遗传算法简介及代码详解
遗传算法遗传算法

(5)遗传算法在解空间进行高效启发式搜索,而非盲 目地穷举或完全随机搜索;
(6)遗传算法对于待寻优的函数基本无限制,它既不 要求函数连续,也不要求函数可微,既可以是数学解 析式所表示的显函数,又可以是映射矩阵甚至是神经 网络的隐函数,因而应用范围较广;
(7)遗传算法具有并行计算的特点,因而可通过大规 模并行计算来提高计算速度,适合大规模复杂问题的 优化。
26
(4)基本遗传算法的运行参数 有下述4个运行参数需要提前设定:
M:群体大小,即群体中所含个体的数量,一般取为 20~100; G:遗传算法的终止进化代数,一般取为100~500; Pc:交叉概率,一般取为0.4~0.99;
Pm:变异概率,一般取为0.0001~0.1。
27
10.4.2 遗传算法的应用步骤
遗传算法简称GA(Genetic Algorithms)是1962年 由美国Michigan大学的Holland教授提出的模拟自然 界遗传机制和生物进化论而成的一种并行随机搜索最 优化方法。
遗传算法是以达尔文的自然选择学说为基础发展起 来的。自然选择学说包括以下三个方面:
1
(1)遗传:这是生物的普遍特征,亲代把生物信息交 给子代,子代总是和亲代具有相同或相似的性状。生 物有了这个特征,物种才能稳定存在。
18
(3)生产调度问题 在很多情况下,采用建立数学模型的方法难以对生
产调度问题进行精确求解。在现实生产中多采用一些 经验进行调度。遗传算法是解决复杂调度问题的有效 工具,在单件生产车间调度、流水线生产车间调度、 生产规划、任务分配等方面遗传算法都得到了有效的 应用。
19
(4)自动控制。 在自动控制领域中有很多与优化相关的问题需要求
10
遗传算法

2019/12/10
4
轮盘法
6.5% 25.4%
42.2%
(1) 计算每个染色体xi 的适应度f(xi);
35.9%
popsize
(2) 找出群体的适应度之和;SUM f ( xi )
群体(population) 由染色体组成的集合。
代遗传操作 遗传操作作用于群体而产生新的群体。
2019/12/10
2
二、基本算法
用于比较不同的解以 确定哪 一个解是更好 的一个措施。
2019/12/10
3
三、基本遗传算子
选择算子(Selection)
用于模拟生物界去劣存优的自然选择现象。它从旧 种群中选择出适应性强的某些染色体,放人匹配集(缓 冲区),为染色体交换和变异运算产生新种群作准备。
1
一、相关概念
染色体(chromosome)或个体(individual) 把每一个 可能的解编码为一个向量,用来描述基本的遗传结构。 例如,用0,1 组成的串可以表示染色体。
基因
向量中的每一个元素
适应度(fitness) 每个染色体所对应的一个适应值。 在优化问题中,适应度来自于一个目标评价函数。
(7) 重复执行(5)(6)直到缓冲区中有足够多的染色体。
2019/12/10
5
交叉算子(Crossover)
具体做法:
(1) 缓冲区中任选两个染色体(双染色体);
(2) 随机选择交换点位置J,0<J<L(染色体长度);
(3) 交换双亲染色体交换点右边的部分。(单点交叉)
遗传算法详解(含MATLAB代码)

遗传算法详解(含MATLAB代码)Python遗传算法框架使用实例(一)使用Geatpy实现句子匹配在前面几篇文章中,我们已经介绍了高性能Python遗传和进化算法框架——Geatpy的使用。
本篇就一个案例进行展开讲述:pip install geatpy更新至Geatpy2的方法:pip install --upgrade --user geatpy查看版本号,在Python中执行:import geatpyprint(geatpy.__version__)我们都听过“无限猴子定理”,说的是有无限只猴子用无限的时间会产生特定的文章。
在无限猴子定理中,我们“假定”猴子们是没有像人类那样“智能”的,而且“假定”猴子不会自我学习。
因此,这些猴子需要“无限的时间"。
而在遗传算法中,由于采用的是启发式的进化搜索,因此不需要”无限的时间“就可以完成类似的工作。
当然,需要产生的文章篇幅越长,那么就需要越久的时间才能完成。
下面以产生"T om is a little boy, isn't he? Yes he is, he is a good and smart child and he is always ready to help others, all in all we all like him very much."的句子为例,讲述如何利用Geatpy实现句子的搜索。
之前的文章中我们已经讲述过如何使用Geatpy的进化算法框架实现遗传算法编程。
这里就直接用框架。
把自定义问题类和执行脚本编写在下面的"main.py”文件中:# -*- coding: utf-8 -*-import numpy as npimport geatpy as eaclass MyProblem(ea.Problem): # 继承Problem父类def __init__(self):name = 'MyProblem' # 初始化name(函数名称,可以随意设置) # 定义需要匹配的句子strs = 'Tom is a little boy, isn't he? Yes he is, he is a good and smart child and he is always ready to help others, all in all we all like him very much.'self.words = []for c in strs:self.words.append(ord(c)) # 把字符串转成ASCII码M = 1 # 初始化M(目标维数)maxormins = [1] # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)Dim = len(self.words) # 初始化Dim(决策变量维数)varTypes = [1] * Dim # 初始化varTypes(决策变量的类型,元素为0表示对应的变量是连续的;1表示是离散的)lb = [32] * Dim # 决策变量下界ub = [122] * Dim # 决策变量上界lbin = [1] * Dim # 决策变量下边界ubin = [1] * Dim # 决策变量上边界# 调用父类构造方法完成实例化ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)def aimFunc(self, pop): # 目标函数Vars = pop.Phen # 得到决策变量矩阵diff = np.sum((Vars - self.words)**2, 1)pop.ObjV = np.array([diff]).T # 把求得的目标函数值赋值给种群pop的ObjV执行脚本if __name__ == "__main__":"""================================实例化问题对象============================="""problem = MyProblem() # 生成问题对象"""==================================种群设置================================"""Encoding = 'RI' # 编码方式NIND = 50 # 种群规模Field = ea.crtfld(Encoding, problem.varTypes, problem.ranges,problem.borders) # 创建区域描述器population = ea.Population(Encoding, Field, NIND) # 实例化种群对象(此时种群还没被初始化,仅仅是完成种群对象的实例化)"""================================算法参数设置=============================="""myAlgorithm = ea.soea_DE_rand_1_L_templet(problem, population) # 实例化一个算法模板对象myAlgorithm.MAXGEN = 2000 # 最大进化代数"""===========================调用算法模板进行种群进化========================="""[population, obj_trace, var_trace] = myAlgorithm.run() # 执行算法模板population.save() # 把最后一代种群的信息保存到文件中# 输出结果best_gen = np.argmin(obj_trace[:, 1]) # 记录最优种群是在哪一代best_ObjV = obj_trace[best_gen, 1]print('最优的目标函数值为:%s'%(best_ObjV))print('有效进化代数:%s'%(obj_trace.shape[0]))print('最优的一代是第 %s 代'%(best_gen + 1))print('评价次数:%s'%(myAlgorithm.evalsNum))print('时间已过 %s 秒'%(myAlgorithm.passTime))for num in var_trace[best_gen, :]:print(chr(int(num)), end = '')上述代码中首先定义了一个问题类MyProblem,然后调用Geatpy内置的soea_DE_rand_1_L_templet算法模板,它实现的是差分进化算法DE-rand-1-L,详见源码:运行结果如下:种群信息导出完毕。
遗传算法代码python

遗传算法代码python一、简介遗传算法是一种通过模拟自然选择和遗传学原理来寻找最优解的优化算法。
它广泛应用于各种领域,包括优化问题、搜索和机器学习等。
二、代码概述以下是一个简单的遗传算法的Python代码示例,用于解决简单的优化问题。
该算法使用一个简单的二进制编码方式,并使用适应度函数来评估每个个体的适应度。
三、代码实现```pythonimportnumpyasnp#遗传算法参数POPULATION_SIZE=100#种群规模CROSSOVER_RATE=0.8#交叉概率MUTATION_RATE=0.1#变异概率MAX_GENERATIONS=100#最大迭代次数#适应度函数deffitness(individual):#在这里定义适应度函数,评估每个个体的适应度#这里简单地返回个体值的平方,可以根据实际问题进行调整returnnp.sum(individual**2)#初始种群生成pop=np.random.randint(2,size=(POPULATION_SIZE,))#迭代过程forgenerationinrange(MAX_GENERATIONS):#评估种群中每个个体的适应度fitness_values=np.apply_along_axis(fitness,1,pop)#选择种群selected_idx=np.random.choice(np.arange(POPULATION_SIZE), size=POPULATION_SIZE,replace=True,p=fitness_values/fitness_va lues.sum())selected_pop=pop[selected_idx]#交叉操作ifCROSSOVER_RATE>np.random.rand():cross_points=np.random.rand(POPULATION_SIZE,2)<0.5#随机选择交叉点cross_pop=np.array([np.hstack((individual[cross_points[i, 0]:cross_points[i,1]]+individual[cross_points[i,1]:],other))f ori,otherinenumerate(selected_pop)]).T#合并个体并随机交叉得到新的个体cross_pop=cross_pop[cross_points]#将交叉后的个体重新排列成原始种群大小selected_pop=np.vstack((selected_pop,cross_pop))#将新个体加入种群中#变异操作ifMUTATION_RATE>np.random.rand():mutated_pop=selected_pop+np.random.randn(POPULATION_SIZE, 1)*np.sqrt(np.log(POPULATION_SIZE))*(selected_pop!=pop).astyp e(np.float)#根据变异概率对个体进行变异操作,得到新的个体种群mutated_pop=mutated_pop[mutated_pop!=0]#将二进制种群中值为0的个体去掉,因为这些个体是随机的二进制串,不是解的一部分,不应该参与变异操作selected_pop=mutated_pop[:POPULATION_SIZE]#将新种群中除最后一个以外的部分加入原始种群中(即新的种群被排除了适应度最差的个体)#选择当前最好的个体(用于更新最优解)best_idx=np.argmax(fitness_values)best_solution=selected_pop[best_idx]print(f"Generation{generation}:Bestsolution:{best_solutio n}")```四、使用示例假设要解决一个简单的优化问题:求一个一维函数的最小值。
