查询树的优化
MySQL查询性能优化

MySQL查询性能优化⼀、MySQL查询执⾏基础1. MySQL查询执⾏流程原理<1> 客户端发送⼀条查询给服务器。
<2> 服务器先检查查询缓存,如果命中了缓存,则⽴刻返回存储在缓存中的结果。
否则进⼊下⼀阶段。
<3> 服务器进⾏SQL解析、预处理,再由优化器⽣成对应的执⾏计划。
<4> MySQL根据优化器⽣成的执⾏计划,调⽤存储引擎的API来执⾏查询。
<5> MySQL将结果返回给客户端,同时保存⼀份到查询缓存中。
2. MySQL客户端/服务器通信协议<1> 协议类型:半双⼯。
<2> Mysql通常需要等所有的数据都已经发送给客户端才能释放这条查询所占⽤的资源。
<3> 在PHP函数中,mysql_query()会将整个查询的结果集缓存到内存中,⽽mysql_unbuffered_query()则不会缓存结果,直接从mysql服务器获取结果。
当结果集很⼤时,使⽤后者能减少内存的消耗,但服务器的资源会被这个查询占⽤⽐较长的时间。
3. 查询状态 可以使⽤命令来查询mysql当前查询的状态:show full processlist。
返回结果中的“State”键对应的值就表⽰查询的状态,主要有以下⼏种:<1> Sleep:线程正在等待客户端发送新的请求。
<2> Query:线程正在执⾏查询或正在将结果发送给客户端。
<3> Locked:在MySQL服务器层,该线程正在等待表锁。
(在没⾏锁的引擎出现)<4> Analyzing and statistics:线程正在收集存储引擎的统计信息,并⽣成查询的执⾏计划。
<5> Copying to tmp [on disk]:线程正在执⾏查询,并且将其结果集都复制到⼀个临时表中,这种状态要么是在做group by操作,要么是⽂件排序操作,或者是union操作。
第四章全局查询处理和优化

§4.4 查询优化的基础
2、查询树 在查询树中,叶子表 示关系,中间节点表 示运算,前序遍历关 系表示运算次序。 定义: ROOT:=T T:=R/(T) /TbT/UT U:=σF/ПA b: =∞/X/∪/∩//∝
§4.4 查询优化的基础
3、举例 例4.2.1 设有一供应关系数据库,有供应者和供应两关系,如下: 供应者:SUPPLIER{SNO,SNAME,AREA} 供应者编号 供应者姓名 供应者所属地域 供应:SUPPLY{SNO,PNO,QTY} 供应者编号 零件号 质量 查询要求:找出地域在″北方″供应100号零件的供应商的信息。 SQL查询语句:SELECT SNO,SNAME FROM SUPPLIER,SUPPLY WHERE AREA=″北方″AND PNO=100 AND SUPPLIER.SNO=SUPPLY.SNO
§4.4 查询优化的基础
(2)等价变换 重复律:UR ≡ UUR 交换律:U1U2R ≡ U2U1R 分配律:U(RbS)≡(UR)b(US) 结合律:Rb1(Sb2T)≡ (Rb1S)b2T 提取律:(UR)b(US) ≡ U(RbS) 其中:R、S、T为关系,U1、U2、U为一元运算符 ,b1、b2、 b为二元运算符。
§4.4 查询优化的基础
3、举例 等价的关系表达式: Q1:ПSNO,SNAMEσAREA=″北方″σPNO=100 (SUPPLIER∞SUPPLY) 查询树:
§4.2 Overview of Query Processing
通常用SQL语言操纵语言来表达全局查询。之后, 由系统将其转换成内部表示。实际上,在查询执 行过程时,最终涉及的是具体场地上的物理关系 的查询。影响查询处理效率的因素有:网络传输 代价(数据量和延迟等)、局部I/O代价及CPU 使用情况代价等,但主要由网络通信代价和局部 I/O代价来衡量。不同的分布式数据库系统可能对 评估查询处理的传输代价和I/O代价的侧重不同, 同时,为提高查询的效率,在查询处理过程中还 要进行优化处理,查询优化就是确定出一种执行 代价最小的查询执行策略或寻找相对较优的操作 执行步骤。一般可采用多级优化。本章介绍全局 查询的处理与优化。
表连接优化
浓密树 它连接的两个输入可能都不是表,这种树的结构是完全自由的,查询优化 器只有在没有其他选择的情况下才会选择他。他常会出现在有无法合并的 视图或者子查询的时候。
连接的类型 两种写法 1、SQL-86 2、oracle9i开始支持SQL-92 我们下面来看看连接类型 1、交叉连接(笛卡尔连接) 将一张表的所有记录与另一张表的所有记录进行组合的操作。
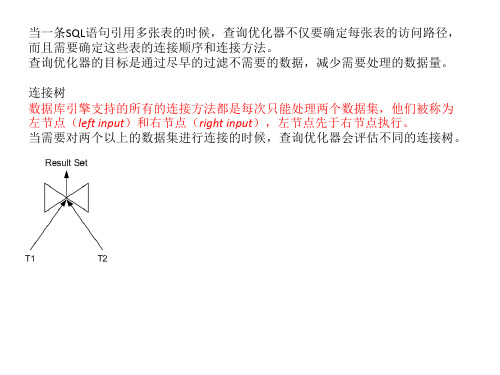
当一条SQL语句引用多张表的时候,查询优化器不仅要确定每张表的访问路径, 而且需要确定这些表的连接顺序和连接方法。 查询优化器的目标是通过尽早的过滤不需要的数据,减少需要处理的数据量。
连接树 数据库引擎支持的所有的连接方法都是每次只能处理两个数据集,他们被称为 左节点(left input)和右节点(right input),左节点先于右节点执行。 当需要对两个以上的数据集进行连接的时候,查询优化器会评估不同的连接树。
连接条件 限制条件
从实现的角度看,查询优化器误用限制条件与连接条件也是正常的,一 方面,连接条件可用来过滤数据,另一方面,为了最大程度的降低连接 使用的数据量,限制条件可能会在连接条件之前进行过滤。
首先执行的是限制条件 然后进行表连接
嵌套循环连接 嵌套循环连接处理的两个数据集被称为外部循环(outer loop,也就是驱动 数据源,driving row source)和内部循环(inner loop)。 外部循环作为左子节点,内部循环作为右子节点。 当外部循环执行一次的时候,内部循环需要针对外部循环返回的每条记录 执行一次。
注意:无法控制块预取功能的使用,如何以及是否使用块预取是数据库引擎自行 决定的。
其他可选的执行计划 只有当内部循环或者外部循环是 基于唯一索引扫描的时候才会使 用这种类型的执行计划。
sql 语法树

