Broadcasting Methods in Mobile Ad Hoc Networks An Overview
计算机科学ESI期刊汇总

期刊全称期刊简称Acm Computing Surveys ACM COMPUT SURV Acm Journal On Emerging Technologies in Computing Systems ACM J EMERG TECH COM Acm Sigcomm Computer Communication Review ACM SIGCOMM COMP COMAcm Sigplan Notices ACM SIGPLAN NOTICES Acm Transactions On Algorithms ACM T ALGORITHMS Acm Transactions On Applied Perception ACM T APPL PERCEPT Acm Transactions On Architecture and Code Optimization ACM T ARCHIT CODE OPAcm Transactions On Autonomous and Adaptive Systems ACM T AUTON ADAP SYS Acm Transactions On Computational Logic ACM T COMPUT LOGAcm Transactions On Computer Systems ACM T COMPUT SYST Acm Transactions On Computer-Human Interaction ACM T COMPUT-HUM INT Acm Transactions On Database Systems ACM T DATABASE SYST Acm Transactions On Design Automation of Electronic Systems ACM T DES AUTOMAT EL Acm Transactions On Embedded Computing Systems ACM T EMBED COMPUT S Acm Transactions On Graphics ACM T GRAPHIC Acm Transactions On Information and System Security ACM T INFORM SYST SE Acm Transactions On Information Systems ACM T INFORM SYST Acm Transactions On Intelligent Systems and Technology ACM T INTEL SYST TEC Acm Transactions On Internet Technology ACM T INTERNET TECHN Acm Transactions On Knowledge Discovery From Data ACM T KNOWL DISCOV D Acm Transactions On Mathematical Software ACM T MATH SOFTWARE Acm Transactions On Modeling and Computer Simulation ACM T MODEL COMPUT S Acm Transactions On Multimedia Computing Communications and Applications ACM T MULTIM COMPUT Acm Transactions On Programming Languages and Systems ACM T PROGR LANG SYS Acm Transactions On Reconfigurable Technology and Systems ACM T RECONFIG TECHN Acm Transactions On Sensor Networks ACM T SENSOR NETWORK Acm Transactions On Software Engineering and Methodology ACM T SOFTW ENG METH Acm Transactions On Storage ACM T STORAGEAcm Transactions On the Web ACM T WEBActa Informatica ACTA INFORMAd Hoc & Sensor Wireless Networks AD HOC SENS WIREL NEAd Hoc Networks AD HOC NETWAdvances in Computers ADV COMPUTAdvances in Engineering Software ADV ENG SOFTW Aeu-International Journal of Electronics and Communications AEU-INT J ELECTRON C Annals of Telecommunications-Annales Des Telecommunications ANN TELECOMMUNApplied Clinical Informatics APPL CLIN INFORMApplied Ontology APPL ONTOLApplied Soft Computing APPL SOFT COMPUTArtificial Intelligence ARTIF INTELLArtificial Intelligence Review ARTIF INTELL REVArtificial Life ARTIF LIFEAutomated Software Engineering AUTOMAT SOFTW ENG Autonomous Agents and Multi-Agent Systems AUTON AGENT MULTI-AG Bell Labs Technical Journal BELL LABS TECH JBioinformatics BIOINFORMATICSBmc Bioinformatics BMC BIOINFORMATICSBriefings in Bioinformatics BRIEF BIOINFORM Business & Information Systems Engineering BUS INFORM SYST ENG+China Communications CHINA COMMUN Cluster Computing-the Journal of Networks Software Tools and Applications CLUSTER COMPUT Cmc-Computers Materials & Continua CMC-COMPUT MATER CONCmes-Computer Modeling in Engineering & Sciences CMES-COMP MODEL ENGCognitive Computation COGN COMPUTCognitive Systems Research COGN SYST RESCommunications of the Acm COMMUN ACMComputational Biology and Chemistry COMPUT BIOL CHEMComputational Geosciences COMPUTAT GEOSCIComputational Linguistics COMPUT LINGUISTComputer COMPUTERComputer Aided Geometric Design COMPUT AIDED GEOM D Computer Animation and Virtual Worlds COMPUT ANIMAT VIRT W Computer Applications in Engineering Education COMPUT APPL ENG EDUCComputer Communications COMPUT COMMUNComputer Graphics Forum COMPUT GRAPH FORUMComputer Journal COMPUT JComputer Languages Systems & Structures COMPUT LANG SYST STR Computer Methods and Programs in Biomedicine COMPUT METH PROG BIO Computer Methods in Applied Mechanics and Engineering COMPUT METHOD APPL M Computer Methods in Biomechanics and Biomedical Engineering COMPUT METHOD BIOMECComputer Music Journal COMPUT MUSIC JComputer Networks COMPUT NETW Computer Science and Information Systems COMPUT SCI INF SYSTComputer Speech and Language COMPUT SPEECH LANGComputer Standards & Interfaces COMPUT STAND INTER Computer Supported Cooperative Work-the Journal of Collaborative Computing COMPUT SUPP COOP W J Computer Systems Science and Engineering COMPUT SYST SCI ENGComputer Vision and Image Understanding COMPUT VIS IMAGE UNDComputer-Aided Design COMPUT AIDED DESIGN Computers & Chemical Engineering COMPUT CHEM ENGComputers & Education COMPUT EDUCComputers & Electrical Engineering COMPUT ELECTR ENGComputers & Fluids COMPUT FLUIDSComputers & Geosciences COMPUT GEOSCI-UKComputers & Graphics-Uk COMPUT GRAPH-UKComputers & Industrial Engineering COMPUT IND ENGComputers & Operations Research COMPUT OPER RESComputers & Security COMPUT SECURComputers & Structures COMPUT STRUCTComputers and Concrete COMPUT CONCRETE Computers and Electronics in Agriculture COMPUT ELECTRON AGRComputers and Geotechnics COMPUT GEOTECHComputers in Biology and Medicine COMPUT BIOL MEDComputers in Industry COMPUT INDComputing COMPUTINGComputing and Informatics COMPUT INFORMComputing in Science & Engineering COMPUT SCI ENG Concurrency and Computation-Practice & Experience CONCURR COMP-PRACT EConnection Science CONNECT SCIConstraints CONSTRAINTS Cryptography and Communications-Discrete-Structures Boolean Functions and Sequences CRYPTOGR COMMUNCryptologia CRYPTOLOGIACurrent Bioinformatics CURR BIOINFORMData & Knowledge Engineering DATA KNOWL ENG Data Mining and Knowledge Discovery DATA MIN KNOWL DISCDecision Support Systems DECIS SUPPORT SYST Design Automation For Embedded Systems DES AUTOM EMBED SYST Designs Codes and Cryptography DESIGN CODE CRYPTOGRDigital Investigation DIGIT INVESTDisplays DISPLAYSDistributed and Parallel Databases DISTRIB PARALLEL DATDistributed Computing DISTRIB COMPUTEmpirical Software Engineering EMPIR SOFTW ENGEngineering With Computers ENG COMPUT-GERMANYEnterprise Information Systems ENTERP INF SYST-UK Environmental Modelling & Software ENVIRON MODELL SOFTWEtri Journal ETRI J Eurasip Journal On Wireless Communications and Networking EURASIP J WIREL COMM European Journal of Information Systems EUR J INFORM SYSTEvolutionary Bioinformatics EVOL BIOINFORMEvolutionary Computation EVOL COMPUTExpert Systems EXPERT SYSTFormal Aspects of Computing FORM ASP COMPUTFormal Methods in System Design FORM METHOD SYST DES Foundations and Trends in Information Retrieval FOUND TRENDS INF RETFrontiers in Neurorobotics FRONT NEUROROBOTICSFrontiers of Computer Science FRONT COMPUT SCI-CHI Frontiers of Information Technology & Electronic Engineering FRONT INFORM TECH ELFundamenta Informaticae FUND INFORMture Generation Computer Systems-the International Journal of Grid Computing and EscienFUTURE GENER COMP SY Genetic Programming and Evolvable Machines GENET PROGRAM EVOL MGraphical Models GRAPH MODELSHuman-Computer Interaction HUM-COMPUT INTERACT Ibm Journal of Research and Development IBM J RES DEVIcga Journal ICGA JIeee Annals of the History of Computing IEEE ANN HIST COMPUTIeee Communications Letters IEEE COMMUN LETTIeee Communications Magazine IEEE COMMUN MAG Ieee Communications Surveys and Tutorials IEEE COMMUN SURV TUTIeee Computational Intelligence Magazine IEEE COMPUT INTELL M Ieee Computer Architecture Letters IEEE COMPUT ARCHIT L Ieee Computer Graphics and Applications IEEE COMPUT GRAPHIeee Design & Test IEEE DES TESTIeee Internet Computing IEEE INTERNET COMPUT Ieee Journal of Biomedical and Health Informatics IEEE J BIOMED HEALTHIeee Journal On Selected Areas in Communications IEEE J SEL AREA COMMIeee Micro IEEE MICROIeee Multimedia IEEE MULTIMEDIAIeee Network IEEE NETWORKIeee Pervasive Computing IEEE PERVAS COMPUTIeee Security & Privacy IEEE SECUR PRIVIeee Software IEEE SOFTWAREIeee Systems Journal IEEE SYST JIeee Transactions On Affective Computing IEEE T AFFECT COMPUT Ieee Transactions On Autonomous Mental Development IEEE T AUTON MENT DE Ieee Transactions On Broadcasting IEEE T BROADCASTIeee Transactions On Communications IEEE T COMMUN Ieee Transactions On Computational Intelligence and Ai in Games IEEE T COMP INTEL AIIeee Transactions On Computers IEEE T COMPUTIeee Transactions On Cybernetics IEEE T CYBERNETICS Ieee Transactions On Dependable and Secure Computing IEEE T DEPEND SECURE Ieee Transactions On Evolutionary Computation IEEE T EVOLUT COMPUT Ieee Transactions On Haptics IEEE T HAPTICS Ieee Transactions On Information Forensics and Security IEEE T INF FOREN SEC Ieee Transactions On Information Theory IEEE T INFORM THEORYIeee Transactions On Learning Technologies IEEE T LEARN TECHNOLIeee Transactions On Mobile Computing IEEE T MOBILE COMPUT Ieee Transactions On Multimedia IEEE T MULTIMEDIA Ieee Transactions On Neural Networks and Learning Systems IEEE T NEUR NET LEAR Ieee Transactions On Parallel and Distributed Systems IEEE T PARALL DISTR Ieee Transactions On Services Computing IEEE T SERV COMPUTIeee Transactions On Software Engineering IEEE T SOFTWARE ENG Ieee Transactions On Visualization and Computer Graphics IEEE T VIS COMPUT GR Ieee Transactions On Wireless Communications IEEE T WIREL COMMUN Ieee Wireless Communications IEEE WIREL COMMUN Ieee-Acm Transactions On Computational Biology and Bioinformatics IEEE ACM T COMPUT BI Ieee-Acm Transactions On Networking IEEE ACM T NETWORKIeice Transactions On Communications IEICE T COMMUN Ieice Transactions On Information and Systems IEICE T INF SYSTIet Biometrics IET BIOMETRICSIet Computer Vision IET COMPUT VIS Iet Computers and Digital Techniques IET COMPUT DIGIT TEC Iet Information Security IET INFORM SECUR Iet Radar Sonar and Navigation IET RADAR SONAR NAVIet Software IET SOFTWInformatica INFORMATICA-LITHUAN Information and Computation INFORM COMPUT Information and Software Technology INFORM SOFTWARE TECH Information Fusion INFORM FUSION Information Processing Letters INFORM PROCESS LETT Information Retrieval INFORM RETRIEVALInformation Sciences INFORM SCIENCESInformation Systems INFORM SYSTInformation Systems Frontiers INFORM SYST FRONTInformation Systems Management INFORM SYST MANAGEInformation Technology and Control INF TECHNOL CONTROL Information Visualization INFORM VISUAL Informs Journal On Computing INFORMS J COMPUT Integrated Computer-Aided Engineering INTEGR COMPUT-AID E Integration-the Vlsi Journal INTEGRATIONIntelligent Data Analysis INTELL DATA ANALInteracting With Computers INTERACT COMPUT International Arab Journal of Information Technology INT ARAB J INF TECHN International Journal For Numerical Methods in Biomedical Engineering INT J NUMER METH BIO International Journal of Ad Hoc and Ubiquitous Computing INT J AD HOC UBIQ CO International Journal of Approximate Reasoning INT J APPROX REASONInternational Journal of Bio-Inspired Computation INT J BIO-INSPIR COM International Journal of Computational Intelligence Systems INT J COMPUT INT SYS International Journal of Computer Networks and Communications INT J COMPUT NETW CO International Journal of Computers Communications & Control INT J COMPUT COMMUN International Journal of Cooperative Information Systems INT J COOP INF SYSTInternational Journal of Data Mining and Bioinformatics INT J DATA MIN BIOINInternational Journal of Data Warehousing and Mining INT J DATA WAREHOUSInternational Journal of Distributed Sensor Networks INT J DISTRIB SENS NInternational Journal of Foundations of Computer Science INT J FOUND COMPUT S International Journal of General Systems INT J GEN SYST International Journal of High Performance Computing Applications INT J HIGH PERFORM C International Journal of Information Security INT J INF SECUR International Journal of Information Technology & Decision Making INT J INF TECH DECIS International Journal of Machine Learning and Cybernetics INT J MACH LEARN CYB International Journal of Network Management INT J NETW MANAG International Journal of Neural Systems INT J NEURAL SYST International Journal of Parallel Programming INT J PARALLEL PROG International Journal of Pattern Recognition and Artificial Intelligence INT J PATTERN RECOGN International Journal of Satellite Communications and Networking INT J SATELL COMM N International Journal of Sensor Networks INT J SENS NETW International Journal of Software Engineering and Knowledge Engineering INT J SOFTW ENG KNOW International Journal of Uncertainty Fuzziness and Knowledge-Based Systems INT J UNCERTAIN FUZZ International Journal of Unconventional Computing INT J UNCONV COMPUT International Journal of Wavelets Multiresolution and Information Processing INT J WAVELETS MULTI International Journal of Web and Grid Services INT J WEB GRID SERVInternational Journal of Web Services Research INT J WEB SERV RESInternational Journal On Artificial Intelligence Tools INT J ARTIF INTELL T International Journal On Document Analysis and Recognition INT J DOC ANAL RECOG International Journal On Semantic Web and Information Systems INT J SEMANT WEB INFInternet Research INTERNET RESIt Professional IT PROF Journal of Ambient Intelligence and Humanized Computing J AMB INTEL HUM COMP Journal of Ambient Intelligence and Smart Environments J AMB INTEL SMART EN Journal of Applied Logic J APPL LOGIC Journal of Artificial Intelligence Research J ARTIF INTELL RES Journal of Automated Reasoning J AUTOM REASONING Journal of Bioinformatics and Computational Biology J BIOINF COMPUT BIOL Journal of Biomedical Informatics J BIOMED INFORMJournal of Cellular Automata J CELL AUTOMJournal of Cheminformatics J CHEMINFORMATICS Journal of Communications and Networks J COMMUN NETW-S KOR Journal of Communications Technology and Electronics J COMMUN TECHNOL EL+Journal of Computational Analysis and Applications J COMPUT ANAL APPL Journal of Computational Science J COMPUT SCI-NETH Journal of Computer and System Sciences J COMPUT SYST SCI Journal of Computer and Systems Sciences International J COMPUT SYS SC INT+ Journal of Computer Information Systems J COMPUT INFORM SYSTJournal of Computer Science and Technology J COMPUT SCI TECH-CHJournal of Computers J COMPUTJournal of Cryptology J CRYPTOLJournal of Database Management J DATABASE MANAGE Journal of Experimental & Theoretical Artificial Intelligence J EXP THEOR ARTIF IN Journal of Functional Programming J FUNCT PROGRAMJournal of Grid Computing J GRID COMPUTJournal of Heuristics J HEURISTICS Journal of Information Science and Engineering J INF SCI ENGJournal of Information Technology J INF TECHNOLJournal of Intelligent & Fuzzy Systems J INTELL FUZZY SYSTJournal of Intelligent Information Systems J INTELL INF SYST Journal of Internet Technology J INTERNET TECHNOLJournal of Logic and Computation J LOGIC COMPUT Journal of Logical and Algebraic Methods in Programming J LOG ALGEBR METHODS Journal of Machine Learning Research J MACH LEARN RES Journal of Management Information Systems J MANAGE INFORM SYSTJournal of Mathematical Imaging and Vision J MATH IMAGING VISJournal of Molecular Graphics & Modelling J MOL GRAPH MODEL Journal of Multiple-Valued Logic and Soft Computing J MULT-VALUED LOG S Journal of Network and Computer Applications J NETW COMPUT APPLJournal of Network and Systems Management J NETW SYST MANAG Journal of New Music Research J NEW MUSIC RES Journal of Next Generation Information Technology J NEXT GENER INF TEC Journal of Optical Communications and Networking J OPT COMMUN NETW Journal of Organizational and End User Computing J ORGAN END USER COM Journal of Organizational Computing and Electronic Commerce J ORG COMP ELECT COM Journal of Parallel and Distributed Computing J PARALLEL DISTR COM Journal of Real-Time Image Processing J REAL-TIME IMAGE PR Journal of Research and Practice in Information Technology J RES PRACT INF TECH Journal of Software-Evolution and Process J SOFTW-EVOL PROC Journal of Statistical Software J STAT SOFTW Journal of Strategic Information Systems J STRATEGIC INF SYST Journal of Supercomputing J SUPERCOMPUT Journal of Systems and Software J SYST SOFTWAREJournal of Systems Architecture J SYST ARCHITECTJournal of the Acm J ACM Journal of the Association For Information Systems J ASSOC INF SYST Journal of the Institute of Telecommunications Professionals J I TELECOMMUN PROF Journal of Universal Computer Science J UNIVERS COMPUT SCI Journal of Visual Communication and Image Representation J VIS COMMUN IMAGE R Journal of Visual Languages and Computing J VISUAL LANG COMPUT Journal of Visualization J VISUAL-JAPANJournal of Web Engineering J WEB ENGJournal of Web Semantics J WEB SEMANT Journal of Zhejiang University-Science C-Computers & Electronics J ZHEJIANG U-SCI C Journal On Multimodal User Interfaces J MULTIMODAL USER INKnowledge and Information Systems KNOWL INF SYSTKnowledge Engineering Review KNOWL ENG REVKnowledge-Based Systems KNOWL-BASED SYST Ksii Transactions On Internet and Information Systems KSII T INTERNET INF Language Resources and Evaluation LANG RESOUR EVALLogical Methods in Computer Science LOG METH COMPUT SCIMalaysian Journal of Computer Science MALAYS J COMPUT SCI Mathematical and Computer Modelling of Dynamical Systems MATH COMP MODEL DYN Mathematical Modelling of Natural Phenomena MATH MODEL NAT PHENO Mathematical Programming MATH PROGRAM Mathematical Structures in Computer Science MATH STRUCT COMP SCI Medical Image Analysis MED IMAGE ANALMemetic Computing MEMET COMPUT Microprocessors and Microsystems MICROPROCESS MICROSY Minds and Machines MIND MACHMobile Information Systems MOB INF SYSTMobile Networks & Applications MOBILE NETW APPLMultidimensional Systems and Signal Processing MULTIDIM SYST SIGN PMultimedia Systems MULTIMEDIA SYST Multimedia Tools and Applications MULTIMED TOOLS APPLNatural Computing NAT COMPUTNetworks NETWORKSNeural Computation NEURAL COMPUTNeural Network World NEURAL NETW WORLDNeural Networks NEURAL NETWORKSNeural Processing Letters NEURAL PROCESS LETTNeurocomputing NEUROCOMPUTINGNew Generation Computing NEW GENERAT COMPUT New Review of Hypermedia and Multimedia NEW REV HYPERMEDIA M Online Information Review ONLINE INFORM REV Optical Switching and Networking OPT SWITCH NETWOptimization Methods & Software OPTIM METHOD SOFTWParallel Computing PARALLEL COMPUT Peer-To-Peer Networking and Applications PEER PEER NETW APPLPerformance Evaluation PERFORM EVALUATION Personal and Ubiquitous Computing PERS UBIQUIT COMPUTPervasive and Mobile Computing PERVASIVE MOB COMPUTPhotonic Network Communications PHOTONIC NETW COMMUN Presence-Teleoperators and Virtual Environments PRESENCE-TELEOP VIRT Problems of Information Transmission PROBL INFORM TRANSM+Programming and Computer Software PROGRAM COMPUT SOFT+ Rairo-Theoretical Informatics and Applications RAIRO-THEOR INF APPLReal-Time Systems REAL-TIME SYSTRequirements Engineering REQUIR ENGResearch Synthesis Methods RES SYNTH METHODS Romanian Journal of Information Science and Technology ROM J INF SCI TECH Science China-Information Sciences SCI CHINA INFORM SCIScience of Computer Programming SCI COMPUT PROGRAMScientific Programming SCI PROGRAMMING-NETH Security and Communication Networks SECUR COMMUN NETW Siam Journal On Computing SIAM J COMPUTSiam Journal On Imaging Sciences SIAM J IMAGING SCISigmod Record SIGMOD REC Simulation Modelling Practice and Theory SIMUL MODEL PRACT TH Simulation-Transactions of the Society For Modeling and Simulation International SIMUL-T SOC MOD SIMSoft Computing SOFT COMPUTSoftware and Systems Modeling SOFTW SYST MODELSoftware Quality Journal SOFTWARE QUAL J Software Testing Verification & Reliability SOFTW TEST VERIF REL Software-Practice & Experience SOFTWARE PRACT EXPERSpeech Communication SPEECH COMMUNStatistics and Computing STAT COMPUTSwarm Intelligence SWARM INTELL-USTelecommunication Systems TELECOMMUN SYST Theoretical Biology and Medical Modelling THEOR BIOL MED MODEL Theoretical Computer Science THEOR COMPUT SCI Theory and Practice of Logic Programming THEOR PRACT LOG PROG Theory of Computing Systems THEOR COMPUT SYST Transactions On Emerging Telecommunications Technologies T EMERG TELECOMMUN T Universal Access in the Information Society UNIVERSAL ACCESS INFUser Modeling and User-Adapted Interaction USER MODEL USER-ADAPVirtual Reality VIRTUAL REAL-LONDONVisual Computer VISUAL COMPUTVldb Journal VLDB JWiley Interdisciplinary Reviews-Data Mining and Knowledge Discovery WIRES DATA MIN KNOWL Wireless Communications & Mobile Computing WIREL COMMUN MOB COM Wireless Networks WIREL NETW Wireless Personal Communications WIRELESS PERS COMMUN World Wide Web-Internet and Web Information Systems WORLD WIDE WEBISSN EISSN ESI学科名称0360-03001557-7341COMPUTER SCIENCE 1550-48321550-4840COMPUTER SCIENCE 0146-48331943-5819COMPUTER SCIENCE 0362-13401558-1160COMPUTER SCIENCE 1549-63251549-6333COMPUTER SCIENCE 1544-35581544-3965COMPUTER SCIENCE 1544-35661544-3973COMPUTER SCIENCE 1556-46651556-4703COMPUTER SCIENCE 1529-37851557-945X COMPUTER SCIENCE 0734-********-7333COMPUTER SCIENCE 1073-05161557-7325COMPUTER SCIENCE 0362-59151557-4644COMPUTER SCIENCE 1084-43091557-7309COMPUTER SCIENCE 1539-90871558-3465COMPUTER SCIENCE 0730-********-7368COMPUTER SCIENCE 1094-92241557-7406COMPUTER SCIENCE 1046-81881558-2868COMPUTER SCIENCE 2157-69042157-6912COMPUTER SCIENCE 1533-53991557-6051COMPUTER SCIENCE 1556-46811556-472X COMPUTER SCIENCE 0098-35001557-7295COMPUTER SCIENCE 1049-33011558-1195COMPUTER SCIENCE 1551-68571551-6865COMPUTER SCIENCE 0164-09251558-4593COMPUTER SCIENCE 1936-74061936-7414COMPUTER SCIENCE 1550-48591550-4867COMPUTER SCIENCE 1049-331X1557-7392COMPUTER SCIENCE 1553-30771553-3093COMPUTER SCIENCE 1559-11311559-114X COMPUTER SCIENCE 0001-59031432-0525COMPUTER SCIENCE 1551-98991552-0633COMPUTER SCIENCE 1570-87051570-8713COMPUTER SCIENCE 0065-2458null COMPUTER SCIENCE 0965-99781873-5339COMPUTER SCIENCE 1434-84111618-0399COMPUTER SCIENCE 0003-43471958-9395COMPUTER SCIENCE 1869-03271869-0327COMPUTER SCIENCE 1570-58381875-8533COMPUTER SCIENCE 1568-49461872-9681COMPUTER SCIENCE 0004-37021872-7921COMPUTER SCIENCE 0269-28211573-7462COMPUTER SCIENCE 1064-54621530-9185COMPUTER SCIENCE 0928-89101573-7535COMPUTER SCIENCE 1387-25321573-7454COMPUTER SCIENCE 1089-70891538-7305COMPUTER SCIENCE 1367-48031460-2059COMPUTER SCIENCE 1471-21051471-2105COMPUTER SCIENCE 1467-54631477-4054COMPUTER SCIENCE 1867-02021867-0202COMPUTER SCIENCE 1673-5447null COMPUTER SCIENCE 1386-78571573-7543COMPUTER SCIENCE 1546-22181546-2226COMPUTER SCIENCE1526-14921526-1506COMPUTER SCIENCE 1866-99561866-9964COMPUTER SCIENCE 1389-0417null COMPUTER SCIENCE 0001-07821557-7317COMPUTER SCIENCE 1476-92711476-928X COMPUTER SCIENCE 1420-05971573-1499COMPUTER SCIENCE 0891-********-9312COMPUTER SCIENCE 0018-91621558-0814COMPUTER SCIENCE 0167-83961879-2332COMPUTER SCIENCE 1546-42611546-427X COMPUTER SCIENCE 1061-37731099-0542COMPUTER SCIENCE 0140-36641873-703X COMPUTER SCIENCE 0167-70551467-8659COMPUTER SCIENCE 0010-46201460-2067COMPUTER SCIENCE 1477-84241873-6866COMPUTER SCIENCE 0169-26071872-7565COMPUTER SCIENCE 0045-78251879-2138COMPUTER SCIENCE 1025-58421476-8259COMPUTER SCIENCE 0148-92671531-5169COMPUTER SCIENCE 1389-12861872-7069COMPUTER SCIENCE 1820-02141820-0214COMPUTER SCIENCE 0885-23081095-8363COMPUTER SCIENCE 0920-54891872-7018COMPUTER SCIENCE 0925-97241573-7551COMPUTER SCIENCE 0267-6192null COMPUTER SCIENCE 1077-31421090-235X COMPUTER SCIENCE 0010-44851879-2685COMPUTER SCIENCE 0098-13541873-4375COMPUTER SCIENCE 0360-13151873-782X COMPUTER SCIENCE 0045-79061879-0755COMPUTER SCIENCE 0045-79301879-0747COMPUTER SCIENCE 0098-30041873-7803COMPUTER SCIENCE 0097-84931873-7684COMPUTER SCIENCE 0360-83521879-0550COMPUTER SCIENCE 0305-05481873-765X COMPUTER SCIENCE 0167-40481872-6208COMPUTER SCIENCE 0045-79491879-2243COMPUTER SCIENCE 1598-81981598-818X COMPUTER SCIENCE 0168-16991872-7107COMPUTER SCIENCE 0266-352X1873-7633COMPUTER SCIENCE 0010-48251879-0534COMPUTER SCIENCE 0166-36151872-6194COMPUTER SCIENCE 0010-485X1436-5057COMPUTER SCIENCE 1335-9150null COMPUTER SCIENCE 1521-96151558-366X COMPUTER SCIENCE 1532-06261532-0634COMPUTER SCIENCE 0954-********-0494COMPUTER SCIENCE 1383-71331572-9354COMPUTER SCIENCE 1936-24471936-2455COMPUTER SCIENCE 0161-11941558-1586COMPUTER SCIENCE 1574-89362212-392X COMPUTER SCIENCE 0169-023X1872-6933COMPUTER SCIENCE 1384-58101573-756X COMPUTER SCIENCE0167-92361873-5797COMPUTER SCIENCE 0929-55851572-8080COMPUTER SCIENCE 0925-10221573-7586COMPUTER SCIENCE 1742-28761873-202X COMPUTER SCIENCE 0141-93821872-7387COMPUTER SCIENCE 0926-87821573-7578COMPUTER SCIENCE 0178-27701432-0452COMPUTER SCIENCE 1382-32561573-7616COMPUTER SCIENCE 0177-06671435-5663COMPUTER SCIENCE 1751-75751751-7583COMPUTER SCIENCE 1364-81521873-6726COMPUTER SCIENCE 1225-64632233-7326COMPUTER SCIENCE 1687-14991687-1499COMPUTER SCIENCE 0960-085X1476-9344COMPUTER SCIENCE 1176-93431176-9343COMPUTER SCIENCE 1063-65601530-9304COMPUTER SCIENCE 0266-47201468-0394COMPUTER SCIENCE 0934-********-299X COMPUTER SCIENCE 0925-98561572-8102COMPUTER SCIENCE 1554-06691554-0677COMPUTER SCIENCE 1662-52181662-5218COMPUTER SCIENCE 2095-22282095-2236COMPUTER SCIENCE 2095-91842095-9230COMPUTER SCIENCE 0169-29681875-8681COMPUTER SCIENCE 0167-739X1872-7115COMPUTER SCIENCE 1389-25761573-7632COMPUTER SCIENCE 1524-07031524-0711COMPUTER SCIENCE 0737-********-7051COMPUTER SCIENCE 0018-86462151-8556COMPUTER SCIENCE 1389-6911null COMPUTER SCIENCE 1058-61801934-1547COMPUTER SCIENCE 1089-77981558-2558COMPUTER SCIENCE 0163-68041558-1896COMPUTER SCIENCE 1553-877X1553-877X COMPUTER SCIENCE 1556-603X1556-6048COMPUTER SCIENCE 1556-60561556-6064COMPUTER SCIENCE 0272-17161558-1756COMPUTER SCIENCE 2168-2356null COMPUTER SCIENCE 1089-78011941-0131COMPUTER SCIENCE 2168-21942168-2194COMPUTER SCIENCE 0733-********-0008COMPUTER SCIENCE 0272-17321937-4143COMPUTER SCIENCE 1070-986X1941-0166COMPUTER SCIENCE 0890-********-156X COMPUTER SCIENCE 1536-12681558-2590COMPUTER SCIENCE 1540-79931558-4046COMPUTER SCIENCE 0740-74591937-4194COMPUTER SCIENCE 1932-81841937-9234COMPUTER SCIENCE 1949-30451949-3045COMPUTER SCIENCE 1943-06041943-0612COMPUTER SCIENCE 0018-93161557-9611COMPUTER SCIENCE 0090-67781558-0857COMPUTER SCIENCE 1943-068X1943-0698COMPUTER SCIENCE0018-93401557-9956COMPUTER SCIENCE 2168-22672168-2275COMPUTER SCIENCE 1545-59711941-0018COMPUTER SCIENCE 1089-778X1941-0026COMPUTER SCIENCE 1939-14122329-4051COMPUTER SCIENCE 1556-60131556-6021COMPUTER SCIENCE 0018-94481557-9654COMPUTER SCIENCE 1939-13821939-1382COMPUTER SCIENCE 1536-12331558-0660COMPUTER SCIENCE 1520-92101941-0077COMPUTER SCIENCE 2162-237X2162-2388COMPUTER SCIENCE 1045-92191558-2183COMPUTER SCIENCE 1939-13741939-1374COMPUTER SCIENCE 0098-55891939-3520COMPUTER SCIENCE 1077-26261941-0506COMPUTER SCIENCE 1536-12761558-2248COMPUTER SCIENCE 1536-12841558-0687COMPUTER SCIENCE 1545-59631557-9964COMPUTER SCIENCE 1063-66921558-2566COMPUTER SCIENCE 1745-13451745-1345COMPUTER SCIENCE 1745-13611745-1361COMPUTER SCIENCE 2047-49382047-4946COMPUTER SCIENCE 1751-96321751-9640COMPUTER SCIENCE 1751-86011751-861X COMPUTER SCIENCE 1751-87091751-8717COMPUTER SCIENCE 1751-87841751-8792COMPUTER SCIENCE 1751-88061751-8814COMPUTER SCIENCE 0868-49521822-8844COMPUTER SCIENCE 0890-********-2651COMPUTER SCIENCE 0950-58491873-6025COMPUTER SCIENCE 1566-25351872-6305COMPUTER SCIENCE 0020-01901872-6119COMPUTER SCIENCE 1386-45641573-7659COMPUTER SCIENCE 0020-02551872-6291COMPUTER SCIENCE 0306-43791873-6076COMPUTER SCIENCE 1387-33261572-9419COMPUTER SCIENCE 1058-05301934-8703COMPUTER SCIENCE 1392-124X null COMPUTER SCIENCE 1473-87161473-8724COMPUTER SCIENCE 1091-98561526-5528COMPUTER SCIENCE 1069-25091875-8835COMPUTER SCIENCE 0167-92601872-7522COMPUTER SCIENCE 1088-467X1571-4128COMPUTER SCIENCE 0953-********-7951COMPUTER SCIENCE 1683-3198null COMPUTER SCIENCE 2040-79392040-7947COMPUTER SCIENCE 1743-82251743-8233COMPUTER SCIENCE 0888-613X1873-4731COMPUTER SCIENCE 1758-03661758-0374COMPUTER SCIENCE 1875-68911875-6883COMPUTER SCIENCE 0975-********-9322COMPUTER SCIENCE 1841-98361841-9844COMPUTER SCIENCE 0218-84301793-6365COMPUTER SCIENCE。
E-车载自组网(VANET)讲解学习

