基于clementine的数据挖掘算法决策树
基于Clementine数据挖掘模型评估

基于Clementine的数据挖掘模型评估摘要:本文采用clementine数据挖掘工具生成了某商业银行的客户响应具体模型,并评估了所生成的模型。
通过分析报告和评估图的方式,最终比较了决策表、神经网络和决策树c5.0算法预测的效果。
关键词:数据挖掘;clementine;模型评估;c5.0中图分类号:tp311.13目前,银行的数据库和数据仓库中都收集和存储了大量有关客户的宝贵数据,它们涵盖了从客户基本资料、购买记录以及客户反馈等多个环节。
利用这些数据,进一步分析、挖掘出大量隐藏在其中的有用信息,可以帮助银行更好地做到客户关系管理,实现crm的功能和目标。
在分析当前客户关系管理中数据挖掘的应用的基础上,以某商业银行的crm系统开发为背景,建立客户响应预测模型,生成商业银行的客户响应具体模型,分析维度表中的相关变量对目标变量(客户是否响应)的影响。
最终对所生成的模型进行评估,比较不同算法预测的效果。
1clementine软件clementine(ibm spss modeler)最早属英国isl(integral solutions limited)公司的产品,后被spss公司收购。
2009年,spss被ibm公式收购。
自2000年以来,kdnuggets公司面向全球开展“最近12个月你使用的数据挖掘工具”的跟踪调查,clementine一直列居首位。
clementine具有分类、预测、聚类、关联分析等数据挖掘的全部分析方法。
这些分析方法经过组合,或单独使用,可用于研究客户响应问题。
其crisp-dm标准能够帮助用户规范数据挖掘的整个过程。
clementine的操作与数据分析的一般流程相吻合。
clementine 形象地将各个环节表示成若干个节点,将数据分析过程看作是数据在各个节点之间的流动,并通过图形化的“数据流”方式,直观表示整个数据挖掘。
操作使用clementine的目标:建立数据流,即根据数据挖掘的实际需要,选择节点,依次连接节点建立数据流,不断修改和调整流中节点的参数,执行数据流,最终完成相应的数据挖掘任务。
如何使用数据挖掘工具Clementine——以我国图书情报类期刊学术影响力评价为例

T k n hn s irr n nom d n Ju as A a e c a igC iee Lbaya dIfr a o o r l ’ c d mi n
I a tE au t n a n Emprc sa c mp c v l ai s A o i a Re e rh il
以我 国图书情报 类期 刊学术 影 响力评 价 为例
李 许 扬 阳 培
( 北京协 和 医学院 医学信 息研 究所 ,北 京 102) 000
( 摘 要)本文首 先简要介绍了数据挖掘工具 geel 的特 点及若干基本功能 ( l nn m te 即若干模块) ,然后 以基 于 《 中国期刊 高
D : 0.9 9 i n.0 8—0 2 .0 2. 1 0 5 OI1 3 6 s 1 0 s 8 1 2 1 O .3
[ 中图分类号]G5 . ( 215 文献标识码) [ A 文章编号]10 — 81( 1) 1 04 0 08 02 2 2 O — 1 0 6— 4
Ho t e Clme t e a Da a l n n o w o Us e n i sA t n t g To l n v
lg yce d ̄ o hns u a 2 1 e i )pbse yITC h ae vl t e cdmcipc b s g II t i e f i e or l 00vro ulhdb / ,t ppr a a dt iaae i m at yui id id n C e j n s( sn i S e e ue hr n
该软件将一系列数据处理程序或技术整合成相互独立的模块例如将聚类决策树神经网络关联规则等多种数据挖掘技术集成在直观的可视化图形界面中并采用图形用户交互式界面因此对于不谙编程但又经常面临大量数据处理任务的用户来说它的确要比excel更易用更高效而且处理方法有重用性即这次构建的数据流经保存后可在下一个类似任务中稍做修改便可使用或者一条数据流可以支持相似数据的分析不需要再翻看复杂的编程手册在excel里频繁使用各种函数整理数据等
Clementine12中的数据挖掘算法

Clementine12中的数据挖掘算法SPSS 2010-03-31 08:39:10 阅读14 评论0 字号:大中小最近老有朋友问我Clementine12中都有哪些算法?感觉Clementine12中的算法很多,很齐全并且根据商业目的做了大体的分类(预测的、分类的、细分的、关联的),所以大家只要清楚自己的商业问题是哪类问题、用什么算法能达到自己想要的目的就可以根据Clementine12中的模型划分,迅速的找到自己想要的mode;下图是Clementine12中所有数据挖掘的算法:下面是谢邦昌教授的数据挖掘(Data Mining)十种分析方法,以便于大家对模型的初步了解,不过也是日常挖掘中经常遇到的算法,希望对大家有用!(甚至有数据挖掘公司,用其中的一种算法就能独步天下)1、记忆基础推理法(Memory-Based Reasoning;MBR)记忆基础推理法最主要的概念是用已知的案例(case)来预测未来案例的一些属性(attribute),通常找寻最相似的案例来做比较。
记忆基础推理法中有两个主要的要素,分别为距离函数(distance function)与结合函数(combination function)。
距离函数的用意在找出最相似的案例;结合函数则将相似案例的属性结合起来,以供预测之用。
记忆基础推理法的优点是它容许各种型态的数据,这些数据不需服从某些假设。
另一个优点是其具备学习能力,它能藉由旧案例的学习来获取关于新案例的知识。
较令人诟病的是它需要大量的历史数据,有足够的历史数据方能做良好的预测。
此外记忆基础推理法在处理上亦较为费时,不易发现最佳的距离函数与结合函数。
其可应用的范围包括欺骗行为的侦测、客户反应预测、医学诊疗、反应的归类等方面。
2、市场购物篮分析(Market Basket Analysis)购物篮分析最主要的目的在于找出什么样的东西应该放在一起?商业上的应用在藉由顾客的购买行为来了解是什么样的顾客以及这些顾客为什么买这些产品,找出相关的联想(association)规则,企业藉由这些规则的挖掘获得利益与建立竞争优势。
基于Clementine决策树的空间数据挖掘方法探讨