(完整版)遗传算法c语言代码

}
}
}
//拷贝种群
for(i=0;i<num;i++)
{
grouptemp[i].adapt=group[i].adapt;
grouptemp[i].p=group[i].p;
for(j=0;j<cities;j++)
grouptemp[i].city[j]=group[i].city[j];
{
group[i].p=1-(double)group[i].adapt/(double)biggestsum;
biggestp+=group[i].p;
}
for(i=0;i<num;i++)
group[i].p=group[i].p/biggestp;
//求最佳路劲
bestsolution=0;
for(i=0;i<num;i++)
printf("\n******************是否想再一次计算(y or n)***********************\n");
fflush(stdin);
scanf("%c",&choice);
}while(choice=='y');
return 0;
}
遗传算法代码
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<math.h>
#include<time.h>
#define cities 10 //城市的个数
python遗传算法代码

python遗传算法代码遗传算法是一种模拟生物进化过程的优化算法,常用于解决复杂的优化问题。
Python是一种简单易用且功能强大的编程语言,非常适合实现遗传算法。
下面是一个简单的Python遗传算法代码示例,用于求解一个二进制字符串中最长连续1的长度。
```pythonimport random# 设置遗传算法的参数POPULATION_SIZE = 100 # 种群大小GENERATION_COUNT = 50 # 迭代次数MUTATION_RATE = 0.01 # 变异率# 初始化种群def initialize_population():population = []for i in range(POPULATION_SIZE):individual = []for j in range(10): # 假设二进制字符串长度为10gene = random.randint(0, 1)individual.append(gene)population.append(individual)return population# 计算适应度def calculate_fitness(individual):fitness = 0current_streak = 0for gene in individual:if gene == 1:current_streak += 1fitness = max(fitness, current_streak)else:current_streak = 0return fitness# 选择操作:轮盘赌选择def selection(population):total_fitness = sum([calculate_fitness(individual) for individual in population])probabilities = [calculate_fitness(individual) /total_fitness for individual in population]selected_population = []for _ in range(POPULATION_SIZE):selected_individual = random.choices(population, weights=probabilities)[0]selected_population.append(selected_individual)return selected_population# 交叉操作:单点交叉def crossover(parent1, parent2):point = random.randint(1, len(parent1) - 1)child1 = parent1[:point] + parent2[point:]child2 = parent2[:point] + parent1[point:]return child1, child2# 变异操作def mutation(individual):for i in range(len(individual)):if random.random() < MUTATION_RATE:individual[i] = 1 - individual[i] # 变异位点翻转return individual# 主函数def genetic_algorithm():population = initialize_population()for _ in range(GENERATION_COUNT):population = selection(population)# 交叉操作new_population = []for i in range(0, POPULATION_SIZE, 2):parent1 = population[i]parent2 = population[i + 1]child1, child2 = crossover(parent1, parent2)new_population.append(child1)new_population.append(child2)# 变异操作population = [mutation(individual) for individual in new_population]best_individual = max(population, key=calculate_fitness) return best_individual# 运行遗传算法best_individual = genetic_algorithm()best_fitness = calculate_fitness(best_individual)print('Best individual:', best_individual)print('Best fitness:', best_fitness)```该代码首先初始化一个种群,然后通过选择、交叉和变异操作迭代地更新种群,并最终返回适应度最高的个体。
遗传算法(浮点数编码)

浮点数编码实现遗传算法遗传算法主要包括三个主要操作,选择、交叉和变异。
用浮点数编码进行运算,三种操作方法如下:选择:1. 计算i f 和n i S f =∑2. 计算ii nf P S =3. 累计概率1ii j j g P ==∑4. 产生均匀分布0~1的随机数r5. 将r 与i g 比较,如果1i i g r g -≤≤,则选择个体i 进入到下一代新群体6. 反复执行4和5,直至新群体的个体数目等于父代群体规模交叉:11(1)(1)t tt A B A t t t B A Bx x x x x x αααα++=+-=+- 其中,1t A x +和1t B x +是交叉之后的个体,t A x 和tB x 是随机选择的两个个体,α是交叉的一个常数, 取值为(0,1]。
变异:1max min()()%20()()%21t t t A A A tt A A x k x x r rand x x k x x r rand +⎧+⋅-⋅==⎨-⋅-⋅=⎩,,1t A x +是变异之后的个体,tA x 是变异之前的个体,k 是变异的一个常数,取值为(0,1],max x 是个体的上限,min x 是个体的下限,r 是产生的随机数。
适应度线性变换:F aF b '=+其中F 是原适应度,F '是变换之后的适应度,a,b 是变换的系数。
适应度线性变换要满足下面两个条件:条件一:avgavg F F '= 条件二:maxavg F C F '=⋅C=1.2~2缩放时参数a,b 的计算方法可以用如下方法: 如果满足:maxmin 1avg C F F F C ⋅->-就令:max (1)avg avg C a F F F -=-max max avg avg avgF C F b F F F -⋅=-否则:min avgavg F a F F =- min min avgavg F F b F F ⋅=- 实现代码如下:#include<stdio.h>#include<stdlib.h>#include<math.h>#include<time.h>#define M 80 //种群数量#define XMIN -1 //下限#define XMAX 2 //上限#define PI 3.1415926#define PC 0.8 //交叉概率#define PM 0.18 //变异概率#define PA 0.01 //交叉因子struct Node{double Pmember;double Myfitness; //Myfitness是适应度double Myfitsum; //Myfitsum是适应度占总体适应度的百分比,然后从第一个个体往后累加,主要用于选择操作}Nownode[M],Nextnode[M]; //本代群体和下一代群体int nodeindex[M]; //交叉时随机配对,存放配对的群体下标int T=0;double fx(double x) //根据x计算fx{double y;y=x*sin(10*PI*x)+2;//y=100-(x-5)*(x-5);return y;}int calfitness() //计算适应度值{int i;double minfitness,maxfitness,avefitness=0;double C=1.7,a,b;double temp;minfitness=Nownode[0].Myfitness=fx(Nownode[0].Pmember);maxfitness=minfitness;avefitness=maxfitness;for(i=1;i<M;i++){Nownode[i].Myfitness=fx(Nownode[i].Pmember);avefitness+=Nownode[i].Myfitness;if(minfitness>Nownode[i].Myfitness){minfitness=Nownode[i].Myfitness;}if(maxfitness<Nownode[i].Myfitness){maxfitness=Nownode[i].Myfitness;}}if(minfitness<0)//如果有负的适应度值,就把所以的适应度都加上一个数,使适应度全都为正数{temp=minfitness;Nownode[0].Myfitness+=-temp;avefitness=Nownode[0].Myfitness;maxfitness=Nownode[0].Myfitness;minfitness=Nownode[0].Myfitness;for(i=1;i<M;i++){Nownode[i].Myfitness+=-temp;avefitness+=Nownode[i].Myfitness;if(minfitness>Nownode[i].Myfitness){minfitness=Nownode[i].Myfitness;}if(maxfitness<Nownode[i].Myfitness){maxfitness=Nownode[i].Myfitness;}}}//适应度线性变换avefitness=avefitness/M;//计算平均适应度if(minfitness>(C*avefitness-maxfitness)/(C-1)){a=(C-1)*avefitness/(maxfitness-avefitness);b=(maxfitness-C*avefitness)*avefitness/(maxfitness-avefitness);}else{a=avefitness/(avefitness-minfitness);b=minfitness*avefitness/(avefitness-minfitness);}for(i=0;i<M;i++){Nownode[i].Myfitness=a*Nownode[i].Myfitness+b;}Nownode[0].Myfitsum=Nownode[0].Myfitness;for(i=1;i<M;i++){Nownode[i].Myfitsum=Nownode[i].Myfitness+Nownode[i-1].Myfitsum;//每一个Myfitsum都是自己的适应度加上前一个的Myfitsum}for(i=0;i<M;i++){Nownode[i].Myfitsum=Nownode[i].Myfitsum/Nownode[M-1].Myfitsum;//每一个Myfitsum除以所有适应度之和,使Myfitsum为0~1之间}return 