10
③ C2C-CC,“ Car2Car Communication Consortium ”是由6家欧洲汽车制造商(BMW、 DaimlerChrysler、Volkswagen等)组成,目标是为 car2car 通信系统建立一个公开的欧洲标准,不同制 造商的汽车能够相互通信。Car2Car通信系统是采用 基于无线局域网 WLAN技术,确保在欧洲范围内车间 通信的正常运行。
Vehicles can find their neighbors through periodic beacon messages, which also enclose the physical location of the sender.
Vehicles are assumed to be equipped with pre-load digital maps, which provide street-level map and traffic statistics (such as traffic density and vehicle speed on roads at different times of the day)
5
6
专用短距离通信技术—DSRC,是专门为车载 通信开发的技术
7
Ad Hoc网络移动模型综述

追逐移动模型(Pursue Mobility Mode1)[37]模拟节点追逐某物时的移动模式,其节点新位置按下式计算:
new_position=old_position+acceleration(target-old_position)+random_vector。
其中acceleration(target-old_position)是加速函数,表示被追逐节点移动的量;random_vector表示追逐节点移动的偏离量,可以通过某一个体移动模型(如随机漫步模型)获得。
Basagni[8-10]和Gerla[11]修订了随机漫步模型,提出等速度随机方向模型(Constant Velocity Random Direction MobilityMode1)。该模型有着固定的速度大小并且只有在边界才改变方向。
2.2随机路径点模型
随机路径点模型(Random Waypoint Mode1)[12-15]定义为:在移动区域内随机取起始点S和目的点D。随机取速度v∈(vmin,vmax),使用速度v从S沿直线移动到D,其中vmax是节点的最大移动速度;vmin是节点的最小移动速度。在D随机选取一个时间tpause∈(tmin,tmax)暂停,其中tmax是节点的最大暂停时问;tmin是节点的最小暂停时间。这样完成一个Step过程。将本次的目的点D作为下次运动的起始点S,进行下一个Step过程,如此反复。
类似地,市区移动模型(City Section Mobility Mode1)模拟了市区内公路或街道行人的移动模式。文献[25]结合交通理论提出了市区、地区、街区移动模型(City Area,Area Zone,Street Unit Mobility Models)。Lam[26]提出的城市、国家、国际移动模型(Metropolitan Mobility Model,NationalMobility Model,International Mobility Mode1)是一种分层移动模型(Hierarchy of Mobility Mode1),3个模型关注不同区域层次的移动。障碍物移动模型(Obstacle Mobility Mode1)[27]中,建筑物等障碍物被建模。基于图的移动模型(Graph-based Mobility Mode1)[28]利用图来建模环境设施对节点移动的限制。虚拟路径组移动模型(Virtual Track basedGroup Mobility Mode1)[29]利用“虚拟路径”建模组移动。
An Efficient Counter-Based Broadcast Scheme for Mobile Ad Hoc Networks