sql 语法树
SQL语法树(SQL syntax tree)是指将SQL语句转化为树形结构表示的方式。
SQL语法树可以帮助理解SQL语句的结构和语义,并且可以用于编写查询优化器、解析器等数据库引擎组件。
SQL语法树的结构通常由节点和边组成。
每个节点代表SQL语句中的一个语法元素,如SELECT、FROM、WHERE等,每个边表示语法元素之间的关系,如子节点、父节点、兄弟节点等。
SQL语法树的构建过程通常包括以下步骤:
1. 词法分析:将SQL语句拆分成多个词法单元,如关键字、标识符、运算符等。
2. 语法分析:根据SQL语法规则,将词法单元组合成语法元素,并构建语法树。
3. 语义分析:对语法树进行语义检查,如表是否存在、列是否重复等。
4. 优化:根据查询优化规则,对语法树进行优化,如重写查询计划、选择索引等。
5. 执行:根据优化后的语法树,执行查询操作。
SQL语法树的使用可以帮助开发人员理解和调试SQL语句,同时也可以用于数据库引擎的开发和优化工作。
第四章全局查询处理和优化

查询处理概述
查询处理问题
集中查询处理器必须:
将演算查询转换为代数操作 选择最好的执行计划
例如:
SELECT ENAME FROM E,G WHERE RESP = “Manager” and E.ENO=G.ENO
第四章 分布查询处理和优化
查询处理概述
关系代数 1: ( RESP " M anager " E . EM O G . EN O ( E G )) EN AM E
查询优化的基础
• 读取自然连接结果, 执行选择运算, 需50s, 选择结果均可放 在内存 • 投影运算: • 总花费为: 105+50+50=205s 3.4分钟 Q3= sname( Students Cno=„2‟(SC))
Q3代价计算(仅考虑I/O代价)
计算对SC做选择运算的代价 • 需读SC到内存进行选择运算 • 读SC块数为: 10000/100=100 • 花费为: 100/20=5s • 选择结果为50个SC元组, 均可放在内存
域演算:{ x 1 , x 2 , . . . x n | F ( x 1 , x 2 , . . . , x n )} 其中 x‟s: 域变量, F(x1,…,xn): wff 例如: { x , y | E ( x , y , " manager
" )}
第四章 分布查询处理和优化
查询处理概述
第四章 分布查询处理和优化
第四章 分布查询处理和优化
查询处理概述
优化的查询
G 1 ' RESP
E1 '
" Manager "
( G 1)
第9章 9.3 代数优化

5)选择与投影的交换
6)选择与笛卡尔积的交换
如果F中涉及的属性都是 E1中的属性, 则 F ( E1 E2 ) F ( E1 ) E 2 如果F F1 F 2, 且F1只涉及E1中的属性,F 2只涉及E 2中的属性, 则 F ( E1 E2 ) F 1 ( E1 ) F 2 ( E 2) 如果F1只涉及E1中的属性, F 2涉及E1和E 2两者的属性, 则 F ( E1 E2 ) F 2 ( F 1 ( E1 ) E 2)
第九章
关系查询处理及其查询优化
9.1 关系数据库系统的查询处理 9.2 关系数据库系统的查询优化 9.3 代数优化 9.4 物理优化 9.5 小 结
RDBMS查询处理步骤
9.3 代 数 优 化
要解决两个问题: 如何构造查询树(语法分析树)? 如何进行代数优化?依据(规则)是什么? 代数优化: 是指关系代数表达式的优化。各种关系查询语言都可以等价地 转换为关系代数表达式,因此关系代数表达式的优化是查询优 化的基本课题 代数优化策略:通过对关系代数表达式的等价变换来提高查 询效率
SP.QUAN 10000
P
S
SP
优化算法练习
学生-课程关系数据库中包括以下关系模式: S(S#,Sname,Age,Sex) SC(S#,C#,Grade) C(C#,Cname,Teacher) 现有一查询操作: 检索学习了刘老师课程的女学生的学号和姓名。 要求: (1)写出SQL查询语句 (2)画出用关系代数表示的语法树,并用优化算法对语法树进行优化。
9.3.3 关系代数表达式的优化步骤
把上述得到的“优化”后的语法树的内节点分组。
每一双目运算(×,∞,∪,-)和它所有的直接祖先为一组
分布式数据库系统其应用(徐俊刚 第三版)重点课后习题

