实验5-6 预测分析表方法
管理会计实验指导书

管理会计实验指导书会计教研室实验指导管理会计是一门理论性、实践性较强的课程。
为了适应教育教学改革,使学生全面理解和掌握管理会计的基本理论、基本知识和基本技能,提高分析问题、解决问题的能力,加强实践教学,突出培养学生创新思维,增强实际操作技能,更好适应社会、企业的需要,我们编写了《管理会计实验指导书》。
一、特点本指导书具有以下特点:1、实务性及操作性强该书的资料源于实践,背景真实,资料丰富充实,具有较强的可操作性。
2、适用性强该书既遵循教学规律、尊重实务规律,又强调理论与实践的融合。
二、教学目的通过该课的实施,达到以下教学目的:1、使学生了解熟悉企业实际日常业务;2、培养学生处理解决实际日常业务的能力;3、使理论教学与实践融会贯通;4、为学生从书本、课堂走向社会、走向实际奠定基础。
三、实验要求1、实验指导书不可能包罗万象,要求学生在学习中要举一反三,不受该指导书的束缚,2、保证出勤,独立完成3、要培养独立思考、勇于创新的能力。
4、要灵活运用管理会计理论及方法来解决实际问题,以培养自己分析问题、解决问题的能力,更好适应社会、企业的需要。
实验一成本性态分析实验准备:复习准备《管理会计》第二章成本性态分析内容实验目的:通过实验,掌握混合成本的数学分解方法。
实验资料1:假定兴华工厂今年上半年6个月运输费(混合成本)的历史资料如下所示:月份1月2月3月4月5月6月运输量(吨/公里)运输费(元)3003,4002002,5005205,6002503,8004004,3002502,800实验要求:根据上述资料分别按以下方法将运输费分解为变动成本和固定成本,并写出混合成本公式。
1.采用高低点法2.采用回归直线法实验资料2:华通工厂今年下半年的混合成本维修费的资料如下表所示:月份7月8月9月10月11月12月业务量(千机器/小时)维修费(元)2001,1601601,0002601,4002401,3202801,4802201,250实验要求:1:根据上述资料采用高低点法将维修费分解为变动成本和固定成本,并写出混合成本公式。
流行病学实习指导习题练习(供参考)

流行病学实习指导流行病学教研室实习一疾病的分布【目的】掌握流行病学常用疾病频率测量指标的概念、应用条件和具体计算方法,掌握疾病按时间、地区及人群分布的流行病学描述方法。
【时间】3学时【内容】一、频率指标计算流行病学研究中疾病频率测量常用的指标有发病率(incidence rate)[包括累积发病率(cumulative incidene, CI)和发病密度(incidence density, ID)]、罹患率(attack rate)、患病率(prevalence raet)、感染率(infection rate)、续发率(secondary attack rate, SAR)、引入率(introducing rate)、死亡率(mortality rate, death rate)、病死率(fatality rate)、超额死亡率(excess mortality rate)、累积死亡率(cumulative death rate)等。
请复习上述指标的概念。
【课题一】某地1995年年初人口为2528人,1995~1998年某病三年间发病情况见图1-1,期间死亡、迁走或拒绝检查者。
图1-1 1995~1998年某病发生情况问题:请计算1995年1月1日、1996年1月1日、1997年1月1日的患病率,三年平均的年患病率。
【课题二】1998年在某镇新诊断200名糖尿病人,该镇年初人口数为9500人,年末人口数为10500人,在年初该镇有800名糖尿病患者,在这一年中有40人死于糖尿病。
问题:1. 1998年该镇糖尿病的发病率。
2. 1998年该镇糖尿病的死亡率。
3. 1998年该镇糖尿病的病死率。
4. 1998年1月1日该镇糖尿病的患病率。
5. 1998年该镇糖尿病的期间患病率。
二、疾病三间分布(一)疾病的时间分布【课题三】 1. 意大利(在北半球)和阿根廷(在南半球)脊髓灰质炎的季节分布如图1-2。
实验5LL(1)语法分析程序的设计与实现(C语言)

实验五LL(1)文法识别程序设计之宇文皓月创作一、实验目的通过LL(1)文法识别程序的设计理解自顶向下的语法分析思想。
二、实验重难点FIRST集合、FOLLOW集合、SELECT集合元素的求解,预测分析表的构造。
三、实验内容与要求实验内容:1.阅读并理解实验案例中LL(1)文法判此外程序实现;2.参考实验案例,完成简单的LL(1)文法判别程序设计。
四、实验学时4课时五、实验设备与环境C语言编译环境六、实验案例1.实验要求参考教材93页预测分析方法,94页图5.11 预测分析程序框图,编写表达式文法的识别程序。
要求对输入的LL(1)文法字符串,程序能自动判断所给字符串是否为所给文法的句子,并能给出分析过程。
表达式文法为:E→E+T|TT→T*F|FF→i|(E)2.参考代码为了更好的理解代码,建议将图5.11做如下标注:/* 程序名称: LL(1)语法分析程序 *//* E->E+T|T *//* T->T*F|F *//* F->(E)|i *//*目的: 对输入LL(1)文法字符串,本程序能自动判断所给字符串是否为所给文法的句子,并能给出分析过程。
/********************************************//* 程序相关说明 *//* A=E' B=T' *//* 预测分析表中列号、行号 *//* 0=E 1=E' 2=T 3=T' 4=F *//* 0=i 1=+ 2=* 3=( 4=) 5=# *//************************************/#include"iostream"#include "stdio.h"#include "malloc.h"#include "conio.h"/*定义链表这种数据类型拜见:http://wenku.百度.com/link?url=_owQzf8PRZOt9H-5oXIReh4X0ClHo6zXtRdWrdSO5YBLpKlNvkCk0qWqvFFxjgO0KzueVwEQcv9aZtVKEEH8XWSQCeVTjXvy9lxLQ_mZXeS###*/struct Lchar{char char_ch;struct Lchar *next;}Lchar,*p,*h,*temp,*top,*base;/*p指向终结符线性链表的头结点,h指向动态建成的终结符线性链表节点,top和base分别指向非终结符堆栈的顶和底*/ char curchar; //存放当前待比较的字符:终结符char curtocmp; //存放当前栈顶的字符:非终结符int right;int table[5][6]={{1,0,0,1,0,0},{0,1,0,0,1,1},{1,0,0,1,0,0},{0,1,1,0,1,1},{1,0,0,1,0,0}};/*存放预测分析表,1暗示有发生式,0暗示无发生式。
统计与预测的基本方法

统计与预测的基本方法统计与预测的基本方法是中小学数学课程中的一部分,它涉及到数据的收集、整理、分析和解释。
以下是统计与预测的基本知识点:1.数据收集:数据收集是统计与预测的第一步,可以通过调查、观察、实验等方式获取。
收集数据时要注意数据的真实性、完整性和可靠性。
2.数据整理:数据整理包括数据的清洗、排序和分类。
常用的整理方法有制作表格、绘制图表等,以便更好地理解和分析数据。
3.数据分析:数据分析是对数据进行解释和推理的过程。
常用的分析方法有描述性统计、推断性统计和概率论等。
描述性统计包括计算均值、中位数、众数等,推断性统计包括假设检验和置信区间等。
4.数据预测:数据预测是根据已有的数据来估计未来的趋势或结果。
常用的预测方法有趋势分析、时间序列分析和回归分析等。
5.概率论:概率论是统计与预测的基础,它研究随机事件的可能性。
常用的概率计算方法有排列组合、条件概率和贝叶斯定理等。
6.假设检验:假设检验是用来判断样本数据是否支持某个假设的方法。
常用的假设检验方法有t检验、卡方检验和F检验等。
7.置信区间:置信区间是用来估计总体参数的一个范围。
常用的置信区间计算方法有t分布、正态分布和卡方分布等。
8.相关性分析:相关性分析是用来衡量两个变量之间关系的强度和方向。
常用的相关性分析方法有皮尔逊相关系数和斯皮尔曼等级相关系数等。
9.线性回归:线性回归是用来建立自变量和因变量之间线性关系的模型。
常用的线性回归方法有最小二乘法和最大似然估计等。
10.时间序列分析:时间序列分析是用来研究时间上的数据变化的规律。
常用的时间序列分析方法有平稳性检验、自相关函数和滑动平均模型等。
11.指数平滑:指数平滑是一种用于时间序列预测的方法,它根据历史数据的权重来预测未来的趋势。
12.决策树:决策树是一种用于分类和回归的方法,它通过树状结构来表示不同特征的组合,并预测相应的结果。
13.聚类分析:聚类分析是一种无监督学习方法,它将数据分为若干个类别,以发现数据中的潜在模式和结构。
excel预测与决策分析实验报告

