Clementine数据挖掘快速上手
第5章 Clementine使用简介

第5章 Clementine使用简介5.1Clementine 概述Clementine数据挖掘平台是一个可视化的、强大的数据分析平台。
用户可以通过该平台进行与商业数据操作相关的操作。
数据流区域:它是Clementine窗口中最大的区域,这个区域的作用是建立数据流,或对数据进行操作。
选项板区域:它是在Clementine的底部,每个选项卡包含一组相关的可以用来加载到数据流区域的节点组成。
它包括:数据源、记录选项、字段选项、图形、建模和输出。
管理器:它位于Clementine的右上方,包括流、输出和模型三个管理器。
项目区域:它位于Clementine的右下方,主要对数据挖掘项目进行管理。
并且,它提供CRISP-DM和类两种视图。
另外,Clementine还包括类似于其他windows软件的菜单栏、工具栏和状态栏。
Clementine非常容易操作,包含很多经典数据挖掘算法和一些较新的数据挖掘算法通常,大多数数据挖掘工程都会经历以下过程:检查数据以确定哪些属性可能与相关状态的预测或识别有关。
保留这些属性(如果已存在),或者在必要时导出这些属性并将其添加到数据中。
使用结果数据训练规则和神经网络。
使用独立测试数据测试经过训练的系统。
Clementine的工作就是与数据打交道。
最简单的就是“三步走”的工作步骤。
首先,把数据读入Clementine中,然后通过一系列的操作来处理数据,最后把数据存入目的文件。
Clementine数据挖掘的许多特色都集成在可视化操作界面中。
可以运用这个接口来绘制与商业有关的数据操作。
每个操作都会用相应的图标或节点来显示,这些节点连接在一起,形成数据流,代表数据在操作间的流动。
Clementine用户界面包括6个区域。
数据流区域(Stream canvas):数据流区域是Clementine窗口中最大的区域,在这个区域可以建立数据流,也可以对数据流进行操作。
每次在Clementine中可以多个数据流同时进行工作,或者是同一个数据流区域有多个数据流,或者打开一个数据流文件。
数据挖掘 培训SPSS clementine11

数据准备:
© 2006 SPSS Inc.
10
课程计划
建模技术:
监督学习技术,
神经网络、归纳规则(决策树)、线性回归、Logistic 回归 Kohonen 网络、两步聚类、 K-means 聚类
非监督学习技术,
关联规则、时序探测
模型评估 如何应用 CRISP-DM 流程研究数据挖掘问题
© 2006 SPSS Inc.
11
第二章 Clementine简介
Clementine 简介
内容
熟悉 Clementine 中的工具和面板 介绍可视化编程的思想 初步了解 Clementine 的功能 课程的数据文件存放在目录―C:\培训\基础培训1‖中
目的
数据
© 2006 SPSS Inc.
在挖掘数据前,需要做什么样的数据预整理和 数据清洗?
将会使用什么样的数据挖掘技巧? 将会如何评估数据挖掘的分析结果?
© 2006 SPSS Inc.
8
CRISP-DM 过程模型
跨行业数据挖掘标准过程 (CRISP-DM)
定位是面向行业、工具导 向、面向应用 适用于大型工业和商业实 践的一般标准
13
Clementine用户界面
菜单栏 工具栏 数据流, 输出和模型 管理器
数据流区域
选项板区 项目窗口
节点
© 2006 SPSS Inc.
14
可视化编程
节点
一个图标代表在 Clementine 中进行的一个操作 一系列连接在一起的节点 包含一系列不同功能的图标
如何使用数据挖掘工具Clementine——以我国图书情报类期刊学术影响力评价为例

T k n hn s irr n nom d n Ju as A a e c a igC iee Lbaya dIfr a o o r l ’ c d mi n
I a tE au t n a n Emprc sa c mp c v l ai s A o i a Re e rh il
以我 国图书情报 类期 刊学术 影 响力评 价 为例
李 许 扬 阳 培
( 北京协 和 医学院 医学信 息研 究所 ,北 京 102) 000
( 摘 要)本文首 先简要介绍了数据挖掘工具 geel 的特 点及若干基本功能 ( l nn m te 即若干模块) ,然后 以基 于 《 中国期刊 高
D : 0.9 9 i n.0 8—0 2 .0 2. 1 0 5 OI1 3 6 s 1 0 s 8 1 2 1 O .3
[ 中图分类号]G5 . ( 215 文献标识码) [ A 文章编号]10 — 81( 1) 1 04 0 08 02 2 2 O — 1 0 6— 4
Ho t e Clme t e a Da a l n n o w o Us e n i sA t n t g To l n v
lg yce d ̄ o hns u a 2 1 e i )pbse yITC h ae vl t e cdmcipc b s g II t i e f i e or l 00vro ulhdb / ,t ppr a a dt iaae i m at yui id id n C e j n s( sn i S e e ue hr n
该软件将一系列数据处理程序或技术整合成相互独立的模块例如将聚类决策树神经网络关联规则等多种数据挖掘技术集成在直观的可视化图形界面中并采用图形用户交互式界面因此对于不谙编程但又经常面临大量数据处理任务的用户来说它的确要比excel更易用更高效而且处理方法有重用性即这次构建的数据流经保存后可在下一个类似任务中稍做修改便可使用或者一条数据流可以支持相似数据的分析不需要再翻看复杂的编程手册在excel里频繁使用各种函数整理数据等
课题_SPSS Clementine 数据挖掘入门 (3)

SPSS Clementine 数据挖掘入门(3)了解SPSS Clementine的基本应用后,再对比微软的SSAS,各自的优缺点就非常明显了。
微软的SSAS是Service Oriented的数据挖掘工具,微软联合SAS、Hyperion等公司定义了用于数据挖掘的web服务标准——XMLA,微软还提供OLE DB for DM接口和MDX。
所以SSAS的优势是管理、部署、开发、应用耦合方便。
但SQL Server 2005使用Visual Studio 2005作为客户端开发工具,Visual Studio的SSAS项目只能作为模型设计和部署工具而已,根本不能独立实现完整的Crisp-DM流程。
尽管MS Excel也可以作为SSAS的客户端实现数据挖掘,不过Excel显然不是为专业数据挖掘人员设计的。
PS:既然说到Visual Studio,我又忍不住要发牢骚。
大家都知道Visual Studio Team System是一套非常棒的团队开发工具,它为团队中不同的角色提供不同的开发模板,并且还有一个服务端组件,通过这套工具实现了团队协作、项目管理、版本控制等功能。
SQL Server 2005相比2000的变化之一就是将开发客户端整合到了Visual Studio中,但是这种整合做得并不彻底。
比如说,使用SSIS开发是往往要一个人完成一个独立的包,比起DataStage 基于角色提供了四种客户端,VS很难实现元数据、项目管理、并行开发……;现在对比Clementine也是,Clementine最吸引人的地方就是其提供了强大的客户端。
当然,Visual Studio本身是很好的工具,只不过是微软没有好好利用而已,期望未来的SQL Server 2K8和Visual Studio 2K8能进一步改进。
所以我们不由得想到如果能在SPSS Clementine中实现Crisp-DM过程,但是将模型部署到SSAS就好了。
实验一 Clementine12.0数据挖掘分析方法与应用