第一章1.1 采用分布式数据库系统的主要原因是什么?集中式数据库系统的不足:1.数据按实际需要已经在网络上分布存储,如果再采用集中式处理,势必造成附加成本和通信开销,2,。
应用程序集中在一台计算机上运行,一旦该计算机发生故障,将会影响整个系统的运行,可靠性不高。
3集中式处理导致系统的规模和配置都不够灵活,系统的可扩展性较差。
1.2 分布式数据库系统有哪几种分类方法?这些方法是如何分类的?1.按局部数据库管理系统的数据模型的类型分类。
(1)同构型:同构同质型:各个站点上的数据库的数据模型都是同一类型的,而且是同一种DBMS。
同构异质型:各个站点上的数据库的数据模型都是同一类型的,但不是同一种DBMS。
(2)异构型:各个站点上的数据库的数据模型各不相同。
2.按分布式数据库系统全局控制系统类型分类(1)全局控制集中型DDBS(2)全局控制分散型DDBS(3)全局控制可变型DDBS1.3 什么是分布式数据库系统?它具有那些主要特点?怎样区分分布式数据库系统与只提供远程数据访问的网络数据库系统?分布式数据库系统是物理上分散而逻辑上集中的数据库系统,其可以看成是计算机网络和数据库系统的有机结合。
基本特点:物理分布性、逻辑整体性、站点自治性。
导出特点:数据分布透明性、集中与自治相结合的机制、存在适当的数据冗余度、事务管理的分布性。
区分:分布式数据库的分布性是透明的,用户感觉不到远程与本地结合的接缝的存在。
1.6分布式DBMS具有哪些集中式DBMS不具备的功能?数据跟踪,分布式查询处理,分布式事务管理,复制数据管理,安全性,分布式目录管理1.14分布式数据库系统的主要优点是什么?存在哪些技术问题?分布式数据库系统优点:良好地可靠性和可用性;提高系统效率,降低通信成本;较大的灵活性和可伸缩性;经济型和保护投资;适应组织的分布式管理和控制;数据分布式具有透明性和站点具有较好的自治性;提高了资源利用率;实现了数据共享。
sql查询的执行流程

sql查询的执行流程SQL查询的执行流程SQL(Structured Query Language)是用于管理和操作关系数据库的标准语言。
在实际的数据库操作中,查询是最常用的操作之一。
SQL查询的执行流程包括以下几个步骤:解析、编译、优化、执行和返回结果。
1. 解析在执行SQL查询之前,数据库管理系统(DBMS)首先需要对查询语句进行解析。
解析的目的是将查询语句分解为语法分析树或解析树,以便后续的处理。
解析器会检查查询语句的语法是否正确,并将其转换为内部的数据结构。
如果查询语句存在语法错误,解析器会返回相应的错误信息。
2. 编译在解析完成后,DBMS会将解析树转换为可执行的代码。
这个过程被称为编译。
编译器会将解析树转换为DBMS内部的中间表示形式,这种形式通常是一种虚拟机指令或类似于机器码的形式。
编译器会对查询进行语义分析,并生成一个执行计划。
执行计划描述了如何从数据库中获取所需的数据以及如何执行其他操作,如连接、排序和聚合。
3. 优化在生成执行计划后,DBMS会对执行计划进行优化。
优化器会尝试找到最佳的执行计划,以便在最短的时间内返回正确的结果。
优化的过程包括选择合适的索引、调整连接顺序、重新排序操作等。
优化器会考虑查询的各种因素,如表的大小、索引的选择性、统计信息等,以确定最佳的执行路径。
4. 执行在优化完成后,DBMS会执行生成的执行计划。
执行器会按照执行计划的指令逐步执行,从数据库中获取所需的数据,并进行相应的操作。
执行的过程包括访问磁盘、读取数据、进行计算和过滤等。
执行器会按照指定的顺序依次执行查询中的各个操作,并将结果保存在临时表或内存中。
5. 返回结果在执行完成后,DBMS会将查询的结果返回给用户。
结果可以是一个数据集,也可以是一个标量值。
用户可以通过应用程序或命令行界面获取查询的结果。
返回的结果可能需要经过进一步的处理和格式化,以便于用户的查看和分析。
总结SQL查询的执行流程包括解析、编译、优化、执行和返回结果这几个关键步骤。
第3章 分布式数据库中的查询处理和优化