基于Clementine决策树的空间数据挖掘方法探讨∗ ——以平阴县安城乡为例 郑新奇1、2 刘晓丽2 1、中国地质大学(北京)土地科学技术系,北京 1000832、山东师范大学人口・资源与环境学院,济南 250014摘要:土地利用现状数据库中隐含有大量的信息。
通常在完成数据库建设后,很少有人再对数据库中隐含的可用知识加以关注。
为扩大该类数据库应用面,需要对它进行数据挖掘。
本文借助Clementine软件,以决策树C5.0和C&R为数据挖掘的方法,以平阴县安城乡2004年土地利用变更调查数据为挖掘对象,对该地区土地利用类型进行了初步的挖掘计算。
结果反映出安城乡土地利用的主导类型及其分布规律。
研究结果可作为土地利用优化配置等工作的借鉴。
关键词:空间数据挖掘,决策树,Clementine,土地利用类型 Discussion on the methods of Spatial Data Mining based onDecision Tree of Clementine——A case of Ancheng of Pingyin countyZheng Xinqi1、2 Liu Xiaoli21、Department of Land science&Technology,China University of Geosciences (Beijing), 100083,China2、School of population,resources and environment,Shandong Normal University,Ji’nan 250014, China Abstract:There are plenty of implici t information in land use actuality databased. After finished database, peoples pay attention to the implicit knowledge in the database. To enlarge this database applied field, the data mining of this data database was needed to try. Based on Clementine software, the actuality database of land use in Ancheng in 2004 was calculated in Ancheng of Pingyin county in 2004. The mining methods were the C5.0 and C&D of decision tree.The results find the dominant types of the land use in this area and their distribution characteristics. Research results can offer reference such as optimum disposition of land use.Keywords:spatial data mining; decision tree; Clementine; land use types1 引言 当今我们正面临这样一个问题,一边是对知识的饥渴,另一边却是大量数据的闲置未被利用,“我们被淹没在信息里,但却感受到知识的饥饿”。
clementine算法原理

clementine算法原理Clementine算法原理Clementine算法是一种常用的数据挖掘算法,用于发现数据集中的隐含模式和关联规则。
它是一种基于决策树的分类算法,可以用于预测未知数据的类别。
本文将介绍Clementine算法的原理及其应用。
一、Clementine算法的基本原理Clementine算法的基本原理是通过对已知数据集的学习,构建一个决策树模型,然后利用该模型对未知数据进行分类。
算法的核心思想是将数据集划分为多个子集,每个子集对应一个决策树节点,通过比较不同特征的取值来划分数据。
在构建决策树的过程中,算法会根据某种准则选择最佳的特征作为划分依据,直到所有数据都被正确分类或无法继续划分为止。
二、Clementine算法的具体步骤1. 数据预处理:对原始数据进行清洗、去噪、缺失值处理等操作,保证数据的质量和完整性。
2. 特征选择:根据特征的重要性和相关性对数据进行特征选择,筛选出对分类结果有影响的特征。
3. 数据划分:将数据集划分为训练集和测试集,通常采用70%的数据作为训练集,30%的数据作为测试集。
4. 构建决策树:根据训练集的数据,利用信息增益、基尼系数等准则选择最佳的特征进行划分,递归地构建决策树。
5. 决策树剪枝:为了避免过拟合现象,需要对决策树进行剪枝操作,去除一些不必要的节点和分支。
6. 模型评估:使用测试集对构建好的决策树模型进行评估,计算分类准确率、召回率、F1值等指标,评估模型的性能。
三、Clementine算法的应用领域Clementine算法在数据挖掘领域有着广泛的应用。
它可以用于市场分析、客户分类、信用评估等多个领域。
1. 市场分析:通过对市场数据的分析,可以预测产品的销售情况、消费者的购买偏好等,为企业的市场决策提供依据。
2. 客户分类:通过对客户的个人信息、购买记录等进行分析,可以将客户划分为不同的类别,为企业的客户管理和营销活动提供指导。
3. 信用评估:通过对个人信用记录、收入状况等进行分析,可以评估个人的信用水平,为银行等金融机构的信贷决策提供参考。
数据挖掘中的决策树算法使用教程