《EXCEL预测与决策分析》实验报告册2014- 2015 学年第学期班级:学号:姓名:授课教师: 实验教师:实验学时: 实验组号:信息管理系目录实验一网上书店数据库的创建及其查询 (3)实验二贸易公司销售数据的分类汇总分析 (7)实验三餐饮公司经营数据时间序列预测 (9)实验四住房建筑许可证数量的回归分析 (12)实验五电信公司宽带上网资费与电缆订货决策 (15)实验六奶制品厂生产/销售的最优化决策 (17)实验七运动鞋公司经营投资决策 (18)实验一网上书店数据库的创建及其查询【实验环境】•Microsoft Office Access 2003;•Microsoft Office Query 2003。
【实验目的】1.实验1-1:•理解数据库的概念;•理解关系(二维表)的概念以及关系数据库中数据的组织方式;•了解数据库创建方法。
实验1-2:•理解DOBC的概念;•掌握利用Microsoft Query进行数据查询的方法。
实验1-3:•掌握复杂的数据查询方法: 多表查询、计算字段和汇总查询。
【实验步骤】实验1-1一、表的创建和联系的建立步骤1: 创建空数据库“xddbookstore”。
步骤2: 数据库中表结构的定义。
步骤3: 保存数据表。
步骤4: 定义“响当当”数据库的其他表。
步骤5: “响当当”数据库中表之间联系的建立。
二、付款方式表的数据输入步骤1: 选中需要输入数据的表(如付款方式表)。
步骤2: 输入数据。
三、订单表的数据导入在本书配套磁盘提供的xddbookstore.xls文件中, 包含了响当当数据库所有表的数据。
可以利用该文件将订单表数据导入到“xddbookstore.mdb”数据库中。
步骤1: 选择要导入的文件。
步骤2: 规定要导入的数据表。
步骤3: 指明在要导入的数据中是否包含列标题。
步骤4:规定数据应导入到哪个表中, 可以是新表或现有的表。
步骤5: 完成数据导入工作。
实验1-2一、建立odbc数据源在利用 microsoft office query对“响当当”网上书店进行数据查询之前, 必须先建立一个用于连接该数据库的odbc数据源“bookstore”, 具体步骤如下:步骤1: 启动microsoft office query应用程序。
实验5---语法分析器(自下而上):LR(1)分析法

实验5---语法分析器(自下而上):LR(1)分析法一、实验目的构造LR(1)分析程序,利用它进行语法分析,判断给出的符号串是否为该文法识别的句子,了解LR(K)分析方法是严格的从左向右扫描,和自底向上的语法分析方法。
二、实验内容程序输入/输出示例(以下仅供参考):对下列文法,用LR(1)分析法对任意输入的符号串进行分析:(1)E->E+T(2)E->E—T(3)T->T*F(4)T->T/F(5)F-> (E)(6)F->i输出的格式如下:(1)LR(1)分析程序,编制人:姓名,学号,班级(2)输入一个以#结束的符号串(包括+—*/()i#):在此位置输入符号串(3)输出过程如下:3.对学有余力的同学,测试用的表达式事先放在文本文件中,一行存放一个表达式,同时以分号分割。
同时将预期的输出结果写在另一个文本文件中,以便和输出进行对照。
三、实验方法1.实验采用C++程序语言进行设计,文法写入程序中,用户可以自定义输入语句;2.实验开发工具为DEV C++。
四、实验步骤1.定义LR(1)分析法实验设计思想及算法①若ACTION[sm , ai] = s则将s移进状态栈,并把输入符号加入符号栈,则三元式变成为:(s0s1…sm s , #X1X2…Xm ai , ai+1…an#);②若ACTION[sm , ai] = rj则将第j个产生式A->β进行归约。
此时三元式变为(s0s1…sm-r s , #X1X2…Xm-rA , aiai+1…an#);③若ACTION[sm , ai]为“接收”,则三元式不再变化,变化过程终止,宣布分析成功;④若ACTION[sm , ai]为“报错”,则三元式的变化过程终止,报告错误。
2.定义语法构造的代码,与主代码分离,写为头文件LR.h。
3.编写主程序利用上文描述算法实现本实验要求。
五、实验结果1. 实验文法为程序既定的文法,写在头文件LR.h中,运行程序,用户可以自由输入测试语句。
预测分析方法--C++版
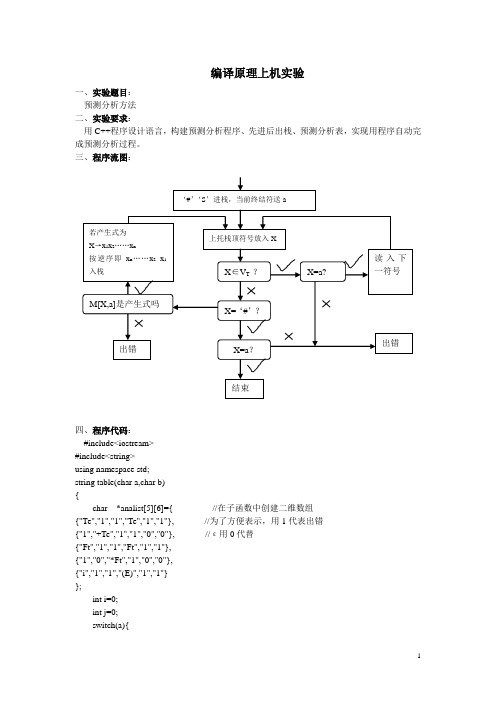
编译原理上机实验一、实验题目:预测分析方法二、实验要求:用C++程序设计语言,构建预测分析程序、先进后出栈、预测分析表,实现用程序自动完成预测分析过程。
三、程序流图:四、程序代码:#include<iostream>#include<string>using namespace std;string table(char a,char b){char *analist[5][6]={ //在子函数中创建二维数组{"Te","1","1","Te","1","1"}, //为了方便表示,用1代表出错{"1","+Te","1","1","0","0"}, //ε用0代替{"Ft","1","1","Ft","1","1"},{"1","0","*Ft","1","0","0"},{"i","1","1","(E)","1","1"}};int i=0;int j=0;switch(a){case 'E':i=0;break;case 'e':i=1;break;case 'T':i=2;break;case 't':i=3;break;case 'F':i=4;break;}switch(b){case 'i':j=0;break;case '+':j=1;break;case '*':j=2;break;case '(':j=3;break;case ')':j=4;break;case '#':j=5;break;}return analist[i][j];}bool isVt(char d) //判断是否是终结符{char vt[5] = {'i','+','*','(',')'};for(int i=0;i<5;i++){if(vt[i]==d)return true;}return false;}void main(){int op1,op2; //op1、op2分别为两个栈的栈顶指针string inputstr; //inputstr表示输入待分析的符号串int mark=0; //mark用来记录程序执行的次数string str; //定义str表示返回的产生式char a,X; //流程图中的a、Xchar stack1[30]; //用两个数组定义两个栈char stack2[30];op1=0; //初始化栈顶指针op2=0;stack1[op1]='#'; //#放入栈1op1++;stack1[op1]='E'; //E放入栈1cout<<endl; //输出所要打印的表头cout<<"****************自顶向下预测分析过程****************"<<endl;cout<<endl;cout<<endl;cout<<"LL(1)文法为:"<<endl;cout<<endl;cout<<"E->Te"<<endl;cout<<"e->+Te|ε"<<endl;cout<<"T->Ft"<<endl;cout<<"t->*Ft|ε"<<endl;cout<<"F->i|(E)"<<endl;cout<<endl;cout<<"请输入待分析符号串:"<<endl;cin>>inputstr; //输入待分析符号串cout<<endl;for(int i=1;i<inputstr.length()+1;i++){ //输入符号串入栈2stack2[i]=inputstr[inputstr.length()-i];}op2=inputstr.length();a=stack2[op2];op2--;cout<<"对符号串"<<inputstr<<" 的分析过程:"<<endl<<endl;cout<<"步骤"<<'\t'<<"分析栈"<<'\t'<<'\t'<<"剩余输入串"<<'\t'<<"推导所用产生式或匹配"<<endl;sign:mark++;cout<<mark<<'\t'; //输出程序执行的次数for(int j=0;j<(op1+1);j++) //输出分析栈1{cout<<stack1[j];}cout<<'\t'<<'\t';X=stack1[op1]; //上托栈顶符号放入Xop1--;for(int k=op2+1;k!=0;k--) //输出剩余符号串(即输出栈2){cout<<stack2[k];}cout<<'\t'<<'\t';//cout<<endl;if(isVt(X)){if(X!=a){cout<<"出错,符号串不符合文法。
实验5 A3144开关霍尔传感器