5 6
7
由此可见,一个好的查询处理应该使数据的传输量和通信次 数最少,这样才能使查询所花费的数据传输/或通信时间减少, 从而减少查询的总代价。 如果对第6种方法利用分布式的并行处理,即在A地选择男 生和B地选择‘MATHS’课程名同时进行,这样的总的处理时间还 可以减少。
8
9
3.2 分布式查询优化中的基础知识
3.2.1 用关系代数表达式SQL语句表示一个查询 分布式数据库基本上都采用关系数据模型,以非过程化语言 作为与用户接口的主要语言。这些非过程化语言一般都与SQL语 言兼容,且大多数就是SQL语言。因此,用户向分布式数据库发 出的一个查询,总是可以用关系代数表达式或SQL语言的 SELECT语句来表示。 1、用SQL语句来表示一个查询 SQL已被选作关系数据库的标准语言,查询语句SELECT是 一个功能极强的查询语句。对关系数据库的各种复杂的查询要求, 都可以用SELECT语句来表示。 例3.2 教学数据库中,有三个全局关系: 学生信息S(S#,SNAME,AGE,SEX) 课程设置关系C(C#,CNAME,TEACHER) 选课关系SC(S#,C#,GRADE) 查询选修课程号为‘C03’的学生姓名。
4
(2)在高速局域网中 传输时间比局部处理时间要短得多。在这种情下,往往以响 应时间作为优化目标。响应时间既与通信时间有关,也与局部处 理时间有关,但局部处理时间是关键,所以减少局部处理的时间 是问题的主要方面。 在某些情况下,查询处理同时以减少通信费用与响应时间作 为优化目标。这时,算法往往需要在这两者之间做出权衡。 3、查询代价的估算方法 设一个查询执行的预期代价为QC,则 在集中式中:QC=I/O代价+CPU代价 在分布式中:QC=I/O代价+CPU代价+通信代价 通信代价可用如下公式作粗略估算: TC(X)=C0+C1*X 其中,X为数据的传输量,通常以bit为单位计算; C0为两站点间通信初始化一次所花费的时间,它由通信系统确 定,近似一个常数,以秒为单位; C1为传输率(传输速度的倒数),即单位数据传输的时间,单 5 位是 b/s。
简述空间索引的类型

简述空间索引的类型空间索引是一种用于加快空间数据查询的技术。
它能够将空间数据按照特定的规则进行组织和排序,以便快速检索和访问。
在地理信息系统、数据库和数据挖掘等领域中广泛应用。
一、R树索引R树是一种常用的空间索引方法,它是一种多叉树结构,每个节点代表一个矩形范围。
树的叶子节点保存了实际的空间对象,而非叶子节点保存了其子节点所代表的矩形范围。
通过不断调整节点的位置和大小,R树能够保持树的平衡性和紧凑性,提高查询效率。
二、Quadtree索引Quadtree是一种将二维空间划分为多个象限的树状结构。
每个节点代表一个象限,而非叶子节点代表的象限又被划分为更小的象限,最终形成一棵树。
Quadtree适用于对空间数据进行递归划分和查询,能够有效地处理空间数据的分布不均匀情况。
三、Grid索引Grid索引将空间数据划分为规则的网格单元,每个单元代表一个空间范围。
每个单元可以存储多个空间对象,通过网格索引可以快速定位到包含目标对象的单元,进而加快查询速度。
Grid索引适用于对空间数据进行分区和统计分析。
四、kd树索引kd树是一种二叉树结构,用于对k维空间数据进行划分和查询。
树的每个节点代表一个k维空间范围,非叶子节点按照某个维度的值进行划分,形成左右子树。
kd树索引能够高效地处理高维空间数据的查询问题。
五、R*-tree索引R*-tree是对R树的改进和优化,通过引入一系列策略和算法,提高了R树的查询性能和存储效率。
R*-tree索引在处理大规模和高维空间数据时表现出色,被广泛应用于地理信息系统和数据库领域。
六、Hilbert R树索引Hilbert R树是一种基于Hilbert曲线的空间索引方法,通过将空间数据映射到一条曲线上,实现对空间数据的排序和查询。
Hilbert R 树索引能够有效地处理多维空间数据的查询问题,具有较好的查询性能和存储效率。
空间索引是空间数据处理和查询的重要工具,能够提高数据查询的效率和准确性。
数据库索引原理及优化——查询算法