An Efficient Counter-Based Broadcast Scheme forMobile Ad Hoc NetworksAminu Mohammed, Mohamed Ould-Khaoua, and Lewis MackenzieDepartment of Computing Science, University of Glasgow, G12 8RZ,Glasgow, United Kingdom{maminuus,mohamed,lewis}@Abstract. In mobile ad hoc networks (MANETs), broadcasting plays afundamental role, diffusing a message from a given source node to all the othernodes in the network. Flooding is the simplest and commonly used mechanismfor broadcasting in MANETs, where each node retransmits every uniquelyreceived message exactly once. Despite its simplicity, it however generatesredundant rebroadcast messages which results in high contention and collisionin the network, a phenomenon referred to as broadcast storm problem. Pureprobabilistic approaches have been proposed to mitigate this problem inherentwith flooding, where mobile nodes rebroadcast a message with a probability pwhich can be fixed or computed based on the local density. However, theseapproaches reduce the number of rebroadcasts at the expense of reachability.On the other hand, counter-based approaches inhibit a node from broadcasting apacket based on the number of copies of the broadcast packet received by thenode within a random access delay time. These schemes achieve betterthroughput and reachability, but suffer from relatively longer delay. In thispaper, we propose an efficient broadcasting scheme that combines theadvantages of pure probabilistic and counter-based schemes to yield asignificant performance improvement. Simulation results reveal that the newscheme achieves superior performance in terms of saved-rebroadcast,reachability and latency.Keywords: MANETs, Flooding, Broadcast storm problem, Saved-rebroadcast,Reachability, Latency.1 IntroductionBroadcasting is a means of diffusing a message from a given source node to all other nodes in the network. It is a fundamental operation in MANETs and a buil- ding block for most other network layer protocols. Several unicast routing protocols such as Dynamic Source Routing (DSR), Ad Hoc on Demand Distance Vector (AODV), Zone Routing Protocol (ZRP), and Location Aided Routing (LAR), as well multicast protocols employ broadcasting to detect and maintain routes in a dynamic environment. Currently, these protocols typically rely on simplistic form of broadcasting called simple flooding, in which each mobile node retransmits every unique received packet exactly once. Although flooding is simple and easy to K. Wolter (Ed.): EPEW 2007, LNCS 4748, pp. 275–283, 2007.© Springer-Verlag Berlin Heidelberg 2007276 A. Mohammed, M. Ould-Khaoua, and L. Mackenzieimplement, it often causes unproductive and harmful bandwidth congestion, a phenomenon referred to as the broadcast storm problem [1], [2], [3].Several broadcast schemes have been proposed that mitigate the broadcast storms problem. The performance of these schemes is measured in terms of reachability, which is the fraction of the total nodes that receive the broadcast messages, the saved-rebroadcast, that is the fraction of the total nodes that does not rebroadcast the messages, and the latency, that is the time between the first and the last instant that the broadcast message is transmitted [4]. These schemes are usually divided into two categories [4], [5]: deterministic schemes and probabilistic schemes. Deterministic schemes require global topological information of the network and are guaranteed a reachability of 1 considering an ideal MAC layer. However, they incur large overhead in terms of time and message complexity for maintaining the global knowledge requirements due to the inherent dynamic topology of MANETs. On the other hand, probabilistic schemes do not require global topological information of the network to make a rebroadcast decision. As such every node is allowed to rebroadcast a message based on a predetermined forwarding probability p. As a consequence, these schemes incur a smaller overhead and demonstrate superior adaptability in dynamic environment when compared to deterministic schemes [6]. However, they typically sacrifice reachability as a trade-off against overhead.Among the probabilistic schemes that have been proposed are probability-based and counter-based schemes [1], [2], [3]. In probability-based schemes, a mobile node rebroadcasts a message according to certain probability p which can be fixed or computed based on the local density. Current probabilistic schemes assume a fixed probability value and it is shown [1], [4], [7] that the optimal rebroadcast probability is around 0.65. However, these approaches reduce the number of rebroadcast at the expense of reachability [2]. In contrast, messages are rebroadcast only when the number of copies of the message received at a node is less than a threshold value in counter-based schemes. This lead to better throughput and reachability, but suffer from relatively longer delay [3], [4].In this paper, we proposed an efficient counter-based scheme that combines the advantages of probabilistic and counter-based schemes. We set a rebroadcast probability at each node (as in [1], [4] and [7]) if the packet counter is less than the threshold value rather than rebroadcasting the message automatically. This is because the packet counter is not exactly equal to the node number of neighbors. Otherwise we drop the message. We compare this scheme with simple flooding, fixed probability and counter-based scheme. Simulation results reveal that this simple adaptation can lead to a significant performance improvement.The rest of the paper is organized as follows: In Section 2, we introduce the related work on probabilistic and counter-based schemes. The description of our scheme is presented in Section 3. We evaluate the performance of our scheme and present the simulation results in Section 4. Finally, concluding remarks are presented in Section 5.2 Related WorkThis section sheds some light on the research work related to probabilistic and counter-based broadcasting schemes.An Efficient Counter-Based Broadcast Scheme for Mobile Ad Hoc Networks 277 Ni et al [2] proposed a probability-based scheme to reduce redundant rebroadcast by differentiating the timing of rebroadcast to avoid collision. The scheme is similar to flooding, except that nodes only rebroadcast with a predetermined probability P. Each mobile node is assigned the same forwarding probability regardless of its local topological information. In the same work, counter-based scheme is proposed after analysing the additional coverage of each rebroadcast when receiving n copies of the same packet.Cartigny and Simplot [8] have proposed an adaptive probabilistic scheme. The probability p for a node to rebroadcast a packet is determined by the local node density and a fixed value k for the efficiency parameter to achieve the reachability of the broadcast. However, the critical question thus becomes how to optimally select k, since k is independent of the network topology.In Ni et al follow-on work [3], the authors have proposed an adaptive counter-based scheme in which each node dynamically adjusts its threshold value C based on its number of neighbors. Specifically, they extend the fixed threshold C to a function C(n), where n is the number of neighbors of the node. In this approach there should be a neighbor discovery mechanism to estimate the current value of n. This can be achieved through periodic exchange of ‘HELLO’ packets among mobile nodes.Recently, Zhang and Agrawal [9] have described a dynamic probabilistic broadcast scheme which is a combination of the probabilistic and counter-based approaches. The scheme is implemented for route discovery process using AODV as base routing protocol. The rebroadcast probability P is dynamically adjusted according to the value of the local packet counter at each mobile node. Therefore, the value of P changes when the node moves to a different neighborhood; for example, in sparser areas, the rebroadcast probability is large compared to denser areas. To suppress the effect of using packet counter as density estimates, two constant values d and d1 are used to increment or decrement the rebroadcast probability. However, the critical question is how to determine the optimal value of the constants d and d1.In this paper, we propose an efficient counter-based scheme which combines the merits of probability-based and counter-based algorithms to yield a significant performance improvement in terms of saved rebroadcast, reachability and end-to-end delay which are simple enough for easy implementation. The detail of the scheme is described in the next section.3 Efficient Counter-Based Scheme (ECS)In this section, we present the efficient counter-based scheme that aims to mitigate the broadcast storm problem associated with flooding. The use of ECS for broadcasting enables mobile nodes to make localized rebroadcast decisions on whether or not to rebroadcast a message based on both counter threshold and forwarding probability values. Essentially, this adaptation provides a more efficient broadcast solution in sparse and dense networks.In ECS, a node upon reception of a previously unseen packet initiates a counter c that will record the number of times a node receives the same packet. Such a counter is maintained by each node for each broadcast packet. After waiting for a random assessment delay (RAD, which is randomly chosen between 0 and T max seconds), if c278 A. Mohammed, M. Ould-Khaoua, and L. Mackenziereaches a predefined threshold C, we inhibit the node from this packet rebroadcast. Otherwise, if c is less than the predefined threshold, C, the packet is rebroadcast with a probability P as against automatically rebroadcasting the message in counter-based scheme. The use of a rebroadcast probability stem from the fact that packet counter value does not necessarily correspond to the exact number of neighbours of a node, since some of its neighbours may have suppressed their rebroadcast according to their local rebroadcast probability. Thus, the selection of an optimal forwarding probability is vital to the performance of our scheme. Based on [1], [4], and [7], we opt for a rebroadcast probability of 0.65. A snapshot of our algorithm is presented in figure 1.4 Performance AnalysisThis section studies the performance of our scheme, counter-based, fixed probability and flooding in terms of reachability, saved-rebroadcast and latency. In order to isolate the effects of various design choices of the broadcast algorithms on performance we do not simulate other protocol layers such as the MAC and physical layers. Our performance analysis is based on the assumptions widely used in literature[11], [12], [17].i.All nodes participate fully in the protocol of the network. In particular eachparticipating node should be willing to forward packets to other nodes in thenetwork.Algorithm : Efficient Counter-Based SchemeOn hearing a broadcast message m at a node X-initialize the counter c = 1;-set and wait for RAD to expire;-for every duplicate message m received within RADo increment c, c = c +1;o if (c < C) (counter threshold-value) {wait for RAD to expires;rebroadcast probability P = P1; }else{ //where P1 = 0.65stop waitingDrop the message }-Generate a random number RN over [0, 1]-If RN ≤ Po Rebroadcast the message;elseo Drop the messageFig. 1. A snapshot of efficient counter-based scheme algorithmAn Efficient Counter-Based Broadcast Scheme for Mobile Ad Hoc Networks 279 ii.Packet may be corrupted or lost in the wireless transmission medium during propagation. A node has the capability of detecting a corrupted receivedpacket and can discard it.iii.All mobile nodes are homogeneous. The wireless transmission range and the interface card are the same. Likewise the wireless channel is shared by allnodes and can be accessed by any node at random time. Therefore, collisionis a possible phenomenon with the channel.4.1 Simulation SetupWe use ns-2 packet level simulator (v.2.29) [10] to simulate a square 600m by 600m area populated with 25, 50, 75, …, 150 mobile nodes that are uniformly distributed in the region, each with a circular radio transmission range of radius 100m. This corresponds to networks consisting of multi-hops radio across while the selected mobile nodes represent the various network densities ranging from sparse to high density network. The radio propagation model used in this study is the ns-2 default, which uses characteristic similar to a commercial radio interface, Lucent’s WaveLAN card with a 2Mbps bit rate [13]. The distributed coordination function (DCF) of the IEEE 802.11 protocol [14] is utilized as MAC layer protocol while random waypoint model [15] is used as the mobility model. Because it takes time for the random way point model to reach a stable distribution of mobile nodes [16], the modified random waypoint mobility model [15] used take care of this node distribution problem. The simulation is allowed to run for 900 seconds for each simulation scenario. Other simulation parameters that have been used in our experiment are shown in Table 1.Table 1. Simulation ParametersSimulation Parameter ValueSimulator Transmission range Bandwidth Interface queue length Packet sizeTraffic typePacket rate Topology size Number of nodes Number of trials Simulation time Maximum speed Counter threshold (C) RAD Tmax NS-2 (v.2.29) 100 meters2 Mbps50512 byte CBR10 packets/sec 600 x 600 m2 25, 50, …, 150 30900 sec20 m/s40.01 secondsEach data point represents an average of 30 different randomly generated mobility models with 95% confidence interval. Likewise, the maximum speed used is the ns-2 default which characterise a high mobility network.280 A. Mohammed, M. Ould-Khaoua, and L. Mackenzie4.2 Simulation ResultsIn this section, we present the performance results of ECS (efficient counter-based broadcast scheme) side by side with counter-based, fixed probability and flooding. The simulation output is collected using replication mean method where each data point represents an average of 30 different randomly generated mobility models with 95% confidence intervals. Our main focus is to mitigate the broadcast storm problem therefore reducing the contention in the network and decreasing the probability of packet collisions. As a result, end-to-end delay can be reduced, and the percentage of saved rebroadcast can be improved.4.2.1 Saved Rebroadcast (SRB)Figure 2 shows the performance comparisons of fixed probability, counter-based, flooding and ECS in terms of SRB with varying network density. The four schemes achieve different SRB percentages with increasing network density. The figure demonstrates that ECS can significantly mitigate the contentions and collisions incur during broadcasting especially in dense networks with node moving at 20 m/s. In sparse networks, ECS has superior SRB of 46% and about 56% in medium and high dense networks. Under the same network conditions, the SRB achieved by the other algorithms are as follows: fixed probability has 39% and 35%; counter-based has 22% and 32%; and flooding has 4% and 1% for sparse and medium – high dense network respectively. Thus, ECS has superior SRB performance in various network densities. As shown in Figure 2, ECS can substantially reduce the number of rebroadcast because nodes rebroadcast a packet with a certain probability value (0.65) rather than automatically rebroadcasting every received packet. However, sending too few rebroadcast can result in broadcast packet not reaching all the nodes in the network. 4.2.2 ReachabilityFigure 3 shows that reachability increases when network density increases regardless of which scheme is used. Flooding has best performance in terms of reachability, reaching about 100% of the nodes. The performance of ECS scheme shows that the reachability is about 95% in sparse networks and above 98% in medium and high density network. In high density networks, very similar and comparable results are obtained for all the four schemes. However, in the case of low density networks (specifically 25 nodes), flooding and counter-based schemes achieved better reachability performance than ECS. As redundant rebroadcasts also contribute to chances of packet collisions which may eventually cause packet drops, thus negatively affecting the reachability. Depending on the value of the probability, ECS may have lower reachability compared to flooding and counter-based schemes. However, by choosing appropriate probability value, we can achieve acceptable reachability. ECS ‘s inferior reachability performance in sparse network is due to fact that the network might be partition and thus increasing the likelihood of more broadcast packets not reaching all the nodes in the network.4.2.3 LatencyIn this section we measure the end-to-end delay of the broadcast packet that has been received by all nodes in the network. The results in figure 4 show the effects ofAn Efficient Counter-Based Broadcast Scheme for Mobile Ad Hoc Networks 281 network density on the latency of broadcast packets. When node density increases, more broadcast packets fail to reach all the nodes due to high probability of packet collision and channel contention caused by excessive redundant retransmission of broadcast packets. Therefore the waiting time of packets in the interface queues increases. As shown in figure 4, ECS exhibits lower latency than counter-based, fixed probability and flooding. Since rebroadcast packets collide and content for channel with each other, and the ECS incurs the lowest number of rebroadcasts (highest saved-rebroadcast), it should have the lowest latency.Fig. 2. Saved-Rebroadcast of the four schemes against network densityFig. 3. Reachability of the four schemes against network density282 A. Mohammed, M. Ould-Khaoua, and L. MackenzieFig. 4. Latency of the four schemes against network density5 ConclusionThis paper has proposed an efficient counter-based broadcast scheme for MANETs that mitigate the broadcast storm problem associated with flooding. The scheme uses two different probability values to distinguish between rebroadcast probability for nodes in sparse network and that of a dense network. In order to reduce the broadcast overhead and without sacrificing the network connectivity in dense networks, the rebroadcast probability of nodes located in sparse areas is set high and that of nodes located in dense areas is set low. Compared to flooding, fixed probability and counter-based schemes, our simulation results have revealed that the adjusted counter-based scheme can achieve up to 56% saved rebroadcast without sacrificing reachability in both medium to high density networks. Likewise the scheme has better latency.As a continuation of this research in the future, we plan to investigate the performance of our scheme under a more realistic scenario (non uniform node distribution) and that achieved by a routing protocol when they employ ECS broadcast schemes. Furthermore, we intend to build an analytical model for our efficient counter-based scheme in order to facilitate its validation strategy. References1.Ni, S., Tseng, Y., Chen, Y., Sheu, J.: The Broadcast Storm Problem in a Mobile Ad HocNetworks. In: The Broadcast Storm Problem in a Mobile Ad Hoc Networks, pp. 151–162.IEEE Computer Society Press, Los Alamitos (1999)2.Tseng, Y.-C., Ni, S.-Y., Chen, Y.-S., Sheu, J.-P.: The Broadcast Storm Problem in aMobile Ad Hoc Network. Wireless Networks. 8, 153–167 (2002)An Efficient Counter-Based Broadcast Scheme for Mobile Ad Hoc Networks 283 3.Tseng, Y.-C., Ni, S.-Y., Shih, E.-Y.: Adaptive Approaches to Relieving Broadcast Stormsin a Wireless Multihop Ad Hoc Networks. IEEE Transactions on Computers. 52, 545–557 (2003)4.Williams, B., Camp, T.: Comparison of Broadcasting Techniques for Mobile Ad HocNetworks. In: Williams, B., Camp, T. (eds.) Proceeding MOBIHOC., pp. 194–205.Lausanne, Switzerland (2002)5.Lou, W., Wu, J.: Localized Broadcasting in Mobile Ad Hoc Networks Using NeighbourDesignation. CRC Press, Boca Raton, USA (2003)6.Alireza, K-H., Vinay, R., Rudolf, R.: Color-Based Broadcasting for Ad Hoc Networks. 4thInternational Symposium on Modeling and Optimization in Mobile, Ad Hoc, and Wireless Networks, pp. 1–10 (2006)7.Haas, Z.J., Halpern, J.Y., Li, L.: Gossip-based ad hoc routing. In: Proceeding of IEEEINFOCOM, IEEE Computer Society Press, Los Alamitos (2002)8.Cartigny, J., Simplot, D.: Border node retransmission based probabilistic broadcastprotocols in ad hoc networks. Telecommunication Systems. 22, 189–204 (2003)9.Zhang, Q., Agrawal, D.P.: Dynamic Probabilistic Broadcasting in MANETs. Parallel andDistributed Computing. 65, 220–233 (2005)10.The Network Simulator ns-2, /nsnam/ns/11.Perkins, C.E., Moyer, E.M.: Ad-hoc on-demand distance vector routing. In: Proceedings of2nd IEEE Workshop on Mobile Computing Systems and Applications, pp. 90–100. IEEE Computer Society Press, Los Alamitos (1999)12.Johnson, D.B., Maltz, D.A.: Dynamic source routing in ad hoc wireless networks. MobileComputing, pp. 153–181. Dordrecht Academic Publishers, The Netherlands (1996)13.IEEE802.11 WaveLAN PC Card - User’s Guide, A-114.Internet Standard Comm: Wireless LAN medium access control (MAC) and physical layer(PHY) specifications. IEEE standard 802.11-1997. IEEE, New York (1997)15.Navidi, W., Camp, T., Bauer, N.: Improving the accuracy of random waypoint simulationthrough steady-state initialization. In: Proceedings of the 15th International Conference on Modeling and Simulation (MS’04), Marina Del Rey, Califonia, USA (2004)16.Camp, T., Boleng, J., Davies, V.: A survey of mobility models for ad hoc networkresearch. Wireless Communication and Mobile Computing (WCMC), vol. 2 (2002)17.Colagrosso, M.D.: Intelligent broadcasting in mobile ad hoc networks: Three classes ofadaptive protocols. EURASIP Journal on Wireless Communication and Networking. 2007, p. 16 (2007)。
移动Ad Hoc网络的自适应加权聚类算法(IJCNIS-V8-N4-4)