实验5 A3144开关型霍尔传感器实验班级:B13512 学号:20134051204 姓名:闭雨哲一、实验目的:1、了解开关型霍尔传感器A3144的原理。
2、通过单片机和A3144模拟电动车刹把工作过程。
二、实验内容和要求:1. 按实验原理连接设备。
2、通过A3144检测电动车是否刹车,若未检测到刹车,则发送“run”信息至串口显示,同时使电机转动;若检测到刹车,则发送“stop”信息至串口助手显示,并点亮1个led灯,并另电机停止转动。
三、使用的设备和软件:PC、单片机开发板、霍尔传感器、电机、KEIL、STC-ISP、串口调试助手四、硬件原理与连接:霍尔式传感器是由两个环形磁钢组成梯度磁场和位于梯度磁场中的霍尔元件组成。
当霍尔元件通过恒定电流时,霍尔元件在梯度磁场中上、下移动时,输出的霍尔电势V取决于其在磁场中的位移量X,所以测得霍尔电势的大小便可获知霍尔元件的静位移。
在正极和输出接电阻(1到10K)。
在负极和输出间接一个发光二极管。
接电后用磁铁靠近或远离或反正面反复在霍尔印章面可以看到发光二极管是否发光变化(磁钢靠近有霍尔有输出变化的那一面为S极)。
五、实验代码voidSensor_init_TTL(void){ //IO口初始化GPIO_InitTypeDefGPIO_InitStructure;RCC_APB2PeriphClockCmd(SENSOR_CLOCK,ENABLE);GPIO_InitStructure.GPIO_Pin=Sensor_IO_PIN2;GPIO_InitStructure.GPIO_Mode=GPIO_Mode_IPU;//上拉输入GPIO_Init(Sensor_IO_PORT,&GPIO_InitStructure);}voidGetSensorData(u8*data){ //采集数据函数data[0]=0;data[1]=0;//如果是声音、震动传感器,则采用中断方式检测if(senser_type==SENSOR_SOUND||senser_type==SENSOR_801S){data[2]=sensor_exit_flag;sensor_exit_flag=0;}elsedata[2]=SENSOR2_IN();data[3]=0;data[4]=0;//数据校正,开关型传感器,0(默认)是正常,1是发生变化//光照、倾斜、霍尔传感器if(senser_type==SENSOR_LIGHT5537|senser_type==SENSOR_TILT|senser_type==SENSOR_HDS10|sens er_type==SENSOR_HALL3144) {data[2]=(~data[2])&0x01; } }解释:霍尔传感器使用data[2]=SENSOR2_IN();进行数据采集,其中SENSOR2_IN();的宏定义为((Sensor_IO_PORT->IDR&Sensor_IO_PIN2)>>Sensor_IO_NUM2);其本质也就是采集PB7口的电平变化情况来判断检测磁铁的状态。
实验五 回归分析

实验五回归分析一.实验目的和要求回归分析是研究自变量与因变量之间的关系形式的研究方法,其目的在于根据已知自变量来估计和预测因变量的总平均值。
本次实验根据已有的银行业务数据信息进行回归分析,找出影响不良贷款的因素,进而控制并减少不良贷款,降低银行进一步的损失。
二.实验内容1.实验数据2010年该银行所属的25家分行的有关业务数据如下表所示。
某商业银行2010年的制药业务数据表分行编号不良贷款(亿元)y各项贷款余额(亿元)x1本年累计应收贷款(亿元)x2贷款项目个数(个)x3本年固定资产投资额(亿元)x41 1.2 70.6 7.7 6 54.72 1.4 114.6 20.7 17 93.83 5.1 176.3 8.6 18 76.64 3.5 83.9 8.1 11 18.55 8.2 202.8 17.5 20 66.36 2.9 19.5 3.4 2 4.97 1.9 110.7 11.7 17 23.68 12.7 188.9 27.9 18 46.99 1.3 99.6 2.6 11 56.110 2.9 76.1 10.1 16 67.611 0.6 67.8 3.1 12 45.912 4.3 135.6 12.1 25 79.813 1.1 67.7 6.9 16 25.914 3.8 177.9 13.6 27 120.115 10.5 266.6 16.5 35 149.916 3.3 82.6 9.8 16 32.717 0.5 17.9 1.5 4 45.618 0.7 76.7 6.8 13 28.619 1.3 27.8 5.9 6 16.820 7.1 143.1 8.1 29 67.821 11.9 371.6 17.7 34 167.222 1.9 99.2 4.7 12 47.823 1.5 112.9 11.2 16 70.224 7.5 199.8 16.7 18 43.125 3.6 105.7 12.9 12 100.22.实验过程分别绘制不良贷款与贷款余额、应收贷款、贷款项目数、固定资产投资额之间的散点图。
实验三自顶向下语法分析--预测分析

实验三预测分析法判断算术表达式的正确性学时数:4-6一、实验目的和要求1、用预测分析技术实现语法分析器;2、理解自顶向下语法分析方法;3、熟练掌握预测分析程序的构造方法。
二、实验内容算术表达式的文法是G[E]:E→E+T| TT→T*F| FF→(E)| i用预测分析法按文法G[E]对算术表达式(包括+、*、()的算术表达式)进行语法分析,判断该表达式是否正确。
三、实验步骤1、准备:阅读课本有关章节,将上述算术表达式的文法改造成LL(1)文法(即消除左递归和提取左公因子);设计出预测分析表;按算法4.5(P90)编写程序。
2、上机调试,发现错误,分析错误,再修改完善。
四、测试要求1、为降低难度,表达式中不含变量(只含单个无符号整数或i);2、如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);3、测试用的表达式建议事先放在文本文件中,一行存放一个表达式,以分号结束。
而语法分析程序的输出结果写在另一个文本文件中;4、选作:对学有余力的同学,可增加功能:当判断一个表达式正确时,输出计算结果。
5、程序输入/输出示例:如参考C语言的运算符。
输入如下表达式(以分号为结束)和输出结果:(a)1; 或 i;输出:正确(b)1+2; 或 i+i;输出:正确(c)(1+2)*3+4-(5+6*7); 或 (i+i)*i+i-(i+i*i);输出:正确(d)((1+2)*3+4 或 ((i+i)*i+i;输出:错误,缺少右括号(e)1+2+3+(*4/5) 或 i+i+i+(*4/5);输出:错误五、实验报告要求1、写出修改后LL(1)文法,所构造的预测分析表。
2、通过对核心代码做注释或通过程序流程图的方式说明预测分析程序的实现思想。
3、写出调试程序出现的问题及解决的方法。
4、给出测试的结果。
六、思考(选作)文法G[E]所构造算术表达式只包含+和*。
请修改文法和程序,使得该语法程序可判断包含减号和除号的算术表达式的正确性。
计量地理学实验报告