数据库索引原理及优化——查询算法 我们知道,数据库查询是数据库的最主要功能之⼀。
我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的⾓度进⾏优化。
那么有哪些查询算法可以使查询速度变得更快呢?顺序查找(linear search )最基本的查询算法当然是顺序查找(linear search),也就是对⽐每个元素的⽅法,不过这种算法在数据量很⼤时效率是极低的。
数据结构:有序或⽆序队列复杂度:O(n)实例代码://顺序查找int SequenceSearch(int a[], int value, int n){int i;for(i=0; i<n; i++)if(a[i]==value)return i;return -1;}⼆分查找(binary search)⽐顺序查找更快的查询⽅法应该就是⼆分查找了,⼆分查找的原理是查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某⼀特定元素⼤于或者⼩于中间元素,则在数组⼤于或⼩于中间元素的那⼀半中查找,⽽且跟开始⼀样从中间元素开始⽐较。
如果在某⼀步骤数组为空,则代表找不到。
数据结构:有序数组复杂度:O(logn)实例代码://⼆分查找,递归版本int BinarySearch2(int a[], int value, int low, int high){int mid = low+(high-low)/2;if(a[mid]==value)return mid;if(a[mid]>value)return BinarySearch2(a, value, low, mid-1);if(a[mid]<value)return BinarySearch2(a, value, mid+1, high);}⼆叉排序树查找⼆叉排序树的特点是:1. 若它的左⼦树不空,则左⼦树上所有结点的值均⼩于它的根结点的值;2. 若它的右⼦树不空,则右⼦树上所有结点的值均⼤于它的根结点的值;3. 它的左、右⼦树也分别为⼆叉排序树。
第四章 关系数据库系统的查询优化

34
(3)优化器可以考虑数百种不同的执 行计划,而程序员一般只能考虑有限 的几种可能性。
35
(4)优化器中包括了很多复杂的优化 技术,这些优化技术往往只有最好的 程序员才能掌握。
36
系统的自动优化相当于使得所有人 都拥有这些优化技术。
关系数据库查询优化的总目标是: 选择有效的策略,求得给定关系表 达式的值。
21
准则6 视图更新准则。
所有理论上可更新的视图也应该允 许由系统更新。 什么叫“一个视图是理论上可更新 的视图”呢? 它是指对此视图的更新要求,存在 一个与时间无关的算法,该算法可以 无二义性地把更新要求转换为对基本 表的更新序列。
22
准则7 高级的插入、修改和删除操作。 关系系统的操作对象是单一的关 系。以关系为操作对象不仅简化了用 户查询,提高了用户生产率,而且也 为系统提供了很大的余地来进行查询 优化,提高了系统的运行效率。 它允许系统来选择存取路径,以便 得到最有效的运行代码。
17
准则2 保证访问准则。 依靠表名、主码和列名的组合,保证 能以逻辑方式访问关系数据库中的每个数 据项(分量值)。 保证访问准则表明关系系统所采用的 是关联寻址(association addressing)的 访问模式,而不是那种面向机器的寻址方 法。这是关系系统独有的方式。
18
准则3 空值的系统化处理。 全关系型的DBMS应支持空值的概念, 并用系统化的方式处理空值。 以往处理空值的办法常常是对每个允 许取空值的字段定义一种特殊的值来表示 空值。 这不是系统化的好办法。因为这样的 话,用户必须对每个字段或域采用不同的 方法来处理空值。这种方法必然会大大降 低用户生产率。
39
⑷ 生成查询计划。
查询计划也称查询执行方案,是由 一系列内部操作组成的。 这些内部操作按一定的次序构成查 询的一个执行方案。 通常这样的执行方案有多个,需要 对每个执行计划计算代价,从中选择 代价最小的一个。
基于树形结构的查询优化方法

基于树形结构的查询优化方法咱先得知道啥是树形结构呀。
你就想象一棵树,有树干,有树枝,还有树叶。
在数据结构里呢,树形结构也是类似的,有根节点,然后有分支节点,最后是叶节点。
这就像是家族树一样,有老祖宗(根节点),然后有一代一代的子孙(分支和叶节点)。
那这个树形结构咋在查询优化里起作用呢?比如说我们有大量的数据要查询。
如果没有树形结构的优化,就像在一个大仓库里乱找东西,没个头绪。
但是有了树形结构呢,就好比给这个仓库分了区,每个区又分了小格子。
我们可以根据树形结构的特点,快速定位到我们要找的数据可能在的区域。
举个例子哈,假如我们要在一个图书馆找一本书。
如果没有合理的分类(类似树形结构),那可就惨喽,得一排排书架挨着找。
但要是图书馆按照树形结构来分类,比如先按照学科分类(这就是树干部分),然后再按照作者、年代等细分(树枝和树叶),那找起书来就轻松多啦。
在数据库查询里,树形结构可以帮助我们减少不必要的搜索路径。
就像我们要找住在某个小区某栋楼的一个朋友。
我们不会先在整个城市乱转,而是先找到小区,再找到楼,最后找到房间。
树形结构在查询优化里就是这么个聪明的导航员。
而且哦,树形结构还能根据节点的层级关系,对查询进行优先级的安排。
比如说根节点附近的重要信息,我们可以优先查询。
这就像是在找宝藏的时候,先找大线索,再找小线索一样。
不过呢,树形结构也不是万能的啦。
有时候数据太复杂,树形结构可能也会变得有点混乱。
这时候就需要我们不断调整和优化这个树形结构,就像修剪树木一样,把那些多余的、没用的枝丫去掉,让树形结构更加清晰,查询起来也就更高效啦。
总之呢,树形结构的查询优化方法是个很有趣又很实用的小技巧哦。
你认为智慧树平台有哪些地方可以改进优化的