0;}double randn() //产生XMIN到XMAX之间的随机数{return XMIN+1.0*rand()/RAND_MAX*(XMAX-XMIN);}int initpopulation() //初始化种群{int i;for(i=0;i<M;i++){Nownode[i].Pmember=randn();}calfitness(); //计算适应度return 0;}int assignment(struct Node *node1,struct Node *node2)//把node2的值赋值给node1{node1->Pmember=node2->Pmember;node1->Myfitness=node2->Myfitness;node1->Myfitsum=node2->Myfitsum;return 0;}int copypopulation() //复制操作{int i,num=0;double temp;while(num<M){temp=1.0*rand()/RAND_MAX;for(i=1;i<M;i++){if(temp<=Nownode[0].Myfitsum){assignment(&Nextnode[num++],&Nownode[0]);//把第一个个体复制到下一代break;}if(temp>=Nownode[i-1].Myfitsum&&temp<=Nownode[i].Myfitsum)//把第i个个体复制到下一代{assignment(&Nextnode[num++],&Nownode[i]);break;}}}for(i=0;i<M;i++){assignment(&Nownode[i],&Nextnode[i]); //更新本代个体}calfitness(); //计算适应度return 0;}int isrepeat(int temp,int n) //产生随机下标判断是否重复{int i;for(i=0;i<n;i++){if(nodeindex[i]==temp)return 1;}return 0;}int crossover(){int i,temp;double temp_pc;for(i=0;i<M;i++) //产生交叉点的下标{do {temp=rand()%M;} while(isrepeat(temp,i));nodeindex[i]=temp;}for(i=0;i<M;i=i+2){temp_pc=1.0*rand()/RAND_MAX; //如果满足交叉的条件,就开始交叉if(temp_pc<=PC){Nownode[nodeindex[i]].Pmember=PA*Nownode[nodeindex[i+1]].Pmember+(1-PA)*Nowno de[nodeindex[i]].Pmember;Nownode[nodeindex[i+1]].Pmember=PA*Nownode[nodeindex[i]].Pmember+(1-PA)*Nowno de[nodeindex[i+1]].Pmember;}}calfitness(); //计算适应度return 0;}int mutation() //变异操作{int i,temp;double k=0.8,temp_pm;for(i=0;i<M;i++){temp_pm=1.0*rand()/RAND_MAX;if(temp_pm<=PM) //如果满足变异条件,就开始变异{temp=rand()%2;if(temp==0){Nownode[i].Pmember=Nownode[i].Pmember+k*(XMAX-Nownode[i].Pmember)*1.0*rand( )/RAND_MAX;}else{Nownode[i].Pmember=Nownode[i].Pmember-k*(Nownode[i].Pmember-XMIN)*1.0*rand()/ RAND_MAX;}}}calfitness(); //计算适应度return 0;}int findmaxfit()//找到适应度最大的个体{int i,index=0;double temp=0;for(i=0;i<M;i++){if(temp<Nownode[i].Myfitness){index=i;temp=Nownode[i].Myfitness;}}return index;}int main(){int i=0,index;int num=0,num1=0,num2=0;srand(time(NULL));while(num++<1000){T=0;initpopulation();while(T++<200){copypopulation();crossover();mutation();}index=findmaxfit();if(fabs(Nownode[index].Pmember-1.85)<=0.1){num1++;}else{num2++;}}printf("正确的次数有%d次\n",num1);printf("错误的次数有%d次\n",num2);return 0;}。
遗传算法matlab程序代码

遗传算法matlab程序代码遗传算法是一种优化算法,用于在给定的搜索空间中寻找最优解。
在Matlab中,可以通过以下代码编写一个基本的遗传算法:% 初始种群大小Npop = 100;% 搜索空间维度ndim = 2;% 最大迭代次数imax = 100;% 初始化种群pop = rand(Npop, ndim);% 最小化目标函数fun = @(x) sum(x.^2);for i = 1:imax% 计算适应度函数fit = 1./fun(pop);% 选择操作[fitSort, fitIndex] = sort(fit, 'descend');pop = pop(fitIndex(1:Npop), :);% 染色体交叉操作popNew = zeros(Npop, ndim);for j = 1:Npopparent1Index = randi([1, Npop]);parent2Index = randi([1, Npop]);parent1 = pop(parent1Index, :);parent2 = pop(parent2Index, :);crossIndex = randi([1, ndim-1]);popNew(j,:) = [parent1(1:crossIndex),parent2(crossIndex+1:end)];end% 染色体突变操作for j = 1:NpopmutIndex = randi([1, ndim]);mutScale = randn();popNew(j, mutIndex) = popNew(j, mutIndex) + mutScale;end% 更新种群pop = [pop; popNew];end% 返回最优解[resultFit, resultIndex] = max(fit);result = pop(resultIndex, :);以上代码实现了一个简单的遗传算法,用于最小化目标函数x1^2 + x2^2。
遗传算法介绍并附上Matlab代码
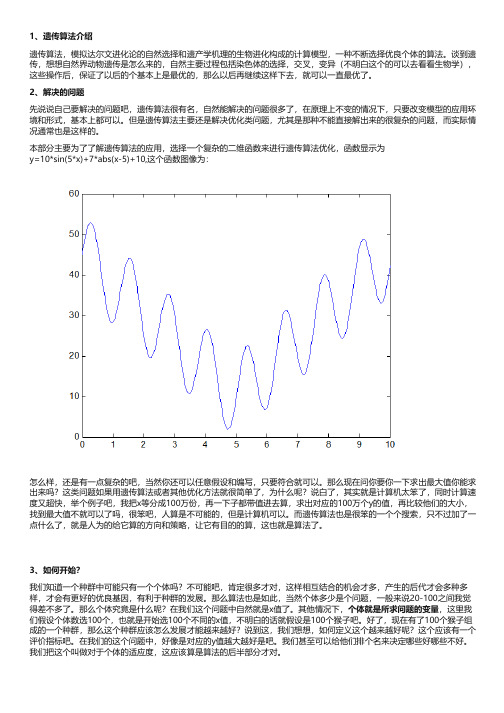
1、遗传算法介绍遗传算法,模拟达尔文进化论的自然选择和遗产学机理的生物进化构成的计算模型,一种不断选择优良个体的算法。
谈到遗传,想想自然界动物遗传是怎么来的,自然主要过程包括染色体的选择,交叉,变异(不明白这个的可以去看看生物学),这些操作后,保证了以后的个基本上是最优的,那么以后再继续这样下去,就可以一直最优了。
2、解决的问题先说说自己要解决的问题吧,遗传算法很有名,自然能解决的问题很多了,在原理上不变的情况下,只要改变模型的应用环境和形式,基本上都可以。
但是遗传算法主要还是解决优化类问题,尤其是那种不能直接解出来的很复杂的问题,而实际情况通常也是这样的。
本部分主要为了了解遗传算法的应用,选择一个复杂的二维函数来进行遗传算法优化,函数显示为y=10*sin(5*x)+7*abs(x-5)+10,这个函数图像为:怎么样,还是有一点复杂的吧,当然你还可以任意假设和编写,只要符合就可以。
那么现在问你要你一下求出最大值你能求出来吗?这类问题如果用遗传算法或者其他优化方法就很简单了,为什么呢?说白了,其实就是计算机太笨了,同时计算速度又超快,举个例子吧,我把x等分成100万份,再一下子都带值进去算,求出对应的100万个y的值,再比较他们的大小,找到最大值不就可以了吗,很笨吧,人算是不可能的,但是计算机可以。
而遗传算法也是很笨的一个个搜索,只不过加了一点什么了,就是人为的给它算的方向和策略,让它有目的的算,这也就是算法了。
3、如何开始?我们知道一个种群中可能只有一个个体吗?不可能吧,肯定很多才对,这样相互结合的机会才多,产生的后代才会多种多样,才会有更好的优良基因,有利于种群的发展。
那么算法也是如此,当然个体多少是个问题,一般来说20-100之间我觉得差不多了。
那么个体究竟是什么呢?在我们这个问题中自然就是x值了。
其他情况下,个体就是所求问题的变量,这里我们假设个体数选100个,也就是开始选100个不同的x值,不明白的话就假设是100个猴子吧。
遗传算法 c语言代码

以下是一个简单的遗传算法的C语言代码示例:c#include <stdio.h>#include <stdlib.h>#include <time.h>#include <math.h>#define POPULATION_SIZE 100#define GENE_LENGTH 10#define MAX_GENERATIONS 1000#define MUTATION_RATE 0.01#define CROSSOVER_RATE 0.8typedef struct Individual {char genes[GENE_LENGTH];double fitness;} Individual;double calculate_fitness(Individual* individual) {// 计算适应度函数,这里使用简单的二进制字符串中1的个数作为适应度 int count = 0;for (int i = 0; i < GENE_LENGTH; i++) {if (individual->genes[i] == '1') {count++;}}return count;}void initialize_population(Individual* population) {// 初始化种群for (int i = 0; i < POPULATION_SIZE; i++) {for (int j = 0; j < GENE_LENGTH; j++) {population[i].genes[j] = rand() % 2 ? '0' : '1';}population[i].fitness = calculate_fitness(&population[i]); }}void selection(Individual* population, Individual* parents) {// 选择操作,采用轮盘赌算法选择两个父代个体double total_fitness = 0;for (int i = 0; i < POPULATION_SIZE; i++) {total_fitness += population[i].fitness;}double rand1 = rand() / (double)RAND_MAX * total_fitness;double rand2 = rand() / (double)RAND_MAX * total_fitness;double cumulative_fitness = 0;int parent1_index = -1, parent2_index = -1;for (int i = 0; i < POPULATION_SIZE; i++) {cumulative_fitness += population[i].fitness;if (rand1 < cumulative_fitness && parent1_index == -1) {parent1_index = i;}if (rand2 < cumulative_fitness && parent2_index == -1) {parent2_index = i;}}parents[0] = population[parent1_index];parents[1] = population[parent2_index];}void crossover(Individual* parents, Individual* offspring) {// 交叉操作,采用单点交叉算法生成两个子代个体int crossover_point = rand() % GENE_LENGTH;for (int i = 0; i < crossover_point; i++) {offspring[0].genes[i] = parents[0].genes[i];offspring[1].genes[i] = parents[1].genes[i];}for (int i = crossover_point; i < GENE_LENGTH; i++) {offspring[0].genes[i] = parents[1].genes[i];offspring[1].genes[i] = parents[0].genes[i];}offspring[0].fitness = calculate_fitness(&offspring[0]);offspring[1].fitness = calculate_fitness(&offspring[1]);}void mutation(Individual* individual) {// 变异操作,以一定概率翻转基因位上的值for (int i = 0; i < GENE_LENGTH; i++) {if (rand() / (double)RAND_MAX < MUTATION_RATE) {individual->genes[i] = individual->genes[i] == '0' ? '1' : '0'; }}individual->fitness = calculate_fitness(individual);}void replace(Individual* population, Individual* offspring) {// 替换操作,将两个子代个体中适应度更高的一个替换掉种群中适应度最低的一个个体int worst_index = -1;double worst_fitness = INFINITY;for (int i = 0; i < POPULATION_SIZE; i++) {if (population[i].fitness < worst_fitness) {worst_index = i;worst_fitness = population[i].fitness;}}if (offspring[0].fitness > worst_fitness || offspring[1].fitness > worst_fitness) {if (offspring[0].fitness > offspring[1].fitness) {population[worst_index] = offspring[0];} else {population[worst_index] = offspring[1];}}}。
人工智能遗传算法及python代码实现

人工智能遗传算法及python代码实现人工智能遗传算法是一种基于生物遗传进化理论的启发式算法,常用于求解复杂的优化问题。
它的基本思想是通过自然选择和基因交叉等机制,在种群中不断进化出适应性更强的个体,最终找到问题的最优解。
遗传算法通常由以下几个步骤组成:1. 初始化种群:从问题空间中随机生成一组解作为初始种群。
2. 评价适应度:利用一个适应度函数来评价每个解的适应性,通常是优化问题的目标函数,如最小化代价、最大化收益等。
3. 选择操作:从种群中选择一些具有较高适应度的个体用于产生新的种群。
选择操作通常采用轮盘赌选择方法或精英选择方法。
4. 交叉操作:将两个个体的染色体进行交叉、重组,生成新的子代个体。
5. 变异操作:对新产生的子代个体随机变异一些基因,以增加种群的多样性。
6. 生成新种群:用选择、交叉和变异操作产生新的种群,并进行适应度评价。
7. 终止条件:如果达到终止条件,算法停止,否则返回步骤3。
遗传算法的优点是可以适应各种优化问题,并且求解精度较高。
但由于其需要进行大量的随机操作,因此效率相对较低,也较容易陷入局部最优解。
在实际应用中,遗传算法常与其他算法结合使用,以求得更好的结果。
以下是使用Python实现基本遗传算法的示例代码:import randomimport math# 定义适应度函数,用于评价每个个体的适应程度def fitness_func(x):return math.cos(20 * x) + math.sin(3 * x)# 执行遗传算法def genetic_algorithm(pop_size, chrom_len, pcross, pmutate, generations):# 初始化种群population = [[random.randint(0, 1) for j in range(chrom_len)] for i in range(pop_size)]# 迭代指定代数for gen in range(generations):# 评价种群中每个个体的适应度fits = [fitness_func(sum(population[i]) / (chrom_len * 1.0)) for i in range(pop_size)]# 选择操作:轮盘赌选择roulette_wheel = []for i in range(pop_size):fitness = fits[i]roulette_wheel += [i] * int(fitness * 100)parents = []for i in range(pop_size):selected = random.choice(roulette_wheel)parents.append(population[selected])# 交叉操作:单点交叉for i in range(0, pop_size, 2):if random.uniform(0, 1) < pcross:pivot = random.randint(1, chrom_len - 1)parents[i][pivot:], parents[i+1][pivot:] = parents[i+1][pivot:], parents[i][pivot:]# 变异操作:随机翻转一个基因for i in range(pop_size):for j in range(chrom_len):if random.uniform(0, 1) < pmutate:parents[i][j] = 1 - parents[i][j]# 生成新种群population = parents# 返回种群中适应度最高的个体的解fits = [fitness_func(sum(population[i]) / (chrom_len * 1.0)) for i in range(pop_size)]best = fits.index(max(fits))return sum(population[best]) / (chrom_len * 1.0)# 测试遗传算法print("Result: ", genetic_algorithm(pop_size=100, chrom_len=10, pcross=0.9, pmutate=0.1, generations=100))上述代码实现了遗传算法,以优化余弦函数和正弦函数的和在某个区间内的最大值。
算法】超详细的遗传算法(GeneticAlgorithm)解析

算法】超详细的遗传算法(GeneticAlgorithm)解析01 什么是遗传算法?1.1 遗传算法的科学定义遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。
遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。
其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。
1.2 遗传算法的执行过程(参照百度百科)遗传算法是从代表问题可能潜在的解集的一个种群(population)开始的,而一个种群则由经过基因(gene)编码的一定数目的个体(individual)组成。
每个个体实际上是染色体(chromosome)带有特征的实体。
染色体作为遗传物质的主要载体,即多个基因的集合,其内部表现(即基因型)是某种基因组合,它决定了个体的形状的外部表现,如黑头发的特征是由染色体中控制这一特征的某种基因组合决定的。
因此,在一开始需要实现从表现型到基因型的映射即编码工作。
由于仿照基因编码的工作很复杂,我们往往进行简化,如二进制编码。
初代种群产生之后,按照适者生存和优胜劣汰的原理,逐代(generation)演化产生出越来越好的近似解,在每一代,根据问题域中个体的适应度(fitness)大小选择(selection)个体,并借助于自然遗传学的遗传算子(genetic operators)进行组合交叉(crossover)和变异(mutation),产生出代表新的解集的种群。
遗传算法java代码

遗传算法java代码遗传算法(Genetic Algorithm)是一种基于生物进化的启发式算法,通过模拟自然选择、交叉和突变等基因操作来优化问题的解。
以下是一个基于Java的遗传算法示例代码:```javaimport java.util.ArrayList;import java.util.List;import java.util.Random;//假设我们要求解的问题是求一个二进制序列的最大值,这个序列的长度为10public class GeneticAlgorithm//染色体长度private static final int CHROMOSOME_LENGTH = 10;//种群大小private static final int POPULATION_SIZE = 100;//迭代次数private static final int MAX_GENERATIONS = 100;//交叉概率private static final double CROSSOVER_RATE = 0.8;//变异概率private static final double MUTATION_RATE = 0.1; //随机数生成器private static final Random RANDOM = new Random(; //个体类private static class Individual//染色体private int[] chromosome;//适应度private double fitness;public Individuachromosome = new int[CHROMOSOME_LENGTH];fitness = 0.0;}//初始化染色体public void initializeChromosomfor (int i = 0; i < CHROMOSOME_LENGTH; i++) chromosome[i] = RANDOM.nextInt(2);}}//计算个体的适应度public void calculateFitnesint decimalValue = 0;for (int i = CHROMOSOME_LENGTH - 1; i >= 0; i--) decimalValue += chromosome[i] * Math.pow(2, CHROMOSOME_LENGTH - i - 1);}fitness = decimalValue;}//获取个体的适应度public double getFitnesreturn fitness;}//获取染色体public int[] getChromosomreturn