概率论与数理统计第7章
概率论与数理统计复习7章

( n − 1) S 2 ( n − 1) S 2 = 1 − α 即P 2 <σ2 < 2 χα 2 ( n − 1) χ1−α 2 ( n − 1) ( n − 1) S 2 ( n − 1) S 2 置信区间为: 2 , χα 2 ( n − 1) χ12−α 2 ( n − 1)
则有:E ( X v ) = µv (θ1 , θ 2 ,⋯ , θ k ) 其v阶样本矩是:Av = 1 ∑ X iv n i =1
n
估计的未知参数,假定总体X 的k阶原点矩E ( X k ) 存在,
µ θ , θ ,⋯ , θ = A k 1 1 1 2 µ2 θ1, θ 2 ,⋯ , θ k = A2 用样本矩作为总体矩的估计,即令: ⋮ µ θ , θ ,⋯ , θ = A k k k 1 2 ɵ ɵ ˆ 解此方程即得 (θ1 , θ 2 ,⋯ , θ k )的一个矩估计量 θ 1 , θ 2 ,⋯ , θ k
+∞
−∞
xf ( x ) dx = ∫ θ x θ dx =
1 0
令E ( X ) = X ⇒
θ +1
θ
ˆ = X ⇒θ =
( )
X 1− X
θ +1
2
θ
7.2极大似然估计法
极大似然估计法: 设总体X 的概率密度为f ( x,θ ) (或分布率p( x,θ )),θ = (θ1 ,θ 2 ,⋯ ,θ k ) 为 未知参数,θ ∈ Θ, Θ为参数空间,即θ的取值范围。设 ( x1 , x2 ,⋯ , xn ) 是 样本 ( X 1 , X 2 ,⋯ , X n )的一个观察值:
i =1 n
概率论与数理统计第7章参数估计PPT课件

a1(1, ,k )=v1
1 f1(v1, ,vk )
假定方程组a2(1, ,k ) v2 ,则可求出2 f2(v1, ,vk )
ak (1, ,k ) vk
k fk (v1, ,vk )
则x1 xn为X的样本值时,可用样本值的j阶原点矩Aj估计vj,其中
Aj
1 n
n i1
xij ( j
L(x1, ,xn;ˆ)maxL(x1, ,xn;),则称ˆ(x1, ,xn)为
的一种参数估计方法 .
它首先是由德国数学家
高斯在1821年提出的 ,然而, 这个方法常归功于英国统
Gauss
计学家费歇(Fisher) . 费歇在1922年重新发现了
这一方法,并首先研究了这
种方法的一些性质 .
Fisher
10
极大似然估计是在已知总体分布形式的情形下的 点估计。
极大似然估计的基本思路:根据样本的具体情况
注:估计量为样本的函数,样本不同,估计量不 同。
常用估计量构造法:矩估计法、极大似然估计法。
4
7.1.1 矩估计法
矩估计法是通过参数与总体矩的关系,解出参数, 并用样本矩替代总体矩而得到的参数估计方法。 (由大数定理可知样本矩依概率收敛于总体矩, 且许多分布所含参数都是矩的函数)
下面我们考虑总体为连续型随机变量的情况:
n
它是的函数,记为L(x1, , xn; ) f (xi , ), i 1
并称其为似然函数,记为L( )。
注:似然函数的概念并不仅限于连续随机变量 ,
对于离散型随机变量,用 P {Xx}p(x,)
替代f ( x, )
即可。
14
设总体X的分布形式已知,且只含一个未知参数,
《概率论与数理统计》第七章假设检验.

《概率论与数理统计》第七章假设检验.第七章假设检验学习⽬标知识⽬标:理解假设检验的基本概念⼩概率原理;掌握假设检验的⽅法和步骤。
能⼒⽬标:能够作正态总体均值、⽐例的假设检验和两个正态总体的均值、⽐例之差的假设检验。
参数估计和假设检验是统计推断的两种形式,它们都是利⽤样本对总体进⾏某种推断,然⽽推断的⾓度不同。
参数估计是通过样本统计量来推断总体未知参数的取值范围,以及作出结论的可靠程度,总体参数在估计前是未知的。
⽽在假设检验中,则是预先对总体参数的取值提出⼀个假设,然后利⽤样本数据检验这个假设是否成⽴,如果成⽴,我们就接受这个假设,如果不成⽴就拒绝原假设。
当然由于样本的随机性,这种推断只能具有⼀定的可靠性。
本章介绍假设检验的基本概念,以及假设检验的⼀般步骤,然后重点介绍常⽤的参数检验⽅法。
由于篇幅的限制,⾮参数假设检验在这⾥就不作介绍了。
第⼀节假设检验的⼀般问题关键词:参数假设;检验统计量;接受域与拒绝域;假设检验的两类错误⼀、假设检验的基本概念(⼀)原假设和备择假设为了对假设检验的基本概念有⼀个直观的认识,不妨先看下⾯的例⼦。
例7.1 某⼚⽣产⼀种⽇光灯管,其寿命X 服从正态分布)200 ,(2µN ,从过去的⽣产经验看,灯管的平均寿命为1550=µ⼩时,。
现在采⽤新⼯艺后,在所⽣产的新灯管中抽取25只,测其平均寿命为1650⼩时。
问采⽤新⼯艺后,灯管的寿命是否有显著提⾼?这是⼀个均值的检验问题。
灯管的寿命有没有显著变化呢?这有两种可能:⼀种是没有什么变化。
即新⼯艺对均值没有影响,采⽤新⼯艺后,X 仍然服从)200 ,1550(2N 。
另⼀种情况可能是,新⼯艺的确使均值发⽣了显著性变化。
这样,1650=X 和15500=µ之间的差异就只能认为是采⽤新⼯艺的关系。
究竟是哪种情况与实际情况相符合,这需要作检验。
假如给定显著性⽔平05.0=α。
在上⾯的例⼦中,我们可以把涉及到的两种情况⽤统计假设的形式表⽰出来。
《概率论与数理统计》7