你认为智慧树平台有哪些地方可以改进优化的
智慧树平台的话嗯,我那个那个给你的平台给你优化的地方还是比较多的,可以在学习的资料方面可以优化一些,添加一些比较多的创新力量是比较好的智慧树平台的话用的人比较多的比较好用的,我们现在现在的人比较多的,智慧树平台的话多开进一些,有的话也是比较好的,用着比较方便的比较好用的
都会刷网课,这些行为是不规范的,另外的话也是不好的行为,所以可以进行添加人脸识别,这样的话,能督促学生来学习吧,毕竟,能够端正学习态度,所以的话,这样会好一些。
hashmap树化和反树化条件

hashmap树化和反树化条件HashMap是Java中常用的一种基于键值对存储数据的数据结构,它实现了一个哈希表,可以通过键值对的方式进行快速的查找、插入、删除等操作。
在JDK1.8之前,HashMap采用“链式散列”的方式,即对于相同的哈希值,将其对应的键值对插入到链表的尾部。
虽然链表是一种简单高效的数据结构,但是当一个桶中存储的键值对数量特别多时,链表的查询效率就变得低下。
因此,在JDK1.8中,HashMap进行了优化,引入了“红黑树”这种数据结构,将链表转化为红黑树,从而提高了查询效率。
本文将介绍HashMap树化和反树化的条件及实现。
1. HashMap的树化条件当HashMap中某一条链表的长度超过8时,HashMap会将这个链表转换为红黑树,从而减少查询的时间复杂度。
转化为红黑树的条件有以下几点:(1)节点数大于阈值8。
(2)HashMap的容量大于64。
(3)链表长度超过8。
树化的过程是通过将链表中的所有节点放入一个数组中,再将这个数组按照“红黑树”的插入规则插入到新的树中实现的。
树化后的结构类似于二叉搜索树,能够快速地查找节点。
2. HashMap的反树化条件与树化相反,HashMap中的红黑树也会在满足一定条件的情况下被转换为链表,这样做是为了防止出现“红黑树”的退化情况,从而避免查询效率的下降。
反树化的条件有以下几点:(1)节点数小于等于6。
(2)HashMap的容量小于64。
(3)链表长度小于等于6。
在这种情况下,HashMap会将树中的所有节点按照“链表”的顺序重新排列,并将它们放回到哈希表中,形成一个新的链表结构。
在这个过程中,我们需要从树的底层开始遍历,找到节点值最小的节点,并将它作为链表的头节点。
反树化后的结构类似于链表,查询效率相比树结构略低,但是在节点数较少的情况下,链表的查询效率仍然很高效。
总之,HashMap的树化和反树化是Java中一项非常重要的优化技术,能够极大地提高HashMap对于大量数据的处理效率,从而帮助开发者更好地处理数据量大、性能要求高的任务。
aggregatingmergetree 条件中使用max字段 -回复

aggregatingmergetree 条件中使用max字段-回复在aggregatingmergetree(聚合合并树)条件中使用max字段确实可以带来很多好处。
在本文中,我们将一步一步地回答这个问题,从什么是聚合合并树开始,解释max字段的含义,以及如何在条件中使用max字段来优化查询性能。
第一部分:介绍聚合合并树聚合合并树是一种用于处理大规模数据集的高效算法。
它将原始数据集分割成多个小数据块,并在这些块之间进行逐层聚合和合并。
聚合合并树可以通过并行处理和减少数据传输量来提高查询性能。
它基于二叉树的结构,其中每个节点都代表一个数据块,并包含有关该数据块的聚合信息。
第二部分:解释max字段的含义max字段代表一个数据块中的最大值。
它可以是数字类型、日期类型或字符串类型的字段。
通过使用max字段,可以轻松找到具有最大值的数据块,而无需遍历所有数据。
这对于查询中需要查找最大值的条件非常有用,因为它可以显著减少查询时间。
第三部分:使用max字段来优化查询性能在条件中使用max字段可以提高查询性能的两个主要方面。
首先,它可以减少需要检查的数据块数量。
通过查找具有最大值的数据块,可以排除其他数据块,从而减少了不必要的计算。
这可以大大加快查询速度,尤其是在数据集非常大的情况下。
其次,使用max字段还可以减少数据传输量。
当处理大规模数据集时,数据的传输是一个昂贵的操作。
通过仅传输具有最大值的数据块,可以大大减少数据传输的成本。
这对于分布式计算和云计算环境特别有用,其中网络通信可以成为瓶颈。
为了使用max字段来优化查询性能,可以采取以下步骤:第一步:确定要查找最大值的字段。
首先,需要确定查询中需要查找最大值的字段是什么。
这可以是数字类型、日期类型或字符串类型的字段。
第二步:在聚合合并树中配置max字段。
将查询的数据集分割成多个数据块,并在每个数据块中计算max字段的值。
聚合合并树的每个节点都应该包含有关其子节点的max字段的信息。
基于部分求值的Twig查询优化