chromosome;}//设置染色体public void setChromosome(int[] chromosome)this.chromosome = chromosome;}}//生成初始种群private static List<Individual> createInitialPopulatioList<Individual> population = new ArrayList<>(;for (int i = 0; i < POPULATION_SIZE; i++)Individual individual = new Individual(;individual.initializeChromosome(;population.add(individual);}return population;}//选择父母个体private static Individual selectParent(List<Individual> population)double sumFitness = 0.0;for (Individual individual : population)sumFitness += individual.getFitness(;}double randomFitness = RANDOM.nextDouble( * sumFitness;double cumulativeFitness = 0.0;for (Individual individual : population)cumulativeFitness += individual.getFitness(;if (cumulativeFitness > randomFitness)return individual;}}return population.get(0);}//交叉操作private static Individual crossover(Individual parent1, Individual parent2)Individual offspring = new Individual(;int[] parent1Chromosome = parent1.getChromosome(;int[] parent2Chromosome = parent2.getChromosome(;int crossoverPoint = RANDOM.nextInt(CHROMOSOME_LENGTH - 1) + 1;int[] offspringChromosome = new int[CHROMOSOME_LENGTH];System.arraycopy(parent1Chromosome, 0, offspringChromosome, 0, crossoverPoint);System.arraycopy(parent2Chromosome, crossoverPoint, offspringChromosome, crossoverPoint, CHROMOSOME_LENGTH - crossoverPoint);offspring.setChromosome(offspringChromosome);return offspring;}//变异操作private static void mutate(Individual individual)int[] chromosome = individual.getChromosome(;for (int i = 0; i < CHROMOSOME_LENGTH; i++)if (RANDOM.nextDouble( < MUTATION_RATE)chromosome[i] = chromosome[i] == 0 ? 1 : 0;}}individual.setChromosome(chromosome);}//遗传算法主函数public static void main(String[] args)List<Individual> population = createInitialPopulation(;for (int generation = 0; generation < MAX_GENERATIONS; generation++)for (Individual individual : population)individual.calculateFitness(;}Individual bestIndividual = population.get(0);for (Individual individual : population)if (individual.getFitness( > bestIndividual.getFitness() bestIndividual = individual;}}System.out.println("Generation: " + generation + " Best Individual: " + bestIndividual.getFitness();List<Individual> newPopulation = new ArrayList<>(;while (newPopulation.size( < POPULATION_SIZE)Individual parent1 = selectParent(population);Individual parent2 = selectParent(population);Individual offspring = crossover(parent1, parent2);mutate(offspring);newPopulation.add(offspring);}population = newPopulation;}}```以上示例代码实现了一个简单的二进制序列的最大化遗传算法。
遗传算法解释及代码(一看就懂)

遗传算法( GA , Genetic Algorithm ) ,也称进化算法。
遗传算法是受达尔文的进化论的启发,借鉴生物进化过程而提出的一种启发式搜索算法。
因此在介绍遗传算法前有必要简单的介绍生物进化知识。
一.进化论知识作为遗传算法生物背景的介绍,下面内容了解即可:种群(Population):生物的进化以群体的形式进行,这样的一个群体称为种群。
个体:组成种群的单个生物。
基因 ( Gene ) :一个遗传因子。
染色体 ( Chromosome ):包含一组的基因。
生存竞争,适者生存:对环境适应度高的、牛B的个体参与繁殖的机会比较多,后代就会越来越多。
适应度低的个体参与繁殖的机会比较少,后代就会越来越少。
遗传与变异:新个体会遗传父母双方各一部分的基因,同时有一定的概率发生基因变异。
简单说来就是:繁殖过程,会发生基因交叉( Crossover ) ,基因突变( Mutation ) ,适应度( Fitness )低的个体会被逐步淘汰,而适应度高的个体会越来越多。
那么经过N代的自然选择后,保存下来的个体都是适应度很高的,其中很可能包含史上产生的适应度最高的那个个体。
二.遗传算法思想借鉴生物进化论,遗传算法将要解决的问题模拟成一个生物进化的过程,通过复制、交叉、突变等操作产生下一代的解,并逐步淘汰掉适应度函数值低的解,增加适应度函数值高的解。
这样进化N代后就很有可能会进化出适应度函数值很高的个体。
举个例子,使用遗传算法解决“0-1背包问题”的思路:0-1背包的解可以编码为一串0-1字符串(0:不取,1:取);首先,随机产生M个0-1字符串,然后评价这些0-1字符串作为0-1背包问题的解的优劣;然后,随机选择一些字符串通过交叉、突变等操作产生下一代的M个字符串,而且较优的解被选中的概率要比较高。
这样经过G代的进化后就可能会产生出0-1背包问题的一个“近似最优解”。
编码:需要将问题的解编码成字符串的形式才能使用遗传算法。
遗传算法(GeneticAlgorithms)

遗传算法(GeneticAlgorithms)遗传算法前引:1、TSP问题1.1 TSP问题定义旅⾏商问题(Traveling Salesman Problem,TSP)称之为货担郎问题,TSP问题是⼀个经典组合优化的NP完全问题,组合优化问题是对存在组合排序或者搭配优化问题的⼀个概括,也是现实诸多领域相似问题的简化形式。
1.2 TSP问题解法传统精确算法:穷举法,动态规划近似处理算法:贪⼼算法,改良圈算法,双⽣成树算法智能算法:模拟退⽕,粒⼦群算法,蚁群算法,遗传算法等遗传算法:性质:全局优化的⾃适应概率算法2.1 遗传算法简介遗传算法的实质是通过群体搜索技术,根据适者⽣存的原则逐代进化,最终得到最优解或准最优解。
它必须做以下操作:初始群体的产⽣、求每⼀个体的适应度、根据适者⽣存的原则选择优良个体、被选出的优良个体两两配对,通过随机交叉其染⾊体的基因并随机变异某些染⾊体的基因⽣成下⼀代群体,按此⽅法使群体逐代进化,直到满⾜进化终⽌条件。
2.2 实现⽅法根据具体问题确定可⾏解域,确定⼀种编码⽅法,能⽤数值串或字符串表⽰可⾏解域的每⼀解。
对每⼀解应有⼀个度量好坏的依据,它⽤⼀函数表⽰,叫做适应度函数,⼀般由⽬标函数构成。
确定进化参数群体规模、交叉概率、变异概率、进化终⽌条件。
案例实操我⽅有⼀个基地,经度和纬度为(70,40)。
假设我⽅飞机的速度为1000km/h。
我⽅派⼀架飞机从基地出发,侦察完所有⽬标,再返回原来的基地。
在每⼀⽬标点的侦察时间不计,求该架飞机所花费的时间(假设我⽅飞机巡航时间可以充分长)。
已知100个⽬标的经度、纬度如下表所列:3.2 模型及算法求解的遗传算法的参数设定如下:种群⼤⼩M=50;最⼤代数G=100;交叉率pc=1,交叉概率为1能保证种群的充分进化;变异概率pm=0.1,⼀般⽽⾔,变异发⽣的可能性较⼩。
编码策略:初始种群:⽬标函数:交叉操作:变异操作:选择:算法图:代码实现:clc,clear, close allsj0=load('data12_1.txt');x=sj0(:,1:2:8); x=x(:);y=sj0(:,2:2:8); y=y(:);sj=[x y]; d1=[70,40];xy=[d1;sj;d1]; sj=xy*pi/180; %单位化成弧度d=zeros(102); %距离矩阵d的初始值for i=1:101for j=i+1:102d(i,j)=6370*acos(cos(sj(i,1)-sj(j,1))*cos(sj(i,2))*...cos(sj(j,2))+sin(sj(i,2))*sin(sj(j,2)));endendd=d+d'; w=50; g=100; %w为种群的个数,g为进化的代数for k=1:w %通过改良圈算法选取初始种群c=randperm(100); %产⽣1,...,100的⼀个全排列c1=[1,c+1,102]; %⽣成初始解for t=1:102 %该层循环是修改圈flag=0; %修改圈退出标志for m=1:100for n=m+2:101if d(c1(m),c1(n))+d(c1(m+1),c1(n+1))<...d(c1(m),c1(m+1))+d(c1(n),c1(n+1))c1(m+1:n)=c1(n:-1:m+1); flag=1; %修改圈endendendif flag==0J(k,c1)=1:102; break %记录下较好的解并退出当前层循环endendendJ(:,1)=0; J=J/102; %把整数序列转换成[0,1]区间上实数即染⾊体编码for k=1:g %该层循环进⾏遗传算法的操作for k=1:g %该层循环进⾏遗传算法的操作A=J; %交配产⽣⼦代A的初始染⾊体c=randperm(w); %产⽣下⾯交叉操作的染⾊体对for i=1:2:wF=2+floor(100*rand(1)); %产⽣交叉操作的地址temp=A(c(i),[F:102]); %中间变量的保存值A(c(i),[F:102])=A(c(i+1),[F:102]); %交叉操作A(c(i+1),F:102)=temp;endby=[]; %为了防⽌下⾯产⽣空地址,这⾥先初始化while ~length(by)by=find(rand(1,w)<0.1); %产⽣变异操作的地址endB=A(by,:); %产⽣变异操作的初始染⾊体for j=1:length(by)bw=sort(2+floor(100*rand(1,3))); %产⽣变异操作的3个地址%交换位置B(j,:)=B(j,[1:bw(1)-1,bw(2)+1:bw(3),bw(1):bw(2),bw(3)+1:102]);endG=[J;A;B]; %⽗代和⼦代种群合在⼀起[SG,ind1]=sort(G,2); %把染⾊体翻译成1,...,102的序列ind1num=size(G,1); long=zeros(1,num); %路径长度的初始值for j=1:numfor i=1:101long(j)=long(j)+d(ind1(j,i),ind1(j,i+1)); %计算每条路径长度endend[slong,ind2]=sort(long); %对路径长度按照从⼩到⼤排序J=G(ind2(1:w),:); %精选前w个较短的路径对应的染⾊体endpath=ind1(ind2(1),:), flong=slong(1) %解的路径及路径长度xx=xy(path,1);yy=xy(path,2);plot(xx,yy,'-o') %画出路径以上整个代码中没有调⽤GA⼯具箱。