《计量地理学》实验报告学院:班级:学号:姓名:指导老师:实验地点:目录一、第一次实验(1)多元线性回归分析··3(2)逐步回归分析··6二、第二次实验(1)主成分回归分析··10(2)方差分析··13三、第三次实验(1)非线性回归分析··17(2)聚类分析··20四、第四次实验趋势面分析··22第一次实验1.实验名称:多元线性回归分析实验目的:通过探讨自变量与因变量之间变动的比例关系,建立模型,揭示地理要素之间的线性相关关系。
实验内容:以《贵州省遵义市海龙坝水源地供水水文地质详查报告》中的数据资料为例,对该地区地下水流量进行预测。
从详查报告可以看出,该区地下水流量的动态变化主要受降雨量及人工开采两个因素的影响,因此主要通过研究区降雨量及人工开采用水资料来预测地下水各观测孔流量的变化,而不考虑其它因素的影响,则模型可简化为:22110x x y ∂+∂+∂=式中,y 为观测孔地下水流量的变化;21,x x 分别为降雨量和人工开采量。
年份 降雨量1x /mm人工开采量2x /3m观测孔流量y/(L/s)1990 954 658.8 51.54 1991 1389.5 723.1 63.71 1992 864 701.9 54.44 1993 1193.2 689.5 56.78 1994 841 734.6 53.45 1995 1378.4 699.2 65.92 19961686.9685.467.581997 1592.1 704.7 64.591998 1956.7 613.7 75.31实验步骤:(1)在DPS系统中对原始数据进行回归分析,将上表中数据编辑、定义成数据块;(2)在“多元分析”菜单下选择“回归分析”中的“线性回归”,系统给出下图界面点击右下角的“返回编辑”,得到以下数据:多元线性回归分析结果:方差来源平方和df 均方F值p值相关系数R=0.962768 决定系数RR=0.926923 调整相关R'=0.950034press=117.3509 剩余标准差sse= 2.4622 预测误差标准差MSPE=4.4225 Durbin-Watson d=2.2597回 归461.39792230.6989 38.0527 0.0004剩 余36.3757 6 6.0626总 的497.77368 62.2217变量 回归系数 标准系数 偏相关 标准误t 值p-值 b0 26.3907 21.6685 1.21790.2627b1 0.0201 0.9914 0.9523 0.0026 7.6450 0.0001 b2 0.01250.05680.17600.02840.43790.6746序号观察值拟合值残差标准残差 学生残差cook 距离成果处理:经过以上分析,由上表可知,该区地下水流量计算模型为:210125.00201.03907.26x x y ++=通过对回归方程进行F 显著性检验,该地下水流量预测模型显著性很好,符合1 51.5400 53.7836 -2.2436 -0.9112 -1.3434 0.7061 2 63.7100 63.3429 0.3671 0.1491 0.1774 0.00443 54.4400 52.5106 1.92940.78360.93320.12144 56.7800 58.9766 -2.1966 -0.8921 -0.9563 0.04545 53.4500 52.4554 0.9946 0.4039 0.5048 0.0477 6 65.9200 62.8219 3.09811.25821.35180.09407 67.5800 68.8541 -1.2741 -0.5175 -0.5965 0.0390 8 64.5900 67.1881 -2.5981 -1.0552 -1.2416 0.1976 975.3100 73.3868 1.92320.78111.48581.9270通径系数分析直接作用 通过x1通过x2 x1 0.9914 -0.0298x20.0568-0.5206剩余通径系数=0.270327该地区的实际情况,因此可以通过该模型对研究区地下水流量进行预测。
实验五 LL(1)分析步骤和讲解

实验五LL(1) 分析法一、实验目的:一、实验目的:根据某一文法编制调试LL (1)分析程序,以便对任意输入的符号串进行)分析程序,以便对任意输入的符号串进行析。
本次实验的目主要是加深对预测分析。
本次实验的目主要是加深对预测分LL (1)分析法的理解。
)分析法的理解。
(所需学时:4学时)二、实验二、实验原理1、LL (1)分析法的功能)分析法的功能LL (1)分析法的功能是利用)分析法的功能是利用)分析法的功能是利用LL (1)控制程序根据显示栈顶内容、向前)控制程序根据显示栈顶内容、向前)控制程序根据显示栈顶内容、向前)控制程序根据显示栈顶内容、向前看符号以及LL (1)分析表,对输入符号串自上而下的过程。
)分析表,对输入符号串自上而下的过程。
2、LL (1)分析法的前提)分析法的前提改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为改造文法:消除二义性、左递归提取因子,判断是否为LL (1)文法,3、LL (1)分析法实验设计思想及算)分析法实验设计思想及算X∈VN‘#’‘ S’ 进栈,当前输入符送进栈,当前输入符送进栈,当前输入符送进栈,当前输入符送a栈顶符号放入栈顶符号放入X若产生式为若产生式为X X1X2…X n按逆序即Xn…X 2X1入栈出错X=’ X=’ X=’ #’X∈VTX=aX=aM[X,a] M[X,a]M[X,a] M[X,a]是产生式吗是产生式吗出错X=a读入下一个符号读入下一个符号结束是是是是否否否否否是三、实验要求对文法G(E) 如下,用LL(1)分析法对任意输入的符号串进行分析:E→E+T│TT→T*F│FF→(E)│i消除文法左递归,改写为:E →TE'E' →+TE' | εT →FT'T' →*FT' | εF →( E ) | i(1)计算每个语法单位的first 和follow 集合;(2)构造预测分析表;(3)写出分析程序。
最新广东海洋大学编译原理LL(1)文法分析器实验(java)