I. J. Computer Network and Information Security, 2016, 4, 30-36Published Online April 2016 in MECS (/)DOI: 10.5815/ijcnis.2016.04.04Adaptive Weighted Clustering Algorithm forMobile Ad-hoc NetworksDr. Adwan YasinDepartment of Computer Science Arab American University Jenin, PalestineE-mail: Adwan.yasin@Salah JabareenDepartment of Computer Information Technology Arab American University Jenin, PalestineE-mail: Salah.jabareen@Abstract—In this paper we present a new algorithm for clustering MANET by considering several parameters. This is a new adaptive load balancing technique for clustering out Mobile Ad-hoc Networks (MANET). MANET is special kind of wireless networks where no central management exits and the nodes in the network cooperatively manage itself and maintains connectivity. The algorithm takes into account the local capabilities of each node, the remaining battery power, degree of connectivity and finally the power consumption based on the average distance between nodes and candidate cluster head. The proposed algorithm efficiently decreases the overhead in the network that enhances the overall MANET performance. Reducing the maintenance time of broken routes makes the network more stable, reliable. Saving the power of the nodes also guarantee consistent and reliable network.Index Terms—MANET, Clustering, Connectivity, Power, Node Capabilities, Transmission range.I.I NTRODUCTIONWireless communication and the wide spread of personal mobile devices has led to increase the need for forming means of communication among these devices; those networks are called MANET [1] [2]. This kind of networks has special characteristics :( 1) no central administration unit – nodes need to manage themselves. (2) Mobility: the networks consists of mobile devices like laptops, smartphones, and PDAs etc. (3) battery-powered nodes and limited resources clients. Fig 1 shows a simple form of MANET networks. Any node could communicate directly with other (within transmission range) nodes in the network, or by using the assistance of other intermediate nodes to reach the desired destinations. Hence, the nodes in the network should act as routers capable of forwarding packets to the desired reachable destinations.Designing and implementing efficient routing protocol is a big challenge, the desired protocol has to achieve a group of properties and satisfy MANET special needs. Dynamic topology change, mobility, power, resources and many other factors needs to be considered.The main goal when designing efficient routing protocol is to consider the overhead of the network, we need primarily to reduce control messages to the minimum and reduce the delay.Fig.1. Simple form of MANETWhen considering overhead an on-demand (reactive) routing mechanism is deployed, this mechanism does not require the nodes to periodically collect information about the network topology and store that information in its routing table for all the reachable destinations in the network. Instead, it works only based on routing requests from the nodes. Any source node in the network wants to communicate with other destination node; it first floods the network with a routing request message, the message propagates throughout the network until reaching its desired destination, the destination will reply with a route reply message using the same intermediate nodes to its originator. Finally, the originator selects a route among all routes reply messages received and use it to send data packets. An example of such routing protocols are AODV [3], DSR [4] and TORA [5].On-demand routing significantly reduces the number of control messages needed to adapt topology change, but this mechanism may cause a significant initial delay as each node wants to send data to its destination has to wait some time before it can start sending data. To overcome this delay, the routing information should be kept inarouting table all the time. This requires that routing tables needs to be fresh and up to date all the time and aware of fast topological change. This mechanism of routing called (proactive routing) where all information required are collected in advance and used directly when needed. The nodes in the network periodically floods the network with control messages and updates their routing tables based on the data collected. This will guarantee freshness of the routes and no delay time to maintain a route to any destination. Sample proactive protocols include DSDV [6] and OLSR [7].Proactive routing could cause a lot of extra overhead because of the periodic control messages flooded over the network. Some of those protocols has shown better performance results than others [8] Minimizing the number of control messages needed in the network is an important issue because the resources available in MANET like bandwidth, power and local resources of the nodes are limited. Due to nodes heterogeneity, the resources in the network may vary, this will lead to a hierarchy in the roles of nodes in the network. In addition, end-to-end and initial delay time are very important performance metrics and needs to be reduced to the minimum. In this paper, we propose a new algorithm for enhancing routing in MANET and reducing the overhead and delay time by using balanced weighted clustering technique. This technique make use of reactive and proactive routing mechanisms by considering nodes power, degree of connectivity and nodes local processing and memory capabilities.The rest of the paper is organized as follows: in section II we introduce the concept of clustering and some common clustering algorithims. In section III we introduce the related work about clustering in more details. Section IV shows details about transmission range and power consumption. Our proposed AWCAMAN algorithm is presented in section V. section VI introduces the concept on gateways and how it operates in the clustering scheme. And finally we conclude in section VII.II.C LUSTERINGMANET consists of heterogeneous nodes that interacts with each other. The limited resources available and to reduce the overhead and the amount of control messages flooded throughout the network, we need to build clusters. Clustering depends on dividing the geographical area into smaller operational areas that has a central administrator node to operate the operations over its local cluster [15]. The idea of clustering is to group the nodes into operational logical clusters, routing occurs using paths between clusters instead of all nodes. This will reduce control messages exchange among network and increases lifetime of routes. Nodes in the network can register to any cluster and become a member within a group that administrated by a cluster head. The cluster head also can be any node that has the optimal requirements for operating a cluster like power, processing and mobility conditions.The concept of clustering have been proposed in several algorithms, for example some algorithms works based on a local variable called the node identifier that assigned to every node and the cluster head is elected based on that identifier [8][16]. Another approaches depends on the connectivity of the nodes, where the distance between nodes is considered and the number of the neighbor nodes is calculated to elect the cluster head [12][17][18]. The mobility of nodes within the network is a major factor that affects the stability and reliability of the network as overall, this metric has been figured in clustering algorithms like in [19][20]. The power metric has been considered in [11] [21].Clusters depends on selecting a specific node within a group of nodes called Cluster Head (CH), cluster head will be responsible for custom activities within its group (i.e. cluster). It will be responsible coordinating its cluster’s nodes. Cluster head will take responsibility of communicating with other cluster heads in the network during data transmission. Communication process between clusters occurs using intermediate ordinary nodes, those nodes has direct access to two or more cluster heads. Fig. 2 shows an example of MANET that uses clustering.Fig.2. ClusteringWhen a node in a cluster wants to communicate with other node, it will communicate first with its cluster head. Cluster head in turn forwards data to its destination within the same cluster. If the destination is not within the same cluster, CH will forward the data to the gateway, which will in turn, passes the message to next cluster head. The message will propagate to the entire network using gateways and cluster heads only and hence reducing the overhead of the network and enhances the scalability and reliability of the network.To further illustrate clustering and the communication process occurs in clusters scheme suppose the network in Fig. 3 which represents a group of mobile nodes {i0….i22} that forms a MANET, the nodes initially forms the clusters by electing cluster heads to operat thecluster,clusters here are formed based on any of the algorithims we mentioned before, the cluster heads in the example are (i1, i3, i8, i14 and i18), these cluster heads will be responsible for all the operations for all nodes belonging to its logical cluster. Any message from or to a node belongs to its cluster will pass throughout the cluster head. Suppose node i0 wants to communicate with node i15, first node i0 will initiate a route request to its cluster head i1, the cluster head will ask its adjacent cluster heads (in this example i3) for a route to the destination, the cluster i3 in turn asks for path from it’s adjacent cluster heads (i8and i18in our example) and also these CHs asks the adjacent CHs (i14). At this point CH i14replies that the desired node (i15) belongs to its cluster. The response message passes through the same path to the origin node i0. The communication process starts using the path shown in Fig.3. Note the the path is not nessesary the shortest path from source i0 to destination node i15. Actually this is the idea behind clustering, the heavy work is done by a central node instead of using all nodes participate in every path finding and transmitting process. Further more, CH knows the list of nodes belongs to its cluster and hence can handle the requests and communications apart from other nodes in the cluster.Fig.3. Example of Communication Process using ClustersIII.R ELATED W ORKSThe most important factor in clustering is the mechanism in which cluster head elected. Nodes are responsible for electing a cluster head within a group of nodes. Different algorithms proposed for electing the ideal cluster head:Nodes assigned a unique ID each. This ID used to elect the cluster head. Cluster head is the node that has the minimum ID number like in (LIC) [8]. The algorithm selects the node with the lowest ID to be the cluster head among a group of directly accessed nodes. Initially each node broadcasts its ID, any node receives a message with a lower ID it will consider it as its cluster head. If no lower IDs received than its own it will broadcasts itself as the cluster head. The problem with that algorithm, it only elects cluster head based on its ID and only the node with the lower ID will be elected, no other properties participate in the election. Moreover, nodes with lower IDs are mostly the only candidates to be the cluster heads all the time and this will drain their power.Another major factor that affects clustering is mobility of nodes. High Mobility of nodes may increase overhead and cause fast change of network topology. When selecting cluster heads it is important to take into consideration the stability of cluster heads movement. The mobility-based d-hop clustering algorithm [9] calculates the mobility of nodes and uses nodes stability as a metric for electing the cluster head. It uses signal strength to estimate the distances between neighbors. The stronger the signal the shorter the distance. It uses signal strength in several points to calculate the relative mobility. The relative mobility and estimated distance are used to calculate the local stability of a node and hence electing the node of higher stability to be the cluster head. The problem with this algorithm is that the estimated distance between nodes not precise because the nodes with lower battery may transmit signals at lower strength.LBC [10] is an algorithm that balances the load of cluster heads based on nodes power. The algorithm specifies a unique virtual ID for each node. The one with the largest ID within a group of adjacent nodes will be elected as cluster head. The elected cluster head will remain in his role for a specific period of time (user-predefined time) then it resigns and sets its virtual ID to 0 and remains a non-cluster head node. The node with the higher ID then then takes the role within the same cluster. This way the algorithm will guarantee that power will be saved for all nodes. The problem with LBC that it only uses power saving time which is not enough indicator to select the cluster head. Another algorithm called Power-aware connected dominant set [11], the algorithm uses the power level of a node to guarantee the stability of network by making nodes serve as much time as possible. The algorithm builds a dominant set of nodes. The target is to minimize the power consumption of the dominant set nodes. This set is prone to lose power as they do extra jobs serving as cluster heads. Only the node with a higher level of power within a cluster will be elected as the cluster head and if any other dominant node exists within the same cluster it will be excluded from the dominant set and become an ordinary node. This algorithm ignores other nodes in the network and only thinks about the dominant set to save their power.Other algorithms of clustering depends on the degree of connectivity. The degree of connectivity represents the number of nodes that are directly connected to a node; the higher the number of nodes is the higher the degree of connectivity [8]. The cluster heads remains longer time but it shows lower throughput as the number of nodes in the cluster increases. Another approach is to set a threshold limit for the number of nodes a cluster head can manage like in [12] to reduce the delay may result from the big number a cluster head may manage and causes bottleneck. In t his way the load will be balanced amongnodes rather than only some few clusters.IV.T RANSMISSION R ANGE AND P OWER C ONSUMPTION The power needed to transmit some amount of data depends on the distance between nodes and the propagation environment, the relation between distance and consumed power is given in the following formula [13]:() (1) Where P r is receiving power, P t is the transmitted power;d is the distance between sender and receiver node and n is the transmission factor whose value depends on the propagation environment.To measure the distance between node i and node j we incorporate the effect of path loss exponent and shadowing parameters [14]:(2) Where:d ij: distance from node i to node j.RSSI : receiving signal strength indicator.A: is received power from reference distance which is 1 metern: is the transmission factor whose value depends on the propagation environment.Eq. (2) shows the estimated distance between every two nodes in the system, the distance used to decide which node can act as cluster head based on its location among its neighbors. The node that is closer to its neighbors does not consume a lot of power to transmit.V.P ROPOSED AWCAMANWe believe that power constrain of nodes in MANET is a master key and a very important factor in that type of networks because it directly affect the consistency and stability of network topology. Moreover, the capabilities of nodes itself is another important factor in selecting the cluster-head, because the cluster-head will be responsible for the monitoring other nodes in the cluster, do the required calculations and hence fire a suitable response. Another important issue is degree of connectivity that proposed by Gerla and Tsai [8], where the node with higher degree of connectivity will be chosen as the cluster head. Here we will build an algorithm that balances those three major constraints: power, capabilities, and nodes connectivity.In our proposed work, the election process depends on the following basis:∙Each node has the chance to be a cluster head based on the calculation of the constraints of power,connectivity, and node capabilities.∙Any elected cluster-head could remain a cluster-head until a better candidate cluster-head elected,i.e. the election process is not limited to a period. ∙The remaining power is a major factor in calculating the chance of being a cluster headwhere the node with a higher remaining batterypower has a higher chance to be selected.∙Node capabilities is a master constrain in selecting cluster head as it represents the ability andperformance of node to cope all the calculations ofits citizens like message passing and topologicalchanges.Based on those features we can present an algorithm that combines all those factors to get an efficient mechanism for clustering the network and hence dividing the network into balanced loaded sections over custom nodes with higher capabilities. The calculation has is done in three situations: start-up of the system, a change in the factors in each node, and when nodes in some clusters are lost or new nodes added to the system. The algorithm for electing a cluster-head will go as follow:∙For every node i in the system find the neighbors (neighbors means the nodes within its transmissionrange).{| (3) Where:Ni is the degree of node i (i.e. Number of neighbors)M is the set of all nodes in the system.i is any node in the system.∙For every node i in the system find the number of nodes it can handle Nmax (i).∙Find the connectivity degree Ci for every node i,(4)∙For every node find the remaining battery power RBP=Battery power/maximum battery power.(5)∙For every node in the system calculate the distance to its neighbors using Eq. (2), then calculate theaverage distance for all the neighbors (D):∑(6)∙Retrieve the node capabilities R i for every node i where R i= processor speed + RAM capacity andspeed.∙Calculate the combined factors value:⁄ (7) ∙Select MAX Vi to be the cluster-head. All the neighbors for that cluster-head will be no moreable to participate in other cluster-head calculationsfor other clusters and will belong to that node withhigher Vi.∙Repeat the process for all nodes who are not in clusters yet.This algorithm works when the system starts over and all nodes are up. Every node will broadcast its unique id to all nodes. Nodes within its transmission range will receive the message and will count all messages received with unique ids and get ―Ni‖ val ue. Moreover, the nodes will also broadcast the value of Vi after calculating Ci and Ri and RBP for its own. At this point each node will receive the Vi value for all neighboring nodes and its Vi, the node will select the larger Vi value as its cluster-head and will not participate in any other calculation until an update occurs. The node that is selected as a cluster-head will broadcast a message to the neighbors informing them that it is the cluster-head,if a node does not receive that message consider itself as not belonging to any cluster and hence it will recalculate the Vi value and finds another cluster-head. If no one of its neighbors is a cluster-head then it will consider itself as a cluster-head with no citizens. The full detailed algorithm goes as follows: //COUNT_NEIGHBORS: a counter for counting the number of neighbor nodes in range//ID: is the associated node id//TIMER1, TIMER2: are constant variable timers.// NEIGHBORS_RESPONSE (ID): the response message for neighbors request message//V_RESPONSE (V, ID): response message containing the combined value V and node ID//V_MAX: is the maximum combined value V//CH: is cluster head.//CH_ACK(ID): is the message informs the nodes that the node (ID) is a cluster head/******************************************* */COUNT_NEIGHBORS=0;Initialize TIMER1;Broadcast NEIGHBORS_REQUEST_MESSAGE (ID);while (TIMER1! = 0 && NEIGHBORS_RESPONSE(ID)!=NULL)COUNT_NEIGHBORS + = 1;Calculate distance to node SUM_D+=10^((RSSI-A)/-10*n));D=SUM_D / COUNT_NEIGHBORS;if (COUNT_NEIGHBORS==0){Consider node as isolated node;Re-initialize algorithm after specific time;END;}Calculate connectivity degree C = COUNT_NEIGHBORS / MAX_CONNECTIVITY Calculate combined value V = C + RBP + R;broadcast V_RESPONSE(V,ID);Listen for V values from neighbors;V_MAX=V;Initialize TIMER2;while( V_RESPONSE !=NULL && TIMER2 != 0){store V value in ARRAY[ ID ];If(ARRAY[ID]>V_MAX)Set V_MAX = Array[ID];}If(V>V_MAX){Consider node as CH;broadcast CH_ACK(ID);wait for JOIN_REQ (ID) messagesstore nodes who send JOIN_REQ () to be its citizens;}else{consider node as member for V_MAX node source;wait for CH_ACK from source node;if (CH_ACK received after specific time)send JOIN_REQ(ID);elsesearch ARRAY [ ] for the next higher V in the array and consider as cluster-head;}ENDThe main goal of clustering using this algorithm is to minimize the operation of finding cluster-heads. In addition, to take into consideration the capabilities variation and heterogeneity of nodes, because the operations and calculations needed for data forwarding and paths finding needs extra operations to execute and it will consume a lot of power, hence we give the remaining power of the node and the average distance to other nodes an extra attention.The parameters used in our algorithm depends on the nature of the MANET network, each type of MANET networks may differ from other networks and each parameter may have higher priority than other. For example, in a high mobile network the distance between nodes play a critical role in selecting cluster head as it affects the power of the nodes. Another example in a limited resources nodes where nodes capabilities are limited and the cluster head is the one with higher resources.The variations of networks requirements and needs can be figured by assigning a weighting factor for each parameter, those factors can be assigned be user to fit his needs during the setup process.We update Eq. (7) as follows:⁄ (8)Where w1...w4are user defined factors; the average distance D represents the average distances of nodes within the transmission range of node i,; the lower D parameter the higher the chance to select as cluster head as it saves more power when transmitting.VI.G ATEWAYSA gateway node is a node that is situated in the transmission range of two neighbor cluster heads. It is used by those cluster heads to bypass messages among them. In Fig. 4 below, green nodes are gateways in there ideal locations. Gateway is a member of only one cluster and also able to communicate directly with at least one another neighbor cluster head (i.e. one cluster head or more). Cluster head uses gateway to bypass data and control messages to other clusters, and when there is no gateway member in its cluster, this cluster will be isolated from the entire network. Fig. 4 shows an example of such a situation.Fig.4. Isolated Cluster SituationFig.5. Isolated Cluster SolutionIn the example above, the node i1 elected as the cluster head during the initialization process. Cluster members are {i0, i2, i3, i4). This cluster has no gateway (i.e. there is no nodes that directly connected to other cluster heads). To solve this problem we need to reform the cluster such that there is at least one gateway connected to its cluster head. The following formula should be implemented:| (9) Where:CH i, CH k the group of nodes that are within the transmission range of cluster heads CHi and CHk.To implement the formula in (9), the cluster head i1 will check the nodes within its cluster, if there is no node can reach another cluster head it will acknowledge its members that it is no more a cluster head. The process of startup will be repeated excluding that cluster head candidate. Nodes will find new cluster head and the new cluster head will check for a gateway. The process still repeated until the ideal situation is reached. Fig. 5 shows the final clusters after the isolated cluster problem solved. Gateways are a major component in each cluster and it’s the medium that passes messages between clusters.VII.C ONCLUSIONHeterogeneity and limited resources of mobile ad-hoc networks are the major limitations when designing protocols, they directly affect the connectivity and reliability of those networks. The best way to handle those limitations is to balance the load and assign the heavy-duty roles to the fittest nodes with higher battery power and higher degree of connectivity and bigger local resources. The algorithm we presented above can adaptively handle big networks, high rate of topological changes, heterogeneous networks; and significantly increases the network connectivity and reliability. Links establishment and maintenance are faster. The user also has the chance to alter the factors of the parameters to fit his needs and to take into consideration the variation among different MANETs.R EFERENCES[1]Charles E.Perkins, ―Ad hoc Networking‖, AddisonWesley, 2001.J.[2]Subir Kumar Sarkar, T.G. Basavaraju, C. Puttamadappa―Ad Hoc Mobile Wireless Networks: Principles, Protocols and Applications‖, Auerbach Publications –Taylor & Francis Group, 2008.[3] C. E. Perkins, E. M. Belding-Royer, and S. Das. Ad hocOnDemand Distance Vector (AODV) Routing. RFC 3561, July 2003.[4]Johnson, David B., David A. Maltz, and Josh Broch."DSR: The dynamic source routing protocol for multi-hop wireless ad hoc networks." Ad hoc networking 5 (2001): 139-172.[5]V. Park and S. Corson, Temporally Ordered RoutingAlgorithm (TORA) Version 1, Functional specification IETF Internet draft (1998).[6]Perkins, Charles E., and Pravin Bhagwat. "Highlydynamic destination-sequenced distance-vector routing (DSDV) for mobile computers." ACMSIGCOMMComputer Communication Review. Vol. 24. No. 4. ACM,1994.[7]Jacquet, Philippe, et al. "Optimized link state routingprotocol for ad hoc networks." Multi Topic Conference,2001. IEEE INMIC 2001. Technology for the 21stCentury. Proceedings. IEEE International. IEEE, 2001. [8]Jha, Rakesh Kumar, and Pooja Kharga. "A ComparativePerformance Analysis of Routing Protocols in MANETusing NS3 Simulator." (2015). I. J. Computer Networkand Information Security, 2015, 4, 62-68.[9]M. Gerla and J. T. Tsai, ―Multiuser, Mobile, MultimediaRadio Network,‖ Wireless Networks, vol. 1, pp. 255–65,Oct. 1995.[10]I. Er and W. Seah. ―Mobility-based d-hop clusteringalgorithm for mobile ad hoc networks‖. IEEE WirelessCommunications and Networking Conference Vol. 4. pp.2359-2364, 2004.[11] A. D. Amis and R. Prakash, ―Load-Balancing Clusters inWireless Ad Hoc Networks,‖ in proceedings of 3rd IEEEASS ET’00, pp. 25–32 Mar. 2000.[12]J. Wu et al., ―On Calculating Power-Aware ConnectedDominating Sets for Efficient Routing in Ad HocWireless Networks,‖ J. Commun. And Networks, vol. 4,no. 1, pp. 59–70 Mar. 2002.[13] F. Li, S. Zhang, X. Wang, X. Xue, H. Shen, ―Vote- BasedClustering Algorithm in Mobile Ad Hoc Networks‖, Inproceedings of International Conference on NetworkingTechnologies, 2004.[14]Zhang Jianwu, Zhang Lu ―Research on DistanceMeasurement Based on RSSI of ZigBee‖ CCCM IEEE2009.[15]Neeraj Choudhary, A jay K Sharma ―PerformanceEvaluation of LR-WPAN for different Path-Loss M odels‖ International Journal of Computer Applications (0975 –8887) Volume 7– No.10, October 2010.[16]M. Joa-Ng and I.-T. Lu, ―A Peer-to-Peer Zone-based ’ko-level Link State Routing for Mobile Ad Hoc Networks‖,IEEE Journal on Selected Areas in Communications, Aug.1999, pp. 1415-1425.[17] A.D. Amis, R. Prakash, T.H.P Vuong, D.T. Huynh. "Max-Min DCluster Formation in Wireless Ad Hoc Networks".In proceedings of IEEE Conference on ComputerCommunications (INFOCOM) Vol. 1.pp. 32-41, 2000. [18]G. Chen, F. Nocetti, J. Gonzalez, and I. Stojmenovic,―Connectivity based k-hop clustering in wirelessnetworks‖. Proceedings of the 35th Annual HawaiiInternational Conference on System Sciences. Vol. 7, pp.188.3, 2002.[19]T. Ohta, S. Inoue, and Y. Kakuda, ―An AdaptiveMultihop Clustering Scheme for Highly Mobile Ad HocNetworks,‖ in proceedings of 6th ISADS’03, Apr. 2003. [20]P. Basu, N. Khan, and T. D. C. Little, ―A Mobility BasedMetric for Clustering in Mobile A d Hoc Networks,‖ in proceedings of IEEE ICDCSW’ 01, pp. 413–18, Apr.2001.[21] A. B. MaDonald and T. F. Znati, ―A Mobility-basedFrame Work for Adaptive Clustering in Wireless Ad Hoc Networks,‖ IEEE JSAC, vol. 17, pp. 1466–87, Aug. 1999.[22]J.-H. Ryu, S. Song, and D.-H. Cho, ―New ClusteringSchemes for Energy Conservation in Two-Tiered Mobile Ad-Hoc Networks,‖ in proceedings of IEEE ICC’01, vo1.3, pp. 862–66, June 2001.Authors’ ProfilesDr. Adwan Yasin PH.D Computer SystemEngineering /Computer security /KievNational Technical University of Ukraine,1996. Master degree in computer SystemEngineering- Donetsk Polytechnic institute,Ukraine, 1992. An associate professorformer Dean of the Engineering andInformation Technology Faculty of the Arab American University of Jenin, Palestine. Previously he worked as Chair Person of Computer Science Department- AAUJ, Assistant professor of the computer Science Department -The Arab American University- Palestine. Assistant professor of the computer & Information System Department, Philadelphia University- Jordan. Assistant professor of the Computer science department, Zarka Private University- Jordan. He has many publications in the fields of computer networking and security in different international journals. His research interests Computer Security, Computer Architecture and Computer Networks.Salah Jabareen Master Student at thedepartment of computer Science at ArabAmerican University –Jenin, Palestine.Finished his BA in computer science field atthe Arab American University in Palestine.He works as teacher assistant at the facultyof Engineering and Information Technologyat Arab American University –Jenin, Palestine. His research interest include computer networks, artificial intelligence, computer architecture and security.How to cite this paper:Adwan Yasin, Salah Jabareen,"Adaptive Weighted Clustering Algorithm for Mobile Ad-hocNetworks", International Journal of Computer Network and Information Security(IJCNIS), Vol.8, No.4, pp.30-36, 2016.DOI: 10.5815/ijcnis.2016.04.04。
ad+hoc网络的网关技术研究及改进