数据挖掘中的决策树算法使用教程数据挖掘是一种从大量数据中提取模式和知识的过程,而决策树算法是数据挖掘中常用的一种方法。
决策树是一种基于树形结构来进行决策的算法,通过将数据集分割成不同的子集,并根据某些规则进行决策。
决策树算法具有简单、易于理解和解释等特点,因此广泛应用于数据挖掘和机器学习领域。
一、决策树的基本原理决策树的基本原理是通过对数据集进行划分来构建一个树形结构,使得在每个划分上都能使得目标变量有最好的分类结果。
通常情况下,我们使用信息增益或者基尼指数来选择最佳的划分特征。
信息增益是一种衡量划分有效性的度量,它计算了在划分前后目标变量的不确定度减少的程度。
基尼指数是另一种常用度量,它衡量样本集合中不确定性的程度。
二、决策树算法的步骤决策树算法的一般步骤如下:1. 收集数据:收集一组样本数据,包含目标变量和特征。
2. 准备数据:对收集到的数据进行处理和预处理,确保数据的质量和可用性。
3. 分析数据:使用可视化工具对数据进行分析和探索,获取对数据的基本认识和理解。
4. 训练算法:使用数据集训练决策树模型。
根据具体的算法选择划分特征和生成决策树的规则。
5. 测试算法:使用训练好的决策树模型对新样本进行预测,并评估模型的准确性和性能。
6. 使用算法:完成决策树模型的训练和测试后,可以使用该模型来进行实际决策。
三、常见的决策树算法决策树算法有很多种变种,包括ID3、C4.5、CART等。
以下介绍几种常见的决策树算法。
1. ID3算法:ID3算法是使用信息增益作为选择划分特征的准则,适用于离散的特征值和分类问题。
2. C4.5算法:C4.5算法是ID3算法的扩展,不仅可以处理离散的特征值,还可以处理连续的特征值,并且可以处理缺失值。
3. CART算法:CART算法是Classification And Regression Trees的缩写,既可以用于分类问题,也可以用于回归问题。
它使用基尼指数来选择划分特征。
基于clementine的数据挖掘算法决策树

从变量自身 考察
变量重要性分析方法
变量与输出变量
、变量间的相关 程度
变量值中缺失值所占比例 分类变量中,类别个数占样本比例 数值变量的变异系数 数值型变量的标准差
输入、输出变量均为数值型:做两个变量的相
关性分析
输入变量为数值型、输出变量为分类型:方差 分析(输出变量为控制变量、输入变量为观测变 量) 输入变量为分类型、输出为数值型:方差分析 (输入变量为控制变量、输出变量为观测变量) 输入、输出变量均为分类型:卡方检验
2、计算每个属性的熵。
(1)先计算属性“年龄”的熵。 • 对于年龄=“<=30”:s11=2,s21=3,p11=2/5,p21=3/5, 对于年龄=“31…40”:s12=4,s22=0,p12=4/4=1,p22=0, 对于年龄=“>40”:s13=3,s23=2,p13=3/5,p23=2/5, •
s1 j s2
smj
pij
是 Sj 中的样本属于类 Ci 的概率。
sij sj
Gain( A) I ( S ) E ( A)
Gain A I
s1 , s2 ,
, sm
E A
C5.0算法应用场景
场景:利用决策树算法分析具有哪些特点的用户最可能流失:
用户 1 年龄 <=30 出账收入 智能机 信用等级 高 否 一般 类别:是否流失 否
核心问题
决策树的生长 决策树的减枝 树剪枝的原因:完整的决策树对训练样本特征的 捕捉“过于精确”--- 过拟和 常用的修剪技术: 预修剪:用来限制决策树的充分生长。
利用训练样本集完成决策树的建立
过程 分枝准则的确定涉及:
•第一,如何从众多的输入变量中
数据挖掘算法与clementine实践第3章

Gain( D, 年龄) I (s1 , s2 ) E( D, 年龄) 0.9406 0.6936 0.247
同理,若以“收入水平”为分裂属性:
E ( D, 收入水平) 4 2 2 2 2 6 4 4 2 2 ( log2 log2 ) ( log2 log2 ) 14 4 4 4 4 14 6 6 6 6 4 3 3 1 1 ( log2 log2 ) 0.2857 0.3936 0.2318 0.9111 14 4 4 4 4
按照这个方法,测试每一个属性的信
设S是s个样本组成的数据集。 若S的类标号属性具有m个不同的取值,即
定义了m个不同的类Ci(i=1,2,…,m)。设属 于类Ci的样本的个数为si
那么数据集S的熵为:
pi是任意样本属于类别Ci的概率,用si/s来估
计
根据属性A将数据集S划分
属性A具有v个不同值{ a1,a2,…,av}
决策树是指具有下列三个性质的树:
每个非叶子节点都被标记一个分裂属性Ai;
每个分支都被标记一个分裂谓词,这个分裂谓
词是分裂父节点的具体依据; 每个叶子节点都被标记一个类标号Cj∈C。
任何一个决策树算法,其核心步骤都是为
每一次分裂确定一个分裂属性,即究竟按 照哪一个属性来把当前数据集划分为若干 个子集,从而形成若干个“树枝”。
Gain( D, 收入水平) I (s1 , s2 ) E( D, 收入水平) 0.9406 0.9111 0.0295
若以“有固定收入”为分裂属性:
7 4 4 3 3 7 6 6 1 1 E ( D,固定收入) ( log2 log2 ) ( log2 log2 ) 14 7 7 7 7 14 7 7 7 7 0.4927 0.2959 0.7886
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
基于clementine的数据挖掘指导

基于clementine的数据挖掘实验指导目录clementine决策树分类模型 (2)一.基于决策树模型进行分类的基本原理概念 (2)二. 范例说明 (2)三. 数据集说明 (3)四. 训练模型 (3)五. 测试模型 (7)clementine线性回归模型 (10)一. 回归分析的基本原理 (10)二. 范例说明 (10)三. 数据集说明 (10)四. 训练模型 (10)五. 测试模型 (15)Clementine聚类分析模型 (18)一. 聚类分析的基本原理 (18)二. 范例说明 (18)三. 数据集说明 (18)四. 建立聚类模型 (19)Clementine关联规则模型 (24)一. 关联规则的基本原理 (24)二. 范例说明 (24)三. 数据集说明 (25)四. 关联规则模型 (26)clementine决策树分类模型一.基于决策树模型进行分类的基本原理概念分类就是:分析输入数据,通过在训练集中的数据表现出来的特性,为每一个类找到一种准确的描述或者模型。
由此生成的类描述用来对未来的测试数据进行分类。
数据分类是一个两步过程:第一步,建立一个模型,描述预定的数据类集或概念集;第二步,使用模型进行分类。
clementine 8.1中提供的回归方法有两种:C5.0(C5.0决策树)和Neural Net(神经网络)。
下面的例子主要基于C5.0决策树生成算法进行分类。
C5.0算法最早(20世纪50年代)的算法是亨特CLS(Concept Learning System)提出,后经发展由J R Quinlan在1979年提出了著名的ID3算法,主要针对离散型属性数据;C4.5是ID3后来的改进算法,它在ID3基础上增加了:对连续属性的离散化;C5.0是C4.5应用于大数据集上的分类算法,主要在执行效率和内存使用方面进行了改进。
优点:在面对数据遗漏和输入字段很多的问题时非常稳健;通常不需要很长的训练次数进行估计;比一些其他类型的模型易于理解,模型推出的规则有非常直观的解释;也提供强大的增强技术以提高分类的精度。
《基于Clementine的数据挖掘》课件—05决策树2