实验一Clementine12.0数据挖掘分析方法与应用一、[实验目的]熟悉Clementine12.0进行数据挖掘的基本操作方法与流程,对实际的问题能熟练利用Clementine12.0开展数据挖掘分析工作。
二、[知识要点]1、数据挖掘概念;2、数据挖掘流程;3、Clementine12.0进行数据挖掘的基本操作方法。
三、[实验内容与要求]1、熟悉Clementine12.0操作界面;2、理解工作流的模型构建方法;3、安装、运行Clementine12.0软件;4、构建挖掘流。
四、[实验条件]Clementine12.0软件。
五、[实验步骤]1、主要数据挖掘模式分析;2、数据挖掘流程分析;3、Clementine12.0下载与安装;4、Clementine12.0功能分析;5、Clementine12.0决策分析实例。
六、[思考与练习]1、Clementine12.0软件进行数据挖掘的主要特点是什么?2、利用Clementine12.0构建一个关联挖掘流(购物篮分析)。
实验部分一、Clementine简述Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台,Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比,Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
为了解决各种商务问题,企业需要以不同的方式来处理各种类型迥异的数据,相异的任务类型和数据类型就要求有不同的分析技术。
基于Clementine的毛细管电泳数据挖掘方法研究

神 经 网络 模 型 进 行 预 测 会 得 到 比较 好 的 结 果 。
关 键 词 : 据挖 掘 ; 经 网络 ;药 学 数 神 中 图 分 类 号 :P 9 T 31 文献 标识 码 : A d i 1 .9 9ji n 10 -45 2 1 .50 7 o: 0 36 /.s .0 627 .0 10 .3 s
刘 硕 董 鸿 哗 ,
( . 阳 药科 大 学 药 学 院 , 宁 沈 阳 I0 1 ;. 阳 药 科 大 学 基 础 学 院 , 宁 沈 阳 10 1 ) 1沈 辽 10 6 2 沈 辽  ̄0 6 摘 要 : 预 测毛 细 管 电 泳 迁移 时 间 , 用 数 据 挖 掘 软 件 Ce e t e的神 经 网络 模 型 对 维 生 素 B 等 7种 药 物 的 3 0个 迁移 为 利 l ni m n 1 5 时 间数 据进 行 预 测 , 于 药物 的 5 对 0组 数 据 , 4 取 9组 作 为 学 习集 ( 称 训 练 集 ) 行 训练 , 后 用 训 练 好 的 网络 对 剩 下的 l 或 进 然
效地 利 用 这 些 数 据 , 有 可 能 导 致 严 重 的 数 据 灾 这
e t ei s h n 1 %,te p e it n r s t s mo ea c r t , r a g a l aa u ig n u  ̄ n t o k mo e aa mi i g t n i sl st a 0 n e h rdp e d t sn e r ew r d l d t nn O o l i o l f o
clementine算法原理

clementine算法原理Clementine算法原理Clementine算法是一种常用的数据挖掘算法,用于发现数据集中的隐含模式和关联规则。
它是一种基于决策树的分类算法,可以用于预测未知数据的类别。
本文将介绍Clementine算法的原理及其应用。
一、Clementine算法的基本原理Clementine算法的基本原理是通过对已知数据集的学习,构建一个决策树模型,然后利用该模型对未知数据进行分类。
算法的核心思想是将数据集划分为多个子集,每个子集对应一个决策树节点,通过比较不同特征的取值来划分数据。
在构建决策树的过程中,算法会根据某种准则选择最佳的特征作为划分依据,直到所有数据都被正确分类或无法继续划分为止。
二、Clementine算法的具体步骤1. 数据预处理:对原始数据进行清洗、去噪、缺失值处理等操作,保证数据的质量和完整性。
2. 特征选择:根据特征的重要性和相关性对数据进行特征选择,筛选出对分类结果有影响的特征。
3. 数据划分:将数据集划分为训练集和测试集,通常采用70%的数据作为训练集,30%的数据作为测试集。
4. 构建决策树:根据训练集的数据,利用信息增益、基尼系数等准则选择最佳的特征进行划分,递归地构建决策树。
5. 决策树剪枝:为了避免过拟合现象,需要对决策树进行剪枝操作,去除一些不必要的节点和分支。
6. 模型评估:使用测试集对构建好的决策树模型进行评估,计算分类准确率、召回率、F1值等指标,评估模型的性能。
三、Clementine算法的应用领域Clementine算法在数据挖掘领域有着广泛的应用。
它可以用于市场分析、客户分类、信用评估等多个领域。
1. 市场分析:通过对市场数据的分析,可以预测产品的销售情况、消费者的购买偏好等,为企业的市场决策提供依据。
2. 客户分类:通过对客户的个人信息、购买记录等进行分析,可以将客户划分为不同的类别,为企业的客户管理和营销活动提供指导。
3. 信用评估:通过对个人信用记录、收入状况等进行分析,可以评估个人的信用水平,为银行等金融机构的信贷决策提供参考。
数据挖掘软件CLEMENTINE介绍

电商行业
用户画像
利用clementine对电商用户数据进行分析,构建用户画像,了解用户需求和购物习惯,优化产品推荐 和营销策略。
销量预测
通过clementine对历史销售数据进行分析,预测未来销量趋势,帮助电商企业制定库存管理和采购计 划。
医疗行业
疾病预测
利用clementine对医疗数据进行分析,预测疾病发病率和流行趋势,为公共卫生部门 提供决策支持。
可视化界面
Clementine采用直观的可视 化界面,使得用户无需编程 基础即可轻松上手,降低了 使用门槛。
高效性能
Clementine在数据预处理、 模型训练和评估等方面具有 较高的性能,能够快速完成 大规模数据的挖掘任务。
支持多种数据源
Clementine支持多种数据源 的导入,包括关系型数据库、 Excel、CSV等格式的文件, 方便用户进行数据挖掘。
缺点分析
学习成本高
虽然Clementine提供了可视化界 面,但对于一些高级功能和参数 设置,用户仍需要具备一定的专 业知识才能理解和掌握。
定制性不足
Clementine的功能虽然丰富,但 对于一些特定需求的用户来说, 其定制性可能不够灵活,难以满 足个性化需求。
社区支持有限
与其他开源软件相比, Clementine的社区支持可能不够 活跃,对于一些问题的解决可能 会有些困难。
06
Clementine的未来发展 展望
技术发展趋势
人工智能与机器学习技术的融合
随着人工智能和机器学习技术的不断发展,Clementine有望进一步集成这些先进技术, 提高数据挖掘的智能化程度和自动化水平。
大数据处理能力的提升
随着大数据时代的来临,Clementine将不断优化其数据处理能力,提高大规模数据的 处理速度和准确性。
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
数据挖掘软件CLEMENTINE介绍

Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。1999年SPSS公司收购了ISL公司, 对Clementine产品进行重新整合和开发,现在Clementine 已经成为SPSS公司的又一亮点。 作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。 强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。 同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比,Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
相关技术 神经网络 决策树 (C5.0 C&RT) Logistic 回归 等等
相关技术 K-Means 两步骤 Kohonen 等等
相关技术 分类跟估计的所有方法
相关技术 Apriori GRI 等等
相关技术 决策树规则 各类图表 等等
分类 目标变量(因变量、反应变量数)为类別的狀況 信用卡公司將既有资料分为「伪卡」「非伪卡」找出伪卡的模式
Statistics节点----研究连 续型字段间线性相关关系
得到Na_to_K的统计属性,及它 与Age的线性关系
2规则归纳模型 规则归纳模型 c5.0
3 crt决策树
4 kohonen聚类
5 k--means聚类
6 two step 聚类
Clementine中的Data Mining 的方法
Classification Clustering Estimation Prediction Market Basket Analysis Description
SPSS_Clementine_数据挖掘入门

目录SPSS Clementine数据挖掘入门(1) (2)客户端基本界面 (3)项目区 (3)工具栏 (3)源工具(Sources) (3)记录操作(Record Ops)和字段操作(Field Ops) (4)图形(Graphs) (4)输出(Output) (4)模型(Model) (4)数据流设计区 (4)管理区 (5)Outputs (5)Models (5)SPSS Clementine数据挖掘入门(2) (6)1.定义数据源 (6)2.理解数据 (8)3.准备数据 (9)4.建模 (13)5.模型评估 (14)6.部署模型 (15)SPSS Clementine数据挖掘入门(3) (17)分类 (20)决策树 (20)Naïve Bayes (23)神经网络 (24)回归 (26)聚类 (27)序列聚类 (30)关联 (31)SPSS Clementine数据挖掘入门(1)SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
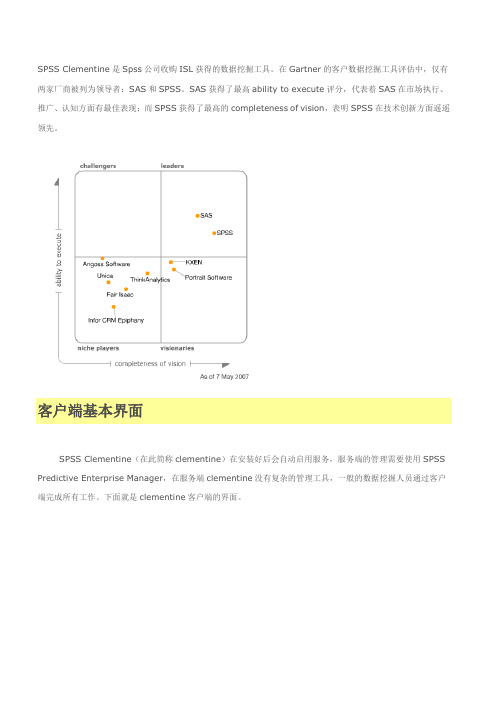
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
数据挖掘软件SPSS-Clementine-12安装教程

数据挖掘软件SPSS Clementine 12安装教程SPSS Clementine 12安装包比较特殊,是采用ISO格式的,而且中文补丁、文本挖掘模块都是分开的,对于初次安装者来说比较困难。
本片文章将对该软件的安装过程进行详细介绍,相信大家只要按照本文的安装说明一步一步操作即可顺利完成软件的安装和破解。
步骤一:安装前准备1、获取程序安装包SPSS Clementine 12的安装包获取的方法比较多,常用的方法是通过baidu或google搜索关键词,从给出的一些上进行下载。
为了方便大家安装,这里给出几个固定的下载供大家安装:论坛上下载:.kddchina./thread-538-1-1.html百度网盘:pan.baidu./s/1pEcS9提取密码:rhor腾讯微云:/OVYtFW相信这么多下载方式大家一定能成功获得安装程序的。
2、ISO文件查看工具由于程序安装包是ISO光盘镜像形式的,如果你的操作系统是win8之前的系统,那么就需要安装能够打开提取ISO文件的工具软件了。
在此推荐UltraISO这款软件,主要是既能满足我们的需要,而且文件又较小,安装方便。
这里提供几个下载UltraISO程序的地址:百度网盘pan.baidu./s/1mqkmN腾讯微云:pan.baidu./s/1qZY5GUltraISO安装成功后在计算机资源管理器中可以看到如下虚拟光驱的图标(接下来需要用到)右键点击该图标可以看到如下的一些选项,点击“加载”,选择相应的ISO文件就可以将文件加载到虚拟光驱中并打开。
步骤二:安装Clementine 121、安装Clementine 12主程序在计算机资源管理器中右键“CD驱动器”>>UtraISO>>加载,选择”SPSS_Clementine_v12.0-CYGiSO.bin”这个文件然后在打开计算机资源管理器可以看到如下情况双击打开,选择setup.exe运行,在弹出框中选择第一个选项(Install Clementine)即可,然后依次完成安装过程。
分类工具spss Clementine的介绍
分类工具spss Clementine 的介绍数据挖掘的工具平台有很多,常见的有Spss Clementine 、Weka 、Matlab 等。
本研究采用的是Spss Clementine 12.0汉化版,下面简单介绍Clementine 工具。
Clementine 软件充分利用了计算机系统的运算能力和图形展示能力,将方法、应用与工具紧密地结合在一起,是解决数据挖掘的理想工具。
它不但集成了诸多计算机学科中机器学习的优秀算法,同时也综合了一些行之有效的数学统计分析方法,成为内容最为全面,功能最为强大、使用最为方便的数据挖掘工具。
由于其界面友好、操作简便,十分适合普通人员快速实现对数据的挖掘,使其大受用户欢迎,已经连续多年雄踞数据挖掘工具之首[96]。
操作使用Clementine 的目的是建立数据流,即根据数据挖掘的实际需要选择节点,一次连接节点建立数据流,不断修改和调整流中节点的参数,执行数据流,最终完成相应的数据挖掘任务。
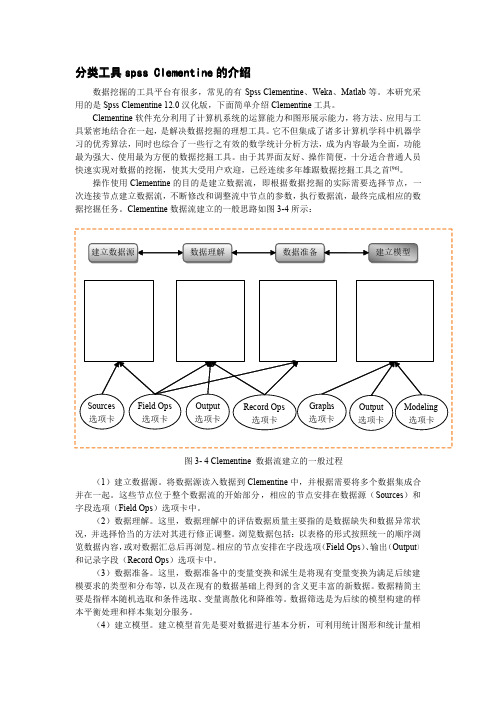
Clementine 数据流建立的一般思路如图3-4所示:(1)建立数据源。
将数据源读入数据到Clementine 中,并根据需要将多个数据集成合并在一起。
这些节点位于整个数据流的开始部分,相应的节点安排在数据源(Sources )和字段选项(Field Ops )选项卡中。
(2)数据理解。
这里,数据理解中的评估数据质量主要指的是数据缺失和数据异常状况,并选择恰当的方法对其进行修正调整。
浏览数据包括:以表格的形式按照统一的顺序浏览数据内容,或对数据汇总后再浏览。
相应的节点安排在字段选项(Field Ops )、输出(Output )和记录字段(Record Ops )选项卡中。
(3)数据准备。
这里,数据准备中的变量变换和派生是将现有变量变换为满足后续建模要求的类型和分布等,以及在现有的数据基础上得到的含义更丰富的新数据。
数据精简主要是指样本随机选取和条件选取、变量离散化和降维等。
clementine的中文教程