(完整版)遗传算法简介及代码详解

遗传算法简述及代码详解声明:本文内容整理自网络,认为原作者同意转载,如有冒犯请联系我。
遗传算法基本内容遗传算法为群体优化算法,也就是从多个初始解开始进行优化,每个解称为一个染色体,各染色体之间通过竞争、合作、单独变异,不断进化。
遗传学与遗传算法中的基础术语比较染色体:又可以叫做基因型个体(individuals)群体/种群(population):一定数量的个体组成,及一定数量的染色体组成,群体中个体的数量叫做群体大小。
初始群体:若干染色体的集合,即解的规模,如30,50等,认为是随机选取的数据集合。
适应度(fitness):各个个体对环境的适应程度优化时先要将实际问题转换到遗传空间,就是把实际问题的解用染色体表示,称为编码,反过程为解码/译码,因为优化后要进行评价(此时得到的解是否较之前解优越),所以要返回问题空间,故要进行解码。
SGA采用二进制编码,染色体就是二进制位串,每一位可称为一个基因;如果直接生成二进制初始种群,则不必有编码过程,但要求解码时将染色体解码到问题可行域内。
遗传算法的准备工作:1) 数据转换操作,包括表现型到基因型的转换和基因型到表现型的转换。
前者是把求解空间中的参数转化成遗传空间中的染色体或者个体(encoding),后者是它的逆操作(decoding)2) 确定适应度计算函数,可以将个体值经过该函数转换为该个体的适应度,该适应度的高低要能充分反映该个体对于解得优秀程度。
非常重要的过程。
遗传算法基本过程为:1) 编码,创建初始群体2) 群体中个体适应度计算3) 评估适应度4) 根据适应度选择个体5) 被选择个体进行交叉繁殖6) 在繁殖的过程中引入变异机制7) 繁殖出新的群体,回到第二步实例一:(建议先看实例二)求 []30,0∈x 范围内的()210-=x y 的最小值1) 编码算法选择为"将x 转化为2进制的串",串的长度为5位(串的长度根据解的精度设 定,串长度越长解得精度越高)。
jupyter 遗传算法代码

一、什么是Jupyter和遗传算法Jupyter是一种交互式计算环境,可以用于数据清洗和转换、数值模拟、统计建模、数据可视化和机器学习等多种数据处理工作。
而遗传算法是一种模拟自然选择和遗传规律的优化算法,主要用于解决复杂的优化问题。
二、Jupyter中的遗传算法实现在Jupyter中,可以使用Python编程语言来实现遗传算法。
首先需要引入相关的库,如numpy、random等,然后按照遗传算法的基本原理来编写代码。
三、遗传算法的基本原理1. 初始化种裙:随机生成一定数量的个体作为初始种裙。
2. 选择:根据个体的适应度值,利用适应度函数进行选择,选择适应度高的个体作为父母个体。
3. 交叉:通过交叉操作,将父母个体的基因进行组合,产生新的个体。
4. 变异:对新个体的基因进行变异操作,引入新的基因信息。
5. 重复选择、交叉和变异操作,直到满足终止条件。
6. 最终得到适应度较高的个体,即为所求的优化解。
四、使用Jupyter编写遗传算法代码的步骤1. 引入相关的库```pythonimport numpy as npimport random```2. 初始化种裙```pythondef init_population(pop_size, chromosome_length):population = np.random.randint(0, 2, (pop_size, chromosome_length))return population```3. 选择```pythondef select(population, fitness_value):index = np.random.choice(np.arange(len(population)),size=len(population), replace=True,p=fitness_value/fitness_value.sum())return population[index]```4. 交叉```pythondef crossover(parents, pc=0.6):children = np.empty(parents.shape)for i in range(0, len(parents), 2):if np.random.rand() < pc:crossover_point = np.random.randint(1, len(parents[i])) children[i] = np.concatenate((parents[i][:crossover_point], parents[i+1][crossover_point:]))children[i+1] =np.concatenate((parents[i+1][:crossover_point],parents[i][crossover_point:]))else:children[i] = parents[i]children[i+1] = parents[i+1]return children```5. 变异```pythondef mutate(children, pm=0.01):for i in range(len(children)):for j in range(len(children[i])):if np.random.rand() < pm:children[i][j] = 1 - children[i][j]return children```6. 遗传算法主程序```pythonpop_size = 100chromosome_length = 10max_gen = 100population = init_population(pop_size, chromosome_length)for gen in range(max_gen):fitness_value = calculate_fitness_value(population)parents = select(population, fitness_value)children = crossover(parents)new_population = mutate(children)population = new_population```五、总结通过Jupyter和Python编程语言,我们可以比较轻松地实现遗传算法,并用于解决各种优化问题。
遗传算法求解选址问题的python代码

遗传算法求解选址问题的python代码选址问题是一种组合优化问题,其中目标是最小化总成本,总成本通常由多个因素决定,例如运输成本、设施成本等。
遗传算法是一种启发式搜索算法,可以用于求解这类问题。
以下是一个使用遗传算法求解选址问题的Python代码示例:```pythonimport numpy as npimport random定义适应度函数def fitness_func(individual):计算总成本total_cost = 0for i in range(len(individual) - 1):total_cost += abs(individual[i] - individual[i + 1])total_cost += abs(individual[-1] - individual[0])return total_cost定义遗传算法参数pop_size = 100 种群大小chrom_length = 10 染色体长度(即候选地址数量)num_generations = 100 迭代次数mutation_rate = 变异率初始化种群pop = (0, chrom_length, (pop_size, chrom_length))进行迭代进化for generation in range(num_generations):计算适应度值fitness = ([fitness_func(chrom) for chrom in pop]) 选择操作:轮盘赌选择法idx = (pop_size, size=pop_size, replace=True, p=fitness/()) pop = pop[idx]交叉操作:单点交叉for i in range(0, pop_size, 2):if () < :cross_point = (1, chrom_length-1)temp = pop[i][:cross_point] + pop[i+1][cross_point:]pop[i] = temppop[i+1] = temp[::-1]变异操作:位反转变异法for i in range(pop_size):if () < mutation_rate:flip_point = (0, chrom_length-1)pop[i][flip_point] = pop[i][flip_point] + (1 if pop[i][flip_point] % 2 == 0 else -1) % chrom_length```。
遗传算法解释及代码(一看就懂)
遗传算法( GA , Genetic Algorithm ) ,也称进化算法。
遗传算法是受达尔文的进化论的启发,借鉴生物进化过程而提出的一种启发式搜索算法。
因此在介绍遗传算法前有必要简单的介绍生物进化知识。
一.进化论知识作为遗传算法生物背景的介绍,下面内容了解即可:种群(Population):生物的进化以群体的形式进行,这样的一个群体称为种群。
个体:组成种群的单个生物。
基因 ( Gene ) :一个遗传因子。
染色体 ( Chromosome ):包含一组的基因。
生存竞争,适者生存:对环境适应度高的、牛B的个体参与繁殖的机会比较多,后代就会越来越多。
适应度低的个体参与繁殖的机会比较少,后代就会越来越少。
遗传与变异:新个体会遗传父母双方各一部分的基因,同时有一定的概率发生基因变异。
简单说来就是:繁殖过程,会发生基因交叉( Crossover ) ,基因突变( Mutation ) ,适应度( Fitness )低的个体会被逐步淘汰,而适应度高的个体会越来越多。
那么经过N代的自然选择后,保存下来的个体都是适应度很高的,其中很可能包含史上产生的适应度最高的那个个体。
二.遗传算法思想借鉴生物进化论,遗传算法将要解决的问题模拟成一个生物进化的过程,通过复制、交叉、突变等操作产生下一代的解,并逐步淘汰掉适应度函数值低的解,增加适应度函数值高的解。
这样进化N代后就很有可能会进化出适应度函数值很高的个体。
举个例子,使用遗传算法解决“0-1背包问题”的思路:0-1背包的解可以编码为一串0-1字符串(0:不取,1:取);首先,随机产生M个0-1字符串,然后评价这些0-1字符串作为0-1背包问题的解的优劣;然后,随机选择一些字符串通过交叉、突变等操作产生下一代的M个字符串,而且较优的解被选中的概率要比较高。
这样经过G代的进化后就可能会产生出0-1背包问题的一个“近似最优解”。
编码:需要将问题的解编码成字符串的形式才能使用遗传算法。
遗传算法挖掘因子 python代码

遗传算法是一种优化搜索技术,它是通过模拟自然选择和遗传过程来寻找最优解的。
以下是一个使用Python实现的简单遗传算法的例子,用于挖掘因子。