模型的对比分析
选择通用指标评价:如误差、收益率、提升度等 Analysis节点:用于评价单个模型
区分预测置信度和倾向性得分。通常倾向性得 分高于0.5,则可判断其预测类别为Yes。决 策树中仅根据预测置信度无法判断预测类别
在逻辑回归中,一般置信水平越高,预测正确 率会越高,但通常不分析置信水平和预测正确 率的关系,原因是分析结果是一个模型
随着值增大,得到子树序列。它们的复杂度 依次降低,但代价复杂度的变化情况并不确定
CART:剪枝算法
剪枝过程 选择k个子树中代价复杂度最低的子树,也可 以允许考虑误差项
放大因子
R(Topt ) min k R (Tk ) m SE(R(Tk ))
SE(R(Tk ))
R(Tk )(1 R(Tk )) N'
收益(Gains):模型对数据规律提炼的能力 利润(Profit):财务角度反映模型价值 角度:每条推理规则、决策树整体
效益评价:收益评价(单个节点)
收益:对具有某类特征的数据,输入和输出变量 取值规律的提炼的能力 针对用户关心的“目标”类别。例:流失yes
收益评价指标 【收益:n】:节点中样本属目标类别的样本量 【响应(%)】:节点中样本属目标类别的样本 量占本节点样本的百分比(置信程度) 【收益(%)】:节点中样本属目标类别的样本 量占目标类别总样本的百分比(适用广泛性)
决策树得到是模型集合,为评价哪些模型更好 ,应分析置信水平和预测正确率的关系
模型的对比分析
Analysis节点: 给出各种情况下的置信水平 预测正确(错误)的规则的平均置信度 置信度到达怎样水平时,预测正确率将达 到怎样的程度
Analysis节点:用于不同模型的对比评价
Clementine_数据挖掘入门
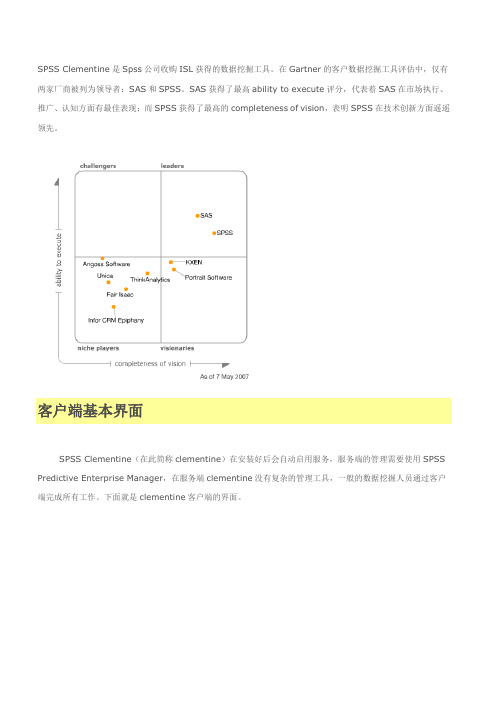
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:/esestt/archive/2007/06/03/769411.html)。
应用Clementine进行客户数据挖掘分析

C&RT(分类和回归树)节点生成可用于预测和分 类未来观测值的决策树
CHAID 使用卡方统计量来生成决策树,以确定最 佳的分割。CHAID 与C&RT节点不一样,它可以 生成非二元树,这意味着有些分割将有多于 两个的分支。
Clementine模型的类型(2)
CHAID分析结果
结果解释
查看器-生成树
第二个树比第一个树包含的树节点要少,但其是否 能够有效分出对于促销活动相应的客户?
有效性比较-收益
选择目标类别为1(即响应营销活动的),将树的 终端节点分组为四分位数。要比较两个模型的有效 性,可查看每个表中 四分位数的提升(即指数值的 变化)。
数据源:customer_dbase.sav
使用 CHAID 决策树开发模型,用以预测最有 可能响应某一次促销活动(Response_01)的 客户。
方法:
不使用特征选择。数据集中的所有预测变量字 段用作 CHAID 树的输入。
使用特征选择模型。使用特征选择节点选择最 佳的 10 个预测变量,然后将其输入到 CHAID 树中。
建模分析(1):CHAID决策树
背景:某电话公司的数据仓库包含有关该公司 的 5000 名客户对特定促销活动响应的信息。 数据中包括客户年龄、职业、收入和电话使用 统计量。其中有三个“目标”字段,显示客户 是否响应这三种促销。公司希望利用此数据帮 助预测未来中最有可能对类似的促销活动作出 响应的客户。
排序:根据一个或多个字段值对记录进行升序 或降序排列
三、字段选项
类型:指定字段的一系列重要属性; 过滤:(1)从通过的记录中过滤或剔除字段;(2)
数据挖掘 决策树上机内容