一,Clementine数据挖掘的基本思想数据挖掘(Data Mining)是从大量的,不完全的,有噪声的,模糊的,随机的实际应用数 据中,提取隐含在其中的,人们事先不知道的,但又是潜在有用的信息和知识的过程,它是一 种深层次的数据分析方法.随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法. 它结合了人工智能(AI)和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些 高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于 自己所要解决的问题. Clementine为我们提供了大量的人工智能,统计分析的模型(神经网络,关联分析,聚类分 析,因子分析等) ,并用基于图形化的界面为我们认识,了解,熟悉这个软件提供了方便.除了 这些Clementine还拥有优良的数据挖掘设计思想, 正是因为有了这个工作思想, 我们每一步的工 作也变得很清晰. (如图一所示)图一CRISP-DM process model如图可知,CRISP-DM Model包含了六个步骤,并用箭头指示了步骤间的执行顺序.这些顺 序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行.通 过对这些步骤的执行,我们也涵盖了数据挖掘的关键部分. Business understanding:商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段 里我们需要明确商业目标,评估商业环境,确定挖掘目标以及产生一个项目计划. Data understanding:数据是我们挖掘过程的"原材料",在数据理解过程中我们要知道都有些什么数据,这些 数据的特征是什么,可以通过对数据的描述性分析得到数据的特点. Date preparation:在数据准备阶段我们需要对数据作出选择,清洗,重建,合并等工作. 选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作. Modeling:建模过程也是数据挖掘中一个比较重要的过程.我们需要根据分析目的选出适 合的模型工具,通过样本建立模型并对模型进行评估. Evaluation: 并不是每一次建模都能与我们的目的吻合, 评价阶段旨在对建模结果进行评估, 对效果较差的结果我们需要分析原因,有时还需要返回前面的步骤对挖掘过程重新定义. Deployment:这个阶段是用建立的模型去解决实际中遇到的问题,它还包括了监督,维持, 产生最终报表,重新评估模型等过程.二,Clementine的基本操作方法1,操作界面的介绍图二 Clementine操作界面 1.1数据流程区 Clementine在进行数据挖掘时是基于数据流程形式,从读入数据到最后的结果显示都是由 流程图的形式显示在数据流程区内.数据的流向通过箭头表示,每一个结点都定义了对数据的 不同操作,将各种操作组合在一起便形成了一条通向目标的路径. 数据流程区是整个操作界面中最大的部分,整个建模过程以及对模型的操作都将在这个区 域内执行.我们可以通过File-new stream新建一个空白的数据流,也可以打开已有的数据流. 所有在一个运行期内打开的数据流都将保存在管理器的Stream栏下. 1.2选项面板 选项面板横跨于Clementine操作界面的下部, 它被分为Favorites, Sources, Record Ops, Fields Ops,Graphs,Modeling,Output七个栏,其中每个栏目包含了具有相关功能的结点. 结点是数据流的基本组成部分,每一个结点拥有不同的数据处理功能.设置不同的栏是为了将 不同功能的结点分组,下面我们介绍各个栏的作用. Sources:该栏包含了能读入数据到Clementine的结点.例如Var. File结点读取自由格式的文 本文件到Clementine,SPSS File读取spss文件到Clementine. Record Ops: 该栏包含的结点能对数据记录进行操作. 例如筛选出满足条件的记录 (select) , 将来自不同数据源的数据合并在一起(merge) ,向数据文件中添加记录(append)等. Fields Ops:该栏包含了能对字段进行操作的结点.例如过滤字段(filter)能让被过滤的字段不作为模型的输入,derive结点能根据用户定义生成新的字段,同时我们还可以定义字段的数 据格式. Graphs:该栏包含了纵多的图形结点,这些结点用于在建模前或建模后将数据由图形形式 输出. Modeling:该栏包含了各种已封装好的模型,例如神经网络(Neural Net) ,决策树(C5.0) 等. 这些模型能完成预测 (Neural Net, Regression, Logistic ) 分类 , (C5.0, C&R Tree, Kohonen, K-means,Twostep) ,关联分析(Apriori,GRI,Sequece)等功能. Output:该栏提供了许多能输出数据,模型结果的结点,用户不仅可以直接在Clementine 中查看输出结果,也可以输出到其他应用程序中查看,例如SPSS和Excel.Favorites:该栏放置了用户经常使用的结点,方便用户操作.用户可以自定义其Favorites 栏,操作方法为:选中菜单栏的Tools,在下拉菜单中选择Favorites,在弹出的Palette Manager 中选中要放入Favorites栏中的结点. 图三 Favorites栏的设置 1.3管理器管理器中共包含了Streams,Outputs,Models三个栏.其中Streams中放置了运行期内打开的 所有数据流,可以通过右键单击数据流名对数据流进行保存,设置属性等操作.Outputs中包含 了运行数据流时所有的输出结果,可以通过双击结果名查看输出的结果.Models中包含了模型 的运行结果,我们可以右键单击该模型从弹出的Browse中查看模型结果,也可以将模型结果加入到数据流中.图四 管理器窗口中对stream的设置 1.4项目窗口的介绍 项目窗口含有两个选项栏,一个是CRISP-DM,一个是Classes.CRISP-DM的设置是基于CRISP-DM Model的思想,它方便用户存放在挖掘各个阶段形成的 文件.由右键单击阶段名,可以选择生成该阶段要拥有的文件,也可以打开已存在的文件将其 放入该阶段.这样做的好处是使用户对数据挖掘过程一目了然,也有利于对它进行修改.图五 将各阶段的文件归类 Classes窗口具有同CRISP-DM窗口相似的作用,它的分类不是基于挖掘的各个过程,而是 基于存储的文件类型.例如数据流文件,结点文件,图表文件等.2,数据流基本操作的介绍2.1生成数据流的基本过程数据流是由一系列的结点组成,当数据通过每个结点时,结点对它进行定义好的操作.我 们在建立数据流是通常遵循以下四步: ①,向数据流程区增添新的结点; ②,将这些结点连接到数据流中; ③,设定数据结点或数据流的功能; ④,运行数据流. 2.2向数据流程区添/删结点 当向数据流程区添加新的结点时,我们有下面三种方法遵循: ①,双击结点面板中待添加的结点; ②,左键按住待添加结点,将其拖到数据流程区内; ③,选中结点面板中待添加的结点,将鼠标放入数据流程区,在鼠标变为十字形时单击数 据流程区. 通过上面三种方法我们都将发现选中的结点出现在了数据流程区内. 当我们不再需要数据流程区内的某个结点时,可以通过以下两种方法来删除: ①左键单击待删除的结点,用delete删除; ②右键单击待删除的结点,在出现的菜单中选择delete. 2.3将结点连接到数据流中 上面我们介绍了将结点添加到数据流程区的方法,然而要使结点真正发挥作用,我们需要 把结点连接到数据流中.以下有三种可将结点连接到数据流中的方法: ①,双击结点 左键选中数据流中要连接新结点的结点(起始结点) ,双击结点面板中要连 接入数据流的结点(目标结点) ,这样便将数据流中的结点与新结点相连接了; 图六 双击目标结点以加入数据流 ②,通过鼠标滑轮连接在工作区内选择两个待连接的结点,用左键选中连接的起始结点,按住鼠标滑轮将其拖曳 到目标结点放开,连接便自动生成. (如果鼠标没有滑轮也选用alt键代替) 图七 由滑轮连接两结点 ③,手动连接 右键单击待连接的起始结点,从弹出的菜单栏中选择Connect.选中Connect后鼠标和起始 结点都出现了连接的标记,用鼠标单击数据流程区内要连接的目标结点,连接便生成.图八 选择菜单栏中的connect 图九 点击要连入的结点 注意:①,第一种连接方法是将选项面板中的结点与数据流相连接,后两种方法是将已在 数据流程区中的结点加入到数据流中 ②,数据读取结点(如SPSS File)不能有前向结点,即在 连接时它只能作为起始结点而不能作为目标结点. 2.4绕过数据流中的结点 当我们暂时不需要数据流中的某个结点时我们可以绕过该结点.在绕过它时,如果该结点 既有输入结点又有输出结点那么它的输入节点和输出结点便直接相连;如果该结点没有输出结 点,那么绕过该结点时与这个结点相连的所有连接便被取消.方法:用鼠标滑轮双击需要绕过的结点或者选择按住alt键,通过用鼠标左键双击该结点来 完成.图十 绕过数据流中的结点 2.5将结点加入已存在的连接中 当我们需要在两个已连接的结点中再加入一个结点时,我们可以采用这种方法将原来的连 接变成两个新的连接.方法:用鼠标滑轮单击欲插入新结点的两结点间的连线,按住它并把他拖到新结点时放手, 新的连接便生成. (在鼠标没有滑轮时亦可用alt键代替) 图十一 将连线拖向新结点图十二 生成两个新的连接 2.6删除连接 当某个连接不再需要时,我们可以通过以下三种方法将它删除: ①,选择待删除的连接,单击右键,从弹出菜单中选择Delete Connection; ②,选择待删除连接的结点,按F3键,删除了所有连接到该结点上的连接;③,选择待删除连接的结点,从主菜单中选择Edit Node Disconnect. 图十三 用右键删除连接 2.7数据流的执行 数据流结构构建好后要通过执行数据流数据才能从读入开始流向各个数据结点.执行数据 流的方法有以下三种:①,选择菜单栏中的按钮,数据流区域内的所有数据流将被执行;②,先选择要输出的数据流,再选择菜单栏中的按钮,被选的数据流将被执行; ③,选择要执行的数据流中的输出结点,单击鼠标右键,在弹出的菜单栏中选择Execute选项,执行被选中的数据流.图十四 执行数据流的方法三,模型建立在这部分我们将介绍五种分析方法的建立过程, 它们分别是因子分析, 关联分析, 聚类分析, 决策树分析和神经网络.为了方便大家练习,我们将采用Clementine自带的示例,这些示例在 demos文件夹中均可找到,它们的数据文件也在demos文件夹中.在模型建立过程中我们将介绍 各个结点的作用.1,因子分析(factor. str)示例factor.str是对孩童的玩具使用情况的描述,它一共有76个字段.过多的字段不仅增添了 分析的复杂性,而且字段之间还可能存在一定的相关性,于是我们无需使用全部字段来描述样 本信息.下面我们将介绍用Clementine进行因子分析的步骤: Step一:读入数据Source栏中的结点提供了读入数据的功能,由于玩具的信息存储为toy_train.sav,所以我们 需要使用SPSS File结点来读入数据.双击SPSS File结点使之添加到数据流程区内,双击添加到数据流程区里的SPSS File结点,由此来设置该结点的属性. 在属性设置时,单击Import file栏右侧的按钮,选择要加载到数据流中进行分析的文件,这 里选择toy_train.sav.单击Annotations页,在name栏中选择custom选项并在其右侧的文本框中输 入自定义的结点名称.这里我们按照原示例输入toy_train. Step二:设置字段属性进行因子分析时我们需要了解字段间的相关性,但并不是所有字段都需要进行相关性 分析,比如"序号"字段,所以需要我们将要进行因子分析的字段挑选出来.Field Ops栏中 的Type结点具有设置各字段数据类型,选择字段在机器学习中的的输入/输出属性等功能, 我们利用该结点选择要进行因子分析的字段.首先,将Type结点加入到数据流中,双击该 结点对其进行属性设置: 由上图可看出数据文件中所有的字段名显示在了Field栏中,Type表示了每个字段的数 据类型. 我们不需要为每个字段设定数据类型, 只需从Values栏中的下拉菜单中选择<Read> 项,然后选择Read Value键,软件将自动读入数据和数据类型;Missing栏是在数据有缺失 时选择是否用Blank填充该字段;Check栏选择是否判断该字段数据的合理性;而Direction 栏在机器学习模型的建立中具有相当重要的作用,通过对它的设置我们可将字段设为输入/ 输出/输入且输出/非输入亦非输出四种类型.在这里我们将前19个字段的Direction设置为 none,这表明在因子分析我们不将这前19个字段列入考虑,从第20个字段起我们将以后字 段的direction设置为In,对这些字段进行因子分析. Step三:对数据进行因子分析 因子分析模型在Modeling栏中用PCA/Factor表示.在分析过程中模型需要有大于或等 于两个的字段输入,上一步的Type结点中我们已经设置好了将作为模型输入的字段,这里 我们将PCA/Factor结点连接在Type结点之后不修改它的属性,默认采用主成分分析方法.在建立好这条数据流后我们便可以将它执行.右键单击PCA/Factor结点,在弹出的菜 单栏中选择Execute执行命令.执行结束后,模型结果放在管理器的Models栏中,其标记为 名称为PCA/Factor的黄色结点.右键单击该结果结点,从弹出的菜单中选择Browse选项查看输出结果.由结果可知参 与因子分析的字段被归结为了五个因子变量,其各个样本在这五个因子变量里的得分也在 结果中显示. Step四:显示经过因子分析后的数据表 模型的结果结点也可以加入到数据流中对数据进行操作.我们在数据流程区内选中 Type结点,然后双击管理器Models栏中的PCA/Factor结点,该结点便加入到数据流中. 为了显示经过因子分析后的数据我们可以采用Table结点,该结点将数据由数据表的形式输 出. 4.1为因子变量命名 在将PCA/Factor(结果)结点连接到Table结点之前,用户可以设置不需要显示的字段, 也可以更改因子变量名,为了达到这个目的我们可以添加Field Ops栏中的filter结点.在对filter结点进行属性设置时,Filter项显示了字段的过滤与否,如果需要将某个字段过滤,只需用鼠标单击Filter栏中的箭头,当箭头出现红“×”时该字段便被过滤。
SPSS+Clementine8.1(英文版)数据挖掘平台入门操作指南