未知参数 , ,, 的函数.分别令
12
k
L(1,,k ) 0,(i 1,2,...,k)
或令
i
ln L(1,,k ) 0,(i 1,2,...,k)
i
由此方程组可解得参数 i 的极大似然估计值 ˆi.
例5 设X~b(1,p), X1, X2 , …,Xn是来自X的一个样本,
求参数 p 的最大似然估计量.
解 E( X ) ,E( X 2 ) D( X ) [E( X )]2 2 2
由矩估计法,
【注】
X
1
n
n i 1
X
2 i
2
2
ˆ X ,
ˆ
2
1 n
n i 1
(Xi
X )2
对任何总体,总体均值与方差的矩估计量都不变.
➢常见分布的参数矩估计量
(1)若总体X~b(1, p), 则未知参数 p 的矩估计量为
7-1
第七章
参数估计
统计 推断
的 基本 问题
7-2
参数估 计问题
(第七章)
点估计 区间估 计
假设检 验问题 (第八章)
什么是参数估计?
参数是刻画总体某方面概率特性的数量.
当此数量未知时,从总体抽出一个样本, 用某种方法对这个未知参数进行估计就 是参数估计.
例如,X ~N ( , 2),
若, 2未知, 通过构造样本的函数, 给出
k = k(A1, A2 , …, A k)
用i 作为i的估计量------矩估计量.
例1 设总体X服从[a,b]上的均匀分布,a,b未知,
X1, X2 , …,Xn为来自总体X的样本,试求a,b的 矩估计量.
解 E(X ) a b , D(X ) (b a)2
《概率论与数理统计》第七章

n
n
ln xi
(4)的极大似然估计量为:ˆ
n
n2 i1
lnX
i
2
i1
第七章 参数估计 ‹#›
例 9 设X~b(1,p), X1,X2,…,Xn是来自X的一个样本, 试求参数p的最大似然估计量
解: 设x1, x2,, xn,是相应于样本X1,X2,…,Xn 的一个样本值,X
的分布律为:
(3)以样本各阶矩A1, ,Ak代替总体各阶矩1,
得各参数的矩估计
ˆi gi(A1, ,Ak ), i 1, , k
, k,
第七章 参数估计 ‹#›
注意:
在实际应用时,为求解方便,也可以用
中心矩 i 代替原点矩i,相应地以样本中心矩Bi 估计 i.
(二)最大似然估计法
最(极)大似然估计的原理介绍
第七章
参数估计
目录/Contents
第1章 随机事件与 2 概率
§ 1 点估计
§3
估计量的评选标准
第七章 参数估计 ‹#›
问题的提出:
在实际进行统计时,有不少总体的(我们关心的某 确定指标)概率分布是已知的。比如
例 1 产品寿命服从的分布
X~
f
(
x)
1
x
e
x0
0
其他
但其中有参数是未知的: θ
n
似然函数 L f xi , 。 i 1
, xn ,
极大似然原理:L(ˆ( x1 ,
,
xn
))
max
L(
).
计算简化方法:
在求L 的最大值时,通常转换为求:lnL 的最大值,
lnL 称为对数似然函数.
利用
概率论和数理统计(李慧斌)复习大纲-第7章-置信区间-Confidence-Intervals

概率论与数理统计(李慧斌)复习大纲Chapter 7 Confidence Intervals置信区间7.1 Sampling Distribution 抽样分布统计量的分布称为抽样分布。
在本节中,我们将从正态分布推导出随机样本的样本方差分布,以及样本均值和样本方差的各种函数的分布。
复习:Thm 5.5.2若X1, X2,…, X n独立且满足,i= 1,2,…,n,若C1, C2,…, C n不全为零,则Corollary 5.5.2 设随机变量X1, X2,…, X n组成随机样本,满足正态分布,其中均值μ和方差σ2,则7.2 χ2Distribution卡方分布定义:若随机变量X1, X2,…, X n独立同分布且其中每个随机变量都满足标准正态分布,所以有着以n阶自由度卡方分布(χ2distribution with n degrees of freedom),记作,n来源于独立随机变量中以n阶自由度的χ2分布的概率密度函数其中欧拉函数定义为χ2分布的性质:定理1定理2 (χ2分布的可加性)若X ~χ2 (n) , Y ~χ2(m),X, Y独立,则X+Y ~ χ2 (n+m)例:设X1, X2,…, X n是正态分布的随机样本,证明Thm 7.3.1 设X1, X2,…, X n是正态分布的随机样本,则:(1)与独立;(2)注:,虽然基于n个,但是它们之和为0,所以指定数量的n-1确定剩余值。
因此有n-1阶自由度。
结果表明,只有从正态分布中抽取随机样本,样本均值和样本方差才是独立的。
证明如下:的联合概率分布函数为其中A为正交矩阵(orthogonal matrix),且的联合概率分布函数为因此独立且⇒与独立且7.4 The t Distribution t分布定义:设X ~ N(0, 1), Y ~χ2 (n)且X和Y独立,则随机变量所满足的分布称为n阶自由度t分布,记作,其中的概率密度函数为t分布的性质:(1)f(x)图像呈钟型,且中心为0;(2)它的一般形状类似于平均分布0的正态分布的概率密度函数。
概率论和数理统计(第三学期)第7章数理统计的基本概念