基于部分求值的Twig查询优化高万辰;廖湖声;苏航【摘要】TreeMatch算法是一种有效的Twig查询匹配算法,但其存在反复分析Twig模式的缺点.针对该问题,引入编译中的部分求值技术,提出一种Twig查询优化方案.通过部分求值提前完成对Twig模式的分析,生成查询专用的指令序列代替原查询程序,并给出查询机执行引擎,从而消除重复计算,优化XML树模式查询过程.实验结果表明,在不同Twig模式下,该优化方案能够有效提高XML查询的执行效率.【期刊名称】《计算机工程》【年(卷),期】2016(042)003【总页数】9页(P53-60,68)【关键词】可扩展标记语言数据库;XQuery语言;XPath语言;Twig查询;编译;部分求值;树模式查询【作者】高万辰;廖湖声;苏航【作者单位】北京工业大学计算机学院,北京100124;北京工业大学计算机学院,北京100124;北京工业大学计算机学院,北京100124【正文语种】中文【中图分类】TP391在针对XML数据的查询请求中,经常出现多个结构连接组成的查询模式。
以祖先后代(Ancestor-descendant,AD)关系和双亲子女(Parent-child,PC)关系组成的树型查询模式被认为是XML查询的核心操作,亦称作Twig模式[1]。
针对Twig模式匹配算法的研究多年来得到了广泛的关注:从早期的MPMGJN[2]等二元结构连接算法,到TwigStack[3],TwigList[4],TJFast[5]等整体匹配算法,而TreeMatch算法[6]的设计由于深入分析了中间结果的空间开销,因此被认为是最好的Twig模式匹配算法之一。
在编译技术领域,部分求值被认为是一种通用的程序优化方法。
针对需要多个输入的计算,在程序执行的某个阶段,只要部分输入(静态输入)的取值不变,即可通过部分求值来提前完成与这些输入相关的计算,生成负责后续计算的程序代码(滞留程序)。
mysql where执行原理

mysql where执行原理MySQL是一种常用的关系型数据库管理系统,其where语句是一种重要的查询语句,用于从数据库中选择满足特定条件的数据。
本文将介绍MySQL where执行的原理。
在MySQL中,where语句用于过滤数据,只返回满足特定条件的记录。
where语句通常用于select、update和delete语句中,可以根据不同的条件来过滤数据。
MySQL的执行引擎在执行where语句时,会对where条件进行解析和优化,以提高查询效率。
首先,MySQL会将where条件解析为一个查询树,其中每个节点代表一个条件操作符,如等于、大于、小于等。
然后,MySQL会根据查询树的结构和查询表的索引信息,选择合适的索引来加速查询。
在执行过程中,MySQL使用B+树索引结构来存储和管理表中的数据。
B+树是一种平衡树结构,可以快速定位和访问数据。
当where条件中包含索引字段时,MySQL可以利用索引的特性,快速定位满足条件的记录。
当查询树中存在多个条件操作符时,MySQL会根据操作符的优先级和逻辑关系来执行查询。
一般情况下,MySQL会先执行具有较高优先级的操作符,然后再执行具有较低优先级的操作符。
这样可以避免不必要的计算和数据访问,提高查询效率。
除了使用索引来加速查询,MySQL还可以使用其他优化技术来提高查询性能。
例如,MySQL可以使用预处理技术,将一些常用的查询条件预先计算好,并缓存起来,以便下次查询时直接使用,避免重复计算。
此外,MySQL还可以通过分区和分表等技术,将大表拆分成多个小表,以减少查询的数据量,提高查询效率。
MySQL的where语句在执行过程中,会经过解析、优化和执行等多个步骤。
MySQL会根据查询树的结构和索引信息,选择合适的索引来加速查询。
同时,MySQL还可以使用其他优化技术来提高查询性能。
通过合理使用where语句,可以快速、准确地从数据库中获取所需数据。
calcite mysql解析