SPSS Clementine8.1(英文版)数据挖掘平台入门操作指南一、基本操作1.工作区简介1)可视化界面操作:管理器数据流区域项目区选项板区2.基本符号1)收藏夹用于存放常用的节点。
2)数据源用来将数据读进Clementine系统的节点。
3)记录选项用来在数据记录上进行操作的节点。
4)字段选项用来在数据字段上进行操作的节点。
5)图在建模之前和之后用来可视化数据的节点。
6) 建模在Clementine 系统中可用的代表有效算法的节点。
7)输出用来给出Clementine数据的各种输出、图表和模型结果。
3.基本操作1)向数据流中增加数据流节点从节点选项板中向数据流增加节点有三种方式:●在选项板上双击一个节点,自动将它连接到当前的数据流上●将一个节点从选项板拖放到数据流区域中●在选项板上点击一个节点,然后在数据流区域中点击一下向数据流区域增加节点以后,双击这个节点来显示它的对话框。
2)删除节点●点击数据流中的节点并按Delete键●或者单击鼠标右键从菜单中选择“Delete”3)在数据流中连接节点●通过双击鼠标左键来增加和连接节点●使用鼠标中间键来连接节点(如果鼠标没有中间键,可通过按住Alt键后单击鼠标左键来完成)●手工连接节点a)选择一个节点并单击鼠标右键打开内容菜单b)从菜单中选择“Connect”c)一个连接符号将同时出现在开始节点上和鼠标上,点击数据流区域上的第二个节点将两个节点连接在一起如果试图做下列任何类型的连接,将会收到一个错误信息:a)导向一个来源节点的连接b)从一个最终节点导出的连接c)一个超过其输入连接最大值的节点d)连接两个已被连接的节点e)循环(数据返回一个它已经经过的节点)4)绕开一个节点●在数据区域上,使用鼠标中间键来双击想要绕开的节点●或者按住Alt键后双击鼠标左键来完成5)在当前连接中增加节点●使用鼠标中间键,点击连接箭头不放,并拖到想要插入的节点上●或者按住Alt键后,使用鼠标左键点击连接箭头,并拖到想要插入的节点上来完成●选择一个节点,从主菜单中选择:Edit→Note→Disconnect6)执行数据流●从工具菜单中选择Execute●点击工具栏上的执行按钮用户可以执行整个数据流或者只是执行数据流的一部分a)单击鼠标右键选择一个最终节点,可以执行一个简单的数据流b)单击鼠标右键选择任何一个非最终节点,可执行所选节点后的所有操作7)删除节点间的连接●在连接箭头的头部单击鼠标右键打开内容菜单,从菜单中选择“Delete Connection”选择一个节点并按F3键,来删除该节点所有的连接4.基本流程数据流:通过一系列节点来执行数据的过程称为一个数据流。
Clementine12.0操作