n i1
i
1 n
n
Ei
i1
D
D 1 n
n i 1
i
1 n2
n
Di
i 1
2
n
2
S~ 1 n
n i 1
i
2
1 n
n i 1
i2 2i
2
1 n
n
i2
i 1
2
n
i
i 1
n
2
1 n
n
i2
i 1
2
2
2
1 n
n
i2
i 1
2
E S~2
E
1 n
n
i2
i 1
23
.209
2
2 0.95
20
10
.851
当自由度n 45时,可用下面近似公式去求2 n:
x2 n
1 2
u
2
2n 1
例3
求
2 0.05
60 .
解
2 0.05
60
1 2
u0.05
2
2 60 1
1 1.645
2
119 78.798
2
3、t分布的上侧分位点
对于给定的α(0<α<1),使
2
e
xi 2 2
2
(2
) e 2
n 2
1
2 2
n i1
xi 2
在数理统计中,总体的分布往往是未知的,需 要通过样本找到一个分布来近似代替总体分布。
§7.3 分布的估计
频率分布 例 某炼钢厂生产的钢由于各种因素的影响,各炉
钢的含硅量可以看作是一个随机变量,现记录了 120炉钢的含硅量百分数,求出这个样本的频数分 布与频率分布。
概率论与数理统计教程第七章答案

.第七章假设检验7.1设总体J〜N(4Q2),其中参数4, /为未知,试指出下面统计假设中哪些是简洁假设,哪些是复合假设:(1) W o: // = 0, σ = 1 ;(2) W o√∕ = O, σ>l5(3) ∕70:// <3, σ = 1 ;(4) % :0< 〃 <3 ;(5)W o :// = 0.解:(1)是简洁假设,其余位复合假设7.2设配么,…,25取自正态总体息(19),其中参数〃未知,无是子样均值,如对检验问题“0 :〃 = 〃o, M :4工从)取检验的拒绝域:c = {(x1,x2,∙∙∙,x25)r∣x-χ∕0∖≥c},试打算常数c ,使检验的显著性水平为0. 05_ Q解:由于J〜N(〃,9),故J~N(",二)在打。
成立的条件下,一/3 5cP o(∖ξ-^∖≥c) = P(∖ξ-μJ^∖≥-)=2 1-Φ(y) =0.05Φ(-) = 0.975,-= 1.96,所以c=L176°3 37. 3 设子样。
,乙,…,25取自正态总体,cr:已知,对假设检验%邛=μ0, H2> /J。
,取临界域c = {(X[,w,…,4):片>9)},(1)求此检验犯第一类错误概率为α时,犯其次类错误的概率夕,并争论它们之间的关系;(2)设〃o=0∙05, σ~=0. 004, a =0.05, n=9,求"=0.65 时不犯其次类错误的概率。
解:(1)在儿成立的条件下,F~N(∕o,军),此时a = P^ξ≥c^ = P0< σo σo )所以,包二为册=4_,,由此式解出c°=窄4f+为% ∖∣n在H∣成立的条件下,W ~ N",啊 ,此时nS = %<c°) = AI。
气L =①(^^~品)二①匹%=①(2δξ^历σoA∣-σ+A)-A-------------- y∕n)。
东华大学《概率论与数理统计》课件 第七章 假设检验

1. 2为已知, 关于的检验(U 检验 )
在上节中讨论过正态总体 N ( , 2 ) 当 2为已知时, 关于 = 0的检验问题 :
假设检验 H0 : = 0 , H1 : 0 ;
我们引入统计量U
=
− 0 0
,则U服从N(0,1)
n
对于给定的检验水平 (0 1)
由标准正态分布分位数定义知,
~
N (0,1),
由标准正态分布分位点的定义得 k = u1− / 2 ,
当 x − 0 / n
u1− / 2时, 拒绝H0 ,
x − 0 / n
u1− / 2时,
接受H0.
假设检验过程如下:
在实例中若取定 = 0.05, 则 k = u1− / 2 = u0.975 = 1.96, 又已知 n = 9, = 0.015, 由样本算得 x = 0.511, 即有 x − 0 = 2.2 1.96,
临界点为 − u1− / 2及u1− / 2.
3. 两类错误及记号
假设检验是根据样本的信息并依据小概率原
理,作出接受还是拒绝H0的判断。由于样本具有 随机性,因而假设检验所作出的结论有可能是错
误的. 这种错误有两类:
(1) 当原假设H0为真, 观察值却落入拒绝域, 而 作出了拒绝H0的判断, 称做第一类错误, 又叫弃
设 1,2, ,n 为来自总体 的样本,
因为 2 未知, 不能利用 − 0 来确定拒绝域. / n
因为 Sn*2 是 2 的无偏估计, 故用 Sn* 来取代 ,
即采用 T = − 0 来作为检验统计量.
Sn* / n
当H0为真时,
− 0 ~ t(n −1),
Sn* / n
由t分布分位数的定义知
浙大版概率论与数理统计答案---第七章