GDOU-B-11-112广东海洋大学学生实验报告书(学生用表)实验名称实验3:语法分析课程名称编译原理课程号16242211 学院(系) 数学与计算机学院专业计算机科学与技术班级计科1141学生姓名学号实验地点科425 实验日期2017.4.21一、实验目的熟悉语法分析的过程;理解相关文法的步骤;熟悉First集和Follow集生成二、实验要求对于给定的文法,试编写调试一个语法分析程序:要求和提示:(1)可选择一种你感兴趣的语法分析方法(LL(1)、算符优先、递归下降、SLR(1)等)作为编制语法分析程序的依据。
(2)对于所选定的分析方法,如有需要,应选择一种合适的数据结构,以构造所给文法的机内表示。
(3)能进行分析过程模拟。
如输入一个句子,能输出与句子对应的语法树,能对语法树生成过程进行模拟;能够输出分析过程每一步符号栈的变化情况。
设计一个由给定文法生成First集和Follow集并进行简化的算法动态模拟。
三、实验过程1:文法:E->TE’E’->+TE’|εT->FT’T’->*FT’|εF->(E)|i:2程序描述(LL(1)文法)本程序是基于已构建好的某一个语法的预测分析表来对用户的输入字符串进行分析,判断输入的字符串是否属于该文法的句子。
基本实现思想:接收用户输入的字符串(字符串以“#”表示结束)后,对用做分析栈的一维数组和存放分析表的二维数组进行初始化。
然后取出分析栈的栈顶字符,判断是否为终结符,若为终结符则判断是否为“#”且与当前输入符号一样,若是则语法分析结束,输入的字符串为文法的一个句子,否则出错若不为“#”且与当前输入符号一样则将栈顶符号出栈,当前输入符号从输入字符串中除去,进入下一个字符的分析。
若不为“#”且不与当前输入符号一样,则出错。
四、程序流程图本程序中使用以下文法作对用户输入的字符串进行分析:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→i|(E)该文法的预测分析表为:五:结果及截图1、显示预测分析表,提示用户输入字符串2、输入的字符串为正确的句子:3、输入的字符串中包含了不属于终结符集的字符4、输入的字符串不是该文法能推导出来的句子程序代码:package complier;import java.io.*;public class LL {String Vn[] = { "E", "E'", "T", "T'", "F" }; // 非终结符集String Vt[] = { "i", "+", "*", "(", ")", "#" }; // 终结符集String P[][] = new String[5][6]; // 预测分析表String fenxi[] ; // 分析栈int count = 1; // 步骤int count1 = 1;//’分析栈指针int count2 = 0, count3 = 0;//预测分析表指针String inputString = ""; // 输入的字符串boolean flag;public void setCount(int count, int count1, int count2, int count3){ this.count = count;this.count1 = count1;this.count2 = count2;this.count3 = count3;flag = false;}public void setFenxi() { // 初始化分析栈fenxi = new String[20];fenxi[0] = "#";fenxi[1] = "E";}public void setP() { // 初始化预测分析表for (int i = 0; i < 5; i++) {for (int j = 0; j < 6; j++) {P[i][j] = "error";}}P[0][0] = "->TE'";P[0][3] = "->TE'";P[1][1] = "->+TE'";P[1][4] = "->ε";P[1][5] = "->ε";P[2][0] = "->FT'";P[2][3] = "->FT'";P[3][1] = "->ε";P[3][2] = "->*FT'";P[3][4] = "->ε";P[3][5] = "->ε";P[4][0] = "->i";P[4][3] = "->(E)";// 打印出预测分析表System.out.println(" 已构建好的预测分析表");System.out.println("----------------------------------------------------------------------");for (int i=0; i<6; i++) {System.out.print(" "+Vt[i]);}System.out.println();System.out.println("----------------------------------------------------------------------");for (int i=0; i<5; i++) {System.out.print(" "+Vn[i]+" ");for (int j=0; j<6; j++) {int l = 0;if (j>0) {l = 10-P[i][j-1].length();}for (int k=0; k<l; k++) {System.out.print(" ");}System.out.print(P[i][j]+" ");}System.out.println();}System.out.println("----------------------------------------------------------------------");}public void setInputString(String input) {inputString = input;}public boolean judge() {String inputChar = inputString.substring(0, 1); // 当前输入字符boolean flage = false;if (count1 >= 0) {for (int i=0; i<6; i++) {if (fenxi[count1].equals(Vt[i])) { // 判断分析栈栈顶的字符是否为终结符flage = true;break;}}}if (flage) {// 为终结符时if (fenxi[count1].equals(inputChar)) {if (fenxi[count1].equals("#")&&inputString.length()==1) { // 栈顶符号为结束标志时// System.out.println("最后一个");String fenxizhan = "";for (int i=0; i<=P.length; i++) { // 拿到分析栈里的全部内容(滤去null)if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" " + count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.println("接受");flag = true;return true;} else {// 分析栈栈顶符号不为结束标志符号时String fenxizhan = "";for (int i=0; i<=P.length; i++) { // 拿到分析栈里的全部内容(滤去null)if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" "+count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.println("\"" + inputChar + "\"" + "匹配");// 将栈顶符号出栈,栈顶指针减一fenxi[count1] = null;count1 -= 1;if (inputString.length() > 1) { // 当当前输入字符串的长度大于1时,将当前输入字符从输入字符串中除去inputString = inputString.substring(1, inputString.length());} else { // 当前输入串长度为1时inputChar = inputString;}// System.out.println(" "+count+" "+fenxizhan+"// "+inputString +" "+P[count3][count2]);// System.out.println(count + inputChar + "匹配 ");count++;judge();}}else { // 判断与与输入符号是否一样为结束标志System.out.println(" 分析到第" + count + "步时出错!");flag = false;return false;}} else {// 非终结符时boolean fla = false;for (int i=0; i<6; i++) { // 查询当前输入符号位于终结符集的位置if (inputChar.equals(Vt[i])) {fla = true;count2 = i;break;}}if(!fla){System.out.println(" 分析到第" + count + "步时出错!");flag = false;return false;}for (int i=0; i<5; i++) { // 查询栈顶的符号位于非终结符集的位置if (fenxi[count1].equals(Vn[i])) {count3 = i;break;}}if (P[count3][count2] != "error") { // 栈顶的非终结符与输入的终结符存在产生式时String p = P[count3][count2];String s1 = p.substring(2, p.length()); // 获取对应的产生式if (s1.equals("ε")) { // 产生式推出“ε”时String fenxizhan = "";for (int i=0; i<=P.length; i++) {if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" " + count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int k=0; k<farWay; k++) {System.out.print(" ");}System.out.println(fenxi[count1] + P[count3][count2]);// 将栈顶符号出栈,栈顶指针指向下一个元素fenxi[count1] = null;count1 -= 1;count++;judge();} else { // 产生式不推出“ε”时int k = s1.length();String fenxizhan = "";for (int i=0; i<=P.length; i++) {if (fenxi[i] == null) {break;} else {fenxizhan = fenxizhan + fenxi[i];}}// 输出当前分析栈情况,输入字符串,所用产生式或匹配System.out.print(" "+count);String countToString = Integer.toString(count);int farWay = 14 - countToString.length();for (int o=0; o<farWay; o++) {System.out.print(" ");}System.out.print(fenxizhan);farWay = 20 - fenxizhan.length();for (int o=0; o<farWay; o++) {System.out.print(" ");}System.out.print(inputString);farWay = 25 - inputString.length();for (int o=0; o<farWay; o++) {System.out.print(" ");}System.out.println(fenxi[count1] + P[count3][count2]);for (int i=1; i<=k; i++) { // 将产生式右部的各个符号入栈String s2 = s1.substring(s1.length() - 1,s1.length());s1 = s1.substring(0, s1.length() - 1);if (s2.equals("'")) {s2= s1.substring(s1.length() - 1, s1.length())+ s2;i++;s1 = s1.substring(0, s1.length() - 1);}fenxi[count1] = s2;if (i < k)count1++;// System.out.println("count1=" + count1);}// System.out.println(" "+count+" "+fenxizhan+"// "+inputString +" "+P[count3][count2]);count++;// System.out.println(count);judge();}} else {System.out.println(" 分析到第" + count + "步时出错!");flag = false;return false;}}return flag;}public static void main(String args[]) {LL l = new LL();l.setP();String input = "";boolean flag = true;while (flag) {try {InputStreamReader isr = new InputStreamReader(System.in);BufferedReader br = new BufferedReader(isr);System.out.println();System.out.print("请输入字符串(输入exit退出):");input = br.readLine();} catch (Exception e) {e.printStackTrace();}if(input.equals("exit")){flag = false;}else{l.setInputString(input);l.setCount(1, 1, 0, 0);l.setFenxi();System.out.println();System.out.println("分析过程");System.out.println("----------------------------------------------------------------------");System.out.println(" 步骤 | 分析栈 | 剩余输入串 | 所用产生式 ");System.out.println("----------------------------------------------------------------------");boolean b = l.judge();System.out.println("----------------------------------------------------------------------");if(b){System.out.println("您输入的字符串"+input+"是该文发的一个句子");}else{System.out.println("您输入的字符串"+input+"有词法错误!");}}}}}六:实验心得通过本次实验基本掌握了语法分析的原理和LL(1)语法分析方法,以及预测分析表的构造,进一步熟悉了语法分析的详细过程,收获还是蛮大的,值得我们认真对待。
关于统计预测实验报告(3篇)

第1篇一、实验目的本实验旨在通过统计方法对数据进行分析和预测,掌握统计预测的基本原理和操作步骤,提高对实际问题的分析和解决能力。
通过本次实验,我们希望达到以下目标:1. 理解统计预测的基本概念和原理。
2. 掌握常用统计预测方法,如线性回归、时间序列分析等。
3. 能够运用统计软件(如Excel、R等)进行预测分析。
4. 提高对实际问题的分析和解决能力。
二、实验内容本次实验主要分为以下几个部分:1. 数据收集与整理2. 描述性统计分析3. 时间序列分析4. 线性回归预测5. 结果分析与讨论三、实验步骤1. 数据收集与整理我们收集了某城市过去五年的GDP数据,并将其整理成表格形式。
2. 描述性统计分析使用Excel对数据进行描述性统计分析,包括计算均值、标准差、最大值、最小值等。
3. 时间序列分析利用R软件对时间序列数据进行处理,包括趋势分析、季节性分析等。
4. 线性回归预测建立线性回归模型,以GDP为因变量,时间(年)为自变量,进行预测。
5. 结果分析与讨论分析预测结果,讨论预测的准确性,并探讨影响预测结果的因素。
四、实验结果与分析1. 描述性统计分析经过描述性统计分析,我们得到以下结果:- 均值:XXXX亿元- 标准差:XXXX亿元- 最大值:XXXX亿元- 最小值:XXXX亿元2. 时间序列分析通过时间序列分析,我们发现该城市GDP呈现逐年增长的趋势,且具有明显的季节性。
3. 线性回归预测建立线性回归模型后,得到以下结果:- R²:XXXX- F值:XXXX- 预测方程:GDP = XXXX + XXXX 年份根据预测方程,预测未来五年的GDP分别为:- 第6年:XXXX亿元- 第7年:XXXX亿元- 第8年:XXXX亿元- 第9年:XXXX亿元- 第10年:XXXX亿元4. 结果分析与讨论从预测结果来看,该城市GDP在未来五年内将持续增长。
然而,预测结果可能受到以下因素的影响:- 经济政策- 社会环境- 自然灾害因此,在分析预测结果时,需要综合考虑各种因素。
SPSS实验指导书(5.6.7.8)