pythonimport numpy as np# 适应度函数def fitness_function(solution):# 此处是一个例子,具体的适应度函数应根据你的问题来定义return sum(solution)# 遗传算法def genetic_algorithm(population_size, gene_length, generations):# 初始化种群population = np.random.randint(2, size=(population_size, gene_length))for generation in range(generations):# 计算适应度值fitness = np.array([fitness_function(ind) for ind in population])# 选择操作parents = population[np.random.choice(population_size, population_size, replace=False)][:, np.random.choice(gene_length, gene_length, replace=False)] parents = parents[(fitness[np.arange(population_size)[:, None], parents] > fitness[parents, np.arange(gene_length)]).all()]# 交叉操作children = np.empty((0, gene_length), dtype=int)while len(children) < population_size:parent1 = parents[np.random.randint(0, len(parents))]parent2 = parents[np.random.randint(0, len(parents))]if parent1 != parent2:child = np.where(np.random.randint(2, size=(gene_length, 2)) > 0, parent1, parent2)children = np.append(children, child, axis=0)parents = np.delete(parents, np.where((parents == parent1).all() | (parents == parent2).all())[0])population = children# 变异操作for i in range(population_size):if np.random.rand() < 0.01: # 变异率可以根据实际情况调整for j in range(gene_length):if np.random.rand() < 0.5: # 变异点可以在这里调整population[i][j] = 1 if population[i][j] == 0 else 0 # 返回最优解return population[np.argmax(fitness)]# 运行遗传算法best_solution = genetic_algorithm(100, 10, 1000)print("Best solution:", best_solution)print("Best solution fitness:", fitness_function(best_solution))注意:这只是一个基础的遗传算法实现,实际应用中可能需要进行更复杂的操作,例如更复杂的编码方式、更复杂的交叉和变异操作、精英策略等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
遗传算法简述及代码详解声明:本文内容整理自网络,认为原作者同意转载,如有冒犯请联系我。
遗传算法基本内容遗传算法为群体优化算法,也就是从多个初始解开始进行优化,每个解称为一个染色体,各染色体之间通过竞争、合作、单独变异,不断进化。
遗传学与遗传算法中的基础术语比较染色体(chromosome) 数据,数组,序列基因(gene) 单个元素,位等位基因(allele) 数据值,属性,值基因座(locus) 位置,iterator位置表现型(phenotype) 参数集,解码结构,候选解染色体:又可以叫做基因型个体(individuals)群体/种群(population):一定数量的个体组成,及一定数量的染色体组成,群体中个体的数量叫做群体大小。
初始群体:若干染色体的集合,即解的规模,如30,50等,认为是随机选取的数据集合。
适应度(fitness):各个个体对环境的适应程度优化时先要将实际问题转换到遗传空间,就是把实际问题的解用染色体表示,称为编码,反过程为解码/译码,因为优化后要进行评价(此时得到的解是否较之前解优越),所以要返回问题空间,故要进行解码。
SGA采用二进制编码,染色体就是二进制位串,每一位可称为一个基因;如果直接生成二进制初始种群,则不必有编码过程,但要求解码时将染色体解码到问题可行域内。
遗传算法的准备工作:1)数据转换操作,包括表现型到基因型的转换和基因型到表现型的转换。
前者是把求解空间中的参数转化成遗传空间中的染色体或者个体(encoding),后者是它的逆操作(decoding)2) 确定适应度计算函数,可以将个体值经过该函数转换为该个体的适应度,该适应度的高低要能充分反映该个体对于解得优秀程度。
非常重要的过程。
遗传算法基本过程为:1) 编码,创建初始群体2) 群体中个体适应度计算3) 评估适应度4) 根据适应度选择个体5) 被选择个体进行交叉繁殖6) 在繁殖的过程中引入变异机制7) 繁殖出新的群体,回到第二步实例一:(建议先看实例二)求 []30,0∈x 范围内的()210-=x y 的最小值 1) 编码算法选择为"将x 转化为2进制的串",串的长度为5位(串的长度根据解的精度设 定,串长度越长解得精度越高)。
(等位基因的值为0 or 1)。
2) 计算适应度的方法是:先将个体串进行解码,转化为int 型的x 值,然后使用()210-=x y 作为其适应度计算合适(由于是最小值,所以结果越小,适应度也越好)。
需要说明,将原目标函数设置为适应度函数是一种选择,但未必是最贴切的方法。
3) 正式开始,先设置群体大小为4,然后初始化群体 => (在[0,31]范围内随机选取4个整 数就可以编码)4) 计算适应度Fi(由于是求解最小值,可以选取一个大的基准线1000()2101000--=x Fi ) 5) 计算每个个体的选择概率,选择概率要能够反映个体的优秀程度。
这里用一个很简单的 方法来确定选择概率)(/Fi TOTAL Fi p =6) 选择根据所有个体的选择概率进行淘汰选择。
这里使用的是一个赌轮的方式进行淘汰选择。
先按照每个个体的选择概率创建一个赌轮,然后选取4次,每次先产生一个0-1的随机小数,然后判断该随机数落在那个段内就选取相对应的个体。
这个过程中,选取概率p 高的个体将可能被多次选择,而概率低的就可能被淘汰。
下面是一个简单的赌轮的例子13% 35% 15% 37%----------|----------------------------|------------------|---------------------------------|个体1 个体2 个体3 ^0.67 个体4随机数为0.67落在了个体4的端内,本次选择了个体4。
被选中的个体将进入配对库(mating pool ,配对群体)准备开始繁殖。
7) 简单交叉先对配对库中的个体进行随机配对,然后在配对的2个个体中设置交叉点,交换2个个体的信息后产生下一代。
比如( | 代表简单串的交叉位置)( 0110|1,1100|0 ) --交叉--> (01100,11001)( 01|000,11|011 ) --交叉--> (01011,11000)2个父代的个体在交叉后繁殖出了下一代的同样数量的个体.复杂的交叉在交叉的位置,交叉的方法,双亲的数量上都可以选择.其目的都在于尽可能的培育出更优秀的后代8) 变异变异操作时按照基因座来的,比如说每计算2万个基因座就发生一个变异(我们现在的每个个体有5个基因座。
也就是说要进化1000代后才会在其中的某个基因座发生一次变异)变异的结果是基因座上的等位基因发生了变化。
我们这里的例子就是把0变成1或则1变成0。
至此,我们已经产生了一个新的(下一代)群体,然后回到第4步,周而复始,生生不息下去。
实例二:为了便于理解,手工计算来简单地模拟遗传算法的各个主要执行步骤:(1)个体编码 遗传算法的运算对象是表示个体的符号串,所以必须把变量 x1, x2 编码为一种符号串。
本题中,用无符号二进制整数(编码方式较多)来表示。
因 x1, x2 为 0 ~ 7之间的整数,所以分别用3位无符号二进制整数来表示,将它们连接在一起所组成的6位无符号二进制数就形成了个体的基因型,表示一个可行解。
例如,基因型 X =101110 所对应的表现型是:x =[ 5,6 ]。
个体的表现型x 和基因型X 之间可通过编码和解码程序相互转换。
(2) 初始群体的产生遗传算法是对群体进行的进化操作,需要给其淮备一些表示起始搜索点的初始群体数据。
本例中,群体规模的大小(随机选取)取为4,即群体由4个个体组成,每个个体可通过随机方法产生。
如:011101,101011,011100,111001(3) 适应度汁算遗传算法中以个体适应度的大小来评定各个个体的优劣程度,从而决定其遗传机会的大小。
本例中,目标函数总取非负值,并且是以求函数最大值为优化目标,故可直接利用目标函数值作为个体的适应度(适应度函数可以有许多)。
(4) 选择运算选择运算(或称为复制运算)把当前群体中适应度较高的个体按某种规则或模型遗传到下一代群体中。
一般要求适应度较高的个体将有更多的机会遗传到下一代群体中。
本例中,我们采用与适应度成正比的概率来确定各个个体复制到下一代群体中的数量。
其具体操作过程是:• 先计算出群体中所有个体的适应度的总和 ∑===M i M i fiFI 1),,1( ;• 其次计算出每个个体的相对适应度的大小),,1(/M i FI fi =,它即为每 个个体被遗传到下一代群体中的概率;• 每个概率值组成一个区域,全部概率值之和为1;• 最后再产生一个0到1之间的随机数,依据该随机数出现在上述哪一个概率 区域内来确定各个个体被选中的次数。
(详见下图)(5)交叉运算交叉运算是遗传算法中产生新个体的主要操作过程,它以某一概率相互交换某两个个体之间的部分染色体。
本例采用单点交叉的方法,其具体操作过程是:• 先对群体进行随机配对;• 其次随机设置交叉点位置;• 最后再相互交换配对染色体之间的部分基因。
(6) 变异运算变异运算是对个体的某一个或某一些基因座上的基因值按某一较小的概率进行改变,它也是产生新个体的一种操作方法。
本例中,我们采用基本位变异的方法来进行变异运算,其具体操作过程是:• 首先确定出各个个体的基因变异位置,下表所示为随机产生的变异点位置,其中的数字表示变异点设置在该基因座处;• 然后依照某一概率将变异点的原有基因值取反。
对群体P(t)进行一轮选择、交叉、变异运算之后可得到新一代的群体p(t+1)。
从上表中可以看出,群体经过一代进化之后,其适应度的最大值、平均值都得到了明显的改进。
事实上,这里已经找到了最佳个体“111111”。
[注意]需要说明的是,表中有些栏的数据是随机产生的。
这里为了更好地说明问题,我们特意选择了一些较好的数值以便能够得到较好的结果,而在实际运算过程中,有可能需要一定的循环次数才能达到这个最优结果。
选择要能够合理的反映“适者生存”的自然法则,而交叉必须将有利的基因尽量遗传给下一代 (这是算法的关键!)算法过程当中有几个随机过程:(1)初始种群的产生是随机产生,但有时为了更好迭代,知道解在某一个值附近,可以认为设定初始种群(2)确定个体被选中次数时,运用到轮赌法,其产生的数据为随机数据(3)交叉点(4)变异点伪代码://Init populationforeach individual in population{individual = Encode(Random(0,31));}while (App.IsRun){//计算个体适应度int TotalF = 0;foreach individual in population{individual.F = 1000 - (Decode(individual)-10)^2;TotalF += individual.F;}//------选择过程,计算个体选择概率-----------foreach individual in population{individual.P = individual.F / TotalF;}//选择for(int i=0;i<4;i++){//SelectIndividual(float p)是根据随机数落在段落计算选取哪个个体的函数 MatingPool[i] = population[SelectIndividual(Random(0,1))];}//-------简单交叉---------------------------//由于只有4个个体,配对2次for(int i=0;i<2;i++){MatingPool.Parents[i].Mother = MatingPool.RandomPop();MatingPool.Parents[i].Father = MatingPool.RandomPop();}//交叉后创建新的集团population.Clean();foreach Parent in MatingPool.Parents{//注意在copy 