第七章 参数估计注意: 这是第一稿(存在一些错误)1、解 由θθθμθ2),()(01===⎰d x xf X E ,204103)(2221θθθ=-==X D v ,可得θ的矩估计量为X 2^=θ,这时θθ==)(2)(^X E E ,nnX D D 5204)2()(22^θθθ=⋅==。
3、解 由)1(2)1(2)1(2)(21θθθθμ-=-+-==X E ,得θ的矩估计量为:3262121^=-=-=X θ。
建立关于θ的似然函数:482232)1(4)1())1(2()()(θθθθθθθ-=--=L令0148))1ln(4ln 8()(ln =--=∂-+∂=∂∂θθθθθθθL ,得到θ的极大似然估计值:32^=θ 4、解:矩估计:()1012122μθλθλθλ=⋅+⋅+⋅--=--,()()()()2222222121νθλθθλλθλθλ=--++-++--, 11A =,234B =, 故()()()()222ˆˆ221,3ˆˆˆˆˆˆˆˆˆˆ222121.4θλθλθθλλθλθλ⎧--=⎪⎨--++-++--=⎪⎩解得1ˆ,43ˆ.8λθ⎧=⎪⎪⎨⎪=⎪⎩为所求矩估计。
极大似然估计:(){}()33214526837,0,2,11L P X X X X X X X X θλθλθλ==========--,()()(),ln ,3ln 2ln 3ln 1l L θλθλθλθλ==++--,()(),330,1,230.1l l θλθθθλθλλλθλ∂⎧=-=⎪⎪∂--⎨∂⎪=-=⎪∂--⎩解得3ˆ,81ˆ.4θλ⎧=⎪⎪⎨⎪=⎪⎩即为所求。
5、解 由33)1(3)1(3)(222+-=-+-+=p p p p p p X E ,所以得到p 的矩估计量为^394(3)34322X X p -----==建立关于p 的似然函数:3210)1()2)1(3()()2)1(()(22n n n n p p p p p p p L ---= 令0)(ln =∂∂pp L ,求得到θ的极大似然估计值:n n n n p 22210^++=6、解:(1)()1112EX x x dx θθθθ+=+=+⎰, 由ˆ1ˆ2X θθ+=+得21ˆ1X X θ-=-为θ的矩估计量。
概率论与数理统计课件第7章参数估计

一、矩估计
4
A B
一、矩估计 例1
5
01
OPTION
02
OPTION
一、矩估计 解
6
一、矩估计
7
一、矩估计
8
解(1)
一、矩估计
9
解(2)
一、矩估计 例3
10
一、矩估计 解
11
一、矩估计
12
关于矩估计量有下列结论:
一、矩估计
13
例4
解
一、矩估计
14
01
OPTION
02
OPTION
一、无偏性 定义1
51
ˆ lim E θ 如果 n+ X1 ,
, X n θ
一、无偏性
52
例1
试求 1 3 2
解
(1)由矩估计定义可知
一、无偏性
53
故
一、无偏性
54
一、无偏性 例2
55
一、无偏性
56
解
一、无偏性 定理 1
57
则有
因此, 样本均值是总体均值的无偏估计, 样本
二、极大似然估计
48
极大似然估计求解
似然函数 对数似然求导法
直接法
49
目录/Contents
7.1 7.2
点估计 点估计的优良性评判标 准 置信区间 单正态总体下未知参数的置信区间 两个正态总体下未知参数的置信区间
7.3
7.4 7.5
50
目录/Contents
7.2
点估计的优良性评判标准 一、无偏性 二、有效性 三、相合性
置信区间
69
置信区间
70
置信区间
《概率论与数理统计》课件 第七章 随机变量的数字特征

i 1,2, , 如果 xi pi , 则称 i 1 E( X ) xi pi 为随机变量X的数学期望; i 1
或称为该分布的数学期望,简称期望或均值.
(2)设连续随机变量X的密度函数为p( x),
如果
+
x p( x)dx ,
则称
-
E( X ) xp( x)dx 为随机变量X的数学期望.
5
例2.求二项分布B(n, p)的数学期望.
P(X
k)
n!
k!n
k !
pk
(1
p)nk ,k
1, 2,
, n.
n
解:EX kP{ X k}
k0
n
k
k0
n!
k!n
k !
pk
(1
p)nk
n
np
k 1
k
n 1! 1!n
pk1
k!
(1
p)nk
np[ p (1 p)]n1 np.
特别地,若X服从0 1分布,则EX p.
6
例3. 求泊松分布P( )的数学期望.
注:P( X k) k e , k 1, 2, .
k!
解:EX k k e e
k1
e
k1
k0 k !
k1 k 1 !
k1 k 1 !
ee
e x 1 x 1 x2 1 xn [这里,x ]
当 a 450时,平均收益EY 最大.
28
第二节 方差与标准差
29
引例
比较随机变量X、Y 的期望
X3 4 5 Y1 4 7 P 0.1 0.8 0.1 P 0.4 0.2 0.4
01 2 3 4 5 67
概率论与数理统计第7章参数估计习题及答案

