 2000
2
ቤተ መጻሕፍቲ ባይዱ
3.2 機器學習技術
類神經網路是類比神經系統執行的簡單模型。它的基 本單位是神經元,它們一般組織在一起形成層次。
© ISL 2000
3
3.2 機器學習技術(續1)
類神經網路較不令人滿意的地方在於做決策時是不透明 的,然而決策樹模型在這方面的表現卻是相當優異。
© ISL 2000
© ISL 2000
11
CRISP-DM過程模型
3.5 小技巧
要使用歸納方法、類神經網路、或是統計模型?
●如果你不肯定哪些屬性是重要的,首先通過歸納得出一
條規則通常是有意義的。然後根據規則結果,利用filter 節點,把資料的欄位進行刪剪,只留下那些重要的,規 則明顯的欄位。這可在訓練一個網路或統計模型前選擇 一個較好的欄位子集。 ●統計方法常是迅捷且相對簡單。因此,它們常做爲基準 模型,去比較需要耗時的機器學習技術。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1. 定义数据源
将一个Datebase源组件加入到数据流设计区,双击组件,设置数据源为
dbo.vTargetMail视图。
在Types栏中点“Read Values”,会自动读取数据个字段的Type、Values等信息。
Values是字段包含的值,比如在数据集中NumberCardsOwned字段的值是从0到4的数,HouseOwnerFlag只有1和0两种值。
Type是依据Values判断字段的类型,Flag类型只包含两种值,类似于boolean;Set是指包含有限个值,类似于enumeration;Ragnge是连续性数值,类似于float。
通过了解字段的类型和值,我们可以确定哪些字段能用来作为预测因子,像AddressLine、Phone、DateFirstPurchase等字段是无用的,因为这些字段的值是无序和无意义的。
Direction表明字段的用法,“In”在SQL Server中叫做“Input”,“Out”在SQL Server中叫做“PredictOnly”,“Both”在SQL Server中叫做“Predict”,“Partition”用于对数据分组。
2. 理解数据
在建模之前,我们需要了解数据集中都有哪些字段,这些字段如何分布,它们之间是否隐含着相关性等信息。
只有了解这些信息后才能决定使用哪些字段,应用何种挖掘算法和算法参数。
在除了在建立数据源时Clementine能告诉我们值类型外,还能使用输出和图形组件对数据进行探索。
例如先将一个统计组件和一个条形图组件拖入数据流设计区,跟数据源组件连在一起,配置好这些组件后,点上方绿色的箭头。
等一会,然后这两个组件就会输出统计报告和条形图,这些输出会保存在管理区中(因为条形图是高级可视化组件,其输出不会出现在管理区),以后只要在管理区双击输出就可以看打开报告。
3. 准备数据
将之前的输出和图形工具从数据流涉及区中删除。
将Field Ops中的Filter组件加入数据流,在Filter中可以去除不需要的字段。
我们只需要使用MaritalStatus、Gender、YearlyIncome、TatalChildren、NumberChildrenAtHome、EnglishEducation、EnglishOccupation、HouseOwnerFlag、NumberCarsOwned、CommuteDistance、Region、Age、BikeBuyer 这些字段。
加入Sample组件做随机抽样,从源数据中抽取70%的数据作为训练集,剩下30%作为检验集。
注意为种子指定一个值,学过统计和计算机的应该知道只要种子不变,计算机产生的伪随机序列是不变的。
因为要使用两个挖掘模型,模型的输入和预测字段是不同的,需要加入两个Type 组件,将数据分流。
决策树模型用于预测甚麽人会响应促销而购买自行车,要将BikeBuyer字段作为预测列。
神经网络用于预测年收入,需要将YearlyIncome设置为预测字段。
有时候用于预测的输入字段太多,会耗费大量训练时间,可以使用Feature Selection组件筛选对预测字段影响较大的字段。
从Modeling中将Feature Selection字段拖出来,连接到神经网络模型的组件后面,然后点击上方的Execute Selection。
Feature Selection模型训练后在管理区出现模型,右击模型,选Browse可查看模型内容。
模型从12个字段中选出了11个字段,认为这11个字段对年收入的影响比较大,所以我们只要用这11个字段作为输入列即可。
将模型从管理区拖入数据流设计区,替换原来的Feature Selection组件。
4. 建模
加入Nearal Net和CHAID模型组件,在CHAID组件设置中,将Mode项设
为”Launch interactive session”。
然后点上方的绿色箭头执行整个数据流。
Clementine在训练CHAID树时,会开启交互式会话窗口,在交互会话中可以控制树生长和对树剪枝,避免过拟合。
如果确定模型后点上方黄色的图标。
完成后,在管理区又多了两个模型。
把它们拖入数据流设计区,开始评估模型。
5. 模型评估
修改抽样组件,将Mode改成“Discard Sample”,意思是抛弃之前用于训练模型的那70%数据,将剩下30%数据用于检验。
注意种子不要更改。
我这里只检验CHAID决策树模型。
将各种组件跟CHAID模型关联。
执行后,得到提升图、预测准确率表……
6. 部署模型
Export组件都可以使用Publish发布数据流,这里会产生两个文件,一个是pim 文件,一个是par文件。
pim 文件保存流的所有信息,par文件保存参数。
有了这两个文件就可以使用clemrun.exe来执行流,clemrun.exe是Clementine Solution Publisher的执行程序。
Clementine Solution Publisher是需要单独授权的。
在SSIS中pim 和par类似于一个dtsx文件,clemrun.exe就类似于dtexec.exe。
如果要在其他程序中使用模型,可以使用Clementine执行库(CLEMRTL),相比起Microsoft的ole db for dm,SPSS的提供的API在开发上还不是很好用。