读取数据文件
• • • • • • • • 内容及节点: 2.1 Clementine可以读取的数据格式 2.2 读取文本数据与查看数据 2.3 读取SPSS数据 2.4 读取数据库数据 2.5 Clementine中的字段类型 2.6 Clementine中的字段方向 2.7 保存Clementine流
Clementine 面板
•
Clementine 可视化程序使用基础
• • • • • • 鼠标应用 三键与双键鼠标 左键 选择节点或图标置于流区域 右键 激活Context菜单 中键 连接或断开两个节点 帮助
节点操作
• 1.3 节点选项板 在clementine系统窗口底部的选项板 (palette)中装有用来建立数据流的所有可能的 节点。 1、收藏夹(Favorites):用于存放最常用的节点 2、数据源(sources):用来将数据读clementine 系统的节点
• Derive:增加一个或多个属性集;
• 数据集drug1n中有7个字段,只有Na,K是人 体所含的矿物质元素。影响人体的BP和 Cholesterel的是这两种元素的比例。
状态检测实例
• 例3:利用clementine系统提供的数据集 C0ND1n,对一台机器提供的状态信息进行 监测,识别和预测故障状态的问题。
• • • • • •
1.7 通过双击来增加和连接节点 1.8 手工连接节点 1.9 在数据列中绕过节点 2.0 绕开一个节点 2.1 在当前的连接中增加节点 2.2 删除节点间的连接
2 读取数据文件
• 目的 掌握Clementine如何读取文本格式数据 了解Clementine可以读取的数据格式 掌握Clementine中的字段类型和方 向
Clementine利用经典实例

下面利用Adventure Works数据库中的Target Mail作例子,通过成立分类树和神经网络模型,决策树用来预测哪些人会响应促销,神经网络用来预测年收入。
Target Mail数据在SQL Server样本数据库AdventureWorksDW中的视图,关于Target Mail详见:概念数据源将一个Datebase源组件加入到数据流设计区,双击组件,设置数据源为视图。
在Types栏中点“Read Values”,会自动读取数据个字段的Type、Values等信息。
Values是字段包括的值,比如在数据集中NumberCardsOwned字段的值是从0到4的数,HouseOwnerFlag只有1和0两种值。
Type是依据Values判定字段的类型,Flag类型只包括两种值,类似于boolean;Set是指包括有限个值,类似于enumeration;Ragnge是持续性数值,类似于float。
通过了解字段的类型和值,咱们能够确信哪些字段能用来作为预测因子,像AddressLine、Phone、DateFirstPurchase等字段是无用的,因为这些字段的值是无序和无心义的。
Direction说明字段的用法,“In”在SQL Server中叫做“Input”,“Out”在SQL Server 中叫做“PredictOnly”,“Both”在SQL Server中叫做“Predict”,“Partition”用于对数据分组。
2. 明白得数据在建模之前,咱们需要了解数据集中都有哪些字段,这些字段如何散布,它们之间是不是隐含着相关性等信息。
只有了解这些信息后才能决定利用哪些字段,应用何种挖掘算法和算法参数。
在除在成立数据源时Clementine能告知咱们值类型外,还能利用输出和图形组件对数据进行探讨。
例如先将一个统计组件和一个条形图组件拖入数据流设计区,跟数据源组件连在一路,配置好这些组件后,点上方绿色的箭头。
实验四 Clementine数据挖掘

实验四 数据挖掘实验指导一、目的掌握数据挖掘工具Clementine 的基本方法与操作。
二、任务利用Clementine 对药物数据进行简单的数据挖掘操作,熟悉数据挖掘的基本步骤。
三、要求了解数据挖掘的基本步骤,完成针对给定数据的决策树挖掘/关联规则分析/聚类分析,并写出实验报告。
四、实验内容利用Clementine 对Drug.txt 中药物研究数据进行决策树、关联规则分析,观察挖掘的结果,比较这些方法挖掘结果的异同,根据观察的结果写出实验报告。
注:药物研究数据来源于对治疗同一疾病病人的处方,这些病人服用不同药物,取得了相同效果。
其中所含数据项如下:Age: 年龄 Sex: 性别(M\F) Drug: 病人所服药物种类(A/B/C/X/Y) BP: 血压(High\Normal\Low)Cholesterol: 胆固醇(Normal\High) Na: 唾液中钠元素含量 K: 唾液中钾元素含量 希望通过数据挖掘发现这些处方中隐藏的规律,给出不同临床特征病人更适合服务哪种药物的建议,为未来医生填写处方提供参考。
五、实验环境1、 硬件:P4/256MB 台式计算机2、 软件:Windows 2000 Professional/SQL Server 2000/Clementine 8.1及以上3、 数据:Drugs 数据 (文件Drug.txt) 六、步骤(一) 启动clementine双击桌面数据挖掘工具“clementine 8.1” 图标或C:\Clementine 8.1\bin\Clementine.exe ,即可启动该挖掘工具,界面如图4-1所示。
主工作区结果输出区(二)数据挖掘操作1.挖掘流(stream)操作(1)新建:File菜单→New Stream命令(2)保存/另存:File菜单→Save Stream /Save Stream As…命令→指定保存位置、文件名称→保存按钮(3)打开:File菜单→Open Stream…命令→指定要打开流的位置、文件名称→打开按钮2.挖掘步骤(1)建立连接数据源1)在挖掘工具区选项卡“Sources”中将“Var. File”节点拖入到主工作区。
基于决策树的数据挖掘算法