概率论与数理统计第7章参数估计习题及答案第7章参数估计 ----点估计⼀、填空题1、设总体X 服从⼆项分布),(p N B ,10<计量=pXN. 2、设总体)p ,1(B ~X,其中未知参数 01<则 p 的矩估计为_∑=n 1i i X n 1_,样本的似然函数为_ii X 1n1i X )p 1(p -=-∏__。
3、设 12,,,n X X X 是来⾃总体 ),(N ~X 2σµ的样本,则有关于 µ及σ2的似然函数212(,,;,)n L X X X µσ=_2i 2)X (21n1i e21µ-σ-=∏σπ__。
⼆、计算题1、设总体X 具有分布密度(;)(1),01f x x x ααα=+<<,其中1->α是未知参数,n X X X ,,21为⼀个样本,试求参数α的矩估计和极⼤似然估计.解:因?++=+=101α2α1α102++=++=+|a x 令2α1α++==??)(X X EXX --=∴112α为α的矩估计因似然函数1212(,,;)(1)()n n n L x x x x x x ααα=+∑=++=∴ni i X n L 1α1αln )ln(ln ,由∑==++=??ni i X nL 101ααln ln 得,α的极⼤似量估计量为)ln (?∑=+-=ni iXn11α2、设总体X 服从指数分布 ,0()0,x e x f x λλ-?>=??其他,n X X X ,,21是来⾃X 的样本,(1)求未知参数λ的矩估计;(2)求λ的极⼤似然估计.解:(1)由于1()E X λ=,令11X Xλλ=?=i x nn L x x x eλλ=-∑=111ln ln ln 0nii ni ni ii L n x d L n n x d xλλλλλ====-=-=?=∑∑∑故λ的极⼤似然估计仍为1X。
概率论与数理统计习题及答案-第七章

1 F(x,β)=
x
,
x ,
0,
x .
其中未知参数 β>1,α>0,设 X1,X2,…,Xn 为来自总体 X 的样本 (1) 当 α=1 时,求 β 的矩估计量; (2) 当 α=1 时,求 β 的极大似然估计量; (3) 当 β=2 时,求 α 的极大似然估计量. 【解】
2 0.025
(19)
32.852,
2 0.975
(19)
8.907
(1) μ的置信度为 0.95 的置信区间
s
18.14
x ta/2 (n 1) 76.6
2.093 (68.11,85.089)
n
20
(2) 2 的置信度为 0.95 的置信区间
(2)
D( ˆ1 )
2
2
D( X1 )
1
2
D(X2 )
4
X
2
5
2
,
3
3
9
9
3
2
1
2
3
5 2
D(ˆ2 ) D( X1) D( X 2 ) ,
4
4
8
D(ˆ3
)
1
2
D( X1 )
D(X
2
)
2
(
x),
0 x ,
0,
其他.
X1,X2,…,Xn 为其样本,试求参数θ的矩法估计.
概率论与数理统计第七章课后习题及参考答案