分割,如将样本分为训练集合测试集。
图形(Graphs)选项卡中的Plot节点和Multiplot节点。 Plot节点指定X和Y轴的变量(每个坐标轴只能指定一个变量),描画相应的散点图; Multiplot节点指定X和Y轴的变量,Y轴变量可以是多个,描画相应的折线图。
2015/10/8
9
总体介绍
41
建模指导-回归
智慧数据 财富未来
第二步:创建流
2015/10/8
42
建模指导-回归 第三步:设置参数
智慧数据 财富未来
2015/10/8
43
建模指导-回归
智慧数据 财富未来
2015/10/8
44
建模指导-回归 第四步:生成模型
智慧数据 财富未来
2015/10/8
45
建模指导-回归
智慧数据 财富未来
13
建模指导-分类
智慧数据 财富未来
输入项:购买量、保养情况、车门数、 座位数、底盘、安全性
输出项:汽车类别
2015/10/8
14
建模指导-分类 第一步:导入数据
智慧数据 财富未来
2015/10/8
15
建模指导-分类
智慧数据 财富未来
第二步:创建流
2015/10/8
16
建模指导-分类 第三步:设置参数
3.设置节点参数。
节点是用来处理数据的,需要对某些节点针对数据处理的方式设置参数。双击相应节点,或者右击 相应节点,选择弹出菜单中的Edit即可。
4.执行数据流。
当数据流建立完成后,若要得到数据分析结果,则需要执行数据流。选择主菜单Tools->Execute,
或右击会得结果的节点,选择弹出菜单中的Execute。
Clementine_数据挖掘入门
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:/esestt/archive/2007/06/03/769411.html)。
实验二、SPSSClementine数据可视化