calcite mysql解析Calcite是一个开源的SQL解析器和查询优化器。
它可以将SQL语句解析为一个抽象的查询树,然后通过对查询树进行优化,生成执行计划。
Calcite支持很多不同的后端数据库,包括MySQL。
在使用Calcite解析MySQL语句时,可以使用Calcite的MySQL适配器模块,该模块提供了将MySQL语法转换为Calcite内部查询树的功能。
以下是一个使用Calcite解析MySQL语句的示例代码:```javaimport org.apache.calcite.jdbc.CalciteConnection;import org.apache.calcite.sql.SqlNode;import org.apache.calcite.sql.parser.SqlParseException;import org.apache.calcite.sql.parser.SqlParser;import java.sql.Connection;import java.sql.DriverManager;import java.sql.SQLException;import java.util.Properties;public class CalciteMySQLParser {public static void main(String[] args) throws SQLException, SqlParseException {// 创建Calcite连接Connection connection =DriverManager.getConnection("jdbc:calcite:");CalciteConnection calciteConnection =connection.unwrap(CalciteConnection.class);// 创建MySQL解析器Properties properties = new Properties();properties.setProperty("lex", "MYSQL");SqlParser.Config config =SqlParser.configBuilder().setProperties(properties).build();SqlParser parser = SqlParser.create("SELECT * FROM table", config);// 解析查询语句SqlNode sqlNode = parser.parseQuery();// 打印解析结果System.out.println(sqlNode.toString());// 关闭连接connection.close();}}```在上述代码中,我们首先创建了一个Calcite连接,然后从这个连接中获取一个CalciteConnection对象。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
求IS系年龄大于19岁的学生:
Sdept ' IS ' ( Sage19 ( S )) Sdept ' IS 'Sage19 ( S )
5. 选择与投影的交换率
F ( A , A ,
1 2
, An
( E) ) A1 , A2 ,
, An
( F ( E) )
10. 投影于笛卡尔积的分配律
设E1和E2是两个关系表达式,A是E1的属性组, B是E2的属性组。则:
A ,A ,
1 2 1 2
, An , B1 , B2 , , Bm , An
( E1 E2 )
, Bm
A ,A ,
( E1 ) B1 ,B2 ,
( E2 )
注:先做投影可以减少读取写入的数据,因此减少磁盘IO 量,从而提高了效率。
2. 连接、笛卡尔积的结合率 设E1,E2,E3是关系代数表达式,F1和F2是 连接运算的条件,则有:
( E1 E2 ) E3 E1 ( E2 E3 )
( E1 E2 )
F1
E3 E1
F2
( E2
F1
E3 )
F2
( E1
E2 )
) T { trts tt (tr R) (ts S ) (tt T )}
查找所有学生可能的选课对:
Sname,Cname (S C ) Sname (S ) Cname (C )
E1 E2 E2 E1
E1 E2 E2
F
E1
F
E1
E2 E2
E1
笛卡尔积
R S { tr ts (tr R ) (t s S )}
S R { tstr (tr R ) (t s S )}
自然连接
R
S R. AS .B ( R S )
此时,条件F只涉及属性组A。若条件中有不属 于A的属性组B,那么有更一般的规则:
A ,A ,
1 2 1 2
, An
( F ( E ) ) ( F ( A1 , A2 ,
, An , B1 , B2 , , Bm
A ,A ,
, An
(E) ) )
Sage19 ( Sname,Sage ( S )) Sname,Sage ( Sage19 ( E ))
9. 选择对自然连接的分配率
F ( E1
E2 ) F ( E1)
F ( E2 )
F只涉及E1和E2的公共属性。
注:先做选择可以减少做笛卡儿积的数据,结果关系的数 据量也同步减少,因此减少磁盘IO量,提高了效率。
查找‘95001’这位学生的选课记录:
Sno'95001' (S SC ) Sno'95001' (S ) Sno'95001' (SC )
8. 选择与差运算的分配率
设E1和E2有相同的属性名,则:
F ( E1 E2 ) F ( E1) F ( E2 )
注:先做选择可以减少读取写入的数据,因此减少磁盘IO 量,从而提高了效率。
设S1是计科041的学生关系表, S3是计科专业的学生关系表:
Sage19 ( S3 S1 ) Sage19 ( S3 ) Sage19 ( S1 )
等价的概念:
若关系表达式f(E1,E2,…,En)的结果 与关系表达式g(E1,E2,…,En)的结果 是同一个关系,那么称这两个表达式等价。 若关系表达式E1和E2是等价的可以记为:
E1 E2
等价变换规则
1.
连接、笛卡儿积交换率 设E1和E2是关系代数表达式,F是连接运算的条 件,则有:
求所有的学生姓名:
Sname ( Sname,Sage (S )) Sname (S )
4. 选择的串接定律
F ( F (E) ) F F ( E)
1 2 1 2
E是关系代数表达式,F1和F2是选 择条件。选择的串接定律说明选择条件 可以合并,这样一次就可以检查全部的 条件。
(1)F只涉及E1的属性。 (2)F=F1∧F2,且F1只涉及E1的属性,F2只 涉及E2的属性。 (3) F=F1∧F2,且F1只涉及E1的属性,而 F2涉及E1和E2的属性。
(1) 实例:95001这个学生可能的选课情况:
Sno'95001' (S C) Sno'95001' (S ) C
(2)证明:
F ( E1 E2 ) F F ( E1 E2 )
1 2
F2 ( F1 ( E1 E2 ) ) F2 ( F1 ( E1 ) E2 ) F1 ( E1 ) F2 ( E2 )
7. 选择与并的分配率
设E=E1∪E2,E1和E2有相同的属性名,则:
F ( E1 E2 ) F ( E1 ) F ( E2 )
注:先做选择可以减少读取写入的数据,因此减少磁盘IO 量,从而提高了效率。
设S1是计科041的学生关系表, S2是计科042的学生关系表:
Sage19 ( S1 S2 ) Sage19 ( S1 ) Sage19 ( S2 )
R ( S T ) { tr tstt (tr R) (ts S ) (tt T )}
3. 投影的串接定律
A ,A ,
1 2
, An
( B1,B2 ,
,Bm
( E) ) A1 , A2 ,
, An
( E)
这里,E是关系代数表达式,Ai(i=1, 2,…,n),Bj(j=1,2,…,m)是属性 名且{A1,A2,… An} 是{B1,B2,…,Bm} 的子集。
Sname ( Sage19 ( S )) Sname ( Sage19 ( Sname,Sage ( E )))
6.选择与笛卡尔积的交换
F ( E1 ) E2 () 1 F ( E1 E2 ) F1 ( E1 ) F2 ( E2 ) (2 ) ( 3 ) ( ( E ) E ) 2 F2 F1 1