湖南大学硕士学位论文Ad Hoc网络的网关技术研究及改进姓名:***申请学位级别:硕士专业:通信与信息系统指导教师:***20070413硕士学位论文摘要无线自组织网(Ad Hoc)是一种新型的网络,它可以在几乎任何环境下动态的完成配置而不需要其它基础设施。
和传统的网络相比,它具有自组织、多跳路由和动态拓扑等特点,网络中的节点具有移动终端和路由器的双重功能。
移动IP是一种简单的可扩展的全球Internet移动解决方案,它可以使移动节点不需改变原有的IP地址,也可在不同的子网间切换而同时又能保持正在进行的通信。
它的可扩展性使其可以在整个Internet上应用,因此将移动IP技术应用于Ad Hoc网络可以很好的实现Ad Hoc网络与 Internet的互联,从而使得移动Ad Hoc网络用户能够通过移动IP方便的获得Internet上已有的丰富的服务。
AODVPlus是一种改进的按需路由协议,该协议通过引入网关广告消息机制,使得移动Ad Hoc网络能与Internet互联。
本论文通过建立一个Ad Hoc网络模型,对AODVPlus协议和应用移动IP的AODV协议进行仿真比较,对传输率、丢包率及端到端时延统计后的数据进行分析,AODVPlus解决方案相对移动IP有较明显的性能提升,但是在网关切换时,移动IP表现得更稳定。
无论是移动IP整合方案,还是AODVPlus互联方案,都需要进行定期的消息广播以维护路由链接,这都将消耗掉大量网络资源。
本论文通过修改NS2中移动节点结构引入多信道多接口,使得路由协议能够灵活调用多信道功能。
对于增加的信道需要对其进行合理分配。
根据AODVPlus协议的实现机制,本论文提出一种对应的信道分配策略,并通过仿真模拟与单信道进行比较分析。
多信道多接口在一定程度上改善了网络互通的性能,但有效的多信道分配策略显得尤为重要。
关键词:无线自组织网;移动IP;按需路由协议;多信道多接口;分配策略Ad Hoc网络的网关技术研究及改进AbstractAd Hoc network is a newly-style networks, and it can be flexibly deployed in almost any environment without the need of infrastructure based stations. Ascompared with traditional networks, Ad Hoc network has some characteristics such as autonomous, multi-hop routes and dynamic topology, and in which mobile node is not only a mobile terminal but also a router.Mobile IP is a simple and extensible mobility solution for global Internet and it can help mobile nodes being able to keep normal communications while roaming between different subnetworks, but not need to change IP address. Because of its extensibility, Mobile IP is applicable to global Internet, and so applying Mobile IP to Ad hoc networks which can achieve integration of Mobile IP and Ad Hoc network. Via this integration, mobile hosts which in Ad Hoc networks can enjoy tremendous services already exist on the Internet through Mobile IP, and for which Ad Hoc network is more adaptive to modern communication.In this thesis the Ad Hoc routing protocol AODV is used and modified to examine the interconnection between a mobile Ad Hoc network and the Internet by broadcasting gateway advertisement. For this purpose, Network Simulator 2 has been used. Moreover, the evaluation has been done according to three metrics: the bit rate, the packet loss and the end-to-end delay. The network performance is improved largely while it did not outperform through Mobile IP while switching gateways.Both Mobile IP and AODVPlus send broadcast advertisements periodically to keep the link of route, it will use up the resource of mobile Ad Hoc network. In this thesis, the architecture of mobile node has been modified to support multiple channels and multiple interfaces in AODVPlus, a distributive strategy of multiple channels has been simulated to analysis according to characteristic of AODVPlus. In some degree, the network performance is imporved, while the distributive strategy is the key to mulitple channels.Key Words: Ad Hoc; Mobile IP; AODVPlus; Multi-channels;Distributive Strategy硕士学位论文插图索引图2.1 Ad Hoc网络节点结构 (5)图2.2 平面结构 (5)图2.3 单频分级结构 (6)图2.4 多频分级结构 (6)图2.5 三种类型网关 (8)图2.6 Ad Hoc路由分类 (11)图2.7 AODV协议的基本工作流程 (13)图2.8 单信道反向链路信息 (14)图3.1 OSI模型、TCP/IP参考模型、MANET协议栈 (16)图3.2 移动节点、网关、Internet节点使用的协议栈 (17)图3.3 NOAH模型 (18)图3.4 静态路由配置 (18)图3.5 移动 IP的隧道 (20)图3.6 移动 IP的三角路由 (22)图3.7 移动 IP的优化路由 (22)图3.8 Ad Hoc网络与Internet互联 (23)图3.9 路由发现过程 (23)图3.10 FA- RREP过程 (24)图3.11 网关广告消息(GWADV)格式 (25)图3.12 RREQ_I请求消息格式 (26)图3.13 混合网关发现方式 (27)图3.14 Tcl/C++分裂模型 (27)图3.15 仿真模型 (29)图3.16 传输率 (29)图3.17 丢包率 (30)图3.18 端到端传输时延 (31)图4.1 移动节点结构 (34)图4.2 多信道多接口移动节点结构 (35)图4.3 AODVPlus多信道分配 (38)图4.4 AODVPlus多信道数据传输 (38)图4.5 多信道反向链路信息 (39)Ad Hoc网络的网关技术研究及改进图4.6 路由缓冲区溢出 (39)图4.7 运动模型 (40)图4.8 传输率 (41)图4.9 丢包率 (41)图4.10 传输时延 (42)硕士学位论文附表索引表3.1 节点初始设置 (28)表3.2 模型参数设置 (28)表3.3 部分MIP路由表 (31)表3.4 部分AODVPlus路由表 (31)表4.1 环境配置 (40)湖南大学学位论文原创性声明本人郑重声明:所呈交的论文是本人在导师的指导下独立进行研究所取得的研究成果。
Ad hoc网络中的一种动态均匀区域广播算法

Ab ta t sr c' .Ad h ewo k i o o sa o a yi fa t cu e n e n d c n st r n la d r u e a v r ey o n t r fn t t n r n r s u t r ,a d t o e a t g a mia n t rC mo efe l . c s i r h i e o n T e d n mial y h y a c l s mmer a r a ag r h wa b s d o h p o a i si g r m a d t e c u trb s d a g rt m. y til a e o i m s a e n t e r b b l t a o t c l t i cl i h n h o ne - a e o h l i
Z A G X —un Q A h H N i a g, I N S u h
(col I o ao ni en,ot r Ynt n ei,W xJ ns 112C i ) Sh n r tnEg e i Su e agz Ui rt uii gu 42, h a oo f m i f n rg hn e v0 0 7年 6月
文 章 编 号 :0 1 9 8 (0 7 0 10 — 0 1 20 )6—19 0 2 8— 3
Ad-Hoc网络中基于CDS的广播算法仿真

本科生毕业论文(设计)题目Ad-Hoc网络中基于CDS的广播算法仿真学院软件学院专业软件工程学生姓名学号年级指导教师教务处制表二Ο一一年六月一日Ad-Hoc网络中基于CDS的广播算法仿真软件工程[摘要] 在Ad-Hoc移动网络中,广播是一种常用的手段。
许多网络路由协议就是通过广播来需找两个节点间的路径,也有不少的网络应用通过广播来传播消息。
但是由于Ad-Hoc网络中节点允许自由移动而导致网络拓扑在动态改变,所以在维护网络结构和每次广播在路由上都会导致过高的开销。
根据图论中连通支配集的概念,本文对一种通过寻找网络节点的连通支配集进行广播的算法进行了仿真,在模拟的Ad-Hoc网络环境中测试评估了算法的广播性能。
这是一种能够减少广播包总量的同时有效减少信息冗余的广播算法,继而减少包的丢失。
每个节点在接收到信息后只需利用到网络的拓扑信息来执行广播算法,节点便可以寻找到其下级的支配节点集并将信息传播出去。
[主题词] 广播;Ad-Hoc移动网络;连通支配集;算法;邻居节点;仿真Simulation of CDS-Based Broadcast Algorithm in MobileAd-Hoc NetworksSoftware EngineeringStudent: Guo Jiwei Adviser: Lin Feng[Abstract]In Mobile Ad-Hoc Networks, broadcast is a common and important operation for delivering information in many network applications. Also, many Ad-Hoc route protocols rely on it to discover the route between any two nodes. Because of the dynamic topology led by the moving of nodes in Mobile Ad-Hoc Networks, high cost of routing is required when broadcasting. According to the conception in graph theory, an algorithm that relys on discovering the dominating set of the node to broadcast is emulated and evaluated in the simulative Ad-Hoc network enviroment. The algorithm can reduce the message redundancy while minimizing the total number of transmitted message, additionally reduce the packet loss.Only the topolopy information is used in the calculation of the algorithm after the node receiveing a message, then it can find the sub-dominators and delivery the message forward.[Key Words]broadcast;Mobile Ad-Hoc Networks;Connected Dominating Set;algorithm;neighbor node;simulation目录1 引言 (1)1.1研究背景 (1)1.2研究目的 (3)1.3论文组织与结构 (4)2 AD-HOC网络广播算法 (6)2.1基于概率的算法 (6)2.2基于计数的算法 (6)2.3基于距离或位置信息的算法 (7)2.3.1基于距离的算法 (7)2.3.2基于位置信息的算法 (8)2.4基于邻居信息的算法 (8)2.4.1 SBA广播算法 (8)2.4.2 MR算法(多点中继算法) (9)2.4.3 AD-HOC BROADCAST PROTOCOL(AHBP算法) (10)3 基于连通支配集的广播算法 (11)3.1图论中涉及的概念 (11)3.1.1支配集 (11)3.1.2连通支配集 (11)3.1.3最小连通支配集 (12)3.1.4求最小连通支配集问题 (12)3.2图的标记规则 (12)3.3节点操作的流程 (12)3.3.1节点工作原理及流程 (13)3.3.2计算CDS算法流程 (13)3.4 CDS算法的优点及所解决的问题 (14)3.5 CDS算法性能的评价标准 (15)4 基于连通支配集的广播算法的仿真程序设计 (16)4.1网络仿真 (16)4.1.1网络拓扑仿真 (16)4.1.2网络节点的仿真 (17)4.1.3广播算法的仿真 (17)4.2仿真程序架构 (17)4.2.1仿真程序开发环境 (18)4.2.2仿真程序设计 (18)5 结果分析 (20)5.1 仿真环境 (20)5.1.1网络参数设置 (20)5.1.2变量参数选取和数据采集方法 (20)5.2 结果分析 (21)5.2.1以节点数为变量,节点的无线传输距离为常量的仿真结果 (21)5.2.2以节点的无线传输距离为变量,节点数为常量的仿真结果 (23)6 相关工作 (26)7 总结与展望 (29)7.1 工作总结 (29)7.2 工作展望 (30)参考文献 (31)声明 (32)致谢 (33)附录 (34)1引言1.1研究背景自上个世纪90年代后期,一种名为Ad-Hoc的网络技术在无线通信领域中迅速发展,从最初专项的军事通讯领域不断地向民用通讯领域渗透。
AD HOC综述

综合评论电l对荸娃簟i}玲Adhoc综述张蕾(北京邮电大学信息工程学院,北京100876)摘要:Adhoc作为一种自创造、自组织和自管理的网络,由于其组网的快速灵活性,节点的分布性等诸多的优点,在战争、救灾等特殊领域有着不可替代的作用。
文中介绍了Adhoc的概念、特点、发展历史及国内外的研究现状,并指出了其中需要研究的一些关键技术。
关键词:Aadhoc;无线网络;动态路由算法;自组织中图分类号:TN915文献标识码:A1引言近年来,无线通信网络无论在技术上、还是在商业上都获得了飞速的发展,并且已经在世界范围内被广泛地应用。
无线通信网络由于能快速、灵活、方便地支持用户的移动性而使它成为个人通信和In—ternet发展的方向,而且也只有通过无线通信网络才能实现“任何人在任何时间、任何地点与任何人进行任何种类的信息交换”的理想的通信目标。
我们经常提及的无线通信网络一般都是有中心的,要基于预设的基础设施才能运行。
例如,GSM(GlobalSystemMobileCommunication)‘1|、CDMA(CodeDivisionMultipleAccess)【2j等蜂窝移动通信系统要有基站的支持;无线局域网一般也工作在有AP接入点和有线骨干网的模式下。
但对于有些特殊场合来说,有中心的移动网络并不能胜任。
比如,战场上部队快速展开和推进,地震或水灾后的营救等。
这些场合的通信不能依赖于任何预设的基础设施,而需要一种能够临时快速自动组网的移动网络。
无线Adhoc网络可以满足这样的需求。
2Adhoc网络的概念及特点Adhoc一词来源于拉丁语,是“特别或专门”的收稿日期:2005—03—03修订日期:2005—09—20意思。
这里提出的“Adhoc网络”所指的就是一种特定的无线网络结构,强调的是多跳、自组织、无中心的概念,比较正规的表述为:无线Adhoc网络是指一组无线移动节点组成的多跳的临时性的无基础设施支持的无中心网络旧,4J。
Vote-based Clustering Algorithm in Mobile Ad-hoc Networks