实验报告学院 南徐学院 班级 09428031 姓名 朱亚军 成绩课程 名称 数据挖掘实验项目名 称SPSS Clementine 数据可视化指导教师教师评语教师签名:年 月 日一、 实验目的1、熟悉SPSS Clementine 绘图。
2、了解SPSS Clementine 图形选项面板各节点的使用方法。
3、熟练掌握SPSS Clementine 数据可视化流程。
二、实验内容1、打开SPSS Clementine 软件,逐一操作各图形选项面板,熟悉软件功能。
2、打开一有数据库、或新建数据文件,读入SPSS Clementine,并使用各种输出节点,熟悉数据输入输出。
(要求:至少做分布图、直方图、收集图、多重散点图、时间散点图)三、实验步骤1、启动 Clementine:请从 Windows 的“开始”菜单中选择:所有程序SPSS Clementine 12.0SPSS Clementine client 12.02、建立一个流、导入相关数据,打开图形选项面板3、绘制以下各类图形 (1)以颜色为层次的图(2)以大小为层次的图(3)以颜色、大小、形状和透明度为层次的图(4)以面板图为层次的图(5)三维收集图(6)动画散点图(7)分布图(8)直方图(9)收集图(10)多重散点图(11)网络图四、实验体会熟悉了SPSS Clementine 的绘图特点,了解SPSS Clementine 图形选项面板各节点的使用方法并熟练掌握SPSS Clementine 数据可视化流程。
Clementine上机操作实验指导