基于决策树的数据挖掘算法从数据挖掘的角度来看,决策树是一种在监督学习中被广泛应用的方法。
它是一个基于树状结构的模型,可以用来处理各种类型的数据,包括定量和定性的数据、连续和离散的数据等。
决策树的本质是建立一种映射关系,将输入数据的特征与输出的结果联系起来,并在此基础上进行分类或预测。
决策树算法具有简单、直观、易于理解等优点,因此被广泛应用于数据挖掘、机器学习、人工智能等领域。
一、决策树算法介绍决策树是一种具有层级结构的图形模型,由根节点、内部节点、叶子节点组成。
根节点表示整个数据集,内部节点表示特征属性,叶子节点表示具体的分类或回归结果。
在决策树算法中,需要针对某个特定属性选择一个最优的分裂点,将数据集划分为多个子集,然后在每个子集上递归地应用相同的分裂策略。
这个过程一直持续到所有属性都被用完,或者数据集达到某个特定条件(如纯度达到一定值)为止。
最终得到一棵决策树,可用于分类或者回归预测。
二、决策树算法的特点(一)简单易用相对于其他算法(如神经网络、支持向量机等),决策树算法的实现比较简单,不需要太多的数学知识。
决策树的结构非常直观,容易理解和解释,可以用于可视化和分析。
同时,决策树算法的运行速度比较快,适用于大规模的数据处理需求。
(二)可解释性强决策树模型可以被看做是一种“逻辑规则”模型,对于输入数据的分类或预测结果,可以通过直接的路径分析和决策规则来解释。
因此,决策树模型在医疗、金融、面向消费者的应用等场景中具有很高的可接受度。
同时,由于其可解释性强,也是决策树被用于透明度要求较高的领域的原因之一。
(三)很容易过拟合决策树算法的一个缺点是容易产生过拟合问题。
由于决策树算法采用贪心算法,往往不能够获得全局最优解,因此容易导致模型没有泛化能力,无法在新数据上进行有效的预测。
(四)对错误数据敏感由于决策树算法是基于离散特征进行分类的,对于噪声和错误数据比较敏感。
如果输入数据存在错误或者缺失值,会影响模型的分类和预测效果。
Clementine决策树CHAID算法