Vote-based Clustering Algorithmin Mobile Ad-hoc NetworksFei Li1,Shile Zhang1,Xin Wang1,Xiangyang Xue1,and Hong Shen21Department of Computer Science,Fudan University,200433Shanghai,China {021021107,0024131,xinw,xyxue}@2Department of Information Systems,JAIST,Japanshen@jaist.ac.jpAbstract.Unlike current clustering methods,the presented vote-basedclustering(VC)algorithm not only uses node location and ID informa-tion,but also battery time information.In VC,each mobile host(MH)counts Hello messages from its neighbors.At the same time it calcu-lates its own vote that is the weighted sum of the normalized number ofvalid neighbors and its normalized remaining battery time.The one withhigher vote than its neighbors will be selected preferentially as a clusterhead(CH).When the number of dominated MHs of a CH is more thana balance threshold,neither of new coming MHs will be permitted toparticipate in the current cluster.Analysis and simulation results showthat VC method can improve cluster structure than Lowest ID(LID)algorithm and Highest Degree(HD)algorithm.31IntroductionA MANET is a multi-hop wireless network in which mobile hosts(MHs)commu-nicate without the support of a wired backbone[1].In a MANET,the network topology changes frequently,the control overhead is very large and a wireless link is easy to break down.So how to reduce the number of control packets and repair a wireless route becomes very important.However,people can only get a tradeoffbetween the above two ambivalent objects.Clustering is such an effective method,which is a common method in a com-munication network topology description,and used to group network nodes into clusters.It provides a convenient framework for the development of important features such as code separation(among clusters),channel access,routing,power control,virtual circuit support and bandwidth allocation.With an underlying cluster platform,non-ordinary MH can be the dominant forwarding nodes.In comparison withfixed communication networks,clustering in MANET turns difficult.Because of node mobility and wireless link weakness,more control in-formation must be paid to clustering a MANET.A representative of each cluster 3This work was supported in part by NSFC-60003017,NSFC-60373020,863-2001AA114120,863-2002AA103065,SRF for ROCS.SEM,Shanghai Municipal RD Foundation under contracts035107008,03DZ15019and03DZ14015,and Youth Foundation of Fudan University under No.EXH6286301.2Fei Li et al.is named as a cluster head(CH)and a MH belonging to more than2clusters at the same time is called a gateway.Other members are called ordinary MHs. Generally a cluster is defined by its CH’s transmission range.Cluster architecture in MANET may be with or without CHs in every clus-ter[2].CH-based clustering can reduce storage and exchange information of ordinary MHs.In clusters without CHs,every MH has to store and exchange more topology information,thus the bottleneck of CHs can be eliminated.CH Y.Yi and M.Gera partitioned2approaches to construct a MANET cluster platform,i.e.active clustering and passive clustering[4].In active clustering, MHs cooperate to elect CHs by periodically exchanging information,regardless of data transmission.On the other hand,passive clustering suspends cluster-ing algorithm until the data traffic commences[4].It exploits on-going traffic to propagate”cluster-related information”(e.g.,the state of a node in a cluster,the IP address of the node)and collects neighbor information through promiscuous packet receptions.Thus,it eliminates setup latency and major control overhead of active clustering required collecting neighbor information.Recently multipoint relays(MPRs)are often used in clustering to reduce the number of gateways in active clustering.MPR Hosts are selected to forward broadcast messages during theflooding process[5].This technique substantially reduces the message overhead as compared to a classicalflooding mechanism, where every node retransmits each message when it receives thefirst copy of the ing MPRs,the Optimized Link State Routing(OLSR)proto-col can provide optimal routes,and at the same time minimize the number of control messagesflooded in the network[6].present a novel vote-based clus-tering(VC)algorithm A good clustering method should be able to partition a MANET quickly with little control overhead.Because of node mobility,it is difficult to construct the best clustering structure in a MANET.To this end, two distributed clustering algorithms are considered.They are Lowest ID algo-rithm(LID)[7].and Highest Degree algorithm(HD)[8].Both of them belong to passive clustering.In LID algorithm,each node is assigned a distinct ID.Periodically,the node broadcasts the list of nodes that it can hear(including itself).The lowest-ID node in a neighborhood is elected as the CH.LID method has the following4 rules:(1)A node which only hears nodes with ID higher than itself is a CH.(2)The lowest-ID node that a node hears is its CH,unless the lowest-ID specially gives up its role as a CH(deferring to a yet lower ID node).(3)A node which can hear two or more CHs is a gateway.(4)Otherwise,a node is an ordinary node.In HD algorithm,the highest degree node in a neighborhood becomes the CH.The algorithm is described below:(1)Each node broadcasts the list of nodes that it can hear(including itself).(2)A node is elected as a CH if it is the most highly connected node of all its”uncovered”neighbor nodes(in case of a tie,lowest ID prevails).Lecture Notes in Computer Science3(3)A node which has not elected its CH yet is an”uncovered”node,otherwise it is a”covered”node.(4)A node which has already elected another node as its CH gives up its role as a CH.An optimized cluster protocol about LID was proposed in[2].It ensures MHs who do not receive Hello messages during a certain time can issue a new cluster or participate in an existing cluster after a while.LID method is a quick clustering method,which only uses2Hello message periods to get the cluster structure.Also it provides a more stable cluster forma-tion than HD method.In HD style even if one link drops due to node movement, the current CH may fail to be re-elected again.HD method can get fewer clusters than LID.It is very helpful in a large-scale network.In current clustering schemes,stability,quantity and convergence are of very importance.However,fewer clusters don’t always mean better.A CH dominates so many mobile nodes that its resources(puting,bandwidth,and etc.) will be exhausted soon.So the control of cluster scale is very important.On the other hand,under mobile computing environment,apart from position and ID, power is another important factor for one MH.The fore-mentioned clustering methods didn’t mention cluster scale and power factor,we do it in this paper.The rest of the paper is organized as follows:in Section2,the vote-based clustering algorithm is presented,which includes3parts:vote-based partition algorithm,mobile management method and cluster load balance method.Per-formance simulation and analysis are shown in Section3.Finally,conclusions and future work are given in Section4.2Vote-based clustering algorithmIn MANET clustering,we should consider not only position and ID but also other factors.LID is a quick clustering method,which only uses2Hello message periods to get the cluster structure.In LID,only ID information was used to distinguish every MH.Obviously,it did not make use of MHs’position informa-tion and cannot get few clusters.HD method needs3Hello message periods,for that each MH must know its neighbor host’s neighbors’number.It uses position information and ID information of one MH.Fig.1shows a simple comparison of HD clustering and LID clustering.In a MANET including15mobile hosts,LID method gets6clusters but HD method gets only4clusters.The virtue of VC is using every MH’s mutual location information.On the other hand,Both of LID and HD method cannot trade offamong different clusters.Maybe one CH dominates fewer MHs,but another CH holds more MHs.We want to eliminate this possibility to avoid one CH be exhausted.ID is used to distinguish every MH anywhere,anytime.By position information,we know a MH’s one-hop neighbors,two-hop neighbors,etc.In our case,considering the relation between power consumption of one CH and the number of its dominated MHs,we select the lasting time of MH’s battery4Fei Li et al.Fig.1.A simple comparison of HD clustering and LID clusteringas one performance parameter.Our algorithm is based on two important per-formance factors,neighbors’number and remaining battery time of every MH. Then we use voting method to select cluster head and determine members of a cluster.2.1Network ModelA MANET can be divided into several overlapped clusters.A cluster is composed of a subset of nodes,which can communicate directly with a cluster head and with each other.Hereby the scenario is modelled as an undirected graph G(V,E) where V is the set of all MHs in the network and E is the set of all links(i,j) where i,j∈E.Each link signifies that two MHs are within transmission range of each other.Let S i be the set of all nodes that can be reached by node i.We assume every link is bi-directional so that link(i,j)exists if and only if j∈S i. The topology of G is the set of nodes and edges.Each MH has a unique identifier(ID)number,which is a positive integer. The basic information inside the network is Hello message,which is transmitted in the common channel.Every MH acquires information from neighbor hosts’periodic Hello message.We assume that only when the2MHs lie inside the mutual transmission range,they can communicate directly with each other,i.e.a bi-directional link exists.One another important information for every MH is its battery lasting time,which is a positive integer.2.2Vote-based clustering schemeIn our proposal,we consider the clustering architecture with cluster heads.It is also assumed that one MH can only participate in a unique cluster at the same time,so Fig.2shows this case and the communication procedure betweenLecture Notes in Computer Science5munication Procedure between Cluster2and Cluster5Fig.3.Hello message format2clusters.A cluster is tagged with its Cluster ID number,e.g.Cluster2and Cluster5in Fig.2.The proposed vote-based clustering protocol includes3parts: vote-based partition algorithm,mobile management method and cluster load balance method.2.2.1Vote-based partition methodMaking use of node location information and power information,we introduce the concept of”vote”and proposed vote-based partition algorithm shown later. Fig.3.shows the Hello message format in Vote-based clustering algorithm(VC). MH ID item is MH’s own ID and CH ID item is MH’s CH IDVote item means MH’s vote value,i.e.weighted sum of number of valid neighbors and remaining battery time.Option item is used to realize cluster load balance in part3.V ote=w1×(n/N)+w2×(m/M).(1) w1,w2:Weighted coefficient of location factors and battery time,respectively, n:Number of neighbors,N:Network size or the Maximum of members in a cluster,m:Remaining battery time,M:The maximum of battery time remaining battery time.m is a characteristic parameter for every MH.Each MH consumes the battery energy anytime.Each CH spends more than a common MH,obviously.The algorithm includes the following steps:(1)Each MH sends a Hello message randomly during a Hello cycle.If a MH is a new user to the MANET,it reset”CH ID”item.That means the MH does not belong to any cluster and does not know whether it has neighbor hosts.(2)Each MH counts how many Hello messages it can receive during a Hello period,and considers the number of received Hello messages as its own n.(3)Each MH sends another Hello message,in which”vote”item is set to its own vote value and got from Equation1.6Fei Li et al.(4)Recording Hello message during2Hello cycles,each MH knows the sender with highest vote and not belongs to any existing cluster is its cluster head.It set its next sending Hello message item”CH ID”to the cluster head’s ID value. One noticeable issue is when two or more mobile nodes receive the same number of hello packets,the one who owns the lower ID will be prior to others.Following the above-mentioned approach,every MH knows its cluster head ID after2Hello message periods.That is to say,we canfinish clustering scheme during2Hello cycles.We also know that the cluster head sends a Hello message, in which”MH ID”is the same as”CH ID”.2.2.2Mobile management methodAll moving MHs can be classified into2kinds by their current status.For a moving cluster member,if it receives a Hello message with bigger vote from another CH or non-CH host,the latter will become its new cluster head.For a moving CH host,it uses the same method to participate in a new cluster. However in this case,all its dominated mobile hosts must start a new cluster discovery process.Once a member hostfinds its CH turns a member host by analyzing the received Hello message,it will reset the”CH ID”item to0.Using this kind of mobile management method,real-time modification of the cluster structure can be realized.2.2.3Adaptive cluster load balance methodIn LID or HD clustering scheme,one cluster head can be exhausted when it serves too many MHs.It is not good and the CH becomes a bottleneck.So we proposed an adaptive cluster load balance method.In Table1,there is an ”Option”item.If a sender MH is a cluster head,it will set the number of its dominated MHs as”Option”value.When a sender MH is not a cluster head or it is undecided(CH or non-CH),”Option”item will be reset to0.When a CH’s Hello message shows its dominated MHs’number exceeds a threshold (the maximum number one CH can manage),there will not be any new MH participate in this cluster.As a result,we can eliminate the CH bottleneck phenomenon and optimize the cluster structure.As stated in the above description,VC can get load balance between various clusters.Thus,resource consumption and information transmission will be dis-tributed to all clusters,not only to some certain clusters.On the other hand,the consideration of battery lasting time can help us to get a steady cluster struc-ture.Because in VC method,through inducting weighted battery lasting time, the probability of a MH without enough battery energy will be reduced.3Performance simulation and analysisIn this part,we simulate the proposed clustering protocol under C++program-ming environment.The simulation network is a square plane area with50m∗50m. There are totally N mobile hosts in the square space and N can be10,20,30,Lecture Notes in Computer Science7Fig.4.Average cluster head number with3methodsFig.5.Average cluster head change with3methodsFig.6.Variance of cluster size with3methods8Fei Li et al.and up to150.Each mobile host stays in the space randomly at the start.Ev-ery MH will move at a proportional rate between0∼5m/s,and at a random direction.If they move to the boundary,they will be bounced back.The Hello message is sent at5ms period.When using VC with load balance method,the threshold for a dominating MH is defined as15.Each simulation lasts out1 minute.The initial battery time of each MH is a random value between0and 1,3,or5minutes.We tested some parameters using LID method and VC method,respectively. From the fore description,it is easy to see that VC without load balance and without battery time limit is HD method indeed.The parameters include number of cluster heads,average change of cluster heads and variance of cluster size. 3.1Number of cluster headsWe count the number of cluster heads every1s and compute the arithmetic average every5simulations.In our simulation,an isolated MH will not become a cluster head,because it cannot communicate with any other mobile host.Fig.4illustrated the average cluster head number in the MANET.For a medium-scale network,VC method can reduce clusters obviously.When the network is very sparse,VC method cannot play very well.However,we know that in that case clustering will be not a good mechanism at all.In addition,with the network scale increased,VC with load balance will result in more clusters even than LID.It is because it can save a cluster heads resource to avoid its premature exhaustion.3.2Average change of cluster headsIf we define A and B as aggregate of cluster heads in previous test moment and current test moment,respectively,the change of cluster heads equation holds:δ=|(A∪B−|A∩B).(2) We computed the arithmetic average of every5simulations.Fig.5illustrated average change of cluster heads.Since LID only uses not node location information but ID information,so its cluster status is steadier than VC.Obviously,VC with load balance is worse than VC without load bal-ance about this parameter when network size exceeds a certain scale.When N is bigger than70,in VC with load balance method cluster heads change very frequently.3.3Variance of cluster sizeWe recorded current cluster size every second,C i,i=1,2,...,M(M is number of cluster heads).We define C and D as below:C=Mi=1C i/M.(3)Lecture Notes in Computer Science9Fig.7.Average change of CHs with different battery time proportionD=Mi=1(C i−C)2/M.(4)Fig.6illustrated variance of cluster size,D.Simulation results show that LID methods variance of cluster size is less than VC method.From the above3figures,we know that VC method can optimize cluster structure by reducing cluster head number.The cost is more cluster head change and higher variance of cluster size.3.4Average change of CHs with different battery time proportion Like in3.2,we can get the average of CHs when w2is equal to1,0.5and0.9, respectively.It is noticeable in the simulation,at every Hello period,a common MHs battery time drops down at a constant space.For a CH,its battery time decreases in proportion to the number of current dominated MHs.Fig.7illustrated average change of cluster heads with different battery time proportion.When w2is equal to zero,it means battery time is not considered in clustering.As w2is increased step by step,battery time takes a more important role in clustering.The curve shows that the more proportion battery time owns, the steadier the cluster structure turns.If w2is equal to1,the VC method only uses battery time information,not position information.4Conclusions and Future workIn this paper we present a novel vote-based clustering algorithm for MANET. Unlike current clustering method,VC not only uses node location information and ID information,but also battery time information.In VC method,each MH counts Hello messages from its neighbors.At the same time it calculates its own vote that is the weighted sum of the normalized number of valid neighbors and its normalized remaining batter time.The one with higher vote than its neighbors will be selected preferentially as a CH.When10Fei Li et al.the number of dominated MHs of a CH is more than a balance threshold,neither of new coming MHs will be permitted to participate in the current cluster.Analysis and simulation results show that VC method can improve cluster structure than LID and HD algorithm.Atfirst,VC can get less cluster number than LID.Secondly,VC can support adaptive cluster size balance to avoid one CH of being exhausted,better than LID and HD.Thirdly,VC can get steadier cluster structure than HD,since it uses battery information.As to LID and VC,on the one hand,LID uses fewer clusters since it only uses ID information,which is constant for every MH.On the other hand,VC improves stability of cluster structure by inducting battery information.Any MH with little battery time may be not selected as a CH.We will study VC-based routing further.In current method,cluster structure maybe is changed even if only one MH comes or leaves,since many MHs’vote is changed.Apparently,it is not very good.In next-step work,we will focus on boosting up VC’s robustness.We will also study VC-based routing and multicast algorithms.In clustering, we reduce the effect of node mobility and link state on cluster structure and make cluster structure repaired with little spending.However in routing,we hope discovery in time and little cost to get a route quickly.We ever used spine structure in multicast[9]and will use VC structure in multicast later. References1. C.E.Perkins,E.M.Belding-Royer,and S.R.Das,Ad hoc on-demand distancevector(AODV)routing,IETF RFC3561,July2003.2.Liu Kai,Li Jiandong,Mobile cluster protocol in wireless ad hoc network,in Pro-ceeding FIP/WCC2000(ICCT2000),Beijing,China,Aug.2000,pp.568-573.3.Y.Yi,M.Gerla,T.Jin Kwon,”Efficient Flooding in Ad hoc Networks:a Compar-ative Performance Study”,2003082210.4.Y.Yi,T.J.Kwon and M.Gerla,”Passive Clustering(PC)in Ad Hoc Networks”,Internet Draft,draft-ietf-yi-manet-pac-00.txt,Nov.2001.5. A.Qayyum,L.Viennot and ouiti,”Multipoint relaying:An efficient techniqueforflooding in mobile wireless networks”,(HICSS’2001).6.T.Clausen,P.Jacquet,”Optimized Link State Routing Protocol”,Internet Draft,draft-ietf-manet-olsr-11.txt,Jul.2003.7.Jack Tsai and Mario Gerla,”Multicluster,mobile,multimedia radio network”,ACM-Baltzer Journal of Wireless Networks,Vol.1,No.3,pp.255-65,1995.8.Abhay K.Parekh,”Selecting routers in ad-hoc wireless networks”,in ITS,1994.9.Xin WANG,Fei LI,Susumu Ishihara and Tadanori Mizuno,A Multicast RoutingAlgorithm Based on Mobile Multicast Agents in Ad-hoc Networks,IEICE Transac-tions on Communications,Vol.E84-B No.8,August2001,pp.2087-2094。
第7章 移动Ad hoc网络

Full dump, carries all available routing information
Incremental, smaller packets used to relay only that information which has changed since the last full dump.
Ad Hoc On-Demand Distance Vector Routing
Ad Hoc On-Demand Distance Vector Routing
AODV utilizes destination sequence numbers to ensure all routes are loop-free and contain the most recent route information. Each node maintains its own sequence number and a broadcast ID which is incremented for every RREQ the node initiates. SN, ID and node’s IP address together uniquely identifies an RREQ.
移动Ad Hoc网络路由算法仿真

移动Ad Hoc网络路由算法仿真研究Simulation Study of Routing Protocols for Mobile Ad Hoc Network尚 杨 张凤登(上海理工大学光学与电子信息工程学院, 上海 200093)摘 要:移动Ad Hoc网络是由一组具有路由和转发功能的移动节点组成的临时性自组织网络,其路由算法是近年研究的热点。
在NS2仿真平台下,对两种典型协议(按需距离矢量路由AODV和动态源路由DSR)的性能进行横向间的比较分析,得出了两种协议的适用性定量结果和彼此间的差别。
关键词:Ad Hoc网络 按需距离矢量路由 动态源路由 NS2Abstract:Ad Hoc network is a collection of mobile nodes which can be router and forwarder,and its routing protocols are popularly studied these years. The paper investigates the performance of two typical routing protocols(Ad HocOn-Demand Distance Vector and Dynamic Source Routing ) and aquires quantitative measurement results based the simulation platform NS2.Keywords:Ad Hoc network AODV DSR NS20 引言由于MANET(mobile ad hoc network)网络具有多跳、无固定基础结构且网络拓扑动态变化的特点[1],传统的有线网络路由于协议不能很好地适应这种移动环境,主要原因有两点:一是通常这些协议采取周期性的消息来更新路由,从而产生大量的开销;二是由于路由建立更新过程对拓扑变化的收敛比较慢。
Distributed Group Rekeying Algorithms for Mobile Ad-Hoc Networks

∗ Supported by the National Natural Science Foundation of China under Grant Nos.90104001, 90204005 (国家自然科学基金 )
作者简介 : 况晓辉 (1975- ), 男 ,湖南新化人 ,博士生 ,主要研究领域为计算机网络 ,信息安全 ;朱培栋 (1971- ),男 ,博士 ,副教授 ,主 要研究领域为网络路由 ,组播技术 ,高性能路由器 ; 卢锡城 (1946- ),男 ,教授 , 博士生导师 ,中国工程院院士 , 主要研究领域为先进网络技 术 ,高性能计算 ,并行与分布处理 .
在移动自组网络分布式组密钥管理框架(distributed group key management framework,简称 DGKMF)的基础上, 提出了一种组密钥更新算法 —— DGR(distributed group rekeying)算法 .该算法能够利用局部密钥信息更新组密 钥 , 适合拓扑结构变化频繁、连接短暂、带宽有限的移动自组网络 .为了进一步降低算法的通信代价 , 通过在组
况晓辉 等:移动自组网络分布式组密钥更新算法 • 节点的组成员资格证书(certj)SK∗; • 组通信密钥种子生成函数 g(x); •g(m))SK),m 表示组密钥种子初始序号. 节点的共享密钥由组控制节点根据拉各朗日插值秘密共享方案生成,生成过程如下:令 SK=(d,n),门限为 k, N 且 1 < k < . 组控制节点随机选择 k−1 阶多项式: 2 f ( x) = d + ∑ fi xi ,
+ Corresponding author: Phn: +86-10-66356599, E-mail: xiaohui_kuang@
METHOD FOR DISPLAYING BROADCASTING CONTENTS IN MOB

专利名称:METHOD FOR DISPLAYING BROADCASTINGCONTENTS IN MOBILE TERMINAL ANDMOBILE TERMINAL THEREOF发明人:Kihoa Nam,Youngseok Ko,SoolimYou,Beomseok Cho申请号:US12836479申请日:20100714公开号:US20110016415A1公开日:20110120专利内容由知识产权出版社提供专利附图:摘要:A mobile terminal includes a controller initiating at least one widget present inthe mobile terminal and obtaining updated information with regard to the at least one initiated widget, a user input unit receiving an input for selecting a channel which provides broadcasting content, a wireless communication unit receiving the broadcasting contents, and a display displaying the broadcasting contents. The controller determines whether any of the at least one initiated widget is associated with the selected channel and registered with the selected channel and the display displays one or more of the at least one widget that are associated with the selected channel with the broadcasting content when the controller determines that the one or more of the at least one widget that are associated with the selected channel are registered.申请人:Kihoa Nam,Youngseok Ko,Soolim You,Beomseok Cho地址:Seoul KR,Seoul KR,Seoul KR,Seoul KR国籍:KR,KR,KR,KR更多信息请下载全文后查看。
Method and system for providing broadcast services
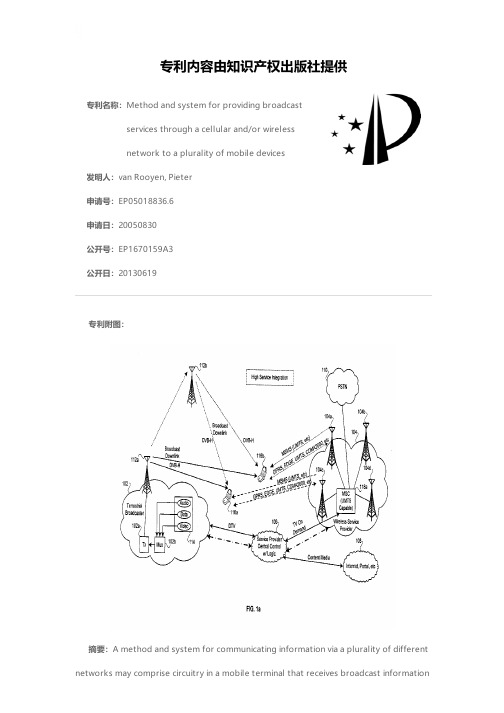
专利名称:Method and system for providing broadcastservices through a cellular and/or wirelessnetwork to a plurality of mobile devices发明人:van Rooyen, Pieter申请号:EP05018836.6申请日:20050830公开号:EP1670159A3公开日:20130619专利内容由知识产权出版社提供专利附图:摘要:A method and system for communicating information via a plurality of different networks may comprise circuitry in a mobile terminal that receives broadcast informationvia a VHF/UHF broadcast communication path and simultaneously receives in the mobile terminal, cellular information via a cellular communication path. The system may further comprise circuitry in the mobile terminal that switches between processing of the broadcast information received via the VHF/UHF broadcast communication path and the cellular information received via the cellular communication path based on a measured broadcast signal statistic associated with a signal bearing the broadcast information and a measured cellular signal statistic associated with a signal bearing the cellular information. The broadcast information and the cellular information may be the same information. The broadcast information and the cellular information may comprise video data. The cellular information may comprise voice data.申请人:Broadcom Corporation地址:5300 California Avenue Irvine, CA 92617 US国籍:US代理机构:Jehle, Volker Armin更多信息请下载全文后查看。
pervasive game