数据流的基本操作
向数据流区域添节点
双击选项板区中待添加的节点; 左键按住待添加节点,将其拖入数据流区域内; 先选中选项板区中待添加的节点,然后将鼠标放入数据
流区域,在鼠标变为十字形时单击数据流区域的任何空 白处。
向数据流区域删节点
左键单击待删除的节点,按键盘上的delete键删除; 右键单击待删除的节点,在快捷菜单中选择delete。
管理器窗口
管理器窗口中共包含了“流”、“输出”、“模 型”三个栏。
工程管理区
工程管理区含有两个选项栏,一个是“CRISPDM”,一个是“类”。
数据流的基本操作
生成数据流的基本过程
向数据流区域增添新的节点; 将这些节点连接到数据流中; 设定数据节点或数据流的功能; 运行数据流。
调节因子η
点击“执行”按钮,即可在管理器窗口的“模型” 标签下显示生成的K-Means模型节点。
右键单击管理器窗口“模型”标签下生成的K-Means模型节点,在快 捷菜单中选择“浏览”,打开“K-Means”对话框,在“模型”标签 下会显示划分出来的三个聚类,点击“全部展开”,则可以显示每个 簇的一些统计信息
SmallSampleComma.txt
字段实例化 将ID字段的类型修改为
无类型
字段方向
输入:输入或者预测字 段
输出:输出或者被预测 字段字段
两者:既是输入又是输 出,只在关联规则中用 到
无:建模过程中不使用 该字段
分区:将数据拆分为训 练、测试(验证)部分
字段方向设置只有在建 模时才起作用
如果数据是列界定的(字段未被分隔,但是 始于相同的位置并有固定长度),应该使用固 定文本文件导入固定文件节点
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据挖掘快速上手Version1.0Prepared by高处不胜寒14094415QQ群:群:140944152009-10-15、Clementine数据挖掘的基本思想数据挖掘(Data Mining )是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程,它是一种深层次的数据分析方法。
随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法。
它结合了人工智能(AI )和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于自己所要解决的问题。
Clementine 为我们提供了大量的人工智能、统计分析的模型(神经网络,关联分析,聚类分析、因子分析等),并用基于图形化的界面为我们认识、了解、熟悉这个软件提供了方便。
除了这些Clementine 还拥有优良的数据挖掘设计思想,正是因为有了这个工作思想,我们每一步的工作也变得很清晰。
(如图一所示)CRI CRIS S P-DM p r ocess mo modd e l 如图可知,CRISP-DM Model 包含了六个步骤,并用箭头指示了步骤间的执行顺序。
这些顺序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行。
通过对这些步骤的执行,我们也涵盖了数据挖掘的关键部分。
商业理解(B u s i n e s s un under der ders s t a nd ndii n g ):商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段里我们需要明确商业目标、评估商业环境、确定挖掘目标以及产生一个项目计划。
数据理解(D a t a und under er erstanding standing standing)):数据是我们挖掘过程的“原材料”,在数据理解过程中我们要知道都有些什么数据,这些数据的特征是什么,可以通过对数据的描述性分析得到数据的特点。
数据准备(D a t e p r e p a r at ation ion ion)):在数据准备阶段我们需要对数据作出选择、清洗、重建、合并等工作。
选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。
建模(Mo Mod d e lin lingg ):建模过程也是数据挖掘中一个比较重要的过程。
我们需要根据分析目的选出适合的模型工具,通过样本建立模型并对模型进行评估。
模型评估(E v aluat aluati i on on)):并不是每一次建模都能与我们的目的吻合,评价阶段旨在对建模结果进行评估,对效果较差的结果我们需要分析原因,有时还需要返回前面的步骤对挖掘过程重新定义。
结果部署(Deployment Deployment)):这个阶段是用建立的模型去解决实际中遇到的问题,它还包括了监督、维持、产生最终报表、重新评估模型等过程。
、Clementine的基本操作方法1.操作界面的介绍Cl Cleme eme emenn t i n e 操作界面.1数据流程区Clementine在进行数据挖掘时是基于数据流程形式,从读入数据到最后的结果显示都是由流程图的形式显示在数据流程区内。
数据的流向通过箭头表示,每一个结点都定义了对数据的不同操作,将各种操作组合在一起便形成了一条通向目标的路径。
数据流程区是整个操作界面中最大的部分,整个建模过程以及对模型的操作都将在这个区域内执行。
我们可以通过"文件"(File)-"新建流"(new stream)新建一个空白的数据流,也可以打开已有的数据流。
所有在一个运行期内打开的数据流都将保存在管理器的Stream栏下。
1.2选项面板选项面板横跨于Clementine操作界面的下部,它被分为收藏夹(Favorites)、数据源(Sources)、记录选项(Record Ops)、字段选项(Fields Ops)、图形(Graphs)、建模(Modeling)、输出(Output)、导出八个栏,其中每个栏目包含了具有相关功能的结点。
结点是数据流的基本组成部分,每一个结点拥有不同的数据处理功能。
设置不同的栏是为了将不同功能的结点分组,下面我们介绍各个栏的作用。
数据源(Sources):该栏包含了能读入数据到Clementine的结点。
例如V ar.File结点读取自由格式的文本文件到Clementine,SPSS File读取spss文件到Clementine。
记录选项(Record Ops):该栏包含的结点能对数据记录进行操作。
例如筛选出满足条件的记录(select)、将来自不同数据源的数据合并在一起(merge)、向数据文件中添加记录(append)等。
字段选项(Field Ops):该栏包含了能对字段进行操作的结点。
例如过滤字段(filter)能让被过滤的字段不作为模型的输入、导出(derive)结点能根据用户定义生成新的字段,同时我们还可以定义字段的数据格式。
Graph h s):该栏包含了众多的图形结点,这些结点用于在建模前或建模后将数据由图形形式图形(Grap输出。
Modeling)):该栏包含了各种已封装好的模型,例如神经网络(Neural Net)、决策树(C5.0)建模(Modeling等。
这些模型能完成预测(Neural Net,Regression,Logistic)、分类(C5.0,C&R Tree,Kohonen,K-means,T wostep)、关联分析(Apriori,GRI,Sequece)等功能。
输出(O u tp tput ut ut)):该栏提供了许多能输出数据、模型结果的结点,用户不仅可以直接在Clementine 中查看输出结果,也可以输出到其他应用程序中查看,例如SPSS和Excel。
Fav v oriteorites s):该栏放置了用户经常使用的结点,方便用户操作。
用户可以自定义其收藏夹(FaFavorites栏,操作方法为:选中菜单栏的工具(T ools),在下拉菜单中选择收藏夹(Favorites),在弹出的Palette Manager中选中要放入Favorites栏中的结点。
1.3管理器理器中共包含了流(Streams)、输出(Outputs)、模型(Models)三个栏。
其中流(Streams)中放置了运行期内打开的所有数据流,可以通过右键单击数据流名对数据流进行保存、设置属性等操作。
输出(Outputs)中包含了运行数据流时所有的输出结果,可以通过双击结果名查看输出的结果。
模型(Models)中包含了模型的运行结果,我们可以右键单击该模型从弹出的浏览(Browse)中查看模型结果,也可以将模型结果加入数据流中。
1.4项目窗口的介绍项目窗口含有两个选项栏,一个是CRISP-DM,一个是类(Classes)。
CRISP-DM的设置是基于CRISP-DM Model的思想,它方便用户存放在挖掘各个阶段形成的文件。
由右键单击阶段名,可以选择生成该阶段要拥有的文件,也可以打开已存在的文件将其放入该阶段。
这样做的好处是使用户对数据挖掘过程一目了然,也有利于对它进行修改。
类(Classes)窗口具有同CRISP-DM窗口相似的作用,它的分类不是基于挖掘的各个过程,而是基于存储的文件类型。
例如数据流文件、结点文件、图表文件等。
2、数据流基本操作的介绍2.1生成数据流的基本过程数据流是由一系列的结点组成,当数据通过每个结点时,结点对它进行定义好的操作。
我们在建立数据流是通常遵循以下四步:①、向数据流程区增添新的结点;②、将这些结点连接到数据流中;③、设定数据结点或数据流的功能;④、运行数据流。
2.2向数据流程区添/删结点当向数据流程区添加新的结点时,我们有下面三种方法遵循:①、双击结点面板中待添加的结点;②、左键按住待添加结点,将其拖到数据流程区内;③、选中结点面板中待添加的结点,将鼠标放入数据流程区,在鼠标变为十字形时单击数据流程区。
通过上面三种方法我们都将发现选中的结点出现在了数据流程区内。
当我们不再需要数据流程区内的某个结点时,可以通过以下两种方法来删除:①左键单击待删除的结点,用删除(delete);②右键单击待删除的结点,在出现的菜单中选择删除(delete)。
2.3将结点连接到数据流中上面我们介绍了将结点添加到数据流程区的方法,然而要使结点真正发挥作用,我们需要连接到数据流中。
以下有三种可将结点连接到数据流中的方法:①、双击结点左键选中数据流中要连接新结点的结点(起始结点),双击结点面板中要连接入数据流的结点(目标结点),这样便将数据流中的结点与新结点相连接了;图六双击目标结点以加入数据流②、通过鼠标滑轮连接在工作区内选择两个待连接的结点,用左键选中连接的起始结点,按住鼠标滑轮将其拖曳到目标结点放开,连接便自动生成。
(如果鼠标没有滑轮也选用alt键代替)由滑轮连接两结点③、手动连接右键单击待连接的起始结点,从弹出的菜单栏中选择连接(Connect)。
选中连接(Connect)后鼠标和起始结点都出现了连接的标记,用鼠标单击数据流程区内要连接的目标结点,连接便生成。
onn n ec ect t图八选择菜单栏中的连接c on图九点击要连入的结点注意:①、第一种连接方法是将选项面板中的结点与数据流相连接,后两种方法是将已在数据流程区中的结点加入到数据流中②、数据读取结点(如SPSS File)不能有前向结点,即在连接时它只能作为起始结点而不能作为目标结点。
2.4绕过数据流中的结点当我们暂时不需要数据流中的某个结点时我们可以绕过该结点。
在绕过它时,如果该结点既有输入结点又有输出结点那么它的输入节点和输出结点便直接相连;如果该结点没有输出结点,那么绕过该结点时与这个结点相连的所有连接便被取消。
:用鼠标滑轮双击需要绕过的结点或者选择按住alt键,通过用鼠标左键双击该结点来完成。
2.5将结点加入已存在的连中当我们需要在两个已连接的结点中再加入一个结点时,我们可以采用这种方法将原来的连接变成两个新的连接。
方法:用鼠标滑轮单击欲插入新结点的两结点间的连线,按住它并把他拖到新结点时放手,新的连接便生成。
(在鼠标没有滑轮时亦可用alt键代替)2.6删除连接当某个连接不再需要时,我们可以通过以下三种方法将它删除:①、选择待删除的连接,单击右键,从弹出菜单中选择Delete Connection;②、选择待删除连接的结点,按F3键,删除了所有连接到该结点上的连接;、选择待删除连接的结点,从主菜单中选择断开连接(Edit NodeDisconnect)。