目录(一)因子分析........................................................................................... (二)聚类分析........................................................................................... (三)回归分析........................................................................................... (四)判别分析...........................................................................................实验一:因子分析一、实验目的:运用因子分析方法分析数据二、内容:1.SPSS操作2.因子分析三、案例背景:现有24名同学身高、体重、坐高、胸围、肩宽、盆骨宽此6项数据,有没有可能用更少的数据说明每位同学的身体状况?实验步骤:步骤一:导入数据步骤二:确定数据类型(Variable View)步骤三:输入数据(data view)并确定分析方法Variables列表框:用箭头按钮从左边列表框中选择想要分析的变量名移动到右边,准备分析。
Descriptive按钮:单击该按钮,打开对话框,并在其中设置描述统计量(在需要得到的统计量前的括号打钩)。
Univariate descriptive:计算单变量描述信息,包括个变量有效值的个数,均值和标准差。
Initial solution:计算初始解。
包括变量的初始共同度,因子特征值,各特征值占特征值之和的百分数及累计百分数。
Coefficients:生成相关系数矩阵。
Significance levels:生成相关系数矩阵中的单侧显著性水平Determinant:生成相关系数矩阵的行列式。
实验-基因结构预测分析

学院:______ 班级:_______ 学号:_________ 姓名:__________ 成绩:______实验五基因结构预测分析目的:1、熟悉并掌握从基因组核酸序列中发现基因的方法。
内容:1、用NCBI的ORF Finder分析原核生物核酸序列或真核生物的cDNA序列中的开放阅读框;2、使用GENSCAN在线软件预测真核生物基因;3、使用POL YAH在线预测转录终止信号;4、使用PromoterScan在线预测启动子区域。
操作及问题:随着测序技术的不断发展,越来越多的模式生物启动了全基因组测序计划,完成全基因组测序的物种也越来越多,使得基因结构和功能的预测成为可能。
同时,通过基因组文库筛选也可得到目的基因所在克隆。
获得克隆序列后,同样也需要对目的基因做结构预测以便指导后续功能研究。
本实验介绍几种常用的基因预测分析工具,预测核酸序列的开放阅读框、转录终止信号、启动子、CpG岛等信息。
一、开放阅读框(open reading frame,ORF)的识别ORF是指从核酸序列上5’端翻译起始密码子到终止密码子的蛋白质编码序列。
原核生物与真核生物的基因结构存在很大不同,真核生物的ORF除外显子(平均150bp)外,还含有内含子,因此真核生物基因的预测远比原核生物复杂。
(一)利用NCBI ORF Finder预测原核生物核酸序列或真核生物的cDNA序列中的开放阅读框。
ml1、在NCBI上查找AC 号为AE008569 的核酸记录。
(见实验五中的AE008569.mht)问题1:这个序列的名称?问题2:这个序列来源物种所属的生物学大分类?2、进入OFR Finder,首先在页面下方的Genetic codes下拉菜单中浏览现有的22 种遗传密码选择项(这里我们只使用默认的standard code),利用AC 号或其ra w sequence(即不带任何注释信息的全序列)进行ORF finding。
第五章 蛋白质分析及预测方法(新)

常采用参数Q3:Q3=(Pα+Pβ+Pcoil)/T, 其中Pα、Pβ、Pcoil分别代表预测α螺旋、β 折叠和无规则卷曲正确的氨基酸残基数,T 为总氨基酸残基数。
亦有人建议用不同二级结构预测的相关系数
Ci来评估。如Cα表示α螺旋预测相关系数:
C (PN UO) (N U)(N O)(P U)(P O)
三、二级结构预测的准确度 总的来讲,单序列的预测准确度在60%左右, 应用多重序列对比信息的二级结构预测准确 度在65%~85%之间。
从1994年起每两年国际上都要举行一届关于 蛋白质结构预测进展方面的评估(critical assessment of protein structure prediction, CASP)
应用蛋白酶将胶上或膜上分离出的蛋白断裂成肽 片段,通过MALDI-MS或ESI-MS得到肽质指纹图 谱,搜索数据库,可对蛋白质进行鉴定。常用的 在 线 肽 质 指 纹 图 谱 分 析 工 具 有 ExPASy 的 PeptIdent (/tools/peptident.html)
Cuff J. A. and Barton G.(1999) Jones, D. T. (1999)
准确性
作者评测:Q3=57% CASP2:Q3=55.4%(41.9-62.5)
作者评测:Q3=63%
作者评测:Q3=70.1% CASP2:Q3=69.5% [57.3-87.2]
作者评测:Q3=75%
(http://npsa-pbil.ibcp.fr/cgibin/npsa_automat.pl?page=/NPSA/npsa_seccons. html)服务,其二级结构预测可由用户从SOPM、 HNN、DPM、DSC、GOR、PHD、PREDATOR、 SIMPA96等12种方法中任选几种进行预测,然后根 据预测结果汇集整理成一个“一致的结果”
实验二--LL分析法实验报告