5.设总体 X 的概率密度为
f
(x,
)
(
1) x
,0
x
1,
0, 其他.
其中 1是未知参数, X1 , X 2 ,…, X n 是来自 X 的一个样本.试求参数
2
的矩估计和极大似然估计.现有样本观测值 0.1 ,0.2 ,0.9 ,0.8 ,0.7 及 0.7 ,
求参数 的矩估计值和极大似然估计值.
1 2 2 c 2 2 ( 1 c) 2 ,
n
n
取 c 1 即可. n
14.设总体 X 的均值为 ,方差为 2 ,从总体中抽取样本 X1 , X 2 , X 3 ,证明
(
x,
,
2
)
1
1
1
e 2 2
(ln x )2
,
x
0,
2 x
0,
x 0.
其中 , 0 为未知参数, X1 , X 2 ,…, X n 是取自该总体的一
个样本,求参数 , 2 的极大似然估计.
解: xi 时,似然函数为
L(, 2 )
(
1 2 )n
1 x1x2 xn
exp{
dL
d
n exp{
n i 1
( xi
)}
0,
所以 L( ) 是 的单调增函数,从而对满足条件 xi 的任意 ,有
n
n
L( ) exp{ i1 (xi )} exp{ i1 (xi m1iinn{xi})} ,
即 L( ) 在 m1iinn{xi} 时取最大值, 故 的极大似然估计值为ˆ m1iinn{xi} . 7.(1) 设总体 X 具有分布律
ˆ1 X1 ;
ˆ2
概率论与数理统计第七章参数估计
例1. 设总体X的数学期望和方差分别是μ,
σ2 ,求μ , σ2的矩估计量。
E(X )
E( X 2 ) D( X ) [EX ]2 2 2
(3) 写出方程 ln L 0
i1
若方程有解,
求出L(θ)的最大值点 ˆ(x1,x2,..x.n,)
于 是 ˆ ˆ ( X 1 , X 2 , . . . , X n ) 即 为 的 极 大 似 然 估 计 量
例2. 设总体X服从参数λ>0的泊松分布,求 参数λ的极大似然估计量。
例3. 已知某产品的不合格率为p,有简单随机样本 X1 ,X2 ,…, Xn,求p的极大似然估计量。 若抽取100件产品,发现10件次品,试估计p.
ˆ(x1,x2,..x.n,),使得
L (ˆ) m a x L (), (或 L (ˆ) s u p L ())
则 称 ˆ ( x 1 ,x 2 , . . . ,x n ) 为 的 极 大 似 然 估 计 值
称 ˆ ( X 1 ,X 2 ,...,X n ) 为 极 大 似 然 估 计 量
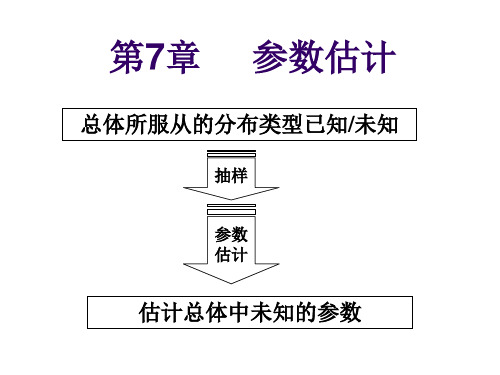
第7章 参数估计
总体所服从的分布类型已知/未知
抽样
参数 估计
估计总体中未知的参数
参数估计 参数估计问题是利用从总体抽样得到的信息
来估计总体的某些参数. 估计新生儿的体重
估计废品率
估计湖中鱼数
§7.1
点估计
设有一个统计总体,总体的分布函数
为 F(x, ),其中为未知参数 (可以是向量) .
概率论与数理统计第七章

估计 为1.68,这是点估计.
估计在区间[1.57, 1.84]内,这是区间估计.
一、点估计概念及讨论的问题
例1 已知某地区新生婴儿的体重X~ N(,2),
, 2未知,
…
随机抽查100个婴儿
得100个体重数据
9, 7, 6, 6.5, 5, 5.2, … 而全部信息就由这100个数组成.
求:两个参数a,b的矩估计
解: 写出方 V E 程 (X a(X )r组 ) ˆˆ2
其 中uˆˆ2Xn1in1(Xi X)2
但是
E
(
X
)
Var ( X )
a
b 2 (b a)2
12
即有
(ab2ba)2 12
X
ˆ
2
由方程组求解出a,b的矩估计:
a ˆX 3 ˆ b ˆX 3 ˆ
其中 ˆ:ˆ2 n 1i n1 ( XiX)2
(4) 在最大值点的表达式中, 用样本值代入 就得参数的极大似然估计值 .
两点说明:
1、求似然函数L( ) 的最大值点,可以应
用微积分中的技巧。由于ln(x)是x的增函
数,lnL( )与L( )在 的同一值处达到 它的最大值,假定是一实数,且lnL( ) 是 的一个可微函数。通过求解所谓“似 然方程”: dlnL() 0
E(X1m)=E(X2m)==E(Xnm)= E(Xm)=am . 根据大数定律,样本原点矩Am作为 X1m,X2m, ,Xnm的算术平均值依概率收敛到均 值am=E(Xm).即:
n 1i n1Xim pE(Xm)am
例1 设总体X的概率密度为
f(x)(1)x,
大连理工大学《概率论与数理统计》课件-第7章