How to Host a Pervasive GameSupporting Face-to-Face Interactions in Live-ActionRoleplayingJay Schneider, Gerd KortuemUniversity of OregonDepartment of Computer and Information ScienceWearable Computing Research GroupEugene, OR 97403jay@, kortuem@Abstract. We describe a ubiquitous computing gaming environment thatsupports live-action roleplaying. This environment is designed to enhance live-action games and provide a testing ground for our sociability enhancing mobilead-hoc network applications.1 Introduction"You are invited to the Bauer mansion for dinner and to help solve a murder." Invitations like this one have been sent out by the millions, inviting friends and family to a multiplayer murder mystery party, often from the best-selling "How to Host a Murder" series of games. At these parties the players gather at a friend's house for dinner imagining it to be a mansion in the 1930's. The party goers often dress up and interact as characters and spend an enjoyable evening together solving a murder mystery.Multi-player games such as these are based on social interactions as the key feature contributing to the players’ enjoyment. Although the earliest documented live-action variants of board games date back to 735AD, when games of chess were played with real people, they remained rare until recently. In the last two decades live versions of roleplaying games such as Hasbro's Dungeons and Dragons and White Wolf's Vampire, the Masquerade have become extremely popular, according to our own estimates there are over 100,000 regular players of live-action roleplaying (LARP) games worldwide.Multi-player and LARP games have evolved over time to incorporate generally available technology. Originally these games were traditional board games such as Clue or 221B Baker Street. With the general acceptance of videocassette recorders (VCR) these games adopted the television and the VCR as support tools that could interact with the players and enhance the realism of the game.Today we are surrounded by a wide array of computing and communication technologies. It is a widely held notion that we are moving towards a networked world of possibly billions of interconnected intelligent devices that permeate the physical world. This vision, which is referred to as Pervasive Computing, leads to a world where the physical and digital space fuse together, where data and informationdiffuse throughout every part of the physical world. We are interested in how pervasive technology can be incorporated into multi-player LARP games and what effect this will have on the character and nature of games.We define a Pervasive Game as a LARP game that is augmented with computing and communication technology in a way that combines the physical and digital space together. In a Pervasive Game, the technology is not the focus of the game but rather the technology supports the game. Although technology is ubiquitous in a Pervasive Game, its role is a supporting one and thus the technology is kept as unobtrusive as possible.In this paper we are proposing a game, Pervasive Clue, played with personal digital assistants (PDAs) that will support game play and sociability in the game. We intend to use Pervasive Clue as a reusable testing environment, varying the rules and PDA applications in order to test various hypotheses in a controlled and limited environment that is informative and enjoyable for both the players and researchers.2 Pervasive CluePervasive Clue is a live-action roleplaying game based loosely on Hasbro's classic board game Clue augmented with short-range radio frequency (RF) PDA devices. The goal of Pervasive Clue is to discover who killed the host, Mr. Bauer, where it was done and what was the murder weapon. Solving the murder is done through the discovery of clues, when a player feels they can solve the crime they are allowed to make an accusation. If any of the crime facts (murderer, location or weapon) are incorrect the player is eliminated.Up to six players will gather in a campus building set up as the Bauer household. Each player will assume a role similar to the 1930's archetypes used in the classic board game Clue. These roles are: the mysterious and vain femme fatale, the monocle-wearing retired war veteran, the faithful(?) maid to the Bauer household, a balding businessman in a suit, an elderly gossip mongering spinster and the absent-minded professor. As this is a roleplaying game an award will be given to the best roleplayer. However, roleplaying will not directly affect the gathering of clues.The game building will contain ten rooms. Nine rooms will contain clues and be possible crime scenes, the tenth is a central meeting room, containing refreshments and seating, for the players to meet, talk and roleplay. Due the nature of the game, clues found in Pervasive Clue are always negative clues, i.e. "the murder weapon was not the candlestick" or "the murder did not take place in the study." Players are each equipped with a Cluefinder, an RF enabled PDA device with a large magnifying glass attached. Although the magnifying glass is entirely cosmetic its design illustrates the function of the device, how it is used and promotes use of the Cluefinder as a roleplaying prop. Each room contains up to 3 hidden clues. Each clue has a physical representation (i.e. knife, book, candlestick) as well as a hidden short range RF beacon <1 foot, broadcasting its clue. These clue beacons are similar in function to the close range proximity beacons described in [1]. Players find game clues by searching a room with the Cluefinders and coming within 1 foot of the beacon.Players are allowed to search a room for up to 5 minutes. After searching a room the players must return to the main room and stay there for at least 5 minutes (although they may stay in the central room longer if they choose.) Every 10 minutesthe Cluefinder will determine a new room the player is allowed to enter. This determination replaces the die roll that decides player movement in traditional Clue. Players may also gain clues by exchanging them with other players. The rules of the game do not restrict a player’s ability to give or trade clues with other players. However, the rules also do not enforce agreements between players nor do they force the players to be truthful about the clues they provide.Although social encounters can occur in any of the rooms the majority of the encounters are likely to occur in the main room. During these encounters the Cluefinder PDA will perform its most important role, helping to establish and support player face-to-face interactions. The Cluefinder PDA accomplishes its task of promoting sociability by applying modified versions of applications we have already developed that support sociability in real world face-to-face encounters. These include: an application for finding nearby people based on their public profile [2]; an application for trading items that uses a game-theoretic approach to suggest exchanges that are favorable to both parties involved [3]; an application for capturing and disseminating reputation information about people for use in evaluating a player’s trustworthiness based on his or her behavior (like cheating or lying) in past games [4].Figure 1 Cluefinder PrototypeThis following example illustrates the Cluefinder supporting game play in Pervasive Clue: The businessman player has just returned to the central room after investigating the Study. After a quick snack, he decides to see who might be willing to trade some clues regarding the location of the crime. The Cluefinder introduction application suggests he talk with the player playing the role of the femme fatale whohas just entered the room. The Cluefinder trade-broker system suggests that he might consider offering to trade some of the information he has just discovered in the Study. The Cluefinder reputation system warns him though, that femme fatales are not to be trusted.We must stress that although from a research perspective the sociability enhancing applications are the focus, to the players of the game the devices and the applications play a supporting role. In the above example the Cluefinder applications made suggestions but took no game actions. For example, the Cluefinder might suggest a possibly beneficial trade of clues, but it is up to the players to act upon it or to ignore it.The Cluefinder knows what clues the player has discovered by search, yet trades are only made by players outside of the Cluefinders, in the physical space. The players might choose to inform the Cluefinder application about information gained in the physical space to enable the Cluefinder to reason on it but that choice is left up to the player.. Much as in the real world, players often will have reasons for not providing information to their personal devices including: distrust of the device, distrust of the information, roleplaying or just not wanting the information to be used by the Cluefinder as a basis for decision making. The game features of the technology playing a supporting role and the technology only having complete information from the digital space distinguishes Pervasive Games from other games, they are not computer games but rather computer- augmented games.3 Augmenting Social InteractionsOne of our primary research assumptions is that PDAs in wireless ad hoc networks, such as the one in Pervasive Clue, can augment social interactions. This assumption is based on our belief that a PDA or a mobile phone is much more than an electronic device you carry around. It becomes part of you as it goes everywhere you go and you personalize it with information that is critical for you to have at your fingertips. To support this general hypothesis we have designed several applications for RF-enabled PDAs. The PROEM application [2], in the real world is a profile-based introduction system, yet in Pervasive Clue PROEM helps players identify whom to talk with, based on which player is best suited to provide information needed to solve the murder. Likewise the WALID system [3], was originally designed as a wireless ad hoc task trading application. As Pervasive Clue is a task-oriented domain, a modified WALID system exchanges clues instead of tasks, and we are assured that WALID will propose optimal clue trades. DIOGENES [4], our distributed reputation server designed to support Wearable Communities, will attempt to live up to its namesake and "search the [game]world for an honest man" with whom to exchange clues.The sociability augmenting applications we have developed leverage the contextual information of proximity. As we have limited the transmission range on our RF devices to under 15 feet, when two personal devices are in communication they know their owners are in each others social space and can communicate face-to-face. We expect the applications described above to give a tremendous advantage to those game players who use them..As Pervasive Clue is a test bed, we developed several variants of the basic game designed to illustrate the utility of our sociability enhancing applications. One variantis the single liar version of Pervasive Clue where only the murderer is allowed to lie. This variant should illustrate the functionality of the DIOGENES distributed reputation server as the players as a group learn which player is providing the misleading clues, without each of them having to be duped along the way. Another variant will allow complex clues, consisting of several pieces of information. Under these circumstances, not all clues will be of equal weight. It seems likely that the WALID system modified for clue trading will be very useful in determining a deal that is pareto-optimal and as balanced as possible to both parties. The two applications mentioned are both face-to-face "facilitating" applications. PROEM is in a different category as it is a face-to-face "enabling" application. It allows users to broadcast information about themselves and find other users with desirable characteristics. To illustrate the utility of PROEM a variant is being considered where clues are not located all in the same building but rather distributed across the campus. PROEM as an introduction application is designed to enable encounters finding other players with whom it might be beneficial to meet up with and trade clues.4 Status and Future Research IssuesWe are in the process of implementing Pervasive Clue and expect completion of an initial version by the end of the year. The implementation is based upon our mobile peer-to-peer application development toolkit described in [5]. This toolkit facilitates the development of decentralized applications for mobile ad hoc network environments. Although results from using this toolkit have been promising, it seems likely that an extension to the toolkit might be beneficial to support the needs of developing pervasive games. We expect Pervasive Clue to provide valuable insight into the limitations and possible extensions of the toolkit.Aside from our planned exploration into the environment of pervasive games, we see the following research issues to be open and worthy of further examination: • What features make pervasive computer games fun for the players? What are the pitfalls to avoid that detract from player enjoyment?• How can we measure the effectiveness or effect of pervasive technology in games?• What makes a game a "hit"? How does it vary among demographics?• What are the characteristics of pervasive games? Can we use these characteristics to categorize pervasive games?• What are the core set of applications needed by all pervasive games?5 ConclusionThere is a broad range of potential pervasive games and almost any game that can be modified to be played in a live action manner can be made into a pervasive game. Pervasive Clue is our initial entry into the genre but it seems likely in the future that we will experiment with other pervasive games as the need arises. Our hope is that asymbiosis will exist between pervasive games and real world mobile peer-to-peer systems with each providing benefits to the other.AcknowledgementsThe authors would like to thank and acknowledge the assistance of the other students and staff at the University of Oregon Wearable Computing group, with special thanks to Megan Foster and Dustin Preuitt for their work on this project.References[1] Björk, S., Falk, J., Hansson, R., & Ljungstrand, P. Pirates! - Using the Physical World as aGame Board. Paper at Interact 2001, IFIP TC.13 Conference on Human-Computer Interaction, July 9-13, Tokyo, Japan.[2] Kortuem, G., Segall, Z., Cowan Thompson, T.G. Close Encounters: Supporting MobileCollaboration through Interchange of User Profiles. Proceedings First International Symposium on Handheld and Ubiquitous Computing (HUC99), 1999, Karlsruhe, Germany [3] Kortuem, G., Schneider, J., Suruda, J., Fickas, S., Segall, Z. When Cyborgs Meet: BuildingCommunities of Cooperating Wearable Agents. Proceedings 3rd International Symposium on Wearable Computers (ISWC 99), October 1999, San Francisco.[4] Schneider, J., Kortuem, G., Jager, J., Fickas, S., Segall, Z. Disseminating Trust Informationin Wearable Communities. 2nd International Symposium on Handheld and Ubiquitous Computing (HUC2K), Sept., 2000, Bristol, England.[5] Kortuem, G., Schneider, J., Preuitt, D., Cowan Thompson, T.G., Fickas, S., Segall Z. WhenPeer-to-Peer comes Face-to-Face: Collaborative Peer-to-Peer Computing in Mobile Ad-hoc Networks. 2001 International Conference on Peer-to-Peer Computing (P2P2001), Aug.2001, Linköpings, Sweden。
基于粒子滤波步行长度预测的移动ad hoc网络路由算法

基于粒子滤波步行长度预测的移动ad hoc网络路由算法张玲;聂少华【摘要】For the problems of mobile ad hoc network( MANET) such as big change of topology structure, high routing complexity,and low data transmission performance,this paper proposes a new mobile commu-nication system using an adaptive routing algorithm. In order to make the network topology closer to the characteristics of the mobile network intermittent connection,an improved Levy Walk Mobility Model is a-dopted in the network structure. And then,a particle filtering walking length method prediction is used to get a recursive Bayesian filter throush Monte Carlo sampling,and the walking length is predicted after parti-cle filtering to determine the number of copies of message, thereby reducing the energy consumption for node forwarding a copy to bring too many messages and improve the message delivery efficiency. Simulation results show that compared with two routing algorithms of ant colony-based optimization and profit optimi-zation-based model,the proposed algorithm improves the message passing success rate of 0. 08 and 0. 04, node average energy efficiency of 17. 9% and 13. 4%,respectively. So it achieves better results in impro-ving the success rate of data transfer and saving energy.%针对移动ad hoc网络拓扑结构变化大、路由复杂度高、数据传输性能低等问题,提出了一种新的移动通信系统自适应路由算法。
(陈浪)Adhoc网络广播算法分析研究最终稿

学科分类号:___________ 湖南人文科技学院本科生毕业论文论文题目:Ad Hoc网络广播算法研究(英文):The Research on The Broadcasting Algorithm of Ad Hoc Network学生姓名:陈浪学号07408135系部:计算机科学技术系专业年级:计算机科学与技术 2007级指导教师:刘浩论文提交时间:2011-5-13湖南人文科技学院教务处制湖南人文科技学院原创性声明本人郑重声明:所呈交的论文是本人在导师的指导下独立进行研究所取得的研究成果。
除了文中特别加以标注引用的内容外,本论文不包含任何其他个人或集体已经发表或撰写的成果作品。
对本文的研究做出重要贡献的个人和集体,均已在文中以明确方式标明。
本人完全意识到本声明的法律后果由本人承担。
作者签名:二O 年月日摘要Ad Hoc网络是当前无线通信领域一种新兴网络技术,它从开始的军事应用正迅速渗透到相关的民用通信领域。
Ad Hoc网络是一种自组织的无线多跳网络,其中各个节点可以自由移动,通过共享的无线信道进行通信,无需任何固定的信息基站。
各个节点互为中继节点,这样可以与一些不在自身信号覆盖范围的节点进行通信。
在这样的移动自组网络中,广播被频繁的用于路由发现、地址解读和许多其他网络服务中。
还有在Ad Hoc中,通常两个信息节点通信要经过中间的一个或多个信息点的路由,也就是说这样一个广播可能会被许多节点转发以保证这两个节点的通信。
由此可见,一个低效的广播算法会导致产生许多冗余的转发包,所以广播的效率对Ad Hoc的性能有着十分重要的意义。
因此拥有高效率的广播算法是无线路由协议研究的关键和前提。
本文在研究学习了许多前人提出的广播算法后,主要采取了从网络中节点转发概率着手研究。
在网络中节点转发概率的研究中主要实现根据节点间的距离动态调整转发概率。
改进以概率为基础的算法,参考转发节点间的距离,针对各种网络结构设置最佳的概率值。
Ad Hoc 网络均匀区域广播算法