CHAID算法(Chi-Square Automatic Interaction Detection)CHAID提供了一种在多个自变量中自动搜索能产生最大差异的变量方案。
不同于C&R树和QUEST节点,CHAID分析可以生成非二进制树,即有些分割有两个以上的分支。
CHAID模型需要一个单一的目标和一个或多个输入字段。
还可以指定重量和频率领域。
CHAID分析,卡方自动交互检测,是一种用卡方统计,以确定最佳的分割,建立决策树的分类方法。
1.CHAID方法(卡方自动交叉检验)CHAID根据细分变量区分群体差异的显著性程度(卡方值)的大小顺序,将消费者分为不同的细分群体,最终的细分群体是由多个变量属性共同描述的,因此属于多变量分析。
在形式上,CHAID非常直观,它输出的是一个树状的图形。
1.它以因变量为根结点,对每个自变量(只能是分类或有序变量,也就是离散性的,如果是连续变量,如年龄,收入要定义成分类或有序变量)进行分类,计算分类的卡方值(Chi-Square-Test)。
如果几个变量的分类均显著,则比较这些分类的显著程度(P值的大小),然后选择最显著的分类法作为子节点。
2.CHIAD可以自动归并自变量中类别,使之显著性达到最大。
3.最后的每个叶结点就是一个细分市场CHAID 自动地把数据分成互斥的、无遗漏的组群,但只适用于类别型资料。
当预测变量较多且都是分类变量时,CHAID分类最适宜。
2.CHAID分层的标准:卡方值最显著的变量3.CHAID过程:建立细分模型,根据卡方值最显著的细分变量将群体分出两个或多个群体,对于这些群体再根据其它的卡方值相对最显著的细分变量继续分出子群体,直到没有统计意义上显著的细分变量可以将这些子群体再继续分开为止。
4.CHAID的一般步骤-属性变量的预处理-确定当前分支变量和分隔值属性变量的预处理:-对定类的属性变量,在其多个分类水平中找到对目标变量取值影响不显著的分类,并合并它们;-对定距型属性变量,先按分位点分组,然后再合并具有同质性的组;-如果目标变量是定类变量,则采用卡方检验-如果目标变量为定距变量,则采用F检验(统计学依据数据的计量尺度将数据划分为三大类,即定距型数据(Scale)、定序型数据(Ordinal)和定类型数据(Nominal)。
clementine决策树c5.0算法
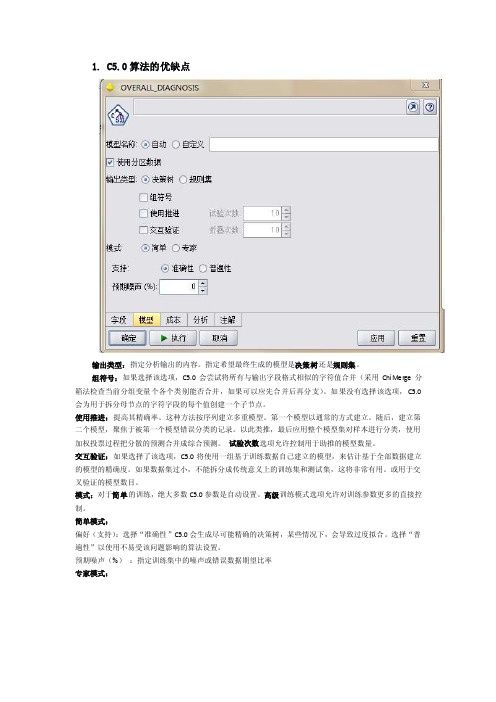
1.C5.0算法的优缺点输出类型:指定分析输出的内容。
指定希望最终生成的模型是决策树还是规则集。
组符号:如果选择该选项,C5.0会尝试将所有与输出字段格式相似的字符值合并(采用ChiMerge分箱法检查当前分组变量个各个类别能否合并,如果可以应先合并后再分支)。
如果没有选择该选项,C5.0会为用于拆分母节点的字符字段的每个值创建一个子节点。
使用推进:提高其精确率。
这种方法按序列建立多重模型。
第一个模型以通常的方式建立。
随后,建立第二个模型,聚焦于被第一个模型错误分类的记录。
以此类推,最后应用整个模型集对样本进行分类,使用加权投票过程把分散的预测合并成综合预测。
试验次数选项允许控制用于助推的模型数量。
交互验证:如果选择了该选项,C5.0将使用一组基于训练数据自己建立的模型,来估计基于全部数据建立的模型的精确度。
如果数据集过小,不能拆分成传统意义上的训练集和测试集,这将非常有用。
或用于交叉验证的模型数目。
模式:对于简单的训练,绝大多数C5.0参数是自动设置。
高级训练模式选项允许对训练参数更多的直接控制。
简单模式:偏好(支持):选择“准确性”C5.0会生成尽可能精确的决策树,某些情况下,会导致过度拟合。
选择“普遍性”以使用不易受该问题影响的算法设置。
预期噪声(%):指定训练集中的噪声或错误数据期望比率专家模式:修剪纯度:决定生成决策树或规则集被修剪的程度。
提高纯度值将获得更小,更简洁的决策树。
降低纯度值将获得更加精确的决策树。
子分支最小记录数:子群大小可以用于限制决策树任一分支的拆分数。
全局修剪:第一阶段:局部修剪;第二阶段:全局修剪。
辨别属性:如果选择了该选项,C5.0会在建立模型前检测预测字段的有用性。
被发现与分析无关的预测字段将不参与建模过程。
这一选项对许多预测字段元的模型非常有用,并且有助于避免过度拟合。
C5.0”成本”选项见“CHAID“成本”选项----误判成本值,调整误判C5.0的模型评价可通过Analysis节点实现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
确定培训目标
模型 应用 步骤5
将数据挖掘结果形 成报告
落实培训成果
落实培训成果 模型评估
是否符合商业目的 选择算法 建立模型
设计培训方案
数据清洗 指标筛选
评估数据质量
商业目的 模型输出 模型定义
确定培训需求
数据准备—重要性分析
变量重要性分析,是去除变量冗余,是对变量的浓缩和提炼,保留对输出变量的预测有重要贡献的 变量和样本,剔除不重要的变量和样本。
组间方差/ 组内方差
学历
得分 27 93 60 28 90 56 87 32 58
组内 均值
组内 方差
组间 方差
组间方差/ 组内方差
29
14
60
2178
58
8
1862
46.55
中学生
2 3 1
58
1928
2
0.00036
90
18
大学生
2 3
59
1514
可以看出学历对做数学题的影响显著 但对做智力题的影响不明显
E
A
j 1
j
v
E( A ) s s
1 j
v
s1 j s2 j smj
s smj
j 1
2 j
s
I
p
m
s 1 i 1j , s2
ij
log2 pij
j
,
, smj
s1 j s2 j smj s 其中, 是第j个子集的权, s
则属性变量A带来的信息增益为
信息熵在C5.0算法中的应用
设S是s个数据样本的集合。目标变量C有m个不同值Ci(i=1,2,…,m)。设si中S属于Ci类的样本数,则 集合S的信息熵定义为:
I ( S ) pi log2 ( pi )
i 1
m
其中
pi
si
是任意样本属于 Ci的概率。 s
设属性A具有v个不同值{a1,a2,…,av}。可以用属性A将S划分为v个子集{S1,S2,…,SV};其中, 设 sij 是子集 Sj 中类 Ci 的样本数。根据由A划分成子集的熵为:
• 决策树(Decision Tree)模型,也称规则推理模型 – 通过对训练样本的学习,建立分类规则 – 依据分类规则,实现对新样本的分类 – 属于有指导(监督)式的学习方法,有两类变 量: • 目标变量(输出变量) • 属性变量(输入变量)
常用的算法有CHAID、CART、 Quest 和C5.0。 对每个决策都要求分成的组之间的“差异”最大。各 种决策树算法之间的主要区别就是对这个“差异”衡 量方式的区别。
核心问题