第7章参数的点估计及其优良性一. 矩估计二. 极大似然估计三.估计量的优良性和评选标准(),抽样n X X X 21,EX X P −→−,构造∑==n i i X n X 11 ,05.8=x 称为点估计量,X X =μˆ记为(),n X X X 21,()n x x x ,...,21()n X X X g ,...,21(),n X X X g ,...,ˆ21=θ()n x x x g ,...,ˆ21=θ:参数μ()为一组观察值,,,9.785,8.7 的点估计值,称为μ05.8(只需估计总体分布中未知参数,我们所关注的特征值均为未知参数的函数)1.矩法2.极大似然法点估计:设总体 X 的分布函数 F (x,θ) 形式已知,其中含有未知参数 θ。
从总体中抽取样本为样本观察值。
作为 θ 的估计量 。
记为:是 θ 的估计值。
⎩⎨⎧,2A =().,..., 21n X X X 抽样EX A P −→−1(),,~b a U X 例如:∑==n i i X nX 11∑==n i i X nA 12212?2EX A −→−2b a EX +=3222b ab a EX ++=EX A =122EX A =⎪⎪⎩⎪⎪⎨⎧++=+=3ˆˆˆˆ2ˆˆ2221b b a a A b a A 有()()⎪⎪⎩⎪⎪⎨⎧+=-=∑∑==2121-3ˆ-3ˆn i i n i i X X n X b X X n X a 解得2X 设总体2EX 期望为()22221,n X X X 抽样∑=n i i X n 121构造样本均数.22EX A P −→−由大数定律=1A EX X P−→−由大数定律−P 可令足够大只要,n ()辛钦大数定律()()()⎪⎪⎩⎪⎪⎨⎧===t t t t t EX EX EX θθθμθθθμθθθμ ,,,,,,212122211⎪⎪⎩⎪⎪⎨⎧t A A A21,则样本均数∑=n i i X n 11()由大数定律−→−P ,∑==n i k i k X n A 11EX A P −→−1k P k EX A −→−(),,,,21t x F θθθ ()是样本,n X X X 21,()个参数阶样本矩构造前t t ()存在是未知参数的函数阶总体矩求出前k EX t ()n X X X EX X 21,,,抽样期望总体()k k k k k n X X X EX X 21,,,抽样期望总体,则样本均数∑=n i k i X n 11t k 2,1=,令k k EX A = tθθθˆ,ˆ,ˆ21 从中解出()212-1∑==n i i X X n B 而()()()222因为EX EX X E X E DX -=-=,或者 2⎩⎨⎧==DX B EX X ,⎩⎨⎧==221EX A EX A ()()()⎪⎪⎩⎪⎪⎨⎧===t t t t t A A A θθθμθθθμθθθμˆ,ˆ,ˆˆ,ˆ,ˆˆ,ˆ,ˆ212122211 得212A A -=2121X X n n i i -=∑=DX B p −→−2个参数,可令一般的分布,若只有两22ˆB X Xn m m -=,ˆ 解出2m mX B X p -=⎩⎨⎧-==)ˆ1(ˆˆˆˆ2p p n B p n X m 得⎩⎨⎧==DXB EX X m 2令2B ,构造m X (),抽样m X X X 21,⎩⎨⎧-==)1(p np DX np EX 。
概率论与数理统计教程(茆诗松)第7章厦大版