Ad Hoc 网络均匀区域广播算法刘鹃梅;王小玲【期刊名称】《计算机工程》【年(卷),期】2011(037)002【摘要】Considering of node connectivity, remaining energy and node relative distance, this paper advances a new broadcasting algorithm that is weighted-based symmetrical area broadcasting algorithm. According to the node weights, it construct.s and determines independent dominating sets,and selects candidate control node connect to independent dominating sets. And it optimizes the broadcast algorithm, eliminates some redundant forward nodes and enhances the performance of the broadcast algorithm. Theoretical analysis and simulation result show the efficiency of broadcasting time delay decreases under the situation that nodes are dense and uneven distributed.%综合考虑节点连通度、剩余能量和节点相对距离3个因素,提出一种新的基于权值的均匀区域广播算法.根据节点权值构建独立支配集并确定候选支配节点,选取候选支配节点连通独立支配集,在此基础上对广播算法进行优化,进一步消除冗余转播节点,提高广播算法的性能.理论分析和仿真结果表明,该算法在节点密集和稠密分布不均的情况下能有效降低广播时延.【总页数】4页(P78-80,84)【作者】刘鹃梅;王小玲【作者单位】中南大学信息科学与工程学院,长沙,410073;中南大学信息科学与工程学院,长沙,410073【正文语种】中文【中图分类】TP393【相关文献】1.解决Ad Hoc网络广播冗余竞争冲突的高效广播算法 [J], 王庆文;史浩山;戚茜2.Ad Hoc网络中一种基于自裁减的广播算法 [J], 曾启;陶洋;李峰3.Ad hoc网络中的一种动态均匀区域广播算法 [J], 张曦煌;钱舒4.Ad hoc网络跨层动态概率广播算法 [J], 程青青; 陈戈珩5.Ad Hoc网络中按需路由协议的动态广播算法 [J], 扈鹏;刘元安;马晓雷;高松因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Broadcasting Methods in Mobile Ad HocNetworks:An Overview∗Demetres Kouvatsos∗and Is-Haka Mkwawa+∗Department of Computing,University of Bradford,UK.+Department of Computer Science,University College Dublin,Ireland.∗D.D.Kouvatsos,+I.M.Mkwawa@AbstractOptimal broadcasting in mobile ad hoc networks is crucial for pro-viding control and routing information for multicast and point to pointcommunication algorithms.This tutorial presents an overview on the state of the art of broadcast-ing techniques in mobile ad hoc networks and makes recommendations toimprove the efficiency and performance of the current and future broad-casting techniques.1IntroductionA mobile ad hoc network(MANET)is a special type of wireless mobile network which forms a temporary network without the aid of an established infrastruc-ture or a centralised administration.The applications of MANETs range fromthe civilian use to emergency rescue sites and in battlefield.Each node in MANET is a router.If a source node is unable to send a message directly to its destination node due to limited transmission range,the source node uses intermediate nodes to forward the message towards the destination node.The main challenges in MANET are reliability,bandwidth and battery power.The network has unpredictable characteristics,it’s topology,signal strengthsfluctuates with environment and time,communication routes breaks and new ones are formed dynamically.In this context,communication algorithms and protocols should have very light in computational and storage needs in order to conserve energy and bandwidth(c.f.,[1–5]).∗This work is partially supported by the EU NoE Euro-NGI.T09/1Broadcasting is the process in which a source node sends a message to all other nodes in MANET.Broadcasting is important in MANET for routing information discovery,for instance,protocols such as dynamic source routing (DSR)[6],ad hoc on demand distance vector(AODV)[7],zone routing pro-tocol(ZRP)[2,8,9]and location aided routing(LAR)[10]use broadcasting to establish routes.Broadcasting MANET poses more challenges than in wired networks due to node mobility and scarce system resources.Because of the mobility there is no single optimal scheme for all scenario.This tutorial is organised as follows,Section2reviews the probabilistic and de-terministic broadcasting methods.Section3and4review the cluster and tree based broadcasting methods,respectively.Tree based an cluster based broad-casting methods improvements are included in Section5and6,respectively. Conclusions follow in the last Section7.The reviewed broadcasting methods are clearly depicted in Figure1.2Broadcasting MethodsBroadcasting methods have been categorised into four families utilising the IEEE802.11MAC specifications[11].Note that for the comparisons of these categories the reader is referred to[12].1.Simpleflooding[13,14],requires each node in a MANET to rebroadcastall packets2.probability based[15],assigns probabilities to each node to rebroadcastdepending on the topology of the network3.area based[15],common transmission distance is assumed and a node willrebroadcast if there is sufficient coverage area and4.neighbourhood based[16–20],State on the neighbourhood is maintainedby neighbourhood method,the information obtained from the neighbour-ing nodes is used for rebroadcastApart from simpleflooding,each broadcasting category aims at optimising en-ergy and bandwidth by minimising message retransmission.Each category is described in the following subsection.2.1Simple Flooding MethodIn this method,a source node of a MANET disseminates a message to all its neighbours,each of these neighbours will check if they have seen this message before,if yes the message will be dropped,if no the message will re-disseminated at once to all their neighbours.The process goes on until all nodes have the message.Although this method is very reliable for a MANET with low densityT09/2broadcastdeterministicself−pruningscalable broadcastingprobalistic distance−basedcounter−basedlocation−basedad hoc broadcastingsimple floodingcluster−basedFigure 1:Broadcasting methodsnodes and high mobility but it is very harmful and unproductive as it causes severe network congestion and quickly exhaust the battery power.A polynomial number of messages is of the magnitude (n 2)in a MANET of size n and is depicted in Figure 2.2.2Probability Based Methods 2.2.1Probability Based ApproachThe probability based approach tries to solve the problems of the simple flood-ing method.Each node i ∈N is given a predetermined probability p i for re-broadcasting.In this context,having some nodes not to rebroadcast min-imises the network congestion and collisions.In this approach there is a danger that some nodes will not receive the broadcast message.∀i s.t.p i =1,theT09/30 204060 80100 0 2 46 8 10N u m b e r o f M e s s a g e s Number of Nodes messages Vs nodesx**2-xFigure 2: (n 2)number of messages in a simple flooding methodprobability based approach is reduced to a simple flooding approach.More effi-cient broadcasting reduces p i as the number of neighbour density increase and vise versa.2.2.2Counter-Based Scheme ApproachIn this approach the random assessment delay (RAD)is set,a threshold K is determined and a counter k >=1is formed on the number of times the broadcast message is received.During the RAD,the counter k is incremented by one for each redundant message received and if k >K when RAD expires,the message is dropped.Otherwise,it is rebroadcast.In this approach,some nodes will not rebroadcast in a more dense MANET while in a less dense MANET all nodes will rebroadcast.2.3Area Based MethodThis method is comprised of distance and location based approaches.2.3.1Distance Based ApproachIn Section 2.2.2the counter is used to decide either to drop a message or to rebroadcast,in this section a distance between a receiving node and it’s neigh-bours will decide between the two.Let d be the distance between the receiving node and the source node,if d is very small then the rebroadcast coverage of the receiving node is also very small.If d is large then the rebroadcast coverageT09/4is large.If d=0then the rebroadcast coverage is0too.A receiving node will normally determine the threshold distance D and set the RAD and redundant messages will be stored until the RAD expires.When RAD expires,all distances from source nodes will be checked,if d<D then the received messages will be dropped,otherwise the messages will be rebroadcast. Ni et al[15]has suggested that the signal strengths can be used to calculate the distance from the source node.The role of distance can even be directly replace by the signal strength by setting the signal strength threshold.2.3.2Location Based ApproachIn this approach each node must have the means to establish it’s own location in order to estimate the additional coverage more precisely.This approach can be supported by global positioning system(GPS)[21].Each node in a MANET will add its own location to the header of each message it sends or rebroadcasts.When a node received a message,thefirst thing will be to note the location of the sender and compute the additional coverage area to rebroadcast.If the additional coverage area to rebroadcast is less than the given threshold,the message is dropped when the RAD expires,otherwise the message will be rebroadcast.The problem of the location based approach is the cost of calculating additional coverage areas,which is calculating many intersections among many circles. This will drain the scarcely available energy.2.4Neighbour Knowledge Method2.4.1Self PruningEach node in this approach is required to have knowledge of it’s neighbours, this knowledge can be achieved by periodic”Hello”messages.The receiving node willfirst compare its neighbour lists to that of sender’s list,the receiving node will rebroadcast if the additional nodes could be reached,otherwise the receiving node will drop the message.This is the simplest approach in the neighbour knowledge method.In Figure3,after receiving a message from node 2node1will rebroadcast the message to node4and node3as it’s only additional nodes.Note that node5also will rebroadcast the same message to node4as it’s only additional node.In this situation still the message redundancy takes place.2.4.2Scalable Broadcasting ApproachThis approach improves the self pruning approach as the chances of message retransmission are still higher in the later approach.T09/5324567 1Figure3:Self pruning approachThis approach requires that all nodes in a MANET have knowledge of their neighbours up to a two hop distance.This knowledge is established by”Hello”messages.In this approach,each node has a two hop topology information.In Figure3,node1receives a message from node2,since node2is a neighbour, node1has knowledge of all its own and node2neighbours who have received the broadcast message.The additional nodes of node2will receive the message rebroadcast by node2with the aid of RAD.Note that still node4will receive the redundant message.Pen and Lu[18]dynamically adjusted RAD according to a given MANET conditions.Each node will look for a neighbour with maximum degree in it’s knowledge base.When a neighbour with the maximum numberdegreeδi is found,the RAD is computed based on the ratioδiδ,whereδis thedegree of the current node.Nodes with large RAD will always rebroadcastfirst.2.4.3Ad Hoc Broadcasting ApproachIn this approach,only nodes selected as gateway nodes and a broadcast message header are allowed to rebroadcast the message.The approach is described as follow,1.locate all two hop neighbours that can only be reached by a one hopneighbour.select these one hop neighbours as gateways.2.calculate the cover set that will receive the message from the currentgateway set3.for the neighbours not yet in the gateway set,find the one that wouldcover the most two hop neighbours not in the cover set.Set this one hop neighbour as a gateway.T09/64.repeat process2and3until all two hop neighbours are covered.5.when a node receives a message and is a gateway,this node determineswhich of its neighbours already received the message in the same transmis-sion.These neighbours are considered already covered and are dropped from the neighbour used to select the next hop getways.In Figure4,node2has1,5and6nodes as one hop neighbours,3and4nodes has two hop neighbours.Node3can be reached through node1as a one hop neighbour of node2.Node4can be reached through node1or node5as one hop neighbours of node2.Node3selects node1as a gateway to rebroadcast the message to nodes3and4.Upon receiving the message node5will not rebroadcast the message as it is not a gateway.324516Figure4:Ad Hoc broadcast approach2.5Shortcoming of Existing Broadcasting MethodsThe shortcomings are deduced from a detailed comparative studies in[12].1.all methods apart from neighbour based methods require more rebroad-casts,with respect to the number of retransmitting nodes[15].2.methods that make use of RAD suffer in high density MANETs unless amechanism to adapt a nodes RAD to its local environmental behaviour are developed.3.because it does not use local information to decide whether to rebroadcastor not,the ad hoc broadcasting approach have difficulties in a very high mobile MANET.Base on the comparative studies by[12],none of the existing broadcasting pro-tocols are satisfactory for wide ranging MANET environments.T09/7Because of its adaptive nature,scalable broadcast approach has significant im-provements over the non adaptive approaches.Due to these shortcomings there is a need to develop new efficient broadcasting approaches with the common goal of conserving the available scarce resource in MANETs.3Cluster Based MethodsThe methods highlighted in Section2are based on statistical and geometrical models which estimate the additional coverage of re-broadcasting,in this section clustering based methods,based on graphic theoretic concepts are introduced.Note that the clustering approach has been used to address traffic coordination schemes[23],routing problems[23]and fault tolerance issues[24].Note that cluster approach proposed in[15]was adopted in[22]in order to reduce the complexity of the storm broadcasting problem.Each node in a MANET periodically sends”Hello”messages to advertise its presence.Each node has a unique ID.A cluster is a set of nodes formed as follows.A node with a local minimal ID will elect itself as a cluster head.All surrounding nodes of a head are members of the cluster identified by the heads ID.Within a cluster,a member that can communicate with a node in another cluster is a gateway.To take mobility into account,when two heads meet,the one with a larger ID gives up its head role.This cluster formation is depicted in Figure5.HX XHX GatewayH HeadFigure5:Clustered MANETNi et al[15]assumed that the cluster formed in a MANET will be maintainedT09/8regularly by the underlying cluster formation algorithm.In a cluster,the heads rebroadcast can cover all other nodes in it’s cluster.To rebroadcast message to nodes in other clusters,gateway nodes are used,hence there is no need for a non-gateway nodes to rebroadcast the message.As different clusters may still have many gateway nodes,these gateways will still use any of the broadcasting approaches described in Section2to determine whether to rebroadcast or not. Ni et al[15]showed that the performance of the cluster based method where the location based approach was incorporated compared favourably to the orig-inal location based scheme.The method saved much more rebroadcasts and leads to shorter average broadcast latencies.Unfortunately,the reachability was unacceptable in low density MANETs.4Tree Based MethodsAlthough broadcasting using tree methods in wired networks is a well known and widely used technique,it is typically claimed to be inappropriate for MANETs because of their dynamic change in network topologies.On the contrary[25] has shown that the tree based method is an efficient,reliable and stable even in case of the ever changing network structure of the MANETs.The tree constructed in[25]was a spanning tree.The broadcasting using this tree is done by forwarding a broadcast message not to all neighbours but only to those who are neighbours in this tree.Since a tree is acyclic,each message is received only once by each node,giving advantages over the existing methods. Several proposed algorithms in the literature can be used for constructing and maintaining trees such as the spanning tree algorithm of bridged Ethernet net-works[26].However,most of these algorithms are developed to work in a stable networks and not in the constantly changing topology of a MANET.Authors in[27–31]are devoted to work in multicast trees and more specifi-cally[32]is dealing with multicast trees in MANETs.Their algorithms,however, are not suitable for handling the topology changes.Some algorithms although involve constructing a spanning tree,they are not appropriate for the mainte-nance of the tree in a dynamically changing topology.A feature that differentiates the tree based method reported in[25]from the other methods is that it specifically optimises the concept of one to one trans-missions.In this way the many drawbacks of local broadcasts do not affect the algorithm and thus,the method is very well suited to perform reliable broad-casts.Moreover,whilst all other methods require extra messaging to keep up network states,the proposed method in[25]has been designed to minimise this extra signalling traffic.More details on how the algorithm constructs and maintains the spanning tree,can be seen in[25].T09/95Tree Based Methods ImprovementThis section highlights some improvements that can be made to improve the tree based methods in Section4.In the context of one to one transmission mechanism(c.f.,[25]),it seems appropriate to propose an efficient and fast broadcasting scheme that aims at improving the broadcasting time in MANETs. Spanning trees with one to one transmission will not give an optimal time,bi-nomial trees are therefore suggested for this purpose.A binomial tree B k(c.f., Figure6)is an ordered tree defined recursively.For the binomial tree B k,there are n=2k nodes,the height of the tree is k and the root has degree k.The maximum degree of any node in a binomial tree is log2n.BkB0B k-1B k-1B B B B0123...B1B0B k-1B k-2B kB2B4Depth1234Figure6:A binomial tree B kA binomial tree structure is one of the most frequently used tree structures for parallel applications in various systems.Lo et al[33]has identified the bi-nomial tree as an ideal computation structure for parallel divide and conquer algorithms.Binomial trees can easily be embedded into a fully connected graphT09/10with constant dilation 1(c.f.,[34]).In a one to one transmission,binomial tree gives an optimal broadcasting time,this is because the informed number of nodes at most doubles at each step.For a binomial tree,there are exactly ni nodes at depth i for i =0,1,...,k ,andthe root has degree k ,which is greater than that of any other node,moreover all nodes are labelled as binary string of length k .Two nodes are connected if their corresponding strings differ precisely in one position.The root node (i.e.,a node at depth i =0)of the tree is labelled as 000...0where k binomial trees are attached.Nodes at depth i =1will have a single 1in their labels in ascending order from left to right (i.e.,u 1<u 2<u 3<...u (n i )).Nodes at depth i =2will have a two 1s in their labels in ascending order from left to right.This goes on to the last node of the tree at depth k with 111...1label.In the context of a one hop ad hoc network,the binomial tree will reduce thenumber of forwarding nodes into at most N 1(u )2−1as there N 1(u )2leaf nodes.The binomial tree can easily reconfigure as nodes leave and join the transmis-sion range.A node joining the transmission range will be connected to depth 1of the tree provided that |i |< n i where i =1and |i |represents the number of nodes at depth i .If |i |= n i for i =1,then the joining node will start a new level 0.If any node at any depth i,0≤i ≤k is leaving the transmission range r ,the far right node of depth 1(i.e.,u j ,1≤j ≤ n i )will take the position of the leaving node.No action will be taken if the far right node of depth 1is leaving or the root node with only one adjacent node to depth 1.For a multi hop MANET,the tree structure will be a heap of binomial trees.The MANET will look like a cluster of binomial trees.6Cluster Based Methods ImprovementsThe clustering method described in Section 3is so trivial and hence still suffers message redundancy and reachability problems.These problems can consider-ably be reduced by taking into account the MANET signal strengths.Nodes with strong signal strengths should be logically clustered together,this will en-hance nodes reachability and if tree based are incorporated,this approach will eliminate the message redundancy problem.By clustering the MANET nodes with strong signal strengths,the stability of the MANETs is guaranteed and hence tree based methods will ideally fit in this approach.There are numerous clustering methods in the literature,however,the majority of them are designed for wired networks.Clustering techniques usually demandT09/11intensive mathematical computations which will drain the MANETs battery power.7ConclusionsBroadcasting is an essential building block of any MANET,so it is imperative to utilize the most efficient broadcast methods possible to ensure a reliable network. This tutorial has offered an overview on all major broadcasting methods in the literature focusing on their functionalities and shortcomings and,moreover,sug-gesting improvements for some of them,as appropriate.Due to dynamic change of MANET topology and its scarce resource availability,however,there is no single optimal algorithms available for all relevant scenarios.References[1]V.Park and S.Corson.A Highly Adaptive Distributed Routing Algorithmfor Mobile Wireless COM97,1407-1415,1997.[2]Z.Haas.A New Routing Protocol for Reconfigurable Wireless Networks.ICUPC97,562-566,1997.[3]C.Perkins and E.Royer Ad hoc on Demand Distance Vector Routing.2nd IEEE Workshop on Mobile Computing Systems and Applications,3-12, 1999.[4]P.Sinha,R.Sivakumar and V.Bharghavan.CEDAR:A Core ExtractionDistributed Ad hoc Routing COM99,202-209,1999. [5]D.Johnson and D.Maltz.Dynamic Source Routing in Ad hoc WirelessNetworks.Mobile Computing,Academic Publishers,153-181,1996.[6]D.Johnson,D.Maltz and Y.Hu.The Dynamic Source Routing Protocol forMobile Ad hoc Networks.Internet Draft:draft-ietf-manet-dsr-09.txt,2003.[7]C.Perkins,E.Beldig-Royer and S.Das.Ad hoc on Demand Distance Vector(AODV)Routing.Request for Comments3561,July2003.[8]Z.Haas and M.Pearlman.The Performance of Query Control Schemesfor the Zone Routing Protocol.IEEE/ACM Transactions on Networking, 9(4):427–438,2001.[9]Z.Haas and B.Liang.Ad hoc mobility management with randomizeddatabase groups.Proceedings of the IEEE International Conference on Com-munications,1756-1762,1999.T09/12[10]Y.Ko and N.Vaidya.Location-aided Routing(LAR)in Mobile Ad hocNetworks.Proceedings of the ACM/IEEE International Conference on Mo-bile Computing and Networking(MOBICOM),66-75,1998.[11]mittee.Wireless LAN Medium ACCESS CONTROL(MAC)andPhysical Layer Specifications.IEEE802.11Standard.IEEE,New York, ISBN1559379359,1997.[12]B.Williams and parison of Broadcasting Techniques forMobile Ad hoc Networks.In Proceedings of the ACM Symposium on Mobile Ad Hoc Networking and Computing(MOBIHOC),194–205,2002.[13]C.Ho,K.Obraczka,G.Tsudik and K.Viswanath.Flooding for ReliableMulticast in Multi-hop Ad hoc Networks.International Workshop in Dis-crete Algorithms and Methods for Mobile Computing and Communication, 64–71,1999.[14]J.Jetcheva,Y.Hu,D.Maltz and D.Johnson.A Simple Protocol forMulticast and Broadcast in Mobile Ad hoc Networks.Internet Draft,draft-ietf-manet-simple-mbcast-01.txt,2001.[15]S.Ni,Y.Tseng,Y.Chen and J.Sheu.The Broadcast Storm Problem in aMobile Ad hoc Network.International Workshop on Mibile Computing and Networks,151–162,1999.[16]H.Lim and C.Kim.Multicast Tree Construction and Flooding in Wire-less Ad hoc Networks.In Proceedings of the ACM International Work-shop on Modeling,Analysis and Simulation of Wireless and Mobile Systems (MSWIM),2000.[17]W.Peng and X.Lu.Efficient Broadcast in Mobile Ad hoc Networks usingConnected Dominating Sets.Journal of Software,1999.[18]W.Peng and X.Lu.On the Reduction of Broadcast Redundancy in MobileAd hoc Networks.In Proceedings of MOBIHOC,2000.[19]W.Peng and X.Lu.AHBP:An Efficient Broadcast Protocol for MobileAd hoc Networks.Journal of Science and Technology,2002.[20]J.Sucec and I.Marsic.An Efficient Distributed Network-wide BroadcastAlgorithm for Mobile Ad hoc Networks.CAIP Technical Report248-Rut-gers University,September2000.[21]E.D.Kaplan.Understanding GPS:Principles and Applications.ArtechHouse,Boston,MA,1996.[22]M.Jiang,J.Li,and Y.C.Tay.Cluster Based Routing Protocol FunctionalSpecification.Internet Draft,1998.[23]M.Gerla and J.T.Tsai.Multicluster,Mobile,Multimedia Radio Network.ACM-Baltzer Journal of Wireless Networks,1(3):255–265,1995.T09/13[24]S.Alagar,S.Venkatesan,and J.Cleveland.Reliable Broadcast in Mo-bile Wireless Networks.In Military Communications Conference,MILCOM Conference Record,1:236-240,1995.[25]Alpr Jttner and dm Magi.Tree Based Broadcast in Ad hoc Networks.MONET Special Issue on WLAN Optimization at the MAC and Network Levels,2004.to appear.[26]IEEE Specification820.1d MAC Bridges D9,July14,1989.[27]A.Ballardie,P.Francis and J.Crowcroft.Core Based Trees(CBT)anArchitecture for Scalable Interdomain Multicast Routing.SIGCOMM93, San Francisco,85–95,1993.[28]D.Estrin.Protocol Independent MulticastSparse Mode(PIM-SM).Proto-col Specification RFC2362,June1998.[29]A.Adams,J.Nicholas and W.Siadak.Protocol Independent Multicast-Dense Mode(PIM-DM).Protocol Specification(Revised),IETF Internet-Draft,draft-ietf-pim-dm-new-v2-02.txt,October2002.[30]D.Waitzman,C.Partridge and S.Deering.Distance Vector MulticastRouting Protocol.RFC1075,November1988.[31]J.Moy.Multicast Routing Extensions for OSPF.CACM,37:61–66,1994.[32]C.Perkins,E.Royer and S.Das.Ad hoc On-demand Distance Vector(AODV)Routing.IETF Internet-Draft,draft-ietf-manet-aodv-11.txt,Aug 2002.[33]V.M.Lo,S.Rajopadhye,S.Gupta,D.Keldesn,M.A.Mohamed andJ.Telle.Mapping divide and conquer Algorithms to Parallel Architectures.Proc.of the1990International Conference on Parallel Processing.(March 1990),pp.128–135.[34]J.Wu and ardo and Y.Luo.Embedding of Binomial Trees inHypercubes with Link Faults.Journal of Parallel and Distributed Computing 10October(1998);54(1),pp.59–74.T09/14。