双亲的染色体时在某个基因座上发生的变异未表现.child1 = Parent.Mother.DivHeader + Parent.Father.DivEnd;child2 = Parent.Father.DivHeader + Parent.Mother.DivEnd;population.push(child1);population.push(child2);}}完整代码如下:#include"stdafx.h"#include<stdio.h>#include<stdlib.h>#include<time.h>#define POPSIZE 500#define MAXIMIZATION 1 //求解函数为求最大值#define MINIMIZATION 2 //求解函数为求最小值#define Cmax 100 //求解最大值时适应度函数的基准数#define Cmin 0 //求解最小值时适应度函数的基准数#define LENGTH1 10 //每一个解用位基因表示#define LENGTH2 10#define CHROMLENGTH LENGTH1+LENGTH2int FunctionMode=MAXIMIZATION; //函数值求解类型是最大值int PopSize=80; //种群规模int MaxGeneration =100; //最大世代数,即最大迭代数double Pc = 0.6; //变异概率double Pm = 0.001; //交叉概率struct individual//定义个体{char chrom[CHROMLENGTH+1]; //个体数double value; //个体对应的变量值double fitness; //个体适应度};int generation;int best_index;int worst_index;struct individual bestindividual;struct individual worstindividual;struct individual currentbest;struct individual population[POPSIZE];void GenerateInitialPopulation(void); / /初始种群生成void GenerateNextPopulation(void); //产生下一代种群void EvaluatePopulation(void);void CalculateObjectValue(void);long DecodeChromosome(char *,int,int); //译码void CalculateFitnessValue(void);void FindBestAndWorstIndividual(void);void PerformEvolution(void);void SelectionOperator(void);void CrossoverOperator(void);void MutationOperator(void);void OutputTextReport(void);void main(void){generation=0;GenerateInitialPopulation(); //初始种群生成EvaluatePopulation(); //计算种群值,即计算种群适应度while(generation<MaxGeneration){generation++;GenerateNextPopulation(); //产生下一代种群EvaluatePopulation(); //计算种群值,即计算种群适应度PerformEvolution();OutputTextReport();}}void GenerateInitialPopulation(void) //随机产生初始种群,且用0,1表示{int i,j;for(i=0;i<PopSize; i++){for(j=0;j<CHROMLENGTH;j++){population[i].chrom[j]=(rand()%10<5)?'0':'1';//rand()%n产生一个// ~n-1的数}population[i].chrom[CHROMLENGTH]='\0';}}void GenerateNextPopulation(void){SelectionOperator();CrossoverOperator();MutationOperator();}void EvaluatePopulation(){CalculateObjectValue();CalculateFitnessValue();FindBestAndWorstIndividual();}long DecodeChromosome(char *string,int point,int length) //译码,换算为十进//制数{int i;long decimal=0L;char *pointer;for(i=0,pointer=string+point;i<length;i++,pointer++){decimal+=(*pointer-'0')<<(length-1-i); //移位操作,染色体实现十进//制化}return(decimal);}void CalculateObjectValue(void) //计算函数值{int i;long temp1,temp2;double x1,x2;for (i=0;i<PopSize;i++){ //从染色体中读取基因temp1=DecodeChromosome (population [i ].chrom ,0,LENGTH1);temp2=DecodeChromosome (population [i ].chrom ,LENGTH1,LENGTH2); x1=4.0 *temp1/1023.0-2.0 ; //x ∈[a, b];x2=4.0 *temp2/1023.0-2.0 ; // 121*)(10--+=temp a b a x population [i ].value =100*(x1*x2+x2)*(x1*x2-x2)*x2;// 函数表达式}}void CalculateFitnessValue (void ) //针对不同函数类型计算个体适应度{int i ;double temp ;for (i =0;i <PopSize ;i ++){if (FunctionMode ==MAXIMIZATION ) //函数类型为求解最大值{if ((population [i ].value +Cmin )>0.0){temp =Cmin +population [i ].value ; }else{temp=0.0;}}else if(FunctionMode==MINIMIZATION) //函数类型为求解最小值{if(population[i].value<Cmax){temp=Cmax-population[i].value;}else{temp=0.0;}}population[i].fitness=temp;}}void FindBestAndWorstIndividual(void ){int i;double sum=0.0;bestindividual=population[0];worstindividual=population[0];for (i=1;i<PopSize; i++){if (population[i].fitness>bestindividual.fitness) {bestindividual=population[i];best_index=i;}else if (population[i].fitness<worstindividual.fitness) {worstindividual=population[i];worst_index=i;}sum+=population[i].fitness; }if (generation==0){currentbest=bestindividual;}else{if(bestindividual.fitness>=currentbest.fitness){ currentbest=bestindividual;}}}void PerformEvolution(void) //执行进化{if (bestindividual.fitness>currentbest.fitness){currentbest=population[best_index];}else{population[worst_index]=currentbest;}}void SelectionOperator(void) //选取最优进化代{int i,index;double p,sum=0.0;double cfitness[POPSIZE];struct individual newpopulation[POPSIZE];for(i=0;i<PopSize;i++){sum+=population[i].fitness;}for(i=0;i<PopSize; i++){cfitness[i]=population[i].fitness/sum; // 个体的适应度比例}for(i=1;i<PopSize; i++){cfitness[i]=cfitness[i-1]+cfitness[i];}for (i=0;i<PopSize;i++){p=rand()%1000/1000.0;index=0;while (p>cfitness[index]){index++;}newpopulation[i]=population[index];}for(i=0;i<PopSize; i++){population[i]=newpopulation[i];}}void CrossoverOperator(void) //染色体交叉{int i,j;int index[POPSIZE];int point,temp;double p;char ch;for (i=0;i<PopSize;i++){index[i]=i;}for(i=0;i<PopSize;i++) //随机化种群内染色体{point=rand()%(PopSize-i);temp=index[i];index[i]=index[point+i];index[point+i]=temp;}for (i=0;i<PopSize-1;i+=2){p=rand()%1000/1000.0; //随机产生交叉概率if (p<Pc){point=rand()%(CHROMLENGTH-1)+1;for (j=point; j<CHROMLENGTH;j++) //交叉{ch=population[index[i]].chrom[j];population[index[i]].chrom[j]=population[index[i+1]].chrom[j];population[index[i+1]].chrom[j]=ch;}}}}void MutationOperator(void) //基因变异{int i,j;double p;for(i=0;i<PopSize;i++){for(j=0;j<CHROMLENGTH;j++){p=rand()%1001/1000.0;if (p<Pm){population[i].chrom[j]=(population[i].chrom[j]==0)?'1':'0';}}}}void OutputTextReport(void) //列印结果{int i;double sum;double average;sum=0.0;for(i=0;i<PopSize;i++){sum+=population[i].value;}average=sum/PopSize;printf("gen=%d,avg=%f,best=%f,",generation,average,currentbest.value);printf("chromosome=");for (i=0;i<CHROMLENGTH;i++){printf("%c",currentbest.chrom[i]);}Long temp1=DecodeChromosome(population[i].chrom,0,LENGTH1);//从染色体中读取基因longtemp2=DecodeChromosome(population[i].chrom,LENGTH1,LENGTH2);double x1=4.0*temp1/1023.0-2.0;//基因型换为表现型double x2=4.0*temp2/1023.0-2.0;printf(" x1=%f,x2=%f",x1,x2);printf("\n");WORD格式整理}专业资料值得拥有。