例 7.1.1
假定某电视机厂(甲方)要从某电子元件厂(乙方)购入一批元 件,用于组装电视机。为了保证产品质量,降低成本,甲方希 望这批元件的合格品率达到99%以上。乙方也保证这一点。问题 是பைடு நூலகம்这批元件的合格品率是否达到99%以上? 如果记这批元件的次品率为p,问题就相当于对假设
H :“ 整批产品的次品率 p 不超过 1 ” %
例7.1.1(续1)
具体的作法是甲、乙双方事先先商定要检测样品的总数 n 和样 品中允许的不合格品数目的临界值 k . 当检测出样品中的不合格品数达到 k 时,甲方就拒绝假设H,同 时也就拒绝这批元件。否则甲方就接受假设H,同时也就接受这 批元件。 这个决定接受或拒绝一个假设的过程就称为“检验”。 现在的问题是:如何确定n? 在确定了n后,又如何确定 k? 这两个问题的关键是在确定了n后,如何指定一个k,指定了一个 k也就确定了一个检验方案,它定得是否恰当关系到甲乙双方的 利益。 直观上容易想到,k定的越小,条件对乙方就越苛刻,反之k定 的越大,条件对乙方就越宽松,因此确定检验方案应有一种公 认的标准,而这种标准应体现客观、公正和科学的原则。统计 假设检验的理论为这种标准的建立提供了科学依据。
或
H 0:F (x)是N ( m ,s 2 )
零假设与备择假设的区别
在假设检验问题中,零假设和备择假设是一对相互排斥的假 设,从实际问题的背景来讲,区分零假设和备择假设是非常重 要的。 由于零假设是作为检验前提而提出来的,因此零假设通常应该 是受到保护的,没有充足的证据是不能被拒绝的。而只有在零 假设被拒绝时才能接受备择假设,因此零假设与备择假设不是 处于同等地位。 从相反的角度看,备择假设可能是我们真正感兴趣的,接受备 择假设可能意味着得到有某种特别意义的结论,或意味着采取 某种重要决断。因此对备择假设应取慎重态度,没有充足的证 据不能轻易接受。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
x 0 , x 0 ,x 1 ,x 2 ,
,x n 为 总 体 X
的 一 个 样 本 ,则 未 知 参 数 的 矩 估 计 ˆ _ _ _ _ _ _ _ _ _ _ _ .
这个例子所作的推断已经体现了极大似然法 的基本思想 .
最大似然估计原理:
设X1,X2,…Xn是取自总体X的一个样本,样 本的联合密度(连续型)或联合分布律 (离散型)为
f (x1,x2,… ,xn ; ) .
当给定样本X1,X2,…Xn时,定义似然函数为:
L() f (x1, x2 ,…, xn; )
得
pˆ1Βιβλιοθήκη nn i 1xix
即为 p 的最大似然估计值 .
从而 p 的最大似然估计量为
p ˆ(X1,
1n ,Xn)ni1Xi X
求最大似然估计(MLE)的一般步骤是:
(1) 由总体分布导出样本的联合分布率(或联 合密度);
(2) 把样本联合分布率 ( 或联合密度 ) 中自变
量看成已知常数,而把参数 看作自变量,得到似然 函数L();
要求:领会
2.2 估计量的有效性、相合性, 要求:领会
3.区间估计
3.1 置信区间的概念,
要求:领会
3.2 求单个正态总体均值和方差的置信区间,要求:简单应用
参数估计
现在我们来介绍一类重要的统计推断问题
参数估计问题是利用从总体抽样得到的信息来估计总体 的某些参数或者参数的某些函数.
估计新生儿的体重
1 p
n
pxi (1p)1xi
i1
n
n
xi
n xi
pi1 (1p) i1
n
n
xi
n xi
L(p)pi1 (1p) i1
对数似然函数为:
n
n
ln L (p ) x iln p ) ((n x i)ln 1 (p )
i 1
i 1
对p求导并令其为0,
dld n L (p p)1 pi n 1xi1 1p(ni n 1xi)=0
θ(X1, ,Xn) 称为 θ 的最大似然估计量 .
两点说明:
1、求似然函数L( ) 的最大值点,可以应用 微积分中的技巧。由于ln(x)是 x 的增函数, lnL( )与L( )在 的同一值处达到它的最大值,假定 是一实数,且lnL( )是 的一个可微函数。通过
求解方程:
dlnL() 0 d
可以得到 的MLE .
第七章 参数估计
(一) 考核知识点 1. 点估计 2. 矩估计法 3. 极大似然估计法 4. 单个正态总体均值和方差的区间估计
(二) 考核要求
1.点估计
1.1 参数估计的概念, 要求:识记
1.2 求参数的矩估计, 要求:简单应用
1.3 求极大似然估计, 要求:简单应用
2.估计量的评价标准
2.1 矩估计的无偏性,
这里 x1, x2 ,…, xn 是样本的观察值
.
似然函数:
L() f (x1,x2,…, xn; )
看作参数 的函数,它可作为 将以多大
可L( )
能产生最样大本似值然x估1,计x法2,…就,是xn用的使一L种(度)量达. 到最大值
的ˆ 去估计 .
L(ˆ)maLx()
称 ˆ为 的最大似然估计值 . 而相应的统计量
用 事 件 A 出 现 的 频 率 估 计 事 件 A 发 生 的 概 率 .
例如我们要估计某队男生的平均身高.
(假定身高服从正态分布 )
N(,0.12)
现从该总体选取容量为5的样本,我们的任
务是要根据选出的样本(5个数)求出总体均值
的估计. 而全部信息就由这5个数组成 .
设这5个数是:
1.65 1.67 1.68 1.78 1.69
.
若是向量,上述方程必须用方程组代替
2、用上述求导方法求参数的MLE有时行不
通,这时要用最大似然原则来求 .
下面举例说明如何求最大似然估计
例5 设X1,X2,…Xn是取自总体 X~B(1, p) 的一 个样本,求参数p的最大似然估计量.
解:似然函数为:
L(p)=
f
(x1,
x2,…,
xn;
p
)
Xi
0 ~ 1 p
估计废品率 估计湖中鱼数
在参数估计问题
估计降雨量 中,假定总体分 布形式已知,未
… 知的仅仅是一个 … 或几个参数.
参数估计问题的一般提法
设有一个统计总体 , 总体的分布函数为
F( x, ) ,其中 为未知参数 ( 可以是向量) .
现从该总体抽样,得样本 X1,X2,…,Xn
要依据该样本对参数 作出估计, 或估计
估计 为1.68,这是点估计.
估计
在区间
[1.57, ,
1.84]
内
这是区间估计.
7.1.2 极大似然法
它是在总体类型已知条件下使用的一种参数估 计方法 .
它首先是由德国数学家高斯在
1821年提出的 . 然而,这个方法常
归功于英国统计学家费希尔 .
Gaus
s
费希尔在1922年重新发现了 这一方法,并首先研究了这种方
Fisher
法的一些性质 .
最大似然法的基本思想
先看一个简单例子 :某位同学与一位猎人一起外 出打猎 . 一只野兔从前方窜过 . 只听一声枪响,野兔应声倒下 . 如果要你推测,是谁打中的呢? 你会如何想呢?
你就会想,只发一枪便打中, 猎人命中的概率 一般大于这位同学命中的概率 . 看来这一枪是猎人 射中的 .
2.(2006-7)设总体X服从泊松分布,即X~P(λ),则参数λ2的极大似然估计量为 __________.
3.(2007-4)设总体X具有区间[0,θ]上的均匀分布(θ>0),x1,x2,…,xn是来自该
总体的样本,则θ的矩估计 ˆ ________.
4 .(2 0 0 7 -7 )设 总 体 X 的 概 率 密 度 为 f(x ) e x, 0 ,
(3) 求似然函数L( ) 的最大值点(常常转化 为求ln L( )的最大值点) ,即 的MLE;
(4) 在最大值点的表达式中, 用样本值代入就 得参数的最大似然估计值 .
1.(2006-4)设总体X服从参数为λ的指数分布,其中λ未知,X1,X2,…,Xn为来自 总体X的样本,则λ的矩估计为________.
的某个已知函数 g( ) .
这类问题称为参数估计.
点估计
参数估计 区间估计
用 样 本 均 值 x 估 计 总 体 均 值 E ( X ) , 即 E ( X ) x ;
用 样 本 二 阶 中 心 矩 s n 2 1 n i n 1 ( x i x ) 2 估 计 总 体 方 差 D ( X ) ,即 D ( X ) s n 2 ;