实验二LL(1) 分析法一、实验目的通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。
有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
二、实验内容及设计原理所谓LL( 1)分析法,就是指从左到右扫描输入串(源程序),同时采用最左推导,且对每次直接推导只需向前看一个输入符号,便可确定当前所应当选择的规则。
实现LL( 1 )分析的程序又称为LL( 1 )分析程序或LL1 ( 1 )分析器。
我们知道一个文法要能进行LL (1)分析,那么这个文法应该满足:无二义性,无左递归,无左公因子。
当文法满足条件后,再分别构造文法每个非终结符的FIRST 和FOLLOW集合,然后根据FIRST和FOLLOW集合构造LL( 1)分析表, 最后利用分析表,根据LL(1) 语法分析构造一个分析器。
LL (1)的语法分析程序包含了三个部分,总控程序,预测分析表函数,先进先出的语法分析栈,本程序也是采用了同样的方法进行语法分析,该程序是采用了C++语言来编写,其逻辑结构图如下:LL( 1)预测分析程序的总控程序在任何时候都是按STACK栈顶符号X和当前的输入符号a做哪种过程的。
对于任何(X,a),总控程序每次都执行下述三种可能的动作之一:(1)若X = a = ‘#',则宣布分析成功,停止分析过程。
(2)若X = a ‘ #',则把X从STACK栈顶弹出,让a指向下一个输入符号。
(3)若X是一个非终结符,则查看预测分析表M若M[A, a]中存放着关于X的一个产生式,那么,首先把X弹出STACK栈顶,然后,把产生式的右部符号串按反序一一弹出STACK S若右部符号为£,则不推什么东西进STAC栈)。
若M[A,a] 中存放着“出错标志”,则调用出错诊断程序ERROR三、程序结构描述1、定义的变量初始化预测分析表:LL E[8]={"TG","TG","error","error","error","error","error","error"};LL G[8]={"error","error","null","+TG"," -TG","error","error","null"};LL T[8]={"FS","FS","error","error","error","error","error","error"};LL S[8]={"error","error","null","null","null","*FS","/FS","null"};LL F[8]={"i","(i)","error","error","error","error","error","error"};const int MaxLen=10; 初始化栈的长度const int Length=10; 初始化数组长度charVn[5]={'E','G','T','S','F'}; 非终结符数组char Vt[8]={'i','(',')','+',' -','*','/','#'}; 终结符数组char ch,X; /全局变量,ch 用于读当前字符,X 用于获取栈顶元素char strToken[Length]; 存储规约表达式2、定义的函数class stack 栈的构造及初始化int length(char *c) 输出字符数组的长度void print(int i,char*c) 剩余输入串的输出void run() 分析程序3、LL(1) 预测分析程序流程图LL(1J预测分祈握序謊程四、程序源代码及运行结果 #in clude<iostream> using n amespace std;const int MaxLe n=10; 〃初始化栈的长度 const int Len gth=10;〃初始化数组长度char Vn[5]={'E','G',T,'S','F'};〃 非终结符数组 char Vt[8]={'i','(',')','+',' -','*','/',#};// 终结符数组char ch,X;〃全局变量,ch 用于读当前字符,X 用于获取栈顶元素 char strToke n[Le ngth];//存储规约表达式 struct LL//ll(1)分析表的构造字初始化 {char*c;};LL E[8]={"TG","TG","error","error","error","error","error","erro 门; LL G[8]={"error","error"," null","+TG"," -TG","error","error"," null"}; LL T[8]={"FS","FS","error","error","error","error","error","error"}; LL S[8]={"error","error"," null"," null"," null","*FS","/FS"," null"};LL F[8]={"i","(i)","error","error","error","error","error","error"}; class stack/栈的构造及初始化 {public:stack();//初 始化 bool empty() con st;//是 否为空观Y 入符号越V取弋成功出铛实验二--LL(1) 分析法实验报告bool full() const;// 是否已满bool get_top(char & c)co nst;/取栈顶元素bool push(c onst charc);/入栈bool pop();〃删除栈顶元素void out();//输出栈中元素~stack(){}// 析构private:in t cou nt;〃栈长度char data[MaxLe n];〃栈中元素};stack::stack(){count=0;}bool stack::empty() const{if(count==0)return true;return false;}bool stack::full() const{if(count==MaxLen)return true;return false;}bool stack::get_top(char &c)const{if(empty())return false;else{c=data[count-1]; return true;}}bool stack::push(const char c){if(full())return false;data[count++]=c; return true;}bool stack::pop(){if(empty()) return false; count--; return true;}void stack::out(){for(int i=0;i<count;i++) cout<<data[i]; cout<<" ";}int length(char *c){int l=0;for(int i=0;c[i]!='\0';i++)l++;return l;}void print(int i,char*c)// 剩余输入串的输出{for(int j=i;j<Length;j++) cout<<c[j];cout<<" ";}void run(){bool flag=true;〃循环条件int step=0,poi nt=O;〃步骤、指针int len;〃长度coutvv"请输入要规约的字符串:"<<e ndl; cin>>strToken;ch=strToke n[ poi nt++];〃读取第一个字符stack s;s.push(#);/栈中数据初始化s.push('E');s.get_top(X);〃取栈顶元素cout«"步骤"<<"分析栈"<<"剩余输入串"<<"所用产生式"<<"动作"<<e ndl;cout<<step++<<" ";s.out(); print(point-1,strToken); cout<<" "<<" 初始化"<<endl;while(flag){if((X==Vt[0])||(X==Vt[1])||(X==Vt[2])||(X==Vt[3])||(X==Vt[4])||(X==Vt[5])||(X==Vt[6])) // 判断是否为终结符(不包括#){if(X==ch)// 终结符,识别,进行下一字符规约{s.pop();s.get_top(X); ch=strToken[point++]; cout<<step++<<" ";s.out();print(point - 1,strToken);cout<<" "<<"GETNEXT(I)"<<endl;}else{flag=false; cout<<"error!"<<endl;}}else if(X=='#')// 规约结束{if(X==ch){cout<<step++<<" ";s.out(); print(point -1,strToken);coutvv" "vvXvv" ->"vvchvv" "<<"结束"<<endl;s.pop();flag=false;}else{flag=false; cout<<"error!"<<endl;}}else if(X==Vn[0]) // 非终结符E{for(int i=0;i<8;i++)// 查分析表if(ch==Vt[i]){if(strcmp(E[i].c,"error")==0)// 出错{flag=false; cout<<"error"<<endl;}else{ //对形如X->X1X2 的产生式进行入栈操作s.pop();len=length(E[i].c) -1; for(int j=len;j>=0;j --) s.push(E[i].c[j]);cout<<step++<<" ";s.out(); print(point -1,strToken); cout<<X<<" ->"<<E[i].c<<""<<"POP,PUSH("; for(int z=len;z>=0;z --) cout<<E[i].c[z];cout<<")"<<endl; s.get_top(X);}}}else if(X==Vn[1]) //同上,处理G{for(int i=0;i<8;i++) if(ch==Vt[i]){if(strcmp(G[i].c,"null")==0){s.pop(); cout<<step++<<" ";s.out(); print(point - 1,strToken);coutvv" "vvXvv" ->"<<" £"<<" "vv"POP"vvendl;s.get_top(X);}else if(strcmp(G[i].c,"error")==0){flag=false;cout<<"error"<<endl;}else{s.pop(); len=length(G[i].c)-1;for(int j=len;j>=0;j --)s.push(G[i].c[j]);实验二--LL(1) 分析法实验报告cout<<step++<<" ";s.out(); print(point -1,strToken);cout<<X<<" ->"<<G[i].c<<" "<<"POP,PUSH(";for(int z=len;z>=0;z --) cout<<G[i].c[z];cout<<")"<<endl; s.get_top(X);}}}else if(X==Vn[2]) // 同上处理T{{for(int i=0;i<8;i++) if(ch==Vt[i])if(strcmp(T[i].c,"error")==0){flag=false; cout<<"error"<<endl;}else{s.pop();len=length(T[i].c) -1; for(int j=len;j>=0;j --) s.push(T[i].c[j]);cout<<step++<<" ";s.out(); print(point - 1,strToken);cout<<X<<" ->"<<T[i].c<<" "<<"POP,PUSH("; for(intz=len;z>=0;z --) cout<<T[i].c[z];cout<<")"<<endl; s.get_top(X);}}}else if(X==Vn[3])// 同上处理S{{for(int i=0;i<8;i++) if(ch==Vt[i])if(strcmp(S[i].c,"null")==0){s.pop();cout<<step++<<" ";s.out();print(point - 1,strToken);coutvv" "vvXvv" ->"<<" £"<<" "vv"POP"vvendl;s.get_top(X);}else if(strcmp(S[i].c,"error")==0){flag=false;cout<<"error"<<endl;}else{s.pop();len=length(S[i].c)-1;for(int j=len;j>=0;j --)s.push(S[i].c[j]);cout<<step++<<" ";s.out();print(point-1,strToken);cout<<X<<"->"<<S[i].c<<" "<<"POP,PUSH(";for(int z=len;z>=0;z--)cout<<S[i].c[z];cout<<")"<<endl;s.get_top(X);}}}else if(X==Vn[4]) //同上处理F{for(int i=0;i<7;i++)if(ch==Vt[i]){if(strcmp(F[i].c,"error")==0){flag=false;cout<<"error"<<endl;}else{s.pop();len=length(F[i].c)-1;for(int j=len;j>=0;j --)s.push(F[i].c[j]);cout<<step++<<" ";s.out();prin t(po in t-1,strToke n);coutv<Xvv"->"vvF[i].cvv" "vv"POP,PUSH(";for(i nt z=le n; z>=O;z--) cout<<F[i].c[z];cout<<")"<<e ndl;s.get_top(X);}}}else /出错处理{flag= false; cout<<"error"<<e ndl;}}}int main(){run();system("pause");return 0;}测试:输入i*i+i#结果:五、实验总结1. 