决策树的生长 决策树的减枝 树剪枝的原因:完整的决策树对训练样本特征的 捕捉“过于精确”--- 过拟和 常用的修剪技术: 预修剪:用来限制决策树的充分生长。
利用训练样本集完成决策树的建立
过程 分枝准则的确定涉及:
•第一,如何从众多的输入变量中
选择一个当前最佳的分组变量 •第二,如何从分组变量的众多取 值中找到一个最佳的分割点
s=14,目标变量“是否流失”有两个不同值,
类C1对应于“是”,类C2对应于“否”。 则s1=9,s2=5,p1=9/14,p2=5/14。 1、计算对给定样本分类所需的期望信息:
2 3
4 5 6 7 8 9 10 11 12 13 14
<=30 31…40
>40 >40 >40 31…40 <=30 <=30 >40 <=30 31…40 31…40 >40
s1 j s2
smj
pij
是 Sj 中的样本属于类 Ci 的概率。
sij sj
Gain( A) I ( S ) E ( A)
Gain A I
s1 , s2 ,
, sm
E A
C5.0算法应用场景
场景:利用决策树算法分析具有哪些特点的用户最可能流失:
用户 1 年龄 <=30 出账收入 智能机 信用等级 高 否 一般 类别:是否流失 否
(176 184) 2 (82 74) 2 (146 146) 2 (59 59) 2 184 74 146 59 2 2 2 (213 182) (42 73) (132 154) (84 62) 2 182 73 154 62 30.86
i
1 P(ui ) log2 P(ui ) P(ui ) i
信息熵等于0,表示只存在唯一的信息发送可能,P(ui)=1,没有发送的不确定性; 如果信源的k个信号有相同的发送概率,P(ui)=1/k,则信息发送的不确定性最大,信息熵达
到最大
P(ui)差别小,信息熵大,平均不确定性大;反之,差别大,信息熵小,平均不确定性小。
fe
RT CT CT * RT * *n n n n
RT指定单元格所在行的观测频数合计,CT指定单元格所在列的观测频数合计,n为观测频数总计。 3、确定临界值 显著性水平A,一般为0.05或0.01 卡方观测值大于卡方临界值,拒绝零假设,变量间不独立 卡方观测值小于卡方临界值,接受零假设,变量间独立
卡方检验
卡方检验的一般流程:
1、提出基本的无效假设:
行分类变量与列分类变量无关联 2、Pearson卡方统计量
r c
卡方检验两个分类变量的 关联性,其根本思想就是 在于比较理论频数和实际 频数的吻合程度
2 i 1 j 1
( f ij0 f ije ) 2 f ije
f0
其中r为列联表的行数,c为列联表的列数, 为观察频数,fe为期望频数。 其中,
由于 “年龄” 属性具有最高信息增益,它被选作测试属性。创建一个节点,用“年龄”标记,
并对每个属性值引出一个分支
C5.0算法应用场景
年龄
<=30 30…40 表1 出账收入 智能机信用等级 高 否 一般 高 否 良好 中等 否 一般 低 是 一般 中等 是 良好
>40
是否流失 否 否 否 是 是
出账收入 中等 低 低 中等 中等
基于clementine的数据挖掘算法
目录
1
数据挖掘概述
章 节 安 排
2
决策树C5.0算法
3
算法
数据挖掘方法论
CRISP-DM数据挖掘实施方法论帮助企业把注 意力集中在解决业务问题上,它包括了六个步 骤,涵盖了数据挖掘的整个过程。 模型 步骤5 评价 建立 步骤4 模型 数据 步骤3 准备 数据 步骤2 理解 业务 步骤1 理解
高 高
中等 低 低 低 中等 低 中等 中等 中等 高 中等
否 否
否 是 是 是 否 是 是 是 否 是 否
良好
一般 一般 一般 良好 良好 一般 一般 一般 良好 良好 一般 良好
否
是 是 是 否 是 否 是 是 是 是 是 否
9 9 5 5 I ( s1 , s2 ) log 2 log 2 0.94 14 14 14 14
标的同一水平(值)内部随机误差对结果的影响,如果某指标对目标总体结果没有影响则组内方差与组间方
差近似相等,而如果指标对目标总体结果有显著影响,则组间方差大于组内方差,当组间方差与组内方差的 比值达到一定程度,或着说达到某个临界点时就可做出待选指标对结果影响显著的判断。
F 组间方差 组内方差
ij
x 组内方差
方差分析
背景 方差分析(Analysis of Variance)是利用样本数据检验两个或两个以上的总体均值间是否有差异的一种方法。 在研究一个变量时,它能够解决多个总体的均值是否相等的检验问题;在研究多个变量对不同总体的影响时, 它也是分析各个自变量对因变量影响程度的方法。 原理与方法 方差分析主要是通过方差比较的方式来对不同总体参数进行假设检验。由于目标总体差异的产生来自两个方 面,一方面由总体组间方差造成即指标的不同水平(值)对结果的影响,另一方面由总;
组内离差平方和除以自由度 ni -1
2
2
xi :表示第i组的均值;
ni 1
ni :表示第i组数据个数;
x :表示全体的均值;
xi x 组间方差 n 1
组内离差平方和除以自由度n-1
n :表示全体分组个数;
方差分析应用场景
2、计算每个属性的熵。
(1)先计算属性“年龄”的熵。 • 对于年龄=“<=30”:s11=2,s21=3,p11=2/5,p21=3/5, 对于年龄=“31…40”:s12=4,s22=0,p12=4/4=1,p22=0, 对于年龄=“>40”:s13=3,s23=2,p13=3/5,p23=2/5, •
从变量自身 考察
变量重要性分析方法
变量与输出变量
、变量间的相关 程度
变量值中缺失值所占比例 分类变量中,类别个数占样本比例 数值变量的变异系数 数值型变量的标准差
输入、输出变量均为数值型:做两个变量的相
关性分析
输入变量为数值型、输出变量为分类型:方差 分析(输出变量为控制变量、输入变量为观测变 量) 输入变量为分类型、输出为数值型:方差分析 (输入变量为控制变量、输出变量为观测变量) 输入、输出变量均为分类型:卡方检验
C5.0算法应用场景
如果样本按“年龄”划分,对一个给定的样本分类所需的期望信息为:
E (年龄 )
5 4 5 I (s11 , s21 ) I (s12 , s22 ) I (s13 , s23 ) 0.694 14 14 14
因此,这种划分的信息增益是 Gain(年龄)=I(s1,s2) - E(年龄)=0.246 (2)以相同方法计算其他属性的增益得到 Gain(出账收入)=I(s1,s2) - E(收入)=0.940-0.911=0.029 Gain(智能机)=I(s1,s2) - E(学生)=0.940-0.789=0.151 Gain(信用等级)=I(s1,s2) - E(信用等级)=0.940-0.892=0.048 3、得到较优的分类变量