本实例能利用正确的LL1 文法分析表判断任意符号串是否属于该文法的句子;显示了具体分析过程;支持打开、新建、保存分析表;保存分析实验二--LL(1) 分析法实验报告结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程实验报告课程名称:编译原理实验项目名称:预测分析表方法专业班级:网络工程姓名:李荣荣学号:20114052223指导教师:李建义完成时间:2014 年 5 月 3 日计算机科学与工程系实验5-6 预测分析表方法一、实验目的理解预测分析表方法的实现原理。
二、实验内容:编写一通用的预测法分析程序,要求有一定的错误处理能力,出错后能够使程序继续运行下去,直到分析过程结束。
可通过不同的文法(通过数据表现)进行测试。
二、实验内容提示1.算法数据构造:构造终结符数组:char Vt[10][5]={“id”,”+”……};构造非终结符数组:char Vn[10]={ };构造follow集数组:char *follow[10][10]={ } (可将follow集与预测分析表合并存放)数据构造示例(使用的预测分析表构造方法1):/*data1.h简单算术表达式数据*/char VN[10][5]={"E","E'","T","T'","F"}; //非终结符表int length_vn=5; //非终结符的个数char VT[15][5]={"id","+","*","(",")","#"}; //终结符表int length_vt=6; //终结符的个数char Fa[15][10]={"TE'","+TE'","","FT'","*FT'","","(E)","id"};//产生式表:0:E->TE' 1:E'->+TE' 2:E'->空// 3:T->FT' 4:T'->*FT' 5:T'->空 6:F->(E) 7:F->idint analysis_table[10][11]={0,-1,-1,0,-2,-2,0,0,0,0,0,-1,1,-1,-1,2,2,0,0,0,0,0,3,-2,-1,3,-2,-2,0,0,0,0,0,-1,5, 4,-1,5, 5,0,0,0,0,0,7,-2,-2,6,-2,-2,0,0,0,0,0};//预测分析表,-1表示出错,-2表示该行终结符的follow集合,用于错误处理,正数表示产生式在数组Fa中的编号,0表示多余的列。
(1)预测分析表的构造方法1给文法的正规式编号:存放在字符数组中,从0开始编号,正规式的编号即为该正规式在数组中对应的下标。
如上述Fa数组表示存储产生式。
构造正规式数组:char P[10][10]={“E->TE’”,”E’->+TE’”,……..}; (正规式可只存储右半部分,如E->TE’可存储为TE’,正规式中的符号可替换,如可将E’改为M ) 构造预测分析表:int analyze_table[10][10]={ } //数组元素值存放正规式的编号,-1表示出错(2)预测分析表的构造方法2可使用三维数组Char analyze_table[10][10][10]={ }或Char *analyze_table[10][10]={ }2.针对预测分析表构造方法1的查预测分析表的方法提示:(1)查非终结符表得到非终结符的序号no1(2)查终结符表得到终结符的序号no2(3)根据no1和no2查预测分析表得到对应正规式的序号no3=analyze_table[no1][no2] ,如果no3=-1 表示出错。
(4)根据no3查找对应的正规式Fa[no3](5)对正规式进行处理3.错误处理机制紧急方式的错误恢复方法(抛弃某些符号,继续向下分析)(1)栈顶为非终结符A,串中当前单词属于FOLLOW(A),则从栈中弹出A(此时可认为输入串中缺少A表示的结构),继续分析。
---------错误编号为1(2)栈顶为非终结符A,串中当前单词不属于FOLLOW(A),则可使串指针下移一个位置(认为输入串中当前单词多余),继续分析。
----------错误编号为2(3)栈顶为终结符,且不等于串中当前单词,则从栈中弹出此终结符(认为输入串中缺少当前单词)或者将串指针下移一个位置(认为串中当前单词多余)。
在程序中可选择上述两种观点中的一种进行处理。
-------------错误编号3因此error()函数的编写方式可按如下方式处理Error(int errornum){If(errornum==1)………………Else if(errornum==2)……………Else ………………..//或者可用choose case语句处理}4.增加了错误处理的预测分析程序预测分析程序的算法:将“#”和文法开始符依次压入栈中;把第一个输入符号读入a;do{把栈顶符号弹出并放入x中;if(x∈VT){if(x==a) 将下一输入符号读入a;else error(3);}elseif(M[x,a]=“x→y1y2…yk”){按逆序依次把yk、yk−1、…、y1压入栈中;输出“x→y1y2…yk”;}else if a∈follow(x)error(1); else error(2);//在前述的数据定义中查表为-2表示a∈follow(x)}while(x!=“#”)三.实验要求给定算术表达式文法,编写程序。
测试数据:1.算术表达式文法E→TE’E’→ +TE’|- TE’|εT→FT’T’→*FT’ |/ FT’ |%FT’|εF→(E) |id|num给定一符合该文法的句子,如id+id*id$,或输入二元式序列(词法分析的结果,预测分析程序只用到二元式中的第一个元的值):(id,0)(+,-)(id,1)(*,-)(id,2),运行预测分析程序,给出分析过程和每一步的分析结果。
输出形式参考下图($为结束符):#include<stdio.h>#include<string.h>#include<stdlib.h>#define TT 0char aa[20]=" ";int pp=0;char VN[5]={'E','R','T','W','F'}; //非终结符表R:E' W:T'int length_vn=5; //非终结符的个数char VT[10]={'+','-','*','/','%','(',')','i','n','#'}; //终结符表i:id n:numint length_vt=10; //终结符的个数char Fa[12][6]={"TR","+TR","-TR","","FW","*FW","/FW","%FW","","(E)","i","n"};char F[12][6]={"E->","R->","R->","R->","T->","W->","W->","W->","W->","F->","F->","F->"}; int analyze_table[5][10]={-2,-2,-2,-2,-2,0,-1,0,0,-1,1,2,-2,-2,-2,-2,3,-2,-2,3,-1,-1,-2,-2,-2,4,-1,4,4,-1,8,8,5,6,7,-2,8,-2,-2,8,-1,-1,-1,-1,-1,9,-1,10,11,-1};//产生式表:0:E->TE' 1:E'->+TE' 2:E'->-TE' 3:E'->空4:T->FT' 5:T'->*FT' 6:T'->/FT' 7:T'->%FT' 8:T'->空9:F->(E) 10:F->id 11:F->numchar stack[50];int top=-1;void initscanner() //程序初始化:输入并打开源程序文件{int i=0;FILE *fp;if((fp=fopen("a.txt","r"))==NULL){printf("Open error!");exit(0);}char ch=fgetc(fp);while(ch!=EOF){aa[i]=ch;i++;ch=fgetc(fp);}fclose(fp);}void push(char a){top++;stack[top]=a;}char pop(){return stack[top--];}int includevt(char x){for(int i=0;i<length_vt;i++){if(VT[i]==x) return 1;}return 0;}int includean(char x,char a){int i,j;for(i=0;i<length_vn;i++)if(VN[i]==x) break;for(j=0;j<length_vt;j++)if(VT[j]==a) break;return analysis_table[i][j];}void destory(){int flag=0;int flagg=0;push('#');push(VN[0]);char a=aa[pp]; //把第一个输入符号读入achar x;do{if(flag==0)x=pop(); //把栈顶符号弹出并放入x中flag=0;printf("%c\t\t\t%c\t",x,a);if(includevt(a)==1){if(includevt(x)==1){if(x==a){if(a=='#'){flagg=1;printf("结束\n");}else printf("匹配终结符%c\n",x);pp++;a=aa[pp]; //将下一输入符号读入a;}else{flag=1;printf("出错,跳过%c\n",a);pp++;a=aa[pp];}}else if(includean(x,a)>=0){int h=includean(x,a);printf("展开非终结符%s%s\n",F[h],Fa[h]);int k;for(k=0;k<10;k++)if(Fa[h][k]=='\0') break;if(k==4){//printf("+++++++++++pop %c \n",x);}else{while(k!=0) //按逆序依次把yk、yk?1、…、y1压入栈中{k--;push(Fa[h][k]);}}}else if(includean(x,a)==-1){flag=1;printf("出错,从栈顶弹出%c\n",x);x=pop();}else{flag=1;printf("出错,跳过%c\n",a);pp++;a=aa[pp];}}else{flag=1;printf("出错,跳过%c\n",a);pp++;a=aa[pp];}}while(x!='#');if(flagg==0){printf("%c\t\t\t%c\t",x,a);printf("结束\n");}}int main(){printf("语法分析工程如下:\n");initscanner();printf("要分析的语句是:%s\n",aa);printf("语法分析工程如下:\n");printf("栈顶元素\t\t当前单词记号\t\t\t动作\n");printf("--------------------------------------------------------------------\n");destory();return 0;}实验总结本次实验是参照了别人的程序,把课本上的例4.10中文法作为例子设计出了预测分析程序。